1. Habilidades de asistente
1.1, algoritmo de optimización
En el entrenamiento de redes neuronales, esperamos que cada entrenamiento reduzca el valor de la pérdida, es decir, los parámetros se ajusten mediante el algoritmo de optimización para hacer que el modelo se desarrolle en la dirección de una pérdida más pequeña.
Algoritmo de descenso de gradiente: encuentre la dirección en la que el valor de la función disminuye al encontrar la derivada parcial, de modo que el parámetro se mueva en esa dirección![]()
Donde Θ es el parámetro que debe ajustarse y L (x, y) es el valor de la función. La dirección (es decir, el gradiente) que reduce L se obtiene por dL / dΘ, y luego se multiplica por la tasa de aprendizaje α para obtener el valor de ajuste del parámetro Reste este valor del current actual para obtener el nuevo parámetro Θ. Similar a un proceso cuesta abajo, Θ es la posición actual, dL / dΘ es la dirección más rápida para encontrar la cuesta abajo, y α es la distancia para moverse en esa dirección. Moverse desde la posición actual a la dirección cuesta abajo por una distancia dará como resultado una nueva, más cerca de la cuesta abajo Ubicación. Si α es demasiado pequeño, la velocidad de "descenso" es demasiado lenta para obtener el valor máximo lo antes posible. Si α es demasiado grande, cruzará el punto más bajo y no podrá alcanzar el punto más alto.
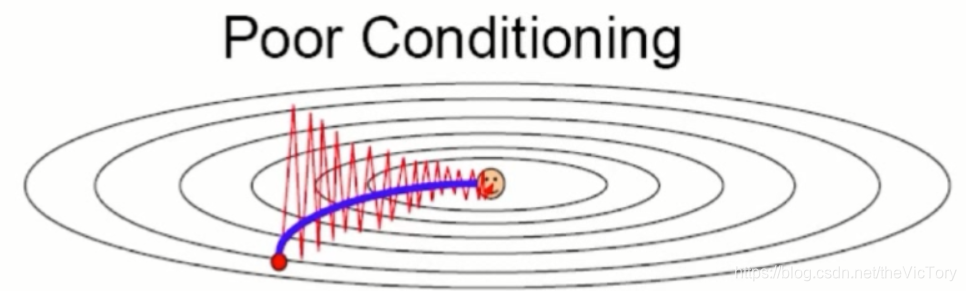
Si calcula la pérdida y el gradiente en todo el conjunto de datos cada vez, traerá una gran cantidad de cálculo. Cuando la cantidad de datos es demasiado grande, la máquina no puede soportarlo. Esto puede emplearse el método de descenso de gradiente estocástico (estocástico pendiente de descenso, SGD), cada muestra se calcula usando sólo un gradiente. Sin embargo, dicha muestra no puede representar la información general de los datos. En este momento, el método de descenso de gradiente Mini Batch se utiliza para seleccionar aleatoriamente una parte de los datos del conjunto como muestra. El descenso del gradiente depende de la derivada para encontrar la dirección de optimización.Cuando la derivada es 0, el descenso del gradiente no tiene ningún efecto. Por ejemplo, la solución óptima local a la izquierda de la figura a continuación es causada por la primera derivada de la función que es 0, y el punto de silla de la derecha es causado por la segunda derivada que es cero. En estos dos casos, dado que la derivada es 0, no continuará optimizándose para encontrar la solución óptima.

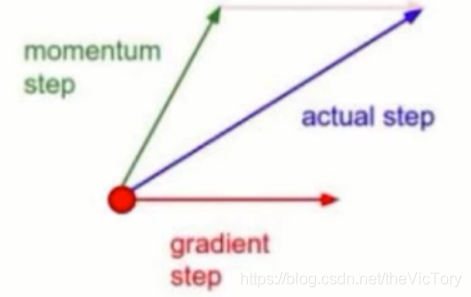
La dirección hacia adelante del método de descenso de gradiente de momento es la suma de la dirección anterior y el vector de dirección actual.Debido a la dirección hacia adelante acumulada previamente, cuando la derivada de gradiente es 0, continuará avanzando, omita la derivada de 0 Trampa para encontrar la solución óptima. Además, cuando se cambia la dirección del gradiente, los vectores en la dirección opuesta se agregan para evitar una oscilación violenta, y cuando las direcciones del gradiente son consistentes, los vectores en la misma dirección se agregan para acelerar el progreso.
