Pila de tecnología de microservicios SpringCloud Seguimiento de Dark Horse 6
- el objetivo de hoy
- 1. Documento de consulta de DSL
- 2. Procesamiento de resultados de búsqueda
- 3. Documento de consulta RestClient
- 4. Caso de turismo Dark Horse
el objetivo de hoy
En el estudio de ayer, importamos una gran cantidad de datos a elasticsearch y realizamos la función de almacenamiento de datos de elasticsearch. Pero lo que mejor hace elasticsearch es la búsqueda y el análisis de datos.
Entonces, hoy, estudiemos la función de búsqueda de datos de elasticsearch. Implementaremos la búsqueda usando DSL y RestClient respectivamente.
1. Documento de consulta de DSL
Las consultas de Elasticsearch todavía se implementan en función de DSL de estilo JSON.
1.1 Clasificación de consultas DSL
Elasticsearch proporciona un DSL ( lenguaje específico de dominio ) basado en JSON para definir consultas. Los tipos de consulta comunes incluyen:
- Consultar todo : consulta todos los datos, para pruebas generales. Por ejemplo: match_all
- Consulta de búsqueda de texto completo (texto completo) : use la palabra segmentador para segmentar el contenido de entrada del usuario y luego conéctelo en la base de datos de índice invertido. Por ejemplo:
- coincidencia_consulta
- consulta_multi_coincidencia
- Consulta precisa : encuentre datos basados en valores de entrada precisos, generalmente buscando palabras clave, numéricos, de fecha, booleanos y otros tipos de campos. Por ejemplo:
- identificaciones
- rango
- término
- Consulta geográfica (geo) : consulta basada en la latitud y la longitud. Por ejemplo:
- geo_distancia
- geo_bounding_box
- Consulta compuesta (compuesto) : la consulta compuesta puede combinar las diversas condiciones de consulta mencionadas anteriormente y fusionar las condiciones de consulta. Por ejemplo:
- bool
- función_puntuación
La sintaxis de consulta es básicamente la misma:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
Tomemos la consulta all como ejemplo, donde:
- El tipo de consulta es match_all
- ninguna condición de consulta
// 查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
Otras consultas no son más que cambios en los tipos de consulta y las condiciones de consulta .
Por ejemplo:
# 查询所有
GET /hotel/_search
{
"query": {
"match_all": {
}
}
}
Resultados de la consulta:

Nota: Aunque aquí se consultan todos, básicamente se muestran 10 elementos de forma predeterminada y no se consultarán todos.
Resumen: ¿
Cuál es la sintaxis básica de la consulta DSL?
● GET /nombre de biblioteca de índice/_ búsqueda
● { "consulta": { "tipo de consulta": { "CAMPO": "TEXTO"}}}
1.2 Consulta de búsqueda de texto completo
1.2.1 Escenarios de uso
El proceso básico de consulta de búsqueda de texto completo es el siguiente:
- Segmenta el contenido de la búsqueda del usuario y obtén la entrada
- De acuerdo con la entrada que coincida en la biblioteca de índice invertido, obtenga la identificación del documento
- Encuentre el documento de acuerdo con la identificación del documento y devuélvalo al usuario
Los escenarios más comunes incluyen:
- Búsqueda en el cuadro de entrada del centro comercial
- Búsqueda de cuadro de entrada de Baidu
Por ejemplo, JD.com:

