Este artículo interpreta el artículo "StreamOps: Cloud-Native Runtime Management for Streaming Services in" publicado conjuntamente por el equipo del profesor Ma Tianbai de la Universidad Nacional de Singapur y el equipo de infraestructura, informática y transmisión de ByteDance en la principal conferencia internacional de gestión de datos y bases de datos VLDB. 2023. "ByteDance", presenta una solución de control y gestión del tiempo de ejecución de tareas de streaming extraída por ByteDance basada en decenas de miles de prácticas de gestión de tareas de streaming de Flink, que resuelve eficazmente varios tipos de operaciones expuestas debido a cambios en el tráfico y el entorno operativo durante la ejecución de Trabajos de streaming: Los problemas que a veces requieren intervención manual para gestionarse son necesarios para promover las capacidades centrales basadas en NoOps. Admite la gestión de trabajos de transmisión a gran escala y proporciona capacidades que incluyen expansión y contracción automática, migración automática de nodos lentos y diagnóstico inteligente de retrasos/fallos. También puede ampliar funciones mediante complementos. StreamOps se ha verificado a gran escala dentro de Bytedance, ahorrando un 15% de los recursos informáticos diariamente, migrando efectivamente nodos lentos aproximadamente 1000 veces al día, reduciendo las llamadas manuales en un 75% y reduciendo significativamente los costos de mantenimiento de las tareas de transmisión en ultra -escenarios a gran escala.

Enlace del artículo: https://www.vldb.org/pvldb/vol16/p3501-mao.pdf.
introducción
En los últimos años, la computación en flujo se ha utilizado ampliamente en el procesamiento de datos y la toma de decisiones a gran escala en tiempo real. ByteDance ha elegido Flink como su motor de procesamiento de computación en streaming. Cada día se ejecutan decenas de miles de trabajos de Flink en clústeres internos, con un tráfico máximo que alcanza los 9 mil millones de datos por segundo. Dado que los trabajos de streaming suelen durar días o más, sus cargas de trabajo y entornos operativos tienden a cambiar con el tiempo. La diferencia de tráfico entre el período pico y el período mínimo de las operaciones de transmisión dentro de Byte es de 4 a 5 veces en promedio, y siempre se enfrenta a problemas como la congestión de recursos subyacente y las diferencias en los modelos de máquina. Dichos cambios provocarán varios problemas de tiempo de ejecución, como acumulación de datos y diversas fallas, lo que resultará en la necesidad de intervención manual frecuente o una reserva excesiva de recursos que generará desperdicio. Con el rápido crecimiento de la informática de flujo, se necesita con urgencia un sistema de control y gestión del tiempo de ejecución para resolver automáticamente estos problemas de tiempo de ejecución. Sin embargo, es un desafío diseñar un servicio de administración del tiempo de ejecución de trabajos de transmisión en un escenario como ByteDance: el servicio debe ser lo suficientemente escalable para administrar de manera uniforme todos los trabajos de transmisión a nivel de clúster y utilizar estrategias efectivas de administración y control. también necesita tener una buena escalabilidad para desarrollar nuevas estrategias de gestión y control para nuevos problemas de tiempo de ejecución.
En respuesta a los desafíos anteriores, este artículo propone un sistema de control y gestión del tiempo de ejecución de tareas de transmisión StreamOps basado en la nube nativa, que puede reducir efectivamente el costo de mantenimiento de las tareas de transmisión de usuarios en escenarios a gran escala. StreamOps está diseñado como un sistema de control y gestión liviano y escalable que se ejecuta independientemente de los trabajos de transmisión para administrar de manera uniforme trabajos de transmisión a gran escala. Resume una capa de paradigma de programación de estrategias de gestión y control para respaldar la construcción rápida de nuevas estrategias de gestión y control. Basado en la experiencia práctica interna a largo plazo de Byte, admite la expansión y contracción automática de tareas de transmisión, la migración automática de nodos lentos y Diagnóstico inteligente de retrasos/fallos Tres estrategias centrales de gestión y control. Este artículo presenta las decisiones de diseño y las experiencias relacionadas que tomamos al diseñar StreamOps y realiza experimentos en un entorno de producción interno para verificar el efecto de StreamOps.
Introducción a SteamOps
La figura anterior muestra la arquitectura general y el flujo de trabajo de StreamOps. Incluye principalmente 3 componentes:
-
Servicio de plano de control: un servicio sin estado escalable horizontalmente para administrar trabajos de transmisión a nivel de clúster. Se implementa independientemente de los trabajos de transmisión para desacoplar el plano de control y el motor informático de transmisión para una mayor flexibilidad y escalabilidad.
-
Almacenamiento global: almacena indicadores de trabajo, registros y otros datos necesarios para las decisiones de políticas de gestión y control, así como los datos de estado del propio servicio del plano de control.
-
Activador de administración de tiempo de ejecución: cada trabajo de transmisión está equipado con un activador de administración de tiempo de ejecución para enviar solicitudes al servicio del plano de control para activar operaciones de administración. Las solicitudes se pueden activar periódicamente, cuando se cumple una condición específica, o manualmente.
El flujo de trabajo general es:
-
Un único trabajo de transmisión desencadena operaciones de gestión y control en el servicio del plano de control en función de la política de activación.
-
Después de recibir la solicitud, el servicio del plano de control extrae datos como indicadores de trabajo y el estado de la propia política de gestión y control del almacenamiento global para tomar decisiones sobre políticas de gestión y control.
-
Una vez que la estrategia de gestión y control toma una decisión, iniciará cambios de configuración cuando se esté ejecutando el trabajo de transmisión o emitirá un recordatorio de alarma al usuario.
servicios de control de aviones
StreamOps adopta el principio de diseño de separación de políticas y mecanismos y divide el proceso de control general en dos partes: estrategia de control y mecanismo de control. Las estrategias de gobernanza se centran en decisiones de modelos responsables, y la implementación se define mediante un paradigma de programación común que abstrae los tres pasos de descubrimiento-diagnóstico-resolución. El mecanismo de gestión y control es responsable de interactuar con sistemas externos, ejecutar la adquisición de índices y ejecutar operaciones de cambio de control en base a decisiones.El mecanismo general de adquisición de índices y cambio de control está encapsulado y puede reutilizarse. A través de las medidas anteriores, se puede ampliar e implementar una nueva estrategia de gestión y control a bajo costo.
Estrategia de control

La figura anterior muestra el proceso general de toma de decisiones de la estrategia de gestión y control. La estrategia de gestión y control primero obtiene los indicadores y la información de configuración cuando el trabajo de transmisión se ejecuta desde el recolector de indicadores, y luego sigue el proceso de descubrimiento de tres pasos. diagnóstico y resolución para obtener los indicadores y la información de configuración. Las decisiones se toman y finalmente se entregan al cambiador de configuración del trabajo de transmisión para su ejecución. Los mecanismos de ejecución comunes incluyen expansión y contracción, migración de nodos o simplemente enviar alarmas para que los usuarios las manejen manualmente.
Mecanismo de control
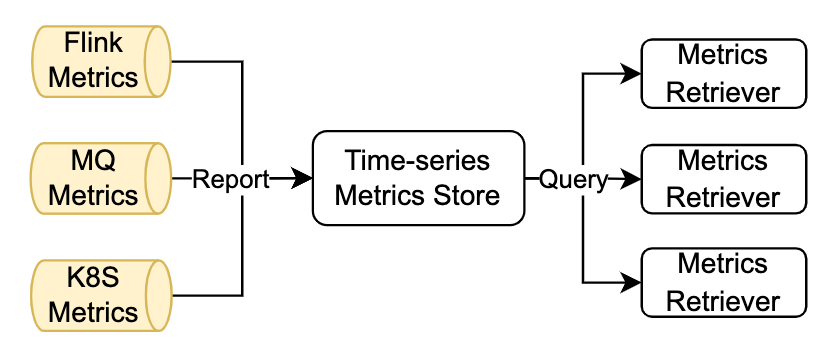
1. Colección de indicadores
Además de los indicadores del motor de cálculo en sí, la información de indicadores comúnmente utilizada para la gestión y el control de trabajos de transmisión también incluye indicadores relacionados con la fuente de datos en el lado MQ y indicadores relacionados con recursos en el lado K8. ByteDance almacena en caché internamente los tres tipos de indicadores. a través de la base de datos central de series temporales. StreamOps está conectado al sistema interno de base de datos de series de tiempo y la estrategia de gestión y control puede realizar operaciones de consulta enriquecidas en diferentes tipos de indicadores según sea necesario.
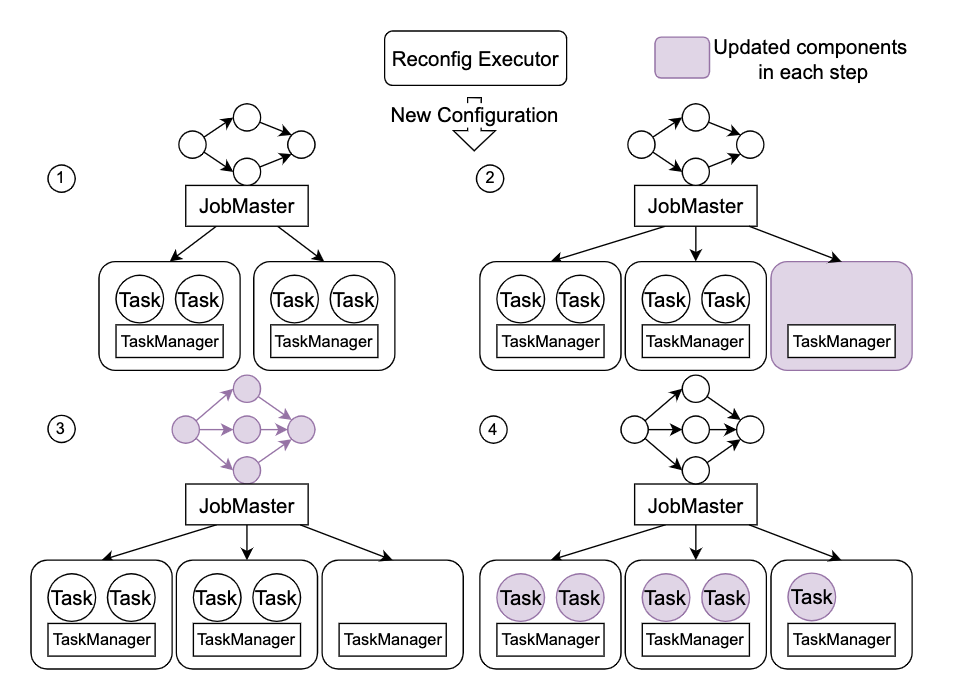
2. Cambios de configuración cuando se ejecutan trabajos de transmisión
Los cambios de configuración del trabajo se pueden completar reiniciando, pero esto tiene un mayor impacto en los usuarios. En términos de cambios, primero usamos la API para acelerar las actualizaciones de trabajos. Además, nuestro análisis encontró que hay mucho espacio para la optimización en este tipo de operaciones. En primer lugar, una gran parte del tiempo en operaciones que involucran cambios de recursos. Se gasta en la aplicación de recursos. Para trabajos de estado pequeño, el más alto Puede alcanzar el 70%. Implementa un conjunto de mecanismos de preaplicación de recursos y está conectado a StreamOps. Para tareas de estado grande, la mayor parte del tiempo se dedica a la recuperación del estado. Hemos optimizado el mecanismo de fusión y poda de bases de datos para RocksDB y el tiempo general de recuperación del estado se ha acelerado 10 veces. Después de nuestra optimización general, el tiempo total de interrupción se redujo de los minutos necesarios para un reinicio completo a segundos, lo que lo hace casi insensible para los usuarios.
Implementación de estrategias centrales de gestión y control.
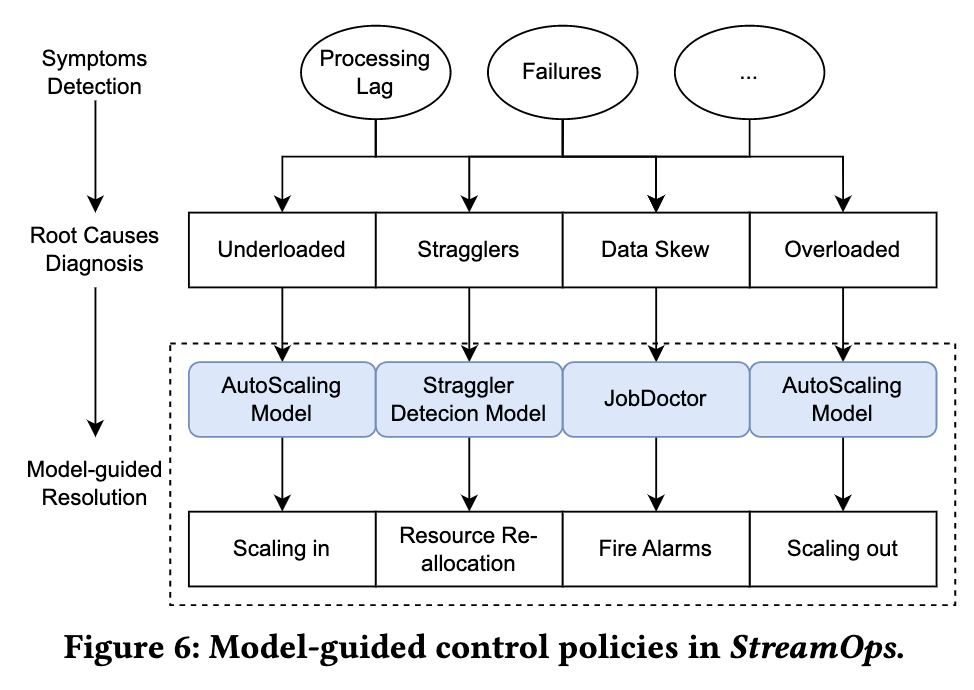
Los objetivos de la estrategia central de gestión y control de StreamOps son: 1. Garantizar que el procesamiento de trabajos se mantenga al día con la velocidad de datos entrantes y resolver el problema de la acumulación de mensajes y las excepciones del tiempo de ejecución; 2. Mejorar la utilización de los recursos del clúster y reducir los costos. En la práctica de producción de Byte, se descubrió que hay dos razones principales para la acumulación de mensajes: recursos generales insuficientes y desequilibrio de carga. El desequilibrio de carga se puede subdividir en máquinas (nodos lentos) con una eficiencia de ejecución lenta y sesgo de datos. Las excepciones en tiempo de ejecución tienen varias causas y muchas veces no se pueden resolver desde el motor de cálculo. Por lo tanto, StreamOps implementa tres estrategias centrales de gestión y control, como se muestra en la figura anterior:
-
Expansión y contracción automática: resuelva el problema de la asignación insuficiente/excesiva de recursos del trabajo general.
-
Migración automática de nodos lentos: resuelva la acumulación de mensajes causada por máquinas con una eficiencia de funcionamiento lenta.
-
Diagnóstico inteligente: proporcione diagnósticos y sugerencias para problemas como distorsión de datos y anomalías en el tiempo de ejecución que a menudo no se pueden resolver desde el motor informático.
Expansión y contracción automática.

Basado en el modelo DS2 [1], hemos ampliado e implementado un modelo de expansión y contracción automática adecuado para bytes. El proceso general de toma de decisiones es el anterior. El modelo considera exhaustivamente la acumulación de mensajes del trabajo y las condiciones de carga del operador para determinar si se necesitan operaciones de expansión y contracción. Para la expansión y contracción, también considerará la situación de la carga de trabajo en el período anterior para eliminar situaciones anormales como sesgos graves de datos y ejecución del trabajo. fracasos para evitar errores decisión. Durante el proceso de procesamiento, combinado con mecanismos como la actualización en caliente del trabajo, la fusión de bases de datos de RocksDB y la aceleración de recorte, se puede lograr una recuperación rápida con un tiempo de inactividad casi nulo.
Migración automática de nodos lentos.

Para el problema de los nodos lentos causado por una pequeña cantidad de máquinas que se ejecutan en el entorno, el modelo de detección puede eliminar situaciones regulares mediante algoritmos, detectar nodos anormalmente lentos con alta agregación de máquinas en la topología del trabajo y migrarlos y restaurarlos. Durante el proceso de procesamiento, se utilizan métodos de optimización como el bloqueo de nodos y la aplicación previa de recursos para hacerlo más rápido y estable.
Diagnóstico inteligente
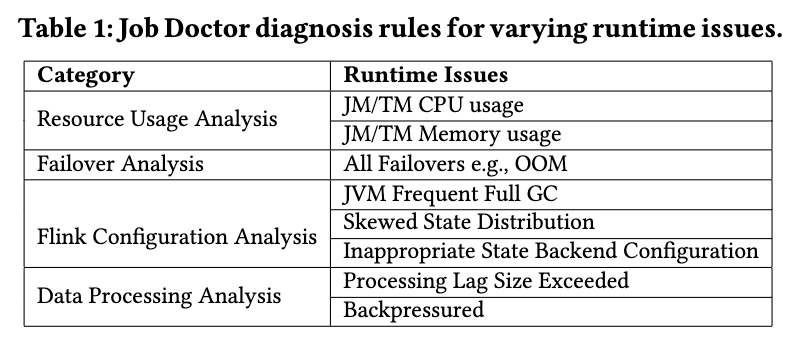
Al mismo tiempo, StreamOps implementa un sistema de diagnóstico inteligente (Job Doctor) y proporciona una plataforma de visualización para que los usuarios y el personal de operación y mantenimiento la analicen y utilicen. Cubre principalmente los siguientes cuatro tipos de reglas de diagnóstico: análisis y sugerencias de uso de recursos, análisis y sugerencias de recopilación de excepciones en ejecución, análisis y sugerencias de configuración de Flink y análisis y sugerencias de procesamiento de cuellos de botella. Los usuarios pueden realizar una detección independiente y el sistema también realizará inspecciones periódicas, enviará advertencias a los usuarios y proporcionará las sugerencias de procesamiento correspondientes.
Resultados experimentales
Efecto general del plano de control
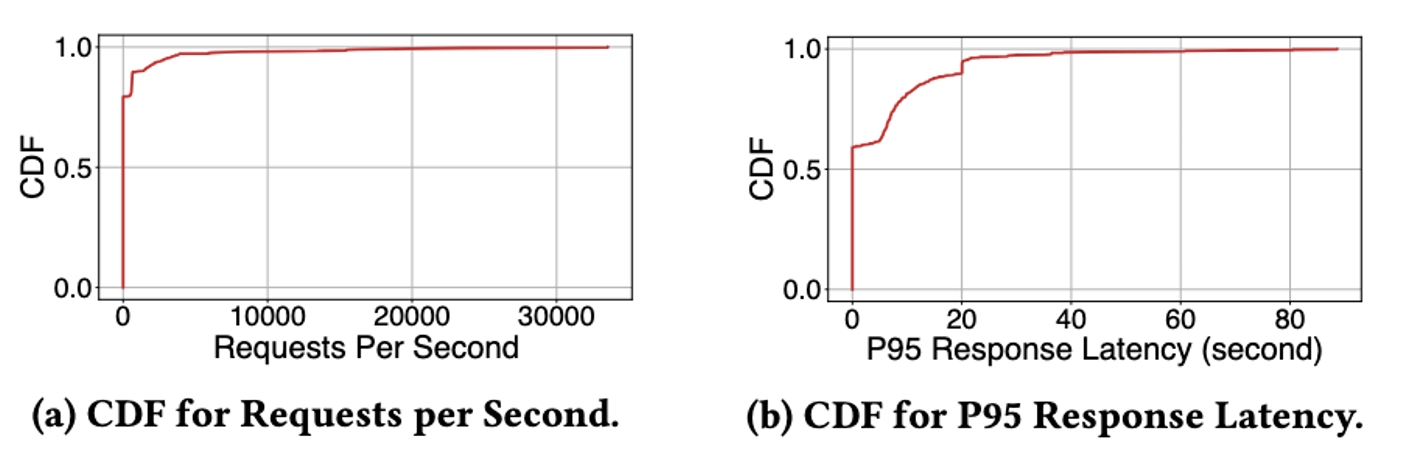
Primero, demostramos la evaluación de StreamOps de las capacidades de control y gestión de operaciones a gran escala de los trabajos a nivel de clúster. Implementamos un clúster StreamOps que consta de 50 nodos en el entorno de producción para pruebas de estrés. Cada nodo se configuró con una CPU de 16 núcleos y 32 GB de memoria. Como se puede ver en la figura siguiente, StreamOps puede lograr un tiempo de respuesta de P95 en 60 segundos con un máximo de 33.000 solicitudes por segundo, lo que demuestra que el sistema tiene una buena escalabilidad.
Efecto de expansión y contracción automática.
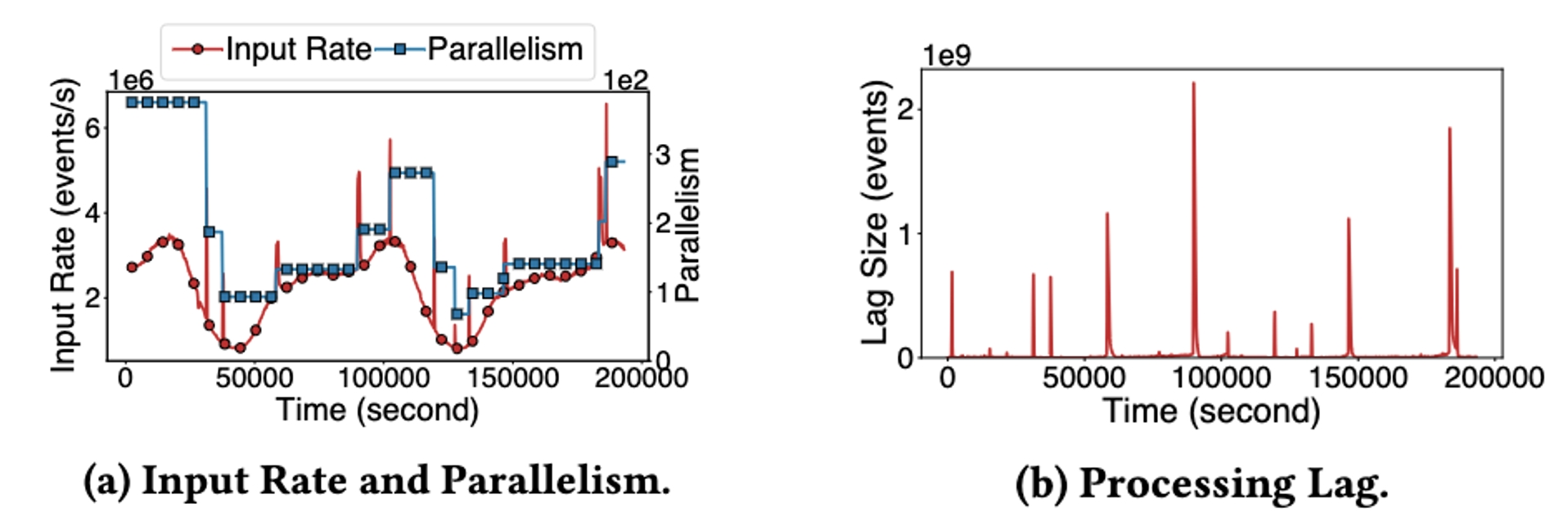
Esto muestra el efecto de ejecución de la expansión y contracción automática en un trabajo de producción de gran tráfico: la Figura a muestra el cambio del paralelismo del trabajo con la tasa de entrada de trabajos, y la Figura b muestra el cambio en la acumulación de mensajes durante el período. Se puede ver que StreamOps puede aumentar y reducir efectivamente de acuerdo con la tasa de entrada de trabajos y puede ahorrar al menos el 60% de los recursos de la CPU. Por supuesto, también se puede ver que la expansión y la contracción en sí causarán una acumulación temporal de mensajes, por lo que cada trabajo puede ajustar los parámetros de una manera más detallada para sopesar el costo de la expansión y la contracción y la sensibilidad de la expansión y contracción automáticas. contracción.
Efecto de migración automática de nodos lentos.
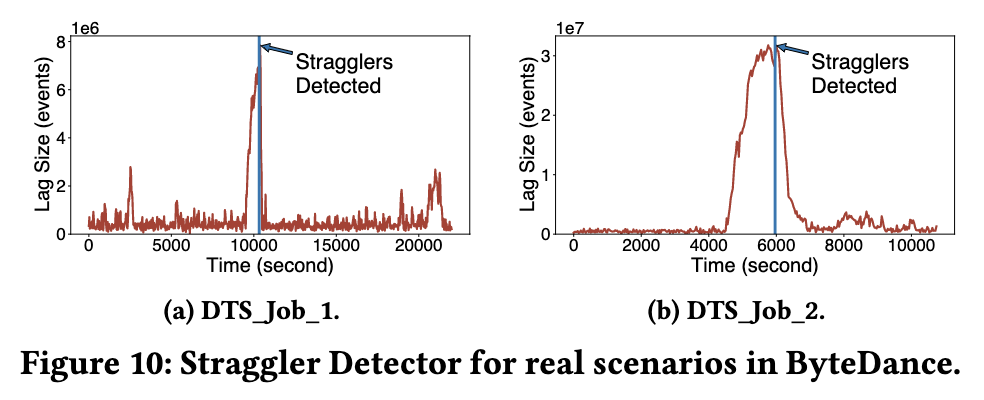
La siguiente figura muestra dos trabajos de producción representativos dentro de Byte que se vieron afectados por nodos lentos, lo que resultó en una acumulación de mensajes. StreamOps puede identificar con precisión y migrar automáticamente los nodos lentos, resolviendo efectivamente el problema de la acumulación de mensajes causado por los nodos lentos.
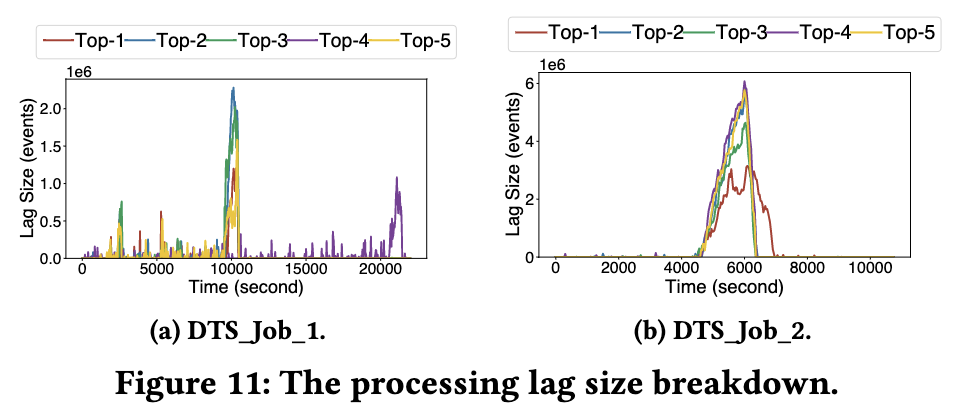
La siguiente figura muestra además las particiones y los trabajos pendientes correspondientes de los 5 trabajos pendientes principales de los dos trabajos anteriores. Se puede ver que más del 80% del trabajo pendiente de mensajes se concentra en las 5 particiones principales, lo que indica que los nodos que consumen estos Las particiones se ejecutan en nodos lentos StreamOps Estos nodos lentos se identificaron con precisión y el trabajo pendiente se resolvió después de la migración.
Efecto de diagnóstico inteligente
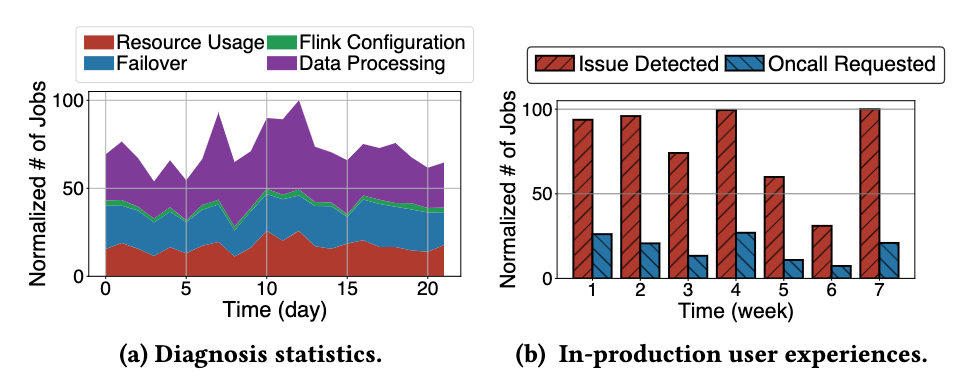
La Figura a muestra la cantidad de varios tipos de problemas de tiempo de ejecución diagnosticados con éxito todos los días usando StreamOps durante un período de tiempo. La Figura b muestra la comparación entre la cantidad de problemas diagnosticados con éxito todos los días dentro de una semana y continuar ingresando al procesamiento manual de guardia después de usar el diagnóstico. . En el pasado, cuando los usuarios encontraban problemas de tiempo de ejecución, generalmente iniciaban llamadas manuales directamente, se puede ver que acceder al diagnóstico inteligente reduce efectivamente la cantidad de llamadas manuales.
Resumir
Este artículo propone StreamOps, un sistema de control y gestión del tiempo de ejecución de tareas de transmisión basado en la nube nativa. El autor lo implementa como un servicio sin estado independiente del trabajo de transmisión, de modo que pueda administrar de manera eficiente y uniforme trabajos de transmisión a gran escala. Se propone dividir el proceso general de gestión y control en dos partes: estrategia y mecanismo general de interacción con sistemas externos, y abstraer la parte de estrategia en un paradigma de programación universal de tres pasos de descubrimiento-diagnóstico-solución, de modo que la nueva gestión y El control se puede implementar rápidamente a bajo costo Estrategia. Implementa tres estrategias principales de gestión y control: expansión y contracción automática, migración automática de nodos lentos y diagnóstico inteligente de retrasos/fallas. Resuelve los puntos débiles de la acumulación de mensajes, las fallas en el tiempo de ejecución y el desperdicio de recursos en la práctica de producción, y ha sido verificado. en el entorno de producción interno de ByteDance: su eficiencia y eficacia.
Cita
[1] https://www.usenix.org/conference/osdi18/presentation/kalavri
Información del autor:
Chen Zhanghao, ingeniero de infraestructura de ByteDance. Experto en informática de streaming, colaborador de Apache Flink. Maestría de la Universidad de Illinois en Urbana-Champaign. Después de graduarse, se dedicó a la investigación y el desarrollo relacionados con la computación de flujo.
Zhang Yifan, ingeniero de infraestructura de ByteDance. Un experto en informática de transmisión con una maestría de la Universidad de Ciencia y Tecnología Electrónica de Hangzhou, una vez trabajó para NetEase y actualmente trabaja a tiempo completo en la investigación y el desarrollo de sistemas y servicios de informática de transmisión en ByteDance.