La desventaja de los dos algoritmos de descenso de gradiente anteriores es que están muy afectados por la tasa de aprendizaje inicial, y es imposible especificar personalmente diferentes tasas de aprendizaje para cada dimensión. El algoritmo AdaGrade obtiene un valor acumulado basado en la suma de los cuadrados de los gradientes anteriores, que se utiliza como el denominador de la tasa de aprendizaje, disminuyendo así la tasa de aprendizaje continuamente y eliminando la dependencia del valor inicial de la tasa de aprendizaje. En la primera etapa de la capacitación, el valor acumulado es relativamente pequeño, por lo que la tasa de aprendizaje es grande y el proceso de aprendizaje se acelera. En la etapa posterior del entrenamiento, el valor acumulado se hace más grande, la tasa de aprendizaje disminuye en consecuencia y puede encontrar mejor la solución óptima. El gradiente cuadrado acumulativo se cambia al gradiente cuadrado promedio para obtener el algoritmo RMSProp , que resuelve el problema de terminar el aprendizaje temprano en el AdaGrade tardío debido a un valor acumulado demasiado grande y una tasa de aprendizaje demasiado pequeña.
El algoritmo Adam combina las ventajas del algoritmo de descenso de gradiente de momento y el algoritmo AdaGrade, solo necesita establecer la velocidad de aprendizaje inicial, se ajustará automáticamente y encontrará el valor óptimo. Se puede usar cuando necesita entrenar una red más profunda y compleja y necesita converger rápidamente.
1.2, función de activación
La función de activación común se muestra a continuación:
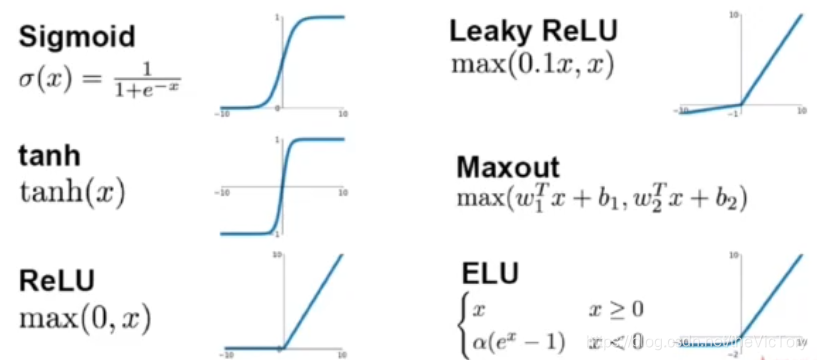
Función sigmoidea : se puede ver en la imagen que cuando el valor absoluto de la función Sigmoide aumenta, el cambio de salida tiende a ser suave y el valor de salida promedio es positivo. Se puede ver por su expresión que su cálculo es más complicado, y su derivación muestra que cuando la red neuronal se vuelve más profunda, el gradiente desaparece.
El gradiente de salida de la función tanh desaparecerá cuando el valor absoluto de entrada sea mayor y el valor promedio de la salida sea 0, lo cual es complicado
La función ReLU emite 0 cuando la entrada es menor que 0 y emite el valor original cuando es mayor que 0. No habrá desaparición de gradiente, pequeña cantidad de cálculo y velocidad de convergencia rápida.Después de su aparición, reemplaza la función de activación que Sigmoid llama la más utilizada. La desventaja es que cuando la entrada de la neurona tiene un valor negativo, emite 0 y no hay derivada, por lo que no se puede activar y la neurona no se actualizará. Para resolver este problema, se propone la función Leaky ReLU , es decir, en lugar de generar 0 cuando la entrada es negativa, se multiplica por un coeficiente pequeño y luego se emite. La función ELU es un proceso exponencial para una entrada menor que 0, de modo que el valor promedio de la salida es cercano a 0 y su cantidad de cálculo se hace mayor. La función Maxout también es una generalización de ReLU. Para las entradas positivas y negativas, se utilizan dos conjuntos de parámetros para calcular y generar.
1.3, inicialización de red
Una red inicializada no solo entrena rápido, sino que también logra mejores resultados. El valor de un buen valor de inicialización después de la función de activación se distribuirá en un intervalo fijo. Si todos se concentran en un cierto valor, el valor inicializado no es bueno.
