1. Introducción al análisis de datos
1.1 Idea central
1. ¿Qué es el análisis de datos comerciales?
Es el proceso de analizar una gran cantidad de datos recopilados con métodos de análisis apropiados, extraer información útil y formar conclusiones.
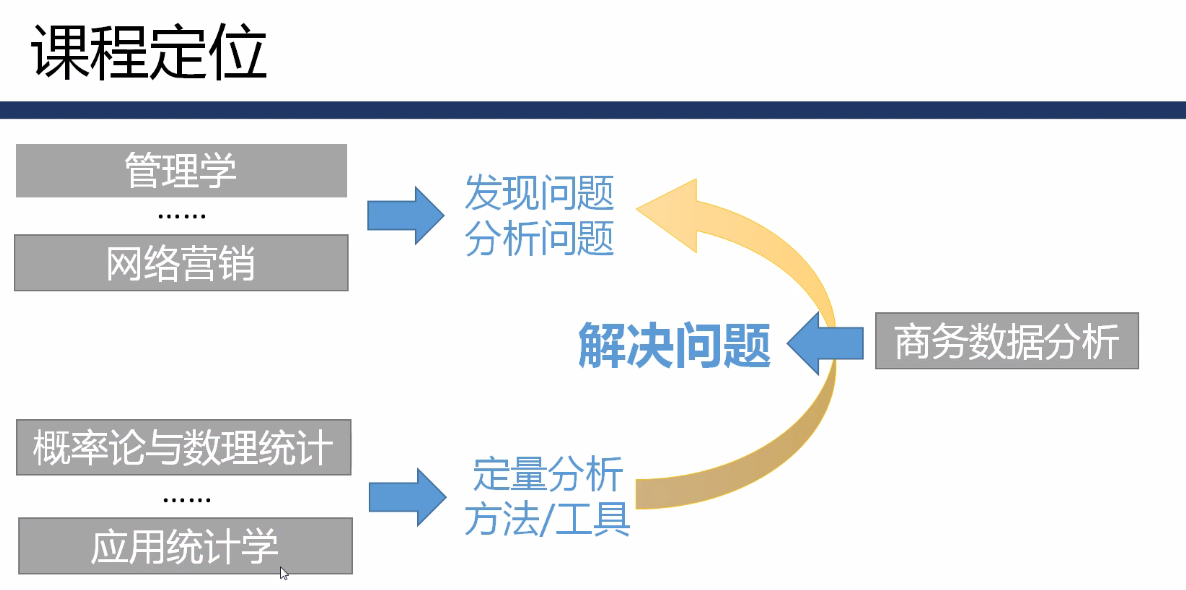
1.2 Orientación del curso
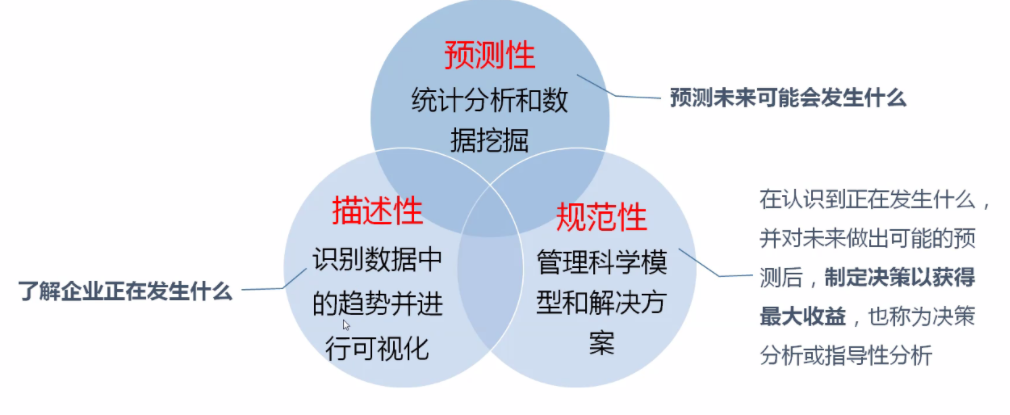
1.3 Tres tipos de análisis de datos
1.4 Escala de medición de datos
(1) Escala de clasificación:
- medida nominal
- Una medida de una clase o propiedad de algo.
- Computable: frecuencia, frecuencia
ej., género, ciudad, ocupación
(2) medida ordinal
- Una medida de la diferencia de rango u orden entre cosas Computable: frecuencia, frecuencia, orden
ej., educación, grado
(3) medición de intervalo
- Una medida de la distancia entre clases u órdenes de cosas, generalmente medida en unidades físicas o naturales Computable: frecuencia, frecuencia, ordenación, suma y resta
por ejemplo, temperatura
(4) medición de escala
- Capacidad para medir la relación entre dos valores medidos
- Computable: frecuencia, frecuencia, clasificación, suma y resta, multiplicación y división, por ejemplo, edad, peso
- Hay un "punto cero" absoluto fijo, "O" significa que no
Resumen:
1. Datos categóricos, datos ordinales: datos categóricos, discretos, cualitativos
2. Datos de intervalo, datos de razón:Datos numéricos , continuos y cuantitativos
1.5 Use diferentes gráficos estadísticos para diferentes atributos de datos
| Número de variables | tipo variable | gráficos opcionales |
|---|---|---|
| univariado | Discreto | Gráfico de columnas, gráfico de barras, gráfico circular, gráfico de anillos |
| Continuo | Histograma, gráfico de líneas, diagrama de caja | |
| bivariado | discreto + discreto | gráfico de columnas apiladas |
| Discreta (tipos distintos) + continua (numérica) | Gráfico de líneas (dos grupos), diagrama de caja agrupado | |
| continuo + continuo | Gráfico de dispersión | |
| multivariado | discreto + múltiple continuo | Diagrama de dispersión con series múltiples |
| tres consecutivos | gráfico de burbujas | |
| múltiples consecutivos | Gráfico de radar, gráfico de líneas de varias series temporales |
Explicación popular:
- Tipo discreto univariante: consiste en contar una determinada columna de atributo según la diferencia del valor del atributo
- Tipo continuo univariado: dibuje un histograma para contar el valor económico de un cierto intervalo; dibuje un gráfico de líneas para el conteo de atributos en un cierto período [Describa la tendencia de cambio del ingreso bajo la serie de tiempo]
- Bivariado Discreto + Discreto: Histograma apilado [¿Están relacionados la categoría de la película y el nivel de restricción de la película?]
- Discreto + continuo bivariado: bajo la influencia de diferentes valores de atributo de una determinada columna de atributo x, cuánto valor económico y se produce, dibujar un diagrama de caja agrupado [calcular el impacto de las categorías en los ingresos de taquilla]; gráfico de líneas [describir ingresos y gastos en el tiempo La relación bajo la secuencia]
El diagrama es el siguiente :

1.6 Campo de aplicación
El análisis de datos ya ha penetrado en varias industrias e industrias, que incluyen principalmente: Internet, comercio electrónico, finanzas y seguros, educación en línea, fabricación, biomedicina, transporte y logística, entrega de alimentos, energía, gestión urbana, deportes y entretenimiento y otras industrias.

2. Fuente de datos
Fuentes externas: compra de datos, extracción de datos, datos gratuitos y de código abierto, etc.
Fuentes internas: datos de ventas, datos financieros, datos de comunicación social, etc.
Dirección de la fuente:
China Internet Information Center
Analysys Analysis
National Data
National Bureau of Statistics Dirección de recursos del sitio web de la plataforma de datos de fuente abierta
UCI
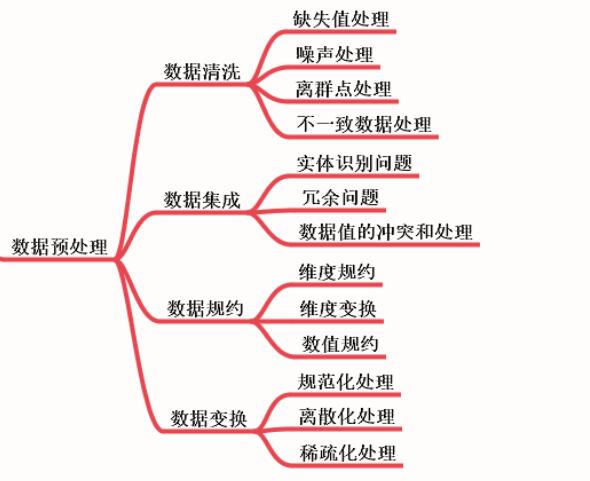
3. Preprocesamiento de datos
4. Operaciones de preprocesamiento de datos actualizadas continuamente
1. El método de procesamiento del valor NAN en la columna de atributos de datos:
Descripción dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)de los parámetros:
axis: El valor predeterminado es 0, es decir, eliminar la fila. 1 o columnas es eliminar la columna
how: método de eliminación. any elimina filas/columnas con al menos un NaN; all elimina filas/columnas con todos los NaN
thresh: Umbral. int, filas/columnas para eliminar con al menos n valores NaN
subset: lista. columnas o índice, solo elimine las columnas/filas especificadas
2. Dividir la función según los caracteres especiales:
each = each[0].split(',')
3. Elimine el espacio al principio de la columna de atributos de datos: each.strip()
4. Elimine los caracteres especiales en la columna de atributos: item.append(each.strip('["{","/","}"]'))
5. Reemplace los caracteres chinos
# 也可以用于去除非法字符
df_1 = df_1.replace('--', np.nan)
6. .renameMétodo, cambie el nombre de la columna o el nombre del índice
7. Extraiga la columna de datos específica del marco de datos de acuerdo con la columna de índice de atributos
df_1 = df.iloc[1:,[1,2,3,4,5,7]]
8. Reemplace todos los valores correspondientes del marco de datos 1 de acuerdo con el marco de datos 2:
import pandas as pd
df1 = pd.DataFrame({
'col1': [1, 2, 3], 'col2': [4, 5, 6]})
df2 = pd.DataFrame({
'col1': [2, 3, 4], 'col2': [7, 8, 9]})
merged_df = pd.merge(df1, df2, on='col1', how='inner')
for index, row in merged_df.iterrows():
df2.at[df2['col1'] == row['col1'], 'col2'] = row['col2']
print(df2)
9. Use la agrupación para encontrar el valor medio y complete el valor vacante:
df_1['Budget'] = df_1.groupby('Genre')['Budget'].apply(lambda x: x.fillna(x.mean()))
10. Comprobar valores nulos
print(pd.isnull(data["时间戳"]).value_counts())
5. Modelos y métodos comunes de análisis de datos
Modelos comunes de análisis de datos:
análisis comparativo, análisis de embudo, análisis de retención, pruebas A/B, análisis de ruta de comportamiento del usuario, agrupación de usuarios, análisis de retratos de usuarios, etc. Métodos comunes de
análisis de datos:
estadísticas descriptivas, prueba de hipótesis, análisis de confiabilidad, análisis de correlación, Análisis de varianza, análisis de regresión, análisis de conglomerados, análisis discriminante, análisis de componentes principales, análisis factorial, análisis de series temporales, etc.
Visualización de datos
- Visualización de datos: la visualización de datos se refiere al uso de expresiones visuales para explorar, comprender y comunicar datos. ·Transformar datos invisibles o difíciles de mostrar en gráficos, símbolos, colores, etc. perceptibles, para mejorar la eficiencia del reconocimiento de datos y brindar información efectiva.
- El papel de la visualización de datos:
- Registro de información: registre cosas abstractas e información en forma de gráficos, por ejemplo, los antiguos en nuestro país registraron la información astrológica observada en forma de cartas astrológicas para calcular el calendario.
- Apoye el razonamiento y el análisis de la información: la visualización de datos reduce en gran medida la complejidad de la comprensión de los datos, mejora efectivamente la eficiencia de la cognición de la información, lo que ayuda a las personas a analizar y razonar información efectiva más rápido
- Difusión de información y colaboración
- Análisis visual Análisis visual: el análisis visual es un proceso dinámico e iterativo en el que puede crear rápidamente diferentes vistas para explorar el camino infinito del "qué" y el "por qué" detrás de él. El análisis visual puede ayudarlo a explorar, encontrar respuestas y crear historias en sus datos. Incluso va más allá de los conocimientos iniciales, por lo que todos los que ven la visualización pueden hacer preguntas y hacer descubrimientos inesperados. En pocas palabras, el análisis visual es un método de exploración visual de datos en tiempo real.
Principales herramientas utilizadas: python
matplotlib,seabornbiblioteca
Bibliotecas de visualización de datos de uso común en Python: Matplotlib, Seaborn.
Gráficos comunes de visualización de datos:

————————————————————————————————————
Dirección de aprendizaje de referencia:
https://blog.csdn.net/ longxibendi/article/details/82558801
https://www.cnblogs.com/caochucheng/p/10539282.html
https://www.cnblogs.com/HuZihu/p/11274171.html
https://www.cnblogs.com /bigmonkey/p /11820614.html
https://blog.csdn.net/weixin_43913968/article/details/84778833
https://www.zhihu.com/collection/275297497
http://www.woshipm.com/data- análisis/1035908.html
https://www.sensorsdata.cn/blog/20180512/
http://meia.me/act/1/schedule/112?lang=
http://www.360doc.com/content/20 /0718/00 /144930_924966974.shtml
https://zhuanlan.zhihu.com/p/51658537
https://www.cnblogs.com/ljt1412451704/p/9937833.html
https://www.cnblogs.com/peter-lau/p/12419989.html
https://zhuanlan.zhihu.com/p/138671551
https://zhuanlan.zhihu.com/p/83403033
https://blog .csdn.net/qq_33457248/article/details/79596384?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase& depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachine LearnPai2-1.nonecase
https: //blog.csdn.net/YYIverson/article/details/100068865?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase& depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1. ningún caso
https://blog.csdn.net/weixin_30487317/article/details/101566492?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase& depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommen dFromMachineLearnPai2- 1.ningún caso