Debido a que está emparejando términos, los campos que participan en la búsqueda también deben ser campos de tipo texto que se puedan segmentar.
1.2.2 Sintaxis básica
Las consultas comunes de búsqueda de texto completo incluyen:
- consulta de coincidencia: consulta de un solo campo
- consulta de coincidencia múltiple: consulta de varios campos, cualquier campo cumple las condiciones, incluso si cumple con las condiciones de consulta, la
sintaxis de consulta de coincidencia es la siguiente: la consulta general es un campo de tipo TEXTO
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
La sintaxis de mulit_match es la siguiente:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
1.2.3 Ejemplos
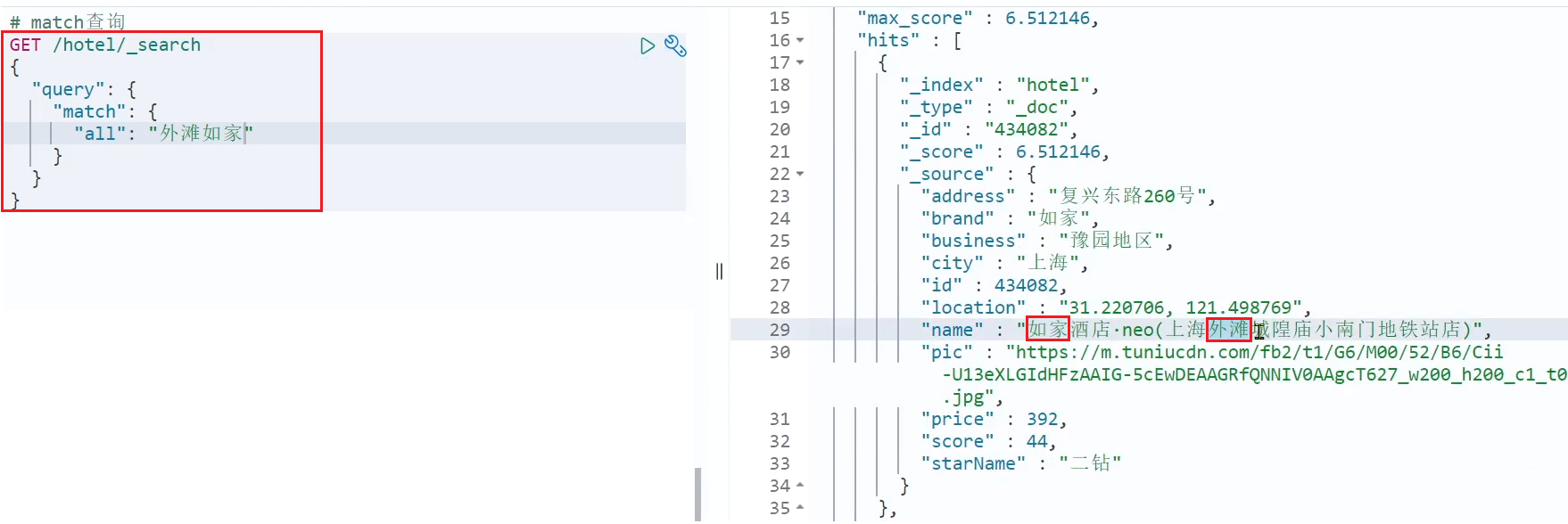
Ejemplo de consulta de coincidencia:
# match查询
GET /hotel/_search
{
"query": {
"match": {
"all": "外滩如家"
}
}
}
Ejemplo de una consulta multi_match:
# multi_match查询查询
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩如家",
"fields": ["brand","name","business"]
}
}
}
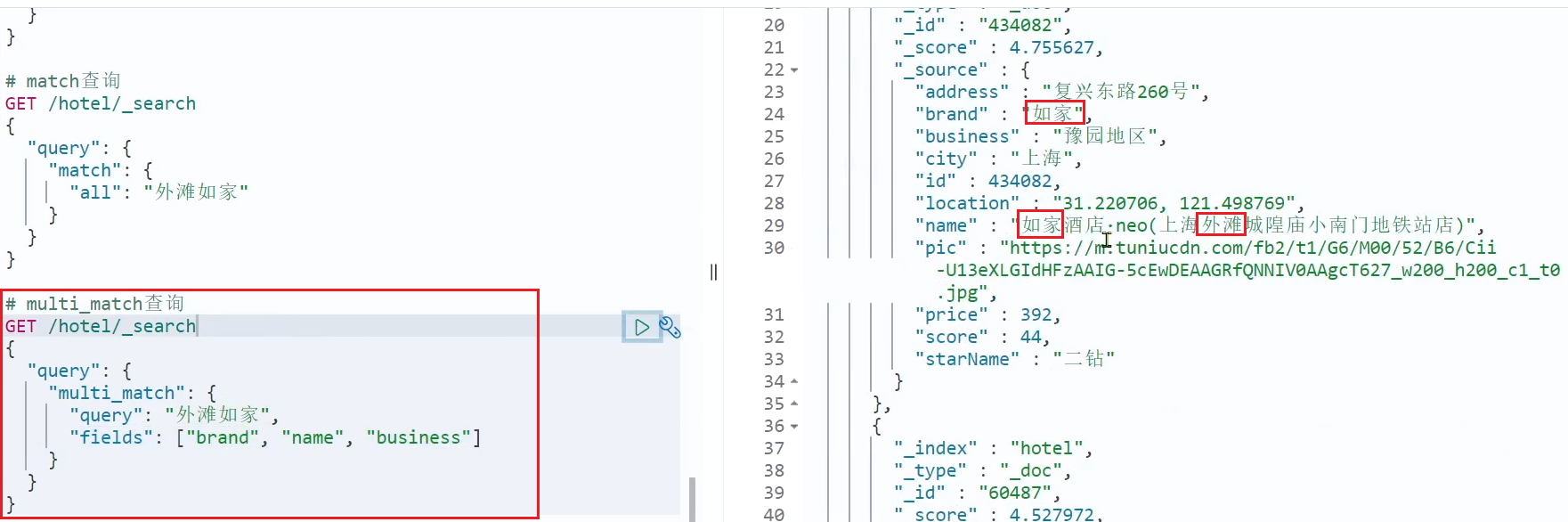
Se puede ver que los resultados de las dos consultas son iguales, ¿por qué?
Porque copiamos la marca, el nombre y los valores comerciales en el campo all usando copy_to. Por lo tanto, busca en función de tres campos y, por supuesto, el mismo efecto que buscar en todos los campos.
Sin embargo, cuantos más campos de búsqueda, mayor será el impacto en el rendimiento de la consulta, por lo que se recomienda utilizar copy_to y luego la consulta de un solo campo.
1.2.4 Resumen
¿Cuál es la diferencia entre partido y multi_partido?
- coincidencia: consulta basada en un campo
- multi_match: consulta basada en múltiples campos, cuantos más campos estén involucrados en la consulta, peor será el rendimiento de la consulta
1.3 Consulta precisa
La consulta precisa es generalmente para buscar palabras clave, valor, fecha, booleano y otros tipos de campos. Por lo tanto, no se realizará la segmentación por palabras de las condiciones de búsqueda . Además, los resultados de la búsqueda y los resultados de la consulta deben coincidir exactamente. Los más comunes son:
- term: consulta basada en el valor exacto del término
- rango: consulta basada en el rango de valores
1.3.1 Consulta de términos
Dado que el campo de búsqueda de consulta exacta es un campo sin segmentación por palabra, la condición de consulta también debe ser una entrada sin segmentación por palabra . Al consultar, solo cuando el contenido ingresado por el usuario coincide exactamente con el valor automático se considera que cumple la condición. Si el usuario ingresa demasiado contenido, los datos no se pueden buscar.
Descripción gramatical:
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
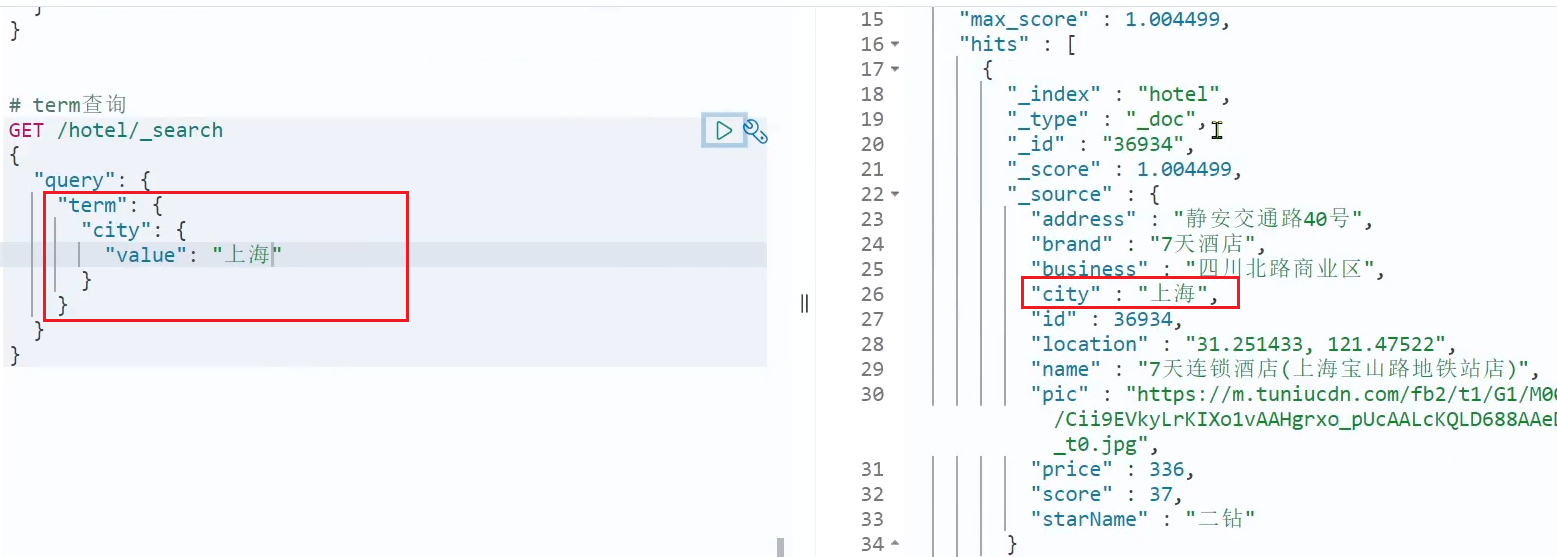
Ejemplo:
Cuando busco términos exactos, puedo consultar correctamente los resultados:
# 精确查询
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
Resultados de la consulta
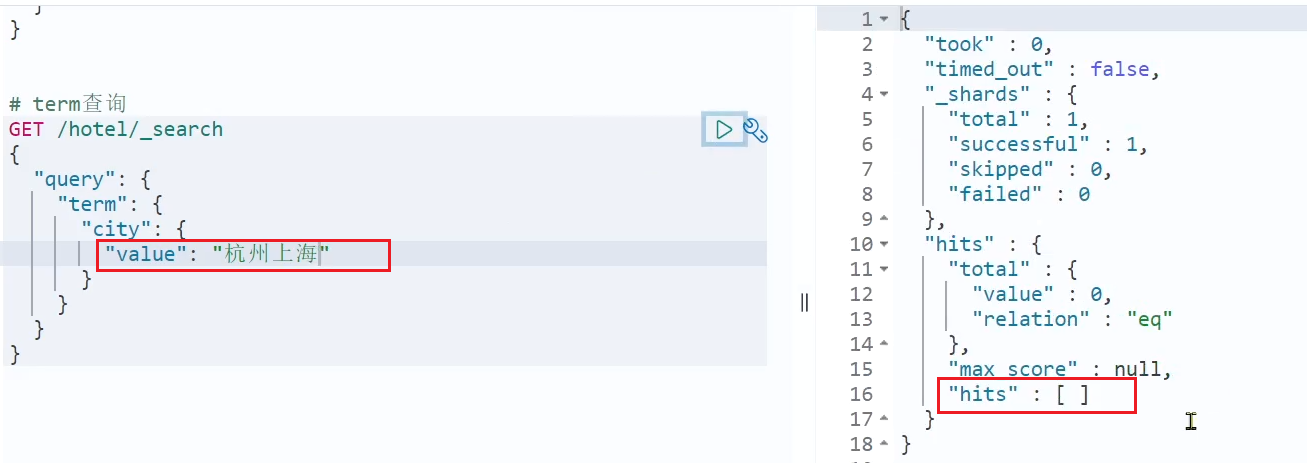
Sin embargo, cuando el contenido de mi búsqueda no es una entrada, sino una frase formada por varias palabras, no se puede buscar:
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "杭州上海"
}
}
}
}
resultado de búsqueda:
1.3.2 consulta de rango
La consulta de rango se usa generalmente cuando se realiza el filtrado de rango en tipos numéricos. Por ejemplo, realice un filtrado de rango de precios.
Sintaxis básica:
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
}
}
}
}
Ejemplo:
# 精确查询 range
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 1000,
"lte": 3000
}
}
}
}
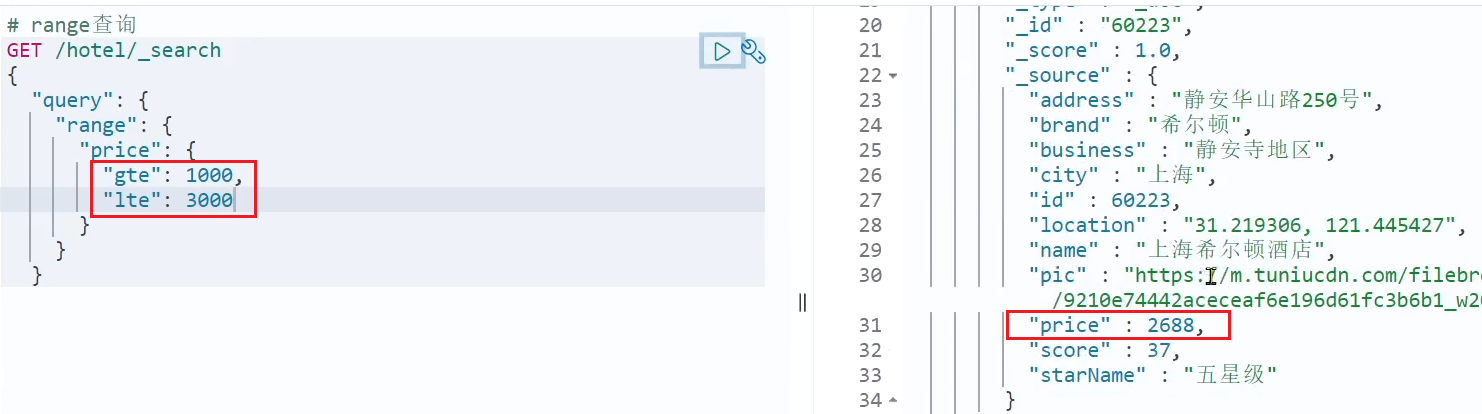
gte: mayor o igual a
lte: menor o igual a
gt: mayor o igual a
lt: menor que
1.3.3 Resumen
¿Cuáles son los tipos comunes de consulta precisa?
- Consulta de términos: coincidencia exacta basada en términos, tipo de palabra clave de búsqueda general, tipo numérico, tipo booleano, campos de tipo de fecha
- consulta de rango: consulta basada en el rango de valores, que pueden ser rangos de valores y fechas
1.4 Consulta de coordenadas geográficas
La llamada consulta de coordenadas geográficas se basa en realidad en consulta de longitud y latitud, documentos oficiales: consulta basada en longitud y latitud (documentos oficiales)
Los escenarios de uso comunes incluyen:
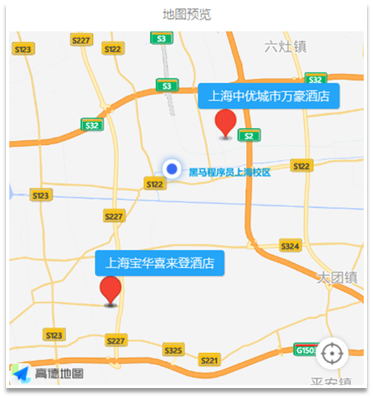
- Ctrip: Buscar hoteles cerca de mí
- Didi: Encuentra taxis cerca de mí
- WeChat: Buscar personas cerca de mí
Hoteles cercanos:
Coches cercanos:
1.4.1 Consulta de rango rectangular
La consulta de rango rectangular, es decir, la consulta geo_bounding_box, consulta todos los documentos cuyas coordenadas se encuentran dentro de un determinado rango rectangular:
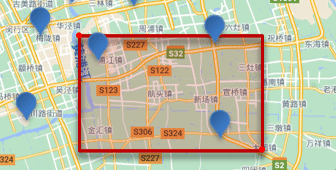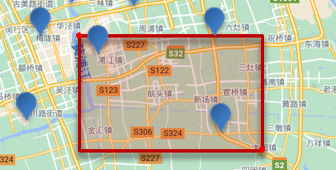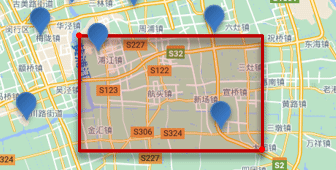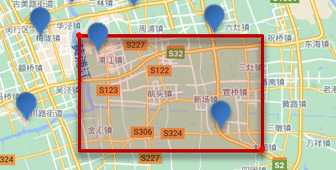
Al consultar, debe especificar las coordenadas de los puntos superior izquierdo e inferior derecho del rectángulo y luego dibujar un rectángulo, y todos los puntos que se encuentran dentro del rectángulo son puntos elegibles.
La sintaxis es la siguiente:
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
// 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
// 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
Esto no satisface las necesidades de las "personas cercanas", por lo que no lo haremos.
1.4.2 Consulta cercana
Consulta cercana, también llamada consulta de distancia (geo_distance): consulta todos los documentos cuyo punto central especificado es menor que un cierto valor de distancia.
En otras palabras, encuentre un punto en el mapa como el centro del círculo, dibuje un círculo con la distancia especificada como el radio, y las coordenadas que caen dentro del círculo se consideran elegibles: Descripción gramatical
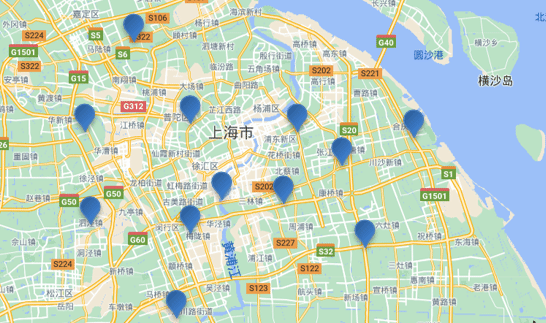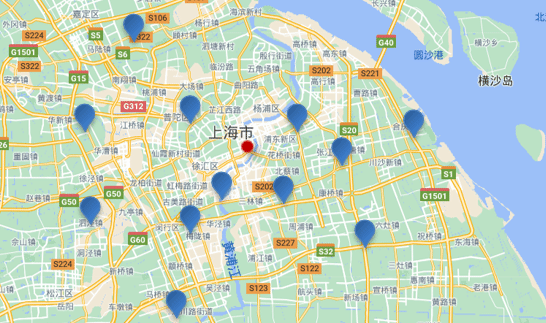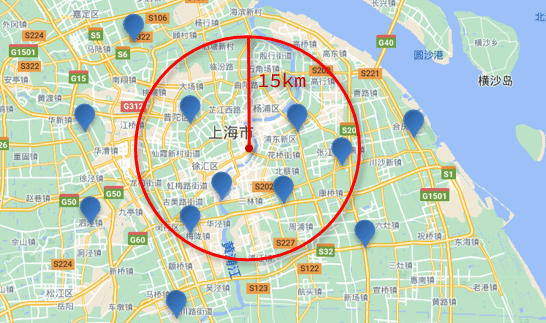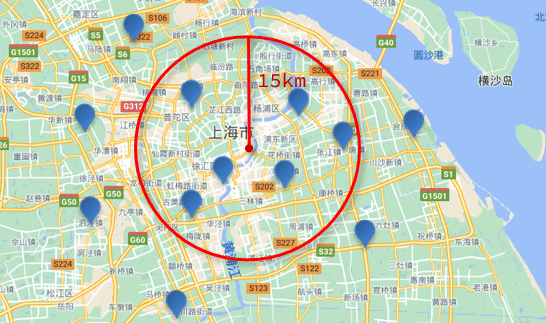
:
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
Ejemplo:
# 附近的
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance" : "15km",
"location" : "31.21,121.5"
}
}
}
Busquemos hoteles en un radio de 15 km cerca de Lujiazui:
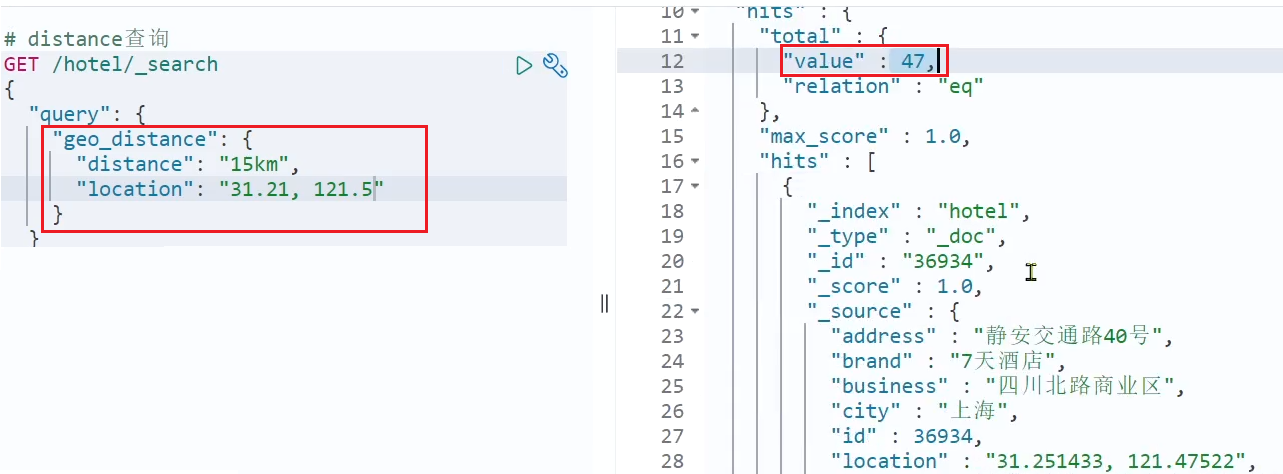
Se encontraron un total de 47 hoteles.
Luego acorte el radio a 3 km:
# 附近的
GET /hotel/_search
{
"query": {
"geo_distance":{
"distance" : "3km",
"location" : "31.21,121.5"
}
}
}
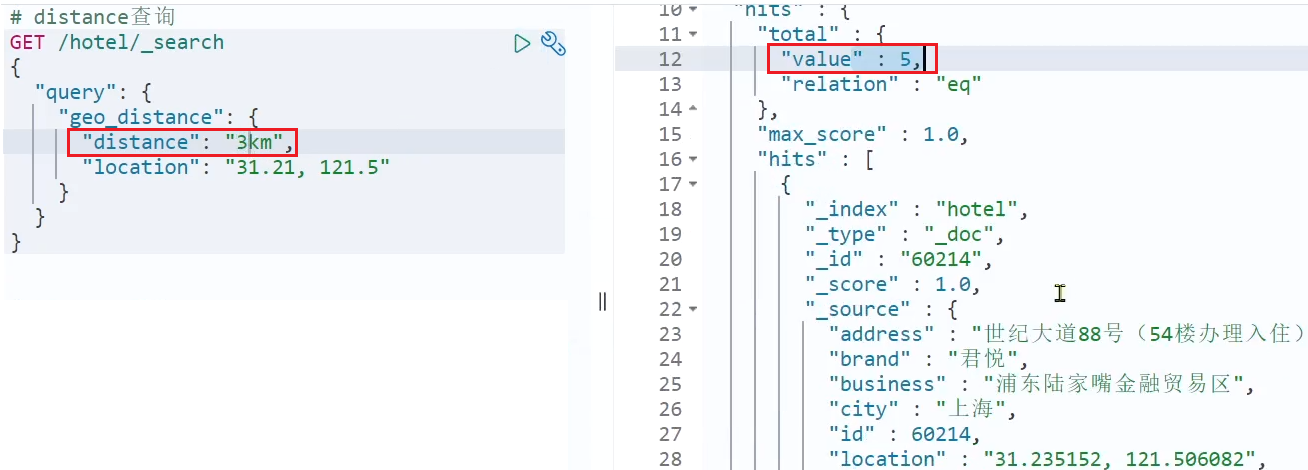
Se puede encontrar que el número de hoteles buscados se ha reducido a 5.
1.5 Consulta compuesta
Consulta compuesta: una consulta compuesta puede combinar otras consultas simples para implementar una lógica de búsqueda más compleja. Hay dos comunes:
- puntuación de función: consulta de función de cálculo, que puede controlar el cálculo de la relevancia del documento y controlar la clasificación de los documentos
- consulta booleana: consulta booleana, que utiliza relaciones lógicas para combinar varias otras consultas para lograr búsquedas complejas
1.5.1 Puntuación de correlación
Cuando usamos la consulta de coincidencia, los resultados del documento se calificarán (_score) de acuerdo con la relevancia del término de búsqueda, y los resultados devueltos se clasificarán en orden descendente de la calificación.
Por ejemplo, si buscamos "Hongqiao Home Inn", los resultados son los siguientes:
[
{
"_score" : 17.850193,
"_source" : {
"name" : "虹桥如家酒店真不错",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "外滩如家酒店真不错",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "迪士尼如家酒店真不错",
}
}
]
En elasticsearch, el algoritmo de puntuación temprana es el algoritmo TF-IDF, la fórmula es la siguiente:

En la actualización posterior de la versión 5.1, elasticsearch mejoró el algoritmo al algoritmo BM25, la fórmula es la siguiente:

El algoritmo TF-IDF tiene una falla, es decir, cuanto mayor es la frecuencia del término, mayor es la puntuación del documento y un solo término tiene un mayor impacto en el documento. Sin embargo, BM25 tendrá un límite superior para la puntuación de una sola entrada y la curva será más suave:
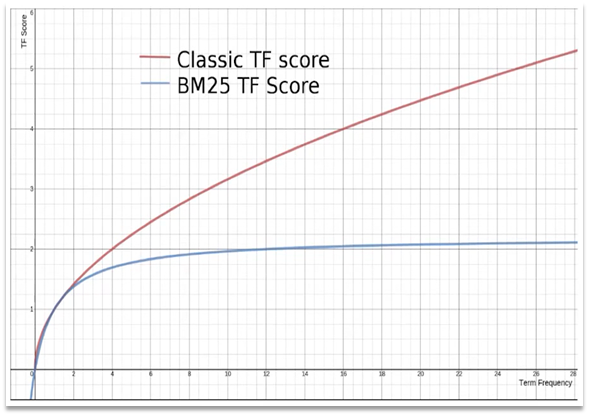
Resumen: elasticsearch puntuará según la relevancia de los términos y documentos.Hay dos algoritmos:
- Algoritmo TF-IDF
- Algoritmo BM25, el algoritmo adoptado después de la versión 5.1 de elasticsearch
1.5.2 Consulta de función de puntuación
La puntuación basada en la relevancia es un requisito razonable, pero no es necesariamente lo que necesitan los gerentes de producto .
Tomando Baidu como ejemplo, en sus resultados de búsqueda, no es que cuanto mayor sea la relevancia, mayor será la clasificación, sino que cuanto mayor sea la clasificación es para quien paga más. Como se muestra en la imagen:
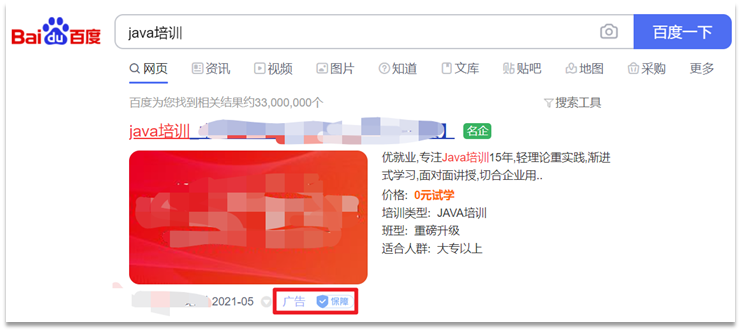
Si desea controlar el puntaje de correlación, debe usar la consulta de puntaje de función en elasticsearch .
1) Descripción gramatical
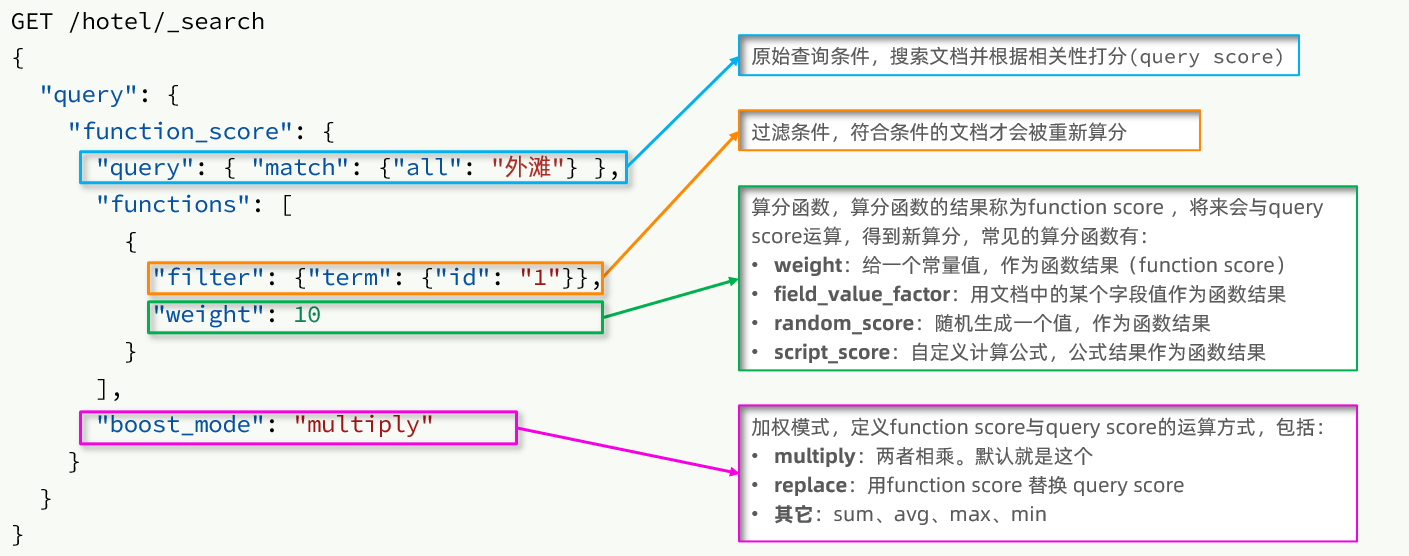
La consulta de puntuación de función consta de cuatro partes:
- Condición de consulta original : parte de consulta, búsqueda de documentos según esta condición y puntuación del documento según el algoritmo BM25, la puntuación original (puntuación de consulta)
- Condición de filtro : la parte del filtro, los documentos que cumplan esta condición serán recalculados
- Función de cálculo : los documentos que cumplen con las condiciones del filtro deben calcularse de acuerdo con esta función y el puntaje de función obtenido (puntaje de función), hay cuatro funciones
- peso: el resultado de la función es una constante
- field_value_factor: use un valor de campo en el documento como el resultado de la función
- random_score: utiliza números aleatorios como resultado de la función
- script_score: algoritmo de función de puntuación personalizado
- Modo de cálculo : el resultado de la función de cálculo, la puntuación del cálculo de correlación de la consulta original y el método de cálculo entre los dos, incluidos:
- multiplicar: multiplicar
- reemplazar: reemplazar el puntaje de la consulta con el puntaje de la función
- Otros, como: sum, avg, max, min
El proceso de operación de la puntuación de función es el siguiente:
- 1) Consultar y buscar documentos de acuerdo con las condiciones originales , y calcular la puntuación de relevancia, llamada puntuación original (puntuación de consulta)
- 2) Según las condiciones del filtro , filtre los documentos
- 3) Para los documentos que cumplen las condiciones del filtro , la puntuación de la función se obtiene a partir del cálculo de la función de puntuación
- 4) La puntuación original (puntuación de la consulta) y la puntuación de la función (puntuación de la función) se calculan en función del modo de funcionamiento y el resultado final se obtiene como una puntuación de correlación.
Así que los puntos clave aquí son:
- Condiciones de filtro: determine qué documentos tienen sus puntajes modificados
- Función de puntuación: el algoritmo para determinar la puntuación de la función
- Modo de cálculo: determine el resultado final del cálculo
2) Ejemplo
Requisitos: Clasificación más alta de los hoteles con la marca "Home Inn"
Traducir este requisito en los cuatro puntos mencionados anteriormente:
- Condición original: incierto, puede cambiar arbitrariamente
- Condición del filtro: marca = "Home Inn"
- Función de cálculo: puede ser simple y grosero, y dar directamente un resultado de cálculo fijo, peso
- Modo de operación: como la suma
Primero usemos la consulta más original para consultar hoteles cerca del Bund
# 把如家酒店排名靠前
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
}
}
}
}
Los resultados de la consulta son los siguientes: Mostrar que el Grand Hyatt Hotel está cerca del frente

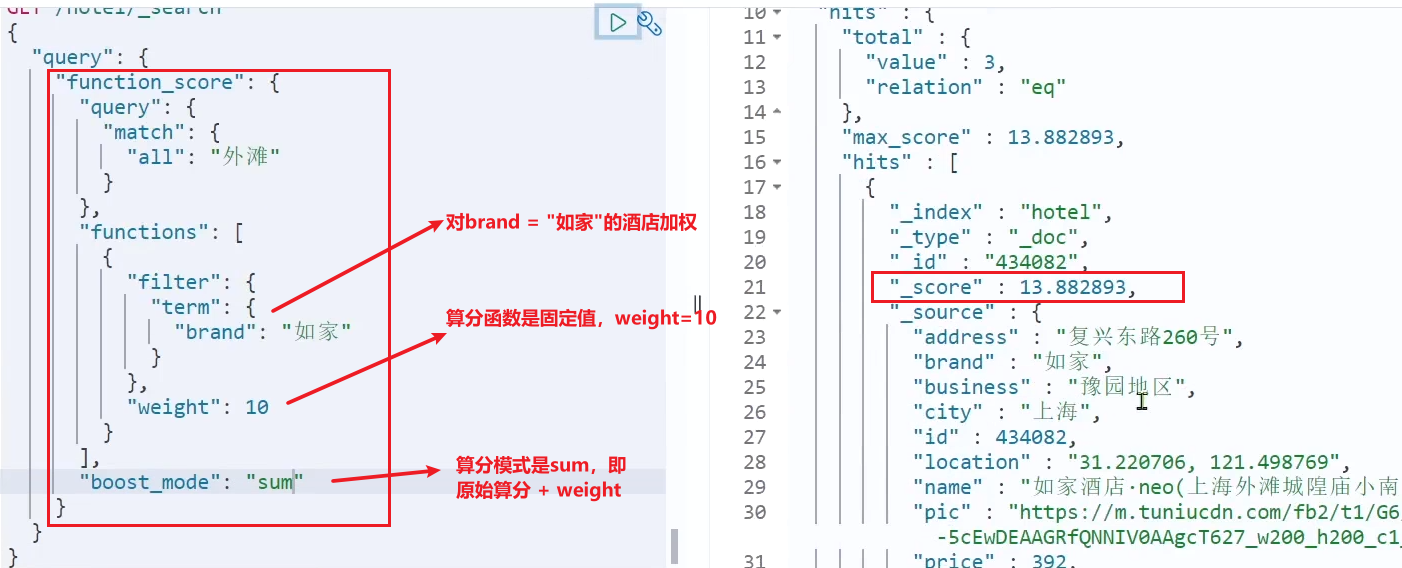
Ahora agregamos funciones
para que la declaración final de DSL sea la siguiente:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
.... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": {
// 满足的条件,品牌必须是如家
"term": {
"brand": "如家"
}
},
"weight": 2 // 算分权重为2
}
],
"boost_mode": "sum" // 加权模式,求和
}
}
}
Prueba, cuando no se agrega la función de puntaje, el puntaje de Home Inn es el siguiente:
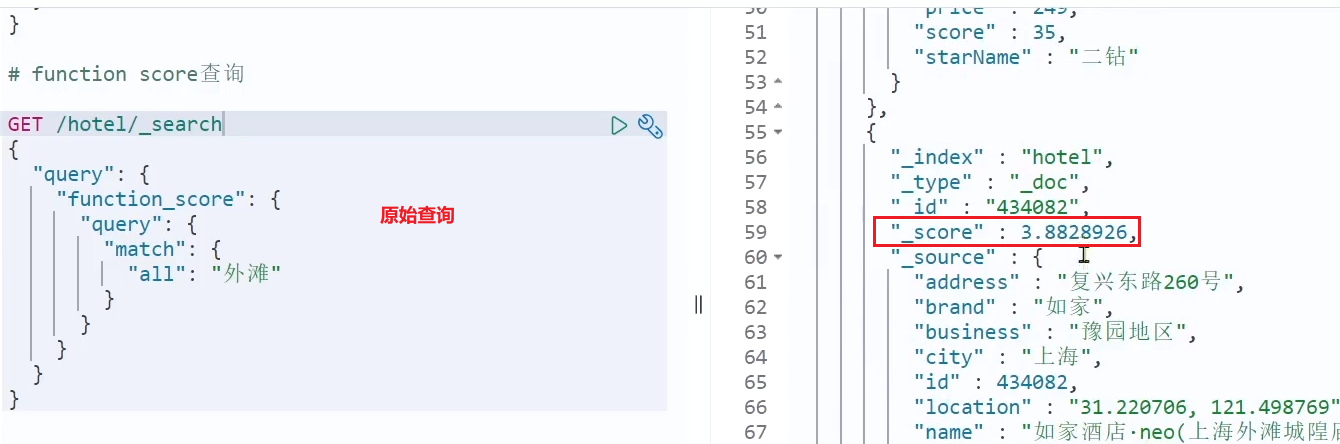
Después de agregar la función de puntaje, se mejora el puntaje de Home Inn:
3) Resumen
¿Cuáles son los tres elementos definidos por consulta de puntuación de función?
- Criterios de filtro: qué documentos deben agregarse puntos
- Función de cálculo: cómo calcular la puntuación de la función
- Método de ponderación: cómo calcular la puntuación de la función y la puntuación de la consulta
1.5.3 Consulta compuesta – Consulta booleana
Una consulta booleana es una combinación de una o más cláusulas de consulta, cada una de las cuales es una subconsulta . Las subconsultas se pueden combinar de las siguientes maneras:
- debe: debe coincidir con cada subconsulta, similar a "y"
- debería: subconsulta de coincidencia selectiva, similar a "o"
- must_not: no debe coincidir, no participa en la puntuación , similar a "no"
- filtro: debe coincidir, no participar en la puntuación
Por ejemplo, al buscar hoteles, además de la búsqueda por palabra clave, también podemos filtrar en función de campos como marca, precio y ciudad:
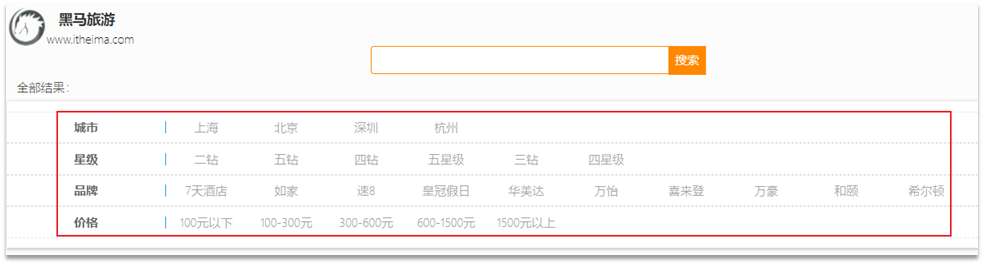
Cada campo diferente tiene diferentes condiciones y métodos de consulta, y debe ser varias consultas diferentes. Para combinar estas consultas, debe usar consultas booleanas.
Cabe señalar que al buscar, cuantos más campos participen en la puntuación, peor será el rendimiento de la consulta . Por lo tanto, se recomienda hacer esto cuando se consulta con múltiples condiciones:
- La búsqueda de palabras clave en el cuadro de búsqueda es una consulta de búsqueda de texto completo, el uso debe consultar y participar en la puntuación
- Para otras condiciones de filtro, utilice la consulta de filtro. No participar en la puntuación.
1) Ejemplo de gramática:
Consulta:
Ciudad: Shanghái
Marca: Crowne Plaza o Ramada
Precio: superior a 500, no implicado en la puntuación
Puntuación: mayor o igual a 45, no implicado en el cálculo de puntos
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"city": "上海" }}
],
"should": [
{
"term": {
"brand": "皇冠假日" }},
{
"term": {
"brand": "华美达" }}
],
"must_not": [
{
"range": {
"price": {
"lte": 500 } }}
],
"filter": [
{
"range": {
"score": {
"gte": 45 } }}
]
}
}
}
2) Ejemplo
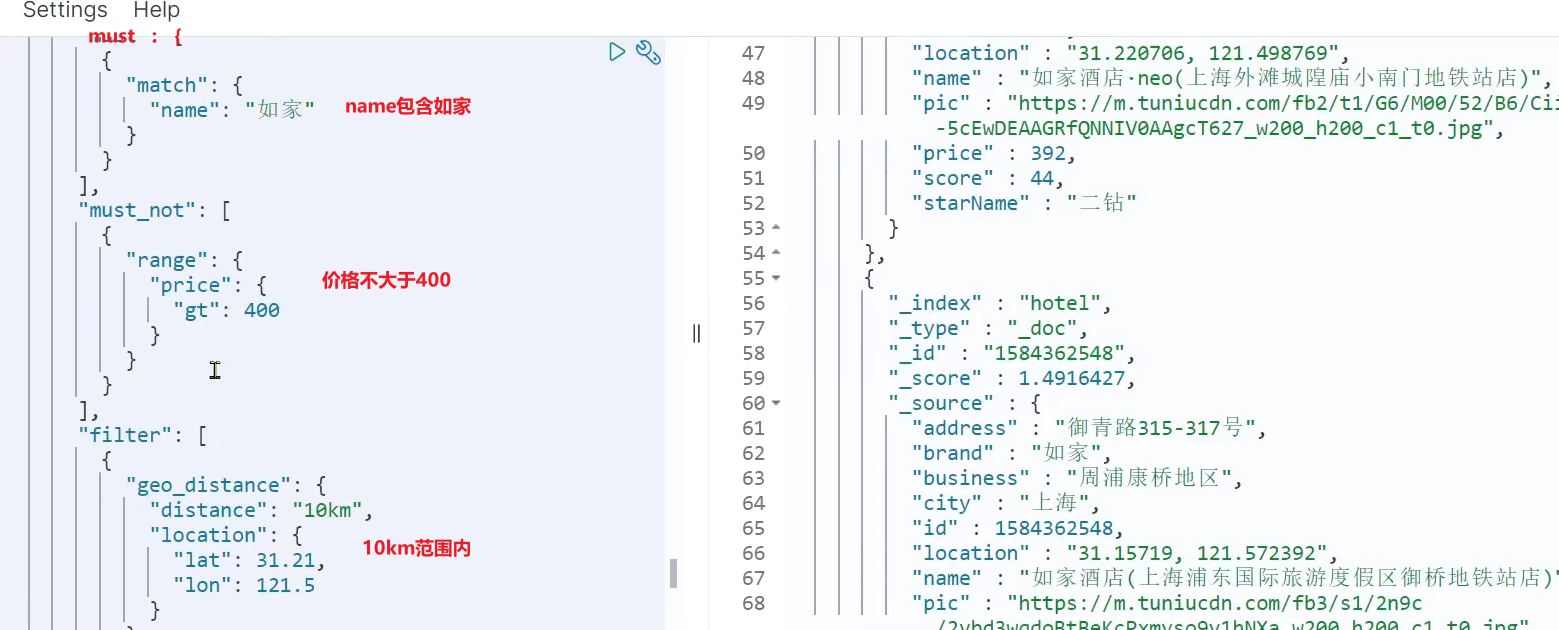
Requisito: Busque hoteles cuyo nombre contenga "Home Inn", el precio no sea superior a 400, y dentro de los 10 km alrededor de las coordenadas 31.21, 121.5.
analizar:
- La búsqueda de nombre es una consulta de búsqueda de texto completo y debe estar incluida en la puntuación. poner en debe
- Si el precio no es superior a 400, utilice el rango de consulta, que pertenece a la condición de filtro y no participa en el cálculo de puntos. poner en must_not
- Dentro del rango de 10 km, utilice geo_distance para consultar, que pertenece a la condición de filtro y no participa en el cálculo de puntos. poner en filtro
# 复合搜索--布尔查询
# 搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
Los resultados de la consulta son los siguientes:
3) Resumen
¿Cuántas relaciones lógicas tiene bool query?
- debe: condiciones que deben coincidir, puede entenderse como "y"
- debería: la condición para la coincidencia selectiva, que puede entenderse como "o"
- must_not: condiciones que no deben coincidir, no participar en la puntuación
- filtro: condiciones que deben cumplirse, no participar en la puntuación
2. Procesamiento de resultados de búsqueda
Los resultados de la búsqueda se pueden procesar o mostrar de la forma especificada por el usuario.
2.1 Clasificación
Elasticsearch clasifica según la puntuación de correlación (_score) de forma predeterminada, pero también admite formas personalizadas de clasificar los resultados de búsqueda . Los tipos de campo que se pueden ordenar incluyen: tipo de palabra clave, tipo numérico, tipo de coordenadas geográficas, tipo de fecha, etc.
2.1.1 Clasificación de campos ordinarios
La sintaxis para ordenar por palabra clave, valor y fecha es básicamente la misma.
gramática :
GET /indexName/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
La condición de clasificación es una matriz, es decir, se pueden escribir varias condiciones de clasificación. De acuerdo con el orden de declaración, cuando la primera condición es igual, ordene de acuerdo con la segunda condición, y así sucesivamente.
Ejemplo :
Descripción del requisito: los datos del hotel se ordenan en orden descendente de calificación del usuario (puntuación), y la misma calificación se ordena en orden ascendente de precio (precio). El
código es el siguiente:
# 需求描述:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"score": {
"order": "desc"
},
"price": {
"order": "asc"
}
}
]
}
resultado de búsqueda:

2.1.2 Clasificación por coordenadas geográficas
El orden de las coordenadas geográficas es ligeramente diferente.
Descripción gramatical :
GET /indexName/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
El significado de esta consulta es:
- Especificar una coordenada como el punto de destino
- Calcule la distancia desde las coordenadas del campo especificado (debe ser del tipo geo_point) hasta el punto de destino en cada documento
- Ordenar por distancia
Ejemplo:
Descripción del requisito: Realice la clasificación de los datos del hotel en orden ascendente según la distancia a las coordenadas de su ubicación
Sugerencia: la forma de obtener la latitud y la longitud de su ubicación: mapa de Gaud para obtener la latitud y la longitud
Supongamos que mi ubicación es: 31.034661, 121.612282, buscando el hotel más cercano a mi alrededor.
# 假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
GET /hotel/_search
{
"query": {
"match_all": {
}
}
, "sort": [
{
"_geo_distance": {
"location": {
"lat": 31.034661,
"lon": 121.612282
},
"order": "asc",
"unit": "km"
}
}
]
}
resultado de búsqueda:
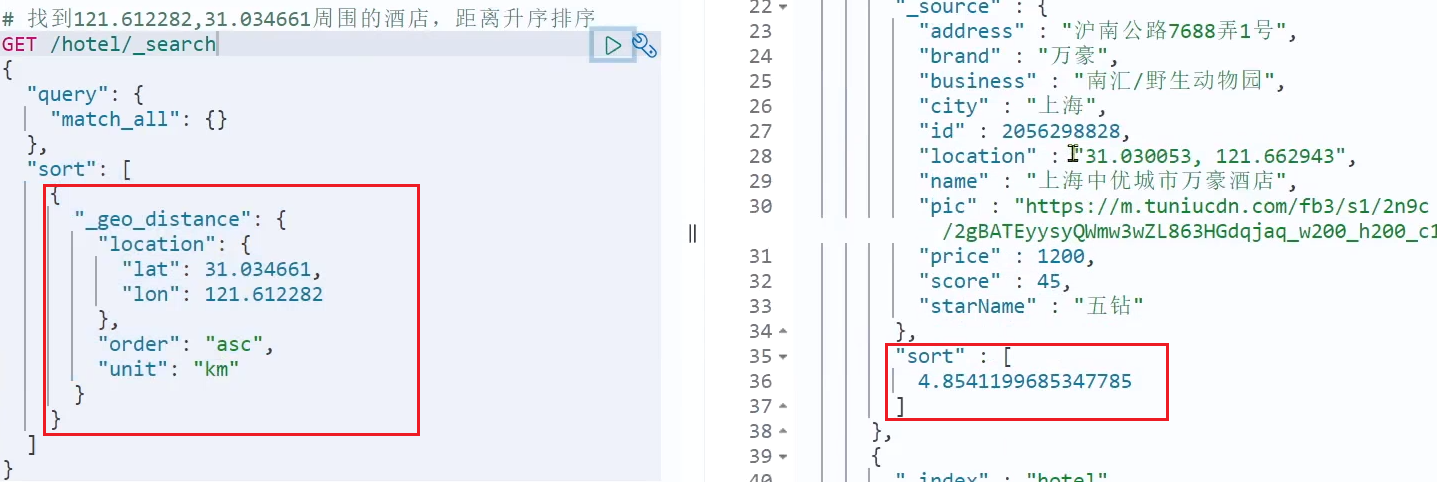
2.2 Paginación
Elasticsearch solo devuelve los 10 datos principales de forma predeterminada. Y si desea consultar más datos, debe modificar los parámetros de paginación. En elasticsearch, modifique los parámetros from y size para controlar los resultados de paginación que se devolverán:
- from: comienza desde los primeros documentos
- tamaño: cuántos documentos consultar en total
similar a mysqllimit ?, ?
2.2.1 Paginación básica
La sintaxis básica de la paginación es la siguiente:
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{
"price": "asc"}
]
}
Ejemplo: Consultar información de hoteles en las páginas 0 a 20, en orden descendente por precio
# 示例:查询0 ~ 20页的酒店信息,按照价格降序
GET /hotel/_search
{
"query": {
"match_all": {
}
}
, "sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0,
"size": 20
}
resultado de búsqueda:

2.2.2 Problema de paginación profunda
Ahora, quiero consultar los datos de 990~1000, la lógica de consulta debe escribirse de la siguiente manera:
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{
"price": "asc"}
]
}
Aquí están los datos a partir de la consulta 990, es decir, los datos 990 a 1000.
Sin embargo, al paginar dentro de elasticsearch, primero debe consultar 0~1000 entradas y luego interceptar las 10 entradas de 990~1000:
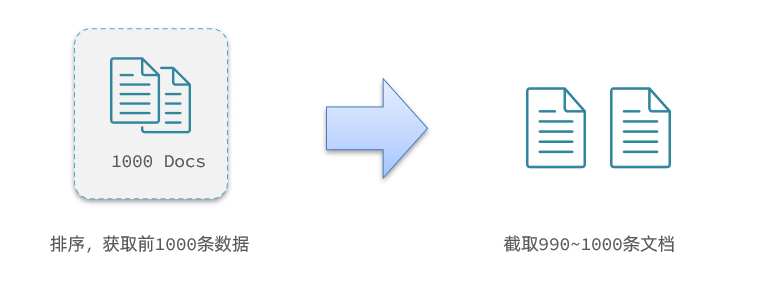
Consulta TOP1000, si es un modo de punto único, esto no tiene mucho impacto.
Pero elasticsearch debe ser un clúster en el futuro. Por ejemplo, mi clúster tiene 5 nodos y quiero consultar los datos TOP1000. No es suficiente consultar 200 elementos por nodo.
Porque el TOP200 del nodo A puede clasificarse más allá de 10 000 en otro nodo.
Por lo tanto, si desea obtener el TOP1000 de todo el clúster, primero debe consultar el TOP1000 de cada nodo. Después de resumir los resultados, vuelva a clasificar y volver a interceptar el TOP1000.
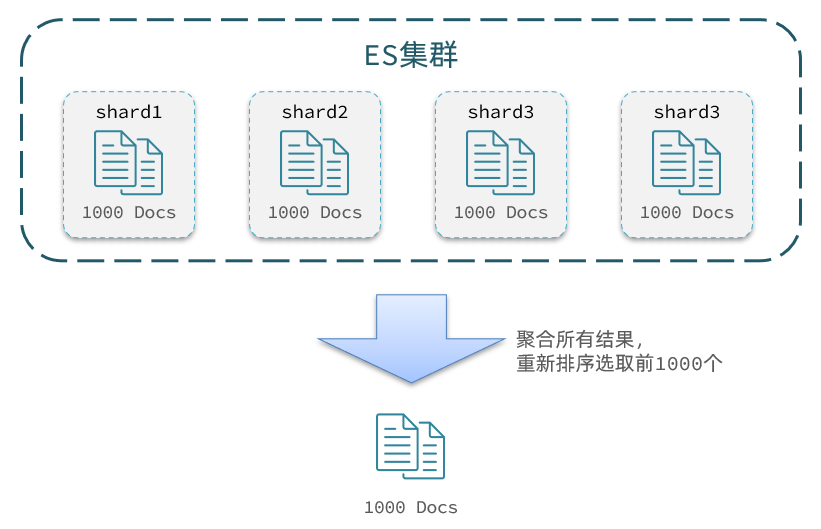
Entonces, ¿qué pasa si quiero consultar los datos de 9900~10000? ¿Necesitamos consultar TOP10000 primero? ¿Entonces cada nodo tiene que consultar 10.000 entradas? agregado en la memoria?
Cuando la profundidad de paginación de la consulta es grande, habrá demasiados datos de resumen, lo que ejercerá mucha presión sobre la memoria y la CPU. Por lo tanto, elasticsearch prohibirá las solicitudes con un tamaño from+ superior a 10 000.
Para la paginación profunda, ES proporciona dos soluciones, documentos oficiales :
- buscar después: se requiere ordenar al paginar, el principio es consultar la siguiente página de datos a partir del último valor de ordenación. La forma oficial recomendada de usar.
- scroll: el principio es formar una instantánea de los identificadores de documentos ordenados y almacenarlos en la memoria. Está oficialmente en desuso.
2.2.3 Resumen
Esquemas de implementación comunes y ventajas y desventajas de la consulta de paginación:
from + size:- Ventajas: Admite cambio de página aleatorio
- Desventajas: problema de paginación profunda, el límite superior de consulta predeterminado (desde + tamaño) es 10000
- Escenario: búsquedas aleatorias que cambian de página, como Baidu, JD.com, Google y Taobao
after search:- Ventajas: sin límite superior de consulta (el tamaño de una sola consulta no supera los 10000)
- Desventaja: solo puede consultar hacia atrás página por página, no admite el cambio de página aleatorio
- Escenario: búsqueda sin requisitos de cambio de página aleatorios, como que el teléfono móvil se desplace hacia abajo para cambiar de página
scroll:- Ventajas: sin límite superior de consulta (el tamaño de una sola consulta no supera los 10000)
- Desventajas: habrá un consumo de memoria adicional y los resultados de la búsqueda no son en tiempo real
- Escenario: Adquisición y migración de datos masivos. No se recomienda comenzar desde ES7.1 Se recomienda utilizar la solución de búsqueda posterior.
2.3 Resaltar
2.3.1 Principio de resaltado
¿Qué es resaltar?
Cuando buscamos en Baidu y JD.com, la palabra clave se volverá roja, lo que llama más la atención. A esto se le llama resaltado: la

implementación del resaltado se divide en dos pasos:
- 1) Agregue una etiqueta a todas las palabras clave del documento, como
<em>etiqueta - 2) La página
<em>escribe estilos CSS para las etiquetas.
2.3.2 Lograr el resaltado
Sintaxis resaltada :
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": {
// 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
Ejemplo: Por ejemplo, queremos destacar Home Inn
# 示例:如家显示高亮
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>"
, "post_tags": "</em>"
}
}
}
}
El resultado es el siguiente:

Aviso:
- El resaltado es para palabras clave, por lo que las condiciones de búsqueda deben contener palabras clave , no consultas de rango.
- De forma predeterminada, el campo resaltado debe ser el mismo que el campo especificado por la búsqueda ; de lo contrario, no se puede resaltar
- Si desea resaltar campos que no son de búsqueda, debe agregar un atributo: required_field_match=false
Ejemplo :
# 示例:如家显示高亮
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<em>",
"post_tags": "</em>",
"require_field_match": "false"
}
}
}
}
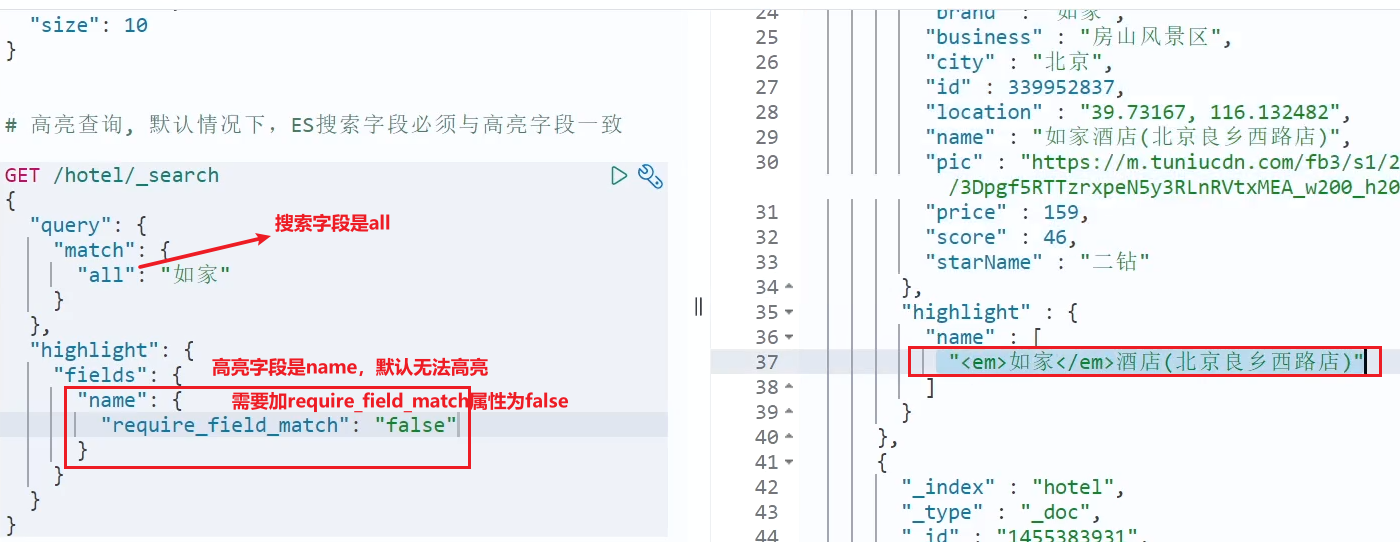
2.4 Resumen
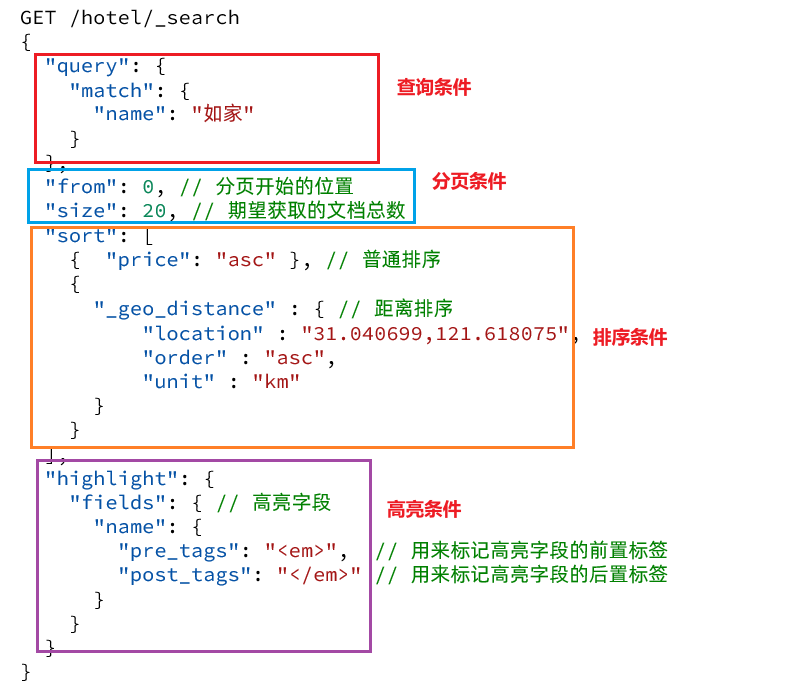
La consulta DSL es un objeto JSON grande con las siguientes propiedades:
- consulta: condición de consulta
- desde y tamaño: condiciones de paginación
- sort: condiciones de clasificación
- resaltar: resaltar la condición
Ejemplo:
3. Documento de consulta RestClient
La consulta de documentos también es aplicable al objeto RestHighLevelClient aprendido ayer. Los pasos básicos incluyen:
- 1) Preparar el objeto Solicitud
- 2) Preparar parámetros de solicitud
- 3) Iniciar una solicitud
- 4) Analizar la respuesta
3.1 Inicio rápido
Tomemos como ejemplo la consulta match_all
3.1.1 Iniciar solicitud de consulta
Interpretación del código:
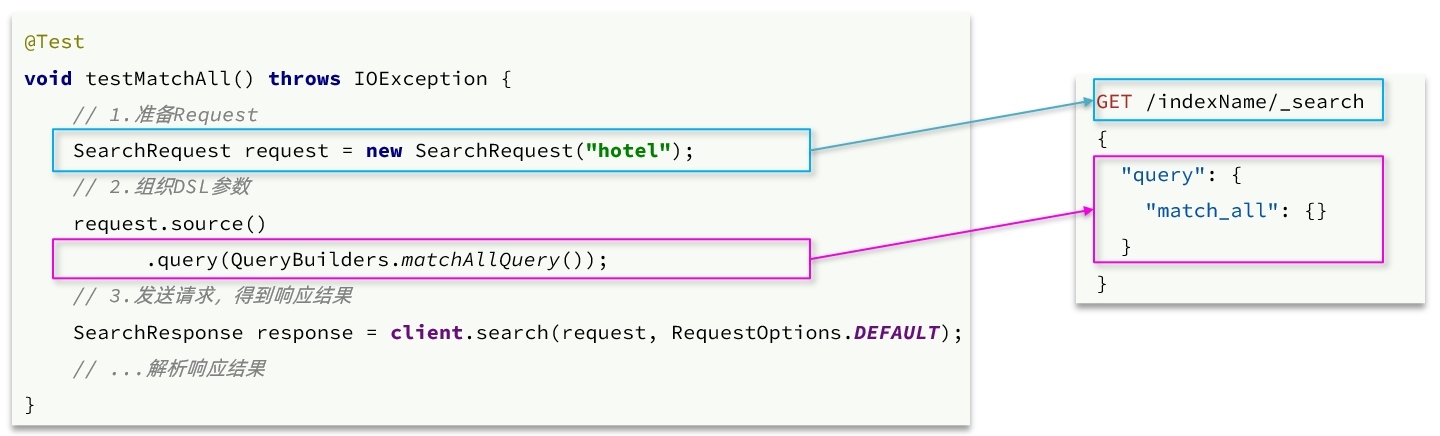
- El primer paso es crear
SearchRequestun objeto y especificar el nombre de la biblioteca de índice - El segundo paso es utilizar
request.source()la construcción de DSL, que puede incluir consulta, paginación, clasificación, resaltado, etc.query(): representa la condición de la consulta, usandoQueryBuilders.matchAllQuery()el DSL para construir una consulta match_all
- El tercer paso es usar client.search() para enviar una solicitud y obtener una respuesta.
Aquí hay dos API clave. Una es request.source()que contiene todas las funciones, como consulta, clasificación, paginación, resaltado, etc.:
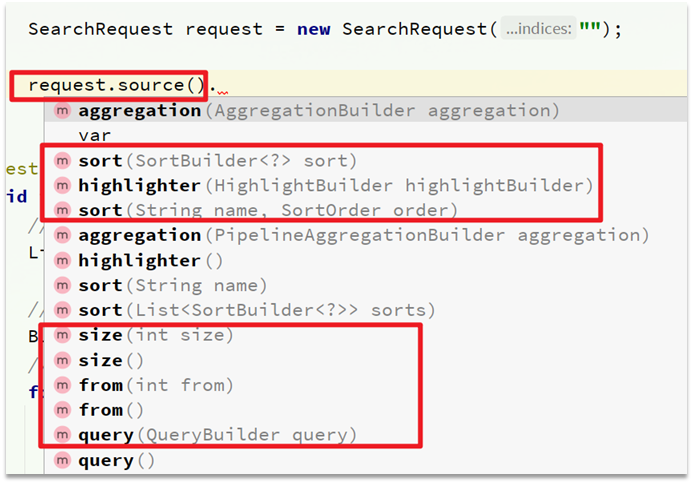
La otra es que QueryBuilderscontiene varias consultas como match, term, function_score, bool:

el código es el siguiente:
HotelSearchTest.java
/**
* DSL查询所有索引matchall
*
* @throws IOException
*/
@Test
void testMatchAll() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("结果是:" + response);
}
Compruebe el resultado después de ejecutar:

3.1.2 Análisis de la respuesta
Análisis del resultado de la respuesta:
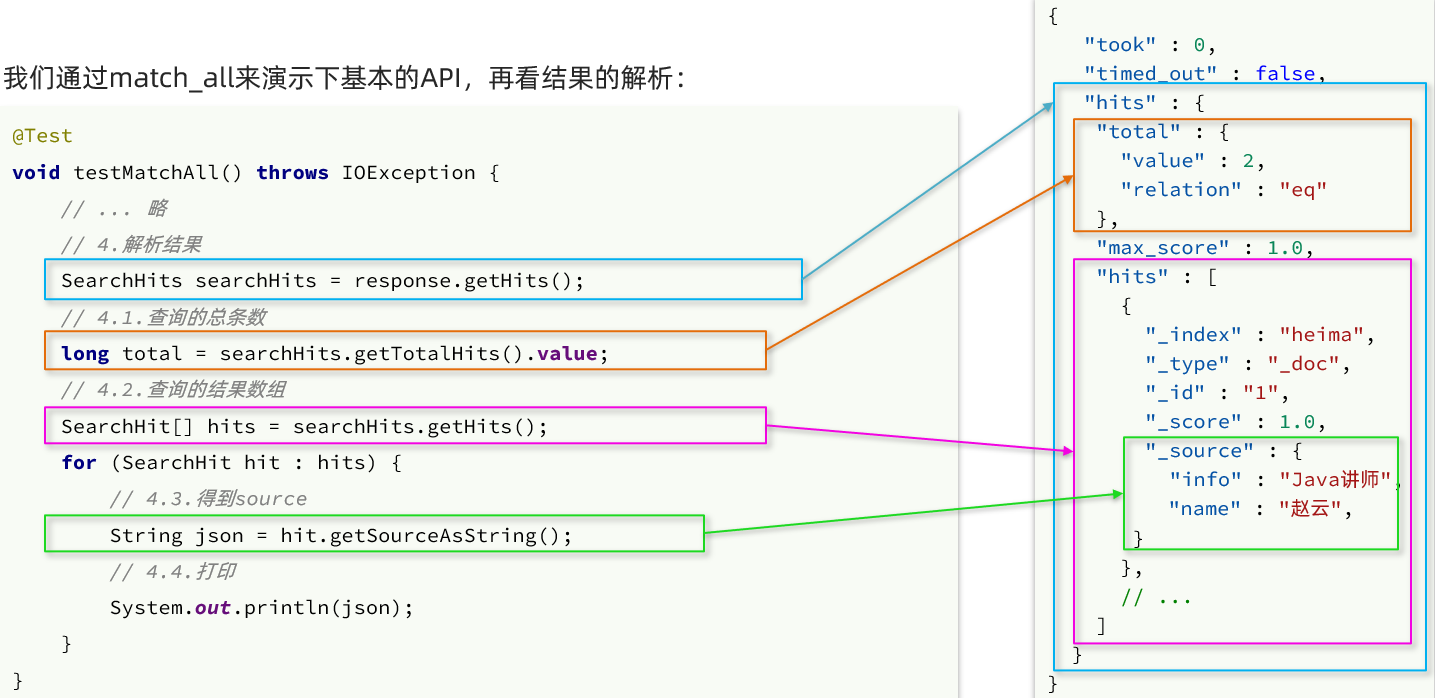
El resultado devuelto por elasticsearch es una cadena JSON, la estructura contiene:
hits: el resultado del golpetotal: El número total de entradas, donde value es el valor de entrada total específicomax_score: la puntuación de relevancia del documento con la puntuación más alta en todos los resultadoshits: una matriz de documentos para resultados de búsqueda, cada uno de los cuales es un objeto json_source: los datos originales en el documento, también un objeto json
Por lo tanto, analizamos el resultado de la respuesta, que consiste en analizar la cadena JSON capa por capa. El proceso es el siguiente:
SearchHits: Obtenido a través de response.getHits(), que son los hits más externos en JSON, que representan el resultado del hitSearchHits#getTotalHits().value: Obtener el número total de informaciónSearchHits#getHits(): obtenga la matriz SearchHit, que es la matriz de documentosSearchHit#getSourceAsString(): obtenga el _source en el resultado del documento, que son los datos del documento json original
3.1.3 Código completo
El código completo es el siguiente:
@Test
void testMatchAll() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
resultado de la operación:

3.1.4 Resumen
Los pasos básicos de una consulta son:
-
Crear un objeto SearchRequest
-
Prepare Request.source(), que es DSL.
① QueryBuilders para crear condiciones de consulta
② Pase el método query() de Request.source()
-
enviar solicitud, obtener resultado
-
Análisis de resultados (consulte los resultados de JSON, de afuera hacia adentro, analice capa por capa)
3.2 consulta de coincidencia
Las consultas de coincidencia y coincidencia múltiple de la búsqueda de texto completo son básicamente las mismas que la API de match_all. La diferencia es la condición de consulta, que es la parte de la consulta.

Por lo tanto, la diferencia en el código Java son principalmente los parámetros en request.source().query(). Utilice también el método proporcionado por QueryBuilders:

El código de análisis resultante es completamente coherente y se puede extraer y compartir.
El código completo es el siguiente:
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
Los resultados de la consulta son los siguientes:

Echemos un vistazo a múltiples coincidencias
HotelSearchTest.java
@Test
public void testMultiMatch() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.multiMatchQuery("如家", "brand", "name", "business"));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("总共有:" + total + "条");
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
El resultado es el siguiente:

3.3 Consulta precisa
Las consultas exactas son principalmente dos:
- término: término coincidencia exacta
- rango: consulta de rango
En comparación con la consulta anterior, la diferencia también está en la condición de consulta, y todo lo demás es igual.
La API para la construcción de condiciones de consulta es la siguiente:

ejemplo de término:
HotelSearchTest.java
@Test
public void testTerm() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.termQuery("city", "深圳"));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("总共有:" + total + "条");
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
Resultado de la consulta:

rango Ejemplo:
HotelSearchTest.java
@Test
public void testRange() throws IOException {
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.rangeQuery("price").gte(300));
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("总共有:" + total + "条");
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
resultado de búsqueda:

3.4 Consultas booleanas
La consulta booleana es para combinar otras consultas con must, must_not, filter, etc. El ejemplo de código es el siguiente:
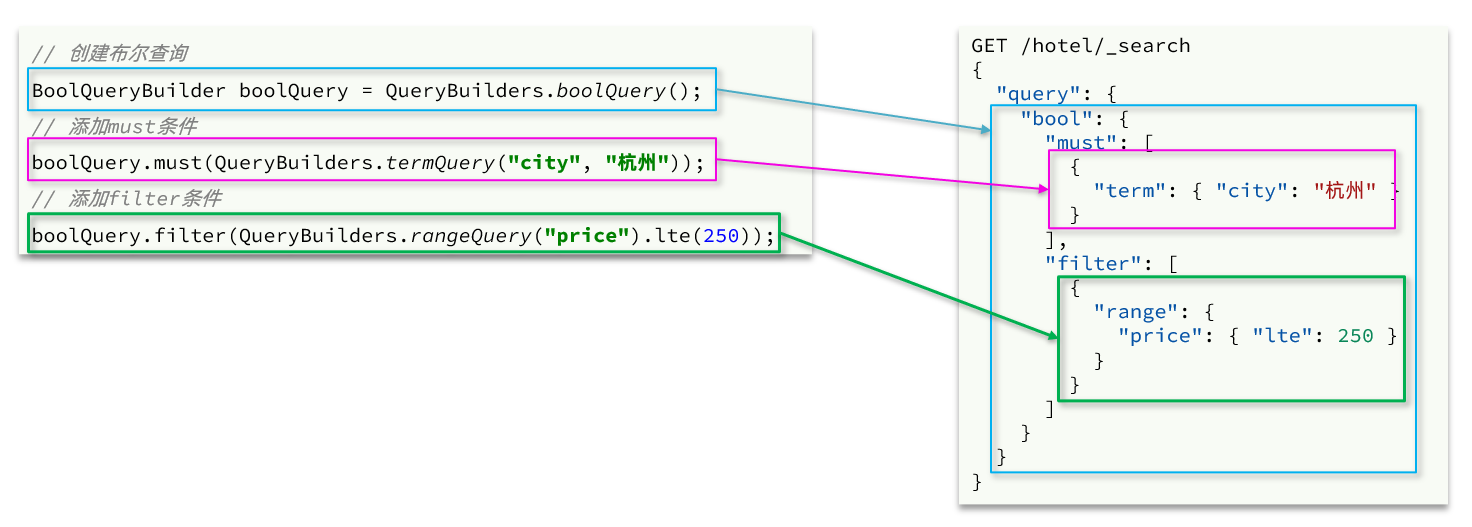
Se puede ver que la diferencia entre la API y otras consultas es que la construcción de las condiciones de la consulta, los QueryBuilders, el análisis de resultados y otros códigos permanecen completamente sin cambios.
El código completo es el siguiente:
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city", "上海"));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(350));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
resultado de búsqueda:

3.5 Clasificación, paginación
La ordenación y paginación de los resultados de la búsqueda son parámetros al mismo nivel que la consulta, por lo que también se configuran mediante request.source().
Las API correspondientes son las siguientes:

Ejemplo de código completo:
@Test
void testPageAndSort() throws IOException {
// 页码,每页大小
int page = 1, size = 5;
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort("price", SortOrder.DESC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
Resultado de la consulta: precio en orden descendente

3.6 Resaltar
El código resaltado es bastante diferente al código anterior, hay dos puntos:
- DSL de consulta: además de las condiciones de consulta, también debe agregar condiciones de resaltado, que también están al mismo nivel que la consulta.
- Análisis de resultados: además de analizar los datos del documento _source, el resultado también debe analizar el resultado resaltado
3.6.1 Creación de solicitud de resaltado
La API de construcción de la solicitud de resaltado es la siguiente:
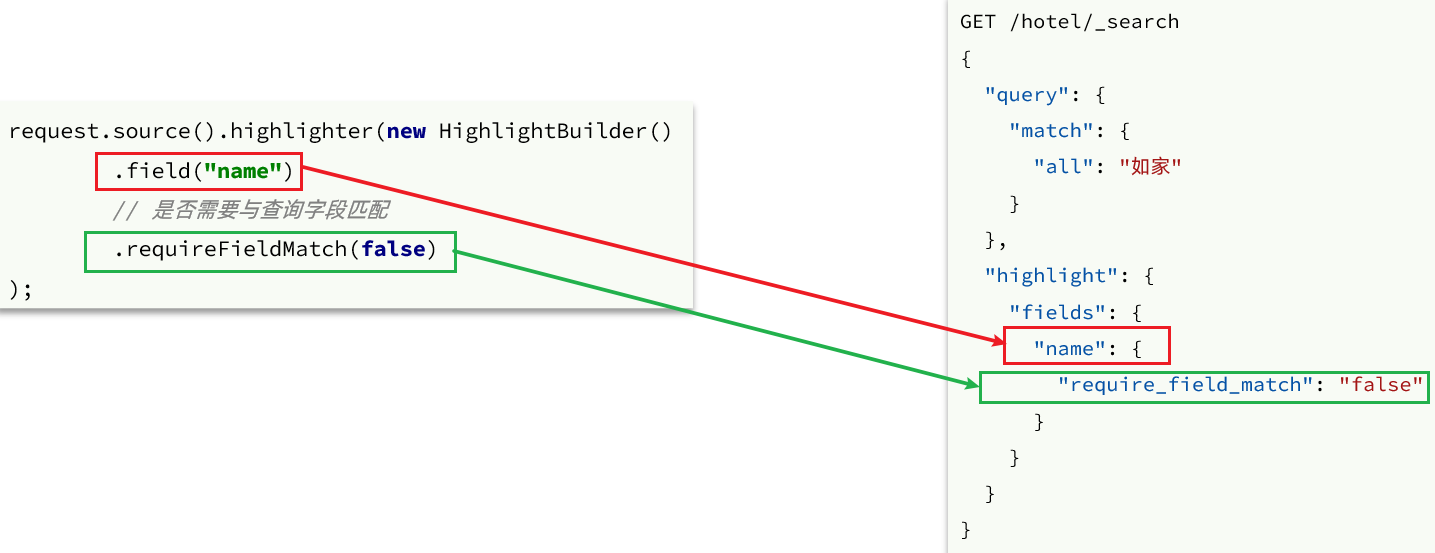
El código anterior omite la parte de la condición de la consulta, pero no olvide: la consulta resaltada debe usar búsqueda de texto completo y palabras clave de búsqueda, para que las palabras clave puedan resaltarse en el futuro.
El código completo es el siguiente:
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.6.2 Análisis de resultados destacados
Los resultados resaltados y los resultados del documento de consulta están separados por defecto y no juntos.
Por lo tanto, analizar el código resaltado requiere un procesamiento adicional:
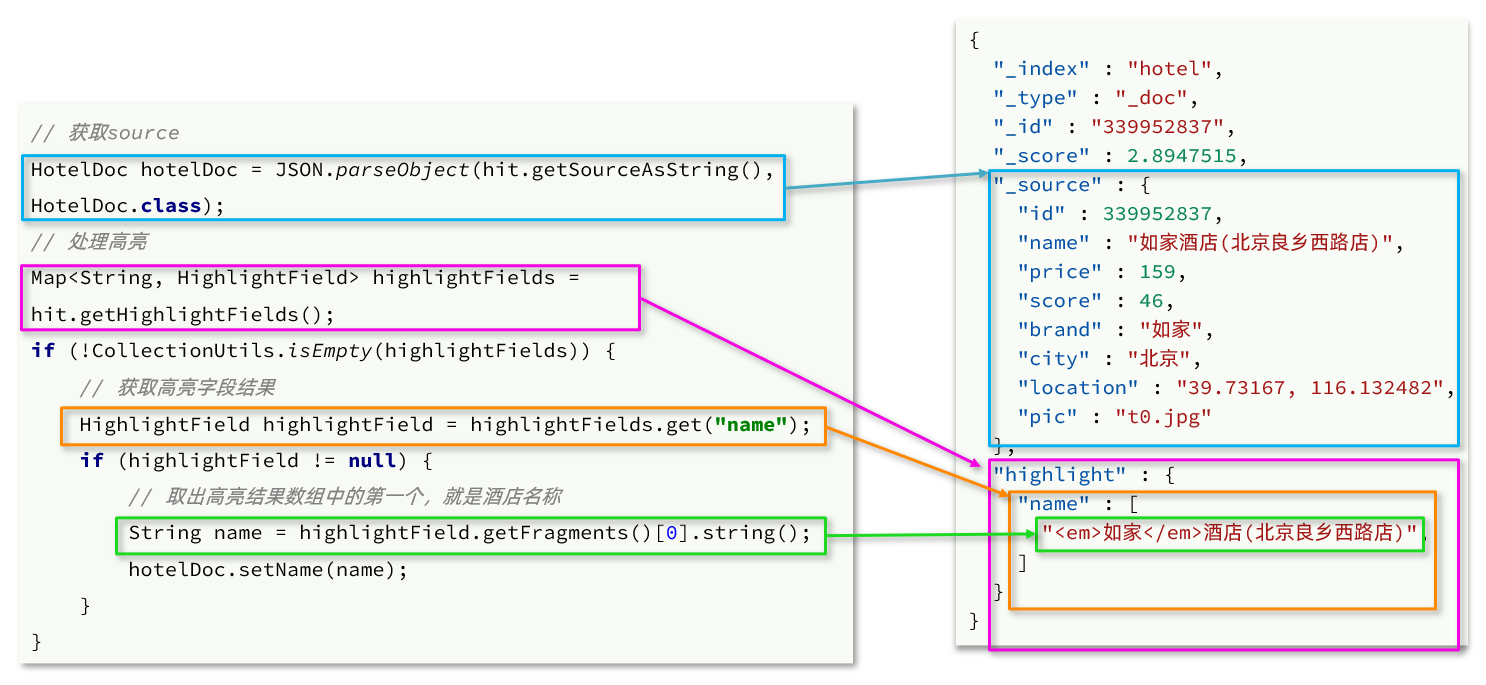
Interpretación del código:
- Paso 1: Obtener la fuente del resultado. hit.getSourceAsString(), esta parte es el resultado no resaltado, cadena json. También debe deserializarse en un objeto HotelDoc.
- Paso 2: Obtenga el resultado resaltado. hit.getHighlightFields(), el valor devuelto es un mapa, la clave es el nombre del campo resaltado y el valor es el objeto HighlightField, que representa el valor resaltado
- Paso 3: obtenga el objeto de valor de campo resaltado HighlightField del mapa de acuerdo con el nombre de campo resaltado
- Paso 4: obtenga fragmentos de HighlightField y conviértalos en cadenas. Esta parte es la cadena real resaltada
- Paso 5: Reemplace los resultados no resaltados en HotelDoc con resultados resaltados
El código completo es el siguiente:
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}
Nota: CollectionUtils.isEmpty usa los resultados de la consulta en este paquete

:

4. Caso de turismo Dark Horse
A continuación, usamos el caso del turismo de caballos oscuros para practicar los conocimientos que hemos aprendido antes.
Implementamos cuatro funciones:
- Búsqueda y paginación de hoteles
- Filtro de resultados de hoteles
- Hoteles cerca de mi
- PPC para hoteles
Inicie el proyecto de demostración de hotel que proporcionamos, su puerto predeterminado es 8089, visite http://localhost:8090, puede ver la página del proyecto:
Abra la consola con F12 y encuentre que se informa un error, porque no hay un código de solicitud de lista que no se haya perfeccionado.

4.1 Búsqueda y paginación de hoteles
Requisitos del caso: realizar la función de búsqueda de hoteles de Heima Tourism, búsqueda completa de palabras clave y paginación
4.1.1 Análisis de la demanda
En la página de inicio del proyecto, hay un gran cuadro de búsqueda y botones de paginación:
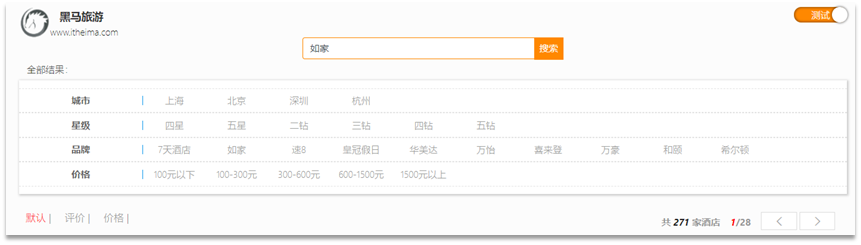
Haga clic en el botón de búsqueda y podrá ver que la consola del navegador ha realizado una solicitud:
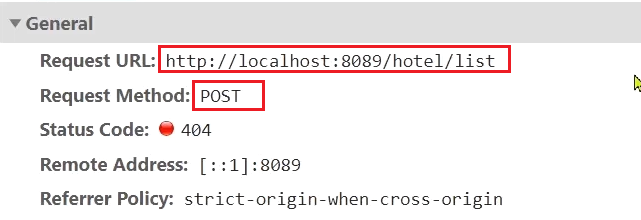
Los parámetros de la solicitud son los siguientes:

A partir de esto, podemos saber que la información de nuestra solicitud es la siguiente:
- Método de solicitud: POST
- Ruta de solicitud: /hotel/lista
- Parámetro de solicitud: objeto JSON, incluidos 4 campos:
- clave: palabra clave de búsqueda
- página: número de página
- tamaño: tamaño de cada página
- sortBy: clasificación, actualmente no implementada
- Valor de retorno: consulta de paginación, que debe devolver el resultado de paginación PageResult, que contiene dos atributos:
total: numero totalList<HotelDoc>: Datos de la página actual
Por lo tanto, nuestro proceso comercial es el siguiente:
- Paso 1: Defina la clase de entidad y reciba el objeto JSON del parámetro de solicitud
- Paso 2: escriba un controlador para recibir solicitudes de página
- Paso 3: escriba la implementación comercial, use RestHighLevelClient para realizar búsquedas y paginación
4.1.2 Definir clase de entidad
Hay dos clases de entidad, una es la entidad de parámetro de solicitud de front-end y la otra es la entidad de resultado de respuesta que el servidor debe devolver.
1) Parámetros de solicitud
La estructura json de la solicitud de front-end es la siguiente:
{
"key": "搜索关键字",
"page": 1,
"size": 3,
"sortBy": "default"
}
Por lo tanto, cn.itcast.hotel.pojodefinimos una clase de entidad bajo el paquete:
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
}
2) Valor devuelto
La consulta paginada debe devolver el resultado paginado PageResult, que contiene dos atributos:
total: numero totalList<HotelDoc>: Datos de la página actual
Por lo tanto, cn.itcast.hotel.pojodefinimos el resultado de retorno en:
package cn.itcast.hotel.pojo;
import lombok.Data;
import java.util.List;
@Data
public class PageResult {
private Long total;
private List<HotelDoc> hotels;
public PageResult() {
}
public PageResult(Long total, List<HotelDoc> hotels) {
this.total = total;
this.hotels = hotels;
}
}
4.1.3 Definir el controlador
Defina un HotelController, declare la interfaz de consulta y cumpla con los siguientes requisitos:
- Método de solicitud: Publicar
- Ruta de solicitud: /hotel/lista
- Parámetro de solicitud: objeto, de tipo RequestParam
- Valor de retorno: PageResult, que contiene dos atributos
Long total: numero totalList<HotelDoc> hotels: datos del hotel
Entonces cn.itcast.hotel.webdefinimos HotelController en:
@RestController
@RequestMapping("/hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
// 搜索酒店数据
@PostMapping("/list")
public PageResult search(@RequestBody RequestParams params){
return hotelService.search(params);
}
}
4.1.4 Realizar servicio de búsqueda
Llamamos a IHotelService en el controlador, pero no implementamos este método, por lo que definiremos el método en IHotelService e implementaremos la lógica empresarial.
1) Defina un método en la interfaz cn.itcast.hotel.serviceen :IHotelService
/**
* 根据关键字搜索酒店信息
* @param params 请求参数对象,包含用户输入的关键字
* @return 酒店文档列表
*/
PageResult search(RequestParams params);
2) Para realizar el negocio de búsqueda, RestHighLevelClient es definitivamente inseparable.Necesitamos registrarlo en Spring como Bean. Declare este frijol en cn.itcast.hotel:HotelDemoApplication
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
3) Implementar el método de búsqueda en cn.itcast.hotel.service.impl:HotelService
@Override
public PageResult search(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 2.2.分页
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 结果解析
private PageResult handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 放入集合
hotels.add(hotelDoc);
}
// 4.4.封装返回
return new PageResult(total, hotels);
}
Ver los resultados después de reiniciar SpringBoot

4.2 Filtrado de resultados de hoteles
Requisitos: agregue funciones de filtro como marca, ciudad, calificación de estrellas, precio, etc.
4.2.1 Análisis de la demanda
Debajo del cuadro de búsqueda de la página, habrá algunos elementos de filtro:
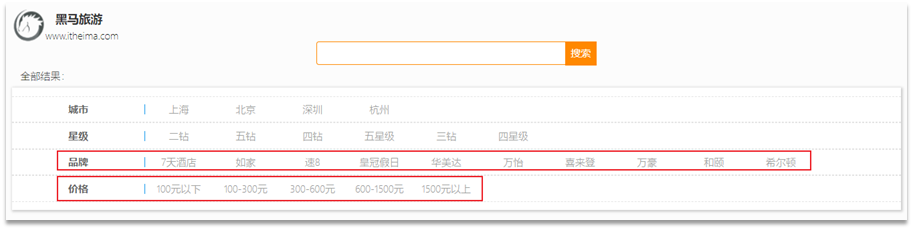
los parámetros pasados se muestran en la figura:
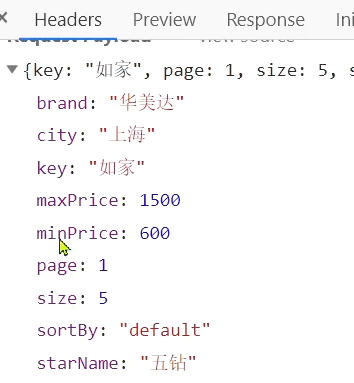
las condiciones de filtro incluidas son:
- marca: valor de marca
- ciudad: ciudad
- minPrice~maxPrice: rango de precio
- nombre estrella: estrella
Tenemos que hacer dos cosas:
- Modifique el objeto RequestParams de los parámetros de solicitud para recibir los parámetros anteriores
- Modifique la lógica de negocios y agregue algunas condiciones de filtro además de las condiciones de búsqueda
4.2.2 Modificar clase de entidad
Modifique cn.itcast.hotel.pojola clase de entidad RequestParams en el paquete:
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
// 下面是新增的过滤条件参数
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
}
4.2.3 Modificar servicio de búsqueda
En el método de búsqueda de HotelService, solo hay un lugar que debe modificarse: la condición de consulta en requet.source().query( ... ).
En el negocio anterior solo había consulta de coincidencia y se buscaba según palabras clave, ahora es necesario agregar filtrado condicional, que incluye:
- Filtrado de marcas: tipo de palabra clave, consulta por término
- Filtro de estrellas: tipo de palabra clave, consulta de término de uso
- Filtrado de precios: es de tipo numérico, consulta con rango
- Filtro de ciudad: tipo de palabra clave, consulta con término
La combinación de varias condiciones de consulta debe combinarse con consultas booleanas:
- Ponga la búsqueda de palabras clave en la necesidad y participe en el cálculo de la puntuación
- Otras condiciones de filtro se colocan en el filtro y no participan en el cálculo de puntos
Debido a que la lógica de la construcción condicional es más complicada, primero se encapsula como una función:
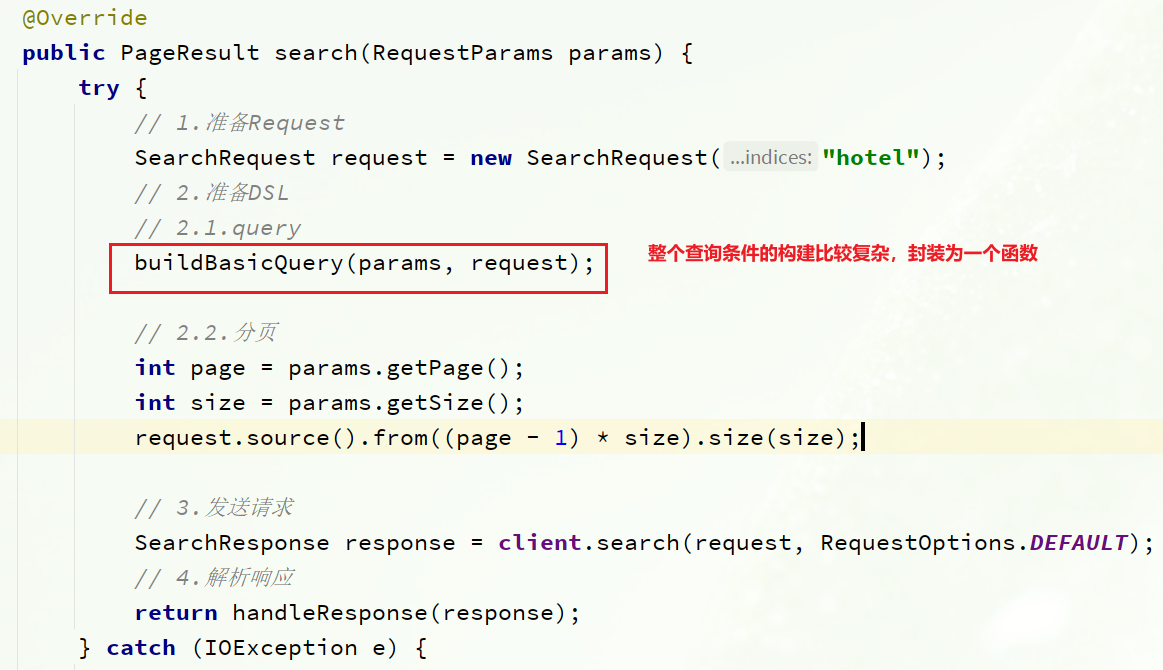
El código para buildBasicQuery es el siguiente:
private void buildBasicQuery(RequestParams params, SearchRequest request) {
// 1.构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.关键字搜索
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 3.城市条件
if (params.getCity() != null && !params.getCity().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 4.品牌条件
if (params.getBrand() != null && !params.getBrand().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 5.星级条件
if (params.getStarName() != null && !params.getStarName().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 6.价格
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQuery.filter(QueryBuilders
.rangeQuery("price")
.gte(params.getMinPrice())
.lte(params.getMaxPrice())
);
}
// 7.放入source
request.source().query(boolQuery);
}
resultado de búsqueda:

4.3 Hoteles a mi alrededor
Demanda: hoteles cerca de mí
4.3.1 Análisis de la demanda
En el lado derecho de la página de la lista de hoteles, hay un pequeño mapa, haga clic en el botón de ubicación del mapa, el mapa encontrará su ubicación:
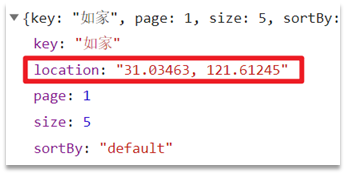
Y se iniciará una solicitud de consulta en el front-end para enviar sus coordenadas al servidor:
Lo que tenemos que hacer es ordenar los hoteles de los alrededores según la distancia en función de las coordenadas de ubicación. La idea de implementación es la siguiente:
- Modifique el parámetro RequestParams para recibir el campo de ubicación
- Modifique la lógica de negocios del método de búsqueda, si la ubicación tiene un valor, agregue la función de ordenar según geo_distance
4.3.2 Modificar clase de entidad
Modifique cn.itcast.hotel.pojola clase de entidad RequestParams en el paquete:
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
// 我当前的地理坐标
private String location;
}
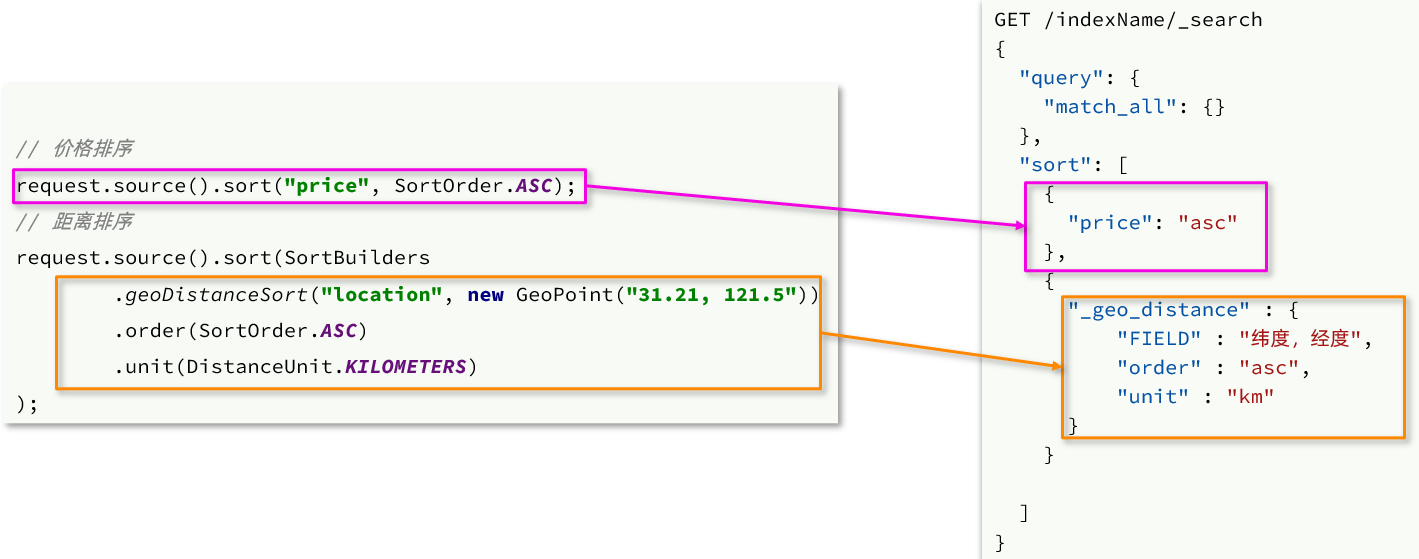
4.3.3 API de clasificación por distancia
Anteriormente hemos aprendido acerca de las funciones de clasificación, incluidos dos tipos:
- Clasificación de campos ordinarios
- Ordenar por coordenadas geográficas
Solo hablamos sobre el método de escritura de Java correspondiente a la clasificación de campos ordinarios. La clasificación de coordenadas geográficas solo ha aprendido la sintaxis DSL, de la siguiente manera:
GET /indexName/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"price": "asc"
},
{
"_geo_distance" : {
"FIELD" : "纬度,经度",
"order" : "asc",
"unit" : "km"
}
}
]
}
Ejemplo de código java correspondiente:
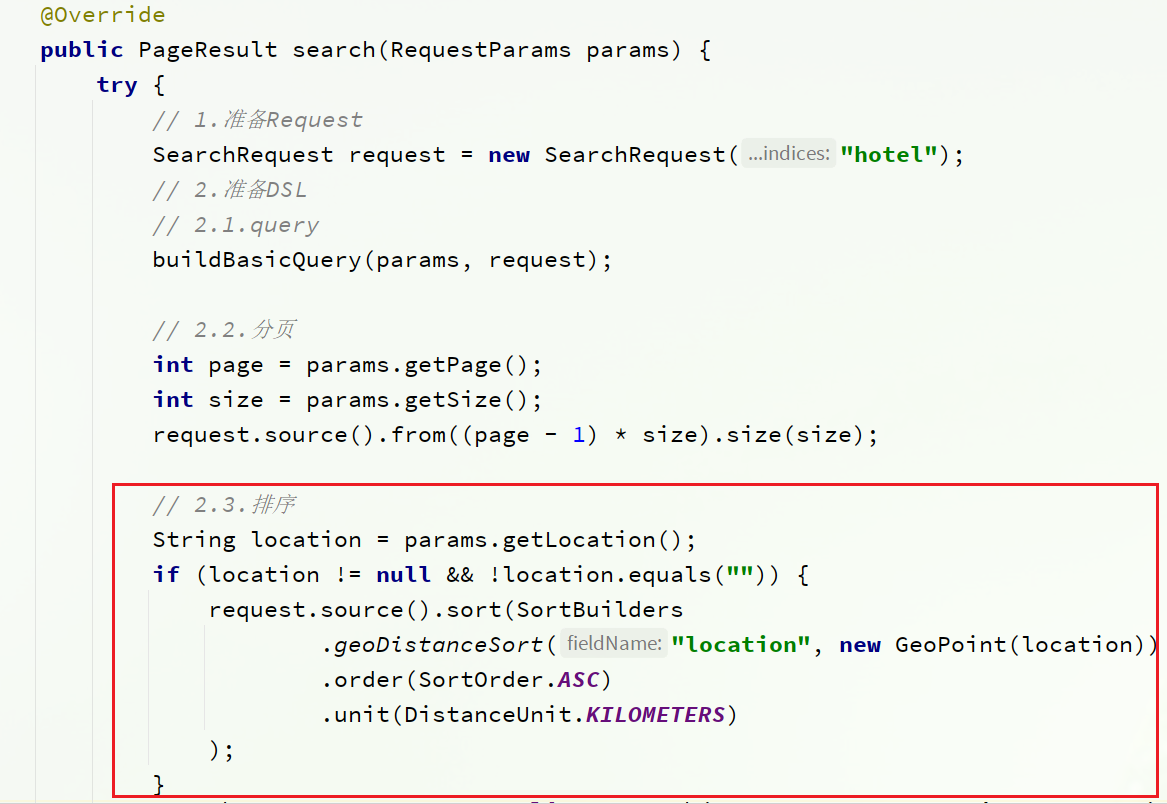
4.3.4 Agregar clasificación por distancia
En el método de cn.itcast.hotel.service.impl, agregue una función de clasificación:HotelServicesearch
Código completo:
@Override
public PageResult search(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.分页
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
// 2.3.排序
String location = params.getLocation();
if (location != null && !location.equals("")) {
request.source().sort(SortBuilders
.geoDistanceSort("location", new GeoPoint(location))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS)
);
}
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
4.3.5 Visualización de la distancia de clasificación
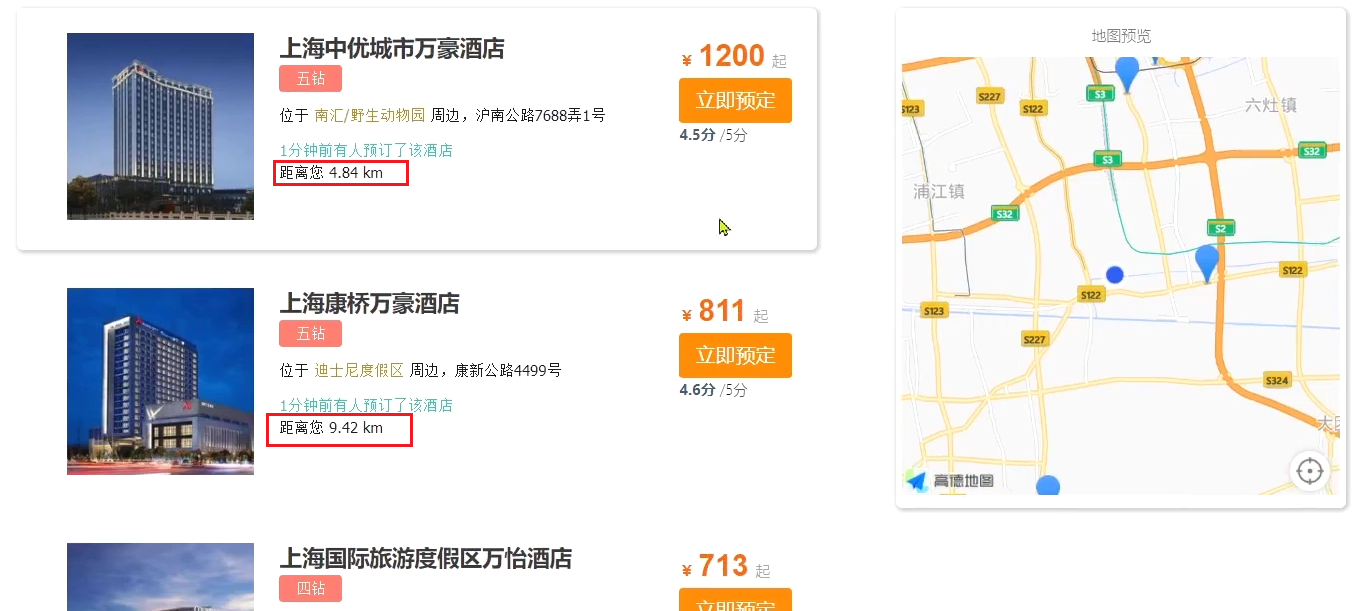
Después de reiniciar el servicio, probé la función de mi hotel:
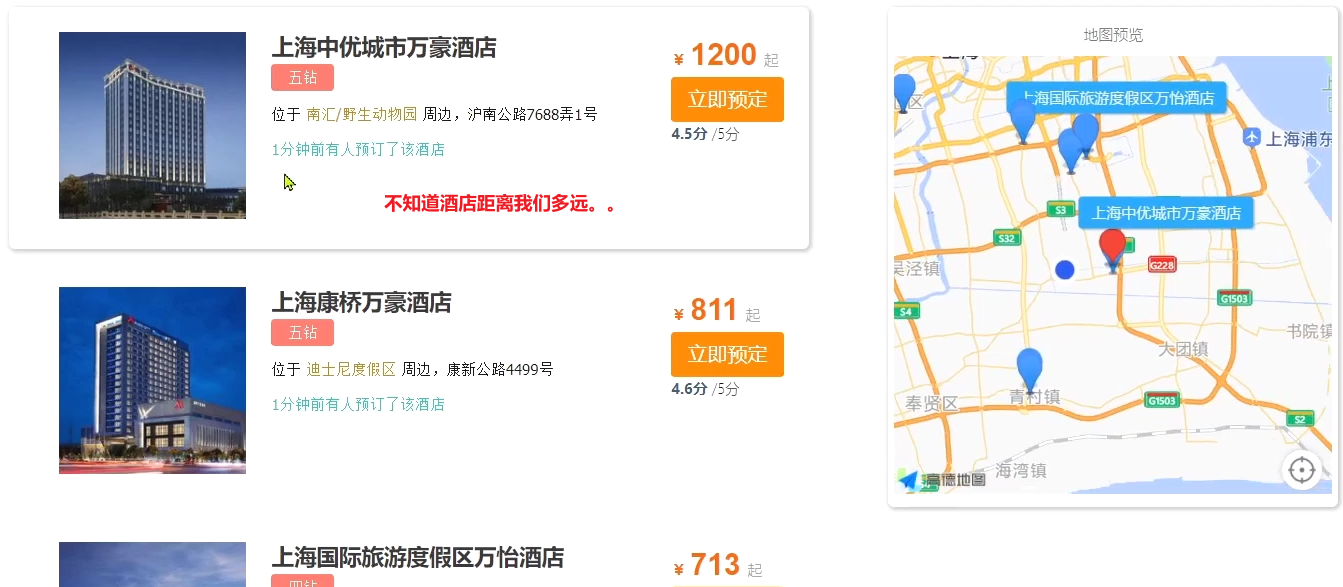
descubrí que sí es posible ordenar los hoteles cercanos a mí, pero no vi qué tan lejos está el hotel de mí. ¿Qué debo hacer?
Una vez completada la clasificación, la página también debe obtener el valor de distancia específico de cada hotel cercano, que es independiente del resultado de la respuesta:
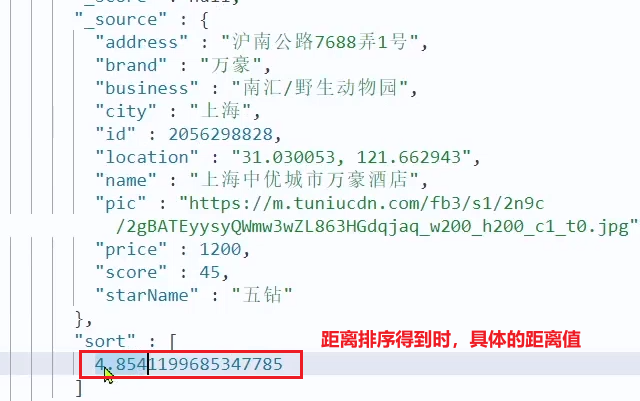
por lo tanto, en la etapa de análisis de resultados, además de analizar la parte de origen, también debemos obtenga la parte de ordenación, es decir, las distancias ordenadas se colocan en el resultado de la respuesta.
Hacemos dos cosas:
- Modifique HotelDoc, agregue un campo de distancia de clasificación para mostrar la página
- Modifique el método handleResponse en la clase HotelService para agregar la adquisición del valor de clasificación
1) Modifique la clase HotelDoc y agregue un campo de distancia
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
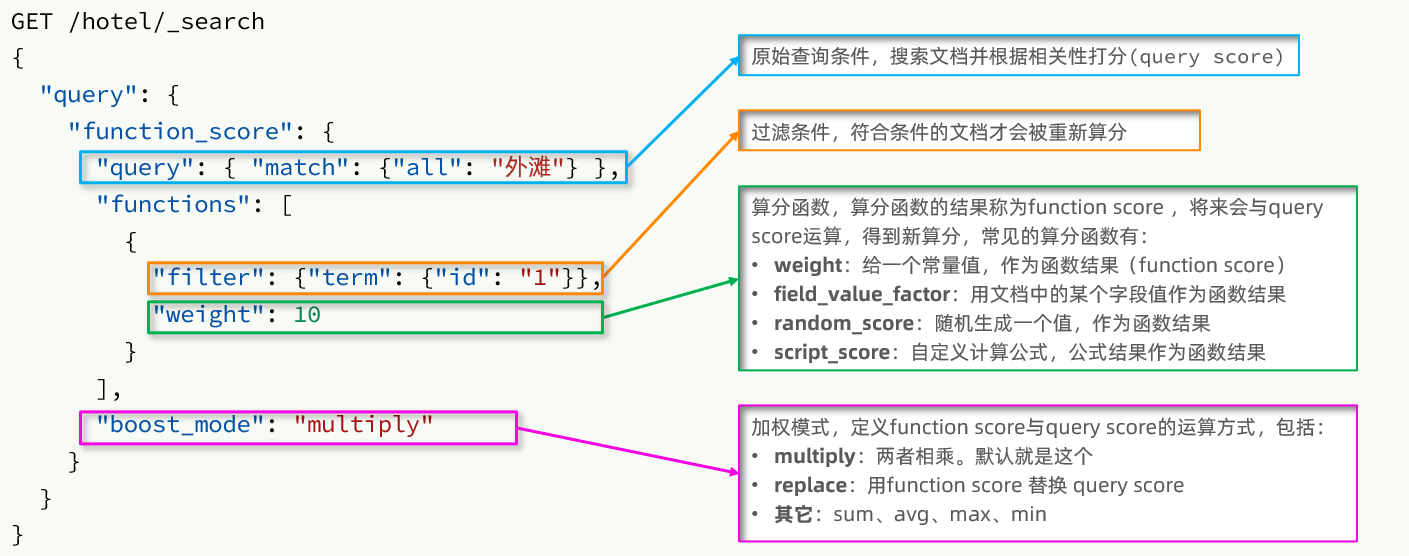
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
// 排序时的 距离值
private Object distance;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
2) Modificar el método handleResponse en HotelService
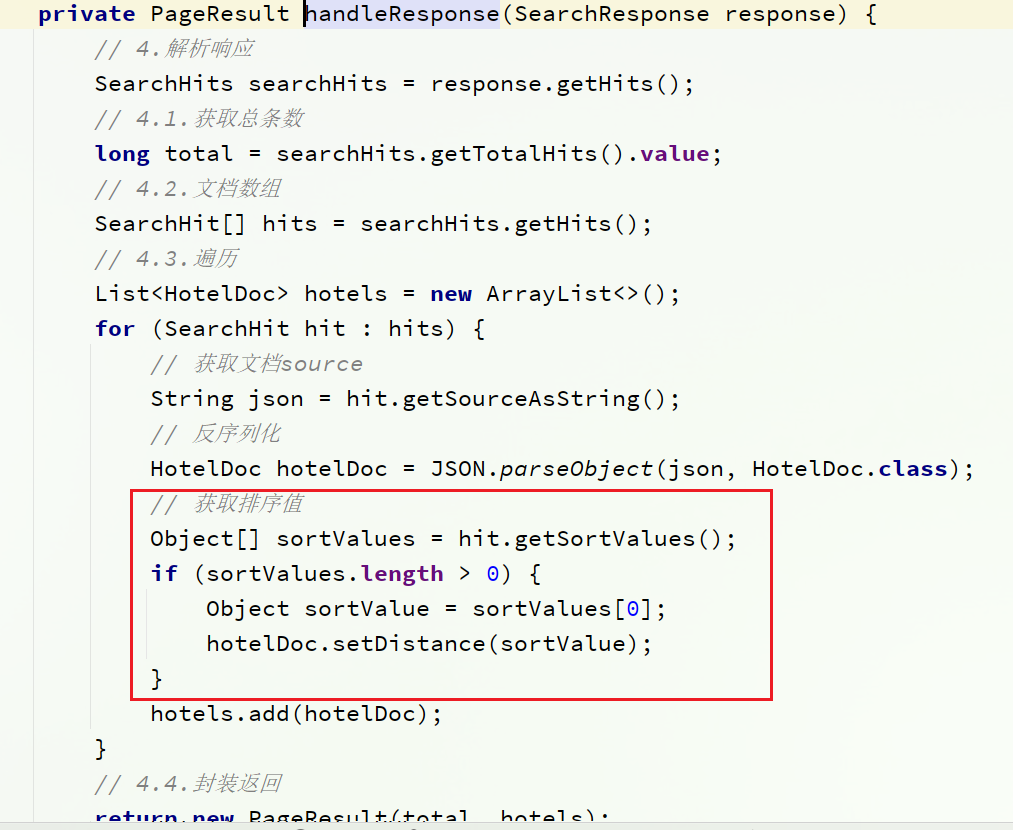
Después de reiniciar la prueba, se encontró que la página puede mostrar correctamente la distancia:
4.4 Ranking de ofertas de hoteles
Requisito: permitir que el hotel especificado se clasifique en la parte superior de los resultados de búsqueda
4.4.1 Análisis de la demanda
Para hacer que el hotel especificado se clasifique en la parte superior de los resultados de búsqueda, el efecto es el que se muestra en la figura:
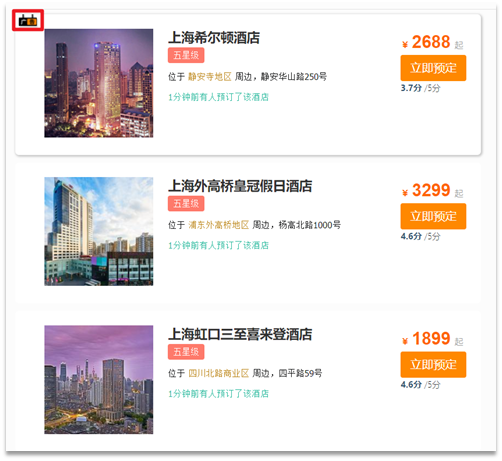
La página agrega una etiqueta de anuncio al hotel especificado .
Entonces, ¿cómo podemos hacer que el hotel designado ocupe el primer lugar?
La consulta function_score que hemos aprendido antes puede afectar la puntuación. Cuanto mayor sea la puntuación, mayor será la clasificación natural. Y function_score contiene 3 elementos:
- Criterios de filtro: qué documentos deben agregarse puntos
- Función de cálculo: cómo calcular la puntuación de la función
- Método de ponderación: cómo calcular la puntuación de la función y la puntuación de la consulta
La demanda aquí es: hacer que el hotel designado ocupe un lugar destacado. Por lo tanto, necesitamos agregar una marca a estos hoteles, para que en la condición de filtro, podamos juzgar de acuerdo con esta marca si debemos aumentar la puntuación .
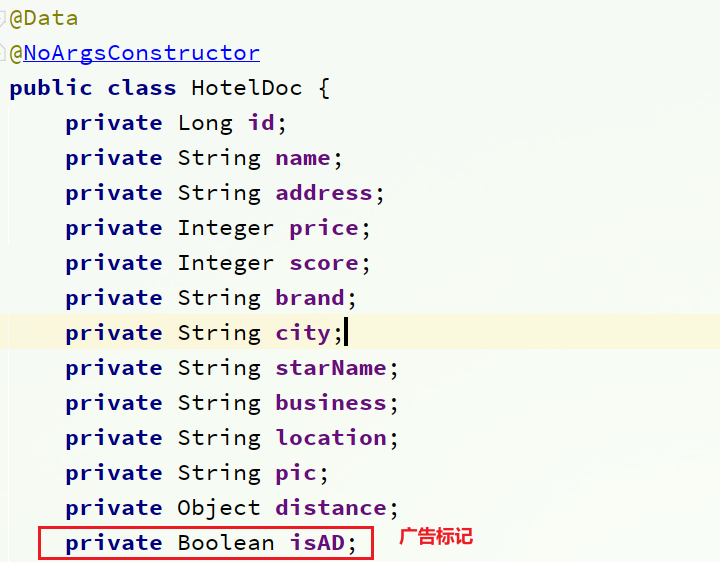
Por ejemplo, le agregamos un campo al hotel: isAD, de tipo booleano:
- cierto: es un anuncio
- falso: no es un anuncio
De esta forma, function_score contiene 3 elementos y es fácil de determinar:
- Condición de filtro: determinar si isAD es verdadero
- Función de cálculo: podemos usar el peso violento más simple, valor ponderado fijo
- Método de ponderación: puede utilizar el método de multiplicación predeterminado para mejorar en gran medida la puntuación del cálculo
Por lo tanto, los pasos de implementación del negocio incluyen:
- Agregue el campo isAD a la clase HotelDoc, tipo booleano
- Elija algunos hoteles que le gusten, agregue el campo isAD a sus datos de documento y el valor es verdadero
- Modifique el método de búsqueda, agregue la función de puntaje de función y agregue peso al hotel cuyo valor isAD es verdadero
4.4.2 Modificar la entidad HotelDoc
Agregue el campo isAD a cn.itcast.hotel.pojola clase HotelDoc en el paquete:
4.4.3 Adición de marcas publicitarias
A continuación, elegimos algunos hoteles, agregamos el campo isAD y lo configuramos como verdadero:
# 增加广告
POST /hotel/_update/36934
{
"doc": {
"isAD" : true
}
}
POST /hotel/_update/38609
{
"doc": {
"isAD" : true
}
}
POST /hotel/_update/38665
{
"doc": {
"isAD" : true
}
}
POST /hotel/_update/47478
{
"doc": {
"isAD" : true
}
}
4.4.4 Añadir consulta de función de cálculo
A continuación, modificaremos las condiciones de la consulta. La consulta booleana se usó antes, pero ahora debe cambiarse a la consulta function_socre.
La estructura de consulta de function_score es la siguiente:
La API de Java correspondiente es la siguiente:
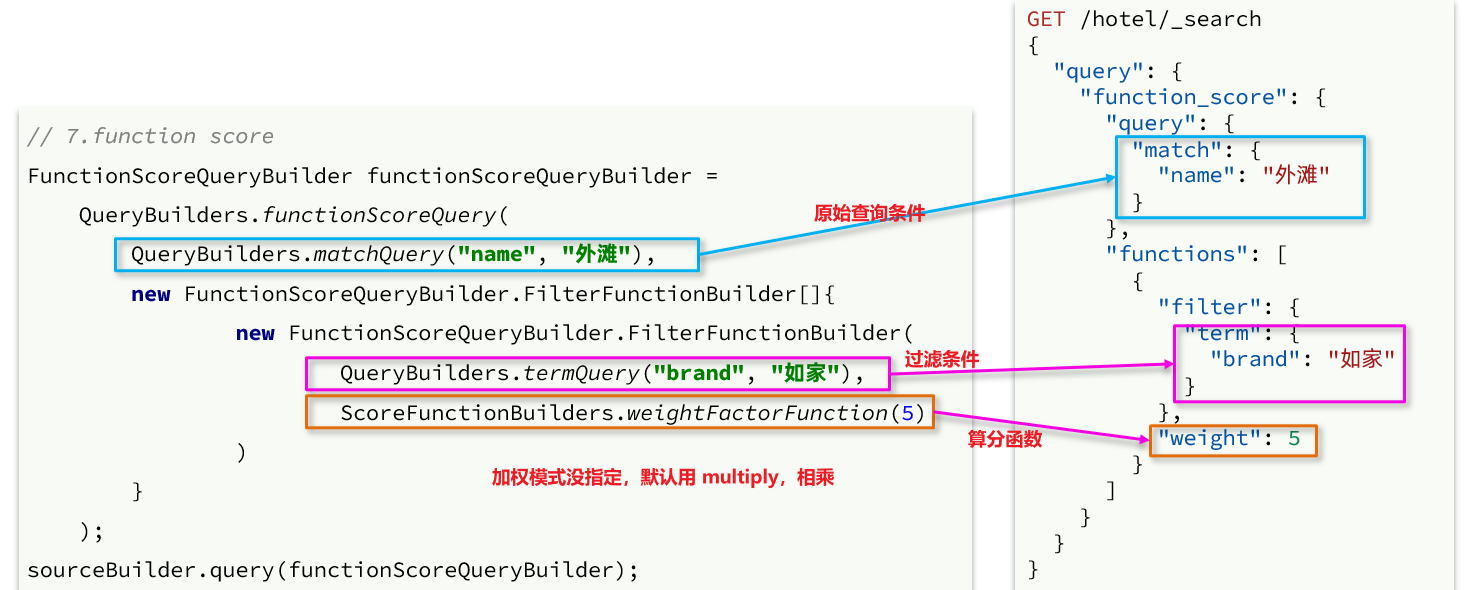
podemos poner la consulta booleana escrita anteriormente como la condición de consulta original en la consulta, y el siguiente paso es agregar condiciones de filtro , funciones de puntuación y modos de ponderación . Por lo tanto, el código original aún se puede usar.
Modifique el método en la clase cn.itcast.hotel.service.implbajo el paquete y agregue la consulta de la función de cálculo:HotelServicebuildBasicQuery
private void buildBasicQuery(RequestParams params, SearchRequest request) {
// 1.构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 关键字搜索
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 城市条件
if (params.getCity() != null && !params.getCity().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
// 品牌条件
if (params.getBrand() != null && !params.getBrand().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
// 星级条件
if (params.getStarName() != null && !params.getStarName().equals("")) {
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
// 价格
if (params.getMinPrice() != null && params.getMaxPrice() != null) {
boolQuery.filter(QueryBuilders
.rangeQuery("price")
.gte(params.getMinPrice())
.lte(params.getMaxPrice())
);
}
// 2.算分控制
FunctionScoreQueryBuilder functionScoreQuery =
QueryBuilders.functionScoreQuery(
// 原始查询,相关性算分的查询
boolQuery,
// function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
// 其中的一个function score 元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// 过滤条件
QueryBuilders.termQuery("isAD", true),
// 算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
}
resultado de búsqueda