Un método de inicialización simple es inicializar todos los parámetros a 0, lo cual solo es aplicable al modelo de red de capa única. La red de capas múltiples hará que el gradiente desaparezca y no se pueda entrenar.
También puede usar la distribución normal como valor de inicialización. Diferentes medias y variaciones tienen diferentes resultados para diferentes funciones de activación.
Para distribuir los datos en un intervalo fijo, se introduce una operación de normalización de lotes , que puede controlar la salida de cada lote de datos en cada capa a una distribución normal estándar con una media de 0 y una varianza de 1 En.
1.4 Otras habilidades
En el ajuste de la red, existen otras técnicas: usar más datos de entrenamiento y realizar más iteraciones, y usar más GPU para acelerar el entrenamiento. Primero implemente la capacitación en una red simple, y luego aumente gradualmente el nivel de la red para mejorar la precisión.
La red se puede probar en algunos conjuntos de datos estándar para garantizar que el modelo de red sea correcto, o se puede comparar con los modelos en otros conjuntos de datos estándar. Si el conjunto de datos es demasiado grande, puede lograr el efecto de sobreajuste en una pequeña parte del conjunto de datos antes de ejecutar los datos grandes. Puede usar el modelo ajustado existente para ajustar el modelo de red previamente entrenado (Ajuste fino)
1.5, ajuste de código
En el código, la capa de convolución generalmente se encapsula como una función convert (), y luego la función de activación y activación de la función de activación utilizada como parámetros se transfieren. La función de convolución de cada capa es igual a estos dos parámetros. De esta manera, cuando se llama a la función convert (), solo se puede cambiar un nombre de llamada y se pueden modificar las funciones de activación e inicialización de todas las capas convolucionales.
def convert(input,activation,initializer): # 将激活函数、初始化函数作为参数传入
# 卷积层1_1
conv1_1=tf.layers.conv2d(input,32,(3,3),padding='same',
activation=activation, #激活函数
kernel_initializer=initializer, # 初始化方法
name='conv1_1'
)
# VggNet两个卷积层,一个池化层
conv1_2=tf.layers.conv2d(conv1_1,32,(3,3),padding='same',activation=activation,kernel_initializer=initializer,name='conv1_2')
# 池化层
pool1=tf.layers.max_pooling2d(conv1_2, (2,2), (2,2), name='pool1')
# 卷积层2_1、2_2与第二个池化层
conv2_1=tf.layers.conv2d(pool1,32,(3,3),padding='same',activation=activation,kernel_initializer=initializer,name='conv2_1')
conv2_2=tf.layers.conv2d(conv2_1,32,(3,3),padding='same',activation=activation,kernel_initializer=initializer,name='conv2_2')
pool2=tf.layers.max_pooling2d(conv2_2,(2,2),(2,2),name='pool2')
# 卷积层3_1、3_2与第三个池化层
conv3_1=tf.layers.conv2d(pool2,32,(3,3),padding='same',activation=activation,kernel_initializer=initializer,name='conv3_1')
conv3_2=tf.layers.conv2d(conv3_1,32,(3,3),padding='same',activation=activation,kernel_initializer=initializer,name='conv3_2')
pool3=tf.layers.max_pooling2d(conv3_2,(2,2),(2,2),name='pool3')
# 将卷积结果返回
return pool3Pase el nombre del método específico al llamar a convert ()
# 调用封装的卷积方法
res=convert(x_img,tf.nn.relu,tf.truncated_normal_initializer(stddev=0.02))Hay otras funciones de activación como tf.nn.sigmoid, otros métodos de inicialización tf.glorot_normal_initializer, tf.keras.initializers.he_normal
La modificación del método de optimización se modifica directamente cuando se define el método de optimización, por ejemplo, adoptando AdamOptimizer:
#定义优化方法
with tf.name_scope('train_op'):
train_op=tf.train.AdamOptimizer(1e-3).minimize(loss)
# 之后在训练时传入train_op方法
loss_val,acc_val,_=sess.run([loss,accuracy,train_op],feed_dict={x:batch_data,y:batch_labels})El método de optimización también se puede definir como descenso de gradiente y métodos de optimización de momento:
tf.train.GradientDescentOptimizer(1e-4).minimize(loss)
tf.train.MomentumOptimizer(learning_rate=1e-4,momentum=0.9).minimize(loss)
2. Visualización de parámetros
Puede usar la herramienta de visualización para ver el estado de los parámetros intermedios de la red, como pérdida, gradiente, precisión y velocidad de aprendizaje.
