Productos secos de Datawhale
Traductor: Zhang Feng, miembro de Datawhale
¡Una guía práctica para hacer que EDA sea más simple (y más hermosa)!
Enlace original: https://towardsdatascience.com/practical-tips-for-improving-exploratory-data-analysis-1c43b3484577
introducir
El análisis de datos exploratorios (EDA) es un paso necesario antes de utilizar cualquier modelo de aprendizaje automático. El proceso EDA requiere la concentración y la paciencia de los analistas y científicos de datos: a menudo lleva mucho tiempo utilizar activamente una o más bibliotecas de visualización antes de obtener información significativa a partir del análisis de datos.
En este artículo, compartiré con ustedes algunos consejos sobre cómo simplificar el programa EDA y hacerlo más conveniente según mi experiencia personal. En particular, les presentaré tres consejos importantes que aprendí en el proceso de "matar" con EDA:
1. Utilice el gráfico no trivial que mejor se adapte a su tarea;
2. Hacer pleno uso de las funciones de la biblioteca de visualización;
3. Encuentre formas más rápidas de producir el mismo contenido.
Nota: En esta publicación, utilizaremos datos de energía eólica proporcionados por Kaggle [2] para hacer infografías. ¡Empecemos!
Consejo 1: no tengas miedo de utilizar gráficos no triviales
Aprendí a aplicar esta técnica mientras escribía un artículo de investigación [1] relacionado con el análisis y la previsión de la energía eólica. Mientras hacía EDA para este proyecto, necesitaba crear una matriz resumida para reflejar todas las relaciones entre los parámetros de la energía eólica con el fin de descubrir qué parámetros tienen la mayor influencia entre sí. La primera idea que me vino a la cabeza fue construir una matriz de correlación "anticuada" , del tipo que he visto en muchos proyectos de análisis/ciencia de datos.
Como todos sabemos, la matriz de correlación se utiliza para cuantificar y resumir la relación lineal entre variables. En el fragmento de código siguiente, la función corrcoef se utiliza en la columna de características de los datos de energía eólica . Aquí, también apliqué la función de mapa de calor de Seaborn para trazar la matriz de correlación como un mapa de calor:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩阵
correlation_matrix = np.corrcoef(data[cols].values.T)
hm = sns.heatmap(correlation_matrix,
cbar=True, annot=True, square=True, fmt='.3f',
annot_kws={'size': 15},
cmap='Blues',
yticklabels=['P', 'Ws', 'Power_curve', 'Wa'],
xticklabels=['P', 'Ws', 'Power_curve', 'Wa'])
# 保存图表
plt.savefig('image.png', dpi=600, bbox_inches='tight')
plt.show()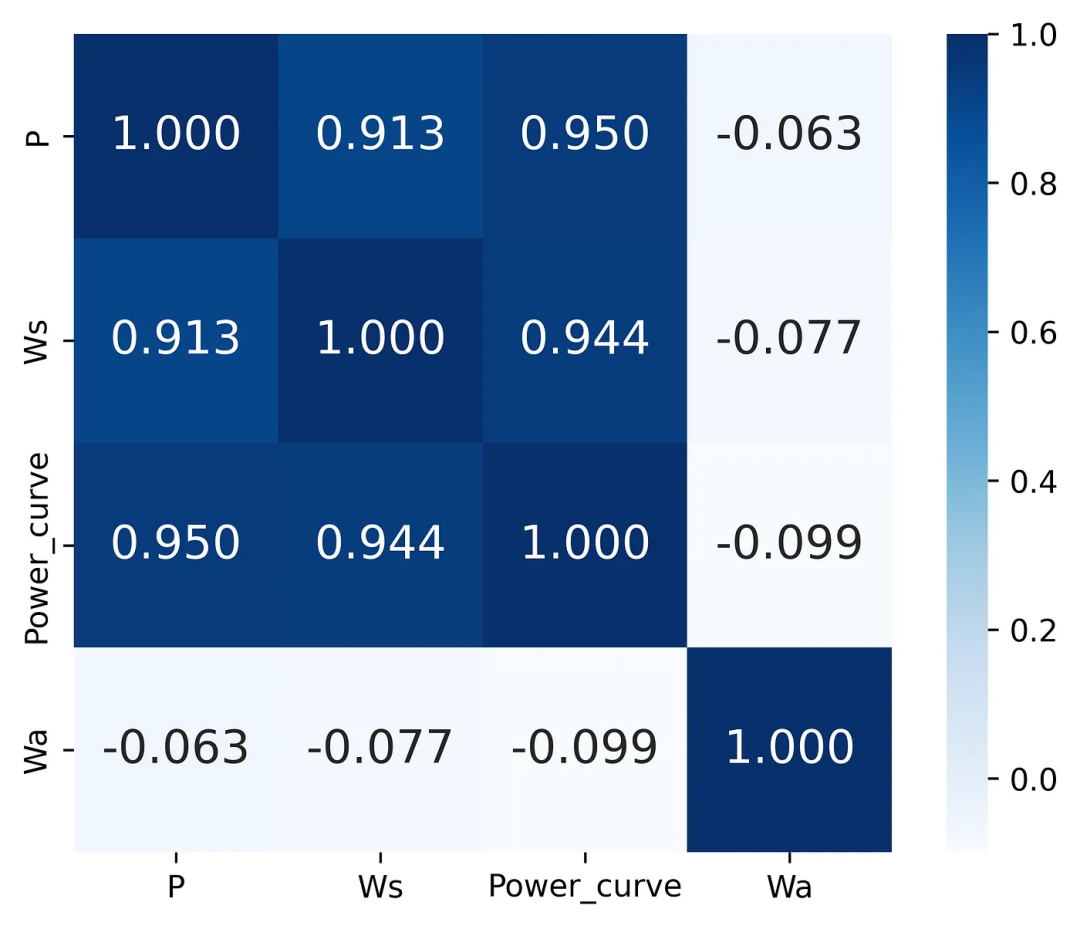
Figura 1 Ejemplo de matriz de correlación establecida
Del análisis de los resultados del gráfico, podemos concluir que existe una fuerte correlación entre la velocidad del viento y la potencia real, pero creo que mucha gente estará de acuerdo conmigo en que esto no es una explicación cuando se utiliza este método de visualización. Método simple para resultados, ya que aquí solo tenemos números.
Una matriz de diagrama de dispersión es una excelente alternativa a una matriz de correlación, ya que le permite visualizar las correlaciones por pares entre diferentes características de su conjunto de datos en un solo lugar. En este caso se debe utilizar sns.pairplot:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩阵
sns.pairplot(data[cols], height=2.5)
plt.tight_layout()
# 保存图表
plt.savefig('image2.png', dpi=600, bbox_inches='tight')
plt.show()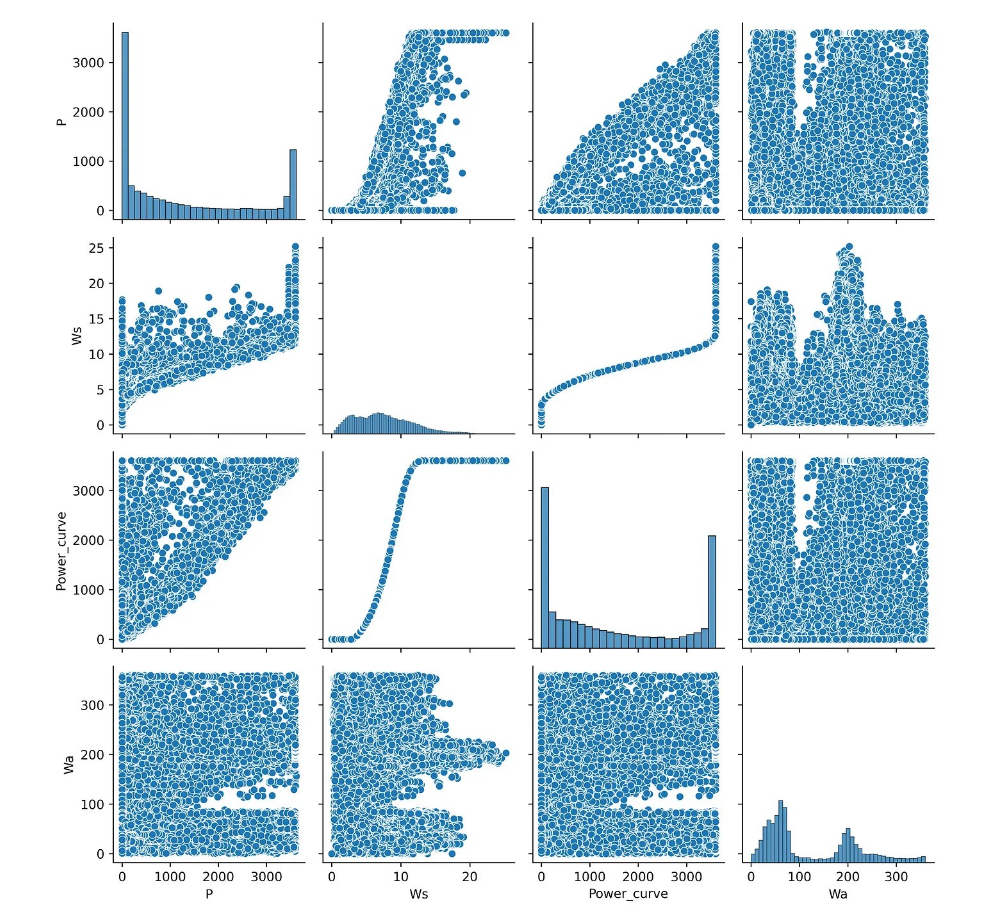
Figura 2 Ejemplo de matriz de diagrama de dispersión
Al observar la matriz del diagrama de dispersión, podemos visualizar rápidamente cómo se distribuyen los datos y si contienen valores atípicos. Sin embargo, la principal desventaja de este tipo de gráfico es que debido al trazado de los datos por pares, habrá datos duplicados.
Al final, decidí combinar los gráficos anteriores en uno, donde la parte inferior izquierda contendrá un diagrama de dispersión del parámetro seleccionado, y la parte superior derecha contendrá burbujas de diferentes tamaños y colores: cuanto más grande sea el círculo, más fuerte será dependencia lineal del parámetro en estudio. La diagonal de la matriz mostrará la distribución de cada característica: un pico estrecho aquí significa que ese parámetro en particular no varía mucho, mientras que otras características varían.
