Directorio de artículos
- 1. Caché distribuido
- 2. Caché multinivel
-
- 2.1 Descripción general
- 2.2 Caché de procesos JVM
- 2.3 Introducción a la sintaxis de Lua
- 2.4 Inicio rápido de OpenResty
- 2.5 Consultar caché local
- 2.6 Consultar Tomcat
- 2.7 Equilibrio de carga del clúster de Tomcat
- 2.8Calentamiento de Redis
- 2.9 Consultar caché de Redis
- 2.10Caché local de Nginx
- 2.11 Sincronización de caché
- 2.12 Resumen
- 3. Mejores prácticas
- Registro
1. Caché distribuido
Resumen de notas:
- Por favor revise cada sección
- Resumen: verifique los detalles
1.1 Descripción general
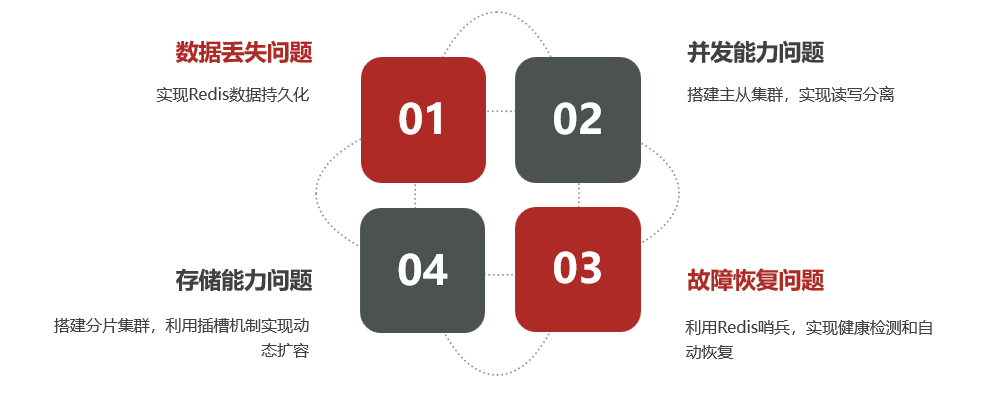
ilustrar:
Problemas con Redis de un solo punto
1.2Persistencia de Redis
Resumen de notas:
- Descripción general: Redis es una base de datos en memoria que puede guardar datos en el disco mediante un mecanismo de persistencia.
- RDB ( archivo de copia de seguridad de datos de Redis ):
- Redis permitirá que subprocesos asincrónicos realicen copias de seguridad automáticas de archivos de datos.
- Redis ejecutará RDB una vez de forma predeterminada cuando se apague.
- Redis modificará el RDB cada quince minutos, lo modificará 10 veces cada cinco minutos y realizará la persistencia de RDB una vez cada 10.000 modificaciones por minuto.
- AOF ( añadir archivo ):
- Cada comando de escritura procesado por Redis se registrará en el archivo AOF.
- Operaciones comunes: activar AOF, modificar la frecuencia de grabación , establecer el umbral de activación
1.2.1 Descripción general
Redis es una base de datos en memoria que puede guardar datos en el disco mediante un mecanismo de persistencia para evitar la pérdida de datos.
1.2.2RDB
1.2.2.1 Descripción general
El nombre completo de RDB es Archivo de copia de seguridad de la base de datos de Redis (archivo de copia de seguridad de datos de Redis), también llamado Instantánea de datos de Redis . En pocas palabras, todos los datos de la memoria se graban en el disco. Cuando la instancia de Redis falla y se reinicia, el archivo de instantánea se lee del disco y se restauran los datos.
Desventajas de RDB: el intervalo de ejecución de Redis es largo y existe el riesgo de pérdida de datos entre dos escrituras de RDB . Bifurcar procesos secundarios, comprimir y escribir archivos RDB requiere mucho tiempo.

ilustrar:
- Los archivos de instantáneas se denominan archivos RDB y se guardan en el directorio de ejecución actual de forma predeterminada. De forma predeterminada, Redis ejecutará RDB una vez cuando se cierre.
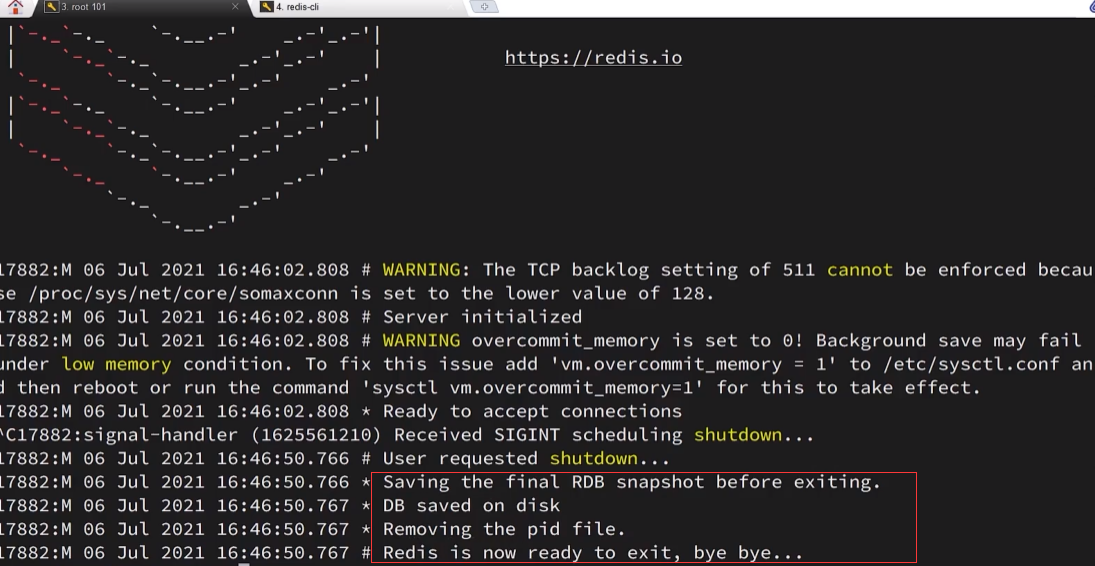
1.2.2.2 Casos de uso básicos
- Modificar la frecuencia de grabación
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
ilustrar:
Existe un mecanismo para activar RDB dentro de Redis, que se puede
redis.confencontrar en el archivo
- Resto de ajustes de parámetros
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./
ilustrar:
- Si la compresión está activada de forma predeterminada
redis.confTambién se pueden establecer otras configuraciones de RDB en el archivo
1.2.2.3 Principio
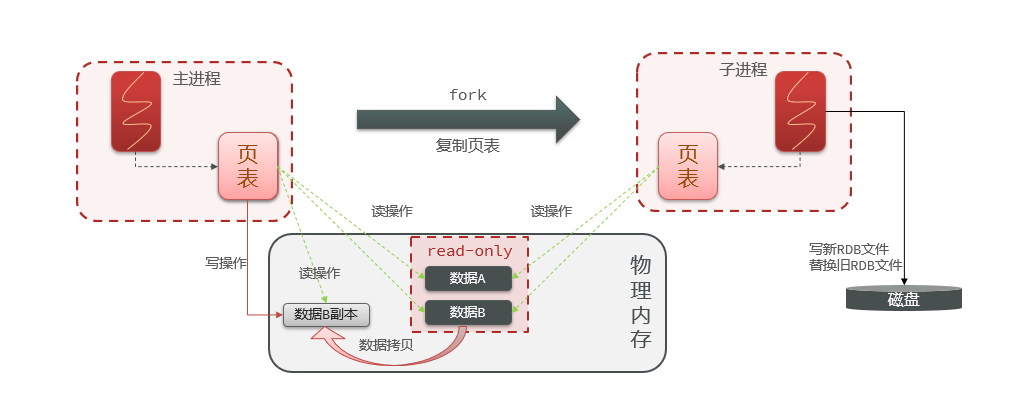
ilustrar:
- En Redis, el proceso principal no lee directamente los datos en la memoria física, sino que asigna la memoria física a través de la tabla de páginas para leer.
bgsaveCuando se inicia el comando,forkel proceso principal obtiene el proceso secundario y el proceso secundario comparte los datos de la memoria del proceso principal . Después de completar la bifurcación, lea los datos de la memoria y escríbalos en el archivo RDB.- Fork utiliza tecnología de copia en escritura : cuando el proceso principal realiza una operación de lectura, accede a la memoria compartida. Cuando el proceso principal realiza una operación de escritura, copia una copia de los datos y realiza la operación de escritura.
1.2.3AOF
1.2.3.1 Descripción general
AOF significa Append Only File. Cada comando de escritura procesado por Redis se registrará en el archivo AOF, que puede considerarse como un archivo de registro de comandos.
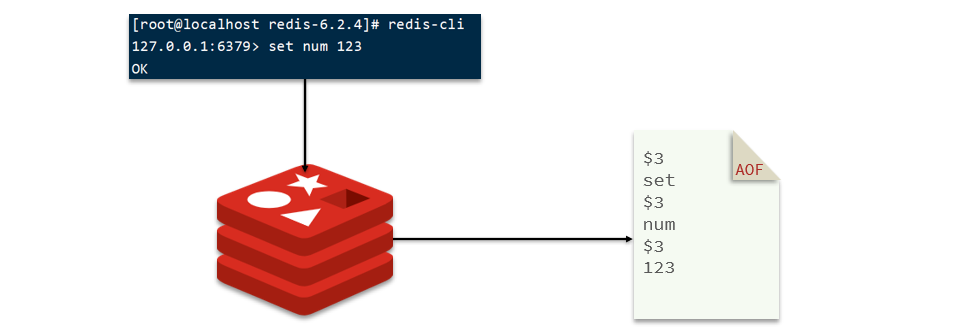
ilustrar:
Cada comando se registra en el archivo AOF y el archivo de comando continúa creciendo.
1.2.3.2 Casos de uso básicos
- Activar AOF
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
ilustrar:
- AOF está desactivado de forma predeterminada. Debe modificar
redis.confel archivo de configuración para activar AOF.- Al activar la función AOF, se recomienda desactivar la función RDB.
- Modificar la frecuencia de grabación
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
ilustrar:
- La frecuencia de grabación del comando AOF también
redis.confse puede configurar a través de archivos.

- Establecer umbral de activación
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
ilustrar:
- Debido a que es un comando de grabación, el archivo AOF será mucho más grande que el archivo RDB. Además, AOF registrará múltiples operaciones de escritura en la misma clave, pero solo la última operación de escritura es significativa.
- Al ejecutar
bgrewriteaofel comando, puede hacer que el archivo AOF realice la función de reescritura y logre el mismo efecto con la menor cantidad de comandos.

1.2.4 Resumen
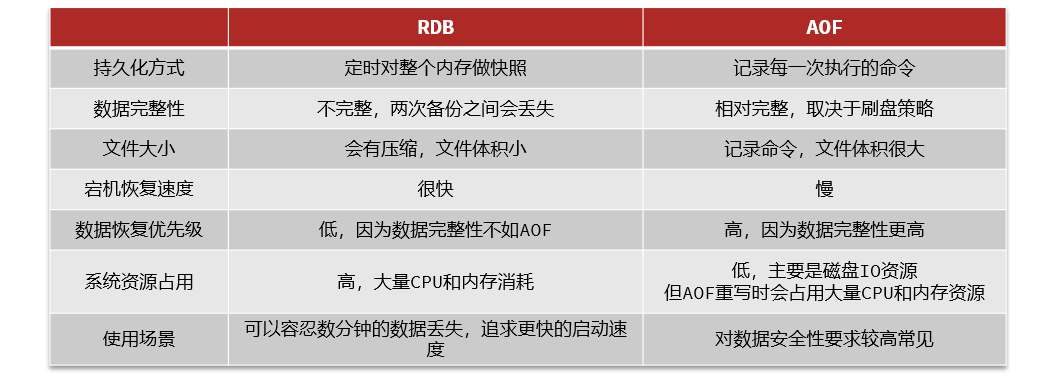
ilustrar:
RDB y AOF tienen cada uno sus propias ventajas y desventajas: si los requisitos de seguridad de los datos son altos, a menudo se usan combinados en el desarrollo real.
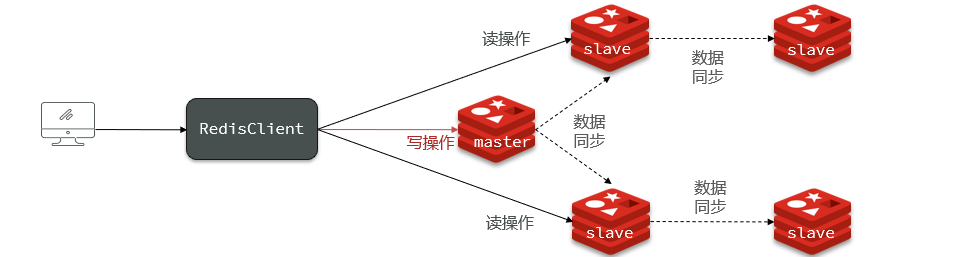
1.3Redis maestro-esclavo
Resumen de notas:
- Descripción general: el clúster maestro-esclavo realiza la separación de lectura y escritura y mejora la confiabilidad e integridad de los datos.
- Principio de sincronización completa: marca
Replicationde datos , desplazamientooffset, archivo generadoRDB, grabación del área de caché de comandosrepl_baklogde Redis- Principio de sincronización incremental: después de reiniciar Redis,
repl_bakloglos comandos en el búfer de comandos se reescriben , se sobrescriben las compensacionesoffsety se realiza una sincronización completa.- Resumen: verifique los detalles
1.3.1 Descripción general
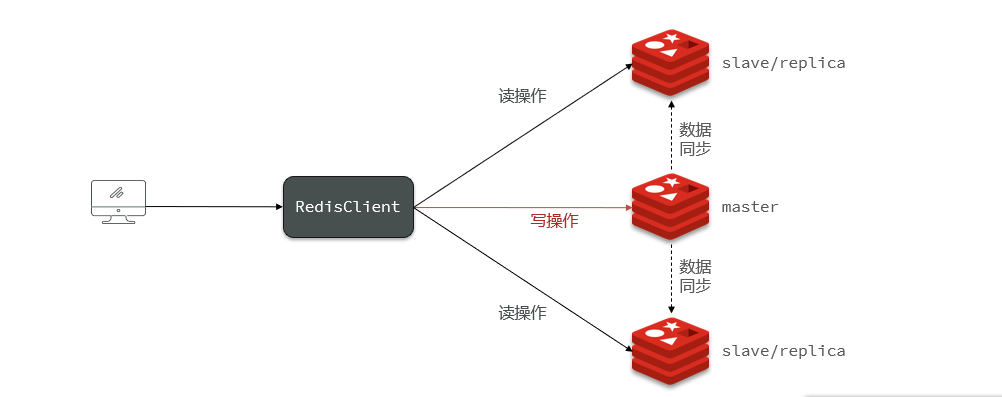
ilustrar:
La capacidad de concurrencia de un solo nodo Redis tiene un límite superior. Para mejorar aún más la capacidad de concurrencia de Redis, es necesario construir un clúster maestro-esclavo para lograr la separación de lectura y escritura.
1.3.2 Construir un clúster maestro-esclavo
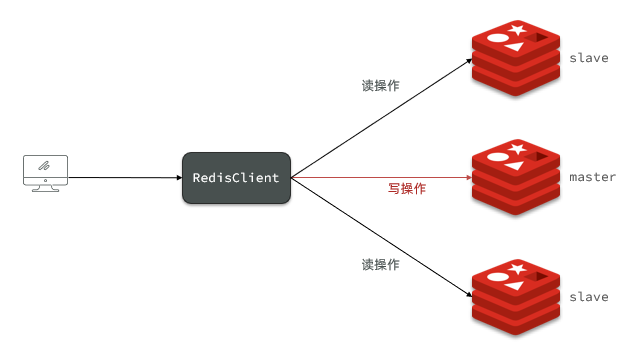
La información de los tres nodos de Redis es la siguiente:
| IP | PUERTO | Role |
|---|---|---|
| 10.13.164.55 | 6379 | maestro |
| 10.13.164.55 | 6380 | esclavo |
| 10.13.164.55 | 6381 | esclavo |
ilustrar:
El nodo maestro se usa para operaciones de escritura y los nodos secundarios se usan para operaciones de lectura.
Paso 1: configurar el entorno
ilustrar:
Este nodo maestro-esclavo de Redis se instala mediante Docker.
1. Crear archivos y directorios
cd /home
mkdir redis
cd redis
mkdir /home/redis/myredis1
mkdir data
touch myredis.conf
// 在myredis2和myredis3目录中分别创建 myredis.conf 配置文件和data目录此处省略命令
mkdir /home/redis/myredis2
mkdir /home/redis/myredis3
Descripción: Ver resultados
myredis.confEl contenido del archivo es el siguiente.
bind 0.0.0.0
protected-mode no
port 6379
tcp-backlog 511
requirepass qweasdzxc
timeout 0
tcp-keepalive 300
daemonize no
supervised no
pidfile /var/run/redis_6379.pid
loglevel notice
logfile ""
databases 30
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-disable-tcp-nodelay no
replica-priority 100
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly yes
appendfilename "appendonly.aof"
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
slowlog-max-len 128
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
masterauth qweasdzxc # 配置主节点Redis的密码
Aviso:
Tenga en cuenta que los puertos deben reemplazarse por 6380 y 6381 respectivamente.
Paso 2: ejecute el servicio Docker
Aviso:
Necesidad de crear
myredis.confarchivos ydatacarpetas con antelación
1. Ejecute los siguientes comandos en el host respectivamente
sudo docker run \
--restart=always \
-p 6379 \
--net=host \
--name myredis1 \
-v /home/redis/myredis1/myredis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis1/data:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
sudo docker run \
--restart=always \
-p 6380 \
--net=host \
--name myredis2 \
-v /home/redis/myredis2/myredis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis2/data:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
sudo docker run \
--restart=always \
-p 6381 \
--net=host \
--name myredis3 \
-v /home/redis/myredis3/myredis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis3/data:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Descripción: Ver resultados

2. Establecer una relación amo-esclavo
slaveof 10.13.164.55 6379 # 配置 主节点的Ip地址以及端口号
Paso 3: prueba
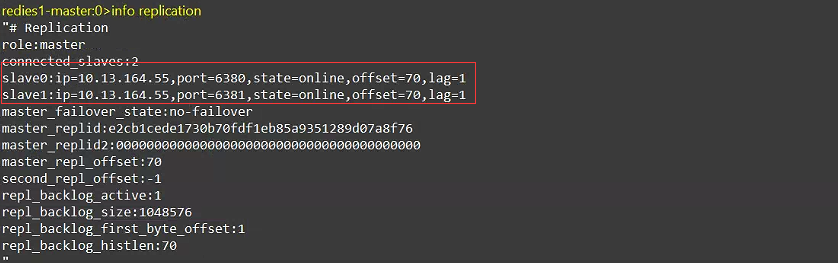
- Verifique el estado de la conexión en el nodo maestro
info repilication
Descripción: Ver resultados
- Aquí se encuentra que la dirección IP y el puerto del nodo secundario se corresponden entre sí.
- Sin embargo, los datos establecidos en el nodo principal aún se pueden leer en los nodos secundarios, lo que indica que la construcción fue exitosa.
1.3.3 Principio de sincronización total
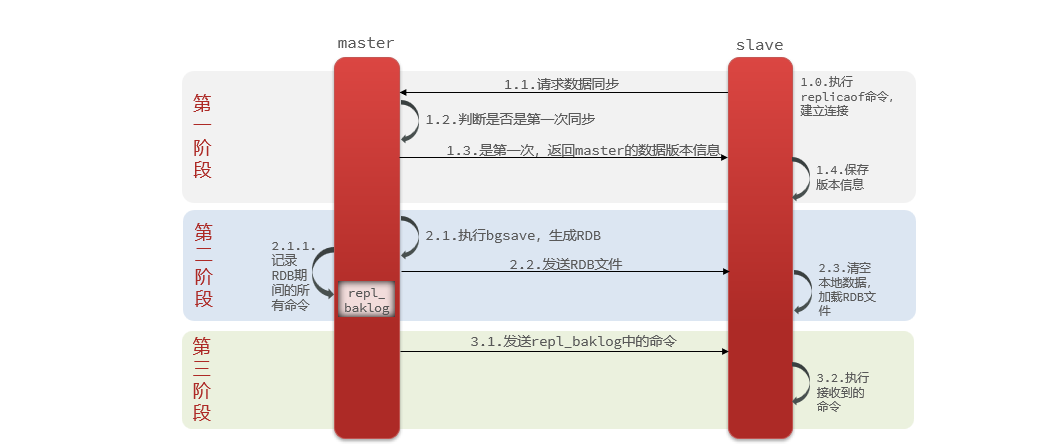
ilustrar:
La primera sincronización maestro-esclavo es la sincronización completa . Cuando el nodo secundario se sincroniza por primera vez, enviará una solicitud al nodo maestro y determinará si contiene versiones de datos anteriores y otra información. Posteriormente, el nodo maestro generará un archivo de datos existentes y
RDBlo enviará a los nodos secundarios. Si hay datos más nuevos en este momento, se registrarán como un comando y se guardarán enrepl_baklogel archivo, sincronizándose constantemente con los nodos secundarios.
Suplemento: ¿Cómo determina el maestro si el esclavo está sincronizando datos por primera vez?
- ID de replicación : Replid para abreviar, es la marca del conjunto de datos. Si la ID es consistente, significa el mismo conjunto de datos. Cada maestro tiene una replicación única y el esclavo heredará la replicación del nodo maestro.
- offset : offset, que aumenta gradualmente a medida que aumentan los datos registrados en repl_baklog. Cuando el esclavo complete la sincronización, también registrará el desplazamiento de sincronización actual.
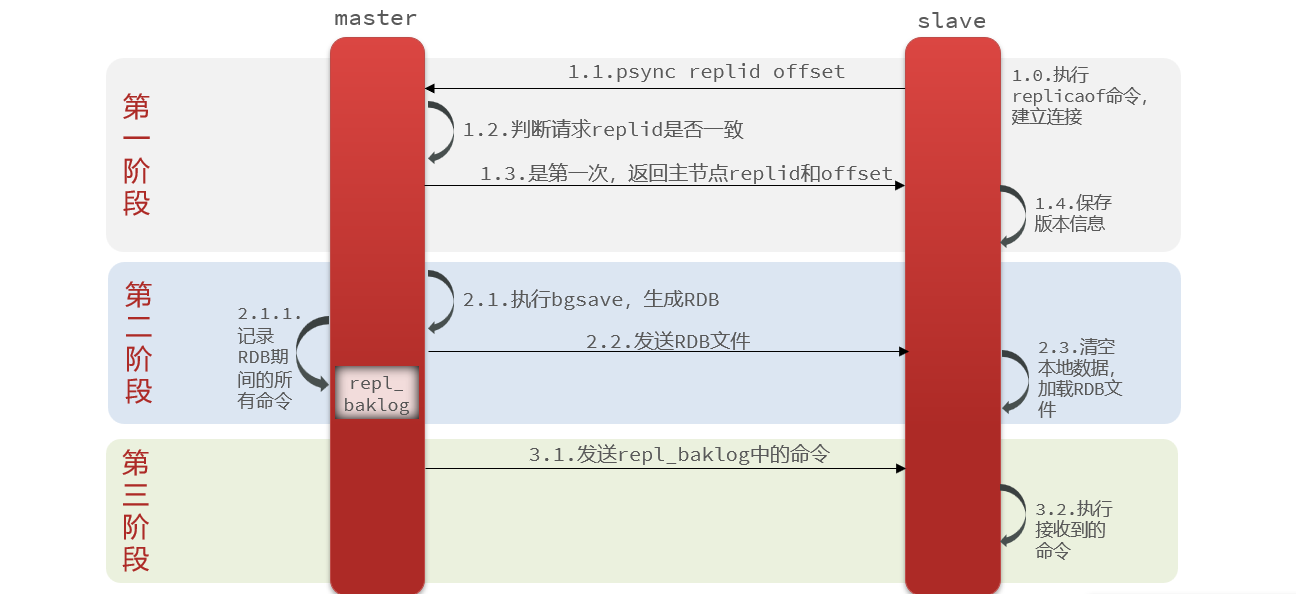
ilustrar:
- Si la réplica del esclavo no coincide con la del nodo maestro, significa la primera sincronización.
- Si el desplazamiento del esclavo es menor que el desplazamiento del maestro, significa que los datos del esclavo van por detrás del maestro y deben actualizarse.
Por lo tanto, cuando el esclavo realiza la sincronización de datos, debe declarar su identificación de replicación y su desplazamiento al maestro, para que el maestro pueda determinar qué datos deben sincronizarse.
Proceso de sincronización:
- El nodo esclavo solicita sincronización incremental.
- El nodo maestro determina la réplica, encuentra inconsistencias y rechaza la sincronización incremental.
- El maestro genera RDB a partir de los datos completos de la memoria y envía el RDB al esclavo.
- El esclavo borra los datos locales y carga el RDB del maestro.
- El maestro registra los comandos durante RDB en
repl_baklogel área de caché de comandos de Redis y envía continuamente los comandos en el registro al esclavo.- El esclavo ejecuta el comando recibido y mantiene la sincronización con el maestro.
1.3.4 Principio de sincronización incremental

