
1. Descripción
Se sabe que la arquitectura Transformer es un gran avance en el campo del procesamiento del lenguaje natural (NLP). Supera la limitación de que los modelos de secuencia a secuencia (como RNN, etc.) no pueden capturar dependencias a largo plazo en el texto. La arquitectura Transformer ha demostrado ser la piedra angular de arquitecturas revolucionarias como BERT, GPT y T5 y sus variantes. Como muchos han dicho, la PNL está en su época dorada, y no está mal decir que todo comenzó en el modelo transformador.
En segundo lugar, la demanda de arquitectura de transformadores.
Como se mencionó anteriormente, la necesidad es la madre de la invención. Los modelos tradicionales de secuencia a secuencia no son buenos para manejar textos largos. Esto significa que el modelo tiende a olvidarse de aprender de la primera mitad de la secuencia de entrada mientras procesa la segunda mitad de la secuencia de entrada . Esta pérdida de información no es deseable.
Aunque las arquitecturas cerradas como LSTM y GRU han mostrado cierta mejora en el manejo de dependencias a largo plazo al descartar información que no es útil para recordar información importante, esto todavía no es suficiente. El mundo necesita algo más poderoso, y en 2015, Bahdanau y otros introdujeron el "mecanismo de atención ". Se utilizan junto con RNN/LSTM para imitar el comportamiento humano, centrándose en cosas selectivas e ignorando el resto. Bahdanau sugiere asignar una importancia relativa a cada palabra en una oración para que el modelo se centre en las palabras importantes e ignore el resto. Se consideró una gran mejora con respecto al modelo codificador-decodificador para tareas de traducción automática neuronal y, pronto, la aplicación de mecanismos de atención también se generalizó en otras tareas.
Era del modelo de transformador
El modelo Transformer se basa completamente en un mecanismo de atención, también conocido como "autoatención". Esta arquitectura se presentó al mundo en el documento de 2017 " La atención es todo lo que necesitas ". Consiste en una arquitectura codificador-decodificador.
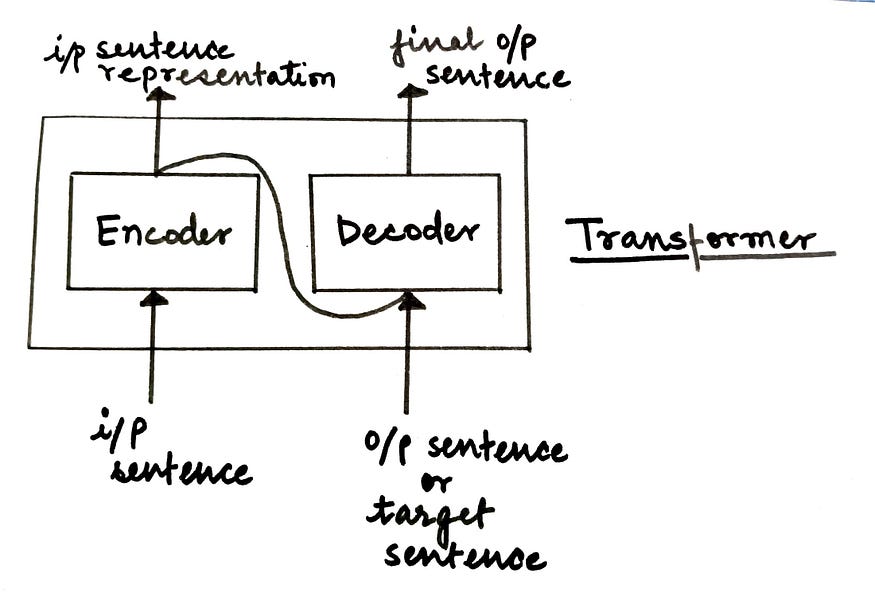
Higo. Arquitectura del modelo de convertidor avanzado (Fuente: Autor)
a un nivel alto,
- El codificador es responsable de tomar una oración de entrada y convertirla en una representación oculta, descartando toda la información inútil.
- El decodificador toma esta representación oculta e intenta generar la oración de destino.
En este artículo, profundizamos en el desglose detallado del componente codificador del modelo de transformador. En el próximo artículo, describiremos el componente decodificador en detalle. ¡Empecemos!
