1. Introducción
Los experimentos muestran que RNN funciona bien en casi todos los problemas de secuencia, incluido el reconocimiento de voz/texto, la traducción automática, el reconocimiento de escritura a mano, el análisis de datos de secuencia (predicción), etc.
En aplicaciones prácticas, existe un problema serio en el diseño interno de RNN: dado que la red solo puede procesar un paso de tiempo a la vez, el paso siguiente debe esperar a que se procese el paso anterior antes de poder realizar la operación . Esto significa que las RNN no se pueden paralelizar masivamente como las CNN, especialmente cuando las RNN/LSTM realizan procesamiento bidireccional de texto. Esto también significa que los RNN son extremadamente intensivos desde el punto de vista computacional, ya que todos los resultados intermedios deben guardarse antes de que se complete la ejecución de la tarea completa.
Cuando CNN procesa una imagen, considera la imagen como un "bloque" bidimensional (matriz m*n). Al migrar a series temporales, la serie puede considerarse como un objeto unidimensional (vector de 1*n). A través de la estructura de red multicapa, se puede obtener un campo receptivo suficientemente grande. Este enfoque hará que la CNN sea muy profunda, pero gracias a las ventajas del procesamiento paralelo masivo, sin importar qué tan profunda sea la red, se puede procesar en paralelo, ahorrando mucho tiempo. Esta es la idea básica de TCN.
1.1 Problemas con las RNN
LightRNN: una red neuronal recurrente que utiliza de manera eficiente la memoria y la computación
Reducir la huella de memoria RNN en un 90 %: la Universidad de Toronto propone una red neuronal cíclica reversible: Reducir la huella de memoria RNN en un 90 %: la Universidad de Toronto propone una red neuronal cíclica reversible-Conocimiento

Las redes neuronales recurrentes (RNN) han logrado un rendimiento de última generación en el procesamiento de datos de secuencia, pero requieren mucha memoria para el entrenamiento y necesitan almacenar estados ocultos .
Recientemente, las redes neuronales recurrentes (RNN) se han utilizado para manejar una variedad de tareas de procesamiento de lenguaje natural (NLP), como el modelado de lenguaje, la traducción automática, el análisis de sentimientos y la respuesta a preguntas. Una arquitectura RNN popular es la red de memoria a corto plazo (LSTM), que puede modelar dependencias a largo plazo y resolver el problema de la desaparición de gradientes a través de celdas de memoria y funciones de activación. Debido a estos elementos, la red neuronal recurrente LSTM logra un rendimiento de última generación en muchas tareas actuales de procesamiento del lenguaje natural, a pesar de aprenderlo casi desde cero.
Aunque RNN se está volviendo cada vez más popular, también tiene una limitación: cuando se aplica a corpus de texto con gran vocabulario, el tamaño del modelo será muy grande. Por ejemplo, cuando se usan RNN para el modelado del lenguaje, las palabras primero deben mapearse desde vectores one-hot (que tienen la misma dimensión que el tamaño del vocabulario) a vectores incrustados a través de la matriz de incrustación de entrada. Luego, para predecir la probabilidad de la siguiente palabra, la capa oculta superior se proyecta en una distribución de probabilidad sobre todas las palabras del vocabulario a través de la matriz de incrustación de salida. Cuando el vocabulario contiene decenas de millones de palabras distintas (lo que es común en los corpus web), las dos matrices de incrustación contendrán decenas de miles de millones de elementos distintos, lo que hace que el modelo RNN sea demasiado grande y, por lo tanto, no pueda caber en la memoria del dispositivo GPU. Tomando el conjunto de datos ClueWeb como ejemplo, su conjunto de vocabulario contiene más de 10 millones de palabras. Si el vector de incrustación tiene 1024 dimensiones y cada dimensión está representada por un punto flotante de 32 bits, el tamaño de la matriz de incrustación de entrada será de unos 40 GB. Teniendo más en cuenta los pesos entre la matriz de incrustación de salida y las capas ocultas, el modelo RNN tendría más de 80 GB, una cifra que supera con creces las capacidades de las mejores GPU del mercado.
Incluso si la memoria de la GPU se puede expandir, la complejidad computacional para entrenar un modelo de volumen de este tipo será prohibitivamente alta. En un modelo de lenguaje RNN, la operación que consume más tiempo es calcular la distribución de probabilidad de todas las palabras del vocabulario, lo que requiere multiplicar la matriz de incrustación de salida y el estado oculto en cada posición de la secuencia. Un simple cálculo muestra que lleva décadas completar el entrenamiento del modelo de lenguaje del conjunto de datos de ClueWeb utilizando el mejor dispositivo de una sola GPU. Además, aparte de la dificultad de la fase de entrenamiento, incluso si finalmente entrenáramos un modelo de este tipo, sería casi imposible para nosotros introducirlo en un dispositivo móvil y convertirlo en una aplicación.
1.2 Antecedentes TCN
Hasta ahora, el tema del modelado de secuencias en el contexto del aprendizaje profundo se ha relacionado principalmente con arquitecturas de redes neuronales recurrentes, como LSTM y GRU. S. Bai y otros (*) argumentan que esta forma de pensar está desactualizada y que las redes convolucionales deben considerarse como uno de los principales candidatos al modelar datos de secuencia. Pudieron demostrar que en muchas tareas, las redes convolucionales pueden lograr un mejor rendimiento que las RNN, al tiempo que evitan los errores comunes de los modelos recurrentes, como problemas de explosión /desaparición de gradientes o falta de preservación de la memoria . Además, el uso de una red convolucional en lugar de una red recurrente puede mejorar el rendimiento porque permite que la salida se calcule en paralelo . Su arquitectura propuesta se llama Red Convolucional Temporal (TCN) y se explicará en las siguientes secciones.
