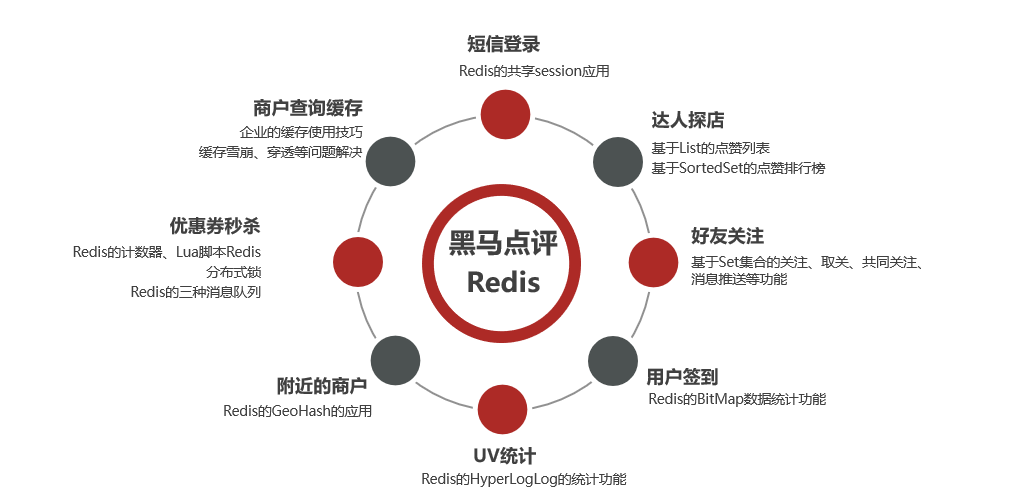
Directorio de artículos
- 1. Información general
- 2.Inicio de sesión por SMS
- 3. Caché de consultas del comerciante
- 4. Venta flash de cupones
-
- 4.1 Descripción general
- 4.2 ID única a nivel mundial
- 4.3 Pedido con cupón de venta flash
- 4.4 Problema de sobreventa de inventario
- 4.5 Función de una persona, una orden (punto difícil)
- 4.6 Bloqueo distribuido
-
- 4.6.1 Descripción general
- 4.6.2 Implementar la versión preliminar del bloqueo distribuido de Redis
- 4.6.3 Implementar una versión mejorada del bloqueo distribuido de Redis
- 4.6.4Herramienta Redisson
-
- 4.6.4.1 Descripción general
- 4.6.4.2 Implementar la versión avanzada del bloqueo distribuido de Redis
- 4.6.4.3 Principio de bloqueo reentrante
- 4.6.4.4 Principio de reintento
- 4.6.4.5 Principio de renovación del tiempo de espera
- 4.6.4.6 Problema de coherencia maestro-esclavo
- 4.6.4.7 Resumen de principios
- 4.7 Venta flash de optimización de Redis (dificultad)
- 4.8La cola de mensajes de Redis implementa ventas flash asíncronas
-
- 4.8.1 Descripción general
- 4.8.2 Simular cola de mensajes según la estructura de lista
- 4.8.3 Cola de mensajes basada en PubSub
- 4.8.4 Cola de mensajes basada en secuencias
- 4.8.5 Diferencias entre los tres métodos de colas de mensajes
- 4.8.6 Implementación de la eliminación flash asíncrona de la cola de mensajes de Redis (puntos clave)
- 5. Los expertos visitan la tienda
- 6. Sigue a tus amigos
- 7. Negocios cercanos
- 8. Inicio de sesión de usuario
- 9.Estadísticas UV
- conocimiento gasolinera
- Registro
1. Información general
ilustrar:
Este proyecto solo demuestra las funciones de la capa de servicio aquí.
2.Inicio de sesión por SMS
Resumen de notas:
Comando Redis:
En la función de enviar el código de verificación por SMS, se utiliza el método
Stringde conjunto de comandos de Redis para completar el guardado del código de verificación.setEn las funciones de inicio de sesión y registro del código de verificación por SMS, se utiliza el método
Hashde conjunto de comandos de Redis para guardar la información de los usuarios que han iniciado sesión.putAll
HashEn la función de verificar el estado de inicio de sesión, el conjunto de comandos Reids se utiliza paraentriesverificar el valor no nulo de la información del usuario que inició sesión y guardar la identidad.Dificultades en la implementación de funciones:
- En la herramienta Hutool, el método de convertir el tipo Bean al tipo Mapa
BeanUtil、beanToMapse utilizaCopyOptions.create().ignoreNullValue().setFieldValueEditor((fieldName, fieldValue) -> fieldValue.toString())para convertir el tipo de parámetro en uno de los atributos.
2.1 Inicio de sesión de implementación de sesión regular
2.1.1 Descripción general
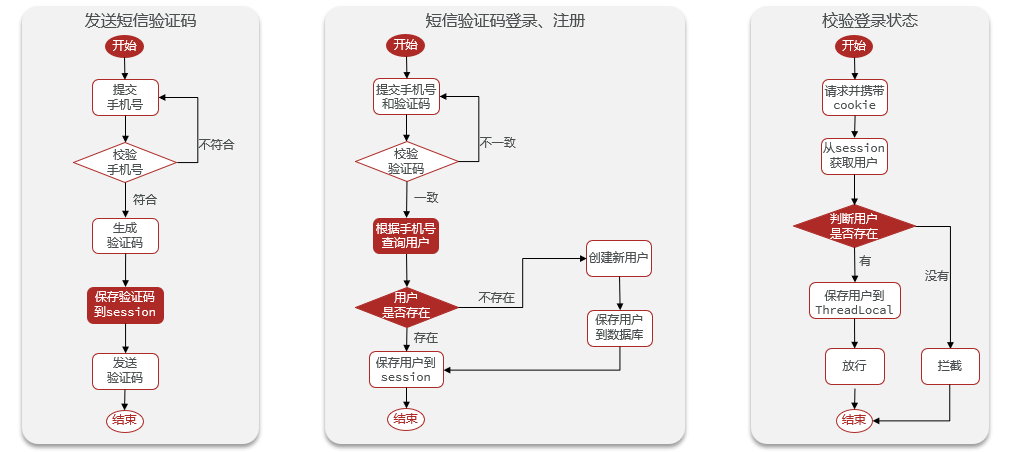
ilustrar:
El inicio de sesión a través de la sesión se divide en enviar los pasos anteriores. Envíe el código de verificación por SMS, el inicio de sesión y el registro del código de verificación por SMS y verifique el estado de inicio de sesión. Al guardar el código de verificación y el usuario en el dominio de sesión, se pueden realizar la gestión de la sesión y otras operaciones.
2.1.2 Casos de uso básicos
Paso 1: enviar código de verificación
- Agregar método
UserServiceImplde clasesendCode
/**
* @param phone 手机号
* @param session session域
* @return Result风格结果
*/
@Override
public Result sendCode(String phone, HttpSession session) {
// 1.校验手机号
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.符合,生成验证码
String code = RandomUtil.randomNumbers(6);
// 4.保存验证码、手机号到session
session.setAttribute("code", code);
session.setAttribute("phone", phone);
// 5.发送验证码
log.debug("发送短信验证码成功,验证码:{},", code);
return Result.ok();
}
Paso 2: Iniciar sesión
- Agregar método
UserServiceImplde claselogin
/**
* @param loginForm 封装登录用户的DTO
* @param session session域
* @return eoken
*/
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1.校验手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone) || ObjectUtil.notEqual(phone, session.getAttribute("phone").toString())) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号错误!");
}
// 3.校验验证码
String code = loginForm.getCode();
if (RegexUtils.isCodeInvalid(code) || ObjectUtil.notEqual(code, session.getAttribute("code").toString())) {
// 4.如果不符合,返回错误信息
return Result.fail("验证码错误!");
}
// 5.判断用户是否存在
LambdaQueryWrapper<User> lambdaQuery = new LambdaQueryWrapper<>();
lambdaQuery.eq(User::getPhone, phone);
User user = userMapper.selectOne(lambdaQuery);
// 6.用户不存在,创建用户,保存到数据库
if (ObjectUtil.isNull(user)) {
user = new User(phone, USER_NICK_NAME_PREFIX + RandomUtil.randomString(5));
userMapper.insert(user);
}
// 7.保存用户到session
// 此处保存用户session信息时,使用Hutool工具的拷贝字节流的方式将属性值存入UserDTO类中,防止过多的用户信息发送给前端,造成安全问题
session.setAttribute("user", BeanUtil.copyProperties(user, UserDTO.class));
return Result.ok();
}
Reponer:
Qué significa DTO, sitio web de referencia: (43 mensajes) Java tiene un conocimiento profundo de DTO y cómo utilizar DTO_Qué es el blog-CSDN de dto_visant
Reponer:
LoginFormDTOamable@Data public class LoginFormDTO { private String phone; private String code; private String password; }
Paso 3: verificar el estado de inicio de sesión
1. Crea LoginInterceptorun interceptor
/*
* 定义拦登录拦截器并实现逻辑,在拦截器中,记录用户身份信息
*/
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取session
HttpSession session = request.getSession();
// 2.获取session中的用户
UserDTO user = (UserDTO) session.getAttribute("user");
// 3.判断用户是否存在
boolean result = ObjectUtil.isNull(user);
// 4.不存在,拦截
if (result) {
// 返回401状态码
response.setStatus(401);
return false;
}
// 5.存在,保存用户信息到ThreadLocal
UserHolder.saveUser(user);
// 6.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 当拦截器完成之后,将内存中ThreadLocal(对线程内)里面保存的用户信息清除,释放内存空间,避免浪费
UserHolder.removeUser();
}
}
2. Cree MvcConfigun archivo de configuración
/*
* 创建配置类,并注册登录拦截器
*/
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 配置相应的放行逻辑
registry.addInterceptor(getLoginInterceptor()).excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
);
}
@Bean
LoginInterceptor getLoginInterceptor() {
return new LoginInterceptor();
}
}
2.1.3 Resumen
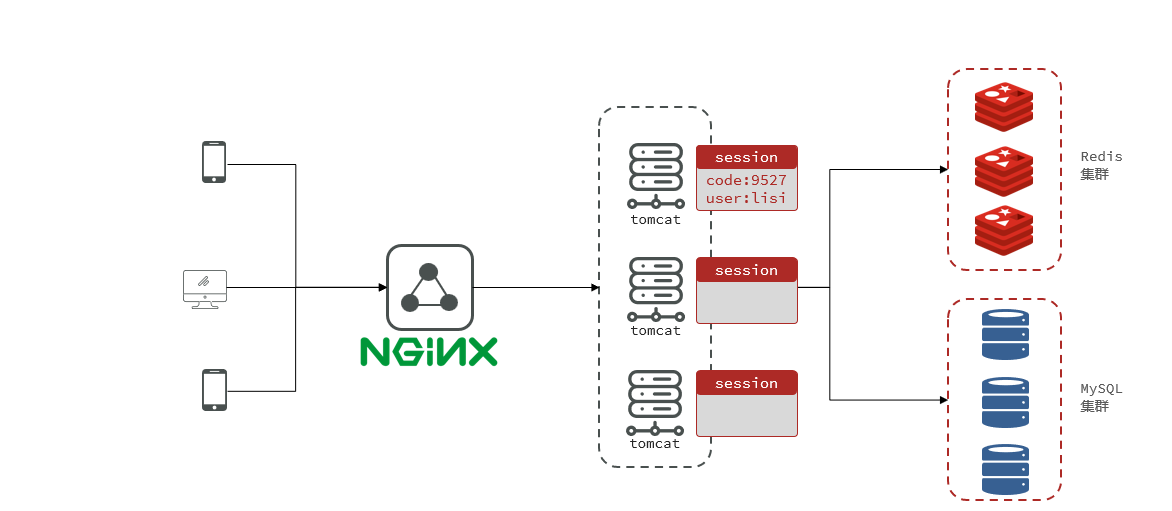
ilustrar:
Según la arquitectura del sistema, cuando es necesario construir un clúster a través de Tomcat, se producirán problemas para compartir sesiones en esta implementación. El dominio de sesión no se puede compartir entre el mismo gato y otro gato.
2.2Redis implementa el inicio de sesión compartido
2.2.1 Descripción general
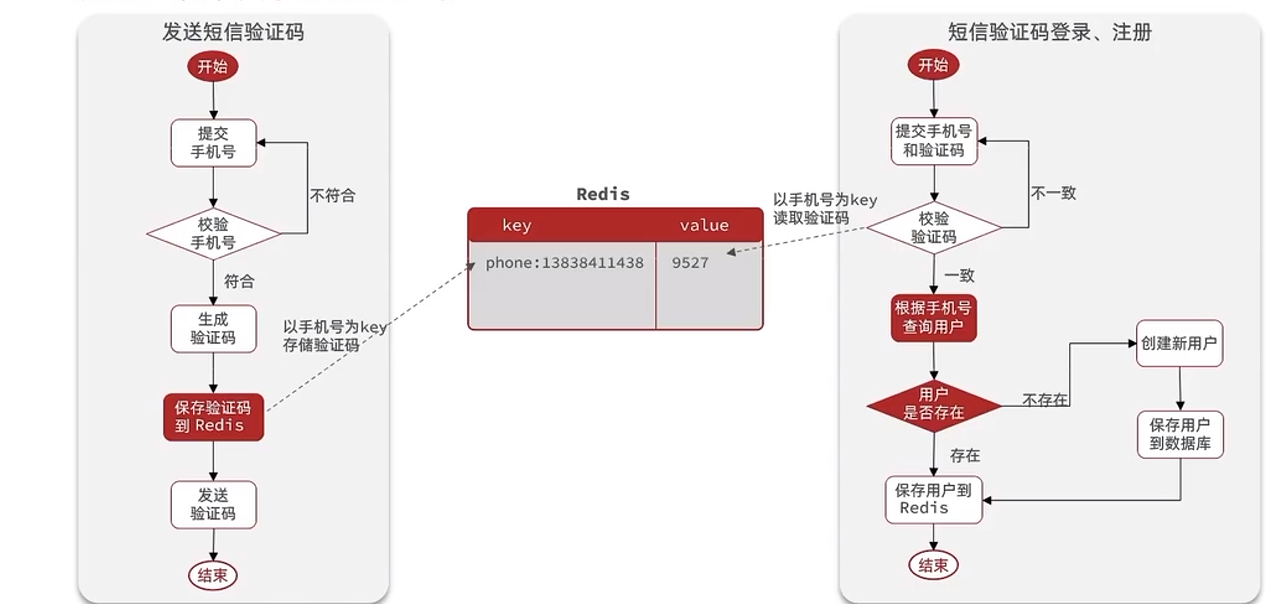
ilustrar:
Guarde la información del código de verificación en Redis en lugar del dominio de sesión, lo que facilita el problema de que varios servidores Tomcat accedan al servicio Redis y resuelva el problema del dominio compartido de sesión.
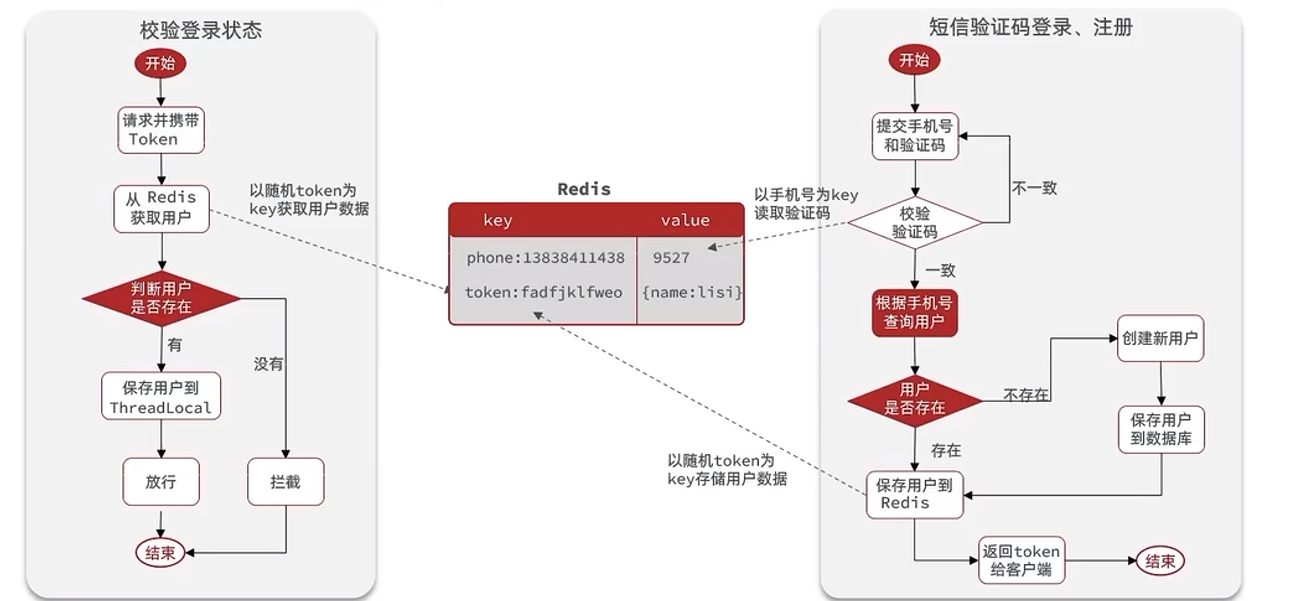
ilustrar:
No se recomienda utilizar directamente el número de teléfono móvil como clave para el Token almacenado en Redis aquí, porque el Token se devolverá al front-end en el futuro y el uso del número de teléfono móvil provocará el riesgo de fuga de información. .
2.2.2 Casos de uso básicos
ilustrar:
Ideas de implementación:
Cuando se envía el código de verificación por SMS, el código de verificación se almacena en Redis. Al verificar el código de verificación, recupérelo de Redis y verifíquelo. Después de iniciar sesión correctamente, el token se almacena en Redis y, al verificar la identidad del usuario, se extrae de Redis y se verifica.
Paso 1: importar dependencias
1. Modifique Pom.xmlel archivo y agregue las siguientes dependencias.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
ilustrar:
Hutool es una biblioteca de clases de herramientas Java pequeña y completa. Utiliza encapsulación de métodos estáticos para reducir el costo de aprendizaje de las API relacionadas y mejorar la eficiencia del trabajo. Hace que Java sea tan elegante como un lenguaje funcional y hace que el lenguaje Java sea "dulce".
Paso 2: escribir Pom.xmlarchivos de configuración
server:
port: 8081
spring:
application:
name: hmdp
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/db1?useSSL=false&serverTimezone=UTC
username: root
password: qweasdzxc
redis:
host: 10.13.164.55
port: 6379
password: qweasdzxc
lettuce:
pool:
max-active: 10
max-idle: 10
min-idle: 1
time-between-eviction-runs: 10s
jackson:
default-property-inclusion: non_null # JSON处理时忽略非空字段
mybatis-plus:
type-aliases-package: com.hmdp.entity # 别名扫描包
logging:
level:
com.hmdp: debug
Paso 3: encapsular el conjunto de resultados del estilo Resultado
1. Cree una clase de resultado en el paquete dto.
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
private Boolean success;
private String errorMsg;
private Object data;
private Long total;
public static Result ok(){
return new Result(true, null, null, null);
}
public static Result ok(Object data){
return new Result(true, null, data, null);
}
public static Result ok(List<?> data, Long total){
return new Result(true, null, data, total);
}
public static Result fail(String errorMsg){
return new Result(false, errorMsg, null, null);
}
}
ilustrar:
Encapsule el conjunto de resultados Result y procese y devuelva uniformemente los resultados de la capa de control.
Paso 4: crear una clase de herramienta
1. Cree una clase constante del sistema.
utilCree unaSystemConstantsclase constante del sistema en el paquete
public class SystemConstants {
public static final String IMAGE_UPLOAD_DIR = "D:\\lesson\\nginx-1.18.0\\html\\hmdp\\imgs\\";
public static final String USER_NICK_NAME_PREFIX = "user_";
public static final int DEFAULT_PAGE_SIZE = 5;
public static final int MAX_PAGE_SIZE = 10;
}
2. Cree una clase de herramienta de verificación.
2.1 Crear expresiones regulares comunes
utilCree unaRegexPatternsclase de verificación de formato en el paquete
public abstract class RegexPatterns {
/**
* 手机号正则
*/
public static final String PHONE_REGEX = "^1([38][0-9]|4[579]|5[0-3,5-9]|6[6]|7[0135678]|9[89])\\d{8}$";
/**
* 邮箱正则
*/
public static final String EMAIL_REGEX = "^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$";
/**
* 密码正则。4~32位的字母、数字、下划线
*/
public static final String PASSWORD_REGEX = "^\\w{4,32}$";
/**
* 验证码正则, 6位数字或字母
*/
public static final String VERIFY_CODE_REGEX = "^[a-zA-Z\\d]{6}$";
}
2.2 Crear reglas de verificación
utilCree unaRegexUtilsclase de validación de parámetros en el paquete
public class RegexUtils {
/**
* 是否是无效手机格式
*
* @param phone 要校验的手机号
* @return true:符合,false:不符合
*/
public static boolean isPhoneInvalid(String phone) {
return mismatch(phone, RegexPatterns.PHONE_REGEX);
}
/**
* 是否是无效邮箱格式
*
* @param email 要校验的邮箱
* @return true:符合,false:不符合
*/
public static boolean isEmailInvalid(String email) {
return mismatch(email, RegexPatterns.EMAIL_REGEX);
}
/**
* 是否是无效验证码格式
*
* @param code 要校验的验证码
* @return true:符合,false:不符合
*/
public static boolean isCodeInvalid(String code) {
return mismatch(code, RegexPatterns.VERIFY_CODE_REGEX);
}
// 校验是否不符合正则格式
private static boolean mismatch(String str, String regex) {
if (StrUtil.isBlank(str)) {
return true;
}
return !str.matches(regex);
}
}
Paso 5: Realice el servicio de envío de código de verificación por SMS
1. UserServiceImplCree un sendCodemétodo de envío en la clase de implementación.
@Autowired
StringRedisTemplate stringRedisTemplate; //利用StringRedisTemplate实现对Redis的操作
@Autowired
UserMapper userMapper;
@Override
public Result sendCode(String phone, HttpSession session) {
// 1.校验手机号
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.符合,生成验证码
String code = RandomUtil.randomNumbers(6);
// 4.保存验证码到redis
stringRedisTemplate.opsForValue().set(RedisConstants.LOGIN_CODE_KEY + phone, code, RedisConstants.LOGIN_CODE_TTL, TimeUnit.MINUTES);
// 5.发送验证码
log.debug("发送短信验证码成功,验证码:{},", code);
return Result.ok();
}
Paso 6: realice el servicio de inicio de sesión
1. UserServiceImplCrea un loginmétodo de envío en la clase.
@Autowired
UserMapper userMapper;
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1.校验手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.从Redis获取校验验证码
String verCode = loginForm.getCode();
String code = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone);
if (RegexUtils.isCodeInvalid(verCode) || ObjectUtil.notEqual(code, verCode)) {
// 4.如果不符合,返回错误信息
return Result.fail("验证码错误!");
}
// 5.判断用户是否存在
LambdaQueryWrapper<User> lambdaQuery = new LambdaQueryWrapper<>();
lambdaQuery.eq(User::getPhone, phone);
User user = userMapper.selectOne(lambdaQuery);
// 6.用户不存在,创建用户,保存到数据库
if (ObjectUtil.isNull(user)) {
user = new User(phone, USER_NICK_NAME_PREFIX + RandomUtil.randomString(5));
userMapper.insert(user);
}
// 7.保存用户到redis
// 7.1使用Hutool的UUID方法随机生成token,作为登录令牌
String token = UUID.randomUUID().toString(true);
// 7.2将User对象转换为HashMap,便于存储Redis
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 此处通过Hutool工具在将Bean数据转换为Map
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO, new HashMap<>(),
CopyOptions.create().ignoreNullValue()
.setFieldValueEditor(new BiFunction<String, Object, Object>() {
@Override
public Object apply(String fieldName, Object fieldValue) {
return fieldValue.toString(); // 因为UserDTO实体类的ID为Long类型,不能直接存入Redis,需要转换为其余类型
}
}));
// 7.3利用Redis的hash方式,存储用户信息
String tokenKey = LOGIN_USER_KEY + token;
stringRedisTemplate.opsForHash().putAll(tokenKey, userMap);
// 7.4设置有效期
stringRedisTemplate.expire(token, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.返回结果
return Result.ok(token); //此处需要将token返回给前端,前端添加到请求头的authorization中
}
Aviso:
Establezca el período de validez del Token, lo cual es conveniente para limpiar el almacenamiento de datos de Redis y también para mejorar la seguridad de los datos.
Debe establecer el tipo en el método de conversión de Bean en Map to String.
ilustrar:
El período de validez del token se establece aquí, lo que significa que cada vez que expire el tiempo del token para iniciar sesión, el usuario se verá obligado a cerrar sesión y volver a iniciarla. Por lo tanto, debe encontrar un lugar para establecer la hora para actualizar el token. Simplemente extienda el período de validez del Token permitiendo que el usuario esté activo dentro de los 30 minutos. Continúe revisando los pasos a continuación.
Reponer:
UserDTOamable@Data public class UserDTO { private Long id; private String nickName; private String icon; }
Paso 7: verificar el estado de inicio de sesión
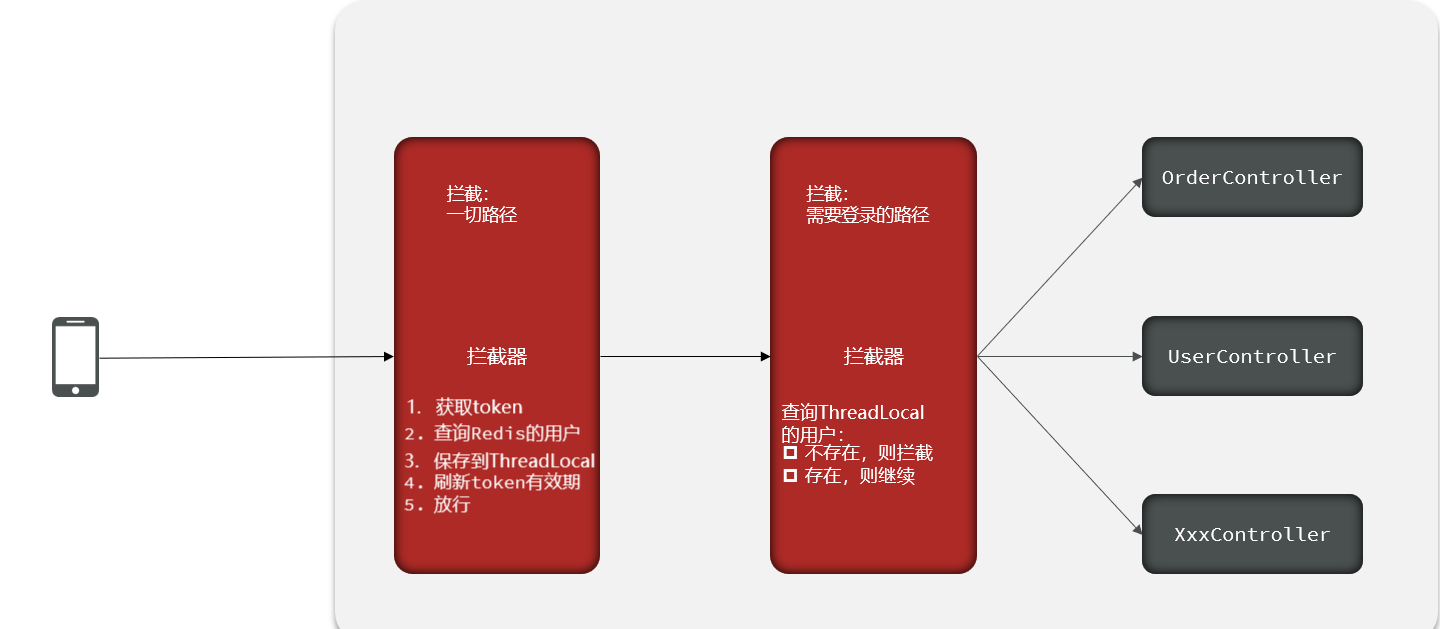
ilustrar:
Agregue un nuevo interceptor, intercepte todas las rutas y procese el tiempo de actualización del dominio de sesión en Redis para todos los recursos a los que se accede en todas las rutas.
1. Agregar RefreshTokenInterceptorinterceptor
public class RefreshTokenInterceptor implements HandlerInterceptor {
@Autowired
StringRedisTemplate stringRedisTemplate;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的Token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
return true;
}
// 2.基于Token获取Redis中的用户
String tokenKey = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(tokenKey);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
// 4.不存在则放行,交给LoginInterceptor拦截器进行处理
return true;
}
// 5.将查询到的Hash数据转换为UserDTO对象(便于存储到ThreadLocal中)-Hutool(BeanUtil.fillBeanWithMap)
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 6.存在,保存用户信息到ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新Token有效期
stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 当执行完Controller内的方法后,对线程内的用户信息进行删除
UserHolder.removeUser();
}
}
ilustrar:
Aquí debe actualizar el período de validez del Token para mantener al usuario en línea.
2. Modificar LoginInterceptorel interceptor
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.判断是否需要拦截用户
if (ObjectUtil.isNull(UserHolder.getUser())) {
// 没有,设置状态码
response.setStatus(401);
// 拦截
return false;
}
// 放行
return true;
}
}
3. Modificar MvcConfigla clase de configuración.
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 设置多个拦截器的先后顺序,让拦截器的执行时机变得有序
registry.addInterceptor(getLoginInterceptor()).excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
).order(1);
registry.addInterceptor(getRefreshTokenInterceptor()).addPathPatterns("/**").order(0);
}
@Bean
LoginInterceptor getLoginInterceptor() {
return new LoginInterceptor();
}
@Bean
RefreshTokenInterceptor getRefreshTokenInterceptor() {
return new RefreshTokenInterceptor();
}
}
2.2.3 Resumen
Al registrar y actualizar el estado de inicio de sesión del usuario a través de Redis, puede facilitar que Tomcat comparta la información operativa de Redis en el clúster, resolviendo así el problema de guardar y verificar la sesión.
3. Caché de consultas del comerciante
Resumen de notas:
Comando Redis:
StringEn la función de agregar caché, el conjunto de comandossety el método de Redisgetse utilizan para completar el almacenamiento en caché y la consulta de datos del comerciante y mejorar la velocidad de respuesta del sistema.En la función de estrategia de actualización de caché, el método
Stirngde conjunto de comandos de Redissetutiliza el atributo de vencimiento del tiempo de espera al implementar la eliminación del tiempo de espera. Al implementar actualizaciones activas, eldeletecomando Redis se utiliza para eliminar la clave.En la función de penetración de caché, se utiliza el método del
Stringconjunto de comandos de Redis y se utilizan técnicas para guardar valores nulos para resolver el problema de penetración de caché.setEn la función de desglose de caché, el método
Stringde conjunto de comandos de RedissetIfAbsentse utiliza para implementar el bloqueo mutex.Dificultades en la implementación de funciones:
- Al implementar la función de estrategia de actualización de caché, utilice la eliminación del tiempo de espera para lograr requisitos de coherencia más bajos. Utilice la actualización activa para realizar el proceso de eliminar primero la base de datos y luego eliminar el caché para lograr mayores requisitos de coherencia.
- Al implementar la función de penetración de caché, al implementar el esquema de bloqueo de exclusión mutua, utilice bloqueos de doble verificación para realizar verificaciones secundarias para evitar la carga repetida de datos.
- Al implementar la función de penetración de caché, al implementar el esquema de caducidad lógica,
RedisDatalas clases se pueden usar inteligentemente para agregar atributos de miembros adicionales de la clase de producto sin modificar la clase original. UtiliceExecutors.newFixedThreadPoolmétodos para crear grupos de subprocesos múltiples y enviar tareas- En la herramienta Hutool, utilice
StrUtil.isNotBlankel método para completar el juicio de existencia de la información de la tienda. Método de usoRandomUtil.randomLong, agregar valores aleatorios, resolver avalanchas de caché. UtiliceJSONUtil.toBeanel método para deserializar el objeto. UsarJSONUtil.toJsonStrmétodos para serializar objetos.
3.1 Agregar caché
3.1.1 Descripción general
significado:
El caché es un búfer para el intercambio de datos (llamado caché [ kæʃ ]), es un lugar temporal para almacenar datos y generalmente tiene un alto rendimiento de lectura y escritura.
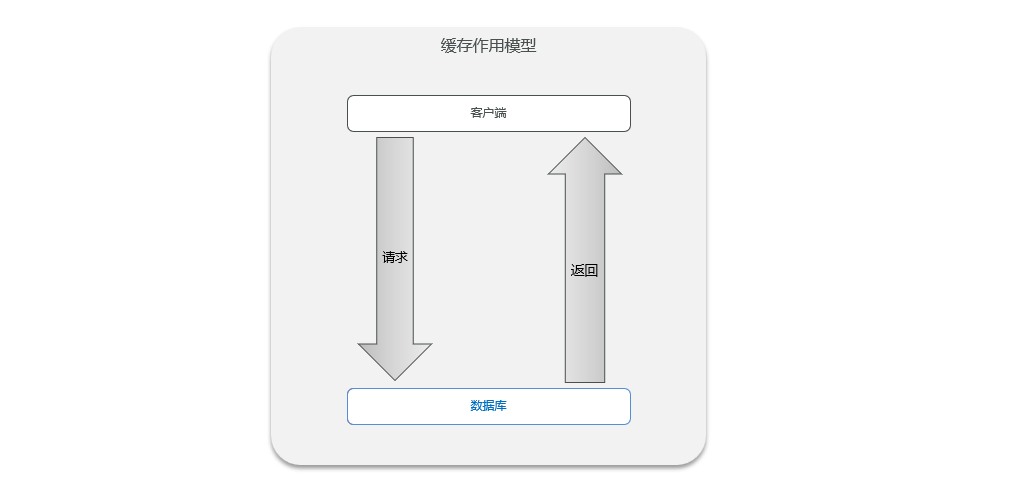
efecto:
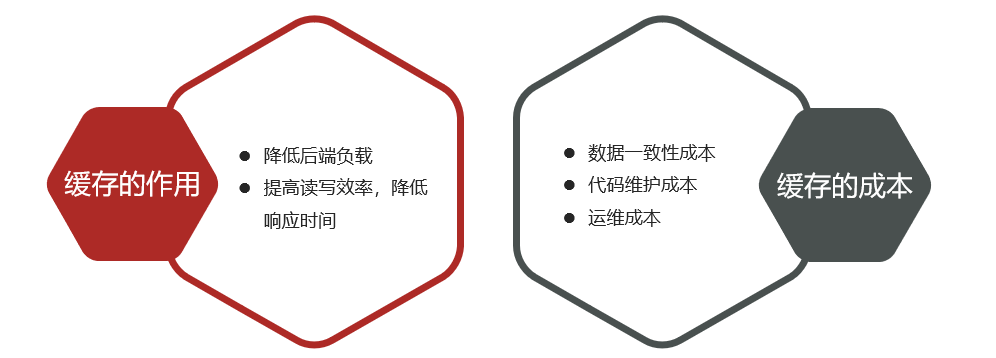
Escenario de aplicación:
Reponer:
El almacenamiento en caché puede traernos muchas ventajas, pero es más propenso a problemas como averías y avalanchas de caché.
ilustrar:
- Cuando el caché no se utiliza para almacenar datos en el búfer, si el cliente desea obtener datos, consultará directamente la base de datos a través del servidor. De esta forma, cuando las solicitudes del cliente alcancen una alta concurrencia, el rendimiento del servidor disminuirá gradualmente. Principalmente debido a la velocidad de lectura y escritura del disco, debido a que la cantidad de lecturas y escrituras en el disco es muy frecuente, afectará el rendimiento del servidor.
- Cuando el cliente quiere obtener datos, solicita al servidor, quien primero obtiene los datos a través de Redis, lo que puede reducir en gran medida la cantidad de lecturas y escrituras en la base de datos, mejorando así en gran medida el rendimiento del servidor. Principalmente por la velocidad de lectura y escritura del disco, porque la cantidad de lecturas y escrituras en el disco se reduce considerablemente, lo que afectará el rendimiento del servidor.
3.1.2 Casos de uso básicos
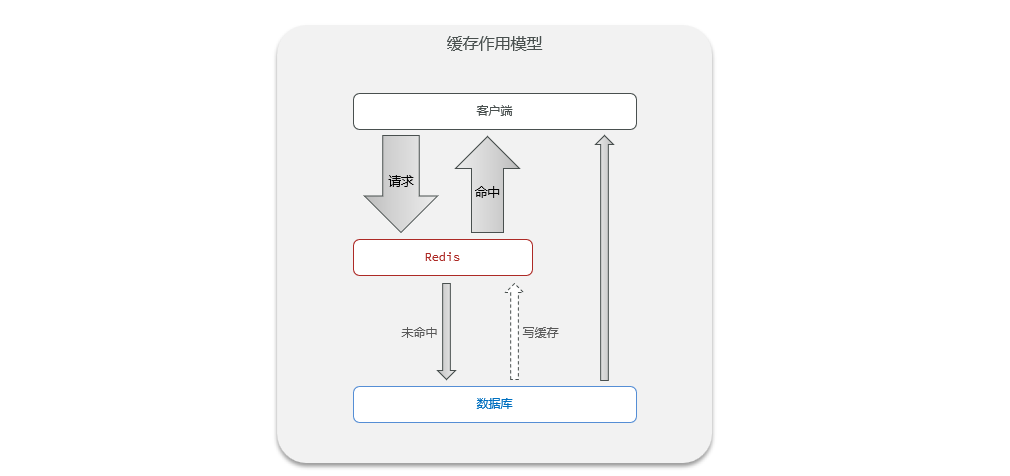
ilustrar:
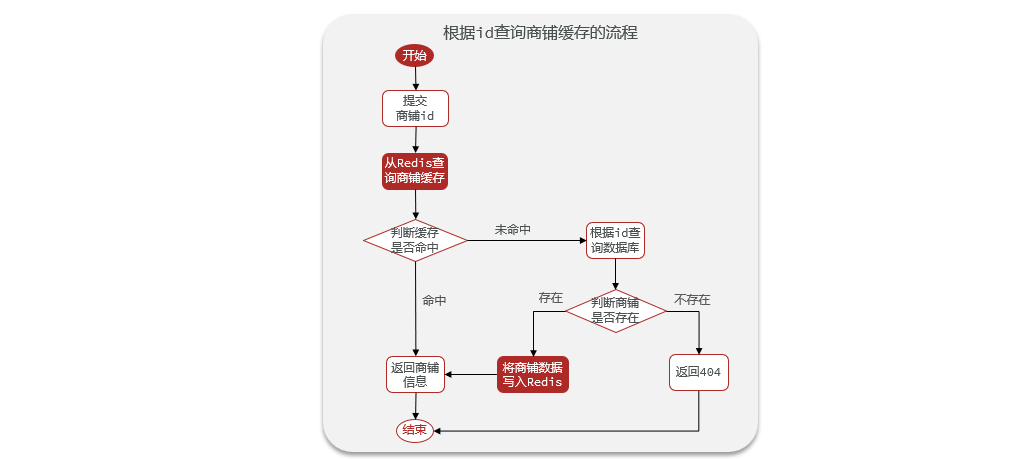
Ideas de implementación:
El cliente envía una solicitud y primero obtiene datos de Redis. Si acierta, regresará. Si no acierta, consultará la base de datos. Si la base de datos existe, se escribirá en Redis y se devolverán los datos, si no existe, se devolverá directamente un error.
- Agregar métodos
ShopServiceImplen clasequeryById
/**
* @param id 商铺的ID
* @return 商铺
*/
@Override
public Result queryById(Long id) {
// 1.从Redis查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 4.不存在,根据Id查询数据库
Shop shop = getById(id);
if (ObjectUtil.isNull(shop)) {
// 5.不存在,返回错误
return Result.fail("店铺不存在!");
}
// 6.存在,写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
// 7.返回结果
return Result.ok(shop);
}
3.2 Estrategia de actualización de caché
3.2.1 Descripción general
Para la estrategia de actualización de caché, se divide en los siguientes tres métodos según los requisitos de coherencia.
Descripción: En escenas de la vida.
- Requisitos de baja coherencia: se recomienda utilizar un mecanismo de expulsión de memoria. Por ejemplo, caché de consultas de tipo de tienda
- Requisitos de alta coherencia: se recomienda utilizar un mecanismo de actualización activo y utilizar la eliminación del tiempo de espera como solución alternativa. Por ejemplo, la consulta de caché de detalles de la tienda.
- Estrategia de actualización proactiva

ilustrar:
- El patrón Cache Aside, que utiliza codificación para actualizar simultáneamente el caché de la base de datos, requiere control
- Lectura/escritura a través del patrón, el costo de desarrollo de dicho código de servicio es demasiado alto
- Write Behind Caching Pattern almacena una gran cantidad de operaciones sobre datos en el caché y espera un cierto período de tiempo antes de operar en la base de datos. Si el caché falla, los datos se perderán
- Patrón de caché aparte

ilustrar:
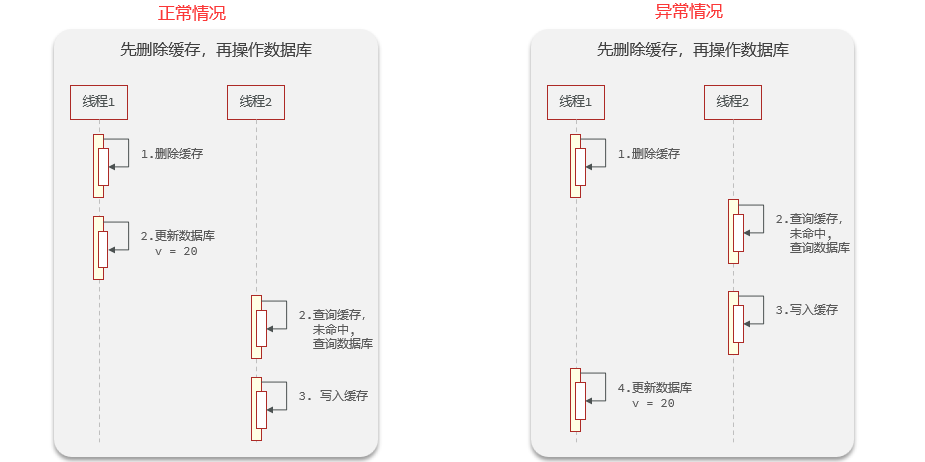
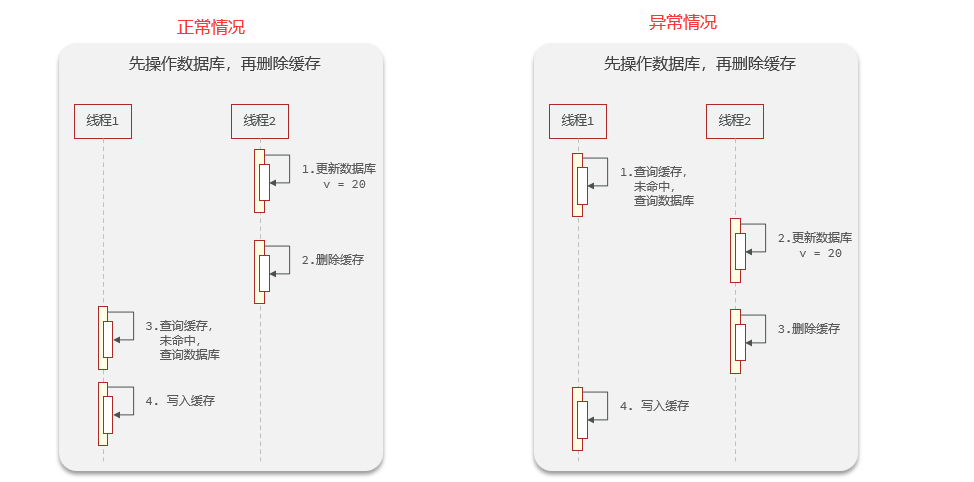
- ¿Cuál es la diferencia entre eliminar el caché primero y eliminarlo después?
- Primero elimine el caché y luego opere la base de datos si el registro anormal es grande. Porque la velocidad de lectura y escritura de la base de datos del sistema operativo es mayor que la velocidad de lectura y escritura del caché
- Primero opere la base de datos, luego elimine el caché y el registro anormal será pequeño. Porque la velocidad de lectura y escritura en el caché es más lenta que la velocidad de lectura y escritura en la base de datos del sistema operativo.
3.2.2 Implementar la eliminación del tiempo de espera
ilustrar:
Ideas de implementación:
Modifique la lógica empresarial en la clase de implementación del producto. Al consultar la tienda según el ID, si falla el caché, consulte la base de datos, escriba los resultados de la base de datos en el caché y establezca el tiempo de espera.
- Modificar métodos
ShopServiceImplen clasequeryById
/**
* @param id 商铺的ID
* @return 商铺
*/
@Override
public Result queryById(Long id) {
// 1.从Redis查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 4.不存在,根据Id查询数据库
Shop shop = getById(id);
if (ObjectUtil.isNull(shop)) {
// 5.不存在,返回错误
return Result.fail("店铺不存在!");
}
// 6.存在,写入Redis
// 为从Redis查询商品设置了商品的过期时间,实现缓存更新策略中的超时剔除的功能
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 7.返回结果
return Result.ok(shop);
}
3.2.3 Implementar actualizaciones activas
ilustrar:
Ideas de implementación:
Modifique la lógica empresarial en la clase de implementación del producto. Al modificar la tienda según el ID, primero modifique la base de datos y luego elimine el caché.
- Agregar métodos
ShopServiceImplen claseupdate
@Override
@Transactional// 因此本项目为单体项目,因此添加事务注解,即可实现事务的同步
public Result update(Shop shop) {
Long id = shop.getId();
if (ObjectUtil.isNull(id)) {
return Result.fail("商铺Id不能为空");
}
// 1.修改数据库
updateById(shop);
// 2.删除缓存
String key = CACHE_SHOP_KEY + id;
stringRedisTemplate.delete(key);
return Result.ok();
}
3.3 Penetración de caché
3.3.1 Descripción general
La penetración de la caché significa que los datos solicitados por el cliente no existen en la caché o en la base de datos, por lo que la caché nunca tendrá efecto. Estas solicitudes llegarán a la base de datos, lo que ejercerá una gran presión sobre la base de datos.
ilustrar:
Si los usuarios ilegales siguen intentando enviar solicitudes de spam en segundo plano, se producirán anomalías en el servicio o incluso fallos.
Hay dos formas comúnmente utilizadas para resolver la penetración de caché:
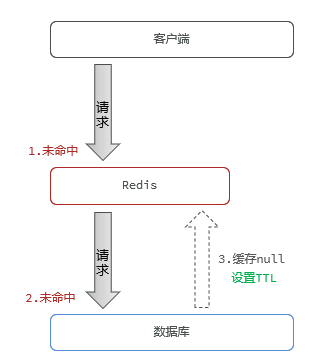
Caché de objetos vacíos :
ilustrar:
- Ventajas: implementación sencilla y fácil mantenimiento
- Desventajas: el consumo de memoria adicional puede provocar inconsistencias a corto plazo (si se insertan datos reales, pero Redis almacenó en caché el resultado, se producirán inconsistencias en los datos)
Filtrado de floración :
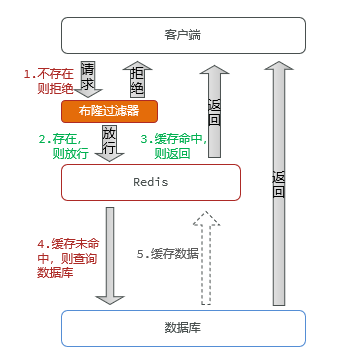
ilustrar:
- Ventajas: menos uso de memoria, sin claves redundantes
- Desventajas: implementación compleja, posibilidad de error de juicio (debido a que los valores Hash calculados pueden ser los mismos, se pensará erróneamente que parecen existir datos inexistentes)
Suplemento: Además, existen las siguientes soluciones:
- Mejore la complejidad de la identificación para evitar adivinar las reglas de identificación
- Realizar verificación de formato básico de datos.
- Fortalecer la verificación de permisos de usuario
- Haga un buen trabajo limitando el flujo actual de parámetros del punto de acceso
3.3.2 Implementar NULLvalores almacenados en caché
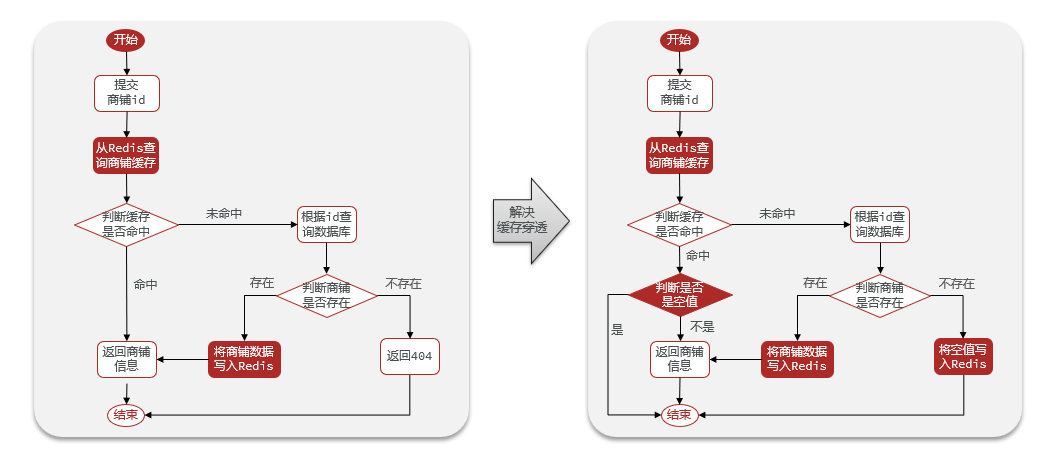
ilustrar:
Ideas de implementación:
Si se alcanza un valor no nulo en Redis, se devolverá un mensaje de error directamente. Cuando se consulta la ID inexistente, el valor nulo se almacena en caché en Redis y se devolverá un mensaje de error una vez que se complete el caché. Esto reducirá la cantidad de consultas a la base de datos la próxima vez que vuelva a consultar.
- Modificar métodos
ShopServiceImplde clasequeryById
/**
* @param id 商铺的ID
* @return 商铺
*/
@Override
public Result queryById(Long id) {
// 1.从Redis查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key); //要么返回null、要么返回非空数据
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// StrUtil.isNotBlank方法会忽略null、空、换行符
// 3.存在,则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 4.判断命中是否为Null值--此处用缓存Null值方案解决缓存穿透
if (ObjectUtil.isNotNull(shopJson)) {
// 不是null值,就为空
return Result.fail("店铺不存在!");
}
// 5.未命中,根据Id查询数据库
Shop shop = getById(id);
// 5.1判断数据库中数据是否存在
if (ObjectUtil.isNull(shop)) {
// 5.2将未命中的数据进行空值写入Redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return Result.fail("店铺不存在!");
}
// 5.3命中,写入Redis--此处用超时剔除,解决缓存中的更新策略、用Key的TTL随机值,解决缓存雪崩
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 6.返回结果
return Result.ok(shop);
}
3.5 Avalancha de caché
3.5.1 Descripción general
La avalancha de caché significa que una gran cantidad de claves de caché caducan al mismo tiempo o que el servicio Redis no funciona, lo que provoca que una gran cantidad de solicitudes lleguen a la base de datos, lo que genera una gran presión.
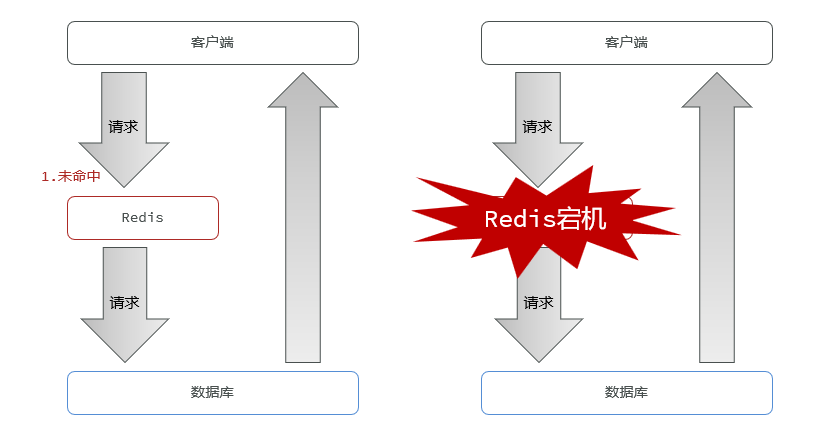
Descripción: Soluciones comunes para almacenar en caché avalanchas
- Agrega valores aleatorios al TTL de diferentes claves
- Utilice el clúster de Redis para mejorar la disponibilidad del servicio
- Agregar una política de limitación actual degradada al negocio de caché
- Agregar caché multinivel
3.5.2 Implementar el esquema TTL agregando valores aleatorios para diferentes claves
ilustrar:
Ideas de implementación:
Agregue un valor aleatorio al tiempo de vencimiento de la clave
- Modificar métodos
ShopServiceImplde clasequeryById
/**
* @param id 商铺的ID
* @return 商铺
*/
@Override
public Result queryById(Long id) {
// 1.从Redis查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 4.判断命中是否未Null值
if (ObjectUtil.isNull(shopJson)) {
return Result.fail("店铺不存在!");
}
// 5.不存在,根据Id查询数据库
Shop shop = getById(id);
if (ObjectUtil.isNull(shop)) {
// 6.将空值写入Redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 不存在,返回错误
return Result.fail("店铺不存在!");
}
// 7.存在,写入Redis-为商品增加随机的TTL值
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL + RandomUtil.randomLong(10), TimeUnit.MINUTES);
// 8.返回结果
return Result.ok(shop);
}
ilustrar:
Este método es relativamente sencillo para resolver el problema de la avalancha de caché: simplemente aumente aleatoriamente el valor TTL. Para soluciones más avanzadas, continúe leyendo a continuación.
3.6 Desglose del caché (énfasis)
3.6.1 Descripción general
El problema de la avería de la caché también se denomina problema de las teclas de acceso rápido, lo que significa que una clave a la que se accede de forma muy concurrente y que tiene un complicado negocio de reconstrucción de la caché de repente deja de ser válida. Innumerables solicitudes de acceso tendrán un gran impacto en la base de datos en un instante.
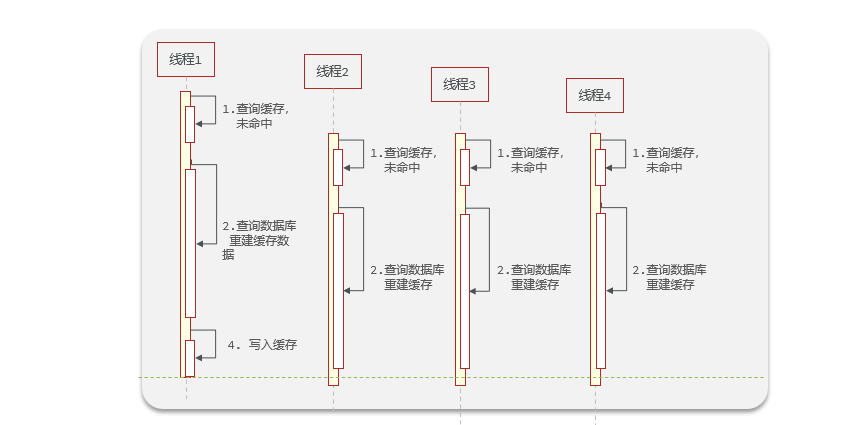
ilustrar:
- En el caso de alta concurrencia, una gran cantidad de subprocesos pierden datos en este momento. Y debido a que se necesita mucho tiempo para consultar el negocio de la base de datos, el tiempo de espera para la consulta comercial de la base de datos será demasiado largo.
- Si una gran cantidad de solicitudes pierden datos en este momento, muchos subprocesos accederán a la base de datos, lo que tendrá un gran impacto en la base de datos.
Hay dos soluciones comunes :
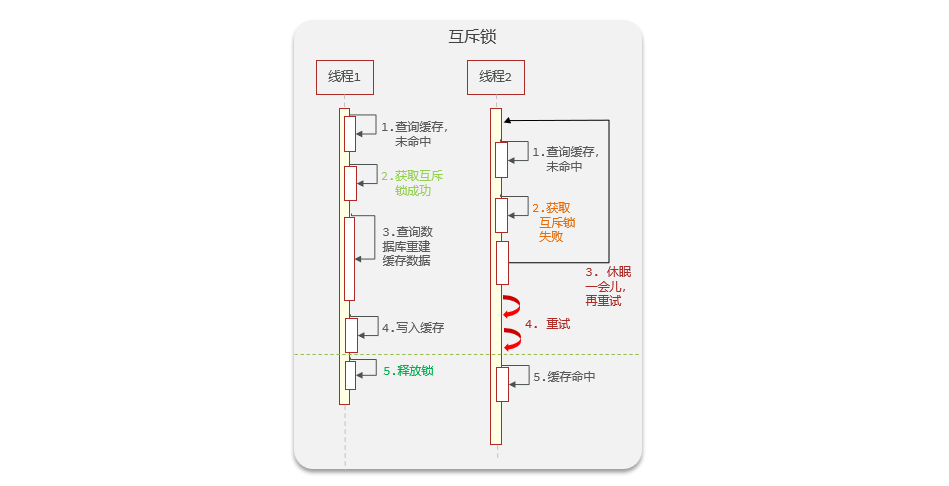
ilustrar:
- La solución a este problema es utilizar un bloqueo mutex . Es decir, cuando un subproceso se bloquea al acceder a la base de datos y luego libera el bloqueo una vez completado el acceso, si otros subprocesos quieren acceder a la base de datos, deben esperar hasta que se libere el bloqueo antes de acceder. Reduce la presión sobre la base de datos.
- Resolverlo mediante el uso de un bloqueo mutex afectará el rendimiento del servidor. Debido a que el servicio siempre está esperando, la obtención de datos es lenta
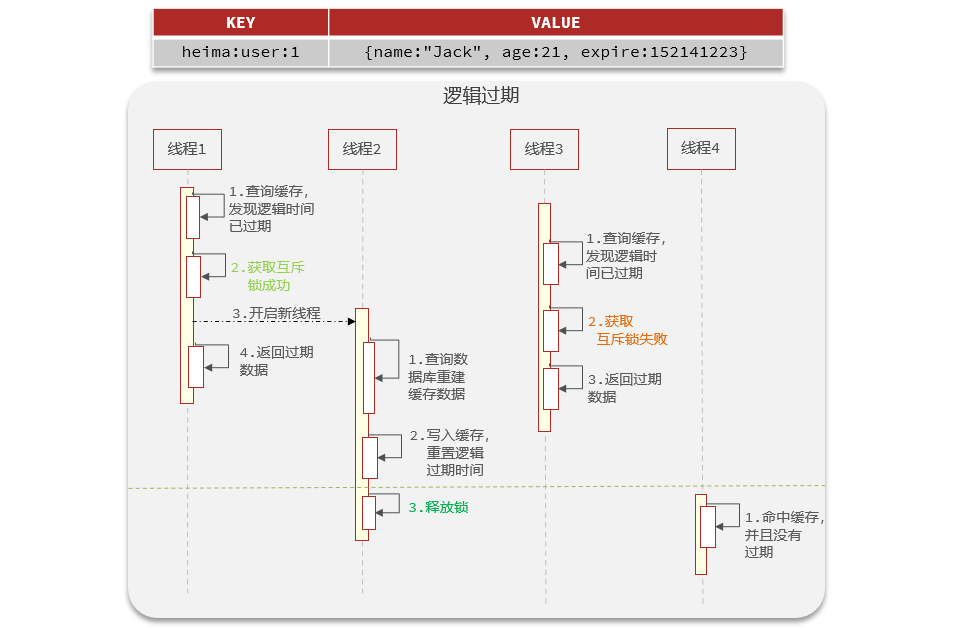
ilustrar:
- La solución a este tipo de solución es resolverla mediante el uso de caducidad lógica . Es decir, cuando un hilo accede a datos en Redis, se agrega un campo de vencimiento lógico a Redis. Si un hilo descubre que los datos han caducado lógicamente, se creará un nuevo hilo para obtener el bloqueo para obtener los datos. El hilo antiguo devuelve los datos antiguos.

ilustrar:
- Las soluciones Mutex y de caducidad lógica tienen sus propias ventajas y desventajas.
3.6.2 Implementar un esquema de bloqueo mutex
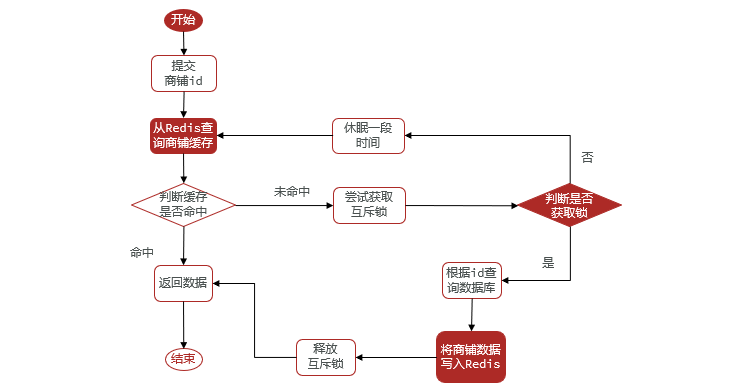
ilustrar:
Ideas de implementación:
El bloqueo que viene con sincronizado o bloqueo no puede cumplir con la lógica de negocios que implementamos. Cuando el hilo no puede obtener el bloqueo, esperará un cierto período de tiempo. Necesitamos implementar la lógica de los bloqueos personalizados a través de bloqueos mutex personalizados.
Paso 1: agregar bloqueo
- Agregar método
ShopServiceImpl_tryLock
/**
* @param key Redis中的键
* @return 加锁是否成功
*/
private Boolean tryLock(String key) {
// 设置锁的过期时间,防止死锁
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(key, "l", LOCK_SHOP_TTL, TimeUnit.MINUTES);
/*
注意:此处通过setIfAbsent方法,返回的结果的类型为boolean类型而不是Boolean类型。
Boolean是boolean的包装类,因此JDK17会进行拆箱。
拆箱可能会出现空指针异常,因此这里借用Hutool工具进行判别
* */
return BooleanUtil.isTrue(result);
}
Paso 2: Libera el bloqueo
- Agregar método
ShopServiceImpl_unLock
/**
* @param key Redis中的键
*/
private void unLock(String key) {
stringRedisTemplate.delete(key);
}
Paso 3: agregue un mecanismo de bloqueo de doble verificación
- Método
ShopServiceImplbajo modificaciónqueryById
@Override
public Result queryById(Long id) {
// 互斥锁解决缓存击穿
Shop shop = queryWithMutex(id);
if (ObjectUtil.isNull(shop)) {
return Result.fail("店铺不存在!");
}
// 7.返回结果
return Result.ok(shop);
}
/**
* 互斥锁解决缓存击穿
*
* @param id 店铺的Id信息
* @return 店铺信息
*/
public Shop queryWithMutex(Long id) {
// 1.从Redis查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key); //要么返回null、要么返回非空数据
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// StrUtil.isNotBlank方法会忽略null、空、换行符
// 3.存在,则直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
// 判断命中是否为Null值--此处用缓存Null值方案解决缓存穿透
if (ObjectUtil.isNotNull(shopJson)) {
// 不是null值,就为空
return null;
}
// 4.实现缓存重建
// 4.1获取互斥锁
String lockKey = "lock:shop" + id;
Shop shop = null;
try {
Boolean isLock = tryLock(lockKey);
// 4.2判断是否获取成功
if (!isLock) {
// 4.3失败,则休眠并重试
Thread.sleep(50);
return queryWithMutex(id);
}
Thread.sleep(200);
// 4.5成功,再次检测Redis缓存是否存在
String shopJsons = stringRedisTemplate.opsForValue().get(key); //此处实现了双重检验锁
if (StrUtil.isNotBlank(shopJsons)) {
return JSONUtil.toBean(shopJsons, Shop.class);
}
// 4.6根据Id查询数据库
shop = getById(id);
if (ObjectUtil.isNull(shop)) {
// 将空值写入Redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 5.不存在,返回错误
return null;
}
// 6.存在,写入Redis--此处用超时剔除,解决缓存中的更新策略、用Key的TTL随机值,解决缓存雪崩
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL + RandomUtil.randomLong(10), TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 7.释放互斥锁
unLock(lockKey);
}
// 8.返回结果
return shop;
}
Explicación: En Redis, ¿por qué se verifica el caché por segunda vez cuando se verifica dos veces el bloqueo?
- Cuando se utiliza el bloqueo de doble verificación para implementar el acceso al caché de Redis, la segunda verificación del caché es para garantizar que después de adquirir el bloqueo, otros subprocesos no hayan actualizado el caché durante este período.
- El bloqueo de doble verificación es una tecnología de control de concurrencia de subprocesos múltiples de uso común, que puede reducir la cantidad de usos de bloqueo y mejorar el rendimiento al tiempo que garantiza la seguridad de los subprocesos. Cuando se utilizan bloqueos de doble verificación, generalmente se realiza primero un juicio asincrónico. Si los datos requeridos existen en el caché, el resultado se devuelve directamente para evitar la sobrecarga de adquirir el bloqueo. Sin embargo, debido a la ejecución simultánea de varios subprocesos, pueden existir las siguientes situaciones:
- El subproceso A primero verifica el caché y descubre que está vacío, por lo que adquiere el bloqueo y comienza a cargar datos en el caché.
- En este momento, el subproceso B también realizó la primera verificación y descubrió que el caché estaba vacío, por lo que también intentó adquirir el bloqueo.
- Antes de que el subproceso B adquiera el bloqueo, el subproceso A completó la carga de los datos y liberó el bloqueo.
- El subproceso B adquiere el bloqueo, pero no sabe que el subproceso A ha cargado los datos en la memoria caché, por lo que continúa cargando los datos.
- Para evitar que el subproceso B cargue datos repetidamente, es necesaria la operación de verificar el caché por segunda vez. Al verificar el caché por segunda vez, el subproceso B verifica el caché nuevamente. Si descubre que el caché no está vacío, significa que otros subprocesos han cargado datos en el caché durante el proceso de adquisición del bloqueo. En este momento, El hilo B puede usar directamente los datos en el caché para evitar la carga repetida de datos.
3.6.3 Implementación del esquema de vencimiento lógico
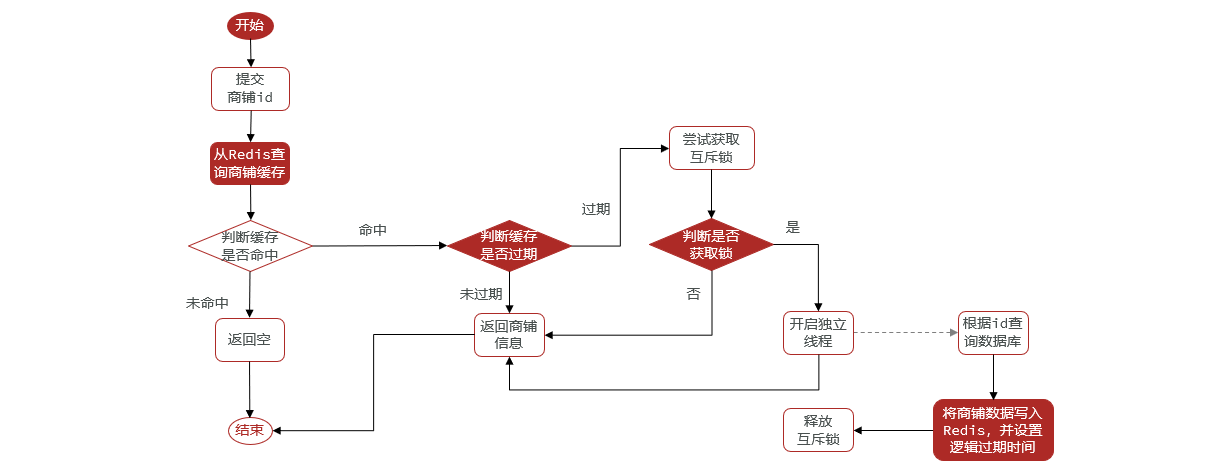
ilustrar:
- Ideas de implementación:
- El punto central es que si el hilo antiguo descubre que los datos han caducado, aún devolverá los datos antiguos, pero al mismo tiempo, se abrirá un nuevo hilo para actualizar los datos.
Paso 1: tiempo de vencimiento lógico
- crear
RedisDataclase
/**
* 用于封装Shop类,在Shop类现有的成员属性上添加新的成员属性(expireTime)
*/
@Data
public class RedisData<T> {
private LocalDateTime expireTime;
private T data; // 此数据类型定义为泛型,便于封装其余需要实现逻辑过期的类
}
ilustrar:
- Agregar tiempo de vencimiento lógico a la clase Shop
Paso 2: guarde los productos calientes
- Agregar método
ShopServiceImpl_shopSave2Redis
/**
* 保存热点商品到Redis
*
* @param id 商铺Id
* @param expireSeconds 过期时间
*/
public void shopSave2Redis(Long id, Long expireSeconds) {
// 1.查询商品
Shop shop = getById(id);
// 2.封装逻辑过期时间
RedisData<Shop> redisData = new RedisData<>();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
// 3.添加缓存
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}
ilustrar:
Agregue un método para guardar productos populares y guardar los productos en Redis
Reponer:
- En cualquier categoría de prueba, agregue productos populares a través del fondo de gestión de productos simulado
@Autowired ShopServiceImpl shopService; /** * 通过模拟商品管理后台,添加热点商品 */ @Test public void testSave() { shopService.shopSave2Redis(1L, 10L); }
Paso 3: agregar caducidad lógica
1. Modificar el método ShopServiceImplen la clase.queryById
@Override
public Result queryById(Long id) {
// 缓存Null值解决缓存穿透
// Shop shop = queryWithPassThrough(id);
// 互斥锁解决缓存击穿
// Shop shop = queryWithMutex(id);
// 逻辑过期方式解决缓存击穿
Shop shop = queryWithLogicExpire(id);
if (ObjectUtil.isNull(shop)) {
return Result.fail("店铺不存在!");
}
// 7.返回结果
return Result.ok(shop);
}
2. Cree un grupo de subprocesos
/**
* 创建线程池
*/
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
ilustrar:
- Cree un grupo de subprocesos para que subprocesos adicionales puedan consultar y actualizar datos
3. Implemente el método de vencimiento lógico y ShopServiceImplagregue queryWithLogicExpiremétodos a la clase.
/**
* 逻辑过期方式解决缓存击穿
*
* @param id 店铺的Id信息
* @return 店铺信息
*/
public Shop queryWithLogicExpire(Long id) {
// 1.从Redis查询商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key); //要么返回null、要么返回非空数据
// 2.判断是否存在
if (StrUtil.isBlank(shopJson)) {
// 3.未命中,直接返回空
return null;
}
// 4.命中,需要先把Json序列化为对象
RedisData<Shop> redisData = JSONUtil.toBean(shopJson, new TypeReference<RedisData<Shop>>() {
}.getType(), false);
Shop shop = redisData.getData();
// 5.检查缓存过期时间
if (redisData.getExpireTime().isAfter(LocalDateTime.now())) {
// 5.1未过期,直接返回旧数据
return shop;
}
// 5.2已过期,缓存重建
// 6.缓存重建
// 6.1获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
Boolean isLock = tryLock(lockKey);
if (isLock) {
// 6.2获取互斥锁成功,再次检查缓存过期时间
String result = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(result)) {
RedisData<Shop> redisData2 = JSONUtil.toBean(result, new TypeReference<RedisData<Shop>>() {
}.getType(), false);
Shop shop2 = redisData2.getData();
if (redisData.getExpireTime().isAfter(LocalDateTime.now())) {
return shop2;
}
}
// 6.3开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 6.3.1重建锁
this.shopSave2Redis(1L, 20L);// 这里便于测试设置时长为20秒。实际情况建议30分钟查一次
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
// 6.3.2释放锁
unLock(lockKey);
}
});
}
// 6.4获取互斥锁失败,直接返回过期数据
return shop;
}
3.7 Empaquetado de herramientas de almacenamiento en caché
ilustrar:
Esta clase de herramienta está escrita con la ayuda de herramientas, genéricos, etc. de Hutool. Esta clase de herramienta ha sido ajustada, verificada y es precisa.
- Ejemplos de uso de herramientas
// 缓存Null值解决缓存穿透
Shop shop = cacheClient.queryWithPassThrough(CACHE_SHOP_KEY, id, Shop.class,this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 逻辑过期方式解决缓存击穿
Shop shop = cacheClient.queryWithLogicExpire(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);
ilustrar:
- Para utilizar la clase de herramienta, debe pasar la clave almacenada en Redis y el tipo de valor de retorno que necesita para consultar la base de datos.
- Crear herramienta de clase CacheClient
@Slf4j
@Component
@AllArgsConstructor
public class CacheClient {
@Autowired
StringRedisTemplate stringRedisTemplate;
/**
* 创建线程池
*/
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
/**
* 加锁
*
* @param key Redis中的键
* @return 加锁是否成功
*/
private Boolean tryLock(String key) {
// 设置锁的过期时间,防止死锁
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(key, "l", LOCK_SHOP_TTL, TimeUnit.MINUTES);
/*
注意:此处通过setIfAbsent方法,返回的结果的类型为boolean类型而不是Boolean类型。
Boolean是boolean的包装类,因此JDK17会进行拆箱。
拆箱可能会出现空指针异常,因此这里借用Hutool工具进行判别
* */
return BooleanUtil.isTrue(result);
}
/**
* 解锁
*
* @param key Redis中的键
*/
private void unLock(String key) {
stringRedisTemplate.delete(key);
}
/**
* 设置存储在Redis中的键,并指定Redis中的过期时间
*
* @param key 键
* @param value 值
* @param time 时间
* @param unit 时间单位
*/
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
/**
* 设置存储在Redis中的键,并指定对象的逻辑过期时间
*
* @param key 键
* @param value 值
* @param time 过期时间
* @param unit 时间单位
*/
public void setWithLogicExpire(String key, Object value, Long time, TimeUnit unit) {
RedisData<Object> redisData = new RedisData<>();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData)); // 此处设置RedisData对象的值
}
/**
* 缓存Null值解决缓存穿透
*
* @param keyPrefix 键的前缀
* @param id 存储键的前缀以及查询数据库的ID
* @param type 存储数据的类型
* @param dbFallback 获取数据库数据的逻辑
* @param time 过期时间
* @param unit 时间单位
* @param <R> 返回值类型
* @param <ID> id类型
* @return 存储数据类的对象
*/
public <R, ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type,
Function<ID, R> dbFallback, Long time, TimeUnit unit) {
// 1.从Redis查询缓存数据
String key = keyPrefix + id;
String strJson = stringRedisTemplate.opsForValue().get(key); //要么返回null、要么返回非空数据
// 2.判断数据是否存在
if (StrUtil.isNotBlank(strJson)) {
// StrUtil.isNotBlank方法会忽略null、空、换行符
// 3.存在,则直接返回
return JSONUtil.toBean(strJson, type);
}
// 4.不存在,则进一步判断
// 4.1判断命中是否为Null值--此处实现了缓存Null值方案(不是null值,就为空),缓解了缓存穿透问题的影响
if (ObjectUtil.isNotNull(strJson)) {
return null;
}
// 4.2查询数据库,获得返回值数据
R r = dbFallback.apply(id);
// 5.判断数据是否存在
if (ObjectUtil.isNull(r)) {
// 5.1不存在
// 将空值写入Redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 返回空
return null;
}
// 5.2存在
// 写入Redis--此处实现了超时剔除功能,缓解了缓存中的更新策略的影响、实现了Key的TTL随机值,缓解了缓存雪崩问题的影响
this.set(key, JSONUtil.toJsonStr(r), time + RandomUtil.randomLong(5), unit);
// 6.返回结果
return r;
}
/**
* 逻辑过期方式解决缓存击穿
*
* @param keyPrefix 键的前缀
* @param id 存储键的前缀以及查询数据库的ID
* @param type 存储数据的类型
* @param dbFallback 获取数据库数据的逻辑
* @param time 过期时间
* @param unit 时间单位
* @param <R> 返回值类型
* @param <ID> id类型
* @return 存储数据类的对象
*/
public <R, ID> R queryWithLogicExpire(String keyPrefix, ID id, Class<R> type,
Function<ID, R> dbFallback, Long time, TimeUnit unit) {
// 1.从Redis查询商铺缓存
String key = keyPrefix + id;
String jsonStr = stringRedisTemplate.opsForValue().get(key); //要么返回null、要么返回非空数据
// 2.判断数据是否命中
if (StrUtil.isBlank(jsonStr)) {
// 2.1未命中,直接返回空
return null;
}
// 2.2.命中,需要先把Json序列化为对象
RedisData<R> redisData = JSONUtil.toBean(jsonStr, new TypeReference<RedisData<R>>() {
}.getType(), false);
R r = redisData.getData(); // 注意,此时因实用Hutool工具进行类型转换,返回的R类型为JSONObject
R bean = JSONUtil.toBean((JSONObject) r, type);
// 3.检查缓存过期时间
if (redisData.getExpireTime().isAfter(LocalDateTime.now())) {
// 3.1未过期,直接返回旧数据
return bean;
}
// 3.2已过期,缓存重建
// 4.缓存重建
// 4.1获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
Boolean isLock = tryLock(lockKey);
if (isLock) {
// 4.2获取互斥锁成功,再次检查缓存过期时间
String jsonStr2 = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(jsonStr2)) {
RedisData<R> redisData2 = JSONUtil.toBean(jsonStr2, new TypeReference<RedisData<R>>() {
}.getType(), false);
R r2 = redisData2.getData();
if (redisData2.getExpireTime().isAfter(LocalDateTime.now())) {
return JSONUtil.toBean((JSONObject) r2, type);
}
}
// 6.3开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 6.3.1重建锁
// 查询商品
R r3 = dbFallback.apply(id); // 此处可用debug进行调试 log.debug("我成功执行");
// 添加缓存
this.setWithLogicExpire(key, r3, time, unit);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
// 6.3.2释放锁
unLock(lockKey);
}
});
}
// 6.4获取互斥锁失败,直接返回过期数据
return bean;
}
}
4. Venta flash de cupones
Resumen de notas:
Comando Redis:
- En la función de lograr una ID única global, se utilizan
Stringlos comandos en Redisincrementy las estadísticas de la cantidad de ID generadas se realizan a través de métodos.- Para implementar la función de bloqueo distribuido, se utilizan
Stringlos comandos de RedissetIfAbsenty la adquisición del bloqueo distribuido se realiza mediante métodos.StringEn la implementación de la función de venta flash de optimización de Redis, los comandos en Redis se utilizansetpara agregar productos más vendidos a través de métodos.Dificultades en la implementación de funciones:
- Al implementar la función de estrategia de actualización de caché, utilice la eliminación del tiempo de espera para lograr requisitos de coherencia más bajos. Utilice la actualización activa para realizar el proceso de eliminar primero la base de datos y luego eliminar el caché para lograr mayores requisitos de coherencia.
- Al resolver el problema del inventario sobrevendido, utilizamos
eqel método de la herramienta MyBatis-Plus para implementar inteligentemente el método CAS para resolver el problema.- Al implementar la función de una persona y una persona,
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();la API se utiliza inteligentemente para obtener el objeto representado por el marco Spring. ysynchronizedel uso inteligente de las cerraduras. El método de usotoStringde métodosintern()garantiza la unicidad del objeto bloqueado.- Al implementar la función de bloqueo distribuido,
Thread.currentThread().getId()la API se utiliza inteligentemente para obtener el ID del hilo actual como clave para obtener el bloqueo. Modifique la lógica de liberación de bloqueo y determine inteligentemente si el bloqueo liberado es su propio bloqueo antes de liberarlo para evitar la eliminación accidental del bloqueo.- Para implementar la función de venta flash de optimización de Redis, se escribió un script
Luapara garantizar que la operación sea atómica y completar la función de pedido de cupones. UtilicestringRedisTemplate.executemétodos para ejecutar scripts Lua. Además del uso de colas de bloqueo, también se incluye la función de procesamiento asincrónico de pedidos. Por favor consulte esta sección para más detalles.- Al utilizar
Redssionherramientas, tenga una comprensión teórica y la aplicación del principio de bloqueo reentrante, el principio de reintento, el principio de renovación del tiempo de espera y los problemas de coherencia maestro-esclavo.- En la herramienta MyBatis-Plus,
update()se utiliza el método y.setSqlel método se utiliza junto con la ejecución complementaria de la declaración SQL.
4.1 Descripción general
La venta flash de cupones es una forma de actividad promocional que atrae a los usuarios a participar en compras urgentes proporcionando cupones en cantidades limitadas dentro de un tiempo limitado, logrando así el propósito de marketing y ventas. La siguiente es una forma sencilla de implementar ventas flash con cupones:
- Prepare cupones: cree un lote de cupones y establezca su cantidad y fecha de vencimiento.
- Mostrar información del evento: muestra información del evento de venta flash en la página de inicio, incluido el descuento del cupón, el precio original, el precio de la venta flash, la hora de inicio y finalización del evento, etc.
- Participación del usuario en Lightning Deal: el usuario ingresa a la página Lightning Deal antes de la hora de inicio del evento y espera a que comience Lightning Deal. Una vez que comienza la venta flash, los usuarios pueden hacer clic en el botón de venta flash para realizar una compra.
- Verificar inventario: cuando el usuario hace clic en el botón de venta flash, primero verifique si el inventario del cupón es suficiente. Si el stock es insuficiente, indicará que la venta flash finalizó o se agotó.
- Procesamiento de pedidos: Si el inventario es suficiente, se genera un pedido y se deduce el inventario de cupones. Las transacciones de la base de datos se pueden utilizar para garantizar la coherencia en la realización de pedidos y las deducciones de inventario.
- Pago del pedido: el usuario paga el monto del pedido y completa el proceso de transacción.
- Finalización de la venta flash: una vez finalizada la actividad de venta flash, se recopilarán los datos de la actividad, como el número de participantes, el número de pedidos exitosos, el uso de cupones, etc.
En el desarrollo real, también es necesario considerar el acceso concurrente y la optimización del rendimiento en escenarios de alta concurrencia, como limitar la frecuencia de ventas flash de los usuarios y utilizar medios técnicos como el almacenamiento en caché distribuido y las colas de mensajes para mejorar las capacidades de procesamiento concurrente del sistema.
Cabe señalar que la venta flash de cupones es una actividad promocional especial que requiere una consideración integral de las necesidades comerciales, el diseño del sistema, el ajuste del rendimiento y otros factores para garantizar la estabilidad del sistema y la experiencia del usuario.
4.2 ID única a nivel mundial
4.2.1 Descripción general
Cada tienda puede publicar cupones:

ilustrar:
Cuando un usuario se apresura a comprar, se generará un pedido y se guardará en la tabla tb_voucher_order, pero si la tabla de pedidos utiliza la base de datos para aumentar automáticamente la ID, habrá algunos problemas. Por ejemplo: 1. La regularidad de la identificación es demasiado obvia, 2. Limitada por la cantidad de datos en una sola tabla.
El generador de ID global es una herramienta utilizada para generar ID únicos globalmente en sistemas distribuidos, generalmente debe cumplir con las siguientes características
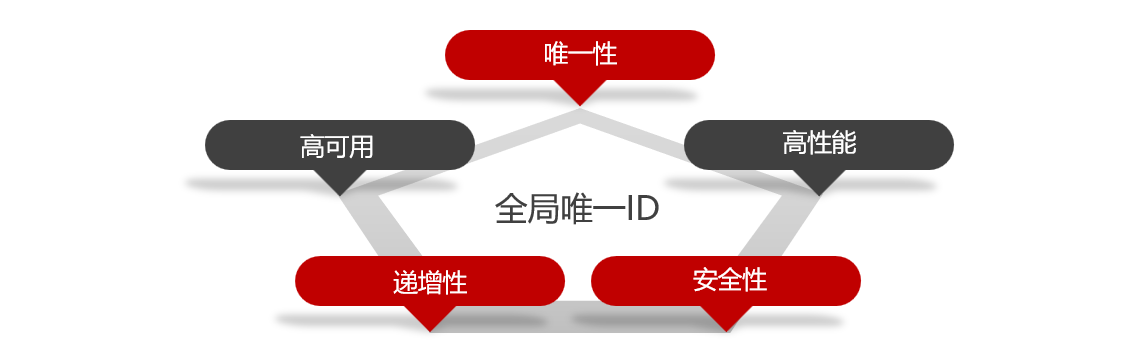
ilustrar:
- Unicidad, singularidad global, sin diferencias.
- Alto rendimiento, puede generar la identificación requerida en muy poco tiempo.
- Alta disponibilidad, capaz de implementar fácilmente operaciones avanzadas como la replicación maestro-esclavo
- Cada vez más, puede ajustarse a ciertas reglas. Seguridad, los usuarios no lo adivinarán fácilmente.
4.2.2 Casos de uso básicos

Descripción: Componentes de la identificación
- Bit de signo: 1 bit, siempre 0
- Marca de tiempo: 31 bits, en segundos, se pueden usar durante 69 años (el valor máximo que puede representar una marca de tiempo de 31 bits es 2 ^ 31 - 1, que es aproximadamente igual a 69 años)
- Número de serie: 32 bits, contador en segundos, admite 2^32 ID diferentes por segundo
Aviso:
Generar una identificación única a nivel mundial requiere cumplir cinco características para garantizar el rendimiento del sistema.
Paso 1: herramienta de generación de identificación personalizada
- Crear
RedisIdWorkerclase de herramienta
@Component
public class RedisIdWorker {
@Resource
StringRedisTemplate stringRedisTemplate;
private final static long BEGIN_TIMESTAMP = 1076630400L; //秒级时间戳有10位,指定日期
public long nextId(String keyPrefix) {
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowTimeStamp = now.toEpochSecond(ZoneOffset.UTC);
long timeStamp = nowTimeStamp - BEGIN_TIMESTAMP;
// 2.生成序列号
// 2.1获取当前日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yy:MM:dd"));
// 2.2自增长
long count = stringRedisTemplate.opsForValue().increment("inc:" + keyPrefix + date); // 若所操作的键不存在,使用Increment可以自动的创建该键
// 3.拼接并返回
return timeStamp << 32 | count;
}
}
Reponer:
En Redis, el tipo de datos utilizado para la operación de incremento automático es un entero de 64 bits con signo, que es del tipo int64. Por lo tanto, el límite superior de la operación de incremento automático es 9223372036854775807 (2^63 - 1). Por lo tanto, se recomienda utilizar claves diferentes para claves diferentes.
Reponer:
- Java convertirá automáticamente binario a decimal cuando se utilice
<<el operador o , por ejemplo|1076630400L01000000 00101100 00010011 10000000
- Cuando un número binario se desplaza 32 bits hacia la izquierda, se añaden 0 hacia la derecha.
01000000 00101100 00010011 10000000 00000000 00000000 00000000 00000000
- Referencia detallada: Operador de turnos en Java - Zhihu (zhihu.com)
Paso 2: prueba
- nueva
Testclase
private static final ExecutorService es = Executors.newFixedThreadPool(500);
@Test
public void testSize() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(300); // 创建一个计数器,初始值为300
Runnable task = () -> {
// 定义一个任务,生成唯一ID并打印
for (int i = 0; i < 100; i++) {
long code = redisIdWorker.nextId("code"); // 生成唯一ID
System.out.println(code); // 打印ID
}
latch.countDown(); // 任务执行完毕,计数器减一
};
long begin = System.currentTimeMillis(); // 记录开始时间
for (int i = 0; i < 300; i++) {
es.submit(task); // 提交任务到线程池执行
}
latch.await(); // 等待计数器归零,即等待所有任务执行完毕
long end = System.currentTimeMillis(); // 记录结束时间
System.out.println(end - begin); // 打印任务执行时间
}
4.3 Pedido con cupón de venta flash
4.3.1 Descripción general
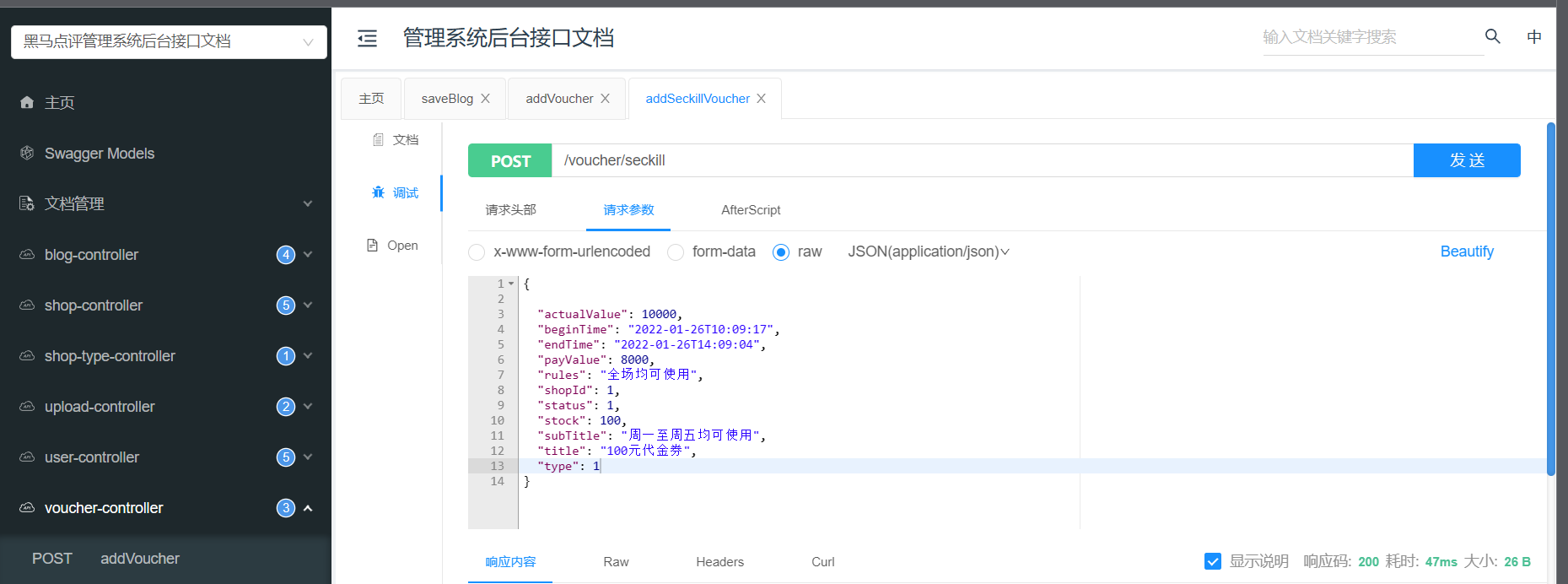
ilustrar:
- Este backend es Knife4j. Consulte el registro para conocer el proceso de implementación detallado.
- Primero debe agregar cupones de venta por tiempo limitado en segundo plano y luego implementar la operación después de que los cupones se hayan agregado correctamente.
4.3.2 Casos de uso básicos
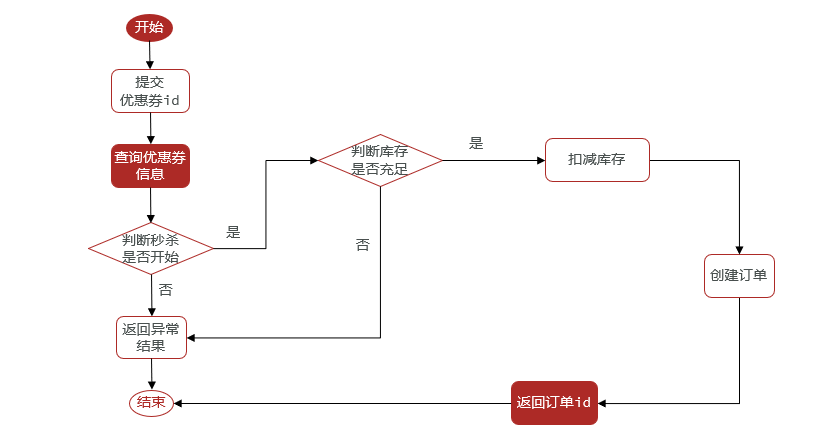
ilustrar:
Ideas de implementación: determinar anomalías de tiempo, determinar el inventario, operar el inventario, crear pedidos, devolver ID de pedidos e implementar funciones básicas de pedido de cupones.
Paso 1: Implementar la lógica de orden de venta flash de cupones
- Modificar métodos
VoucherOrderServiceImplen claseseckillVoucher
@Resource
private ISeckillVoucherService seckillVoucherService;
@Autowired
RedisIdWorker redisIdWorker;
@Override
@Transactional // 设置到多张表的操作,需要添加事务
/**
* 秒杀优惠券业务
*
* @param voucherId 优惠券的Id
* @return 订单信息
*/
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 已经结束
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
return Result.fail("库存不足");
}
// 5.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock -1").eq("voucher_id", voucherId).update();
if (!success) {
// 扣减失败
return Result.fail("库存不足");
}
// 6.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 6.1设置订单ID
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 6.2设置用户ID
Long userId = UserHolder.getUser().getId();
voucherOrder.setUserId(userId);
// 6.3设置优惠券ID
voucherOrder.setVoucherId(voucherId);
// 6.4保存订单
save(voucherOrder);
// 7.返回订单id
return Result.ok(orderId);
}
4.3.3 Resumen

ilustrar:
En este punto, consulte el stock del pedido. Se descubre que el inventario se ha vuelto negativo, lo que indica que el inventario está sobrevendido . Consulte la siguiente sección para resolver este problema.
4.4 Problema de sobreventa de inventario
4.4.1 Descripción general
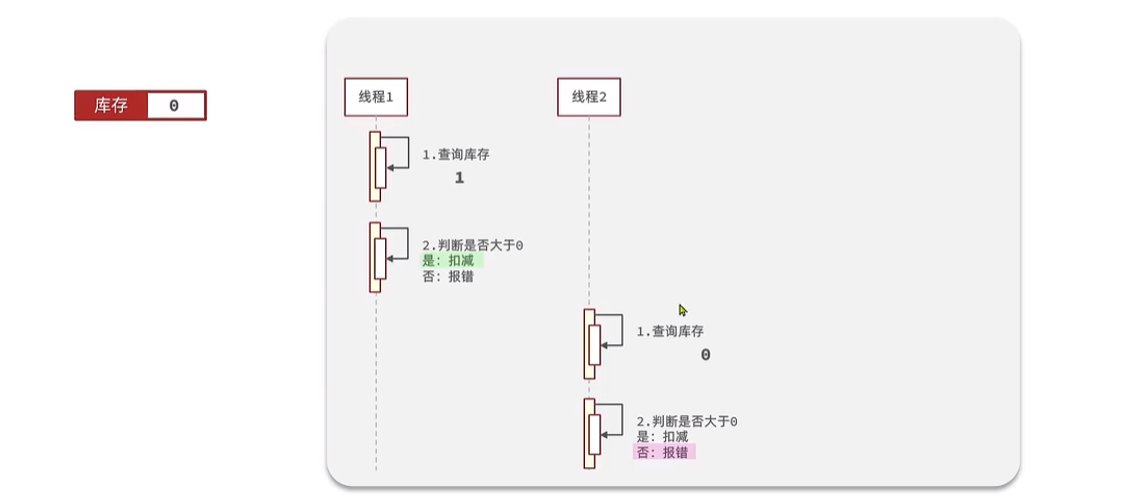
ilustrar:
En circunstancias normales, cuando el hilo 1 encuentra que el inventario es mayor que cero, se deduce el inventario. Inmediatamente después, el subproceso 2 volvió a juzgar el inventario y descubrió que el inventario aún era mayor que cero, por lo que normalmente informó un error.
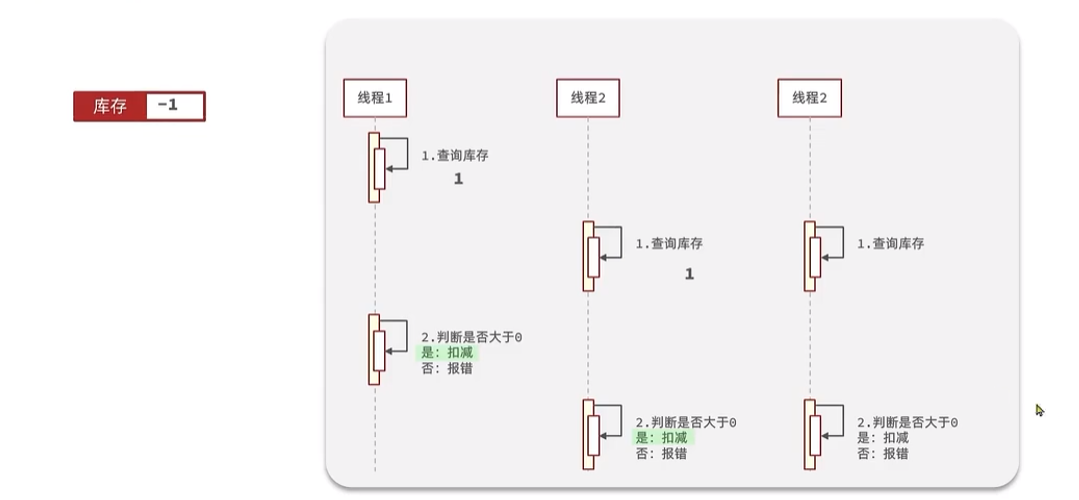
ilustrar:
En circunstancias anormales, cuando el subproceso 1 consulta que el inventario es normal, otros subprocesos consultan y descubren que el inventario es normal , realizan deducciones de inventario a su vez y se producirá el problema de sobreventa.
- Para resolver el problema de sobreventa, puede bloquear, que se divide en bloqueo pesimista y bloqueo optimista.
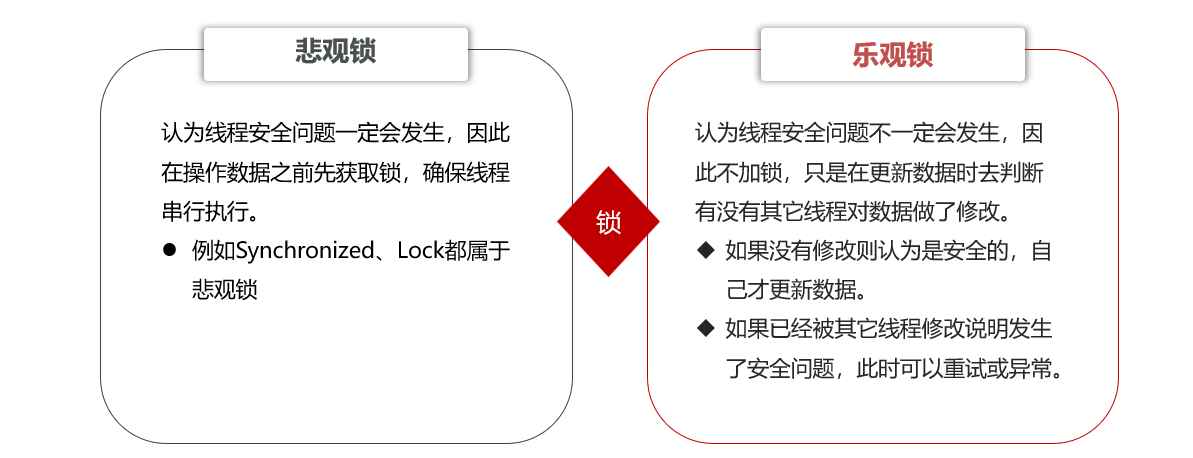
ilustrar:
- Dado que el método de modificación del bloqueo optimista es permitir que los subprocesos se ejecuten en serie, ya se demostró al consultar el caché de productos y no se demostrará aquí.
- El método de modificación del bloqueo optimista verificará si alguien está verificando los datos antes de que el programa los ejecute para ver si alguien los ha actualizado.
- El bloqueo optimista se ejecuta de dos maneras:
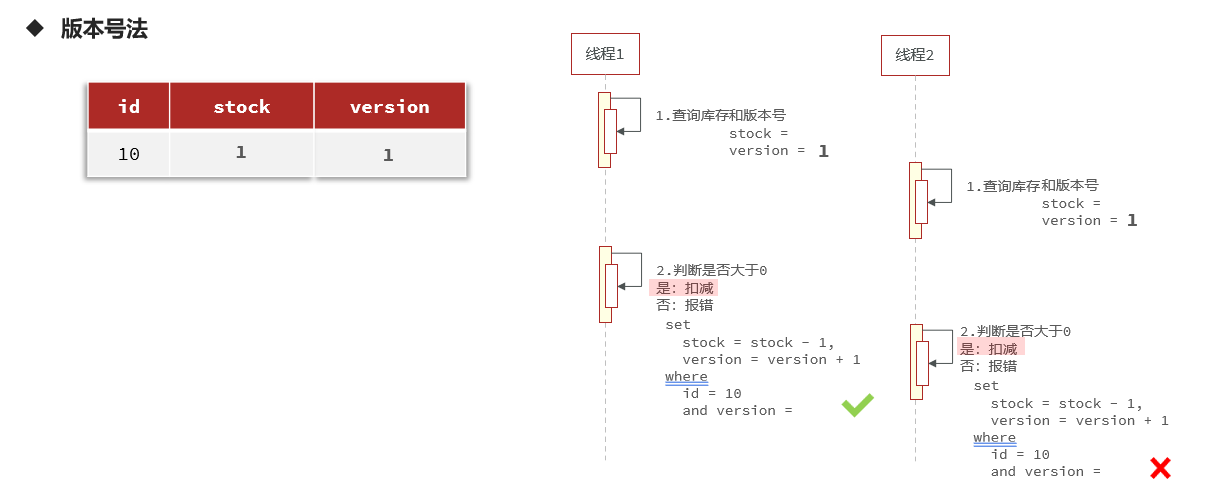
ilustrar:
Antes de cada ejecución de la modificación de la declaración SQL, verifique si la versión es consistente con el número de versión consultado, si es consistente, fallará.
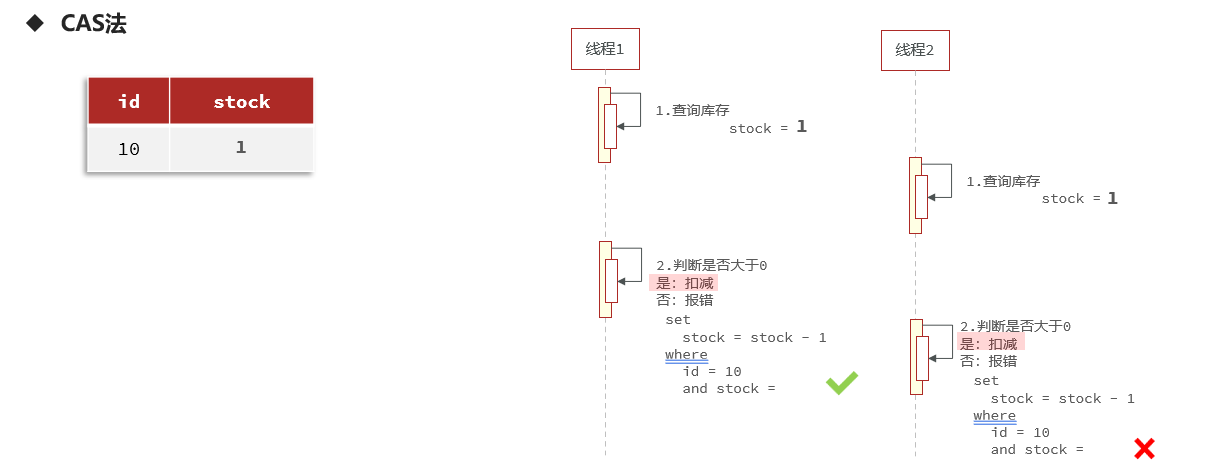
ilustrar:
Dado que consultar el número de versión puede averiguar si los datos se han modificado, consultar el inventario también puede averiguar si los datos se han modificado.
Suplemento: problema de sobreventa resuelto
- Bloqueo pesimista: agregue un bloqueo de sincronización para permitir que los subprocesos se ejecuten en serie
- Ventajas: simple y tosco.
- Desventajas: rendimiento mediocre
- Bloqueo optimista: sin bloqueo, determine si otros subprocesos se están modificando al actualizar
- Ventajas: buen rendimiento
- Desventajas: existe el problema de la baja tasa de éxito.
4.4.2 Implementar el método CAS (Comparar y cambiar)
ilustrar:
Ideas de implementación:
Agregue un bloqueo para implementar un bloqueo optimista, de modo que al actualizar los datos pueda verificar si todavía hay stock, si lo hay, la venta flash será exitosa.
Paso 1: Agregar verificación de consulta CAS
- Método de modificación
VoucherOrderServiceImpl_seckillVoucher
@Override
@Transactional // 设置到多张表的操作,需要添加事务
/**
* 秒杀优惠券业务
*
* @param voucherId 优惠券的Id
* @return 控制层对此业务的处理结果
*/
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 已经结束
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
return Result.fail("库存不足");
}
// 5.扣减库存-使用CAS方式解决超卖问题
boolean success = seckillVoucherService.update()
.setSql("stock = stock -1")
.eq("voucher_id", voucherId)
.gt("stock", 0) // 让库存大于零,若有库存则进行扣库存
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足");
}
// 6.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 6.1设置订单ID
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 6.2设置用户ID
Long userId = UserHolder.getUser().getId();
voucherOrder.setUserId(userId);
// 6.3设置优惠券ID
voucherOrder.setVoucherId(voucherId);
// 6.4保存订单
save(voucherOrder);
// 7.返回订单id
return Result.ok(orderId);
}
ilustrar:
- Al deducir el inventario, se considera que el inventario es mayor que 0 en lugar de compararlo con la cantidad al consultar el inventario.
- A través de la comparación entre pares, el sistema sentirá que existe un problema de seguridad del inventario, lo que provocará que se detenga la compra del inventario.
4.4.3 Resumen
En este momento, habrá una situación en la que una persona compre varios pedidos. Si desea realizar la función de una persona, un pedido, consulte la siguiente sección
4.5 Función de una persona, una orden (punto difícil)
4.5.1 Descripción general
Un mismo usuario solo puede agregar un pedido al mismo cupón
4.5.2 Caso de uso básico
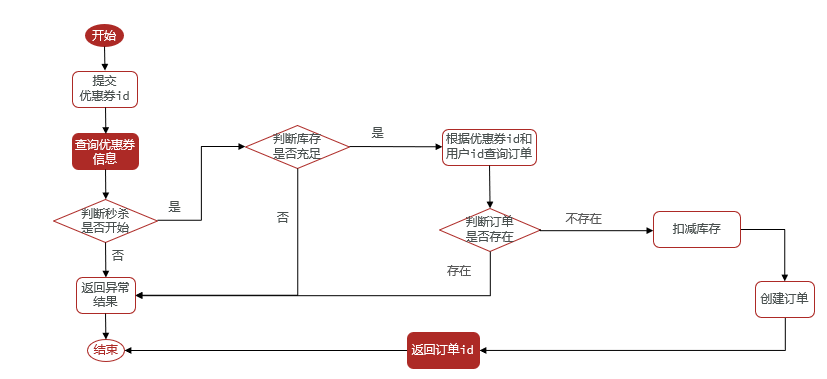
ilustrar:
Ideas de implementación:
Cuando el inventario sea suficiente, determine si el pedido existe según el ID de usuario y el ID del cupón para evitar que una persona realice varios pedidos.
Paso 1: agregar dependencias
- Modificar
pom.xmlarchivos
<!--aspectjweaver-使用API获取动态代理对象时会用到此依赖的底层源码-->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
Paso 2: Implementar una persona, una sola función
- Modificar los métodos
VoucherOrderServiceImplde la claseseckillVouchery agregarcreateVoucherOrdermétodos.
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 已经结束
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
return Result.fail("库存不足");
}
/*
补充:在此处加锁,而不是在createVoucherOrder方法内加锁。此时,代码的逻辑变为事务执行完成之后再进行锁的释放,保证事务的成功提交。若在方法内加锁,代码的逻辑变为锁已经释放了,但是事务还没有执行完成,依旧会造成线程安全问题。
* */
Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
/*
1.使用用户的ID作为锁对象是为了缩小加锁的范围,只为访问此方法的用户加锁。实现了不同用户加不同的锁,保证不同用户之间的并发性能。
2.toString()方法,会在底层new一个新的对象进行加锁,因此添加intern方法,使得率先寻找常量池中的字符串地址值,确保了加锁对象唯一。这样不同的对象就会加不同的锁 */
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); // 通过此API可以拿到当前对象的代理对象(process),此处也就是IVoucherOrderService接口
return proxy.createVoucherOrder(voucherId); // 用代理对象来调用此createVoucherOrder函数,因为此代理对象由Spring进行创建,因此该函数可被Spring进行管理。而不是用原生对象来调用此createVoucherOrder函数,例如this.createVoucherOrder。用原生对象来调用此函数,不能够触发@Transactional注解的功能
}
}
/*
@Transactional此注解的生效,是因为Spring对当前VoucherOrderServiceImpl类做了动态代理,从而拿到了VoucherOrderServiceImpl类的代理对象createVoucherOrder方法。因此用代理对象来做的动态代理,所以才能够实现事务管理的功能
*/
@Transactional
public Result createVoucherOrder(Long voucherId) {
// 5.根据优惠券ID和用户ID判断订单是否存在-实现一人一单功能
// 5.1获取用户ID
Long userId = UserHolder.getUser().getId();
// 5.2判断此订单是否存在
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if (count > 0) {
// 该用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
// 6.扣减库存-使用CAS方式解决超卖问题
boolean success = seckillVoucherService.update()
.setSql("stock = stock -1")
.eq("voucher_id", voucherId)
.gt("stock", 0) // 让库存大于零,若有库存则进行扣库存
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足");
}
// 7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 7.1设置订单ID
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 7.2设置用户ID
voucherOrder.setUserId(userId);
// 7.3设置优惠券ID
voucherOrder.setVoucherId(voucherId);
// 7.4保存订单
save(voucherOrder);
// 8.返回订单id
return Result.ok(orderId);
}
4.5.3 Resumen
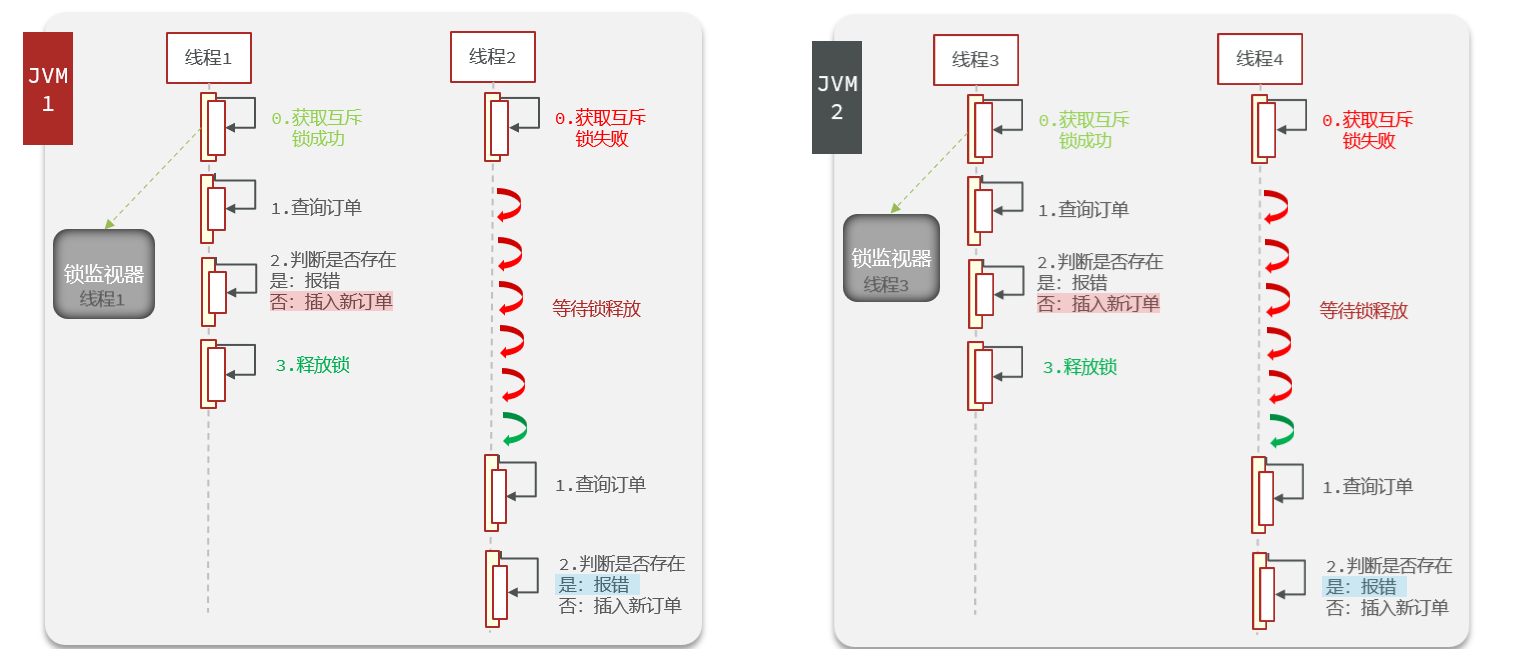
ilustrar:
El bloqueo puede resolver el problema de seguridad de una sola persona en el caso de una sola máquina, pero no funcionará en el modo de clúster.
Después de crear el equilibrio de carga a través de Nginx, se utilizan diferentes monitores de bloqueo en diferentes JVM, por lo que simplemente bloquear al mismo usuario mediante un bloqueo pesimista provocará problemas de seguridad de concurrencia.
Si necesita resolver diferentes monitores de bloqueo, consulte la siguiente sección
4.6 Bloqueo distribuido
4.6.1 Descripción general
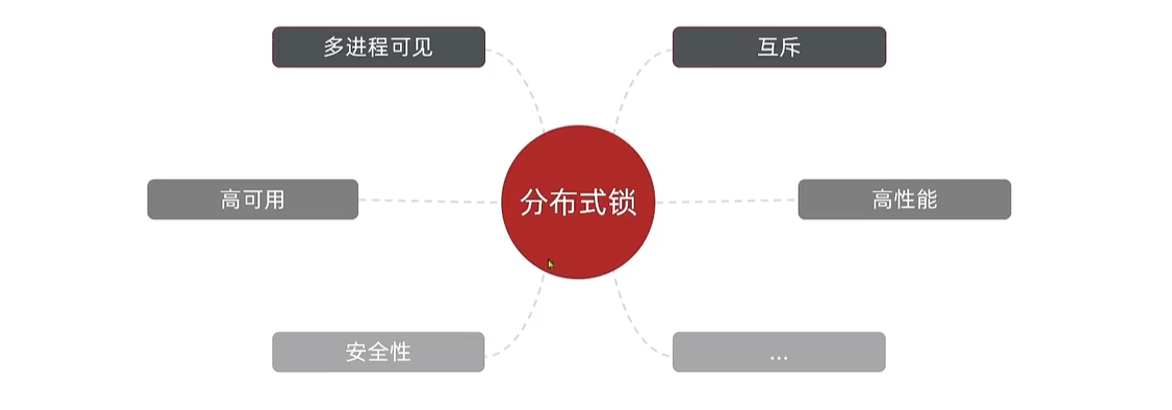
ilustrar:
Bloqueo distribuido: un bloqueo que es visible y mutuamente exclusivo para múltiples procesos en un sistema distribuido o modo de clúster
·El núcleo de los bloqueos distribuidos es lograr la exclusión mutua entre múltiples procesos. Hay muchas formas de lograr este punto y hay tres comunes:
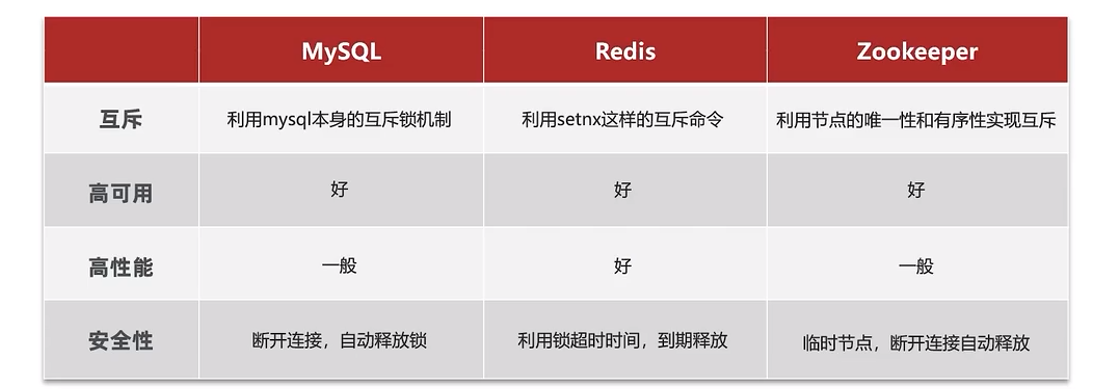
ilustrar:
- Todas las bases de datos MySQL admiten mecanismos de transacción: cuando se escriben datos, se bloquean automáticamente para lograr una exclusión mutua. MySQL admite el modo maestro-esclavo. El rendimiento es ligeramente peor que el de Redis
- Redis usa Setnx para implementar la exclusión mutua, el único inconveniente es que cuando la seguridad no es lo suficientemente alta y se agota el tiempo de espera, es probable que se produzca un punto muerto.
- Zookeeper utiliza el mecanismo de nodo interno para lograr unicidad y orden. El rendimiento es muy consistente, por lo que el mecanismo maestro-esclavo empeorará el rendimiento.
Bloqueo distribuido basado en Redis
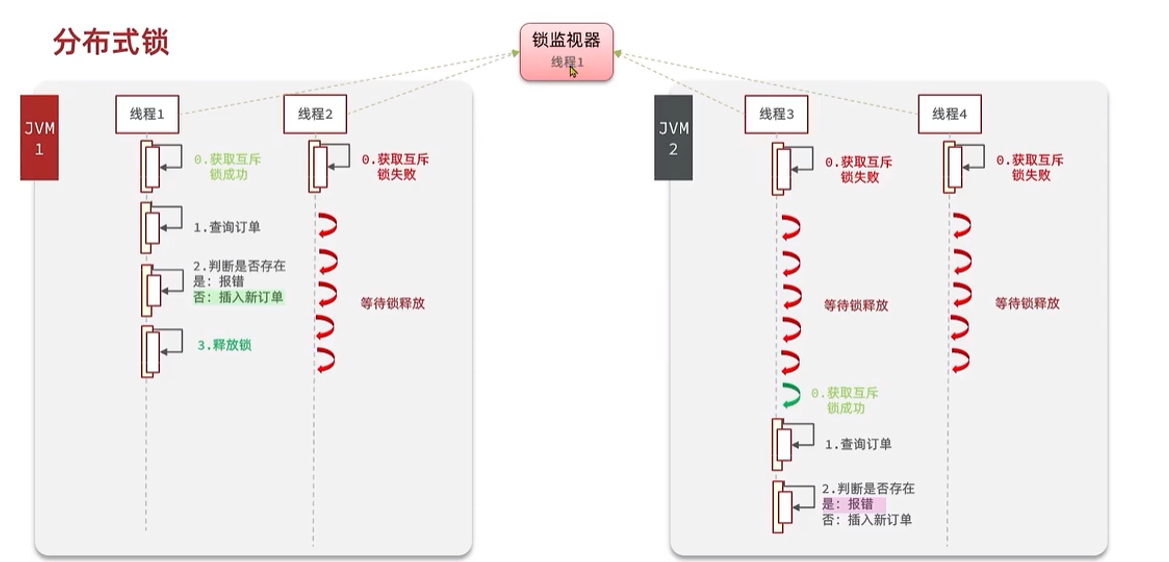
ilustrar:
Al implementar bloqueos distribuidos, solo necesita hacer que el monitor de bloqueo sea visible para cada JVM.
Hay dos métodos básicos que deben implementarse al implementar bloqueos distribuidos: adquirir bloqueos y liberar bloqueos.
La adquisición de candados se divide en métodos mutuamente excluyentes para garantizar que solo un subproceso pueda adquirir el candado. Y la forma sin bloqueo , intente una vez, devuelva verdadero si tiene éxito, devuelva falso si falla
# 添加锁,NX是互斥、EX是设置超时时间 SET lock thread1 NX EX 10 # 同时设置超时与判断,确保操作的原子性La liberación de cerraduras se divide en liberación manual y liberación de tiempo de espera , y se agrega un período de tiempo de espera al adquirir la cerradura.
# 释放锁,删除即可 DEL key
4.6.2 Implementar la versión preliminar del bloqueo distribuido de Redis
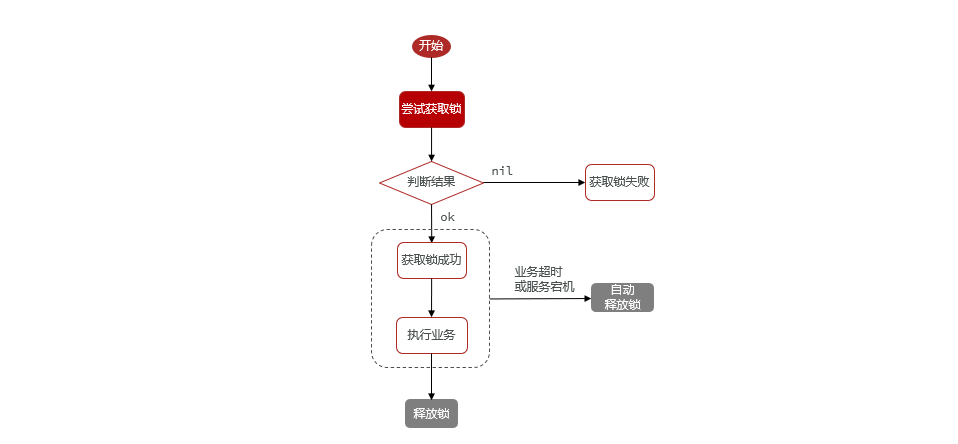
ilustrar:
Ideas de implementación:
Primero establezca un bloqueo distribuido. Antes de iniciar el negocio, intente obtener el candado de Redis, si la adquisición es exitosa, el negocio se ejecutará, de lo contrario fracasará.
Paso 1: crea un candado
- Crear
ILockinterfaz de bloqueo
/**
* 锁的操作方式,获取锁,释放锁
*/
public interface ILock {
/**
* 获取锁
*
* @param timeoutSec 锁持有的超时时间,过期后自动释放
* @return true代表获取锁成功;false代表获取锁失败
*/
boolean tryLock(Long timeoutSec);
/**
* 释放锁
*/
void unLock();
}
ilustrar:
Defina la interfaz de bloqueo, implemente especificaciones operativas básicas, obtenga el bloqueo y libere el bloqueo.
Paso 2: clase de implementación de bloqueo distribuido
- Crea
SimpleRedisLockuna clase e implementa laILockinterfaz de bloqueo.
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
private static final String KEY_PREFIX = "lock:";
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean tryLock(Long timeoutSec) {
long threadID = Thread.currentThread().getId(); //获取线程的ID作为锁值
Boolean success = stringRedisTemplate.opsForValue() // 设置锁的超时时间,防止锁的释放
.setIfAbsent(KEY_PREFIX + name, String.valueOf(threadID), timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success); //因为返回结果为包装类型,拆箱涉及到可能空指针的影响,这里判断一下
}
@Override
public void unLock() {
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
ilustrar:
Según la interfaz que define el bloqueo, implemente operaciones básicas, obtenga el bloqueo y libere el bloqueo.
Paso 3: modificar la lógica empresarial
- Modificar métodos y métodos
VoucherOrderServiceImplen clases.seckillVouchercreateVoucherOrder
@Resource
private ISeckillVoucherService seckillVoucherService;
@Resource
StringRedisTemplate stringRedisTemplate;
@Autowired
RedisIdWorker redisIdWorker;
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 已经结束
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
return Result.fail("库存不足");
}
Long userId = UserHolder.getUser().getId();
// 创建锁对象
SimpleRedisLock simpleRedisLock = new SimpleRedisLock("order:" + userId, stringRedisTemplate); //拼接用户的ID,为每个用户添加自己的锁
// 获取锁
boolean success = simpleRedisLock.tryLock(10L);
if (BooleanUtil.isFalse(success)) {
// 获取锁失败,返回错误或重试
return Result.fail("不允许重复下单");
}
try {
// 获取代理对象
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); //通过此API可以拿到当前对象的代理对象(process),此处也就是IVoucherOrderService接口
return proxy.createVoucherOrder(voucherId); //用代理对象来调用此createVoucherOrder函数,此时该函数可被Spring进行管理。因为此代理对象由Spring进行创建
} finally {
// 释放锁
simpleRedisLock.unLock();
}
}
@Transactional
public Result createVoucherOrder(Long voucherId) {
// 5.根据优惠券ID和用户ID判断订单是否存在-实现一人一单功能
// 5.1获取用户ID
Long userId = UserHolder.getUser().getId();
// 5.2判断此订单是否存在
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if (count > 0) {
// 该用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
// 6.扣减库存-使用CAS方式解决超卖问题
boolean success = seckillVoucherService.update()
.setSql("stock = stock -1")
.eq("voucher_id", voucherId)
.gt("stock", 0) // 让库存大于零,若有库存则进行扣库存
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足");
}
// 7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 7.1设置订单ID
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 7.2设置用户ID
voucherOrder.setUserId(userId);
// 7.3设置优惠券ID
voucherOrder.setVoucherId(voucherId);
// 7.4保存订单
save(voucherOrder);
// 8.返回订单id
return Result.ok(orderId);
}
ilustrar:
- Modifique la lógica empresarial de la clase VoucherOrderServiceImpl para implementar el bloqueo manual y la liberación de bloqueo manual.
- Vale la pena señalar que al crear un objeto de bloqueo, debe especificar el valor de Clave como el identificador único del usuario y crear bloqueos para diferentes usuarios, de modo que se pueda realizar una persona, una persona y una única función. Si no se agrega la identificación única del usuario, la identificación bloqueará a todos los usuarios
Reponer:
- Dependiendo de la implementación de la versión preliminar de bloqueos distribuidos, los subprocesos pueden eliminar accidentalmente los bloqueos de otras personas. Debido a que el bloqueo comercial del subproceso 1 provocó que el bloqueo se liberara con el tiempo, el subproceso 2 descubrió que había adquirido el bloqueo por coincidencia. En este momento, después de que se completó el negocio del subproceso 1, el bloqueo se liberó manualmente, lo que provocó que el bloqueo del subproceso 2 se eliminara accidentalmente y se produjo el problema de la eliminación accidental de subprocesos concurrentes.
- En este momento, si desea cambiar y resolver este problema, puede juzgar si el candado es suyo antes de soltarlo, si es así, libérelo, si no, no lo suelte.
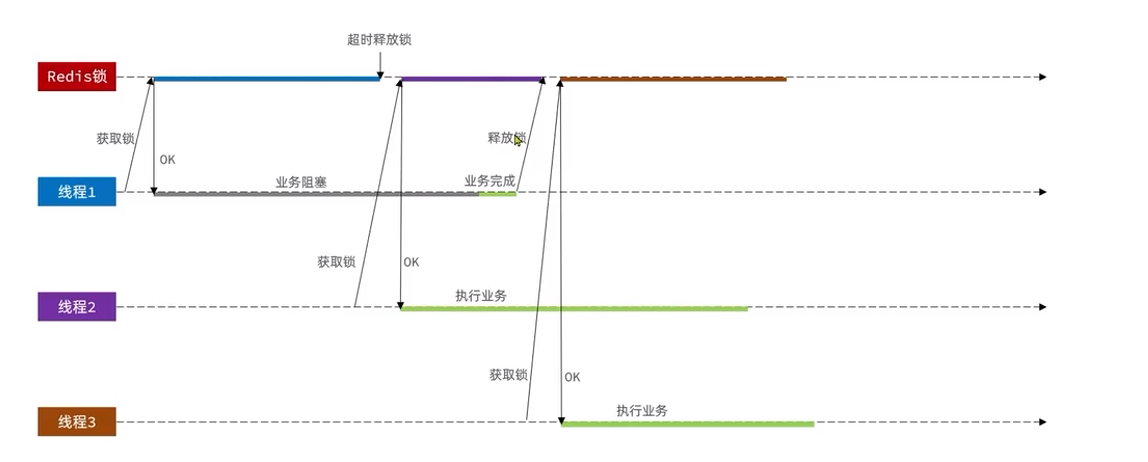
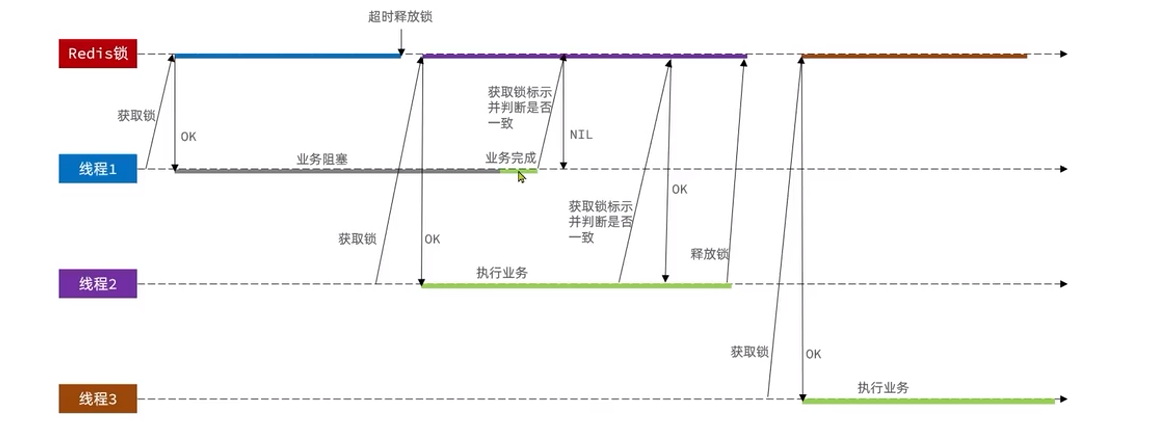
4.6.3 Implementar una versión mejorada del bloqueo distribuido de Redis
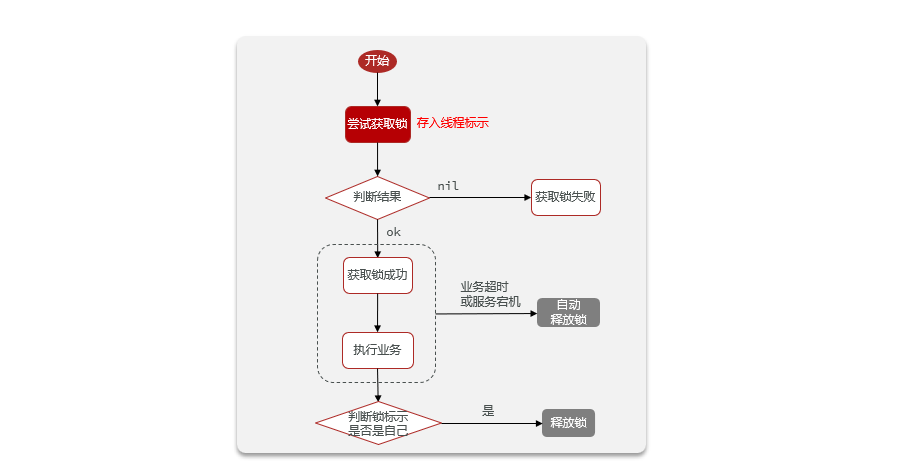
ilustrar:
Ideas de implementación:
1. Almacene el ID del hilo al adquirir el candado (puede estar representado por UUID)
2. Al liberar el bloqueo, primero obtenga el identificador del hilo en el bloqueo y determine si es consistente con el identificador del hilo actual. Si es consistente, suelte el bloqueo; si es inconsistente, no suelte el bloqueo.
Reponer:
¿Por qué se utiliza UUID como identificador del subproceso almacenado? Cada vez que se crea un subproceso dentro de la JVM, se incrementará el ID. En diferentes JVM, pueden ocurrir conflictos si el ID se usa directamente como identificador del subproceso. En este momento, use UUID para distinguir diferentes JVM
Paso 1: use setnx para crear bloqueos distribuidos
- Modificar
SimpleRedisLockclasestryLockyunLockmétodos.
public class SimpleRedisLock implements ILock {
private String name;
private StringRedisTemplate stringRedisTemplate;
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-"; // 标识忽略UUID默认自带的下划线
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean tryLock(Long timeoutSec) {
String threadID = ID_PREFIX + Thread.currentThread().getId(); //获取线程的ID作为锁值
Boolean success = stringRedisTemplate.opsForValue() // 设置锁的超时时间,防止锁的释放
.setIfAbsent(KEY_PREFIX + name, threadID, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success); //因为返回结果为包装类型,拆箱涉及到可能空指针的影响,这里判断一下
}
@Override
public void unLock() {
// 获取线程的标识
String threadID = ID_PREFIX + Thread.currentThread().getId();
// 获取锁的标识
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断锁标识和线程标识是否一致
if (ObjectUtil.equal(threadID, id)) {
// 相等,则删除
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
}
ilustrar:
Haga un juicio antes de eliminar el bloqueo cada vez. Determine si el ID del hilo y el ID del bloqueo son consistentes. Si son iguales, elimínelos. Si no son iguales, no son míos y no se eliminarán.
Reponer:
Dependiendo de la implementación de la versión mejorada del bloqueo distribuido, es posible que los subprocesos eliminen accidentalmente los bloqueos de otras personas. Porque una vez que se completa el negocio del subproceso 1 y se juzga el éxito de su propio subproceso, cuando el mecanismo de liberación del bloqueo está a punto de ejecutarse, el bloqueo del subproceso hace que el bloqueo se libere con el tiempo (el mecanismo de recolección de basura de JVM puede provocar el bloqueo del subproceso). En este momento, el hilo 2 descubrió que obtuvo el candado por coincidencia. En este momento, después de que se completó el negocio del subproceso 1, el bloqueo se liberó manualmente, lo que provocó que el bloqueo del subproceso 2 se eliminara accidentalmente y se produjo el problema de la eliminación accidental de subprocesos concurrentes.
Si podemos completar el juicio del hilo y la liberación del bloqueo después de que el negocio se complete como una transacción (usando el script Lua), garantizar su atomicidad puede completar la implementación del bloqueo distribuido de Redis.
En este momento, dado que Redis ya no admite la operación de scripts Lua en la versión 7.0.x, ya no completaremos la producción de scripts Lua.
Es más, cuando se utiliza Setnx para implementar bloqueos distribuidos de Redis, también ocurrirán los siguientes problemas
A continuación, observe el método Redisson para optimizar los bloqueos distribuidos utilizando el método Redission.
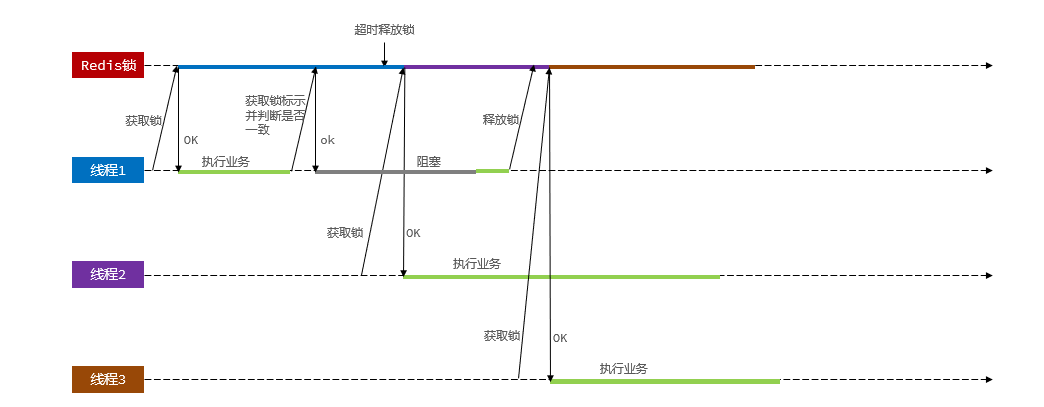

4.6.4Herramienta Redisson
4.6.4.1 Descripción general
Redisson es una cuadrícula de datos en memoria de Java (In-Memory Data Grid) implementada sobre la base de Redis. No solo proporciona una serie de objetos Java comunes distribuidos, sino que también proporciona muchos servicios distribuidos, incluida la implementación de varios bloqueos distribuidos.

Dirección del sitio web oficial: https://redisson.org , Dirección de GitHub: https://github.com/redisson/redisson
4.6.4.2 Implementar la versión avanzada del bloqueo distribuido de Redis
Paso 1: Introducir dependencias
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
Reponer:
Se recomienda que al establecer bloqueos distribuidos, no se recomienda integrar SpringBoot a través del iniciador, porque reemplazará la implementación de la API de Redis proporcionada por el sitio web oficial de Spring.
Paso 2: agregar Redissonclase de configuración
@Configuration
public class RedisConfig {
@Bean
public RedissonClient getRedisClient() {
// 配置类
Config config = new Config();
// 添加redis地址,这里添加了单点的地址,也可以使用config.useClusterServers()添加集群地址
config.useSingleServer().setAddress("redis://10.13.164.55:6379").setPassword("qweasdzxc");
// 创建客户端
return Redisson.create(config);
}
}
ilustrar:
Configuración del cliente Redisson utilizando el método de nodo único de Redis
Paso 3: Se utilizan Redissoncerraduras distribuidas
- Modificar el método
VoucherOrderServiceImplde la clase de implementación.seckillVoucher
/**
* 秒杀优惠券业务
*
* @param voucherId 优惠券的Id
* @return 控制层对此业务的处理结果
*/
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 已经结束
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
return Result.fail("库存不足");
}
Long userId = UserHolder.getUser().getId();
// 创建锁对象
RLock lock = redissonClient.getLock("lock:order:" + userId);
// 获取锁(参数含义分别是,获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位)
boolean isLock = lock.tryLock(); // 默认不重试,锁超过30秒自动释放
if (BooleanUtil.isFalse(isLock)) {
// 获取锁失败,返回错误或重试
return Result.fail("不允许重复下单");
}
try {
// 获取代理对象
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); //通过此API可以拿到当前对象的代理对象(process),此处也就是IVoucherOrderService接口
return proxy.createVoucherOrder(voucherId); //用代理对象来调用此createVoucherOrder函数,此时该函数可被Spring进行管理。因为此代理对象由Spring进行创建
} finally {
// 释放锁(其Redisson内部会自动进行锁释放标识的比对)
lock.unlock();
}
}
ilustrar:
Puede ver que el método utilizado por Redisson es similar al de nuestra clase de bloqueo autoconstruida SimpleRedisLock.
4.6.4.3 Principio de bloqueo reentrante

ilustrar:
Una cerradura reentrante no solo registra la cerradura adquirida en la cerradura, sino que también registra la cantidad de veces que se adquiere la cerradura. El núcleo subyacente utiliza el tipo Hash en Redis para registrar los ID de los subprocesos y registrar el número de reingresos.
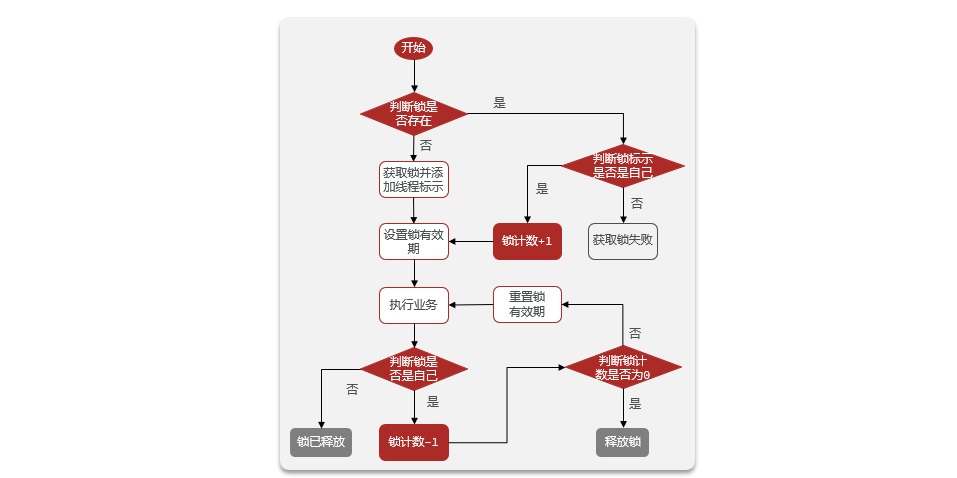
ilustrar:
Este es el principio de las cerraduras reentrantes en Redisson. Según el diagrama de flujo, se puede dividir en dos partes: adquirir bloqueos y liberar bloqueos.
- obtener bloqueo
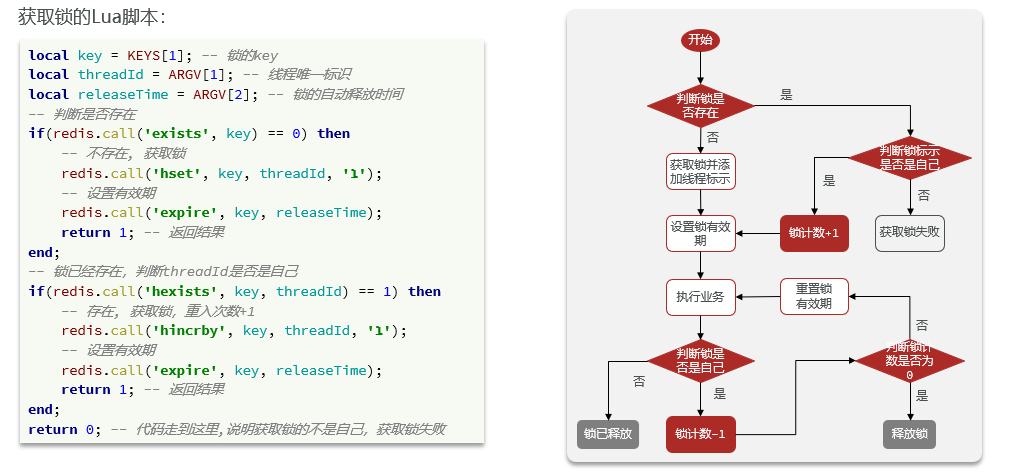
ilustrar:
- Al adquirir un candado, determine si el candado existe.
- Si el candado no existe, agregue el identificador del hilo después de adquirir el candado y luego establezca el período de validez del candado.
- Si el bloqueo existe, determine si le pertenece según el identificador del hilo. Si es así, agregue 1 al recuento y establezca el período de validez del bloqueo. Si no es suyo, puede deberse a que otros hilos están usando el bloquear, por lo que la adquisición falla.
- desbloquear bloqueo
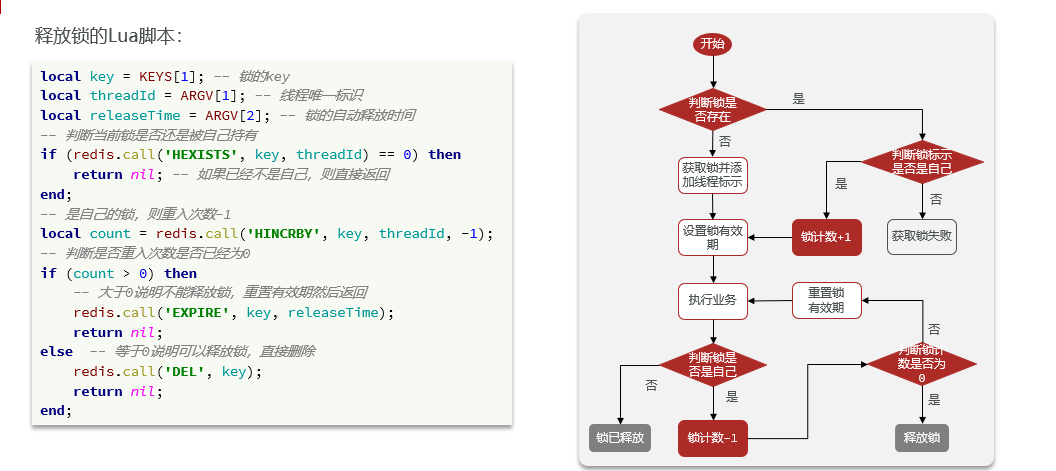
ilustrar:
- Una vez ejecutado el negocio, se vuelve a juzgar si el candado le pertenece.
- Si no es su propio candado, el candado ya no se liberará para evitar la eliminación accidental de candados utilizados por otros subprocesos.
- Si es tu propio candado, la habilidad se reduce en 1.
- En este momento, determine si el recuento es 0. Debido a que el negocio ejecutado por este subproceso puede ser un subnegocio en un negocio anidado, el bloqueo no se puede liberar directamente, sino que se debe determinar si se debe determinar el bloqueo después de que se determine el recuento. liberarlo.
- Si es 0, el bloqueo se libera.
- Si no es 0, restablezca el período de validez del bloqueo y repita los pasos anteriores nuevamente.
- ejemplo de código
@SpringBootTest
@Slf4j
public class RedissonTests {
@Autowired
RedissonClient redissonClient;
RLock lock;
@BeforeEach
void before() {
lock = redissonClient.getLock("order");
}
@Test
void method1() {
boolean isLock = lock.tryLock();
if (!isLock) {
log.error("获取锁失败,1");
return;
}
try {
log.info("获取锁成功,1");
method2();
} finally {
log.info("释放锁,1");
lock.unlock();
}
}
void method2() {
boolean isLock = lock.tryLock();
if (!isLock) {
log.error("获取锁失败, 2");
return;
}
try {
log.info("获取锁成功,2");
} finally {
log.info("释放锁,2");
lock.unlock();
}
}
}
Descripción: resultado

Reponer:
- Redisson obtiene el código fuente del bloqueo
- Al observar el código fuente para adquirir el bloqueo, puede ver que todavía se ejecuta con el script Lua y la lógica es similar al diagrama de flujo dibujado. Pero lo que se devuelve con éxito aquí es
nil, y lo que se devuelve si falla es el tiempo restante.- Código fuente de bloqueo de liberación de Redisson
- Al observar el código fuente publicado, puede ver que todavía se ejecuta con el script Lua y la lógica es similar al diagrama de flujo dibujado. Pero en realidad hay un mensaje publicado aquí.
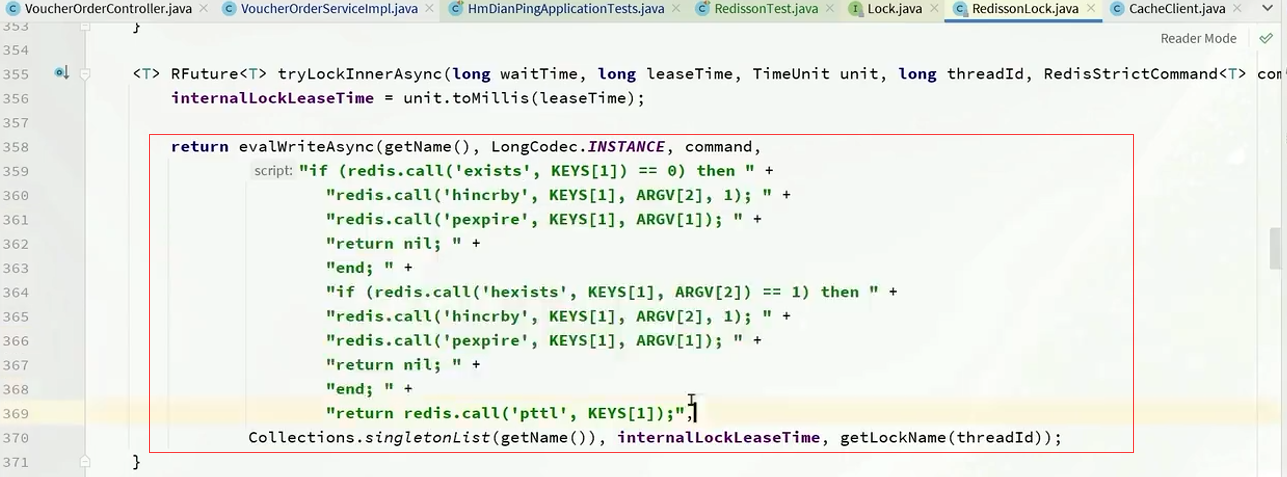
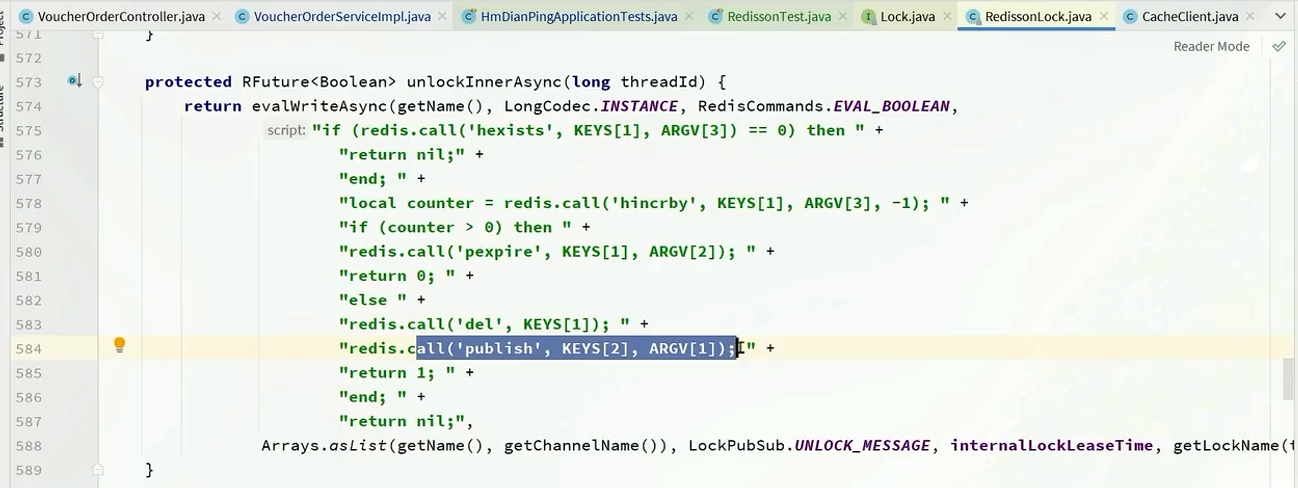
4.6.4.4 Principio de reintento
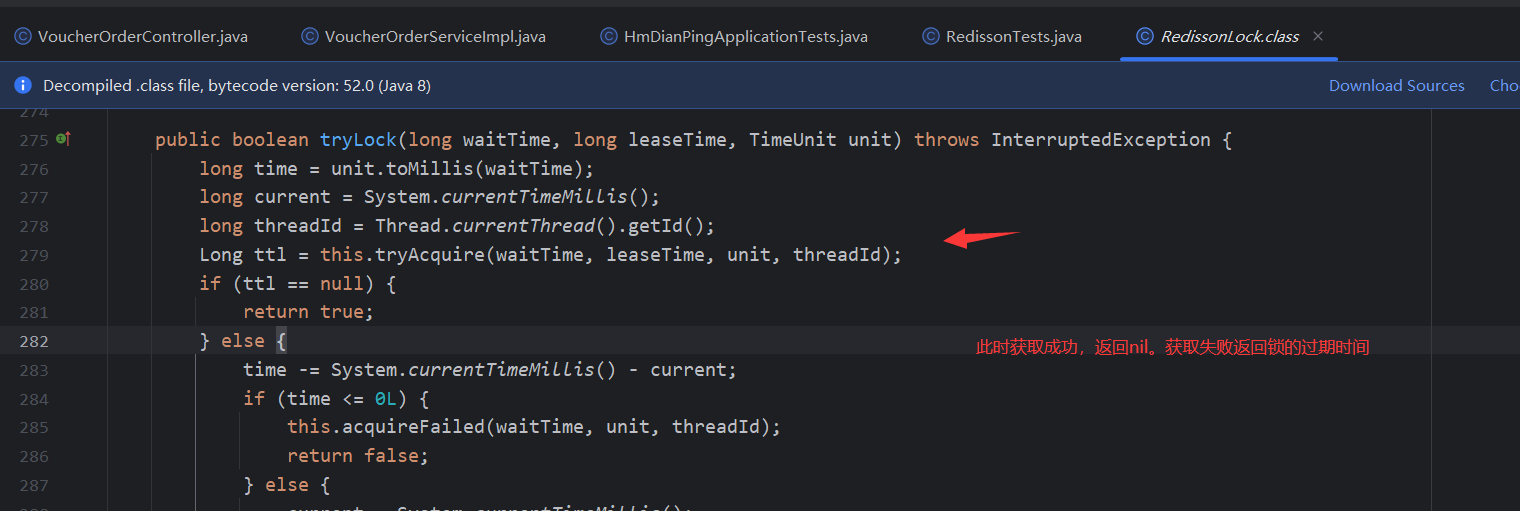
ilustrar:
- En este momento, si la adquisición es exitosa, se devolverá nil. Si la adquisición falla, se devolverá el tiempo de vencimiento del bloqueo.
- Ver código fuente recuperable
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException { long time = unit.toMillis(waitTime); // 将等待时间转换为毫秒 long current = System.currentTimeMillis(); // 当前时间 long threadId = Thread.currentThread().getId(); // 当前线程ID Long ttl = this.tryAcquire(waitTime, leaseTime, unit, threadId); // 尝试获取锁的剩余过期时间 if (ttl == null) { return true; // 成功获取到锁,返回true } else { time -= System.currentTimeMillis() - current; // 计算剩余等待时间 if (time <= 0L) { this.acquireFailed(waitTime, unit, threadId); // 等待时间已经用完,获取锁失败 return false; } else { current = System.currentTimeMillis(); // 更新当前时间 RFuture<RedissonLockEntry> subscribeFuture = this.subscribe(threadId); // 订阅锁释放事件 if (!subscribeFuture.await(time, TimeUnit.MILLISECONDS)) { // 等待一段时间看是否能够获取到锁释放事件的通知 if (!subscribeFuture.cancel(false)) { // 取消订阅 subscribeFuture.onComplete((res, e) -> { if (e == null) { this.unsubscribe(subscribeFuture, threadId); // 取消订阅成功后,执行取消订阅操作 } }); } this.acquireFailed(waitTime, unit, threadId); // 等待时间已经用完,获取锁失败 return false; } else { try { time -= System.currentTimeMillis() - current; // 更新剩余等待时间 if (time <= 0L) { this.acquireFailed(waitTime, unit, threadId); // 等待时间已经用完,获取锁失败 return false; } else { boolean var16; do { long currentTime = System.currentTimeMillis(); // 当前时间 ttl = this.tryAcquire(waitTime, leaseTime, unit, threadId); // 再次尝试获取锁的剩余过期时间 if (ttl == null) { var16 = true; // 成功获取到锁,返回true return var16; } time -= System.currentTimeMillis() - currentTime; // 更新剩余等待时间 if (time <= 0L) { this.acquireFailed(waitTime, unit, threadId); // 等待时间已经用完,获取锁失败 var16 = false; return var16; } currentTime = System.currentTimeMillis(); // 当前时间 if (ttl >= 0L && ttl < time) { ((RedissonLockEntry) subscribeFuture.getNow()).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS); // 使用剩余过期时间进行等待 } else { ((RedissonLockEntry) subscribeFuture.getNow()).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS); // 使用剩余等待时间进行等待 } time -= System.currentTimeMillis() - currentTime; // 更新剩余等待时间 } while (time > 0L); this.acquireFailed(waitTime, unit, threadId); // 等待时间已经用完,获取锁失败 var16 = false; return var16; } } finally { this.unsubscribe(subscribeFuture, threadId); // 释放订阅锁释放事件 } } } } }
- Este método se utiliza para intentar adquirir un bloqueo distribuido. Primero, calcula el tiempo de espera y obtiene el ID del hilo actual. Luego intenta adquirir el tiempo de vencimiento restante del bloqueo. Devuelve verdadero si el bloqueo se adquiere correctamente (el tiempo de vencimiento restante es nulo). Si el tiempo de espera restante se ha agotado, la adquisición del bloqueo falla y devuelve falso.
- Si el tiempo de espera restante aún está disponible, suscríbase al evento de liberación de bloqueo (este evento de liberación se publica cuando se libera el bloqueo) y espere un período de tiempo para ver si puede recibir una notificación del evento de liberación de bloqueo. Si se agota el tiempo de espera o se cancela la suscripción, la adquisición del bloqueo falla y se devuelve falso.
- Si la notificación del evento de apertura del bloqueo se obtiene con éxito, intente nuevamente obtener el tiempo de vencimiento restante del bloqueo. Devuelve verdadero si el bloqueo se adquiere con éxito (el tiempo de vencimiento restante es nulo). Si el tiempo de espera restante se ha agotado, la adquisición del bloqueo falla y devuelve falso.
- En el proceso de adquisición del bloqueo, se utiliza un temporizador para actualizar el tiempo de espera restante y se realiza una operación de espera durante el proceso de espera. Finalmente, libere el evento de liberación de bloqueo suscrito y devuelva el resultado de adquirir el bloqueo.
4.6.4.5 Principio de renovación del tiempo de espera
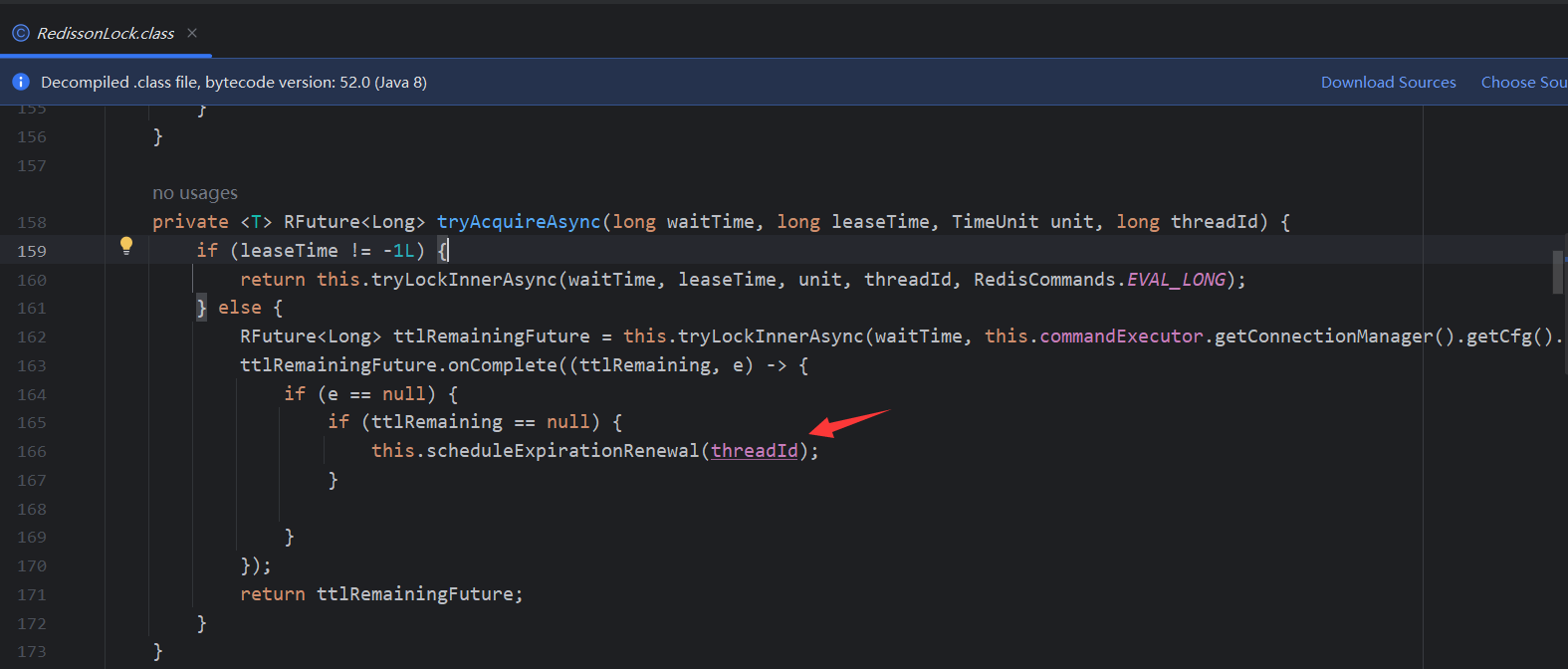
ilustrar:
- Cuando se complete la tarea, se realizará una devolución de llamada. Si se deja el período de validez restante (ttlRemainingFuture) en la devolución de llamada, volverá a actualizar el tiempo de vencimiento del bloqueo.
Reponer:
- Cuando el tiempo de arrendamiento no es igual a menos 1, el mecanismo de vigilancia no se habilitará, es decir, no habrá renovación de horas extras. El bloqueo se liberará automáticamente cuando expire después de 30 segundos.
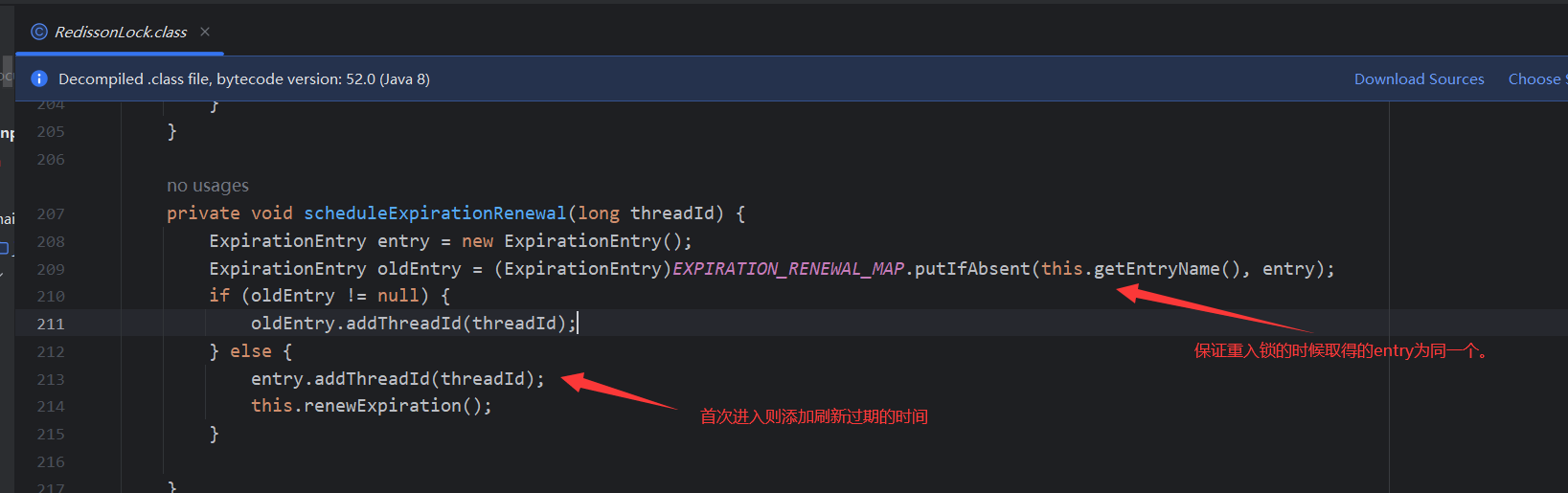
ilustrar:
- Ver código fuente
private void scheduleExpirationRenewal(long threadId) { ExpirationEntry entry = new ExpirationEntry(); // 创建一个过期时间续约条目对象 ExpirationEntry oldEntry = (ExpirationEntry) EXPIRATION_RENEWAL_MAP.putIfAbsent(this.getEntryName(), entry); // 尝试将续约条目放入续约映射中 if (oldEntry != null) { // 如果续约映射中已存在旧的续约条目 oldEntry.addThreadId(threadId); // 将当前线程的ID添加到旧的续约条目中 } else { // 如果续约映射中不存在旧的续约条目 entry.addThreadId(threadId); // 将当前线程的ID添加到新的续约条目中 this.renewExpiration(); // 开始进行过期时间的续约操作 } }
EXPIRATION_RENEWAL_MAPEs una colección de la clase RedissonLockConcurrentMap<String, ExpirationEntry>, que se utiliza para colocar elementos que deben renovarse para facilitar su uso al liberar el bloqueo.
- Al actualizar el tiempo de vencimiento se iniciará una tarea y se actualizará continuamente. En otras palabras, el candado en este momento es un candado que nunca caduca.
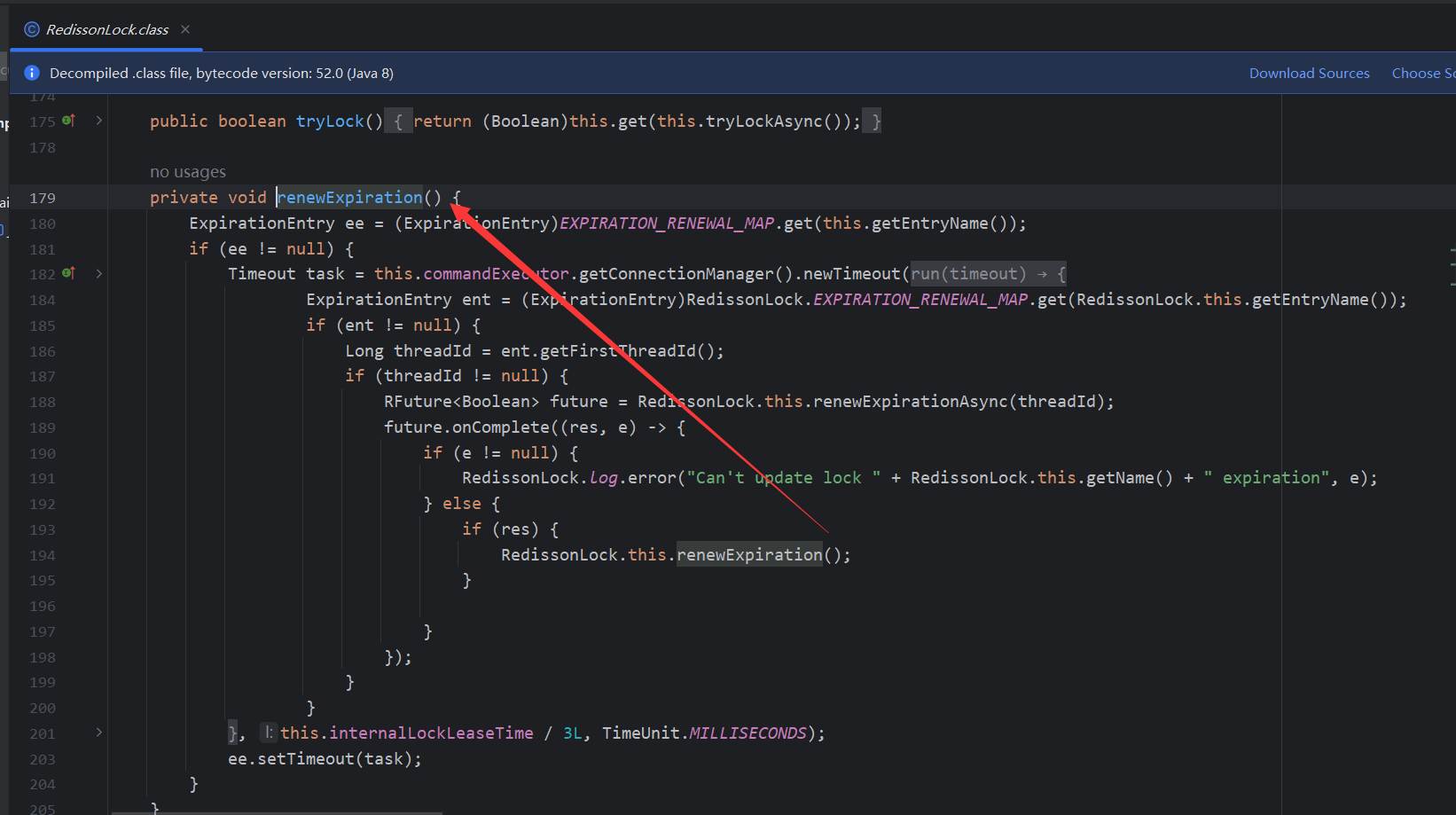
Reponer:
- Entonces, dado que este candado es un candado que nunca vence, ¿cuándo se liberará? De hecho, caducará cuando se libere el bloqueo.
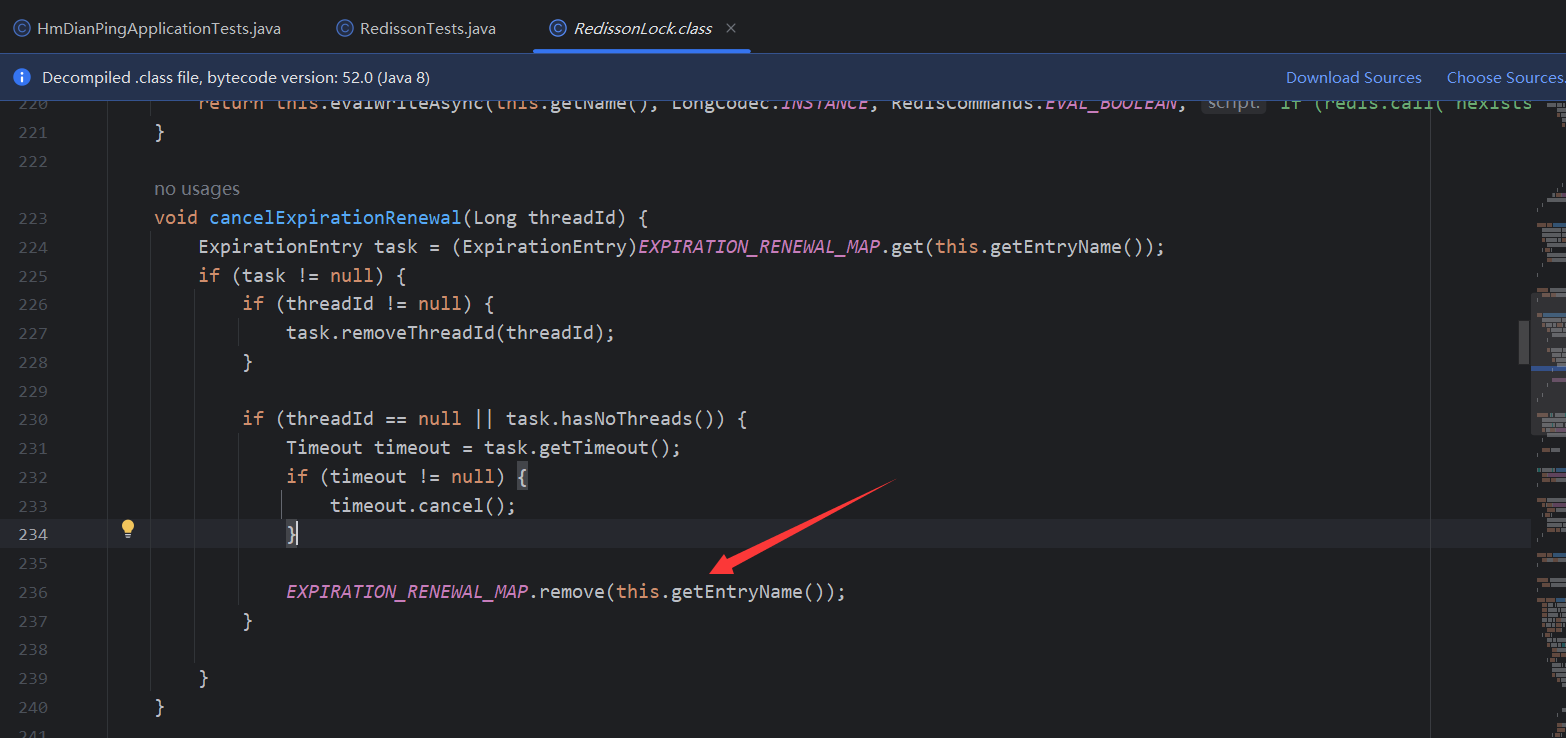
4.6.4.6 Problema de coherencia maestro-esclavo
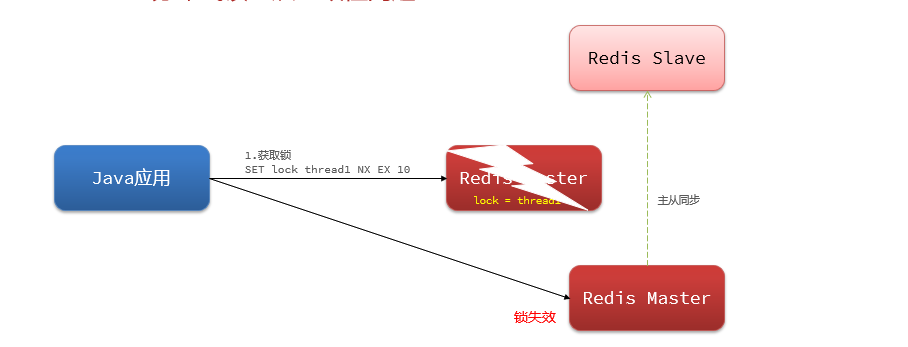
ilustrar:
- Cuando se utiliza el clúster de Redis, es probable que se produzcan problemas de coherencia maestro-esclavo.
- Cuando el nodo maestro que adquiere el bloqueo falla inesperadamente, uno de los nodos esclavos será seleccionado como el nuevo nodo maestro. Sin embargo, en este momento, el nodo maestro antiguo no puede sincronizar datos con el nuevo nodo maestro, lo que resulta en pérdida de datos.
- solución
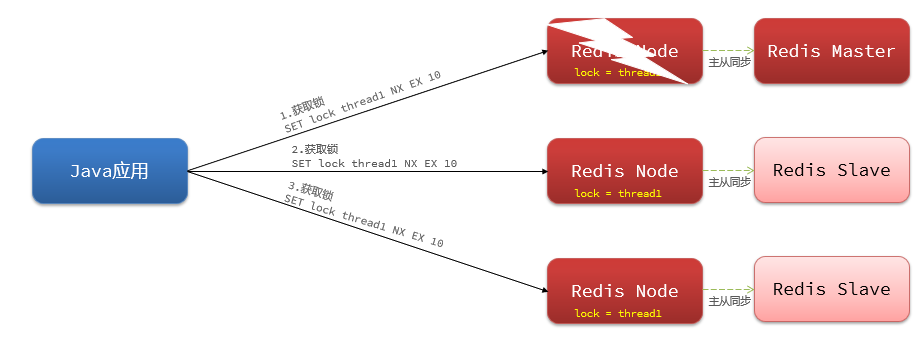
ilustrar:
- Ahora, cree un nuevo clúster de Redis y sincronice los datos del bloqueo con cada nodo maestro cada vez que se adquiera un bloqueo.
- Incluso si el nodo maestro está inactivo, aún puede garantizar que los datos no se perderán
- Código de muestra
1. Modificar RedisConfigel archivo de configuración.
@Configuration
public class RedisConfig {
@Bean
public RedissonClient redissonClient() {
// 配置类
Config config = new Config();
// 添加redis地址,这里添加了单点的地址,也可以使用config.useClusterServers()添加集群地址
config.useSingleServer().setAddress("redis://10.13.164.55:6379").setPassword("qweasdzxc");
// 创建客户端
return Redisson.create(config);
}
@Bean
public RedissonClient redissonClient2() {
// 配置类
Config config = new Config();
// 添加redis地址,这里添加了单点的地址,也可以使用config.useClusterServers()添加集群地址
config.useSingleServer().setAddress("redis://10.13.164.55:6380").setPassword("qweasdzxc");
// 创建客户端
return Redisson.create(config);
}
}
2. Modificar RedissonTestsla clase de prueba.
@SpringBootTest
@Slf4j
public class RedissonTests {
@Autowired
RedissonClient redissonClient;
@Autowired
RedissonClient redissonClient2;
RLock lock;
@BeforeEach
void before() {
RLock lock1 = redissonClient.getLock("order");
RLock lock2 = redissonClient2.getLock("order");
// 创建连锁MultiLock
lock = redissonClient.getMultiLock(lock1, lock2); //这里无论使用哪一个客户端来创建MultiLock都可以
}
@Test
void method1() throws InterruptedException {
boolean isLock = lock.tryLock(1L, TimeUnit.SECONDS);
if (!isLock) {
log.error("获取锁失败,1");
return;
}
try {
log.info("获取锁成功,1");
method2();
} finally {
log.info("释放锁,1");
lock.unlock();
}
}
void method2() {
boolean isLock = lock.tryLock();
if (!isLock) {
log.error("获取锁失败, 2");
return;
}
try {
log.info("获取锁成功,2");
} finally {
log.info("释放锁,2");
lock.unlock();
}
}
}
Reponer:
- Ver el código fuente para obtener el bloqueo.
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException { long newLeaseTime = -1L; // 计算新的租期时间 if (leaseTime != -1L) { if (waitTime == -1L) { newLeaseTime = unit.toMillis(leaseTime); } else { newLeaseTime = unit.toMillis(waitTime) * 2L; } } long time = System.currentTimeMillis(); long remainTime = -1L; // 计算剩余等待时间 if (waitTime != -1L) { remainTime = unit.toMillis(waitTime); } long lockWaitTime = this.calcLockWaitTime(remainTime); int failedLocksLimit = this.failedLocksLimit(); List<RLock> acquiredLocks = new ArrayList<>(this.locks.size()); ListIterator<RLock> iterator = this.locks.listIterator(); while (iterator.hasNext()) { RLock lock = (RLock) iterator.next(); boolean lockAcquired; try { if (waitTime == -1L && leaseTime == -1L) { // 尝试获取锁,不设置等待时间和租期时间 lockAcquired = lock.tryLock(); } else { // 计算实际等待时间 long awaitTime = Math.min(lockWaitTime, remainTime); // 尝试获取锁,设置等待时间和租期时间 lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS); } } catch (RedisResponseTimeoutException var21) { // 获取锁超时,释放已获取的锁 this.unlockInner(Arrays.asList(lock)); lockAcquired = false; } catch (Exception var22) { lockAcquired = false; } if (lockAcquired) { acquiredLocks.add(lock); } else { if (this.locks.size() - acquiredLocks.size() == this.failedLocksLimit()) { // 已获取的锁数量达到失败限制,退出循环 break; } if (failedLocksLimit == 0) { // 已达到失败限制次数,释放已获取的锁 this.unlockInner(acquiredLocks); if (waitTime == -1L) { return false; } // 重新设置失败锁限制和已获取锁列表 failedLocksLimit = this.failedLocksLimit(); acquiredLocks.clear(); while (iterator.hasPrevious()) { iterator.previous(); } } else { // 减少失败锁限制次数 --failedLocksLimit; } } if (remainTime != -1L) { // 更新剩余等待时间 remainTime -= System.currentTimeMillis() - time; time = System.currentTimeMillis(); if (remainTime <= 0L) { // 等待时间已用完,释放已获取的锁并返回失败 this.unlockInner(acquiredLocks); return false; } } } if (leaseTime != -1L) { // 设置锁的租期时间 List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size()); Iterator<RLock> var24 = acquiredLocks.iterator(); while (var24.hasNext()) { RLock rLock = (RLock) var24.next(); // 异步设置锁的租期时间 RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS); futures.add(future); } var24 = futures.iterator(); while (var24.hasNext()) { // 等待设置锁的租期时间操作完成 RFuture<Boolean> rFuture = (RFuture) var24.next(); rFuture.syncUninterruptibly(); } } return true; }
- Varios nodos de Redis independientes deben obtener bloqueos de reentrada en todos los nodos para obtener el bloqueo correctamente. Si falla la adquisición de cualquier bloqueo en todos los nodos, falla la adquisición del bloqueo.
4.6.4.7 Resumen de principios
Resumen de notas:
1) Bloqueo distribuido de Redis no reentrante:
- Principio: use la exclusividad mutua de setnx ; use ex para evitar un punto muerto; determine la etiqueta del hilo al liberar el bloqueo
- Defectos: sin reentrada, sin reintento, falla en el tiempo de espera de bloqueo
2) Bloqueo distribuido de Redis reentrante:
- Principio: use la estructura hash para registrar la identificación del subproceso y los tiempos de reingreso; use watchDog para extender el tiempo de bloqueo; use el semáforo para controlar la espera de reintento del bloqueo
- Defecto: el tiempo de inactividad de Redis provoca un problema de falla de bloqueo
3) MultiLock de Redisson:
- Principio: varios nodos de Redis independientes deben obtener bloqueos reentrantes en todos los nodos para obtener el bloqueo con éxito.
- Desventajas: altos costos de operación y mantenimiento, implementación compleja
- Diagrama esquemático del proceso de adquisición y liberación de cerraduras (en modo de nodo único)
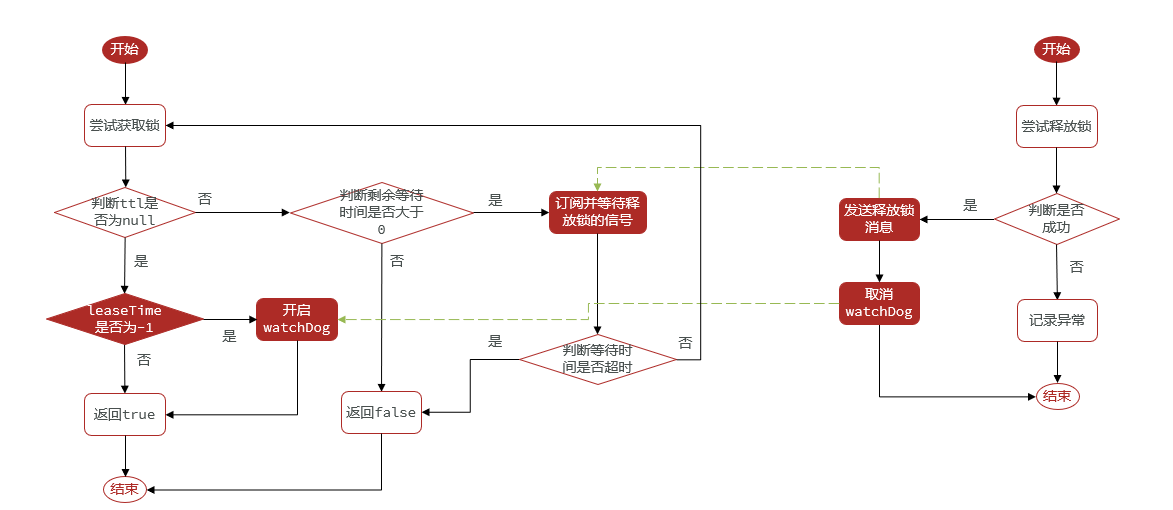
ilustrar:
La imagen de la izquierda muestra el flujo de ejecución lógica al intentar adquirir el bloqueo, y la imagen de la derecha muestra el flujo de ejecución lógica al intentar liberar el bloqueo.
4.7 Venta flash de optimización de Redis (dificultad)
4.7.1 Descripción general
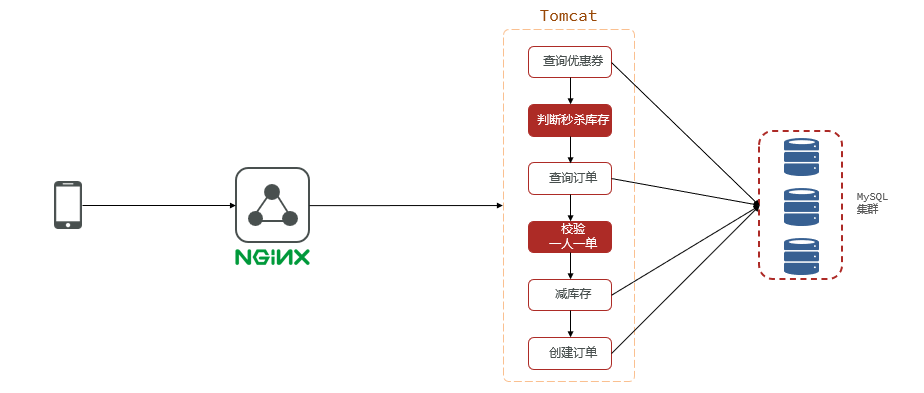
ilustrar:
Según el plan de implementación comercial de venta flash actual, el proceso comercial aún llevará mucho tiempo. Porque al realizar operaciones como consultar cupones y consultar pedidos, se involucran operaciones frecuentes en la base de datos.
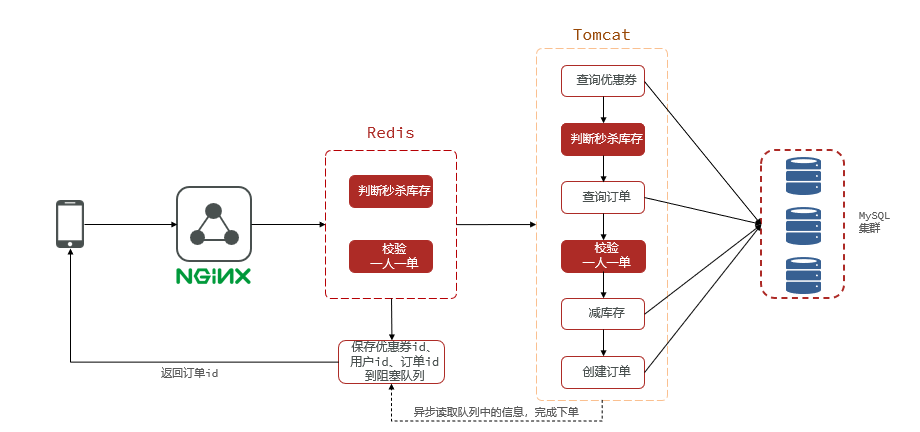
ilustrar:
Ahora usamos Redis para optimizar la función de venta flash y reducir el negocio de operación de la base de datos. Y cambie el método de operación sincrónica de la base de datos a un método asincrónico. Reduzca el proceso de negocio de venta flash y acelere la finalización y ejecución de la venta flash.
4.7.2 Casos de uso básicos
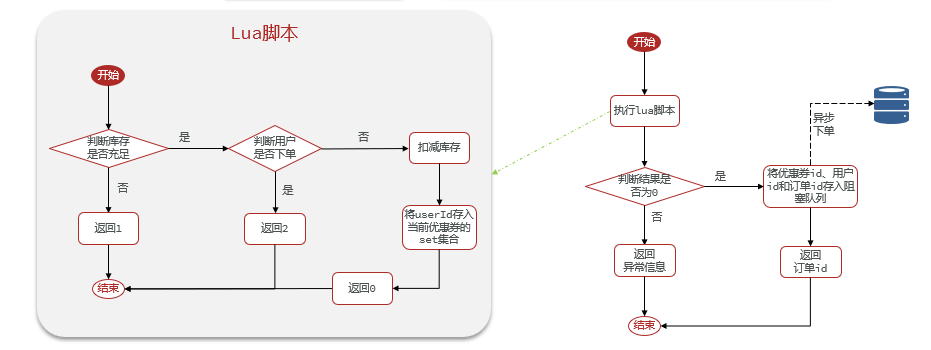
ilustrar:
Ideas de implementación:
Determine si el inventario es suficiente. Si no es suficiente, finalizará. Si es suficiente, será juzgado. Juzgará si el usuario ha completado el pedido. Si el pedido se ha realizado, finalizará. Si no se ha realizado el pedido, se deducirá el inventario. Después de deducir el inventario, la identificación del usuario se guardará en el Conjunto. (Primero use Redis para completar el saldo del inventario, juzgue a una persona y un pedido, y complete el negocio de obtención de pedidos) Si el pedido se realiza correctamente, se devuelve el ID del número de pedido. Si el pedido falla, la venta flash falla ( luego el negocio de pedidos se coloca en la cola de bloqueo y utiliza subprocesos independientes para realizar pedidos de forma asincrónica)
El script Lua se utiliza para garantizar la atomicidad de la operación: el juicio de inventario y la deducción de inventario tienen éxito al mismo tiempo o fallan al mismo tiempo.
- Al guardar la ID de usuario en Set se utiliza la función incorporada de eliminación de duplicaciones para evitar que el usuario realice pedidos repetidos para lograr la función de una persona, un pedido.

Paso 1: mientras agrega cupones de venta flash, guarde la información del cupón en Redis.
- Método de modificación
VoucherServiceImpl_addSeckillVoucher
@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {
// 保存优惠券
save(voucher);
// 保存秒杀信息
SeckillVoucher seckillVoucher = new SeckillVoucher();
seckillVoucher.setVoucherId(voucher.getId());
seckillVoucher.setStock(voucher.getStock());
seckillVoucher.setBeginTime(voucher.getBeginTime());
seckillVoucher.setEndTime(voucher.getEndTime());
seckillVoucherService.save(seckillVoucher);
// 保存库存到redis中
stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), String.valueOf(voucher.getStock()));
}
ilustrar:
Guarde la información de inventario de los cupones de venta flash en Redis para reducir la frecuencia de lectura de la base de datos MySQl.
Paso 2: según el script Lua, determine el inventario de venta flash, un pedido por persona, y determine si el usuario ha realizado la compra con éxito.
ResourcesAgregarseckill.luaguión en
-- 1.参数列表
-- 1.1优惠券id
local voucherId = ARGV[1]
-- 1.2用户id
local userId = ARGV[2]
-- 2.数据key
-- 2.1库存Key,用于获取秒杀券的信息
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2订单Key,用于保存购买用户的用户Id,值为Set集合
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1 判断库存是否充足
if(tonumber(redis.call('get',stockKey)) <= 0) then
-- 3.2 库存不足,返回1
return 1
end
-- 3.3判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5,下单(保存用户) sadd orderKey userId
redis.call('sadd', orderKey, userId)
return 0
Paso 3: Si la recuperación se realiza correctamente, encapsule el ID del cupón y el ID del usuario y guárdelos en la cola de bloqueo.
- Modificar métodos
VoucherOrderServiceImplen claseseckillVoucher
public IVoucherOrderService PROXY; //此时,无法子线程中拿到代理对象,因此定义为成员变量,让子线程可用获取此类的代理对象
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
// 定义一个阻塞队列
private BlockingQueue<VoucherOrder> orderTask = new ArrayBlockingQueue<>(1024 * 1024); //类似于MQ
// 静态代码块,用于初始化秒杀脚本
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
// 设置秒杀脚本的位置为类路径下的 "seckill.lua" 文件
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
// 设置秒杀脚本执行结果的类型为 Long
SECKILL_SCRIPT.setResultType(Long.class);
}
/**
* 秒杀优惠券业务
*
* @param voucherId 优惠券的Id
* @return 控制层对此业务的处理结果
*/
@Override
public Result seckillVoucher(Long voucherId) {
// 获取用户ID
Long userId = UserHolder.getUser().getId();
// 1.执行Lua脚本(参数含义:脚本,key,Value)
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(), // 因为我们的Lua脚本没有Key,因此利用Collections工具传递空集合
voucherId.toString(), //将Long类型转换为String类型
userId.toString()
);
// 2.判断结果是否为0
int r = result.intValue();
if (r != 0) {
// 2.1不为0,代表没有购买资格
return Result.fail(result == 1 ? "库存不足" : "不能重复下单");
}
// 2.2为0,有购买资格,把下单信息保存到阻塞队列
long orderId = redisIdWorker.nextId("order");
// 2.3.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 2.4设置订单ID;
voucherOrder.setId(orderId);
// 2.5设置用户ID
voucherOrder.setUserId(userId);
// 2.6设置优惠券ID
voucherOrder.setVoucherId(voucherId);
// 2.7保存订单到阻塞队列
orderTask.add(voucherOrder);
// 3.获取代理对象
PROXY = (IVoucherOrderService) AopContext.currentProxy();// 在主线程中获取代理对象,便于子线程中使用
// 4.返回订单Id
return Result.ok(orderId);
}
Paso 4: Inicie la tarea del subproceso, obtenga continuamente información de la cola de bloqueo e implemente la función de orden asincrónica
// 定义一个线程池
private final static ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
/**
* 利用Spring框架提供的注解,让在本类初始化完成之后来执行方法内的内容
*/
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
/**
* 定义一个内部类,用于实现异步订单的处理
*/
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true) {
// 此处循环执行代码逻辑
try {
// 1.获取队列中的订单信息
VoucherOrder voucherOrder = orderTask.take(); // 此时,若队列里面没有订单信息,则会阻塞在这里
// 2.创建订单
handleVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("处理订单异常" + e); // 因为这里是子线程来执行任务的处理,因此不用抛出异常,仅仅打印日志即可
}
}
}
}
/**
* 处理订单信息的业务逻辑
*
* @param voucherOrder 阻塞队列里面的订单信息
*/
private void handleVoucherOrder(VoucherOrder voucherOrder) {
// 1.获取用户
Long userId = voucherOrder.getUserId(); //因为此方法交给子线程来执行,因此无法通过主线程的 UserHolder.getUser().getId()方法来获取用户的ID
// 2.获取锁对象
RLock lock = redissonClient.getLock(LOCK_ORDER_KEY + userId); // 其实此处无需加锁,因为每个用户不会有多次下单的操作,除非Redis出现异常。因此,这里加锁判断一下比较好
// 3.获取锁
boolean isLock = lock.tryLock();
// 4.判断锁是否获取成功
if (!isLock) {
// 获取锁失败,返回错误重试
log.error("不允许重复下单");
return;
}
// 5.获取代理对象
try {
// 此时无法从子线程中获取
PROXY.createVoucherOrder(voucherOrder);// 用代理对象来调用此createVoucherOrder函数,此时该函数可被Spring进行管理。因为此代理对象由Spring进行创建
} finally {
// 释放锁
lock.unlock();
}
}
/**
* 创建订单信息
* 这里主要实现了一个对数据库的事务操作,保证
*
* @param voucherOrder 阻塞队列里面的订单信息
*/
@Transactional
public void createVoucherOrder(VoucherOrder voucherOrder) {
// 5.根据优惠券ID和用户ID判断订单是否存在-实现一人一单功能
// 5.1获取用户ID
Long userId = voucherOrder.getUserId();
// 5.2判断此订单是否存在
int count = query().eq("user_id", userId).eq("voucher_id", voucherOrder.getVoucherId()).count();
if (count > 0) {
// 此处同样也不可能出现重复,除非Redis集群宕机
// 该用户已经购买过了
log.error("用户已经购买过一次!");
return;
}
// 6.扣减库存-使用CAS方式解决超卖问题
boolean success = seckillVoucherService.update()
.setSql("stock = stock -1")
.eq("voucher_id", voucherOrder.getVoucherId())
.gt("stock", 0) // 让库存大于零,若有库存则进行扣库存
.update();
if (!success) {
// 扣减失败
log.error("库存不足");
return;
}
// 7.保存订单
save(voucherOrder);
}
Reponer:
Todavía hay problemas con el bloqueo asincrónico y las limitaciones de memoria. En este momento, la cola de bloqueo se almacena en la Jvm, por lo que si la Jvm no funciona, la información del pedido se perderá, lo que provocará problemas de seguridad de los datos.
4.8La cola de mensajes de Redis implementa ventas flash asíncronas
4.8.1 Descripción general
Cola de mensajes (Cola de mensajes) significa literalmente una cola que almacena mensajes.
El modelo de cola de mensajes más simple consta de 3 roles:
- Cola de mensajes: almacena y administra mensajes, también conocido como intermediario de mensajes (Message Broker)
- Productor: envía mensajes a la cola de mensajes.
- Consumidor: obtiene mensajes de la cola de mensajes y los procesa.
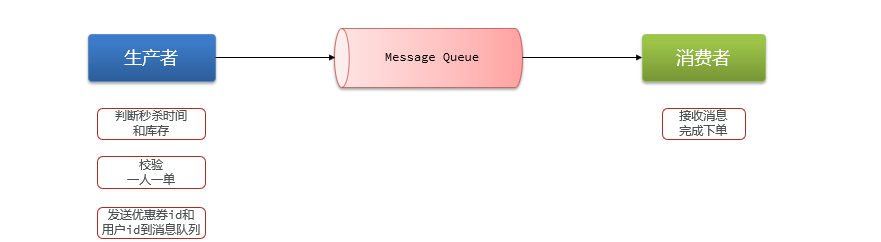
ilustrar:
- MQ no está restringido por Jvm. Los mensajes en MQ persistirán
Entre ellos, Redis proporciona tres formas diferentes de implementar colas de mensajes:
- Estructura de lista: simule la cola de mensajes según la estructura de lista
- PubSub: modelo básico de mensajería peer-to-peer
- Stream: un modelo de cola de mensajes relativamente completo
4.8.2 Simular cola de mensajes según la estructura de lista
Cola de mensajes significa literalmente una cola que almacena mensajes. La estructura de datos de la lista de Redis es una lista vinculada bidireccional, que puede simular fácilmente el efecto de la cola.
La entrada y salida de la cola no están en el mismo lado, por lo que podemos usar: LPUSH combinación RPOPo RPUSH combinado con LPOP para lograrlo.

ilustrar:
- Sin embargo, cabe señalar que cuando no hay ningún mensaje en la cola
RPOPoLPOPla operación devuelve nulo, no bloquea ni espera mensajes como la cola de bloqueo de JVM.BRPOPPor lo tanto, o debería usarse aquíBLPOPpara lograr el efecto de bloqueo.
Suplemento: Ventajas de simular colas de mensajes basadas en la estructura de lista
- ventaja:
- Uso del almacenamiento de Redis, no limitado por el límite superior de memoria JVM
- Basado en el mecanismo de persistencia de Redis, la seguridad de los datos está garantizada
- puede satisfacer el orden del mensaje
- defecto:
- No se puede evitar la pérdida de mensajes
- Solo admite un solo consumidor
- Si el mensaje en la cola de mensajes se obtiene de Redis en este momento y el servicio en la cola de consumo se bloquea, los datos se perderán.
4.8.3 Cola de mensajes basada en PubSub
**PubSub (publicar y suscribirse)** es el modelo de mensajería introducido en la versión Redis2.0. Como su nombre lo indica, los consumidores pueden suscribirse a uno o más canales y después de que el productor envía un mensaje al canal correspondiente, todos los suscriptores pueden recibir el mensaje correspondiente.
- SUSCRIBIRSE al canal [canal]: Suscríbete a uno o más canales
- PUBLICAR mensaje de canal: Enviar un mensaje a un canal
- Patrón PSUBSCRIBE [patrón]: suscríbete a todos los canales que coincidan con el formato del patrón
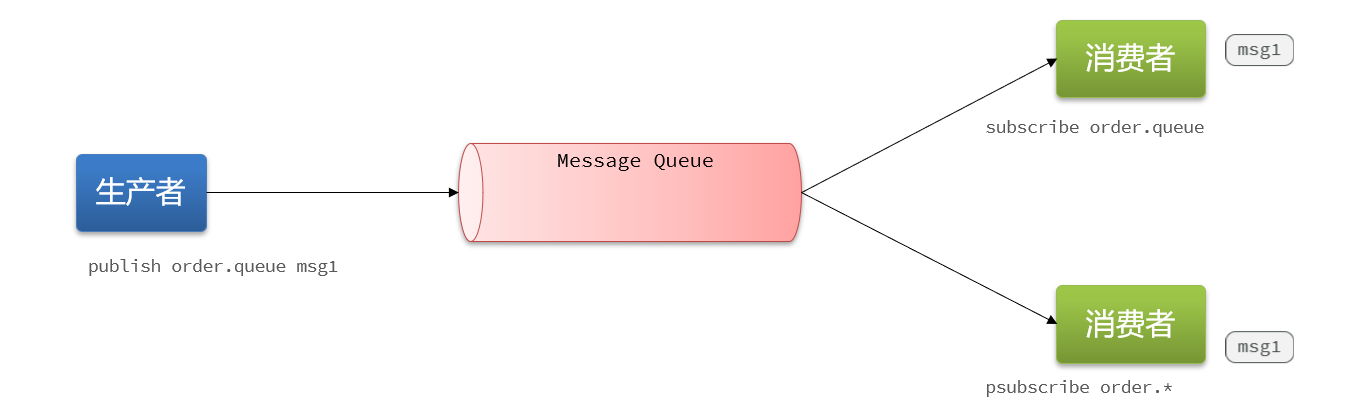
ilustrar:
- El modelo de publicación-suscripción es simplemente un modelo de producción-consumo múltiple.
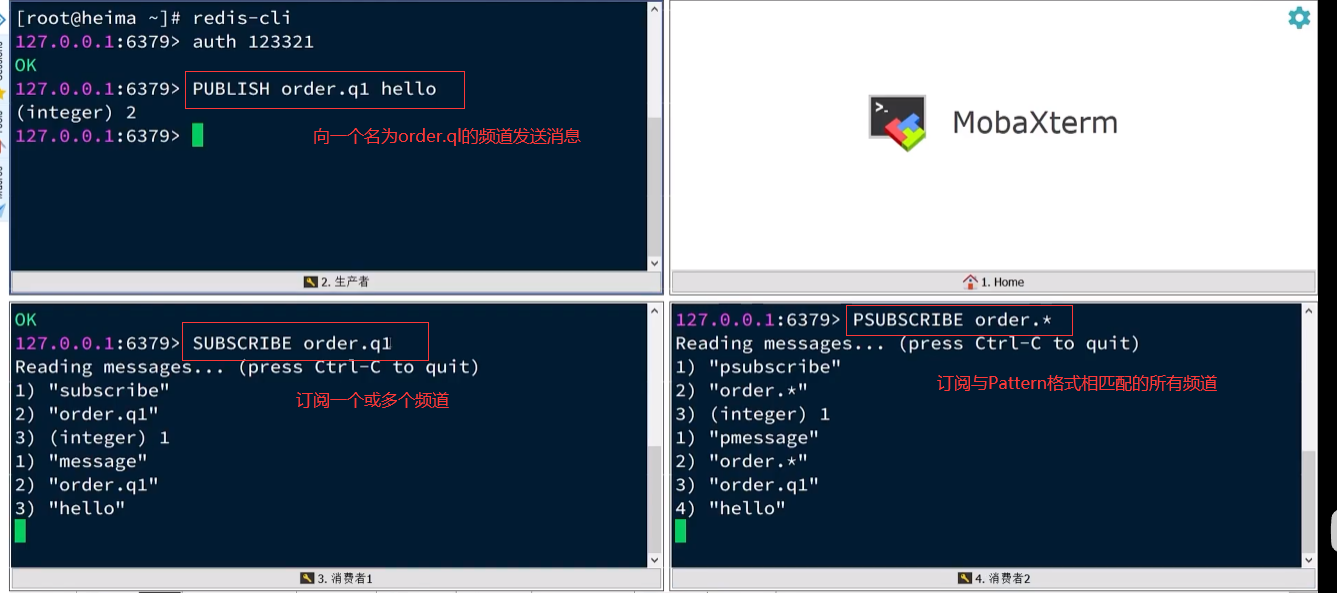
ilustrar:
- Después de suscribirse a todos los canales que coinciden con el formato Pattern, puede recibir múltiples mensajes de consumo de canales que coinciden con el formato.
Suplemento: ¿Cuáles son las ventajas y desventajas de las colas de mensajes basadas en PubSub?
- ventaja:
- Adopte un modelo de publicación-suscripción para respaldar la multiproducción y el multiconsumo.
- defecto:
- No admite la persistencia de datos
- No se puede evitar la pérdida de mensajes
- Hay un límite superior para la acumulación de mensajes y los datos se perderán cuando se supere.
- El modelo de publicación-suscripción basado en PubSub almacena mensajes en los consumidores. Sin embargo, existe un límite superior en el espacio de caché del consumidor y, si se excede, se perderá.
- Los mensajes guardados del cliente se perderán si nadie se suscribe a los datos enviados por el productor en Redis.
4.8.4 Cola de mensajes basada en secuencias
Stream es un nuevo tipo de datos introducido en Redis 5.0, que puede implementar una cola de mensajes muy completa.
Redis Stream se utiliza principalmente para colas de mensajes (MQ, Message Queue). Redis Stream proporciona persistencia de mensajes y funciones de replicación de respaldo primario, lo que permite que cualquier cliente acceda a los datos en cualquier momento y pueda recordar la ubicación de acceso de cada cliente . También asegúrese de que el mensaje no se pierda.
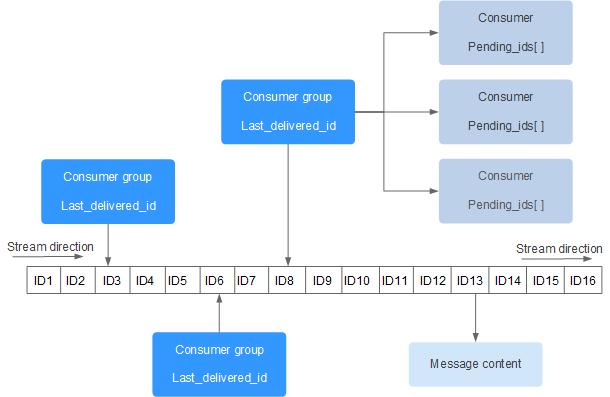
ilustrar:
- Grupo de consumidores : Grupo de consumidores, creado mediante el comando XGROUP CREATE. Un grupo de consumidores tiene varios consumidores (Consumidor)
- last_delivered_id : Cursor. Cada grupo de consumidores tendrá un cursor last_delivered_id. Cualquier consumidor que lea el mensaje moverá el cursor last_delivered_id hacia adelante.
- pendiente_ids : la variable de estado del consumidor (Consumidor), que se utiliza para mantener la identificación no confirmada del consumidor. pendiente_ids registra los mensajes que han sido leídos por el cliente, pero no hay reconocimiento (carácter de reconocimiento: carácter de confirmación)
- Proceso de negocio implementado utilizando el método del consumidor.

ilustrar:
- Cuando se utiliza el bloqueo para leer datos en la cola de mensajes, se devuelve el tiempo de espera
nil- En el desarrollo empresarial, podemos llamar cíclicamente al método de bloqueo XREAD para consultar las últimas noticias, logrando así el efecto de monitorear continuamente la cola.El pseudocódigo es el siguiente:
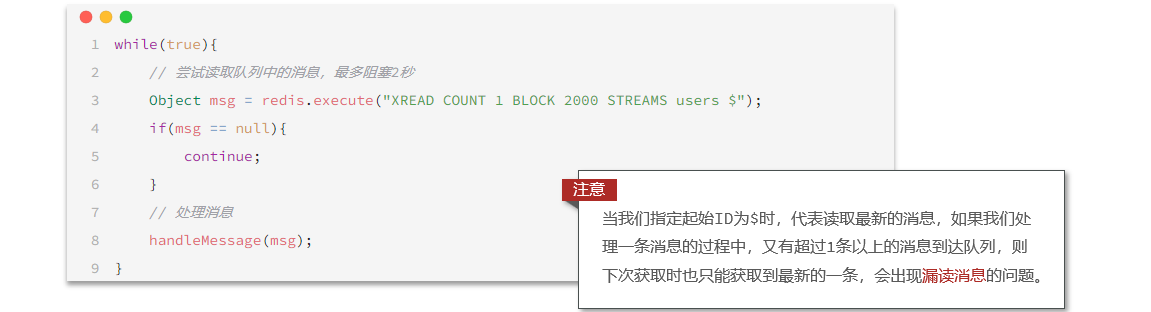
Aviso:
- Cuando el ID especificado
$es , en este momento llegan varios mensajes a la cola, entonces la información obtenida cada vez es la última y habrá una situación de pérdida de lectura.
- Proceso de negocio: implementado utilizando grupos de consumidores.

ilustrar:
El grupo de consumidores (grupo de consumidores) divide a varios consumidores en un grupo y monitorea la misma cola. Con las características anteriores,

ilustrar:
- Lo anterior es el pseudocódigo para implementar ventas flash asíncronas basadas en la cola de mensajes de Stream.
- Si hay una excepción de error, continuará ejecutándose hasta que este mensaje se procese exitosamente.
Suplemento: Funciones del comando XREADGROUP para cola de mensajes de tipo STREAM
- Los mensajes se pueden rastrear
- Varios consumidores pueden competir por las noticias y acelerar el consumo.
- Puede bloquear la lectura
- No hay riesgo de que se pierdan mensajes
- Existe un mecanismo de confirmación de mensaje para garantizar que el mensaje se consuma al menos una vez.
4.8.5 Diferencias entre los tres métodos de colas de mensajes
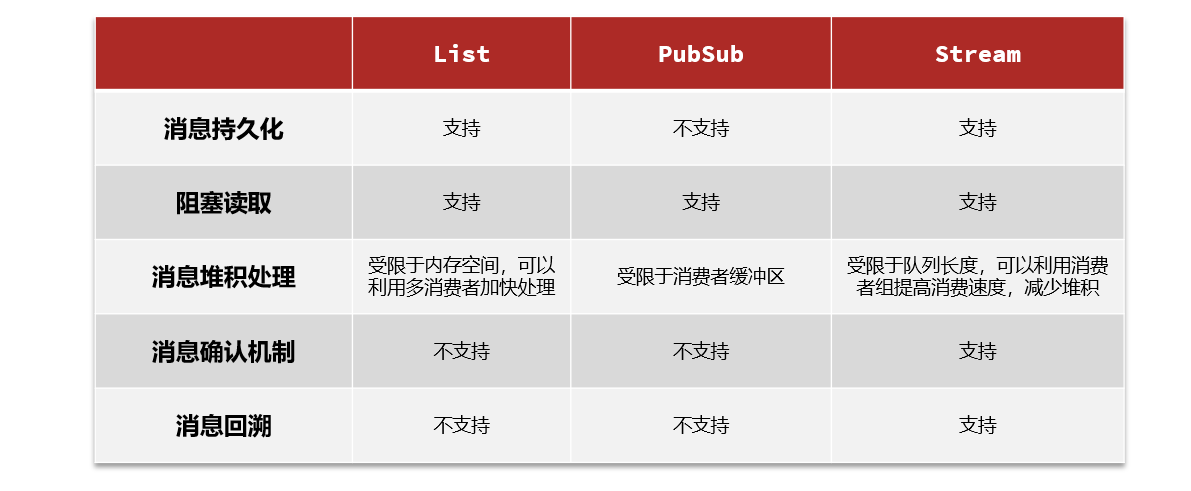
ilustrar:
- La colección List no admite el seguimiento de mensajes: cuando se produce un error o el consumidor sale de forma anormal al procesar un mensaje, es posible que se pierdan los mensajes que se han puesto en cola pero que aún no se han procesado.
- PubSub no admite el seguimiento de mensajes: dado que la publicación y suscripción de mensajes son asincrónicas, no se puede garantizar la secuencia estricta de los mensajes. Además, Redis en sí no es responsable de rastrear el estado de los suscriptores. Cuando un suscriptor se desconecta, no se pueden conocer los cambios en su estado.
4.8.6 Implementación de la eliminación flash asíncrona de la cola de mensajes de Redis (puntos clave)
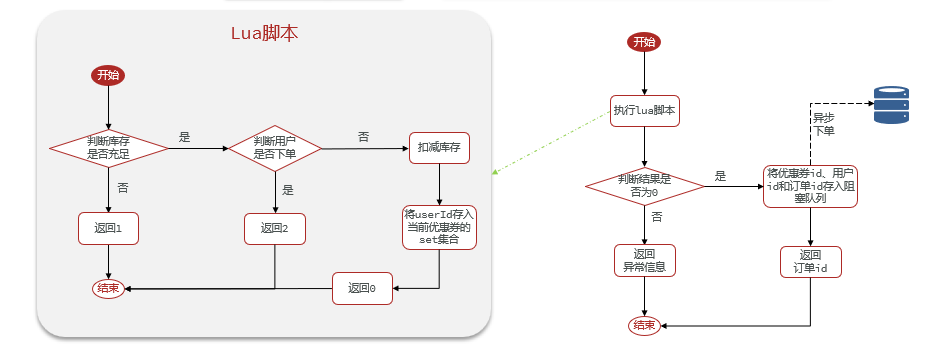
ilustrar:
Idea de implementación: luego modifique la función de venta flash de optimización de Redis en la sección anterior
Paso 1: crear una cola de mensajes de tipo Stream llamada stream.orders
XGROUP CREATE stream.orders g1 0 MKSTREAM
ilustrar:
Utilice la herramienta de línea de comando para crear en Reids con anticipación, porque solo se puede crear uno en todo Redis y no es necesario crear repetidamente.
Paso 2: Modifique el script Lua anterior para pedidos de venta flash. Después de determinar que es elegible para compras urgentes, agregue directamente un mensaje a stream.orders, que contenga voucherId, userId, orderId.
1. ResourcesModifique seckill.luael script en
-- 1.参数列表
-- 1.1优惠券id
local voucherId = ARGV[1]
-- 1.2用户id
local userId = ARGV[2]
-- 1.3订单id
local orderId = ARGV[3]
-- 2.数据key
-- 2.1库存Key,用于获取秒杀券的信息
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2订单Key,用于保存购买用户的用户Id,值为Set集合
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1 判断库存是否充足
if(tonumber(redis.call('get',stockKey)) <= 0) then
-- 3.2 库存不足,返回1
return 1
end
-- 3.3判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5,下单(保存用户) sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.6发送消息到队列中,XADD stream.orders * k1 v1 k2 v2 ...return
redis.call("xadd", "stream.orders","*", "userId", userId,"voucherId", voucherId,"id",orderId)
return 0
ilustrar:
Usando la base de datos operativa
xadd, agregue un script Lua para enviar mensajes a la cola de bloqueo
2. Modificar los métodos VoucherOrderServiceImplen la clase.seckillVoucher
/**
* 秒杀优惠券业务
*
* @param voucherId 优惠券的Id
* @return 控制层对此业务的处理结果
*/
@Override
public Result seckillVoucher(Long voucherId) {
// 获取用户ID
Long userId = UserHolder.getUser().getId();
// 获取订单ID
long orderId = redisIdWorker.nextId("order");
// 1.执行Lua脚本(参数含义:脚本,key,Value)
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(), // 因为我们的Lua脚本没有Key,因此利用Collections工具传递空集合
voucherId.toString(), //将Long类型转换为String类型
userId.toString(),
String.valueOf(orderId)
);
// 2.判断结果是否为0
int r = result.intValue();
if (r != 0) {
// 2.1不为0,代表没有购买资格
return Result.fail(result == 1 ? "库存不足" : "不能重复下单");
}
// 3.获取代理对象
PROXY = (IVoucherOrderService) AopContext.currentProxy();// 在主线程中获取代理对象,便于子线程中使用
// 4.返回订单Id
return Result.ok(orderId);
}
Paso 3: cuando comience el proyecto, inicie una tarea de hilo, intente recibir el mensaje en stream.orders y complete el pedido.
- Modificar métodos
VoucherOrderServiceImplen claseVoucherOrderHandler
/**
* 定义一个内部类,用于实现异步订单的处理
*/
private class VoucherOrderHandler implements Runnable {
String queueName = "stream.orders"; // 注意,此处的队列名称,需要与Lua脚本里的相对于
@Override
public void run() {
while (true) {
try {
// 1.获取消息队列中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS stream.order >
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"), // 读取消费者信息
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create(queueName, ReadOffset.lastConsumed())
);
// 2.判断消息获取是否成功
if (list == null || list.isEmpty()) {
// 2.1 如果获取失败,说明没有消息,继续下一次循环
continue;
}
// 3.解析消息中的订单信息
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> values = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);
// 4.如果获取成功,可以下单
handleVoucherOrder(voucherOrder);
// 5.ACK确认 SACK stream.order g1 id
stringRedisTemplate.opsForStream().acknowledge(queueName, "g1", record.getId()); //设置消息ID
} catch (Exception e) {
log.error("处理订单异常" + e);
handlePendingList();
}
}
}
private void handlePendingList() {
while (true) {
try {
// 1.获取pending-list中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS stream.order 0
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read( // 注意,此处读取消息变为0
Consumer.from("g1", "c1"), // 读取消费者信息
StreamReadOptions.empty().count(1),
StreamOffset.create(queueName, ReadOffset.from("0"))// 未提供API,需要自己上传数据
);
// 2.判断消息获取是否成功
if (list == null || list.isEmpty()) {
// 2.1 如果获取失败,说明pendingList没有消息, 结束循环
break;
}
// 3.解析消息中的订单信息
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> value = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true);
// 4.如果获取成功,可以下单
handleVoucherOrder(voucherOrder);
// 5.ACK确认 SACK stream.order g1 id
stringRedisTemplate.opsForStream().acknowledge(queueName, "g1", record.getId()); //设置消息ID
} catch (Exception e) {
log.error("处理pendingList订单异常" + e);
try {
Thread.sleep(20); // 若抛出异常,可休眠一段时间后再进行PendingList的消息处理
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
}
}
ilustrar:
Modifique el código aquí para implementar la lógica de pseudocódigo de la cola de mensajes basada en Stream
5. Los expertos visitan la tienda
Resumen de notas:
Puntos de función de Redis:
SortedSetEn la función Me gusta, use el comando en Redis parascoreconsultar si al usuario que inició sesión le gusta el blog o cada blog. Utiliceaddel método para registrar la información similar del usuario que inició sesión en este blog. Métodoremovepara eliminar la información Me gusta de este blog por parte de usuarios registrados
SortedSetEn la función de lista de clasificación Me gusta, use el comando en Redisrangepara consultar la clasificación de los usuarios a quienes les gusta el blog a través de métodos.Dificultades en la implementación de funciones:
- Uso básico de usar
eq, y agregar declaraciones SQL en MyBatis-updateplussetSqllast- En Stream, escriba
map()métodos de conversión y terminación.toList()- En la herramienta Hutool, empalmar cadenas
StrUtil.joiny copiar clases de entidadBeanUtil.copyProperties
5.1 Descripción general
La exploración de la tienda de talentos es un tipo de actividad de experiencia de viaje y exploración. Los viajeros o entusiastas de los viajes generalmente actúan como expertos (expertos o guías turísticos) para guiar a otros a explorar la cultura, la historia, la comida y las atracciones de un destino específico.
5.2 Publicar notas de visita a tienda
5.3 me gusta
Reponer:
- Un mismo usuario solo puede dar me gusta una vez, al hacer clic nuevamente se cancelará el me gusta.
- Si al usuario actual le ha gustado, se resaltará el botón Me gusta (la interfaz se ha implementado, a juzgar por el atributo isLike del campo Clase Blog)
Paso 1: agregue un campo isLike a la clase Blog para indicar si le gusta al usuario actual
- Modificar los atributos de miembro de la clase Blog.
/**
* 是否点赞过了
*/
@TableField(exist = false)
private Boolean isLike;
ilustrar:
Se agregó el atributo de miembro isLike, que se utiliza para determinar si al usuario le gusta o no. Este atributo no existe en la base de datos, por lo tanto, agregue una anotación para facilitar su resaltado al realizar la consulta.
Paso 2: Modifique la función Me gusta y use la colección de conjuntos de Redis para determinar si le ha gustado. Si no le ha gustado, la cantidad de Me gusta será +1, y si le ha gustado, la cantidad de Me gusta será -1.
- Modificar el método likeBlog de la clase BlogServiceImpl
@Override
public Result likeBlog(Long id) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
String key = "blog:liked:" + id; //以商铺的Key作为键
// 2.判断当前登录用户是否已经点赞
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
// 3.如果未点赞,可以点赞
if (BooleanUtil.isFalse(isMember)) {
//包装类自动拆箱时,可能为空
// 3.1数据库点赞数+1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2保存用户到Redis的Set集合
if (isSuccess) {
stringRedisTemplate.opsForSet().add(key, userId.toString());
}
} else {
// 4.如果已点赞,取消点赞
// 4.1数据库点赞数-1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2把用户从Redis的set集合中移除
if (isSuccess) {
stringRedisTemplate.opsForSet().remove(key, userId.toString());
}
}
return Result.ok();
}
ilustrar:
Modifique el número total de Me gusta en la base de datos MySQL y consulte a los usuarios de Me gusta en la base de datos de Redis.
Paso 3: Modifique el negocio de consultar el Blog según la ID, determine si al usuario que ha iniciado sesión actualmente le ha gustado y asigne el valor al campo isLike.
- Modifique el método queryBlogById de la clase BlogServiceImpl y encapsule el método queryBlogUser
@Override
public Result queryBlogById(Long id) {
// 1.查询blog
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在!");
}
// 2.查询blog有关的用户
queryBlogUser(blog);
// 3.查询blog是否被点赞
queryBlogLiked(blog);
return Result.ok(blog);
}
// 查询Redis中,该商铺,该用户是否点赞
private void queryBlogLiked(Blog blog) {
UserDTO user = UserHolder.getUser();
if (ObjectUtil.isNull(user)) {
// 用户未登录的情况,不做查询
return;
}
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + blog.getId(); //以商铺的Key作为键
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(ObjectUtil.isNotNull(score));
}
/**
* 根据博客查询用户
*
* @param blog 商铺
*/
private void queryBlogUser(Blog blog) {
Long userId = blog.getUserId();
User user = userService.getById(userId);
blog.setName(user.getNickName());
blog.setIcon(user.getIcon());
}
ilustrar:
Consulta la información detallada del blog en la tienda, consulta el contenido del blog, así como qué usuario publicó el blog y la información sobre los me gusta del blog por parte del usuario que inició sesión.
Paso 4: Modifique la consulta de paginación Blog business, determine si al usuario que ha iniciado sesión actualmente le ha gustado y asigne el valor al campo isLike.
@Override
public Result queryHotBlog(Integer current) {
// 根据用户查询
Page<Blog> page = query()
.orderByDesc("liked")
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
// 查询用户
records.forEach(blog -> {
queryBlogUser(blog);
queryBlogLiked(blog); //每个商铺都需要查询该用户是否已点赞
});
return Result.ok(records);
}
ilustrar:
Recorra todas las tiendas, verifique qué tiendas le han gustado al usuario y configure todas las tiendas que le gustaron al usuario en Verdadero
5.4 Me gusta la lista de clasificación
ilustrar:
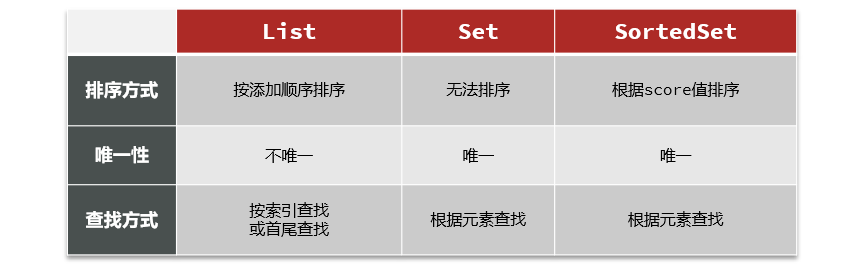
通过SortedSet集合记录用户点赞情况,并且为点赞排行做铺垫。而List、Set在点赞排行上各有缺点
Paso 1: reemplace el conjunto de comandos de Redis que le gusta comoSortedSet
1. Modifique el método likeBlog de la clase BlogServiceImpl
@Override
public Result likeBlog(Long id) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
String key = BLOG_LIKED_KEY + id; //以商铺的Key作为键
// 2.判断当前登录用户是否已经点赞
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
// 3.如果未点赞,可以点赞
if (ObjectUtil.isNull(score)) {
//包装类自动拆箱时,可能为空
// 3.1数据库点赞数+1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2保存用户到Redis的Set集合
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 4.如果已点赞,取消点赞
// 4.1数据库点赞数-1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2把用户从Redis的set集合中移除
if (isSuccess) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();
}
2. Modifique el método queryBlogLiked de la clase BlogServiceImpl
// 查询Redis中,该商铺,该用户是否点赞
private void queryBlogLiked(Blog blog) {
UserDTO user = UserHolder.getUser();
if (ObjectUtil.isNull(user)) {
// 用户未登录的情况,不做查询
return;
}
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + blog.getId(); //以商铺的Key作为键
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(ObjectUtil.isNotNull(score));
}
Paso 2: implementar la función de consulta de clasificación de Me gusta
- Agregue el método queryBlogLikes en la clase BlogServiceImpl
@Override
public Result queryBlogLikes(Long id) {
// 1.查询Top5的点赞用户
String key = BLOG_LIKED_KEY + id;
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
// 2.解析出用户的Id
if (ObjectUtil.isEmpty(top5) || ObjectUtil.isNull(top5)) {
return Result.ok(Collections.emptyList()); // 返回一个空集合
}
List<Long> ids = top5.stream().map(Long::valueOf).toList();
String idStr = StrUtil.join(",", ids);
// 3.根据Id查询用户信息 WHERE id in (5,1) ORDER BY FIELD(id,5,1)
// 因为关系型数据库SQL语句查询in的特性,默认根据ID升序来排序,会改变用户排行榜的顺序,因此需要通过ORDER BY FIELD来进行自定义排序
List<UserDTO> userList = userService.query()
.in("id", ids)
.last("ORDER BY FIELD(id," + idStr + ")") //拼接ID
.list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.toList();
return Result.ok(userList);
}
6. Sigue a tus amigos
Resumen de notas:
- Puntos de función de Redis
- En las funciones de seguir y dejar de seguir, se utiliza
Setel conjunto de comandos de Redis. A travésaddde unremovemétodo, las funciones de seguir y dejar de seguir se implementan para que los usuarios que hayan iniciado sesión sigan a otros blogueros.- En la función de atención conjunta,
Setse utiliza el conjunto de comandos de Redis yintersectla función de atención conjunta se realiza mediante el procesamiento de intersección de los dos conjuntos.SortedSetEn la función de seguimiento push, use el comando en Redisaddpara agregar el blog publicado por el blogger a la bandeja de entrada del fan a través del método (implementado como el modo push del flujo de alimentación). El método de consulta de paginación de desplazamientoreverseRangeByScoreWithScoresrealiza la función de consulta de desplazamiento de paginación- Dificultades en la implementación de funciones:
- Úselo en MyBatis-plus
removeylastagregue declaraciones SQL para su uso.- En el flujo de Stream, el método de conversión de tipo conjunta MyBatis-plus
map()se utiliza junto con- En la herramienta Hutool, el empalme de cadenas realiza consultas ordenadas de múltiples datos
StrUtil.joincompletando el SQL de la base de datos y copiando la clase de entidad para completar la copia de DTO.ORDER BY FIELDBeanUtil.copyProperties- En la función push, la consulta dinámica del modo de transmisión de feeds implementa un algoritmo simple al registrar el tiempo mínimo y la cantidad de elementos omitidos . Consultar la información básica después de escribir un blog y la implementación detallada de información similar.
6.1 Seguir y dejar de seguir
6.1.1 Descripción general
ilustrar:
Implementar funciones de seguir y dejar de seguir
6.1.2 Casos de uso básicos
Paso 1: implementar la siguiente función
- Agregue el método de seguimiento de la clase FollowServiceImpl
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断是关注还是取消关注
if (BooleanUtil.isTrue(isFollow)) {
// 关注
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
save(follow);
} else {
// 取消关注,删除 delete from tb_follow where user_id = ? and follow_user_id = ?
remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId));
}
return Result.ok();
}
Paso 2: implementar la función de consulta y seguimiento
- Se agregó el método isFollow de la clase FollowServiceImpl.
@Override
public Result isFollow(Long followUserId) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.查询是否关注
Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();
// 3.判断
return Result.ok(count > 0);
}
6.2 Preocupaciones comunes
6.2.1 Descripción general
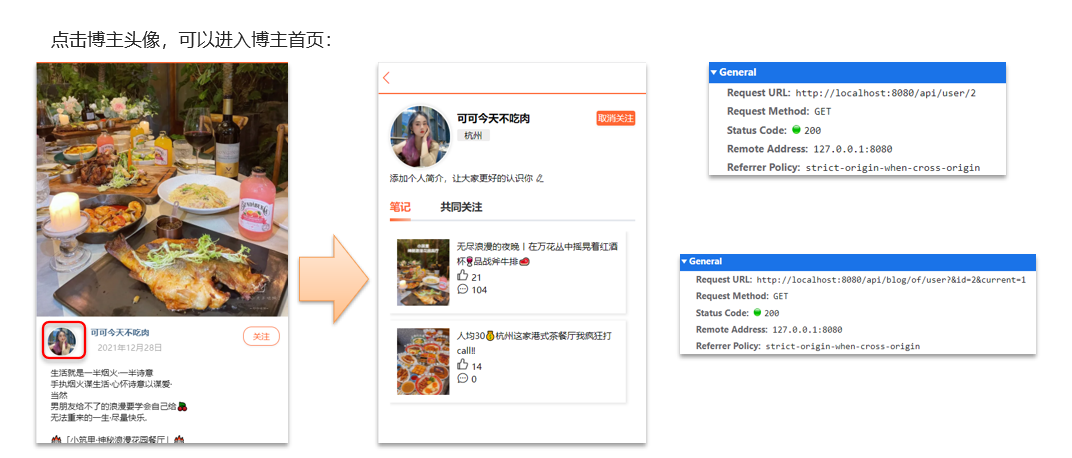
ilustrar:
Implementar funciones de seguir y dejar de seguir
6.2.2 Casos de uso básicos
Paso 1: modificar la lógica de enfoque
- Modifique el método de seguimiento de la clase FollowServiceImpl y agregue registros de seguimiento en Redis
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断是关注还是取消关注
if (BooleanUtil.isTrue(isFollow)) {
// 关注
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
if (isSuccess) {
// 当前登录用户记录被关注者的ID
String key = "follows:" + userId;
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
} else {
// 取消关注,删除 delete from tb_follow where user_id = ? and follow_user_id = ?
boolean isSuccess = remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId));
if (isSuccess) {
// 把关注用户的ID从Redis中移除
String key = "follows:" + userId;
stringRedisTemplate.opsForSet().remove(key, followUserId.toString());
}
}
return Result.ok();
}
Paso 2: implementar una lógica de preocupación común
- Agregue el método followCommon de la clase FollowServiceImpl
@Override
public Result followCommon(Long followUserId) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
String userKey = "follows:" + userId;
String followKey = "follows:" + followUserId;
// 2.查询登录用户与该博客账号共同关注名单
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(userKey, followKey);
// 3.解析Id集合
if (ObjectUtil.isNull(intersect) || ObjectUtil.isEmpty(intersect)) {
return Result.ok(Collections.emptyList());
}
List<Long> ids = intersect.stream().map(Long::valueOf).toList();
// 4.查询用户
List<UserDTO> userIds = userService.query().in("id", ids).list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class)).toList();
return Result.ok(userIds);
}
ilustrar:
Utilizando principalmente el método de colección Set
intersecten Redis para encontrar valores comunes
6.3 Seguir empuje
6.3.1 Descripción general
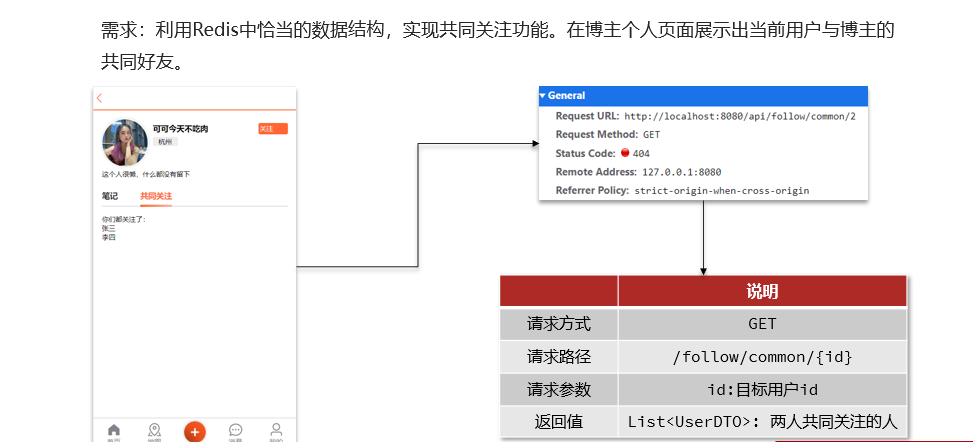
ilustrar:
Follow push también se llama Feed stream , traducido literalmente como alimentación. Proporcione continuamente a los usuarios una experiencia "inmersiva" y obtenga nueva información a través de una actualización desplegable infinita.
6.3.2 Flujo de alimentación
Hay dos modos comunes para los productos de transmisión de feeds:
- Línea de tiempo: sin filtrado de contenido, simplemente ordenando por tiempo de publicación del contenido , a menudo usado para amigos o seguidores. Por ejemplo, círculo de amigos.
- Ventajas: información completa, no faltará. Y es relativamente sencillo de implementar.
- Desventajas: hay mucho ruido de información, los usuarios no necesariamente están interesados y la eficiencia de adquisición de contenido es baja.
- Clasificación inteligente: utilice algoritmos inteligentes para bloquear contenido que viole las regulaciones y no sea de interés para los usuarios. Enviar información que interese a los usuarios para atraer usuarios.
- Ventajas: Proporciona información que interesa a los usuarios, los usuarios tienen alta viscosidad y son fácilmente adictos.
- Desventaja: si el algoritmo no es preciso, puede resultar contraproducente
- La página personal de este ejemplo se basa en los amigos que sigues, por lo que utiliza el modo Línea de tiempo. Hay tres implementaciones de este modo:
- modo de extracción
- modo de empuje
- combinación push-pull
Modo pull : también llamado difusión de lectura
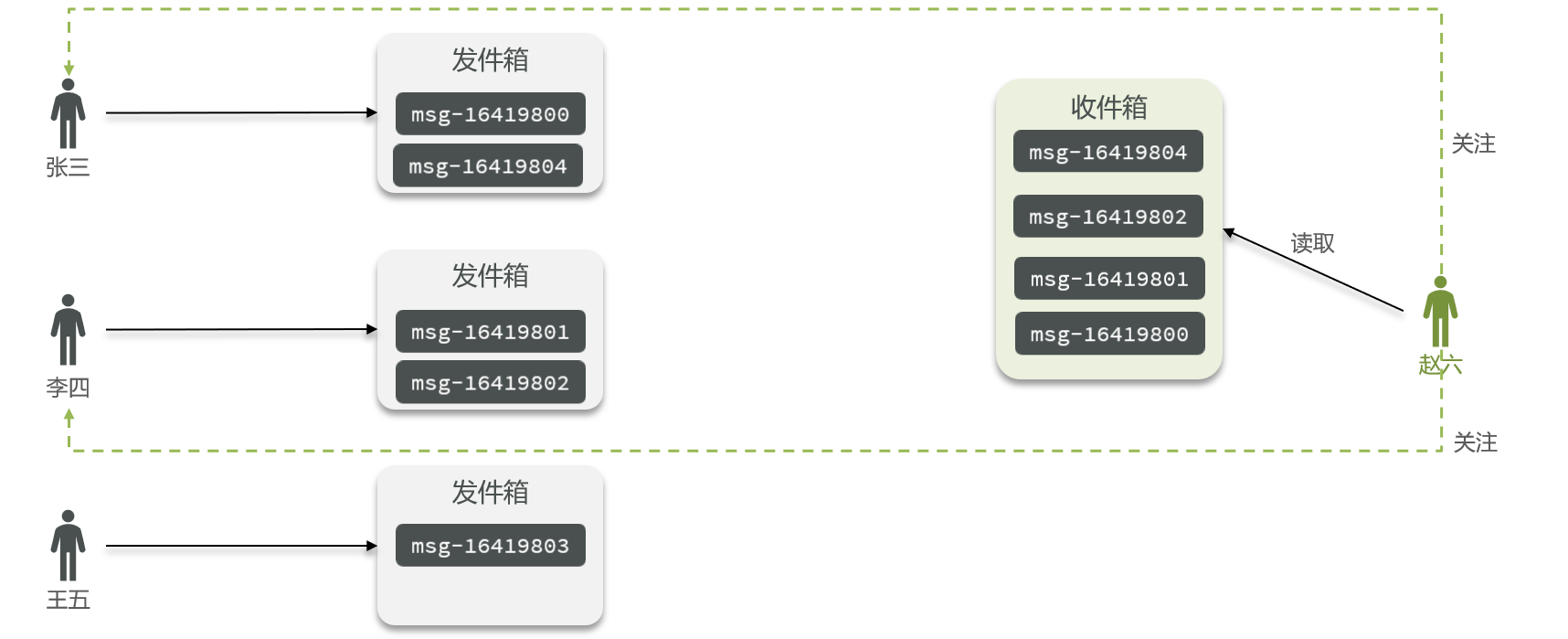
ilustrar:
Cuando un blogger publica un blog, el blog se almacenará en su bandeja de salida. Los fans extraen el contenido de la bandeja de salida en su propia bandeja de entrada y el contenido se ordena automáticamente
Modo Push : también conocido como inundación de escritura.
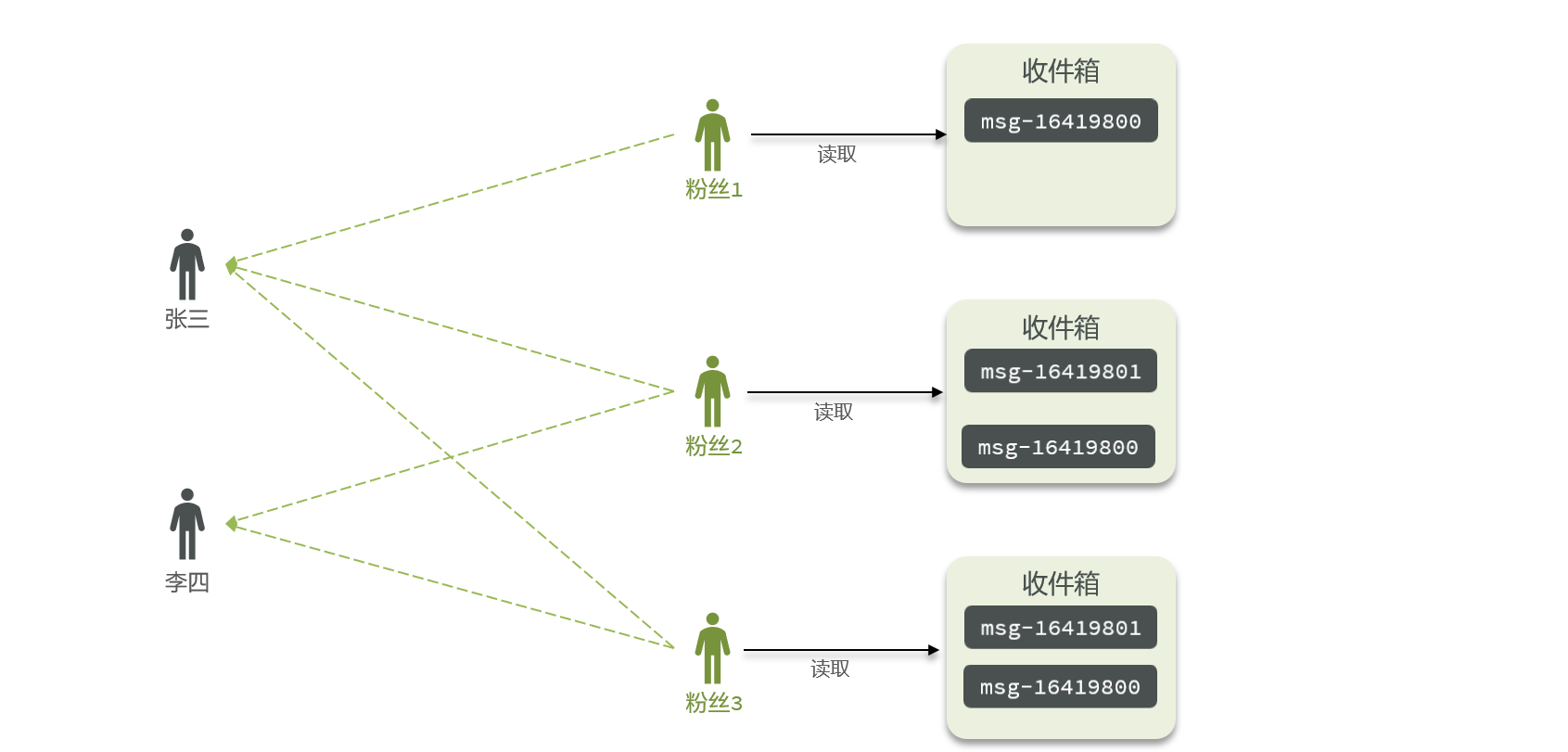
ilustrar:
Cuando un blogger publica un blog, no tiene una bandeja de entrada y envía mensajes directamente a cada usuario fan. Cada usuario fan recibe mensajes del blog desde su propia bandeja de entrada.
Modo combinado push-pull : también llamado híbrido de lectura-escritura, tiene las ventajas de los modos push y pull.
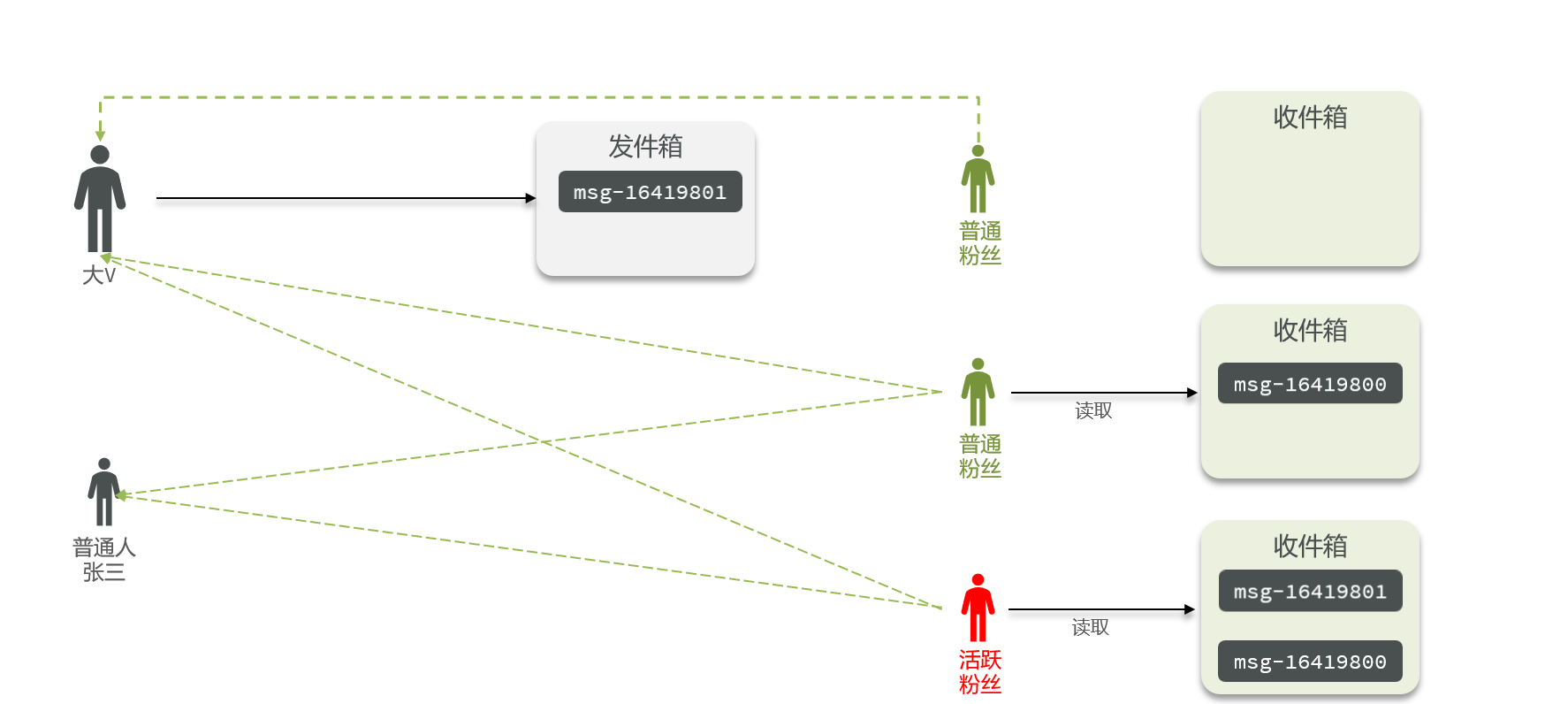
ilustrar:
Los blogueros envían blogs. Si son grandes bloggers V, tienen su propia bandeja de salida. Los fanáticos comunes leen el contenido en la bandeja de salida, mientras que los fanáticos activos reciben directamente los blogs en la bandeja de salida en su propia bandeja de entrada. Si eres un blogger común y corriente, envía el blog directamente a la bandeja de entrada de tus fans.
Esquema de implementación del flujo de alimentación.
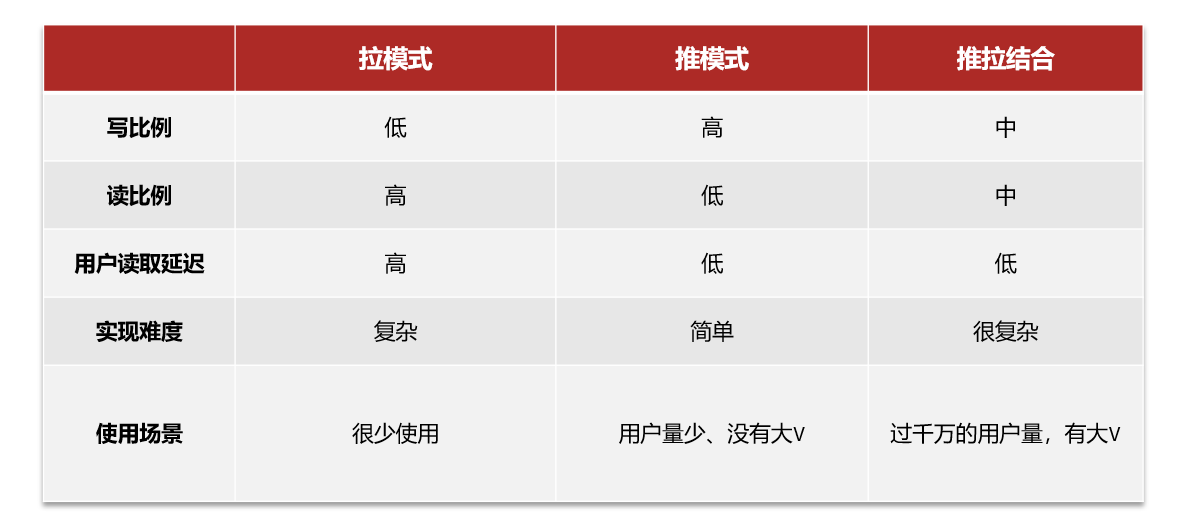
6.3.3 Casos de uso básicos
Paso 1: modifique el negocio de agregar notas de visitas a la tienda, guarde el blog en la base de datos y envíelo a las bandejas de entrada de los fans al mismo tiempo.
- Se agregó el método saveBlog de la clase BlogServiceImpl.
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店博文
boolean isSuccess = save(blog);
if (!isSuccess) {
return Result.fail("新增笔记失败");
}
// 3. 查询笔记作者的所有粉丝
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4. 推送笔记Id到所有粉丝
for (Follow follow : follows) {
// 4.1获取粉丝Id
Long userId = follow.getUserId();
// 4.2推送到粉丝收件箱
String key = "feed:" + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}
Paso 2: implementar la consulta de paginación
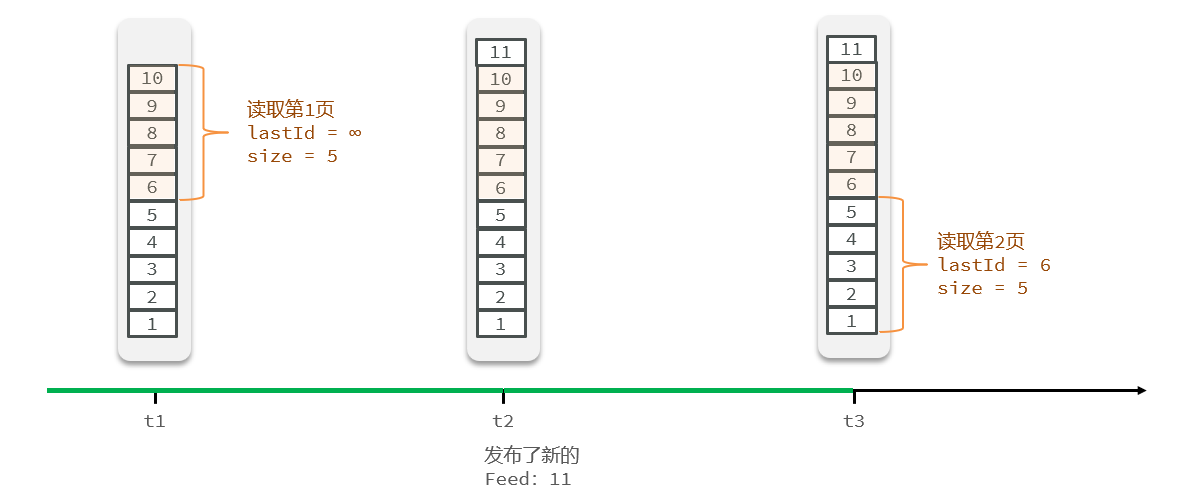
ilustrar:
Utilice la forma de paginación con desplazamiento para implementar la consulta de paginación con desplazamiento del flujo de alimentación
- Modificar el método queryBlogOfFollow de la clase BlogServiceImpl
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok(); // 如果关注列表没有数据,则返回
}
// 4.解析数据:blogId、minTime(时间戳)、offset(集合中分数值等于最新时间的元素个数),拿到最新时间戳粉丝和
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1; //定义需要跳过的元素个数
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
// 4.1.获取id
System.out.println("value:::" + tuple.getValue());
ids.add(Long.valueOf(tuple.getValue())); // 收集一下Blog集合
// 4.2.获取分数(时间戳)
long time = tuple.getScore().longValue(); //记录一下最新时间戳分数
System.out.println("value:::" + tuple.getScore());
if (time == minTime) {
// 如果 最新时间戳跟上一个元素时间戳相同则增加跳过元素次数,避免重复查询
os++;
} else {
minTime = time;
os = 1; // 重置跳过元素的个数
}
}
// 5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); // 因为In语句不能保证查询出的ID
for (Blog blog : blogs) {
// 5.1.查询blog有关的用户
queryBlogUser(blog); // 设置一下博客的基本信息
// 5.2.查询blog是否被点赞
queryBlogLiked(blog); // 该博客是否点赞
}
// 6. 封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os); // 将本次查询跳过次数进行封装返回,避免下一次结果的重复查询
r.setMinTime(minTime);
return Result.ok(r);
}
Reponer:
ZREVRANGEBYSCOREEl comando del método es devolver todos los miembros en el intervalo de puntuación especificado en el conjunto ordenado
7. Negocios cercanos
Resumen de notas:
- Puntos de función de Redis
- En las funciones de seguir y dejar de seguir, se utiliza
Setel conjunto de comandos de Redis. A travésaddde unremovemétodo, las funciones de seguir y dejar de seguir se implementan para que los usuarios que hayan iniciado sesión sigan a otros blogueros.- En la función de atención conjunta,
Setse utiliza el conjunto de comandos de Redis yintersectla función de atención conjunta se realiza mediante el procesamiento de intersección de los dos conjuntos.SortedSetEn la función de seguimiento push, use el comando en Redisaddpara agregar el blog publicado por el blogger a la bandeja de entrada del fan a través del método (implementado como el modo push del flujo de alimentación). El método de consulta de paginación de desplazamientoreverseRangeByScoreWithScoresrealiza la función de consulta de desplazamiento de paginación- Dificultades en la implementación de funciones:
- Úselo en MyBatis-plus
removeylastagregue declaraciones SQL para su uso.- En el flujo de Stream, el método de conversión de tipo conjunta MyBatis-plus
map()se utiliza junto con- En la herramienta Hutool, el empalme de cadenas realiza consultas ordenadas de múltiples datos
StrUtil.joincompletando el SQL de la base de datos y copiando la clase de entidad para completar la copia de DTO.ORDER BY FIELDBeanUtil.copyProperties- En la función push, la consulta dinámica del modo de transmisión de feeds implementa un algoritmo simple al registrar el tiempo mínimo y la cantidad de elementos omitidos . Consultar la información básica después de escribir un blog y la implementación detallada de información similar.
7.1 Descripción general
ilustrar:
Cada tienda tiene un tipo para su clasificación
ilustrar:
En Redis, podemos usar el tipo de tienda como un conjunto de ID como clave de Redis, el ID de cada tienda como valor y la ubicación geográfica de cada tienda como puntuación.
7.2 Casos de uso básicos
Reponer:
Paso 1: importar información de la tienda a GEO
- El método loadShopData en el nuevo método de prueba
/**
* 导入店铺信息到GEO
*/
@Test
public void loadShopData() {
// 1.查询商铺信息
List<Shop> shopList = shopService.list();
// 2.根据商铺typeId分组
Map<Long, List<Shop>> map = shopList.stream().collect(Collectors.groupingBy(Shop::getTypeId));
// 3.分批完成Redis的写入
for (Map.Entry<Long, List<Shop>> entry : map.entrySet()) {
// 3.1获取商铺类型id
Long typeId = entry.getKey();
String key = SHOP_GEO_KEY + typeId;
// 3.2获取同类型的商铺集合
List<Shop> value = entry.getValue();
List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size());
// 3.3写入redis GEOADD key 经度 纬度 member
for (Shop shop : value) {
RedisGeoCommands.GeoLocation<String> e = new RedisGeoCommands.GeoLocation<>(
shop.getId().toString(),
new Point(shop.getX(), shop.getY())
);
locations.add(e);
}
stringRedisTemplate.opsForGeo().add(key, locations);
}
}
Descripción: Agregado exitosamente
Paso 2: Realice consultas de tiendas por tipo de tienda
Método ShopServiceImpl en el nuevo método ShopServiceImpl
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// 1.判断是否通过距离进行查询
if (ObjectUtil.isNull(x) || ObjectUtil.isNull(y)) {
// 根据类型分页查询
Page<Shop> page = query()
.eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
// 返回数据
return Result.ok(page.getRecords());
}
// 2.计算分页查询
String key = SHOP_GEO_KEY + typeId;
Integer from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;
Integer end = current * SystemConstants.DEFAULT_PAGE_SIZE;
// 3.查询redis,按照距离排序、分页。结果:shopId、distance
GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() //GEOSEARSH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE
.search(key,
GeoReference.fromCoordinate(x, y),
new Distance(5000), // 指定距离范围
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance() //返回结果带上距离
.limit(end) //limit方法,指定从 0 到 end
);
// 4.解析出ID
if (ObjectUtil.isNull(results) || ObjectUtil.isEmpty(results)) {
return Result.ok(Collections.emptyList()); //无最新数据
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();
if (list.size() <= from) {
return Result.ok(Collections.emptyList()); //无最新数据
}
// 4.1截取from ~ end的部分
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> skipList = list.stream().skip(from).toList();
List<Long> shopIds = new ArrayList<>(skipList.size());
Map<Long, Distance> shopDistances = new HashMap<>(skipList.size());
for (GeoResult<RedisGeoCommands.GeoLocation<String>> geoLocationGeoResult : skipList) {
// 4.2 获取店铺Id
Long shopId = Long.valueOf(geoLocationGeoResult.getContent().getName());
shopIds.add(shopId);
// 4.3 获取距离
Distance distance = geoLocationGeoResult.getDistance();
shopDistances.put(shopId, distance);
}
// 5.根据ID查询shop
String idStr = StrUtil.join(",", shopIds);
List<Shop> shopList = query().in("id", shopIds).last("ORDER BY FILED(id," + idStr + ")").list();
for (Shop shop : shopList) {
Distance distance = shopDistances.get(shop.getId());
shop.setDistance(distance.getValue());
}
// 6.返回
return Result.ok(shopList);
}
8. Inicio de sesión de usuario
Resumen de notas:
Puntos de función de Redis:
En la función de inicio de sesión, use el comando en Redis para establecer si el usuario inicia sesión ese día
Bitmapa travéssetBitdel método (recuerde que el parámetro del método de compensación comienza desde 0)En la función de estadísticas de inicio de sesión, use el comando en Redis
Bitmapy usebitFieldel método para obtener el número decimal de inicio de sesión en el rango especificado en la matriz.Dificultades en la implementación de funciones:
- En la implementación de la función de estadísticas de inicio de sesión,
&los operadores se utilizan para determinar si el inicio de sesión se basa en un solo dígito y si el resultado de la operación es 0, y el desplazamiento se realiza para registrar el número de inicios de sesión consecutivos. logrando una pequeña implementación del algoritmo.
8.1 Función de inicio de sesión


ilustrar:
BitMap es una buena manera de implementar la idea de inicio de sesión.

ilustrar:
Al operar bitMap, puede contar el número de registros.
8.1.1 Descripción general
8.1.2 Casos de uso básicos
- Agregar métodos
UserServiceImplen claseUserServiceImpl
/**
* 登录方法
*
* @return 成功
*/
@Override
public Result sign() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
// 3.拼接Key
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.写入Redis SETBIT key offset 1
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
return Result.ok();
}
ilustrar:
En StringRedisTemplate, el comando para bitMap se coloca
opsForValueen el método
8.2 Función de estadísticas de check-in
8.2.1 Descripción general


8.2.2 Casos de uso básicos
- Agregar métodos
UserServiceImplen clasesignCount
/**
* 统计最近一次连续签到天数
*
* @return 签到天数
*/
@Override
public Result signCount() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
// 3.拼接Key
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.获取本月截至今天为止的所有签到记录,并返回一个十进制数 BITFIELD sign:5:202303 GET u14 0
List<Long> result = stringRedisTemplate.opsForValue().bitField(key,
BitFieldSubCommands.create().
get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)) //指定从第几天结束
.valueAt(0) // 指定从第几天开始
);
if (ObjectUtil.isNull(result) || ObjectUtil.isEmpty(result)) {
// 没有任何签到结果
return Result.ok(0);
}
Long num = result.get(0);
if (ObjectUtil.isNull(num) || num == 0) {
// 没有任何签到结果
return Result.ok(0);
}
// 6.遍历循环
int count = 0;
while (true) {
// 6.1让这个数字与1做与运算,得到数字的最后一个bit位。判断这个bit位是否位零
if ((num & 1) == 0) {
// 为0,则表示未签到
break;
} else {
//为1,则表示已签到
count++;
}
// 继续位移,判断下一位
num >>>= 1; // num = num >> 1
}
return Result.ok(count);
}
9.Estadísticas UV
Resumen de notas:
Puntos de función de Redis:
En la función de estadísticas de UA, los usuarios se agregan a Redis utilizando
HyperLogLogcomandos en Redis a través de métodos para lograr estadísticas sobre las visitas de los usuarios.add
9.1 Descripción general
UV: El nombre completo es Visitante Único, también llamado visitante único, que se refiere a las personas naturales que acceden y navegan a través de Internet en esta página web. Si un mismo usuario visita el sitio web varias veces durante un día, solo se registrará una vez.
PV: El nombre completo es Vista de página, también llamada vistas de página o clics. Cada vez que un usuario visita una página en el sitio web, se registra un PV. Si el usuario abre la página varias veces, se registran múltiples PV. A menudo se utiliza para medir el tráfico del sitio web.
Es más problemático hacer estadísticas UV en el lado del servidor, porque para determinar si el usuario ya ha contado, es necesario guardar la información del usuario que se ha contado. Pero si cada usuario visitante se guarda en Redis, la cantidad de datos será muy aterradora.
9.2 Casos de uso básicos
- Crear nuevo método de prueba
@Test
public void testHyperLogLog() {
String key = "user:ua:2023:7";
// 准备一个空数组
String[] users = new String[1000];
int index = 0;
for (int i = 1; i <= 1000000; i++) {
users[index++] = "user_" + i;
if (i % 1000 == 0) {
index = 0;
// 发送到redis
stringRedisTemplate.opsForHyperLogLog().add(key, users);
}
}
// 统计数量
Long count = stringRedisTemplate.opsForHyperLogLog().size(key);
System.out.println(count);
}
conocimiento gasolinera
1. Teclas de acceso directo comunes para IDEA
La tecla de acceso directo de Idea Ctrl+alt+u puede mostrar el diagrama de dependencia de relaciones de la clase.
Las teclas de acceso directo de IDEA Ctrl+shift+upondrán en mayúscula el contenido seleccionado
2.Clase de herramienta de coleccionistas
3.Marco ejecutor
Registro
Agregue documentación API en línea de Knife4j
Paso 1: agregar dependencias
<!--knife4j-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
Paso 2: agregar el archivo de configuración
/**
* knife4j配置信息
*/
@Configuration
@EnableSwagger2WebMvc
public class Knife4jConfig {
@Bean
public Docket defaultApi() {
return new Docket(DocumentationType.SWAGGER_2)
.groupName("黑马点评管理系统后台接口文档")
.apiInfo(defaultApiInfo())
.select()
.apis(RequestHandlerSelectors.withClassAnnotation(RestController.class))
.paths(PathSelectors.any())
.build();
}
private ApiInfo defaultApiInfo() {
return new ApiInfoBuilder()
.title("管理系统后台接口文档")
.description("管理系统后台接口文档")
.contact(new Contact("开发组", "", ""))
.version("1.0")
.build();
}
}
Paso 3: modificar la configuración de Yml
spring:
mvc:
pathmatch:
matching-strategy: ant_path_matcher
Paso 4: modificar las reglas del interceptor
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(getLoginInterceptor()).excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login",
"/doc.html/**", // 需要放行此类文件需要的路径请求
"/swagger-resources/**",
"/v2/**"
).order(1);
registry.addInterceptor(getRefreshTokenInterceptor()).addPathPatterns("/**").order(0);
}
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
// 处理一下,静态访问的路径
registry.addResourceHandler("doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}