Pila de tecnología de microservicios SpringCloud Seguimiento de Dark Horse diez
- el objetivo de hoy
- caché distribuida
- 1. Redis persistencia
- 2. Redis maestro-esclavo
- 3. Centinela Redis
- 4. Clúster de fragmentación de Redis
el objetivo de hoy

caché distribuida
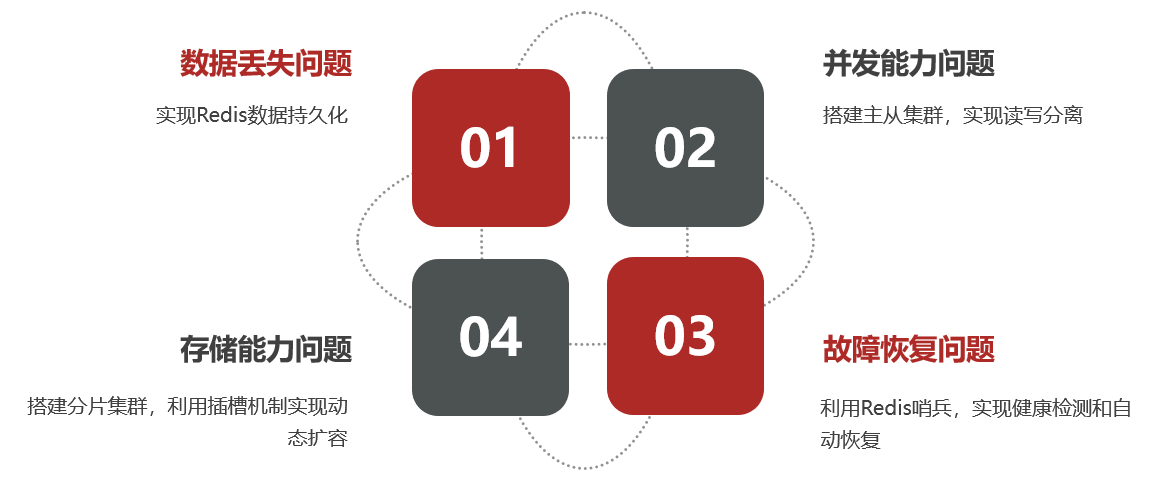
– Basado en el clúster de Redis para resolver los problemas de Redis independiente
Hay cuatro problemas principales en Redis independiente:
1. Redis persistencia
Redis tiene dos esquemas de persistencia:
- persistencia RDB
- persistencia AOF
1.1 Persistencia de RDB
El nombre completo de RDB es Archivo de copia de seguridad de la base de datos de Redis (archivo de copia de seguridad de datos de Redis), también conocido como instantánea de datos de Redis. En pocas palabras, todos los datos en la memoria se graban en el disco. Cuando la instancia de Redis falla y se reinicia, lea el archivo de instantánea del disco y restaure los datos. Los archivos de instantáneas se denominan archivos RDB, que se guardan en el directorio en ejecución actual de forma predeterminada.
1.1.1 Tiempo de ejecución
La persistencia de RDB se realiza en cuatro situaciones:
- Ejecutar el comando de guardar
- Ejecute el comando bgsave
- Cuando Redis está caído
- Cuando se activa una condición RDB
1) Guardar comando
Ejecute el siguiente comando para ejecutar la RDB inmediatamente:

El comando guardar hará que el proceso principal ejecute la RDB y todos los demás comandos se bloquearán durante este proceso. Solo se puede usar durante la migración de datos.
2) comando bgsave⭐
El siguiente comando puede ejecutar RDB de forma asincrónica:

después de ejecutar este comando, se iniciará un proceso independiente para completar el RDB, y el proceso principal puede continuar procesando las solicitudes de los usuarios sin verse afectado.
3) Cuando
Redis está inactivo, ejecutará un comando de guardado para lograr la persistencia de RDB.
Cuando salimos de redis con ctrl + c, se guardará automáticamente una vez

4) Condiciones de activación de RDB
Redis tiene un mecanismo interno de activación de RDB, que se puede encontrar en el archivo redis.conf, el formato es el siguiente:
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000


También se pueden establecer otras configuraciones de RDB en el archivo redis.conf:
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./


1.1.2 Principio de RDB
Al comienzo de bgsave, el proceso principal se bifurcará para obtener el proceso secundario, y el proceso secundario compartirá los datos de memoria del proceso principal. Una vez completada la bifurcación, los datos de la memoria se leen y escriben en el archivo RDB.
fork utiliza tecnología de copia en escritura:
- Cuando el proceso principal realiza una operación de lectura, accede a la memoria compartida;
- Cuando el proceso principal realiza una operación de escritura, se copia una copia de los datos y se realiza la operación de escritura.

1.1.3 Resumen
¿Proceso básico de bgsave en modo RDB?
- Bifurcar el proceso principal para obtener un proceso secundario, espacio de memoria compartida
- El proceso secundario lee los datos de la memoria y los escribe en un nuevo archivo RDB
- Reemplace archivos RDB antiguos con archivos RDB nuevos
¿Cuándo se ejecutará RDB? ¿Qué significa ahorrar 60 1000?
- El valor predeterminado es cuando se detiene el servicio.
- Significa que RDB se activa cuando se realizan al menos 1000 modificaciones en 60 segundos
¿Desventajas de RDB?
- El intervalo de ejecución de RDB es largo y existe el riesgo de pérdida de datos entre dos escrituras de RDB.
- El proceso secundario de bifurcación, la compresión y la escritura de archivos RDB consumen mucho tiempo
1.2 Persistencia de AOF
1.2.1 Principio de AOF
El nombre completo de AOF es Append Only File (archivo adjunto). Cada comando de escritura procesado por Redis se registrará en el archivo AOF, que se puede considerar como un archivo de registro de comandos.
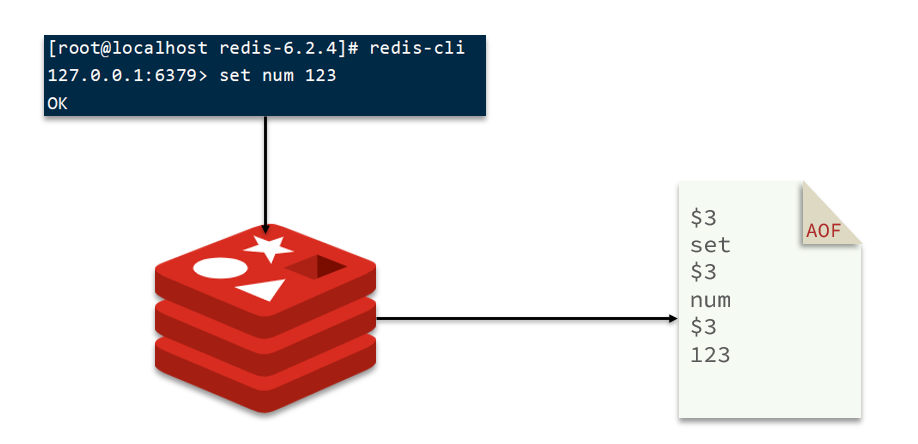
1.2.2 Configuración AOF
AOF está deshabilitado de forma predeterminada, debe modificar el archivo de configuración redis.conf para habilitar AOF:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
Primero deshabilite RDB

y habilite AOF

La frecuencia de grabación de comandos AOF también se puede configurar a través del archivo redis.conf:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no

Reinicie Linux después de la configuración, porque estamos
ejecutando después de que se abra el proceso en segundo plano
select 4
set school 4
Ver el archivo appendonly.aof

Comparación de tres estrategias:

1.2.3 Reescritura de archivos AOF
Debido a que es un comando de registro, el archivo AOF será mucho más grande que el archivo RDB. Y AOF registrará múltiples operaciones de escritura en la misma clave, pero solo la última operación de escritura es significativa.
Por ejemplo, si modificamos num dos veces

y miramos el archivo appendonly.aof, encontramos que se ha grabado dos veces.Al

ejecutar el comando bgrewriteaof, el archivo AOF se puede reescribir para lograr el mismo efecto con la menor cantidad de comandos.

Vamos a hacerlo
BGREWRITEAOF

Luego miramos el archivo appendonly.aof y hacemos un poco de procesamiento de compresión.Luego

reiniciamos Linux y verificamos si los datos existen, y encontramos que todavía existen.

Como se muestra en la figura, AOF originalmente tiene tres comandos, pero set num 123 和 set num 666todos son operaciones en Núm. La segunda vez sobrescribirá el primer valor, por lo que no tiene sentido registrar el primer comando.
Entonces, después de volver a escribir el comando, el contenido del archivo AOF es:mset name jack num 666
Redis también reescribirá automáticamente el archivo AOF cuando se active el umbral. Los umbrales también se pueden configurar en redis.conf:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
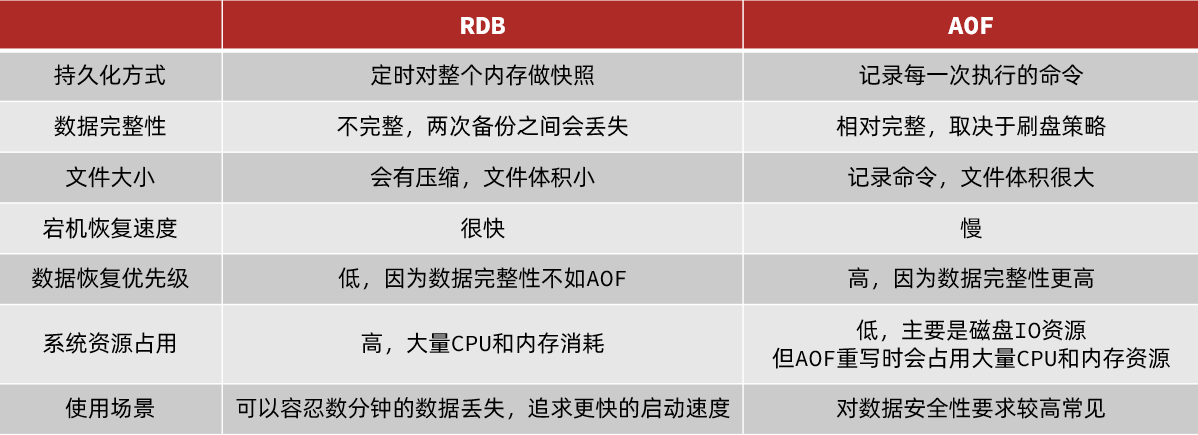
1.3 Comparación entre RDB y AOF
RDB y AOF tienen cada uno sus propias ventajas y desventajas.Si los requisitos de seguridad de datos son altos, a menudo se usan en combinación en el desarrollo real .
2. Redis maestro-esclavo
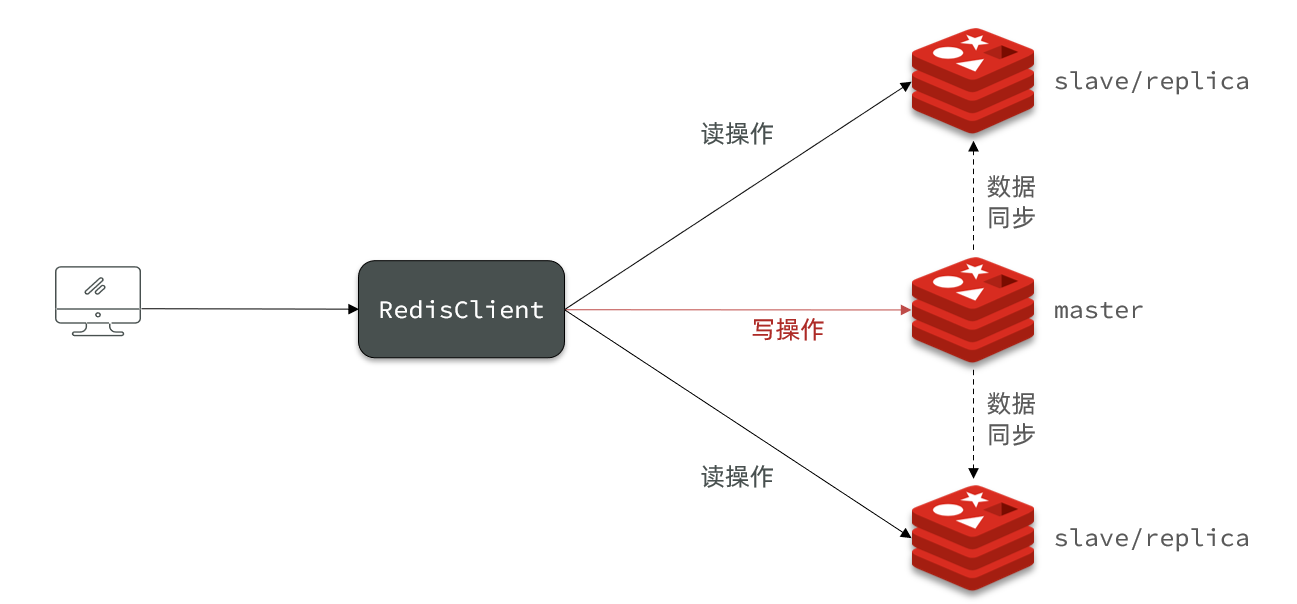
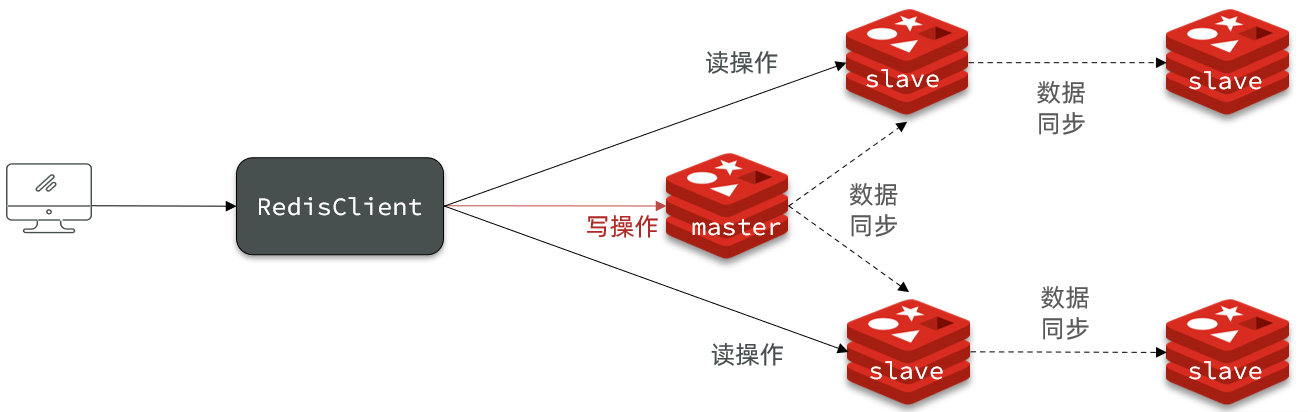
2.1 Construir una arquitectura maestro-esclavo
La capacidad de simultaneidad de Redis de un solo nodo tiene un límite superior. Para mejorar aún más la capacidad de simultaneidad de Redis, es necesario crear un clúster maestro-esclavo para lograr la separación de lectura y escritura.
Para conocer el proceso de construcción específico, consulte el material de preclase "Redis Cluster.md":

2.1.1 Estructura del conglomerado
La estructura de clúster maestro-esclavo que construimos se muestra en la figura:
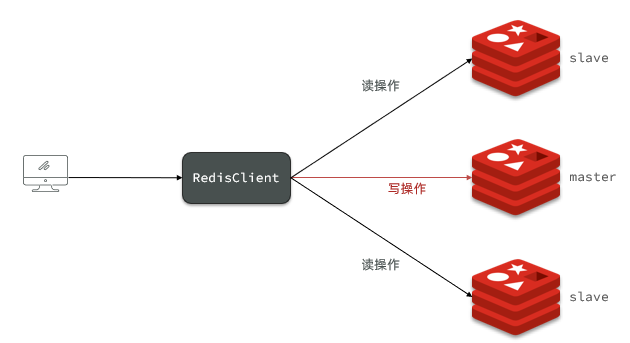
Hay tres nodos en total, un nodo maestro y dos nodos esclavos.
Aquí abriremos 3 instancias de redis en la misma máquina virtual para simular el clúster maestro-esclavo, la información es la siguiente:
| IP | PUERTO | Role |
|---|---|---|
| 192.168.150.101 | 7001 | maestro |
| 192.168.150.101 | 7002 | esclavo |
| 192.168.150.101 | 7003 | esclavo |
2.1.2 Preparar instancia y configuración
Para iniciar tres instancias en la misma máquina virtual, se deben preparar tres archivos y directorios de configuración diferentes. El directorio donde se encuentran los archivos de configuración también es el directorio de trabajo.
1) Crear un directorio
Creamos tres carpetas llamadas 7001, 7002 y 7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003
Como se muestra en la imagen:

2) Restaurar la configuración original
Modifique el archivo redis-6.2.4/redis.conf, cambie el modo de persistencia al modo RDB predeterminado y mantenga AOF desactivado.
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 关闭AOF
appendonly no

cerrar AOF

3) Copie el archivo de configuración en cada directorio de instancia
Luego copie el archivo redis-6.2.4/redis.conf en tres directorios (ejecute el siguiente comando en el directorio /tmp):
# 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf
# 我本机是
echo redis7001 redis7002 redis7003 |xargs -t -n 1 cp /usr/local/src/redis-6.2.6/redis.conf

4) Modificar el puerto y directorio de trabajo de cada instancia
Modifique el archivo de configuración en cada carpeta, modifique los puertos a 7001, 7002 y 7003 respectivamente, y modifique la ubicación de almacenamiento del archivo rdb a su propio directorio (ejecute los siguientes comandos en el directorio /tmp):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
# 我们本机是
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/redis7001\//g' redis7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/redis7002\//g' redis7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/redis7003\//g' redis7003/redis.conf
Se puede ver que la modificación es exitosa y

la modificación del puerto es exitosa

5) Modificar la IP declarada de cada instancia
La máquina virtual en sí tiene varias direcciones IP. Para evitar confusiones en el futuro, debemos especificar la información de la dirección IP vinculante de cada instancia en el archivo redis.conf. El formato es el siguiente:
# redis实例的声明 IP
replica-announce-ip 192.168.150.101
Cada directorio necesita ser cambiado, y podemos completar la modificación con un clic (ejecutar el siguiente comando en el directorio /tmp):
# 逐一执行
sed -i '1a replica-announce-ip 192.168.150.101' redis7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' redis7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' redis7003/redis.conf
# 或者一键修改
printf '%s\n' redis7001 redis7002 redis7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf

Luego ingrese un archivo de configuración para ver

2.1.3 Puesta en marcha
Para ver los registros convenientemente, abrimos tres ventanas ssh, iniciamos tres instancias de redis respectivamente e iniciamos el comando:

# 第1个
redis-server redis7001/redis.conf
# 第2个
redis-server redis7002/redis.conf
# 第3个
redis-server redis7003/redis.conf
Después del inicio:
Si desea detenerse con una tecla, puede ejecutar el siguiente comando:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
2.1.4 Abrir la relación maestro-esclavo
Ahora las tres instancias no tienen nada que ver entre sí.Para configurar el maestro-esclavo, puede usar el comando replicaof o slaveof (antes de 5.0).
Existen dos modalidades, temporal y permanente:
-
Modificar el archivo de configuración (permanente)
- Agregue una línea de configuración a redis.conf:
slaveof <masterip> <masterport>
- Agregue una línea de configuración a redis.conf:
-
Use el cliente redis-cli para conectarse al servicio redis y ejecute el comando slaveof (fallará después de reiniciar):
slaveof <masterip> <masterport>
< strong >< font color='red'>Nota</font>< /strong>: El comando replicaof se agrega después de 5.0, que tiene el mismo efecto que salveof.
Aquí usamos el segundo método por la conveniencia de la demostración.
Conéctese a 7002 a través del comando redis-cli y ejecute el siguiente comando:
# 连接 7002
redis-cli -p 7002
# 执行slaveof
slaveof 192.168.150.101 7001
Conéctese a 7003 a través del comando redis-cli y ejecute el siguiente comando:
# 连接 7003
redis-cli -p 7003
# 执行slaveof
slaveof 192.168.150.101 7001
Luego, conéctese al nodo 7001 para ver el estado del clúster:
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
resultado:
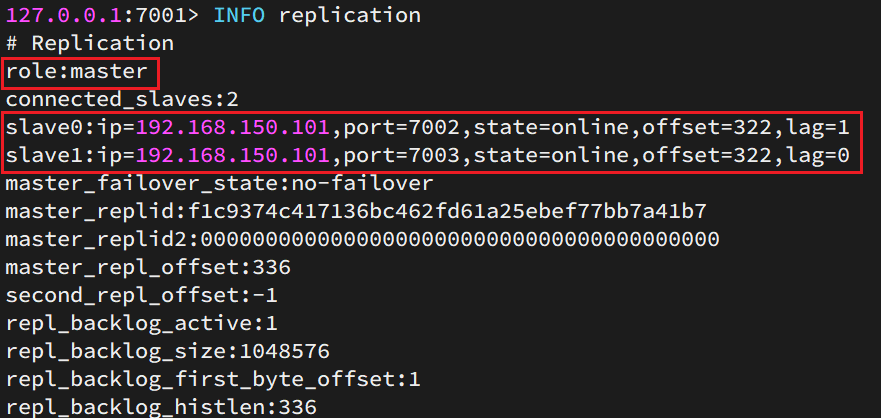
2.1.5 Pruebas
Haga lo siguiente para probar:
- Use redis-cli para conectarse a 7001, ejecute
set num 123

- Use redis-cli para conectarse a 7002, ejecute
get numy luego ejecuteset num 666

- Use redis-cli para conectarse a 7003, ejecute
get numy luego ejecuteset num 888

Se puede encontrar que solo el nodo maestro 7001 puede realizar operaciones de escritura, y los dos nodos esclavos 7002 y 7003 solo pueden realizar operaciones de lectura.
Resumen:
supongamos que hay dos instancias de Redis, A y B, ¿cómo hacer que B sea el nodo esclavo de A?
● Ejecute el comando en el nodo B: slaveof A's IP A's port
2.2 Principio de sincronización de datos maestro-esclavo
2.2.1 Sincronización completa
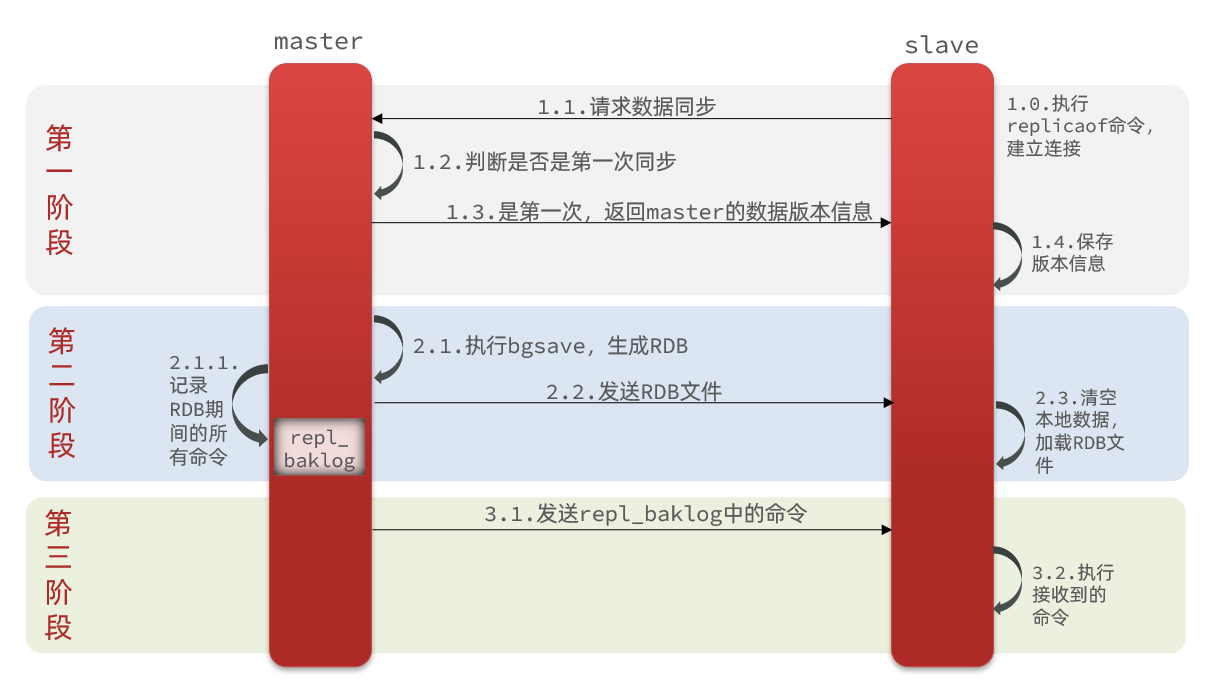
Cuando el maestro-esclavo establece una conexión por primera vez, realizará una sincronización completa y copiará todos los datos del nodo maestro al nodo esclavo, el proceso es el siguiente:
Aquí hay una pregunta, ¿cómo sabe el maestro que el bálsamo se está conectando por primera vez? ?
Hay varios conceptos que se pueden utilizar como base para el juicio:
- ID de replicación : Replid para abreviar, es la marca del conjunto de datos, y la misma ID significa que es el mismo conjunto de datos. Cada maestro tiene una respuesta única y el esclavo heredará la respuesta del nodo maestro.
- offset : el desplazamiento, que aumenta gradualmente a medida que aumentan los datos registrados en repl_baklog. Cuando el esclavo complete la sincronización, también registrará el desplazamiento de sincronización actual. Si el desplazamiento del esclavo es más pequeño que el del maestro, significa que los datos del esclavo van a la zaga del maestro y deben actualizarse.
Por lo tanto, para la sincronización de datos, el esclavo debe declarar su propio ID de replicación y compensación al maestro, para que el maestro pueda determinar qué datos deben sincronizarse.
Debido a que el esclavo es originalmente un maestro con su propia respuesta y compensación, cuando se convierte en esclavo por primera vez y establece una conexión con el maestro, la respuesta y la compensación enviadas son su propia respuesta y compensación.
El maestro juzga que la réplica enviada por el esclavo es inconsistente con la suya, lo que indica que este es un esclavo nuevo y sabe que necesita hacer una sincronización completa.
El maestro enviará su respuesta y compensación al esclavo, y el esclavo guardará la información. En el futuro, la réplica del esclavo será la misma que la del maestro.
Por lo tanto, la base para que el maestro juzgue si un nodo está sincronizado por primera vez es ver si la repetición es consistente .
Figura:

descripción completa del proceso:
- El nodo esclavo solicita sincronización incremental
- El nodo maestro juzga la replicación, encuentra inconsistencias y rechaza la sincronización incremental
- El maestro genera RDB con datos de memoria completos y envía RDB al esclavo
- El esclavo borra los datos locales y carga la RDB del maestro
- El maestro registra los comandos durante el período RDB en repl_baklog y envía continuamente los comandos en el registro al esclavo
- El esclavo ejecuta el comando recibido y se mantiene sincronizado con el maestro
2.2.2 Sincronización incremental
La sincronización completa necesita crear RDB primero y luego transferir el archivo RDB a un esclavo a través de la red, lo cual es demasiado costoso. Por lo tanto, a excepción de la primera sincronización completa, el esclavo y el maestro realizan una sincronización incremental la mayor parte del tiempo .
¿Qué es la sincronización delta? Es para actualizar solo una parte de los datos que es diferente entre el esclavo y el maestro. Como se muestra en la imagen:
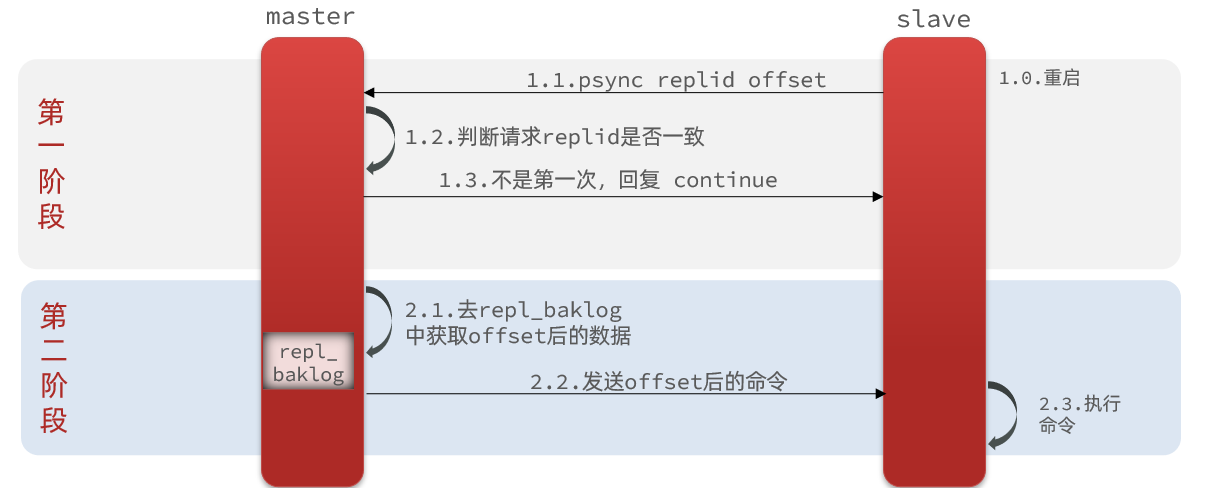
Entonces, ¿cómo sabe el maestro dónde está la diferencia de datos entre el esclavo y él mismo?
2.2.3 Principio repl_backlog
¿Cómo sabe el maestro dónde está la diferencia de datos entre el esclavo y él mismo?
Se trata del archivo repl_baklog durante la sincronización completa.
Este archivo es una matriz con un tamaño fijo, pero la matriz es circular, es decir, después de que el subíndice llegue al final de la matriz, comenzará a leer y escribir desde 0 nuevamente , de modo que los datos en la cabeza de la matriz la matriz se sobrescribirá.
Repl_baklog registrará el registro de comandos y la compensación procesada por Redis, incluida la compensación actual del maestro y la compensación en la que el esclavo ha copiado:
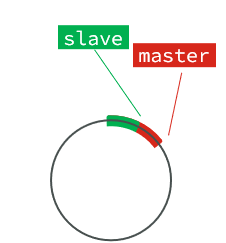
La diferencia entre el desplazamiento del esclavo y el maestro son los datos que el esclavo necesita copiar de forma incremental.
A medida que se siguen escribiendo datos, el desplazamiento del maestro aumenta gradualmente y el esclavo continúa copiando para alcanzar el desplazamiento del maestro:
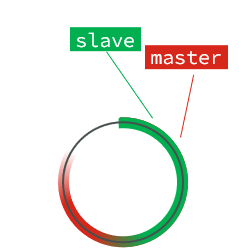
hasta que se llene la matriz:
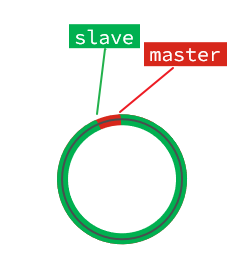
En este punto, si se escriben datos nuevos, se sobrescribirán los datos antiguos de la matriz. Sin embargo, mientras los datos antiguos estén en verde, significa que los datos se han sincronizado con el esclavo, incluso si se sobrescribe, no tendrá efecto. Porque solo la parte roja no está sincronizada.
Sin embargo, si el esclavo tiene congestión en la red, el desplazamiento del maestro supera con creces el desplazamiento del esclavo:
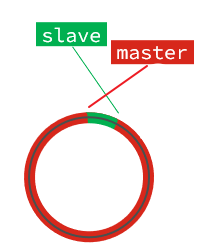
Si el maestro continúa escribiendo nuevos datos, su desplazamiento sobrescribirá los datos antiguos hasta que también se sobrescriba el desplazamiento actual del esclavo:
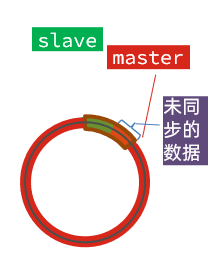
La parte roja en el cuadro marrón son los datos que no se han sincronizado pero que se han sobrescrito. En este momento, si el esclavo se recupera, necesita sincronizarse, pero descubre que su desplazamiento se ha ido y la sincronización incremental no se puede completar. Solo se puede hacer una sincronización completa .

2.3 Optimización de la sincronización maestro-esclavo
La sincronización maestro-esclavo puede garantizar la consistencia de los datos maestro-esclavo, lo cual es muy importante.
Los clústeres maestro-esclavo de Redis se pueden optimizar desde los siguientes aspectos:
- Configure repl-diskless-sync yes en el maestro para habilitar la replicación sin disco para evitar la E/S de disco durante la sincronización completa. (Este escenario se puede utilizar si el ancho de banda de la red es suficiente)
Cambiar configuración redis.conf en masterr

- El uso de memoria en un solo nodo de Redis no debe ser demasiado grande para reducir el exceso de E/S de disco causado por RDB.
- Aumente adecuadamente el tamaño de repl_baklog, realice la recuperación de fallas lo antes posible cuando el esclavo esté inactivo y evite la sincronización completa tanto como sea posible.
- Limite el número de nodos esclavos en un maestro. Si hay demasiados esclavos, puede usar una estructura de cadena maestro-esclavo-esclavo para reducir la presión sobre el maestro
Diagrama de arquitectura maestro-esclavo:
2.4 Resumen
Describa brevemente la diferencia entre la sincronización completa y la sincronización incremental.
- Sincronización completa: el maestro genera una RDB con datos de memoria completos y envía la RDB al esclavo. Los comandos posteriores se registran en repl_baklog y se envían al esclavo uno por uno.
- Sincronización incremental: el esclavo envía su propio desplazamiento al maestro, y el maestro obtiene los comandos después del desplazamiento en repl_baklog al esclavo
¿Cuándo realizar la sincronización completa?
- Cuando el nodo esclavo se conecta al nodo maestro por primera vez
- El nodo esclavo se ha desconectado durante demasiado tiempo y se ha sobrescrito el desplazamiento en repl_baklog
¿Cuándo se realiza una sincronización incremental?
- Cuando el nodo esclavo se desconecta y restaura, y el desplazamiento se puede encontrar en repl_baklog
3. Centinela Redis
Redis proporciona un mecanismo Sentinel para lograr la recuperación automática de fallas del clúster maestro-esclavo.
3.1 Principio centinela

3.1.1 Estructura y función del clúster
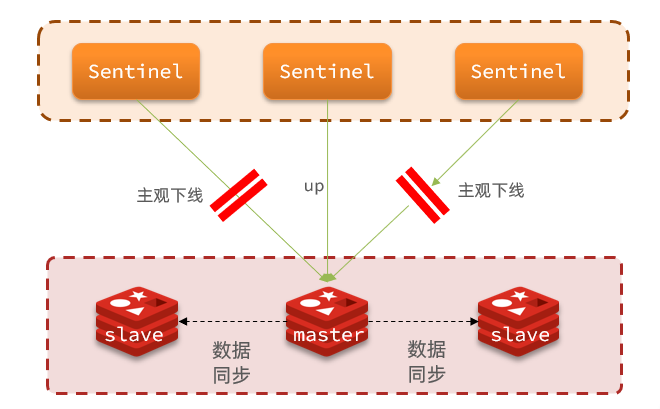
La estructura del centinela se muestra en la figura:

el papel del centinela es el siguiente:
- Monitoreo : Sentinel verifica constantemente que su maestro y esclavo funcionen como se espera
- Recuperación automática de fallas : si el maestro falla, Sentinel promoverá un esclavo a maestro. Cuando la instancia defectuosa se recupera, el nuevo maestro también es el principal
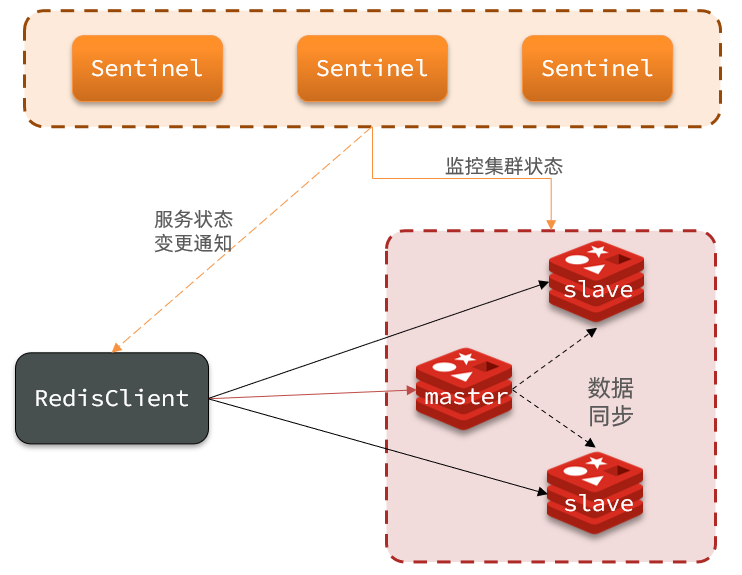
- Notificación : Sentinel actúa como la fuente de detección de servicios para el cliente de Redis y, cuando el clúster falla, enviará la información más reciente al cliente de Redis.
3.1.2 Principio de seguimiento del clúster
Sentinel supervisa el estado del servicio en función del mecanismo de latido y envía un comando ping a cada instancia del clúster cada 1 segundo:
• Desconectado subjetivo: si un nodo centinela detecta que una instancia no responde dentro del tiempo especificado, considera que la instancia está desconectada subjetivamente .
• Objetivo fuera de línea: si más del número especificado (quórum) de centinelas piensan que la instancia está fuera de línea subjetivamente, la instancia estará objetivamente fuera de línea . El valor del quórum es preferiblemente más de la mitad del número de instancias de Sentinel.
3.1.3 Principio de recuperación ante fallos del clúster
Una vez que se encuentra una falla en el maestro, Sentinel necesita seleccionar uno de los ungüentos como el nuevo maestro. La base de selección es la siguiente:
- Primero, juzgará la duración de la desconexión entre el nodo esclavo y el nodo maestro. Si excede el valor especificado (después de milisegundos * 10), el nodo esclavo será excluido
- Luego juzgue el valor de prioridad de esclavo del nodo esclavo, cuanto menor sea la prioridad, mayor será la prioridad, si es 0, nunca participará en la elección.
- Si la prioridad del esclavo es la misma, juzgue el valor de desplazamiento del nodo esclavo. Cuanto mayor sea el valor, más nuevos serán los datos y mayor será la prioridad.
- El último es juzgar el tamaño de la identificación en ejecución del nodo esclavo, cuanto menor sea la prioridad, mayor será la prioridad.
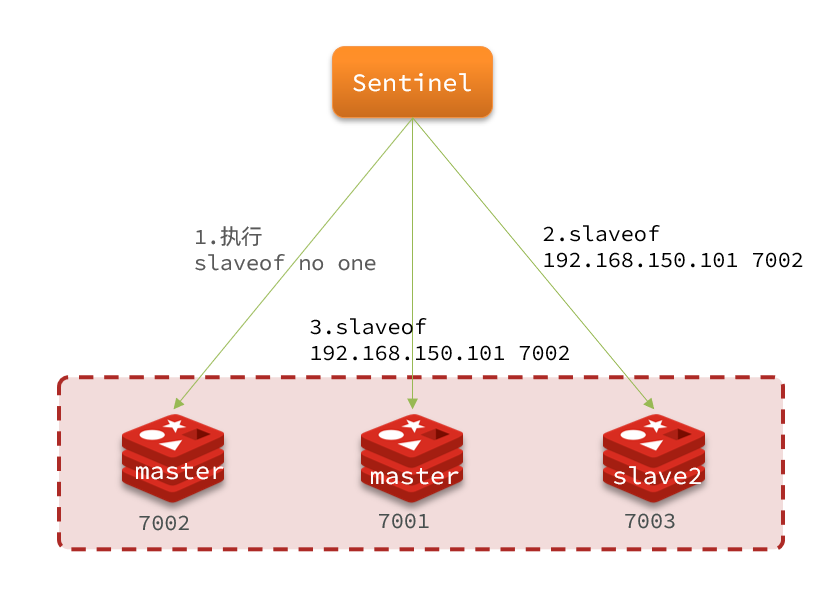
Cuando se elige un nuevo maestro, ¿cómo implementar el cambio?
El proceso es el siguiente:
- Sentinel envía el comando slaveof no one al nodo candidato slave1 para convertir el nodo en maestro
- Sentinel envía el comando slaveof 192.168.150.101 7002 a todos los demás esclavos para que estos se conviertan en nodos esclavos del nuevo maestro y comiencen a sincronizar los datos del nuevo maestro.
- Finalmente, Sentinel marca el nodo fallido como esclavo, y cuando el nodo fallido se recupere, se convertirá automáticamente en el nodo esclavo del nuevo maestro.
3.1.4 Resumen
¿Cuáles son las tres funciones de Sentinel?
- monitor
- conmutación por error
- notificar
¿Cómo juzga Sentinel si una instancia de Redis está en buen estado?
- Envíe un comando ping cada 1 segundo, si no hay comunicación durante un cierto período de tiempo, se considera fuera de línea subjetivo
- Si la mayoría de los centinelas piensa que la instancia está desconectada subjetivamente, se determina que el servicio está desconectado
¿Cuáles son los pasos de conmutación por error?
- Primero seleccione un esclavo como el nuevo maestro, ejecute slaveof no one
- Luego, deje que todos los nodos ejecuten slaveof new master
- Modifique la configuración del nodo defectuoso, agregue esclavo de nuevo maestro
3.2 Construcción de un grupo centinela
Para conocer el proceso de construcción específico, consulte el material de preclase "Redis Cluster.md":

3.2.1 Estructura del conglomerado
Aquí construimos un clúster Sentinel formado por tres nodos para supervisar el clúster maestro-esclavo de Redis anterior. Como se muestra en la imagen:
La información de las tres instancias centinela es la siguiente:
| nodo | IP | PUERTO |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
3.2.2 Preparar instancia y configuración
Para iniciar tres instancias en la misma máquina virtual, se deben preparar tres archivos y directorios de configuración diferentes. El directorio donde se encuentran los archivos de configuración también es el directorio de trabajo.
Creamos tres carpetas llamadas s1, s2, s3:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir sentinel1
mkdir sentinel2
mkdir sentinel3
Como se muestra en la imagen:
Luego creamos un archivo sentinel.conf en el directorio s1 y agregamos el siguiente contenido:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/sentinel1"
Interpretación:
port 27001: es el puerto de la instancia actual de Sentinelsentinel monitor mymaster 192.168.150.101 7001 2: Especifique la información del nodo maestromymaster: nombre de nodo maestro, definido por el usuario, escritura arbitraria192.168.150.101 7001: la ip y el puerto del nodo maestro2: El valor del quórum al elegir al maestro (más de la mitad de las elecciones)
Luego copie el archivo s1/sentinel.conf en los directorios s2 y s3 (ejecute los siguientes comandos en el directorio /tmp):
# 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道组合命令,一键拷贝
echo sentinel2 sentinel3 | xargs -t -n 1 cp sentinel1/sentinel.conf
Modifique los archivos de configuración en las dos carpetas s2 y s3, y cambie los puertos a 27002 y 27003 respectivamente:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
3.2.3 Puesta en marcha
Para ver los registros convenientemente, abrimos tres ventanas ssh, iniciamos tres instancias de redis respectivamente e iniciamos el comando:

El comando es el siguiente:
# 第1个
redis-sentinel sentinel1/sentinel.conf
# 第2个
redis-sentinel sentinel2/sentinel.conf
# 第3个
redis-sentinel sentinel3/sentinel.conf
Después del inicio:
3.2.4 Pruebas
Intente apagar el nodo maestro 7001, verifique el registro de centinela:
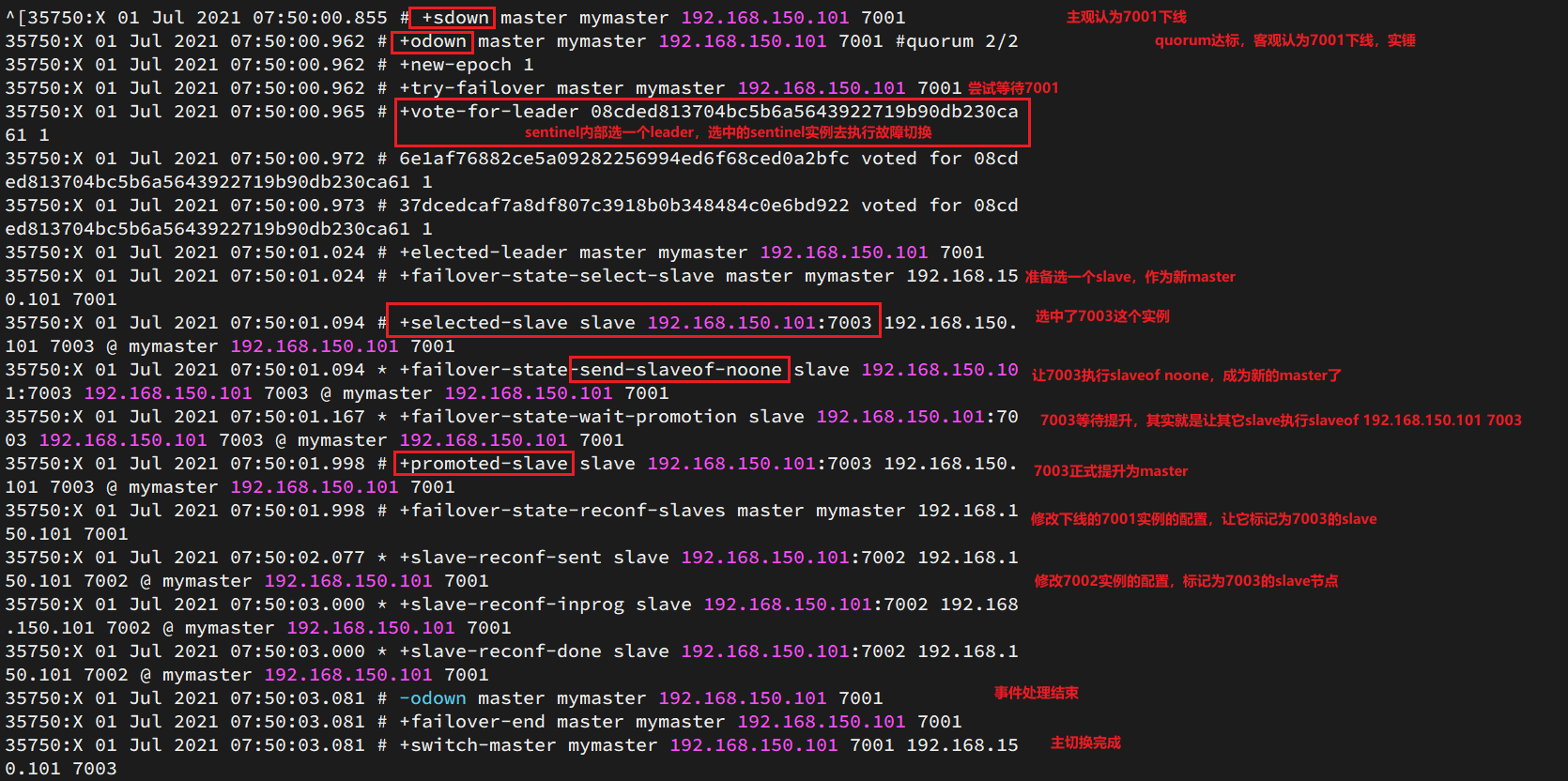
Ver el registro de 7003:
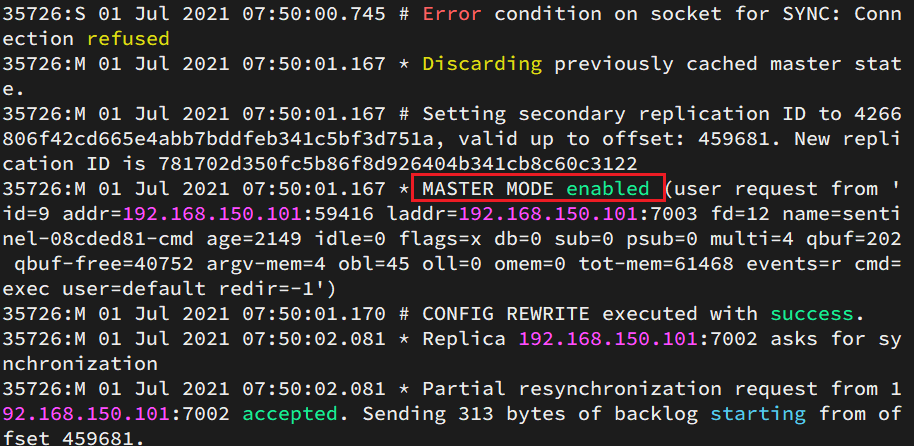
Ver el registro de 7002:
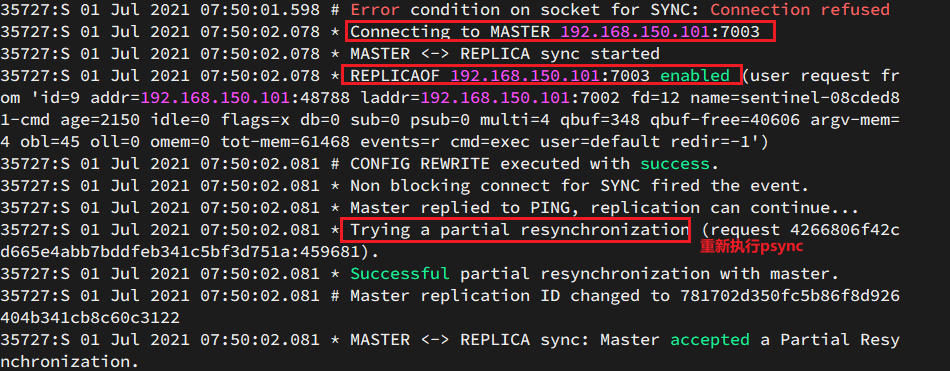
3.3.Plantilla Redis
En el clúster maestro-esclavo de Redis bajo la supervisión del clúster Sentinel, sus nodos cambiarán debido a la conmutación por error automática, y el cliente de Redis debe percibir este cambio y actualizar la información de conexión a tiempo. La capa subyacente de RedisTemplate de Spring usa lechuga para realizar la percepción del nodo y el cambio automático.
A continuación, implementamos el mecanismo centinela de integración de RedisTemplate a través de una prueba.
3.3.1 Importar proyecto de demostración
Primero, presentamos el proyecto de demostración proporcionado por los materiales previos a la clase:

3.3.2 Introducción de dependencias
Introduzca dependencias en el archivo pom del proyecto:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3.3.3 Configurar la dirección de Redis
Luego, especifique la información relacionada con el centinela de redis en el archivo de configuración application.yml:
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.150.101:27001
- 192.168.150.101:27002
- 192.168.150.101:27003
3.3.4 Configurar la separación de lectura y escritura
En la clase de inicio del proyecto, agregue un nuevo bean:
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
o escrito como
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer() {
return new LettuceClientConfigurationBuilderCustomizer() {
@Override
public void customize(LettuceClientConfiguration.LettuceClientConfigurationBuilder clientConfigurationBuilder) {
clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
};
}
Mira los datos en redis

acceso
http://localhost:8080/get/num
Obtener

Mire el registro, la lectura actual es 7002

Repasemos y modifiquemos
http://localhost:8080/set/num/666
Se descubrió que se entregó al nodo maestro

, por lo que apagamos el nodo maestro 7003
y descubrimos que 7001 se convirtió en un nodo maestro

y luego iniciamos 7003, y descubrimos que 7001 sigue siendo un nodo maestro
.
http://localhost:8080/set/num/777
Mire el registro

Este bean está configurado con estrategias de lectura y escritura, incluidos cuatro tipos:
- MAESTRO: leer desde el nodo maestro
- MASTER_PREFERRED: Lea primero desde el nodo maestro, lea la réplica cuando el maestro no esté disponible
- RÉPLICA: leer desde el nodo esclavo (réplica)
- REPLICA _PREFERRED: Lea primero desde el nodo esclavo (réplica), todos los esclavos no están disponibles para leer el maestro
4. Clúster de fragmentación de Redis
4.1 Construir un clúster de fragmentos
Maestro-esclavo y centinela pueden resolver el problema de alta disponibilidad y alta lectura simultánea. Pero todavía hay dos cuestiones sin resolver:
-
Problema de almacenamiento masivo de datos
-
El problema de la alta escritura concurrente
El uso de clústeres fragmentados puede resolver los problemas anteriores, como se muestra en la figura:

Características del clúster fragmentado:
-
Hay varios maestros en el clúster y cada maestro guarda datos diferentes
-
Cada maestro puede tener múltiples nodos esclavos
-
El maestro monitorea el estado de salud de cada uno a través de ping
-
Las solicitudes de los clientes pueden acceder a cualquier nodo del clúster y eventualmente se reenviarán al nodo correcto
Para conocer el proceso de construcción específico, consulte el material de preclase "Redis Cluster.md":

4.1.1 Estructura del conglomerado
Los clústeres fragmentados requieren una gran cantidad de nodos. Aquí construimos un clúster fragmentado mínimo, incluidos 3 nodos maestros, y cada maestro contiene un nodo esclavo. La estructura es la siguiente:
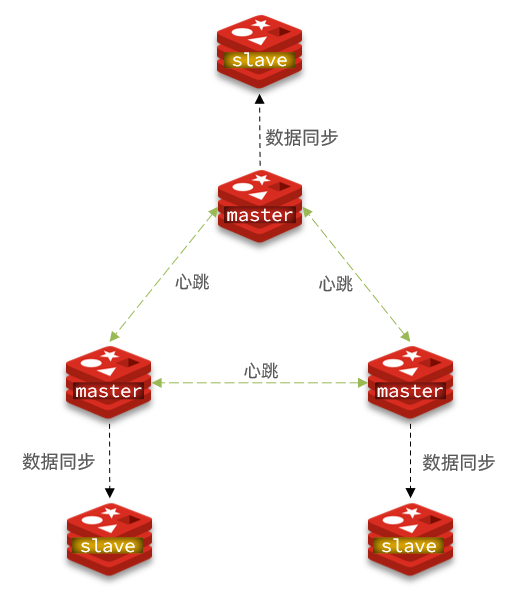
Aquí abriremos 6 instancias de redis en la misma máquina virtual para simular un clúster fragmentado, la información es la siguiente:
| IP | PUERTO | Role |
|---|---|---|
| 192.168.150.101 | 7001 | maestro |
| 192.168.150.101 | 7002 | maestro |
| 192.168.150.101 | 7003 | maestro |
| 192.168.150.101 | 8001 | esclavo |
| 192.168.150.101 | 8002 | esclavo |
| 192.168.150.101 | 8003 | esclavo |
4.1.2 Preparar instancia y configuración
Primero detenga todos los clústeres de redis anteriores
Elimine los directorios anteriores 7001, 7002 y 7003 y vuelva a crear los directorios 7001, 7002, 7003, 8001, 8002 y 8003:
# 进入/tmp目录
cd /tmp
# 删除旧的,避免配置干扰
rm -rf 7001 7002 7003
# 创建目录
mkdir 7001 7002 7003 8001 8002 8003
Prepare un nuevo archivo redis.conf en /tmp con el siguiente contenido:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log
Copie este archivo en cada directorio:
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
Modifique redis.conf en cada directorio y modifique 6379 para que sea coherente con el directorio:
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
4.1.3 Puesta en marcha
Dado que se ha configurado el modo de inicio en segundo plano, el servicio se puede iniciar directamente:
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
Ver estado a través de ps:
ps -ef | grep redis
Los servicios de descubrimiento se han iniciado normalmente:

Si desea cerrar todos los procesos, puede ejecutar el comando:
ps -ef | grep redis | awk '{print $2}' | xargs kill
o (recomendado de esta manera):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
4.1.4 Crear un clúster
Aunque el servicio está iniciado, actualmente cada servicio es independiente sin ninguna asociación.
Necesitamos ejecutar comandos para crear un clúster. Es problemático crear un clúster antes de Redis 5.0. Después de 5.0, los comandos de administración de clústeres están integrados en redis-cli.
1) Antes de Redis5.0
Los comandos de clúster anteriores a Redis 5.0 se implementaron mediante src/redis-trib.rb en el paquete de instalación de redis. Debido a que redis-trib.rb está escrito en lenguaje ruby, es necesario instalar el entorno ruby.
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
Luego use el comando para administrar el clúster:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
2) Después de Redis5.0
Estamos usando la versión Redis6.2.4, administración de clúster e integrado en redis-cli, el formato es el siguiente:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
Descripción del comando:
redis-cli --clusterO./redis-trib.rb: representa un comando de operación de clústercreate: representa la creación de un clúster--replicas 1O--cluster-replicas 1: especifique que el número de copias de cada maestro en el clúster es 1, y节点总数 ÷ (replicas + 1)el número de maestros se obtiene en este momento. Por lo tanto, el primer n en la lista de nodos es el maestro y los demás nodos son todos esclavos, que se asignan aleatoriamente a diferentes maestros.
Apariencia después de ejecutar:
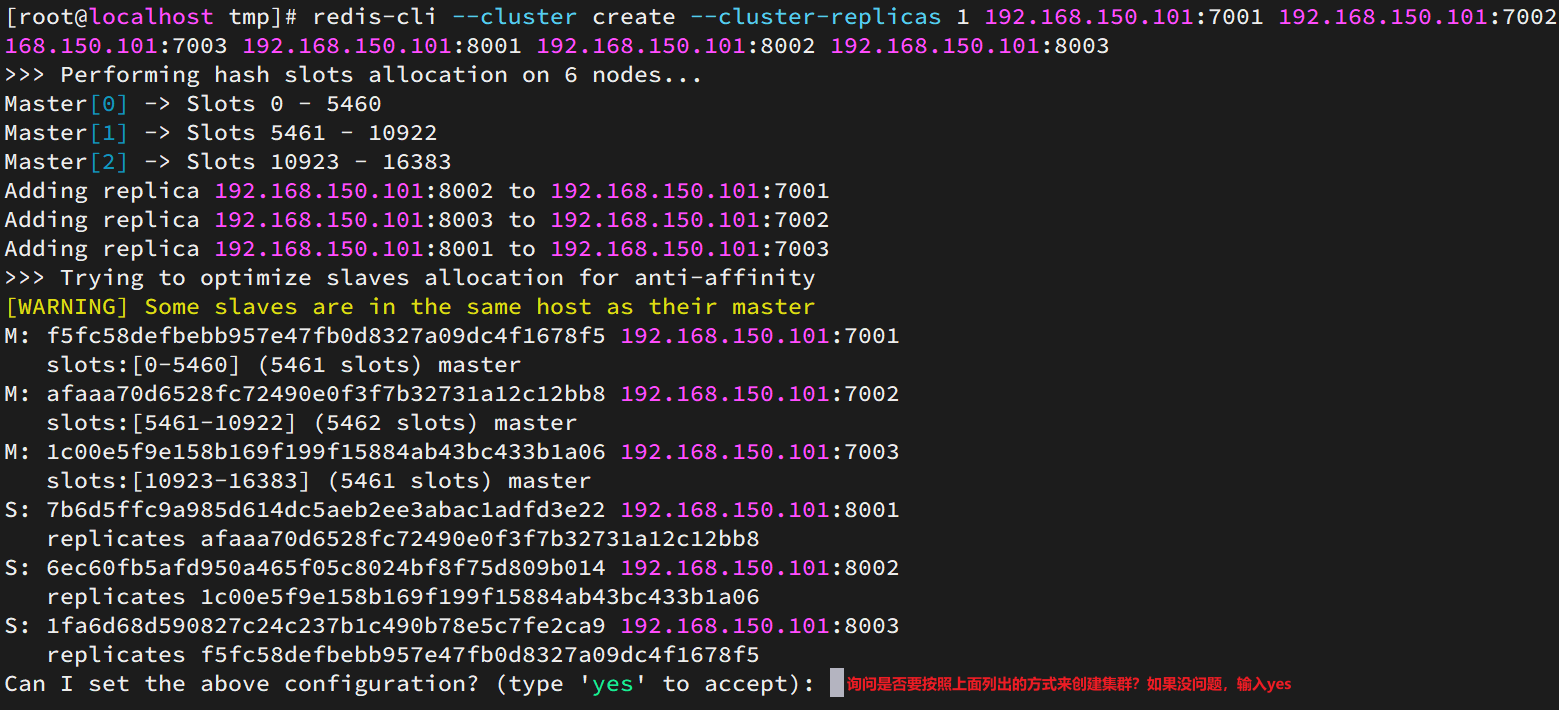
ingrese sí aquí, y el clúster comenzará a crearse:
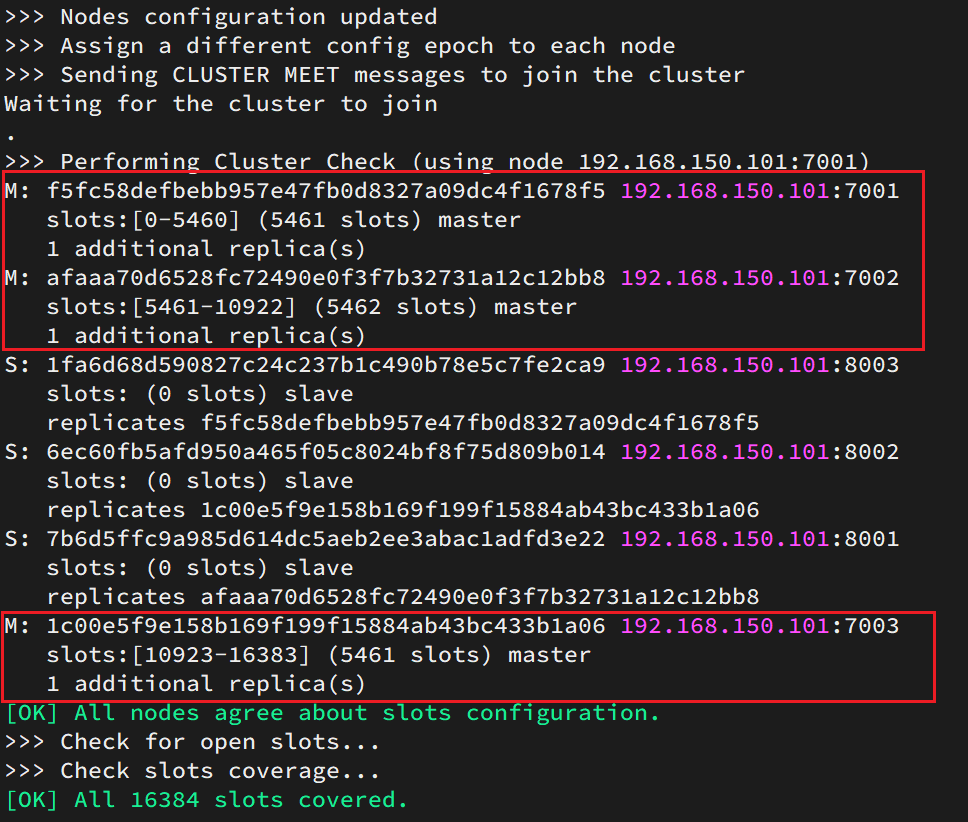
Puede ver el estado del clúster con el comando:
redis-cli -p 7001 cluster nodes

4.1.5 Pruebas
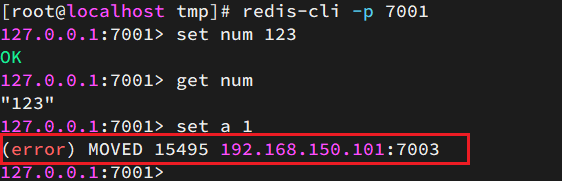
Intente conectarse al nodo 7001 y almacene un dato:
# 连接
redis-cli -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
set a 1
El resultado es trágico:
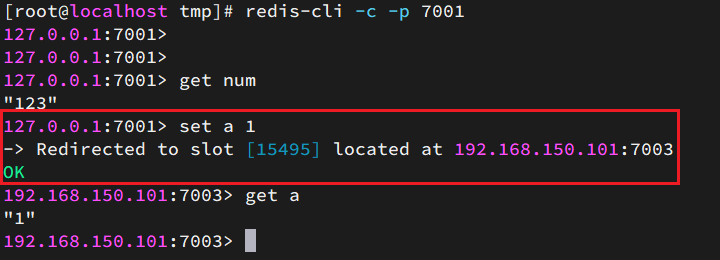
Durante el funcionamiento del clúster, debe redis-cliagregar -cparámetros:
redis-cli -c -p 7001
Esta vez está bien: redirigido significa redirección. Cuando visitamos un nodo, juzgaremos a qué nodo pertenece de acuerdo con la ranura de la ranura y luego redirigiremos al nodo para la consulta.
4.2 Ranuras de hash
4.2.1 Principio de la ranura
Redis asignará cada nodo maestro a un total de 16384 ranuras (ranuras hash) que van de 0 a 16383, que se pueden ver al ver la información del clúster:
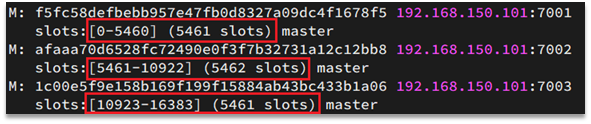
Las claves de datos no están vinculadas a los nodos, sino a las ranuras. Redis calculará el valor de la ranura en función de la parte efectiva de la clave, en dos casos:
- La clave contiene "{}", y "{}" contiene al menos 1 carácter, y la parte en "{}" es una parte válida
- La clave no contiene "{}", la clave completa es una parte válida
Por ejemplo: si la clave es num, se calculará según num, si es {itcast}num, se calculará según itcast. El método de cálculo es usar el algoritmo CRC16 para obtener un valor hash, y luego tomar el resto de 16384, y el resultado obtenido es el valor de la ranura.
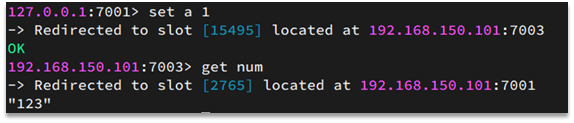
Como se muestra en la figura, cuando se ejecuta set a 1 en el nodo 7001, se realiza una operación hash en a, y se obtiene el resto de 16384, y el resultado es 15495, por lo que debe almacenarse en el nodo 103.
Después de llegar a 7003, get numal ejecutar, realice una operación hash en num, tome el resto de 16384 y el resultado es 2765, por lo que debe cambiar al nodo 7001
4.2.1 Resumen
¿Cómo determina Redis en qué instancia debe estar una clave?
- Asigne 16384 ranuras a diferentes instancias
- Calcule el valor hash de acuerdo con la parte efectiva de la clave y tome el resto de 16384
- El resto se usa como la ranura, solo busque la instancia donde se encuentra la ranura
¿Cómo guardar el mismo tipo de datos en la misma instancia de Redis?
- Este tipo de datos utiliza la misma parte efectiva, por ejemplo, todas las claves tienen el prefijo {typeId}
4.3 Escalado de clústeres
redis-cli --cluster proporciona muchos comandos para operar el clúster, que se pueden ver de las siguientes maneras:
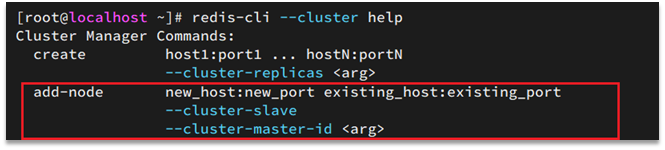
Por ejemplo, el comando para agregar un nodo:
4.3.1 Análisis de la demanda
Requisito: agregue un nuevo nodo maestro al clúster y almacene num = 10 en él
- Inicie una nueva instancia de redis con el puerto 7004
- Agregue 7004 al clúster anterior y actúe como un nodo maestro
- Asigne una ranura al nodo 7004 para que el número de clave se pueda almacenar en la instancia 7004
Aquí se necesitan dos nuevas funciones:
- Agregar un nodo al clúster
- Asignar algunas ranuras a nuevas ranuras
4.3.2 Crear una nueva instancia de redis
Crear una carpeta:
mkdir 7004
Copie el archivo de configuración:
cp redis.conf 7004
Modifique el archivo de configuración:
sed -i s/6379/7004/g 7004/redis.conf
puesta en marcha
redis-server 7004/redis.conf
4.3.3 Agregar nuevos nodos a redis
La sintaxis para agregar un nodo es la siguiente:
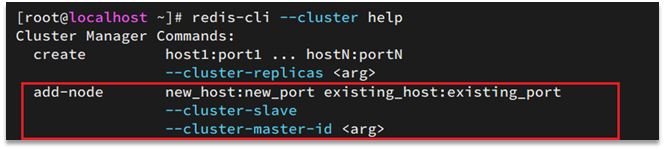
Ejecutando una orden:
redis-cli --cluster add-node 192.168.150.101:7004 192.168.150.101:7001
Verifique el estado del clúster con el comando:
redis-cli -p 7001 cluster nodes
Como se muestra en la figura, 7004 se unió al clúster y es un nodo maestro de manera predeterminada:

Sin embargo, se puede ver que el número de ranuras del nodo 7004 es 0, por lo que no se pueden almacenar datos en el 7004
4.3.4 Ranuras de transferencia
Queremos almacenar num en el nodo 7004, por lo que necesitamos ver cuántas ranuras tiene num:
redis-cli -c -p 7001
get num
get a
get num

Como se muestra arriba, la ranura de num es 2765.
Podemos transferir las ranuras de 0~3000 de 7001 a 7004, el formato de comando es el siguiente:
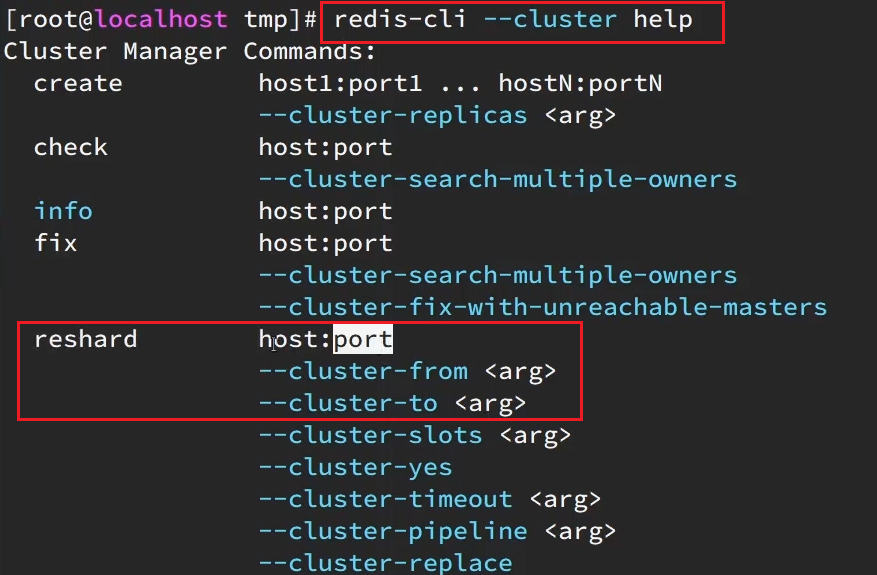
Los comandos específicos son los siguientes:
establecer conexión:
redis-cli --cluster reshard 192.168.150.101:7001

Obtenga los siguientes comentarios:

pregunte cuántas máquinas tragamonedas mover, planeamos ser 3000:
Aquí viene el nuevo problema:

¿Qué nodo para recibir estas ranuras? ?
Obviamente es 7004, entonces, ¿cuál es la identificación del nodo 7004?
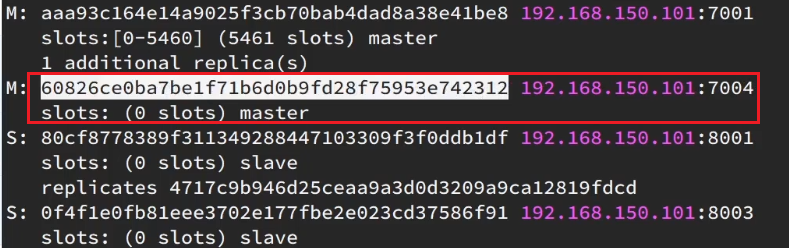
Copie esta identificación y luego cópiela en la consola ahora mismo:
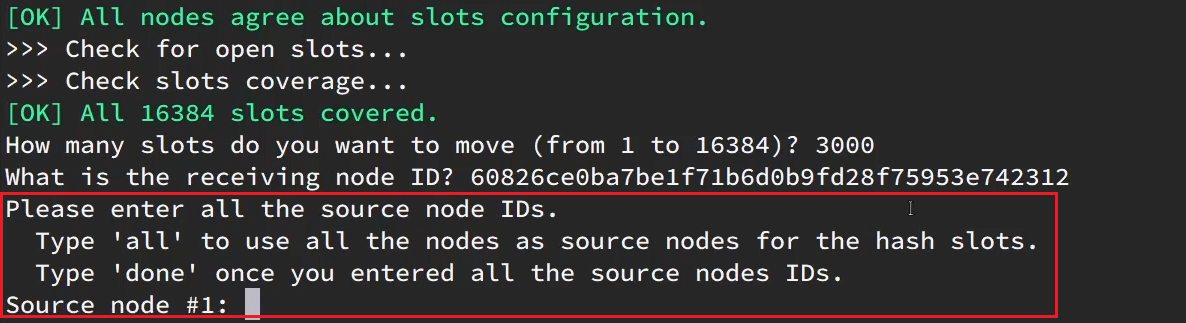
Pregunta aquí, ¿de dónde se movió tu tragamonedas?
- all: representa a todos, es decir, cada uno de los tres nodos transfiere una parte
- Identificación específica: la identificación del nodo de destino
- hecho: no más
Aquí queremos obtener de 7001, así que complete la identificación de 7001:

Una vez rellenado, haga clic en Listo y la transferencia de ranuras estará lista:
¿Estás seguro de que quieres transferir? Ingrese sí:
Luego, vea los resultados con el comando:
redis-cli -p 7001 cluster nodes

puede ser visto:

El objetivo está logrado.
ingresar
redis-cli -c -p 7001

Tarea: eliminar el nodo 7004
Primero verifique el comando para eliminar el nodo
redis-cli --cluster help
Encontré que está escrito en la documentación de ayuda.
del-node host:port node_id
Verifique la identificación del nodo por comando:
redis-cli -p 7001 cluster nodes
Ingrese la operación de clúster
redis-cli -c -p 7001
Eliminar nodo
redis-cli --cluster del-node 192.168.150.101:7004 fce0c2f09c4a2fbf5d9caefdf4aa3e6ab0aeb259
La eliminación directa encontró que se informó un error.

Parece que la ranura de 7004 debe moverse a 7001
redis-cli --cluster reshard 192.168.150.101:7004
Ingrese 3000

, ingrese 7001 como la ranura de recepción,

ingrese la fuente de la ranura,

ingrese sí y

finalmente elimine
redis-cli --cluster del-node 192.168.150.101:7004 fce0c2f09c4a2fbf5d9caefdf4aa3e6ab0aeb259
controlar
redis-cli -p 7001 cluster nodes
Encontré que 7004 se ha ido

4.4 Conmutación por error
El estado inicial del clúster es el siguiente:

Entre ellos, 7001, 7002 y 7003 son maestros y planeamos cerrar 7002.
4.4.1 Conmutación automática por error
¿Qué sucede cuando un maestro en el clúster deja de funcionar?
Detenga una instancia de redis directamente, como 7002:
redis-cli -p 7002 shutdown
1) Primero, la instancia pierde conexión con otras instancias
2) Entonces hay un tiempo de inactividad sospechoso:

3) Finalmente, se determina desconectarse y promover automáticamente un esclavo al nuevo maestro:

4) Cuando el 7002 se reinicie, se convertirá en un nodo esclavo:
redis-server 7002/redis.conf

4.4.2 Conmutación por error manual
Con el comando de conmutación por error del clúster, puede apagar manualmente un maestro en el clúster y cambiar al nodo esclavo que ejecuta el comando de conmutación por error del clúster para realizar la migración de datos sin percepción. El proceso es el siguiente:
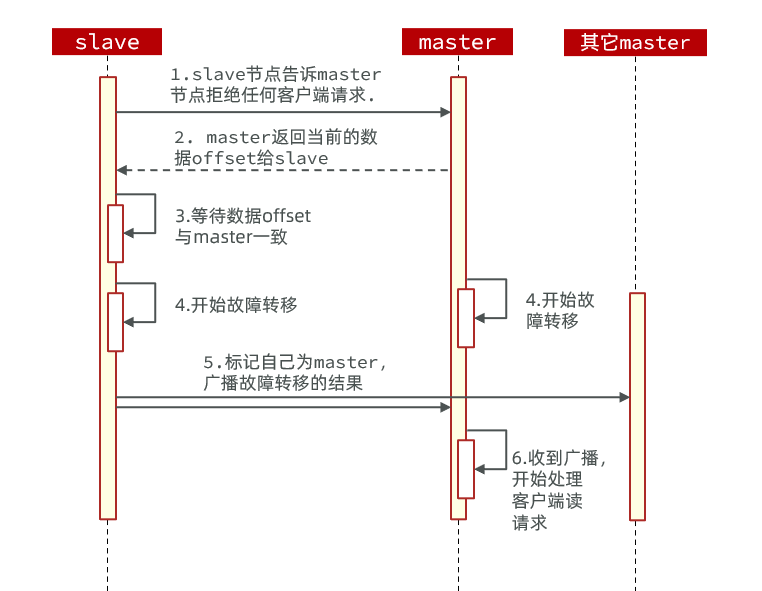
Este comando de conmutación por error puede especificar tres modos:
- Predeterminado: el proceso predeterminado, como se muestra en la Figura 1 ~ 6 pasos
- force: omite la verificación de consistencia de offset
- adquisición: ejecute el paso 5 directamente, ignorando la consistencia de los datos, el estado maestro y otras opiniones maestras
Requisitos del caso : realice una conmutación por error manual en el nodo esclavo 7002 para recuperar el estado maestro
Proceder de la siguiente:
1) Use redis-cli para conectarse al nodo 7002
2) Ejecute el comando de conmutación por error del clúster
Como se muestra en la imagen:
redis-cli -p 7002
cluster failover

Efecto: se encuentra que 7002 se ha convertido en el maestro

4.5 Acceso de RedisTemplate al clúster fragmentado
La capa inferior de RedisTemplate también implementa la compatibilidad con clústeres fragmentados basados en lechuga, y los pasos utilizados son básicamente los mismos que en el modo centinela:
1) Introducir la dependencia inicial de redis
2) Configurar la dirección del clúster de fragmentos
3) Configurar la separación de lectura y escritura
En comparación con el modo centinela, solo la configuración de los clústeres fragmentados es ligeramente diferente, de la siguiente manera:
spring:
redis:
cluster:
nodes:
- 192.168.150.101:7001
- 192.168.150.101:7002
- 192.168.150.101:7003
- 192.168.150.101:8001
- 192.168.150.101:8002
- 192.168.150.101:8003
Reiniciar el servicio después de la configuración
http://localhost:8080/get/num
Obtenga

y visite el nodo esclavo
y luego visite
http://localhost:8080/set/num/777
Se encuentra que se accede al nodo maestro