Suponga que ahora tiene los datos y el presupuesto, todo está listo y está listo para comenzar a entrenar un modelo grande. Una vez que demuestra sus habilidades, "ver todas las flores en Chang'an en un día" parece estar a la vuelta de la esquina. la esquina... ¡Espera un minuto! El entrenamiento no es tan simple como la pronunciación de estas dos palabras. Puede ser útil ver el entrenamiento de BLOOM.
En los últimos años, se ha convertido en norma que los modelos lingüísticos se hagan cada vez más grandes. La gente suele criticar que la información de estos grandes modelos en sí no se divulga para la investigación, pero se presta poca atención al conocimiento detrás de la tecnología de entrenamiento de modelos grandes. Este artículo tiene como objetivo tomar el modelo de lenguaje BLOOM con 176 mil millones de parámetros como ejemplo para aclarar la ingeniería de software y hardware y los puntos técnicos detrás del entrenamiento de dichos modelos, a fin de promover la discusión de la tecnología de entrenamiento de modelos grandes.
Primero, nos gustaría agradecer a las empresas, individuos y grupos que permitieron o patrocinaron la culminación de nuestro grupo de la increíble hazaña de entrenar un modelo de 176 mil millones de parámetros.
Luego, comenzamos a discutir la configuración del hardware y los principales componentes técnicos.

El siguiente es un breve resumen del proyecto:
| hardware | 384 GPU A100 de 80 GB |
| software | Megatron-velocidad profunda |
| modelo de arquitectura | Basado en GPT3 |
| conjunto de datos | 350 mil millones de palabras en 59 idiomas |
| tiempo de entrenamiento | 3,5 meses |
Composición del personal
El proyecto fue concebido por Thomas Wolf (Co-Fundador y CSO de Hugging Face), quien se atrevió a competir con las grandes empresas, proponiendo no solo entrenar a un modelo que se alza sobre el bosque de modelos multilingües más grande del mundo, sino también hacerlo disponible para todos El acceso público a los resultados de la formación cumple los sueños de la mayoría de las personas.
Este artículo se centra en los aspectos de ingeniería del entrenamiento de modelos. Algunas de las partes más importantes de la tecnología detrás de BLOOM son las personas y las empresas que comparten su experiencia y nos ayudan a codificar y capacitar.
Principalmente tenemos que agradecer a 6 grupos:
- El equipo de BigScience de HuggingFace dedicó más de seis empleados de tiempo completo a la investigación y operación de la capacitación, y también proporcionaron o reembolsaron toda la infraestructura además de la computadora de Jean Zay.
- Los desarrolladores del equipo de Microsoft DeepSpeed, que desarrolló DeepSpeed y luego lo integró con Megatron-LM, pasaron semanas investigando los requisitos del proyecto y brindaron muchos consejos prácticos excelentes antes y durante la capacitación.
- El equipo de NVIDIA Megatron-LM que desarrolló Megatron-LM ha estado más que feliz de responder nuestras muchas preguntas y proporcionar consejos de uso de primer nivel.
- El equipo de IDRIS/GENCI, que administra la supercomputadora Jean Zay, donó al proyecto una potencia de cómputo significativa y un sólido soporte de administración del sistema.
- El equipo de PyTorch ha creado un marco poderoso en el que se basa el resto del software y ha sido un gran apoyo para prepararnos para el entrenamiento, corregir varios errores y mejorar la usabilidad del entrenamiento de los componentes de PyTorch de los que dependemos.
- Voluntario del grupo de trabajo de ingeniería de BigScience
Es difícil nombrar a todas las personas brillantes que contribuyeron con la parte de ingeniería del proyecto, así que solo nombraré a algunas personas clave fuera de Hugging Face que sentaron las bases de ingeniería para el proyecto durante los últimos 14 meses:
Olatunji Ruwase, Deepak Narayanan, Jeff Rasley, Jared Casper, Samyam Rajbhandari y Rémi Lacroix
También agradecemos a todas las empresas que permitieron que sus empleados contribuyeran a este proyecto.
descripción general
La arquitectura modelo de BLOOM es muy similar a GPT3 con algunas mejoras, que se analizan más adelante en este documento.
El modelo se entrenó en Jean Zay, una supercomputadora financiada por el gobierno francés administrada por GENCI e instalada en IDRIS, el centro informático nacional del Centro Nacional de Investigación Científica de Francia (CNRS). La potencia informática requerida para la capacitación es generosamente donada a este proyecto por GENCI (número de donación 2021-A0101012475).
Equipo de entrenamiento:
- GPU: 384 GPU NVIDIA A100 de 80 GB (48 nodos) + 32 GPU de repuesto
- 8 GPU por nodo, 4 interconexiones entre tarjetas NVLink, 4 enlaces OmniPath
- CPU: Procesador AMD EPYC 7543 de 32 núcleos
- Memoria de la CPU: 512 GB por nodo
- Memoria GPU: 640 GB por nodo
- Conexión entre nodos: se utiliza la tarjeta de red Omni-Path Architecture (OPA) y la topología de la red es un árbol gordo sin bloqueo
- NCCL - Red de comunicaciones: una subred totalmente dedicada
- Red Disk IO: GPFS compartido con otros nodos y usuarios
Puntos de control:
- puntos de control principales
- Cada punto de control contiene un estado del optimizador con una precisión de fp32 y un peso con una precisión de bf16+fp32, y ocupa un espacio de almacenamiento de 2,3 TB. Si solo se ahorra el peso de bf16, solo se ocuparán 329 GB de espacio de almacenamiento.
conjunto de datos:
- 1,5 TB de texto muy deduplicado y limpio en 46 idiomas, convertidos en tokens de 350B
- El vocabulario del modelo contiene 250.680 fichas
- Para obtener más detalles, consulte The BigScience Corpus A 1.6TB Composite Multilingual Dataset
El entrenamiento del modelo 176B BLOOM tardó unos 3,5 meses en completarse desde marzo hasta julio de 2022 (alrededor de 1 millón de horas informáticas).
Megatron-velocidad profunda
El modelo 176B BLOOM se entrena con Megatron-DeepSpeed , que combina dos técnicas principales:
- Megatron-velocidad profunda :
- DeepSpeed es una biblioteca de optimización de aprendizaje profundo que hace que el entrenamiento distribuido sea simple, eficiente y efectivo.
- Megatron-LM es un marco de modelo de transformador grande y potente desarrollado por el equipo de investigación de aprendizaje profundo aplicado de NVIDIA.
El equipo de DeepSpeed desarrolló un esquema 3D basado en paralelo al combinar ZeRO sharding y Pipeline Parallelism en la biblioteca DeepSpeed con Tensor Parallelism en Megatron-LM. Consulte la siguiente tabla para obtener más detalles sobre cada componente.
Tenga en cuenta que Megatron-DeepSpeed de BigScience se basa en el código base original de Megatron-DeepSpeed , y le hemos agregado bastantes códigos.
La siguiente tabla enumera los componentes de cada uno de los dos marcos que empleamos al entrenar BLOOM:
| componentes | velocidadprofunda | Megatron-LM |
|---|---|---|
| Paralelo de datos ZeRO | Sí | |
| tensor paralelo | Sí | |
| Tubería Paralela | Sí | |
| Optimizador BF16 | Sí | |
| Función de núcleo de fusión CUDA | Sí | |
| cargador de datos | Sí |
Tenga en cuenta que tanto Megatron-LM como DeepSpeed tienen implementaciones de paralelismo canalizado y optimizador BF16, pero usamos la implementación de DeepSpeed porque están integrados en ZeRO.
Megatron-DeepSpeed logra el paralelismo 3D para permitir entrenar modelos grandes de una manera muy eficiente. Analicemos brevemente qué son los componentes 3D.
- Paralelismo de datos (DP) : la misma configuración y modelo se replican varias veces, cada una de las cuales se alimenta con una copia diferente de los datos cada vez. El procesamiento se realiza en paralelo, con todos los recursos compartidos sincronizados al final de cada paso de entrenamiento.
- Paralelismo de tensores (TP) : cada tensor se divide en fragmentos, por lo que cada porción del tensor reside en su GPU asignada, en lugar de que todo el tensor resida en una sola GPU. Durante el procesamiento, cada fragmento se procesa por separado y en paralelo en una GPU diferente y los resultados se sincronizan al final del paso. Esto se llama paralelismo horizontal, porque se hace horizontalmente.
- Pipeline Parallelism (PP) : el modelo se divide verticalmente (es decir, por capa) en varias GPU para que solo una o más capas del modelo se coloquen en una única GPU. Cada GPU procesa diferentes etapas de la canalización en paralelo y procesa una parte del lote.
- Zero Redundancy Optimizer (ZeRO) : también realiza fragmentación de tensor similar a TP, pero todo el tensor se reconstruye a tiempo para el cálculo directo o inverso, por lo que no se requieren modificaciones en el modelo. También admite varias técnicas de descarga para compensar la memoria GPU limitada.
paralelismo de datos
La mayoría de los usuarios con solo unas pocas GPU probablemente estén familiarizados con (DDP), que es la documentación de PyTorchDistributedDataParallel correspondiente . En este enfoque, los modelos se replican completamente en cada GPU y luego todos los modelos sincronizan sus estados entre sí después de cada iteración. Este método puede acelerar el entrenamiento y resolver problemas al invertir más recursos de GPU. Pero tiene la limitación de que solo funciona si el modelo cabe en una sola GPU.
Paralelo de datos ZeRO
El siguiente diagrama muestra muy bien el paralelismo de datos ZeRO (de esta publicación de blog ).
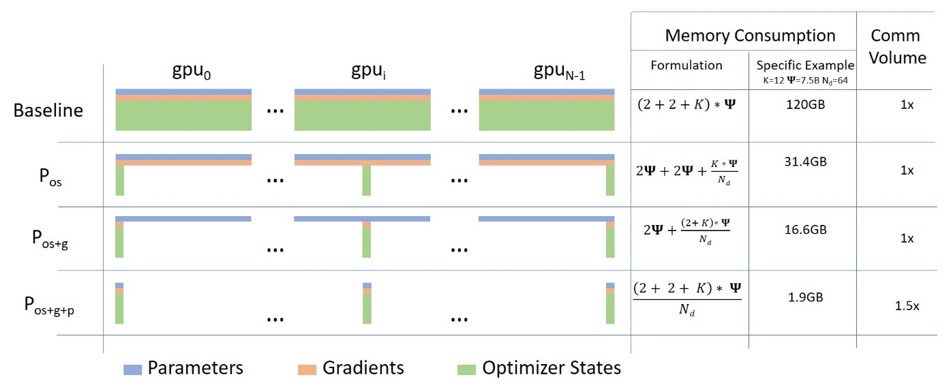
Parece ser relativamente alto, lo que puede dificultarle concentrarse en la comprensión, pero de hecho, el concepto es muy simple. Este es solo el DDP habitual, excepto que, en lugar de que cada GPU reproduzca los parámetros, los gradientes y el estado del optimizador del modelo completo, cada GPU solo almacena una parte. Durante las ejecuciones posteriores, cuando se requieren los parámetros de capa completos para una capa determinada, todas las GPU se sincronizan para proporcionarse entre sí las piezas que faltan, nada más.
Este componente está implementado por DeepSpeed.
tensor paralelo
En Tensor Parallelism (TP), cada GPU procesa solo una parte de un tensor y las operaciones de agregación se activan solo cuando ciertos operadores requieren el tensor completo.
En esta sección, usamos conceptos y diagramas del documento de Megatron-LM Capacitación eficiente de modelos de lenguaje a gran escala en clústeres de GPU .
Los módulos principales del modelo de clase Transformador son: una capa totalmente conectada nn.Linearseguida de una capa de activación no lineal GeLU.
