

Introducción
Este artículo está compilado del discurso de apertura del mismo nombre "La exploración y práctica de BES en escenarios de bases de datos vectoriales a gran escala" en la Conferencia Global de Desarrollo de Software QCon 2023 · Estación de Beijing el 5 de septiembre de 2023 - Subforo de bases de datos vectoriales.
El texto completo tiene 5989 palabras y el tiempo estimado de lectura es de 15 minutos.
Una base de datos vectorial es un sistema de base de datos diseñado específicamente para almacenar y consultar datos vectoriales. A través de la tecnología Embedding, las características de imágenes, sonidos, textos y otros datos se pueden extraer y expresar en forma de vectores. La distancia entre vectores expresa la similitud de características entre los datos originales. Por lo tanto, los vectores de características, como los datos originales, se pueden almacenar en una base de datos de vectores y luego se pueden encontrar datos originales similares mediante tecnología de recuperación de vectores, como las aplicaciones de búsqueda de imágenes.
1. Introducción a las aplicaciones de bases de datos vectoriales.
La tecnología de recuperación de vectores estaba bien desarrollada antes de la aparición de grandes modelos. Con el desarrollo de la tecnología de aprendizaje profundo, las bases de datos vectoriales también se utilizan ampliamente en escenarios de recomendación y búsqueda de imágenes, audio y video, así como en recuperación semántica, preguntas y respuestas de texto, reconocimiento facial y otros escenarios.
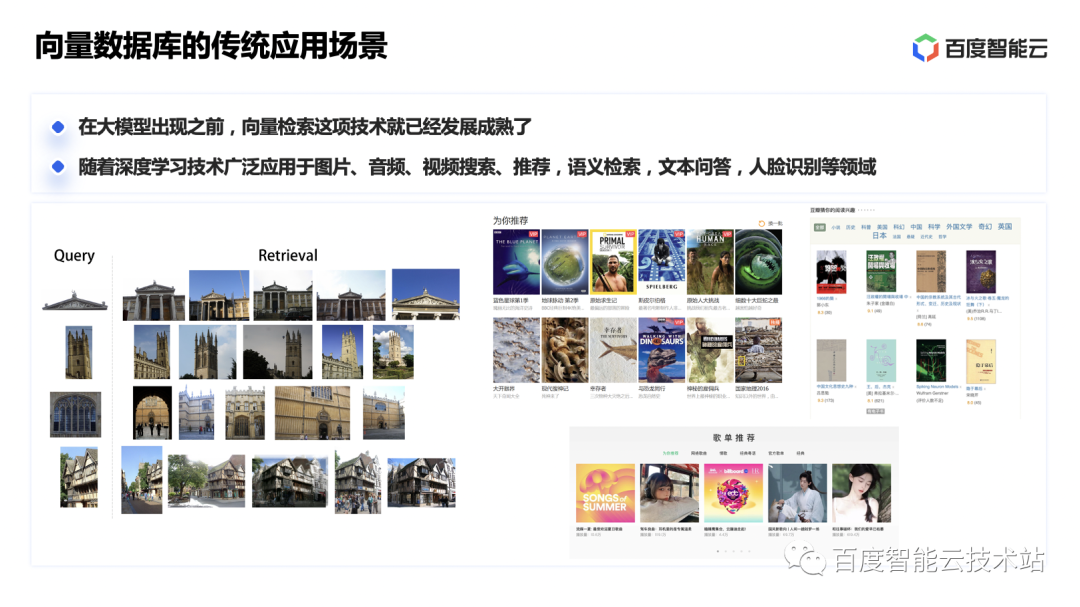
La aparición de grandes modelos ha cambiado la forma de interacción entre humanos y computadoras, ha provocado una nueva revolución en la tecnología de inteligencia artificial y ha generado una gran cantidad de aplicaciones nativas de IA.
Sin embargo, todavía se encuentra en las primeras etapas de desarrollo y todavía existen muchos problemas en la aplicación práctica.
En primer lugar, la capacidad de conocimiento no es lo suficientemente sólida: aunque los modelos grandes pueden responder preguntas generales, en campos verticales, debido a los datos de capacitación limitados, todavía hay margen de mejora en la profesionalidad de las respuestas. Además, los modelos grandes también sufren problemas de alucinaciones y las respuestas distorsionarán los hechos.
Además, el ciclo de entrenamiento y el costo de los modelos grandes son muy altos, por lo que no se pueden entrenar con frecuencia, lo que dificulta la obtención de datos en tiempo real y solo puede responder algunas preguntas generales que no son muy urgentes;
Además del conocimiento, también es difícil garantizar la seguridad de los datos privados en modelos grandes. Por ejemplo, si proporciono algunos datos privados sobre mí a un modelo grande, cuando este modelo grande brinda servicios a otros, es probable que esta información privada se exprese como respuesta.
Entonces, ¿cómo mejorar las capacidades de conocimiento de los modelos grandes y al mismo tiempo proteger la seguridad de los datos privados?
Como se muestra en el lado derecho de la figura siguiente, traer las noticias de advertencia meteorológica emitidas por la Oficina Meteorológica al hacer preguntas puede ayudar al modelo grande a responder con precisión nuestras preguntas.
Este sistema técnico que mejora las capacidades de modelos grandes a través de herramientas y materiales de datos externos se llama ingeniería de palabras rápidas.
De la discusión anterior, podemos ver que la ingeniería de palabras rápidas es de gran importancia para la aplicación de modelos grandes. A continuación, presentaremos en detalle cómo crear un proyecto de Word rápido.

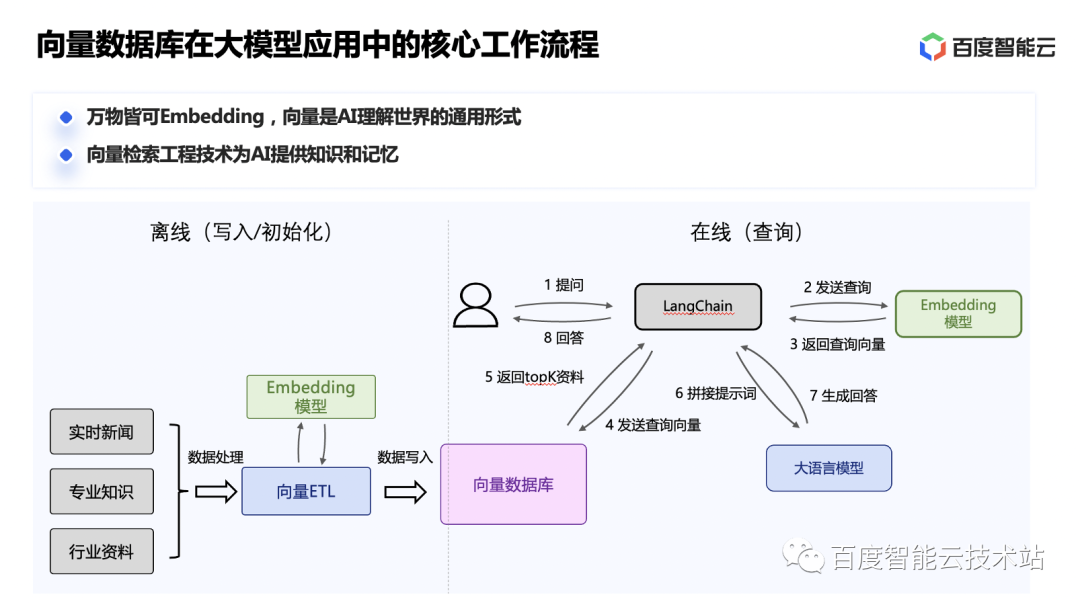
Veamos el flujo de trabajo principal de una aplicación de modelo grande.