3. Codificador de transformador
El bloque codificador del transformador consta de una pila de codificadores N que funcionan en secuencia. La salida de un codificador es la entrada del siguiente codificador y así sucesivamente. La salida del último codificador es la representación final de la sentencia de entrada alimentada al bloque decodificador.

Higo. Módulo Enoder con codificadores apilados (fuente: autor)
Como se muestra en la figura a continuación, cada bloque de codificador se puede dividir en dos componentes.

Higo. Componentes de la capa del codificador (fuente: autor)
Examinemos cada uno de estos componentes en detalle uno por uno para comprender cómo funciona el bloque codificador. El primer componente del módulo del codificador es la atención multicabezal , pero antes de entrar en detalles, entendamos un concepto básico: la autoatención .
3.1 Mecanismo de autoatención
La primera pregunta que puede surgir en la mente de todos: ¿ Son conceptos diferentes la atención y la autoatención? Sí lo son. (¡Eh!
Tradicionalmente, existen mecanismos de atención para tareas de traducción automática neuronal, como se describe en la sección anterior. Por lo tanto, se aplica esencialmente un mecanismo de atención para mapear las oraciones de origen y de destino. Cuando el modelo seq-to-seq realiza la tarea de traducción token por token, el mecanismo de atención nos ayuda a identificar qué tokens en la oración de origen necesitan más atención al generar tokens x para la oración de destino . Con este fin, aprovecha las representaciones de estado oculto del codificador y el decodificador para calcular las puntuaciones de atención y, a partir de estas puntuaciones, genera vectores de contexto como entrada para el decodificador. Si desea obtener más información sobre el mecanismo de atención, salte a este artículo (¡excelente explicación!
Volviendo a la autoatención , la idea principal es calcular la puntuación de atención mientras se asigna la oración fuente a sí misma. Si tienes una oración como esta,
“El niño no cruzó la calle porque era demasiado ancha.
Los humanos entendemos fácilmente que la palabra "eso" en la oración anterior se refiere a "el camino", pero ¿cómo hacemos que nuestro modelo de lenguaje también entienda esta relación? ¡ Aquí es donde entra en juego el autoenfoque !
En un nivel alto, cada palabra de una oración se compara con todas las demás palabras de la oración para cuantificar las relaciones y comprender el contexto. Para fines de representación, puede consultar la imagen a continuación.
Veamos en detalle cómo se calcula (de verdad) esta autoatención.
- Genera incrustaciones para oraciones de entrada
Encuentre incrustaciones de todas las palabras y conviértalas en matriz de entrada. Estas incrustaciones se pueden generar mediante tokenización simple y codificación one-hot, o mediante algoritmos de incrustación como BERT, etc. La dimensión de la matriz de entrada será igual a la longitud de la oración x la dimensión de incrustación . Llamemos a esta matriz de entrada X para futuras referencias.
- Convierta la matriz de entrada a Q, K y V
Para calcular la autoatención, necesitamos transformar X (matriz de entrada) en tres nuevas matrices:
- consulta (Q) - clave (K) - valor (V)
Para calcular estas tres matrices, inicializaremos aleatoriamente tres matrices de peso, a saber, Wq, Wk y Wv . La matriz de entrada X se multiplicará por estas matrices de peso Wq, Wk y Wv para obtener los valores de Q, K y V respectivamente. Los valores óptimos para las matrices de peso se aprenderán en el proceso para obtener valores Q, K y V más precisos.
- Calcula el producto escalar de las transpuestas de Q y K
De la figura anterior, podemos implicar que qi, ki y vi denotan los valores de Q, K y V para la i-ésima palabra en la oración.

Higo. Ejemplo de producto escalar con Q y K transpuestas (Fuente: Autor)
La primera fila de la matriz de salida le dirá cómo la palabra 1 representada por q1 se relaciona con el resto de las palabras en la oración usando el producto escalar. Cuanto mayor sea el valor del producto escalar, más relacionada será la palabra. Para obtener una intuición de por qué se calcula este producto punto, puede comprender las matrices Q (consulta) y K (clave) en términos de recuperación de información. Así que aquí,
- Q o Consulta = el término que está buscando
- K o Clave = un conjunto de palabras clave en el motor de búsqueda para comparar y relacionar con Q.
