
来源:小白学视觉 新机器视觉
本文约5700字,建议阅读11分钟
本文将围绕着环境感知中关键的视觉感知算法进行介绍。Algoritmo de percepción visual de conducción automatizada (1)
La percepción ambiental es el primer eslabón de la conducción autónoma y el vínculo entre el vehículo y el medio ambiente. El rendimiento general de un sistema de conducción automática depende en gran medida de la calidad del sistema de percepción. En la actualidad, existen dos rutas técnicas principales para la tecnología de percepción ambiental:
① Soluciones de fusión de sensores múltiples guiadas por visión, típicamente representadas por Tesla;
②Soluciones técnicas dominadas por lidar y asistidas por otros sensores, representantes típicos como Google y Baidu.
Presentaremos los algoritmos clave de percepción visual en la percepción ambiental. El alcance de las tareas y sus campos técnicos se muestran en la figura a continuación. Lo dividimos en dos secciones para resolver el contexto y la dirección de los algoritmos de percepción visual 2D y 3D.
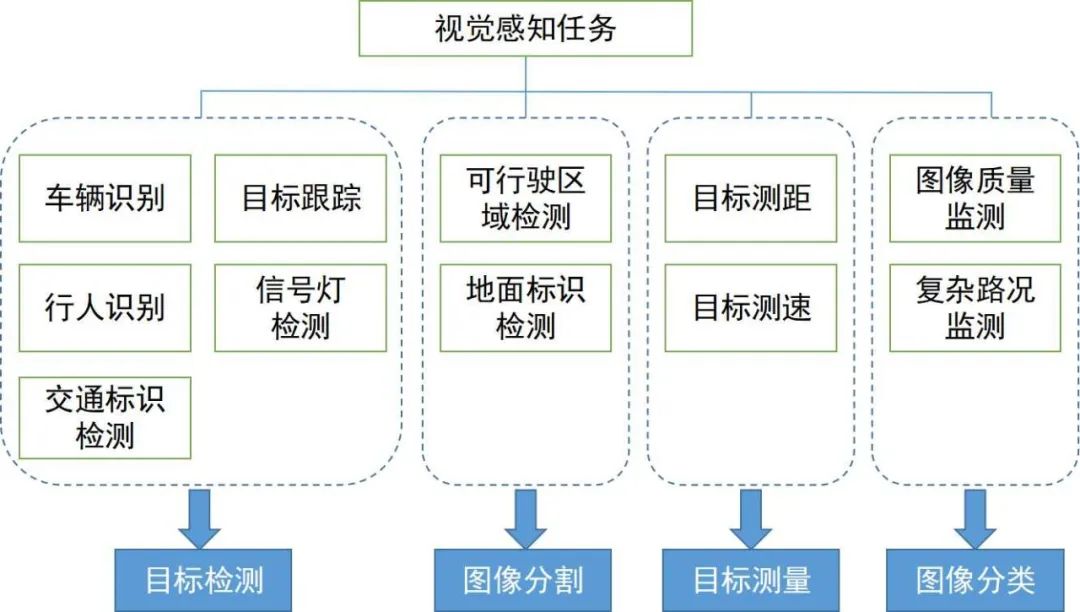
En esta sección, comenzamos con varias tareas ampliamente utilizadas en la conducción autónoma para introducir algoritmos de percepción visual 2D, incluida la detección y seguimiento de objetos 2D basados en imágenes o videos, y la segmentación semántica de escenas 2D. En los últimos años, el aprendizaje profundo ha penetrado en varios campos de la percepción visual y ha obtenido buenos resultados, por lo que hemos seleccionado algunos algoritmos clásicos de aprendizaje profundo.
01 Detección de objetivos
1.1 Detección de dos etapas
La de dos etapas se refiere a la forma de realizar la detección, hay dos procesos, uno es extraer el área del objeto, el otro es realizar la clasificación y reconocimiento CNN en el área, por lo tanto, la "dos etapas" también se denomina la detección de objetivos en función del área candidata (propuesta de Región). Los algoritmos representativos incluyen la serie R-CNN (R-CNN, Fast R-CNN, Faster R-CNN), etc.
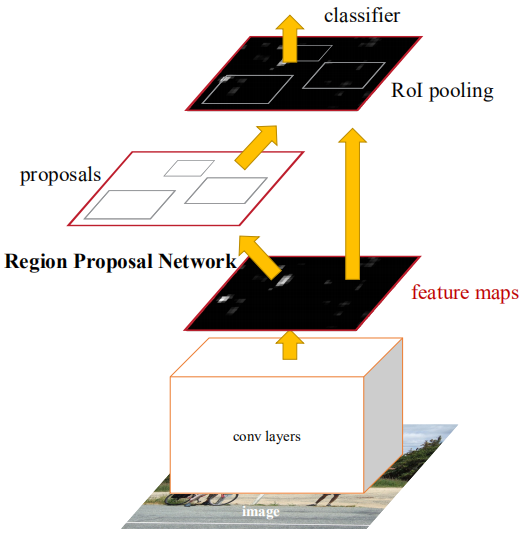
Faster R-CNN es la primera red de detección de extremo a extremo. En la primera etapa, se usa una red de región candidata (RPN) para generar cuadros de candidatos basados en el mapa de características, y se usa ROIPPoling para alinear el tamaño de las características candidatas; en la segunda etapa, se usa una capa completamente conectada para una clasificación refinada y regresión. La idea de Anchor se propone aquí para reducir la dificultad de cálculo y mejorar la velocidad. Cada posición del mapa de funciones generará anclas de diferentes tamaños y relaciones de aspecto, que se utilizan como referencia para la regresión del marco del objeto. La introducción de Anchor hace que la tarea de regresión solo necesite lidiar con cambios relativamente pequeños, por lo que el aprendizaje de la red será más fácil. La siguiente figura es el diagrama de estructura de red de Faster R-CNN.