Al incorporar regularmente noticias externas en tiempo real, conocimientos profesionales, datos de la industria y otros datos en forma vectorial y almacenarlos en la base de datos vectorial, se puede construir de manera incremental una base de conocimientos externa de gran modelo. Cuando los usuarios hacen preguntas, primero pueden obtener el contenido más relevante de la base de conocimientos y luego unir palabras clave para mejorar la capacidad de respuesta del modelo grande.
Esto puede introducir datos y conocimientos externos en tiempo real sin volver a entrenar el modelo grande, mejorar la capacidad de respuesta del modelo grande y reducir la desviación de las respuestas del modelo grande de los hechos. La creación de una base de conocimientos externa a través de una base de datos vectorial también puede garantizar eficazmente la privacidad y seguridad de los datos de la industria.
Además, el historial de conversaciones del usuario se almacena en la base de conocimiento vectorial y se pueden extraer conversaciones históricas muy relevantes durante conversaciones posteriores, resolviendo así el problema de la falta de memoria a largo plazo en modelos de lenguaje grandes causada por el número limitado de tokens. en modelos de lenguaje grandes.
2. Práctica de ingeniería de Baidu Intelligent Cloud BES
Elasticsearch es un motor distribuido de búsqueda y análisis basado en Apache Lucene. Ocupa el primer lugar en el campo de las bases de datos de motores de búsqueda y es la solución de código abierto más popular del mundo. Admite múltiples tipos de datos, incluidos datos estructurados y no estructurados, y La interfaz Es simple y fácil de usar, la documentación es completa y existe una gran cantidad de casos prácticos en la industria.
Baidu Smart Cloud Elasticsearch (BES) es un producto de nube pública maduro construido sobre la base de Elasticsearch de código abierto, con garantía de recursos y capacidades de operación y mantenimiento en la nube. BES se lanzó en 2015 y fue el primer servicio de alojamiento de ES proporcionado por proveedores de nube pública. En 2018, presentamos el complemento de segmentación de palabras NLP de Baidu y admitimos instantáneas y recuperación basadas en BOS de almacenamiento de objetos. En 2020, admitimos capacidades como la arquitectura de separación en frío y en caliente basada en BOS de almacenamiento de objetos y proporcionamos capacidades de recuperación de vectores, que se utilizan ampliamente en Baidu y tienen suficiente acumulación de ingeniería. En 2023, optimizaremos el motor de vectores, los recursos del paquete y otros aspectos de los escenarios de recuperación de vectores para satisfacer las necesidades de escenarios de modelos grandes.

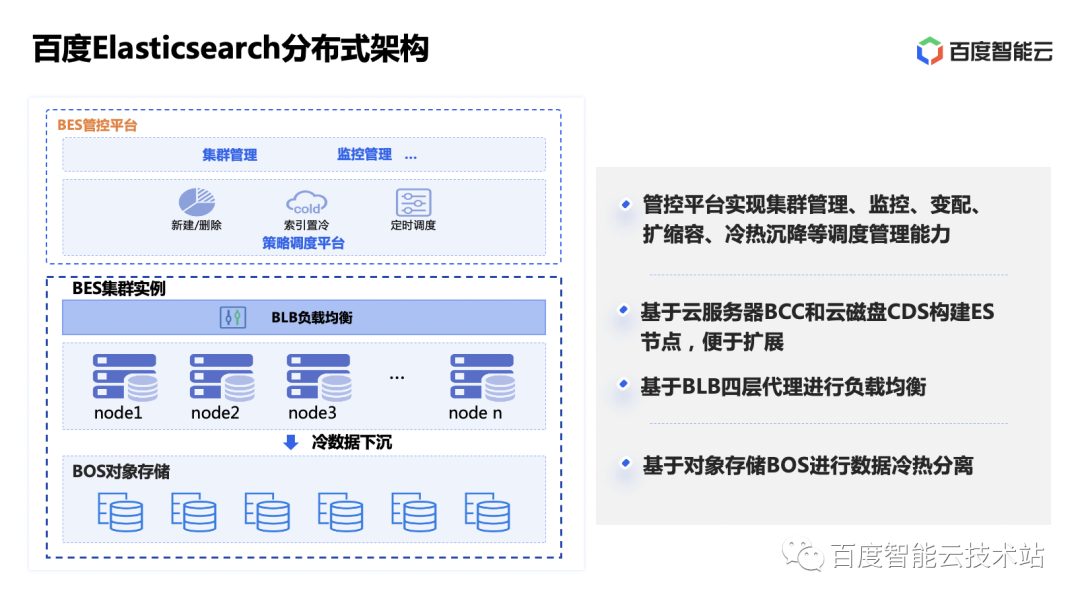
La arquitectura de BES consta de dos partes: la plataforma de gestión y control y la instancia del clúster BES. La plataforma de gestión y control es una plataforma para la gestión, monitoreo y alarmas unificadas de clústeres, expansión y contracción de clústeres y programación de separación de frío y calor a nivel global. La instancia de clúster BES es un conjunto de servicios de clúster de Elasticsearch creados en hosts y discos de nube. El equilibrio de carga de los nodos se realiza a través del proxy de cuatro capas BLB. Los datos del disco se pueden almacenar periódicamente en el BOS de almacenamiento de objetos mediante políticas para reducir los costos de almacenamiento.
