Los vecinos de la máquina de aprendizaje Python-- filtrado colaborativo [más humorística, más fácil de entender el aprendizaje automático]
- 1. ¿Qué es vecinos de filtrado colaborativo
- 2, donde solución similar
- 2,1 filtrado colaborativo basado en la relación de similitud de usuario ilustra
- 2.2 ilustra filtrado colaborativo una relación similar entre elementos basados
- 4, los datos de colaboración Hacer filtro basado en el vecino del usuario
- 5, el extremo de los huevos de papel - fáciles momento
La máquina de aprendizaje más sobre, por favor agregue yo atención ~ ~. Para complacer a los bloggers de contactos de Gabor principal carta privada o contacto:
QQ: 3327908431
carta micro: ZDSL1542334210
Vea aquí los bienes : el aprendizaje de máquina, un sinónimo para el próximo siglo, el futuro del creador de la tecnología, creador de la inteligencia artificial. ¿Por qué es representativo de edad avanzada? Huawei Ren Zhengfei jefe dijo una vez: "la era de los grandes datos es significativo," la era del gran inteligencia artificial de datos es un aprendizaje de la máquina, y se basa en las estadísticas! Hey, no te estoy estadísticas voy a decir, no decimos que estoy fuera estadísticamente profesional.
Entonces, ¿cuál es el filtrado colaborativo? Resumirse en una frase: "Al igual que atrae como la gente en grupos." Por lo que elegir para mirar el artículo hermano Zhu! Después de todo, Zhu hermano sabía que tenía tres mil palabras, cinco años aprender a recitar poemas, pueblo famoso prodigio diez niño! Pero el tiempo es cada vez na (SOB en ...), pero, por desgracia, ah, tengo 18 años de edad (llorando ...), cómo continuar ...
1. ¿Qué es vecinos de filtrado colaborativo
Que es encontrar la similitud entre los productos y recomendaciones make E basado en la similitud. Se divide en filtrado colaborativo basado en elemento y usuario basada filtrado colaborativo. Sin rodeos, es cómo conseguir que más gente compre más artículos diferentes, también lo hacen estas dos palabras ---- están destinadas a la fabricación del dinero (que es una cosa buena, que no le gusta el dinero? Si no te gusta me puede dar! Give niños de las zonas montañosas pobres de poca ayuda ahora! datos de contacto de micro-canales en él, por supuesto, también QQ apoyo).
1.1 Artículo filtrado colaborativo basado
La explicación más simple es que ves una película como "Wolf 2", y luego otro y el sistema "Wolf 2" películas similares como "Lobo 1", "la acción del Mar Rojo" para recomendar a usted en su casa, que se basa en bienes de colaboración filtrado, abreviado como: una persona que quiere comprar más de lo mismo.
1,2 filtrado colaborativo basado en el usuario
Por ejemplo, se ve que los Cachorros, brillante hermano son buenos amigos derecha, luego soportarlo como ver una isla película "Jamaica abajo", los resultados del sistema de hacer la película "Diente de compra abajo" recomendado a la brillante hermano, esto se basa en la década de los usuarios filtrado colaborativo, abreviado como: querer recomendar algo más similar al carácter de las personas (los espectadores ver a tu personaje ellos les gustaría).
2, donde solución similar
Se calcula utilizando la distancia, la distancia entre los objetos o entre las personas en base a los datos históricos, el más cercano se puede ir a una clase, instrucciones similares. Aquí es la primera datos en tabla de dos dimensiones, con base en el usuario si está activada entre la tabla de dos dimensiones de usuario a usuario, que se convierte en el artículo correspondiente al artículo entre la tabla de dos dimensiones. Si seis de seis libros diferentes anotaron los siguientes:

Se puede ver en la tabla, cada marcador de usuario de cada libro, por lo que tenemos que hacer es averiguar el valor de la provisión de vacantes en su totalidad, y luego ser ordenados en orden descendente de acuerdo a los valores de llenado recomendadas. A continuación, estos valores nulos cómo llenarlo? Vamos a pensar en la distancia, sí, pero creemos que de la distancia euclidiana, que es un cálculo directo de la distancia. De hecho, podemos saber que cada usuario tiene datos de más de una dimensión, por lo que nuestra relación es que estos usuarios más direcciones en el espacio, más que su distancia normal, la misma dirección ilustran dos usuarios son similares. Por eso, utilizamos el coeficiente de correlación de coseno:
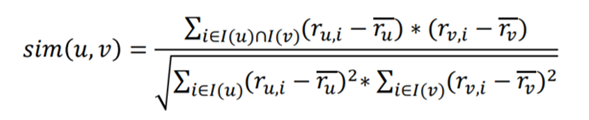
Aquí tenemos un poderoso Python que es relativamente biblioteca, así que no golpee el código a mano. Después de una tabla de dos dimensiones obtenida por el cálculo a continuación.
2,1 filtrado colaborativo basado en la relación de similitud de usuario ilustra
Son similares a la relación correspondiente entre la tabla de dos dimensiones:
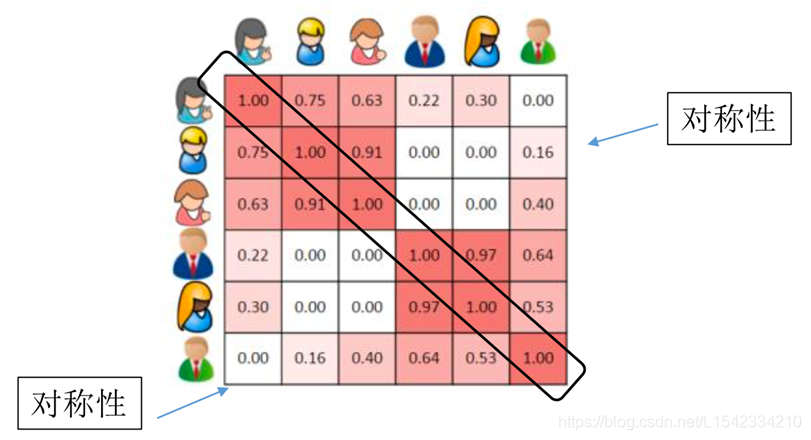
De esta manera, cada usuario puede encontrar exactamente cuántos usuarios con los más similares. El usuario puede comprar artículos similares lo recomendó a otros con usuario similar.
2.2 ilustra filtrado colaborativo una relación similar entre elementos basados
La tabla también provienen de los usuarios de las reseñas de libros, porque queremos que la perspectiva del usuario para determinar su similitud, en lugar de la similitud de los suyos, y nuestro objetivo y la visión es siempre en el cuerpo del usuario.
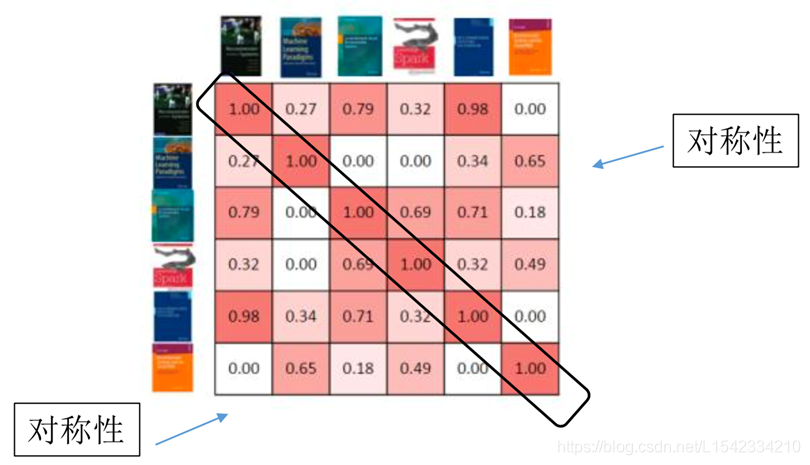
De esta manera, se pueden encontrar cada elemento y qué artículos más similares en perspectiva del usuario pocos. Podemos poner artículos similares recomendado a él.
4, los datos de colaboración Hacer filtro basado en el vecino del usuario
Los Baidu disco de la red descarga de datos ---- código de conexión de extracción: vzqi
#导包
import pandas as pd
import numpy as np
dat='example.txt' # 读入数据 该数据就是 第一张截图里面的表格数据
df = pd.read_csv(dat,header=None)
df.columns=['用户id','物品id','喜好程度'] # 修改列名
# 构建第二张截图的矩阵数据
df_pivot = df.pivot(index="用户id",columns="物品id",values="喜好程度")
freq = df_pivot.fillna(0) #将缺失值填为0
#在sklearn中有自带的余弦相似度计算函数
from sklearn.metrics.pairwise import cosine_similarity
user_similar = cosine_similarity(freq_matrix)
##画热力图来看一下,比较好看
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(user_similar,annot=True,cbar=False)
plt.show(); #热力图
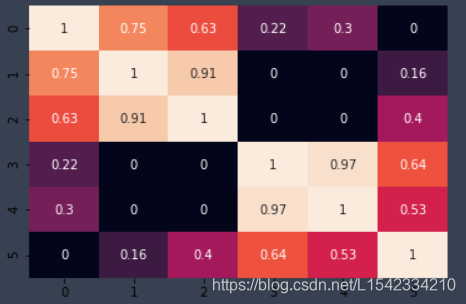
El más claro es el color, peor se representa similares.
Si usted dice que ahora queremos dar los tres primeros usuarios recomiendan el primer cálculo Cinco de los productos básicos en el marcador
user_id_action = freq_matrix[2,:] #取出第三个用户的评分向量
item_id_action = freq_matrix[:,4] #取出用户对第五个物品的评分向量
#假如说我们现在想要找出和该用户最相似的三个用户 k=3
#那么应该从这个user_similar 矩阵中提取出三个最大的值,所对应的用户
k = 3
score = 0 #用于计算评分的分子
weight = 0 #用于计算评分的分母 最终得分为 score/weight,因为给用户相似度一个权重
user_id = 2 #第三个用户
item_id = 4 #第五个用户
similar_index =np.argsort(user_similar[user_id])[::-1][1:k+1] #索引出和第三个用户相似的前三个用户
similar_index # 结果为 1,0,5 说明1,0,5在第五个物品选择上和第三位用户最相似
Calificación del usuario para calcular el promedio
debido a que el valor de la diferencia de resultados es demasiado grande, y el peso del valor de 0-1, bueno para el peso, por lo que la puntuación de la estandarización, el uso de datos estandarizados:
#构建一个基于用户和物品的推荐
def Recommendation_mean(user_id,item_id,similar,k=10):
"""减去平均数的计算方法:
user_id:输入用户ID
item_id:物品ID
similar:计算好余弦距离后的矩阵
k:以计算几个最相近的用户,默认值为10"""
score = 0
weight = 0
user_id_action = freq_matrix[user_id,:] #用户user_id 对所有商品的行为评分
item_id_action = freq_matrix[:,item_id] #物品item_id 得到的所有用户评分
user_id_similar = similar[user_id,:] #用户user_id 对所有用户的相似度
similar_index = np.argsort(user_id_similar)[-(k+1):-1] #最相似的k个用户的index(除了自己)
user_id_i_mean = np.sum(user_id_action)/user_id_action[user_id_action!=0].size# 算出平均值
for j in similar_index :
if item_id_action[j]!=0: #找到物品评分不为零的值
user_id_j_action = freq_matrix[j,:]
user_id_j_mean = np.sum(user_id_j_action)/user_id_j_action[user_id_j_action!=0].size
score += user_id_similar[j]*(item_id_action[j]-user_id_j_mean) #计算该物品的评分均值
weight += abs(user_id_similar[j]) # 得到权重
if weight==0:
return 0
else:
return user_id_j_mean + score/float(weight) #计算最终得分
Construcción de funciones de predicción, la puntuación correspondiente a cada usuario de cada artículo terminado
#构建预测函数
def predict_mean(user_similar):
"""预测函数的功能: 传入相似度矩阵, 通过对每个用户和每个物品进行计算, 计算出一个推荐矩阵"""
user_count = freq_matrix.shape[0]#用户数
item_count = freq_matrix.shape[1]#商品数
predic_matrix = np.zeros((user_count,item_count))
print(user_count)
for user_id in range(user_count):
print(user_id)
for item_id in range(item_count):
if freq_matrix[user_id,item_id] == 0:
#print (user_id,item_id)
predic_matrix[user_id,item_id] = Recommendation_mean(user_id,item_id,user_similar) #调用函数,求出每一个空值对应的分数,如果数据太大时间会很长。
return predic_matrix #返回一个填补完空值的得分表
Obtener matriz de puntuación
user_prediction_matrix = predict_mean(user_similar) #得到每一个用户对应每一个物品的分数
user_prediction_matrix

Quitar los primeros artículos recomendadas
def get_topk(group,n):
# 返回排序后的前n个值
return group.sort_values("推荐指数",ascending=False)[:n]
def get_recommendation(user_prediction_matrix,n=5):
# 将用户预测数据, 构建成一个DataFrame
recommendation_df = pd.DataFrame(user_prediction_matrix,columns=freq.columns,index=freq.index)
# 将数据进行转换
recommendation_df = recommendation_df.stack().reset_index() # reset_index重置索引stack将其行索引变成列索引
# 对列名进行修改
recommendation_df.rename(columns={0:"推荐指数"},inplace=True)
# 根据用户ID列进行分组
grouped = recommendation_df.groupby("用户id")
# 得到分组后的前几个数据
topk = grouped.apply(get_topk,n=n) #的返回值就是func()的返回值
# 删除掉用户ID列
topk = topk.drop(["用户id"],axis=1)
# 删除掉多余的索引
topk.index = topk.index.droplevel(1)
# 索引重排
topk.reset_index(inplace=True)
return topk
funciones de llamada
n=5 #取出前5个 要几个就修改这里就可以了
get_recommendatios=get_recommendation(user_prediction_matrix,n)
get_recommendatios #得到每个用户的前5个推荐的书本编号
Nota: Si lo hace un artículo basado en filtrado colaborativo cerca, simplemente df_pivot transpuesta lo que puede, como en el código, deténgase aquí.
5, el extremo de los huevos de papel - fáciles momento
Bueno todos sabemos, mi hermano es un amigo bueno Liang Wang Ming fuera de la pelea, que no es antes del día nacional de fiesta así, me preguntaba nada a su casa en busca de él para jugar, sólo dos películas, es el resultado de la misma, su padre salió y verlo jugar, dijo :. "casi 25 años de edad, todavía no hay nada, usted sabe jugar todo el día y ver Cai de otras personas con las que contó para iniciar una empresa, como la mayoría de la" brillante hermano y yo no estaba contento y replicó, dame aterrado, dijo, "lo que es tan grande como lo Ma, vistazo a la gente ..." el resultado de su padre repentinamente en silencio, mirando fijamente a él y le dijo: "la razón por la Ma poderosa, porque tiene un hijo bueno ... hay algunos buenos amigos ... energía positiva. " Así que en realidad el padre, tal hijo, él puede colgar Yeliang ruidoso, es un caso así.
Hoy a terminar aquí yo // cada artículo tiene el extremo del huevo - relajado momento yo ~ más el interés de aprender más sobre el conocimiento de aprendizaje automático! Gracias por ver, yo estaba Jetuser-datos
Enlaces: [https://blog.csdn.net/L1542334210]
CSND: L1542334210

Te deseo todo el éxito! diversión de la familia!