Siguiendo la notación del artículo de Megatron, podemos escribir la parte del producto escalar como Y = GeLU (XA), donde Xy Yson los vectores de entrada y salida, Ay es la matriz de pesos.
Es fácil ver cómo la multiplicación de matrices se puede dividir en varias GPU si se expresa en forma de matriz:
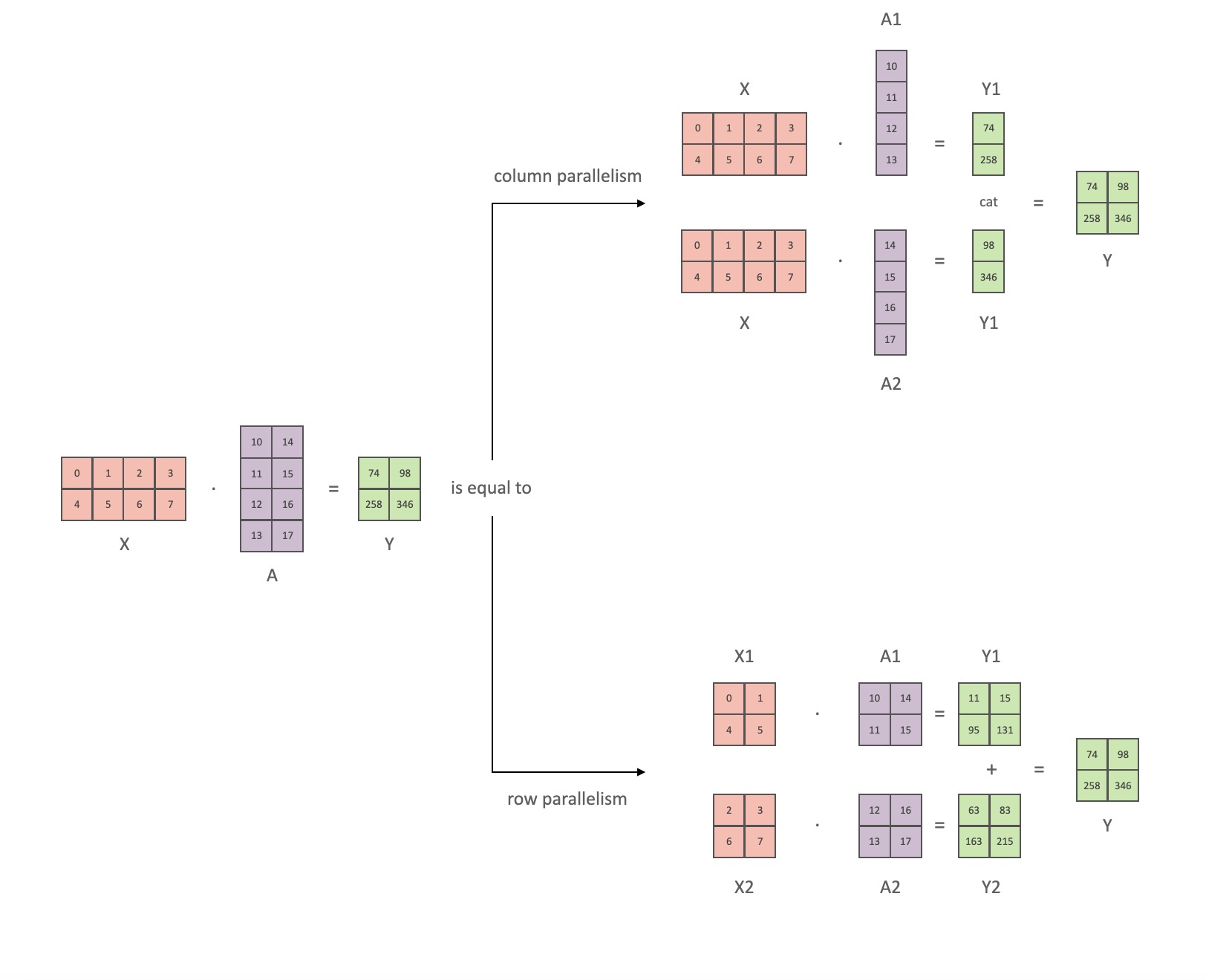
Si dividimos las matrices de peso Apor columnas Nen GPU y luego realizamos multiplicaciones de matrices XA_1en XA_n, terminamos Ncon vectores de salida Y_1、Y_2、…… 、 Y_n, que se pueden alimentar de forma independiente GeLU:
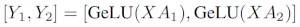
Tenga en cuenta que debido a que Yla matriz está dividida por columnas, podemos elegir el esquema de división por filas para el GEMM posterior, de modo que pueda obtener directamente la salida del GeLU de la capa anterior sin ninguna comunicación adicional.
Usando este principio, podemos actualizar un MLP de profundidad arbitraria, simplemente sincronizando la GPU después de cada 拆列 - 拆行secuencia . Los autores del artículo de Megatron-LM brindan una buena ilustración de esto:
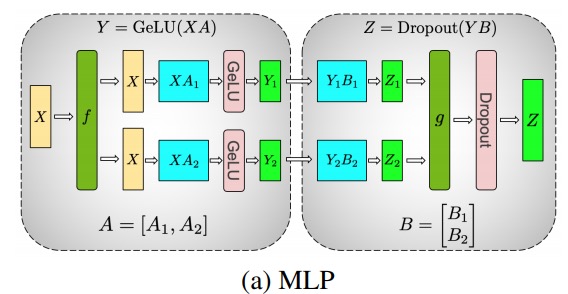
Aquí festá el operador de identidad en el pase hacia adelante y all reduce en el pase hacia atrás, y ges all reduce en el pase hacia adelante y la identidad en el pase hacia atrás.
Paralelizar las capas de atención de varios cabezales es incluso más sencillo, ya que son inherentemente paralelos debido a los múltiples cabezales independientes.
