Presente cómo el sistema de recomendación de la tienda de aplicaciones vivo respalda de manera eficiente las necesidades de recomendación personalizadas.
I. Introducción
Los datos de la aplicación de la tienda provienen principalmente de canales como la programación operativa, CPD, juegos y algoritmos. Una vez que se establece el proyecto de recomendación, no hay cambios. El sistema de recomendación es responsable de acoplarse con la fuente de datos. El servidor de la tienda solo necesita comunicarse con el sistema de recomendación de la aplicación Simplemente haga el acoplamiento.
Si los lectores piensan que simplemente estamos copiando el código del servidor de la tienda en el sistema de recomendación, entonces es realmente demasiado joven, demasiado simple. Es imposible copiar un sistema sin optimización o actualización. Es imposible en esta vida. A continuación, presentaré cómo diseñamos y planificamos el sistema de recomendación de aplicaciones.
2. Desafíos
A los ojos del autor, además del alto rendimiento, la alta disponibilidad y las capacidades de monitoreo de indicadores centrales del sistema de recomendación de aplicaciones de la tienda, otra capacidad central es apoyar de manera eficiente los escenarios de tráfico de la tienda para acceder a recomendaciones personalizadas.
¿Cómo definir un soporte eficiente?
- Al menos puede soportar tres o cuatro demandas paralelas al mismo tiempo.
- Un ciclo de desarrollo de requisitos no debe exceder los 2 días como mínimo.
- Debería haber menos errores. En promedio, no debería haber más de 2 por escena.
- Básicamente, las necesidades normales de los estudiantes de productos se pueden respaldar rápidamente.
Comparta un caso de planificación recomendado por nuestra aplicación:
En el escenario xx,
Si la aplicación principal A pertenece a la categoría de aplicaciones,
- Luego, primero obtenga la cola Q1 de la fuente de datos x1.
- Luego, obtenga la cola Q2 de la fuente de datos x2.
- Luego, use la cola Q2 para truncar la cola Q1 y realice el mismo filtrado de desarrollador y filtrado de clasificación de primer nivel después de la intersección.
- Si la intersección está vacía, use Q2 para ir al final y luego tome los elementos en las posiciones n1 y n2 de la cola de intersección como la cola de retorno.
- Si no hay datos antes, entonces de la tabla xxx de big data de acuerdo con la probabilidad de clics de la aplicación debajo de la aplicación principal, tome n debajo de la categoría con la tasa de clics más alta. Al mismo tiempo, estos datos deben ser filtrados por el mismo desarrollador en la cola.
Si la aplicación principal A pertenece a la categoría de juegos,
- Xxxx
- Realizar filtrado de clasificación secundaria
- Si la cantidad es insuficiente, tome los datos de x (n) y luego procéselos,
- Si hay menos de 3 datos, debe colocar las aplicaciones en el mismo nivel de la lista semanal y seguir las clasificaciones de descarga.
Así es, lectores y amigos no deben dudar de sí mismo Para no confundir a los lectores, acabamos de seleccionar un simple requisito aquí. No es un gran problema implementar una función de este tipo, pero cuando haya docenas de requisitos de recomendación personalizados, ¿entrará en pánico cuando pueda continuar expandiéndose en el futuro? Ahora, echemos un vistazo breve a algunos de los requisitos de nuestra recomendación personalizada, como se muestra en la Figura (1):
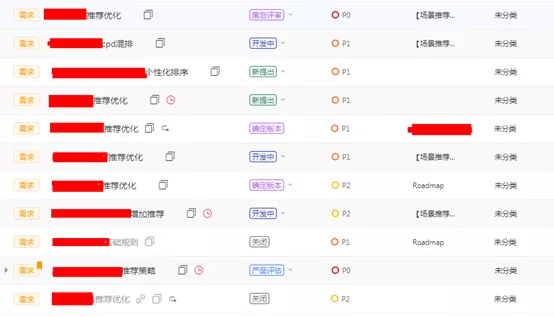
Figura 1)
Utilizando la solución de desarrollo caso por caso antes del servidor de la tienda, en cualquier caso, es imposible lograr el escenario recomendado anteriormente descrito para apoyar el acceso eficiente de la tienda, lo siguiente es cómo podemos lograr el proceso de optimización.
Tres, como resolver
Para explicar mejor las ideas de solución, partimos del proceso de pensamiento real y explicamos el proceso de resolución de problemas paso a paso.
3.1 abstracción de procesos de negocio
Simplemente hablando de la planificación, necesitamos hacer al menos algunas cosas como se muestra en la Figura (2) en cada escena:

Figura II)
- Obtenga la lista de recomendaciones: llame a la cola de recomendaciones obtenida por cada fuente de datos (tenga en cuenta que las interfaces llamadas en diferentes escenarios no son consistentes y los campos y estructuras devueltos por la interfaz pueden ser diferentes).
- Fusión de cola: realice operaciones como intersección o unión como se menciona en 1.
- Filtrado de datos (en cola / entre colas): realice varios filtros en la cola, y la operación de filtrado es principalmente para mejorar la relevancia.
- Tope de datos: cuando los datos de la cola no sean suficientes, utilice la lista para tocar fondo. Puede tomar el mismo nivel de datos de clasificación de los datos de clasificación semanal y el mismo nivel de datos de clasificación.
El autor hizo más ajustes al modelo en función de la conveniencia del desarrollo, y la figura ajustada se muestra en la Figura (3)
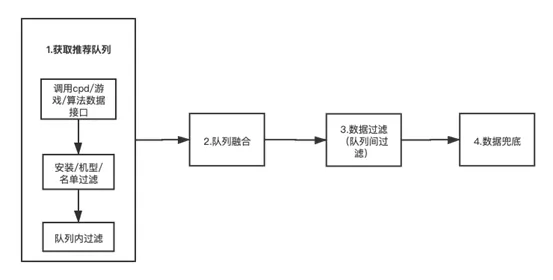
Figura (tres)
Después de obtener la cola, instale y filtre la cola y filtre en la cola (como la aplicación principal y el filtrado del desarrollador, etc.). El proceso se puede fusionar. Las razones principales son las siguientes
- Es conveniente definir la estrategia de filtrado de cada fuente de datos. En la demanda real, diferentes colas también utilizarán diferentes estrategias de filtrado.
- Este enfoque coincide estrechamente con el patrón de diseño de la plantilla y puede garantizar que el proceso de obtención de la lista de recomendaciones sea coherente y estable.
3.2 Extensión del proceso abstracto
Pasando a la Figura (3), los lectores encontrarán que todavía no hemos podido resolver el proceso de diferenciación en los diversos escenarios de recomendación que mencionamos anteriormente.
De hecho, después de contactar con algunos requisitos, encontraremos que es casi imposible resolver una diferencia tan grande en un conjunto de código, o incluso si se implementa, hará que el código sea extremadamente complicado. En lugar de hacer esto, también podríamos enfrentarnos a esta diferencia, dejar que la diferencia se realice en el complemento de escena y gastar más energía para cuidar la columna vertebral.
Entonces, para respaldar las capacidades de expansión flexible de la escena, el autor agrega cuatro enlaces sobre la base de la Figura (3):
- Cola de resultados compartidos dentro de subprocesos: use ThreadLocal para lograrlo. La razón principal para almacenar los resultados de cada cola de recomendaciones es facilitar el uso posterior de una cola de recomendaciones para completar los requisitos. Además, es para evitar la necesidad de solicitar repetidamente la interfaz de datos tripartita y reducir la llamada repetida del interfaz.
- La parte inferior de la cola de complementos: el objetivo principal es utilizar la cola especificada para completar el llenado después del filtrado cuando la cantidad es insuficiente. El complemento de escena también puede completar según sea necesario para realizar la lógica de llenado y realizar el suplemento. del contenido de la cola.
- Devolución de llamada de la interfaz de complemento: este enlace es principalmente para personalizar la cola anterior, como intervenir en la cola, etc. La devolución de llamada de la interfaz de complemento y la cola de complemento no están integradas juntas. La razón principal es que la integración de la cola de complementos puede lograr ajustes configurables.
- Lista de clasificación semanal: proporciona capacidades generales de consulta de datos de lista de clasificación semanal, admite consultas de acuerdo con varias dimensiones, esta parte de los datos como la lista final de la cola.
El diagrama de flujo expandido se muestra en la Figura (4)
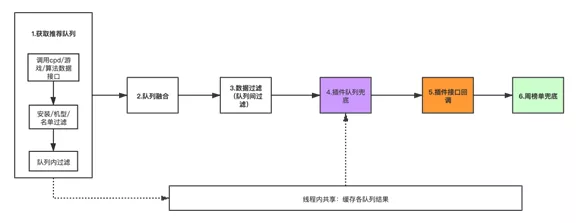
Figura (cuatro)
3.3 Diagrama de bloques lógicos general
A través del análisis anterior, podemos saber que podemos poner el contenido de la escena personalizada en la capa del complemento tanto como sea posible, y la capa del marco es responsable de cargar la lógica de recomendación personalizada específica de cargar los complementos de la escena de acuerdo con la escena. .
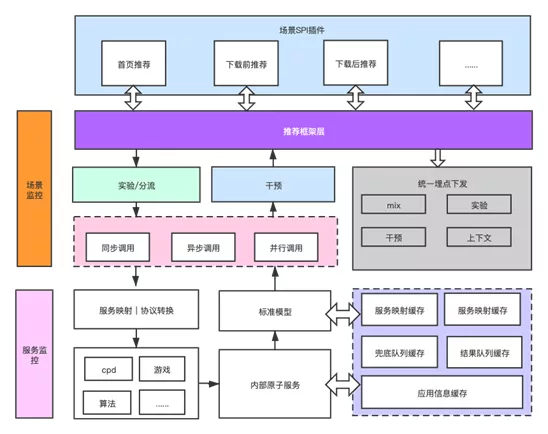
Desde la perspectiva de las capas, el sistema se divide en: capa de complemento, capa de marco, capa de adaptación de protocolo, capa de servicio de fuente de datos, capa de servicio atómico y capa de servicio básico. La capa superior depende de los servicios (interfaces) del capa inferior a través del SDK. Las responsabilidades en cada nivel son:
- Capa de complementos: complementos correspondientes a cada escena, la capa de marco proporciona implementaciones predeterminadas para devoluciones de llamada de complementos o interfaces de extensión, y la capa de complementos implementa lógica específica bajo demanda.
- Capa de marco: define el proceso central y la lógica de ejecución de los datos recomendados e implementa la interfaz de extensión y devolución de llamada de la capa de complemento de devolución de llamada.
- Capa de adaptación de protocolo: responsable de encontrar el servicio de fuente de datos correspondiente a la escena según la escena, y encapsular el protocolo de conversión y realizar la conversión de datos.
- Capa de servicio de fuente de datos: capa de encapsulación de servicio RPC proporcionada por cada proveedor de cola.
- Capa de servicio atómico: servicios relacionados del tipo de filtrado, que dependen principalmente del servicio RPC de la tienda, utilizando el patrón de diseño combinado, los servicios se pueden combinar.
- Capa de servicio básico: admite el juicio de correlación o el filtrado de la latitud del desarrollador, clasificación de primer nivel, clasificación de segundo nivel, tipo de aplicación, etc., como la capa de servicio atómico, esta capa de servicios también tiene granularidad atómica y admite control combinado .
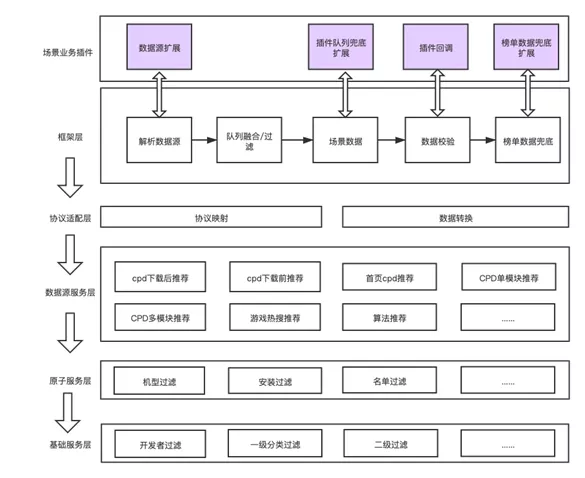
En este punto, creo que todos son conscientes de que para las recomendaciones personalizadas, nuestro trabajo de desarrollo eventualmente se centrará en el desarrollo de complementos de escenarios y no es necesario desarrollar cada proceso comercial adicional.
Arquitectura del sistema de recomendación de aplicaciones
3.4 Realización de claves
Después de completar el diseño general del diagrama de bloques lógicos del tercer paso, realizamos una investigación relacionada sobre la definición de los parámetros de la escena, los principios del diseño del servicio, el uso de patrones de diseño y el intercambio en caliente de escenas, y finalmente nos dimos cuenta de la implementación del plan.
3.4.1 Definición de parámetros de servicio de escenario
Para darnos cuenta de que el escenario recomendado es lo suficientemente universal, mapeamos el contenido de la capa de fuente de datos, la capa de servicio atómico y la capa de servicio básico a la configuración del servicio, y realizamos el mapeo y combinación de servicios definiendo la configuración correspondiente. elementos en la configuración, apuntando a la diferencia El contenido se implementa en la capa de plug-in. Para ilustrar con el siguiente diagrama de elementos de configuración:
- sourceMap: el servicio de escena se define como la situación en la que el mapa se utiliza para admitir varios módulos o grupos experimentales en la escena, donde la clave es el ID del módulo y este parámetro debe llevarse cuando el servidor de la tienda solicita recomendaciones.
- cpdRequest, algorítmRequest, gameRequest: se utilizan para definir los parámetros de solicitud de la llamada RPC correspondiente.
