Pila de tecnología de microservicios SpringCloud Entrevista de seguimiento de Dark Horse
- el objetivo de hoy
- 1. Microservicios
-
- 1.1 ¿Cuáles son los componentes comunes de Spring Cloud?
- 1.2 ¿Cuál es la estructura de registro de servicios de Nacos?
- 1.3 ¿Cómo soporta Nacos la presión de cientos de miles de registros de servicios dentro de Ali?
- 1.4 ¿Cómo evita Nacos los conflictos simultáneos de lectura y escritura?
- 1.5 ¿Cuáles son las diferencias entre Nacos y Eureka?
- 1.6 ¿Cuál es la diferencia entre la limitación de corriente de Sentinel y la limitación de corriente de Gateway?
- 1.7 ¿Cuál es la diferencia entre el aislamiento de subprocesos de Sentinel y el aislamiento de subprocesos de Hystix?
- 2. Artículos MQ
-
- 2.1 ¿Por qué eligió RabbitMQ en lugar de otros MQ?
- 2.2 ¿Cómo asegura RabbitMQ que los mensajes no se pierdan?
- 2.3 ¿Cómo evita RabbitMQ la acumulación de mensajes?
- 2.4 ¿Cómo garantiza RabbitMQ el orden de los mensajes?
- 2.5 ¿Cómo evitar el consumo repetido de mensajes MQ?
- 2.6 ¿Cómo asegurar la alta disponibilidad de RabbitMQ?
- 2.7 ¿Qué problemas se pueden resolver utilizando MQ?
- 3. Artículos Redis
-
- 3.1 ¿Cuál es la diferencia entre Redis y Memcache?
- 3.2 Problema de hilo único de Redis
- 3.2 ¿Qué son los esquemas de persistencia de Redis?
- 3.3 ¿Cuáles son los métodos de agrupación en clústeres de Redis?
- 3.4 ¿Cuáles son los tipos de datos comunes de Redis?
- 3.5 Hable sobre el mecanismo de transacción de Redis
el objetivo de hoy

1. Microservicios
1.1 ¿Cuáles son los componentes comunes de Spring Cloud?
Descripción del problema : este tema examina principalmente la comprensión básica de los componentes de SpringCloud
Dificultad : fácil
Frase de referencia :
Spring Cloud contiene muchos componentes y muchas funciones se repiten. Los componentes más utilizados incluyen:
• Componentes de registro: Eureka, Nacos, etc.
• Componente de equilibrio de carga: Cinta
•Componente de llamada remota: OpenFeign
• Componentes de puerta de enlace: Zuul, puerta de enlace
• Componentes de protección del servicio: Hystrix, Sentinel
• Componentes de gestión de configuración de servicios: SpringCloudConfig, Nacos
1.2 ¿Cuál es la estructura de registro de servicios de Nacos?
Descripción del problema : investigar la comprensión de la estructura jerárquica de los datos de Nacos y el dominio del código fuente de Nacos
Dificultad : Normal
Frase de referencia :
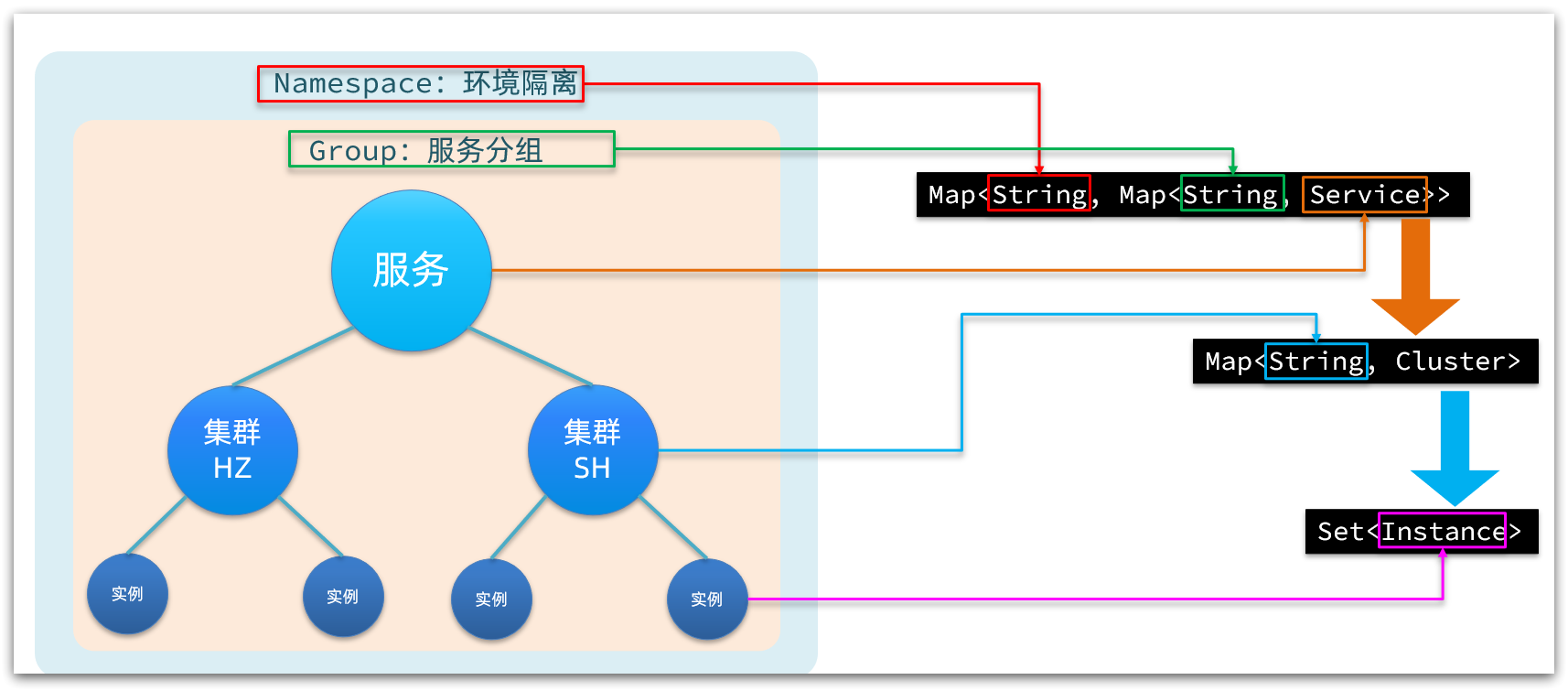
Nacos adopta un modelo de almacenamiento de datos jerárquico y la capa más externa es Namespace, que se utiliza para aislar el entorno. Luego está Group, que se utiliza para agrupar servicios. El siguiente es el servicio (Servicio), un servicio contiene varias instancias, pero puede estar en diferentes salas de computadoras, por lo que hay varios clústeres (Cluster) bajo el Servicio y diferentes instancias (Instancia) bajo el Cluster.
En correspondencia con el código Java, Nacos utiliza un mapa de varias capas para representar. La estructura es Map<String, Map<String, Service>>, donde la clave del mapa más externo es namespaceId y el valor es Map. La clave del mapa interno es el nombre de servicio concatenado del grupo y el valor es el objeto de servicio. Dentro del objeto Servicio hay un Mapa, la clave es el nombre del clúster y el valor es el objeto Clúster. El objeto Cluster mantiene internamente una colección de Instancias.
Como se muestra en la figura:
código de implementación simple
package com.nacos;
import org.junit.Test;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class NacosStructure {
@Test
public void testNacosStructure() {
// 实例
Instance personInfo = new Instance("personInfo");
Instance finance = new Instance("finance");
// 集群(一个地区的机房)
Cluster SZ = new Cluster("SZ");
SZ.getInstance(personInfo);
SZ.getInstance(finance);
// 其中服务组是环境隔离的
NameSpace dev01 = new NameSpace("dev01");
// 集群是部署在服务组中
dev01.putService("01-personInfo", new Service("personInfo"));
dev01.putNameSpace("dev01", dev01.getService("01-personInfo"));
System.out.println(dev01);
}
}
class NameSpace {
private String nameSpaceId;
private Map<String, Map<String, Service>> nameSpaceMap = new HashMap();
private Map<String, Service> groupMap = new HashMap<>();
public void putNameSpace(String nameSpaceId, Map<String, Service> serviceMap) {
nameSpaceMap.put(nameSpaceId, serviceMap);
}
public void putService(String groupId, Service service) {
this.groupMap.put(groupId, service);
}
public Map<String, Service> getService(String groupId) {
return this.groupMap;
}
public NameSpace(String nameSpaceId) {
this.nameSpaceId = nameSpaceId;
}
@Override
public String toString() {
return "NameSpace{" +
"nameSpaceId='" + nameSpaceId + '\'' +
", nameSpaceMap=" + nameSpaceMap +
", groupMap=" + groupMap +
'}';
}
}
class Service {
private String name;
Map<String, Cluster> service = new HashMap();
public Service(String name) {
this.name = name;
}
/**
* 往服务中添加集群
*
* @param c
*/
public void putCluster(Cluster c) {
this.service.put(c.getName(), c);
}
/**
* 往服务中删除集群
*
* @param c
*/
public void deleteCluster(Cluster c) {
this.service.remove(c.getName());
}
@Override
public String toString() {
return "Service{" +
"name='" + name + '\'' +
", service=" + service +
'}';
}
}
class Cluster {
private String name;
private Set<Instance> instance = new HashSet<>();
public Cluster(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* 往集群中添加实例
*
* @param in
*/
public void getInstance(Instance in) {
this.instance.add(in);
}
/**
* 集群中删除实例
*
* @param in
*/
public void removeInstance(Instance in) {
this.instance.remove(in);
}
@Override
public String toString() {
return "Cluster{" +
"name='" + name + '\'' +
", instance=" + instance +
'}';
}
}
class Instance {
private String name;
public Instance(String name) {
this.name = name;
}
@Override
public String toString() {
return "Instance{" +
"name='" + name + '\'' +
'}';
}
}
1. Descarga el código fuente de Nacos y ejecútalo
Para estudiar el código fuente de Nacos, por supuesto, no puede usar el paquete jar del servidor de Nacos empaquetado para ejecutarlo. Debe descargar el código fuente y compilarlo usted mismo.
1.1 Descargar el código fuente de Nacos
Dirección de GitHub de Nacos: https://github.com/alibaba/nacos
El código fuente descargado de Nacos de la versión 1.4.2 se ha proporcionado en los materiales previos a la clase:

Si necesita estudiar otras versiones de los estudiantes, también puede descargarlo usted mismo:
Todos encuentren su página de lanzamiento: https://github.com/alibaba/nacos/tags, busquen la versión 1.4.2:

haga clic para ingresar, descargue el código fuente (zip):
1.2 Importar proyecto de demostración
Nuestros materiales previos a la clase brindan una demostración de microservicios, incluidos servicios como registro y descubrimiento de servicios.

Después de importar el proyecto, vea su estructura de proyecto:

descripción de la estructura:
- cloud-source-demo: directorio principal del proyecto
- cloud-demo: el proyecto principal de microservicios, gestión de dependencias de microservicios
- servicio de pedido: el microservicio de pedido, que necesita acceder al servicio de usuario en el negocio, es un consumidor de servicio
- servicio de usuario: microservicio de usuario, que expone la interfaz de consulta de usuarios en función de la identificación, y es un proveedor de servicios
- cloud-demo: el proyecto principal de microservicios, gestión de dependencias de microservicios
1.3 Importar código fuente de Nacos
Descomprima el código fuente de Nacos descargado previamente en el directorio del proyecto cloud-source-demo:
Luego, usa IDEA para importarlo como un módulo:
1) Seleccione la opción de estructura del proyecto:
Luego haga clic en Importar módulo:
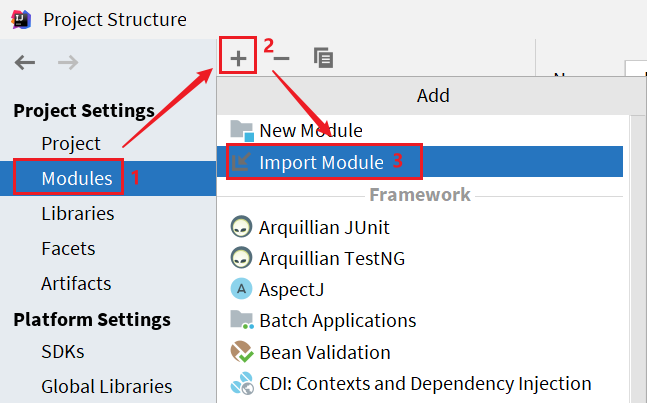
En la ventana emergente, seleccione el directorio del código fuente de nacos:

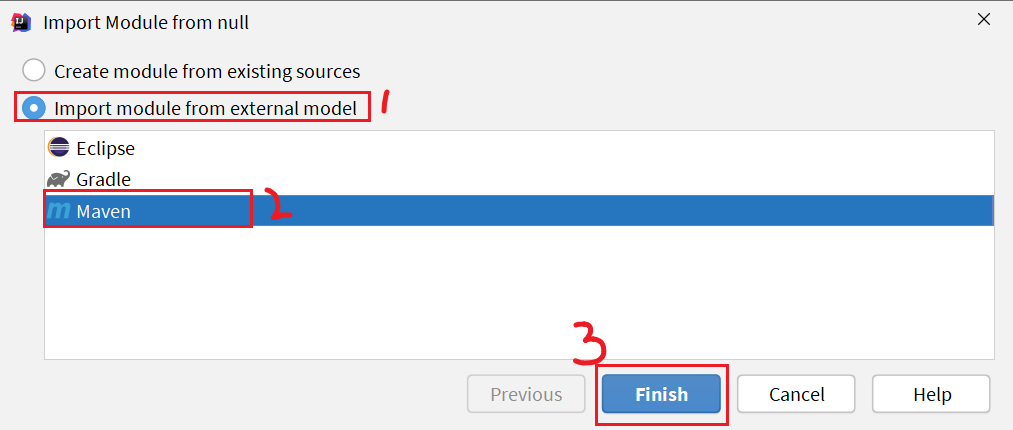
Luego seleccione el módulo maven, termine:
Finalmente, haga clic en Aceptar:

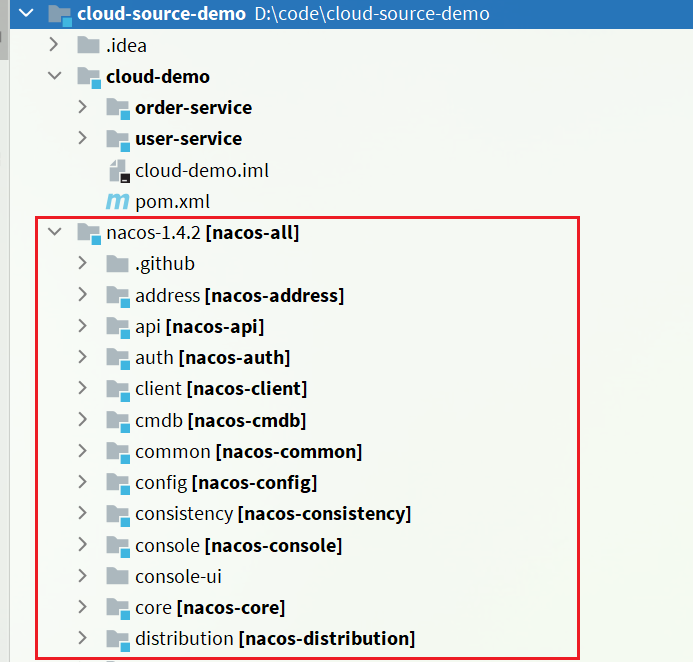
la estructura del proyecto importado:
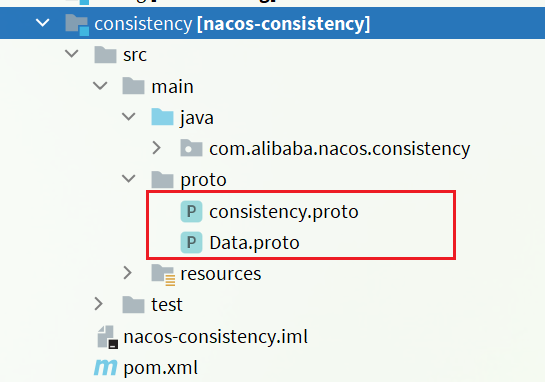
compilación 1.4.proto
La comunicación de datos subyacente de Nacos serializará y deserializará los datos en función de protobuf. Y defina el archivo proto correspondiente en el submódulo de consistencia:
Primero debemos compilar el archivo proto en el código Java correspondiente.
1.4.1 Qué es protobuf
El nombre completo de protobuf es Protocol Buffer, que es un protocolo de serialización de datos proporcionado por Google. Esta es la definición oficial de Google:
Protocol Buffers es un formato de almacenamiento de datos estructurados liviano y eficiente que se puede usar para la serialización de datos estructurados y es muy adecuado para el almacenamiento de datos o el formato de intercambio de datos RPC. Se puede utilizar en formatos de datos estructurados serializados extensibles, independientes del idioma y de la plataforma en protocolos de comunicación, almacenamiento de datos y otros campos.
Puede entenderse simplemente como un formato de transmisión de datos multiplataforma y multilenguaje. La función es similar a json, pero tanto el rendimiento como el tamaño de los datos son mucho mejores que json.
La razón por la que protobuf puede ser multilenguaje es porque el formato de la definición de datos es .protoformat, que debe compilarse en el idioma correspondiente según protoc.
1.4.2 Instalar protocolo
Dirección de GitHub de Protobuf: https://github.com/protocolbuffers/protobuf/releases
Podemos descargar la versión de Windows para usar:

Además, los materiales previos a la clase también proporcionan un paquete de instalación descargado:

descomprímalo en cualquier directorio que no sea chino, y el protoc.exe en el directorio bin puede ayudarnos a compilar:

luego coloque esto directorio bin Configúrelo en la ruta de la variable de entorno, puede consultar el método de configuración de JDK:
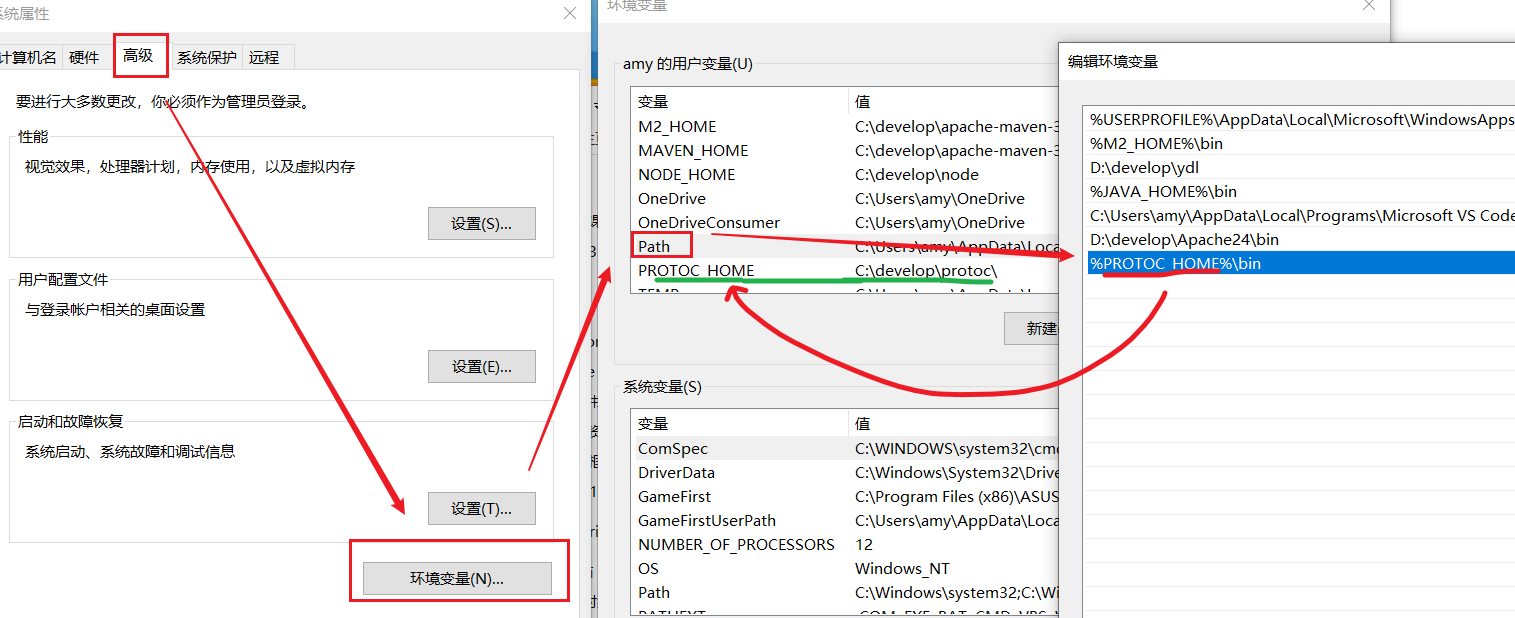
1.4.3 Compilar prototipo
Ingrese al directorio src/main bajo el módulo de consistencia de nacos-1.4.2:
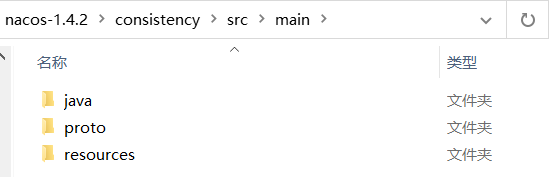
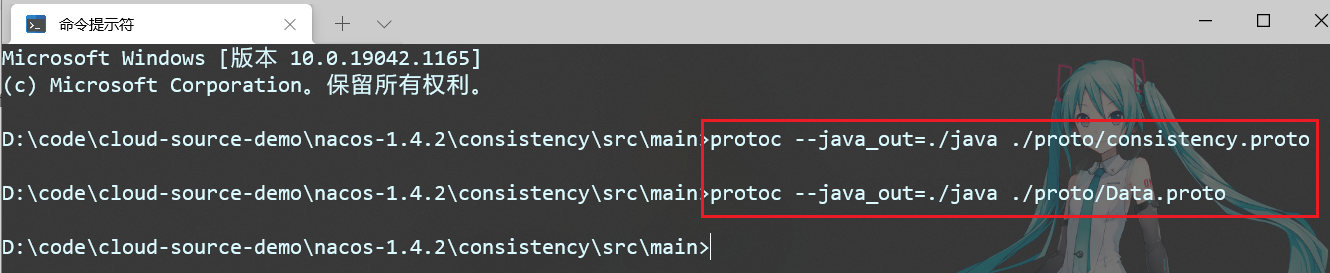
Luego abra una ventana cmd y ejecute los siguientes dos comandos:
protoc --java_out=./java ./proto/consistency.proto
protoc --java_out=./java ./proto/Data.proto
Como se muestra en la figura:
estos códigos java serán compilados en el módulo de consistencia de nacos:

1.5 Ejecutar
La entrada del servidor nacos es la clase Nacos en el módulo de la consola:
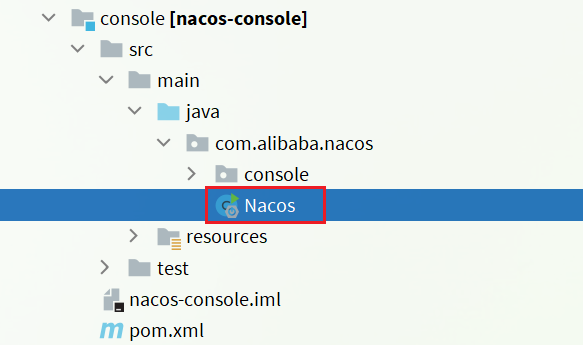
Tenemos que hacer que comience de forma independiente:
Luego crea una nueva SpringBootApplication:
Luego complete la información de la aplicación:
Clase principal: com.alibaba.nacos.Nacos
Opciones de VM: -Dnacos.standalone=true
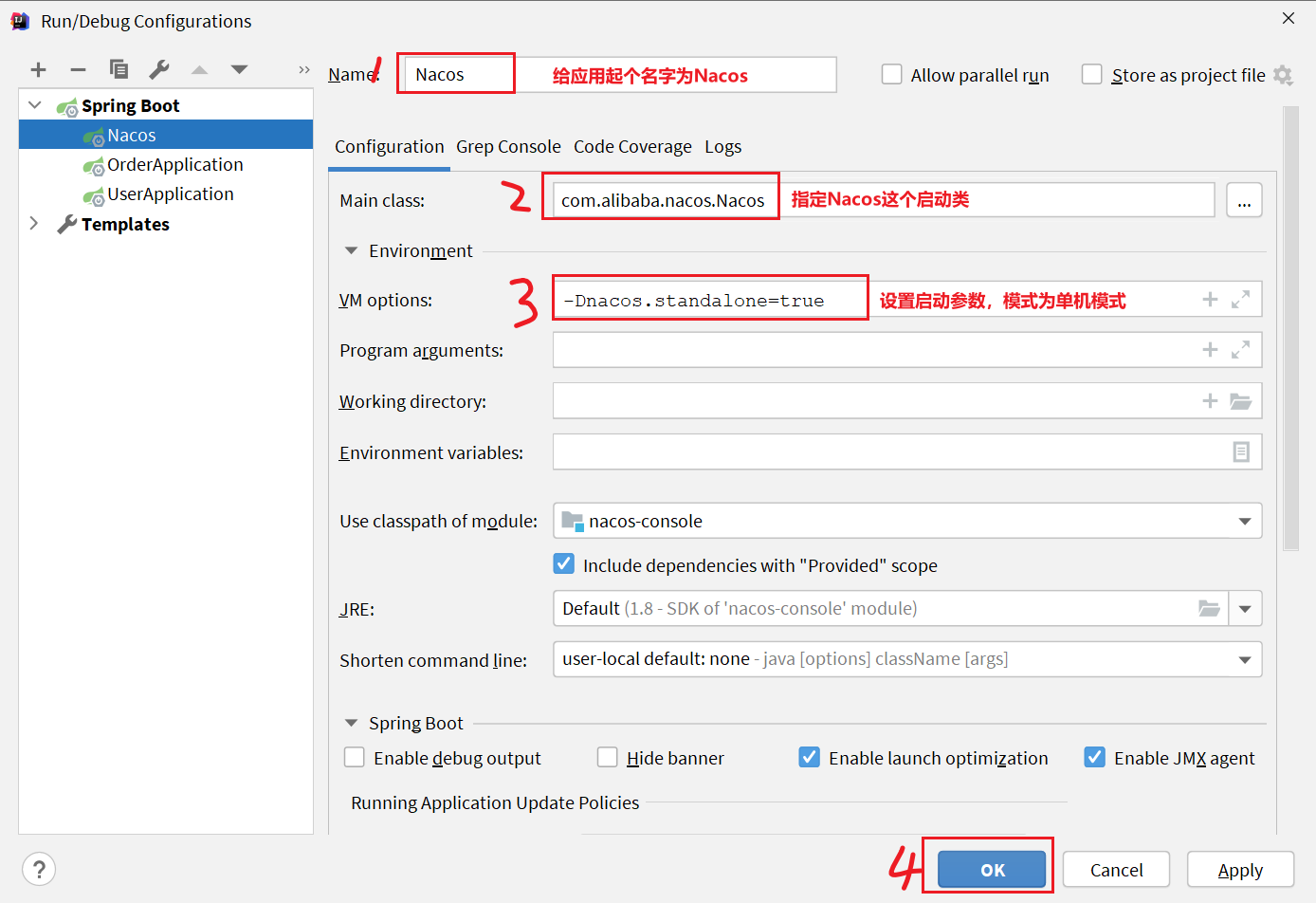
Luego ejecute la función principal de Nacos:
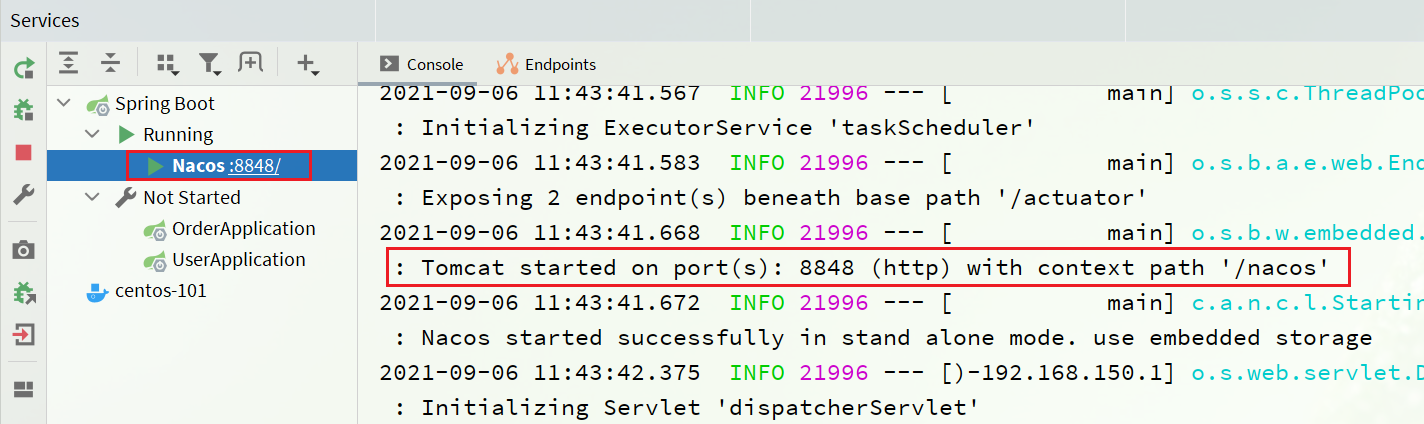
Después de iniciar los servicios de servicio de pedido y servicio de usuario, puede ver la consola de nacos:
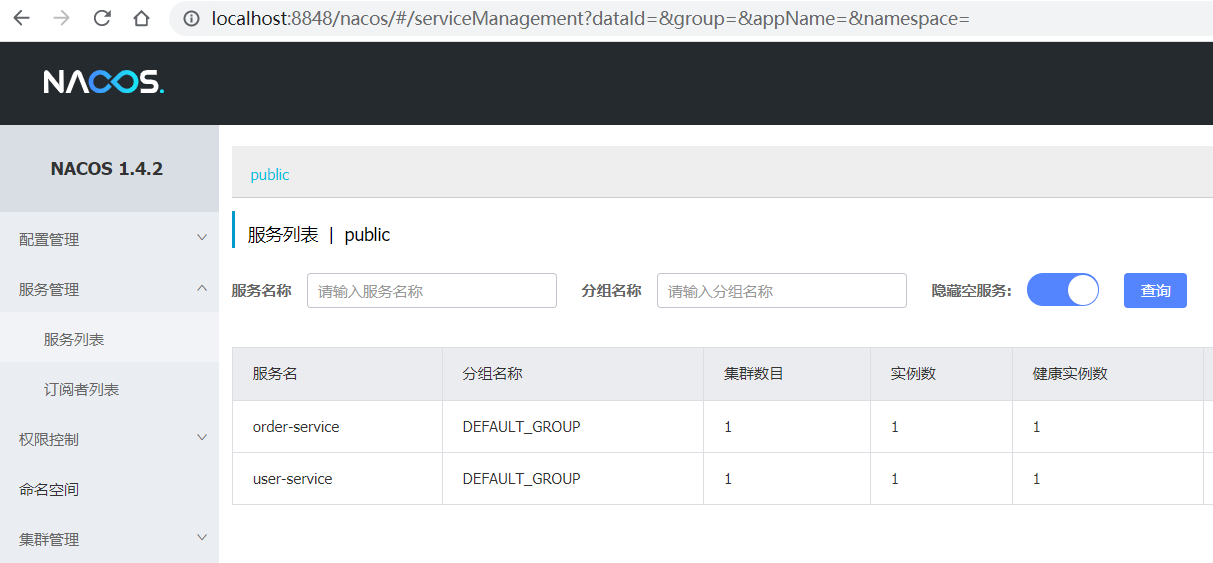
2. Registro de servicios
Después de que el servicio se registre en Nacos, se guardará en un registro local y su estructura es la siguiente:
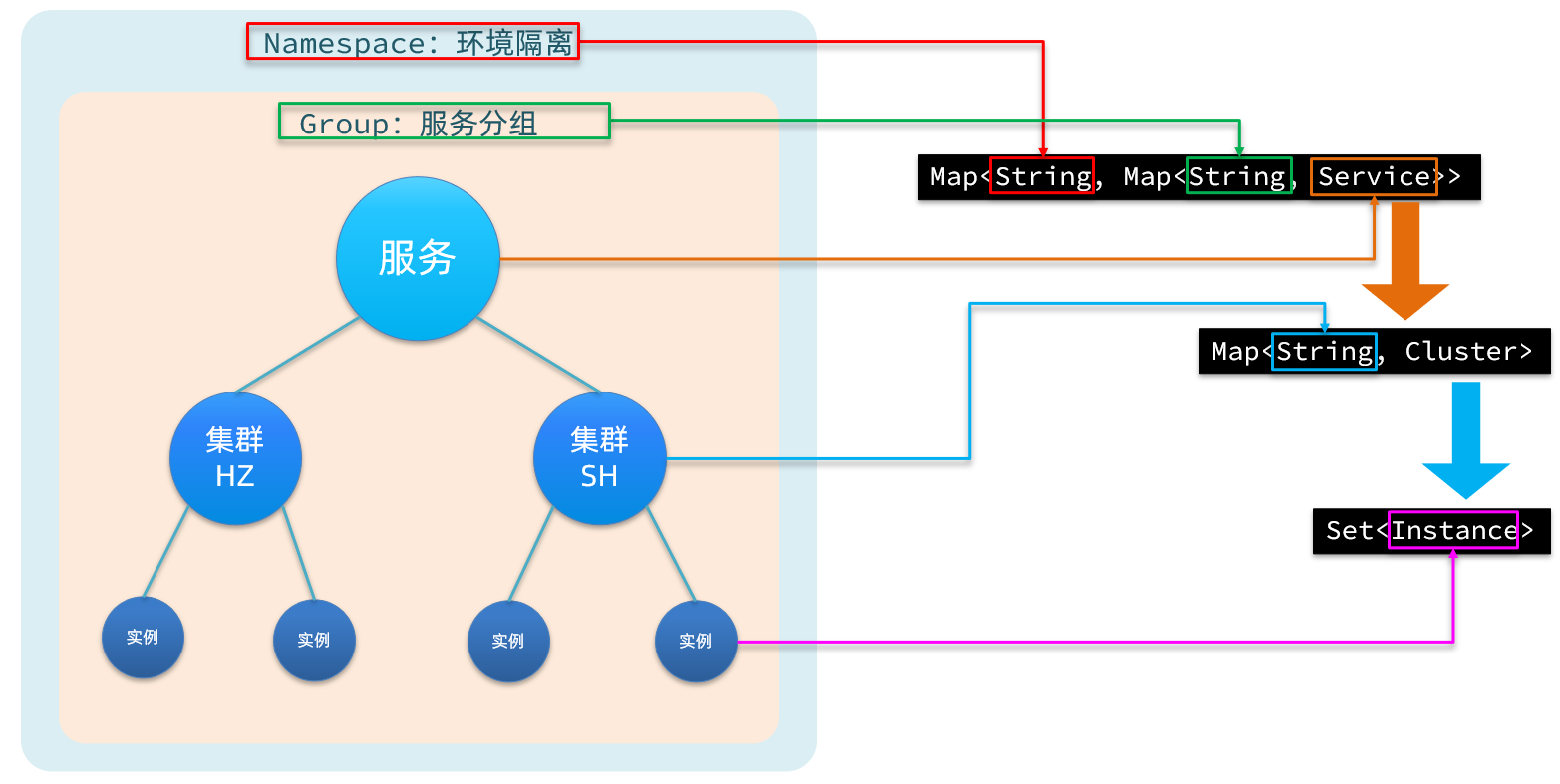
En primer lugar, la capa más externa es un Mapa, la estructura es: Map<String, Map<String, Service>>:
- clave: es namespace_id, que desempeña el papel de aislamiento ambiental. Puede haber varios grupos bajo el espacio de nombres
- valor: Otro
Map<String, Service>, que representa el grupo y los servicios dentro del grupo. Puede haber varios servicios en un grupo.- clave: representa la agrupación de grupos, pero cuando se usa como clave, el formato es nombre_grupo:nombre_servicio
- valor: un determinado servicio en el grupo, como servicio de usuario, servicio de usuario. El tipo es
Service, que también contiene uno internamenteMap<String,Cluster>, y puede haber múltiples clústeres bajo un servicio- clave: nombre del clúster
- valor:
Clustertipo, que contiene la información específica del clúster. Un clúster puede contener varias instancias, es decir, información específica del nodo, incluido unoSet<Instance>, que es la colección de instancias bajo el clúster.- Instancia: información de la instancia, incluida la IP de la instancia, el puerto, el estado de salud, el peso, etc.
Cuando cada servicio se registre en Nacos, la información se organizará y almacenará en este Mapa.
2.1 Interfaz de registro de servicios
Nacos proporciona una interfaz API para el registro del servicio, el cliente solo necesita enviar una solicitud a esta interfaz para realizar el registro del servicio.
**Descripción de la interfaz:** Registre una instancia en el servicio Nacos.
Tipo de solicitud :POST
Solicitud de ruta :/nacos/v1/ns/instance
Parámetros de la solicitud :
| nombre | tipo | ¿Es obligatorio? | describir |
|---|---|---|---|
| ip | cadena | Sí | IP de instancia de servicio |
| puerto | En t | Sí | Puerto de instancia de servicio |
| ID de espacio de nombres | cadena | No | Id. de espacio de nombres |
| peso | doble | No | Pesos |
| activado | booleano | No | ¿Está en línea? |
| saludable | booleano | No | ya sea saludable |
| metadatos | cadena | No | Información extendida |
| clusterName | cadena | No | nombre del clúster |
| Nombre del Servicio | cadena | Sí | Nombre del Servicio |
| Nombre del grupo | cadena | No | Nombre del grupo |
| efímero | booleano | No | ¿Es una instancia temporal? |
Código de error :
| código de error | describir | Semántica |
|---|---|---|
| 400 | Solicitud incorrecta | Error de sintaxis en la solicitud del cliente |
| 403 | Prohibido | Permiso denegado |
| 404 | Extraviado | recurso no encontrado |
| 500 | Error Interno del Servidor | Error Interno del Servidor |
| 200 | DE ACUERDO | normal |
2.2 Cliente
Primero, necesitamos encontrar la entrada para el registro del servicio.
La ruta para que Nacos introduzca una instancia es: /nacos/v1/ns/instanceluego necesitamos encontrar la misma ruta y encontrarla en src/main/java/com/alibaba/nacos/naming/controllers/InstanceController.javael directorio:

y el tipo de solicitud es POST, luego necesitamos encontrar PostMapping, el registro del método es la entrada del centro de registro

1.3 ¿Cómo soporta Nacos la presión de cientos de miles de registros de servicios dentro de Ali?
Descripción del problema : Investigar el dominio del código fuente de Nacos
Dificultad : Difícil
Frase de referencia :
Cuando Nacos recibe una solicitud de registro internamente, no escribe datos inmediatamente, sino que coloca la tarea de registro del servicio en una cola de bloqueo y responde de inmediato al cliente. Luego use el grupo de subprocesos para leer las tareas en la cola de bloqueo y completar la actualización de la instancia de forma asíncrona, mejorando así la capacidad de escritura simultánea.
Aquí está la instancia temporal
1.4 ¿Cómo evita Nacos los conflictos simultáneos de lectura y escritura?
Descripción del problema : Investigar el dominio del código fuente de Nacos
Dificultad : Difícil
Frase de referencia :
Cuando Nacos actualice la lista de instancias, utilizará la tecnología CopyOnWrite . Primero, copie la lista de instancias anterior, luego actualice la lista de instancias copiada y luego sobrescriba la lista de instancias anterior con la lista de instancias actualizada.
De esta forma, durante el proceso de actualización, la solicitud de lectura de la lista de instancias no se verá afectada y no se producirá el problema de lectura sucia.
Es equivalente al proceso concurrente, lo que se modifica es la lista de instancias nuevas (copia de la lista anterior), y lo que se lee es la lista de instancias anteriores. Los dos no se afectan entre sí.
Utilice bloqueos sincronizados para varias instancias del mismo servicio, ejecución en serie, para garantizar la seguridad de la escritura. El

registro de instancias utiliza un solo subproceso, llamando asíncronamente a

un solo subproceso, para garantizar la seguridad de la escritura.

1.5 ¿Cuáles son las diferencias entre Nacos y Eureka?
Descripción del problema : investigar el dominio de la implementación subyacente de Nacos y Eureka
Dificultad : Difícil
Frase de referencia :
Nacos tiene similitudes y diferencias con Eureka, que se pueden describir a partir de los siguientes puntos:
- Método de interfaz : tanto Nacos como Eureka exponen la interfaz API de estilo Rest al mundo exterior, que se utiliza para realizar funciones como el registro y descubrimiento de servicios.
- Tipo de instancia : las instancias de Nacos se dividen en instancias permanentes y temporales; Eureka solo admite instancias temporales
- Detección de estado : Nacos utiliza detección de modo de latido para instancias temporales y solicitud activa para instancias permanentes; Eureka solo admite el modo de latido
- Detección de servicios : Nacos admite dos modos de extracción de tiempo y envío de suscripción; Eureka solo admite el modo de extracción de tiempo
1.6 ¿Cuál es la diferencia entre la limitación de corriente de Sentinel y la limitación de corriente de Gateway?
Descripción del problema : investigar el dominio del algoritmo de limitación actual
Dificultad : Difícil
Palabras de referencia :
limitación actual : limite las solicitudes del servidor de aplicaciones para evitar la sobrecarga o incluso el tiempo de inactividad del servidor debido a demasiadas solicitudes.
Hay tres implementaciones comunes del algoritmo de limitación actual:
1. Ventana de tiempo deslizante
2. Algoritmo de depósito de fichas
3. Algoritmo de depósito con fugas
Gateway utiliza el algoritmo de depósito de fichas basado en Redis.
Sin embargo, Sentinel es más complicado por dentro:
- El modo de limitación de corriente predeterminado se basa en el algoritmo de ventana de tiempo deslizante
- El modo de limitación actual de la cola se basa en el algoritmo de cubeta con fugas
- El límite actual de los parámetros del punto de acceso se basa en el algoritmo del depósito de fichas
Algoritmo de contador de ventana fija
El concepto de algoritmo de contador de ventana fija es el siguiente: ● Divida el tiempo en varias ventanas, el
intervalo de tiempo de la ventana se llama Intervalo, en este ejemplo es 1000 ms ● Si el contador supera el umbral límite actual, se descartarán todas las solicitudes que excedan el umbral.

Algoritmo de contador de ventana deslizante
El algoritmo de contador de ventana deslizante divide una ventana en n intervalos más pequeños, por ejemplo
● El intervalo de tiempo de la ventana es de 1 segundo, el número de intervalos es n = 2, luego el intervalo de tiempo entre cada área pequeña es de 500 ms
● Actual limiting El umbral sigue siendo 3. Cuando las solicitudes dentro de la ventana de tiempo (1 segundo) superan el umbral, la ventana de límite de flujo de solicitud excedida
se moverá de acuerdo con la hora actual de la solicitud (currentTime), y el rango de la ventana es la primera zona horaria after (intervalo de tiempo actual) Comienza y finaliza en la zona horaria donde se encuentra el tiempo actual.

Algoritmo de depósito de tokens
Descripción del algoritmo de depósito de tokens:
● Los tokens se generan a una tasa fija y se almacenan en el depósito de tokens. Si el depósito de tokens está lleno, los tokens sobrantes se descartan. ● Después de que
llega una solicitud, primero debe intentar obtenerla de el token del depósito, solo se puede procesar después de obtener el token.
● Si no hay ningún token en el depósito de tokens, la solicitud espera o se descarta.

Leaky Bucket Algorithm
Leaky Bucket Algorithm Explicación:
● Trate cada solicitud como una "gota de agua" en el balde
con fugas para su almacenamiento; vacío Si está lleno, la "fuga" se detendrá
● Si el "cubo con fugas" está lleno, las "gotas de agua" sobrantes se desecharán directamente.
Se puede entender que la solicitud está en el cubo.colaesperar

Cuando Sentinel implementa el depósito con fugas, adopta el modo de cola de espera:
permite que todas las solicitudes entren en una cola y luego las ejecuta secuencialmente de acuerdo con el intervalo de tiempo permitido por el umbral. Varias solicitudes simultáneas deben esperar,
Tiempo de espera esperado = tiempo de espera esperado de la última solicitud + intervalo permitido.
Si el tiempo de espera previsto para la solicitud supera el tiempo máximo, se rechazará.
Por ejemplo: QPS=5, significa que una solicitud en la cola se procesa cada 200 ms; tiempo de espera = 2000, significa que las solicitudes que se espera que esperen más de 2000 ms serán rechazadas y se generará una excepción.

Comparación de algoritmos de limitación de corriente

1.7 ¿Cuál es la diferencia entre el aislamiento de subprocesos de Sentinel y el aislamiento de subprocesos de Hystix?
Descripción del problema : investigar el dominio del esquema de aislamiento de subprocesos
Dificultad : Normal
Frase de referencia :
Por defecto, Hystix implementa el aislamiento de subprocesos basado en el conjunto de subprocesos. Cada negocio aislado debe crear un conjunto de subprocesos independiente. Demasiados subprocesos generarán una sobrecarga de CPU adicional. El rendimiento es promedio, pero el aislamiento es más fuerte.
Sentinel es un aislamiento de subprocesos basado en un semáforo (contador). No necesita crear un grupo de subprocesos. Tiene un mejor rendimiento, pero el aislamiento es promedio.
2. Artículos MQ
2.1 ¿Por qué eligió RabbitMQ en lugar de otros MQ?
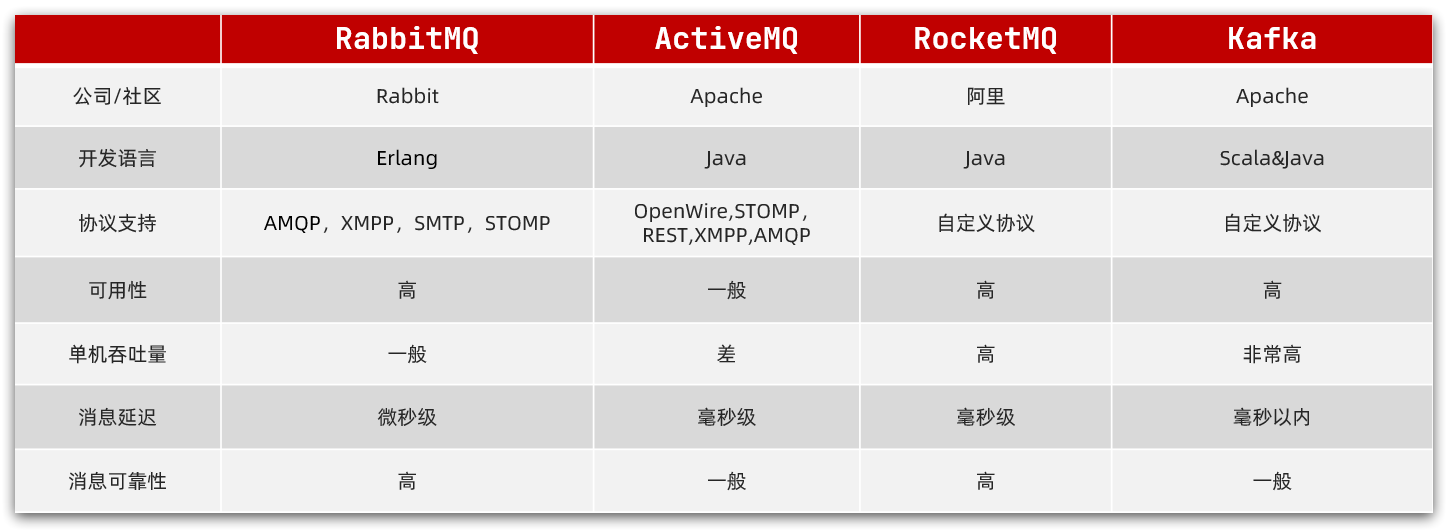
Como se muestra en la imagen:
Palabras:
Kafka es famoso por su alto rendimiento, pero su estabilidad de datos es promedio y no se puede garantizar el orden de los mensajes. También se utiliza la recopilación de registros de nuestra empresa, y RabbitMQ se utiliza en el módulo empresarial.
RocketMQ de Alibaba se basa en el principio de Kafka, que compensa las deficiencias de Kafka y hereda sus ventajas de alto rendimiento.Actualmente, sus clientes son principalmente Java. Pero nos preocupa la estabilidad de los productos de código abierto de Alibaba, por lo que no los usamos.
RabbitMQ está desarrollado en base al lenguaje Erlang orientado a la concurrencia. El rendimiento no es tan bueno como el de Kafka, pero es suficiente para nuestra empresa. Además, la confiabilidad del mensaje es buena, el retraso del mensaje es extremadamente bajo y la construcción del clúster es más conveniente. Soporta múltiples protocolos y tiene clientes en varios idiomas, lo cual es más flexible. El soporte de Spring para RabbitMQ también es relativamente bueno, y es más conveniente de usar y más acorde con las necesidades de nuestra empresa.
Teniendo en cuenta los requisitos de estabilidad y concurrencia de nuestra empresa, elegimos RabbitMQ.
2.2 ¿Cómo asegura RabbitMQ que los mensajes no se pierdan?
Palabras:
RabbitMQ proporciona soluciones específicas para varios lugares donde pueden ocurrir problemas durante la entrega de mensajes:
- Cuando el productor envía un mensaje, es posible que el mensaje no llegue al intercambio debido a problemas de red:
- RabbitMQ proporciona un mecanismo de confirmación del editor
- Después de que el productor envíe el mensaje, puede escribir la función ConfirmCallback
- Después de que el mensaje llegue al conmutador con éxito, RabbitMQ llamará a ConfirmCallback para notificar al remitente del mensaje y devolver ACK
- Si el mensaje no llega al conmutador, RabbitMQ también llamará a ConfirmCallback para notificar al remitente del mensaje y devolver NACK
- También se lanzará una excepción si el mensaje no se envía correctamente después del tiempo de espera.
- RabbitMQ proporciona un mecanismo de confirmación del editor
- Después de que el mensaje llegue al intercambio, si no logra llegar a la cola, el mensaje también se perderá:
- RabbitMQ proporciona un mecanismo de devolución del editor
- Los productores pueden definir la función ReturnCallback
- Cuando el mensaje llega al conmutador pero no a la cola, RabbitMQ llamará a ReturnCallback para notificar al remitente el motivo de la falla.
- RabbitMQ proporciona un mecanismo de devolución del editor
- Después de que el mensaje llega a la cola, el tiempo de inactividad de MQ también puede provocar la pérdida de mensajes:
- RabbitMQ proporciona función de persistencia, función de copia de seguridad de maestro-esclavo de clúster
- Persistencia de mensajes, RabbitMQ conservará conmutadores, colas y mensajes en el disco, y se reiniciará después de que el tiempo de inactividad pueda restaurar los mensajes.
- Tanto los clústeres espejo como las colas de arbitraje pueden proporcionar funciones de copia de seguridad maestro-esclavo. Cuando el nodo maestro se cae, el nodo esclavo cambiará automáticamente a maestro y los datos seguirán en el
- RabbitMQ proporciona función de persistencia, función de copia de seguridad de maestro-esclavo de clúster
- Después de que el mensaje se entrega al consumidor, si el consumidor lo maneja incorrectamente, el mensaje también se puede perder.
- SpringAMQP proporciona un mecanismo de confirmación del consumidor, un mecanismo de reintento del consumidor y una estrategia de procesamiento de fallas del consumidor basada en RabbitMQ:
- Mecanismo de confirmación para los consumidores:
- El consumidor procesa el mensaje con éxito y, cuando no se produce ninguna excepción, Spring devuelve ACK a RabbitMQ y el mensaje se elimina.
- El consumidor no puede procesar el mensaje, lanza una excepción, falla, Spring devuelve NACK o no devuelve el resultado, y el mensaje no es anormal.
- Mecanismo de reintento del consumidor:
- De forma predeterminada, cuando un consumidor no puede procesar, el mensaje volverá a la cola de MQ nuevamente y luego se entregará a otros consumidores. El mecanismo de reintento del consumidor proporcionado por Spring no devuelve NACK después de que falla el procesamiento, sino que vuelve a intentarlo directamente de forma local en el consumidor. Después de que fallan varios reintentos, el mensaje se procesa de acuerdo con la estrategia de manejo de fallas del consumidor. Evita la presión adicional causada por los mensajes frecuentes que ingresan a la cola.
- Estrategia de fracaso del consumidor:
- Cuando un consumidor falla varias veces en los reintentos locales, el mensaje se descarta de forma predeterminada.
- Spring proporciona la estrategia Republish.Después de que fallan varios reintentos y se agota el número de reintentos, el mensaje se vuelve a enviar al conmutador de excepción especificado y la información de la pila de excepciones se llevará para ayudar a localizar el problema.
- Mecanismo de confirmación para los consumidores:
- SpringAMQP proporciona un mecanismo de confirmación del consumidor, un mecanismo de reintento del consumidor y una estrategia de procesamiento de fallas del consumidor basada en RabbitMQ:
2.3 ¿Cómo evita RabbitMQ la acumulación de mensajes?
Palabras:
La razón del problema de la acumulación de mensajes se debe a menudo a que la velocidad de envío de mensajes supera la velocidad de procesamiento de mensajes del consumidor. Así que la solución no es más que los siguientes tres puntos:
- Mejore la velocidad de procesamiento del consumidor
- añadir más consumidores
- Aumentar el límite superior de almacenamiento de mensajes en cola
1) Mejorar la velocidad de procesamiento del consumidor
La velocidad de procesamiento de los consumidores está determinada por el código comercial, por lo que lo que podemos hacer incluye:
- Optimice el código empresarial tanto como sea posible para mejorar el rendimiento empresarial
- Después de recibir el mensaje, abra el grupo de subprocesos y procese varios mensajes al mismo tiempo.
Ventajas: bajo costo, solo cambie el código
Desventajas: habilitar el grupo de subprocesos generará una sobrecarga de rendimiento adicional, lo que no es adecuado para tareas de alta frecuencia y baja latencia. Se recomienda para servicios con un largo período de ejecución de tareas.
2) Agregar más consumidores
Una cola une a varios consumidores para competir juntos por tareas, lo que naturalmente puede aumentar la velocidad del procesamiento de mensajes.
Ventajas: Los problemas que se pueden resolver con dinero no son problemas. Darse cuenta simple y grosero
Desventajas: El problema es que no hay dinero. el costo es demasiado alto
3) Aumentar el límite superior de almacenamiento de mensajes en cola
Después de la versión 1.8 de RabbitMQ, se agregó un nuevo modo de cola: Lazy Queue
Este tipo de cola no guarda los mensajes en la memoria, sino que los escribe directamente en el disco después de recibir los mensajes, teóricamente no hay límite de almacenamiento. Puede resolver el problema de la acumulación de mensajes.
Ventajas: almacenamiento en disco más seguro, almacenamiento ilimitado, evita los problemas de Page Out causados por el almacenamiento de memoria y un rendimiento más estable;
Desventajas: el almacenamiento en disco está limitado por el rendimiento de E/S y la puntualidad de los mensajes no es tan buena como el modo de memoria, pero el impacto no es significativo.
2.4 ¿Cómo garantiza RabbitMQ el orden de los mensajes?
Palabras:
De hecho, RabbitMQ es un almacenamiento en cola, que naturalmente tiene las características de primero en entrar, primero en salir. Mientras el envío de mensajes sea ordenado, teóricamente la recepción también lo es. Sin embargo, cuando varios consumidores están vinculados a una cola, los mensajes pueden sondearse y entregarse a los consumidores, y no se puede garantizar el orden de procesamiento de los consumidores.
Por lo tanto, para garantizar el orden de los mensajes, es necesario realizar los siguientes puntos:
- Garantizar el orden de envío de mensajes
- Asegúrese de que un conjunto de mensajes ordenados se envíen a la misma cola
- Asegúrese de que una cola contenga solo un consumidor
2.5 ¿Cómo evitar el consumo repetido de mensajes MQ?
Palabras:
Las razones del consumo repetido de mensajes son varias e inevitables. Por lo tanto, solo podemos comenzar desde el lado del consumidor. Mientras se pueda garantizar la idempotencia del procesamiento de mensajes, el mensaje no se consumirá repetidamente.
Hay muchas soluciones para garantizar la idempotencia:
- Agregue una identificación única a cada mensaje, registre la tabla de mensajes y el estado del mensaje localmente, y juzgue según la identificación única de la tabla de la base de datos al procesar mensajes
- Lo mismo es registrar la tabla de mensajes y usar el campo de estado del mensaje para realizar el juicio basado en el bloqueo optimista para garantizar la idempotencia.
- Basado en la idempotencia del propio negocio. Por ejemplo, de acuerdo con la eliminación de id, el negocio de consulta es intrínsecamente idempotente; el negocio de agregar y modificar se puede considerar en función de la unicidad de la id de la base de datos o del mecanismo de bloqueo optimista para garantizar la idempotencia. La esencia es similar al esquema de la tabla de mensajes.
2.6 ¿Cómo asegurar la alta disponibilidad de RabbitMQ?
Palabras:
Lograr una alta disponibilidad de RabbitMQ no es más que los siguientes dos puntos:
- Hacer un buen trabajo en la persistencia de conmutadores, colas y mensajes.
- Cree un clúster reflejado de RabbitMQ y haga un buen trabajo de copia de seguridad maestro-esclavo. Por supuesto, también puede usar una cola de quórum en lugar de un clúster reflejado.
2.7 ¿Qué problemas se pueden resolver utilizando MQ?
Palabras:
RabbitMQ puede resolver muchos problemas, como:
- Desacoplamiento: la modificación de varias llamadas de microservicios relacionadas con el negocio a notificaciones asincrónicas basadas en MQ puede desacoplar el acoplamiento comercial entre microservicios. También mejora el rendimiento empresarial.
- Recorte de picos de tráfico: coloque solicitudes comerciales repentinas en MQ como un búfer. El negocio de back-end obtiene mensajes de MQ de acuerdo con su propia capacidad de procesamiento y procesa las tareas una por una. La curva de flujo se vuelve mucho más suave.
- Cola de retraso: basado en la cola de mensajes fallidos de RabbitMQ o el complemento DelayExchange, puede lograr el efecto de retrasar la recepción de mensajes después de que se envían.
3. Artículos Redis
3.1 ¿Cuál es la diferencia entre Redis y Memcache?
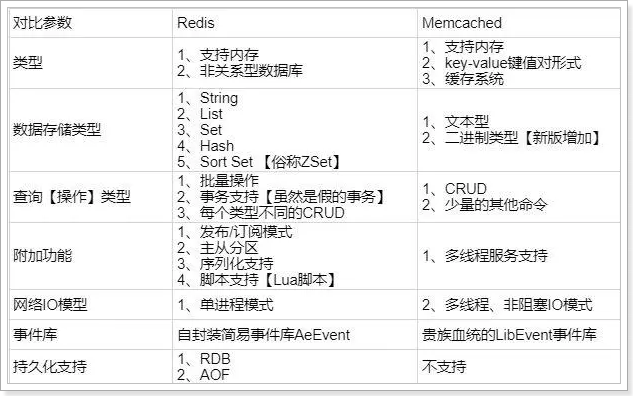
redis支持更丰富的数据类型(Admite escenarios de aplicaciones más complejos): Redis no solo admite datos simples de tipo k/v, sino que también proporciona almacenamiento de estructuras de datos como list, set, zset y hash. Memcache admite un tipo de datos simple, String.Redis支持数据的持久化, los datos en la memoria se pueden mantener en el disco y se pueden cargar y usar nuevamente al reiniciar, mientras que Memecache almacena todos los datos en la memoria.集群模式: memcached no tiene un modo de clúster nativo y necesita depender del cliente para escribir datos en el clúster, pero Redis actualmente admite el modo de clúster de forma nativa.Redis使用单线程: Memcached es un modelo de red de multiplexación de E/S sin bloqueo y de subprocesos múltiples; Redis utiliza un modelo de multiplexación de E/S de multiplexación de un solo subproceso.
3.2 Problema de hilo único de Redis
Entrevistador : Redis usa un solo hilo, ¿cómo garantizar una alta concurrencia?
Discurso de la entrevista :
Las principales razones por las que Redis es rápido son:
- completamente basado en la memoria
- La estructura de datos es simple, y la operación de datos también es simple
- Utilice el modelo de multiplexación de E/S múltiple para aprovechar al máximo los recursos de la CPU
Entrevistador : ¿Cuáles son los beneficios de hacer esto?
Discurso de la entrevista :
Las ventajas del single threading son las siguientes:
- El código es más claro y la lógica de procesamiento es más simple.
- No hay necesidad de considerar varios problemas de bloqueo, no hay operación de liberación de bloqueo y no hay consumo de rendimiento causado por bloqueos.
- No hay cambio de CPU causado por procesos múltiples o subprocesos múltiples, lo que hace un uso completo de los recursos de la CPU
3.2 ¿Qué son los esquemas de persistencia de Redis?
Informacion relevante:
1) persistencia RDB
La persistencia de RDB puede usar save o bgsave. Para no bloquear el negocio del proceso principal, generalmente se usa bgsave. El proceso:
- El proceso de Redis bifurcará un proceso secundario (coherente con los datos de memoria del proceso principal).
- El proceso principal continúa procesando los comandos de solicitud del cliente.
- Escriba todos los datos en la memoria en un archivo RDB temporal por el proceso secundario.
- Una vez completada la operación de escritura, el archivo RDB antiguo será reemplazado por el nuevo archivo RDB.
Las siguientes son algunas configuraciones relacionadas con la persistencia de RDB:
save 60 10000: si 10 000 claves cambian en 60 segundos, realice la persistencia de RDB.stop-writes-on-bgsave-error yes: si Redis no puede realizar la persistencia de RDB (comúnmente debido a una memoria insuficiente en el sistema operativo), Redis ya no aceptará solicitudes de los clientes para escribir datos.rdbcompression yes: Al generar archivos RDB, comprímalos al mismo tiempo.dbfilename dump.rdb: Nombre el archivo RDB dump.rdb.dir /var/lib/redis: Guarde el archivo RDB en/var/lib/redisel directorio.
Por supuesto, en la práctica, generalmente stop-writes-on-bgsave-errorestablecemos la configuración en false, y al mismo tiempo dejamos que el sistema de monitoreo envíe una alarma cuando Redis no puede realizar la persistencia de RDB, para que la intervención manual se pueda resolver en lugar de rechazar de manera grosera la solicitud de escritura del cliente.
Ventajas de la persistencia RDB:
- Los archivos persistentes de RDB son pequeños y la recuperación de datos de Redis es rápida
- El proceso secundario no afecta al proceso principal y el proceso principal puede continuar procesando los comandos del cliente.
- El método copy-on-write se adopta cuando el proceso hijo está bifurcado.En la mayoría de los casos, no hay mucho consumo de memoria y la eficiencia es relativamente buena.
Desventajas de la persistencia de RDB:
- El método de copia en escritura se adopta cuando se bifurca el proceso secundario. Si Redis escribe más en este momento, puede causar un uso de memoria adicional o incluso un desbordamiento de memoria.
- La compresión de archivos RDB reducirá el tamaño del archivo, pero consumirá CPU adicional al pasar
- Si el escenario empresarial valora la durabilidad de los datos (durabilidad), entonces no se debe utilizar la persistencia de RDB. Por ejemplo, si Redis ejecuta la persistencia de RDB cada 5 minutos, si Redis falla inesperadamente, perderá hasta 5 minutos de datos.
2) persistencia AOF
Puede usar appendonly yeselementos de configuración para habilitar la persistencia de AOF. Cuando Redis realiza la persistencia de AOF, agregará el comando de escritura recibido al final del archivo AOF, de modo que Redis pueda restaurar la base de datos a su estado original siempre que reproduzca los comandos en el archivo AOF.
En comparación con la persistencia RDB, una ventaja obvia de la persistencia AOF es que puede mejorar la durabilidad de los datos. Porque en el modo AOF, cada vez que Redis recibe un comando de escritura del cliente, escribirá el comando write()al final del archivo AOF.
Sin embargo, en Linux, write()después de que los datos se transfieran a un archivo, los datos no se descargarán en el disco inmediatamente, sino que se almacenarán temporalmente en el búfer del sistema de archivos del sistema operativo. En el momento adecuado, el sistema operativo vaciará los datos del búfer al disco (si necesita vaciar el contenido del archivo al disco, puede llamar fsync()o fdatasync()).
A través de appendfsynclos elementos de configuración, puede controlar la frecuencia con la que Redis sincroniza los comandos con el disco:
always: cada vez que Redis escribe el comandowrite()en el archivo AOF, se llamaráfsync()para vaciar el comando en el disco. Esto garantiza la mejor durabilidad de los datos, pero puede imponer una sobrecarga significativa en el sistema.no: Redis solo envía comandoswrite()a archivos AOF. Esto permite que el sistema operativo decida cuándo vaciar los comandos en el disco.everysec: además de escribir el comandowrite()en el archivo AOF, Redis lo ejecutará cada segundofsync(). En la práctica, se recomienda utilizar esta configuración, que puede garantizar la persistencia de los datos hasta cierto punto sin reducir significativamente el rendimiento de Redis.
Sin embargo, la persistencia de AOF no está exenta de desventajas: Redis continuará agregando los comandos de escritura recibidos al archivo AOF, lo que hará que el archivo AOF sea cada vez más grande. Los archivos AOF grandes consumen espacio en disco y hacen que Redis se reinicie más lentamente. Para resolver este problema, en las circunstancias apropiadas, Redis reescribirá el archivo AOF para eliminar los comandos redundantes en el archivo para reducir el tamaño del archivo AOF. Durante la reescritura del archivo AOF, Redis iniciará un subproceso, y el subproceso es responsable de reescribir el archivo AOF.
Puede controlar la frecuencia con la que Redis reescribe los archivos AOF a través de los siguientes dos elementos de configuración:
auto-aof-rewrite-min-size 64mbauto-aof-rewrite-percentage 100
El efecto de las dos configuraciones anteriores: cuando el tamaño del archivo AOF es superior a 64 MB, y el tamaño del archivo AOF es al menos el doble del tamaño después de la última reescritura, entonces Redis realizará la reescritura AOF.
ventaja:
- Alta frecuencia de persistencia y alta confiabilidad de datos
- Sin memoria adicional ni consumo de CPU
defecto:
- tamaño de archivo grande
- Los archivos grandes conducen a una baja eficiencia en la recuperación de datos del servicio
Discurso de la entrevista:
Redis proporciona dos métodos de persistencia de datos, uno es RDB y el otro es AOF. De forma predeterminada, Redis usa la persistencia de RDB.
Los archivos persistentes RDB son de tamaño pequeño, pero la frecuencia de guardado de datos es generalmente baja, la confiabilidad es baja y los datos se pierden fácilmente. Además, RDB utilizará la función Fork para copiar el proceso principal al escribir datos, lo que puede tener un consumo de memoria adicional, y la compresión de archivos también tendrá un consumo de CPU adicional.
La persistencia de ROF puede persistir una vez por segundo, con alta confiabilidad. Sin embargo, el archivo persistente es de gran tamaño, lo que resulta en mucho tiempo para leer el archivo durante la recuperación de datos, y la eficiencia es ligeramente baja.
3.3 ¿Cuáles son los métodos de agrupación en clústeres de Redis?
Discurso de la entrevista:
Los clústeres de Redis se pueden dividir en clústeres maestro-esclavo y clústeres fragmentados .
Los clústeres maestro-esclavo generalmente tienen un maestro y varios esclavos. La biblioteca maestra se usa para escribir datos y la biblioteca esclava se usa para leer datos. Combinado con Sentry, el maestro puede ser reelegido cuando la base de datos principal está inactiva, el propósito es garantizar la alta disponibilidad de Redis .
Los clústeres fragmentados son fragmentos de datos. Dejaremos que varios nodos de Redis formen un clúster y asignaremos 16383 ranuras a diferentes nodos. Al almacenar datos, use la operación hash en la clave para obtener el valor de la ranura y almacenarlo en el nodo correspondiente. Debido a que los datos de almacenamiento están orientados a la ranura en lugar del nodo en sí, el clúster se puede escalar dinámicamente. El propósito es permitir que Redis almacene más datos.
1) Clúster maestro-esclavo
El clúster maestro-esclavo también es un clúster de separación de lectura y escritura. Generalmente es un amo y muchos esclavos.
La función de replicación (replicación) de Redis permite a los usuarios crear cualquier cantidad de réplicas del servidor basadas en un servidor Redis, donde el servidor replicado es el servidor maestro (maestro) y la réplica del servidor creada por la replicación es el servidor esclavo (esclavo).
Siempre que la conexión de red entre los servidores maestro y esclavo sea normal, los servidores maestro y esclavo tendrán los mismos datos, y el servidor maestro siempre sincronizará las actualizaciones de datos que le suceden al servidor esclavo, asegurando así que los datos de los servidores maestro y esclavo son los mismos.
- La escritura de datos solo se puede hacer a través del nodo maestro
- La lectura de datos se puede hacer desde cualquier nodo.
- Si está configurado
哨兵节点, cuando el maestro se cae, el centinela elegirá un nuevo maestro del nodo esclavo.
Hay dos tipos de clústeres maestro-esclavo:
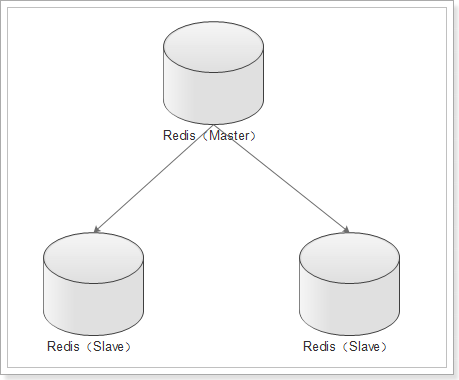
Racimo con centinelas:

2) Clúster de fragmentación
En el clúster maestro-esclavo, cada nodo debe guardar toda la información, lo que es fácil de formar un efecto de barril. Y cuando la cantidad de datos es grande, una sola máquina no puede satisfacer la demanda. En este punto, vamos a utilizar un clúster fragmentado.
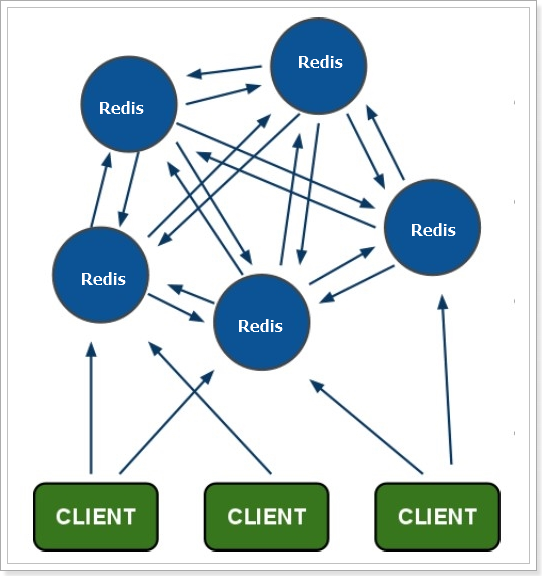
Características del racimo:
-
Cada nodo contiene datos diferentes.
-
Todos los nodos redis están interconectados entre sí (mecanismo PING-PONG), utilizando internamente un protocolo binario para optimizar la velocidad de transmisión y el ancho de banda.
-
La falla de un nodo surte efecto solo cuando más de la mitad de los nodos en el clúster detectan la falla.
-
El cliente está conectado directamente al nodo redis y no se requiere una capa de proxy intermedia para conectarse a ningún nodo disponible en el clúster para acceder a los datos.
-
redis-cluster asigna todos los nodos físicos a [0-16383] slots (ranuras) para lograr escalado dinámico
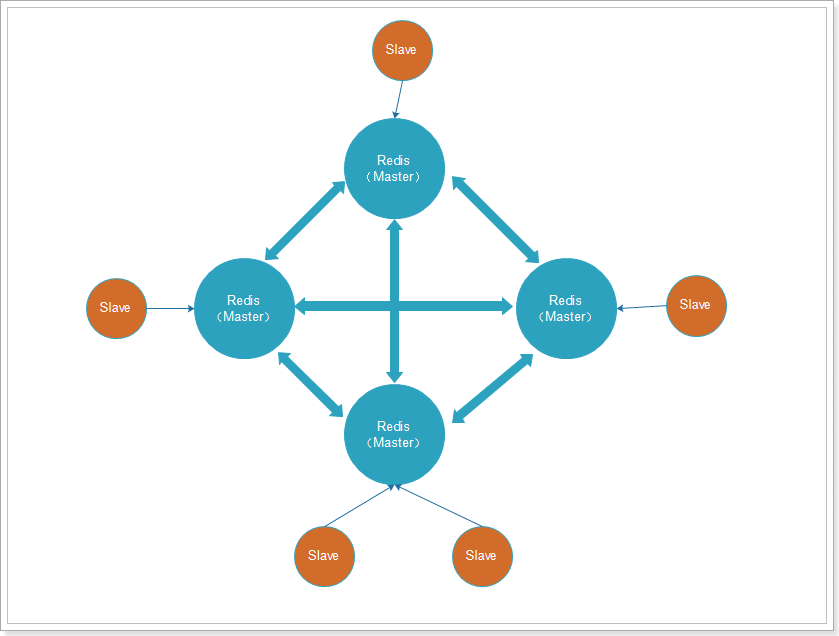
Para garantizar la alta disponibilidad de cada nodo en Redis, también podemos crear una replicación (nodo esclavo) para cada nodo, como se muestra en la figura:
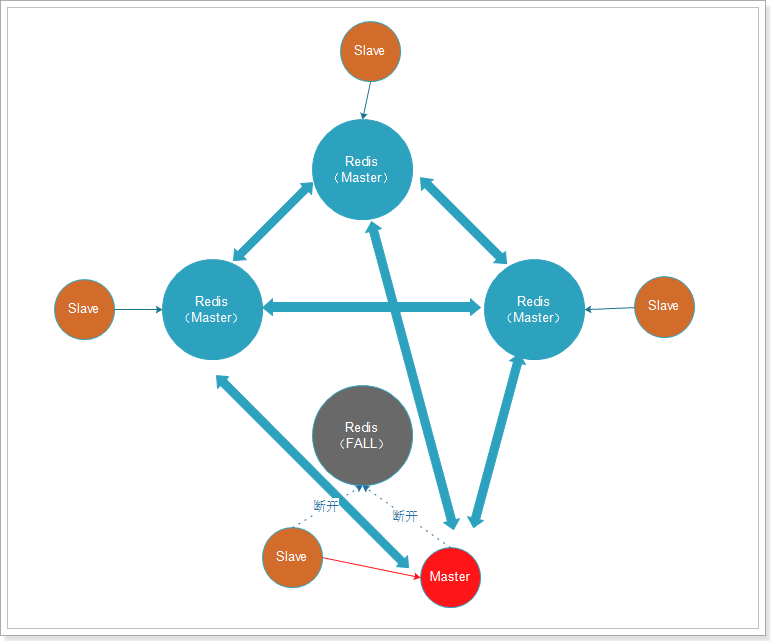
Cuando ocurre una falla, el maestro y el esclavo pueden cambiar a tiempo:
3.4 ¿Cuáles son los tipos de datos comunes de Redis?
Admite múltiples tipos de estructuras de datos, la principal diferencia es que el formato de datos del almacenamiento de valores es diferente:
-
cadena: El tipo de datos más básico, una cadena binaria segura, hasta 512M.
-
lista: una lista de cadenas que mantienen el orden en el orden en que se agregaron.
-
conjunto: una colección desordenada de cadenas sin elementos duplicados.
-
conjunto ordenado: una colección ordenada de cadenas.
-
hash: formato de par clave-valor
3.5 Hable sobre el mecanismo de transacción de Redis
Informacion relevante:
Referencia: http://redisdoc.com/topic/transaction.html
La función de transacción de Redis se realiza a través de las cuatro primitivas de MULTI, EXEC, DISCARD y WATCH. Redis serializa todos los comandos en una transacción y los ejecuta secuencialmente. Sin embargo, las transacciones de Redis no admiten operaciones de reversión.Después de que un comando se ejecuta incorrectamente, el comando correcto continuará ejecutándose.
MULTI: Se utiliza para iniciar una transacción, siempre devuelve OK. Después de ejecutar MULTI, el cliente puede continuar enviando cualquier cantidad de comandos al servidor. Estos comandos no se ejecutarán inmediatamente, sino que se colocarán en una cola de comandos para ser ejecutados.EXEC: Ejecuta todos los comandos en la cola de comandos secuencialmente. Devuelve el valor de retorno de todos los comandos. Durante la ejecución de la transacción, Redis no ejecutará comandos de otras transacciones.DISCARD: borre la cola de comandos y abandone la ejecución de la transacción, y el cliente saldrá del estado de transacciónWATCH: El mecanismo de bloqueo optimista de Redis, que utiliza el principio de comparar y configurar (CAS), puede monitorear una o más claves. Una vez que se modifica una de las claves, las transacciones posteriores no se ejecutarán.
Al usar transacciones, puede encontrar los siguientes dos tipos de errores:
- Los comandos en cola pueden dañarse antes de que se ejecute EXEC. Por ejemplo, un comando puede producir un error de sintaxis (número incorrecto de argumentos, nombre de argumento incorrecto, etc.) u otros errores más graves, como memoria insuficiente (si el servidor usa un límite máximo de memoria
maxmemoryestablecido- A partir de Redis 2.6.5, el servidor registrará la falla al poner en cola el comando, y cuando el cliente llame al comando EXEC, se negará a ejecutar y abandonará automáticamente la transacción.
- El comando puede fallar después de la llamada EXEC. Por ejemplo, un comando en una transacción puede manejar el tipo de clave incorrecto, como usar un comando de lista en una clave de cadena, etc.
- Incluso si algunos/algunos comandos en la transacción generan un error durante la ejecución, otros comandos en la transacción seguirán ejecutándose y no se revertirán.
¿Por qué Redis no admite la reversión (roll back)?
Estas son las ventajas de este enfoque:
- Los comandos de Redis solo pueden fallar debido a una sintaxis incorrecta (y estos problemas no se pueden detectar al poner en cola), o porque el comando se usa en el tipo de clave incorrecto: es decir, desde un punto de vista práctico, el comando que falla es causado por errores de programación , y estos errores deben encontrarse en el proceso de desarrollo, y no deben aparecer en el entorno de producción.
- Dado que no hay necesidad de admitir reversiones, las funciones internas de Redis pueden mantenerse simples y rápidas.
Dado que no existe un mecanismo para evitar los errores causados por los propios programadores, y dichos errores generalmente no aparecen en un entorno de producción, Redis elige una forma más simple y rápida de manejar las transacciones sin retroceder.
Discurso de la entrevista:
Las transacciones de Redis en realidad colocan una serie de comandos de Redis en la cola y luego los ejecutan en lotes sin interrupción por otras transacciones durante la ejecución. Sin embargo, a diferencia de las transacciones de bases de datos relacionales, las transacciones de Redis no admiten operaciones de reversión.Si un comando no se ejecuta en una transacción, se seguirán ejecutando otros comandos.
Para compensar el problema de no poder retroceder, Redis verificará el comando cuando la transacción esté en cola y, si el comando es anormal, se abandonará toda la transacción.
Por lo tanto, siempre que la programación del programador sea correcta, en teoría, Redis ejecutará todas las transacciones correctamente sin retroceder.
Entrevistador: ¿Qué sucede si Redis falla a la mitad de la ejecución de la transacción?
Redis tiene un mecanismo de persistencia. Debido a problemas de confiabilidad, generalmente usamos la persistencia AOF. Todos los comandos de la transacción también se escribirán en el archivo AOF, pero si Redis está inactivo antes de que se ejecute el comando EXEC, la transacción en el archivo AOF estará incompleta. Utilice redis-check-aofel programa para eliminar la información de transacción incompleta en el archivo AOF para asegurarse de que el servidor pueda iniciarse sin problemas.