TCN se refiere a la red convolucional temporal , un nuevo tipo de algoritmo que se puede utilizar para resolver el pronóstico de series temporales.
Este algoritmo fue propuesto por primera vez por Lea et al. en 2016 cuando estaban investigando la segmentación de acciones de video. En términos generales, este proceso de rutina consta de dos pasos: primero, las características de bajo nivel se calculan utilizando una CNN que (generalmente) codifica espacio -información temporal, y segundo, alimentar estas características de bajo nivel en un clasificador que usa (generalmente) un RNN que captura información temporal de alto nivel. La principal desventaja de este enfoque es que se requieren dos modelos separados.
TCN proporciona un enfoque unificado para capturar los dos niveles de información de forma jerárquica.
Dado que la propuesta de TCN ha causado gran repercusión, algunas personas piensan que Time Convolutional Network (TCN) reemplazará a RNN como el rey de NLP o predicción de tiempos.
William Vorhies, director editorial de DataScienceCentral, dio las siguientes razones:
RNN tarda demasiado Dado que la red solo lee y analiza una palabra (o carácter) en el texto de entrada a la vez, la red neuronal profunda debe esperar a que se procese la palabra anterior antes de procesar la siguiente palabra. Esto significa que RNN no puede realizar un procesamiento paralelo masivo como CNN; y los resultados reales de TCN también son mejores que los del algoritmo RNN.
Un TCN puede tomar una secuencia de longitud arbitraria y generarla con la misma longitud. En el caso de una arquitectura de red totalmente convolucional 1D, se utilizan convoluciones causales. Una característica clave es que la salida en el tiempo t solo se convoluciona con elementos que ocurrieron antes de t.
2 funciones TCN
El modelo TCN se basa en el modelo CNN con las siguientes mejoras:
- Modelo de secuencia aplicable: convolución causal
- Historial de la memoria: convolución de agujeros/convolución dilatada, bloque residual
A continuación se presentará la tecnología de extensión de CNN, respectivamente.
Características de TCN :
- Redes convolucionales causales
- Método de convolución de expansión ( convolución de expansión , convolución de agujeros) Convolución causal dilatada
- bloque residual
- función de activación
- normalización
- regularización
- salida del Dr.
2.1 Convolución Causal

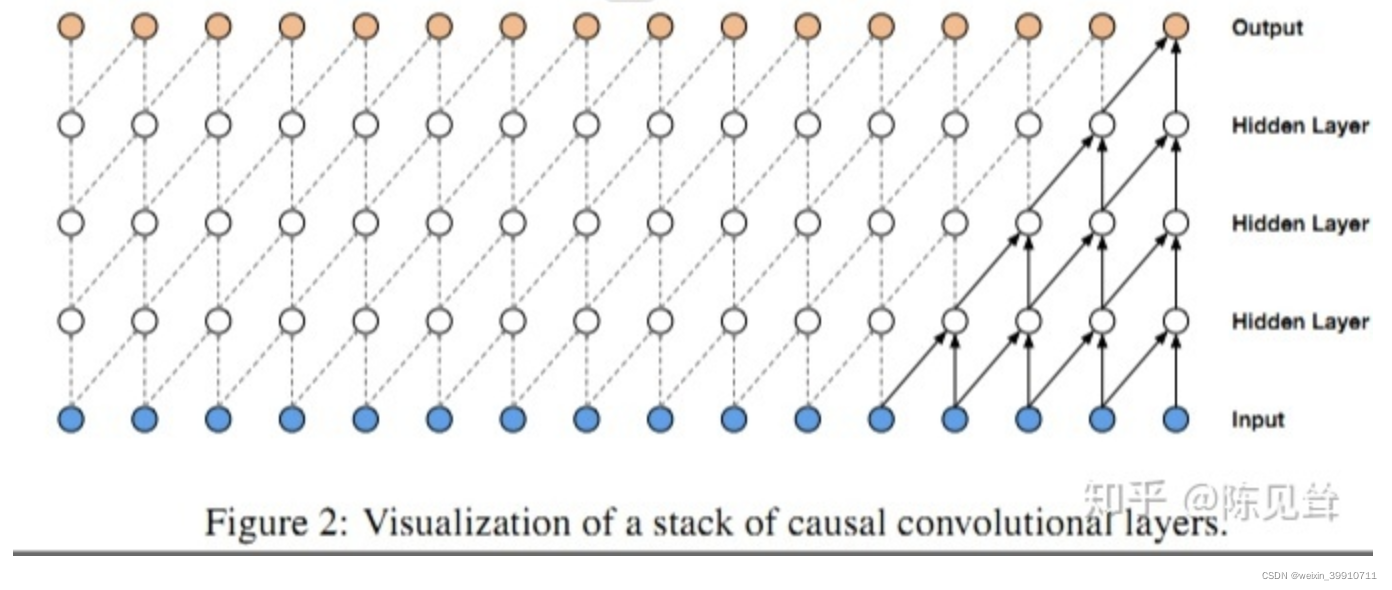
La convolución causal se puede representar visualmente mediante la figura anterior. Es decir, para el valor de la capa anterior en el tiempo t, solo depende del valor de la siguiente capa en el tiempo t y antes. La diferencia con las redes neuronales convolucionales tradicionales es que la convolución causal no puede ver datos futuros y es una estructura unidireccional , no bidireccional. En otras palabras, solo con la causa anterior puede existir el efecto posterior.Es un modelo estrictamente restringido en el tiempo, por lo que se llama convolución causal.
La convolución causal tiene dos características:
- No se considera información futura. Dada una secuencia de entrada
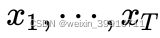 , predecir
, predecir  . Pero al pronosticar
. Pero al pronosticar 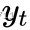 , solo se puede usar la secuencia observada , no la secuencia
, solo se puede usar la secuencia observada , no la secuencia 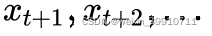 .
. - Cuanto más tiempo se rastrea la información histórica, más capas ocultas hay. En la figura anterior, supongamos que tomamos la segunda capa oculta como salida y su último nodo está asociado con los tres nodos de entrada, es decir,
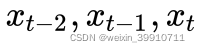 suponiendo que la capa de salida se usa como salida, su último nodo está asociado con los cinco nodos de entrada. nodos.
suponiendo que la capa de salida se usa como salida, su último nodo está asociado con los cinco nodos de entrada. nodos.
2.2 Convolución dilatada/Convolución dilatada
La convolución causal simple todavía tiene el problema de las redes neuronales convolucionales tradicionales, es decir, la duración del tiempo de modelado está limitada por el tamaño del kernel de convolución. Si desea capturar dependencias más largas, necesita apilar muchas capas linealmente. . La CNN estándar puede obtener un campo receptivo más grande agregando una capa de agrupación, pero debe haber un problema de pérdida de información después de la capa de agrupación.
La convolución de agujeros consiste en inyectar agujeros en la convolución estándar para aumentar el campo receptivo. La convolución del agujero tiene una tasa de dilatación de hiperparámetro adicional, que se refiere al número de intervalos del núcleo (la tasa de dilatación es igual a 1 en la CNN estándar) . La ventaja del agujero es que el campo receptivo aumenta sin pérdida de información, por lo que cada salida de convolución contiene una mayor variedad de información. La siguiente figura muestra la CNN estándar (izquierda) y la convolución dilatada (derecha), y la tasa de dilatación en la figura de la derecha es igual a 2.
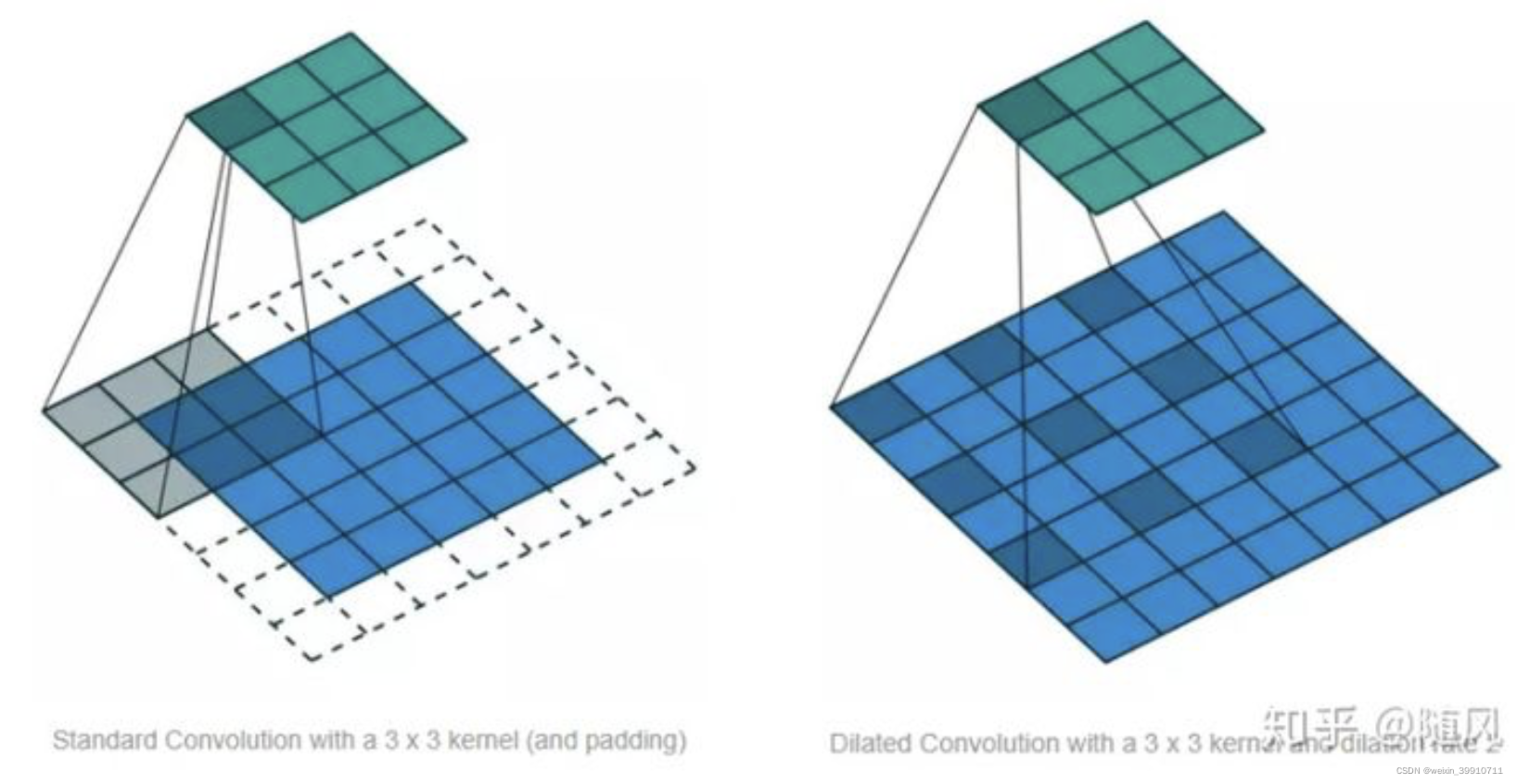
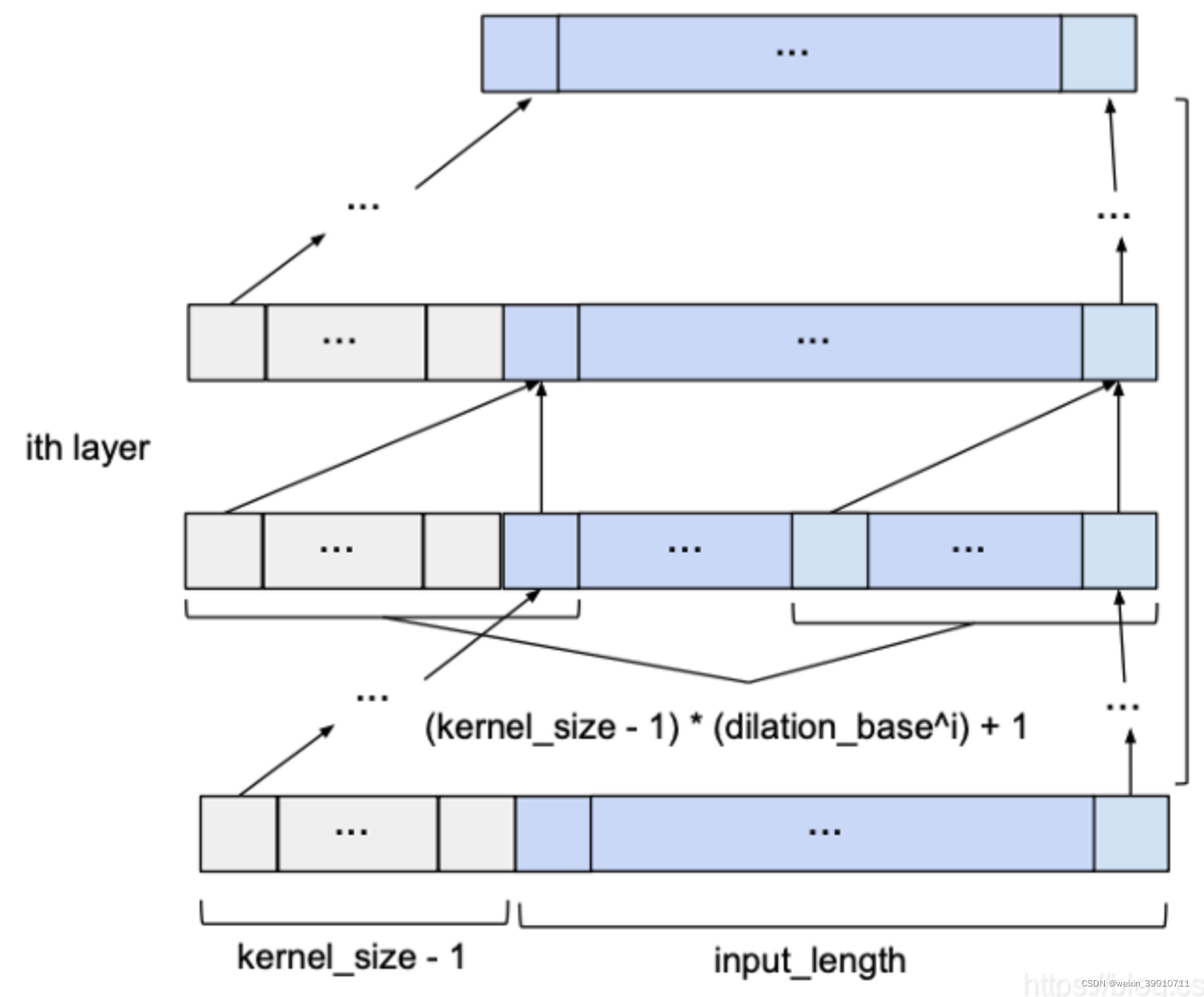
A diferencia de la convolución tradicional, la convolución de expansión permite muestrear la entrada de la convolución a intervalos, y la frecuencia de muestreo está controlada por d en la figura. El d=1 de la capa inferior significa que cada punto se muestrea durante la entrada, y la capa intermedia d=2 significa que cada 2 puntos se muestrean como entrada durante la entrada. En general, los niveles más altos usan tamaños de d más grandes. Por tanto, la convolución dilatada hace que el tamaño de la ventana efectiva crezca exponencialmente con el número de capas. De esta forma, la red convolucional puede obtener un gran campo receptivo con relativamente pocas capas.
Los parámetros de la convolución dilatada:
- d: número de capas
- k: tamaño del núcleo, tamaño del filtro
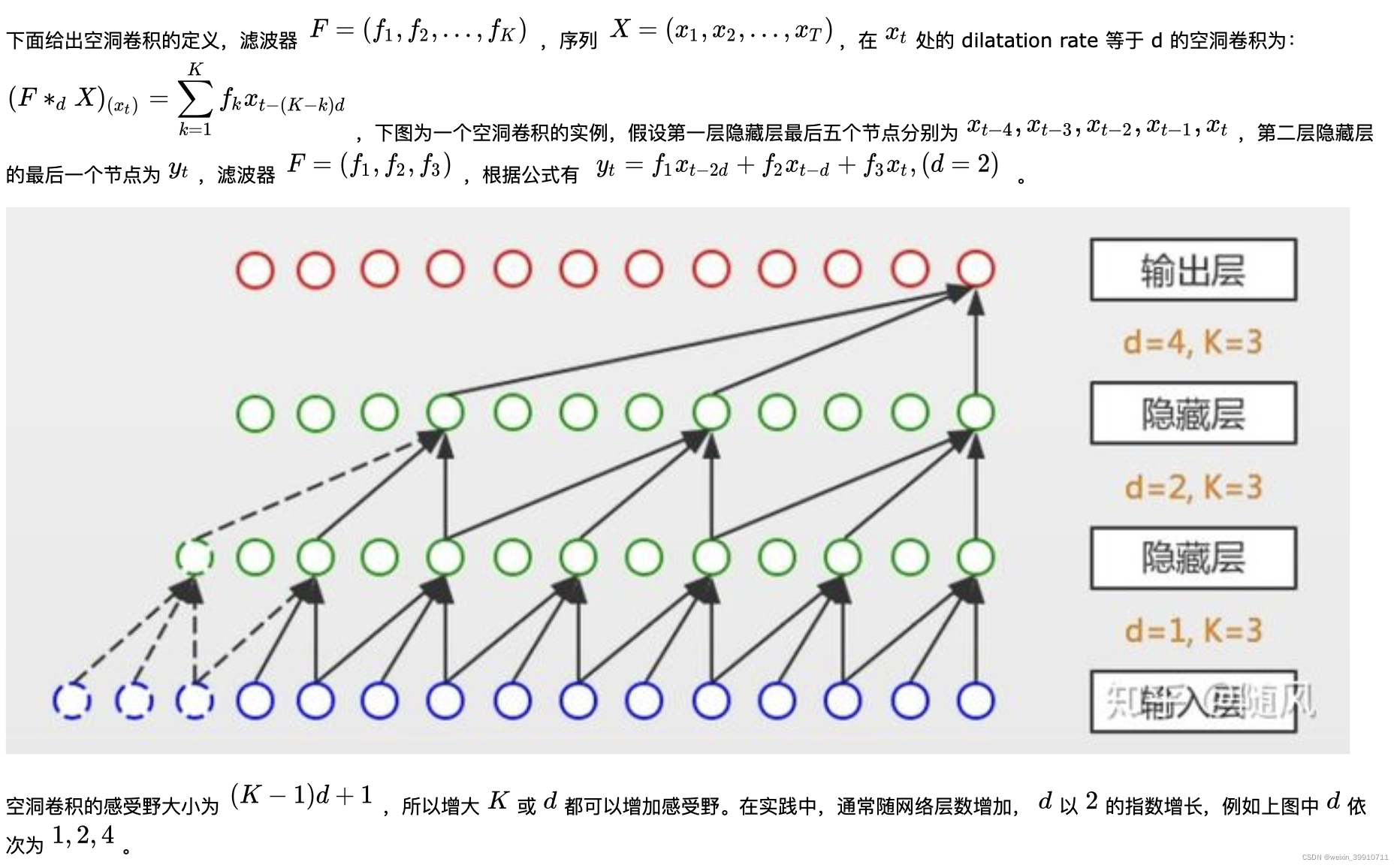
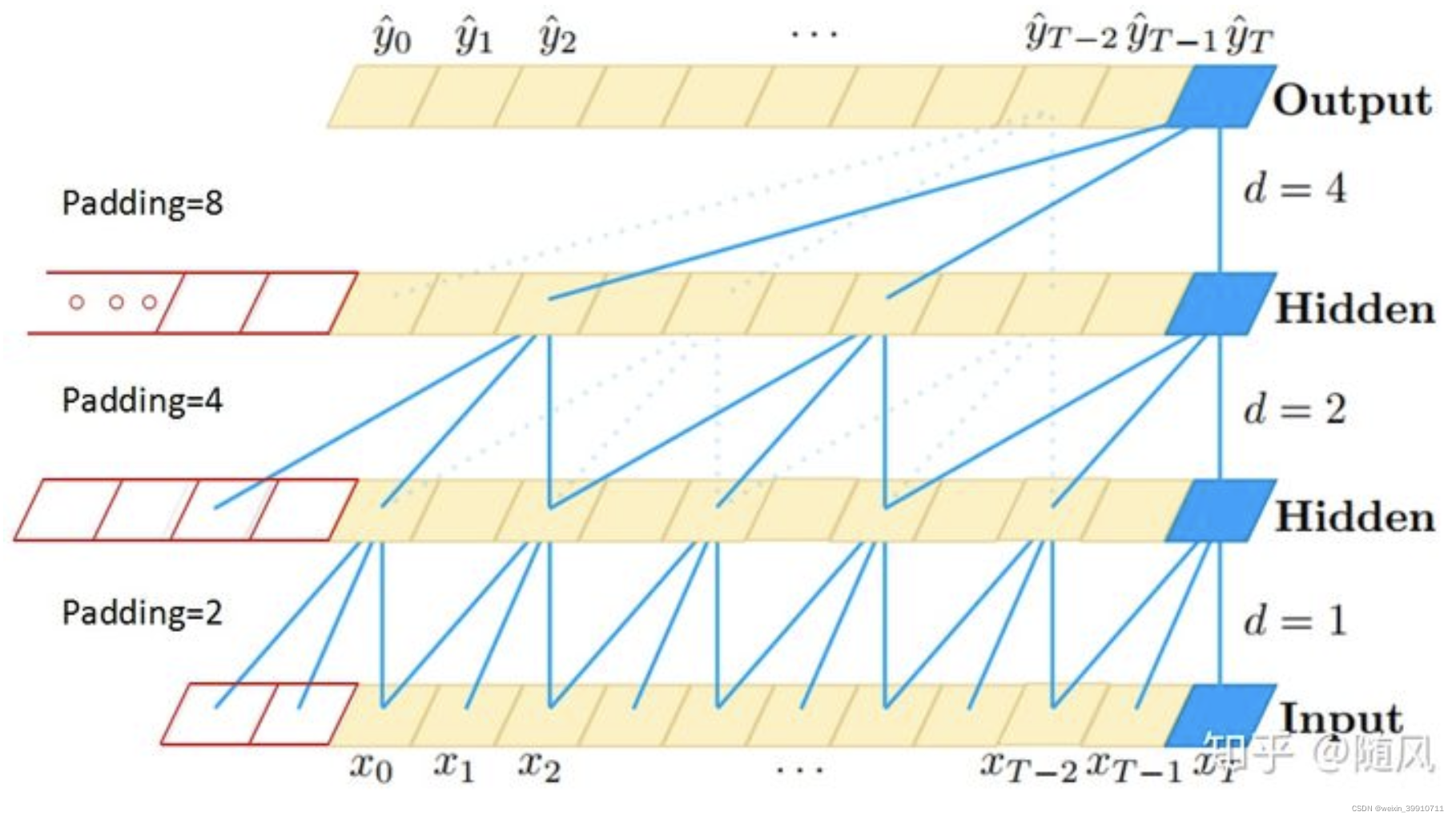
Debido a que el objeto de investigación es una serie temporal, TCN utiliza una red convolucional unidimensional. La imagen de arriba muestra la convolución causal y la convolución de agujeros en la arquitectura TCN. Se puede ver que el valor de cada capa ![]() a la vez solo depende del
a la vez solo depende del ![]() valor de la capa anterior a la vez, lo que refleja las características de la convolución causal; y cada La capa es opuesta a la capa anterior. La extracción de información está saltando, y la tasa dilatada capa por capa aumenta exponencialmente en 2, lo que refleja las características de la convolución dilatada. Debido al uso de convolución de agujeros, se requiere relleno para cada capa (generalmente 0) y el tamaño del relleno es
valor de la capa anterior a la vez, lo que refleja las características de la convolución causal; y cada La capa es opuesta a la capa anterior. La extracción de información está saltando, y la tasa dilatada capa por capa aumenta exponencialmente en 2, lo que refleja las características de la convolución dilatada. Debido al uso de convolución de agujeros, se requiere relleno para cada capa (generalmente 0) y el tamaño del relleno es ![]() .
.
2.3 Bloque residual
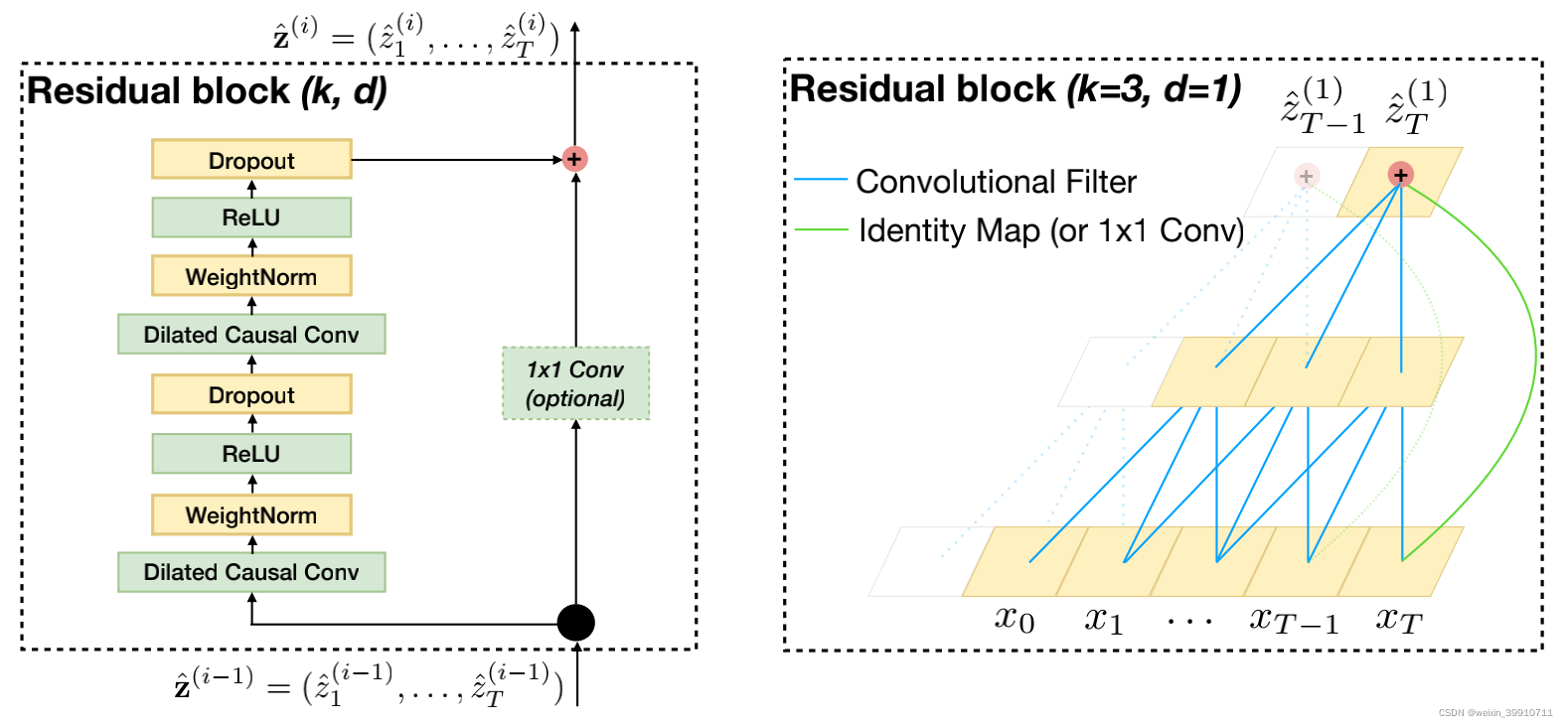
Se ha demostrado que los enlaces residuales son una forma eficaz de entrenar redes profundas, lo que permite que la red transfiera información entre capas. En este documento, se construye un bloque residual para reemplazar la convolución de una capa. Como se muestra en la figura anterior, un bloque residual contiene dos capas de convolución y mapeo no lineal, y se agregan WeightNorm y Dropout a cada capa para regularizar la red.
3 Predicción de Redes Convolucionales Temporales TCN
Dado input_length, kernel_size, dilatation_base y la cantidad mínima de capas necesarias para cubrir todo el historial, una red TCN básica se ve así:
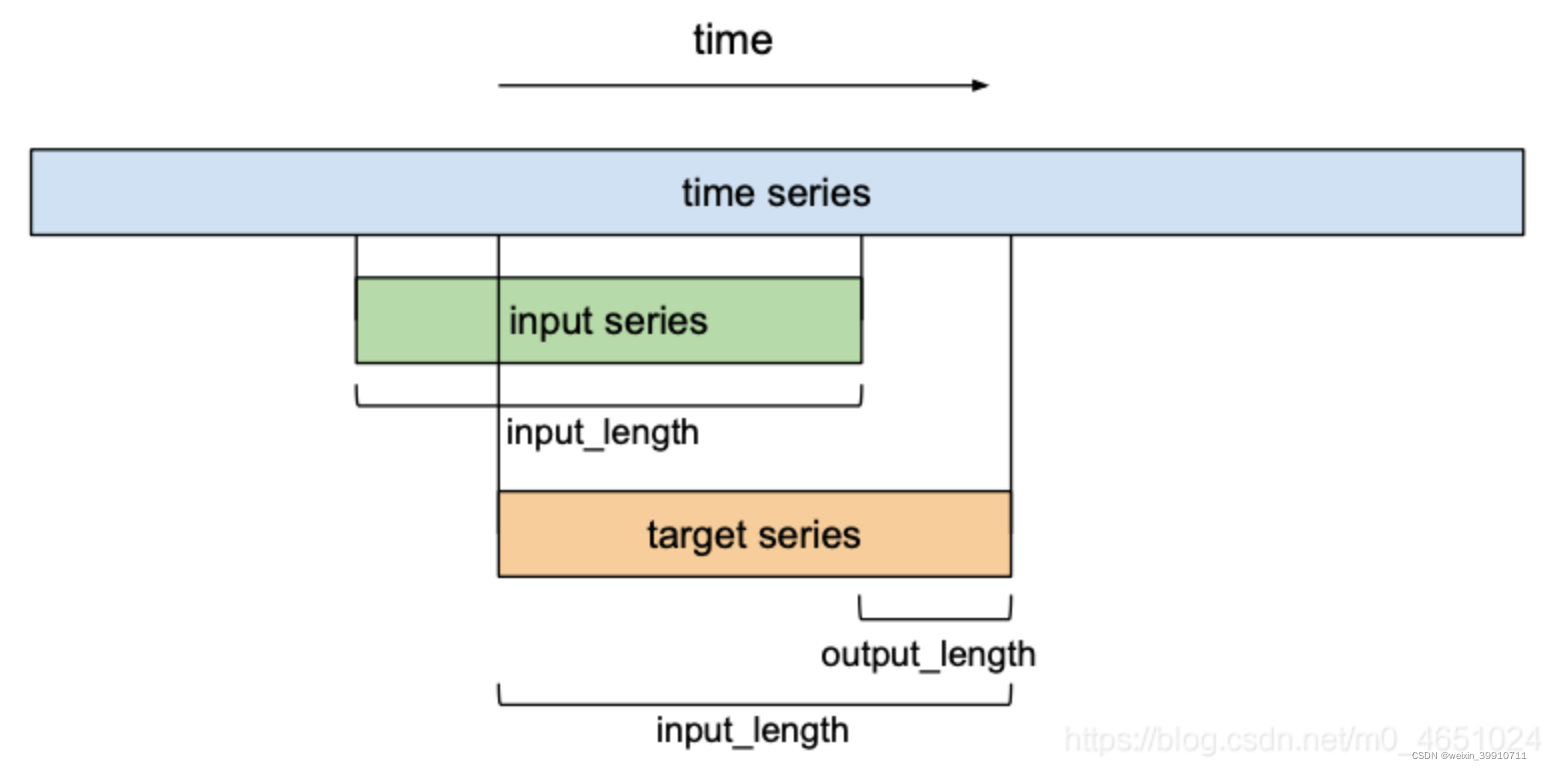
Hasta ahora, solo hemos discutido 'secuencias de entrada' y 'secuencias de salida' sin comprender cómo se relacionan entre sí. En términos de pronóstico, deseamos predecir la próxima entrada de una serie de tiempo futura. Para entrenar nuestra red TCN para la predicción, el conjunto de entrenamiento constará de pares de subsecuencias de igual tamaño (secuencia de entrada, secuencia de destino) de una serie de tiempo dada .
即serie de entrada = serie de destino
Las secuencias de destino serán secuencias desplazadas a la derecha por una cierta cantidad de longitud de salida en relación con sus respectivas secuencias de entrada . Esto significa que una secuencia objetivo de longitud longitud_entrada contiene el último elemento (longitud_entrada - longitud_salida) de su respectiva secuencia de entrada como su primer elemento, y el elemento longitud_salida ubicado después de la última entrada de la secuencia de entrada como su último elemento. En términos de predicciones, esto significa que el horizonte de predicción máximo que el modelo puede predecir es igual a output_length. Usando un enfoque de ventana deslizante, muchas secuencias de entrada y objetivo superpuestas pueden crear una serie de tiempo.
4 Varias ventajas y desventajas de TCN para el modelado de secuencias
ventajas :
- Paralelismo . A diferencia de las RNN, donde las predicciones para los pasos de tiempo subsiguientes deben esperar a que se completen sus predecesores, las circunvoluciones se pueden realizar en paralelo porque cada capa usa los mismos filtros. Por lo tanto, en el entrenamiento y la evaluación, las secuencias de entrada largas se pueden procesar como un todo en TCN, en lugar de secuencialmente como en RNN.
- Tamaño de campo receptivo flexible . TCN puede cambiar el tamaño de su campo receptivo de muchas maneras. Por ejemplo, apilar capas convolucionales más dilatadas (causales), usar un factor de dilatación mayor o aumentar el tamaño del filtro son opciones viables (que pueden tener diferentes interpretaciones). Por lo tanto, TCN puede controlar mejor el tamaño de la memoria del modelo y es fácil de adaptar a diferentes dominios.
- Gradientes estables . A diferencia de las arquitecturas recurrentes, la ruta de retropropagación de TCN es diferente de la dirección temporal de la secuencia. Por lo tanto, los TCN evitan el problema de los gradientes de explosión/desaparición , que es un problema importante con los RNN y ha llevado al desarrollo de LSTM, GRU, HF-RNN (Martens & Sutskever, 2011), etc.
- Bajo requerimiento de memoria durante el entrenamiento . Especialmente con secuencias de entrada largas, los LSTM y las GRU pueden consumir fácilmente mucha memoria para almacenar resultados parciales de sus puertas de unidades múltiples. Mientras que en TCN, los filtros se comparten entre capas y la ruta de propagación hacia atrás solo depende de la profundidad de la red. Por lo tanto, en la práctica, encontramos que los RNN controlados pueden usar más memoria que los TCN.
- Entrada de longitud variable . Al igual que los RNN modelan entradas de longitud variable de manera recurrente, los TCN también pueden aceptar entradas de longitud arbitraria deslizando núcleos de convolución 1D. Esto significa que TCN se puede usar como reemplazo de RNN para secuencias de datos de longitud arbitraria.
Usar TCN también tiene dos desventajas obvias :
- Almacenamiento de datos durante la evaluación . En evaluación/prueba, la RNN simplemente mantiene el estado oculto y toma la entrada actual xt para generar predicciones. En otras palabras, un conjunto de vectores ht de longitud fija proporciona un "resumen" de toda la historia, mientras que las secuencias reales observadas pueden descartarse. Por el contrario, los TCN necesitan recibir secuencias sin procesar de longitud de historial efectiva y, por lo tanto, pueden requerir más memoria durante la evaluación.
- Posible cambio de parámetro para una transferencia de dominio . Diferentes dominios pueden tener diferentes requisitos para la cantidad de historial requerido para las predicciones del modelo. Por lo tanto, al transferir un modelo de un dominio que requiere poca memoria (es decir, k y d pequeños) a un dominio que requiere una memoria más larga (es decir, k y d mucho más grandes), el TCN puede fallar debido a que no tiene un campo receptivo lo suficientemente grande.
论文《Una evaluación empírica de redes convolucionales y recurrentes genéricas para el modelado de secuencias》:https://arxiv.org/pdf/1803.01271.pdf
Red de convolución de tiempo TCN: Conocimiento de la red de convolución de tiempo TCN
Red de convolución en el dominio del tiempo TCN Explicación detallada: Uso de la convolución para el modelado y la predicción de secuencias: Red de convolución en el dominio del tiempo TCN Explicación detallada: Uso de la convolución para el modelado de secuencias y la predicción Blog_deephub-CSDN Blog_tcn Red de convolución en el tiempo
Red convolucional de espacio-tiempo TCN : Red convolucional de espacio-tiempo TCN - USTC、ZCC - 博客园
Darts implementa TCN (Red convolucional de dominio de tiempo): https://blog.csdn.net/liuhaikang/article/details/119704701?spm=1001.2014.3001.5501
Red convolucional de tiempo TCN: https://blog.csdn.net/qq_27586341/article/details/90751794?utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-4.base& depth_1-utm_source = distribuir.pc_relevant.none-task-blog-2~predeterminado~BlogCommendFromMachineLearnPai2~predeterminado-4.base
Series temporales multivariadas, modelos preentrenados y covariables: