Después de hablar sobre el hardware del sensor común en la parte anterior, hablemos sobre los aspectos del software del sensor.
Esta parte se divide principalmente en dos partes: 1. Visión artificial y red neuronal 2. Aplicación perceptiva (parte de visión pura)
Tabla de contenido
1. Visión artificial y redes neuronales
2. Aplicación de percepción (parte de visión pura)
2.1 Soluciones visuales puras (YOLO, SSD, etc.)
1. Visión artificial y redes neuronales
Computer Vision (CV) es familiar para todos y es una de las ciencias de más rápido crecimiento en los últimos tiempos. Su contenido incluye la adquisición, transmisión, procesamiento, almacenamiento, procesamiento y comprensión de la información visual.

Los bordes a menudo ocurren en el valor máximo del diferencial de primer orden de la imagen, y el diferencial de segundo orden es 0. Sin embargo, debido a la influencia del ruido, generalmente eliminamos el ruido de alta frecuencia antes del procesamiento. Nuestro kernel de convolución de filtro diferencial de señal discreta de uso común se usa comúnmente en el operador Robert, el operador Prewitt, el operador Sobel, el operador Laplaciano, etc.
Para las tareas de segmentación, hay segmentación basada en umbrales, segmentación basada en regiones, segmentación basada en detección de bordes, segmentación basada en modelos de profundidad y más. No se ampliará aquí.
La visión por computadora tiene una variedad de aplicaciones en el campo de la conducción autónoma, como la adquisición de profundidad de cámaras binoculares de múltiples ojos y monitoreo del estado del conductor, procesamiento de nubes de puntos, identificación de participantes en el tráfico, estimación de seguimiento y movimiento, detección de señales luminosas, detección de área de conducción , mapeo de alta definición y más.
Esta sección presenta principalmente el método de red neuronal en el aprendizaje profundo.Desde el éxito de AlexNet en el campo de la imagen en 2012, la red neuronal convolucional ha llamado nuestra atención. (La diferencia entre convolución y correlación cruzada es solo si el kernel de convolución está invertido, por lo que la convolución también tiene el efecto de reflejar la correlación, extrayendo así características)
Esta sección cubre
Función de activación : comprensión y resumen de la función de activación común (función de motivación)
Propagación hacia adelante y hacia atrás: propagación hacia adelante y hacia atrás de redes neuronales
Función de pérdida: resumen de las funciones de pérdida de redes neuronales
Las redes neuronales convolucionales más clásicas:
Vgg16 (2014): El punto de innovación radica en una mayor profundidad, utilizando un núcleo de convolución de 3*3 en lugar de un núcleo de convolución de 5*5 o incluso 7*7, introduciendo una no linealidad más fuerte;

GoogleNet: La más famosa es la estructura Inception (inception es también el nombre de la película Inception), que por primera vez explicó el papel del kernel de convolución 1*1, la extracción de características, la reducción de dimensionalidad (el canal correspondiente al filtro ) también se usa para corregir la activación lineal (ReLU), usando unión de características y agregando dos clasificadores auxiliares para ayudar a superar el problema de desaparición del gradiente, lo que hace que la red sea más profunda.