El código para construir la tabla resumen es el siguiente. El mapa aquí consta de tres partes: fig.map_lower, fig.map_diag y fig.map_upper:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
cols = ['P', 'Ws', 'Power_curve', 'Wa']
# 建立矩阵
def correlation_dots(*args, **kwargs):
corr_r = args[0].corr(args[1], 'pearson')
ax = plt.gca()
ax.set_axis_off()
marker_size = abs(corr_r) * 3000
ax.scatter([.5], [.5], marker_size,
[corr_r], alpha=0.5,
cmap = 'Blues',
vmin = -1, vmax = 1,
transform = ax.transAxes)
font_size = abs(corr_r) * 40 + 5
sns.set(style = 'white', font_scale = 1.6)
fig = sns.PairGrid(data, aspect = 1.4, diag_sharey = False)
fig.map_lower(sns.regplot)
fig.map_diag(sns.histplot)
fig.map_upper(correlation_dots)
# 保存图表
plt.savefig('image3.jpg', dpi = 600, bbox_inches = 'tight')
plt.show()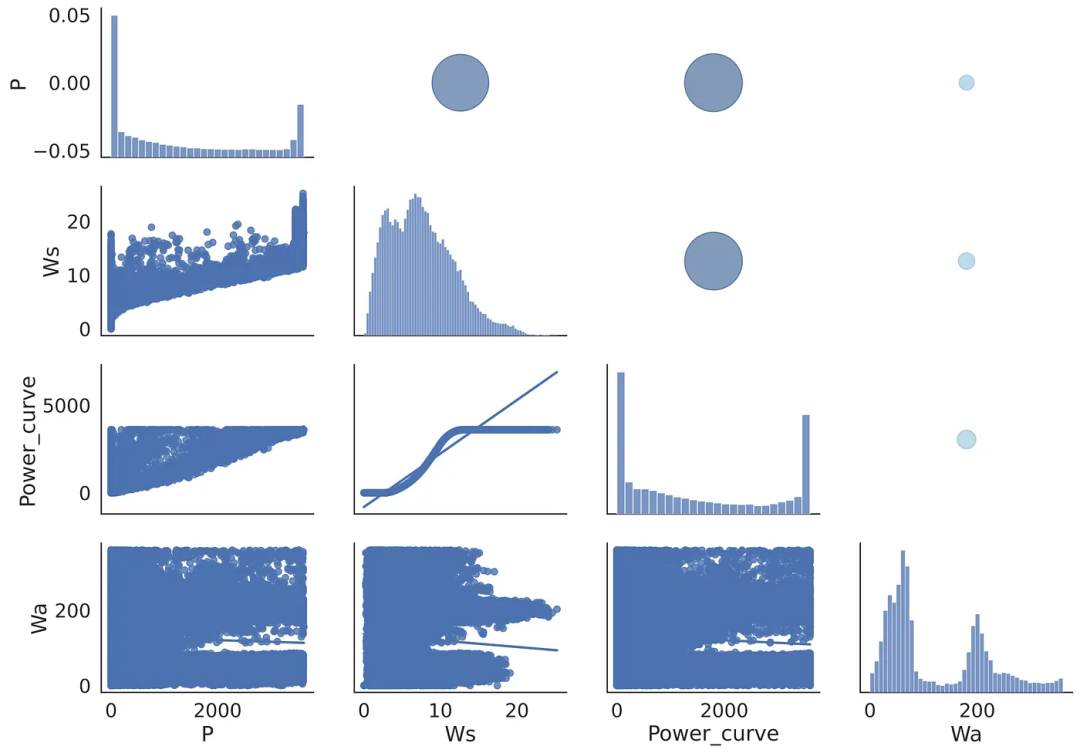
Figura 3 Ejemplo de tabla de resumen
La tabla resumen combina las ventajas de los dos gráficos estudiados anteriormente: su sección inferior (izquierda) imita una matriz de diagrama de dispersión y su fragmento superior (derecha) refleja gráficamente los resultados numéricos de la matriz de correlación.
Consejo 2: aproveche al máximo las capacidades de su biblioteca de visualización
De vez en cuando necesito presentar los resultados de EDA a colegas y clientes, por lo que la visualización es una ayuda importante para mí en esta tarea. Siempre trato de agregar varios elementos, como flechas y anotaciones, al diagrama para hacerlo más atractivo y legible.
Volvamos al ejemplo de implementación de EDA para un proyecto de energía eólica discutido anteriormente. Cuando se trata de energía eólica, uno de los parámetros más importantes es la curva de potencia . Una curva de potencia para una turbina eólica (o un parque eólico completo) es un gráfico que muestra cuánta electricidad se produce a diferentes velocidades del viento. Vale la pena señalar que las turbinas no funcionarán con velocidades de viento bajas. Su activación está relacionada con la velocidad de conexión, que suele estar entre 2,5-5 m/s. La turbina alcanza la potencia nominal cuando la velocidad del viento está entre 12 y 15 m/s. Finalmente, cada turbina tiene un límite superior de velocidad del viento al que puede operar con seguridad. Una vez que se alcance este límite, la turbina eólica no podrá generar electricidad a menos que la velocidad del viento vuelva a caer dentro del rango operativo.