ilustrar:
La primera sincronización entre el maestro y el esclavo es una sincronización completa , pero si el esclavo se sincroniza después de reiniciar , se realiza una sincronización incremental .
Reponer:
Hay un límite superior para el tamaño de repl_baklog y, cuando esté lleno se sobrescribirán los datos más antiguos . Si el esclavo se desconecta durante demasiado tiempo y se sobrescriben los datos de los que aún no se ha realizado una copia de seguridad, no se puede realizar la sincronización incremental basada en el registro y solo se puede volver a realizar la sincronización completa.
1.3.5 Resumen
Si todo el importe está sincronizado, hay que hacerlo. Luego podemos optimizar el clúster maestro-esclavo de Redis para optimizar el clúster maestro-esclavo de Redis
-
Optimización del clúster de Redis
Descripción: Esquema de optimización
- Configure y habilite la replicación sin disco en
masterel archivo de configuración para evitar E/S del disco durante la sincronización completa.repl-diskless-sync yes - El uso de memoria en un único nodo de Redis no debe ser demasiado grande para reducir la E/S excesiva del disco causada por RDB.
- Aumente
repl_baklogadecuadamente el tamaño ,slaverealice la recuperación de fallas lo antes posible cuando se encuentre un tiempo de inactividad y evite la sincronización completa tanto como sea posible. - Limite el número de nodos
masteren unslaveservidor. Si hay demasiadosslave, puede utilizar una estructura de cadena maestro-esclavo-esclavo para reducirmasterla presión.
- Configure y habilite la replicación sin disco en
-
Sincronización completa y sincronización incremental
-
Sincronización completa : el maestro genera RDB a partir de los datos completos de la memoria y envía el RDB al esclavo. Los comandos posteriores se registran
repl_baklogy envían al esclavo uno por uno.ilustrar:
Cuando el nodo esclavo se conecta al nodo maestro por primera vez, cuando el nodo guardado se desconecta durante demasiado tiempo y se sobrescribe el desplazamiento en repl_baklog, se realizará una sincronización completa.
-
Sincronización incremental : el esclavo envía su propio desplazamiento al maestro, y el maestro obtiene los comandos después del desplazamiento en repl_baklog y se los entrega al esclavo
ilustrar:
Cuando el nodo esclavo se desconecta y se restaura, y el desplazamiento se puede encontrar en repl_baklog, se realizará una sincronización incremental .
Aviso:
Sincronización incremental, la sincronización puede fallar, dependiendo de
repl_baklogsi el área está completamente cubierta
-
Reponer:
Una vez que el nodo esclavo está inactivo y se recupera, puede encontrar el nodo maestro para sincronizar los datos, pero si el nodo maestro está inactivo, no se puede recuperar. Para resolver este problema, consulte la siguiente sección.
1.4 Centinela de Redis
Resumen de notas:
- Descripción general:
- Significado: monitorear y administrar la conmutación por error automática de instancias de Redis
- Estado de monitoreo: subjetivo fuera de línea y objetivo fuera de línea
- Derechos de elección maestra: duración del tiempo de desconexión ,
slave-priorityvalor de peso ,offsetcompensación , tamaño de identificación de ejecución- Conmutación por error: convierta
slaveel nodo en un nuevomasternodo esclavo y marque el nodo fallido- Caso de uso básico: importe el nodo maestro centinela con
spring-boot-starter-data-redisdependencias y archivos de configuraciónyml, subnodos del clúster, configuración de clase de configuración yLettuceClientConfigurationBuilderCustomizerestablezca el modo de lectura del clúster- Resumen: verifique los detalles
1.4.1 Descripción general
1.4.1.1 Significado
El mecanismo Sentinel de Redis (Sentinel) es una solución de alta disponibilidad proporcionada por Redis y se utiliza para monitorear y administrar la conmutación por error automática de instancias de Redis.
El núcleo del mecanismo centinela es un conjunto de procesos centinela que se ejecutan de forma independiente, que monitorean el nodo maestro de Redis y sus múltiples nodos esclavos correspondientes, y actualizan automáticamente un nodo esclavo a un nuevo nodo maestro cuando el nodo maestro falla, logrando así la transferencia de fallas.
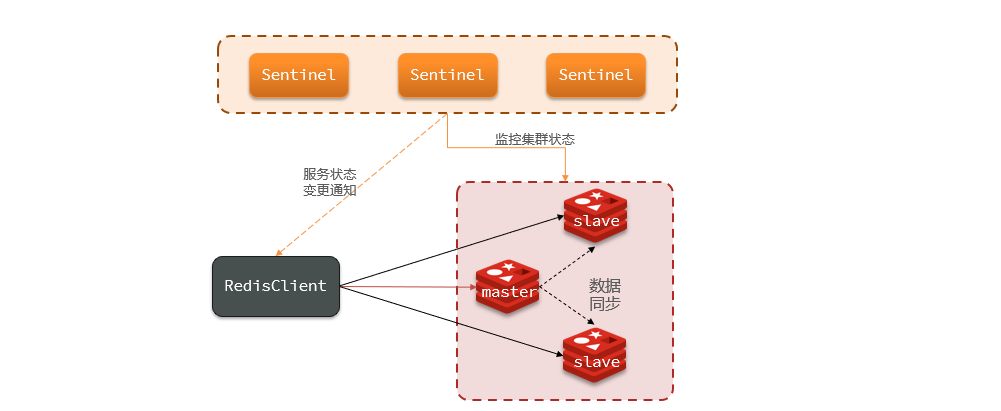
La estructura y funciones de Sentinel incluyen monitoreo : Sentinel comprobará constantemente si su maestro y esclavo funcionan como se esperaba. Recuperación automática de fallas : si el maestro falla, Sentinel promoverá un esclavo a maestro. Cuando se restablezca la instancia fallida, el nuevo maestro asumirá el control. Notificación : Sentinel actúa como una fuente de descubrimiento de servicios para el cliente Redis. Cuando se produce una conmutación por error del clúster, la información más reciente se enviará al cliente Redis.
1.4.1.2 Monitoreo del estado del servicio
Sentinel monitorea el estado del servicio según el mecanismo de latido y envía un comando ping a cada instancia del clúster cada segundo:
- Fuera de línea subjetiva: si un nodo centinela descubre que una instancia no responde dentro del tiempo especificado, se considera que la instancia está fuera de línea subjetiva.
- Objetivo fuera de línea: si más del número especificado (quórum) de centinelas piensan que la instancia está subjetivamente fuera de línea, la instancia estará objetivamente fuera de línea . Preferiblemente, el valor del quórum debe exceder la mitad del número de instancias de Sentinel.
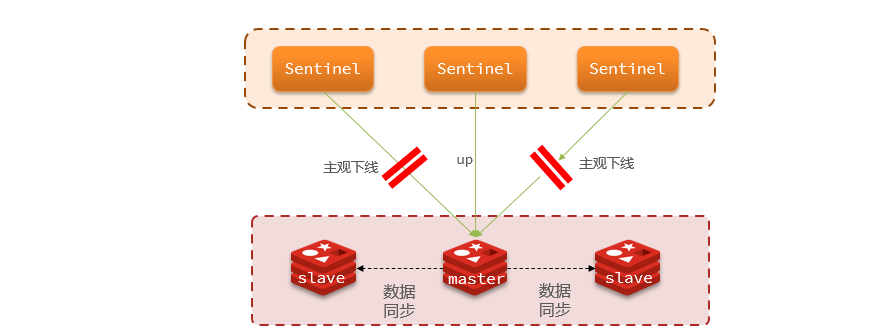
ilustrar:
En el archivo de configuración de Redis, se puede configurar en la mitad del número de Sentinel
1.4.1.3Derechos de voto maestros
Si Sentinel descubre que el nodo maestro está defectuoso, Sentinel debe seleccionar uno de los esclavos como nuevo maestro. Las reglas son las siguientes:
- Primero, determinará el período de tiempo que el nodo esclavo está desconectado del nodo maestro . Si excede el valor especificado (después de milisegundos * 10), el nodo esclavo será excluido.
- Luego determine el valor de prioridad de esclavo del nodo esclavo. Cuanto menor sea la prioridad, mayor será la prioridad. Si es 0, nunca participará en la elección.
- Si la prioridad del esclavo es la misma, juzgue el valor de compensación del nodo esclavo . Cuanto mayor sea el valor, más nuevos serán los datos y mayor será la prioridad
- Lo último es juzgar el tamaño de la identificación de ejecución del nodo esclavo . Cuanto menor sea la prioridad, mayor será la prioridad.
1.4.1.4 Conmutación por error
Cuando uno de los esclavos se selecciona como nuevo maestro (por ejemplo, esclavo1), los pasos de conmutación por error son los siguientes:
- Sentinel envía un comando al nodo candidato esclavo1
slaveof no onepara convertirlo en maestro slaveof 192.168.150.101 7002Sentinel envía comandos a todos los demás esclavos para que estos esclavos se conviertan en nodos esclavos del nuevo maestro y comiencen a sincronizar datos del nuevo maestro.- Finalmente, Sentinel marca el nodo defectuoso como esclavo y, cuando se recupera, se convertirá automáticamente en el nodo esclavo del nuevo maestro.
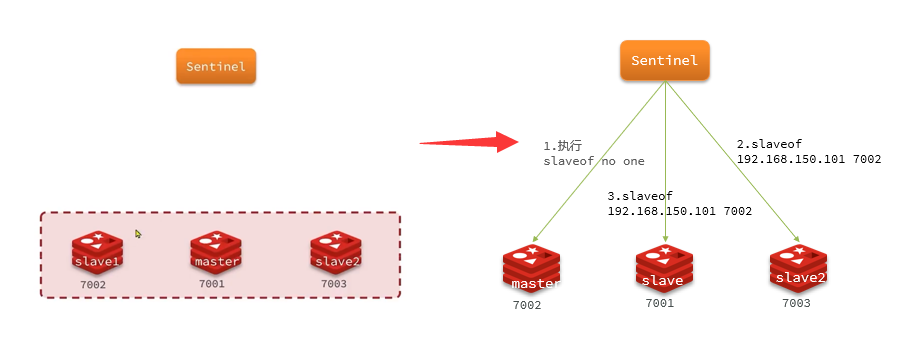
1.4.2 Construyendo un grupo centinela
3 Sentinelinformación de muestra son las siguientes:
| IP | PUERTO |
|---|---|
| 10.13.164.55 | 27001 |
| 10.13.164.55 | 27001 |
| 10.13.164.55 | 27001 |
Paso 1: configurar el entorno
ilustrar:
Los nodos del clúster Sentinel se instalan mediante Docker
1. Crear archivos y directorios
cd /home
mkdir redis
cd redis
mkdir /home/redis/mysentinel1
vim myredis.conf
// 在myredis2和myredis3目录中分别创建 myredis.conf 配置文件
mkdir /home/redis/mysentinel2
mkdir /home/redis/mysentinel3
Descripción: Ver resultados

sentinel.confEl contenido del archivo es el siguiente.
port 27001 # 注意,此处需要将sentinel.conf文件分别替换为 27002、27003
sentinel announce-ip 10.13.164.55
sentinel monitor mymaster 10.13.164.55 6379 2 # 注意此处IP和地址正确无误
sentinel auth-pass mymaster qweasdzxc
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
ilustrar:
port 27001: establezca el puerto de escucha actual de Redis Sentinel en 27001.sentinel announce-ip 10.13.164.55: establezca la dirección IP que Sentinel utiliza al anunciar su dirección IP a otros nodos en 10.13.164.55.sentinel monitor mymaster 10.13.164.55 6379 2: Configure Sentinel para monitorear elmymasternodo maestro nombrado. La dirección IP del nodo maestro es 10.13.164.55 y el número de puerto es 6379.2Esto indica el tiempo que Sentinel debe esperar (en segundos) después de que el nodo maestro entre en estado fuera de línea. Después Esta vez, Sentinel marcará el nodo maestro como desconectado.sentinel auth-pass mymaster qweasdzxc: establezca la contraseña que Sentinel debe usar al conectarse al nodo maestroqweasdzxcpara la autenticación.sentinel down-after-milliseconds mymaster 5000: Establezca el umbral de tiempo para que Sentinel considere que el nodo maestro está fuera de línea en 5000 milisegundos (es decir, 5 segundos). Si no se recibe respuesta del nodo maestro dentro de este tiempo, el nodo maestro se considera fuera de línea.sentinel failover-timeout mymaster 60000: Establezca el tiempo de espera para la conmutación por error en 60000 milisegundos (es decir, 60 segundos). Si la conmutación por error no se completa dentro de este tiempo, se considera fallida.sentinel parallel-syncs mymaster 1: establezca el número de nodos esclavos que se sincronizarán simultáneamente durante la conmutación por error en 1, es decir, sincronice un nodo esclavo al mismo tiempo. Esto puede evitar una carga excesiva de recursos causada por la sincronización de varios nodos esclavos al mismo tiempo.
Paso 2: ejecute el servicio Docker
ilustrar:
Ejecute los siguientes comandos en el host respectivamente
docker run --restart=always \
--net=host \
--name mysentinel1 \
-v /home/redis/mysentinel1/sentinel.conf:/sentinel.conf \
-d redis redis-sentinel /sentinel.conf
docker run --restart=always \
--net=host \
--name mysentinel2 \
-v /home/redis/mysentinel2/sentinel.conf:/sentinel.conf \
-d redis redis-sentinel /sentinel.conf
docker run --restart=always \
--net=host \
--name mysentinel3 \
-v /home/redis/mysentinel3/sentinel.conf:/sentinel.conf \
-d redis redis-sentinel /sentinel.conf
Aviso:
Los archivos de configuración
sentinel.confdeben corresponder a sus respectivos nodos de monitoreo.
Paso 3: prueba
sentinel1. Detener el registro de consultas del nodo maestro
2. Ver el registro de 7003:
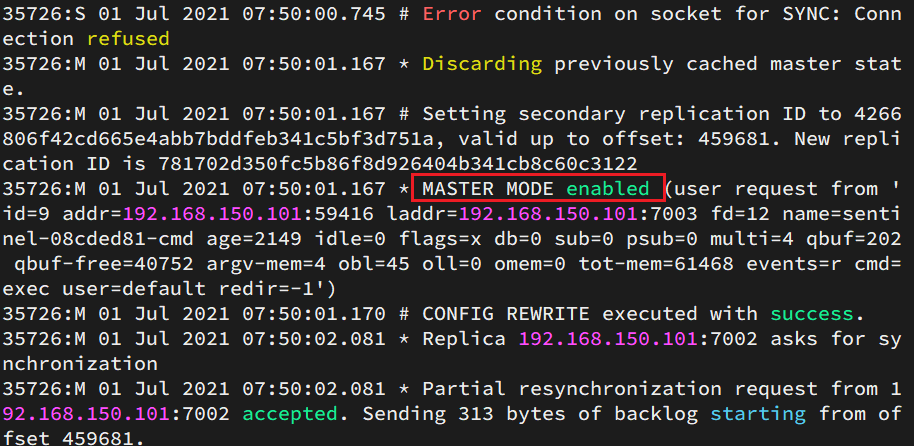
3. Ver el registro de 7002:
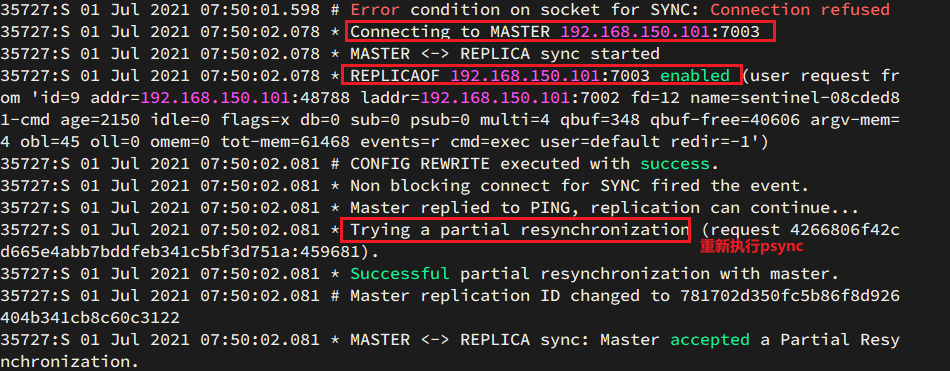
ilustrar:
En este momento, el nodo 7003 ha sido elegido como el nuevo nodo maestro, lo cual es consistente con el mensaje impreso por nuestro nodo 6380 como nodo maestro.
1.4.3 Casos de uso básicos
ilustrar:
En el clúster maestro-esclavo de Redis bajo la supervisión del clúster Sentinel, sus nodos cambiarán debido a la conmutación por error automática. El cliente de Redis debe detectar este cambio y actualizar la información de conexión de manera oportuna. La capa inferior de Spring
RedisTemplateusa lechuga para realizar la percepción de nodos y el cambio automático.
Paso 1: importar dependencias
- Modificar
pom.xmlarchivos
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Paso 2: agregar configuración
1. Modificar application.yamlel archivo de configuración.
logging:
level:
io.lettuce.core: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
server:
port: 8081
spring:
redis:
sentinel:
master: mymaster # 指定master名称
nodes: # 指定redis-sentinel集群信息
- 10.13.164.55:27001
- 10.13.164.55:27002
- 10.13.164.55:27003
password: qweasdzxc
2. Agregar RedisConfigclase de archivo de configuración
@Configuration
public class RedisConfig {
@Bean
LettuceClientConfigurationBuilderCustomizer getLettuceClientConfigurationBuilderCustomizer(){
// 设置集群的读取模式,先读取从结点,若失败则再读取主节点
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
}
Paso 3: prueba
1. Escribe HelloControllerclases de capa de presentación.
@RestController
public class HelloController {
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/get/{key}")
public String hi(@PathVariable String key) {
return redisTemplate.opsForValue().get(key);
}
@GetMapping("/set/{key}/{value}")
public String hi(@PathVariable String key, @PathVariable String value) {
redisTemplate.opsForValue().set(key, value);
return "success";
}
}
2. Ingrese a la consola para solicitar pruebas.

3. Ver el registro de ideas
ilustrar:
El registro se imprime normalmente, lo que indica que la prueba pasó
4. Pruebe el nodo maestro
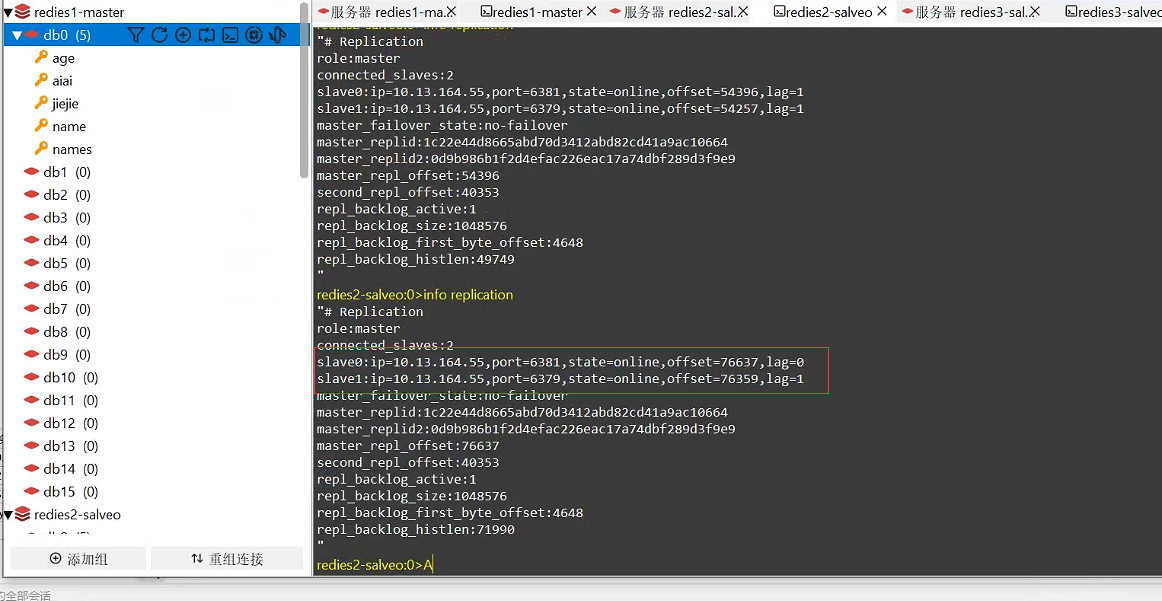
ilustrar:
Una vez restaurado el nodo fallido, se unirá automáticamente al nodo maestro, lo que indica que la prueba ha pasado.
1.4.4 Resumen
- ¿Cuáles son las tres funciones de Sentinel?
- conmutación por error
- monitor
- notificar
- ¿Cómo determina Sentinel si una instancia de Redis está en buen estado?
- Envíe un comando ping cada 1 segundo, si no hay comunicación durante un cierto período de tiempo, se considera subjetivo fuera de línea
- Si la mayoría de los centinelas creen que la instancia está subjetivamente fuera de línea, se determinará que el servicio está fuera de línea.
- ¿Cuáles son los pasos de conmutación por error?
- Primero seleccione un esclavo como nuevo maestro y ejecute esclavo de nadie
- Luego deje que todos los nodos ejecuten esclavo del nuevo maestro
- Modifique el nodo defectuoso y ejecute el esclavo del nuevo maestro
Reponer:
Maestro-esclavo y centinela pueden resolver los problemas de alta disponibilidad y alta lectura concurrente. Pero el problema aún no está resuelto: problema de almacenamiento masivo de datos, problema de escritura altamente concurrente
1.5 Clúster de fragmentación de Redis
Resumen de notas:
- Descripción general: dividir los datos en varios fragmentos y distribuirlos a diferentes nodos puede lograr la expansión horizontal de los datos y el equilibrio de carga. Capacidad y rendimiento del clúster mejorados
- Ranura hash:
- Significado: personalice los datos para que se puedan almacenar en la ranura de Redis especificada.
- Nota: Al personalizar la clave, la clave contiene **"{ }" y "{ }" contiene al menos 1 carácter, y la parte en "{ }" es una parte válida**
- Escalado de clúster:
add-nodeagregar nodos,reshardasignar ranuras ,del-nodeeliminar nodos- Conmutación por error:
cluster failoverconvertirse en maestro , principio, usarOffsetcompensaciones- Acceso Java: importe
spring-boot-starter-data-redisdependencias paraSpringBootintegrar Redis yymlel nodo maestro del archivo de configuración, yLettuceClientConfigurationBuilderCustomizerestablezca el modo de lectura del clúster desde el nodo esclavo del clúster y la configuración de la clase de configuración.
1.5.1 Descripción general
El clúster de fragmentación de Redis es una solución que distribuye datos en múltiples nodos de Redis. Al dividir los datos en múltiples fragmentos y distribuirlos a diferentes nodos, se puede lograr la expansión horizontal y el equilibrio de carga de los datos. Cada nodo puede procesar de forma independiente una parte de los datos y la capacidad y el rendimiento del clúster se pueden ajustar dinámicamente agregando o eliminando nodos.
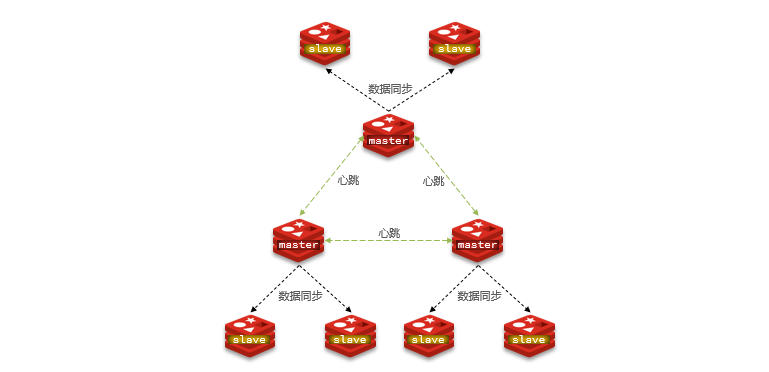
ilustrar:
Hay varios maestros en el clúster y cada maestro guarda datos diferentes . Cada maestro puede tener múltiples nodos esclavos. Los maestros monitorean el estado de salud de los demás mediante ping. Las solicitudes de los clientes pueden acceder a cualquier nodo del clúster y eventualmente se reenviarán al nodo correcto.
1.5.2 Construir un clúster fragmentado
La información de las 6 Redisinstancias es la siguiente:
| IP | PUERTO | Role |
|---|---|---|
| 10.13.164.55 | 7001 | maestro |
| 10.13.164.55 | 7002 | maestro |
| 10.13.164.55 | 7003 | maestro |
| 10.13.164.55 | 7004 | esclavo |
| 10.13.164.55 | 7005 | esclavo |
| 10.13.164.55 | 7006 | esclavo |
Paso 1: configurar el entorno
ilustrar:
Los nodos del clúster Sentinel se instalan mediante Docker
1. Crear archivos y directorios
cd /home
mkdir redis
cd redis
mkdir /home/redis/myredis1
touch /home/redis/myredis1/redis.conf
mkdir /home/redis/myredis1/data
// 在myredis2到myredis6的目录中分别创建 myredis.conf 配置文件和data目录,此处省略命令
mkdir /home/redis/myredis2
……
mkdir /home/redis/myredis6
……
touch myredis.conf
mkdir data
Descripción: Ver resultados