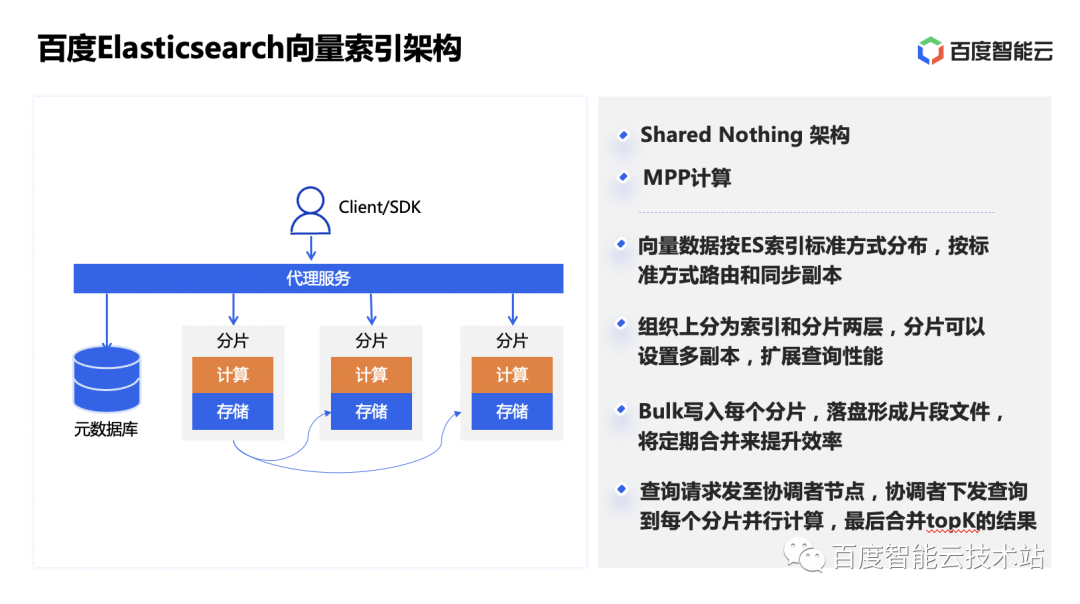
La arquitectura de índice de BES adopta la arquitectura informática Shared Nothing + MPP en su conjunto, que reutiliza el flujo de datos de ES. Los datos se organizan según índices y fragmentos. Se pueden configurar múltiples copias para fragmentos, que se distribuirán en el estándar. forma de ES y enrutamiento. De esta manera, al realizar la recuperación de vectores, se realizarán cálculos locales en nodos con distribución de datos y se mejorará la eficiencia de las consultas mediante la computación paralela de múltiples nodos. Al aumentar la cantidad de réplicas junto con la expansión de la capacidad, se puede aumentar la cantidad de nodos y recursos que pueden participar en las consultas, mejorando así el QPS general de las consultas del servicio.
Los datos vectoriales se administran utilizando los métodos estándar de ES, por lo que su uso no es muy diferente de los datos escalares. Los datos vectoriales se pueden escribir junto con los datos escalares y reutiliza las capacidades de recuperación y procesamiento de ES para datos escalares. Los usuarios pueden escribir datos en lotes a través de la interfaz Bulk de ES. Después de escribir los datos en cada fragmento, se formarán algunos archivos de fragmentos en el disco y luego se proporcionarán capacidades de recuperación. ES programará la fusión de fragmentos periódicamente en segundo plano para mejorar la eficiencia de la recuperación. Al realizar una consulta, la solicitud de consulta se envía a cualquier nodo, y este nodo se convierte en el nodo de coordinación. Emitirá la consulta a cada fragmento para el cálculo paralelo y luego fusionará los resultados de TopK en los resultados y los devolverá.
Usar vectores en BES también es muy simple, veamos un ejemplo de uso a continuación. Primero, debe definir el mapeo del índice y especificar algunos parámetros relacionados con el vector. Este paso equivale a crear una tabla. Luego, los datos se pueden escribir a través de la interfaz Bulk de ES. En escenarios reales, los datos originales generalmente se vectorizan a través de la capacidad de incrustación y luego se escriben en lotes. Luego, la recuperación de vectores se puede realizar mediante la sintaxis que definimos que es cercana al estilo ES.

En términos de la implementación de la indexación de vectores, elegimos implementar capacidades relacionadas con vectores a través de complementos de desarrollo propio. Implementamos el motor central a través de C++ y lo llamamos a través de JNI en ES.
Al elegir complementos de desarrollo propio, en primer lugar, espero lograr un rendimiento extremo más cercano a la capa inferior basada en la implementación de C ++ y facilitar SIMD y otras optimizaciones para acelerar los cálculos; en segundo lugar, espero que la implementación del formato de almacenamiento subyacente pueda ser reescrito, lo cual también es conveniente para lograr un rendimiento más extremo; en tercer lugar, puede controlar la lógica de recuperación de manera más flexible y reescribir el plan de ejecución para implementar consultas más complejas.
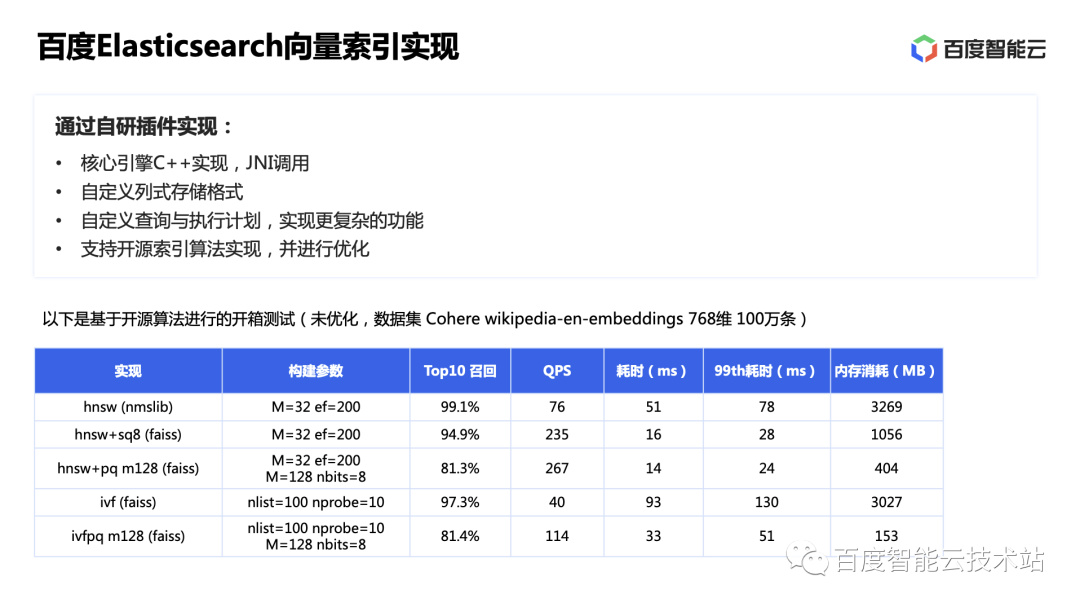
Para la parte principal del motor de recuperación de vectores, elegimos realizar un desarrollo secundario basado en la excelente implementación de la biblioteca de vectores en la comunidad. Comparamos el rendimiento de unboxing de nmslib y faiss en ES (prueba basada en una máquina virtual de 8cu, los segmentos generados por datos escritos no se fusionan, el conjunto de datos SIFT-1M tiene 128 dimensiones), se puede ver que HNSW tiene una tasa de recuperación más alta. El consumo general de memoria es relativamente alto, pero la implementación de nmslib es mejor.
Al transformar la implementación del motor de recuperación de vectores, reutilizamos nuestros datos de almacenamiento en columnas personalizados de Lucene en el tipo de índice HNSW para el almacenamiento de datos vectoriales de nivel 0 y los cargamos a través de mmap. Por un lado, esto reduce la redundancia de datos y reduce el desperdicio de recursos; por otro lado, al cargar datos a través de mmap, cuando la memoria es insuficiente, algunas páginas se intercambiarán fuera de la memoria y luego se cargarán en el memoria cuando es necesario leerlos. En la memoria, los medios de almacenamiento híbridos de memoria + disco también son compatibles hasta cierto punto.