2.1, análisis de curvas
La siguiente figura es un gráfico del valor de la pérdida, donde el amarillo es la pérdida en el conjunto de prueba y el azul en el conjunto de entrenamiento.
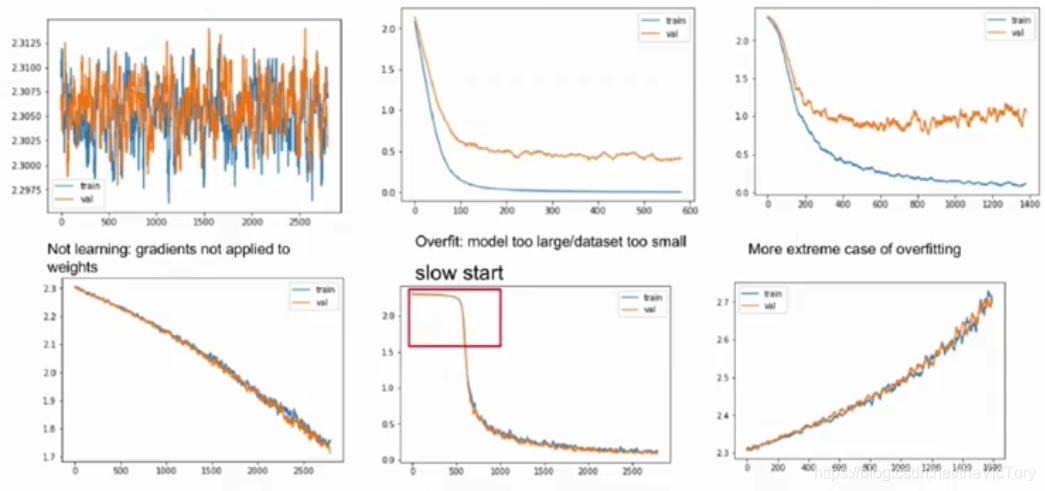
En la primera imagen, puede ver que el valor de pérdida ha estado oscilando, lo que indica que el modelo no está ajustado. Esto puede deberse a que la tasa de aprendizaje es demasiado grande, lo que hace que el modelo cruce repetidamente el punto de valor máximo y no alcance este punto.
Aunque la pérdida en la segunda imagen se ha reducido a un nivel bajo y tiende a ser estable, la pérdida en el conjunto de prueba sigue siendo grande, debido al sobreajuste del modelo. La tercera imagen también está sobreajustada, la pérdida del conjunto de entrenamiento se reduce, pero la pérdida en el conjunto de prueba está aumentando.
Aunque la pérdida en las imágenes de entrenamiento cuarta y tercera está disminuyendo, en comparación con la segunda y tercera imagen, se puede ver que la tendencia a la baja es muy lenta, debido a que la tasa de aprendizaje es demasiado pequeña, lo que resulta en una velocidad de ajuste. Demasiado lento, puede aumentar la tasa de aprendizaje adecuadamente. Y su curva de pérdida todavía tiene una tendencia a la baja, puede aumentar el número de rondas de entrenamiento para continuar entrenando.
El quinto gráfico muestra que la curva disminuye muy lentamente en la etapa inicial y luego aumenta repentinamente, lo que indica que la inicialización no es muy buena.
La pérdida de la sexta imagen no disminuye sino que aumenta, quizás la dirección del gradiente sea incorrecta
2.2 Uso de la placa tensora
Use pasos:
1. Primero defina los parámetros que deben visualizarse y, finalmente, agregue la información
2. Defina la ruta de guardado del archivo de registro
3. Defina el objeto de escritura del registro y escriba la información del registro en un archivo durante el proceso de capacitación.
4. Ejecute Tensor Board a través de la línea de comando: tensorboard --logdir = ruta del archivo de registro
Luego puede ver los resultados de visualización en el navegador, el valor predeterminado es localhost: 6006
# TensorBoard可视化参数
# 1、首先定义需要显示的变量
loss_summary=tf.summary.scalar('loss',loss)
accuracy_summary=tf.summary.scalar('accuracy',accuracy)
# 将输入的图片作逆归一化处理,还原图像值
source_image=(x_img+1)*127.5
input_image=tf.summary.image('input_image',source_image)
# 将所有要显示的信息聚合
merged_train_summary=tf.summary.merge_all()
merged_test_summary=tf.summary.merge([loss_summary,accuracy_summary])
# 2、指定日志保存路径
LOG_DIR='./TensorBoard_VGG_LOG'
if not os.path.exists(LOG_DIR):
print('mkdir log')
os.mkdir(LOG_DIR)
train_log_dir=os.path.join(LOG_DIR,'train')
test_log_dir=os.path.join(LOG_DIR,'test')
if not os.path.exists(train_log_dir):
os.mkdir(train_log_dir)
if not os.path.exists(test_log_dir):
os.mkdir(test_log_dir)
init=tf.global_variables_initializer()
batch_size=20
train_steps=5000
test_steps=100
with tf.Session() as sess:
sess.run(init)
# 3、定义日志写入对象,可以选择将模型图也写入
train_writer=tf.summary.FileWriter(train_log_dir,sess.graph)
test_writer=tf.summary.FileWriter(test_log_dir)
# 保存一份固定的测试集数据
fixed_test_data,fixed_test_labels=test_data.next_batch(batch_size)
for i in range(train_steps):
batch_data,batch_labels=train_data.next_batch(batch_size)
loss_val,acc_val,_=sess.run([loss,accuracy,train_op],feed_dict={x:batch_data,y:batch_labels})
# 每训练100次,执行summary操作并将结果写入日志文件
if (i+1) % 100 ==0:
train_summary_str=sess.run(merged_train_summary,feed_dict={x:batch_data,y:batch_labels})
train_writer.add_summary(train_summary_str,i+1)
test_summary_str=sess.run(merged_test_summary,feed_dict={x:fixed_test_data,y:fixed_test_labels})
test_writer.add_summary(test_summary_str,i+1)
if (i+1) % 500==0:
print("第%d步:损失:%.5f,精确度:%.5f"%(i,loss_val,acc_val))
#每训练1000次,在test数据集上进行一次测试
if (i+1)%1000==0:
# 定义测试集数据对象
test_data=CifarData(test_file,False)
all_acc=[]
for j in range(test_steps):
test_batch_data,test_batch_labels=test_data.next_batch(batch_size)
test_acc=sess.run([accuracy],feed_dict={x:test_batch_data,y:test_batch_labels})
all_acc.append(test_acc)
# 将测得的多个准确率求均值
test_acc_mean=np.mean(all_acc)
print("第%d步测试集准确率%.4f"%(i,test_acc_mean))El resultado de la operación se muestra a continuación.
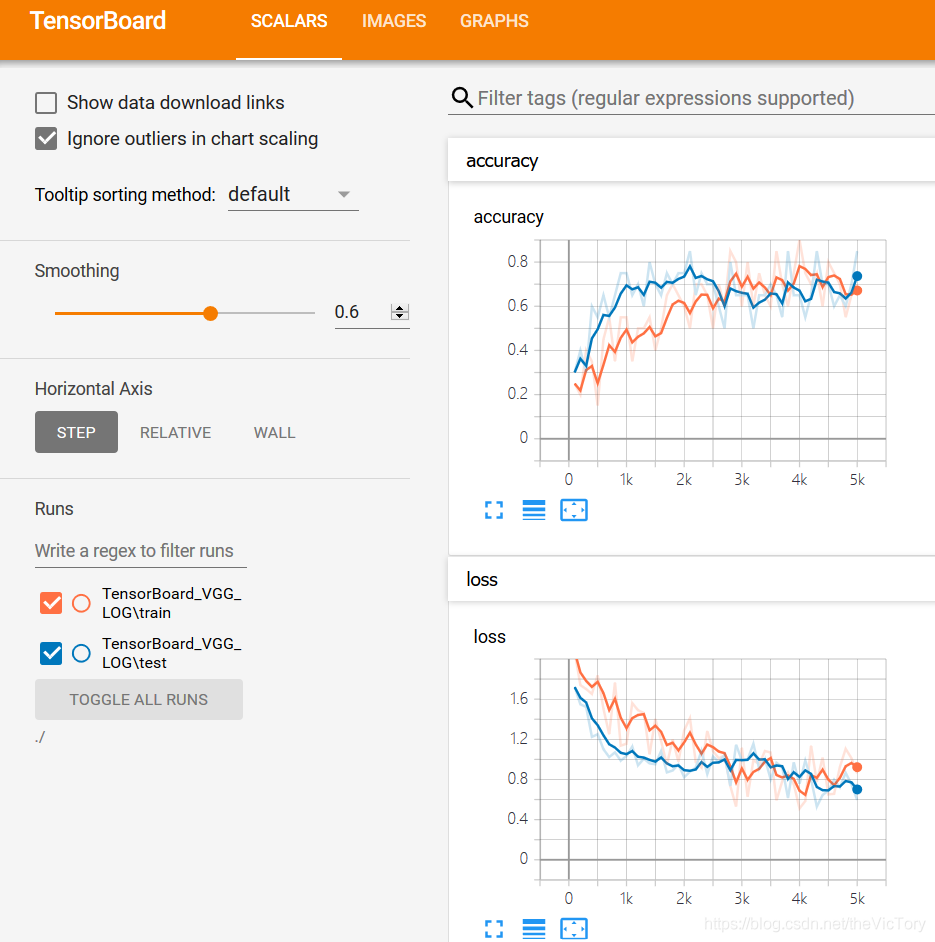
3. Normalización de lotes