La primera etapa de CascadeRCNN es exactamente igual que Faster R-CNN, y la segunda etapa utiliza varias capas de RoiHead para la conexión en cascada. Parte del trabajo de seguimiento se trata principalmente de algunas mejoras de la red mencionada anteriormente o una mezcla de trabajos anteriores, y hay pocas mejoras importantes.
1.2 Detección de una sola etapa
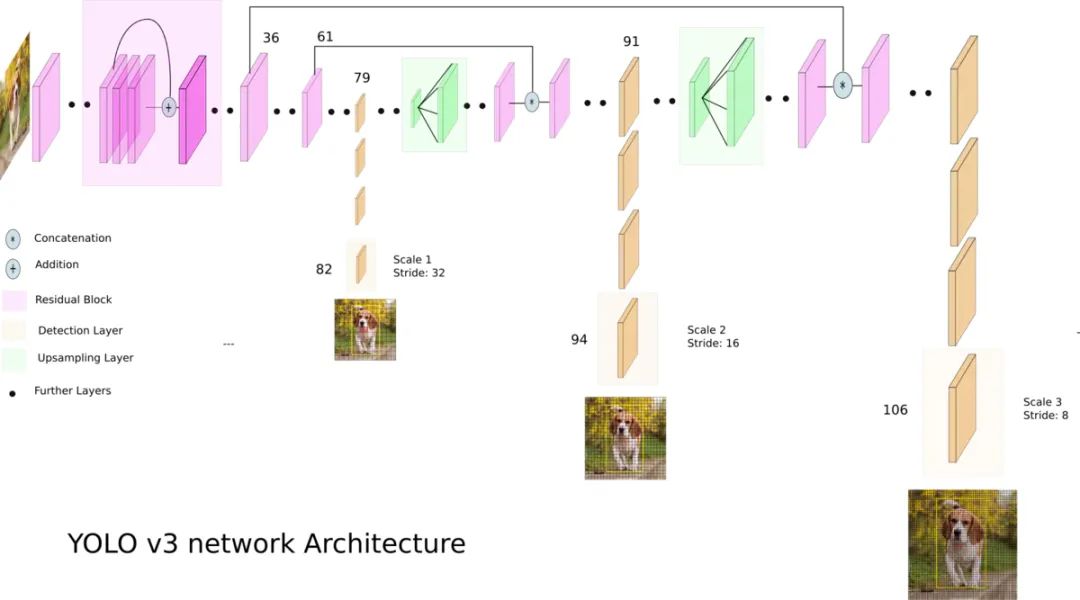
En comparación con el algoritmo de dos etapas, el algoritmo de una sola etapa solo necesita extraer características una vez para lograr la detección de objetivos, y su algoritmo de velocidad es más rápido y la precisión general es ligeramente menor. El trabajo pionero de este tipo de algoritmo es YOLO, que posteriormente fue mejorado por SSD y Retinanet. El equipo que propuso YOLO integró estos trucos que ayudan a mejorar el rendimiento en el algoritmo YOLO y posteriormente propuso cuatro versiones mejoradas YOLOv2 ~ YOLOv5. Aunque la precisión de la predicción no es tan buena como el algoritmo de detección de objetivos de dos etapas, debido a su mayor velocidad de ejecución, YOLO se ha convertido en la corriente principal de la industria. La siguiente figura es el diagrama de estructura de red de YOLOv3.
1.3 Detección sin ancla (sin detección de ancla)
Este tipo de método generalmente representa objetos como algunos puntos clave, y CNN se usa para devolver las posiciones de estos puntos clave. El punto clave puede ser el punto central (CenterNet), el punto de esquina (CornerNet) o el punto representativo (RepPoints) del marco del objeto. CenterNet convierte el problema de detección de objetivos en un problema de predicción del punto central, es decir, el objetivo está representado por el punto central del objetivo y el marco rectangular del objetivo se obtiene al predecir el desplazamiento y el ancho del punto central del objetivo.
El mapa de calor representa información de clasificación, y cada categoría generará un gráfico de mapa de calor separado. Para cada mapa de calor, cuando una determinada coordenada contiene el punto central del objetivo, se generará un punto clave en el objetivo. Usamos un círculo gaussiano para representar todo el punto clave. La siguiente figura muestra los detalles específicos.