El conjunto de datos estudiado incluye curvas de potencia teóricas (que son curvas típicas proporcionadas por el fabricante sin valores atípicos) y curvas reales (si trazamos la potencia eólica versus la velocidad del viento). Estos últimos suelen contener muchos puntos fuera de la forma teórica ideal, que pueden deberse a fallos de los ventiladores, errores de medición SCADA o mantenimiento no planificado.
Ahora crearemos una imagen que muestre ambos tipos de curvas de viento: la primera, sin más añadidos que la leyenda:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 建立图表
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='actual')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='theoretical')
plt.xlabel('Wind Speed')
plt.ylabel('Power')
plt.legend(loc='best')
# 保存图表
plt.savefig('image4.png', dpi=600, bbox_inches='tight')
plt.show()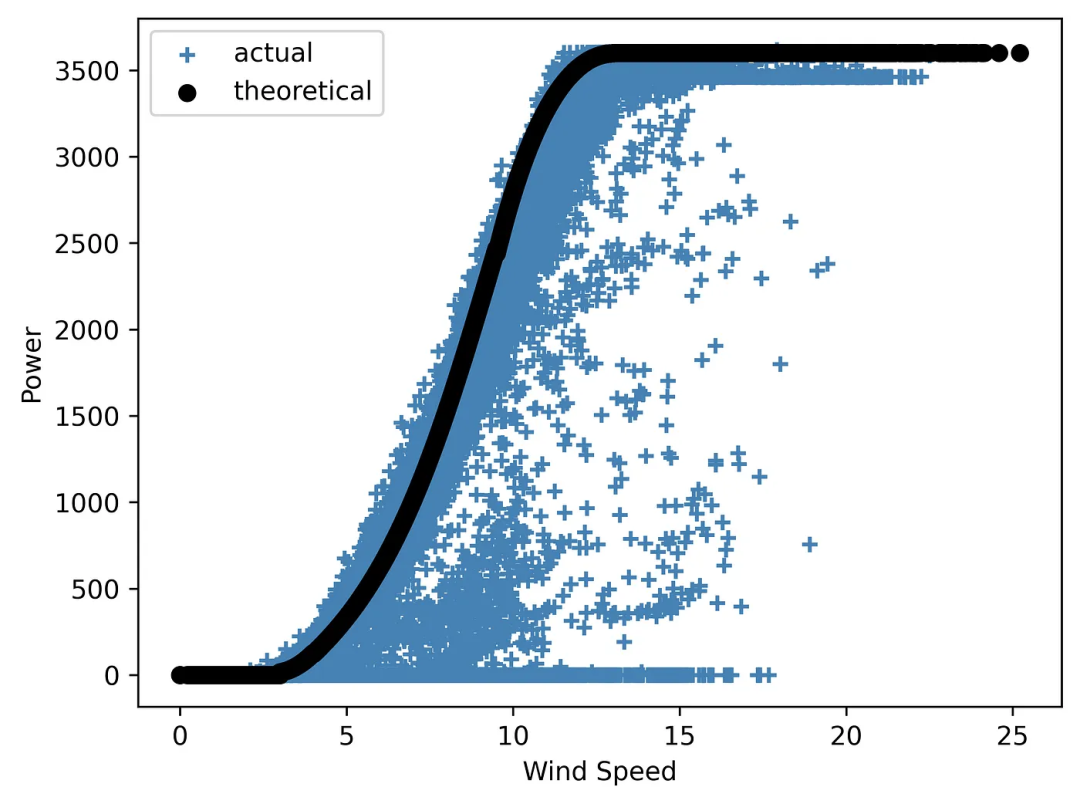
Figura 4 Una curva de energía eólica "silenciosa"
Como puede ver, el diagrama requiere explicación ya que no contiene ningún otro detalle.
Pero, ¿qué pasaría si añadimos líneas para resaltar las tres áreas principales del gráfico, designando la velocidad de corte, la velocidad nominal y la velocidad de corte, y agregamos una nota con una flecha para mostrar uno de los valores atípicos?
