Referencias:
- "Aprendizaje profundo práctico"
3.1 Regresión lineal
3.1.1 Elementos básicos de la regresión lineal
Muestra: nnn表示样本数,x (i) = [x 1 (i) x 2 (i) , ⋯ xd (i)] x^{(i)}=[x^{(i)}_1,x^ {(i)}_2,\cdots,x^{(i)}_d]X( yo )=[ X1( yo ),X2( yo ),⋯,Xd( yo )] significa laiiyo muestras.
Predicción: y ^ = w T x + b \hat{y}=w^Tx+by^=wTX _+b representa el valor predicho de una sola muestra,y ^ = X w + b \hat{y}=Xw+by^=Xw+b representa el valor predicho de todas las muestras.
损失函数:
L ( w , b ) = ∑ i = 1 n 1 2 ( y ^ ( i ) − y ( i ) ) L(w,b)=\sum\limits_{i=1}^{n}\ frac12\Grande(\sombrero{y}^{(i)}-y^{(i)}\Grande)L ( w ,segundo )=yo = 1∑n21(y^( yo )−y( yo ) )
Descenso de gradiente estocástico: en cada iteración, primero muestreamos aleatoriamente un mini lote B \mathcal{B}B , que consiste en un número fijo de muestras de entrenamiento. Luego, los parámetros se actualizan de la siguiente manera:
( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) (\mathbf{w}, b ) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum\limits_{i \in \mathcal{B}} \partial_{(\mathbf{ w },b)} l^{(i)}(\mathbf{w},b)( w ,segundo )←( w ,segundo )−∣ segundo ∣hyo ∈ B∑∂( w , b )yo( yo ) (w,b )
Entre ellos,η \etaη es la tasa de aprendizaje, que es un hiperparámetro.
3.1.2 Aceleración de vectorización
Utilice bibliotecas de álgebra lineal eficientes siempre que sea posible.
3.1.3 Distribución normal y pérdida cuadrática
Asumiendo que las observaciones son ruidosas ϵ \epsilonϵ :
y = w ⊤ x + segundo + ϵ , y = \mathbf{w}^\top \mathbf{x} + segundo + \epsilon,y=w⊤ x+b+ϵ ,
menos ϵ∼ N ( 0 , σ 2 ) \epsilon \sim N(0, \sigma^2)ϵ∼norte ( 0 ,pag2 )。
Determina la ecuación:
P ( y ∣ x ) = 1 2 π σ 2 exp ( − 1 2 σ 2 ( y − w ⊤ x − b ) 2 ) P(y \mid \mathbf{x}) = \frac{ 1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{1}{2\sigma^2}(y - \mathbf{w}^\top \mathbf{ x} - b)^2\derecha)P(y∣x )=2 p.d. _21Exp( -2p _21( y−w⊤ x−segundo )2 )
Entonces la función de verosimilitud es:
L ( w , b ) = ∏ i = 1 np ( y ( i ) ∣ x ( i ) ) L(w,b) = \prod\limits_{i=1}^{n } p(y^{(i)}|\mathbf{x}^{(i)})L ( w ,segundo )=yo = 1∏np(y( yo ) ∣x( yo ) _
_
_ ⊤ X ( yo ) - segundo ) 2 ) . -l(w,b) = \sum\limits_{i=1}^n \bigg(\frac{1}{2} \log(2 \pi \sigma^2) + \frac{1}{2 \ sigma^2} \left(y^{(i)} - \mathbf{w}^\top \mathbf{x}^{(i)} - b\right)^2\bigg).- l ( w ,segundo )=yo = 1∑n(21lo g ( 2 π σ2 )+2p _21( y( yo )−w⊤ x( yo )−segundo )2) .exceptoπ
, σ \pi, \sigmapag ,σ es una constante, por lo que se puede ver a partir de la fórmula anterior que el error cuadrático medio mínimo del modelo lineal es equivalente a la estimación de máxima verosimilitud.
3.1.4 De la regresión lineal a la red profunda
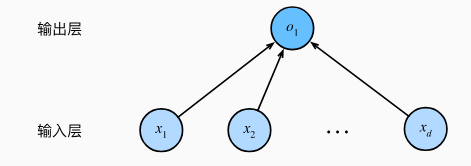
3.2 Implementación de la regresión lineal desde cero
3.2.1 Generar conjunto de datos
Supongamos que queremos generar un conjunto de datos que contenga 1000 muestras, cada muestra contiene 2 características muestreadas de la distribución normal estándar , las etiquetas de las muestras son:
y = X w + b + ϵ \mathbf{y}= \mathbf {X} \mathbf{w} + b + \mathbf\epsilony=Xw+b+ϵ
dondew = [ 2 , − 3.4 ] ⊤ \mathbf{w} = [2, -3.4]^\topw=[ 2 ,− 3.4 ]⊤、segundo = 4.2 segundo = 4.2b=4.2 ,ϵ \epsilonϵ sigue una distribución normal con media 0 y desviación estándar 0,01.
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
# 如果没有y.reshape,那么y将只有一个维度
return X, y.reshape((-1, 1))
3.2.2 Leer conjunto de datos
Dado que el método de descenso de gradiente estocástico requiere que seleccionemos aleatoriamente una parte de la muestra cada vez, podemos definir data_iterpara la extracción de la muestra:
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
# 在一轮训练中要用到所有的样本
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
# 每次参数更新只用到一小部分样本
yield features[batch_indices], labels[batch_indices]
El código anterior solo se usa para comprender el proceso de extracción de muestras, y el iterador incorporado se puede usar en la implementación real.
3.2.3 Parámetros de inicialización
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
3.2.4 Definir el modelo
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
3.2.5 Definir la función de pérdida
def squared_loss(y_hat, y):
"""均方损失"""
# 这里的y.reshape其实是没有必要的,因为labels在前面已经reshape过了
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
3.2.6 Definir el algoritmo de optimización
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
# 表示下一个代码块不需要进行梯度计算
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
# 清空梯度
param.grad.zero_()
3.2.7 Formación
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {
epoch + 1}, loss {
float(train_l.mean()):f}')
3.3 Implementación simple de regresión lineal
3.3.1 Generar datos
Esta parte es la misma que la 3.2.1.
3.3.2 Lectura de conjuntos de datos
from torch.utils import data
Podemos usar directamente datala API para realizar un muestreo de muestra:
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
# TensorDataset相当于把所有tensor打包,传入的tensor的第0维必须相同
# *的作用是“解压”参数列表
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# 访问数据
for input,label in data_iter:
print(input,label)
3.3.3 Definir el modelo
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
En el código anterior, Sequentialse pueden conectar varias capas en serie; Linearse implementa una capa totalmente conectada y sus parámetros 2,1especifican la forma de la entrada y la forma de la salida.
3.3.4 Inicializar parámetros del modelo
# net[0]表示选中网络中的第0层
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
3.3.5 Definir la función de pérdida
# 返回所有样本损失的均值
loss = nn.MSELoss()
3.3.6 Definir el algoritmo de optimización
# SGD的输入为参数和超参数
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
3.3.7 Formación
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
# 使用优化器对参数进行更新
trainer.step()
l = loss(net(features), labels)
print(f'epoch {
epoch + 1}, loss {
l:f}')
3.4 regresión softmax
3.4.1 Problemas de clasificación
Por lo general, las diferentes categorías se representan mediante una codificación one-hot .
3.4.2 Arquitectura de red
Suponiendo que cada muestra tiene 4 características y 3 categorías posibles, la estructura de red de la regresión softmax se muestra en la siguiente figura:
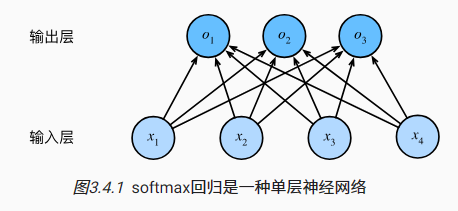
3.4.3 Sobrecarga de parámetros de la capa totalmente conectada
En términos generales, la capa completamente conectada tiene ddentradas d y qqsalida q , entonces su sobrecarga de parámetros esO ( dp ) O(dp)O ( p )。 _
3.4.4 operación softmax
Para problemas de clasificación, lo que queremos obtener es la probabilidad de que la entrada pertenezca a cada categoría, por lo que necesitamos procesar la salida para que satisfaga el axioma básico de probabilidad:
y ^ = softmax ( o ) donde y ^ j = exp ( oj ) ∑ k exp ( ok ) \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{dónde}\quad \hat{y}_j = \ frac{\ exp(o_j)}{\sum\limits_k \exp(o_k)}y^=softmax ( o )eny^j=k∑experiencia ( ok)experiencia ( oj)
Forma, y ^ \hat{\mathbf{y}}y^Cada componente de es constante positiva y la suma es 1 11 , y softmax no cambiaráo \mathbf{o}El orden de magnitud entre o .
3.4.5 Vectorización de muestras de mini lotes
Error de análisis de KaTeX: se esperaba 'EOF', se obtuvo '&' en la posición 13: \mathbf{O} &̲= \mathbf{X}\m.
3.4.6 Función de pérdida
La función de verosimilitud de la regresión softmax es:
L ( θ ) = ∏ i = 1 n P ( y ( i ) ∣ x ( i ) ) L(\theta)=\prod\limits_{i=1}^n P(\ mathbf{y}^{(i)} \mid \mathbf{x}^{(i)})L ( yo )=yo = 1∏nP(y( yo )∣X( yo ) )
取负对数,得:
− Iniciar sesión L ( θ ) = ∑ yo = 1 norte − Iniciar sesión PAGS ( y ( yo ) ∣ X ( yo ) ) = ∑ yo = 1 norte ∑ j = 1 q − yj log y ^ j \begin{align} -\log L(\theta)&=\sum\limits_{i=1}^n -\log P(\mathbf{y}^{(i)} \ mid \mathbf{x}^{(i)})\notag\\ &=\sum\limits_{i=1}^n\sum\limits_{j=1}^q-y_j\log \hat{y} _j \end{alinear}−iniciar sesiónL ( yo )=yo = 1∑n−iniciar sesiónP(y( yo )∣X( yo ) )=yo = 1∑nj = 1∑q− yjiniciar sesióny^j
Explique la fórmula anterior de la siguiente manera: porque la etiqueta de la muestra tiene una longitud de qqLa codificación one-hot de q , por lo que la suma interna es en realidad el logaritmo negativo de la probabilidad de derivar su etiqueta de la entrada, que es lo mismo que − log P ( y ( i ) ∣ x ( i ) ) -\ log P (\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)})−iniciar sesiónP(y( yo )∣X( i ) )son equivalentes.
称:
l ( y , y ^ ) = ∑ j = 1 q − yj log y ^ jl(\mathbf{y}, \hat{\mathbf{y}})=\sum\limits_{j=1}^ q-y_j\log\hat{y}_jyo ( y ,y^)=j = 1∑q− yjiniciar sesióny^j
Una es la pérdida de entropía cruzada (pérdida de entropía cruzada)
l ( y , y ^ ) = − ∑ j = 1 qyj log exp ( oj ) ∑ k = 1 q exp ( ok ) = ∑ j = 1 qyj iniciar sesión ∑ k = 1 q exp (ok) − ∑ j = 1 qyjoj = iniciar sesión ∑ k = 1 q exp (ok) − ∑ j = 1 qyjoj ∂ ojl ( y , y ^ ) = exp ( oj ) ∑ k = 1 q exp ( ok ) − yj = softmax ( o ) j − yj \begin{aligned} l(\mathbf{y}, \hat{\mathbf{y}}) &= - \sum_{ j= 1}^q y_j \log \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)}\notag \\ &= \sum_{j=1}^q y_j \log \sum_{k=1}^q \exp(o_k) - \sum_{j=1}^q y_j o_j\note\\ &= \log \sum_{k=1}^q \exp(o_k) - \ sum_{j=1}^q y_j o_j\note\\ \partial_{o_j} l(\mathbf{y}, \hat{\mathbf{y}}) &= \frac{\exp(o_j)} {\ sum_{k=1}^q \exp(o_k)} - y_j = \mathrm{softmax}(\mathbf{o})_j - y_j\notag \end{alineado}yo ( y ,y^)∂ojyo ( y ,y^)=−j = 1∑qyjiniciar sesión∑k = 1qexperiencia ( ok)experiencia ( oj)=j = 1∑qyjiniciar sesiónk = 1∑qexperiencia ( ok)−j = 1∑qyjoj=iniciar sesiónk = 1∑qexperiencia ( ok)−j = 1∑qyjoj=∑k = 1qexperiencia ( ok)experiencia ( oj)−yj=softmax ( o )j−yj
Se puede ver que el gradiente es el valor observado yyy y valor estimadoy ^ \hat{y}y^, lo que hace que el cálculo de gradientes sea mucho más fácil en la práctica.
3.5 Conjunto de datos de clasificación de imágenes
3.5.2 Lectura de pequeños lotes de datos
batch_size = 256
def get_dataloader_workers():
"""使用4个进程来读取数据"""
return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
3.6 Implementación de la regresión softmax desde cero
3.6.1 Inicializar parámetros del modelo
La entrada es una imagen de 28*28, que se puede considerar como un vector con una longitud de 784; la salida es la probabilidad de pertenecer a 10 categorías posibles, por lo que WWW debería ser una matriz de 784*10,bbb es un vector fila de 1*10:
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
3.6.2 Definir operación softmax
La implementación de softmax consta de tres pasos:
- Exponencia cada término;
- Sume cada fila (cada muestra es una fila en el mini lote) para obtener la constante de normalización para cada muestra;
- Divide cada fila por su constante de normalización, asegurándose de que los resultados suman 1.
El código correspondiente es:
def softmax(X):
X_exp = torch.exp(X)
# 确保求和之后张量的维度不变
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
3.6.3 Definición del modelo
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
¿Por qué la entrada aquí es solo una imagen?
3.6.4 Definir la función de pérdida
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)
Entre ellos, yse encuentra una lista de etiquetas, que representa el número de categoría de la muestra, como [0,1,3].
3.6.5 Precisión de clasificación
Precisión = número de predicciones correctas / número total de predicciones
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
El código anterior dice: Si y_hates una matriz, se supone que la segunda dimensión almacena las puntuaciones pronosticadas para cada clase. Usamos argmaxpara obtener el índice del elemento más grande en cada fila para obtener la clase predicha. Luego ycomparamos las categorías pronosticadas con los elementos de verdad básicos. Dado que el operador de igualdad " ==" es sensible al tipo de datos, y_hatconvertimos el tipo de datos de para que ysea coherente con el tipo de datos de . El resultado es un tensor que contiene 0 (falso) y 1 (verdadero). Finalmente, sumamos para obtener el número de predicciones correctas.
3.7 Implementación simple de la regresión softmax
3.7.1 Inicializar parámetros del modelo
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
# apply会对net里的每一层执行init_weights函数
# 所以init_weights函数里的m是用来限定只初始化Linear层参数的
net.apply(init_weights);
3.7.2 Definir la función de pérdida
CorssEntropyLossLa entrada es o \mathbf{o}o (sin softmax) y una lista de etiquetas, la salida es entropía cruzada. En otras palabras, no necesitamos convertir la salida en una probabilidad a través de softmax al calcular la pérdida, porque la operación exponencial en softmax es muy fácil de desbordar.
# none表示不合并结果,即loss为一个列表,元素为每个样本的交叉熵
# 这里之所以选择none,是因为后面既要用到损失的总和,又要用到损失的均值
loss = nn.CrossEntropyLoss(reduction='none')
3.7.3 Algoritmo de optimización
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
3.7.4 Formación
# 累加器类
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
# 将参数列表逐个加到累加器里
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
# 这里的accuracy出自3.6.5
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
# 训练一轮
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
# 在测试集上测试精度
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
# 这条代码的意思是:如果train_loss<0.5则继续执行,否则报错,报错内容为"train_loss"
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
3.7.5 Pronóstico
y_hat.argmax(axis=1)Solo usa