RepPoints propone representar un objeto como un conjunto de puntos representativos y se adapta al cambio de forma del objeto a través de una convolución deformable. Los conjuntos de puntos finalmente se convierten en cajas de objetos para calcular las diferencias de las anotaciones manuales.
1.4 Detección de transformador
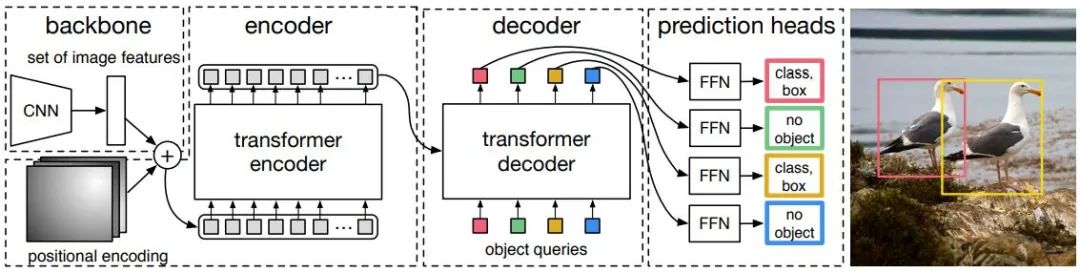
Ya sea que se trate de una detección de objetos de una o dos etapas, ya sea que se utilice el ancla o no, el mecanismo de atención no se utiliza bien. En respuesta a esta situación, Relation Net y DETR utilizan Transformer para introducir el mecanismo de atención en el campo de la detección de objetivos. Relation Net utiliza Transformer para modelar la relación entre diferentes objetivos e incorpora información de relación en las funciones para lograr una mejora de las funciones. DETR propone una nueva arquitectura de detección de objetivos basada en Transformer, que abre una nueva era en la detección de objetivos. La siguiente figura muestra el flujo del algoritmo de DETR. Primero, CNN se usa para extraer características de la imagen, y luego Transformer se usa para modelar el espacio global. Finalmente, se obtiene La salida de se compara con anotaciones manuales mediante un algoritmo de coincidencia de gráficos bipartito.
La precisión de la siguiente tabla utiliza mAP en la base de datos de MSCOCO como indicador, mientras que la velocidad se mide mediante FPS. En comparación con los algoritmos anteriores, hay muchas opciones diferentes en el diseño de la estructura de la red (como diferentes tamaños de entrada, diferentes redes troncales). , etc.), las plataformas de hardware de implementación de cada algoritmo también son diferentes, por lo que la precisión y la velocidad no son completamente comparables, aquí hay solo un resultado aproximado para su referencia.
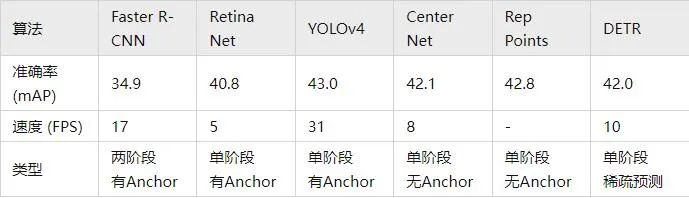
02Seguimiento de objetivos
En la aplicación de conducción autónoma, la entrada son datos de video y hay muchos objetivos a los que se debe prestar atención, como vehículos, peatones, bicicletas, etc. Por lo tanto, esta es una tarea típica de seguimiento de múltiples objetos (MOT). Para la tarea MOT, el marco más popular es Seguimiento por detección, el proceso es el siguiente:
① El detector de objetivos obtiene la salida del cuadro de destino en una imagen de un solo cuadro;
② Extraiga las características de cada objetivo de detección, que generalmente incluye características visuales y características de movimiento;
③ Calcule la similitud entre las detecciones de objetivos de marcos adyacentes de acuerdo con las características para determinar la probabilidad de que provengan del mismo objetivo;
④ Haga coincidir las detecciones de objetivos de marcos adyacentes y asigne la misma ID a objetos del mismo objetivo.
El aprendizaje profundo se aplica en los cuatro pasos anteriores, pero los dos primeros pasos son los principales. En el paso 1, la aplicación del aprendizaje profundo es principalmente para proporcionar detectores de objetivos de alta calidad, por lo que generalmente se seleccionan métodos con mayor precisión. SORT es un método de detección de objetivos basado en Faster R-CNN y utiliza el algoritmo de filtro de Kalman + el algoritmo húngaro, lo que mejora en gran medida la velocidad del seguimiento de objetivos múltiples y al mismo tiempo logra la precisión de SOTA. uno en aplicaciones prácticas algoritmo. En el paso 2, la aplicación del aprendizaje profundo radica principalmente en el uso de CNN para extraer las características visuales de los objetos. La función más importante de DeepSORT es agregar información de apariencia, tomar prestado el módulo ReID para extraer funciones de aprendizaje profundo y reducir la cantidad de cambios de ID. El diagrama de flujo general es el siguiente:
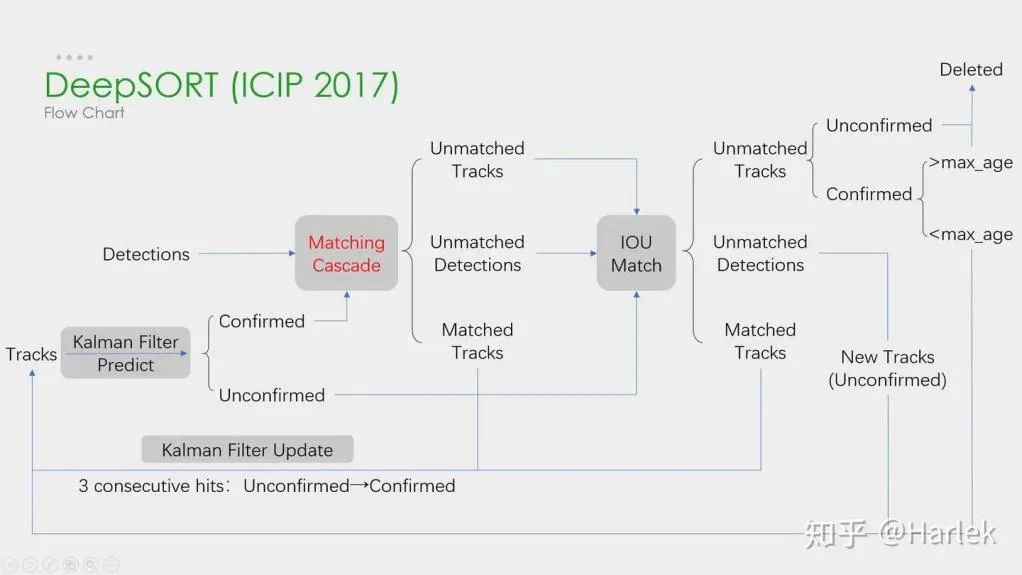
Además, existe un marco de Detección y Seguimiento Simultáneos. Como el CenterTrack representativo, que se originó a partir del algoritmo de detección sin anclaje de una sola etapa CenterNet presentado anteriormente. En comparación con CenterNet, CenterTrack agrega la imagen RGB del marco anterior y el mapa de calor del centro del objeto como entrada adicional, y agrega una rama de desplazamiento para la asociación de los marcos frontal y posterior. En comparación con las múltiples etapas de seguimiento por detección, CenterTrack implementa las etapas de detección y coincidencia con una red, lo que aumenta la velocidad de la inspección técnica.
03 Segmentación Semántica
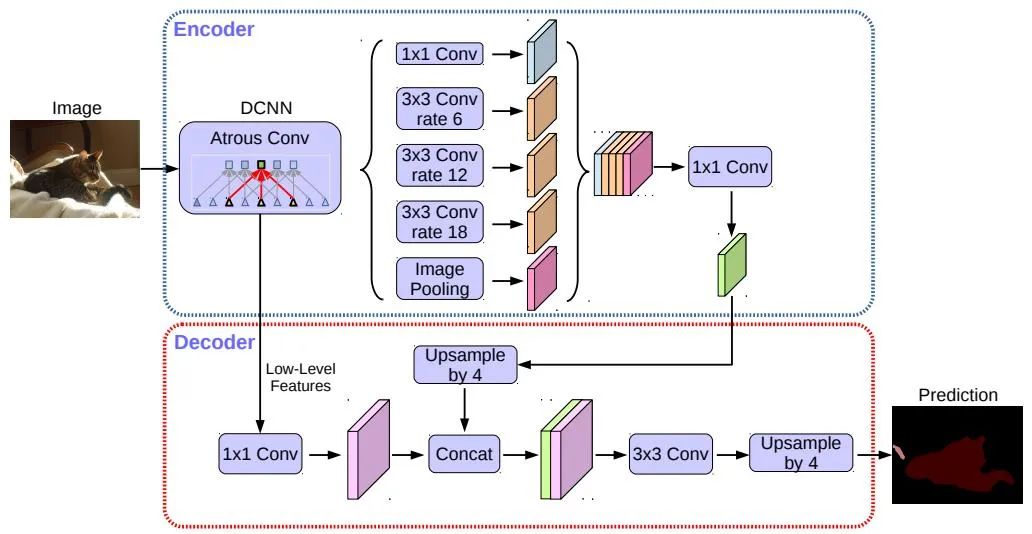
La segmentación semántica se utiliza tanto en tareas de detección de líneas de carril como de detección de áreas transitables para la conducción autónoma. Los algoritmos representativos incluyen FCN, U-Net, serie DeepLab, etc. DeepLab utiliza estructuras de convolución dilatada y ASPP (Atrous Spatial Pyramid Pooling) para realizar un procesamiento multiescala en las imágenes de entrada. Finalmente, el campo aleatorio condicional (CRF) comúnmente utilizado en los métodos tradicionales de segmentación semántica se utiliza para optimizar los resultados de la segmentación. La siguiente figura es la estructura de red de DeepLab v3+.
