¡Haz una fortuna con tu pequeña mano, dale un pulgar hacia arriba!
Introducción a la puntuación de F1
En este artículo [1] , aprenderá sobre los puntajes de F1. La puntuación F1 es una métrica de aprendizaje automático que se puede utilizar para modelos de clasificación. Aunque existen muchas métricas para los modelos de clasificación, a través de este artículo aprenderá cómo se calcula el puntaje F1 y cuándo tiene valor agregado.
La puntuación f1 es una sugerencia de mejora con respecto a dos métricas de rendimiento más simples. Entonces, antes de profundizar en los detalles del puntaje F1, demos una descripción general de las métricas detrás del puntaje F1.
Exactitud
La precisión es una métrica para los modelos de clasificación que mide el número de predicciones correctas como porcentaje del número total de predicciones realizadas. Por ejemplo, si sus predicciones son correctas el 90 % de las veces, entonces tiene una precisión del 90 %.
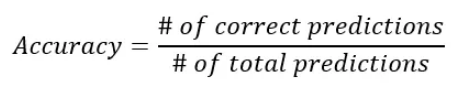
La precisión es solo una métrica útil si las clases en su clasificación están distribuidas uniformemente. Esto significa que si tiene un caso de uso en el que observa más puntos de datos para una clase que para otra, la precisión ya no es una métrica útil. Veamos un ejemplo para ilustrar esto:
Ejemplo de datos desequilibrados
Supongamos que está trabajando con datos de ventas para su sitio web. Usted sabe que el 99% de los visitantes del sitio web no compran y solo el 1% de los visitantes compran. Está creando un modelo de clasificación para predecir qué visitantes del sitio web son compradores y cuáles son solo navegadores.
Ahora imagina un modelo que no funciona bien. Predice que el 100% de los visitantes son solo espectadores y el 0% son compradores. Este es claramente un modelo muy equivocado e inútil.
❝La precisión no es una buena métrica cuando tienes un desequilibrio de clases.
❞
¿Qué sucede si usamos la fórmula de precisión en este modelo? Su modelo predice solo un 1 % de error: todos los compradores se clasifican erróneamente como espectadores. Por tanto, el porcentaje de predicciones correctas es del 99%. El problema aquí es que el 99% de precisión suena bien, mientras que su modelo funciona mal. En resumen: la precisión no es una buena medida cuando se tiene un desequilibrio de clases.
-
Aborde los datos desequilibrados mediante el remuestreo
Una forma de lidiar con el problema del desequilibrio de clases es trabajar en sus muestras. Usando un método de muestreo específico, puede volver a muestrear un conjunto de datos de tal manera que los datos ya no estén desequilibrados. Luego puede usar la precisión como una métrica nuevamente.
-
Aborde los datos desequilibrados con métricas
Otra forma de abordar el problema del desequilibrio de clases es utilizar una mejor métrica de precisión, como la puntuación F1, que tiene en cuenta no solo la cantidad de errores de predicción del modelo, sino también los tipos de errores cometidos.
Base de la puntuación de F1
Precision y Recall son las dos métricas más comunes que tienen en cuenta el desequilibrio de clases. ¡También son la base de los resultados de la F1! Echemos un vistazo más de cerca a Precision y Recall antes de combinarlos en puntajes de F1 en la siguiente sección.
Precisión
La precisión es la primera parte de la puntuación de F1. También se puede utilizar como una métrica de aprendizaje automático independiente. Su fórmula se ve así:

Puedes interpretar esta fórmula de la siguiente manera. Entre todo lo pronosticado como positivo, la precisión calcula el porcentaje correcto:
-
Un modelo impreciso puede encontrar muchos positivos, pero su método de selección es ruidoso: también detectará falsamente muchos positivos que en realidad no son positivos. -
Un modelo preciso es muy "puro": tal vez no encuentre todos los aspectos positivos, pero los que el modelo clasifica como positivos probablemente sean correctos.
Recordar
El recuerdo es el segundo componente de la puntuación F1, aunque el recuerdo también se puede utilizar como una métrica de aprendizaje automático independiente. La fórmula de recuperación es la siguiente:
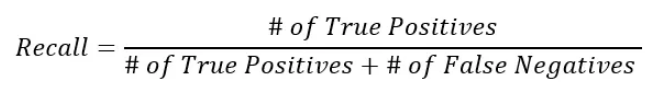
Puedes interpretar esta fórmula de la siguiente manera. De todas las cosas realmente positivas, cuánto logró encontrar el modelo:
-
Los modelos con alto recuerdo son buenos para encontrar todos los ejemplos positivos en los datos, aunque también pueden identificar incorrectamente algunos ejemplos negativos como positivos. -
Un modelo con poca memoria no logra encontrar todos (o la mayoría) de los casos positivos en los datos.
Referencia
Fuente:https://towardsdatascience.com/the-f1-score-bec2bbc38aa6
Este artículo es publicado por mdnice multiplataforma