ResNet (2015): Una red significativa, agregando el cuello de botella de la estructura residual, aliviando el problema de la desaparición del gradiente, haciendo la red más profunda (más de 1000 capas), a diferencia de la red anterior que usa DropOut y usa BN para la regularización.
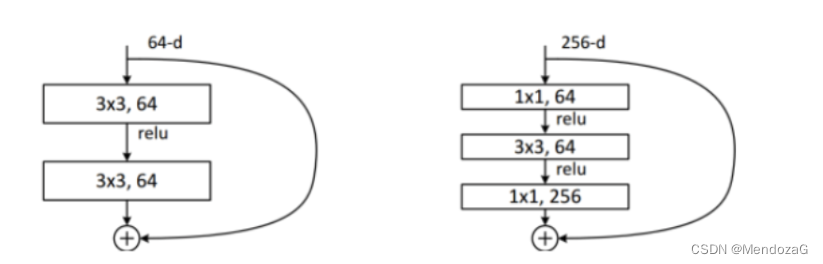
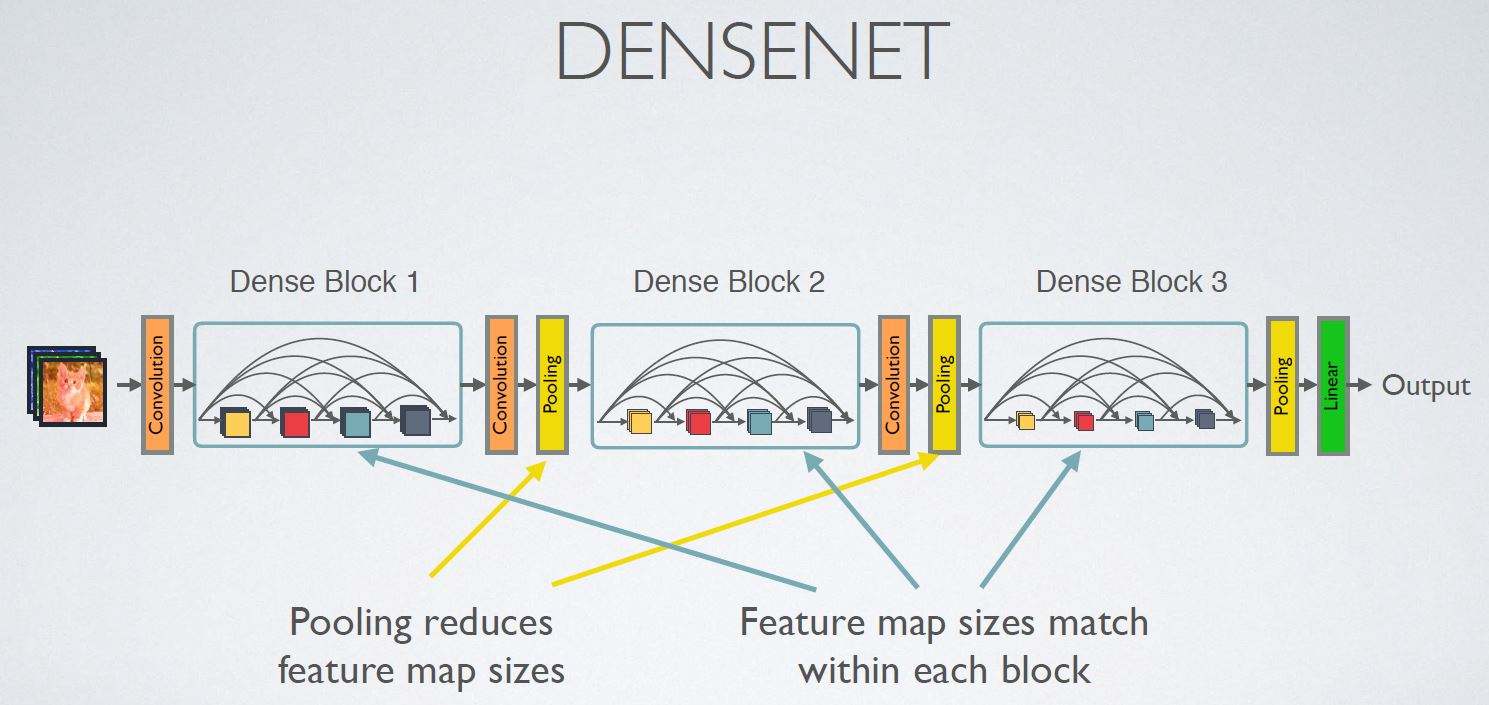
DenseNet (2017): ya no se profundiza la red ni se amplía la estructura de la red (Inception), sino que se mezclan unidades intensivas en funciones. La entrada de cada capa es el empalme de la salida de la capa anterior. El efecto es bueno, pero los requisitos de memoria son mucho más altos.
SENet: la operación Squeeze se comprime en un número real (el ancho es el canal), y luego se generan diferentes pesos a través de la excitación y luego se escalan para completar la recalibración de las características originales en el canal y establecer la conexión entre los canales de características.