En los últimos años, el algoritmo STDC ha adoptado una estructura similar al algoritmo FCN y se ha eliminado la compleja estructura del decodificador del algoritmo U-Net. Pero al mismo tiempo, en el proceso de reducción de resolución de la red, el módulo ARM se usa para fusionar continuamente información de mapas de características de diferentes capas, por lo que también evita la desventaja del algoritmo FCN que solo considera la relación de un solo píxel. Se puede decir que el algoritmo STDC logra un buen equilibrio entre velocidad y precisión, y puede cumplir con los requisitos en tiempo real del sistema de conducción automática. El flujo del algoritmo se muestra en la siguiente figura.

Algoritmo de percepción visual de conducción autónoma (2)
En la sección anterior, presentamos el algoritmo de percepción visual 2D. En esta sección, presentaremos la percepción de escena 3D que es esencial en la conducción autónoma. Porque la información de profundidad, el tamaño tridimensional del objetivo, etc. no se puede obtener en la percepción 2D, y esta información es la clave para el juicio correcto del entorno circundante por parte del sistema de conducción automática. La forma más directa de obtener información 3D es usar LiDAR. Sin embargo, LiDAR también tiene sus desventajas, como el alto costo, la dificultad en la producción en masa de productos para automóviles y una mayor influencia del clima. Por lo tanto, la percepción 3D basada únicamente en cámaras sigue siendo una dirección de investigación muy significativa y valiosa A continuación, clasificamos algunos algoritmos de percepción 3D basados en monoculares y binoculares.
01 Percepción monocular 3D
Percibir un entorno 3D basado en una imagen de una sola cámara es un problema mal planteado, pero puede ser asistido por suposiciones geométricas (como píxeles en el suelo), conocimiento previo o alguna información adicional (como estimación de profundidad). Esta vez, presentaremos algoritmos relacionados a partir de las dos tareas básicas de conducción automática (detección de objetivos 3D y estimación de profundidad).
1.1 Detección de objetos 3D
Conversión de representación (pseudo lidar): la detección de otros vehículos circundantes mediante sensores visuales suele encontrar problemas como la oclusión y la incapacidad para medir distancias. La vista en perspectiva se puede convertir en una representación a vista de pájaro. Aquí se introducen dos métodos de transformación. Uno es el mapeo de perspectiva inversa (IPM), que asume que todos los píxeles están en el suelo y los parámetros extrínsecos de la cámara son precisos. En este momento, la transformación de homografía se puede usar para convertir la imagen a BEV, y luego el método basado en la La red YOLO se utiliza para detectar el marco de puesta a tierra del objetivo. . La segunda es la Transformación de características ortogonales (OFT), que utiliza ResNet-18 para extraer características de imágenes en perspectiva. Luego, las características basadas en vóxeles se generan mediante la acumulación de características basadas en imágenes sobre las regiones de vóxeles proyectadas. Las características de vóxel luego se pliegan verticalmente para producir características de plano de tierra ortogonales. Finalmente, se utiliza otra red de arriba hacia abajo similar a ResNet para la detección de objetos 3D. Estos métodos solo son adecuados para objetos cercanos al suelo, como vehículos y peatones. Para objetivos no terrestres, como señales de tráfico y semáforos, se pueden generar pseudonubes de puntos a través de la estimación de profundidad para la detección 3D. Pseudo-LiDAR primero usa el resultado de la estimación de profundidad para generar una nube de puntos, y luego aplica directamente un detector de objetivos 3D basado en LIDAR para generar un marco de objetivos 3D. El flujo del algoritmo se muestra en la siguiente figura.

Puntos clave y modelos 3D: el tamaño y la forma del objetivo a detectar, como vehículos y peatones, son relativamente fijos y conocidos, y estos pueden usarse como conocimiento previo para estimar la información 3D del objetivo. DeepMANTA es uno de los trabajos pioneros en esta dirección. En primer lugar, se utilizan algunos algoritmos de detección de objetivos, como Faster RNN, para obtener el marco del objetivo 2D y también detectar los puntos clave del objetivo. Luego, estas cajas de objetos 2D y puntos clave se comparan con varios modelos CAD de vehículos 3D en la base de datos, y el modelo con la mayor similitud se selecciona como resultado de la detección de objetos 3D. MonoGRNet propone dividir la detección de objetivos 3D monocular en cuatro pasos: detección de objetivos 2D, estimación de profundidad a nivel de instancia, estimación del centro de proyección 3D y regresión de esquina local. El flujo del algoritmo se muestra en la siguiente figura. Todos estos métodos asumen que el objetivo tiene un modelo de forma relativamente fijo, que generalmente es satisfactorio para los vehículos, pero relativamente difícil para los peatones.
