Pila de tecnología de microservicio SpringCloud Seguimiento de Dark Horse 7
- el objetivo de hoy
- 1. Agregación de datos
- 2. Autocompletar
- 3. Sincronización de datos
- 4. Grupo
el objetivo de hoy

1. Agregación de datos
** Agregaciones ( aggregations ) ** nos permiten realizar las estadísticas, análisis y explotación de datos de forma extremadamente cómoda. Por ejemplo:
- ¿Qué marca de teléfono móvil es la más popular?
- ¿El precio promedio, el precio más alto, el precio más bajo de estos teléfonos?
- ¿Cómo se venden estos teléfonos mensualmente?
Es mucho más conveniente implementar estas funciones estadísticas que el sql de la base de datos, y la velocidad de consulta es muy rápida, lo que puede lograr un efecto de búsqueda casi en tiempo real.
1.1 Tipos de agregación
Hay tres tipos comunes de agregación:
-
Agregación **Cubo**: se utiliza para agrupar documentos
- TermAggregation: agrupar por valor de campo de documento, como agrupar por valor de marca, agrupar por país
- Histograma de fechas: agrupar por escala de fechas, por ejemplo, una semana como grupo o un mes como grupo
-
**Agregación de métricas**: se utiliza para calcular algunos valores, tales como: valor máximo, valor mínimo, valor promedio, etc.
- Promedio: Promedio
- Max: encontrar el valor máximo
- Min: encontrar el valor mínimo
- Estadísticas: busque simultáneamente máximo, mínimo, promedio, suma, etc.
-
**Pipeline** Agregación: Agregación basada en los resultados de otras agregaciones
**Nota:** Los campos que participan en la agregación deben ser palabra clave, fecha, valor y valor booleano.
1.2.DSL realiza la agregación
Ahora, queremos contar las marcas hoteleras en todos los datos, de hecho, agrupamos los datos según la marca. En este punto, la agregación se puede realizar en función del nombre de la marca del hotel, es decir, la agregación de cubos. ### 1.2.1 Sintaxis de agregación de depósitos
La sintaxis es la siguiente:
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": {
// 定义聚合
"brandAgg": {
//给聚合起个名字
"terms": {
// 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
El resultado se muestra en la figura:

1.2.2 Clasificación de resultados de agregación
De forma predeterminada, la agregación del depósito contará el número de documentos en el depósito, lo registrará como _count y ordenará en orden descendente de _count.
Podemos especificar el atributo de orden para personalizar el método de clasificación de la agregación:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
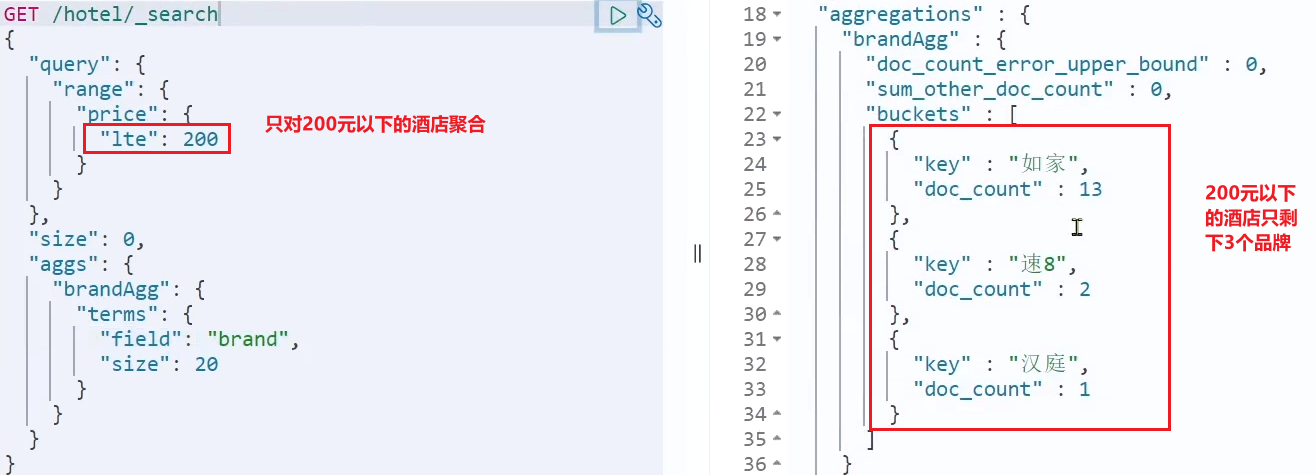
1.2.3 Limitar el alcance de la agregación
De forma predeterminada, la agregación de depósitos agrega todos los documentos en la biblioteca de índices, pero en escenarios reales, los usuarios ingresarán las condiciones de búsqueda, por lo que la agregación debe ser la agregación de los resultados de la búsqueda. Entonces la agregación tiene que ser calificada.
Podemos limitar el rango de documentos que se agregarán agregando condiciones de consulta:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
Esta vez, las marcas agregadas son significativamente menos:
1.2.4 Sintaxis de agregación de métricas
En la última clase, agrupamos los hoteles por marca para formar cubos. Ahora necesitamos realizar cálculos en los hoteles en el cubo para obtener los valores mínimo, máximo y promedio de las calificaciones de los usuarios para cada marca.
Esto requiere el uso de la agregación de métricas, como la agregación de estadísticas: puede obtener resultados como mínimo, máximo y promedio.
La sintaxis es la siguiente:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": {
// 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": {
// 聚合名称
"stats": {
// 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
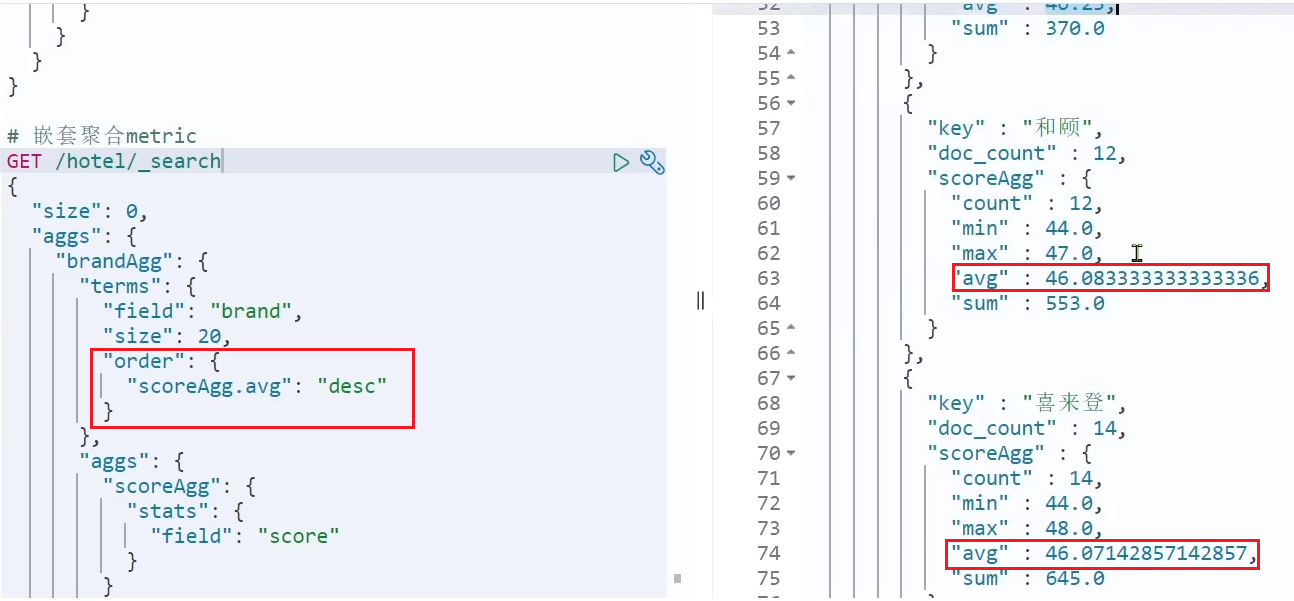
Esta vez, la agregación score_stats es una subagregación anidada dentro de la agregación brandAgg. Porque necesitamos calcular por separado en cada cubeta.
Además, también podemos ordenar los resultados de la agregación, por ejemplo, de acuerdo con el puntaje promedio del hotel de cada categoría:
1.2.5 Resumen
aggs significa agregación, que está al mismo nivel que consulta ¿Cuál es la función de consulta en este momento?
-
Limitar el alcance de los documentos agregados
La agregación debe tener tres elementos: -
nombre agregado
-
tipo de agregación
-
campo agregado
Las propiedades configurables agregadas son:
- tamaño: especifique el número de resultados de agregación
- order: especifique el método de clasificación de los resultados de agregación
- campo: especifique el campo de agregación
1.3 RestAPI implementa la agregación
1.3.1 Sintaxis de la API
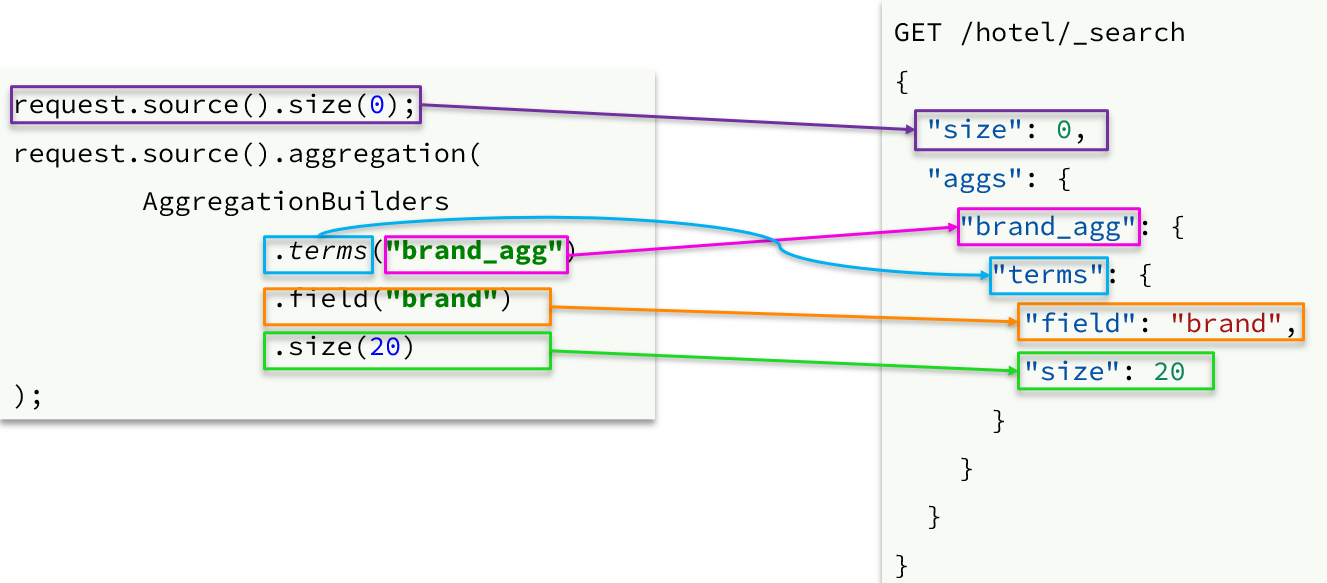
Las condiciones de agregación están al mismo nivel que las condiciones de consulta, por lo que se debe usar request.source() para especificar las condiciones de agregación.
Sintaxis para condiciones agregadas:
El resultado de la agregación también es diferente del resultado de la consulta y la API también es especial. Pero también es JSON análisis capa por capa:
el código final
HotelSearchTest.java
@Test
public void testAggregation() throws IOException {
// 1.准备request
SearchRequest searchRequest = new SearchRequest("hotel");
// 2.准备DSL
searchRequest.source().size(0);
searchRequest.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10).order(BucketOrder.aggregation("_count", true)));
// 3.发出请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4.给出结果
//System.out.println(response);
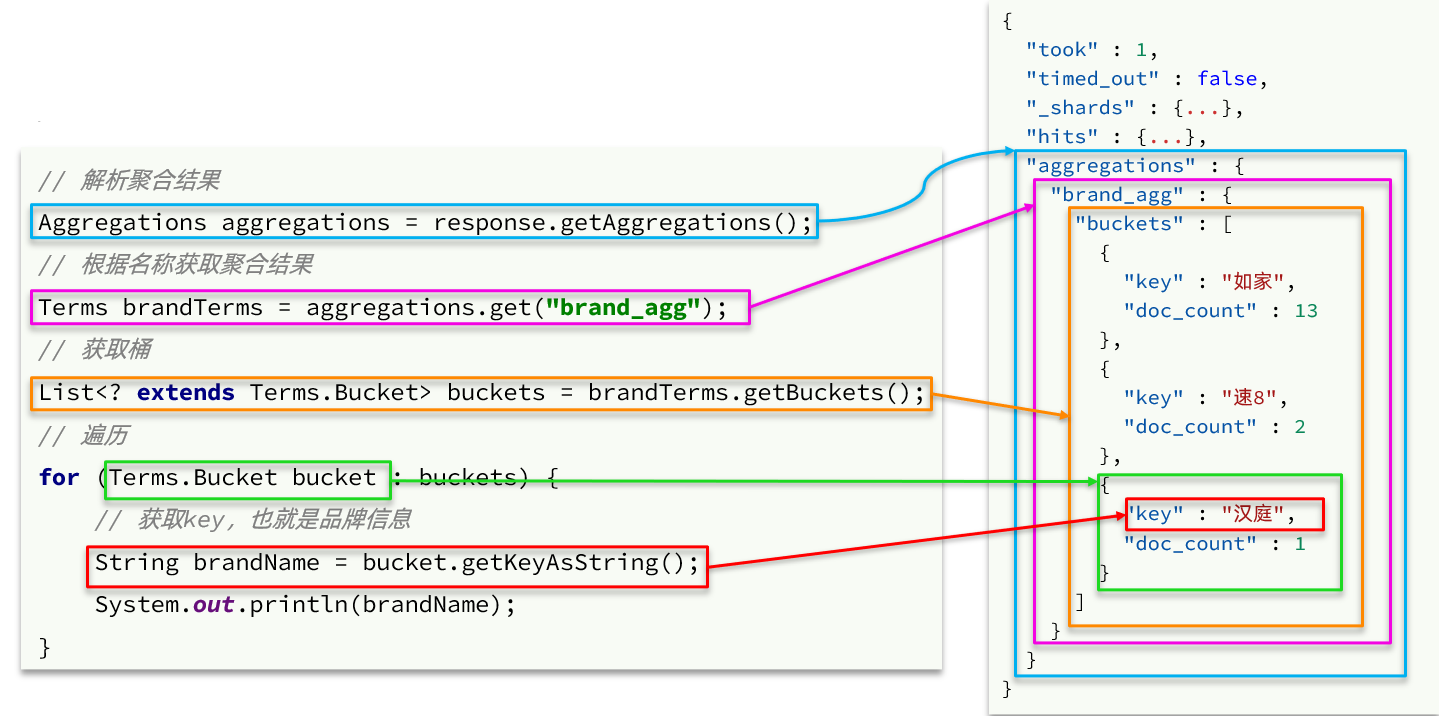
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
System.out.println(brandName);
}
}
Resultado de salida:

1.3.2 Requisitos comerciales
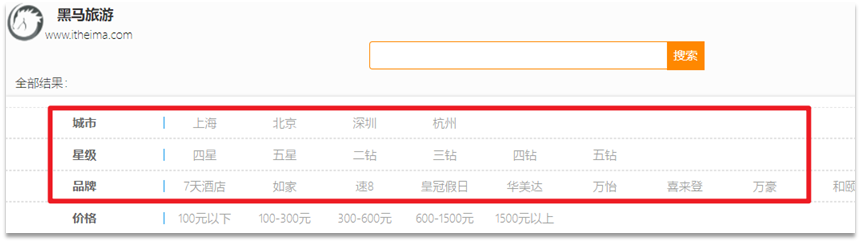
Requisito: la marca, la ciudad y otra información de la página de búsqueda no deben codificarse en la página, sino obtenerse mediante datos agregados del hotel en la base de datos del índice:
analizar:
Actualmente, la lista de ciudades, la lista de estrellas y la lista de marcas en la página están codificadas y no cambiarán a medida que cambien los resultados de la búsqueda. Pero cuando las condiciones de búsqueda del usuario cambien, los resultados de la búsqueda cambiarán en consecuencia.
Por ejemplo, si un usuario busca "Perla Oriental", el hotel buscado debe estar cerca de la Torre de la Perla Oriental de Shanghái. Por lo tanto, la ciudad solo puede ser Shanghái. En este momento, Beijing, Shenzhen y Hangzhou no deben mostrarse en la lista. lista de ciudades
Es decir, qué ciudades se incluyen en los resultados de búsqueda, qué ciudades se deben enumerar en la página, qué marcas se incluyen en los resultados de búsqueda, qué marcas se deben enumerar en la página.
¿Cómo puedo saber qué marcas están incluidas en mis resultados de búsqueda? ¿Cómo puedo saber qué ciudades están incluidas en mis resultados de búsqueda?
Utilice la función de agregación y la agregación de cubos para agrupar los documentos en los resultados de búsqueda según marcas y ciudades, y podrá saber qué marcas y ciudades están incluidas.
Debido a que es una agregación de resultados de búsqueda, la agregación es una agregación de rango limitado , es decir, las condiciones limitantes de la agregación son consistentes con las condiciones del documento de búsqueda.
Mirando el navegador, podemos encontrar que el front-end en realidad ha enviado tal solicitud:
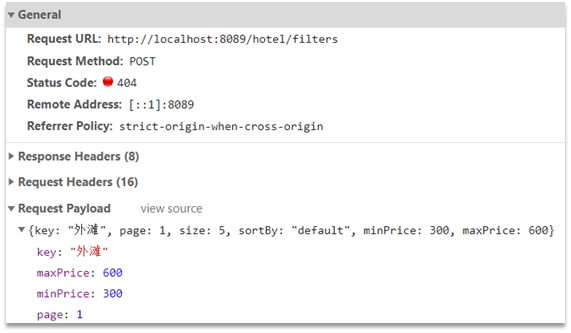
Los parámetros de la solicitud son exactamente los mismos que para la búsqueda de documentos .
El tipo de valor de retorno es el resultado final que se mostrará en la página:
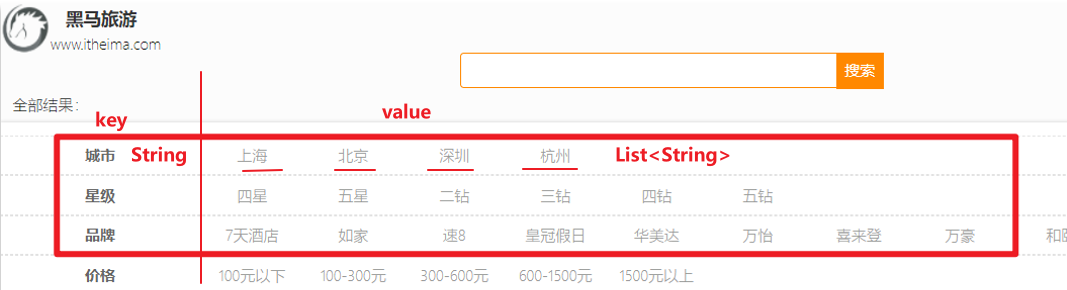
El resultado es una estructura Map:
- la clave es una cadena, ciudad, estrella, marca, precio
- el valor es una colección, como los nombres de varias ciudades
1.3.3 Realización de Negocios
Agregue un método al cn.itcast.hotel.webpaquete HotelController, siguiendo los requisitos:
- Método de solicitud:
POST - Solicitud de ruta:
/hotel/filters - Parámetros de la solicitud:
RequestParams, consistentes con los parámetros del documento de búsqueda - Tipo de valor de retorno:
Map<String, List<String>>
código:
@PostMapping("filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params){
return hotelService.getFilters(params);
}
Aquí se llama al método getFilters en IHotelService, que aún no se ha implementado. Defina el nuevo método en
:cn.itcast.hotel.service.IHotelService
Map<String, List<String>> filters(RequestParams params);
cn.itcast.hotel.service.impl.HotelServiceImplementar el método en :
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.设置size
request.source().size(0);
// 2.3.聚合
buildAggregation(request);
// 3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
// 4.1.根据品牌名称,获取品牌结果
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("brand", brandList);
// 4.2.根据品牌名称,获取品牌结果
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("city", cityList);
// 4.3.根据品牌名称,获取品牌结果
List<String> starList = getAggByName(aggregations, "starAgg");
result.put("starName", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
// 4.1.根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
// 4.2.获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 4.3.遍历
List<String> brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
// 4.4.获取key
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
Ver resultados:

2. Autocompletar
Cuando el usuario ingresa un carácter en el cuadro de búsqueda, debemos solicitar el elemento de búsqueda relacionado con el carácter, como se muestra en la figura:
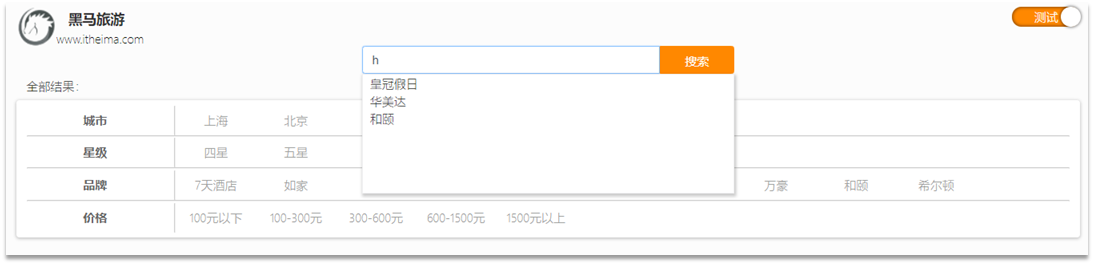
Esta función de solicitar la entrada completa de acuerdo con la letra ingresada por el usuario es una finalización automática.
Debido a que debe inferirse en función de las letras pinyin, se utiliza la función de segmentación de palabras pinyin.
2.1 Tokenizador Pinyin
Para lograr la finalización basada en letras, es necesario segmentar el documento según pinyin. Resulta que hay un complemento de segmentación de palabras pinyin para elasticsearch en GitHub. Dirección: Complemento del separador de palabras Pinyin
El paquete de instalación del separador de palabras Pinyin también se proporciona en los materiales previos a la clase: el
método de instalación es el mismo que el separador de palabras IK, en tres pasos:
①Descomprimir
②Subir a la máquina virtual , el directorio de complementos de
la ubicación del directorio de elasticsearch:
/var/lib/docker/volumes/es-plugins/_data

③Reiniciar búsqueda elástica
docker restart es

④Prueba Para conocer
los pasos de instalación detallados, consulte el proceso de instalación del tokenizador IK.
El uso de la prueba es el siguiente:
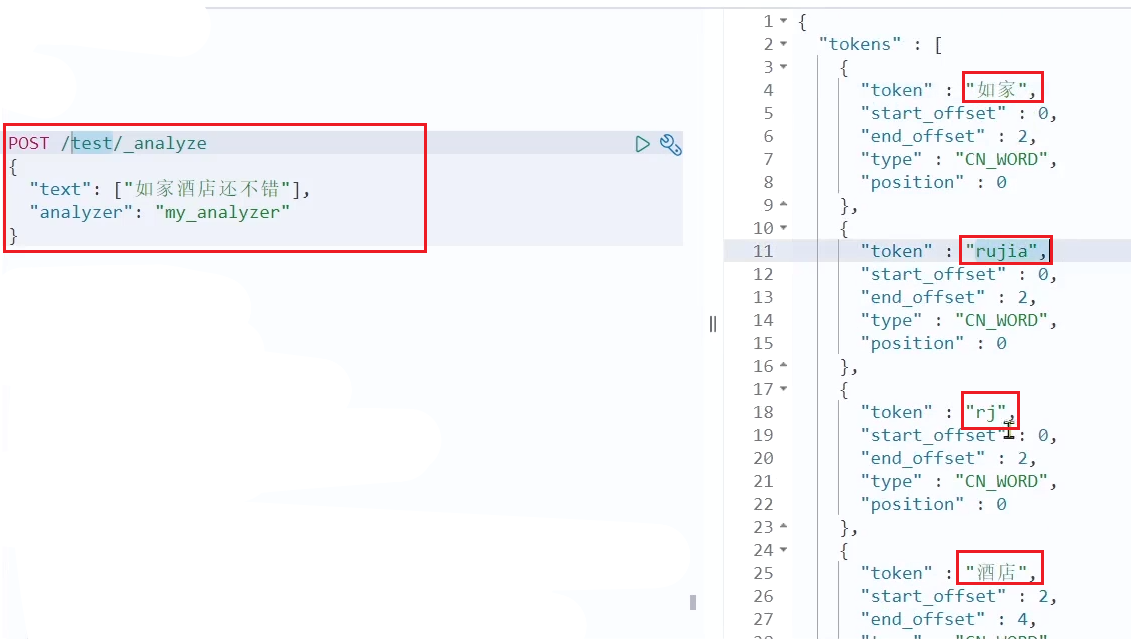
POST /_analyze
{
"text": "如家酒店还不错",
"analyzer": "pinyin"
}
Resultado:

puede ver que hay un problema con el segmentador de palabras Pinyin
1. Solo Pinyin no tiene caracteres chinos, y Pinyin debería ser la guinda del pastel, no solo Pinyin
2. Pinyin no implementa la segmentación de palabras, pero el nombre completo
Con base en los problemas anteriores, necesitamos personalizar el separador de palabras pinyin
2.2 Tokenizador personalizado
El separador de palabras pinyin predeterminado divide cada carácter chino en pinyin, pero queremos que cada entrada forme un conjunto de pinyin, por lo que debemos personalizar el separador de palabras pinyin para formar un separador de palabras personalizado.
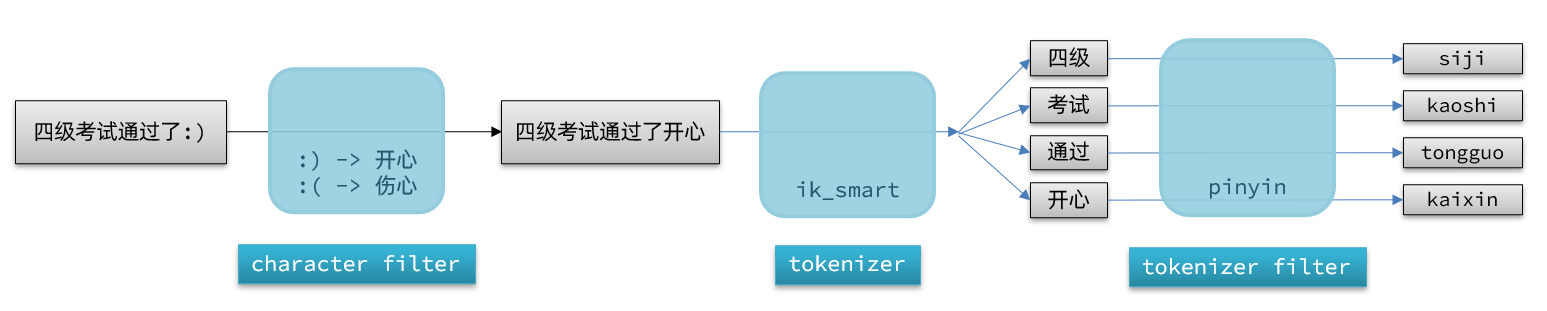
La composición del analizador en elasticsearch consta de tres partes:
- Filtros de caracteres: procesa el texto antes del tokenizador. por ejemplo, eliminar caracteres, reemplazar caracteres
- tokenizer: Cortar el texto en términos de acuerdo a ciertas reglas. Por ejemplo, palabra clave no es participio; también existe ik_smart
- Filtro tokenizador: procesa más las entradas generadas por el tokenizador. Por ejemplo, conversión de casos, procesamiento de sinónimos, procesamiento de pinyin, etc.
Estas tres partes procesarán el documento a su vez al segmentarlo:
la sintaxis para declarar un tokenizador personalizado es la siguiente:
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
// 自定义分词器
"my_analyzer": {
// 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
// 自定义tokenizer filter
"py": {
// 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
}
}
}
}
Prueba:
Otra forma de probar:
# 测试分词器
POST /test/_doc/1
{
"id" : 1,
"name":"狮子"
}
POST /test/_doc/2
{
"id" : 2,
"name":"虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}
Resultado de la prueba:

buscamos caracteres chinos y encontramos piojos, lo que obviamente es incorrecto

Resumir:
¿Cómo usar el tokenizador Pinyin?
-
①Descargue el tokenizador pinyin
-
② Descomprímalo y colóquelo en el directorio de complementos de elasticsearch
-
③Reiniciar
¿Cómo personalizar el tokenizador?
-
① Al crear una biblioteca de índices, configúrela en la configuración, que puede contener tres partes
-
②filtro de caracteres
-
③tokenizador
-
④filtro
¿Precauciones para el separador de palabras pinyin?
- Para evitar la búsqueda de homófonos, no use el separador de palabras pinyin al buscar.

Solución: agregue search_analyzer
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
// 自定义分词器
"my_analyzer": {
// 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
// 自定义tokenizer filter
"py": {
// 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
Buscar aquí de nuevo

2.3 Autocompletar consulta
Elasticsearch proporciona una consulta Sugerente de finalización para lograr la finalización automática. Esta consulta hará coincidir los términos que comienzan con la entrada del usuario y los devolverá. Para mejorar la eficiencia de la consulta de finalización, existen algunas restricciones en los tipos de campos en el documento:
- Los campos que participan en la consulta de cumplimentación deben ser de tipo cumplimentación.
- El contenido del campo es generalmente una matriz formada por múltiples entradas para completar.
Puede eliminar la biblioteca de índice probada anteriormente
DELETE /test
Por ejemplo, una biblioteca de índice como esta:
// 创建索引库
PUT test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
Luego inserte los siguientes datos:
// 示例数据
POST test/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
La instrucción de consulta DSL es la siguiente:
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
Mostrar después de la consulta:

Resumen:
requisitos de autocompletado para los campos:
● El tipo es el tipo de finalización
● El valor del campo es una matriz de varias entradas
2.4 Realice la finalización automática del cuadro de búsqueda de hotel
Ahora, nuestra biblioteca de índices de hoteles no ha configurado un separador de palabras pinyin, y necesitamos modificar la configuración en la biblioteca de índices. Pero sabemos que la biblioteca de índice no se puede modificar, solo se puede eliminar y luego volver a crear.
Además, debemos agregar un campo para completar automáticamente y colocar la marca, la sugerencia, la ciudad, etc. como un aviso para completar automáticamente.
Entonces, para resumir, las cosas que debemos hacer incluyen:
- Modifique la estructura de la biblioteca de índices de hoteles y establezca un separador de palabras pinyin personalizado
- Modifique el nombre y todos los campos de la biblioteca de índice y use un tokenizador personalizado
- La biblioteca de índice agrega una nueva sugerencia de campo, el tipo es el tipo de finalización, utilizando un tokenizador personalizado
- Agregue un campo de sugerencia a la clase HotelDoc, que contiene marca y negocio
- Reimportar datos a la biblioteca del hotel
2.4.1 Modificar la estructura de mapeo de hoteles
El código es el siguiente:
primero elimine la biblioteca de índice anterior
DELETE /hotel
# 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
2.4.2 Modificar la entidad HotelDoc
Se debe agregar un campo en HotelDoc para que se complete automáticamente, y el contenido puede ser información como la marca del hotel, la ciudad, el distrito comercial, etc. Según sea necesario para los campos de autocompletar, preferiblemente una matriz de estos campos.
Entonces agregamos un campo de sugerencia en HotelDoc, el tipo es List<String>, y luego ponemos información como marca, ciudad, negocio, etc.
el código se muestra a continuación:
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
this.suggestion = Arrays.asList(this.brand, this.business);
}
}
2.4.3 Reimportar
Importado por el lote de prueba de unidad anterior

Vuelva a ejecutar la función de importación de datos escrita anteriormente, y podrá ver que los nuevos datos del hotel contienen sugerencias: pero si contiene 2 distritos comerciales, será una coma, entonces debemos dividir la coma

Modifique la clase de entidad HotelDoc.java
para aumentar la división de comas
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
// 组装suggestion
if(this.business.contains("/")){
// business有多个值,需要切割
String[] arr = this.business.split("、");
// 添加元素
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
this.suggestion.add(this.city);
Collections.addAll(this.suggestion, arr);
}else {
this.suggestion = Arrays.asList(this.brand, this.business, this.city);
}
}
}
Luego verifique los resultados:

pruebe también el autocompletado
# 测试提示查询
GET /hotel/_search
{
"suggest": {
"suggestions": {
"text": "sd",
"completion": {
"field": "suggestion",
"skip_duplicates" : true,
"size" : 10
}
}
}
}
Resultado de la consulta:
todos comienzan con SD

2.4.4 API de Java para consulta de autocompletado
Antes, aprendimos el DSL de la consulta de finalización automática, pero no aprendimos la API de Java correspondiente. Aquí hay un ejemplo: el
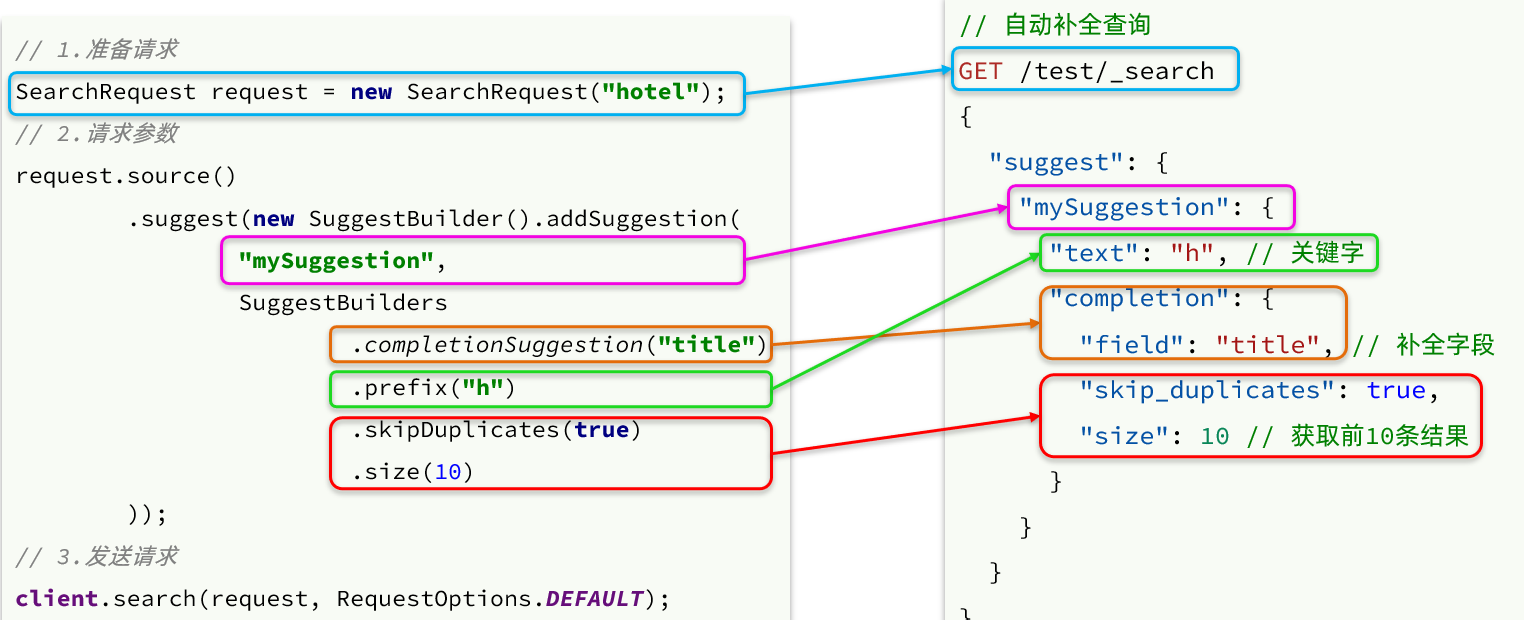
resultado de la finalización automática también es especial, y el código de análisis es el siguiente:

Primero escribamos una clase de prueba para probar
y modificar HotelSearchTest.java
@Test
public void testSuggestionsSearch() throws IOException {
// 1.准备SearchRequest
SearchRequest searchRequest = new SearchRequest("hotel");
// 2.准备DSL
searchRequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("sd").skipDuplicates(true).size(10)));
// 3.发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4.解析结果
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
List<String> list = new ArrayList<>(options.size());
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
System.out.println(list);
}
resultado de búsqueda:

2.4.5 Darse cuenta de la finalización automática del cuadro de búsqueda
Si observamos la página del front-end, podemos encontrar que cuando escribimos en el cuadro de entrada, el front-end iniciará una solicitud ajax:
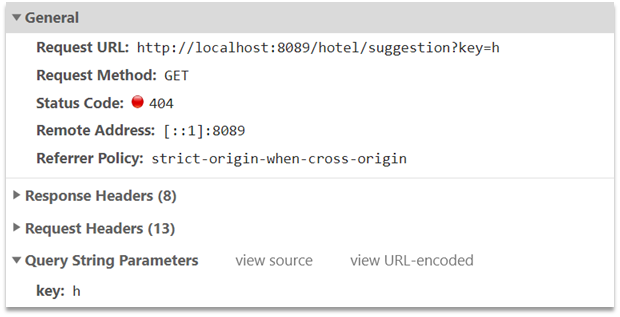
el valor devuelto es una colección de entradas completadas, y el tipo esList<String>
1) Agregue una nueva interfaz cn.itcast.hotel.webdebajo del paquete HotelControllerpara recibir nuevas solicitudes:
@GetMapping("suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix) {
return hotelService.getSuggestions(prefix);
}
2) Agregue el método en cn.itcast.hotel.serviceel paquete :IhotelService
List<String> getSuggestions(String prefix);
3) cn.itcast.hotel.service.impl.HotelServiceImplementar el método en:
@Override
public List<String> getSuggestions(String prefix) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
// 3.发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Suggest suggest = response.getSuggest();
// 4.1.根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
// 4.2.获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
// 4.3.遍历
List<String> list = new ArrayList<>(options.size());
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
resultado de búsqueda:

3. Sincronización de datos
Los datos del hotel en elasticsearch provienen de la base de datos mysql, por lo que cuando los datos mysql cambian, elasticsearch también debe cambiar en consecuencia. Esta es la sincronización de datos entre elasticsearch y mysql .