Veamos cómo queda el gráfico en este caso:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 建立图表
plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='actual')
plt.scatter(data['Ws'], data['Power_curve'], color='black', label='theoretical')
# 添加垂直线、文字注释和箭头
plt.vlines(x=3.05, ymin=10, ymax=350, lw=3, color='black')
plt.text(1.1, 355, r"cut-in", fontsize=15)
plt.vlines(x=12.5, ymin=3000, ymax=3500, lw=3, color='black')
plt.text(13.5, 2850, r"nominal", fontsize=15)
plt.vlines(x=24.5, ymin=3080, ymax=3550, lw=3, color='black')
plt.text(21.5, 2900, r"cut-out", fontsize=15)
plt.annotate('outlier!', xy=(18.4,1805), xytext=(21.5,2050),
arrowprops={'color':'red'})
plt.xlabel('Wind Speed')
plt.ylabel('Power')
plt.legend(loc='best')
# 保存图表
plt.savefig('image4_2.png', dpi=600, bbox_inches='tight')
plt.show()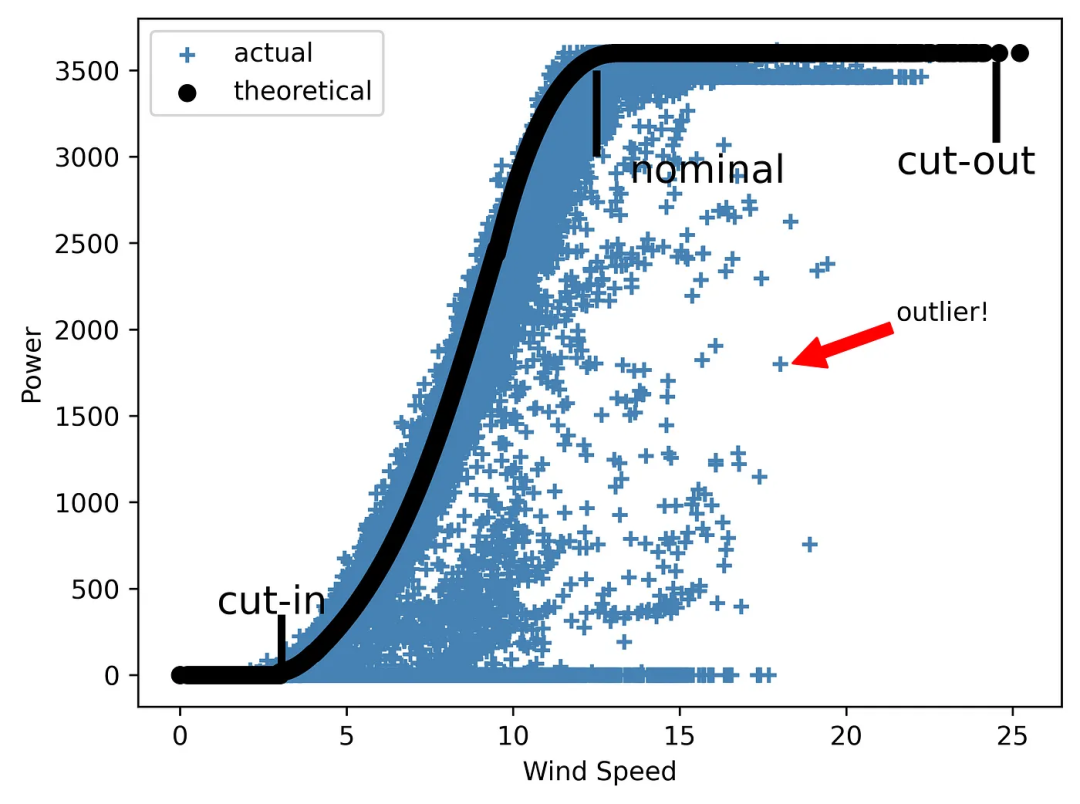
Fig. 5 Un gráfico de la curva de energía eólica de "hablar bien"
Consejo 3: encuentre siempre una manera más rápida de hacerlo
Al analizar datos de energía eólica, a menudo queremos obtener información completa sobre el potencial de la energía eólica. Entonces, además de la dinámica de la energía eólica, es necesario que haya un gráfico que muestre cómo la velocidad del viento varía con la dirección del viento.
Para contabilizar los cambios en la energía eólica, se puede utilizar el siguiente código:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
# 将 10 分钟数据重采样为每小时测量值
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
# 绘制风能动态图
group_data.plot(kind='line')
plt.ylabel('Power')
plt.xlabel('Date/Time')
plt.title('Power generation (resampled to 1 hour)')
# 保存图表
plt.savefig('wind_power.png', dpi=600, bbox_inches='tight')
plt.show()La siguiente figura es el resultado del dibujo:
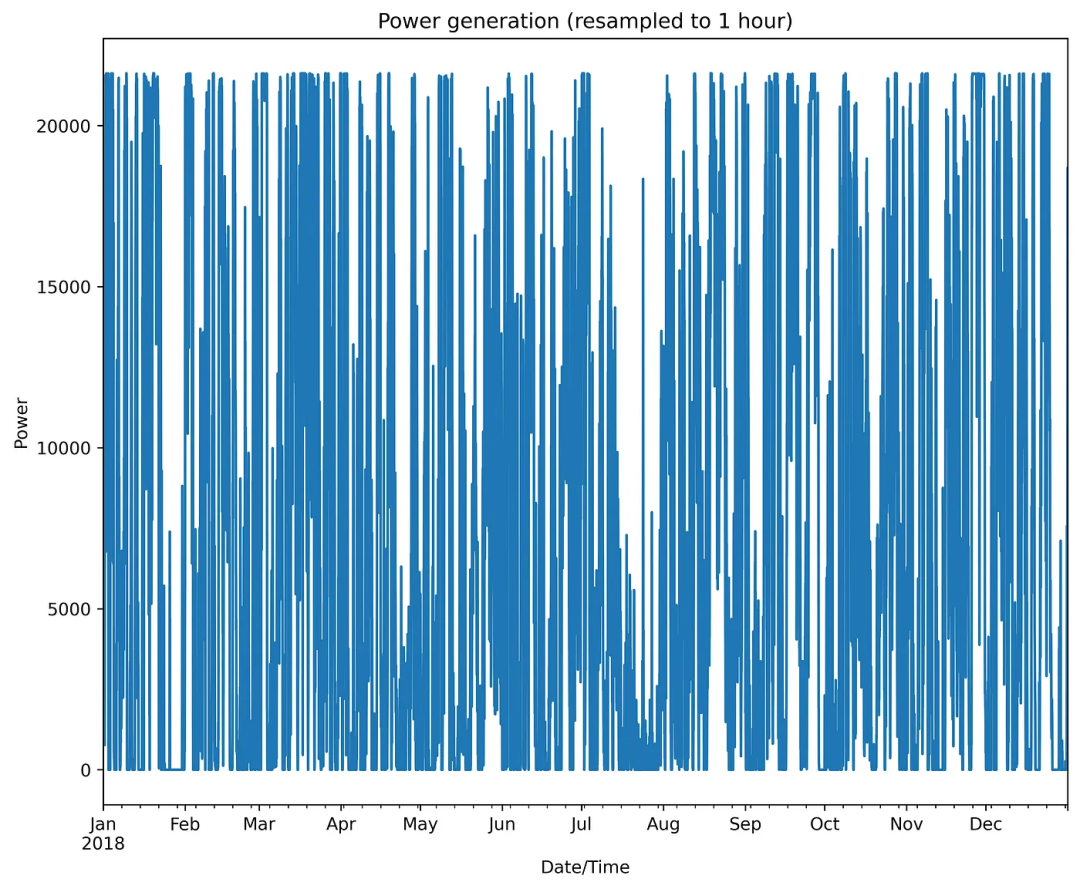
Figura 6 Cambios dinámicos de la energía eólica
Como se puede observar, el perfil dinámico de la energía eólica tiene una forma irregular bastante compleja.
Un gráfico de rosa de los vientos o rosa polar es un gráfico especial que se utiliza para representar la distribución de datos meteorológicos, generalmente la distribución de la dirección de la velocidad del viento [3]. Hay un módulo simple windrose en la biblioteca matplotlib que facilita la creación de este tipo de visualizaciones, por ejemplo:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from windrose import WindroseAxes
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
#为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
wd = data['Wa']
ws = data['Ws']
# 以堆叠直方图的形式绘制正态化风玫瑰图
ax = WindroseAxes.from_ax()
ax.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')
ax.set_legend()
# 保存图表
plt.savefig('windrose.png', dpi = 600, bbox_inches = 'tight')
plt.show()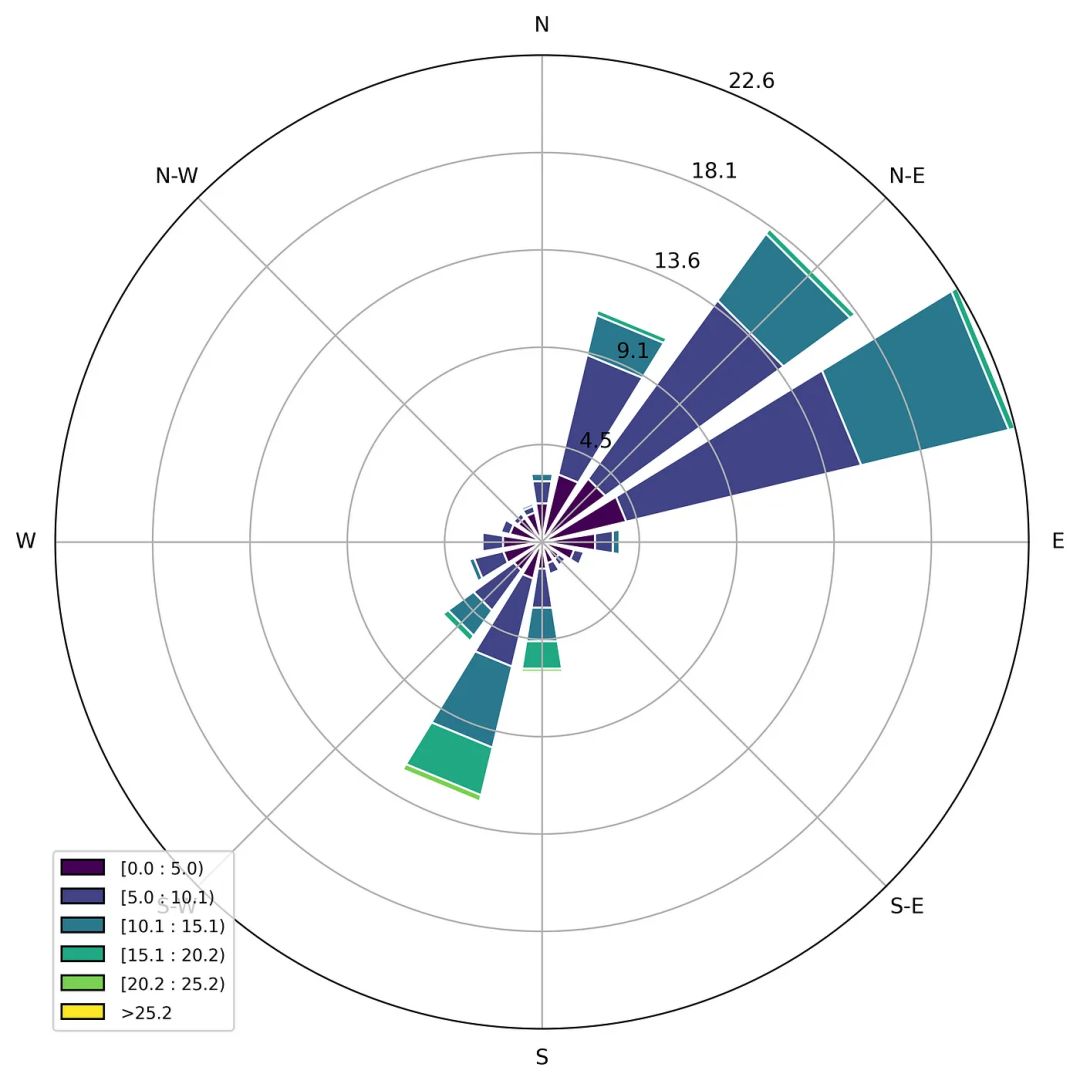
Figura 7 Diagrama de la rosa de los vientos basado en los datos disponibles
Al observar el diagrama de la rosa de los vientos, se puede ver que hay dos direcciones principales del viento: noreste y suroeste.