myredis.confEl contenido del archivo es el siguiente.
Nota: El archivo de configuración correspondiente a cada nodo requiere que el puerto y otra información se configuren por separado.
# 绑定地址
bind 0.0.0.0
# redis端口,不同节点端口不同分别是7001 ~ 7006
port 7001
#redis 访问密码
requirepass qweasdzxc
#redis 访问Master节点密码
masterauth qweasdzxc
# 关闭保护模式
protected-mode no
# 开启集群
cluster-enabled yes
# 集群节点配置
cluster-config-file nodes.conf
# 超时
cluster-node-timeout 5000
# 集群节点IP host模式为宿主机IP
cluster-announce-ip 10.13.164.55
# 集群节点端口,不同节点端口不同分别是7001 ~ 7006
cluster-announce-port 7001
cluster-announce-bus-port 17001
# 开启 appendonly 备份模式
appendonly yes
# 每秒钟备份
appendfsync everysec
# 对aof文件进行压缩时,是否执行同步操作
no-appendfsync-on-rewrite no
# 当目前aof文件大小超过上一次重写时的aof文件大小的100%时会再次进行重写
auto-aof-rewrite-percentage 100
# 重写前AOF文件的大小最小值 默认 64mb
auto-aof-rewrite-min-size 64mb
# 日志配置
# debug:会打印生成大量信息,适用于开发/测试阶段
# verbose:包含很多不太有用的信息,但是不像debug级别那么混乱
# notice:适度冗长,适用于生产环境
# warning:仅记录非常重要、关键的警告消息
loglevel notice
# 日志文件路径
logfile "/data/redis.log"
Paso 2: ejecutar el contenedor
Redis结点1
sudo docker run \
--name myredis1 \
-p 7001:7001 \
-p 17001:17001 \
-v /home/redis/myredis1/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis1/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Redis结点2
sudo docker run \
--name myredis2 \
-p 7002:7002 \
-p 17002:17002 \
-v /home/redis/myredis2/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis2/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Redis结点3
sudo docker run \
--name myredis3 \
-p 7003:7003 \
-p 17003:17003 \
-v /home/redis/myredis3/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis3/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Redis结点4
sudo docker run \
--name myredis4 \
-p 7004:7004 \
-p 17004:17004 \
-v /home/redis/myredis4/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis4/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Redis结点5
sudo docker run \
--name myredis5 \
-p 7005:7005 \
-p 17005:17005 \
-v /home/redis/myredis5/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis5/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Redis结点6
sudo docker run \
--name myredis6 \
-p 7006:7006 \
-p 17006:17006 \
-v /home/redis/myredis6/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis6/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Paso 3: crear un clúster
redis-cli --cluster create --cluster-replicas 1 -h 10.13.164.55 -p 7001 -a qweasdzxc 10.13.164.55:7001 10.13.164.55:7002 10.13.164.55:7003 10.13.164.55:7004 10.13.164.55:7005 10.13.164.55:7006
ilustrar:
- Acceda a uno de los nodos del clúster, conéctese a uno de los clientes y cree un clúster
- Ver el estado del nodo
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc cluster node
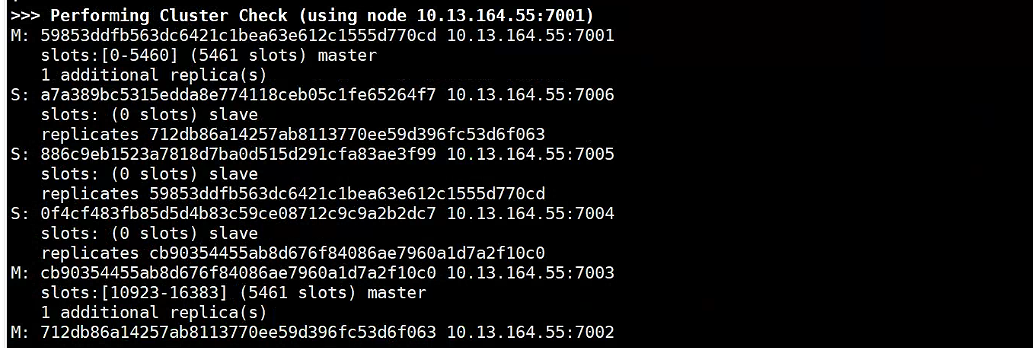
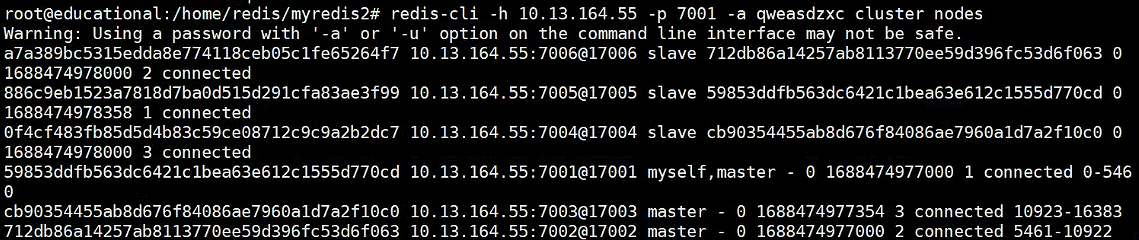
Suplemento: explicación de parámetros
Se utiliza para
--cluster-replicasespecificar la cantidad de nodos esclavos que cada nodo maestro debe tener al crear un clúster de fragmentos de Redis. Para1, significa que se puede crear automáticamente un nodo esclavo para cada nodo maestro.
1.5.3 Ranuras hash
Las ranuras hash son un mecanismo de fragmentación de datos en los clústeres de fragmentación de Redis. Almacena datos distribuidos en múltiples nodos para lograr la distribución horizontal y el equilibrio de carga de los datos.
En un clúster fragmentado de Redis, Redis Cluster divide todo el conjunto de datos en un número fijo de ranuras hash (generalmente 16384 ranuras). Cada clave se calcula mediante una función hash para obtener un número de ranura y luego el par clave-valor se asigna al nodo correspondiente en función del número de ranura.
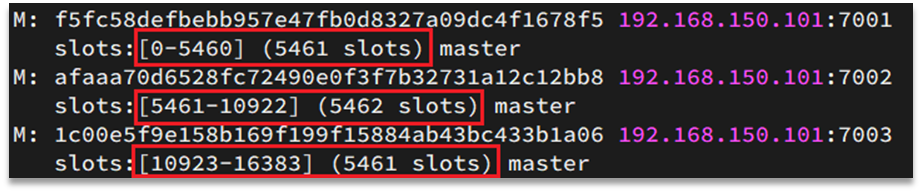
En un clúster de fragmentación de Redis, las claves de datos no están vinculadas a nodos, sino a ranuras . Redis calculará el valor del slot en función de la parte válida de la clave, en dos situaciones:
- La clave contiene "{}" y "{}" contiene al menos 1 carácter. La parte en "{}" es una parte válida.
- La clave no contiene "{}", la clave completa es una parte válida
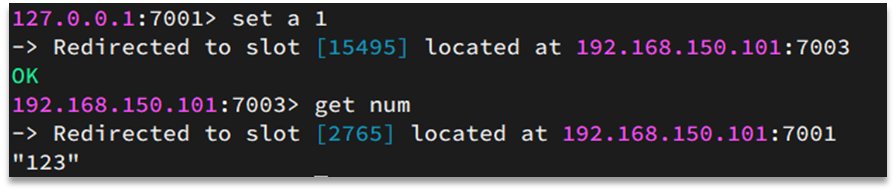
ilustrar:
Si la clave es num, entonces se calcula en función de num. Si es {itcast}num, se calcula en función de itcast. El método de cálculo consiste en utilizar el algoritmo CRC16 para obtener un valor hash y luego tomar el resto de 16384 y el resultado obtenido es el valor de la ranura. Para obtener los datos, calcule el valor hash en función de la parte efectiva de la clave, tome el resto de 16384 y use el resto como ranura, simplemente busque la instancia donde se encuentra la ranura
Reponer:
Si el mismo tipo de datos se guarda de forma fija en la misma instancia de Redis, entonces este tipo de datos utiliza la misma parte válida, por ejemplo, las claves tienen el prefijo {typeId}
1.5.4 Escalado de clúster
- agregar nodo
Paso 1: crear el servicio Redis
ilustrar:
De manera similar a los pasos para construir un clúster de fragmentos, primero cree un nodo 7007 y ejecute
sudo docker run \
--name myredis7 \
-p 7007:7007 \
-p 17007:17007 \
-v /home/redis/myredis7/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis7/data/:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
Paso 2: agregar nodos al clúster existente
# 格式
# add-node new_host:new_port existing_host:existing_port
# --cluster-slave
# --cluster-master-id <arg>
# 例如
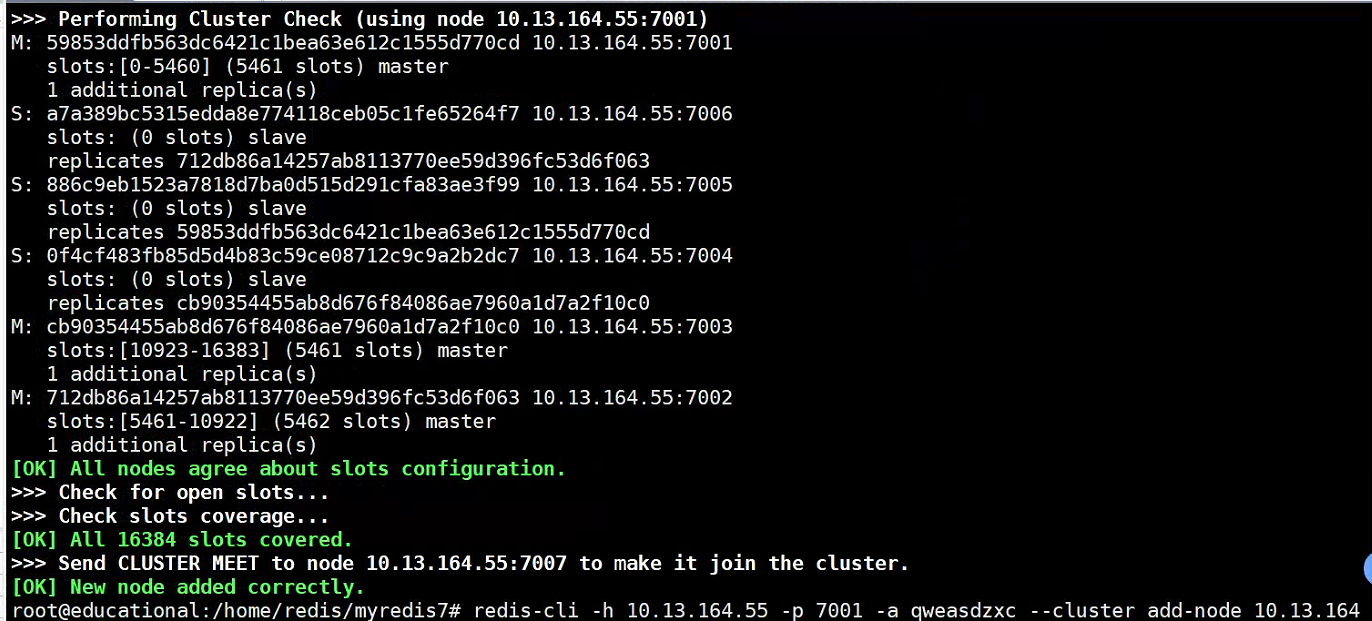
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc --cluster add-node 10.13.164.55:7007 10.13.164.55:7001
Descripción: Ver resultados
- Verifique el número de espacios
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc cluster nodes
- Se descubre que la cantidad de espacios no está asignado a este nodo maestro y es necesario asignar espacios antes de que pueda continuar usándose.
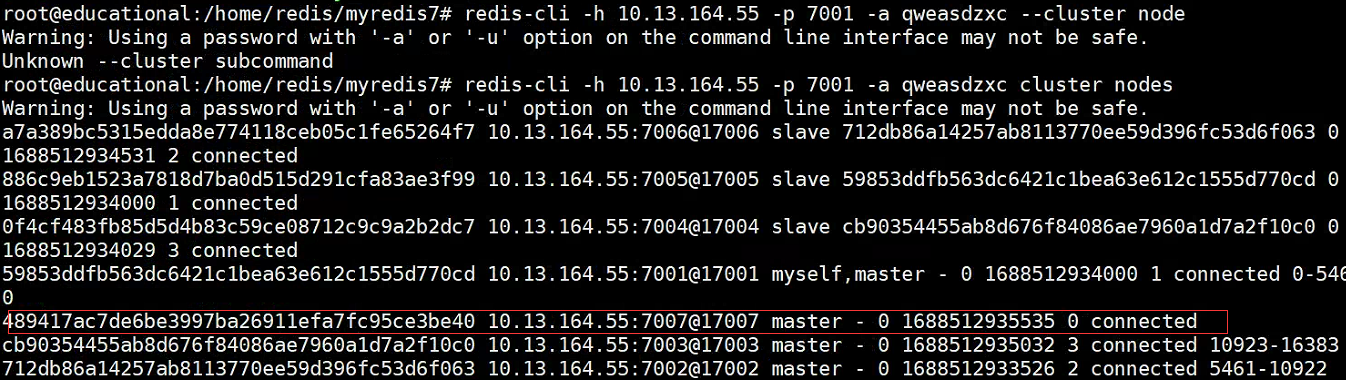
- Asignar espacio
# 格式 reshard host:port
# --cluster-from <arg>
# --cluster-to <arg>
# --cluster-slots <arg>
# --cluster-yes
# --cluster-timeout <arg>
# --cluster-pipeline <arg>
# --cluster-replace
# 例如
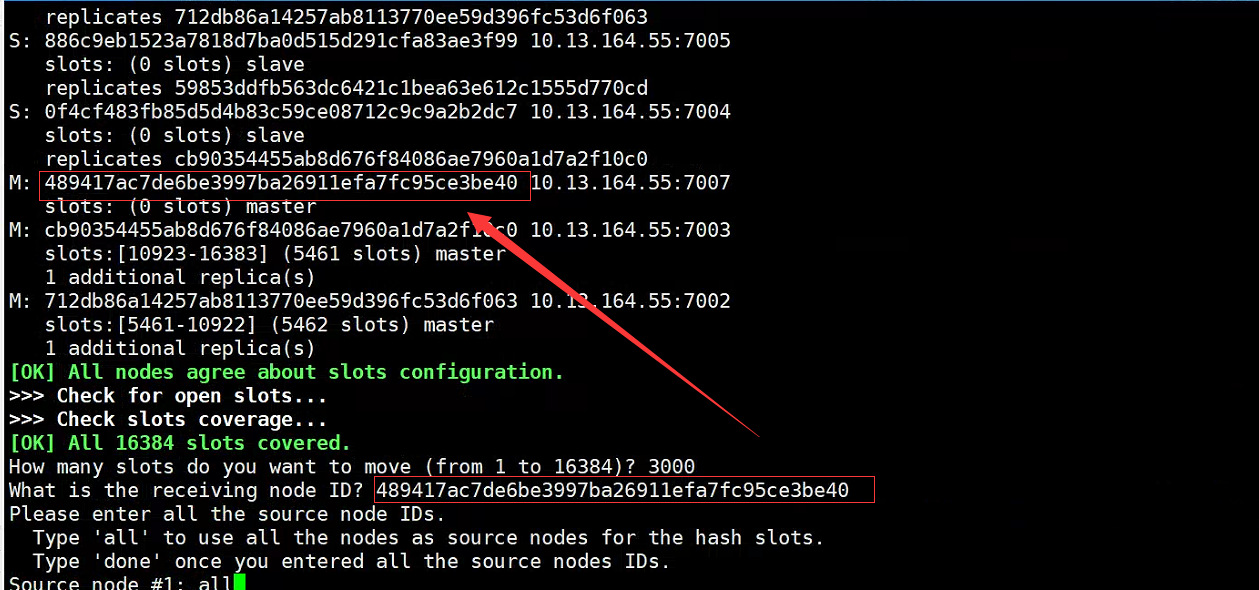
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc --cluster reshard 10.13.164.55:7001
Descripción: Ver resultados
- Reasigne la ranura 7001 al nodo 7007
- Verifique el número de espacios
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc cluster nodes
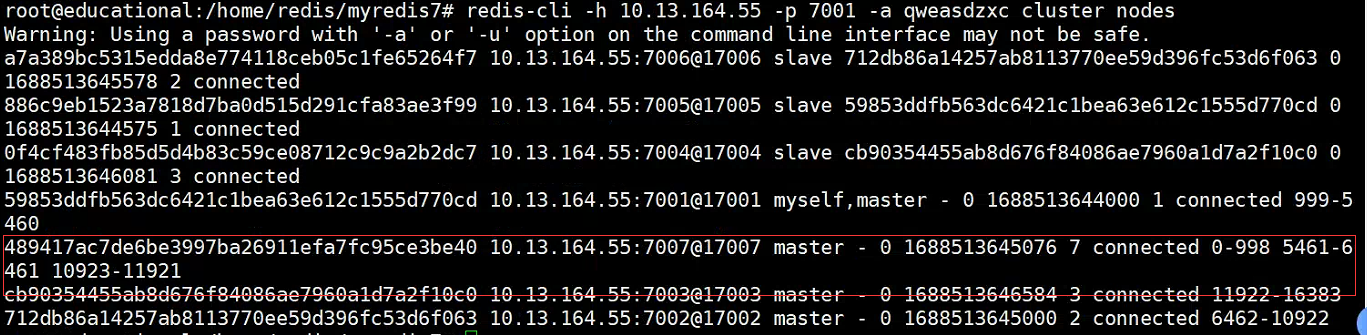
- Eliminar nodo
Paso uno: transferir ranuras
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc --cluster reshard 10.13.164.55:7001
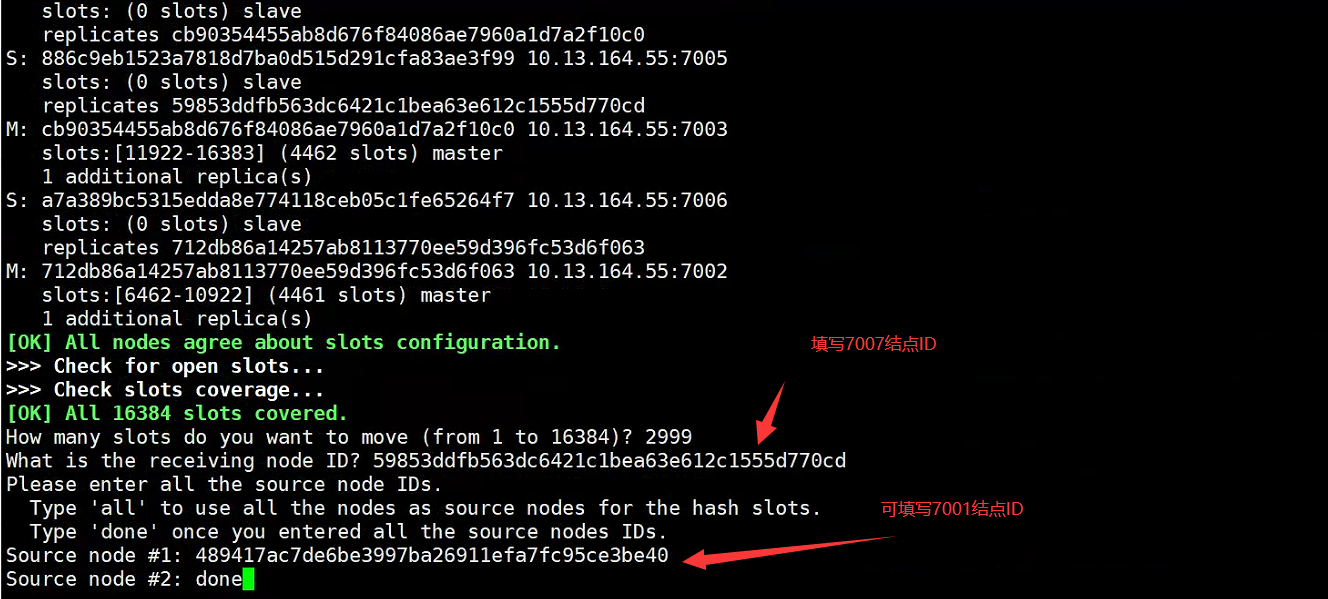
Paso 2: eliminar nodos
# 格式 del-node host:port node_id
# 例如
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc --cluster del-node 10.13.164.55:7007 489417ac7de6be3997ba26911efa7fc95ce3be40
Descripción: Ver resultados
- Verifique el número de espacios
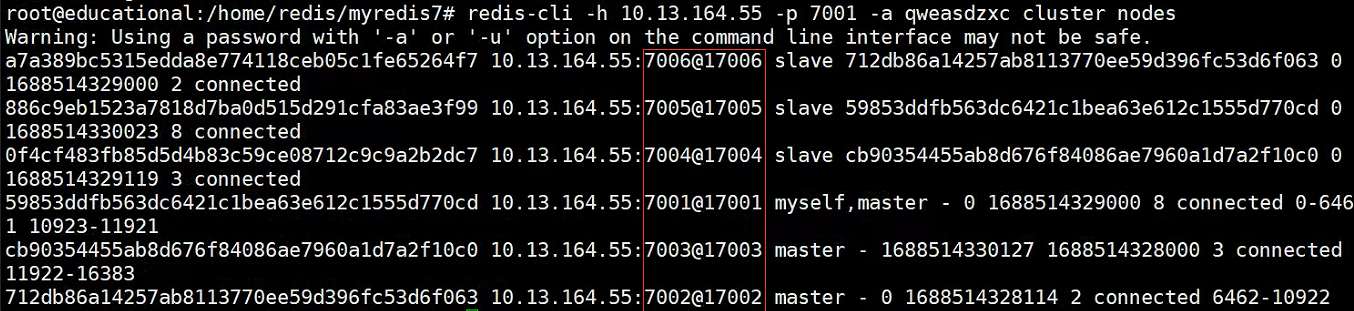
redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc cluster nodes
- En este punto, se puede encontrar que el nodo 7007 ha desaparecido.

1.5.5 Conmutación por error
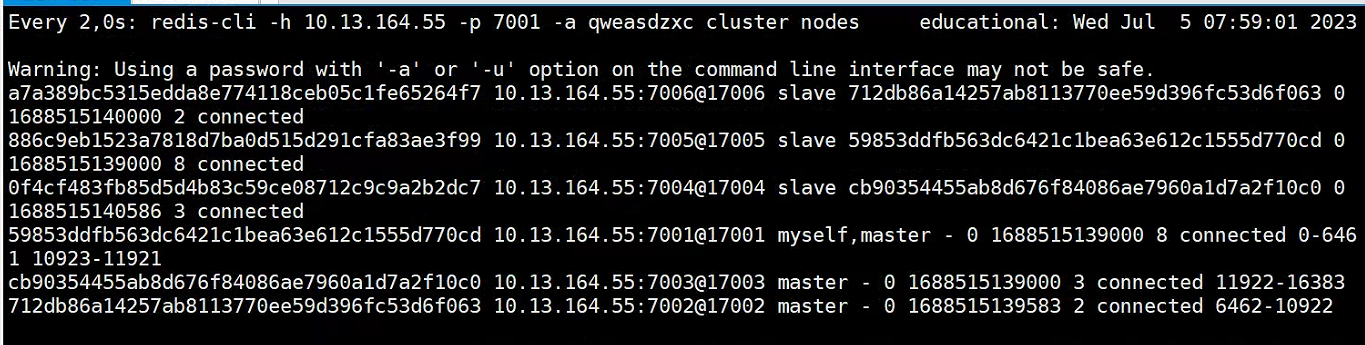
- Ver conmutación maestro-esclavo
watch redis-cli -h 10.13.164.55 -p 7001 -a qweasdzxc cluster nodes
ilustrar:
- Observe los cambios en el nodo maestro y descubra que ha sido reemplazado.
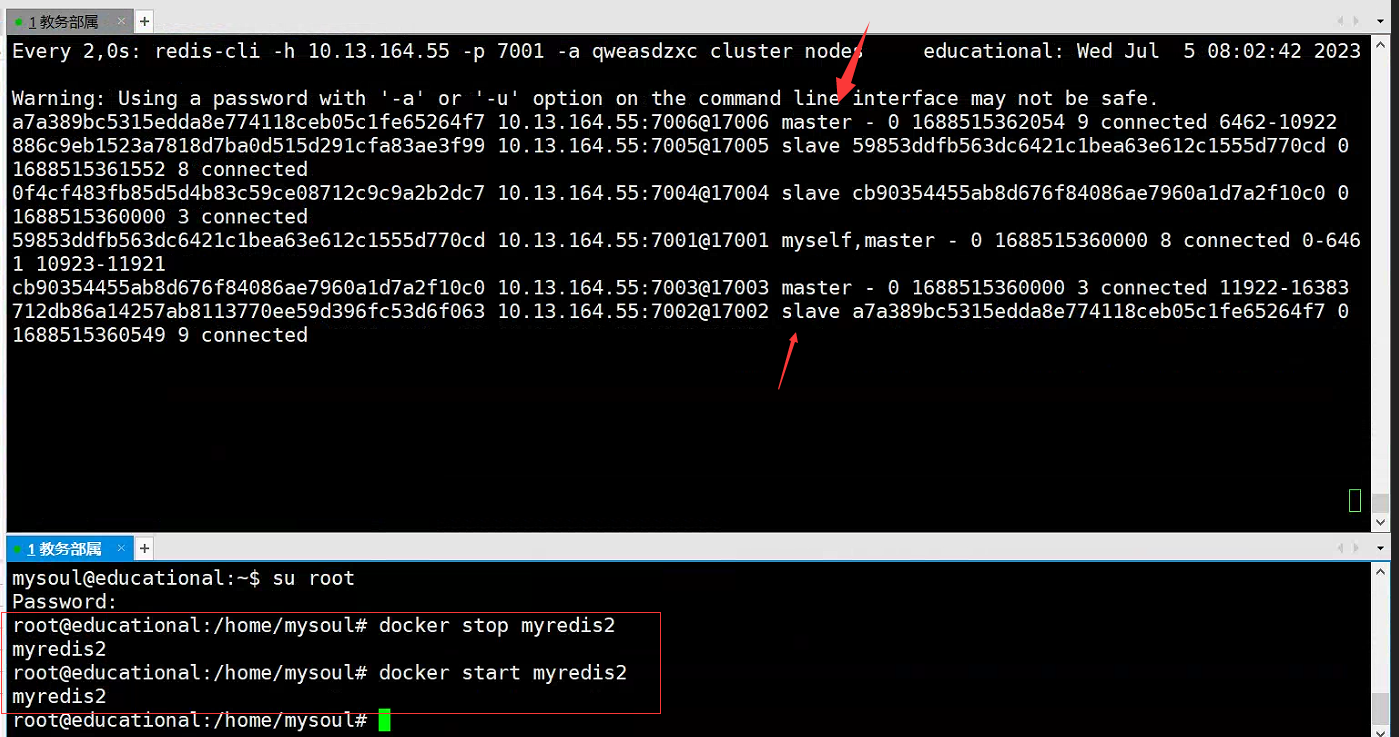
- migración de datos
Paso 1: conectar nodos secundarios
redis-cli -h 10.13.164.55 -p 7002 -a qweasdzxc
Paso 2: cambiar de nodo
cluster failover
ilustrar:
- Como se puede observar, vuelve a ser el nodo maestro.
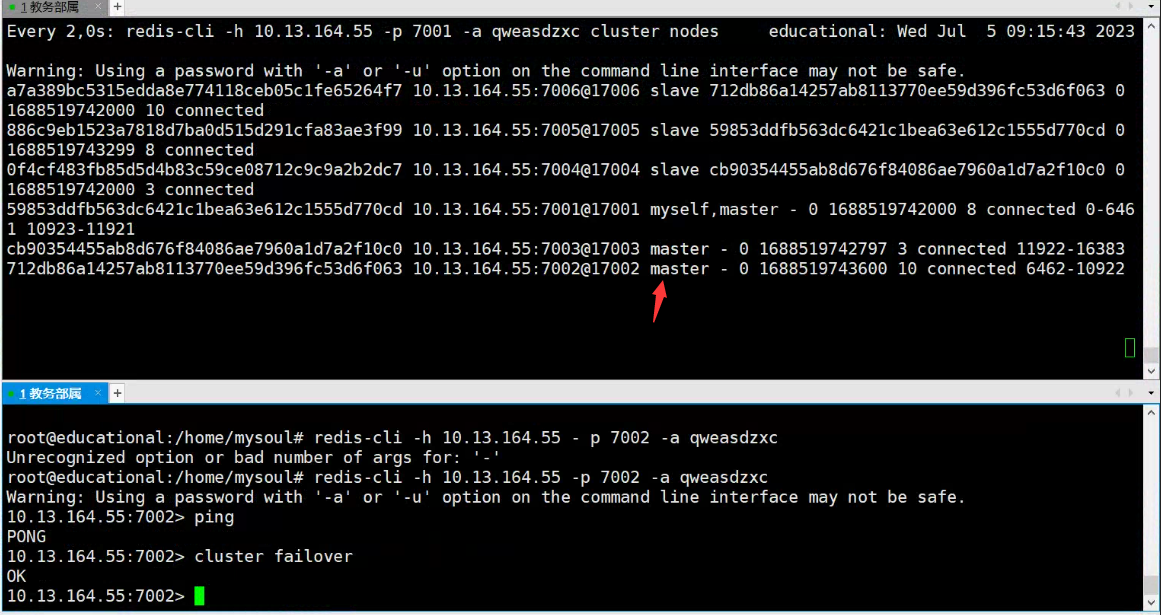
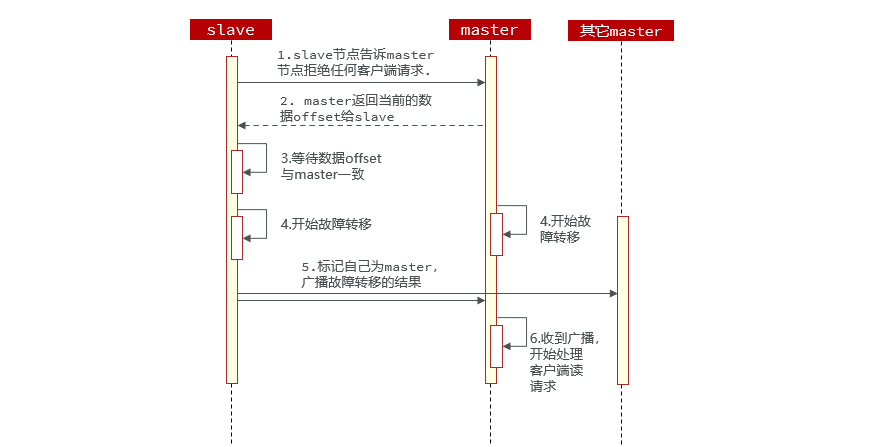
Reponer:
- Puede utilizar el comando de conmutación por error del clúster para apagar manualmente un maestro en el clúster y cambiar al nodo esclavo que ejecuta el comando de conmutación por error del clúster para lograr una migración de datos imperceptible.
- La conmutación por error manual admite tres modos diferentes: predeterminado : el proceso predeterminado, como se muestra en la Figura 1 ~ 6, forzado : omitiendo la verificación de coherencia del desplazamiento, adquisición : ejecutando directamente el quinto paso, ignorando la coherencia de los datos e ignorando el estado maestro y los comentarios de otros maestros
1.5.6 Casos de uso básicos
ilustrar:
En el clúster fragmentado de Redis bajo la supervisión del clúster Sentinel, sus nodos cambiarán debido a la conmutación por error automática. El cliente de Redis debe detectar este cambio y actualizar la información de conexión de manera oportuna. La capa inferior de Spring
RedisTemplateusa lechuga para realizar la percepción de nodos y el cambio automático.
Paso 1: importar dependencias
- Modificar
pom.xmlarchivos
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Paso 2: agregar configuración
1. Modificar application.yamlel archivo de configuración.
logging:
level:
io.lettuce.core: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
server:
port: 8081
spring:
redis:
cluster:
nodes: # 指定分片集群的每一个节点信息
- 10.13.164.55:7001
- 10.13.164.55:7002
- 10.13.164.55:7003
- 10.13.164.55:7004
- 10.13.164.55:7005
- 10.13.164.55:7006
password: qweasdzxc
2. Agregar RedisConfigclase de archivo de configuración
@Configuration
public class RedisConfig {
@Bean
LettuceClientConfigurationBuilderCustomizer getLettuceClientConfigurationBuilderCustomizer(){
// 设置集群的读取模式,先读取从结点,若失败则再读取主节点
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
}
Paso 3: prueba
1. Escribe HelloControllerclases de capa de presentación.
@RestController
public class HelloController {
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/get/{key}")
public String hi(@PathVariable String key) {
return redisTemplate.opsForValue().get(key);
}
@GetMapping("/set/{key}/{value}")
public String hi(@PathVariable String key, @PathVariable String value) {
redisTemplate.opsForValue().set(key, value);
return "success";
}
}
2. Ingrese a la consola para solicitar pruebas.
3. Ver el registro de ideas
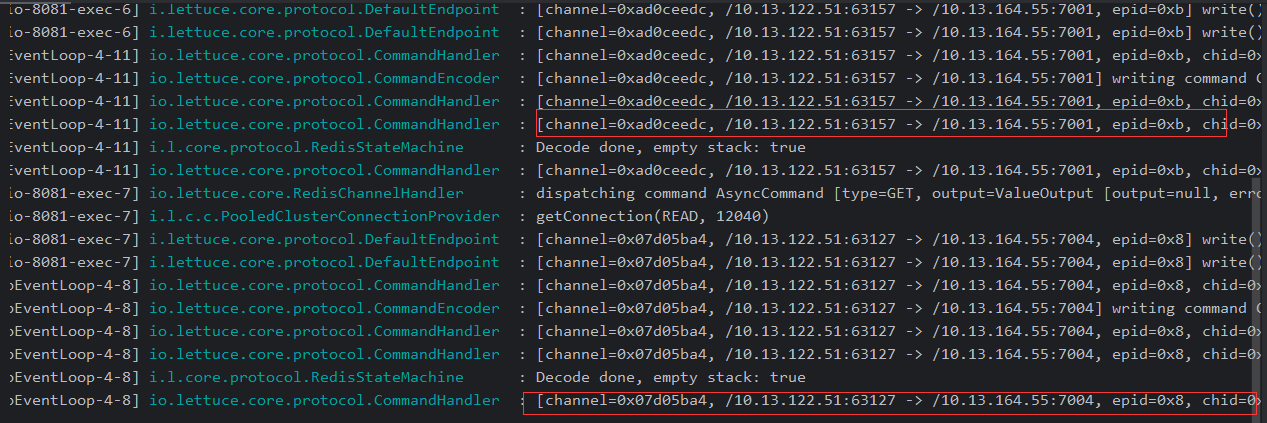
ilustrar:
A través del registro, puede encontrar que la lectura y la escritura están separadas.
1.6 Resumen
1. Comparación de las ventajas y desventajas del clúster maestro-esclavo de Redis y el clúster fragmentado de Redis :
-
Clúster maestro-esclavo de Redis
-
ventaja:
-
Replicación de datos: el nodo maestro copia datos al nodo esclavo para lograr respaldo y redundancia de datos y mejorar la confiabilidad y disponibilidad de los datos .
-
Separación de lectura y escritura: el nodo maestro es responsable de las operaciones de escritura y el nodo esclavo es responsable de las operaciones de lectura, lo que mejora capacidad de procesamiento concurrente y el rendimiento de lectura del sistema .
-
Tolerancia a fallos: cuando el nodo maestro falla, puede cambiar automáticamente al nodo esclavo como nuevo nodo maestro para lograr una alta disponibilidad .
-
-
defecto:
- Las operaciones de escritura dependen del nodo maestro y el rendimiento y la estabilidad del nodo maestro tienen un mayor impacto en todo el clúster.
- La separación de lectura y escritura puede causar retrasos en los datos porque los datos del nodo esclavo no están necesariamente sincronizados con el nodo maestro en tiempo real.
-
-
Clúster fragmentado de Redis
-
ventaja:
-
Fragmentación de datos: el almacenamiento distribuido de datos en múltiples nodos mejora la capacidad de almacenamiento y el rendimiento .
-
Procesamiento paralelo: cada nodo procesa de forma independiente sus propios fragmentos de datos, lo que mejora las capacidades de procesamiento concurrente del sistema .
-
Expansión horizontal: expanda el clúster agregando nodos para admitir el almacenamiento y procesamiento de datos a mayor escala .
-
-
defecto:
-
Impacto de la falla del nodo: cuando un nodo falla, los datos responsables del nodo serán inaccesibles, lo que puede resultar en la pérdida o indisponibilidad de los datos.
-
Coherencia de los datos: la distribución de datos en un clúster fragmentado no es necesariamente uniforme , lo que puede provocar una mayor carga en algunos nodos. Es necesario considerar los problemas de coherencia y equilibrio de datos.
-
Transacciones entre nodos: las operaciones de transacciones en clústeres fragmentados abarcan varios nodos y se debe considerar la coherencia de los datos y la complejidad del control de concurrencia.
-
-
-
Resumir:
- La caché distribuida de Redis tiene alto rendimiento , alta disponibilidad y funciones ricas, y es adecuada para la mayoría de los escenarios. Sin embargo, sus ventajas y desventajas deben sopesarse en función de las necesidades comerciales específicas y las características de los datos, y de una configuración y administración razonables.
- Los clústeres fragmentados son adecuados para escenarios con grandes cantidades de datos y operaciones de lectura y escritura dispersas, y proporcionan expansión horizontal y capacidades de alto rendimiento. Sin embargo, debemos prestar atención a cuestiones como el equilibrio de datos, las fallas de los nodos y las transacciones entre nodos.
2. Estrategia de almacenamiento en caché tradicional:
Descripción:
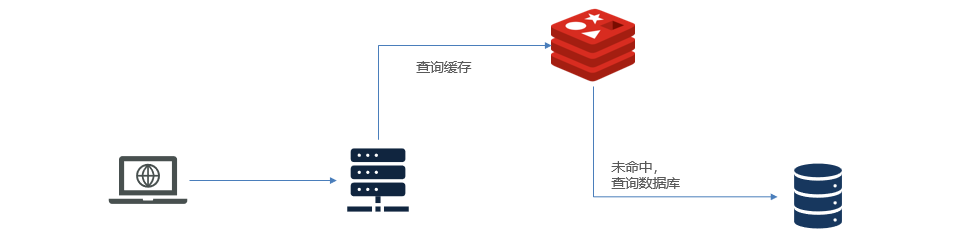
La estrategia de almacenamiento en caché tradicional es generalmente consultar Redis primero después de que la solicitud llega a Tomcat y, si falla, consultar la base de datos. Cuando el volumen de datos alcance el nivel de mil millones, habrá problemas.
- Tomcat procesa las solicitudes y el rendimiento de Tomcat se convierte en el cuello de botella de todo el sistema.
- Cuando falla la caché de Redis, tendrá un impacto en la base de datos.
ilustrar:
Entonces, ¿cómo resolver la falla de la caché y el cuello de botella de Tomcat? Consulte la siguiente sección para obtener más detalles.
2. Caché multinivel
Resumen de notas:
- Por favor revise cada sección
- Resumen: verifique los detalles
2.1 Descripción general
Resumen de notas:
- Descripción general: caché multinivel de Redis, que consta de múltiples niveles de caché para mejorar el rendimiento y la escalabilidad del sistema.
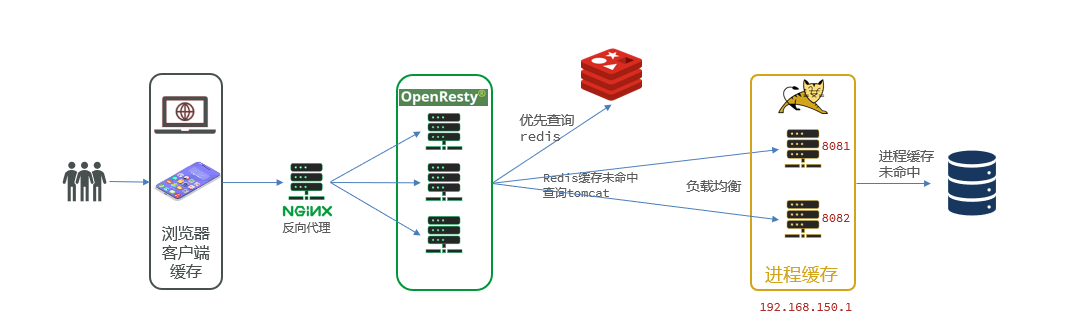
- Flujo de trabajo: cuando se accede a los datos, se consultará en secuencia el caché de primer nivel , el caché de segundo nivel, el caché de tercer nivel ... y finalmente se consultará Tomcat.
La caché multinivel de Redis es una arquitectura de caché común que consta de múltiples niveles de caché para mejorar el rendimiento y la escalabilidad del sistema. Cada nivel de caché tiene diferentes características y propósitos.
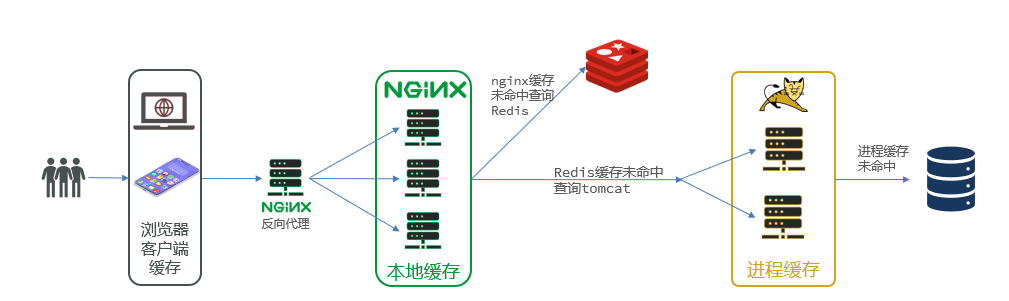
ilustrar:
El Nginx utilizado como caché es el Nginx empresarial, que debe implementarse como un clúster, y se utiliza un Nginx dedicado como proxy inverso.
Al utilizar caché multinivel, se puede mejorar enormemente el rendimiento y la escalabilidad del sistema, se puede reducir la cantidad de accesos al sistema de almacenamiento de datos back-end , se puede reducir la carga del sistema y se puede proporcionar una mejor experiencia de usuario. . Al mismo tiempo, la caché multinivel también se puede configurar y administrar de manera flexible según el modo de acceso y la importancia de los datos para satisfacer diferentes necesidades comerciales.
Proceso principal:
- Cuando la aplicación necesita obtener datos, primero consulta el caché de primer nivel (caché L1), si los datos existen en el caché de primer nivel, los datos se devuelven directamente sin acceder al sistema de almacenamiento de datos de back-end.
- Si los datos requeridos no existen en la caché L1, se consulta la caché L2 (caché L2), y si los datos existen en la caché L2, los datos se devuelven a la aplicación y se actualiza la caché L2.
- Si los datos requeridos tampoco existen en la caché L3, se consulta la caché L3 (caché L3) y, si los datos existen en la caché L3, los datos se devuelven a la aplicación y se actualizan las cachés L3 y L3.
- Si los datos no existen en todos los niveles de caché, la aplicación los recupera del sistema de almacenamiento de datos de back-end y los almacena en todos los niveles de caché para acceso posterior.
2.2 Caché de procesos JVM
Resumen de notas:
- Descripción general: Caffeine es una biblioteca de almacenamiento en caché local de alto rendimiento con la mejor tasa de aciertos
- Uso básico: crear objetos Builder, obtener, configurar
- Política de desalojo de caché: el caché puede establecer la frecuencia de actualización del caché en función del tiempo y la capacidad
maximumSizey establecer el tiempo de caducidad del caché.expireAfterWrite
2.2.1 Descripción general
Caffeine es una biblioteca de caché local de alto rendimiento desarrollada en base a Java8 que proporciona una tasa de aciertos casi óptima. Actualmente, el caché interno de Spring usa Caffeine. Dirección de GitHub: https://github.com/ben-manes/caffeine
2.2.2 Uso básico del caso
- crear
Testclase
@Test
void testBasicOps() {
// 1.创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 2.存数据
cache.put("gf", "迪丽热巴");
// 3.取数据
// 3.1不存在则返回null
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
// 3.2不存在则去数据库查询
String defaultGF = cache.get("defaultGF", key -> {
// 这里可以去数据库根据 key查询value
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}
2.2.3 Estrategia de desalojo de caché
Caffeine es una biblioteca de almacenamiento en caché de alto rendimiento basada en Java que proporciona una variedad de estrategias de desalojo de caché para controlar el tamaño del caché y el uso de la memoria.
Vale la pena señalar que el desalojo del caché lleva una cierta cantidad de tiempo, como 10 segundos o 20 segundos. A continuación se muestran algunas estrategias comunes de desalojo de caché respaldadas por Caffeine
- Basado en capacidad
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();
ilustrar:
Establecer un límite superior en el número de cachés
- basado en el tiempo
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(10)) // 设置缓存有效期为 10 秒,从最后一次写入开始计时
.build();
ilustrar:
Establecer el tiempo de validez de la caché
- basado en cita
ilustrar:
Configure el caché como referencia suave o referencia débil y use GC para reciclar los datos almacenados en caché. Mal rendimiento, no recomendado.
Reponer:
De forma predeterminada, cuando un elemento de caché caduca, Caffeine no lo limpiará ni lo desalojará automáticamente de inmediato. En cambio, la eliminación de datos no válidos se completa después de una operación de lectura o escritura, o durante el tiempo de inactividad.
2.2.4 Casos de uso básicos
Paso 1: importar dependencias
- Modificar
pom.xmlarchivos
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
Paso 2: crear un archivo de configuración
- Crear
CaffeineConfigclase de configuración
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache() {
return Caffeine.newBuilder()
.initialCapacity(100) // 设置缓存的初始容量为100个条目
.maximumSize(10000) // 设置缓存的最大容量为10000个条目
.build();
}
@Bean
public Cache<Long, ItemStock> StockCache() {
return Caffeine.newBuilder()
.initialCapacity(100) // 设置缓存的初始容量为100个条目
.maximumSize(10000) // 设置缓存的最大容量为10000个条目
.build();
}
}
Paso 3: implementar la consulta
- Modificar
ItemControllerla clase de capa de control
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id, key -> itemService.query()
.ne("status", 3).eq("id", key)
.one());
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id) {
return StockCache.get(id, key -> stockService.getById(key));
}
2.3 Introducción a la sintaxis de Lua
Resumen de notas:
- Descripción general: Lua es un lenguaje de secuencias de comandos liviano y compacto diseñado para integrarse en aplicaciones para proporcionar extensiones y personalizaciones flexibles para las aplicaciones .
- La sintaxis es similar a Python; consulte cada sección para obtener más detalles.
2.3.1 Descripción general
Lua es un lenguaje de scripting ligero y compacto escrito en lenguaje C estándar y abierto en forma de código fuente. Está diseñado para integrarse en aplicaciones, proporcionando así extensiones flexibles y funciones de personalización para aplicaciones. Sitio web oficial: https://www.lua.org/

