Introducción de antecedentes
Con el rápido desarrollo de la economía de China y el rápido aumento de la población urbana, ha traído una serie de problemas. Se han causado embotellamientos y daños ambientales. El desarrollo del transporte público puede resolver perfectamente los problemas que enfrentamos ahora. Las bicicletas son flexibles y flexibles. Las ventajas de la protección ambiental y baja en carbono: si las bicicletas pueden reemplazar los vehículos de motor actuales, las carreteras no estarán tan llenas de gente, la eficiencia de viaje de las personas mejorará en gran medida, las emisiones de escape de los automóviles se reducirán en gran medida y la calidad del medio ambiente también mejorará. Al mismo tiempo, para resolver perfectamente la distancia de la "última milla" desde la estación de metro hasta la compañía y desde la estación de autobuses hasta el hogar, surgieron bicicletas compartidas.
El uso compartido de bicicletas resuelve eficazmente la molestia de "caminar cansado, autobús lleno de gente, atascos, taxis caros". Durante la noche, desde el norte hasta Guangzhou, Shenzhen e incluso algunas ciudades de segundo nivel, se pueden ver calles y callejones compartidos en bicicleta en todas partes. Luego del anuncio de una inversión estratégica de decenas de millones de dólares estadounidenses en Didi Express el 26 de septiembre de 2016, las dos partes comenzarán una cooperación profunda en el campo de las bicicletas compartidas. (1.500 millones de RMB), el uso compartido de bicicletas nacionales se ha vuelto más popular y una captura de pantalla reciente de un teléfono móvil se ha vuelto popular en la red roja. En esta captura de pantalla, los íconos de 24 aplicaciones para compartir bicicletas dominan toda la pantalla del teléfono móvil, y realmente es "una imagen que ilustra la feroz competencia de compartir bicicletas". En las calles, como de la noche a la mañana, las bicicletas compartidas han llegado al punto de "inundación", y las calles de las principales ciudades están bordeadas de bicicletas compartidas de varios colores. El desarrollo continuo de la economía compartida ha cambiado gradualmente la vida cotidiana de las personas, y el espíritu de compartir ha penetrado gradualmente en los corazones de las personas.
Fuente de datos (actualizada)
Enlace: https://pan.baidu.com/s/10tC88d1fvuDMV-DtUInt2g
código de extracción: tlq1 Después de
copiar este contenido, abra la aplicación de teléfono móvil del disco de red Baidu, la operación es más conveniente.
código fuente de python
# 1.导包操作:科学计算包numpy,pandas,可视化matplotlib,seaborn
import numpy as np # 导入numpy并重命名为np
import pandas as pd # 导入pandas并重命名为pd
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
from datetime import datetime
import calendar
import matplotlib.pyplot as plt
import seaborn as sn
# weekday方法:日期--》星期值(整数,下标从0开始)
# strptime方法:字符串--》日期
# day_name方法:星期值--》星期(字符串)
# month_name方法:月份值--》月份(字符串)
# month方法:日期--》月份值(整数)(1-12)
# map方法:根据对应字典产生映射
# 2. 数据采集/查看和处理
def collect_and_process_data():
# 2.1 数据读取
bikedata = pd.read_csv('train.csv')
# 2.2 数据查看
print(bikedata.shape) # 查看数据
print(bikedata.head(5)) # 查看数据的前5行
print(bikedata.dtypes) # 查看数据类型
# 2.3数据提取
# 2.3.1提取年月日
# 对datetime这一列应用匿名函数:
# x表示datetime这一列数据
# x.split()以空格符分割,返回字符串列表
# x.split()[0]取出列表的第一个元素
bikedata['date'] = bikedata.datetime.apply(lambda x: x.split()[0]) # 添加一列:date
# 2.3.2提取小时
bikedata['hour'] = bikedata.datetime.apply(lambda x: x.split()[1].split(':')[0])
# 2.3.3 在年月日的基础上提取星期几(格式化字符串)
bikedata['weekday'] = bikedata.date.apply(
lambda dateString: calendar.day_name[datetime.strptime(dateString, '%Y/%m/%d').weekday()])
# 2.3.4 在年月日的基础上提取月份值
bikedata['month'] = bikedata.date.apply(
lambda dateString: calendar.month_name[datetime.strptime(dateString, "%Y/%m/%d").month])
# 2.4 数据转换
# 2.4.1 将season转换为英文季节值
bikedata['season'] = bikedata.season.map({1: 'spring', 2: 'summer', 3: 'fall', 4: 'winter'})
# 2.4.2 将以下变量转化成分类变量
print(bikedata)
varlist = ['hour', 'weekday', 'month', 'season', 'holiday', 'workingday']
for x in varlist:
bikedata[x] = bikedata[x].astype('category') # astype 改变数据类型
print(bikedata.dtypes)
# 2.4.3删除无意义的列
bikedata.drop('datetime', axis=1, inplace=True)
# 2.5数据清洗
# 2.5.1查看数据缺失
print(bikedata.describe())
# 2.5.2查看是否有异常值
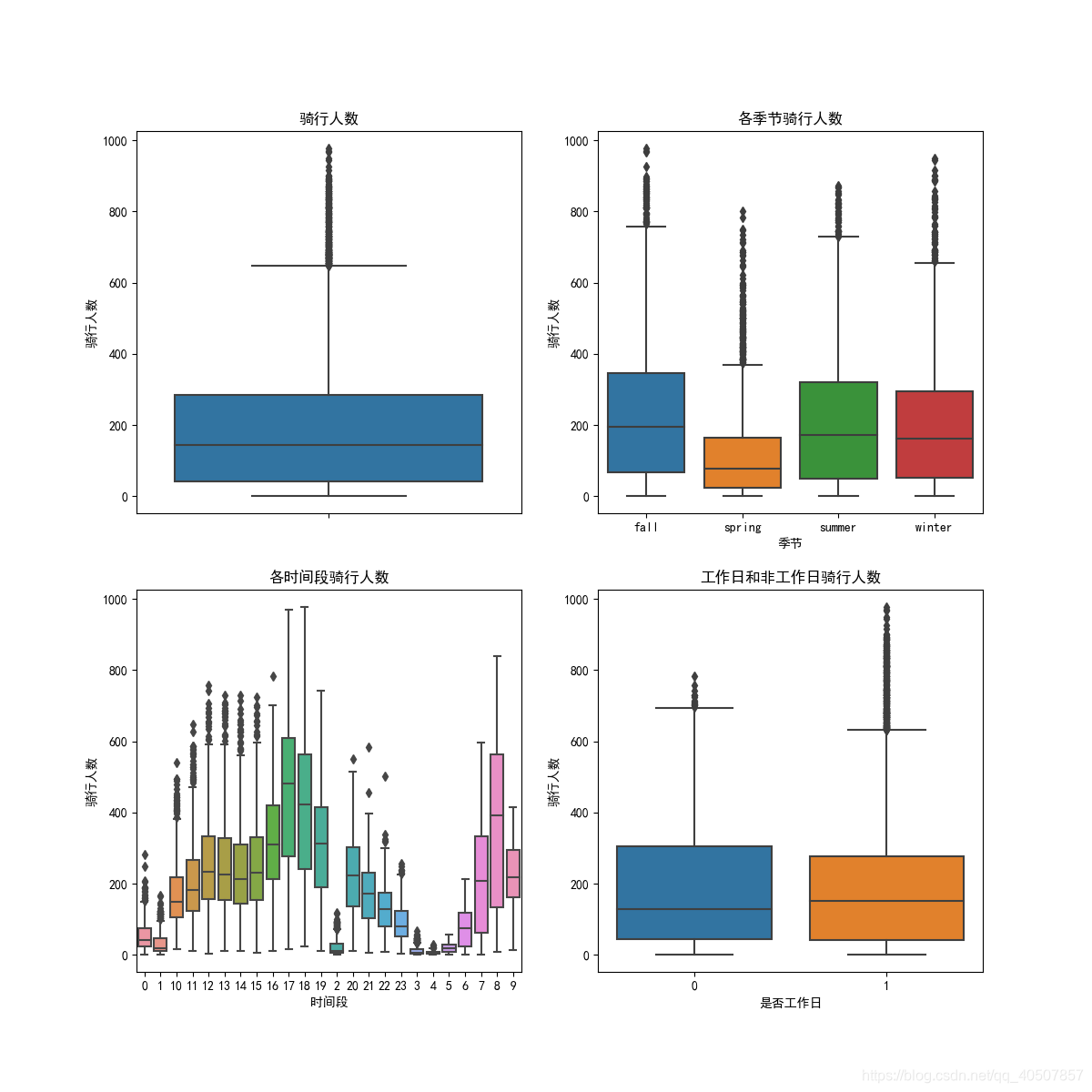
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(12, 12) # 重设大小,单位:英寸
# v垂直 h水平
# 绘制箱型图
sn.boxplot(data=bikedata, y='count', orient='v', ax=axes[0][0])
sn.boxplot(data=bikedata, x='season', y="count", orient='v', ax=axes[0][1])
sn.boxplot(data=bikedata, x='hour', y="count", orient='v', ax=axes[1][0])
sn.boxplot(data=bikedata, x='workingday', y="count", orient='v', ax=axes[1][1])
# 设置横坐标、纵坐标、标题
axes[0][0].set(ylabel="骑行人数", title="骑行人数")
axes[0][1].set(ylabel="骑行人数", xlabel="季节", title="各季节骑行人数")
axes[1][0].set(ylabel="骑行人数", xlabel="时间段", title="各时间段骑行人数")
axes[1][1].set(ylabel="骑行人数", xlabel="是否工作日", title="工作日和非工作日骑行人数")
plt.savefig('collect_and_process_data.png') # 保存图片
plt.show() # 显示图片
# 2.5.3剔除异常数据
print(np.abs(bikedata["count"] - bikedata["count"].mean()))
print(3 * bikedata["count"].std())
print(np.abs(bikedata["count"] - bikedata["count"].mean()) <= (3 * bikedata["count"].std()))
processed_data = bikedata[np.abs(bikedata["count"] - bikedata["count"].mean()) <= (3 * bikedata["count"].std())]
print(processed_data)
processed_data.to_csv('processed_data.csv')
return processed_data
# 3. 数据分析与可视化(不同月份的骑行月份分析)
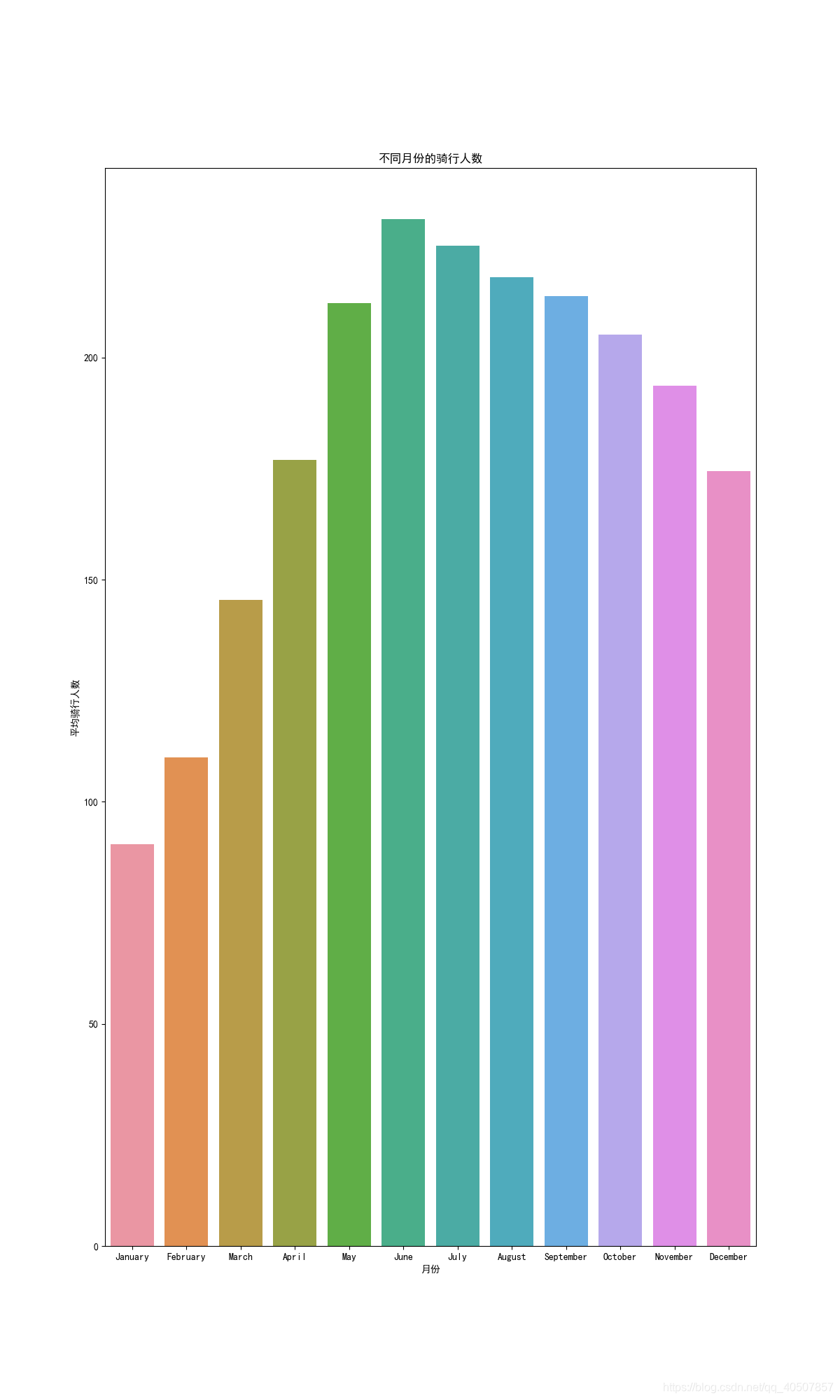
def Data_Analysis_and_Visualization_month(bikedata):
fig, axes = plt.subplots()
fig.set_size_inches(12, 20)
sortOrder = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October",
"November", "December"]
# 判断每个月份有几条记录,并按由大到小顺序排序
monthAggregated = pd.DataFrame(bikedata.groupby("month")["count"].mean()).reset_index()
# print(monthAggregated)
monthSorted = monthAggregated.sort_values(by="count", ascending=False) # 按月份从小到大排序
# print(monthSorted)
# 绘制柱状图
sn.barplot(data=monthSorted, x="month", y="count", order=sortOrder)
axes.set(xlabel="月份", ylabel="平均骑行人数", title="不同月份的骑行人数")
plt.savefig('result_month.png')
# plt.show()
# 4. 数据分析与可视化(不同时间的骑行时间)
def Data_Analysis_and_Visualization_hour(bikedata):
fig, ax = plt.subplots()
fig.set_size_inches(12, 20)
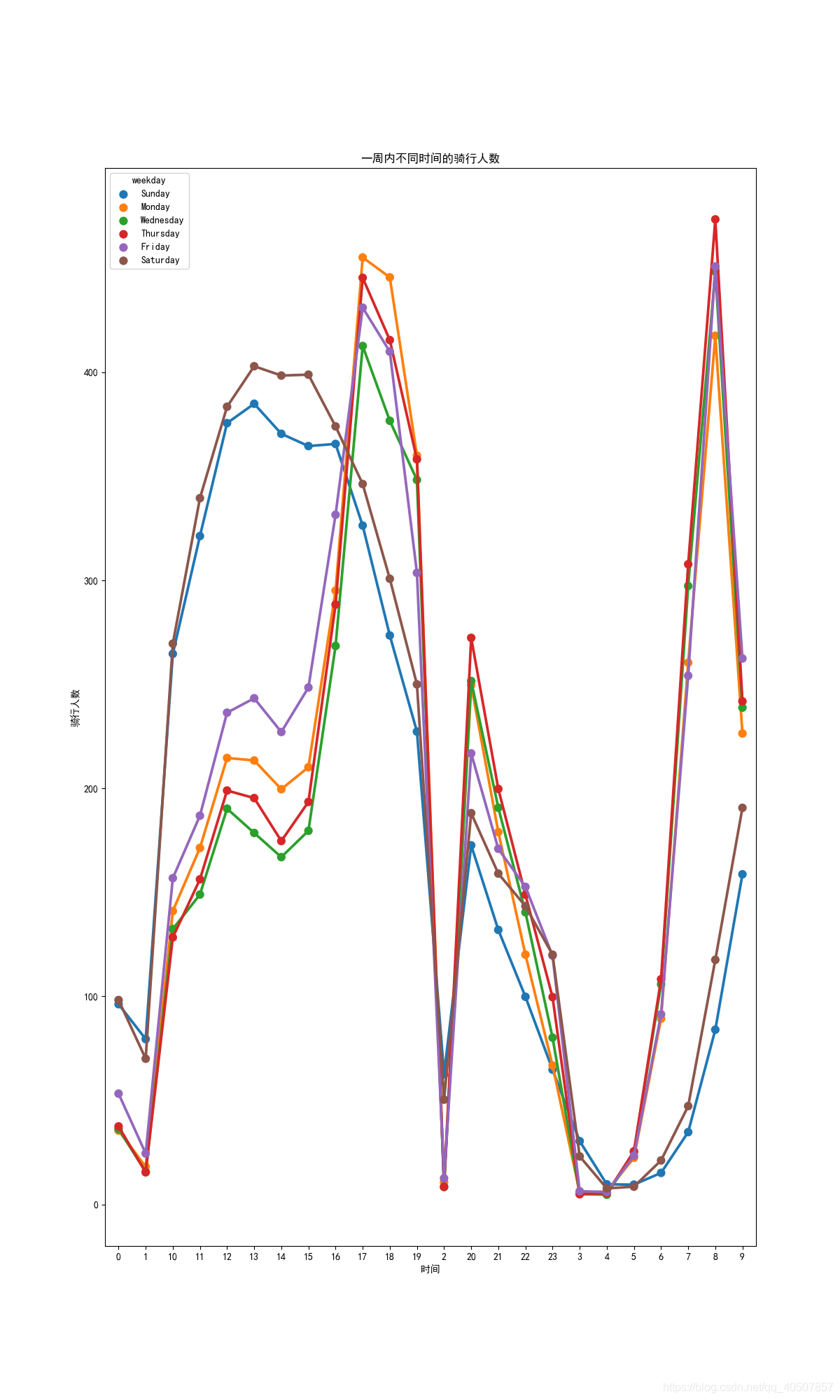
hueOrder = ['Sunday', 'Monday', 'Wednesday', 'Thursday', 'Friday', 'Saturday']
# 一周内不同时间的骑行人数
hourAggregated = pd.DataFrame(bikedata.groupby(['hour', 'weekday'])['count'].mean()).reset_index()
print(hourAggregated)
# 绘制折线图
sn.pointplot(x=hourAggregated['hour'], y=hourAggregated['count'], hue=hourAggregated['weekday'], hue_order=hueOrder,
data=hourAggregated)
ax.set(xlabel='时间', ylabel='骑行人数', title='一周内不同时间的骑行人数')
plt.savefig('result_hour.png')
plt.show()
# 主函数
def main():
# 数据采集/查看和处理
processed_data = collect_and_process_data()
# 数据分析与可视化:月份
Data_Analysis_and_Visualization_month(processed_data)
# 数据分析与可视化:小时
Data_Analysis_and_Visualization_hour(processed_data)
# 主程序
if __name__ == '__main__':
main()
Resultados de analisis
Visualización de datos
Análisis de datos y visualización (análisis de meses de conducción)
Análisis y visualización de datos (análisis del tiempo de viaje)