- filterRequest: se utiliza para definir la solicitud de filtrado en la cola, como el filtrado entre la aplicación principal y el desarrollador.
- unionStrategy: define la fusión y fusión de colas y las reglas de fusión entre colas.
- suplemento: estrategia de fondo;
- sourceList: La fuente de datos utilizada. Como se muestra en la figura anterior, hay dos fuentes de datos definidas, lo que significa que en este escenario, los datos deben obtenerse de las dos fuentes de datos, y luego se realizan la fusión de colas y el posprocesamiento.

3.4.2 Atomización y singularidad del servicio
Lograr la atomización del servicio y la unicidad del servicio es muy importante para este sistema. En el proceso de implementación, se siguen estrictamente los siguientes dos puntos:
El servicio RPC de terceros en el que se basa la recomendación de la aplicación y cierta lógica de filtrado interno se encapsulan en un SDK de servicio (método) atómico detallado. El contenido del SDK no incluye las capacidades comerciales específicas de los escenarios de recomendación personalizados. El enfoque está en los elementos funcionales básicos. El contenido comercial debe implementarse en el complemento del escenario, y los tipos unificados de servicios admiten la combinación tanto como sea posible .
La singularidad del servicio es esencial para lograr la convergencia del sistema y la escala de código controlable, y trabajamos constantemente para lograrlo. Cada capa de servicio proporciona funciones relacionadas en forma de SDK, y la singularidad de la entrada de la llamada de servicio se realiza en el SDK.
3.4.3 Uso razonable de patrones de diseño
Se utilizan muchos patrones de diseño en el sistema para optimizar la arquitectura general. Lo siguiente se centra en los patrones de diseño de la plantilla, los patrones de estrategia y los patrones de combinación utilizados:
El patrón de diseño de la plantilla y el patrón de estrategia se utilizan para lograr este proceso en la obtención de la cola original de recomendaciones.
Los beneficios de utilizar el patrón de diseño de plantilla son obvios y pueden promover fácilmente el flujo de esta parte de la lógica de procesamiento.
Para diferentes fuentes de datos, es necesario utilizar diferentes servicios y métodos de fuentes de datos. La ventaja de usar el modo de estrategia es facilitar la definición de llamadas a diferentes interfaces en diferentes escenarios.
Los servicios o métodos atómicos del mismo tipo admiten el modo compuesto tanto como sea posible, lo que proporcionará una gran comodidad para la expansión posterior.
Para ilustrar el método de implementación real, cuando definimos el tipo de filtro, admitimos la entrada de múltiples tipos de filtro, y los servicios de nivel superior se pueden pasar según sea necesario cuando están en uso. El patrón de diseño del uso de la combinación juega un papel muy importante en la mejora de la escalabilidad.
3.4.4 Intercambio en caliente de escenas
Para realizar el aislamiento y la no interferencia entre escenas en el sistema, el autor utiliza el método Java SPI para definir interfaces de escena en la capa de marco, y las clases de implementación de interfaz se implementan en jarras separadas en cada escena. Este método ayuda al programa de complemento a minimizar la intrusión de la capa de estructura y la capa de servicio básico.
Cuarto, los cambios producidos
En el pasado, el servidor de la tienda escribía la lógica completa de adquisición, fusión, ensamblado y filtrado de la cola de recomendaciones en la capa de servicio de cada interfaz. Había una gran cantidad de contenido duplicado. Y con la iteración continua de la versión, había muchos procesos diferentes lógicas de diferentes versiones mezcladas, lo que resulta en Es difícil de transformar y actualizar, y afectará a todo el cuerpo. El sistema de recomendación de aplicaciones actual ha traído grandes mejoras en dos direcciones:
- La lógica del marco del proceso es completamente abstracta e independiente. Cada escenario empresarial solo necesita escribir una pequeña cantidad de lógica de devolución de llamada de complemento a pedido. (No implica escenarios muy especiales y no es necesario escribir complementos. en extensiones de devolución de llamada en absoluto. Puede configurar la configuración de la regla de escenario correspondiente., Puede estar completamente libre de desarrollo, actualmente alrededor del 30% de las escenas están libres de desarrollo).
- Las escenas están completamente aisladas e independientes, y las actualizaciones de funciones complejas se pueden implementar de forma incremental actualizando la identificación de la escena o la identificación del módulo correspondiente, sin afectar la lógica existente.
Cinco, escribe al final
Mediante la implementación de las soluciones relacionadas mencionadas anteriormente, hemos reducido aproximadamente la carga de trabajo de desarrollo en un 75% para cada escenario recomendado, y la tasa de errores también se ha reducido considerablemente.
Autor: vivo-Huang Xiaoqun