from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
print(faces.target_names)
print(faces.images.shape)
['Ariel Sharon' 'Colin Powell' 'Donald Rumsfeld' 'George W Bush'
'Gerhard Schroeder' 'Hugo Chavez' 'Junichiro Koizumi' 'Tony Blair']
(1348, 62, 47)
fig, ax = plt.subplots(3, 5)
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='bone')
axi.set(xticks=[], yticks=[],
xlabel=faces.target_names[faces.target[i]])

- El tamaño de cada figura es [62 × 47]
- Aquí ponemos cada píxel como una característica, pero esta característica demasiado, con reducción de la dimensión PCA
from sklearn.svm import SVC
#from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
model = make_pipeline(pca, svc)
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,
random_state=40)
Rejilla de búsqueda para seleccionar el parámetro
from sklearn.model_selection import GridSearchCV
param_grid = {'svc__C': [1, 5, 10],
'svc__gamma': [0.0001, 0.0005, 0.001]}
grid = GridSearchCV(model, param_grid)
%time grid.fit(Xtrain, ytrain)
print(grid.best_params_)
Tiempo de pared: 51,5 s
{ 'svc__C': 5 'svc__gamma': 0.001}
model = grid.best_estimator_
yfit = model.predict(Xtest)
yfit.shape
(337,)
Comprobar los resultados del pronóstico
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],
color='black' if yfit[i] == ytest[i] else 'red')
fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14);

from sklearn.metrics import classification_report
print(classification_report(ytest, yfit,
target_names=faces.target_names))
- Precisión (precisión) = número de predicción correcta (TP) / el número de predijo correctamente (TP + FP)
- Recall (recuerdo) = el número de predicción correcta (TP) / el número de predicción (TP + FN)
- F1 = 2 la exactitud de la tasa de Sensibilidad / (+ exactitud de recordatorio)
precision recall f1-score support
Ariel Sharon 0.50 0.50 0.50 16
Colin Powell 0.69 0.81 0.75 54
Donald Rumsfeld 0.83 0.85 0.84 34
George W Bush 0.94 0.88 0.91 136
Gerhard Schroeder 0.72 0.85 0.78 27
Hugo Chavez 0.81 0.72 0.76 18
Junichiro Koizumi 0.87 0.87 0.87 15
Tony Blair 0.85 0.76 0.80 37
avg / total 0.83 0.82 0.82 337
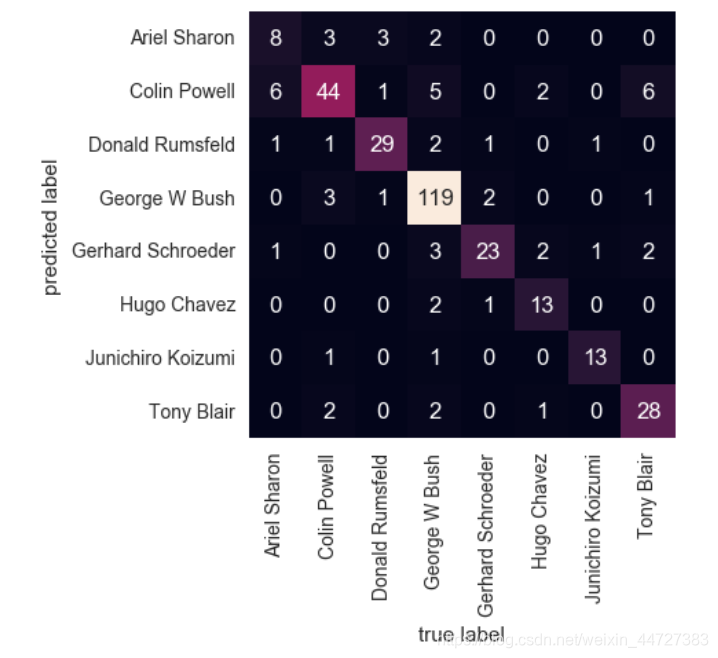
matriz de caos (ver quién es más probable que sea confundido)
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(ytest, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');