2.3.2 Casos de uso básicos
Paso 1: crear un script Lua
touch hello.lua
Paso 2: agrega algo de contenido
print("Hello World!")
Paso 3: ejecutar
lua hello.lua

2.3.3 Tipos de datos
| tipo de datos | describir |
|---|---|
| nulo | Este es el más simple, solo el valor nil pertenece a esta clase, lo que representa un valor no válido (equivalente a falso en una expresión condicional). |
| booleano | Contiene dos valores: falso y verdadero. |
| número | Representa un número real de punto flotante de tipo doble |
| cadena | Una cadena está representada por un par de comillas dobles o comillas simples. |
| función | Función escrita en C o Lua |
| mesa | Una tabla en Lua es en realidad una " matriz asociativa " (matrices asociativas), y el índice de la matriz puede ser un número, una cadena o un tipo de tabla. En Lua, la creación de una tabla se realiza mediante una "expresión de construcción", la expresión de construcción más simple es {}, que se utiliza para crear una tabla vacía. |
ilustrar:
- Ver tipos de datos variables
print(type("hello,world"))
2.3.4 Variables
-- 声明字符串
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
-- 声明数组 key为索引的 table
local arr = {
'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {
name='Jack', age=21}
ilustrar:
- variable de acceso
-- 访问数组,lua数组的角标从1开始 print(arr[1]) -- 访问table print(map['name']) print(map.name)
2.3.5 Bucle
- iterar sobre la matriz
-- 声明数组 key为索引的 table
local arr = {
'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) do
print(index, value)
end
- mesa transversal
-- 声明map,也就是table
local map = {
name='Jack', age=21}
-- 遍历table
for key,value in pairs(map) do
print(key, value)
end
2.3.6 Funciones
- definir función
function 函数名( argument1, argument2..., argumentn)
-- 函数体
return 返回值
end
-- 例如
function printArr(arr)
for index, value in ipairs(arr) do
print(value)
end
end
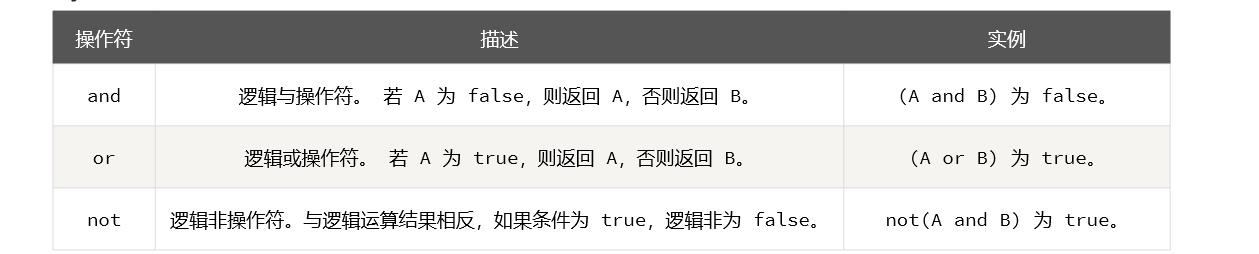
2.3.7 Control de condición
- control condicional
if(布尔表达式)
then
--[ 布尔表达式为 true 时执行该语句块 --]
else
--[ 布尔表达式为 false 时执行该语句块 --]
end
ilustrar:
2.4 Inicio rápido de OpenResty
Resumen de notas:
- Descripción general: OpenResty es una plataforma web de alto rendimiento basada en Nginx , que se utiliza para crear fácilmente aplicaciones web dinámicas, servicios web y puertas de enlace dinámicas que pueden manejar una concurrencia ultraalta y una alta escalabilidad.
2.4.1 Descripción general
OpenResty® es una plataforma web de alto rendimiento basada en Nginx, que se utiliza para crear fácilmente aplicaciones web dinámicas, servicios web y puertas de enlace dinámicas que pueden manejar una concurrencia ultraalta y una alta escalabilidad .
OpenResty tiene las funciones completas de Nginx, se extiende en función del lenguaje Lua, integra una gran cantidad de bibliotecas Lua sofisticadas, módulos de terceros y permite el uso de lógica empresarial y bibliotecas personalizadas de Lua.
Sitio web oficial: https://openresty.org/cn/

2.4.2 Instalación
ilustrar:
Este tutorial instala OpenResty a través de Docker
Paso 1: crear un directorio
cd /home
mkdir openresty
cd /home/openresty
mkdir conf
mkdir lua
Paso 2: Instale OpenResty
docker run -id --name openresty -p 8080:8080 sevenyuan/openresty
Paso 3: configuración de montaje
1.Copiar OpenRestyconfiguración
docker cp openresty:/usr/local/openresty/nginx/conf/nginx.conf /home/openresty/conf
docker cp openresty:/usr/local/openresty/lualib /home/openresty
Descripción: Ver resultados

2. Modificar /home/openresty/nginx/conf/nginx.confla configuración
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8080;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
Paso 4: reinstalar
1.EliminarOpenResty
docker rm -f openresty
2.InstalaciónOpenResty
docker run -id -p 8080:8080 \
--name openresty \
-v /home/openresty/conf/nginx.conf:/usr/local/openresty/nginx/conf/nginx.conf \
-v /home/openresty/lua:/usr/local/openresty/nginx/lua \
-v /home/openresty/lualib/:/usr/local/openresty/lualib \
-v /etc/localtime:/etc/localtime \
-d sevenyuan/openresty
ilustrar:
No agregue
--restart alwaysatributos, de lo contrario el inicio fallará
Paso cinco: OpenRestyinterfaz de control de acceso
ilustrar:
Poder acceder
OpenRestya la interfaz predeterminada en el lado del navegador indica que la instalación se realizó correctamente.
2.5 Consultar caché local
Resumen de notas:
- Descripción general: implementación de una solución de almacenamiento en caché local a través del clúster Nginx
- Solicitud de proxy inverso de Nginx ,
upstreamcómo usarla- Procesamiento dinámico de Nginx de parámetros de solicitud
2.5.1 Descripción general
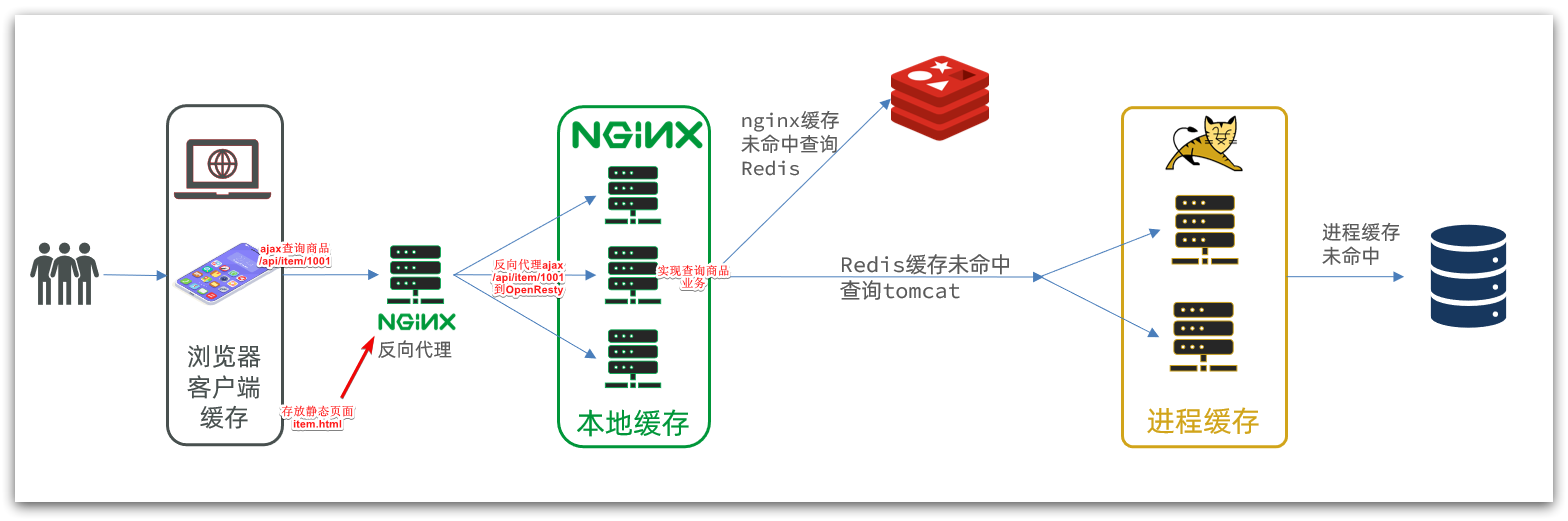
ilustrar:
Cuando el navegador del cliente envía una solicitud, el proxy inverso de NGINX reenviará la solicitud al caché local de NGINX.
2.5.2 Casos de uso básicos
Paso 1: modificar NGINXel proxy inverso
ilustrar:
Deje que
nginxel agente vaya alOpenRestygrupo empresarial para procesar el negocio.
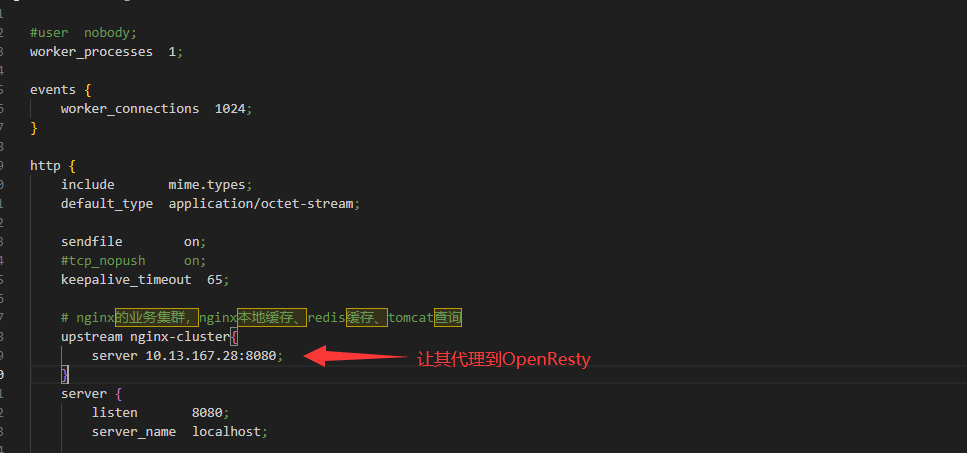
1. Modifique Nginxla ruta desde el proxy inverso al clúster empresarial.
upstream nginx-cluster{
# 定义多个请求代理的服务器
server 10.13.167.28:8080;
}
server {
listen 8080;
server_name localhost;
# 当nginx拦截到任一api开头的请求时,会自动的代理到upstream后端服务器模块中
location /api {
proxy_pass http://nginx-cluster;
}
}
ilustrar:
2. Reinicie Nginxel proxy inverso
nginx.exe -s stop
start nginx
Paso 2: modificar NGINXel caché local
- Perfil
OpenRestyde configuración modificadonginx.conf
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
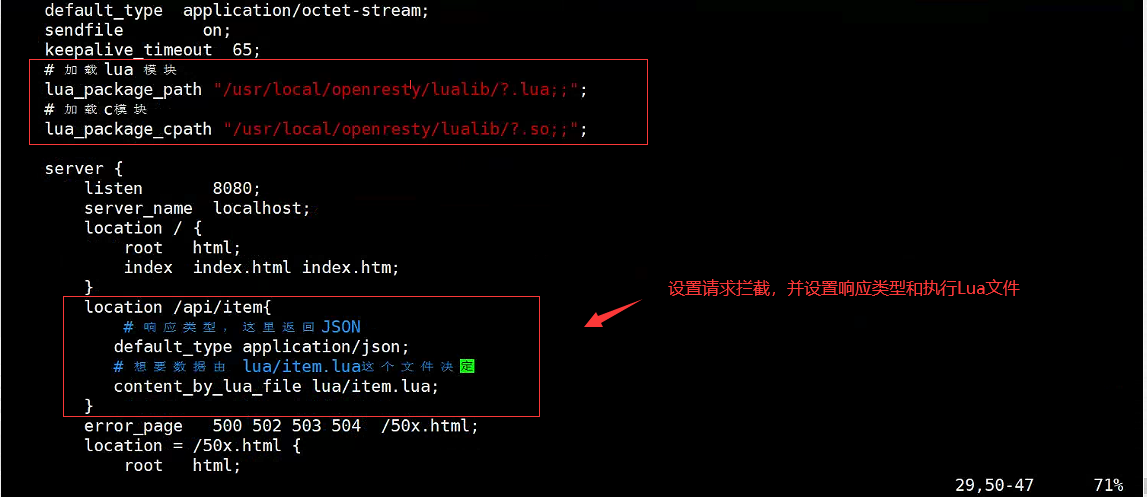
# 添加对OpenResty的Lua模块的加载
#lua 模块
lua_package_path "/home/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/home/openresty/lualib/?.so;;";
server {
listen 8080;
server_name localhost;
# 添加对/api/item这个路径的监听
location /api/item {
# 默认的响应类型
default_type application/json;
# 响应结果有lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
ilustrar:
Después de modificar el archivo de configuración,
OpenRestyse actualizará automáticamente, por lo que no es necesario reiniciar.
Reponer:
Paso 3: agregar el archivo de ejecución del script
1.Escribir item.luadocumentos
vim /home/openresty/lua/item.lua
2. Agregue el contenido del archivo de la siguiente manera
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":27900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
Paso 4: reiniciarOpenResty
docker restart openresty
Paso 5: Ver resultados
1. Ver los datos de respuesta del navegador.

ilustrar:
Indica que la respuesta de datos es exitosa
2. Ver la página de inicio del navegador.
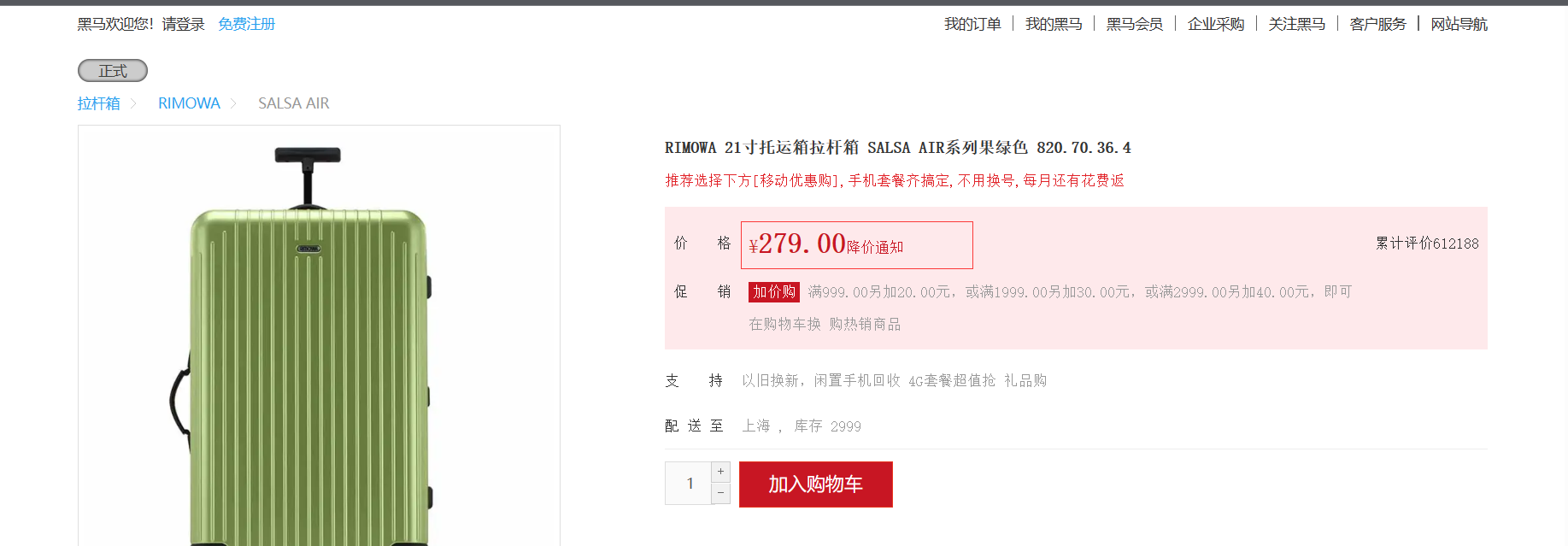
ilustrar:
Puede ver que el precio ha cambiado y que el experimento del proxy Nginx fue exitoso.
2.5.3 Solicitar procesamiento de parámetros
Cómo obtener los parámetros en la dirección de solicitud en OpenResty. De hecho, OpenResty proporciona varias API para obtener diferentes tipos de parámetros de solicitud:

2.5.4 Ejemplo básico: mejoras
ilustrar:
Obtenga los parámetros en el marcador de posición de la ruta
Paso 1: edite Openrestyel archivo de configuración
- Archivo
OpenRestyde configuración modificadonginx.conf
location ~ /api/item/(\d+) {
# 默认的响应类型
default_type application/json;
# 响应结果有lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}
ilustrar:
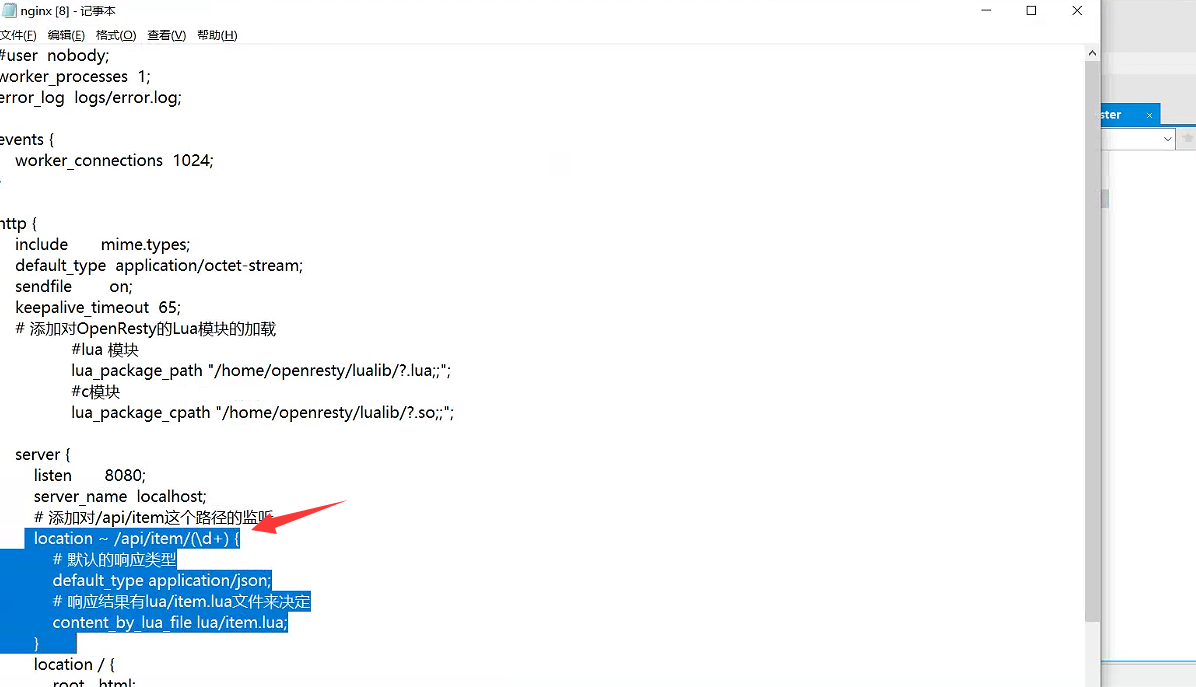
Paso 2: escribe el Luascript correspondiente
- Modificar
item.luaarchivos
local id = ngx.var[1]
ngx.say('{"id":' .. id .. ',"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":27900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
ilustrar:
Representa
..el empalme de cadenas.
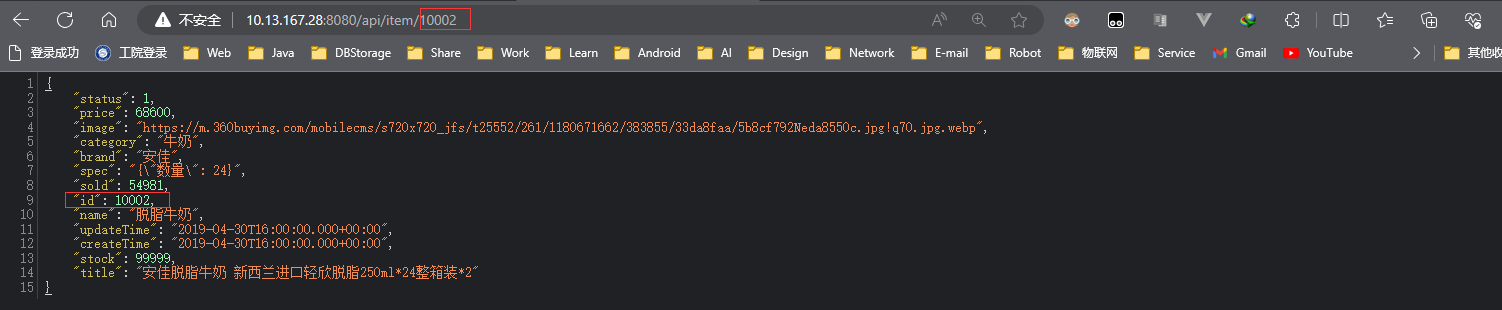
Paso 3: demostración

ilustrar:
Cuando el valor del ID de la solicitud cambia, los datos devueltos seguirán cambiando con la solicitud.
2.6 Consultar Tomcat
Resumen de notas:
- Descripción general: encapsule las solicitudes HTTP del script Lua e implemente la consulta del clúster Tomcat
- Usando CJSON para implementar la serialización y deserialización de objetos
2.6.1 Descripción general

ilustrar:
Al
OpenRestyenviar una solicitud, la primera consulta no consultará directamente al clúster de Redis, sino que consultará a Tomcat para obtenerlo.
2.6.2Enviar solicitud HTTP
Cómo enviar solicitudes en nginx. De hecho, nginx proporciona una API interna para enviar solicitudes Http:
local resp = ngx.location.capture("/path",{
method = ngx.HTTP_GET, -- 请求方式
args = {
a=1,b=2}, -- get方式传参数
body = "c=3&d=4" -- post方式传参数
})
ilustrar:
ngx.location.captureEnviar usando nginx API
El contenido de la respuesta devuelta incluye:
- resp.status: código de estado de respuesta
- resp.header: encabezado de respuesta, que es una tabla
- resp.body: cuerpo de la respuesta, que son los datos de la respuesta
Aviso:
- La ruta aquí es la ruta y no incluye IP ni puerto. Esta solicitud será monitoreada y procesada por el servidor dentro de nginx.
location /path { # 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态 proxy_pass http://192.168.150.1:8081; }
- Pero queremos que esta solicitud se envíe al servidor Tomcat, por lo que también necesitamos escribir un servidor para revertir esta ruta.
2.6.3 Encapsulación de herramientas de solicitud HTTP
Paso 1: crea common.luael archivo
在/home/openresty/lualib目录下创建common.lua文件,便于OpenResty的nginx.conf模块的导入
Paso 2: escribe common.luael archivo
1. Encapsula HTTPla función que envía la solicitud.
-- 函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
2. Exportar el método
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
2.6.4 Clase de herramienta CJSON
OpenResty proporciona un módulo cjson para manejar la serialización y deserialización JSON. Dirección oficial: https://github.com/openresty/lua-cjson/
Cómo utilizar:
- Importar módulo cjson
local cjson = require ("cjson")
- Publicación por entregas
local obj = {
name = 'jack',
age = 21
}
local json = cjson.encode(obj)
- Deserialización
local json = '{"name": "jack", "age": 21}'
-- 反序列化
local obj = cjson.decode(json);
print(obj.name)
2.6.5 Casos de uso básicos
premisa:
Common.lua Funciones que deben encapsularse en
Paso 1: agregar una dirección OpenRestyproxynginx.conf
http {
……
server {
listen 8080;
server_name localhost;
# 这里是配置Tomcat服务的电脑的ip和Java服务端口,需要确保其防火墙处于关闭状态
location /item{
proxy_pass http://10.13.122.51:8081;
}
……
}
Paso 2: modifique item.luael archivo para implementar una lógica empresarial real
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
-- 导入cjson库
local cjson = require('cjson')
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(itemStockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
Paso 3: demostración
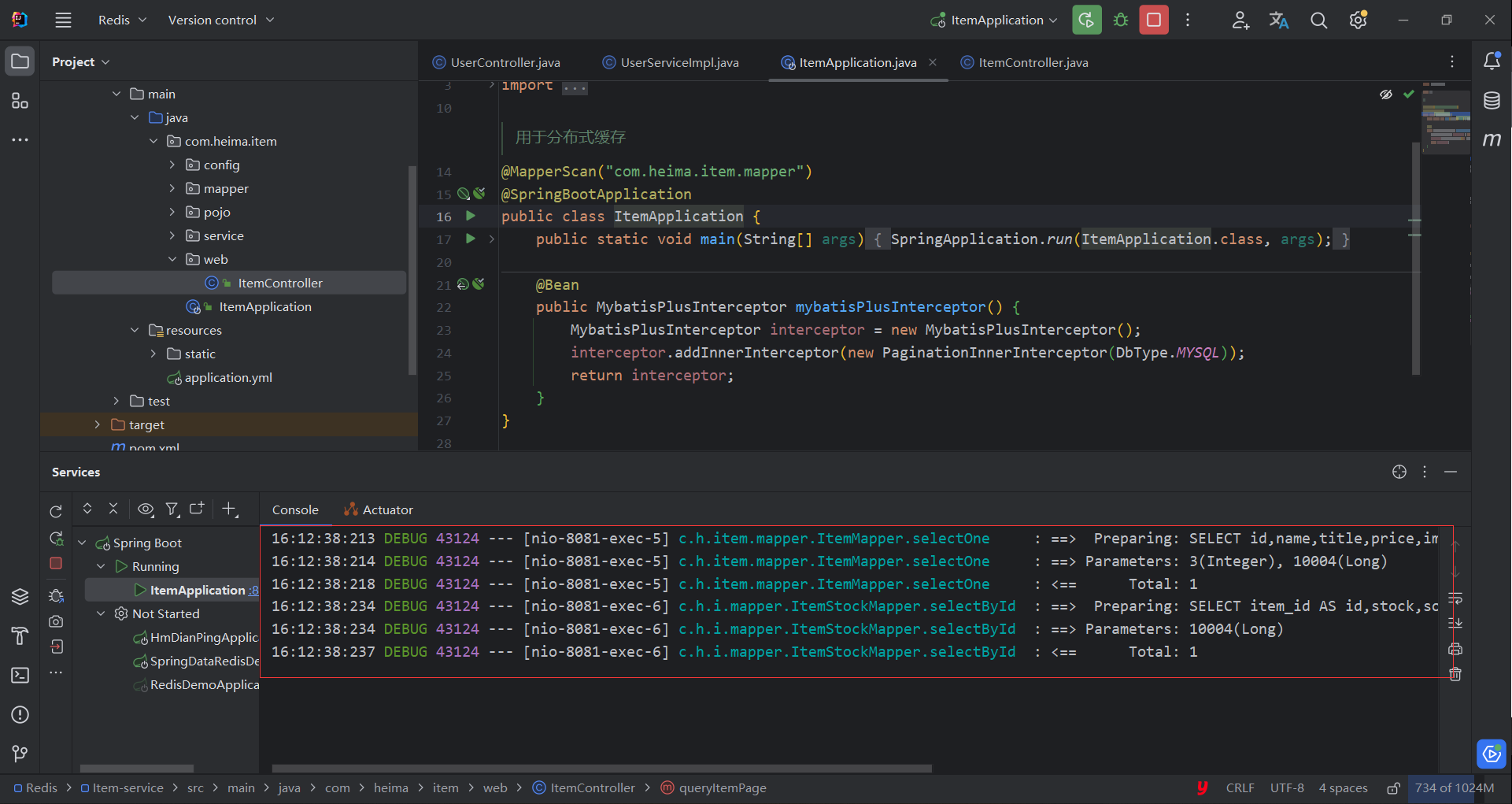
1. Verifique el registro de antecedentes
ilustrar:
Consulta de antecedentes exitosa
2. Ver los datos devueltos por el navegador.
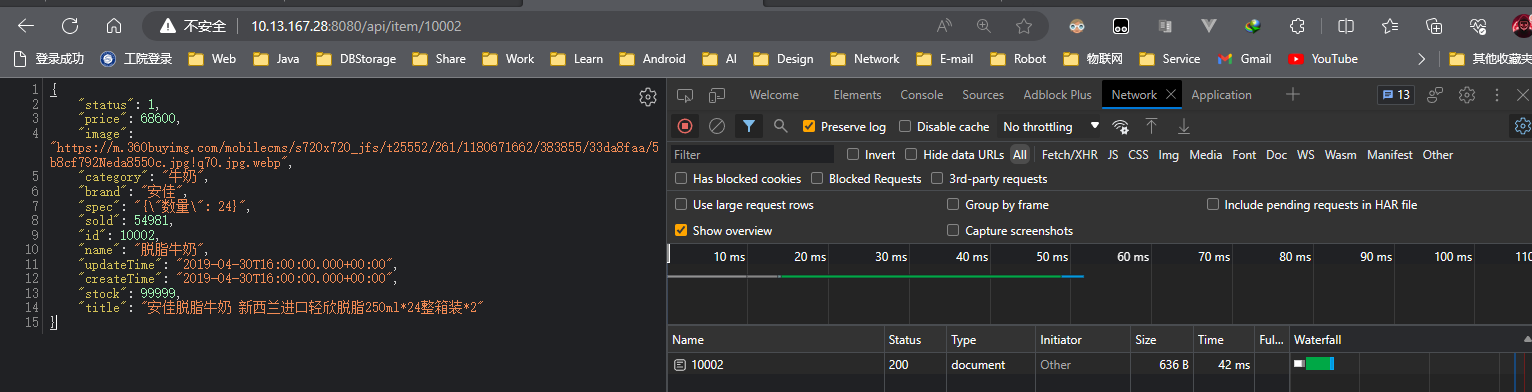
ilustrar:
Los datos del front-end se devolvieron correctamente
2.7 Equilibrio de carga del clúster de Tomcat
Resumen de notas:
- Descripción general: modifique la configuración de Nginx para lograr la configuración
upstreamde equilibrio de carga
2.7.1 Descripción general
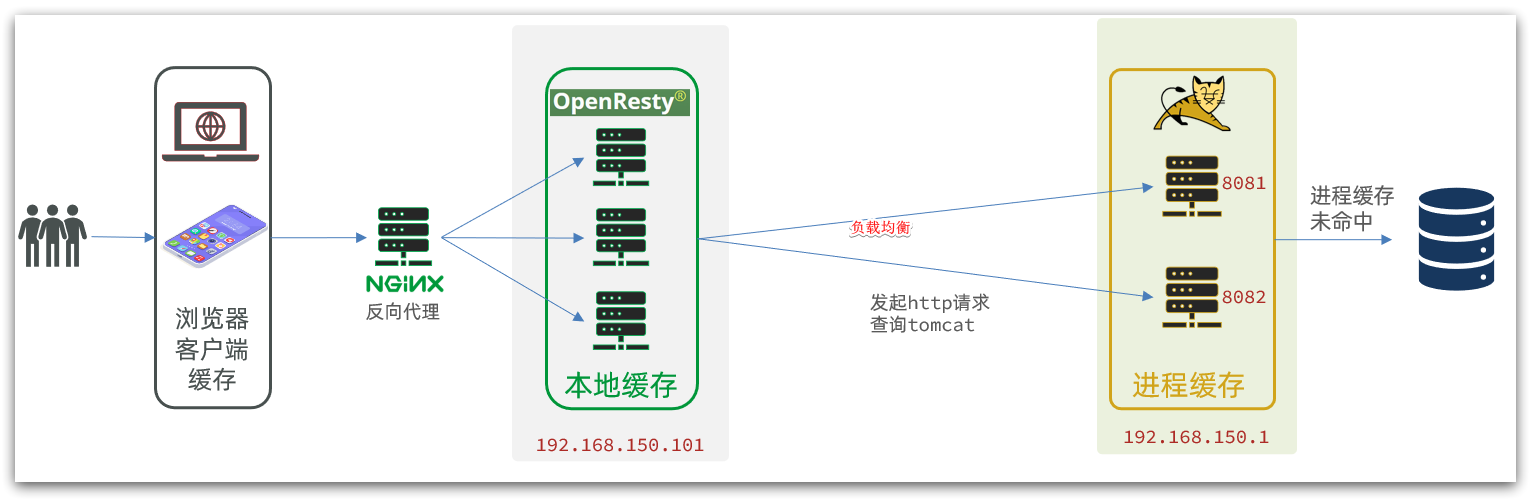
ilustrar:
En el desarrollo real, la implementación del entorno de Tomcat no es necesariamente una sola máquina, sino un clúster de Tomcat, por lo que aquí se implementan pruebas de implementación polimórfica de Tomcat.
2.7.2 Casos de uso básicos
Paso 1: configurar OpenRestyel caché local
1. Archivo OpenRestyde configuración modificadonginx.conf
http{
……
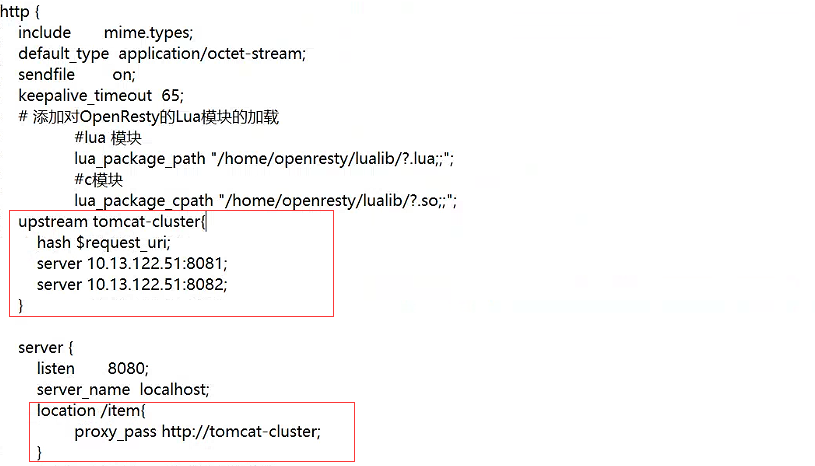
# tomcat集群配置
upstream tomcat-cluster{
hash $request_uri;
server 10.13.122.51:8081;
server 10.13.122.51:8082;
}
upstream tomcat-cluster{
……
server{
……
location /item {
proxy_pass http://tomcat-cluster;
}
……
}
}
Aviso:
Al escribir este archivo de configuración, es necesario unificar el formato del archivo, se recomienda escribirlo a mano y no copiarlo , de lo contrario se producirán errores extraños. !
ilustrar:
- El algoritmo de equilibrio de carga de Nginx
hash $request_uri;se utiliza aquí para evitar la redundancia de datos de Tomcat de diferentes procesos.
2. ReiniciarOpenreSty
docker restart openresty
ilustrar:
Configuración actualizada
openresty_nginx.conf
Paso 2: iniciar Tomcatel clúster
- Idea ejecuta múltiples
Tomcatinstancias
Paso 3: demostración
- Ver
Idearegistro
ilustrar:
Verifique el navegador, el acceso es exitoso.
2.8Calentamiento de Redis
Resumen de notas:
- Descripción general: implementar la carga temprana de datos en Redis cuando comienza el proyecto
- Caso de uso básico: cree
Handleruna clase de procesamiento, implementeInitializingBeanla interfaz, reescriba el método e implemente el precalentamiento de la cachéafterPropertiesSeten este método
2.8.1 Descripción general
ilustrar:
Cuando el servicio recién se inicia, no hay caché en Redis. Si todos los datos del producto se almacenan en caché durante la primera consulta, puede ejercer una mayor presión sobre la base de datos. Por lo tanto, se utiliza el precalentamiento de la caché para iniciar.
Precalentamiento de caché :
en el desarrollo real, podemos usar big data para contar los datos importantes a los que acceden los usuarios, consultar estos datos importantes con anticipación y guardarlos en Redis cuando se inicia el proyecto.
2.8.2 Casos de uso básicos
premisa:
Es necesario que exista un servicio con contraseña
Redis. Consulte搭建Redisel registro para obtener más detalles.
Paso 1: importar dependencias
- Importar dependencias
Springbootde integraciónRedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Paso 2: agregar el archivo de configuración
1. Modificar application.ymlel archivo de configuración.
spring:
redis:
host: 10.13.167.28
port: 6379
password: qweasdzxc
Redis2.Mecanismo de tratamiento térmico agregado
ilustrar:
Este elemento tiene menos datos, por lo que se saca todo y se coloca en Redis.
@Configuration
public class RedisHandler implements InitializingBean {
@Autowired
StringRedisTemplate stringRedisTemplate;
@Autowired
IItemService itemService;
@Autowired
IItemStockService iItemStockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
/**
* 初始化缓存
* 此方法会在项目启动时,本类加载完成,和@Autowired加载完成之后执行该方法
* @throws Exception 异常
*/
public void afterPropertiesSet() throws Exception {
// 1.获得Item数据
List<Item> itemList = itemService.list();
for (Item item : itemList) {
// 2.设置Key
String key = "item:id:" + item.getId();
// 3.将数据序列化
String jsonItem = MAPPER.writeValueAsString(item);
stringRedisTemplate.opsForValue().set(key, jsonItem);
}
// 4.获取stock数据
List<ItemStock> stockList = iItemStockService.list();
for (ItemStock itemStock : stockList) {
// 5.设置Key
String key = "itemStock:id:" + itemStock.getId();
// 6.将数据序列化
String jsonItem = MAPPER.writeValueAsString(itemStock);
stringRedisTemplate.opsForValue().set(key, jsonItem);
}
}
}
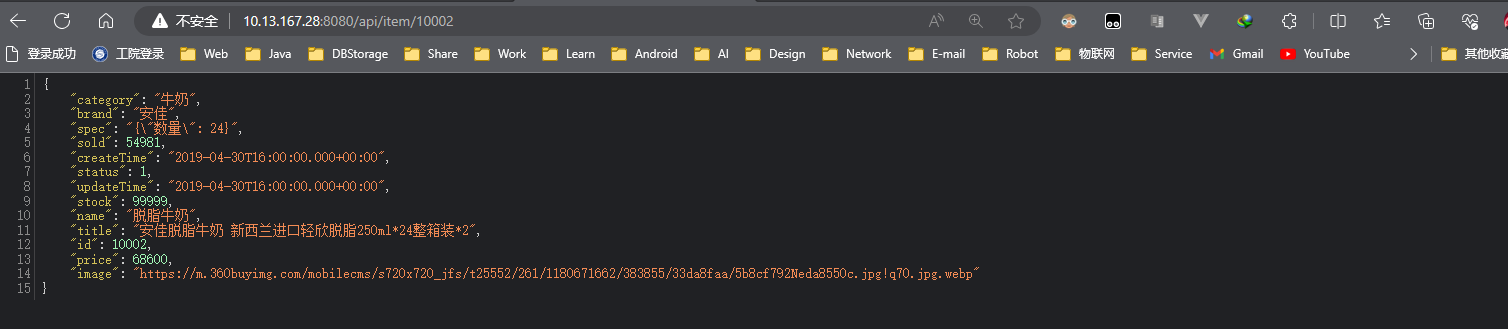
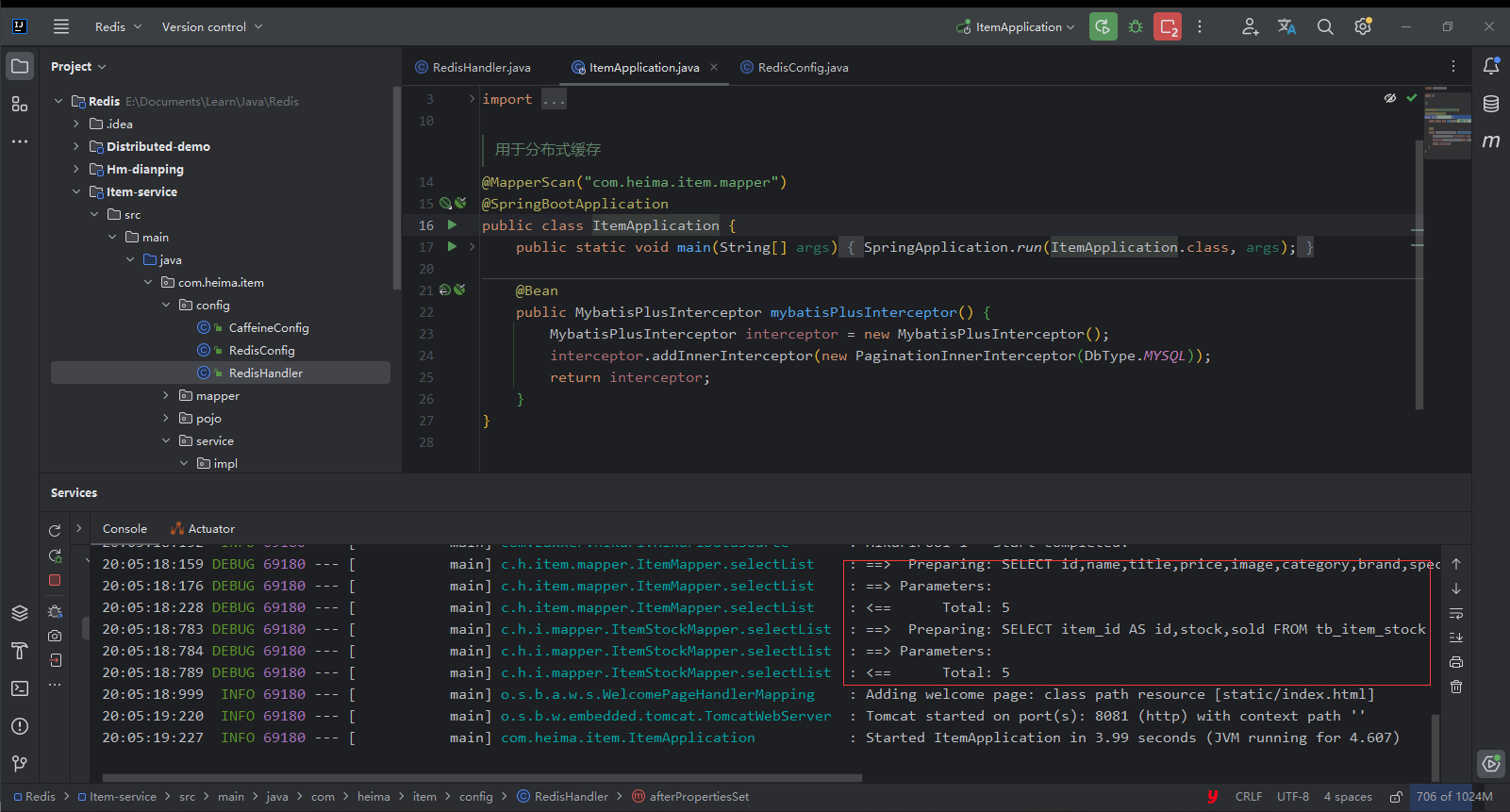
Paso 3: demostración
ilustrar:
Puedes ver que este proyecto ha consultado la base de datos cuando se inició.
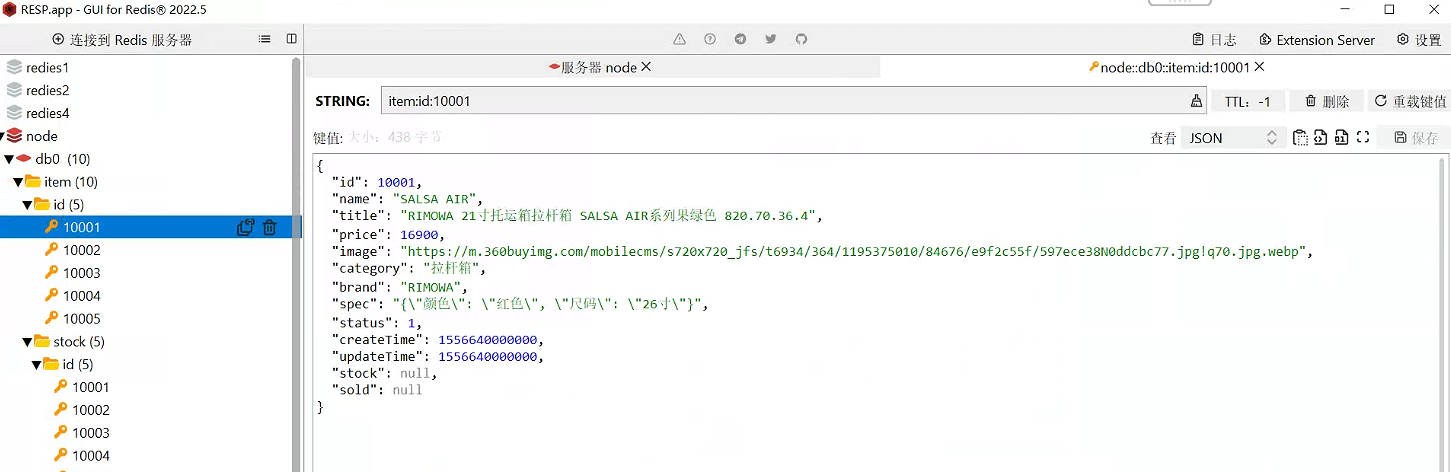
ilustrar:
Se puede ver a través del software de control de Redis que los datos ya existen en Redis.
2.9 Consultar caché de Redis
Resumen de notas:
- Descripción general: encapsule la función de consulta de Redis del script Lua para implementar la consulta de datos de consulta de Redis
2.9.1 Descripción general
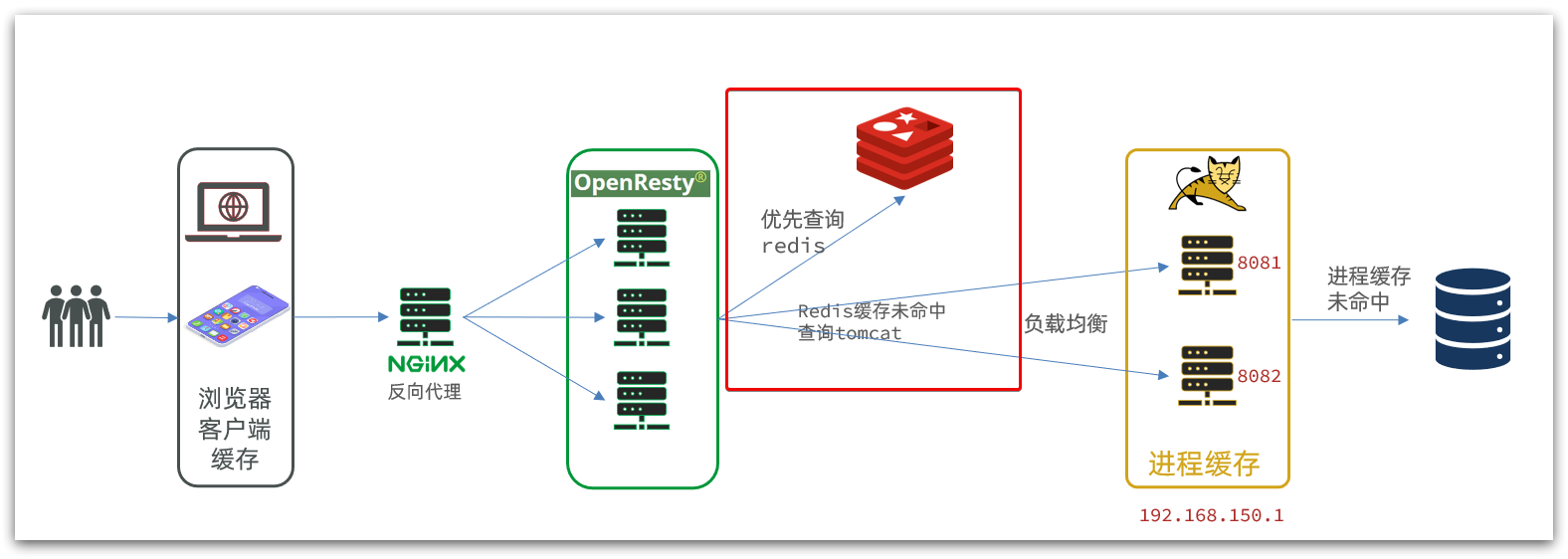
ilustrar:
Tomcat ha cargado datos en Redis en forma de precalentamiento. Modifique la lógica del proyecto para
OpenRestyconsultar Redis primero y luego Tomcat
2.9.2 Encapsulación de la herramienta de consulta Reids
Paso 1: crear/reescribir common.luaarchivo
在/home/openresty/lualib目录下创建/改写common.lua文件,便于OpenResty的nginx.conf模块的导入
Paso 2: escribe common.luael archivo
1. Importe Redisel módulo e inicialice Redisel objeto.
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)
2. Encapsule la Redisfunción de conexión de liberación.
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
3. Encapsule la Redisfunción de consulta según la clave
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, password, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 验证密码
if password then
local res, err = red:auth(password)
if not res then
ngx.log(ngx.ERR, "Redis 密码认证失败: ", err)
close_redis(red)
return nil
end
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
4.Exportar el método
-- 将方法导出
local _M = {
read_http = read_http, -- 此方法为封装HTTP请求的工具导出
read_redis = read_redis
}
return _M
Aviso:
Las conexiones en este
common.luaarchivo solo son adecuadas para conectarse a Redis en un solo nodo y no se pueden usar para conectar clústeres maestro-esclavo o fragmentados de Redis. Si necesita conectarse al clúster de Redis, consulte lua para conectarse al clúster de redis_lua para conectarse al clúster de redis_blog-CSDN del blog de CurryYoung11
Suplemento: Ver Common.luael código completo
-- 导入redis local redis = require('resty.redis') -- 初始化redis local red = redis:new() red:set_timeouts(1000, 1000, 1000) -- 关闭redis连接的工具方法,其实是放入连接池 local function close_redis(red) local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒 local pool_size = 100 --连接池大小 local ok, err = red:set_keepalive(pool_max_idle_time, pool_size) if not ok then ngx.log(ngx.ERR, "放入redis连接池失败: ", err) end end -- 查询redis的方法 ip和port是redis地址,key是查询的key local function read_redis(ip, port, password, key) -- 获取一个连接 local ok, err = red:connect(ip, port) if not ok then ngx.log(ngx.ERR, "连接redis失败 : ", err) return nil end -- 验证密码 if password then local res, err = red:auth(password) if not res then ngx.log(ngx.ERR, "Redis 密码认证失败: ", err) close_redis(red) return nil end end -- 查询redis local resp, err = red:get(key) -- 查询失败处理 if not resp then ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key) end --得到的数据为空处理 if resp == ngx.null then resp = nil ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key) end close_redis(red) return resp end -- 封装函数,发送http请求,并解析响应 local function read_http(path, params) local resp = ngx.location.capture(path,{ method = ngx.HTTP_GET, args = params, }) if not resp then -- 记录错误信息,返回404 ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args) ngx.exit(404) end return resp.body end -- 将方法导出 local _M = { read_http = read_http, read_redis = read_redis } return _M
2.9.3 Casos de uso básicos
Paso 1: modifique item.luael archivo para implementar una lógica empresarial real
1. Importar commonbiblioteca de funciones
-- 导入common函数库
local common = require('common')
local read_redis = common.read_redis
2. Encapsular la función de consulta
-- 封装查询函数
function read_data(key, path, params)
-- 查询本地缓存
local val = read_redis("10.13.164.55", 7001, "qweasdzxc", key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
-- 返回数据
return val
end
3. Modificar el negocio de consulta de bibliotecas y productos básicos.
-- 获取路径参数
local id = ngx.var[1]
-- 根据Id查询商品
local itemJSON = read_data("item:id:" .. id, "/item/" .. id,nil)
-- 根据Id查询商品库存
local stockJson = read_data("item:stock:id:" .. id, "/item/stock/" .. id,nil)
Suplemento: Ver Item.luael código completo
-- 导入common函数库 local common = require('common') local read_http = common.read_http local read_redis = common.read_redis -- 导入cjson库 local cjson = require('cjson') -- 封装查询函数 function read_data(key, path, params) -- 查询本地缓存 local val = read_redis("10.13.167.28", 6379, "qweasdzxc", key) -- 判断查询结果 if not val then ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key) -- redis查询失败,去查询http val = read_http(path, params) end -- 返回数据 return val end -- 获取路径参数 local id = ngx.var[1] -- 查询商品信息 local itemJSON = read_data("item:id:" .. id, "/item/" .. id, nil) -- 查询库存信息 local stockJSON = read_data("item:stock:id:" .. id, "/item/stock/" .. id, nil) -- JSON转化为lua的table local item = cjson.decode(itemJSON) local stock = cjson.decode(stockJSON) -- 组合数据 item.stock = stock.stock item.sold = stock.sold -- 把item序列化为json 返回结果 ngx.say(cjson.encode(item))
Paso 2: reiniciarOpenResty
docker restart openresty
ilustrar:
Reinicie el servicio y actualice la configuración de Nginx.conf
Paso 3: demostración
1. VerIdea
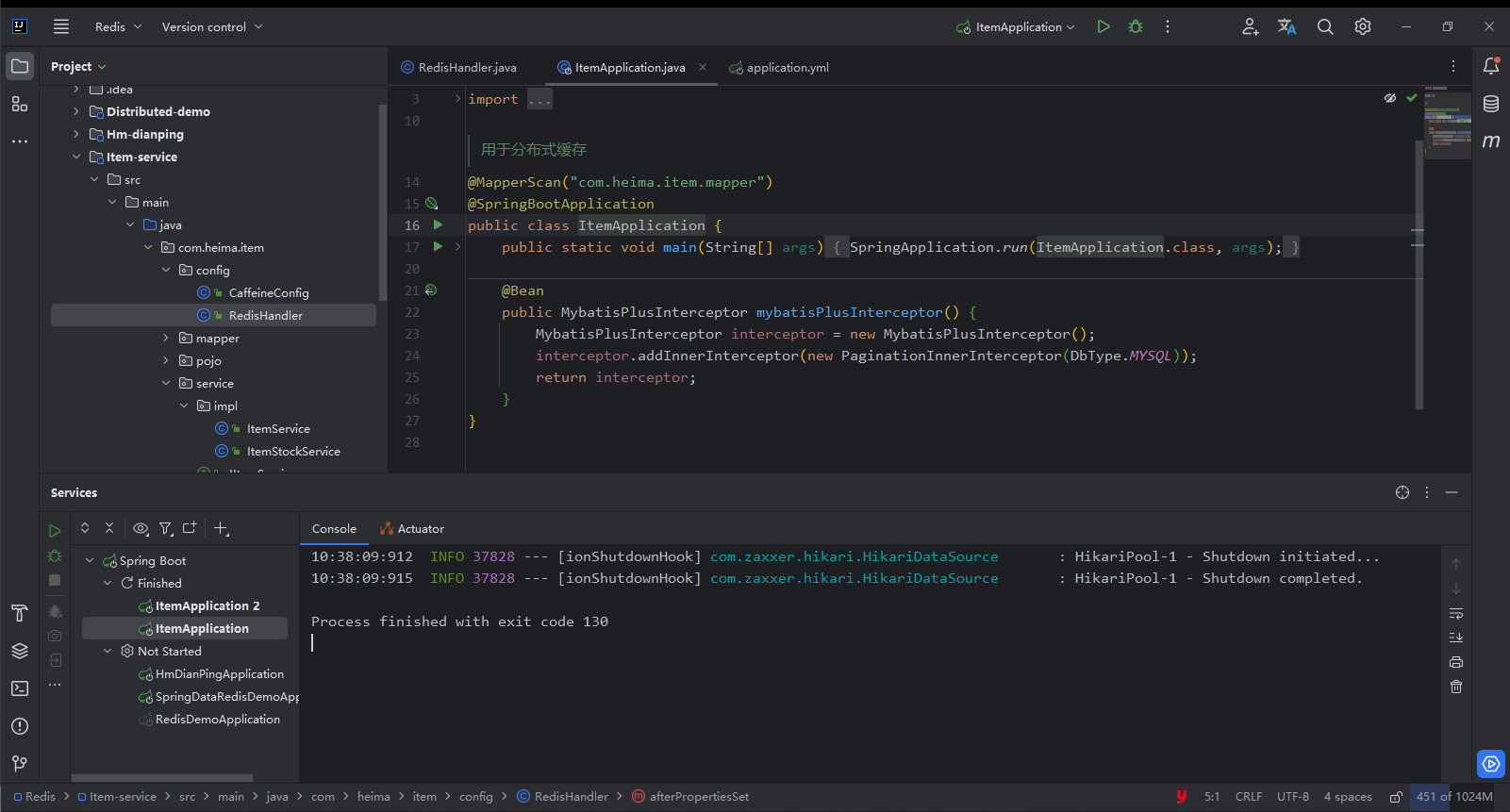
ilustrar:
Dado que Redis se calentó antes, detenga el servicio Tomcat ahora.
2. Ver navegador
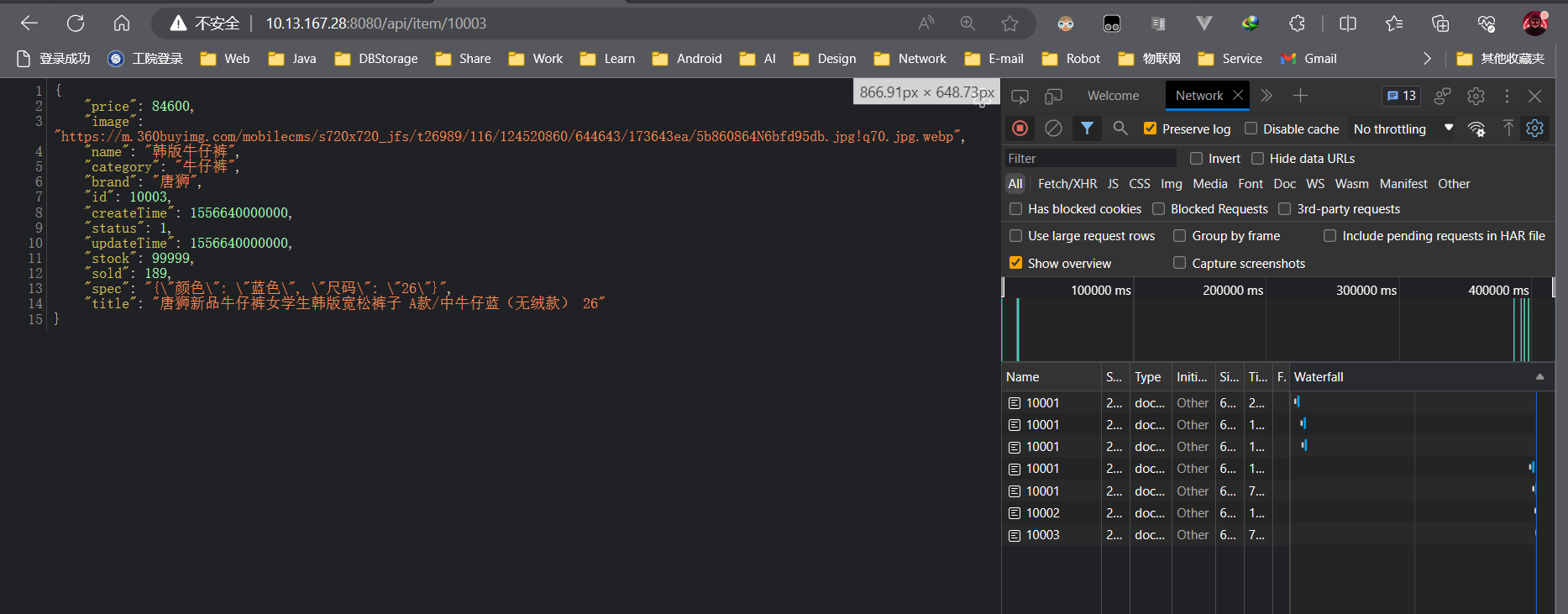
ilustrar:
Aunque el servicio Tomcat está detenido, los datos se almacenan en Redis.
OpenrestyEl clúster primero consultará Redis, por lo que los datos aún se muestran normalmente.
2.10Caché local de Nginx
Resumen de notas:
Descripción general: encapsule la función de consulta Nginx del script Lua para implementar la consulta de datos de caché local de Nginx
2.10.1 Descripción general
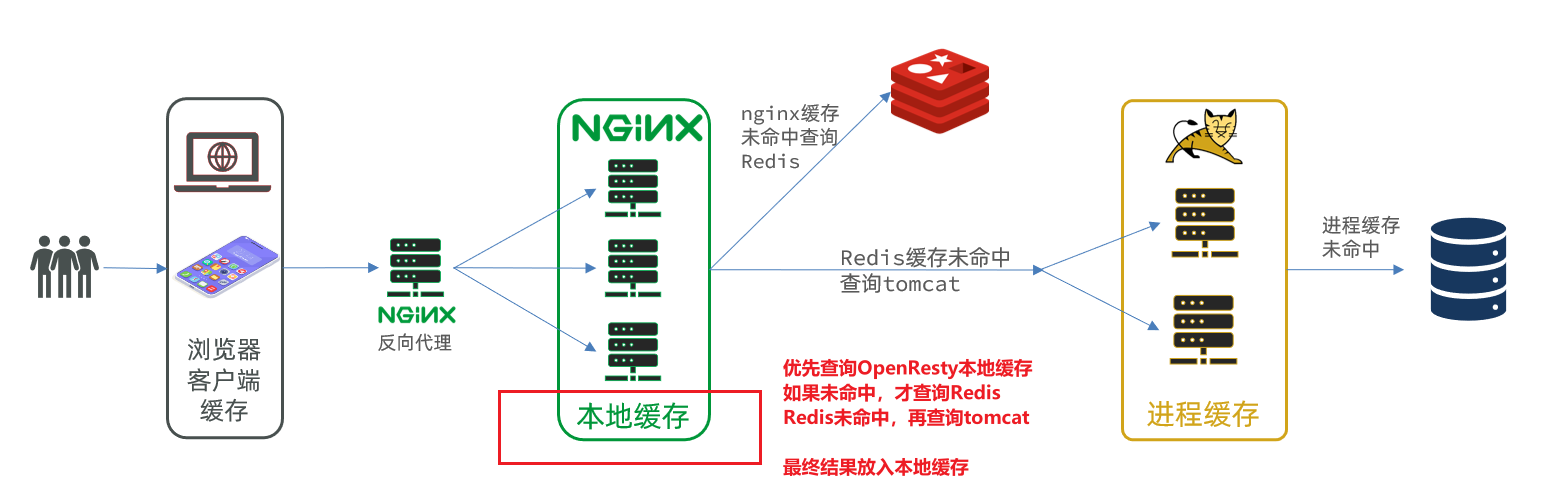
ilustrar:
Cuando el cliente accede,
OpenRestyprimero consulta el caché local y luego realiza la consulta de Redis. Si la consulta de Redis no tiene éxito, consulta el Tomcat. Implementación del nivel final de almacenamiento en caché multinivel
2.10.2 API de caché local
OpenResty proporciona la función shard dict para Nginx, que puede compartir datos entre varios trabajadores de nginx e implementar funciones de almacenamiento en caché.
Caso de uso básico:
- Habilitar diccionario compartido
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
ilustrar:
Configuración modificada
Openresty_nginx.conf
- Manipular diccionarios compartidos
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')
2.10.2 Casos de uso básicos
premisa:
Openresty Configuración de caché compartida que debe habilitarse
Paso 1: modificar la función de consulta
1. Modifique la función item.luaen el archivo read_datapara verificar primero el caché local, luego verificar el caché de Redis y finalmente consultar Tomcat.
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key, expire, path, params)
-- 首先,查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)
-- 然后,查询redis
val = read_redis("10.13.167.28", 6379, "qweasdzxc", key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- 最后,redis查询失败,去查询http
val = read_http(path, params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
2. Modifique item.luala instancia de llamada en el archivo.
-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, 60, "/item/stock/" .. id, nil)
Suplemento: item.luacódigo completo
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)
-- 查询redis
val = read_redis("10.13.167.28", 6379, "qweasdzxc", key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, 60, "/item/stock/" .. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
Paso 2: demostración
1. Actualizar Nginxlos datos del clúster de caché local
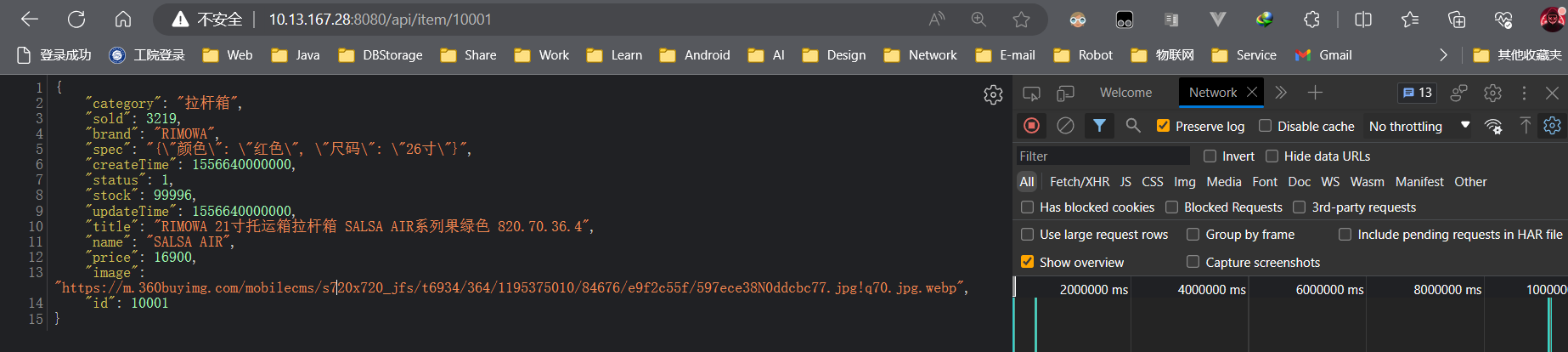
ilustrar:
Cuando el usuario no puede acceder al caché de Nginx por primera vez, se consultará a Redis.
2. Detener Redisel servicio
docker stop myredis
3. Consultar datos del navegador
ilustrar:
Cuando se detiene el servicio Redis, la respuesta de datos es exitosa, lo que indica que se ha iniciado el caché de Nginx
2.11 Sincronización de caché
Resumen de notas:
- Descripción general: actualice sincrónicamente los datos de la caché compartidos entre varios nodos
- Canal: se utiliza para el análisis de registros incrementales de la base de datos y proporciona suscripción y consumo de datos incrementales. Monitorear el registro incremental de la base de datos para implementar la sincronización y el procesamiento correspondiente de las solicitudes de datos.
2.11.1 Descripción general
La sincronización de caché se refiere al proceso de compartir datos de caché y mantener la coherencia entre múltiples nodos en un sistema distribuido. Cuando los datos en el caché cambian, estos cambios deben sincronizarse con los cachés de otros nodos para garantizar que los datos obtenidos por todos los nodos sean los más recientes.
Cómo sincronizar datos de caché:
-
Establecer período de validez : establezca el período de validez para el caché y se eliminará automáticamente después de su vencimiento. Actualizar al volver a consultar
- Ventajas: simple y conveniente
- Desventajas: poca puntualidad, el caché puede ser inconsistente antes de que expire
- Escenario: Empresa con baja frecuencia de actualización y bajos requisitos de puntualidad
-
Doble escritura sincrónica : modifica directamente el caché mientras modificas la base de datos
- Ventajas: gran puntualidad, gran coherencia entre el caché y la base de datos
- Desventajas: intrusión de código y alto acoplamiento;
- Escenario: datos en caché con altos requisitos de coherencia y puntualidad
-
**Notificación asincrónica:** La notificación de evento se envía cuando se modifica la base de datos y los servicios relevantes modifican los datos almacenados en caché después de escuchar la notificación.
- Ventajas: bajo acoplamiento, se pueden notificar múltiples servicios de caché al mismo tiempo
- Desventajas: Puntualidad promedio, puede haber inconsistencias intermedias
- Escenario: Los requisitos de puntualidad son promedio y hay múltiples servicios que deben sincronizarse.
La notificación asincrónica implementa la sincronización de caché
1. Notificación asincrónica basada en MQ

ilustrar:
Una vez que el servicio del producto completa la modificación de los datos, solo necesita enviar un mensaje a MQ. El servicio de caché escucha los mensajes MQ y luego completa las actualizaciones del caché.
2. Notificaciones basadas en canales
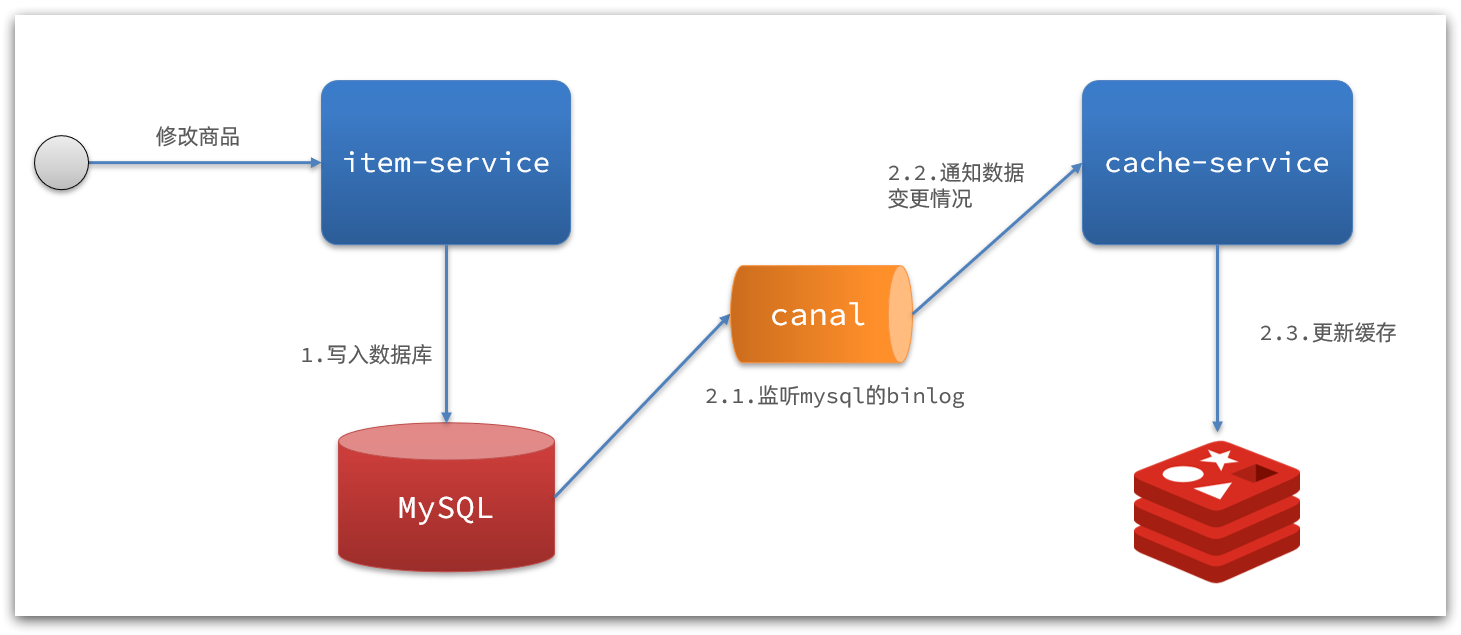
ilustrar:
Una vez que el servicio del producto completa la modificación del producto, el negocio finaliza directamente sin ninguna intrusión de código. Canal monitorea los cambios de MySQL. Cuando se encuentran cambios, se notifica inmediatamente al servicio de caché. El servicio de caché recibe la notificación del canal y actualiza el caché.
2.11.2 Introducción al canal
Descripción general
Canal [kə'næl], traducido como vía fluvial/tubería/zanja, canal es un proyecto de código abierto de Alibaba, desarrollado en base a Java. Según el análisis de registros incrementales de la base de datos, se proporciona la suscripción y el consumo de datos incrementales. Dirección de GitHub: https://github.com/alibaba/canal
Canal se implementa en base a la sincronización maestro-esclavo de MySQL. El principio de sincronización maestro-esclavo de MySQL es el siguiente:
- MySQL master escribe los cambios de datos en el registro binario (registro binario) y los datos registrados se denominan eventos de registro binario
- El esclavo MySQL copia los eventos de registro binario del maestro en su registro de retransmisión (registro de retransmisión)
- El esclavo MySQL reproduce eventos en el registro de retransmisión y refleja los cambios de datos en sus propios datos.
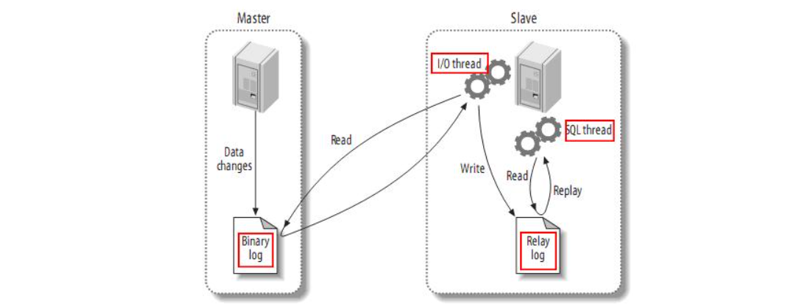
ilustrar:
Realice la sincronización maestro-esclavo basada en el registro binario generado por MySQL
Canal se disfraza como un nodo esclavo de MySQL para monitorear los cambios del registro binario del maestro. Luego, la información de cambio obtenida se notifica al cliente de Canal y luego se completa la sincronización de otras bases de datos.
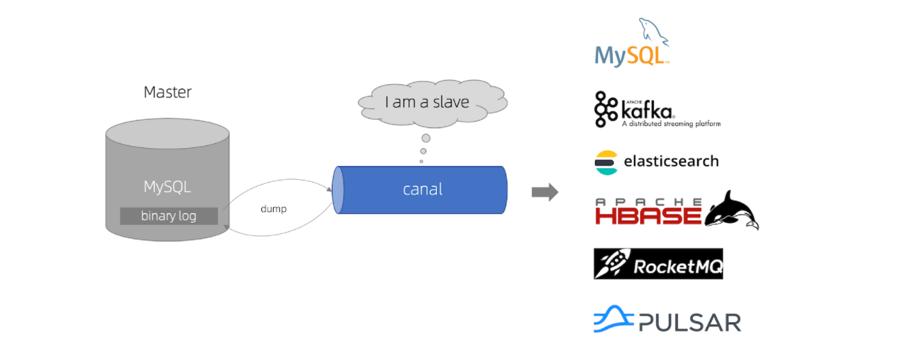
ilustrar:
Cuando se usa
Canal, también se puede completar la sincronización con otras bases de datos.
2.11.3 Instalar y configurar Canal
Paso 1: configurar MySQL maestro y esclavo
1. Modificar my.cnfy abrirBinlog
vim /home/mysql/conf/my.cnf
2.Agregue el siguiente contenido
log-bin=/home/mysql/mysql-bin # 设置binary log文件的存放地址和文件名,叫做mysql-bin
binlog-do-db=heima # 指定对哪个database记录binary log events,这里记录heima这个库
Suplemento: my.cnfcontenido completo
[mysqld] skip-name-resolve character_set_server=utf8 datadir=/home/mysql server-id=1000 log-bin=/home/mysql/mysql-bin # 设置binary log文件的存放地址和文件名,叫做mysql-bin binlog-do-db=heima # 指定对哪个database记录binary log events,这里记录heima这个库
3.Establecer permisos de usuario
3.1 Agregar cannalusuarios y establecer permisos
create user canal@'%' IDENTIFIED by 'canal'; # 创建canal新用户,并指定密码canal
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT, SUPER ON *.* TO canal@'%';# 授予权限
FLUSH PRIVILEGES; # 刷新权限
3.2 Reiniciar Mysqlel contenedor
docker restart mysql
3.3 Ver el registro binario de la base de datos principal
show master status;
Descripción: Ver resultados
Positiones el desplazamiento de los datos sincronizados, similar alRedisdesplazamiento en y para lograr la sincronización maestro-esclavo

Paso 2: configurar la red
1. Crea una red
docker network create heima
ilustrar:
Crea una red y coloca MySQL y Canal en la misma red Docker
2. MySQLÚnete a la red
docker network connect heima mysql
Paso 3: instalar el canal
1. Tira la imagen
docker pull canal/canal-server:v1.1.5
2. Ejecute Canalel contenedor
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:latest
Aviso:
Recuerda cambiar la cuenta correspondiente y la contraseña de conexión
ilustrar:
Al ejecutar
Canalel contenedor, únaseheimaa la red.
Suplemento: significado del parámetro
-p 11111:11111: Este es el puerto de escucha predeterminado del canal.-e canal.instance.master.address=mysql:3306: Dirección y puerto de la base de datos. Si no conoce la dirección del contenedor mysql, puededocker inspect 容器idverificarla a través de-e canal.instance.dbUsername=canal: nombre de usuario de la base de datos-e canal.instance.dbPassword=canal: contraseña de la base de datos-e canal.instance.filter.regex=: el nombre de la tabla a monitorear
Suplemento: regularidad del nombre de la tabla
- El análisis de datos de MySQL se centra en tablas y expresiones regulares de Perl. Varias expresiones regulares están separadas por comas (,) y el carácter de escape requiere barras dobles (\), por ejemplo:
- Todas las tablas: .* o . \…
- Todas las tablas bajo el esquema del canal: canal\…
- La tabla que comienza con canal debajo de canal: canal\.canal.
- Una tabla bajo el esquema del canal: canal.test1
- Utilice varias reglas en combinación y sepárelas con comas: canal\…*,mysql.test1,mysql.test2
Paso 4: demostrar
1. Verificar Canalestado
docker logs canal
ilustrar:
- Indica
Canalun inicio exitoso
2. Ver heimaregistros de la base de datos
docker exec -it canal bash # 进入容器内部
tail -f /home/admin/canal-server/logs/heima/heima.log
Descripción: Ver resultados
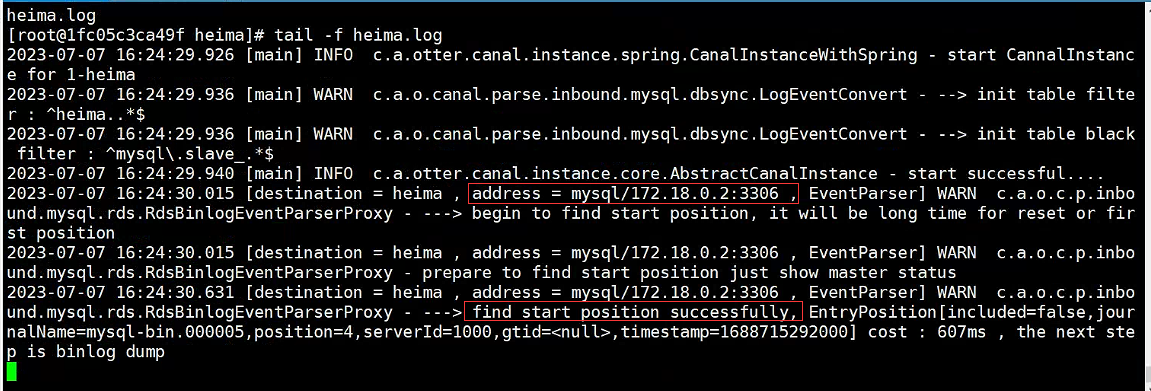
Reponer:
- Si la salida del registro informa un error
2023-07-07 16:22:16.085 [MultiStageCoprocessor-other-heima-0] WARN com.taobao.tddl.dbsync.binlog.LogDecoder - Skipping unrecognized binlog event Unknown from: mysql-bin.000005:2262
- La versión actual de MySQL no coincide con la versión de Canal, cambie las dos versiones.

2.11.4 Casos de uso básicos
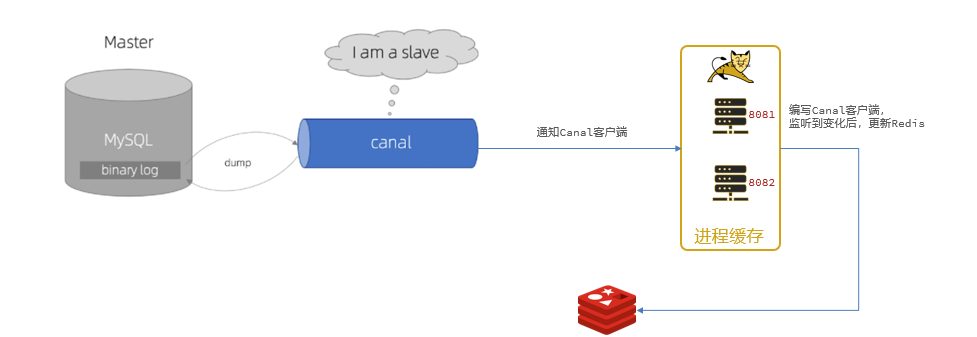
ilustrar:
Configure Canal para actualizar automáticamente el caché de Redis y el caché de JVM después de cambios en MySQL
premisa:
Finalizada la instalación y configuración de Canal
Paso 1: importar dependencias
- Modificar
pom.xmlarchivos
<!--canal-->
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
Paso 2: escribir la configuración
- Revisar
application.yml
canal:
destination: heima # canal实例名称,要跟canal-server运行时设置的destination一致
server: 10.13.164.55:11111 # canal地址
Paso 3: escribir la clase de entidad
- Modificar
Itemclase de entidad
@Data
@TableName("tb_item")
public class Item {
@TableId(type = IdType.AUTO)
@Id //canal中, 标记表中的id字段
private Long id;//商品id
@Column(name = "name") //canal中, 标记表中与属性名不一致的字段,此处便于做演示,因此设置一下
private String name;//商品名称
private String title;//商品标题
private Long price;//价格(分)
private String image;//商品图片
private String category;//分类名称
private String brand;//品牌名称
private String spec;//规格
private Integer status;//商品状态 1-正常,2-下架
private Date createTime;//创建时间
private Date updateTime;//更新时间
@TableField(exist = false)
@Transient // canal中,标记不属于表中的字段
private Integer stock;
@TableField(exist = false)
@Transient
private Integer sold;
}
ilustrar:
Lo que Canal envía al cliente de canal es la fila de datos modificada (fila), y el cliente de canal que presentamos nos ayudará a encapsular los datos de la fila en la clase de entidad Elemento. En este proceso, necesita conocer la relación de mapeo entre la base de datos y las entidades, y necesita utilizar varias anotaciones de JPA.
Paso 4: escribe al oyente
- Agregue nuevas
ItemHandlerclases, implementeEntryHandler<Item>interfaces y anuleinsert、update、deletemétodos
@CanalTable("tb_item") //指定要监听的表
@Component // 将监听交给Spring管理
public class ItemHandler implements EntryHandler<Item> {
@Autowired
RedisHandler redisHandler;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private Cache<Long, Item> itemCache;
private static final ObjectMapper MAPPER = new ObjectMapper();
/**
* 监听到商品插入
*
* @param item 商品
*/
@Override
public void insert(Item item) {
// 写数据到JVM进程缓存
itemCache.put(item.getId(), item);
// 写数据到redis
saveItem(item);
}
/**
* 监听到商品数据修改
*
* @param before 商品修改前
* @param after 商品修改后
*/
@Override
public void update(Item before, Item after) {
// 写数据到JVM进程缓存
itemCache.put(after.getId(), after);
// 写数据到redis
saveItem(after);
}
/**
* 监听到商品删除
*
* @param item 商品
*/
@Override
public void delete(Item item) {
// 删除数据到JVM进程缓存
itemCache.invalidate(item.getId());
// 删除数据到redis
deleteItemById(item.getId());
}
private void saveItem(Item item) {
try {
String json = MAPPER.writeValueAsString(item);
stringRedisTemplate.opsForValue().set("item:id:" + item.getId(), json);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
private void deleteItemById(Long id) {
stringRedisTemplate.delete("item:id:" + id);
}
}
Paso 5: demostrar
1. Verifique IDEAel registro
ilustrar:
CanalMonitoreo de mensajes MySQL implementado en el proyecto actual
2. Después de modificar la información de la base de datos, verifique que los datos del navegador hayan sido modificados.
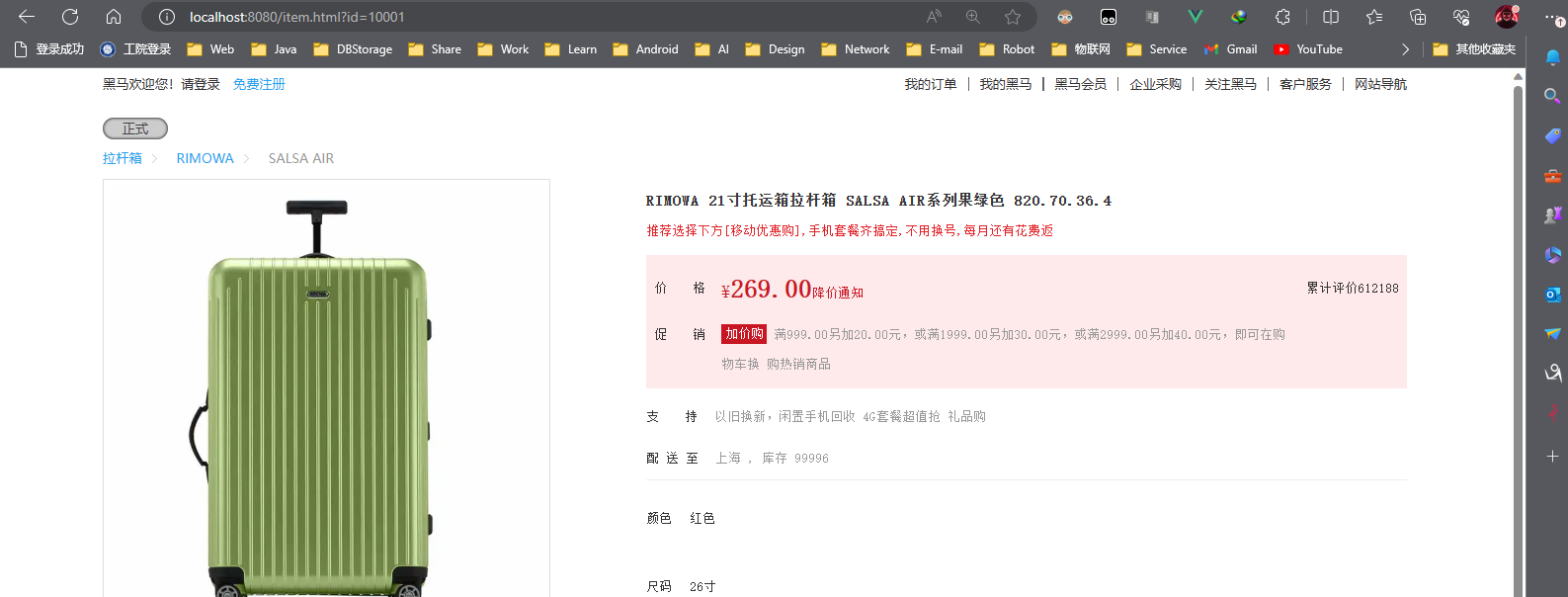
ilustrar:
Cuando vea cambios en los datos, significa que el caché JVM se actualizó y los datos de Redis se actualizaron. Si no lo cree, compruébelo usted mismo.
2.12 Resumen
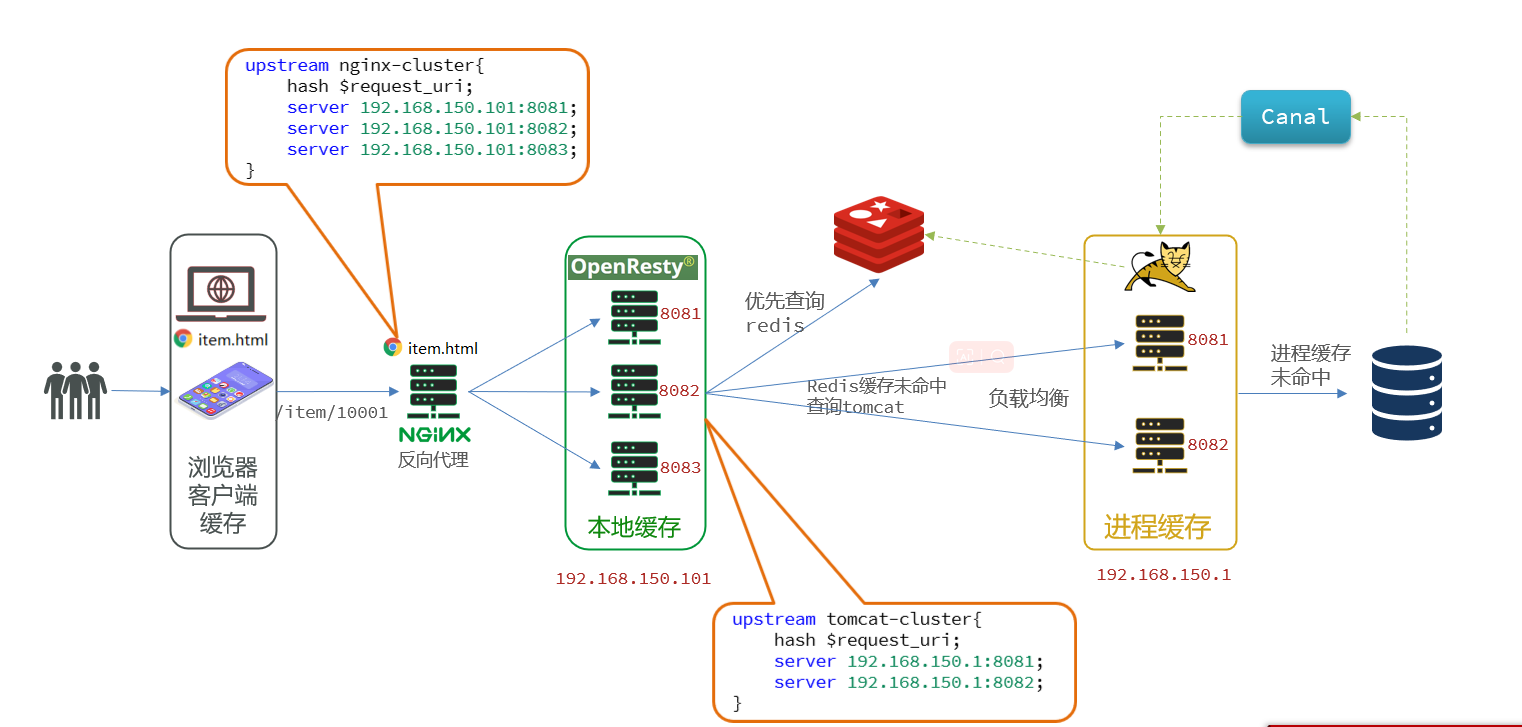
ilustrar:
Ahora, el proyecto local ha completado la construcción de un solo nodo
OpenResty. Si necesita construir varios nodos, recuerde configurar el clúster de caché local y crear un equilibrador de carga cuando utilice el proxy inverso de Nginx.
Con base en el aprendizaje de Redis6, ahora se plantean las siguientes preguntas:
- Si
Openrestyfalla el caché, ¿cómo solucionarlo? Implementar actualizaciones proactivas para datos confidenciales Redis¿ Cómo solucionar el tiempo de inactividad de un solo nodo ? Necesita usar el script Lua para acceder al clúster de Redis- ¿Existen otras alternativas al almacenamiento en caché multinivel? No se ha encontrado todavía
3. Mejores prácticas
3.1 Diseño de valor clave de Redis
Resumen de notas: ver cada resumen
3.1.1 Estructura de clave elegante
Resumen de notas:
- Mejores prácticas clave:
- Formato fijo: [Nombre de la empresa]:[Nombre de los datos]:[id]
- Bastante corto: no más de 44 bytes
- No contiene caracteres especiales
- Mejores prácticas para el valor:
- Divida los datos razonablemente y rechace BigKey
- Elija la estructura de datos adecuada
- El número de entradas en la estructura Hash no debe exceder las 1000.
- Establecer un tiempo de espera razonable
- Tipo de datos apropiado, como estructura Hash, etc.
Aunque la clave de Redis se puede personalizar, es mejor seguir las siguientes mejores prácticas:
- Siga el formato básico: [Nombre de la empresa]:[Nombre de los datos]:[id]
- No más de 44 bytes de longitud
- No contiene palabras especiales.
Descripción: Por ejemplo

ventaja:
- Legible
- Evite conflictos clave
- Fácil de administrar
- Más ahorro de memoria: la clave es de tipo cadena y la codificación subyacente incluye int, embstr y raw. embstr se usa cuando tiene menos de 44 bytes, usa espacio de memoria continuo y la huella de memoria es menor
Reponer:
- Cuando el valor de la clave supera los 44 bytes, el formato se utilizará automáticamente
rawen lugar del espacio no continuo, ocupando así más memoria.
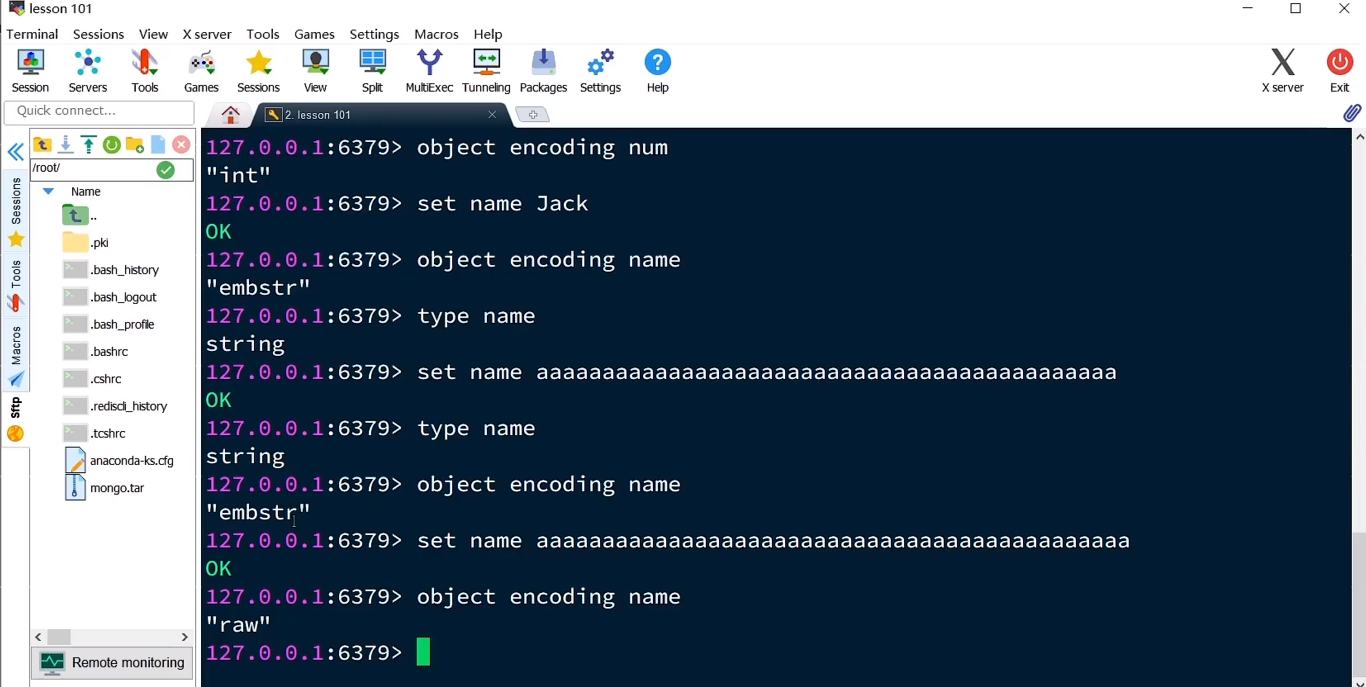
Reponer:
Al almacenar un dato, a menudo ocupa más bytes en la memoria que el valor de los datos en sí, porque la capa subyacente de Redis almacena metainformación.
3.1.2 Rechazar BigKey
significado:
En Redis, BigKey (clave grande) se refiere a un par clave-valor que ocupa una gran cantidad de espacio de almacenamiento. Cuando el tamaño de un par clave-valor excede el umbral de configuración de Redis (el valor predeterminado es 10 KB), se considera una BigKey.
- La cantidad de datos en la clave en sí es demasiado grande : una clave de tipo cadena con un valor de 5 MB.
- Demasiados miembros en la clave : una clave tipo ZSET tiene 10.000 miembros.
- El volumen de datos de los miembros en la Clave es demasiado grande: una Clave de tipo Hash tiene solo 1000 miembros, pero el tamaño total del Valor (valor) de estos miembros es de 100 MB.
Peligros de BigKey:
-
congestión en la red
Al ejecutar una solicitud de lectura para BigKey, una pequeña cantidad de QPS puede provocar que el uso del ancho de banda esté lleno, provocando que la instancia de Redis e incluso la máquina física donde se encuentra se ralentice.
-
sesgo de datos
El uso de memoria de la instancia de Redis donde se encuentra BigKey es mucho mayor que el de otras instancias y los recursos de memoria de los fragmentos de datos no se pueden equilibrar.
-
Bloqueo de Redis
Realizar operaciones en hash, list, zset, etc. con muchos elementos llevará mucho tiempo y provocará que se bloquee el hilo principal.
-
presión de la CPU
La serialización y deserialización de datos de BigKey hará que el uso de la CPU se dispare, lo que afectará las instancias de Redis y otras aplicaciones locales.
Descubra BigKey:
-
redis-cli --grandes claves
Con el parámetro –bigkeys proporcionado por redis-cli, puede recorrer y analizar todas las claves y devolver la información estadística general de la clave y la clave grande Top1 de cada dato.
-
escanear escanear
Prográmelo usted mismo, use scan para escanear todas las claves en Redis y use strlen, hlen y otros comandos para determinar la longitud de la clave (no se recomienda el USO DE MEMORIA aquí)
-
Herramientas de terceros ✔️
Utilice herramientas de terceros, como Redis-Rdb-Tools , para analizar archivos instantáneos RDB y analizar exhaustivamente el uso de la memoria.
-
Monitoreo de red
Herramienta personalizada para monitorear datos de red dentro y fuera de Redis y alertar proactivamente cuando se excede el valor de advertencia.
Eliminar clave grande:
-
redis 3.0 y por debajo
Si es un tipo de colección, recorra los elementos de BigKey, primero elimine los subelementos uno por uno y finalmente elimine BigKey
-
Redis 4.0 y posteriores
Redis proporciona un comando de eliminación asincrónico después de 4.0: desvincular
ilustrar:
3.1.3 Tipos de datos apropiados
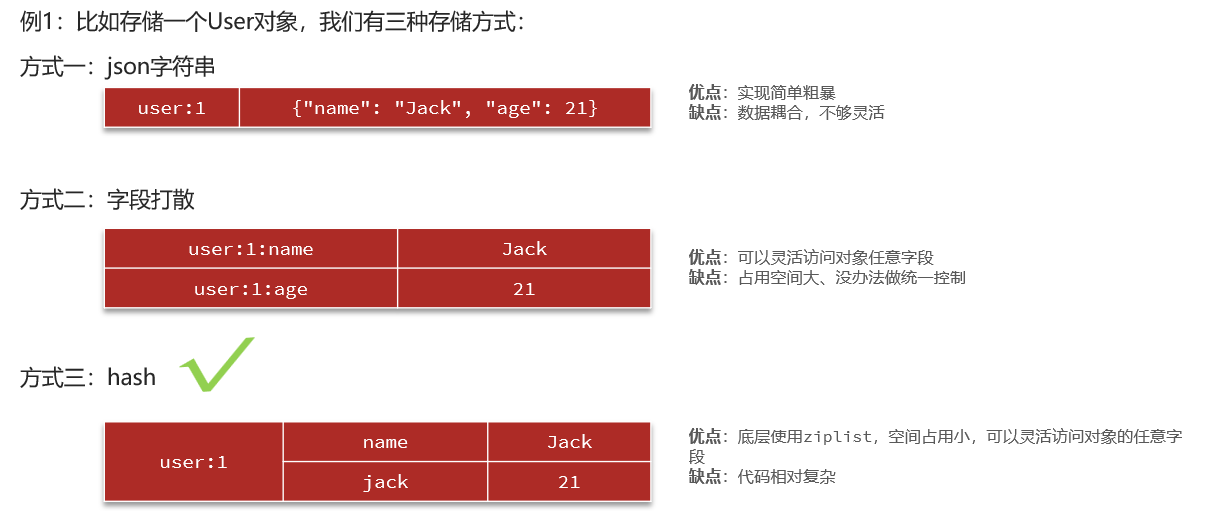
ilustrar:
Elija estructuras de datos adecuadas para el almacenamiento y la capa inferior ocupará menos espacio.

ilustrar:
El problema más grave ahora es que hay demasiadas entradas, lo que provoca problemas con BigKey. Entonces, ¿cómo solucionarlo?
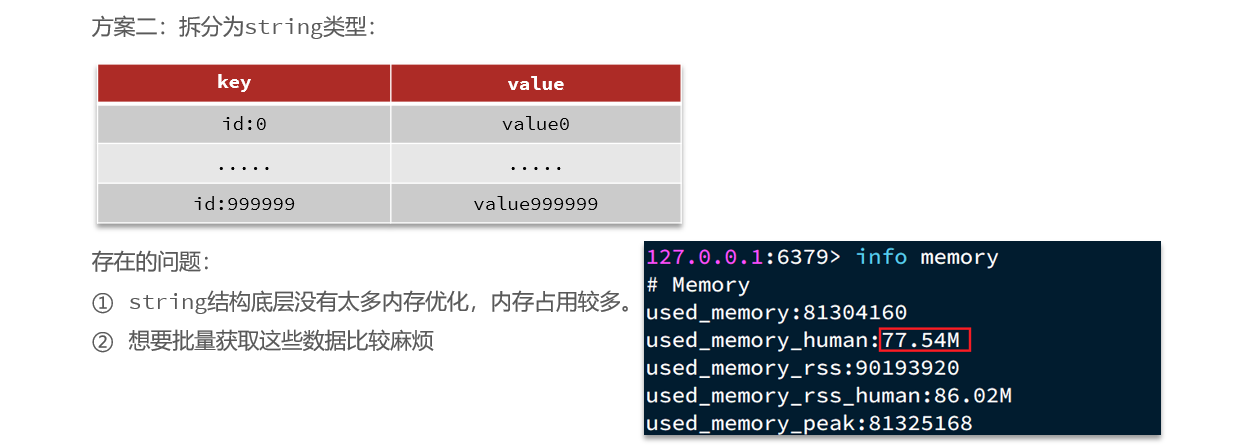
ilustrar:
El tipo String es tremendamente simple, pero no hay mucha optimización de la memoria.
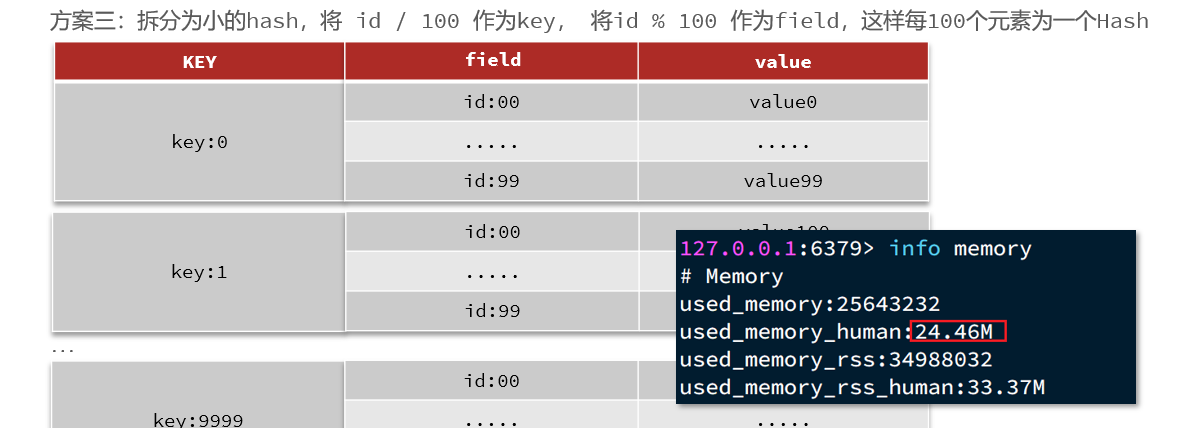
ilustrar:
Al dividir el valor de la Clave, deje que la entrada de cada Hash sea 100, para que
entryno supere 500, así los datos se almacenarán en una tabla Hash, reduciendo así el almacenamiento de memoria.
3.2 Optimización del procesamiento por lotes
Resumen de notas:
- Descripción general: cuando la cantidad de datos a transferir es demasiado grande, se puede utilizar una solución de procesamiento por lotes para reducir el tiempo de transmisión de la red y mejorar el tiempo de ejecución empresarial.
- Plan de procesamiento por lotes:
- Operaciones M nativas
- Procesamiento por lotes de tuberías
- Nota: Los múltiples comandos de Pipeline no son atómicos. No se recomienda llevar demasiados comandos a la vez durante el procesamiento por lotes.
3.2.1 Descripción general
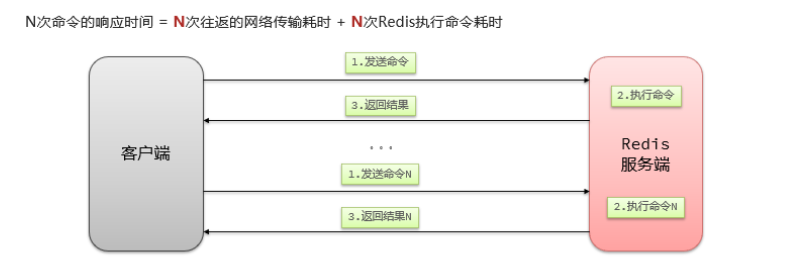
ilustrar:
Cuando hay N respuestas de comando, el tiempo de respuesta aumentará debido al retraso de la red durante la transmisión de cada comando. Debido a que la concurrencia del tiempo de ejecución del comando Redis no es alta, es una entre 50.000. Por lo tanto, el tiempo de respuesta del comando aumentará considerablemente debido a la transmisión de red que consume mucho tiempo.
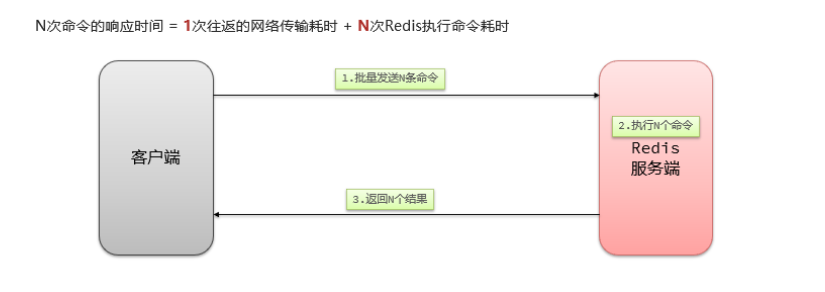
ilustrar:
Cuando hay N respuestas de comandos, la ejecución de varios comandos a la vez reducirá el tiempo de retraso de la red. En este momento, la concurrencia durante la ejecución del comando Redis no es alta. Por tanto, el tiempo de respuesta del comando se reducirá considerablemente.
3.2.2MSET
Redis proporciona muchos comandos, como Mxxx, que pueden insertar datos en lotes, por ejemplo:
- mset
- hmset
Ejemplo de código: utilice mset para insertar 100.000 datos en lotes
@Test
void testMxx() {
String[] arr = new String[2000];
int j;
for (int i = 1; i <= 100000; i++) {
j = (i % 1000) << 1;
arr[j] = "test:key_" + i;
arr[j + 1] = "value_" + i;
if (j == 0) {
jedis.mset(arr);
}
}
}
ilustrar:
Cuando se utiliza el operador de desplazamiento para mover un bit, cualquier número se multiplicará por 2 y, en este momento, la matriz con capacidad de 2000 simplemente se completa en el formato Clave:valor
Aviso:
No transmita demasiados comandos en un lote; de lo contrario, un solo comando ocupará demasiado ancho de banda y provocará congestión en la red.
3.2.1 Tubería
Aunque MSET puede realizar procesamiento por lotes, solo puede operar con algunos tipos de datos, por lo que si necesita procesamiento por lotes de tipos de datos complejos, se recomienda utilizar la función Pipeline.
@Test
void testPipeline() {
// 创建管道
Pipeline pipeline = jedis.pipelined();
for (int i = 1; i <= 100000; i++) {
// 放入命令到管道
pipeline.set("test:key_" + i, "value_" + i);
if (i % 1000 == 0) {
// 每放入1000条命令,批量执行
pipeline.sync();
}
}
}
ilustrar:
En el proceso, puede agregar cualquier comando. Envíe los comandos en proceso a Redis en lotes y ejecútelos secuencialmente. Se necesita más tiempo para ejecutar el comando que
MSETel comando, porque cuando los comandos en la canalización llegan a Redis, se formará una cola y se ejecutará secuencialmente. Si se ejecutan varios comandos en Redis en este momento, se retrasará la ejecución de los comandos en la canalización.
3.2.2 Optimización por lotes en clúster

ilustrar:
El procesamiento por lotes, como MSET o Pipeline, debe transportar varios comandos en una solicitud. Si Redis es un clúster, las múltiples claves del comando por lotes deben estar en una ranura; de lo contrario, la ejecución fallará.
Ejemplo de código:
@SpringBootTest
public class MultipleTest {
@Test
void testMsetInCluseter() {
StringRedisTemplate stringRedisTemplate = new StringRedisTemplate();
Map<String, String> map = new HashMap<>();
map.put("name", "yueyue");
map.put("age", "18");
stringRedisTemplate.opsForValue().multiSet(map);
}
}
ilustrar:
Cuando se utilizan comandos por lotes, un conjunto de operaciones por lotes para Redis proporcionadas por el marco Spring determinará si se debe procesar el clúster.
3.3 Optimización del lado del servidor
Resumen de notas:
- Configuración de persistencia: reserve suficiente espacio de memoria y no lo implemente junto con aplicaciones que consuman mucha CPU
- Consulta lenta: configure el umbral de consulta lenta y el límite de capacidad de consulta lenta , la lista de registros de consultas lentas, la consulta de longitud de registro y otras operaciones de operación y mantenimiento
- Comandos y configuración de seguridad: deshabilitar
keys *y otros comandos , configurar la contraseña de Redis, habilitar el firewall
3.3.1 Configuración de persistencia
Aunque la persistencia de Redis puede garantizar la seguridad de los datos, también genera muchos gastos generales adicionales, por lo que siga las siguientes sugerencias para la persistencia:
- Las instancias de Redis utilizadas para el almacenamiento en caché deberían intentar no habilitar la persistencia.
- Se recomienda desactivar la función de persistencia RDB y utilizar la persistencia AOF.
- Utilice scripts para crear RDB periódicamente en el nodo esclavo para lograr una copia de seguridad de los datos.
- Establezca un umbral de reescritura razonable para evitar bgrewrite frecuentes
- Configure no-appendfsync-on-rewrite = yes para prohibir AOF durante la reescritura y evitar el bloqueo causado por AOF.

Recomendaciones de implementación:
- La máquina física de la instancia de Redis debe reservar suficiente memoria para hacer frente a la bifurcación y la reescritura.
- El límite superior de memoria para una única instancia de Redis no debe ser demasiado grande, como 4G u 8G. Puede acelerar la bifurcación y reducir la presión de la sincronización maestro-esclavo y la migración de datos.
- No implementar con aplicaciones que consuman mucha CPU
- No lo implemente con aplicaciones de alta carga de disco. Por ejemplo: base de datos, cola de mensajes
3.3.2 Consulta lenta
Consulta lenta : El registro de consultas lentas es un registro en el que el servidor Redis calcula el tiempo de ejecución de cada comando antes y después de que se ejecute el comando y se registra cuando excede un cierto umbral.

ilustrar:
La consulta lenta esperará porque Redis ejecuta muchos comandos y la espera excede el umbral.
Ver la lista de registros de consultas lentas:
- slowlog len: consulta la longitud del registro de consultas lentas
- slowlog get [n]: lee n registros de consultas lentas
- reinicio de registro lento: borre la lista de consultas lentas
Reponer:

Establezca el umbral de consulta lenta:
- slowlog-log-slower-than : umbral de consulta lento, en microsegundos. El valor predeterminado es 10000, se recomienda 1000
ilustrar:
Generalmente, se necesitan unos diez microsegundos para ejecutar un comando.
Las consultas lentas se colocarán en el registro de consultas lentas. La longitud del registro tiene un límite superior , que se puede especificar mediante la configuración:
- slowlog-max-len : la longitud del registro de consultas lentas (esencialmente una cola). El valor predeterminado es 128, se recomienda 1000
ilustrar:
El registro de consultas lentas se puede ajustar para facilitar la consulta y la recuperación.
Suplemento: Para modificar estas dos configuraciones, puede usar: config setcomando
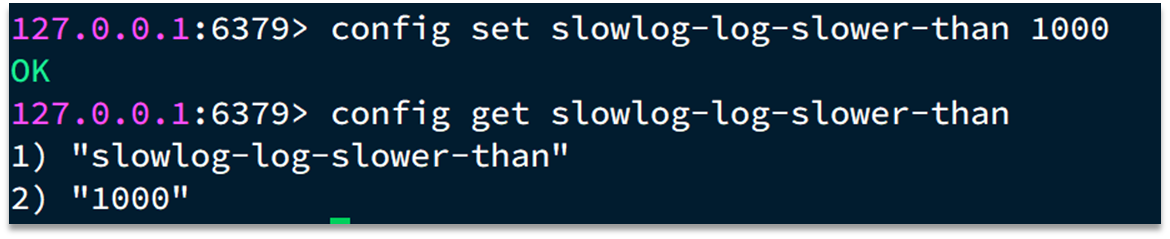

3.3.3 Comandos y configuración de seguridad
Redis estará vinculado a 0.0.0.0:6379, lo que expondrá el servicio de Redis a la red pública. Si Redis no realiza la autenticación de identidad, habrá graves agujeros de seguridad.
Cómo reproducir la vulnerabilidad: https://cloud.tencent.com/developer/article/1039000
Las razones principales de la vulnerabilidad son las siguientes:
- Redis no tiene contraseña establecida
- Utilice el comando Redis config set para modificar dinámicamente la configuración de Redis.
- Inicie Redis usando los permisos de la cuenta raíz
Para evitar este tipo de vulnerabilidades, aquí hay algunas sugerencias:
-
Redis debe establecer una contraseña
-
Está prohibido utilizar los siguientes comandos en línea: claves, flusall, flushdb, config set y otros comandos. Se puede desactivar usando el comando cambiar nombre.
ilustrar:
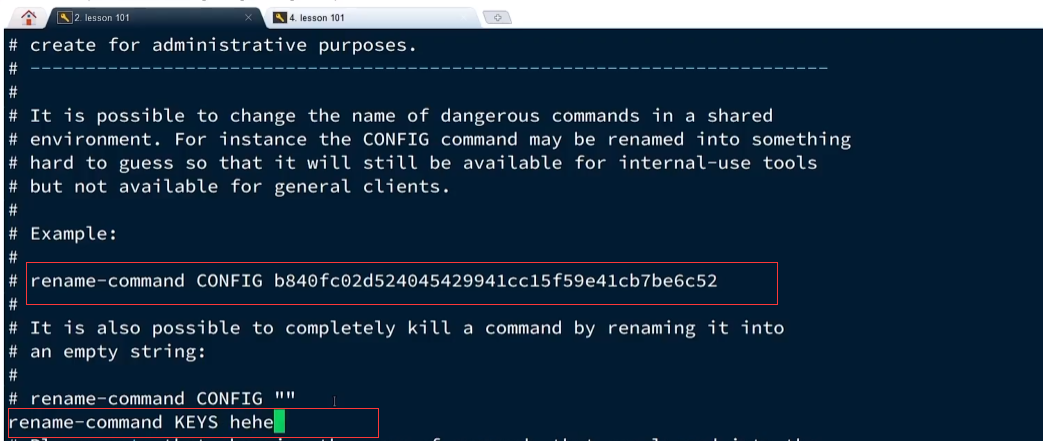
-
enlazar: restringe la tarjeta de red y prohíbe el acceso a tarjetas de red externas
ilustrar:
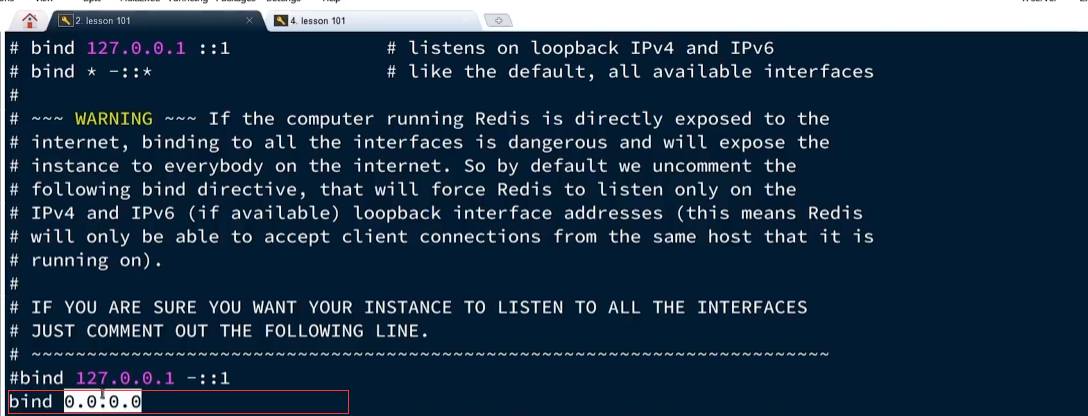
-
Enciende el cortafuegos
-
No utilice la cuenta Root para iniciar Redis
-
Intenta no tener un puerto predeterminado
3.4 Configuración de la memoria
Resumen de notas:
- Descripción general: configure adecuadamente la capacidad de memoria del área de caché de copia en la memoria, el área de caché AOF y el área de caché del cliente para mejorar el rendimiento
3.4.1 Descripción general
Cuando la memoria de Redis es insuficiente, puede causar problemas como eliminación frecuente de claves, tiempo de respuesta prolongado y QPS inestable. Cuando el uso de la memoria alcanza más del 90%, debemos estar atentos y localizar rápidamente la causa del uso de la memoria.
| Uso de memoria | ilustrar |
|---|---|
| memoria de datos | Es la parte más importante de Redis y almacena la información del valor clave de Redis. Los principales problemas son los problemas de BigKey y los problemas de fragmentación de la memoria. |
| memoria de proceso | La ejecución del proceso principal de Redis en sí definitivamente requiere memoria, como código, grupo constante, etc.; esta parte de la memoria ocupa aproximadamente varios megabytes, que pueden ignorarse en comparación con la memoria ocupada por los datos de Redis en la mayoría de los entornos de producción. |
| memoria intermedia | Generalmente incluye búfer de cliente, búfer AOF , búfer de copia, etc. Los búferes de cliente incluyen búferes de entrada y búferes de salida. El uso de memoria de esta parte fluctúa mucho; el uso inadecuado de BigKey puede provocar un desbordamiento de la memoria. |
Redis proporciona algunos comandos para ver el estado actual de asignación de memoria de Redis:
- memoria de información

- memoria xxx

3.4.2 Configuración del búfer de memoria
Hay tres tipos comunes de buffers de memoria:
- Búfer de replicación: repl_backlog_buf de replicación maestro-esclavo . Si es demasiado pequeño, puede provocar una replicación completa frecuente y afectar el rendimiento. Establecido por repl-backlog-size , predeterminado 1mb
- Búfer AOF: el área de caché antes del vaciado de AOF y el búfer donde AOF ejecuta la reescritura. No se puede establecer el límite de capacidad
- Búfer de cliente: dividido en búfer de entrada y búfer de salida, el búfer de entrada máximo es 1G y no se puede configurar. El búfer de salida se puede configurar

La configuración predeterminada es la siguiente:

3.5 Mejores prácticas del grupo
Resumen de notas:
- Descripción general: la creación de un clúster requiere considerar el ancho de banda, la asimetría de los datos, la integridad de los datos, el rendimiento del cliente y muchas otras cuestiones.
- Nota: Existen problemas de configuración de integridad de datos de clúster predeterminados en los clústeres fragmentados y en los clústeres maestro-esclavo, que deben configurarse
cluster-require-full-coverageparafalsemejorar el rendimiento del clúster de Redis según las necesidades.- No es fácil construir demasiados nodos para evitar el tiempo de espera comercial entre nodos.
3.5.1 Descripción general
Aunque el clúster tiene características de alta disponibilidad y puede realizar una recuperación automática de fallas, si se usa incorrectamente, habrá algunos problemas:
- Problemas de integridad del clúster
- Problema de ancho de banda del clúster
- Problema de sesgo de datos
- Problemas de rendimiento del cliente
- Problemas de compatibilidad de clústeres con comandos
- Lua y problemas de transacciones
3.5.2 Problemas de integridad del clúster
En la configuración predeterminada de Redis, si se encuentra que alguna ranura no está disponible, todo el clúster detendrá los servicios externos:
Reponer:
Para garantizar una alta disponibilidad, se recomienda configurarlo
cluster-require-full-coveragecomofalse
3.5.3 Problema de ancho de banda del clúster
Los nodos del clúster harán ping constantemente entre sí para determinar el estado de otros nodos del clúster. La información que lleva cada Ping incluye al menos:
- Información de ranura
- Información de estado del clúster
Cuantos más nodos haya en el clúster, mayor será el volumen de datos de la información de estado del clúster. La información relevante de 10 nodos puede alcanzar 1 kb. En este momento, el ancho de banda requerido para la intercomunicación de cada clúster será muy alto.
Soluciones:
- Evite los clústeres grandes. El número de nodos del clúster no debe ser demasiado , preferiblemente menos de 1000. Si el negocio es grande, establezca varios clústeres.
- Evite ejecutar demasiadas instancias de Redis en una sola máquina física
- Configure el valor de tiempo de espera del nodo del clúster apropiado según la cantidad de nodos, el ancho de banda, etc. para garantizar la detección de fallas en los nodos.
3.5.4 Clúster o maestro-esclavo
Aunque el clúster tiene características de alta disponibilidad y puede realizar una recuperación automática de fallas, si se usa incorrectamente, habrá algunos problemas:
- Problemas de integridad del clúster
- Problema de ancho de banda del clúster
- Problema de sesgo de datos
- Problemas de rendimiento del cliente
- Problemas de compatibilidad de clústeres con comandos
- Lua y problemas de transacciones
Aviso:
Redis único (Redis maestro-esclavo) ya puede alcanzar QPS de nivel 10,000 y también tiene características sólidas de alta disponibilidad. Si el maestro y el esclavo pueden satisfacer las necesidades comerciales, intente no crear un clúster de Redis.
Registro
Existe un problema constante de ralentización al crear un centinela de Redis.
sdownIndica que Sentinel cree subjetivamente que este nodo está inactivo.
- Compruebe si la IP y el puerto del nodo maestro del archivo de configuración de Sentinel están configurados correctamente.
- Compruebe si el archivo de configuración de Sentinel configura la contraseña de conexión del clúster
sentinel auth-pass mymaster qweasdzxc - Compruebe si el firewall del sistema abre los puertos de cada nodo en el clúster de Redis
Construir MySQL
Paso 1: preparar el entorno básico
1.Crea un directorio
cd home
mkdir mysql
cd mysql
mkdir logs
mkdir data
mkdir conf
Paso 2: ejecutar el contenedor
- Utilice Docker para ejecutar el siguiente comando
sudo docker run \
-p 3306:3306 \
--name mysql \
-v /home/mysql/logs:/logs \
-v /home/mysql/data:/var/lib/mysql \
-v /home/mysql/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=qweasdzxc \
-d mysql:latest
Paso 3: agregar configuración
1. Ingrese confal directorio para crear my.cnfel archivo.
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/home/mysql
server-id=1000
2. Reinicie el contenedor
docker restart mysql
Paso 4: Inicializar la tabla del proyecto
/*
Navicat Premium Data Transfer
Source Server : 192.168.150.101
Source Server Type : MySQL
Source Server Version : 50725
Source Host : 192.168.150.101:3306
Source Schema : heima
Target Server Type : MySQL
Target Server Version : 50725
File Encoding : 65001
Date: 16/08/2021 14:45:07
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tb_item
-- ----------------------------
DROP TABLE IF EXISTS `tb_item`;
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`title` varchar(264) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品标题',
`name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '商品名称',
`price` bigint(20) NOT NULL COMMENT '价格(分)',
`image` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品图片',
`category` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '类目名称',
`brand` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌名称',
`spec` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '规格',
`status` int(1) NULL DEFAULT 1 COMMENT '商品状态 1-正常,2-下架,3-删除',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `status`(`status`) USING BTREE,
INDEX `updated`(`update_time`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 50002 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '商品表' ROW_FORMAT = COMPACT;
-- ----------------------------
-- Records of tb_item
-- ----------------------------
INSERT INTO `tb_item` VALUES (10001, 'RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4', 'SALSA AIR', 16900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp', '拉杆箱', 'RIMOWA', '{\"颜色\": \"红色\", \"尺码\": \"26寸\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10002, '安佳脱脂牛奶 新西兰进口轻欣脱脂250ml*24整箱装*2', '脱脂牛奶', 68600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t25552/261/1180671662/383855/33da8faa/5b8cf792Neda8550c.jpg!q70.jpg.webp', '牛奶', '安佳', '{\"数量\": 24}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10003, '唐狮新品牛仔裤女学生韩版宽松裤子 A款/中牛仔蓝(无绒款) 26', '韩版牛仔裤', 84600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t26989/116/124520860/644643/173643ea/5b860864N6bfd95db.jpg!q70.jpg.webp', '牛仔裤', '唐狮', '{\"颜色\": \"蓝色\", \"尺码\": \"26\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10004, '森马(senma)休闲鞋女2019春季新款韩版系带板鞋学生百搭平底女鞋 黄色 36', '休闲板鞋', 10400, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/29976/8/2947/65074/5c22dad6Ef54f0505/0b5fe8c5d9bf6c47.jpg!q70.jpg.webp', '休闲鞋', '森马', '{\"颜色\": \"白色\", \"尺码\": \"36\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10005, '花王(Merries)拉拉裤 M58片 中号尿不湿(6-11kg)(日本原装进口)', '拉拉裤', 38900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t24370/119/1282321183/267273/b4be9a80/5b595759N7d92f931.jpg!q70.jpg.webp', '拉拉裤', '花王', '{\"型号\": \"XL\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
-- ----------------------------
-- Table structure for tb_item_stock
-- ----------------------------
DROP TABLE IF EXISTS `tb_item_stock`;
CREATE TABLE `tb_item_stock` (
`item_id` bigint(20) NOT NULL COMMENT '商品id,关联tb_item表',
`stock` int(10) NOT NULL DEFAULT 9999 COMMENT '商品库存',
`sold` int(10) NOT NULL DEFAULT 0 COMMENT '商品销量',
PRIMARY KEY (`item_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;
-- ----------------------------
-- Records of tb_item_stock
-- ----------------------------
INSERT INTO `tb_item_stock` VALUES (10001, 99996, 3219);
INSERT INTO `tb_item_stock` VALUES (10002, 99999, 54981);
INSERT INTO `tb_item_stock` VALUES (10003, 99999, 189);
INSERT INTO `tb_item_stock` VALUES (10004, 99999, 974);
INSERT INTO `tb_item_stock` VALUES (10005, 99999, 18649);
SET FOREIGN_KEY_CHECKS = 1;
Construir Nginx
#user nobody;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
# nginx的业务集群,nginx本地缓存、redis缓存、tomcat查询
upstream nginx-cluster{
server 10.13.164.55:8081;
}
server {
listen 8080;
server_name localhost;
location /api {
proxy_pass http://nginx-cluster;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
Construir Redis
Paso 1: agregar redis.confel archivo de configuración
bind 0.0.0.0
protected-mode no
port 6379
tcp-backlog 511
requirepass qweasdzxc
timeout 0
tcp-keepalive 300
daemonize no
supervised no
pidfile /var/run/redis_6379.pid
loglevel notice
logfile ""
databases 30
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-disable-tcp-nodelay no
replica-priority 100
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly yes
appendfilename "appendonly.aof"
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
slowlog-max-len 128
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
Paso 2: ejecutar Redisel contenedor
sudo docker run \
--restart=always \
-p 6379:6379 \
--name myredis \
-v /home/redis/myredis/redis.conf:/etc/redis/redis.conf \
-v /home/redis/myredis/data:/data \
-d redis redis-server /etc/redis/redis.conf \
--appendonly yes \
--requirepass qweasdzxc
ilustrar:
Si este contenedor Redis necesita conectarse de forma remota, debe configurar una contraseña, es decir, agregar
--requirepassparámetros