Tabla de contenido
(1) Máquina vectorial de soporte linealmente separable
3. Fiabilidad de la predicción de clasificación
(2) Máquina vectorial de soporte lineal no separable
(3) Máquina de vectores de soporte no lineal
2. Combate real (rbf+gamma para clasificación de iris)
1. Introducción
SVM es un modelo de clasificación , que es un clasificador lineal definido con el mayor intervalo (distancia) en el espacio de características .
Idea básica: SVM representa el conjunto de datos de muestra de entrenamiento como puntos en el espacio de características y separa los datos de entrenamiento de cada categoría usando un hiperplano. Al predecir, ingrese un nuevo punto de datos de prueba. Si el punto de datos de prueba está en la posición del espacio de características Si está distribuido en un lado del hiperplano, entonces se considera que la categoría del punto de prueba es la categoría correspondiente al lado .
Hay tres tipos de SVM:
Máquinas de vectores de soporte linealmente separables (maximización de margen duro)
Máquinas de vectores de soporte lineales no separables (maximización de margen suave)
Máquinas de vectores de soporte no lineales (trucos de kernel y maximización de margen suave)
(1) Máquina vectorial de soporte linealmente separable
1. Pregunta original :
El problema de optimización para resolver una máquina de vectores de soporte linealmente separable se toma como el problema de optimización original.
(SVM generalmente se usa para problemas de clasificación binaria, usando -1 y +1 para representar las dos categorías correspondientes, cuando yi = -1, el punto de muestra xi se llama ejemplo negativo, cuando yi = +1, el punto de muestra xi es llamado un ejemplo positivo)
2. SVM
Cuando el conjunto de datos de entrenamiento es linealmente separable, el algoritmo SVM espera poder calcular un hiperplano de separación en el espacio de características de la distribución de datos de muestra, de modo que todas las muestras (ejemplos positivos y ejemplos negativos) puedan distribuirse de acuerdo con sus categorías correspondientes. Ambos lados del hiperplano.
La función de decisión de clasificación f(x) de la máquina de vectores de soporte linealmente separable :
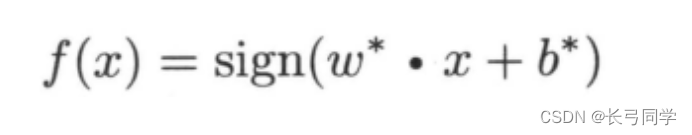
El hiperplano de separación aprendido por maximización de márgenes o resolviendo de manera equivalente el correspondiente problema de programación cuadrática convexa es:
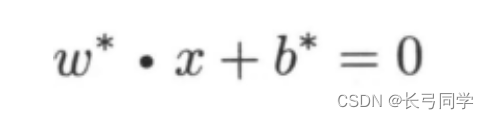
3. Fiabilidad de la predicción de clasificación
Cuando se usa SVM para clasificar muestras de entrenamiento, la confiabilidad de predicción de clasificación generalmente se usa para evaluar la confiabilidad de algoritmos no estándar.
Cuanto más cercana es la distancia al hiperplano de separación, menos fiable es la clasificación de los datos y, a la inversa, cuanto más alejada es la distancia, más fiable es la clasificación de los datos .
Si el signo aritmético de w·xi+b es consistente con el signo de la etiqueta de clasificación yi del punto de datos de la muestra, significa que la clasificación es correcta, de lo contrario, la clasificación es incorrecta .
4. Intervalos de clase
Defina el intervalo geométrico entre el conjunto de datos de entrenamiento T y el hiperplano como:

El objetivo de la máquina de vectores de soporte es encontrar un hiperplano de separación que pueda dividir correctamente el conjunto de datos de muestra de entrenamiento y maximizar su intervalo geométrico.

(En la figura, el punto por el que pasa la línea de puntos es el vector de soporte, y la distancia vertical desde el vector de soporte hasta la línea continua es el intervalo de clasificación γ)
5. Restricciones
Dos preguntas:
(1) Cómo juzgar si el hiperplano de separación clasifica correctamente los puntos de muestra
(2) Para resolver el intervalo de clasificación d, primero debe encontrar el vector de soporte, entonces, ¿cómo encontrar el vector de soporte entre muchas muestras de entrenamiento?
Estos dos problemas son para resolver las restricciones del intervalo de clasificación óptimo, es decir, para resolver las restricciones y limitaciones del hiperplano de separación óptimo.
6. Algoritmo de aprendizaje de máquina de vector de soporte linealmente separable (método de intervalo máximo)
Entrada: Ingrese el conjunto de datos de muestra separables linealmente T para ser entrenado.
Salida: Salida del hiperplano de separación y función de decisión de clasificación del margen máximo.
Proceso del algoritmo:
(1) Resolución de problemas de optimización bajo restricciones y restricciones
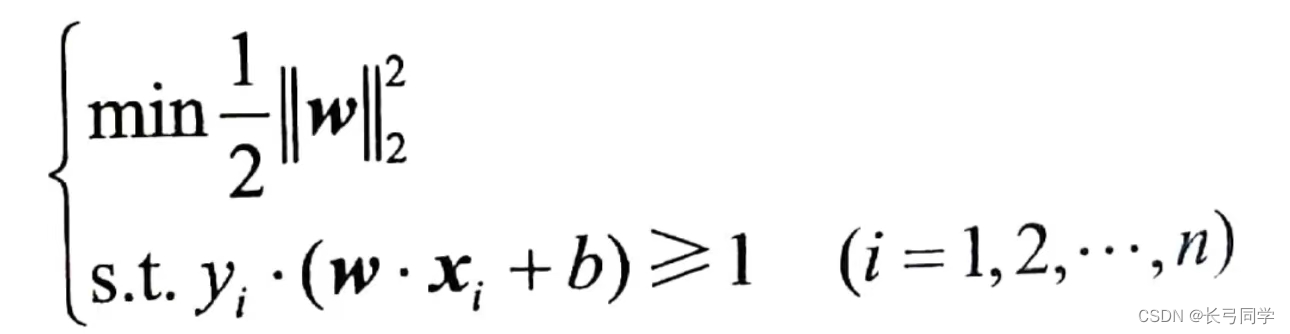
(2) Encuentre la solución óptima (w*, b*)
(3) Obtener el hiperplano de separación óptima w* x+b*=0 y su función de decisión de clasificación f(x)=sign(w* x+b*)
7. Algoritmo dual
El propósito principal de adoptar la ecuación de Lagrange es poner las restricciones en la función objetivo, para transformar el problema de optimización con restricciones en un problema de optimización sin restricciones de la nueva función objetivo.
A través de la dualidad lagrangiana, el problema original se transforma en el problema de encontrar el máximo y el mínimo.
(2) Máquina vectorial de soporte lineal no separable
Proceso del algoritmo:
Entrada: Ingrese el conjunto de datos de muestra T para ser entrenado y el parámetro de penalización C
Salida: genera el hiperplano de separación y la función de decisión de clasificación que maximiza el margen blando
(1) Resolución de problemas de optimización con restricciones
(2) cálculo
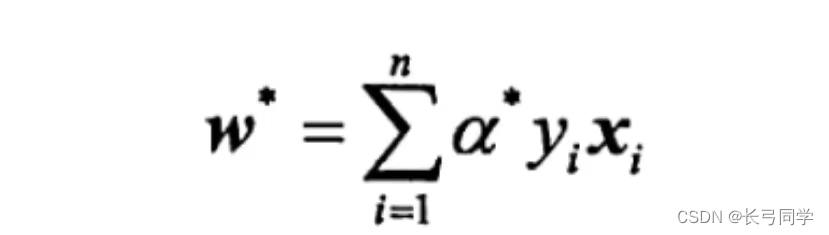
Al mismo tiempo, seleccione cierto componente aj* de a* y calcule
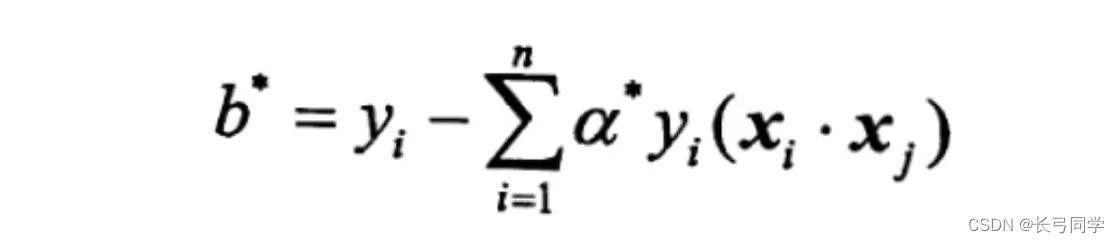
(3) Obtener el hiperplano de separación y la función de decisión de clasificación para maximizar el margen blando
(3) Máquina de vectores de soporte no lineal
1. Problema dual
La función kernel asigna dos vectores x y z en el espacio de entrada al producto interno entre los vectores correspondientes en el espacio de características. Esta forma de reemplazar el producto interno con una función del núcleo se llama el truco del núcleo.