¿Pero cómo fusionar estas dos imágenes en una sola? La forma más obvia es utilizar add_subplot. Pero esta no es una tarea fácil debido a las características específicas de la biblioteca Windrose:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from windrose import WindroseAxes
# 读取数据
data = pd.read_csv('T1.csv')
print(data)
# 为列重命名,使其标题更简短
data.rename(columns={'LV ActivePower (kW)':'P',
'Wind Speed (m/s)':'Ws',
'Theoretical_Power_Curve (KWh)':'Power_curve',
'Wind Direction (°)': 'Wa'},inplace=True)
data['Date/Time'] = pd.to_datetime(data['Date/Time'])
fig = plt.figure(figsize=(10,8))
# 将两个图都绘制为子图
ax1 = fig.add_subplot(211)
group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()
group_data.plot(kind='line')
ax1.set_ylabel('Power')
ax1.set_xlabel('Date/Time')
ax1.set_title('Power generation (resampled to 1 hour)')
ax2 = fig.add_subplot(212, projection='windrose')
wd = data['Wa']
ws = data['Ws']
ax = WindroseAxes.from_ax()
ax2.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')
ax2.set_legend()
# 保存图表
plt.savefig('image5.png', dpi=600, bbox_inches='tight')
plt.show()En este caso el resultado es este:
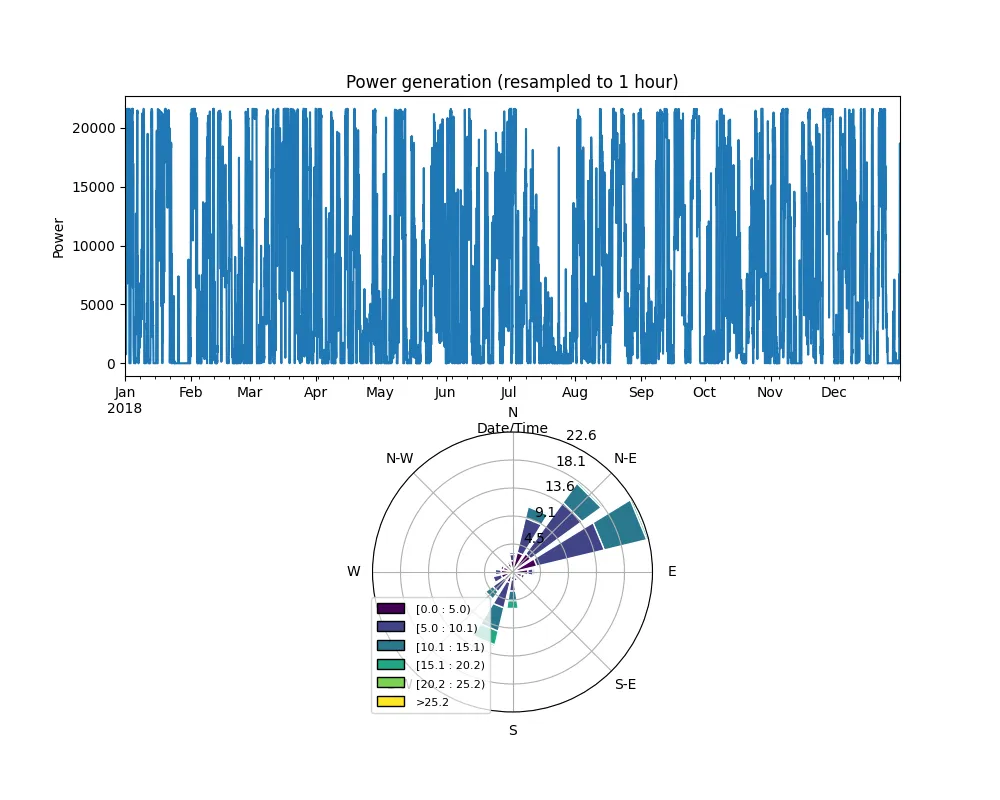
Figura 8 Imagen única que muestra la dinámica de la energía eólica y el diagrama de la rosa de los vientos.
La principal desventaja de esto es que las dos subtramas son de diferentes tamaños, por lo que hay mucho espacio en blanco alrededor de la trama de la rosa de los vientos.
Para mayor comodidad, sugiero un enfoque alternativo, utilizando Python Imaging Library (PIL) [4], que requiere sólo una docena de líneas de código:
import numpy as np
import PIL
from PIL import Image
# 列出需要合并的图片
list_im = ['wind_power.png','windrose.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 调整所有图片的大小,使其与最小图片相匹配
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
# 对于垂直堆叠,我们使用 vstack
images_comb = np.vstack((np.asarray(i.resize(min_shape)) for i in imgs))
images_comb = PIL.Image.fromarray(imgs_comb)
# 保存图表
imgages_comb.save('image5_2.png', dpi=(600,600))Aquí el resultado se ve un poco más bonito, ambas imágenes tienen el mismo tamaño, porque el código elige la imagen más pequeña y reescala las demás para que coincidan:
Una única imagen con la dinámica del viento y una rosa de los vientos obtenida mediante PIL
Por cierto, cuando usamos PIL, también podemos usar apilamiento horizontal, por ejemplo, podemos comparar y contrastar las curvas de viento "silenciosas" y "habladoras":
import numpy as np
import PIL
from PIL import Image
list_im = ['image4.png','image4_2.png']
imgs = [PIL.Image.open(i) for i in list_im]
# 选取最小的图片 ,并调整其他图片 的大小以与之匹配(此处可任意调整图片形状)
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
imgs_comb = np.hstack((np.asarray(i.resize(min_shape)) for i in imgs))
# 保存图表
imgs_comb = PIL.Image.fromarray(imgs_comb)
imgs_comb.save('image4_merged.png', dpi=(600,600))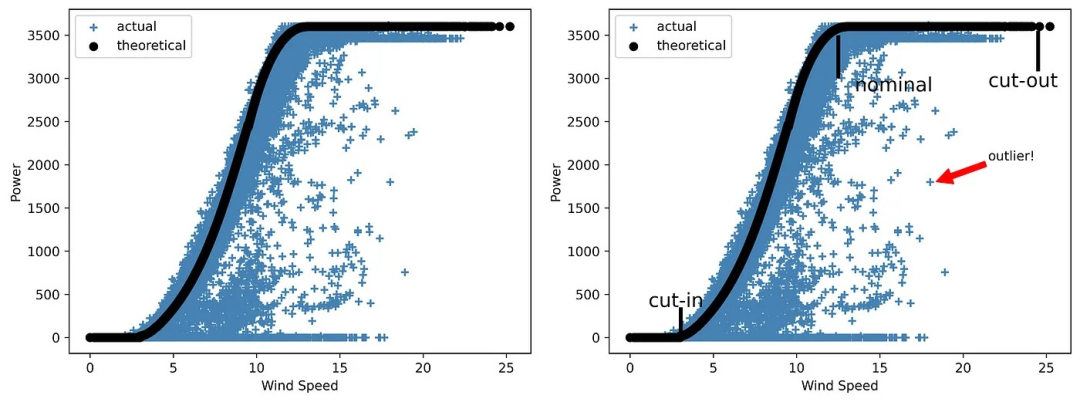
Figura 9 Comparación y contraste de dos curvas de viento
en conclusión
En este artículo, comparto tres consejos sobre cómo facilitar el proceso de EDA. Espero que estas sugerencias sean útiles para que los estudiantes comiencen a aplicarlas a sus tareas de datos.
Estas técnicas encajan perfectamente con la fórmula que he intentado aplicar al hacer EDA: Personalizado → Detallado → Optimizado .
Quizás te preguntes, ¿qué importa esto? Puedo decir que esto realmente importa porque:
Es muy importante personalizar el gráfico según las necesidades específicas del momento. Por ejemplo, en lugar de hacer muchas infografías, piense en cómo combinar varios gráficos en uno, como hicimos cuando hicimos la matriz de resumen, que combina lo mejor de los diagramas de dispersión y de correlación.
Todos los gráficos deberían hablar por sí solos. Por lo tanto, es necesario saber cómo detallar lo que es importante en un gráfico, haciéndolo detallado y fácil de leer. Compare qué tan grande es la diferencia entre las curvas de poder de Silent y Eloquent.
Finalmente, todo científico de datos debería aprender cómo optimizar el proceso EDA para facilitar el trabajo (y la vida). No siempre es necesario utilizar la opción add_subplot si es necesario fusionar dos gráficos en uno.
¿Qué otra cosa? Definitivamente puedo decir que EDA es un paso muy creativo e interesante en el proceso de trabajar con datos (sin mencionar que es súper importante).
¡Haz que tu infografía brille como un diamante y no olvides disfrutar el proceso!
Lista de referencia
Aplicaciones basadas en datos del análisis y previsión de la energía eólica: el caso del parque eólico “La Haute Borne” https://doi.org/10.1016/j.dche.2022.100048
Datos de energía eólica: https://www.kaggle.com/datasets/bhavikjikadara/wind-power-generated-data?resource=download
Tutorial sobre la biblioteca Windrose: https://windrose.readthedocs.io/en/latest/index.html
Biblioteca PIL: https://pillow.readthedocs.io/en/stable/index.html

No es fácil de organizar, por eso me gusta tres veces ↓