Antes de lanzarnos a una optimización específica, revisemos los principios actuales de los algoritmos de gráficos convencionales.
El algoritmo de gráficos es una idea relativamente nueva de recuperación de vectores aproximados. Se basa en la teoría del mundo pequeño navegable. Específicamente, significa que en un gráfico completamente conectado, se pueden conectar dos puntos mediante seis saltos. Al construir una red de "mundo pequeño" similar al mundo real basada en la relación de distancia entre vectores, podemos usar un algoritmo codicioso para establecer conexiones basadas en la distancia y acercarnos al punto fijo del vector objetivo un salto a la vez.
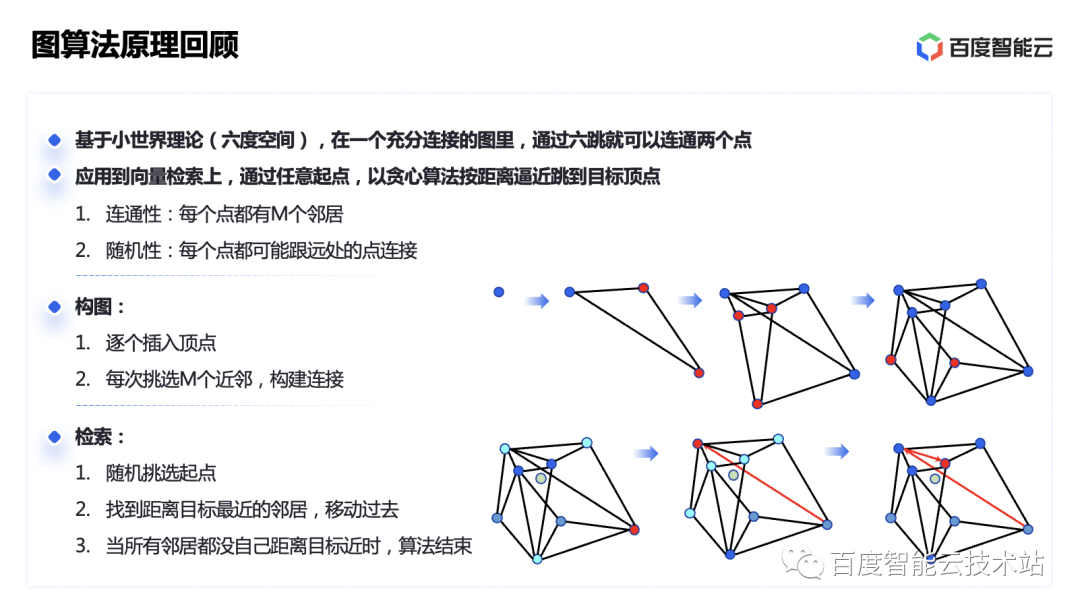
A medida que se siguen insertando puntos en el mundo pequeño, de acuerdo con la idea mencionada anteriormente de seleccionar puntos cercanos para construir bordes, los puntos recién insertados se limitarán cada vez más a un círculo pequeño. Mucho tiempo para establecer una conexión con un punto lejano. El número de saltos ha aumentado.
Para resolver este problema, la industria propuso el algoritmo HNSW, que utiliza una idea similar a la lista de omisión en el algoritmo de búsqueda de listas vinculadas. Construimos gráficos en diferentes niveles y disminuimos exponencialmente el número de puntos fijos hacia arriba para formar un gráfico disperso. De esta manera, cuanto más disperso sea el gráfico, mejor podrá conectarse a lugares distantes.
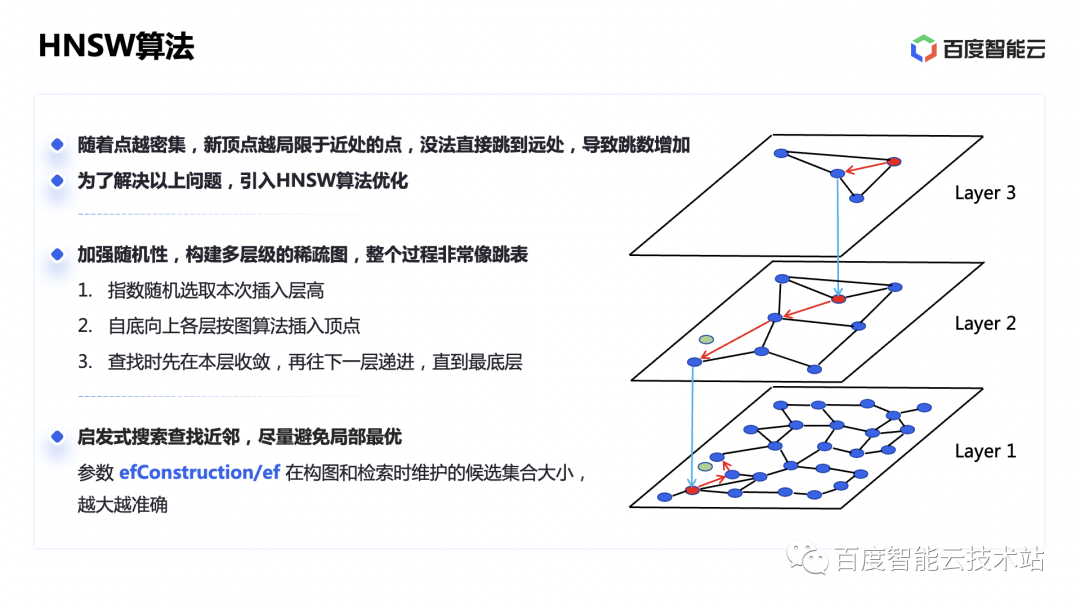
Aunque la respuesta a la consulta del índice HNSW es rápida y la tasa de recuperación es relativamente alta, también tiene deficiencias como una velocidad de composición lenta y una alta sobrecarga de CPU y memoria. En el proceso de composición de HNSW, cada punto insertado requiere recuperación y cálculo. Insertar una gran cantidad de puntos también supone un gran gasto computacional, por lo que la importación de datos será muy lenta y provocará el bloqueo de la recepción.
Por lo tanto, transformamos la construcción del índice vectorial en un mecanismo de construcción asincrónico en segundo plano, y los datos se pueden devolver directamente después de escribirse en el disco; luego, el fondo activa la construcción del índice HNSW en segundo plano a través de la estrategia de fusión de ES o el tiempo del usuario. o activación activa.El método de construcción de transmisión reduce el consumo de memoria en el proceso de composición. Y está construido utilizando un grupo de subprocesos independiente para evitar afectar las solicitudes de consulta de front-end.