3.1 Análisis del pensamiento
Hay tres esquemas comunes de sincronización de datos:
- llamada síncrona
- notificación asíncrona
- registro de binlog del monitor
3.1.1 Llamada síncrona
Solución 1: llamada síncrona

Los pasos básicos son los siguientes:
- hotel-demo proporciona una interfaz para modificar los datos en elasticsearch
- Una vez que el servicio de administración del hotel completa la operación de la base de datos, llama directamente a la interfaz proporcionada por hotel-demo,
3.1.2 Notificación asíncrona
Solución 2: notificación asíncrona
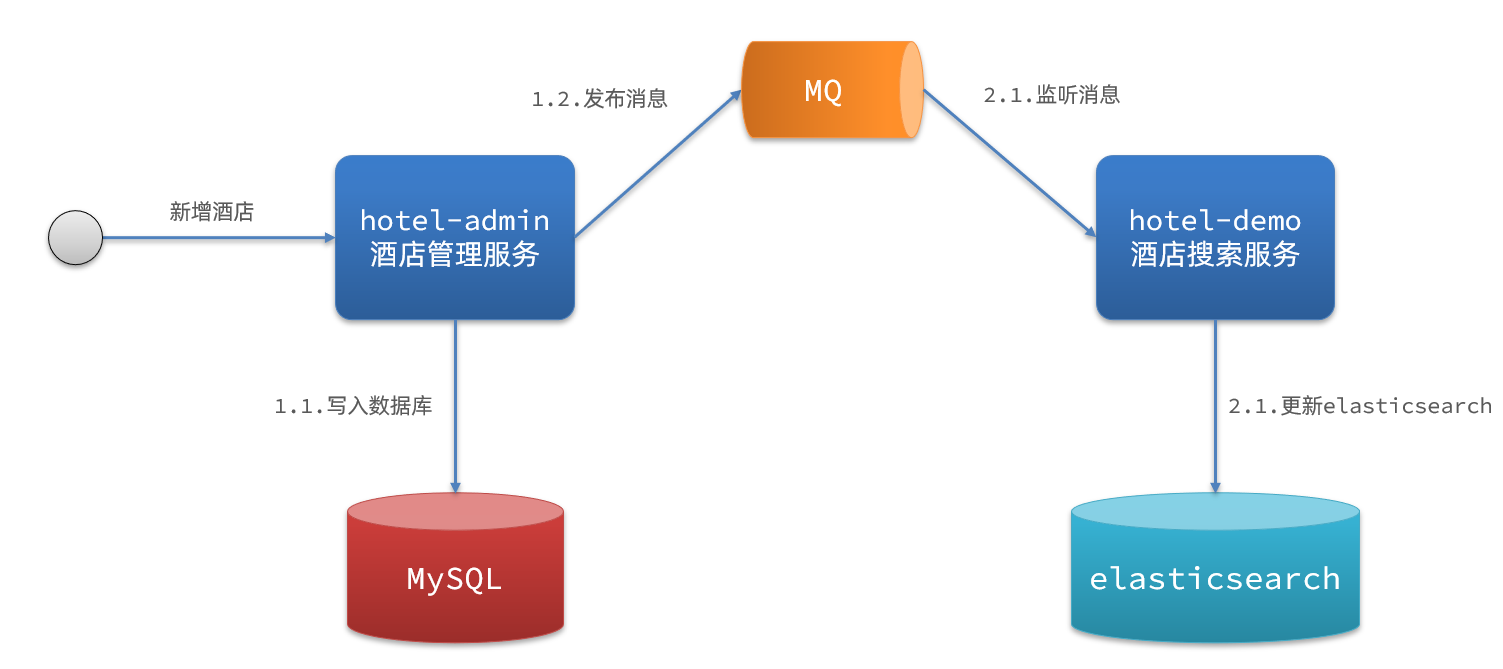
El proceso es el siguiente:
- El administrador del hotel envía un mensaje MQ después de agregar, eliminar y modificar los datos de la base de datos mysql
- Hotel-demo escucha MQ y completa la modificación de datos de elasticsearch después de recibir el mensaje
3.1.3 Supervisar binlog
Solución 3:
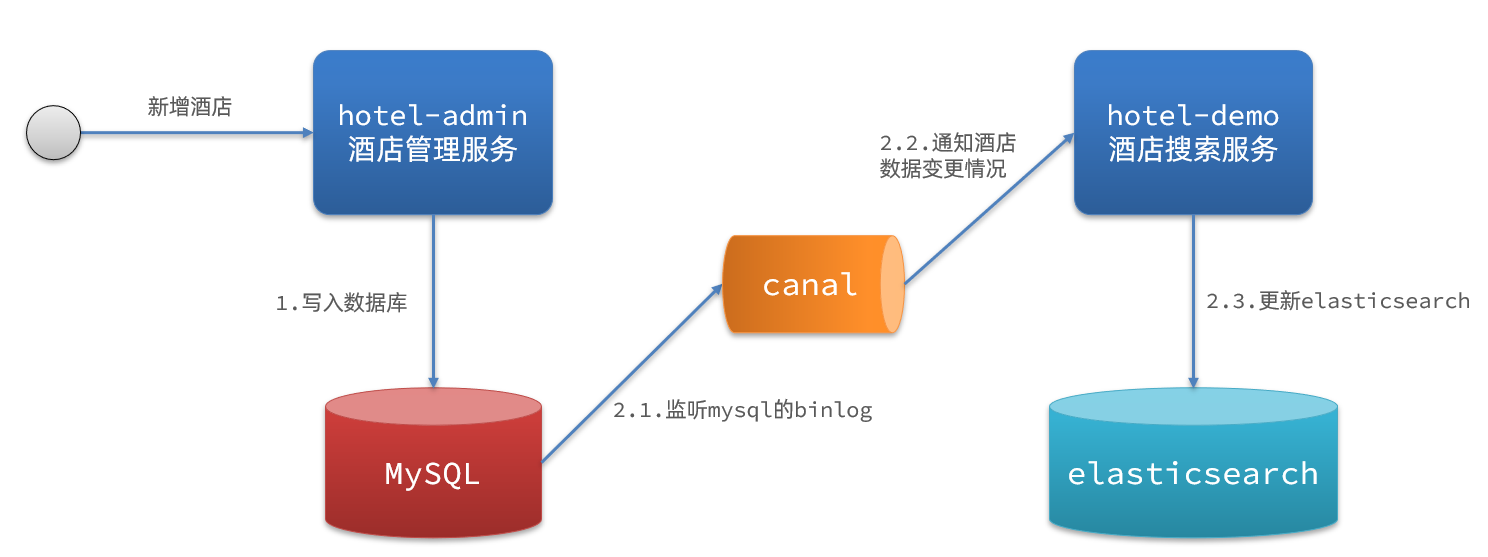
El proceso de monitoreo de binlog es el siguiente:
- Habilite la función binlog para mysql
- Las operaciones de adición, eliminación y modificación de mysql quedarán registradas en el binlog
- Hotel-demo monitorea los cambios de binlog según el canal y actualiza el contenido en elasticsearch en tiempo real
3.1.4 Selección
Método 1: llamada síncrona
- Ventajas: simple de implementar, tosco
- Inconvenientes: alto grado de acoplamiento empresarial
Método 2: notificación asíncrona
- Ventajas: acoplamiento bajo, generalmente difícil de implementar
- Desventajas: confíe en la confiabilidad de mq
Método 3: monitorear binlog
- Ventajas: Desacoplamiento completo entre servicios
- Desventajas: Habilitar binlog aumenta la carga de la base de datos y la alta complejidad de implementación
3.2 Realizar la sincronización de datos
3.2.1 Ideas
Utilice el proyecto de administración de hotel proporcionado por los materiales previos a la clase como un microservicio para la gestión hotelera. Cuando se agregan, eliminan o modifican los datos del hotel, se requiere la misma operación para los datos en elasticsearch.
paso:
- Importe el proyecto de administración del hotel proporcionado por los materiales previos al curso, inicie y pruebe el CRUD de los datos del hotel
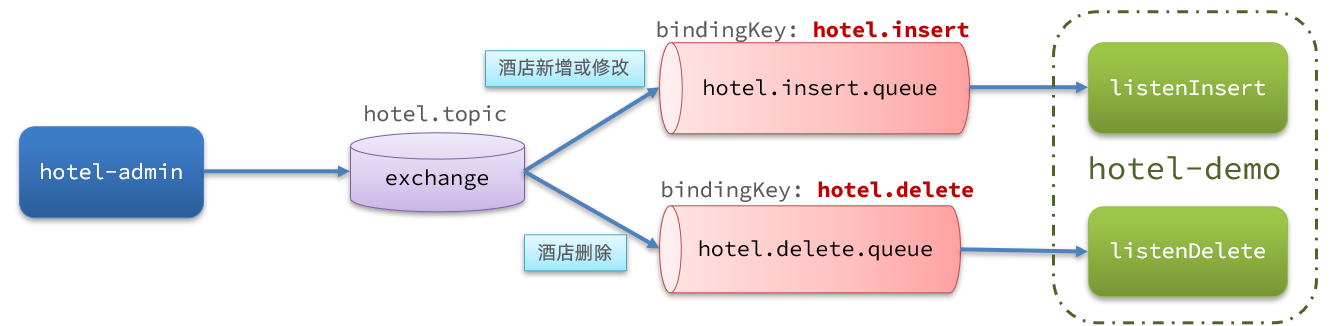
- Declarar intercambio, cola, RoutingKey
- Complete el envío de mensajes en agregar, eliminar y cambiar negocios en hotel-admin
- Monitoreo completo de mensajes en hotel-demo y actualización de datos en elasticsearch
- Iniciar y probar la función de sincronización de datos
3.2.2 Importar demostración
Importe el proyecto de administración del hotel proporcionado por los materiales previos al curso:
Después de ejecutar, visite http://localhost:8099
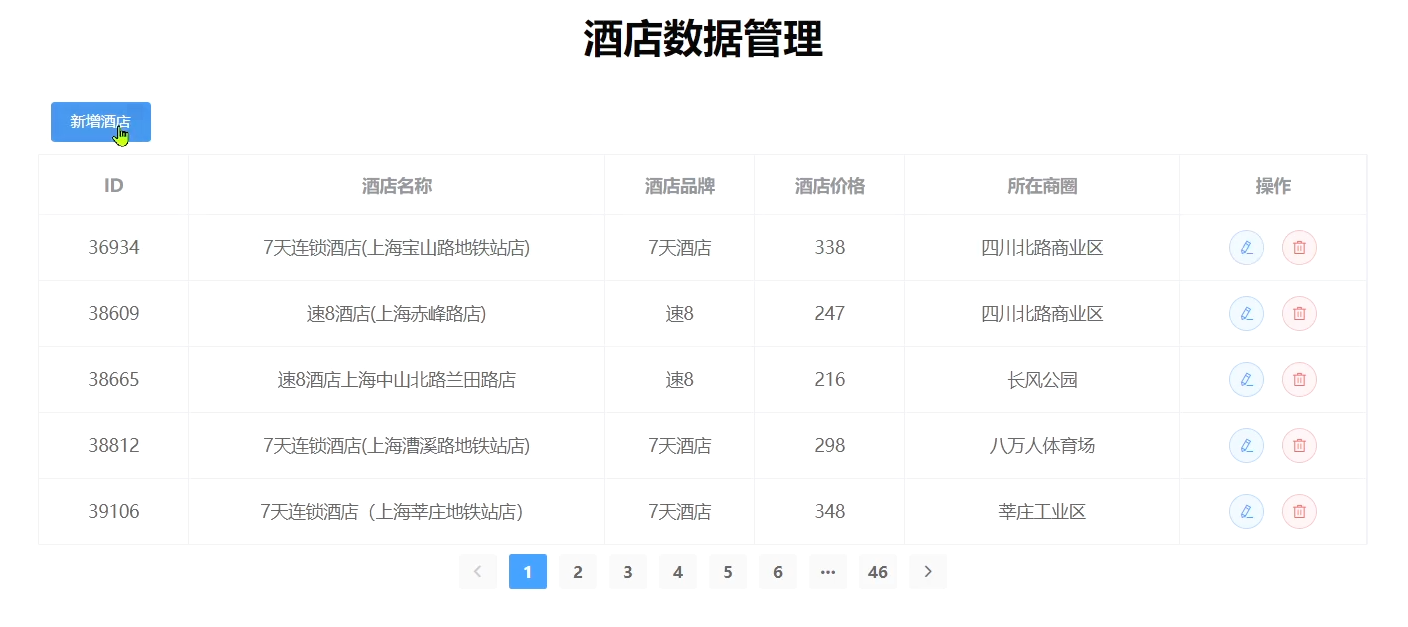
, que contiene la función CRUD del hotel:
 ### 3.2.3 Declare la
### 3.2.3 Declare la
estructura MQ de conmutador y cola como se muestra en la figura:
start mq
docker start mq

1) Introducir dependencias
Introduce la dependencia de rabbitmq en hotel-admin y hotel-demo:
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2) Declarar el nombre del interruptor de cola
cn.itcast.hotel.constatntsCree una nueva clase bajo los paquetes en hotel-admin y hotel-demo MqConstants:
package cn.itcast.hotel.constatnts;
public class MqConstants {
/**
* 交换机
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/**
* 监听新增和修改的队列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/**
* 监听删除的队列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/**
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/**
* 删除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
3) Declarar un cambio de cola
Defina clases de configuración en hotel-demo y hotel-admin respectivamente, y declare colas y conmutadores:
package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MqConfig {
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);
}
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
3.2.4 Enviar mensaje MQ
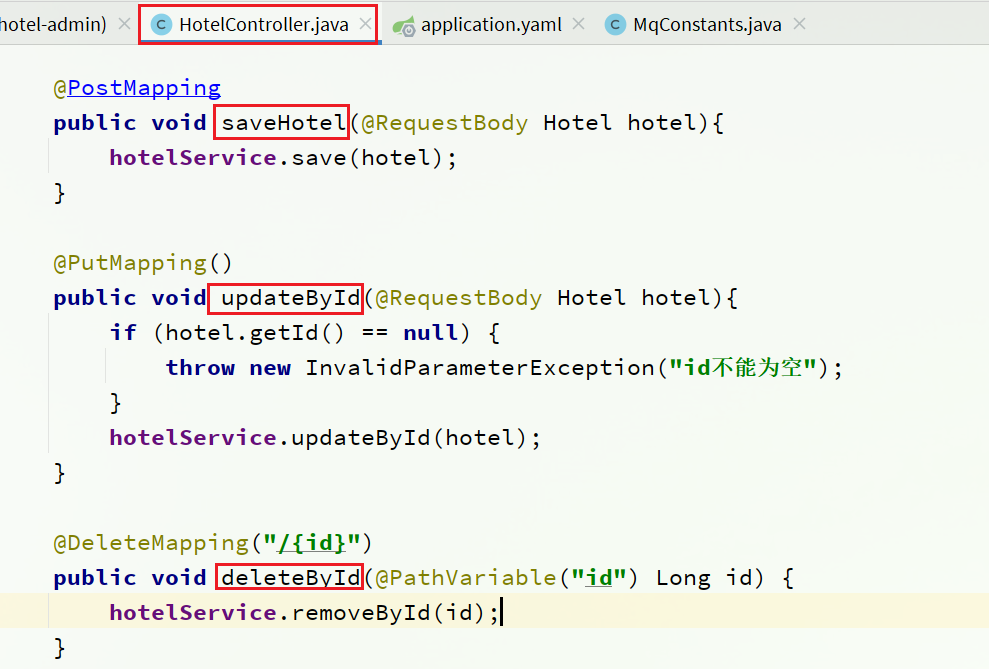
Envíe mensajes MQ por separado en los servicios de agregar, eliminar y modificar en hotel-admin:
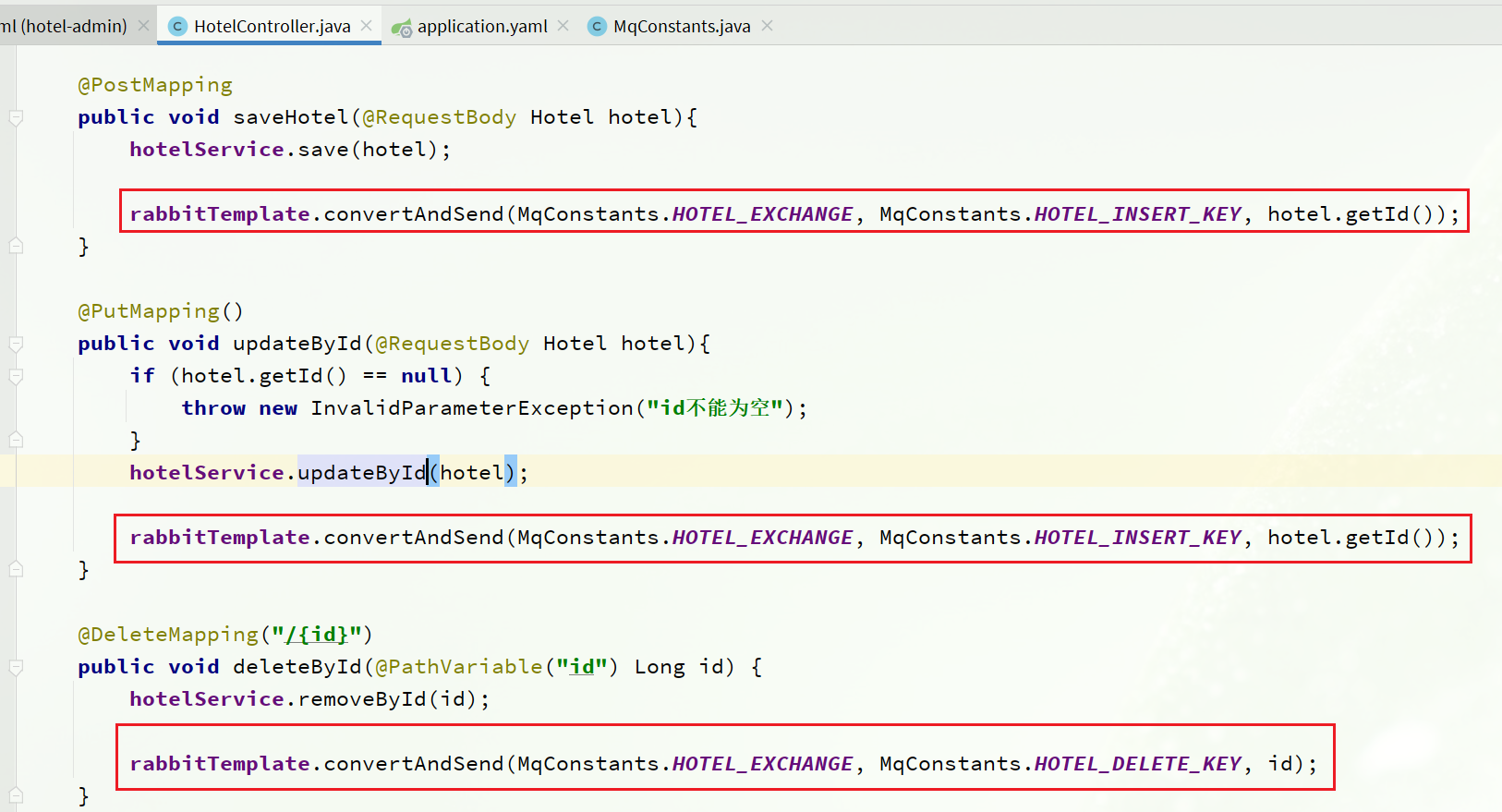
el código es el siguiente:
@PostMapping
public void saveHotel(@RequestBody Hotel hotel) {
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MqConstant.HOTEL_EXCHANGE, MqConstant.HOTEL_INSERT_KEY, hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel) {
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstant.HOTEL_EXCHANGE, MqConstant.HOTEL_INSERT_KEY, hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstant.HOTEL_EXCHANGE, MqConstant.HOTEL_DELETE_KEY, id);
}
3.2.5 Recibir mensaje MQ
Las cosas que hacer cuando hotel-demo recibe mensajes MQ incluyen:
- Nuevo mensaje: consulte la información del hotel de acuerdo con la identificación del hotel pasada y luego agregue un dato a la biblioteca de índice
- Eliminar mensaje: elimine una parte de los datos en la biblioteca de índice de acuerdo con la identificación del hotel pasada
1) Primero, agregue nuevos y elimine servicios en cn.itcast.hotel.serviceel paquete de hotel-demoIHotelService
void deleteById(Long id);
void insertById(Long id);
2) cn.itcast.hotel.service.implImplementar negocios en HotelService bajo el paquete en hotel-demo:
@Override
public void deleteById(Long id) {
try {
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", id.toString());
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void insertById(Long id) {
try {
// 0.根据id查询酒店数据
Hotel hotel = getById(id);
// 转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
// 2.准备Json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
3) Escribe un oyente
Agregue una nueva clase al paquete en hotel-demo cn.itcast.hotel.mq:
package cn.itcast.hotel.mq;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/**
* 监听酒店新增或修改的业务
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void listenHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/**
* 监听酒店删除的业务
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void listenHotelDelete(Long id){
hotelService.deleteById(id);
}
}
Inicie SpringBoot primero, verifique el cliente mq y podrá ver el interruptor


Puede ver que la relación vinculante de la cola es la siguiente:

Probemos la función:
descargue el complemento del navegador de Vue.js, haga clic en Expandir

para agregar una nueva extensión

Busque Vue, descargue Vue.js Devtools

primero verifique la identificación del hotel

, luego vamos a la administración del hotel para cambiar el precio a 334

Luego fuimos a la página de administración de MQ para ver si se había enviado algún mensaje y descubrimos que efectivamente había 1 mensaje.

Mire la página de consulta del hotel, la modificación es exitosa

Pruebe la eliminación, eliminemos el Shanghai Hilton Hotel, primero copiemos la información de Vue

y luego vayamos a la administración del hotel para eliminar el Hilton Hotel.

Después de la eliminación, verificamos la interfaz de mensajes de MQ y encontramos que hay un nuevo mensaje eliminado.

Buscamos en el hotel y encontramos Hilton. De hecho, se ha ido (originalmente 13 artículos)

y luego lo agregaremos nuevamente a Hilton, lo verificaremos,

copiaremos el valor pegado en este momento y

lo agregaremos con éxito.

Después de la adición, verificamos la gestión de MQ y encontramos que se agregó un nuevo mensaje.

Finalmente, verificamos la búsqueda de hoteles y la adición fue exitosa.

4. Grupo
La búsqueda elástica independiente para el almacenamiento de datos inevitablemente enfrentará dos problemas: el almacenamiento masivo de datos y el punto único de falla.
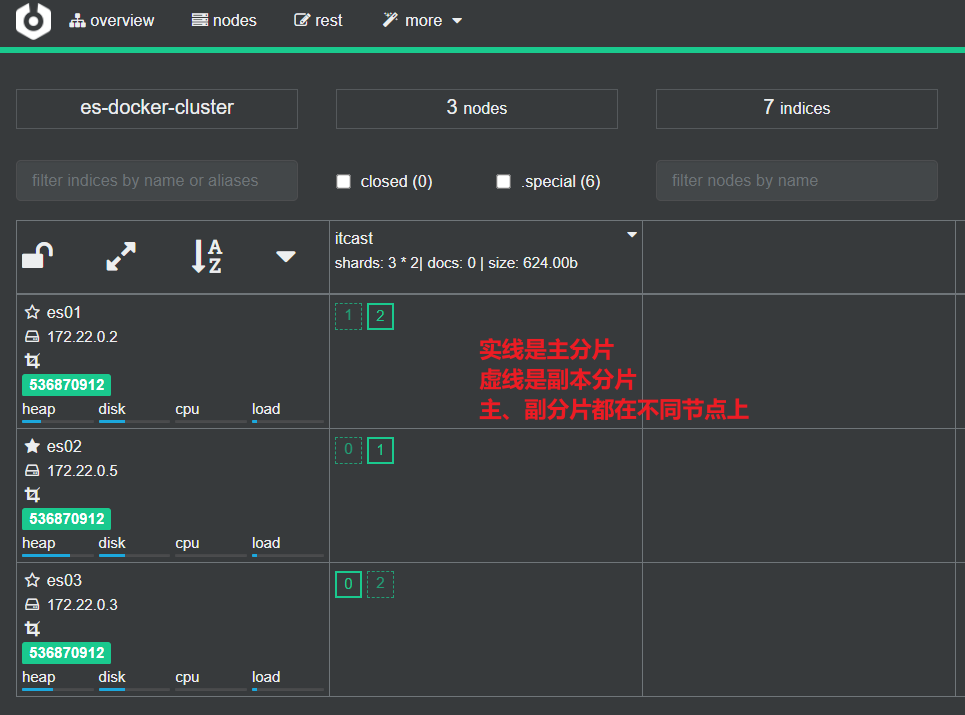
- Problema de almacenamiento masivo de datos: divida lógicamente la biblioteca de índices en N fragmentos (shards) y almacénelos en varios nodos
- Problema de punto único de falla: copia de seguridad de datos fragmentados en diferentes nodos (réplica)
Conceptos relacionados con el clúster ES :
-
Clúster (clúster): Un grupo de nodos con un nombre de clúster común.
-
Nodo (nodo) : una instancia de Elasticearch en el clúster
-
Fragmento : los índices se pueden dividir en diferentes partes para el almacenamiento, llamados fragmentos. En un entorno de clúster, diferentes fragmentos de un índice se pueden dividir en diferentes nodos
Resuelva el problema: la cantidad de datos es demasiado grande y la capacidad de almacenamiento de un solo punto es limitada.
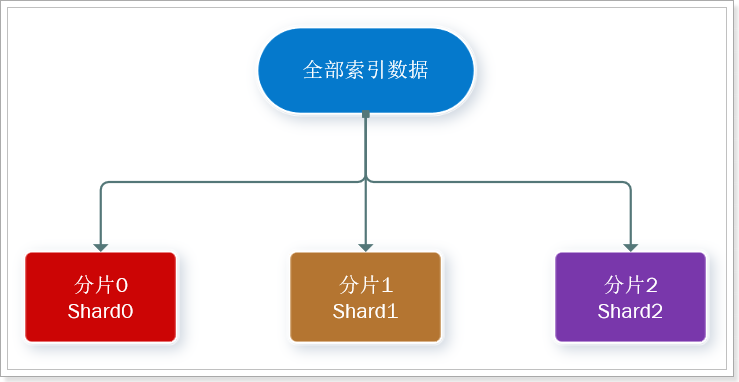
Aquí, dividimos los datos en 3 partes: shard0, shard1, shard2
-
Fragmento primario (Primary shard): relativo a la definición de fragmentos de réplica.
-
Fragmento de réplica (fragmento de réplica) Cada fragmento principal puede tener una o más copias, y los datos son los mismos que los del fragmento principal.
La copia de seguridad de datos puede garantizar una alta disponibilidad, pero si se realiza una copia de seguridad de cada fragmento, la cantidad de nodos necesarios se duplicará y el costo será demasiado alto.
Para encontrar un equilibrio entre alta disponibilidad y costo, podemos hacer esto:
- Primero fragmente los datos y guárdelos en diferentes nodos
- Luego haga una copia de seguridad de cada fragmento y colóquelo en el otro nodo para completar la copia de seguridad mutua
Esto puede reducir en gran medida la cantidad de nodos de servicio requeridos.Como se muestra en la figura, tomamos 3 fragmentos y cada fragmento como una copia de respaldo como ejemplo:
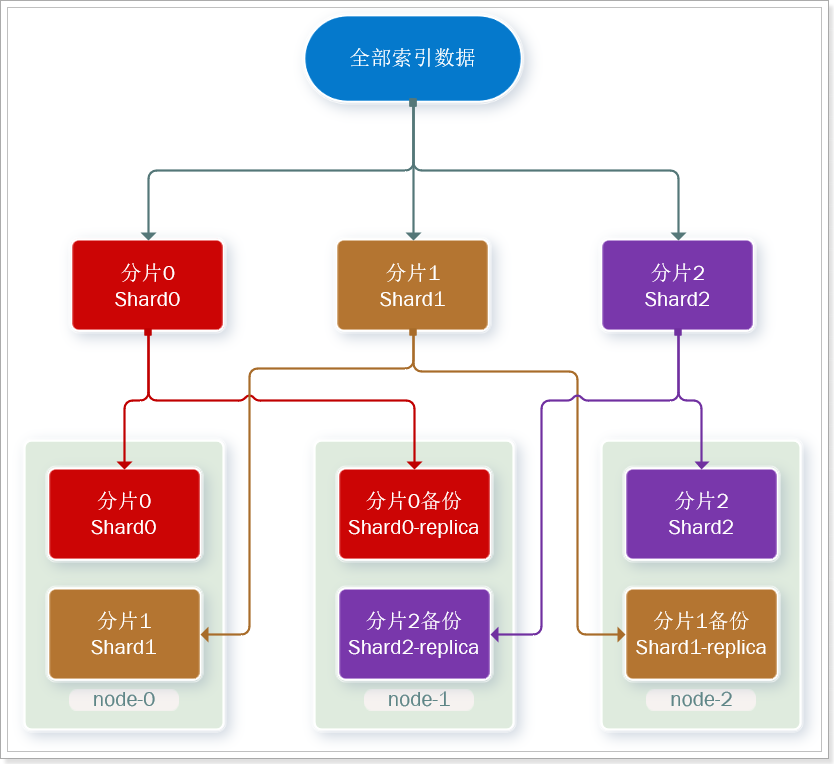
Ahora, cada fragmento tiene 1 copia de seguridad, almacenada en 3 nodos:
- node0: contiene fragmentos 0 y 1
- node1: contiene fragmentos 0 y 2
- nodo2: fragmentos guardados 1 y 2
4.1 Creación de un clúster ES
Refiérase a la documentación de los materiales de preclase:
el cuarto capítulo de la misma:

1. Implementar el clúster es
Usaremos el contenedor docker para ejecutar varias instancias de es en una sola máquina para simular el clúster de es. Sin embargo, en el entorno de producción, se recomienda que solo implemente una instancia de es en cada nodo de servicio.
La implementación de un clúster es se puede hacer directamente usando docker-compose, pero esto requiere su máquina virtual LinuxAl menos 4G de espacio de memoria
1.1 Crear clúster es
Primero escriba un archivo docker-compose con el siguiente contenido:
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
la operación es necesita modificar algunos permisos del sistema linux, modificar /etc/sysctl.confarchivos
vi /etc/sysctl.conf
Agrega el siguiente contenido:
vm.max_map_count=262144

Luego ejecute el comando para que la configuración surta efecto:
sysctl -p

Inicie el clúster a través de docker-compose:
docker-compose up -d

Ver el estado del contenedor
docker ps

1.2 Supervisión del estado del clúster
Kibana puede monitorear clústeres de es, pero la nueva versión necesita confiar en la función x-pack de es, y la configuración es más complicada.
Se recomienda usar cerebro para monitorear el estado del clúster es, sitio web oficial: https://github.com/lmenezes/cerebro
Los materiales previos a la clase han proporcionado el paquete de instalación:
se puede usar después de la descompresión, lo cual es muy conveniente.
El directorio descomprimido es el siguiente:

ingrese el directorio bin correspondiente:
Haga doble clic en el archivo cerebro.bat para iniciar el servicio.
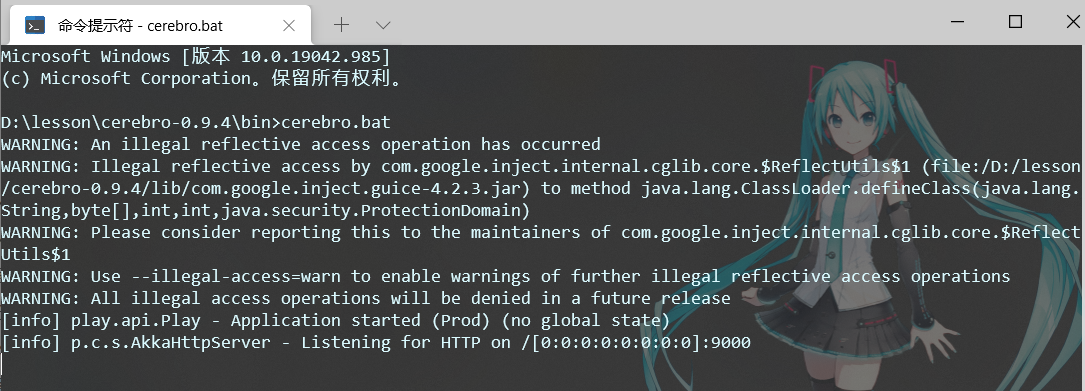
Visite http://localhost:9000 para ingresar a la interfaz de administración:
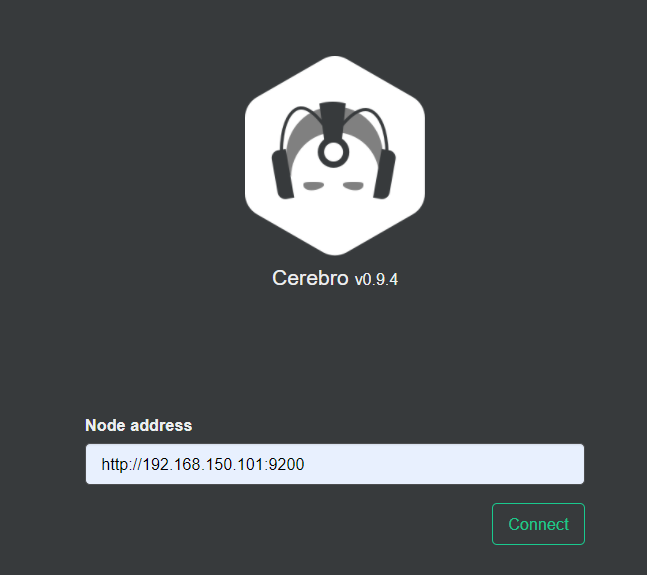
Ingrese la dirección y el puerto de cualquier nodo de su elasticsearch y haga clic en conectar:
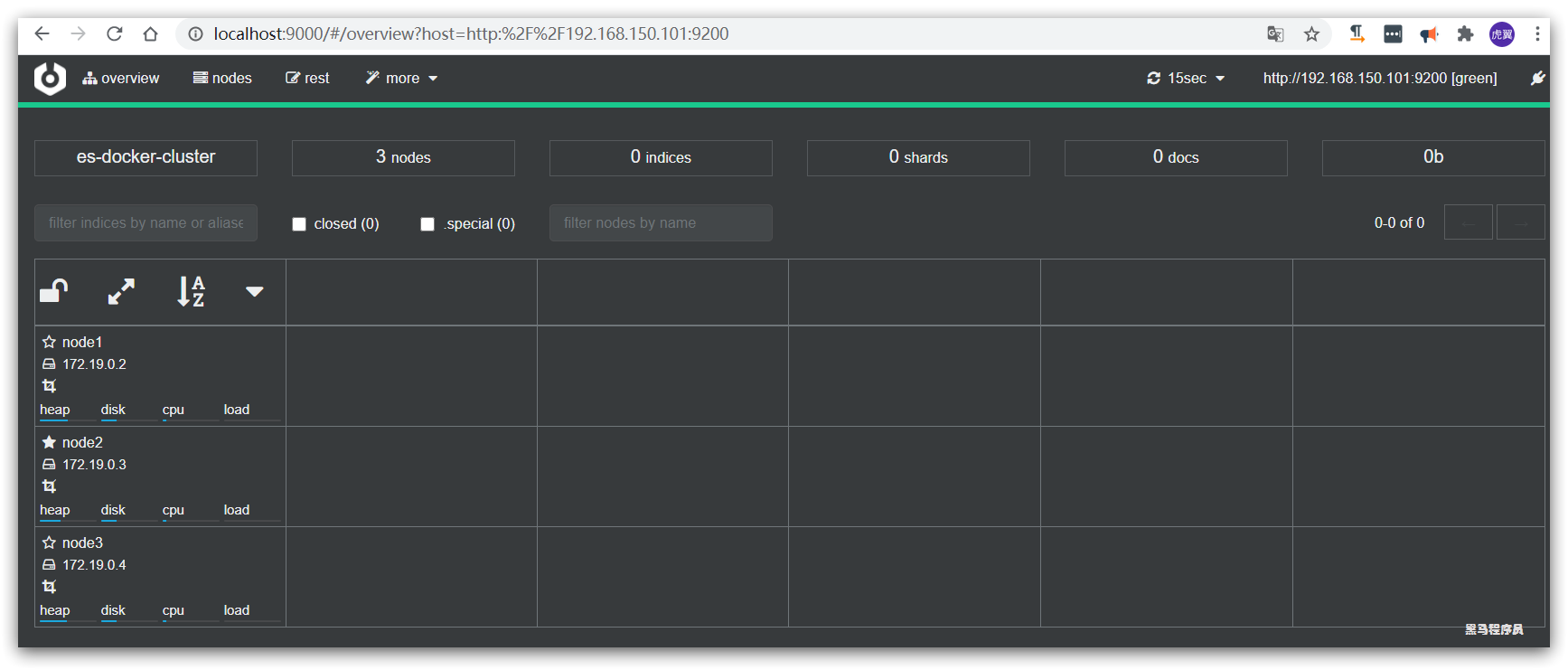
Una barra verde indica que el clúster es verde (bueno).

1.3 Crear una biblioteca de índice
1) Use DevTools de Kibana para crear una biblioteca de índices
Ingrese el comando en DevTools:
PUT /itcast
{
"settings": {
"number_of_shards": 3, // 分片数量
"number_of_replicas": 1 // 副本数量
},
"mappings": {
"properties": {
// mapping映射定义 ...
}
}
}
2) Use cerebro para crear una biblioteca de índices
También puede crear una biblioteca de índices con cerebro:
Complete la información de la biblioteca del índice:
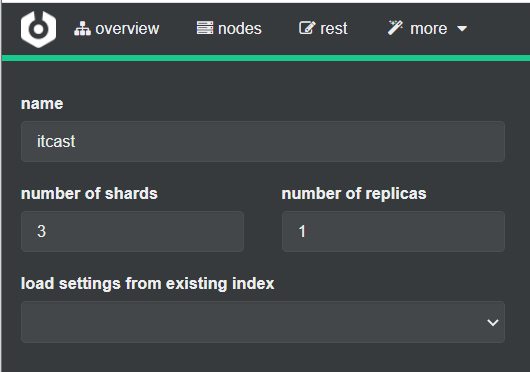
Haga clic en el botón Crear en la esquina inferior derecha:
1.4 Ver el efecto de fragmentación
Regrese a la página de inicio y podrá ver el efecto de fragmentación de la biblioteca de índices:
4.2 Problema de cerebro dividido en racimo
4.2.1 División de responsabilidades del clúster
Los nodos de clúster en elasticsearch tienen diferentes responsabilidades:
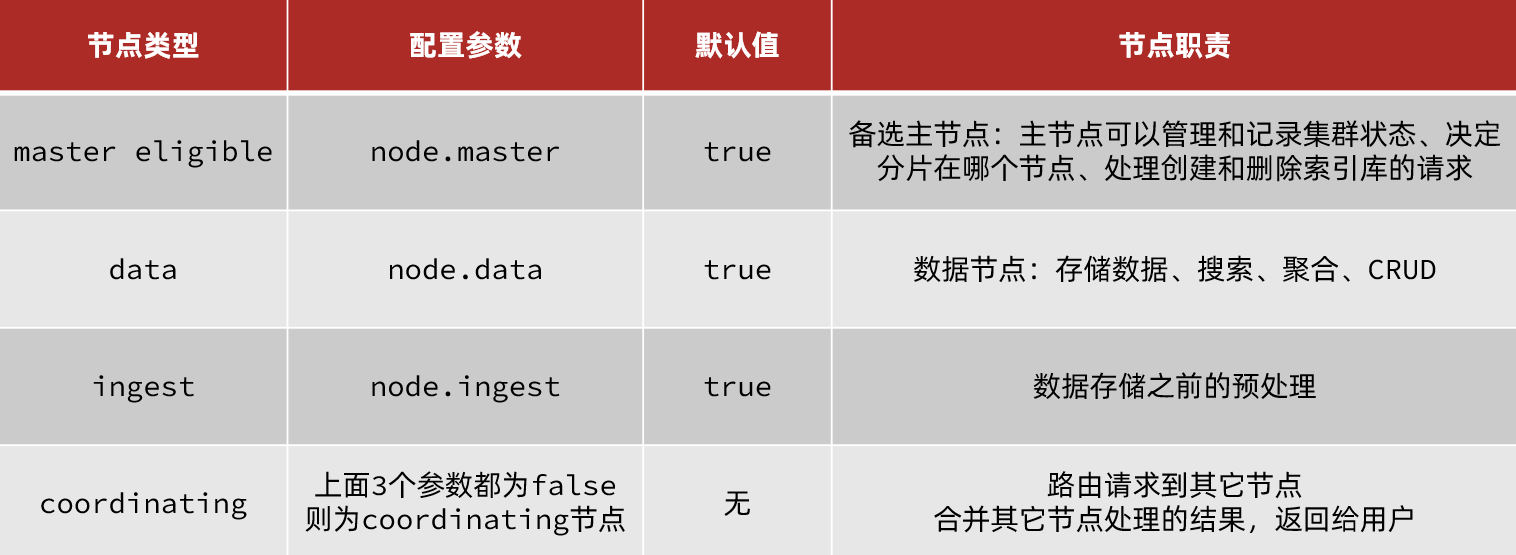
De forma predeterminada , cualquier nodo del clúster tiene las cuatro funciones anteriores al mismo tiempo .
Pero un clúster real debe separar las responsabilidades del clúster:
- nodo maestro: altos requisitos de CPU, pero requisitos de memoria
- nodo de datos: altos requisitos de CPU y memoria
- Nodos de coordinación: altos requisitos de ancho de banda de red y CPU
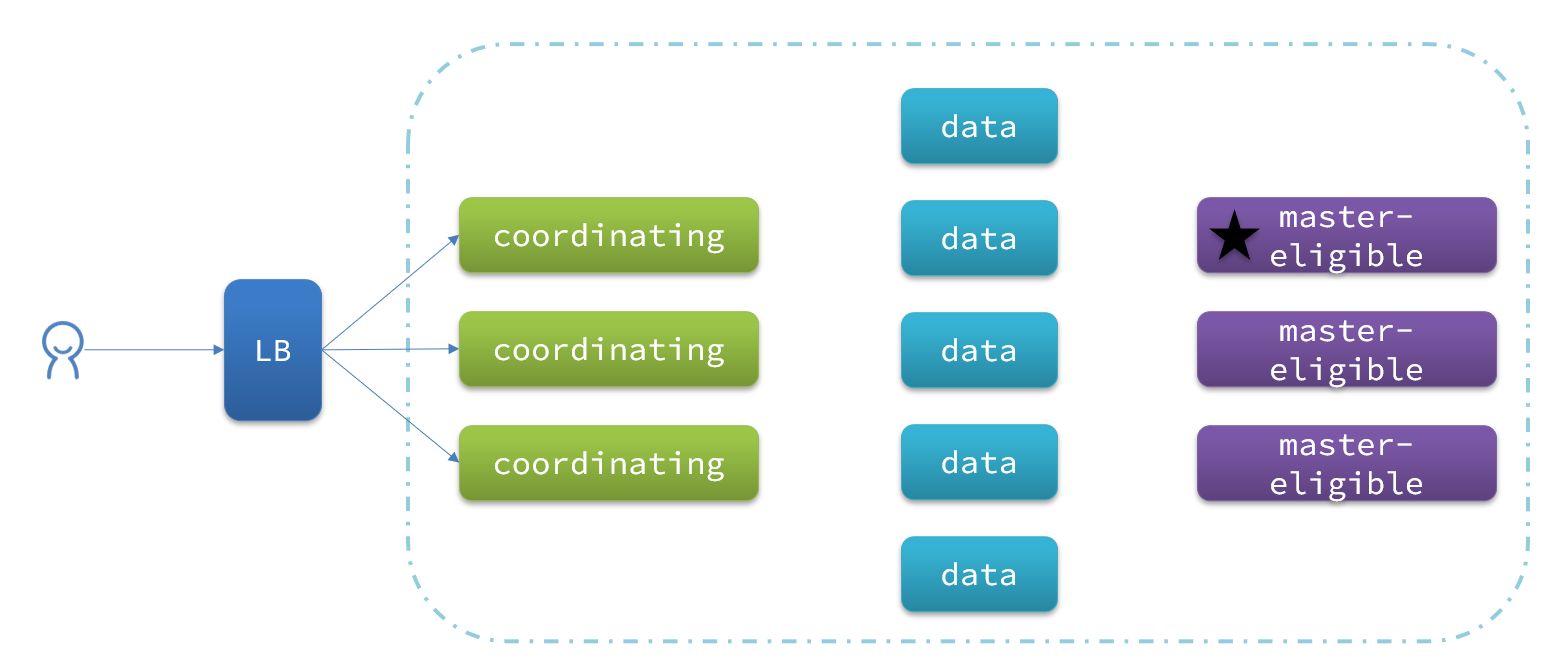
La separación de funciones nos permite asignar diferentes hardware para la implementación de acuerdo con las necesidades de los diferentes nodos. Y evitar la interferencia mutua entre servicios.
En la figura se muestra una división típica de responsabilidad de clúster de es:
4.2.2 Problema del cerebro dividido
Un cerebro dividido es causado por la desconexión de nodos en el clúster.
Por ejemplo, en un clúster, el nodo maestro pierde la conexión con otros nodos:
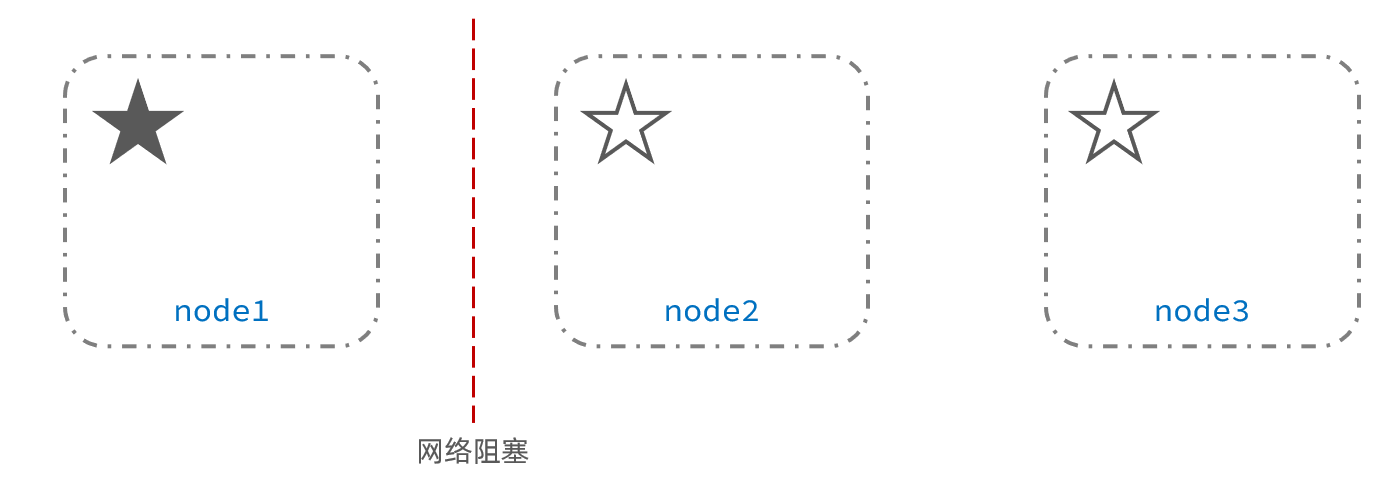
en este momento, el nodo2 y el nodo3 piensan que el nodo1 está caído y volverán a elegir al maestro:
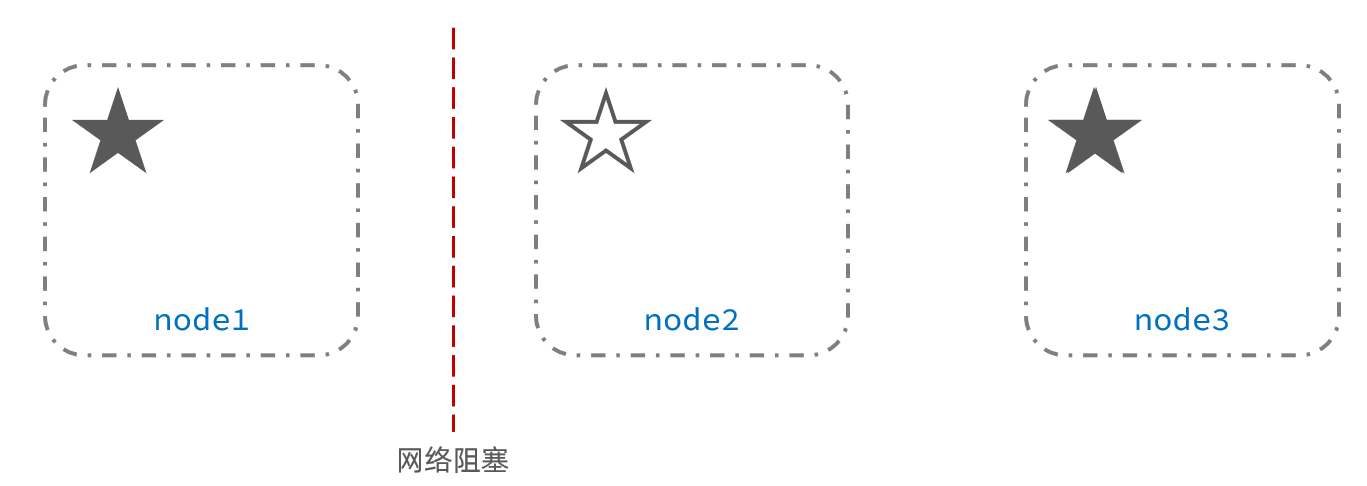
Después de elegir el nodo 3, el clúster continúa brindando servicios externos. El nodo 2 y el nodo 3 forman un clúster y el nodo 1 forma un clúster. Los datos de los dos clústeres no están sincronizados y se producen diferencias de datos.
Cuando se restaura la red, debido a que hay dos nodos principales en el clúster, el estado del clúster es inconsistente y ocurre una situación de cerebro dividido:
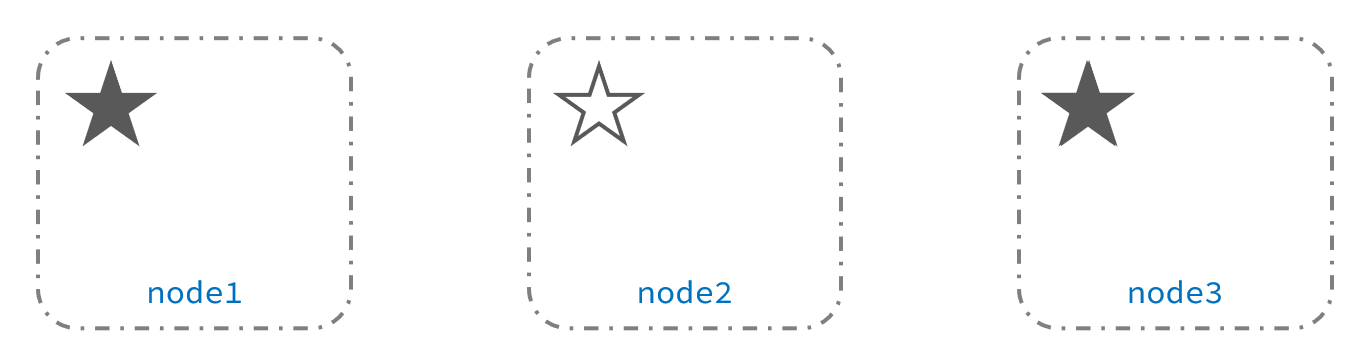
La solución para dividir el cerebro es exigir que los votos excedan (número de nodos elegibles + 1)/2 para ser elegido maestro, por lo que el número de nodos elegibles debería ser preferiblemente un número impar. El elemento de configuración correspondiente es discovery.zen.minimum_master_nodes, que se ha convertido en la configuración predeterminada después de es7.0, por lo que el problema del cerebro dividido generalmente no ocurre.
Por ejemplo: para un clúster formado por 3 nodos, los votos deben superar (3 + 1)/2, que son 2 votos. node3 obtiene los votos de node2 y node3, y es elegido maestro. node1 tiene solo 1 voto para sí mismo y no fue elegido. Todavía hay solo un nodo maestro en el clúster y no hay un cerebro dividido.
4.2.3 Resumen
¿Cuál es el rol del nodo principal elegible?
-
Participar en la elección del grupo.
-
El nodo principal puede administrar el estado del clúster, administrar la información de fragmentación y procesar solicitudes para crear y eliminar bibliotecas de índices. ¿
Cuál es el rol del nodo de datos? -
CRUD de datos
¿Cuál es el papel del nodo coordinador?
-
Enrutar solicitudes a otros nodos
-
Combine los resultados de la consulta y devuélvalos al usuario
4.3 Almacenamiento distribuido en clúster
Cuando se agrega un nuevo documento, debe guardarse en diferentes fragmentos para garantizar el equilibrio de los datos, entonces, ¿cómo determina el nodo coordinador en qué fragmento se deben almacenar los datos?
4.3.1 Prueba de almacenamiento de fragmentos
Inserta tres datos:
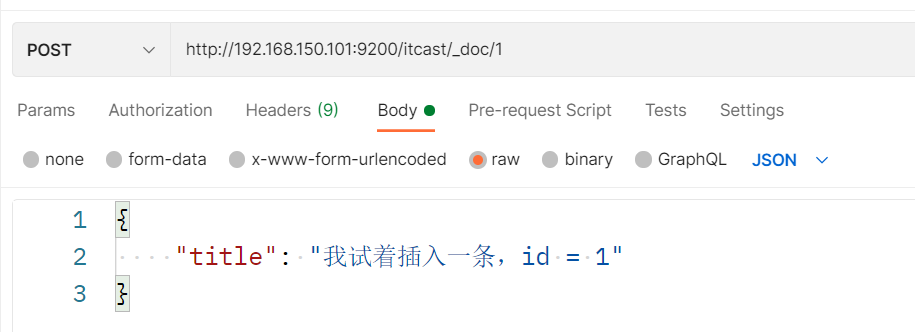
Puede ver en la prueba que los tres datos están en fragmentos diferentes:
resultado:

4.3.2 Principio de almacenamiento de fragmentos
Elasticsearch utilizará el algoritmo hash para calcular en qué fragmento se debe almacenar el documento:

ilustrar:
- _routing por defecto es el id del documento
- El algoritmo está relacionado con la cantidad de fragmentos, por lo que una vez que se crea la biblioteca de índices, ¡la cantidad de fragmentos no se puede modificar!
El proceso de agregar nuevos documentos es el siguiente:
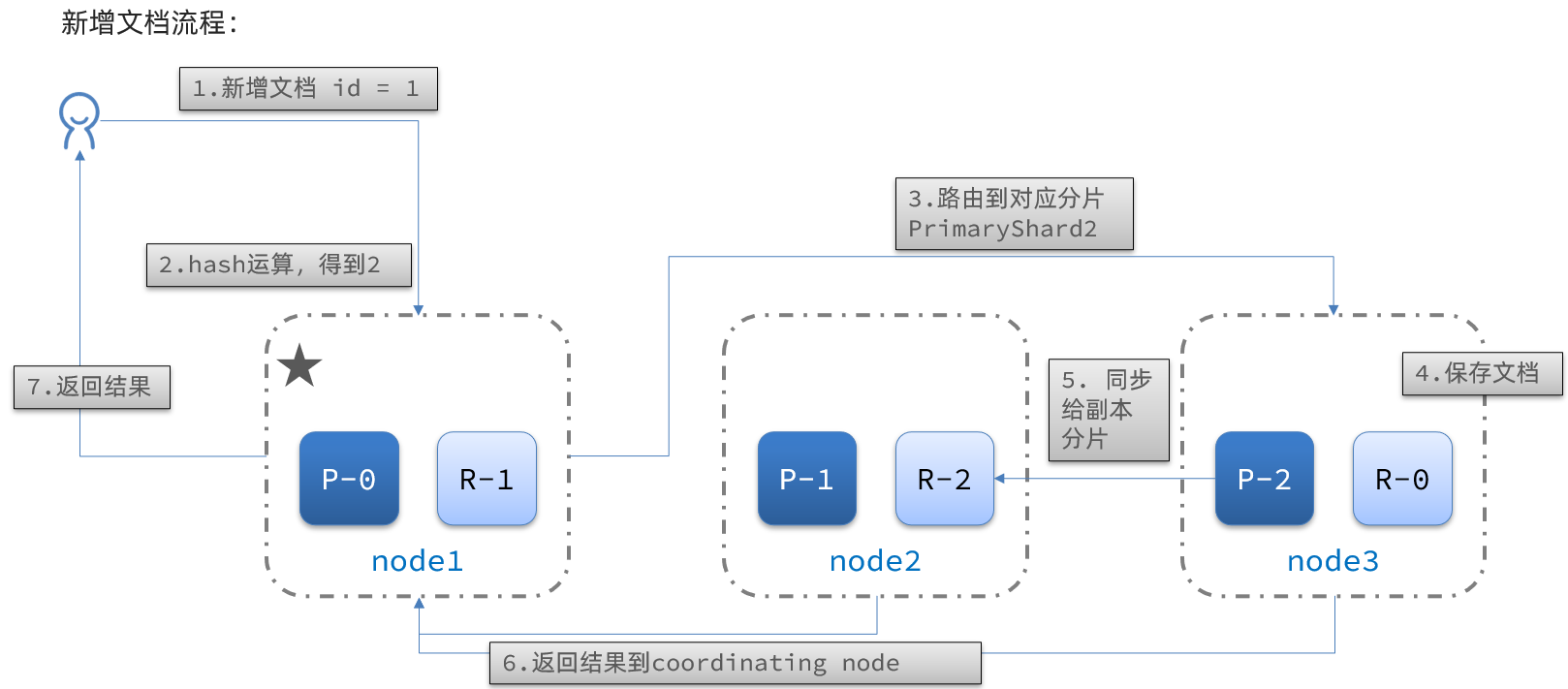
Interpretación:
- 1) Agregar un documento con id=1
- 2) Realice una operación hash en la identificación, si el resultado es 2, debe almacenarse en shard-2
- 3) El fragmento principal del fragmento 2 está en el nodo 3 y los datos se enrutan al nodo 3.
- 4) Guardar el documento
- 5) Sincronizar con la réplica 2 del fragmento 2, en el nodo node2
- 6) Devolver el resultado al nodo del nodo de coordinación
4.4 Consulta distribuida de clúster
La consulta de elasticsearch se divide en dos etapas:
-
fase de dispersión: en la fase de dispersión, el nodo coordinador distribuirá la solicitud a cada fragmento
-
fase de recopilación: la fase de recopilación, el nodo coordinador resume los resultados de búsqueda del nodo de datos, lo procesa como el conjunto de resultados final y lo devuelve al usuario
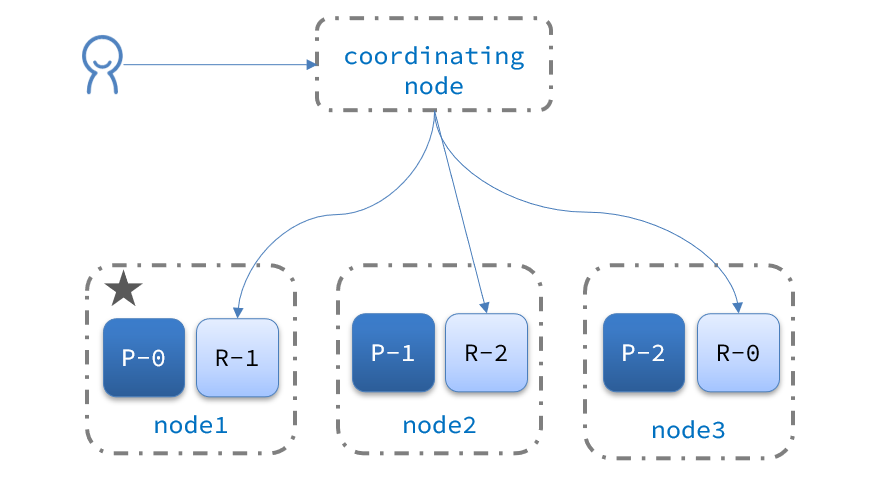
4.5 Conmutación por error del clúster
El nodo maestro del clúster monitoreará el estado de los nodos en el clúster. Si se encuentra que un nodo está inactivo, migrará inmediatamente los datos fragmentados del nodo inactivo a otros nodos para garantizar la seguridad de los datos. Esto se denomina conmutación por error.
1) Por ejemplo, en la figura se muestra una estructura de clúster:
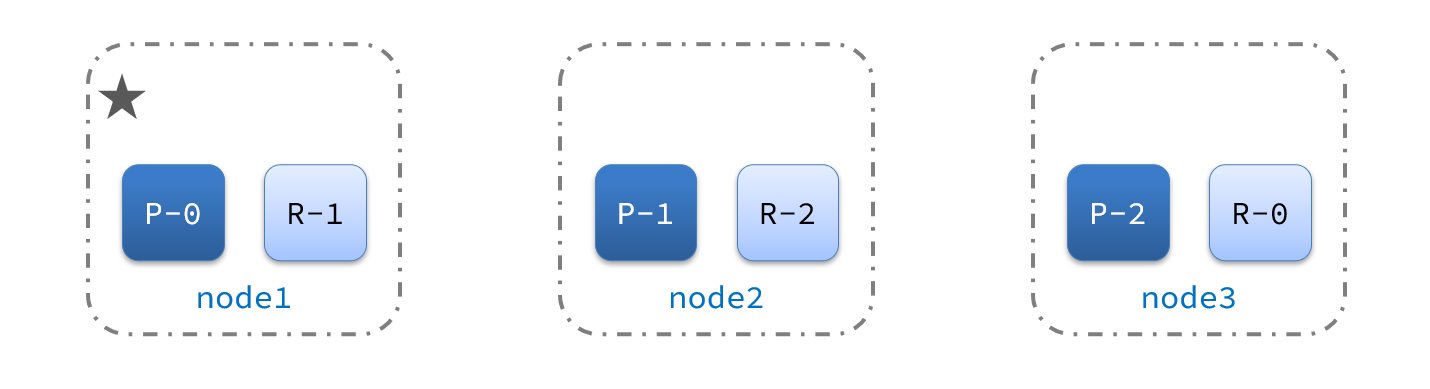
ahora, el nodo 1 es el nodo maestro y los otros dos nodos son los nodos esclavos.
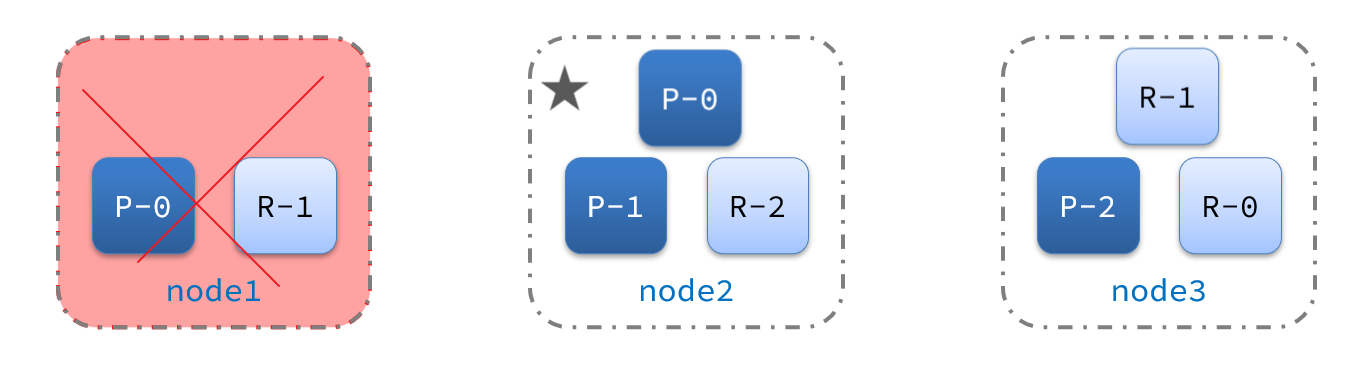
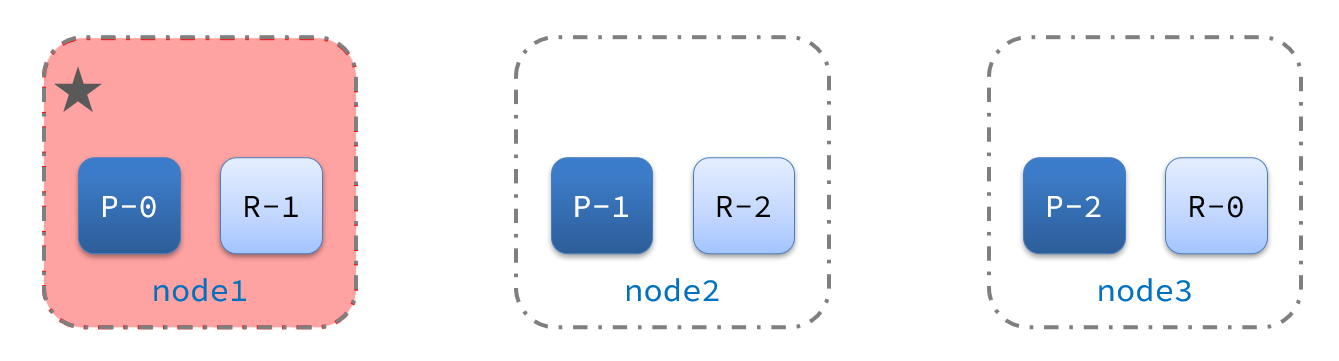
2) De repente, el nodo 1 falla:
lo primero después del tiempo de inactividad es volver a elegir el maestro. Por ejemplo, se selecciona el nodo 2:
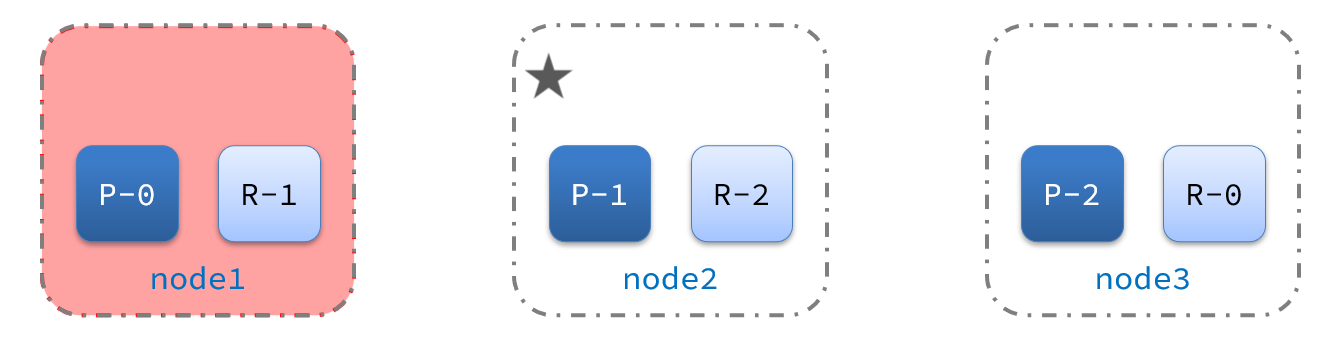
después de que el nodo 2 se convierta en el nodo maestro, detectará el estado de monitoreo del clúster y encontrará que: fragmento-1 y shard-0 no es un nodo de réplica. Por lo tanto, los datos del nodo 1 deben migrarse al nodo 2 y al nodo 3: