Introducción al aprendizaje profundo (60) Red neuronal recurrente - Unidad recurrente cerrada GRU
prefacio
El contenido principal proviene del enlace 1 del blog. Enlace 2 del blog. Espero que puedas apoyar mucho al autor.
Este artículo se usa para registros para evitar el olvido.
Red neuronal recurrente - Unidad recurrente cerrada GRU
cursos
centrarse en una secuencia
No todas las observaciones son igualmente importantes.

Querer recordar solo las observaciones relevantes requiere:
- Mecanismos que se pueden seguir (puerta de actualización)
- Mecanismo de olvido (Reset Gate)
Puerta
estado oculto candidato
estado oculto
Resumir
R t = σ ( X t W xr + H t - 1 W hr + br ) , Z t = σ ( X t W xz + H t - 1 W hz + bz ) , tanh ( X t W xh + ( R t ⊙ H t - 1 ) W hh + segundo ) , H t = Z t ⊙ H t - 1 + ( 1 - Z t ) ⊙ H ~ t \begin{alineado}\begin{alineado} \mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{ W}_{hr} + \mathbf{b}_r),\\ \mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{ t-1} \mathbf{W}_{hz} + \mathbf{b}_z),\\ \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R }_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h),\\\mathbf{H}_t = \mathbf{Z} _t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \assignment{\mathbf{H}}_t. \end{alineado}\end{alineado}Rt=s ( XtWx r+Ht − 1Whora _+br) ,Zt=s ( XtWx z+Ht − 1Wh z+bz) ,sospechoso ( X.)tWx h+( Rt⊙Ht − 1)Weh+bh) ,Ht=Zt⊙Ht − 1+( 1−Zt)⊙H~t.
Libro de texto
En la sección Retropropagación a través del tiempo, discutimos cómo se calculan los gradientes en las redes neuronales recurrentes y el problema de que los productos matriciales sucesivos pueden conducir a la desaparición o explosión de gradientes. Pensemos brevemente en el significado de esta anomalía de gradiente en la práctica:
-
Podemos encontrarnos con situaciones en las que las primeras observaciones son muy importantes para predecir todas las observaciones futuras. Considere un caso extremo donde la primera observación contiene una suma de verificación y el objetivo es discernir al final de la secuencia si la suma de verificación es correcta. En este caso, la influencia del primer lema es crucial. Nos gustaría tener algún mecanismo para almacenar información temprana importante en una celda de memoria. Sin tal mecanismo, tendríamos que asignar un gradiente muy grande a esta observación, ya que afectaría a todas las observaciones posteriores.
-
Es posible que nos encontremos con situaciones en las que algunos tokens no tengan observaciones asociadas. Por ejemplo, cuando se realiza un análisis de opinión en el contenido de una página web, puede haber algunos códigos HTML auxiliares que no tienen nada que ver con la opinión que transmite la página web. Nos gustaría tener algún mecanismo para omitir dichos tokens en la representación del estado oculto.
-
Podemos encontrarnos con situaciones en las que hay rupturas lógicas entre partes de la secuencia. Por ejemplo, puede haber transiciones entre capítulos de un libro, o entre mercados bajistas y alcistas en un valor. En este caso, sería bueno tener una forma de restablecer nuestra representación interna de estado.
Muchos métodos han sido propuestos en la academia para resolver tales problemas. Uno de los primeros métodos es la "memoria a corto plazo" (memoria a corto plazo, LSTM). Una unidad recurrente cerrada (GRU) es una variante ligeramente simplificada que generalmente proporciona un rendimiento equivalente y es significativamente más rápida de calcular. Dado que la unidad recurrente cerrada es más simple, comenzamos con ella.
1 estado oculto cerrado
La diferencia clave entre las unidades recurrentes bloqueadas y las RNN ordinarias es que las primeras admiten la activación de estados ocultos. Esto significa que el modelo tiene mecanismos especializados para determinar cuándo se debe actualizar el estado oculto y cuándo se debe restablecer el estado oculto. Estos mecanismos se pueden aprender y abordan los problemas enumerados anteriormente. Por ejemplo, si el primer token es muy importante, el modelo aprenderá a no actualizar el estado oculto después de la primera observación. Asimismo, el modelo también puede aprender a omitir observaciones casuales irrelevantes. Finalmente, el modelo también aprenderá a restablecer el estado oculto cuando sea necesario. A continuación, analizamos en detalle los distintos tipos de puertas.
1.1 Restablecer puerta y Actualizar puerta
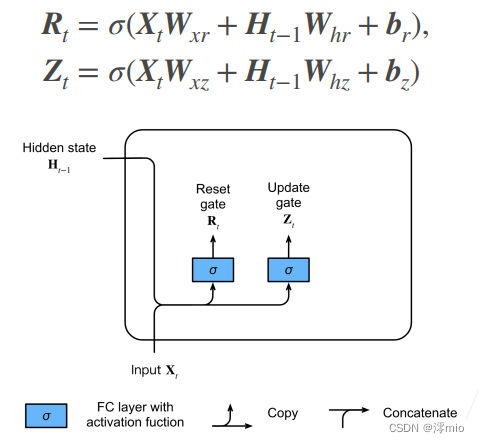
Primero introducimos 重置门(reset gate)y actualizamos la puerta (update gate). Los diseñamos como ( 0 , 1 ) (0, 1)( 0 ,1 ) vectores en el intervalo para que podamos hacer combinaciones convexas. La puerta de reinicio nos permite controlar cuánto del estado pasado "podríamos querer recordar"; la puerta de actualización nos permitirá controlar cuántos del estado nuevo son copias del estado anterior.
Comenzamos construyendo estas puertas. La siguiente figura describe la entrada de la puerta de reinicio y la puerta de actualización en la unidad recurrente cerrada.La entrada viene dada por la entrada del paso de tiempo actual y el estado oculto del paso de tiempo anterior. Las salidas de las dos puertas están dadas por dos capas completamente conectadas que utilizan la función de activación sigmoidea.
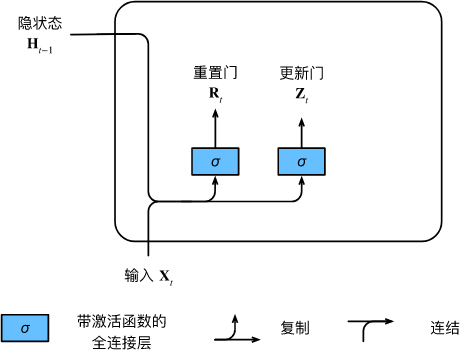
Veamos la representación matemática de una unidad recurrente cerrada. Para un paso de tiempo dado ttt , asumiendo que la entrada es un mini loteX t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d}Xt∈Rn × d (número de muestrasnnn , número de entradaddd ), el estado oculto del último paso de tiempo esH t − 1 ∈ R n × h \mathbf{H}_{t-1} \in \mathbb{R}^{n \times h}Ht − 1∈Rn × h (número de unidades ocultas). Entonces, la puerta de reinicioR t ∈ R n × h \mathbf{R}_t \in \mathbb{R}^{n \times h}Rt∈Rn × h y actualizar la puertaZ t ∈ R n × h \mathbf{Z}_t \in \mathbb{R}^{n \times h}Zt∈RDetermine la función de n × h
: R t = σ ( X t W xr + H t − 1 W hr + br ), Z t = σ ( X t W xz + H t − 1 W hz + bz ) , \ begin {dividir}\begin{align} \mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{W } _{hr} + \mathbf{b}_r),\\ \mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{t - 1} \mathbf{W}_{hz} + \mathbf{b}_z), \end{alineado}\end{dividido}Rt=s ( XtWx r+Ht − 1Whora _+br) ,Zt=s ( XtWx z+Ht − 1Wh z+bz) ,
Para W xr , W xz ∈ R d × h \mathbf{W}_{xr}, \mathbf{W}_{xz} \mathbb{R}^{d \times h}Wx r,Wx z∈Rd × h和W hr , W hz ∈ R h × h \mathbf{W}_{hr}, \mathbf{W}_{hz} \in \mathbb{R}^{h \times h}Whora _,Wh z∈Rh × h es el parámetro de peso,br , bz ∈ R 1 × h \mathbf{b}_r, \mathbf{b}_z \in \mathbb{R}^{1 \times h}br,bz∈R1 × h es el parámetro de sesgo. Tenga en cuenta que se activa un mecanismo de transmisión durante la suma. Usamos la función sigmoidea para convertir el valor de entrada al intervalo( 0 , 1 ) (0, 1)( 0 ,1 )。
1.2 Estados ocultos candidatos
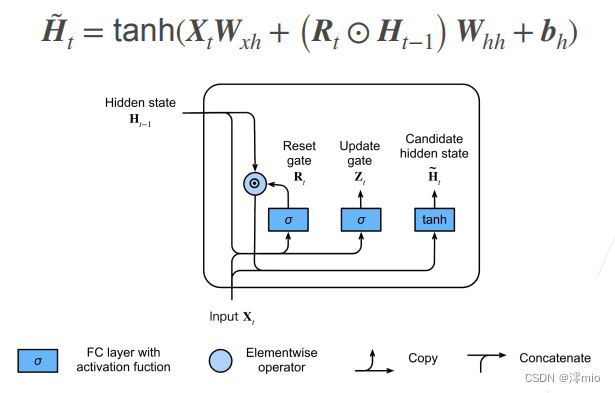
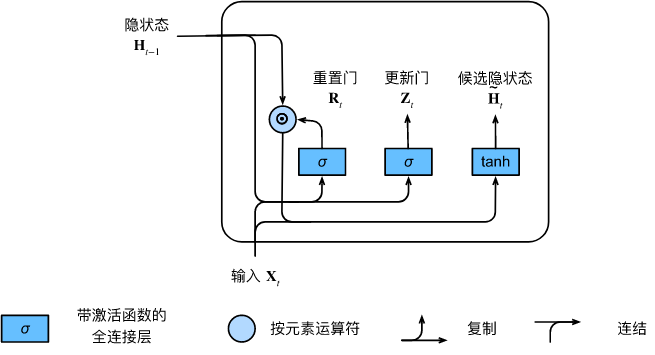
A continuación, restablezcamos la puerta R t \mathbf{R}_tRt与RNN中H t = ϕ ( X t W xh + H t - 1 W hh + segundo ) . \mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{ b}_h).Ht=ϕ ( XtWx h+Ht − 1Weh+bh) Integrando el mecanismo regular de actualización de estado oculto en ., obtenga el paso de tiempottt的候选隐状态(candidate hidden state) H ~ t ∈ R n × h \tilde{\mathbf{H}}_t \in \mathbb{R}^{n \times h}H~t∈Rnorte × h
H ~ t = tanh ( X t W xh + ( R t ⊙ H t − 1 ) W hh + bh ) , \tilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b} _h),H~t=sospechoso ( X.)tWx h+( Rt⊙Ht − 1)Weh+bh) ,
其中W xh ∈ R d × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h}Wx h∈Rd × h和W hh ∈ R h × h \mathbf{W}_{hh} \in \mathbb{R}^{h \times h}Weh∈Rh × h es el parámetro de peso,bh ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h}bh∈R1 × h es un elemento de sesgo, símbolo⊙ \odot⊙ es el operador del producto Hadamard (producto por elementos). Aquí, usamos la función de activación no lineal tanh para garantizar que los valores en los estados ocultos candidatos permanezcan en el intervalo( − 1 , 1 ) (-1, 1)( -1 , _1 ) .
与H t = ϕ ( X t W xh + H t - 1 W hh + segundo ) . \mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{ b}_h).Ht=ϕ ( XtWx h+Ht − 1Weh+bh) Comparado con el R t \mathbf{R}_ten la fórmula anteriorRt和H t − 1 \mathbf{H}_{t-1}Ht − 1Multiplicar los elementos de puede reducir la influencia de estados anteriores. Siempre que la puerta de reinicio R t \mathbf{R}_tRtCuando el término in está cerca de 1, restauramos una red neuronal recurrente normal como en un RNN normal. Para la puerta de reinicio R t \mathbf{R}_tRtTodos los elementos cerrados en 0, el estado oculto candidato es X t \mathbf{X}_tXtEl resultado del perceptrón multicapa como entrada. Por lo tanto, cualquier estado oculto preexistente es ** 重置** ** el valor predeterminado.
La siguiente figura ilustra el flujo de cálculo después de aplicar la puerta de reinicio.
1.4 Estado oculto
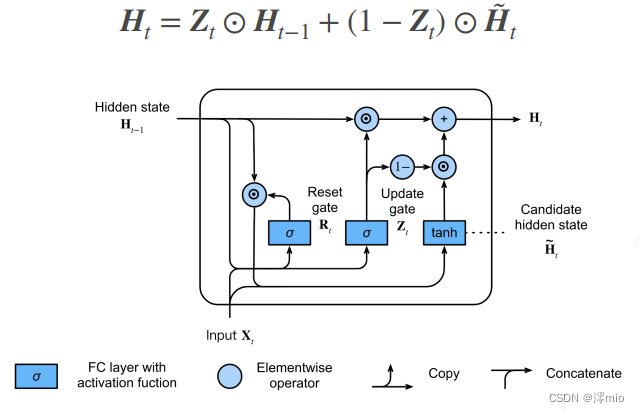
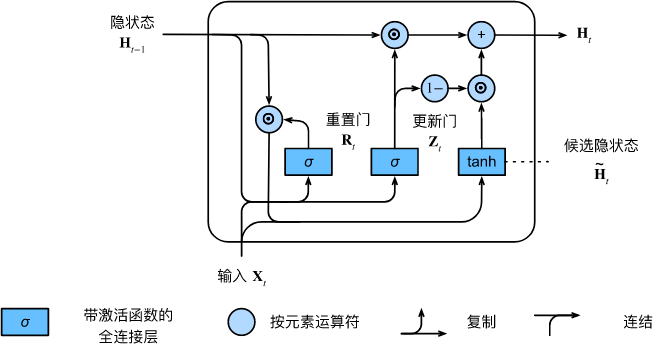
Los resultados de los cálculos anteriores son solo estados ocultos candidatos, aún necesitamos combinar la puerta de actualización Z t \mathbf{Z}_tZtEfecto. Este paso determina el nuevo estado oculto H t ∈ R n × h \mathbf{H}_t \in \mathbb{R}^{n \times h}Ht∈R¿Hasta qué punto n × h proviene del antiguo estadoH t − 1 \mathbf{H}_{t-1}Ht − 1y un nuevo estado candidato H ~ t \tilde{\mathbf{H}}_tH~t. Actualizar puerta Z t \mathbf{Z}_tZtSolo se necesita en H t − 1 \mathbf{H}_{t-1}Ht − 1和H ~ t \tilde{\mathbf{H}}_tH~tEste objetivo se puede lograr realizando una combinación convexa de elementos entre ellos. Esto conduce a la fórmula de actualización final para la unidad recurrente cerrada: H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t . \mathbf{H}_t = \mathbf{Z}_t \ odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t.Ht=Zt⊙Ht − 1+( 1−Zt)⊙H~tSiempre
que actualice la puertaZ t \mathbf{Z}_tZtCuando está cerca de 1, el modelo tiende a mantener solo el estado anterior. En este punto, desde X t \mathbf{X}_tXtLa información de se ignora esencialmente, omitiendo efectivamente el paso de tiempo t en la cadena de dependencia. Por el contrario, cuando Z t \mathbf{Z}_tZtCuando está cerca de 0, el nuevo estado oculto H t \mathbf{H}_tHtEstará cerca del estado oculto candidato H ~ t \tilde{\mathbf{H}}_tH~t. Estos diseños pueden ayudarnos a lidiar con el problema del gradiente de fuga en redes neuronales recurrentes y capturar mejor las dependencias de secuencias con largas distancias de paso de tiempo. Por ejemplo, si la puerta de actualización está cerca de 1 para todos los pasos de tiempo de la subsecuencia completa, el antiguo estado oculto en el paso de tiempo inicial de la secuencia se conservará fácilmente y pasará al final de la secuencia, independientemente de la duración de la misma. la secuencia.
La siguiente figura ilustra el flujo de cálculo después de que la puerta de actualización está en vigor.
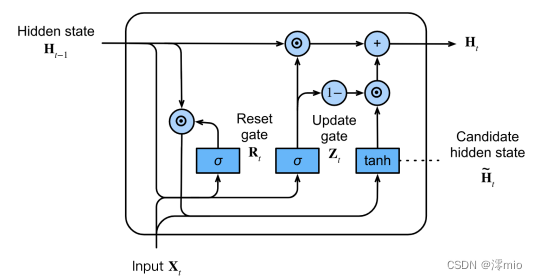
En resumen, las unidades recurrentes cerradas tienen las siguientes dos características destacadas:
-
Las puertas de reinicio ayudan a capturar dependencias a corto plazo en secuencias;
-
Las puertas de actualización ayudan a capturar dependencias a largo plazo en secuencias.
2 Implementación desde cero
Para comprender mejor el modelo de unidad recurrente cerrada, lo implementamos desde cero. Primero, leemos el conjunto de datos de Medium Time Machine:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
2.1 Inicializar parámetros del modelo
El siguiente paso es inicializar los parámetros del modelo. Extraemos pesos de una distribución gaussiana con una desviación estándar de 0,01 y establecemos el término de sesgo en 0, los hiperparámetros num_hiddensdefinen el número de unidades ocultas, instancian todos los pesos relacionados con la puerta de actualización, la puerta de reinicio, el estado oculto candidato y la capa de salida y el sesgo.
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
2.2 Definir el modelo
Ahora definiremos la función de inicialización para el estado oculto init_gru_state. Al igual que la función definida en la sección Implementación RNN desde Cero init_rnn_state, esta función devuelve un (批量大小,隐藏单元个数)tensor de forma, cuyos valores son todos ceros.
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
Ahora estamos listos para definir el modelo Gated Recurrent Unit. La arquitectura del modelo es la misma que la unidad RNN básica, excepto que la fórmula de actualización de peso es más complicada.
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
2.3 Entrenamiento y predicción
El entrenamiento y la predicción funcionan exactamente igual que antes. Después del entrenamiento, imprimimos la perplejidad en el conjunto de entrenamiento y la perplejidad en las secuencias predichas con el prefijo "viajero en el tiempo" y "viajero", respectivamente.
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
producción:
perplexity 1.3, 28030.1 tokens/sec on cuda:0
time traveller wetheving of my investian of the fromaticalllesp
travellery celaner betareabreart of the three dimensions an
3 Implementación concisa
La API de alto nivel contiene todos los detalles de configuración presentados anteriormente, por lo que podemos instanciar directamente el modelo de unidad recurrente cerrada. Este código se ejecuta mucho más rápido porque usa operadores compilados en lugar de Python para manejar muchos de los detalles explicados anteriormente.
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
producción:
perplexity 1.1, 334788.1 tokens/sec on cuda:0
time traveller with a slight accession ofcheerfulness really thi
travelleryou can show black is white by argument said filby
4 Resumen
-
Las redes neuronales recurrentes cerradas pueden capturar mejor las dependencias en secuencias con largas distancias de paso de tiempo.
-
Las puertas de reinicio ayudan a capturar dependencias a corto plazo en secuencias.
-
Las puertas de actualización ayudan a capturar dependencias a largo plazo en secuencias.
-
Cuando la puerta de reinicio está abierta, la unidad recurrente cerrada contiene la red neuronal recurrente básica; cuando la puerta de actualización está abierta, la unidad recurrente cerrada puede omitir subsecuencias.
referencias
[1] Cho, K., Van Merriënboer, B., Bahdanau, D. y Bengio, Y. (2014). Sobre las propiedades de la traducción automática neuronal: enfoques de codificador-decodificador. preimpresión de arXiv arXiv:1409.1259.
[2] Chung, J., Gulcehre, C., Cho, K. y Bengio, Y. (2014). Evaluación empírica de redes neuronales recurrentes cerradas en el modelado de secuencias. preimpresión de arXiv arXiv:1412.3555.