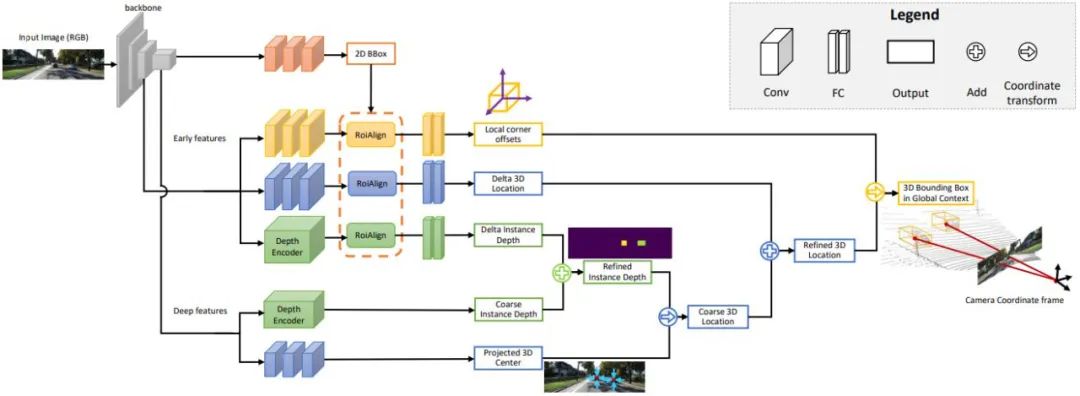
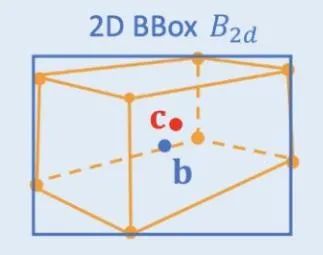
Restricciones geométricas 2D/3D: regresión en las proyecciones del centro 3D y la profundidad aproximada de la instancia y el uso de ambos para estimar la posición 3D aproximada. El trabajo pionero es Deep3DBox, que primero utiliza características de imagen dentro de un cuadro de objeto 2D para estimar el tamaño y la orientación del objeto. Luego, la posición 3D del punto central se resuelve a través de una restricción geométrica 2D/3D. Esta restricción es que la proyección del marco objetivo 3D en la imagen está estrechamente rodeada por el marco objetivo 2D, es decir, al menos un punto de esquina del marco objetivo 3D se puede encontrar a cada lado del marco objetivo 2D. La posición 3D del punto central se puede obtener combinando el tamaño y la orientación predichos previamente con los parámetros de calibración de la cámara. Las restricciones geométricas entre las cajas de objetos 2D y 3D se muestran en la siguiente figura. Sobre la base de Deep3DBox, Shift R-CNN combina el marco objetivo 2D obtenido anteriormente, el marco objetivo 3D y los parámetros de la cámara como entrada, y utiliza una red totalmente conectada para predecir una posición 3D más precisa.
Generación directa de 3DBox: este tipo de método comienza desde el denso cuadro candidato de destino 3D y califica todos los cuadros candidatos a través de las características en la imagen 2D, y el cuadro candidato con la puntuación más alta es el resultado final. Algunos son similares a los métodos tradicionales de ventana deslizante en la detección de objetos. Un algoritmo Mono3D representativo primero genera cuadros de candidatos 3D densos en función de la posición anterior del objeto (la coordenada z está en el suelo) y el tamaño. Después de que estos cuadros de candidatos 3D se proyectan en las coordenadas de la imagen, se puntúan integrando las características en la imagen 2D, y luego CNN obtiene el cuadro objetivo 3D final para dos rondas de puntuación. M3D-RPN es un método basado en Anchor que define Anchor 2D y 3D. El Anclaje 2D se obtiene a través de un muestreo denso en la imagen, y el Anclaje 3D está determinado por el conocimiento previo de los datos del conjunto de entrenamiento (como el valor medio del tamaño real del objetivo). M3D-RPN también utiliza convolución estándar y convolución de reconocimiento de profundidad. El primero tiene invariancia espacial y el segundo divide la fila de la imagen (coordenada Y) en múltiples grupos, cada grupo corresponde a una profundidad de escena diferente y es procesado por un núcleo de convolución diferente. Los métodos de muestreo densos anteriores son muy intensivos desde el punto de vista computacional. SS3D utiliza una detección de etapa única más eficiente, que incluye una CNN para generar representaciones redundantes de cada objeto relevante en la imagen y estimaciones de incertidumbre correspondientes, y un optimizador de cuadro delimitador 3D. FCOS3D también es un método de detección de una sola etapa. El objetivo de regresión agrega un centro 2.5D adicional (X, Y, Profundidad) obtenido al proyectar el centro del cuadro objetivo 3D a la imagen 2D.
1.2 Estimación de profundidad
Ya sea la detección de objetivos 3D mencionada anteriormente u otra tarea importante de segmentación semántica de percepción de conducción autónoma, de 2D a 3D, se aplica más o menos a información de profundidad escasa o densa. La importancia de la estimación de profundidad monocular es evidente, su entrada es una imagen y la salida es una imagen del mismo tamaño que consiste en el valor de profundidad de la escena correspondiente a cada píxel. La entrada también puede ser una secuencia de video, utilizando información adicional proporcionada por la cámara o el movimiento del objeto para mejorar la precisión de la estimación de la profundidad.
En comparación con el aprendizaje supervisado, el método no supervisado de estimación de profundidad monocular no necesita construir un conjunto de datos de valor real muy desafiante y es menos difícil de implementar. Los métodos no supervisados para la estimación de profundidad monocular se pueden dividir en dos tipos basados en secuencias de video monocular y basados en pares de imágenes estéreo sincronizadas. El primero se basa en la suposición de cámaras en movimiento y escenas fijas. En el último método, Garg y otros intentaron por primera vez utilizar el par de imágenes binoculares después de la corrección estéreo al mismo tiempo para la reconstrucción de imágenes.La relación de pose de las vistas izquierda y derecha se obtuvo a través del posicionamiento binocular, y un relativamente ideal se obtuvo el efecto. Sobre esta base, Godard y otros utilizaron restricciones de consistencia de izquierda a derecha para mejorar aún más la precisión.Sin embargo, al extraer características avanzadas capa por capa para aumentar el campo receptivo, la resolución de la característica también disminuye y la granularidad se pierde constantemente. que afecta Proporciona procesamiento de detalles profundos y definición de bordes. Para paliar este problema, Godard y otros introdujeron una pérdida multiescala de resolución completa, que reduce eficazmente los artefactos causados por los agujeros negros y la replicación de texturas en regiones de baja textura. Sin embargo, esta mejora en la precisión es aún limitada.
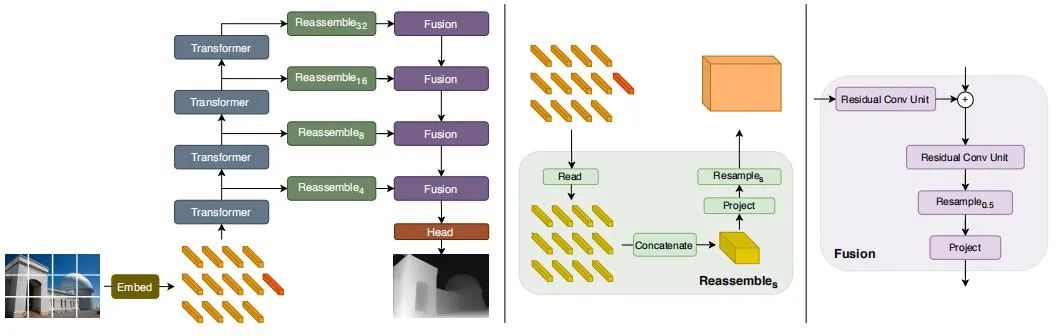
Recientemente, han surgido algunos modelos basados en Transformer, uno tras otro, con el objetivo de obtener un campo receptivo global de etapa completa, que también es muy adecuado para tareas intensivas de estimación de profundidad. En el DPT supervisado, se propone utilizar Transformador y estructura multiescala para garantizar la precisión local y la consistencia global de la predicción al mismo tiempo.La siguiente figura es el diagrama de estructura de la red.
02 Percepción 3D binocular
La visión binocular puede resolver la ambigüedad causada por la transformación de la perspectiva, por lo que teóricamente puede mejorar la precisión de la percepción 3D. Pero el sistema binocular tiene requisitos relativamente altos en hardware y software. En términos de hardware, se requieren dos cámaras con registro preciso y es necesario asegurarse de que el registro sea siempre correcto durante la operación del vehículo. En términos de software, el algoritmo necesita procesar datos de dos cámaras al mismo tiempo, la complejidad del cálculo es alta y el rendimiento en tiempo real del algoritmo es difícil de garantizar. El trabajo binocular es relativamente raro en comparación con el monocular. A continuación, también se hará una breve introducción de dos aspectos de la detección de objetivos 3D y la estimación de profundidad.
2.1 Detección de objetos 3D
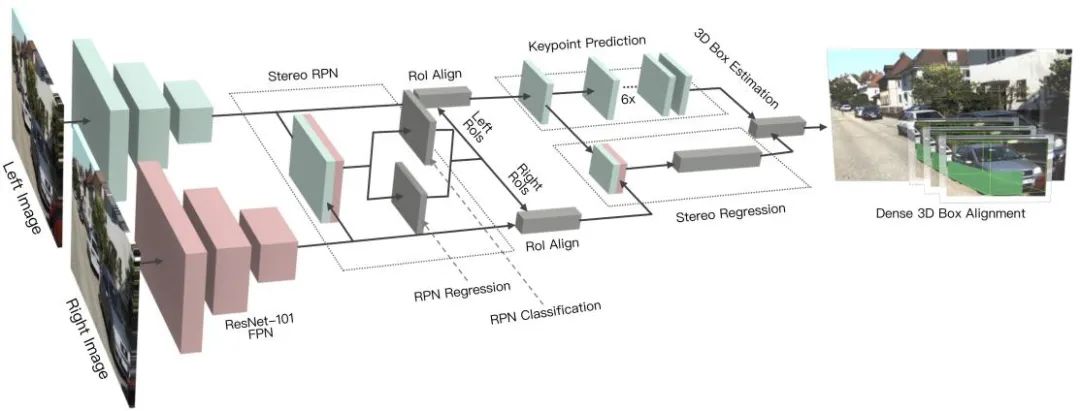
3DOP es un método de detección de dos etapas, que es una extensión del método Fast R-CNN en el campo 3D. Primero, la imagen binocular se usa para generar un mapa de profundidad, y luego el mapa de profundidad se convierte en una nube de puntos y luego se cuantifica en una estructura de datos de cuadrícula, que luego se usa como entrada para generar un cuadro candidato para un objetivo 3D. Similar al Pseudo-LiDAR presentado anteriormente, convierte mapas densos de profundidad (desde monoculares, binoculares o incluso LiDAR de línea baja) en nubes de puntos, y luego aplica algoritmos en el campo de la detección de objetivos de nubes de puntos. DSGN utiliza la coincidencia estéreo para construir volúmenes de escaneo planos y los convierte en geometría 3D para codificar geometría 3D e información semántica. Es un marco integral que puede extraer características a nivel de píxel para coincidencia estéreo y características de alto nivel para reconocimiento de objetos características, y puede estimar simultáneamente la profundidad de la escena y detectar objetos 3D. Stereo R-CNN amplía Faster R-CNN para entrada estéreo para detectar y asociar objetos simultáneamente en las vistas izquierda y derecha. Se agregan ramas adicionales después de RPN para predecir puntos clave dispersos, puntos de vista y dimensiones de objetos, y combinar cuadros delimitadores 2D en las vistas izquierda y derecha para calcular un cuadro delimitador de objetos 3D grueso. Luego, se recupera un cuadro delimitador 3D preciso mediante el uso de alineación fotométrica basada en regiones de las regiones izquierda y derecha de interés.La siguiente figura es su estructura de red.
2.2 Estimación de profundidad
El principio de la estimación de profundidad binocular es muy simple, que se basa en la distancia de píxeles d entre el mismo punto 3D en las vistas izquierda y derecha (suponiendo que las dos cámaras mantienen la misma altura, por lo que solo se considera la distancia en la dirección horizontal ), es decir, el paralaje, la distancia focal f de la cámara, y La distancia B (longitud de la línea de base) entre las dos cámaras se usa para estimar la profundidad del punto 3D. La fórmula es la siguiente, y la profundidad puede ser calculado estimando el paralaje. Entonces, todo lo que se necesita hacer es encontrar un punto coincidente en otra imagen para cada píxel.
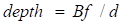
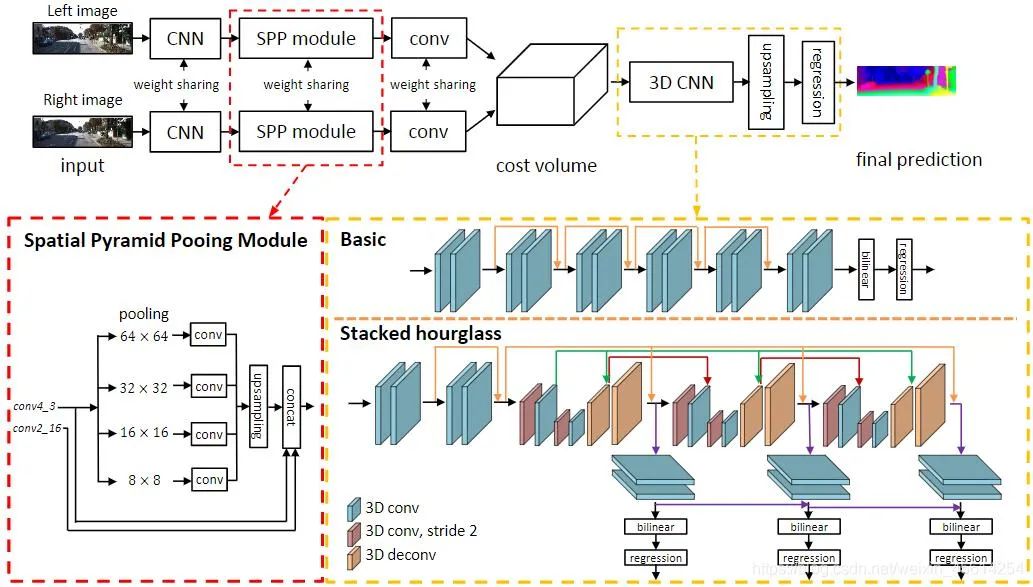
Para cada posible d, se puede calcular el error de coincidencia en cada píxel, por lo que se obtiene un volumen de costo de datos de error tridimensional. A través de Cost Volume, podemos obtener fácilmente la disparidad en cada píxel (correspondiente a la d del error de coincidencia mínimo), para obtener el valor de profundidad. MC-CNN usa una red neuronal convolucional para predecir el grado de coincidencia de dos parches de imagen y lo usa para calcular el costo de coincidencia estéreo. Los costos se refinan mediante la agregación de costos basada en intersecciones y la coincidencia semiglobal, seguidas de verificaciones de coherencia de izquierda a derecha para eliminar errores en regiones ocluidas. PSMNet propone un marco de aprendizaje integral para la coincidencia estéreo que no requiere ningún procesamiento posterior, presenta un módulo de agrupación piramidal, incorpora información contextual global en las características de la imagen y proporciona una CNN 3D de reloj de arena apilada para fortalecer aún más la información global. La siguiente figura es su estructura de red.
Editor: Yu Tengkai
Revisión: Lin Yilin
