PyTorch aprendizaje de redes neuronales
Sitio web de aprendizaje
http://pytorch123.com/SecondSection/neural_networks/
Redes neuronales
Las redes neuronales se pueden construir por paquete torch.nn, que es la construcción de algunos modelos basados en un gradiente de automático, y una capa que comprende un métodos nn.Module hacia adelante (de entrada), pero también devuelve una salida (salida).
A continuación se muestra un simple anticipativo LeNet red neuronal, una simple red neuronal incluye los siguientes puntos:
- Contiene la definición de unos parámetros entrenables de redes neuronales
- Iteration toda entrada
- Procesamiento de la entrada por la red neural
- Cálculo del valor de la función de pérdida
- parámetro gradiente de retropropagación a una red neural
- parámetros de actualización de la red, por lo general un método simple actualización: peso = peso - * · gradiente learning_rate
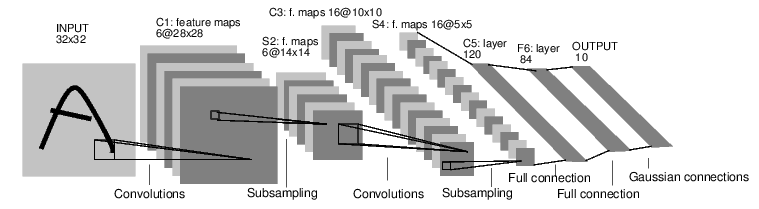
Utilizar la antorcha para escribir la anterior red neuronal
# -*- coding: UTF-8 -*-
"""
Modify: 2019-12-14
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
# super(Net,self) 首先找到 Net 的父类(就是类 nn.Module),
# 然后把类 Net 的对象转换为类 FooParent 的对象
super(Net, self).__init__()
#构建卷积
self.conv1 = nn.Conv2d(1, 6, 5) # 输入 1, 输出 6, 卷积 5*5,即6个不同的5*5卷积
self.conv2 = nn.Conv2d(6, 16, 5) # 输入 6, 输出 16, 卷积 5*5
#构建全连接 y = wx + b
self.fc1 = nn.Linear(16*5*5, 120) # 因为有16张 5*5 map, 所以有 16*5*5 = 400个输入,因此有120个400*1的向量
self.fc2 = nn.Linear(120, 84) # 84 个 120 * 1 个向量
self.fc3 = nn.Linear(84, 10) # 10个 84 * 1 个向量
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # 2*2 的最大值池化, relu为激活函数
x = F.max_pool2d(F.relu(self.conv2(x)), 2) # 如果池化窗口是矩形的,则可以只设定为2
x = x.view(-1, self.num_flat_features(x)) # view函数将张量x变形成一维的向量形式,作为全连接的输入
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 单张图像的size
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
# 输出
# Net(
# (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
# (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
# (fc1): Linear(in_features=400, out_features=120, bias=True)
# (fc2): Linear(in_features=120, out_features=84, bias=True)
# (fc3): Linear(in_features=84, out_features=10, bias=True)
# )
# 一个模型的训练参数可以通过调用 net.parameterss()返回
params = list(net.parameters())
print(len(params))
print(params[0].size())
# 输出
# 10
# torch.Size([6, 1, 5, 5])
#下面尝试随机生成一个32*32的输入。注意:期望的输入维度是32*32
# 为了使用这个网络在MNIST数据上使用,需要把数据集中的图像维度修改为32*32
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
#输出
# tensor([[ 0.0469, 0.0975, 0.0686, 0.0793, 0.0673, 0.0325, -0.0455, -0.0428,
# # -0.0671, -0.0067]], grad_fn=<AddmmBackward>)
#把所有参数梯度缓存器置0, 用随机的梯度来反向传播
net.zero_grad()
out.backward(torch.randn(1, 10))
El código anterior define un fuera de mora nervio, y la propagación de entrada del proceso y la parte posterior llamada.
Los siguientes de inicio, y calcula los valores de pérdida de los pesos actualizado de la red:
- función de pérdida: un par de pérdida de función de entrada requiere: salida del modelo y el objetivo, y calcula la distancia al valor de salida objetivo de evaluar hasta qué punto. paquete nn contiene un número de pérdida de diferentes funciones, una función de pérdida que es simple nn.MSELoss, es decir, el error cuadrático medio.
output = net(input)
target = torch.randn(10) # 目标值
target = target.view(1, -1) # 将其变换成与输出值相同的尺寸格式
criterion = nn.MSELoss() # MSELoss
loss = criterion(output, target) #计算输出与目标之间的损失函数
print(loss)
#输出
#tensor(0.3130, grad_fn=<MseLossBackward>)
- Volver Propagación: Con el fin de reducir la propagación de las pérdidas, hay que hacer es el uso loss.backward (). Se debe borrar primero el gradiente existente, de lo contrario el gradiente existente y acumulado juntos
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
#输出
# conv1.bias.grad before backward
# tensor([0., 0., 0., 0., 0., 0.])
# conv1.bias.grad after backward
# tensor([-0.0040, -0.0041, 0.0244, -0.0020, -0.0054, -0.0084])
- parámetro de la red neuronal actualiza
la forma más fácil es actualizar el cálculo estocástico usando el peso de descenso de gradiente = peso - learning_rate * gradiente
implementaciones de Python
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
torch.optim construyó una variedad de reglas de actualización de peso, similar a SGD, Nesterov-SGD, Adam, RMSProp y así sucesivamente.
Se utiliza de la siguiente manera:
import torch.optim as optim
# 创建优化器
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 在训练的循环中加入一下代码
optimizer.zero_grad() # 将梯度置0
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # 更新权重