En las máquinas de vectores de soporte no lineales, las funciones del kernel de uso común:
(1) Función kernel polinomial
(2) función del núcleo de Gauss
(3) función del núcleo sigmoide
2. Algoritmos
Entrada: conjunto de datos de entrenamiento de entrada T y parámetro de penalización C>0
Salida: parámetros de decisión de clasificación de salida
Proceso del algoritmo:
(1) Seleccione una función kernel adecuada K(x,z) para resolver el problema de optimización con restricciones
(2) cálculo
Al mismo tiempo, seleccione cierto componente aj* de a* y calcule
(3) La función de decisión de clasificación es
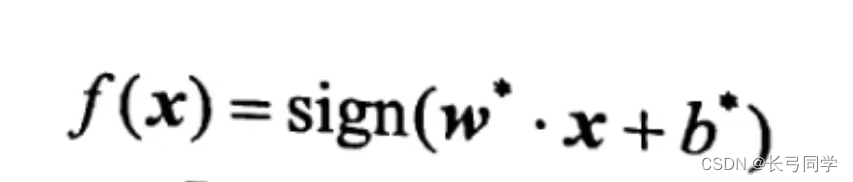
2. Combate real (rbf+gamma para clasificación de iris)
código:
from sklearn import datasets
import numpy as np
from sklearn.model_selection import train_test_split
# 划分数据集为训练集和测试机
from sklearn import svm # 导入SVM
iris=datasets.load_iris()
# 导入鸢尾花数据集
data_train,data_test,target_train,target_test=train_test_split(iris.data,iris.target,test_size=0.3)
# 测试集占总数据集的0.3
svm_classifier=svm.SVC(C=1.0,kernel='rbf',
decision_function_shape='ovr',gamma=0.01)
# 定义一个svm对象
svm_classifier.fit(data_train,target_train)# 训练模型
score=svm_classifier.score(data_test,target_test)
# 把测试集的数据传入即可得到模型的评分
predict=svm_classifier.predict([[0.1,0.2,0.3,0.4]])
# 预测给定样本数据对应的标签
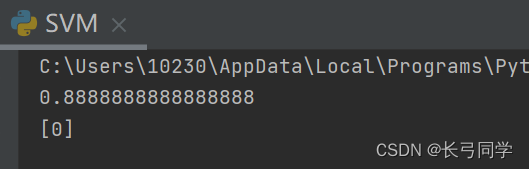
print(score)
print(predict)
Explicación de parámetros:
Cuanto mayor sea el parámetro c , menor será el error del conjunto de entrenamiento, pero es más fácil sobreajustarlo.
El parámetro coef0 es pequeño para evitar el sobreajuste; coef0 es grande para evitar el subajuste.
Cuanto mayor sea gamma , menor será el área afectada por el vector de soporte, mayor será la complejidad del modelo y es fácil sobreajustarlo; cuanto menor sea gamma, más suave será el límite de decisión, menor será la complejidad del modelo y es fácil de desmontar.
Parámetros del núcleo : función del núcleo lineal 'lineal'
Función kernel polinomial 'poly'
Función de kernel de base radial 'rbf'
función del núcleo sigmoide 'sigmoide'
resultado de la operación: