Directorio de artículos
prefacio
Máquina de vectores de soporte (Soporte S (Soporte( V ector de apoyo V ectorV ect o M achine , SVM ) Machine,SVM )Máquina , _ _ _ _SVM ) se originó a partir de la teoría del aprendizaje estadístico, es un modelo de clasificación binaria y es el algoritmo más importante en el aprendizaje automático. Sí, es el "más", no uno de ellos .
1. Márgenes y vectores de soporte
La idea central del método de clasificación de máquinas de vectores de soporte es encontrar un hiperplano en el espacio de características como el límite de decisión para dividir las muestras en clases positivas y negativas, y hacer que el error de generalización del modelo en el conjunto de datos desconocido sea pequeño. como sea posible.
Hiperplano: en geometría, un hiperplano es un subespacio de un espacio, que es un espacio cuya dimensión es uno menos que el espacio en el que reside. Si el espacio de datos en sí es tridimensional, su hiperplano es un plano bidimensional, y si el espacio de datos en sí es bidimensional, su hiperplano es una línea unidimensional.
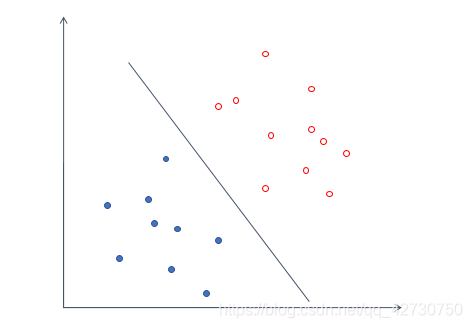
Por ejemplo, el conjunto de datos anterior, podemos dibujar fácilmente una línea para dividir los datos anteriores en dos categorías, y el error es cero. Para un conjunto de datos, puede haber muchos hiperplanos con un error de 0, como los siguientes:
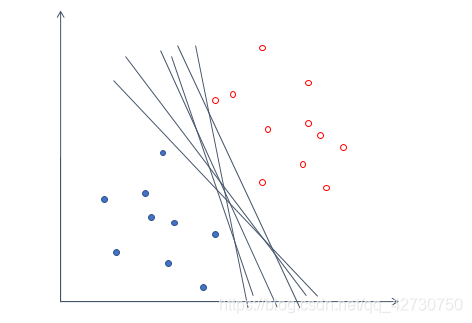
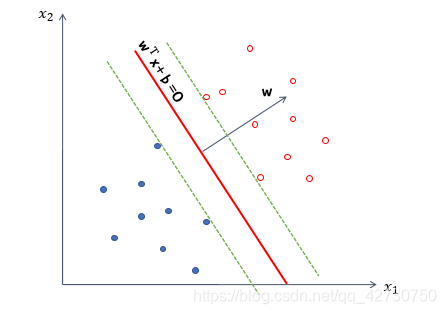
Pero dicho modelo no puede garantizar un buen rendimiento de generalización, es decir, no puede garantizar que este hiperplano también funcione bien en conjuntos de datos desconocidos. Entonces introducimos un sustantivo ------ 间隔( margen ) (margen)( margen ) es trasladar el hiperplano que encontramos a ambos lados hasta que se detiene en el punto de muestra más cercano al hiperplano para formar dos nuevos hiperplanos. La distancia entre los dos hiperplanos se llama "intervalo", y el hiperplano está en medio de este "intervalo", es decir, la distancia entre el hiperplano que elegimos y los dos nuevos hiperplanos después de la traducción es igual. Los pocos puntos de muestra más cercanos al hiperplano se denominan支持向量(apoyo (apoyo( vector de apoyo o t ) vector )v ect o )。 _
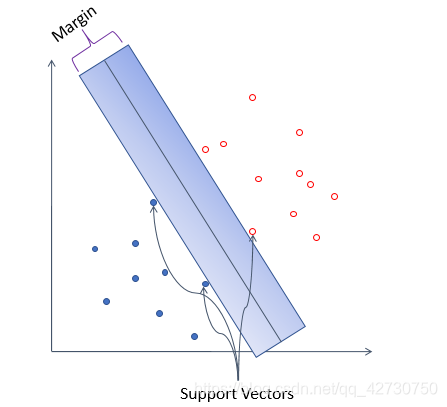

Comparando las dos figuras anteriores, intuitivamente, las muestras se pueden dividir en dos categorías, pero si se le agrega algo de ruido, es obvio que el hiperplano azul tiene la mejor tolerancia a las perturbaciones locales, porque es "lo suficientemente ancho", si No puedo imaginarlo, mire el siguiente ejemplo:
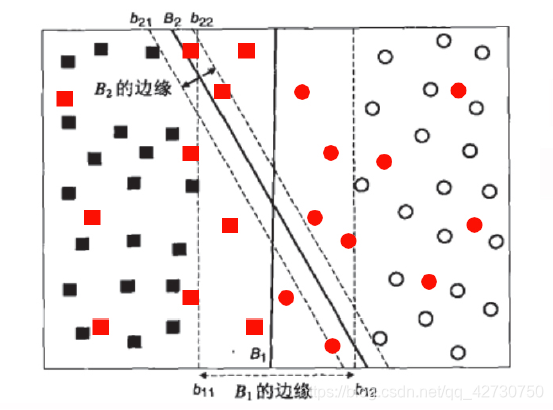
Obviamente, después de introducir algunas muestras de datos nuevos, B 1 B_1B1Este error de hiperplano sigue siendo 0, y el resultado de la clasificación es el más robusto, B 2 B_2B2Este hiperplano tiene un error de clasificación debido al pequeño intervalo. Por lo tanto, cuando buscamos un hiperplano, esperamos que cuanto mayor sea el intervalo, mejor.
Lo anterior es la máquina de vectores de soporte, es decir, 通过找出间隔最大的超平面,来对数据进行分类el clasificador de .
El modelo de máquina de vectores de soporte se puede dividir en los siguientes tres tipos, de simple a complejo:
∙ \bullet∙ Máquinas de vectores de soporte linealmente separables
∙ \bullet∙ Máquinas de vectores soporte lineales
∙ \bullet∙
MaximizaciónSVM no lineal(hard (hard( margen duro margen _m a r g en maximización ) maximización)max x imi z a t i o n ) , aprenda un clasificador lineal, es decir, una máquina de vectores de soporte linealmente separable, también conocida como máquina de vectores de soporte de margen duro; cuando el conjunto de datos de entrenamiento sea aproximadamente separable linealmente, maximice el (soft (soft( so f t margen margenm a r g en maximización ) maximización)max x imi z a t i o n ) , también aprenda un clasificador lineal, es decir, una máquina de vectores de soporte lineal, también conocida como máquina de vectores de soporte de margen suave; cuando el conjunto de datos de entrenamiento es linealmente inseparable, mediante el uso de la técnica kernel (kernel (núcleo( k er n e l truco ) truco)t r ck k ) y maximización de margen suave, aprendiendo máquinas de vectores de soporte no lineales.
La simplicidad es la base de la complejidad, y también es un caso especial de complejidad.
2. Descripción de la ecuación de la función
re = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ... , ( xn , yn ) } , yi ∈ { − 1 , + 1 } re=\{(x_1,y_1 )D={( x1,y1) ,( X2,y2) ,…,( Xn,yn)} ,yyo∈{
- 1 ,+ 1 } , en el espacio de muestra anterior, cualquier línea se puede expresar como: w T x + b = 0 \bm w^T\bm x+b=0wTX _+b=0 其中w = ( w 1 , w 2 , … , wd ) T \bm w=(w_1, w_2,\dots,w_d)^Tw=( w1,w2,…,wre)T es el vector normal, que determina la dirección del hiperplano;bbb es el término de desplazamiento, que determina la distancia entre el hiperplano y el origen. Obviamente, el hiperplano también puede ser un vector normalw \bm ww y desplazamientobbBOK .
Para facilitar la derivación y el cálculo, hacemos las siguientes reglas:
los puntos por encima del hiperplano se marcan como positivos y los puntos por debajo del hiperplano se marcan como negativos, es decir, para( xi , yi ) ∈ D (x_i,y_i)\ en D( Xyo,yyo)∈D,若yi = + 1 y_i=+1yyo=+ 1,则有w T xi + b > 0 \bm w^T\bm x_i+b>0wTX _yo+b>0;若yi = − 1 y_i=-1yyo=− 1,则有w T xi + b < 0 \bm w^T\bm x_i+b<0wTX _yo+b<0,表达式如下: { w T xi + segundo ≥ + 1 , yi = + 1 w T xi + segundo ≤ − 1 , yi = − 1 \begin{casos} \bm w^T\bm x_i+b\geq +1, & y_i=+1\\ \\ \bm w^T\bm x_i+b\leq-1, & y_i=-1 \end{casos}⎩
⎨
⎧wTX _yo+b≥+ 1 ,wTX _yo+b≤− 1 ,yyo=+ 1yyo=− 1 Entre ellos, +1和-1表示两条平行于超平面的虚线到超平面的相对距离.
Entonces, cualquier punto x \bm x en el espacio muestralLa distancia de x al hiperplano se puede escribir como:r = ∣ w T + b ∣ ∣ ∣ w ∣ ∣ r=\frac {|\bm w^T+b|} {||\bm w||}r=∣∣ con ∣∣∣ wT+b∣ _ A partir de esto, la suma de las distancias desde los vectores soporte de dos etiquetas diferentes al hiperplano, es decir, el intervalo, se puede expresar como: γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac {2} {|| \bmw||}C=∣∣ con ∣∣2 Nuestro objetivo es encontrar el hiperplano con el mayor intervalo, es decir, el parámetro w \bm w que satisfaga las siguientes restriccionesw ybbb , tal queγ \gammaγ最大,即maxw , b 2 ∣ ∣ w ∣ ∣ sujeto a yi ( w T xi + b ) ≥ 1 , i = 1 , 2 , ... , n \underset {\bm w,b} {max} \frac { 2} {||\bm w||} \\[3pt] sujeto\ a \ y_i(\bm w^T\bm x_i+b)\geq1,i=1,2,\dots,nw ,bmáximo _∣∣ con ∣∣2S u b j e t o y yo( wTX _yo+segundo )≥1 ,i=1 ,2 ,…,n Obviamente, maximizando el intervaloγ \gammaγ solo necesita ser minimizado∣ ∣ w ∣ ∣ ||\bm w||∣∣ w ∣∣ es suficiente, por lo que las restricciones son las siguientes: minw , b 1 2 ∣ ∣ w ∣ ∣ 2 sujeto a yi ( w T xi + b ) ≥ 1 , i = 1 , 2 , … , n \underset { \bm w,b} {min} \frac {1} {2}||\bm w||^2 \\[3pt] sujeto\ a \y_i(\bm w^T\bm x_i+b)\ geq1 ,i=1,2,\puntos,nw ,bminuto21∣∣ w ∣ ∣2S u b j e t o y yo( wTX _yo+segundo )≥1 ,i=1 ,2 ,…,norte
De hecho, es tomar el recíproco, entonces para qué agregar el cuadrado, como dije antes, L 2 L_2L2Paradigma Bueno, sumar un cuadrado es eliminar la operación de raíz cuadrada y simplificar el proceso de cálculo.
3. Solución de parámetros
Para resolver problemas de optimización con restricciones, se suele utilizar para introducir el multiplicador de Lagrange λ \lambdaλ construye la función lagrangiana. De hecho, esto pertenece al problema del extremo condicional de las funciones multivariadas.Puede consultar el extremo condicional de las funciones multivariadas y el método del multiplicador de Lagrange (estándar\Lagrange\multiplicador\método)en el segundo volumen de matemáticas avanzadas.( método m u l i a l i a r d e s t y d a r d L a g r a g n e ) , repasemos brevemente a continuación .
3.1 Multiplicadores lagrangianos
Para encontrar la función z = f ( x , y ) z=f(x,y)z=f ( x ,y ) en la condición adicionalφ ( x , y ) = 0 \varphi(x,y)=0φ ( x ,y )=Para los posibles puntos extremos debajo de 0 , primero puede hacer la función lagrangiana L ( x , y ) = f ( x , y ) + λ φ ( x , y ) L(x,y)=f(x,y) + \lambda \varphi(x,y)L ( x ,y )=f ( x ,y )+λ φ ( x ,y ) donde,λ \lambdaλ es un parámetro, encuentre su parxxx、 y y y和λ \lambdaLa primera derivada parcial de λ , y hacerla cero, luego las ecuaciones simultáneas: { fx ( x , y ) + λ φ x ( x , y ) = 0 fy ( x , y ) + λ φ y ( x , y ) = 0 φ ( x , y ) = 0 \begin{casos} f_x(x,y)+\lambda \varphi_x(x,y)=0\\ \\ f_y(x,y)+\lambda \varphi_y( x ,y)=0\\ \\ \varphi(x,y)=0\\ \end{casos}⎩
⎨
⎧Fx( X ,y )+l fx( X ,y )=0Ftu( X ,y )+l ftu( X ,y )=0φ ( x ,y )=0 Con este sistema de ecuaciones resuelve xxx、 y y y和λ \lambdaλ , el obtenido( x , y ) (x,y)( X ,y ) es la funciónf ( x , y ) f(x,y)f ( x ,y ) en la condición adicionalφ ( x , y ) = 0 \varphi(x,y)=0φ ( x ,y )=Posibles puntos extremos por debajo de 0 .