- Producto punto escalado
Como en el paso anterior, estamos calculando el producto escalar de dos matrices, es decir, realizando una multiplicación, que tiene el potencial de explotar. Para garantizar que esto no suceda y que el gradiente sea estable, dividimos el producto escalar de las transpuestas de Q y K por la raíz cuadrada de la dimensión de incrustación (dk).
- Normalizar valores usando softmax
La normalización con la función softmax arrojará valores entre 0 y 1. Las celdas con productos de puntos de escala alta se elevarán aún más, mientras que los valores bajos se reducirán, lo que hará que la distinción entre pares de palabras coincidentes sea más clara. La matriz de salida resultante se puede ver como una matriz de puntuación S.
- Calcule la matriz de atención Z
Multiplique la matriz de valor o V por la matriz de puntuación S obtenida en el paso anterior para calcular la matriz de atención Z.
Pero espera, ¿por qué multiplicar?
Supongamos que Si = [0.9, 0.07, 0.03] es el valor de la matriz de puntuación de la i-ésima palabra en la oración. Multiplique este vector con la matriz V para calcular Zi (la matriz de atención para la i-ésima palabra).
Zi = [0,9 * V1 + 0,07 * V2 + 0,03 * V3]
¿Podemos decir que para comprender el contexto de la i-ésima palabra, solo debemos centrarnos en la palabra 1 (es decir, V1) ya que el 90 % del valor de la puntuación de atención proviene de V1? Podemos definir claramente palabras importantes donde se debe prestar más atención para comprender el contexto de la i-ésima palabra.
Por tanto, podemos concluir que cuanto mayor es la contribución de una palabra en la representación Zi, más críticas y relacionadas son las palabras.
Ahora que sabemos cómo calcular la matriz de autoatención, comprendamos el concepto del mecanismo de atención de múltiples cabezas .
3.2 Mecanismo de atención multicabezal
¿Qué sucede si su matriz de puntuación está sesgada hacia una representación de palabra específica? Inducirá a error a su modelo y los resultados no serán tan precisos como esperamos. Veamos un ejemplo para entender esto mejor.
S1: " Todo está bien "
Z(bien) = 0,6*V(todo) + 0,0*v(sí) + 0,4*V(bien)
S2: " El perro comió la comida porque tenía hambre "
Z(it) = 0.0*V(de) + 1.0*V(perro) + 0.0*V(comer) + … + 0.0*V(hambre)
En el caso de S1, se da más importancia a V(todos) al calcular Z(bien). Es incluso más que V (bueno) en sí mismo. No hay garantía de cuán preciso es esto.
En el caso de S2, a la hora de calcular Z(it), se le da toda la importancia a V(perro), mientras que al resto de palabras también se les da una puntuación de 0,0, incluida V(it). Esto parece aceptable ya que la palabra "eso" es ambigua. Tiene sentido asociarlo más con otra palabra que con la palabra misma. Ese es todo el propósito de calcular la autoatención. Maneja el contexto de palabras ambiguas en una oración de entrada.
En otras palabras, podemos decir que si la palabra actual es ambigua, entonces se puede dar más peso a otras palabras al calcular la autoatención, pero en otros casos esto puede ser engañoso para el modelo. ¿Entonces, qué hacemos ahora?
¿Qué pasa si en lugar de calcular una matriz de atención y derivar de ella la matriz de atención final, calculamos múltiples matrices de atención?
¡ Esto es exactamente de lo que se trata la atención de los toros ! Calculamos múltiples versiones de la matriz de atención z1, z2, z3, ..., zm y las concatenamos para obtener la matriz de atención final. De esta manera podemos tener más confianza en nuestra matriz de atención.
Pasando al siguiente concepto importante,
3.3 Codificación de posición
En un modelo de secuencia a secuencia, la oración de entrada se envía palabra por palabra a la red, lo que permite que el modelo realice un seguimiento de dónde están las palabras en relación con otras palabras.
Pero en el modelo del transformador, seguimos un enfoque diferente. En lugar de alimentarse palabra por palabra, se alimentan en paralelo, lo que ayuda a reducir el tiempo de capacitación y aprender dependencias a largo plazo. Pero usando este enfoque, se pierde el orden de las palabras. Sin embargo, el orden de las palabras es muy importante para comprender correctamente el significado de una oración. Para superar este problema, se introduce una nueva matriz llamada " Codificación de posición " (P).
Esta matriz P se envía junto con la matriz de entrada X para contener información relacionada con el orden de las palabras. Por razones obvias, las dimensiones de las matrices X y P son las mismas.
Para calcular el código de posición, se utiliza la fórmula que se indica a continuación.
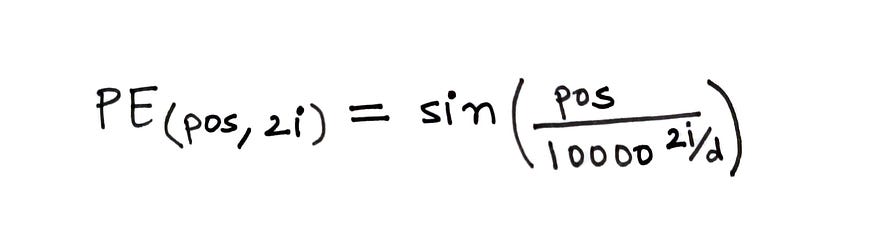
higo. Fórmula para calcular códigos de posición (fuente: autor)
En la fórmula anterior,
- pos = la posición de la palabra en la oración
- d = dimensión de incrustación de palabra/token
- i = representa cada dimensión en la incrustación
En el cálculo, d es fijo, pero pos e i variarán. Si d=512, entonces i ∈ [0, 255], ya que tomamos 2i.
Si desea obtener más información, este video brinda una mirada detallada a las codificaciones posicionales.
Estoy usando algunas de las imágenes del video anterior para explicar el concepto con mis palabras.

Higo. Representación vectorial codificada por posición (fuente: autor)
La figura anterior muestra un ejemplo de un vector codificado por posición con diferentes valores de variable.

Higo. Vector de codificación de posición con constantes i y d (fuente: autor)
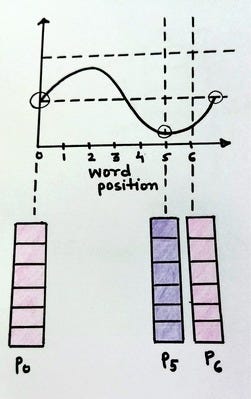
higo. Vector de codificación de posición con constantes i y d (fuente: autor)
La figura anterior muestra cómo cambia el valor de PE (pos, 2i) si i es constante y solo cambia pos. Es bien sabido que una onda sinusoidal es una función periódica que tiende a repetirse después de un intervalo fijo. Podemos ver que los vectores codificados para pos = 0 y pos = 6 son los mismos. Esto no es deseable porque necesitamos diferentes vectores de codificación de posición para diferentes valores pos .
Esto se puede lograr cambiando la frecuencia de la onda sinusoidal.

Higo. Vectores de codificación de posición con diferentes pos e i (fuente: autor)
A medida que varía el valor de i, también lo hace la frecuencia de la onda sinusoidal, resultando en diferentes ondas y, por lo tanto, diferentes valores para cada vector de codificación de posición. Esto es exactamente lo que queremos lograr.
La matriz de codificación de posición (P) se agrega a la matriz de entrada (X) y se alimenta al codificador.
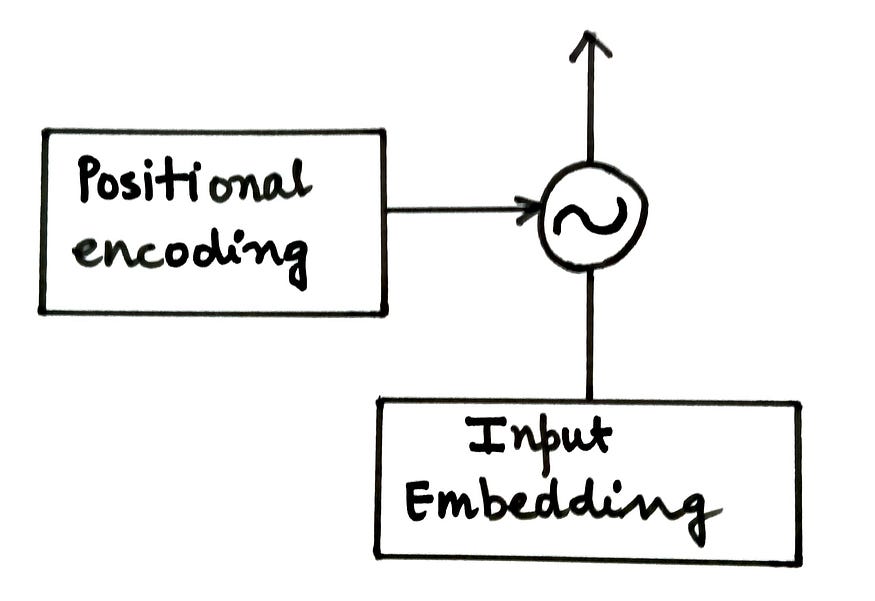
Higo. Agregar codificaciones posicionales a incrustaciones de entrada (fuente: autor)
El siguiente componente del codificador es la red feedforward .
3.4 Red de retroalimentación
Esta subcapa en el bloque codificador es una red neuronal clásica con dos capas densas y activaciones ReLU. Toma información de una capa de atención de múltiples cabezas, realiza algunas transformaciones no lineales en la misma capa y finalmente genera vectores contextualizados. Las capas totalmente conectadas son responsables de considerar cada cabeza de atención y aprender información relevante de ellas. Como los vectores de atención son independientes entre sí, se pueden pasar a la red de transformadores de manera paralela.
El último y último componente del bloque codificador es el componente Add&Norm .
3.5 Agregar y estandarizar componentes
Esta es una capa residual seguida de una normalización de capa . La capa residual garantiza que no se pierda información importante relacionada con la entrada de la subcapa durante el procesamiento. Mientras que las capas de normalización facilitan un entrenamiento más rápido del modelo y evitan grandes cambios en los valores.
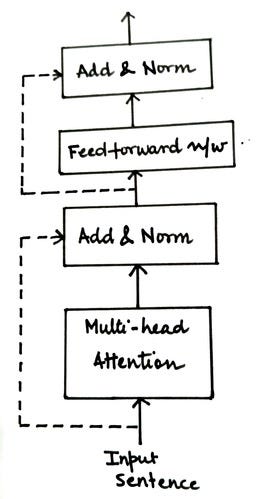
Higo. Componente codificador que contiene agregar y normalizar capas (fuente: autor)
En el codificador, hay dos capas aditivas y de normalización:
- Conecte la entrada de la subcapa de atención de varios cabezales a su salida
- Conecte la entrada de una subcapa de red feedforward a su salida
Hasta ahora, hemos resumido el funcionamiento interno del codificador. Para concluir este artículo, repasemos rápidamente los pasos utilizados por el codificador:
- Genere una representación incrustada o tokenizada de la oración de entrada. Esta será nuestra matriz de entrada X.
- Las incrustaciones posicionales se generan para preservar la información sobre el orden de las palabras de la oración de entrada y se agregan a la matriz de entrada X.
- Inicialice aleatoriamente tres matrices: Wq, Wk y Wv, que son pesos para consultas, claves y valores. Estos pesos se actualizarán durante el entrenamiento del modelo Transformer.
- Multiplique la matriz de entrada X con cada uno de Wq, Wk y Wv para producir matrices Q (consulta), K (clave) y V (valor).
- Calcule el producto escalar de las transpuestas de Q y K, escale el producto dividiéndolo por la raíz cuadrada de dk o la dimensión de incrustación y, finalmente, normalícelo con la función softmax.
- La matriz de atención Z se calcula multiplicando V o la matriz de valor por la salida de la función softmax.
- Pase esta matriz de atención a una red de avance para realizar transformaciones no lineales y generar incrustaciones contextualizadas.
Cuatro Posdata
En el próximo artículo, veremos cómo funciona el componente decodificador del modelo de transformador. Eso es todo por este artículo. Espero que le sea útil. Si lo haces, no olvides aplaudir y compartir con tus amigos.