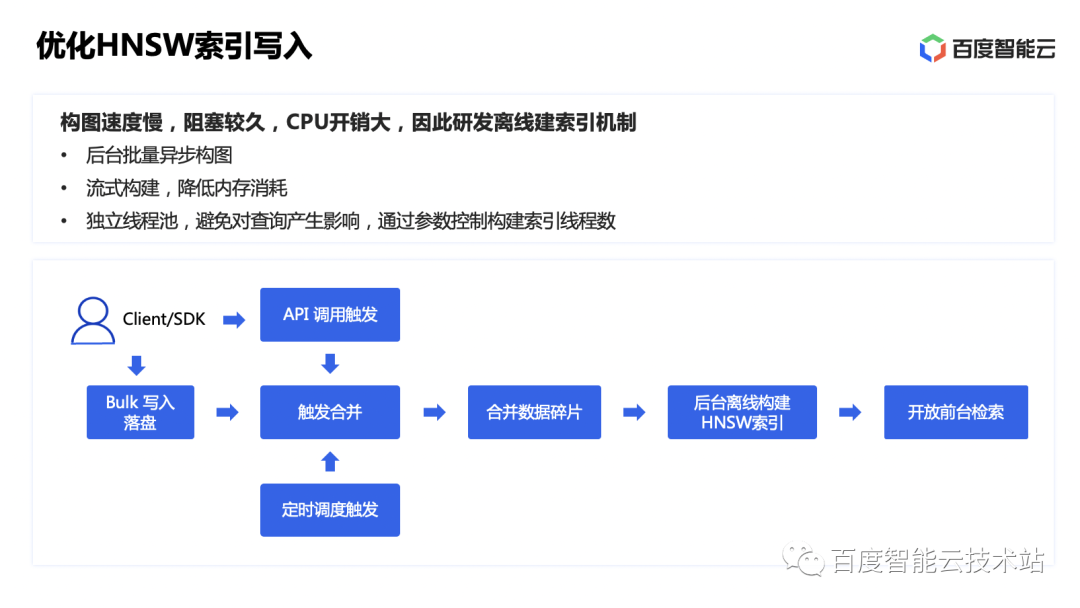
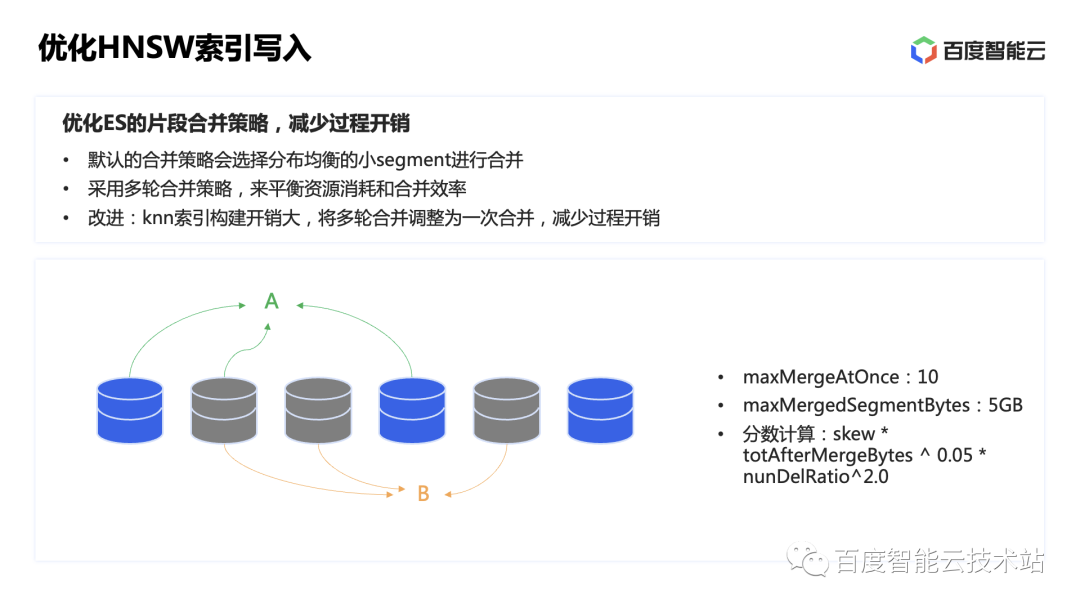
Al mismo tiempo, también hemos optimizado la estrategia de fusión de fragmentos de ES.
La estrategia de fusión predeterminada de ES seleccionará un conjunto de fragmentos para participar en la fusión en función de algunas condiciones, como la cantidad de fragmentos que participan en una fusión, el tamaño de los nuevos fragmentos que generará la fusión, etc., y luego calculará las puntuaciones de diferentes combinaciones para seleccionar la óptima. Las combinaciones de fragmentos se fusionan. Generalmente, se realizan varias rondas de fusión para lograr un equilibrio entre el consumo de recursos y la eficiencia de las consultas. Sin embargo, debido a que el costo de construcción de los índices vectoriales es a menudo mayor que el de los tipos de datos nativos de ES, ajustamos la estrategia de fusión de los índices vectoriales y cambiamos las múltiples rondas de fusión a una sola para reducir la sobrecarga del proceso de fusión de fragmentos.
Además, también admitimos desactivar la construcción automática del índice de destino antes de escribir datos. Después de escribir datos en lotes y fusionar fragmentos, la construcción del índice vectorial se puede completar de una sola vez a través de la API, que es más adecuada para el llenado de bases de datos por lotes. escenarios.
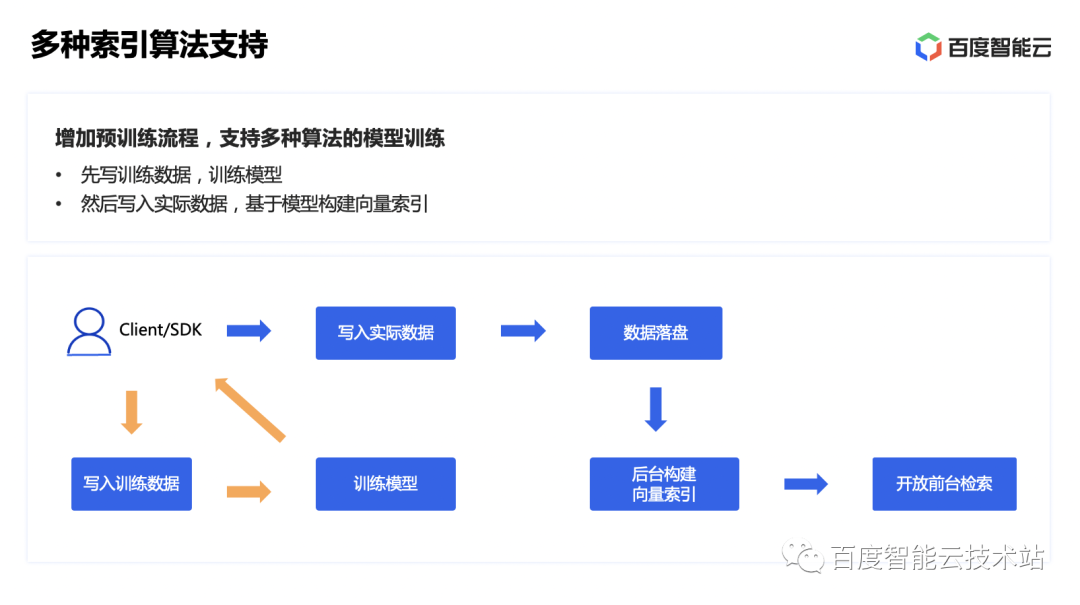
Además, BES también admite múltiples tipos de índices vectoriales y algoritmos de cálculo de distancias. También brindamos soporte de proceso para índices vectoriales que deben generarse mediante capacitación. Por ejemplo, el índice de la serie FIV, primero revisemos los principios del algoritmo de FIV.
IVF significa índice invertido, índice invertido es una terminología de motor de búsqueda que se refiere a extraer palabras clave de las páginas web de documentos para establecer una estructura de búsqueda invertida y encontrar el documento original a través de palabras clave. Entonces, ¿cuáles son las palabras clave para los datos vectoriales? Los vectores en el mundo real generalmente se distribuyen en grupos en distribución espacial y tienen características de agrupación. Por favor vea la imagen a continuación.
Extraiga el centro de agrupación del vector a través del algoritmo k-means. Luego, el centro de agrupación donde se encuentra el vector es la palabra clave del vector. Utilice esto para crear un índice invertido y podrá acceder al centro de agrupación primero como un motor de búsqueda. ., y luego busca violentamente cada vector debajo del centro del clúster, lo que puede filtrar una gran cantidad de datos en comparación con la búsqueda global. Si cree que encontrar un centro de agrupación no es lo suficientemente preciso, también puede encontrar varios más. Cuanto más encuentre, más preciso será el resultado.
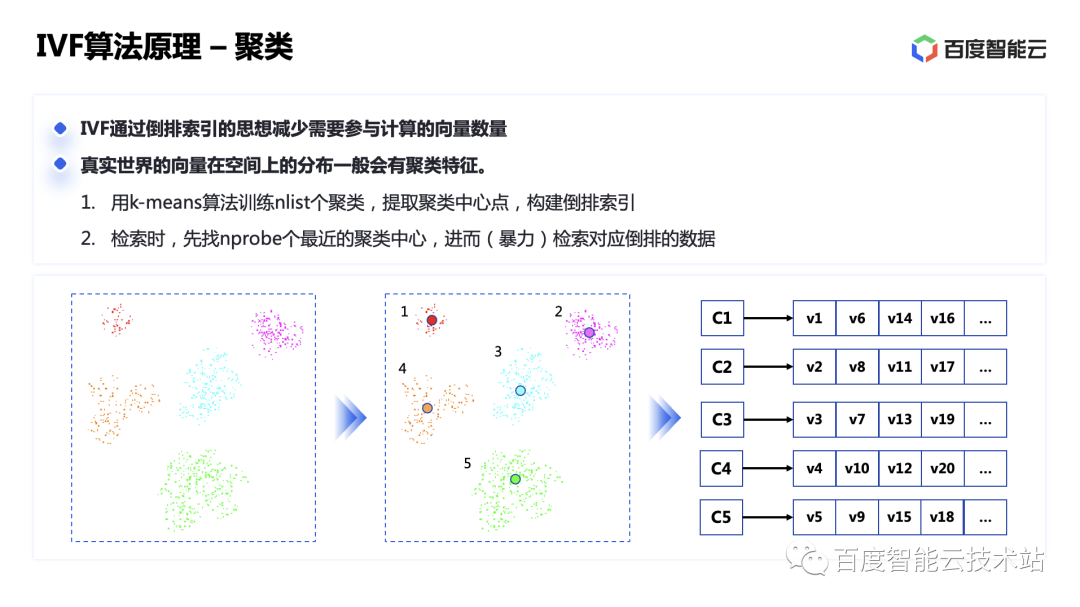
Para índices vectoriales como IVF, el proceso de construcción de BES consiste en escribir primero los datos de entrenamiento y luego llamar a la API para entrenar el modelo. En este paso, la agrupación se realiza en función de los datos de entrenamiento y se calcula el centro de cada grupo. Una vez entrenado el modelo, cree un nuevo índice para escribir los datos reales y cree un índice vectorial basado en el modelo entrenado. El mecanismo específico de construcción y fusión del índice vectorial sigue siendo el mismo que el descrito anteriormente.
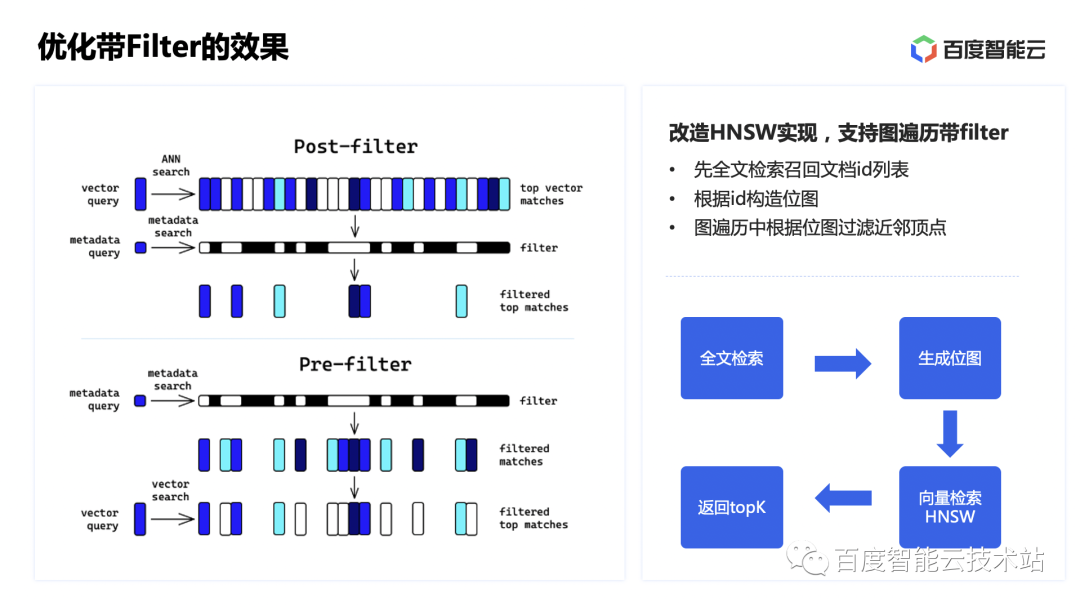
Hay muchos escenarios que requieren filtrar datos de acuerdo con condiciones escalares antes de realizar la recuperación de vectores, como etiquetar datos vectoriales para garantizar que los vectores recuperados puedan coincidir con las etiquetas.
Para soportar tal demanda, existen dos métodos: post-filtro y pre-filtro. El post-filtro se refiere a realizar primero la recuperación de ANN y luego ejecutar el filtro basado en los resultados de la recuperación para obtener el resultado final. Sin embargo, puede causar la El conjunto de resultados será significativamente mayor en tamaño. Menos que K. El prefiltro se refiere a filtrar los datos primero y luego realizar la recuperación del vecino más cercano en función de los resultados del filtrado. Este método generalmente garantiza K resultados.
Por lo tanto, modificamos la implementación HNSW original para que el algoritmo solo considere vectores que cumplan con las condiciones del filtro en el proceso de atravesar el gráfico para seleccionar los vecinos más cercanos. El proceso específico es ejecutar primero el filtro basado en el índice de datos escalares de ES para obtener la lista de identificación de los documentos recuperados; luego construir un mapa de bits basado en la lista de identificación y pasar los datos del mapa de bits al motor vectorial a través de llamadas JNI. Durante el proceso de recuperación de HNSW, el mapa de bits filtra los vértices cercanos para obtener una lista de vectores que cumplen con las condiciones del filtro.
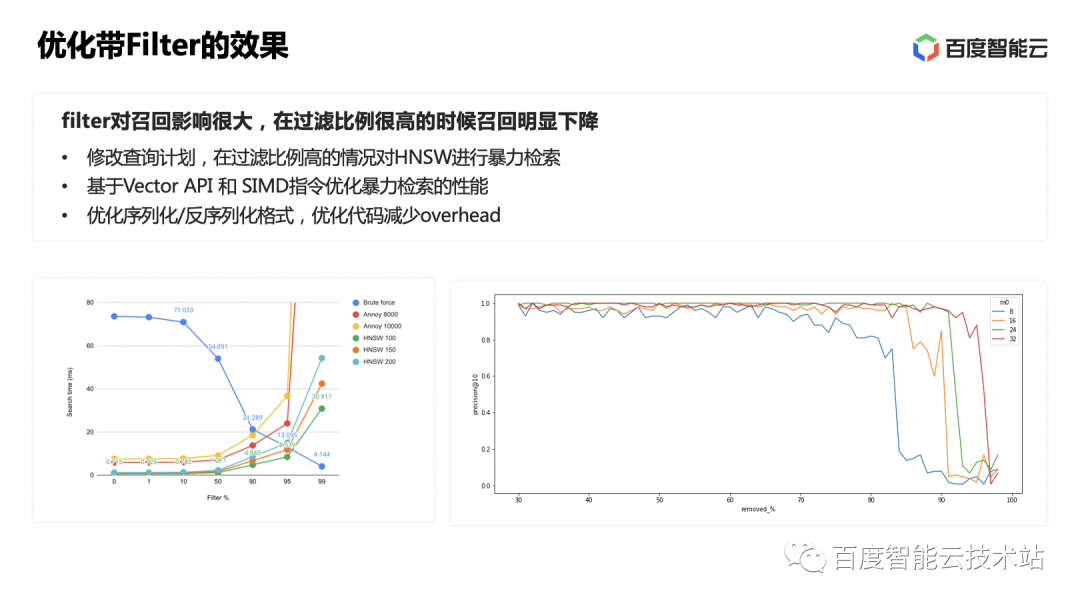
Durante la prueba real, se descubrió que el rendimiento y la recuperación no eran muy satisfactorios. Al probar datos y estudiar cierta información, encontramos que cuando aumenta la relación de filtrado, el número de rutas conectadas disminuye porque los vértices se filtran, lo que afecta directamente la velocidad de convergencia del algoritmo HNSW y es fácil llegar a un callejón sin salida. lo que resulta en una baja tasa de recuperación. Los datos muestran que cuando la tasa de filtrado alcanza más del 90%, el rendimiento y la tasa de recuperación caerán drásticamente.
Por lo tanto, aquí elegimos reescribir el plan de ejecución y combinar el filtrado escalar y los algoritmos de recuperación de fuerza bruta. Cuando la proporción de filtrado alcanza más del 90%, la recuperación de fuerza bruta de los datos de resultados del filtro puede lograr resultados satisfactorios. Al mismo tiempo, las instrucciones SIMD también se utilizan para acelerar la eficiencia de la recuperación violenta.
El plan de desarrollo posterior de BES se centra principalmente en los siguientes aspectos.
El primero es la facilidad de uso. Debido a que la base de datos vectorial está dirigida principalmente a desarrolladores de aplicaciones de modelos grandes, se espera que proporcione una experiencia de producto lista para usar y reduzca el umbral para que los usuarios la comprendan y utilicen. Actualmente, el uso del motor vectorial de desarrollo propio de BES requiere que los usuarios estén familiarizados con ES, por ejemplo, para poder utilizar el DSL de ES para expresar la lógica de consulta. Si se puede proporcionar un método más general y fácil de usar, como admitir la recuperación de knn a través de SQL, será más fácil de usar.
El segundo son las características funcionales, que deben admitir más algoritmos de indexación y algoritmos de similitud, como el algoritmo Puck&Tinker desarrollado por DiskAnn y Baidu, para hacer frente a una variedad de necesidades y escenarios. Y considere admitir capacidades informáticas heterogéneas para mejorar la eficiencia de construcción y recuperación de índices.
En términos de costo de rendimiento, los escenarios de aplicaciones a gran escala requieren una optimización más profunda para reducir la sobrecarga del sistema y optimizar la eficiencia del uso de recursos. Por ejemplo, ES se ejecuta en JVM y el motor vectorial se desarrolla en C++ y se ejecuta mediante llamadas JNI. Entonces, ¿cómo podemos gestionar los recursos de memoria global de manera más flexible, adaptarnos a las diferentes cargas de trabajo de los clientes y maximizar la utilización de los recursos? Ésta será una de nuestras principales direcciones de optimización en el futuro.
Finalmente, BES actualmente tiene la forma de un clúster administrado. Los usuarios deben evaluar los recursos del clúster de acuerdo con sus propios niveles de negocio y elegir paquetes razonables. Esto genera un cierto costo para los usuarios. ¿Cómo podemos hacer que los recursos sean más dinámicos y flexibles y ayudar a los usuarios? ¿Reducir costos?El uso de umbrales y la reducción de costos también es nuestra dirección de optimización.
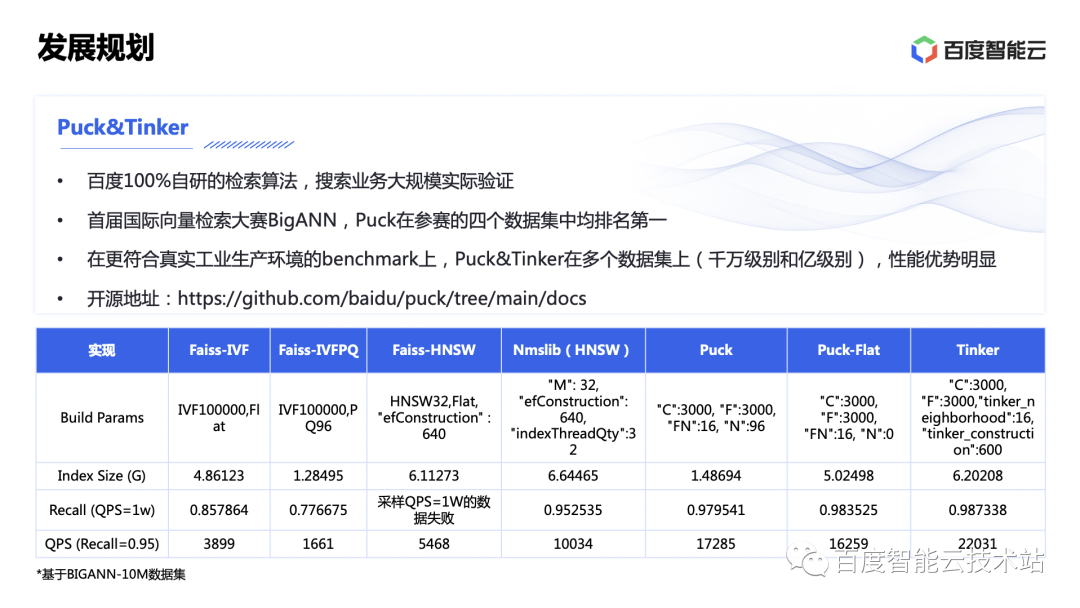
El algoritmo de Puck & Tinker que acabamos de mencionar es el algoritmo de recuperación de vectores 100% desarrollado por Baidu y se ha verificado en búsquedas reales a gran escala en el negocio de las búsquedas.
En el primer concurso internacional de recuperación de vectores, BigANN, Puck ocupó el primer lugar en los cuatro conjuntos de datos participantes. En el conjunto de datos BIGANN-10M, con tasas de recuperación similares, el rendimiento de Puck alcanza 1,7 veces el de HNSW, mientras que su consumo de memoria es solo alrededor del 21% del de HNSW. Puck ha sido de código abierto, todos pueden prestar atención a https://github.com/baidu/puck/tree/main/docs.
3. Compartir casos
3.1 Recuperación de datos multimodal
A continuación se presentan casos de aplicación práctica de BES.
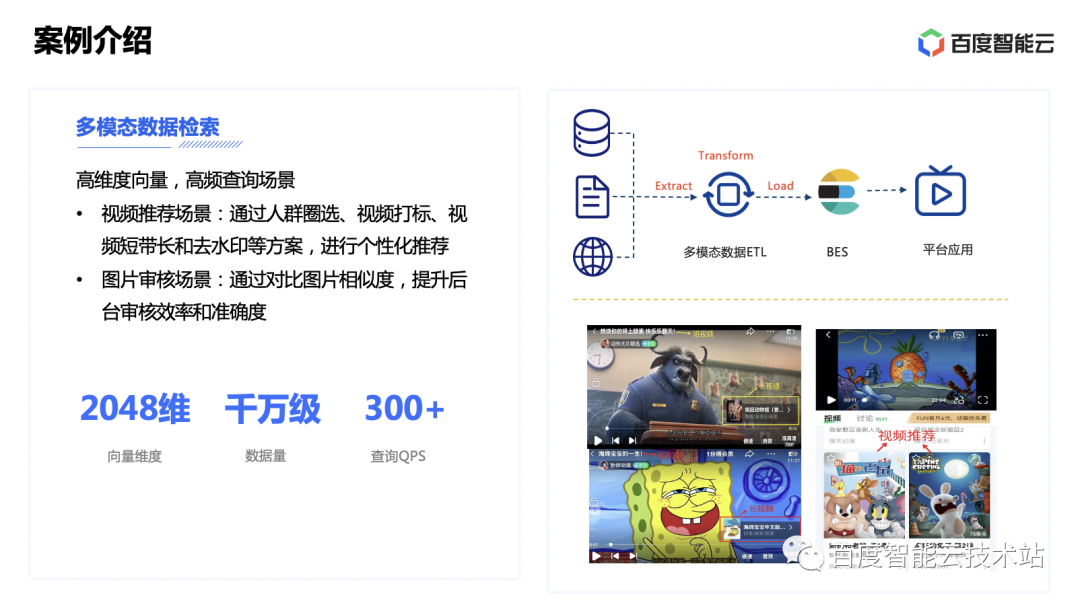
La primera es la aplicación de capacidades vectoriales en escenarios de recuperación multimodal en sitios web de vídeos. El escenario específico es dividir el video en cuadros, realizar procesamiento de características de la imagen y modelado de tiempo en los cuadros, convertir la secuencia de cuadros en vectores a través de redes neuronales, escribirlos en BES y construir una biblioteca de vectores de materiales. Luego, a través de la recuperación de vectores en BES, los resultados con mayor similitud se recuperan y se ingresan en servicios comerciales ascendentes, respaldando escenarios como marcado de video, videos de corta duración y recomendaciones personalizadas.
3.2 Plataforma de modelo grande Qianfan
La base de conocimientos de Qianfan Large Model Platform es un producto diseñado específicamente para escenarios de preguntas y respuestas de conocimientos de modelos de lenguaje grandes, diseñado para gestionar el conocimiento cargado por los clientes y proporcionar funciones rápidas de consulta y recuperación.
Basado en Baidu Intelligent Cloud BES, los usuarios pueden almacenar y recuperar una gran cantidad de documentos de base de conocimientos de manera eficiente, lograr una gestión rápida del conocimiento del dominio privado corporativo y desarrollar la capacidad de crear aplicaciones de preguntas y respuestas sobre conocimientos. Y puede garantizar la privacidad y seguridad de los datos de los clientes.
Aquí hay dos métodos de aplicación. El primer método consiste en implementar de forma independiente una gran base de conocimientos modelo para crear una aplicación de recuperación de conocimientos en el dominio local; el segundo método consiste en vincular directamente aplicaciones complementarias a la plataforma Qianfan para admitir tres tipos de aplicaciones: preguntas y respuestas, generación y tareas.

Lo anterior es todo el contenido compartido.
Haga clic para leer el texto original y conocer más información del producto.
--- FIN ---
Lectura recomendada
Práctica de aplicación de modelos grandes en el campo de la detección de defectos de código.
Hable con InfoQ sobre el motor de búsqueda de alto rendimiento y código abierto de Baidu, Puck
Alibaba Cloud sufrió un fallo grave y todos los productos se vieron afectados (restaurados). Tumblr enfrió el sistema operativo ruso Aurora OS 5.0. Se presentó la nueva interfaz de usuario Delphi 12 y C++ Builder 12, RAD Studio 12. Muchas empresas de Internet contratan urgentemente programadores de Hongmeng. Tiempo UNIX está a punto de entrar en la era de los 1.700 millones (ya entró). Meituan recluta tropas y planea desarrollar la aplicación del sistema Hongmeng. Amazon desarrolla un sistema operativo basado en Linux para deshacerse de la dependencia de Android de .NET 8 en Linux. El tamaño independiente es reducido en un 50%. Se lanza FFmpeg 6.1 "Heaviside"