A medida que se profundiza el número de capas de entrenamiento de la red neuronal, la salida de cada capa de la red (antes de la función de activación) se distribuye gradualmente hacia los extremos superior e inferior del intervalo de valor de la función no lineal, lo que resulta en la desaparición del gradiente de la red neuronal de la capa inferior durante la propagación hacia atrás. Esto hace que la red neuronal converja lentamente. La normalización por lotes es procesar la distribución cada vez más distribuida en una distribución más estándar, de modo que el valor de entrada de activación cae en el área donde la función no lineal es más sensible a la entrada, de modo que el gradiente se hace más grande, evitando el problema de la desaparición del gradiente Generar, acelerar la velocidad de aprendizaje de convergencia y capacitación.
Cada operación de convolución se encapsula en una función, y no se realiza ninguna operación de activación durante la convolución. El resultado de la convolución se normaliza por lotes mediante la función tf.nn.batch_normalization (), y luego el resultado se pasa a través de la función de convolución De vuelta.
def convert_wrapper(x_input,name,train_flag,activation=tf.nn.relu,initializer=None):
conv = tf.layers.conv2d(x_input, #输入
32, #输出通道数
(3,3), #卷积核大小
padding='same', #填充使图小大小不变
activation=None, #激活函数
kernel_initializer=initializer, # 初始化方法
name=name
)
bn = tf.layers.batch_normalization(conv,training=train_flag)
# 将归一化的结果经激活函数后返回
return activation(bn)
def pooling_wrapper(x_input,name):
return tf.layers.max_pooling2d(x_input, #输入
(2,2), #池化核
(2,2), #步长
name=name)
# 卷积层1_1
conv1_1=convert_wrapper(img_input, 'conv1_1',train_flag)
conv1_2=convert_wrapper(conv1_1,'conv1_2',train_flag)
conv1_3=convert_wrapper(conv1_2,'conv1_3',train_flag)
pool1=pooling_wrapper(conv1_3,'pool1')
# 卷积层2_1、2_2与第二个池化层
conv2_1=convert_wrapper(pool1,'conv2_1',train_flag)
conv2_2=convert_wrapper(conv2_1,'conv2_2',train_flag)
conv2_3=convert_wrapper(conv2_2,'conv2_3',train_flag)
pool2=pooling_wrapper(conv2_2,'pool2')
# 卷积层3_1、3_2与第三个池化层
conv3_1=convert_wrapper(pool2,'conv3_1',train_flag)
conv3_2=convert_wrapper(conv3_1,'conv3_2',train_flag)
conv3_3=convert_wrapper(conv3_2,'conv3_3',train_flag)
pool3=pooling_wrapper(conv3_2,'pool3')Puede establecer el parámetro de entrenamiento para controlar si se realiza la normalización por lotes, la normalización se realiza en el conjunto de datos de entrenamiento y no se requiere en el conjunto de datos de prueba. El valor de marcador de posición train_flag se usa para controlar.
train_flag=tf.placeholder(tf.bool,[])
...
# 训练集
for i in range(train_steps):
batch_data,batch_labels=train_data.next_batch(batch_size)
loss_val,acc_val,_=sess.run([loss,accuracy,train_op],feed_dict={x:batch_data,y:batch_labels,train_flag:True})
# 测试集
test_acc=sess.run([accuracy],feed_dict={x:test_batch_data,y:test_batch_labels,train_flag:False})