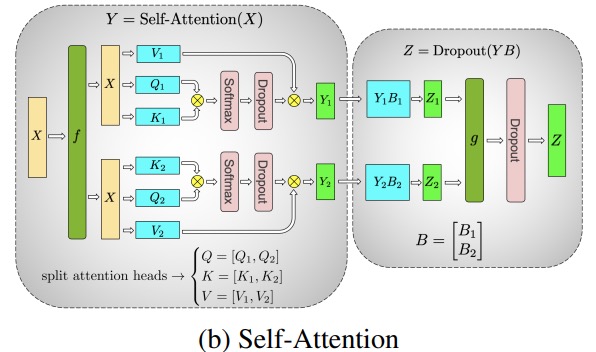
Consideraciones especiales: dado que hay dos reducciones totales por capa en los pases hacia adelante y hacia atrás, TP requiere interconexiones muy rápidas entre dispositivos. Por lo tanto, a menos que tenga una red muy rápida, no se recomienda realizar TP en varios nodos. En nuestra configuración de hardware para entrenar BLOOM, la velocidad entre nodos es mucho más lenta que PCIe. De hecho, si el nodo tiene 4 GPU, es mejor un grado máximo de TP de 4. Si necesita un grado de TP de 8, debe usar un nodo con al menos 8 GPU.
Este componente es implementado por Megatron-LM. Megatron-LM ha ampliado recientemente la capacidad de tensor paralelo y ha agregado la capacidad de paralelismo de secuencias para operadores que son difíciles de usar con el algoritmo de segmentación antes mencionado, como LayerNorm. El documento Reducing Activation Recomputation in Large Transformer Models proporciona detalles de esta técnica. El paralelismo de secuencias se desarrolló después de entrenar a BLOOM, por lo que BLOOM se entrenó sin esta técnica.
Tubería Paralela
El paralelismo de canalización ingenuo (PP ingenuo) consiste en distribuir capas de modelo en grupos en varias GPU y simplemente mover datos de GPU a GPU como si fuera una gran GPU compuesta. El mecanismo es relativamente simple: vincula la capa deseada al dispositivo correspondiente con .to()el método y ahora, cada vez que los datos ingresan o salen de estas capas, las capas cambiarán los datos al mismo dispositivo que la capa, y el resto permanece igual.
Esto es en realidad paralelismo de modelo vertical, porque si recuerda cómo dibujamos la topología de la mayoría de los modelos, en realidad dividimos las capas del modelo verticalmente. Por ejemplo, si la imagen de abajo muestra un modelo de 8 capas:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
Lo cortamos verticalmente en 2 partes, colocando las capas 0-3 en GPU0 y las capas 4-7 en GPU1.
Ahora, cuando los datos pasan de la capa 0 a la capa 1, de la capa 1 a la capa 2 y de la capa 2 a la capa 3, es como un paso hacia adelante normal en una sola GPU. Pero cuando los datos deben pasar de la capa 3 a la capa 4, deben transferirse de GPU0 a GPU1, lo que genera una sobrecarga de comunicación. Si las GPU participantes están en el mismo nodo de cómputo (p. ej., la misma máquina física), la transferencia es muy rápida, pero si las GPU están en nodos de cómputo diferentes (p. ej., varias máquinas), la sobrecarga de comunicación puede ser mucho mayor.
Luego, las capas 4 a 5 a 6 a 7 son como modelos normales nuevamente, y cuando la capa 7 está lista, generalmente necesitamos enviar datos a la capa 0 donde están las etiquetas (o enviar las etiquetas a la última capa). Ahora se puede calcular la pérdida y se puede usar el optimizador para actualizar los parámetros.
pregunta:
- ¿Por qué este método se denomina paralelismo de tubería ingenuo y cuáles son sus inconvenientes? Principalmente porque el esquema tiene todas menos una GPU inactiva en un momento dado. Entonces, si usa 4 GPU, casi está cuadruplicando la cantidad de memoria en una sola GPU, y otros recursos (como cómputo) son prácticamente inútiles. Agregue la sobrecarga de copiar datos entre dispositivos. Por lo tanto, 4 tarjetas de 6 GB en paralelo que utilicen una canalización ingenua podrán contener el mismo modelo de tamaño que 1 tarjeta de 24 GB que se entrena más rápido porque no tiene sobrecarga de transferencia de datos. Pero, por ejemplo, si tiene una tarjeta de 40 GB, pero necesita ejecutar un modelo de 45 GB, puede usar 4 tarjetas de 40 GB (que es suficiente, porque también hay gradientes y estados de optimización que requieren memoria de video).
- Compartir incrustaciones puede requerir copiar de un lado a otro entre las GPU. El paralelismo canalizado (PP) que usamos es casi el mismo que el PP ingenuo anterior, pero resuelve el problema de inactividad de la GPU fragmentando los lotes entrantes en micro lotes y creando canalizaciones artificiales que permiten que diferentes GPU participen en el proceso de cálculo simultáneamente.
La siguiente figura es del documento de GPipe , la parte superior representa el esquema PP ingenuo y la parte inferior es el método PP:

Desde la mitad inferior de la figura, es fácil ver que PP tiene menos zona muerta (lo que significa que la GPU está inactiva), es decir, menos "burbujas".
El grado de paralelismo de los dos esquemas de la figura es 4, es decir, el pipeline está compuesto por 4 GPU. Entonces, hay cuatro caminos directos de F0, F1, F2 y F3, y luego el camino inverso de B3, B2, B1 y B0.
PP introduce un nuevo hiperparámetro para sintonizar, llamado 块 (chunks). Define cuántos bloques de datos se envían secuencialmente a través del mismo nivel de tubería. Por ejemplo, en la mitad inferior de la figura, puede ver chunks = 4. GPU0 ejecuta la misma ruta de avance en los fragmentos 0, 1, 2 y 3 (F0,0, F0,1, F0,2, F0,3) y luego espera hasta que las otras GPU terminen su trabajo antes de que GPU0 comience a funcionar nuevamente, ejecute la ruta hacia atrás para los bloques 3, 2, 1 y 0 (B0,3, B0,2, B0,1, B0,0).
Tenga en cuenta que esto es conceptualmente lo mismo que los pasos de acumulación de gradiente (GAS). PyTorch lo llama 块y DeepSpeed lo llama GAS.
Porque 块, PP introduce el concepto de micro-lotes (MBS). DP divide el tamaño de lote global en tamaños de lote pequeños, por lo que si el grado de DP es 4, el tamaño de lote global 1024 se dividirá en 4 tamaños de lote pequeños, y cada tamaño de lote pequeño es 256 (1024/4). Y si 块el número (o GAS) es 32, terminamos con un tamaño de lote micro de 8 (256/32). Cada etapa de tubo procesa un micro lote a la vez.
La fórmula para calcular el tamaño de lote global para la configuración DP+PP es: mbs * chunks * dp_degree( 8 * 32 * 4 = 1024).
Volvamos atrás y miremos la imagen de nuevo.
Usando PP ingenuo chunks=1, terminas con PP ingenuo, que es muy ineficiente. Y con 块números , terminas con pequeños tamaños de micro lotes, que probablemente tampoco sean muy eficientes. Por lo tanto, se debe experimentar para encontrar 块el número .
El gráfico muestra que hay burbujas de tiempo "muertas" que no se pueden paralelizar porque la última forwardetapa tiene que esperar a backwardque finalice la canalización. Luego, el problema de encontrar el 块número para que todas las GPU participantes puedan lograr una alta utilización simultánea se transforma en realidad en minimizar el número de burbujas.
Este mecanismo de programación se llama 全前全后. Algunas otras opciones son Tandem y Interleaved Tandem .
Si bien tanto Megatron-LM como DeepSpeed tienen sus propias implementaciones del protocolo PP, Megatron-DeepSpeed utiliza la implementación de DeepSpeed porque está integrada con otras funciones de DeepSpeed.
Otro tema importante aquí es el tamaño de la matriz de incrustación de palabras. Si bien, por lo general, las matrices de incrustación de palabras requieren menos memoria que los bloques transformadores, en el caso de BLOOM con un vocabulario de 250k, la capa de incrustación requiere 7,2 GB para los pesos bf16, en comparación con solo 4,9 GB para el bloque transformador. Por lo tanto, tuvimos que hacer que Megatron-Deepspeed tratara la capa de incrustación como un bloque transformador. Así que tenemos una canalización de 72 etapas, 2 de las cuales están dedicadas a la incorporación (la primera y la última). Esto nos permite equilibrar el consumo de memoria de la GPU. Si no hiciéramos esto, tendríamos la primera y la última etapa consumiendo mucha memoria GPU, y el 95% del uso de memoria GPU sería muy poco, por lo que el entrenamiento sería muy ineficiente.
PD+PP
Hay una imagen en el tutorial de DeepSpeed Pipeline Parallel que demuestra cómo combinar DP y PP, como se muestra a continuación.
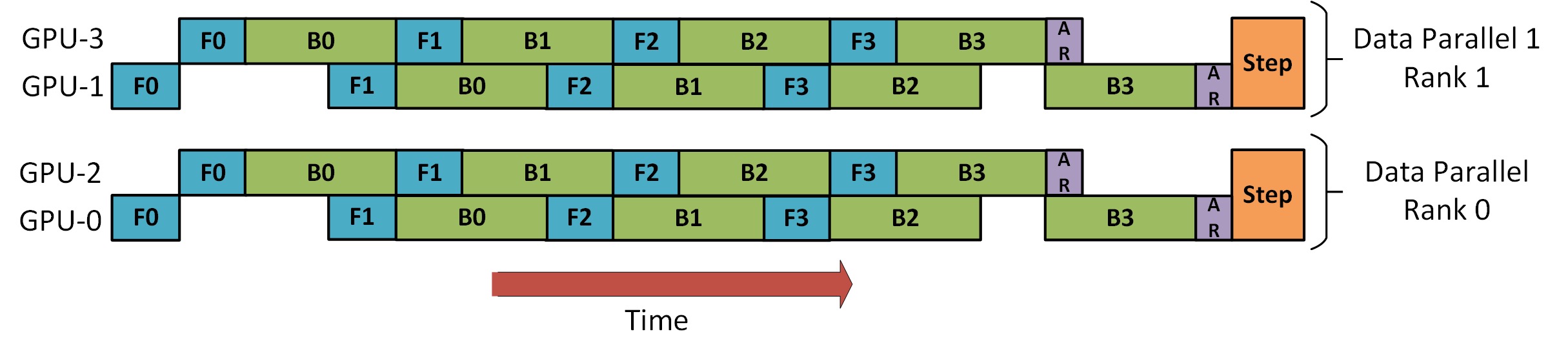
Lo importante que debe entender aquí es que el rango 0 de DP no puede ver GPU2, y el rango 1 de DP no puede ver GPU3. Para DP, solo hay GPU 0 y 1, y se les envían datos. GPU0 usa PP para descargar "en secreto" parte de su carga a GPU2. Asimismo, GPU1 también recibirá ayuda de GPU3.
Dado que se requieren al menos 2 GPU para cada dimensión, aquí se requieren al menos 4 GPU.
PD+PP+TP
Para un entrenamiento más eficiente, se pueden combinar PP, TP y DP, lo que se denomina paralelismo 3D, como se muestra en la siguiente figura.
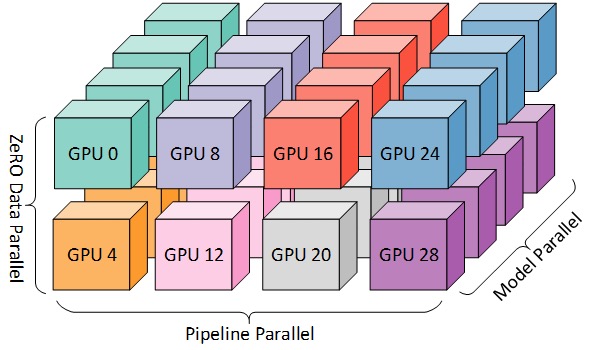
Esta figura es de la publicación de blog 3D Parallelism: Scaling to Trillion Parameter Models ), que también es un buen artículo.