Si la función tiene más de dos variables independientes y más de una condición adicional, por ejemplo, la función u = f ( x , y , z , t ) u=f(x,y,z,t)tu=f ( x ,y ,z ,t ) bajo la condición adicionalφ ( x , y , z , t ) = 0 ψ ( x , y , z , t ) = 0 \varphi (x,y,z,t)=0 \\[3pt] \psi (x,y,z,t)=0φ ( x ,y ,z ,t )=0ψ ( x ,y ,z ,t )=0 , primero puedes hacer la función lagrangianaL ( x , y , z , t ) = f ( x , y , z , t ) + λ f ( x , y , z , t ) + μ f ( x , y , z , t ) L(x,y,z,t)=f(x,y,z,t)+\lambda f(x,y,z,t)+\mu f(x, y, z, t )L ( x ,y ,z ,t )=f ( x ,y ,z ,t )+λ f ( x ,y ,z ,t )+μ f ( x ,y ,z ,t ) entre ellos,λ , μ \lambda,\muyo ,μ es un parámetro, encuentre su parxxx、 y y y ,zzz ,ttt、λ \lambdaλ和μ \muDerivada parcial de primer orden de μ y conviértala en cero, luego resuelva las ecuaciones simultáneas para obtener( x , y , z , t ) (x,y,z,t)( X ,y ,z ,t )。
Ven, veamos un pequeño problema:
encuentra la función u = x 2 + y 2 + z 2 u=x^2+y^2+z^2tu=X2+y2+z2 en las restriccionesz = x 2 + y 2 z=x^2+y^2z=X2+y2和x + y + z = 4 x+y+z=4X+y+z=Los valores máximos y mínimos menores de 4 .

3.2 Función dual lagrangiana
Problemas de optimización convexa: la función en sí es cuadrática (cuadrática) (cuadrática)( cuadrática ) , las restricciones de la función son lineales bajo sus parámetros, tal función se llama un problema de optimización convexo .
Primero construya la función de Lagrange de la máquina de vectores de soporte, es decir, la función de pérdida: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − yi ( w T xi + segundo ) ) ( α yo ≥ 0 ) L(\bm w,b,\bm \alpha)=\frac {1} {2}||\bm w||^2+\sum_{i=1} ^ m\alpha_i\bigg(1-y_i\big(\bm w^T\bm x_i+b\big)\bigg)\ (\alpha_i \geq0)L ( w ,b ,un )=21∣∣ w ∣ ∣2+yo = 1∑mayo( 1−yyo( wTX _yo+b ) ) ( un yo≥0 ) entre ellos,α = ( α 1 , α 2 , … , α n ) T \alpha=(\alpha_1,\alpha_2,\dots,\alpha_n)^Ta=( un1,a2,…,an)t._ _
Se puede ver que la función de Lagrange se divide en dos partes: la primera parte es la misma que nuestra función de pérdida original y la segunda parte expresa nuestras restricciones. Esperamos que la función de pérdida construida no solo pueda representar nuestra función de pérdida y restricciones originales, sino que también exprese que queremos minimizar la función de pérdida para resolverw \bm ww ybbLa intención de b , entonces tenemos que empezar conα \alphaα es un parámetro, resuelveL ( w , b , α ) L(\bm w,b,\alpha)L ( w ,b ,α ) , entoncesw \bm ww ybbb es un parámetro, resuelveL ( w , b , α ) L(\bm w,b,\alpha)L ( w ,b ,α ) valor mínimo. Por lo tanto, nuestro objetivo se puede escribir de la siguiente manera: minw , b max α i ≥ 0 L ( w , b , α ) ( α i ≥ 0 ) \underset {\bm w,b} {min}\ \underset {\alpha_i \geq0} {máx} \ L(\bm w,b,\alpha)\ (\alpha_i \geq0)w ,bminuto ayo≥ 0máximo _ L ( w ,b ,un ) ( un yo≥0 )