2. Aplicación de percepción (parte de visión pura)
Como mencionamos antes, las aplicaciones de percepción se encuentran en la detección de objetos, áreas manejables, líneas de carril, detección de semáforos y más. En esta sección utilizamos principalmente herramientas de aprendizaje profundo.
2.1 Soluciones visuales puras (YOLO, SSD, etc.)
Debido a la Propuesta de región propuesta por RCNN, se extrae el área candidata y luego se realiza la extracción de características en el área candidata, y se usa AlexNet simple para ajustar el aprendizaje de características y, finalmente, el resultado se emite a través de SVM (SVM es mejor, mejor que softmax), que es un método clásico de The 2stage. La desventaja es que la velocidad es lenta y no se puede procesar en tiempo real. Debido a que las razones de implementación generalmente requieren que podamos procesar en tiempo real, aquí solo se comparten dos redes clásicas de 1 etapa.
Hablemos primero de YOLOv1, que se lanzó en 2016. Es un algoritmo típico de 1 etapa. Se divide en dos partes: detección y entrenamiento, en el que el problema de detección del objetivo se transforma en un problema de regresión.

La imagen de entrada primero se redimensiona, se divide en celdas de cuadrícula s * s y se pasa a través de la red neuronal para obtener la disposición del bbox del tipo de objeto. A través de NMS, solo se muestran los resultados de detección con la probabilidad total más alta. (Para cada celda de la cuadrícula, solo se determinan n bboxes)

Los indicadores generales de evaluación para la predicción de los resultados dependen de Pascal VOC (20 categorías) y COCO (80 categorías).
Su diseño de red es el siguiente:
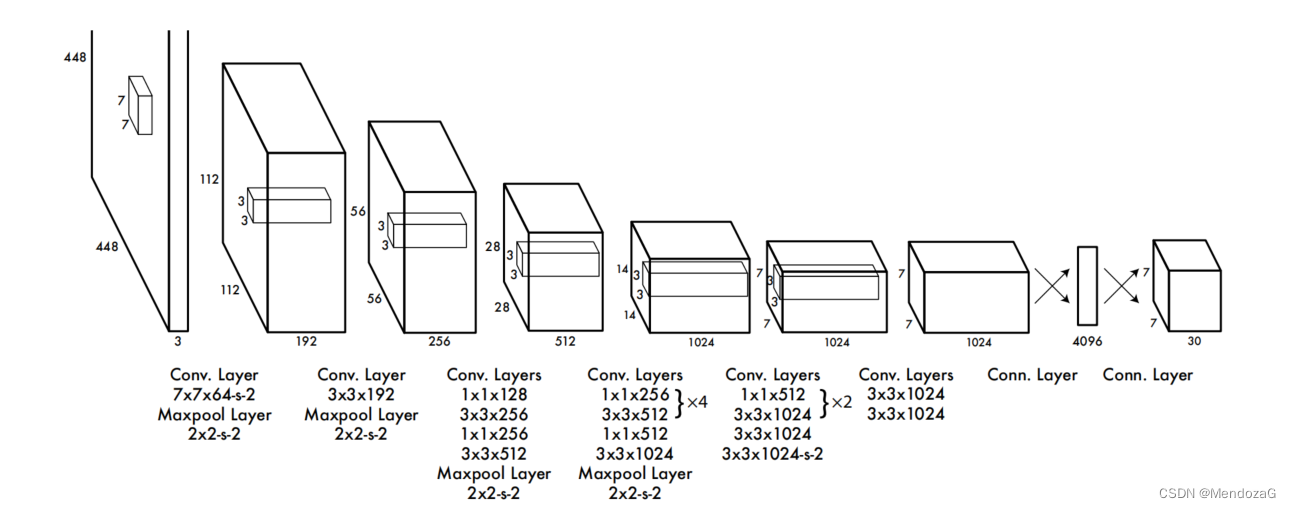
El primero es cambiar el tamaño de la imagen a 448*488, incluidas 24 capas de capas de extracción de características convolucionales y 2 capas de capas FC, y finalmente volver a obtener un tensor de 7*7*30.
Entre ellos, 7*7 es el tamaño correspondiente a la celda de la cuadrícula, y la información contenida en 30 es: para 20 tipos de VOC, hay cinco posiciones y tamaños de confianza, x, y, w, h, es decir, el bbox. También hay veinte probabilidades condicionales correspondientes al objetivo. Debido a que una celda de cuadrícula aquí solo genera dos bboxes, hay 5*2+20=30 dimensiones en total.
Entonces, si se divide en celdas de cuadrícula de 7*7 como en el documento, se generará una salida de 7*7*30. Y para cada 7*7 usamos NMS (visto desde el lado izquierdo de la salida) para extraer el resultado más probable en cada cuadrícula.
Su función de pérdida se define como:

El primer elemento es el error del punto central de la caja de detección negativa (x, y), el segundo elemento es el error de posicionamiento del ancho y la altura de detección (w, h), la razón para agregar el signo raíz es hacer que la caja pequeña sea sensible, y los elementos tercero y cuarto representan El error de confianza de regresión se divide en muestras positivas y muestras negativas, el bbox responsable de detectar objetos y el bbox no responsable de detectar objetos; el quinto elemento representa el error de clasificación de celdas de cuadrícula de detección de objetos.

Comparado con RCNN, YOLO es obviamente más rápido. Comparado con RCNN, atraviesa todas las regiones de la imagen en lugar de extraer un área determinada de interés, por lo que su capacidad de migración es muy buena, pero debido a que cada cuadro solo puede detectar un tipo de objeto, para El efecto de los objetos pequeños y densos será muy pobre También se puede ver en la figura anterior que la tasa de error de YOLO para el fondo es mucho mejor que la de RCNN, gracias a su recorrido de todas las imágenes.

YOLO más Fast-RCNN logró muy buenos resultados.
YOLO ha iterado dos versiones bajo el autor original. Debido a que no está dispuesto a usarse para monitoreo militar y otros fines, no se actualizará. En la actualidad, YOLO ha iterado a la séptima versión (reclamada), y la versión v5 es actualmente reconocida como relativamente completa.
Meituan lanzó recientemente la versión v6. Si está interesado, puede consultar mi artículo:
A continuación, introduzca el algoritmo SSD (Single SHOT Multibox Detection)

A diferencia de YOLO, SSD detecta el mapa de características obtenido por cada convolución y, finalmente, utiliza la capa de convolución para la detección y utiliza marcos candidatos de diferentes escalas. La siguiente figura muestra mapas de características de diferentes escalas. Los gatos más pequeños usan celdas de cuadrícula más finas y los perros más grandes usan celdas de cuadrícula más grandes, que tienen una relación de escala. (Vale la pena señalar que hay 21 niveles de confianza para VOC, porque se agrega el fondo)

La entrada debe escalarse a 300*300, utilizando una red troncal vgg16 recortada. El uso de capa convolucional 1*1 y capa convolucional 3*3.

El siguiente flujo será más claro:
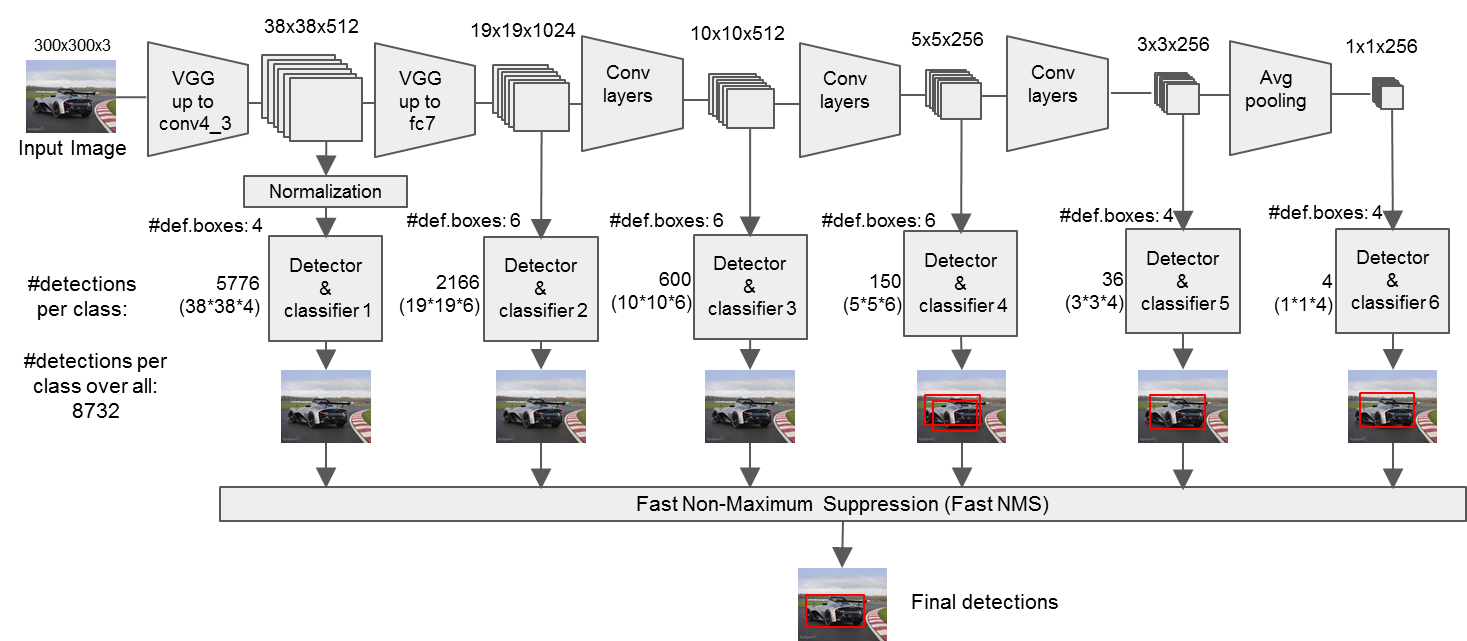
La escala y el aspecto del cuadro predeterminado de diferentes capas de entidades:

Se generarán 8732 casillas por defecto.
Función de pérdida:

La pérdida de la segunda pérdida de posicionamiento (igual que Faster RCNN):

La pérdida de confianza del primer elemento es una pérdida softmax multicategoría:

Resultados en el equipo de prueba PASCAL VOC2017:
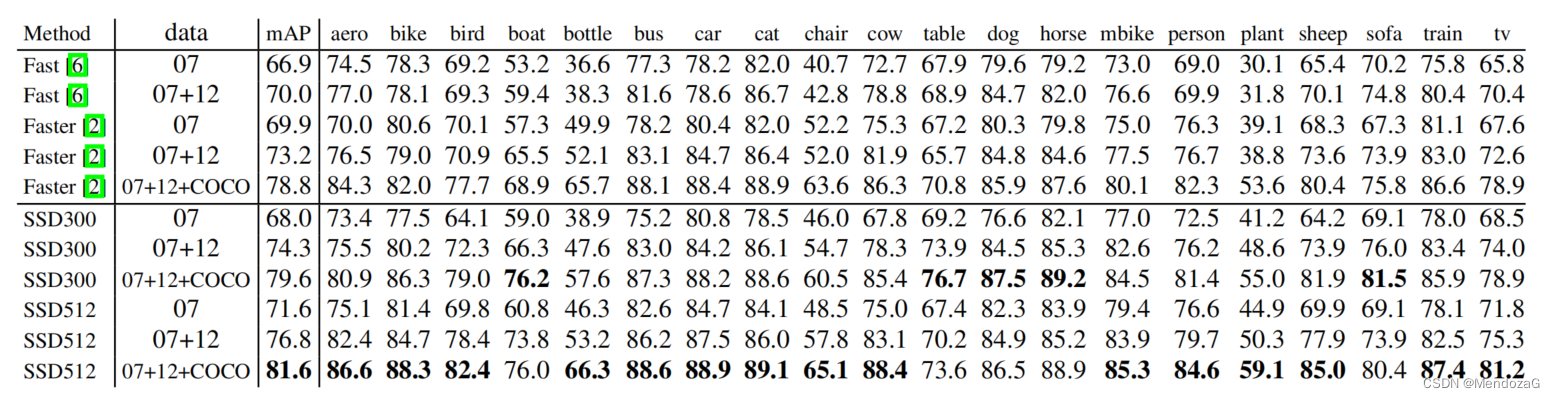
Por qué el rendimiento de SSD es mejor, el autor prueba con variables de control:

Se puede ver que el aumento de datos es el indicador de impacto más crítico.
Prueba de velocidad: ( tamaño de lote 8 usando Titan X y cuDNN v4 con Intel Xeon [email protected]. )