Dado que necesita al menos 2 GPU por dimensión, aquí necesita al menos 8 GPU para un paralelismo 3D completo.
Cero DP+PP+TP
Una de las características principales de DeepSpeed es ZeRO, que es una versión mejorada súper escalable de DP, que hemos discutido en la sección [ZeRO Data Parallel] (#ZeRO- Data Parallel). Por lo general, es una función independiente y no requiere PP o TP. Pero también se puede combinar con PP, TP.
Cuando ZeRO-DP se combina con PP (y, por lo tanto, TP), generalmente solo habilita la fase 1 de ZeRO, que solo fragmenta el estado del optimizador. La etapa 2 de ZeRO también fragmenta los gradientes y la etapa 3 también fragmenta los pesos del modelo.
Si bien es teóricamente posible usar ZeRO etapa 2 con paralelismo de canalización, puede tener un impacto negativo en el rendimiento. Cada micro lote requiere una comunicación adicional de reducción de dispersión para agregar gradientes antes de la fragmentación, lo que agrega una sobrecarga de comunicación potencialmente significativa. De acuerdo con la naturaleza paralela de la canalización, utilizaremos microlotes pequeños y nos centraremos en el equilibrio entre la intensidad aritmética (tamaño de microlote) y la minimización de las burbujas de canalización (número de microlotes). Por lo tanto, la mayor sobrecarga de comunicación perjudica el paralelismo de la tubería.
Además, debido a PP, la cantidad de capas ya es menor de lo normal, por lo que no ahorra mucha memoria. PP ha reducido el tamaño del gradiente 1/PP, por lo que el segmento de gradiente sobre esta base no ahorra mucha memoria en comparación con el DP puro.
ZeRO stage 3 también se puede usar para entrenar modelos de este tamaño, sin embargo, requiere más comunicación que DeepSpeed 3D en paralelo. Hace un año, después de una cuidadosa evaluación de nuestro entorno, descubrimos que el paralelismo 3D Megatron-DeepSpeed rendía mejor. El rendimiento de ZeRO Phase 3 ha mejorado significativamente desde entonces, y si tuviéramos que volver a evaluarlo hoy, tal vez elegiríamos Phase 3.
Optimizador BF16
Entrenar grandes modelos LLM con FP16 es un no-no.
Hemos demostrado esto por nosotros mismos al pasar meses entrenando el modelo 104B que, como puede ver en Tensorboard , fracasó por completo. En el proceso de luchar contra la pérdida de película siempre divergente, aprendimos mucho:
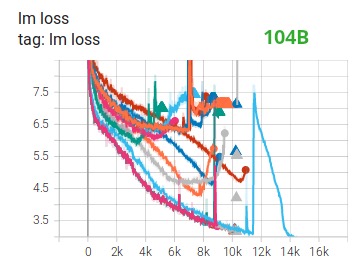
También recibimos la misma sugerencia de los equipos de Megatron-LM y DeepSpeed después de que entrenaron el modelo 530B . El OPT-175B lanzado recientemente también informó que entrenaron muy duro en FP16.
Así que en enero sabíamos que íbamos a entrenar en el A100 que admite el formato BF16. Olatunji Ruwase desarrolló un "BF16Optimizer" para entrenar a BLOOM.
Si no está familiarizado con este formato de datos, consulte su diseño de bits . La clave del formato BF16 es que tiene la misma cantidad de exponentes que FP32, por lo que no se desbordará, ¡pero FP16 a menudo se desborda! FP16 tiene un rango de valor máximo de 64k, solo puede multiplicar números más pequeños. Por ejemplo puedes hacer 250*250=62500, pero si lo intentas 255*255=65025, te desbordarás, que es la causa principal de los problemas con el entrenamiento. Esto significa que sus pesos deben mantenerse pequeños. Una técnica llamada pérdida de escala ayuda a aliviar este problema, pero el pequeño rango de FP16 aún puede ser un problema cuando los modelos son muy grandes.
El BF16 no tiene este problema, puedes hacerlo fácilmente 10_000*10_000=100_000_000, sin ningún problema.
Por supuesto, dado que BF16 y FP16 tienen el mismo tamaño, 2 bytes, no hay comida gratis, y la desventaja de usar BF16 es que tiene muy poca precisión. Sin embargo, debe recordar que el método de descenso de gradiente estocástico y sus variantes que usamos en el entrenamiento, este método es un poco como tambalearse, si no encuentra la dirección perfecta en este paso, está bien, lo corregirá en el siguiente paso Propio.
Ya sea que use BF16 o FP16, hay una copia de los pesos que siempre está en FP32: esto es lo que actualiza el optimizador. Entonces, el formato de 16 bits solo se usa para los cálculos, el optimizador actualiza los pesos FP32 con total precisión y luego los convierte al formato de 16 bits para la próxima iteración.
Todos los componentes de PyTorch se han actualizado para garantizar que realicen cualquier acumulación en FP32, por lo que no se produce pérdida de precisión.
Una cuestión clave es la acumulación de gradientes, que es una de las principales características del paralelismo de tubería, ya que los gradientes procesados por cada microlote se acumulan. La implementación de la acumulación de gradientes en FP32 para la precisión del entrenamiento es fundamental, y eso es exactamente BF16Optimizerlo que se hizo .
Entre otras mejoras, creemos que el uso del entrenamiento de precisión mixta BF16 convirtió una pesadilla potencial en un proceso relativamente fluido, como se puede ver en el siguiente diagrama de pérdida de película:
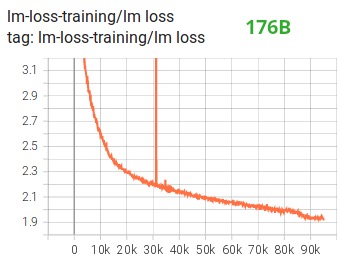
Función de núcleo de fusión CUDA
La GPU hace principalmente dos cosas. Puede escribir y leer datos de la memoria de video y realizar cálculos sobre esos datos. Cuando la GPU está ocupada leyendo y escribiendo datos, las unidades informáticas de la GPU están inactivas. Si queremos utilizar la GPU de manera eficiente, queremos mantener el tiempo de inactividad al mínimo.
Una función del kernel es un conjunto de instrucciones que implementan una operación específica de PyTorch. Por ejemplo, torch.addcuando , pasa por un planificador de PyTorch , que decide qué código debe ejecutar en función de los valores de los tensores de entrada y otras variables, y finalmente lo ejecuta. Los núcleos CUDA usan CUDA para implementar estos códigos y, por lo tanto, solo se ejecutan en GPU NVIDIA.
Ahora, c = torch.add (a, b); e = torch.max ([c,d])cuando , normalmente lo que PyTorch hará es lanzar dos kernels separados, uno que agrega ya , y el otro que toma el máximo de ambos . En este caso, la GPU obtiene la suma de su memoria de video, realiza la suma y luego vuelve a escribir el resultado en la memoria de video. Luego toma y realiza la operación y vuelve a escribir el resultado en la memoria de video.bcdabcdmax
Si tuviéramos que fusionar estas dos operaciones, es decir, ponerlas en una "función de kernel fusionada" y luego ejecutar ese kernel, en lugar de cescribir el resultado intermedio en la memoria de video, lo mantendríamos dhacer el cálculo final. Esto ahorra muchos gastos generales y evita que la GPU esté inactiva, por lo que toda la operación es mucho más eficiente.
La función del núcleo de fusión hace precisamente eso. Principalmente reemplazan múltiples cálculos discretos y movimiento de datos hacia y desde la memoria de video con cálculos fusionados con muy poco movimiento de datos. Además, algunos núcleos de fusión transforman matemáticamente las operaciones para que ciertas combinaciones de cálculos se puedan realizar más rápido.
Para entrenar a BLOOM de forma rápida y eficiente, es necesario utilizar varias funciones personalizadas de núcleo fusionado de CUDA proporcionadas por Megatron-LM. En particular, hay un kernel de fusión LayerNorm y kernels para varias combinaciones de operaciones de fusión de escalado, enmascaramiento y softmax. Bias Add también está integrado con GeLU a través de la función JIT de PyTorch. Todas estas operaciones están vinculadas a la memoria, por lo que es importante fusionarlas para maximizar la cantidad de cómputo después de cada lectura de la memoria de video. Entonces, por ejemplo, ejecutar Bias Add mientras se ejecuta una operación GeLU cuyo cuello de botella está en la memoria no aumentará el tiempo de ejecución. Estas funciones del núcleo se pueden encontrar en la biblioteca de códigos de Megatron-LM .
conjunto de datos
Otra característica importante de Megatron-LM es el cargador de datos eficiente. Antes de que comience el primer entrenamiento, cada muestra en cada conjunto de datos se divide en muestras de longitud de secuencia fija (BLOOM es 2048), y se crea un índice para numerar cada muestra. En función de los hiperparámetros de entrenamiento, determinaremos la cantidad de épocas en las que debe participar cada conjunto de datos y, en función de esto, crearemos una lista ordenada de índices de muestra y luego la mezclaremos. Por ejemplo, si un conjunto de datos tiene 10 muestras que deben entrenarse para 2 épocas, el sistema primero clasifica los índices de muestra en [0, ..., 9, 0, ..., 9]orden luego mezcla el orden para crear el orden global final para el conjunto de datos. Tenga en cuenta que esto significa que el entrenamiento no iterará simplemente sobre todo el conjunto de datos y repetirá, puede ver la misma muestra dos veces antes de ver otra, pero al final del entrenamiento, el modelo solo verá cada muestra dos veces. Esto ayuda a garantizar una curva de entrenamiento suave durante todo el entrenamiento. Estos índices, incluido el desplazamiento de cada muestra en el conjunto de datos original, se guardan en un archivo para evitar volver a calcularlos cada vez que se inicia el entrenamiento. Finalmente, varios de estos conjuntos de datos se pueden combinar con diferentes pesos en los datos finales utilizados para el entrenamiento.
Norma de capa incrustada
En nuestros esfuerzos por evitar la divergencia del modelo 104B, descubrimos que agregar una LayerNorm adicional después de la primera capa de incrustación de palabras hizo que el entrenamiento fuera más estable.
Esta idea proviene de experimentos con bits y bytes , que tiene una operación que es una incrustación normal con una LayerNorm inicializada con una función uniforme de xavier.StableEmbedding
código de localización
Basado en el documento Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , también reemplazamos las incorporaciones posicionales normales con AliBi, que permite la extrapolación de secuencias de entrada más largas que las secuencias de entrada utilizadas para entrenar el modelo. Por lo tanto, aunque entrenamos con secuencias de longitud 2048, el modelo puede manejar secuencias más largas durante la inferencia.
dificultades en el entrenamiento
Con la arquitectura, el hardware y el software listos, pudimos comenzar la capacitación a principios de marzo de 2022. Desde entonces, sin embargo, las cosas no han sido tan fáciles. En esta sección, discutimos algunos de los principales obstáculos que encontramos.
Antes de que comience el entrenamiento, hay muchas preguntas que resolver. En particular, encontramos varios problemas que solo aparecieron después de que comenzamos a entrenar en 48 nodos, no a pequeña escala. Por ejemplo, CUDA_LAUNCH_BLOCKING=1para evitar que el marco se cuelgue, debemos dividir el grupo del optimizador en grupos más pequeños; de lo contrario, el marco se bloqueará nuevamente. Puedes leer más sobre esto en las Crónicas previas al entrenamiento.
El tipo principal de problemas encontrados durante el entrenamiento son fallas de hardware. Dado que este es un clúster nuevo con alrededor de 400 GPU, en promedio experimentamos 1 o 2 fallas de GPU por semana. Guardamos un punto de control cada 3 horas (100 iteraciones). Como resultado, perdemos un promedio de 1,5 horas de capacitación por semana debido a fallas de hardware. El administrador del sistema Jean Zay luego reemplazará la GPU defectuosa y restaurará el nodo. Mientras tanto, tenemos nodos de repuesto disponibles.
También hemos tenido varios otros problemas que dieron como resultado un tiempo de inactividad de 5 a 10 horas varias veces, algunos relacionados con errores de interbloqueo en PyTorch, otros debido a la falta de espacio en el disco. Si te interesan los detalles, consulta las crónicas de entrenamiento .
Todo este tiempo de inactividad se planeó en el análisis de factibilidad de entrenar este modelo, y elegimos el tamaño de modelo apropiado y la cantidad de datos que queríamos que el modelo consumiera en consecuencia. Entonces, incluso con estos problemas de tiempo de inactividad, logramos completar la capacitación dentro del tiempo estimado. Como se mencionó anteriormente, se tarda aproximadamente 1 millón de horas de cómputo en completarse.
Otro problema es que SLURM no fue diseñado para ser utilizado por un grupo de personas. Los trabajos de SLURM son propiedad de un solo usuario y, si no están presentes, otros miembros del grupo no pueden hacer nada con el trabajo en ejecución. Tenemos un esquema de finalización que permite que otros usuarios del grupo finalicen el proceso actual sin la presencia del usuario que inició el proceso. Esto funciona muy bien en el 90% de los problemas. Si los diseñadores de SLURM leen esto, agregue el concepto de un grupo Unix para que un trabajo SLURM pueda ser propiedad de un grupo.
Dado que la capacitación se lleva a cabo las 24 horas del día, los 7 días de la semana, necesitamos a alguien de guardia, pero dado que tenemos personas en Europa y la costa oeste de Canadá, no es necesario que alguien lleve un buscapersonas y somos bastante buenos para respaldarnos mutuamente. Por supuesto, hay que vigilar el entrenamiento de fin de semana. Automatizamos la mayoría de las cosas, incluida la recuperación automática de fallas de hardware, pero a veces aún se requiere la intervención humana.
en conclusión
La parte más difícil y estresante del entrenamiento son los 2 meses antes de que comience el entrenamiento. Estábamos bajo mucha presión para comenzar a entrenar lo antes posible y, debido al tiempo limitado asignado por los recursos, no tuvimos acceso a la A100 hasta el último minuto. Así que fue un momento muy difícil, teniendo en cuenta BF16Optimizerque se escribió en el último minuto, necesitábamos depurarlo y corregir varios errores. Como se mencionó en la sección anterior, encontramos nuevos problemas que solo aparecieron después de que comenzamos a entrenar en 48 nodos, y no a pequeña escala.
Pero una vez que resolvimos eso, el entrenamiento en sí fue sorprendentemente fluido y sin contratiempos importantes. La mayoría de las veces, solo uno de nosotros observa y solo unas pocas personas involucradas en la resolución de problemas. Tuvimos un gran apoyo por parte de la gerencia de Jean Zay, quien atendió con prontitud la mayoría de las necesidades que surgieron durante la capacitación.
En general, fue una experiencia súper intensa pero gratificante.
El entrenamiento de modelos de lenguaje grandes sigue siendo una tarea desafiante, pero esperamos que al construir y compartir esta técnica públicamente, otros puedan aprender de nuestra experiencia.
recurso
Links importantes
- principal documento de formación
- Tablero de tensor
- guion de slurm para entrenamiento
- cronica de entrenamiento
Papeles y Artículos
Es imposible para nosotros explicar todo en detalle en este artículo, por lo que si las técnicas presentadas aquí despiertan su curiosidad y le dan ganas de aprender más, lea los siguientes documentos:
Megatron-LM:
- Capacitación eficiente de modelos de lenguaje a gran escala en clústeres de GPU .
- Reducción del recálculo de activación en modelos de transformadores grandes
Velocidad profunda:
- ZeRO: Optimizaciones de memoria para entrenar billones de modelos de parámetros
- ZeRO-Offload: democratización del entrenamiento de modelos a escala de miles de millones
- ZeRO-Infinity: rompiendo el muro de memoria de la GPU para el aprendizaje profundo de escala extrema
- DeepSpeed: entrenamiento de modelos a escala extrema para todos
Megatron-LM y Deepspeedeed combinados:
Coartada:
- Tren corto, prueba larga: la atención con sesgos lineales permite la extrapolación de longitud de entrada
- ¿Qué modelo de lenguaje entrenar si tiene un millón de horas de GPU? - Allí encontrará los experimentos que finalmente nos llevaron a elegir ALiBi.
BitsNBytes:
- Optimizadores de 8 bits a través de Cuantificación por bloques (usamos el LaynerNorm incrustado en este documento, pero otras partes del documento y sus técnicas también son muy buenas, la única razón por la que no usamos optimizadores de 8 bits es que ya usamos DeepSpeed-ZeRO para ahorrar memoria del optimizador).
publicación de blog gracias
Muchas gracias a las siguientes personas que hicieron buenas preguntas y ayudaron a mejorar la legibilidad del artículo (en orden alfabético):
- britney muller,
- Douwe Kiela,
- Jared Casper,
- Jeff Rasley,
- Julián Launay,
- Leandro von Werra,
- Omar Sanseviero,
- Stefan Schweter y
- Tomás Wang.
Los gráficos de este artículo fueron creados principalmente por Chunte Lee.
Texto original en inglés: https://hf.co/blog/bloom-megatron-deepspeed
Autor original: Stas Bekman
Traductor: Matrix Yao (Yao Weifeng), un ingeniero de aprendizaje profundo de Intel, trabaja en la aplicación de modelos de familias de transformadores en varios datos modales y en el entrenamiento y razonamiento de modelos a gran escala.
Corrección y composición tipográfica: zhongdongy (Adong)