Pila de tecnología de microservicio SpringCloud Seguimiento de Dark Horse 11
- el objetivo de hoy
- 1. ¿Qué es un caché multinivel?
- 2. Caché de proceso de JVM
- 3. Introducción a la gramática lua
- 4. Implemente el almacenamiento en caché de varios niveles
- 5. Sincronización de caché
el objetivo de hoy

1. ¿Qué es un caché multinivel?
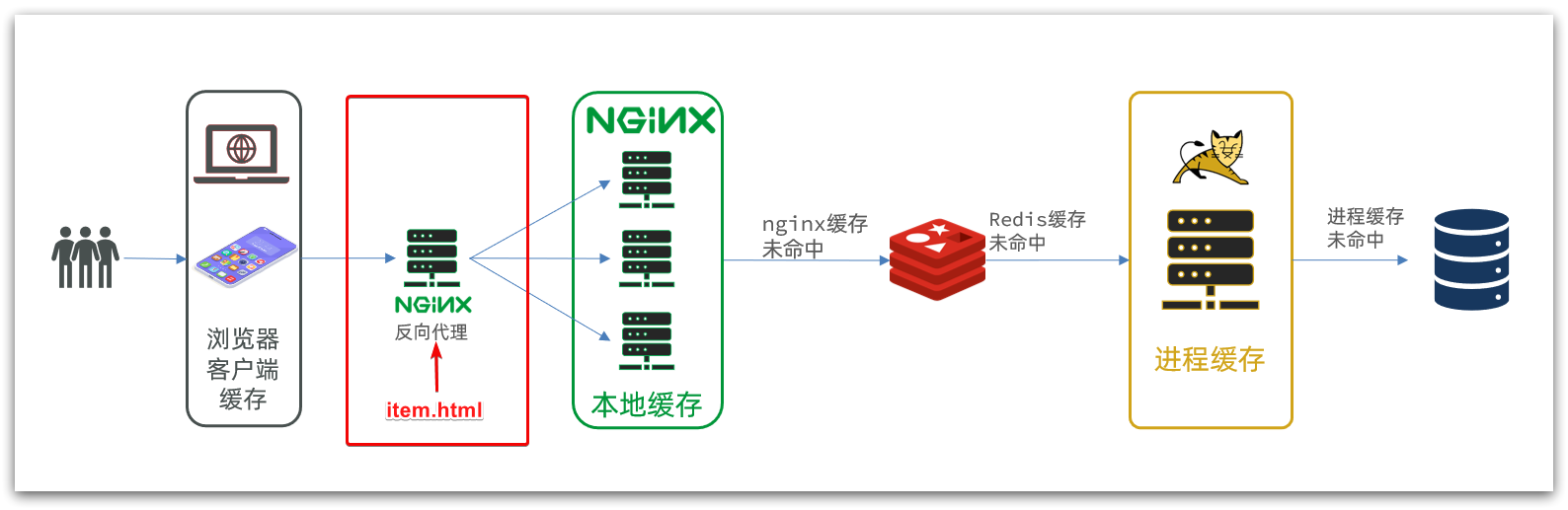
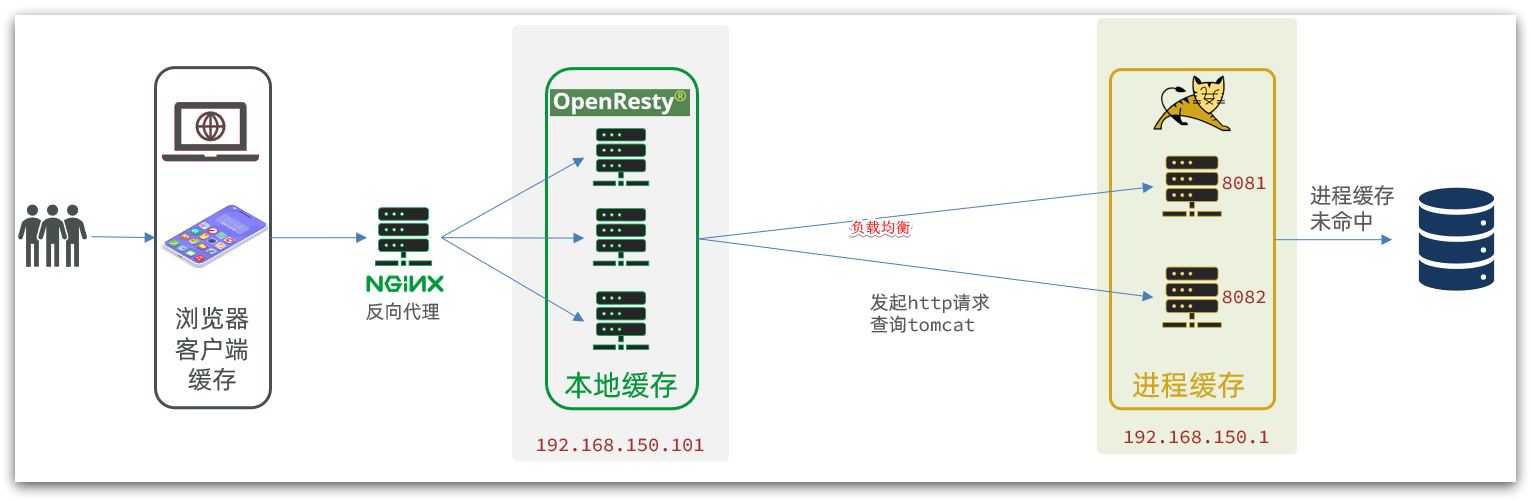
La estrategia de almacenamiento en caché tradicional generalmente es consultar Redis primero después de que la solicitud llega a Tomcat y luego consultar la base de datos si falla, como se muestra en la figura:
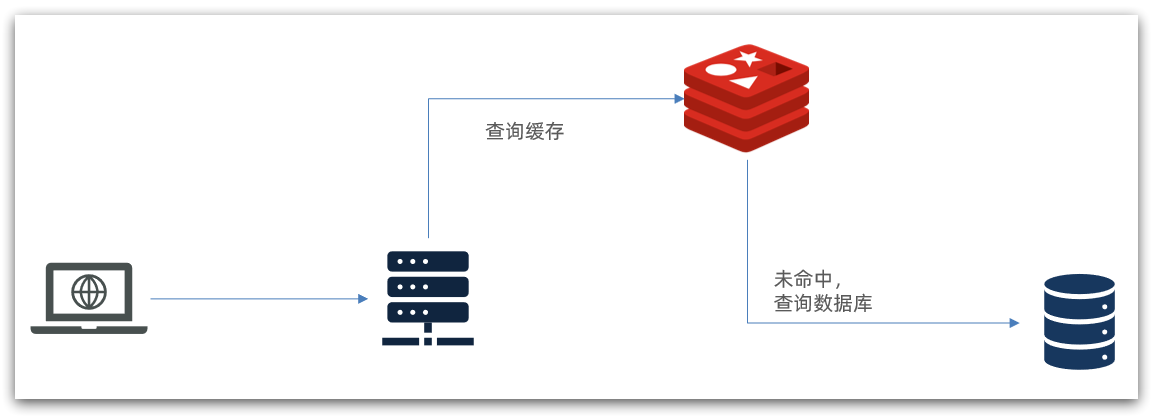
Existen los siguientes problemas:
•La solicitud debe ser procesada por Tomcat, y el rendimiento de Tomcat se convierte en el cuello de botella de todo el sistema
•Cuando falla la caché de Redis, tendrá un impacto en la base de datos
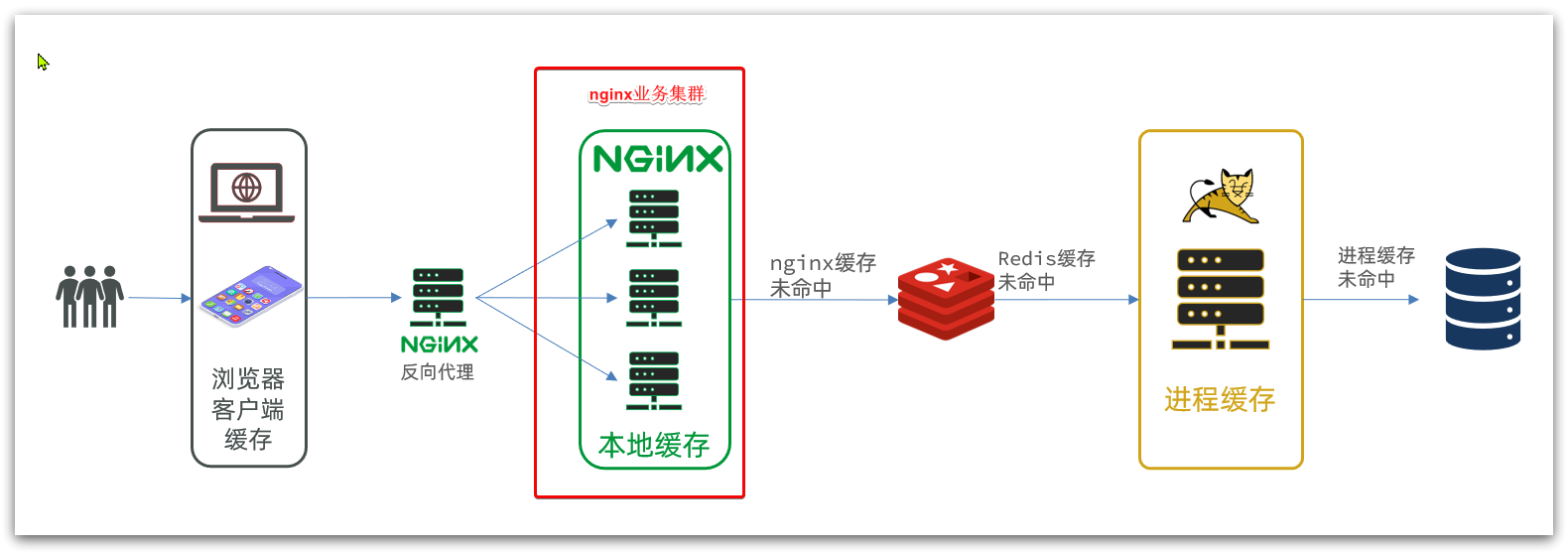
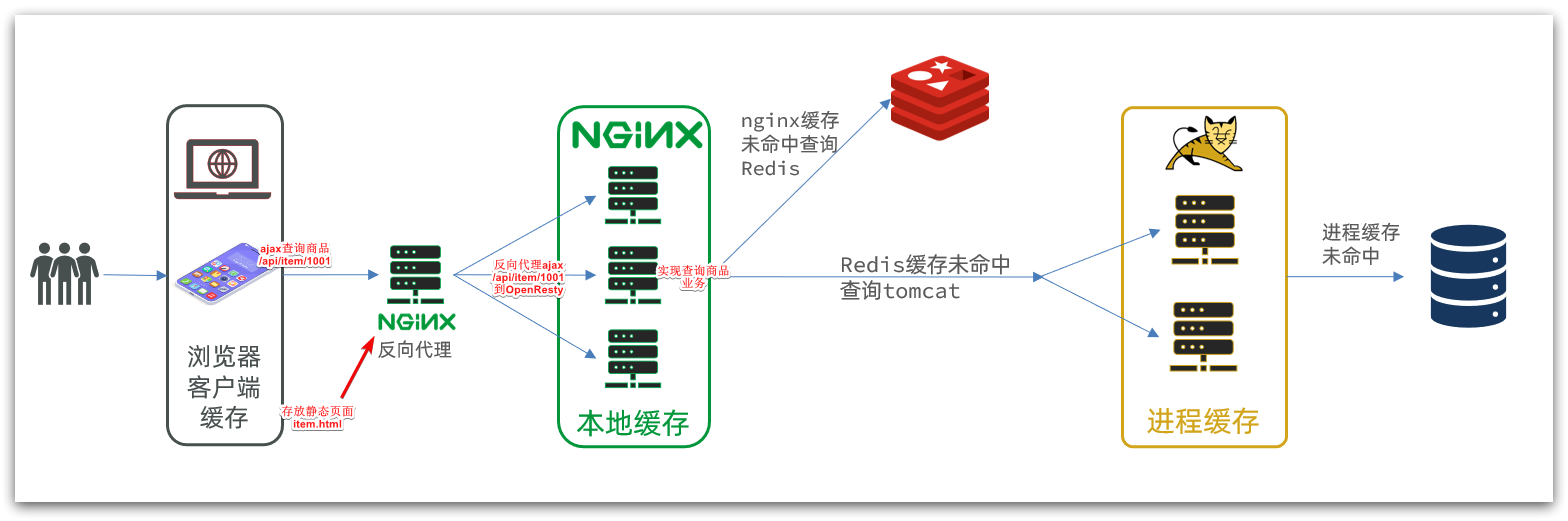
La caché de varios niveles es para hacer un uso completo de cada enlace de procesamiento de solicitudes, agregar caché por separado, reducir la presión sobre Tomcat y mejorar el rendimiento del servicio:
- Cuando el navegador accede a recursos estáticos, lee preferentemente el caché local del navegador
- Al acceder a recursos no estáticos (datos de consulta ajax), acceda al servidor
- Después de que la solicitud llegue a Nginx, lea primero el caché local de Nginx
- Si falla la memoria caché local de Nginx, consulte a Redis directamente (sin Tomcat)
- Consulta Tomcat si la consulta de Redis falla
- Después de que la solicitud ingresa a Tomcat, primero se consulta el caché del proceso JVM
- Consultar la base de datos si falta la memoria caché del proceso JVM
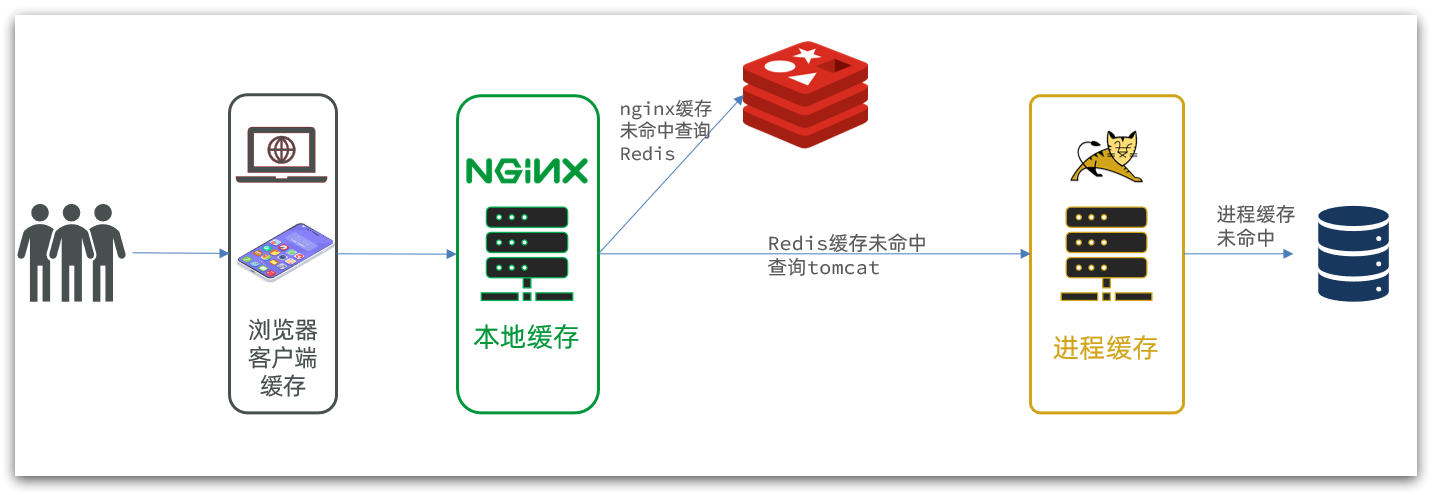
En la arquitectura de caché de varios niveles, Nginx necesita escribir la lógica comercial de la consulta de caché local, la consulta de Redis y la consulta de Tomcat. Por lo tanto, dicho servicio nginx ya no es un servidor proxy inverso , sino un servidor web para escribir negocios .
Por lo tanto, un servicio Nginx comercial de este tipo también necesita crear un clúster para mejorar la concurrencia y luego tener un servicio nginx especial como proxy inverso, como se muestra en la figura:
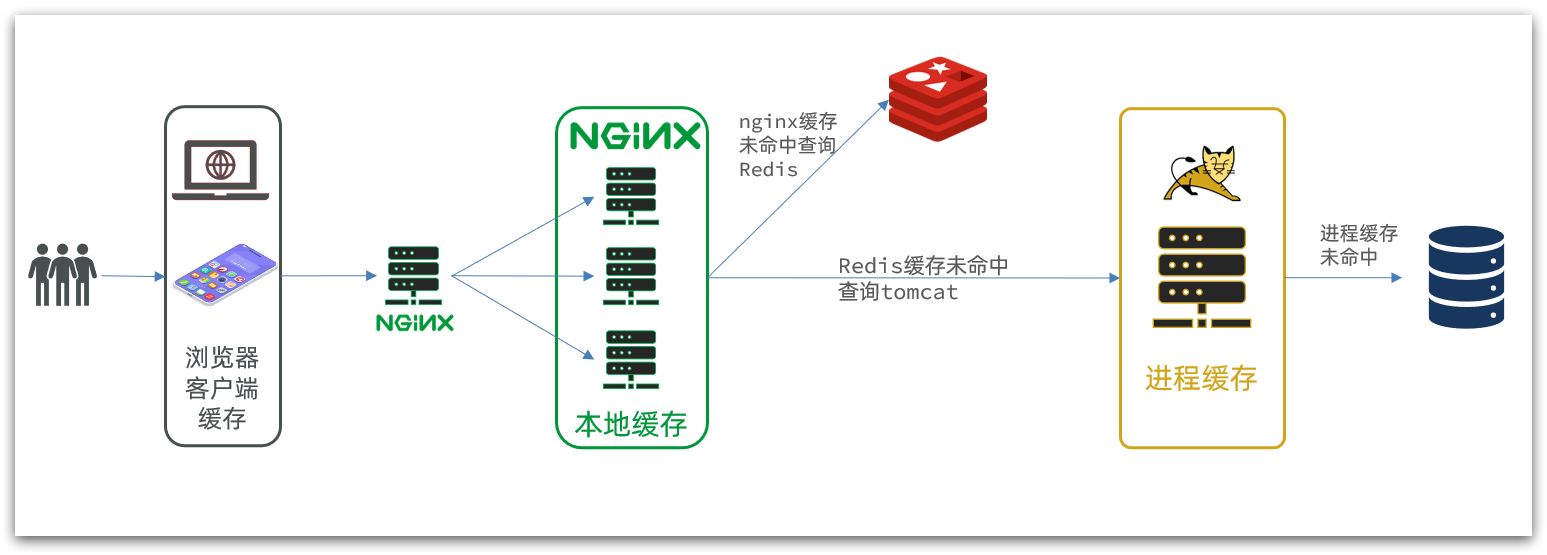
Además, nuestro servicio Tomcat también se implementará en modo clúster en el futuro:
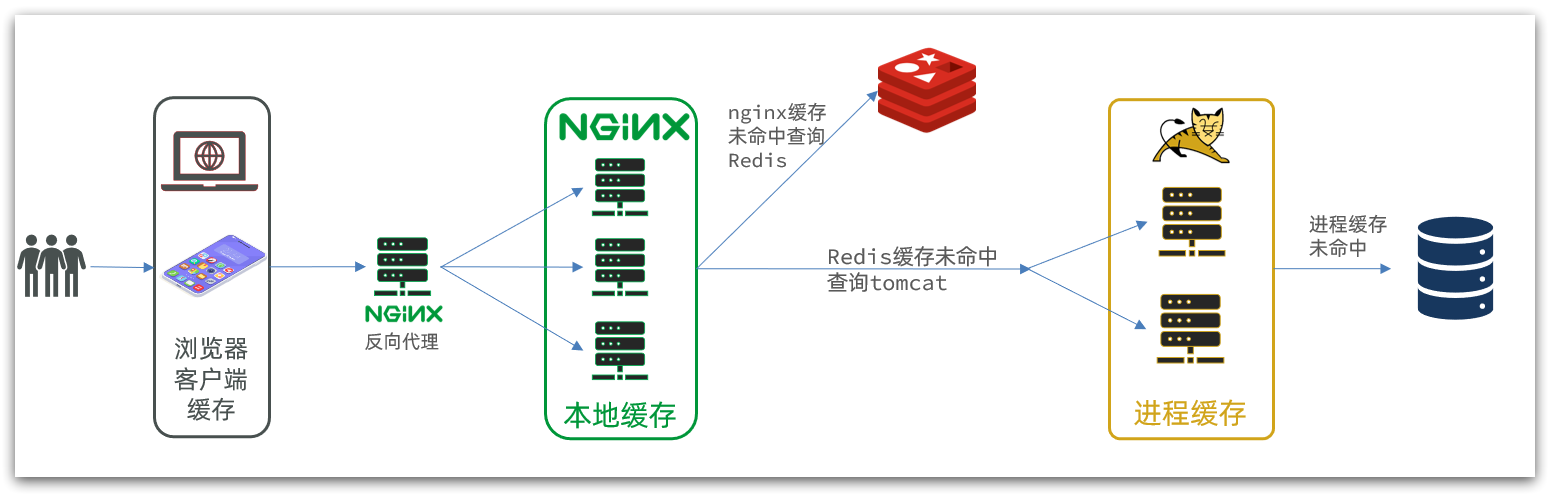
Se puede ver que hay dos claves para el almacenamiento en caché de varios niveles:
-
Una es escribir negocios en nginx para realizar consultas de caché local nginx, Redis, Tomcat
-
El otro es implementar el caché de procesos de JVM en Tomcat
Entre ellos, la programación de Nginx utilizará el framework OpenResty combinado con lenguajes como Lua.
Esta es también la dificultad y el enfoque de la lección de hoy.

2. Caché de proceso de JVM
Para demostrar el caso del almacenamiento en caché de varios niveles, primero preparamos un negocio de consulta de productos básicos.
2.1 Caso de importación
Consulte los materiales previos a la clase: "Instrucciones de importación de casos.md"

Instrucciones de importación de casos
Para demostrar el almacenamiento en caché de varios niveles, primero importamos un caso de gestión de productos, que incluye la función CRUD de productos. Agregaremos el almacenamiento en caché de varios niveles para los elementos de consulta en el futuro.
2.1.1 Instalar MySQL
La sincronización de datos posterior debe usar la función maestro-esclavo de MySQL, por lo que debe usar Docker para ejecutar un contenedor MySQL en una máquina virtual.
2.1.1.1 Preparar directorio
Para facilitar la configuración posterior de MySQL, primero preparamos dos directorios para montar los directorios de archivos de datos y configuración del contenedor:
porque estaba instalado antes, aquí lo renombré mysql_cluster
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql_cluster
# 进入mysql目录
cd mysql_cluster
2.1.1.2 Comando de ejecución
Después de ingresar al directorio mysql_cluster, ejecute el siguiente comando de Docker:
docker run \
-p 3306:3306 \
--name mysql \
-v $PWD/conf:/etc/mysql_cluster/conf.d \
-v $PWD/logs:/logs \
-v $PWD/data:/var/lib/mysql_cluster \
-e MYSQL_ROOT_PASSWORD=123 \
--privileged \
-d \
mysql:5.7.25
ver contenedor
docker ps

2.1.1.3 Modificar configuración
Agregue un archivo my.cnf en el directorio /tmp/mysql_cluster/conf como archivo de configuración de mysql:
# 创建文件
touch /tmp/mysql_cluster/conf/my.cnf

El contenido del archivo es el siguiente:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql_cluster
server-id=1000

2.1.1.4 Reiniciar
Después de los cambios de configuración, el contenedor debe reiniciarse:
docker restart mysql_cluster
2.1.2 Importar SQL
Luego, use el cliente Navicat para conectarse a MySQL y luego importe el archivo sql proporcionado por los materiales previos a la clase:
preste atención para conectarse con la dirección IP de la máquina virtual
Contiene dos tablas:
- tb_item: tabla de productos, incluyendo información básica del producto
- tb_item_stock: tabla de inventario de productos básicos, incluida la información de inventario de productos básicos
La razón por la que se separa el inventario es porque el inventario es información que se actualiza con frecuencia y hay muchas operaciones de escritura. Otra información se modifica con muy poca frecuencia.
Conéctese a la base de datos a través de ip

Cree una base de datos llamada heima
y luego importe sql Inventario
de productos básicos


2.1.3 Importar proyecto de demostración
Importe el proyecto proporcionado por los materiales previos a la clase a continuación:
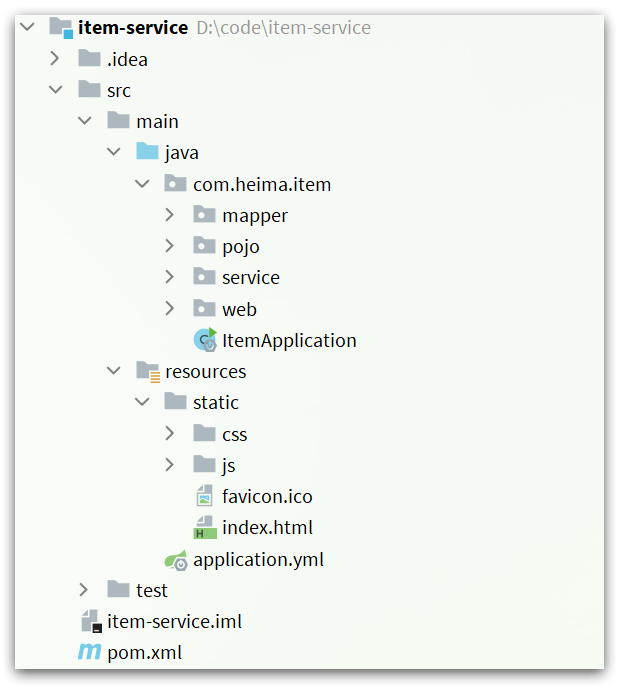
La estructura del proyecto se muestra en la figura:
el negocio incluye:
- Consultar productos por página
- nuevo producto
- modificar producto
- modificar inventario
- Eliminar elemento
- Consultar productos por id
- Consultar inventario por id
Todo el negocio se implementa utilizando mybatis-plus, modifique la lógica comercial usted mismo si es necesario.
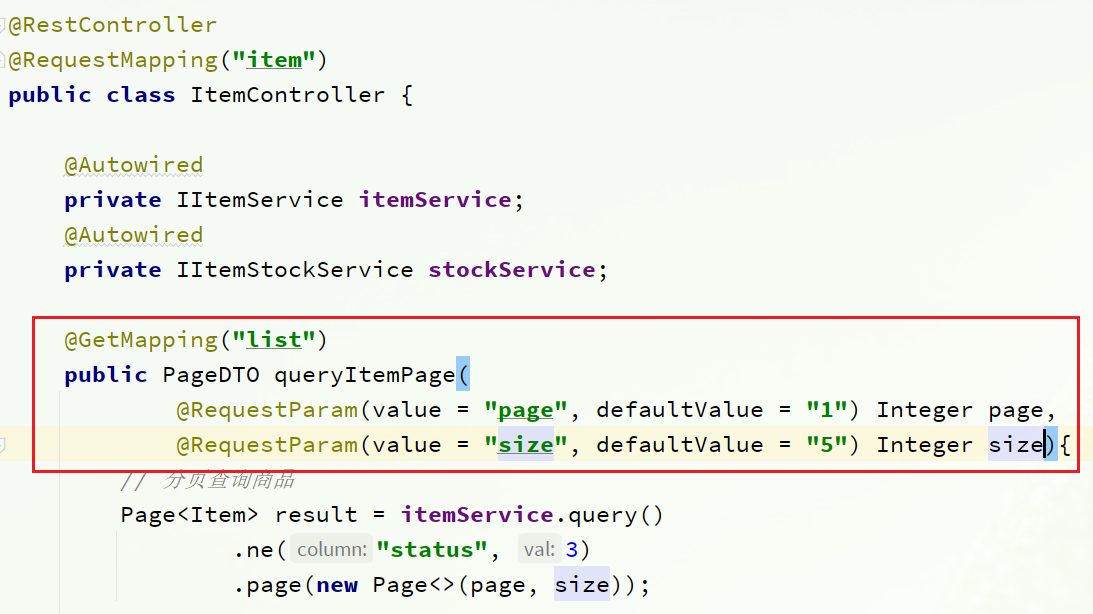
2.1.3.1 Consulta de productos por página
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:
2.1.3.2 Nuevos productos
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:

2.1.3.3 Modificar el producto
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:

2.1.3.4 Modificar inventario
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:

2.1.3.5 Eliminar producto
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:

Aquí, la eliminación lógica se utiliza para modificar el estado del producto a 3
2.1.3.6 Consultar productos por id
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:

Aquí solo se devuelve la información del producto, sin incluir el inventario
2.1.3.7 Consultar inventario según id
Puede ver la definición de la interfaz en com.heima.item.webel paquete ItemController:

2.1.3.8 Puesta en marcha
Preste atención para modificar la información de la dirección mysql configurada en el archivo application.yml:
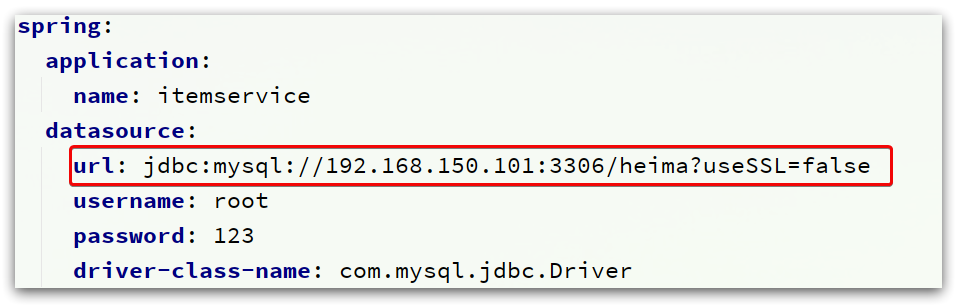
Debe modificarse con la información de la dirección de su propia máquina virtual, así como el número de cuenta y la contraseña.
Después de la modificación, inicie el servicio y visite: http://localhost:8081/item/10001 para consultar los datos
Ver información del producto
http://localhost:8081/item/10001

Ver información bursátil
http://localhost:8081/item/stock/10002

2.1.4 Importar página de consulta de productos
La consulta de productos básicos es una página de compras, que está separada de la página de administración de productos.
El método de implementación es como se muestra en la figura:
necesitamos preparar un servidor proxy inverso nginx, como se muestra en el cuadro rojo de arriba, y colocar la página del producto estático en el directorio nginx.
Los datos requeridos por la página se consultan al servidor (nginx business cluster) a través de ajax.
2.1.4.1 Ejecución del servicio nginx
Aquí he preparado un servidor proxy inverso nginx y recursos estáticos para usted.
Encontramos el directorio nginx de los materiales previos a la clase:
Cópielo en un directorio que no sea chino y ejecute el servicio nginx.
Nginx es el puerto 80. Generalmente, es más probable que esté ocupado el puerto 80. Modificamos el archivo nginx.conf para
establecer aleatoriamente un número de puerto desocupado

y lo modificamos de la siguiente manera:

Ejecute el comando:
start nginx.exe
Visite, vea la página de bienvenida de nginx
localhost:8934

entonces visita
http://localhost:8934/item.html?id=10001
Puede:
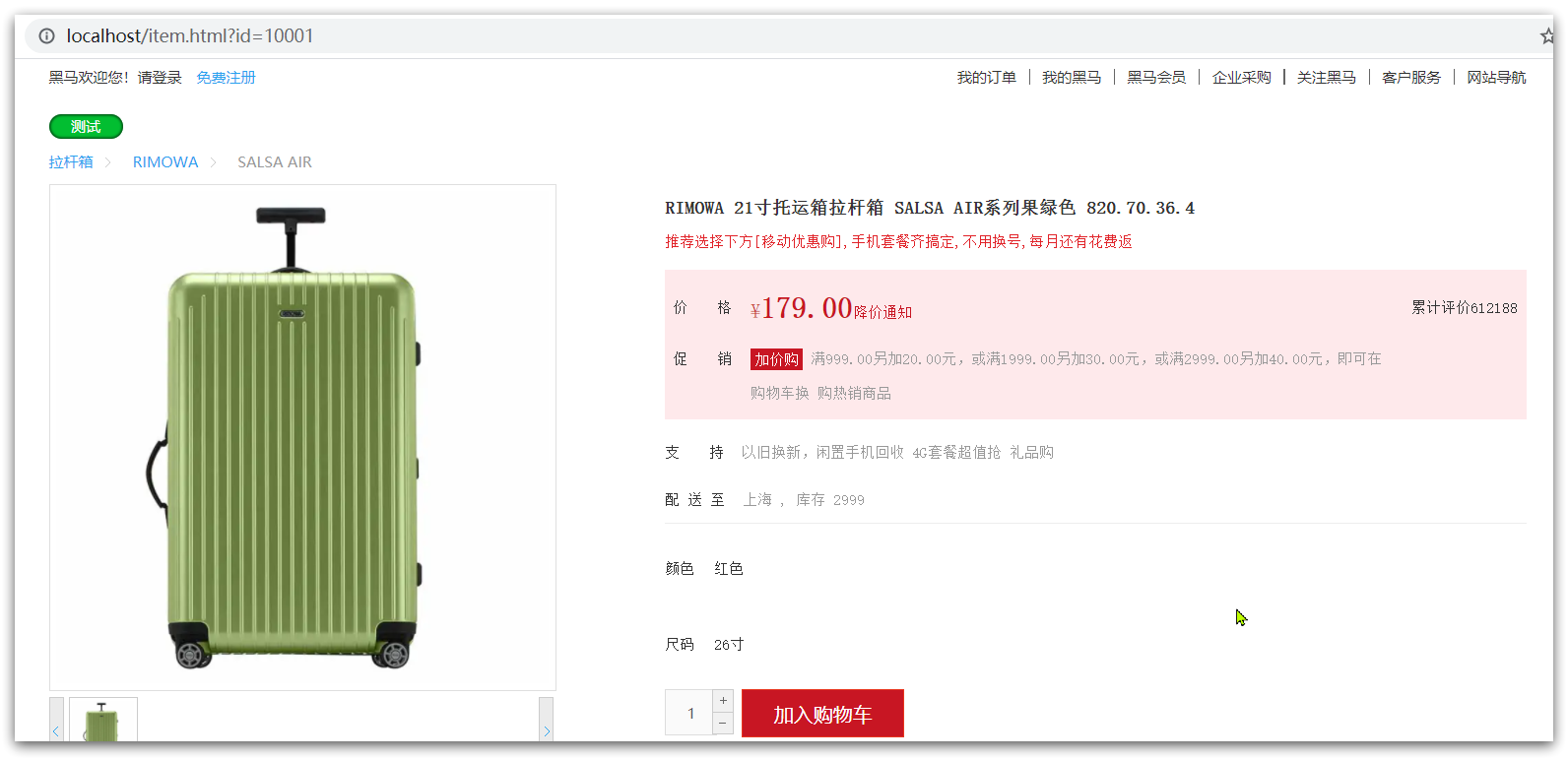
2.1.4.2 Proxy inverso
Ahora, la página se muestra con datos falsos. Necesitamos enviar una solicitud ajax al servidor para consultar los datos del producto.
Abra la consola, puede ver que la página ha iniciado datos de consulta ajax:
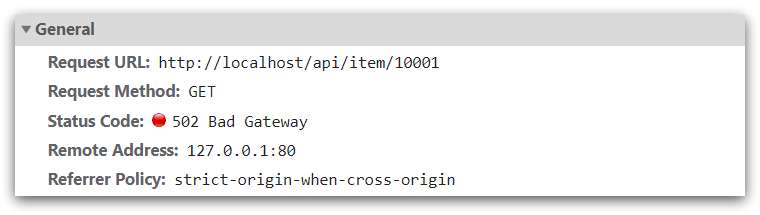
Y esta dirección de solicitud también es el puerto 80, por lo que el nginx actual tiene un proxy inverso.
Vea el archivo nginx.conf en el directorio nginx conf:
Las configuraciones clave son las siguientes:
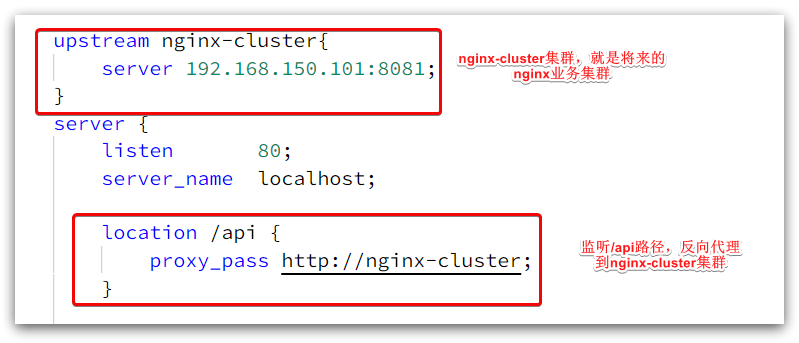
Entre ellos, 192.168.150.101 es la IP de mi máquina virtual, que es donde se implementará mi clúster empresarial Nginx: el
contenido completo es el siguiente:
#user nobody;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
upstream nginx-cluster{
server 192.168.150.101:8081;
}
server {
listen 80;
server_name localhost;
location /api {
proxy_pass http://nginx-cluster;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
2.2 Conociendo la Cafeína
El caché juega un papel vital en el desarrollo diario. Debido a que se almacena en la memoria, la velocidad de lectura de los datos es muy rápida, lo que puede reducir en gran medida el acceso a la base de datos y reducir la presión sobre la base de datos. Dividimos los cachés en dos categorías:
- Caché distribuida, como Redis:
- Ventajas: mayor capacidad de almacenamiento, mejor confiabilidad y se puede compartir entre clústeres
- Desventaja: acceder al caché tiene una sobrecarga de red
- Escenario: la cantidad de datos almacenados en caché es grande, los requisitos de confiabilidad son altos y deben compartirse entre clústeres
- Procese el caché local, como HashMap, GuavaCache:
- Ventajas: leer la memoria local, sin sobrecarga de red, más rápido
- Desventajas: capacidad de almacenamiento limitada, baja confiabilidad, no se puede compartir
- Escenario: requisitos de alto rendimiento, pequeña cantidad de datos en caché
Hoy usaremos el marco Caffeine para implementar el caché del proceso JVM.
Caffeine es una biblioteca de caché local de alto rendimiento desarrollada en base a Java 8 que proporciona una tasa de aciertos casi óptima. Actualmente, el caché interno de Spring usa cafeína. Dirección de GitHub: https://github.com/ben-manes/caffeine
El rendimiento de Caffeine es muy bueno. La siguiente figura es la comparación oficial de rendimiento: ¡
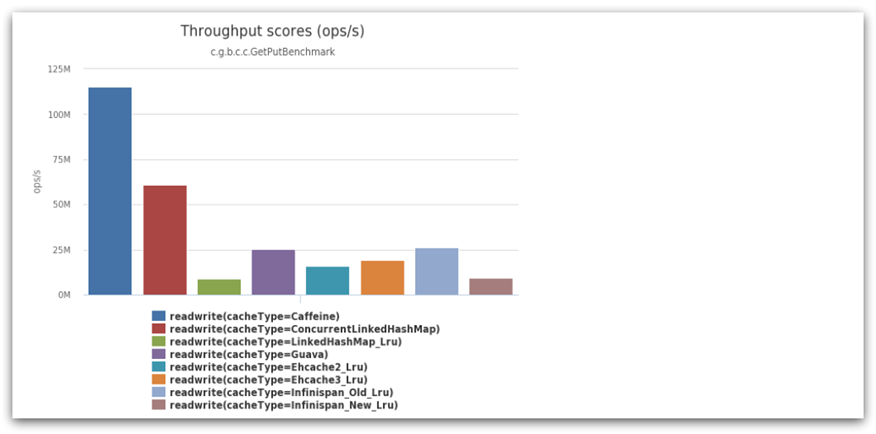
puede ver que el rendimiento de Caffeine está muy por delante!
La API básica utilizada por el caché:
@Test
public void testBasic() {
// 构建cache对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据
cache.put("gf", "迪丽热巴");
String gf = cache.getIfPresent("gf");
System.out.println("获取到数据:" + gf);
// 另一种获取不到就去数据库中查询,然后返回
String defaultGF = cache.get("defaultGF", key -> {
return "柳岩";
});
System.out.println("获取到默认数据:" + defaultGF);
}
resultado de búsqueda
获取到数据:迪丽热巴
获取到默认数据:柳岩
Dado que Caffeine es un tipo de caché, debe tener una estrategia de limpieza de caché, de lo contrario, la memoria siempre se agotará.
La cafeína proporciona tres estrategias de desalojo de caché:
-
Basado en la capacidad : establezca un límite superior en la cantidad de cachés
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() .maximumSize(1) // 设置缓存大小上限为 1 .build();
Ejemplo:
CafeínaTest.java
@Test
public void testByVolume() {
Cache<String, String> cache = Caffeine.newBuilder().maximumSize(1).build();
cache.put("derrick", "rose");
cache.put("kobe", "byrant");
cache.put("machel", "jordan");
String derrick = cache.getIfPresent("derrick");
String kobe = cache.getIfPresent("kobe");
String machel = cache.getIfPresent("machel");
System.out.println("derrick:" + derrick);
System.out.println("kobe:" + kobe);
System.out.println("machel:" + machel);
}
resultado de la operación
derrick:rose
kobe:byrant
machel:jordan
Aquí se encuentra que no hay un límite superior en la capacidad de los resultados de ejecución. Esto se debe a que lleva tiempo limpiar después del límite superior. Aumentamos el tiempo de sueño y encontramos que después del aumento, solo el último

-
Basado en el tiempo : establezca el tiempo efectivo del caché
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder() // 设置缓存有效期为 10 秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build();
Ejemplo básico:
CaffeineTest.java
@Test
public void testByTime() throws InterruptedException {
Cache<Object, Object> cache = Caffeine.newBuilder().expireAfterWrite(Duration.ofSeconds(1)).build();
// 存数据
cache.put("gf", "柳岩");
System.out.println("gf:" + cache.getIfPresent("gf"));
// 休眠一会儿
Thread.sleep(2000L);
System.out.println("gf:" + cache.getIfPresent("gf"));
}
El resultado de la salida
se borrará después de que se encuentre que excede 1 segundo
gf:柳岩
gf:null
- Basado en referencia : establezca la memoria caché como una referencia blanda o débil y use GC para recuperar los datos almacenados en la memoria caché. Bajo rendimiento, no recomendado.
Nota : De manera predeterminada, cuando un elemento almacenado en caché caduca, Caffeine no lo limpiará automáticamente ni lo expulsará de inmediato. En cambio, el desalojo de datos obsoletos se realiza después de una operación de lectura o escritura, o durante el tiempo de inactividad.
2.3 Realizar caché de proceso JVM
2.3.1 Requisitos
Use cafeína para lograr los siguientes requisitos:
- Agregue un caché al negocio de consultar productos en función de la identificación y consulte la base de datos cuando falte el caché
- Agregue un caché al negocio de consultar el inventario de productos básicos en función de la identificación y consulte la base de datos cuando falte el caché
- El tamaño inicial del caché es 100
- El límite de caché es 10000
2.3.2 Implementación
En primer lugar, debemos definir dos objetos de caché de cafeína para guardar los datos de caché de productos básicos e inventario, respectivamente.
com.heima.item.configDefina la clase en el paquete artículo-servicio CaffeineConfig:
package com.heima.item.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
// 分隔符便于阅读
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long, ItemStock> stockCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}
Luego, modifique com.heima.item.webla clase ItemController bajo el paquete en item-service y agregue la lógica de almacenamiento en caché:
@RestController
@RequestMapping("item")
public class ItemController {
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
@Autowired
private Cache<Long, Item> itemCache;
@Autowired
private Cache<Long, ItemStock> stockCache;
// ...其它略
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id, key -> itemService.query()
.ne("status", 3).eq("id", key)
.one()
);
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id) {
return stockCache.get(id, key -> stockService.getById(key));
}
}
reiniciar
el acceso al servicio
http://localhost:8081/item/10001
Encontré que hay registros de sentencias SQL de consulta.

Borre los registros y vuelva a visitar. Si no hay registros, significa que el caché ha tenido efecto.

3. Introducción a la gramática lua
La programación de Nginx necesita usar el lenguaje Lua, por lo que primero debemos comenzar con la sintaxis básica de Lua.
3.1 Conociendo a Lua por primera vez
Lua es un lenguaje de secuencias de comandos ligero y compacto escrito en lenguaje C estándar y abierto en forma de código fuente. Está diseñado para integrarse en aplicaciones para proporcionar funciones flexibles de expansión y personalización para aplicaciones. Sitio web oficial: sitio web oficial de Lua

Lua a menudo se integra en programas desarrollados en lenguaje C, como desarrollo de juegos, complementos de juegos, etc.
Nginx en sí también está desarrollado en lenguaje C, por lo que también permite la expansión basada en Lua.
3.1.HolaMundo
CentOS7 ha instalado el entorno de idioma Lua de forma predeterminada, por lo que puede ejecutar el código Lua directamente.
1) En cualquier directorio de la máquina virtual Linux, cree un archivo hello.lua

2) Agrega el siguiente contenido
print("Hello World!")
3) correr

3.2 Variables y bucles
El aprendizaje de cualquier idioma es inseparable de las variables, y la declaración de variables debe saber primero el tipo de datos.
3.2.1 Tipos de datos Lua
Los tipos de datos comunes admitidos en Lua incluyen:

Además, Lua proporciona la función type() para determinar el tipo de datos de una variable:
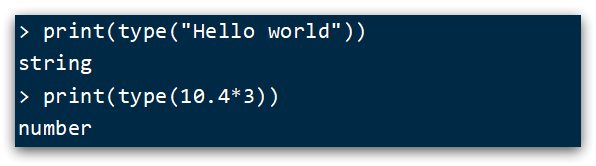
los resultados impresos son los siguientes:

3.2.2 Declaración de variables
Lua no necesita especificar el tipo de datos al declarar variables, pero usa local para declarar variables como variables locales:
-- 声明字符串,可以用单引号或双引号,
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
El tipo de tabla en Lua se puede usar como matriz y como mapa en Java. Una matriz es una tabla especial, y la clave es solo un subíndice de la matriz:
-- 声明数组 ,key为角标的 table
local arr = {
'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {
name='Jack', age=21}
Los subíndices de la matriz en Lua comienzan desde 1, y el acceso es similar al de Java:
-- 访问数组,lua数组的角标从1开始
print(arr[1])
Se puede acceder a las tablas en Lua usando las teclas:
-- 访问table
print(map['name'])
print(map.name)
Tenga en cuenta que la declaración de variables y la impresión deben estar en la misma línea
lua
local str3 = 'hi' .. 'i am' print(str3)

Ejemplo:
local arr = {
'java','Pathon','C++'} print(arr[1])

Declarar variables globales
arr = {
'hello','worl','java'}
print(arr[1])

declarar tabla
map = {
name = 'jack',age = 20}
# 打印元素
print(map['name'])
print(map.name)

3.2.3 Ciclo
Ctrl + C puede salir del comando Lua
Para la tabla, podemos usar for loop para atravesar. Sin embargo, las matrices y el recorrido de tablas ordinarias son ligeramente diferentes.
Iterar sobre la matriz:
-- 声明数组 key为索引的 table
local arr = {
'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) do
print(index, value)
end
Traverse mesa ordinaria
-- 声明map,也就是table
local map = {
name='Jack', age=21}
-- 遍历table
for key,value in pairs(map) do
print(key, value)
end
Ejemplo, editar hola.lua

el código se muestra a continuación:
local arr = {
'java','C++','Python'}
local map = {
name='jack',age=22}
for index,value in ipairs(arr) do
print(index,value)
end
for key,value in pairs(map) do
print(key,value)
end
resultado:

3.3 Control condicional, función
Las declaraciones de función y control condicional en Lua son similares a las de Java.
3.3.1 Funciones
Sintaxis para definir una función:
function 函数名( argument1, argument2..., argumentn)
-- 函数体
return 返回值
end
Por ejemplo, defina una función para imprimir una matriz:
function printArr(arr)
for index, value in ipairs(arr) do
print(value)
end
end
Ejemplo: continuar modificando hello.lua
local function printArr(arr)
for index,value in ipairs(arr) do
print(index,value)
end
end
local ints = {
1,2,3,4,5,6,7}
printArr(ints)
resultado

3.3.2 Control de condiciones
Control condicional similar a Java, como if, else sintaxis:
if(布尔表达式)
then
--[ 布尔表达式为 true 时执行该语句块 --]
else
--[ 布尔表达式为 false 时执行该语句块 --]
end
A diferencia de Java, las operaciones lógicas en expresiones booleanas se basan en palabras en inglés:

3.3.3 Caso
Requisito: personalice una función que pueda imprimir la tabla y, cuando el parámetro sea nulo, imprima el mensaje de error,
no el ejemplo.
function printArr(arr)
if not arr then
print('数组不能为空!')
end
for index, value in ipairs(arr) do
print(value)
end
end
otra forma de escribir
local arr = {
'java','python','C++'}
local arrnull = nil
function printArr(arr)
if(nil == arr)
then print('错误信息')
else
for index,value in ipairs(arr) do
print(index,value)
end
end
end
printArr(arrnull)
printArr(arr)
Resultado:

y ejemplo:
local banana = 30
local apple = 20
if(banana == 30 and apple == 10)
then
print('方案一')
else
print('方案二')
end
resultado:
方案二
4. Implemente el almacenamiento en caché de varios niveles
La realización del almacenamiento en caché multinivel es inseparable de la programación Nginx, y la programación Nginx es inseparable de OpenResty.
4.1 Instalar OpenResty
OpenResty® es una plataforma web de alto rendimiento basada en Nginx, que se utiliza para crear fácilmente aplicaciones web dinámicas, servicios web y puertas de enlace dinámicas que pueden manejar una concurrencia ultra alta y una alta escalabilidad. Tiene las siguientes características:
- Con funcionalidad completa de Nginx
- Basado en el lenguaje Lua, integra una gran cantidad de excelentes bibliotecas Lua y módulos de terceros.
- Permite el uso de Lua para personalizar la lógica empresarial y las bibliotecas personalizadas.
Sitio web oficial: https://openresty.org/cn/

Para instalar Lua, puede consultar "Instalación de OpenResty.md" proporcionado por los materiales previos a la clase:
Instalar OpenResty
4.1.1 Instalación
Primero su máquina virtual LinuxSe requiere conexión a Internet
1) Instalar la biblioteca de desarrollo
Primero, instale la biblioteca de desarrollo dependiente de OpenResty y ejecute el comando:
yum install -y pcre-devel openssl-devel gcc --skip-broken
2) Instalar el repositorio de OpenResty
Puede agregar openrestyel repositorio para que pueda instalar o actualizar fácilmente nuestros paquetes en el futuro (a través yum check-updatedel comando). Ejecute el siguiente comando para agregar nuestro repositorio:
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
Si se le solicita que el comando no existe, ejecute:
yum install -y yum-utils
Luego repita el comando anterior
3) Instalar OpenResty
El paquete se puede instalar así, por ejemplo openresty:
yum install -y openresty
4) Instale la herramienta opm
opm es una herramienta de gestión de OpenResty, que puede ayudarnos a instalar un módulo Lua de terceros.
Si desea instalar las herramientas de línea de comandos opm, puede instalar openresty-opmel paquete :
yum install -y openresty-opm
5) Estructura del directorio
Por defecto, el directorio donde está instalado OpenResty es:/usr/local/openresty
¿Has visto el directorio nginx dentro? OpenResty integra algunos módulos Lua basados en Nginx.

6) Configurar las variables de entorno de nginx
Abra el archivo de configuración:
vi /etc/profile
Agregue dos líneas en la parte inferior:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH
NGINX_HOME: seguido del directorio nginx en el directorio de instalación de OpenResty
y luego deje que la configuración surta efecto:
source /etc/profile
4.1.2 En funcionamiento
La capa inferior de OpenResty se basa en Nginx. Vea el directorio nginx del directorio OpenResty. La estructura es básicamente la misma que la de nginx instalado en Windows: por lo que
el modo de operación es básicamente el mismo que el de nginx:
# 启动nginx
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stop
Hay demasiados comentarios en el archivo de configuración predeterminado de nginx, lo que afectará nuestra edición posterior. Aquí, elimine la parte del comentario en nginx.conf y conserve la parte válida.
Modifique /usr/local/openresty/nginx/conf/nginx.confel archivo de la siguiente manera:
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
Ingrese el comando en la consola de Linux para iniciar nginx:
nginx
Luego visite la página: http://192.168.150.101:8081, preste atención para reemplazar la dirección IP con la IP de su propia máquina virtual:

4.1.3 Observaciones
Cargue el módulo lua de OpenResty:
Continúe modificando el archivo nginx.conf para agregar
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";

Modificar la solicitud de seguimiento ver más abajo
común.lua
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
Libere la API de conexión de Redis:
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
API para leer datos de Redis:
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
Para habilitar diccionarios compartidos:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
4.2 Inicio rápido de OpenResty
La arquitectura de caché multinivel que esperamos lograr se muestra en la figura:
en:
-
Nginx en Windows se usa como un servicio de proxy inverso para enviar la solicitud ajax del producto de consulta de front-end al clúster de OpenResty.
-
El clúster OpenResty se usa para escribir negocios de caché de varios niveles
4.2.1 Proceso de proxy inverso
Ahora, la página de detalles del producto está utilizando datos de productos falsos. Sin embargo, en el navegador, puede ver que la página inicia una solicitud ajax para consultar datos reales del producto.
Esta solicitud es la siguiente:
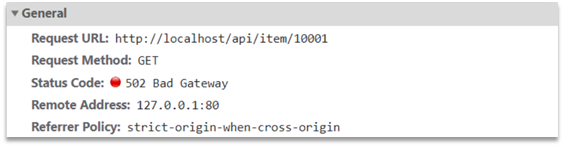
La dirección de solicitud es localhost, el puerto es 80 y la recibe el servicio Nginx instalado en Windows. A continuación, utilice el proxy para el clúster de OpenResty:
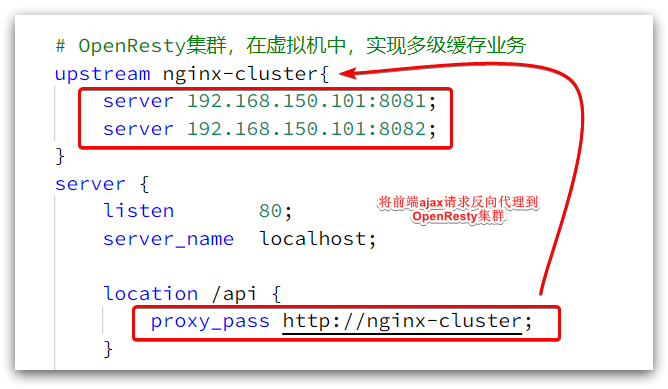
Necesitamos escribir negocios en OpenResty, consultar los datos del producto y volver al navegador.
Pero esta vez, primero recibimos la solicitud en OpenResty y devolvemos datos de productos falsos.
4.2.2 OpenResty escucha solicitudes
Muchas funciones de OpenResty dependen de la biblioteca Lua en su directorio. Debe especificar el directorio de la biblioteca dependiente en nginx.conf e importar las dependencias:
1) Agregue la carga del módulo Lua de OpenResty
Modifique /usr/local/openresty/nginx/conf/nginx.confel archivo, agregue el siguiente código en http:
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
2) Escuche la ruta /api/item
Modifique /usr/local/openresty/nginx/conf/nginx.confel archivo, agregue un monitor para la ruta /api/item en el servidor de nginx.conf:
location /api/item {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}

Este monitoreo es similar a hacer un mapeo de rutas en SpringMVC @GetMapping("/api/item").
En cambio content_by_lua_file lua/item.lua, es equivalente a llamar al archivo item.lua, ejecutar el negocio en él y devolver el resultado al usuario. Es equivalente a llamar al servicio en java.
4.2.3 Escribir item.lua
1) /usr/loca/openresty/nginxCrea una carpeta en el directorio: lua

2) /usr/loca/openresty/nginx/luaDebajo de la carpeta, cree un nuevo archivo: item.lua
3) Escriba item.lua, devuelva datos falsos
en item.lua, use la función ngx.say() para devolver datos a Response y cambie la interfaz a 26 pulgadas y 199 precios
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 26寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":19900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')

4) Recargar configuración
nginx -s reload
Actualizar la página del producto:
http://localhost:8934/item.html?id=10001
Puedes ver el efecto:

4.3 Procesamiento de parámetros de solicitud
En la sección anterior, recibimos solicitudes de front-end en OpenResty, pero devolvimos datos falsos.
Para devolver datos reales, debe consultar la información del producto de acuerdo con la identificación del producto pasada desde el front-end.
Entonces, ¿cómo hacer que los parámetros de los productos básicos pasen por el front-end?
4.3.1 API para la obtención de parámetros
OpenResty proporciona algunas API para obtener diferentes tipos de parámetros de solicitud de front-end:

4.3.2 Obtener parámetros y devolver
La solicitud ajax iniciada en el front-end se muestra en la figura:
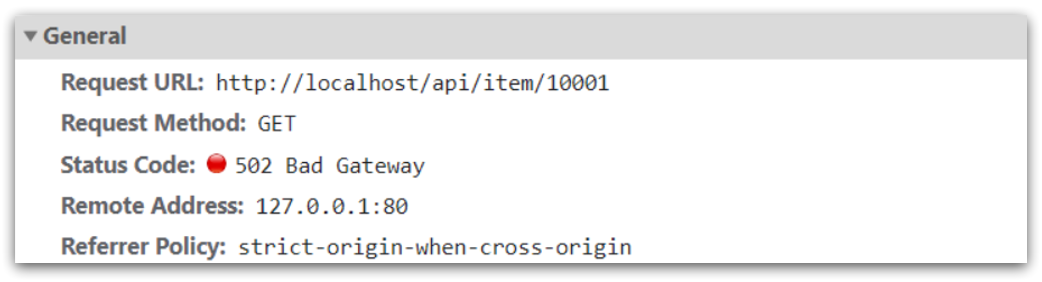
Puede ver que la identificación del producto se pasa como un marcador de posición de ruta, por lo que puede usar la coincidencia de expresiones regulares para obtener la identificación.
1) Obtenga la identificación del producto
Modifique /usr/loca/openresty/nginx/nginx.confel código que monitorea /api/item en el archivo y use expresiones regulares para obtener la ID:
location ~ /api/item/(\d+) {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}

2) Empalme la identificación y regrese
Modifique /usr/loca/openresty/nginx/lua/item.luael archivo, obtenga la identificación y empalme en el resultado para devolver:

-- 获取商品id
local id = ngx.var[1]
-- 拼接并返回
ngx.say('{"id":' .. id .. ',"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
3) Recargar y probar
Ejecute el comando para recargar la configuración de OpenResty:
nginx -s reload
acceso
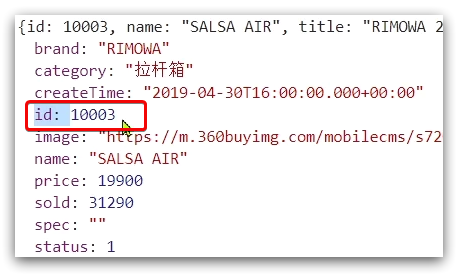
http://localhost:8934/item.html?id=10002

Actualice la página para ver que el ID ya está incluido en el resultado:
4.4 Consulta Tomcat
Después de obtener la identificación del producto, debemos ir al caché para consultar la información del producto, pero aún no hemos establecido los cachés nginx y redis. Por lo tanto, aquí primero vamos a Tomcat para consultar la información del producto de acuerdo con la identificación del producto. Nos damos cuenta de la parte que se muestra en la figura:
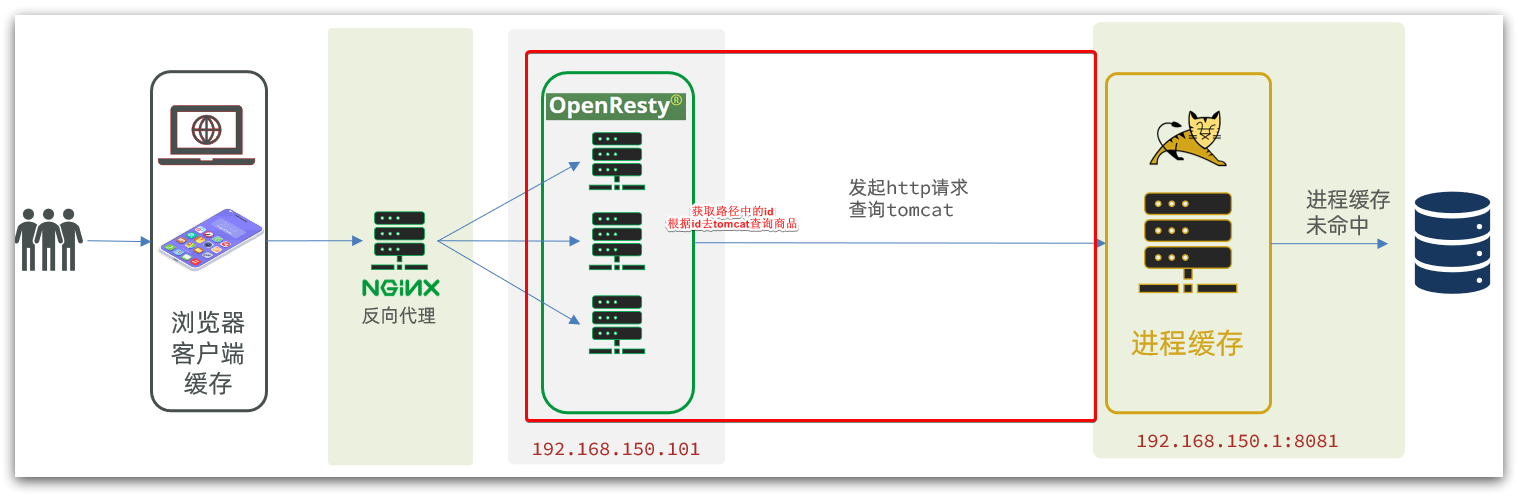
Cabe señalar que nuestro OpenResty está en una máquina virtual y Tomcat está en una computadora con Windows.Las dos IP no deben confundirse.
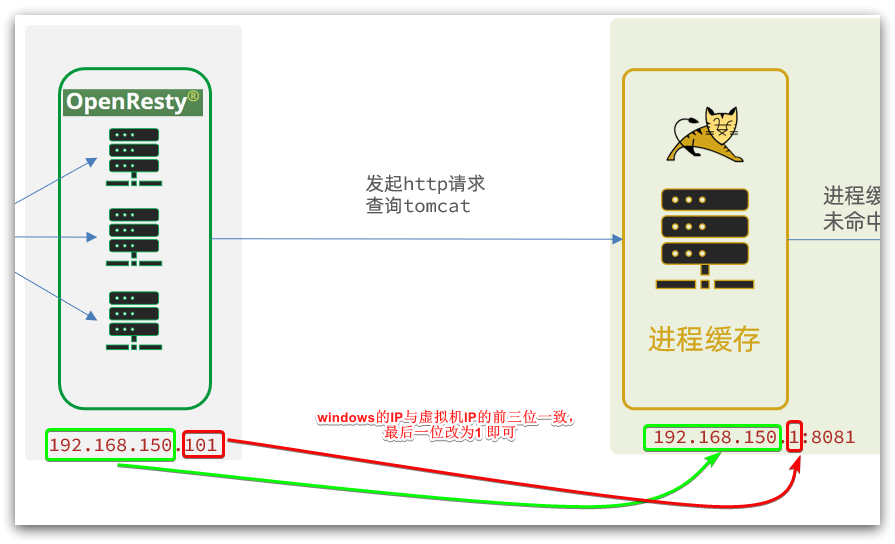
Los casos de demanda son los siguientes:

4.4.1 API para enviar solicitudes http
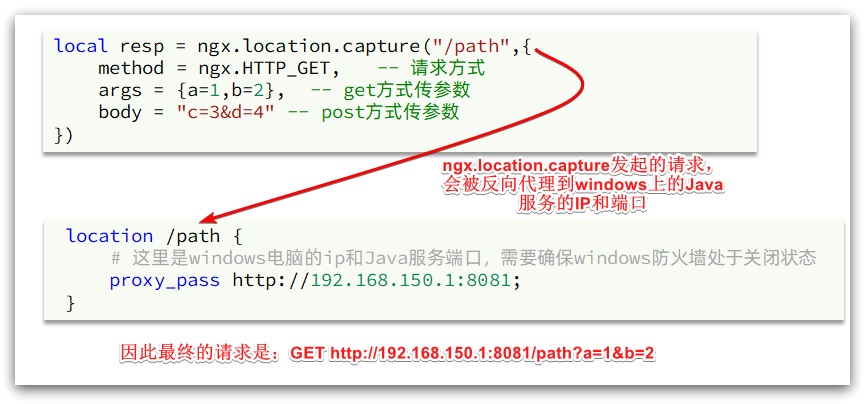
nginx proporciona una API interna para enviar solicitudes http:
local resp = ngx.location.capture("/path",{
method = ngx.HTTP_GET, -- 请求方式
args = {
a=1,b=2}, -- get方式传参数
})
El contenido de la respuesta devuelta incluye:
- resp.status: código de estado de respuesta
- resp.header: encabezado de respuesta, que es una tabla
- resp.body: cuerpo de respuesta, que son los datos de respuesta
Nota: La ruta aquí es una ruta, sin incluir IP ni puerto. Esta solicitud será monitoreada y procesada por el servidor dentro de nginx.
Pero queremos que esta solicitud se envíe al servidor Tomcat, por lo que debemos escribir un servidor para revertir el proxy en esta ruta:
location /path {
# 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态
proxy_pass http://192.168.150.1:8081;
}
El principio se muestra en la figura:
4.4.2 Paquete de herramientas http
A continuación, encapsulamos una herramienta para enviar solicitudes Http y consultamos Tomcat en función de ngx.location.capture.
1) Agregar proxy inverso al servicio Java de Windows
Debido a que todas las interfaces en item-service comienzan con /item, escuchamos la ruta /item y hacemos proxy al servicio Tomcat en Windows.
Modifique /usr/local/openresty/nginx/conf/nginx.confel archivo y agregue una ubicación:
Tenga en cuenta que esta es la ip de la máquina
location /item {
proxy_pass http://192.168.150.1:8081;
}
En el futuro, siempre que llamemos ngx.location.capture("/item"), podremos enviar solicitudes al servicio Tomcat de Windows.
2) Clase de herramienta de encapsulación
Como dijimos antes, OpenResty cargará los archivos de la herramienta en los siguientes dos directorios cuando se inicie:
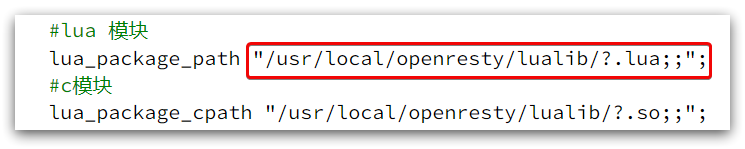
Por lo tanto, las herramientas http personalizadas también deben colocarse en este directorio.
En /usr/local/openresty/lualibel directorio, cree un nuevo archivo common.lua:
vi /usr/local/openresty/lualib/common.lua
El contenido es el siguiente:
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http请求查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
Esta herramienta encapsula la función read_http en una variable del tipo de tabla _M y la devuelve, que es similar a exportar.
Al usar, puede usar require('common')para importar la biblioteca de funciones, donde común es el nombre de archivo de la biblioteca de funciones.
3) Realizar consulta de productos básicos
Finalmente, modificamos /usr/local/openresty/nginx/lua/item.luael archivo y usamos la biblioteca de funciones recién encapsulada para consultar tomcat:
-- 引入自定义common工具模块,返回值是common中返回的 _M
local common = require("common")
-- 从 common中获取read_http这个函数
local read_http = common.read_http
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)
Probamos para devolver la información de un producto primero

Después de reiniciar, puede ver que la página cambia
http://localhost:8934/item.html?id=10003

El resultado de la consulta aquí es una cadena json, y contiene dos cadenas json de bienes e inventario. Lo que finalmente necesita la página es empalmar los dos json en un json:
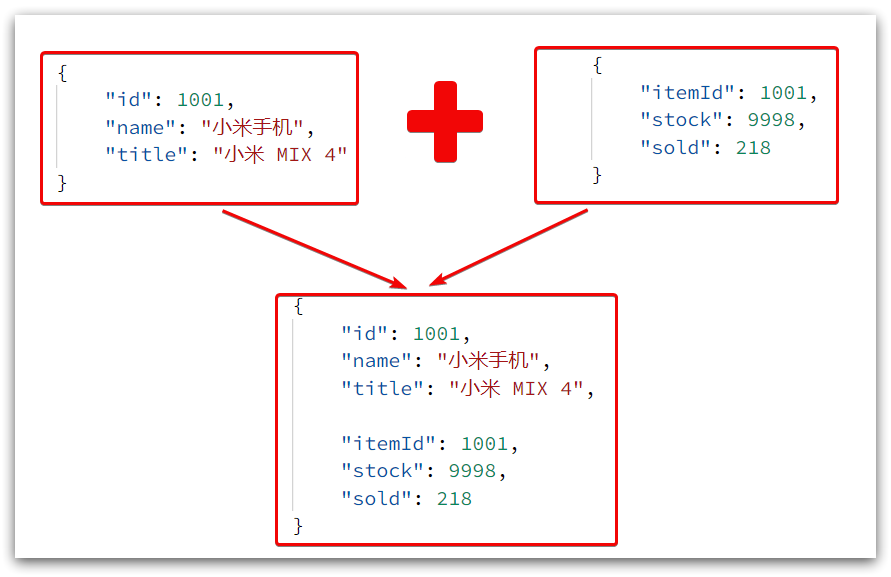
Esto requiere que primero convirtamos JSON en una tabla lua y luego la convertamos a JSON después de completar la integración de datos.
4.4.3 Clase de herramienta CJSON
OpenResty proporciona un módulo cjson para manejar la serialización y deserialización de JSON.
Dirección oficial: https://github.com/openresty/lua-cjson/
1) Importar el módulo cjson:
local cjson = require "cjson"
2) Serialización:
local obj = {
name = 'jack',
age = 21
}
-- 把 table 序列化为 json
local json = cjson.encode(obj)
3) Deserialización:
local json = '{"name": "jack", "age": 21}'
-- 反序列化 json为 table
local obj = cjson.decode(json);
print(obj.name)
4.4.4 Realizar consulta Tomcat
A continuación, modificamos el negocio anterior en item.lua y agregamos la función de procesamiento json:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
-- 导入cjson库
local cjson = require('cjson')
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))

reiniciar nginx
nginx -s reload
acceso
http://localhost:8934/item.html?id=10004
Se encuentra que tanto el vendido como el stock tienen valor.

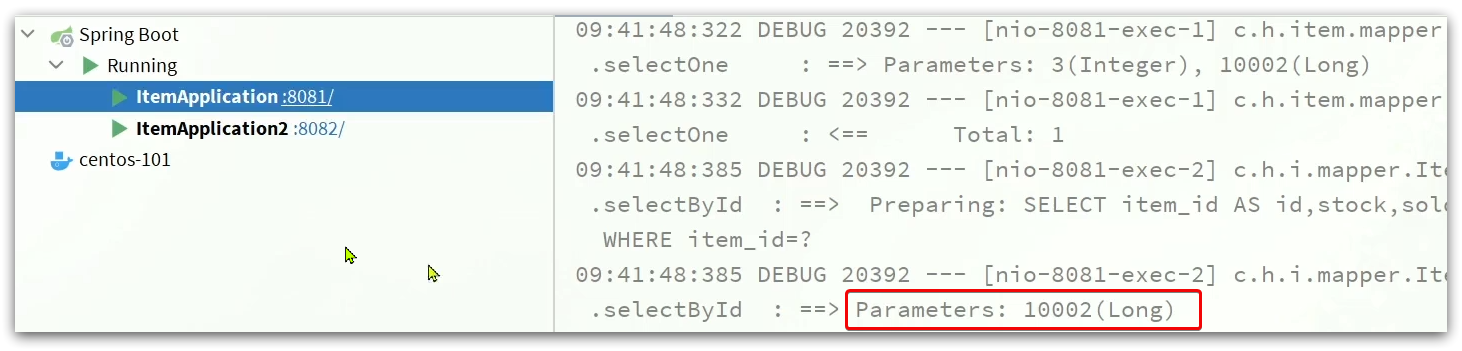
4.4.5 Equilibrio de carga basado en ID
En el código de ahora, nuestro Tomcat se implementa en una sola máquina. En el desarrollo real, Tomcat debe estar en modo clúster:
Por lo tanto, OpenResty necesita equilibrar la carga del clúster Tomcat.
La regla de equilibrio de carga predeterminada es el modo de sondeo, cuando consultamos /item/10001:
- Por primera vez, se accederá al servicio tomcat en el puerto 8081 y se formará un caché de proceso JVM dentro del servicio.
- Por segunda vez, se accederá al servicio tomcat en el puerto 8082. No hay caché de JVM dentro del servicio (porque el caché de JVM no se puede compartir) y se consultará la base de datos.
- …
Verá, debido al sondeo, la caché de JVM formada al consultar 8081 por primera vez no tiene efecto, y no tendrá efecto hasta el próximo acceso a 8081, y la tasa de aciertos de caché es demasiado baja.
¿qué hacer?
Si el mismo producto puede acceder al mismo servicio de tomcat cada vez que se consulta, la caché de JVM definitivamente tendrá efecto.
En otras palabras, debemos equilibrar la carga en función de la identificación del producto en lugar de realizar un sondeo.
1) Principio
Nginx proporciona un algoritmo para el equilibrio de carga basado en rutas de solicitud:
Nginx realiza una operación de hash de acuerdo con la ruta de la solicitud y toma el resto del valor obtenido de la cantidad de servicios de tomcat.Si el resto es unos pocos, accederá a la cantidad de servicios para lograr el equilibrio de carga.
Por ejemplo:
- Nuestra ruta de solicitud es /item/10001
- El número total de tomcat es 2 (8081, 8082)
- El resultado del resto de la operación hash en la ruta de solicitud /item/1001 es 1
- Luego acceda al primer servicio tomcat, que es 8081
Siempre que la identificación permanezca sin cambios, el resultado de cada operación hash no cambiará, por lo que se puede garantizar que el mismo producto acceda al mismo servicio Tomcat todo el tiempo, lo que garantiza que la caché de JVM surta efecto.
2) darse cuenta
Modifique /usr/local/openresty/nginx/conf/nginx.confel archivo para lograr el equilibrio de carga en función del ID.
Primero, defina el clúster de tomcat y configure el equilibrio de carga basado en rutas:
upstream tomcat-cluster {
hash $request_uri;
server 192.168.150.1:8081;
server 192.168.150.1:8082;
}
Luego, modifique el proxy inverso para el servicio tomcat y el destino apunta al clúster tomcat:
location /item {
proxy_pass http://tomcat-cluster;
}
Recargar OpenResty
nginx -s reload
3) prueba
Inicie dos servicios Tomcat:
Iniciar simultáneamente:
Después de borrar el registro, visite la página nuevamente
http://localhost:8934/item.html?id=10004
Puede ver productos con diferentes identificaciones y ha accedido a diferentes servicios de Tomcat:
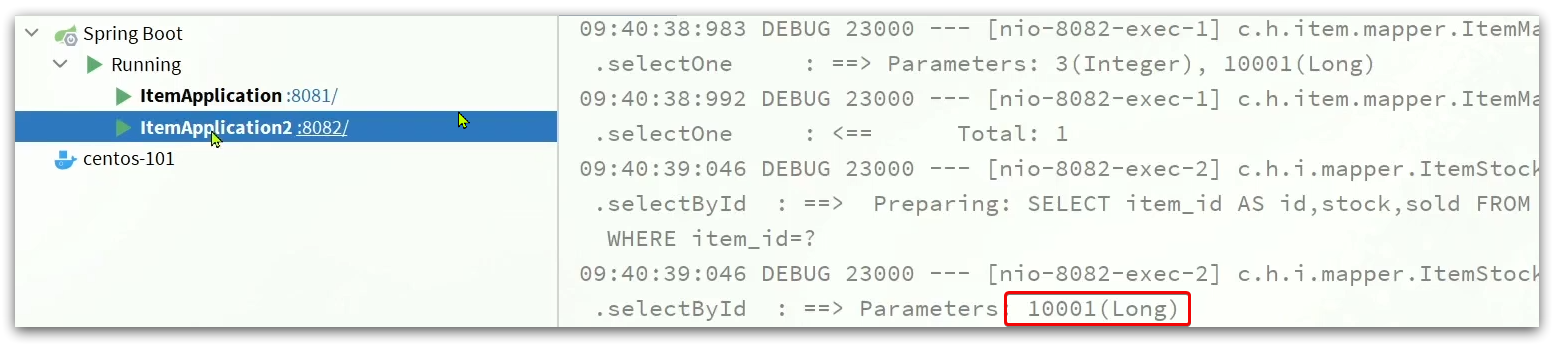
para la misma identificación de producto, varias visitas tendrán un caché
4.5 Calentamiento de caché de Redis
La memoria caché de Redis enfrentará un problema de inicio en frío:
Inicio en frío : cuando el servicio recién se inicia, no hay caché en Redis. Si todos los datos del producto se almacenan en caché en la primera consulta, puede ejercer una gran presión sobre la base de datos.
Calentamiento de caché : en el desarrollo real, podemos usar big data para contar los datos calientes a los que acceden los usuarios, y consultar y guardar estos datos calientes por adelantado en Redis cuando comience el proyecto.
Tenemos una pequeña cantidad de datos y no hay ninguna función relacionada con las estadísticas de datos.Actualmente, todos los datos se pueden poner en el caché al inicio.
1) Use Docker para instalar Redis, habilitar la operación en segundo plano y la persistencia
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes
2) Introducir la dependencia de Redis en el servicio de servicio de artículos
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3) Configurar la dirección de Redis
spring:
redis:
host: 192.168.150.101
4) Escribe la clase de inicialización
El calentamiento de la memoria caché debe completarse cuando se inicia el proyecto y debe obtenerse después de RedisTemplate.
Aquí usamos la interfaz InitializingBean para implementar, porque InitializingBean se puede ejecutar después de que Spring crea el objeto y se inyectan todas las variables miembro.
package com.heima.item.config;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void afterPropertiesSet() throws Exception {
// 初始化缓存
// 1.查询商品信息
List<Item> itemList = itemService.list();
// 2.放入缓存
for (Item item : itemList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(item);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:id:" + item.getId(), json);
}
// 3.查询商品库存信息
List<ItemStock> stockList = stockService.list();
// 4.放入缓存
for (ItemStock stock : stockList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(stock);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);
}
}
}
Después de comenzar, verifique redis y descubra que el precalentamiento es exitoso

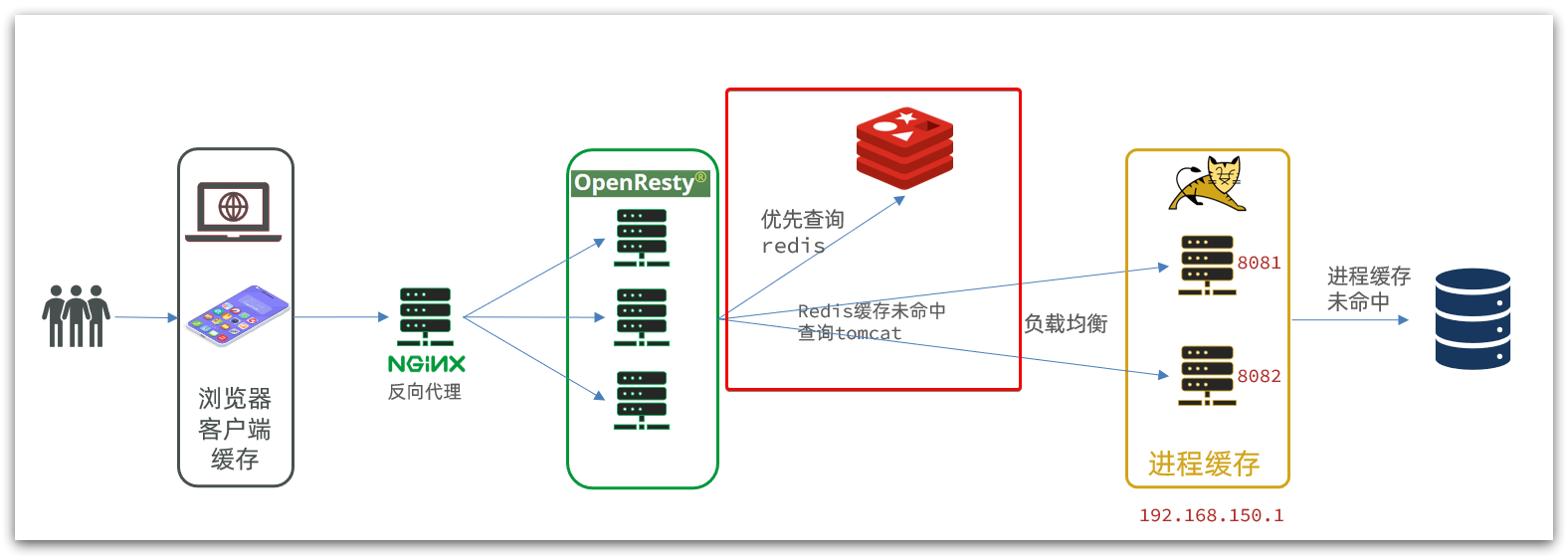
4.6 Consultar caché de Redis
Ahora que el caché de Redis está listo, podemos implementar la lógica de consultar Redis en OpenResty. Como se muestra en el cuadro rojo de la figura a continuación:
Cuando la solicitud ingresa a OpenResty:
- Primero consulte el caché de Redis
- Si la memoria caché de Redis falla, consulte Tomcat
4.6.1 Paquete de herramientas de Redis
OpenResty proporciona un módulo para operar Redis, podemos usarlo directamente siempre que importemos este módulo. Pero por comodidad, encapsulamos la operación de Redis en la biblioteca de herramientas common.lua anterior.
Modificar /usr/local/openresty/lualib/common.luael archivo:
1) Introduzca el módulo Redis e inicialice el objeto Redis
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)
2) La función de encapsulación se usa para liberar la conexión de Redis, que en realidad se coloca en el grupo de conexiones.
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
3) Encapsular la función, consultar los datos de Redis según la clave
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
4) exportar
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
El common.lua completo:
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
4.6.2 Realizar consulta de Redis
A continuación, podemos modificar el archivo item.lua para consultar Redis.
La lógica de consulta es:
- Consultar Redis basado en id
- Continuar consultando a Tomcat si la consulta falla
- Devolver resultados de consulta
1) Modifique /usr/local/openresty/lua/item.luael archivo y agregue una función de consulta:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 封装查询函数
function read_data(key, path, params)
-- 查询本地缓存
local val = read_redis("127.0.0.1", 6379, key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
-- 返回数据
return val
end
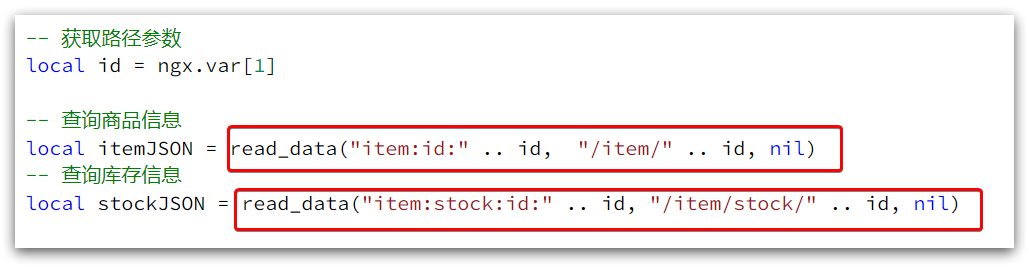
2) Luego modifique el negocio de la consulta de productos básicos y la consulta de inventario:
3) Código completo item.lua:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 封装查询函数
function read_data(key, path, params)
-- 查询本地缓存
local val = read_redis("127.0.0.1", 6379, key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
-- 返回数据
return val
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, "/item/stock/" .. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
Una vez completadas todas las configuraciones, reinicie nginx
nginx -s reload
acceder primero
http://localhost:8934/item.html?id=10002
Luego, detenga los dos tomcats de IDEA y acceda a ellos a través de redis cache, y descubra que son correctos

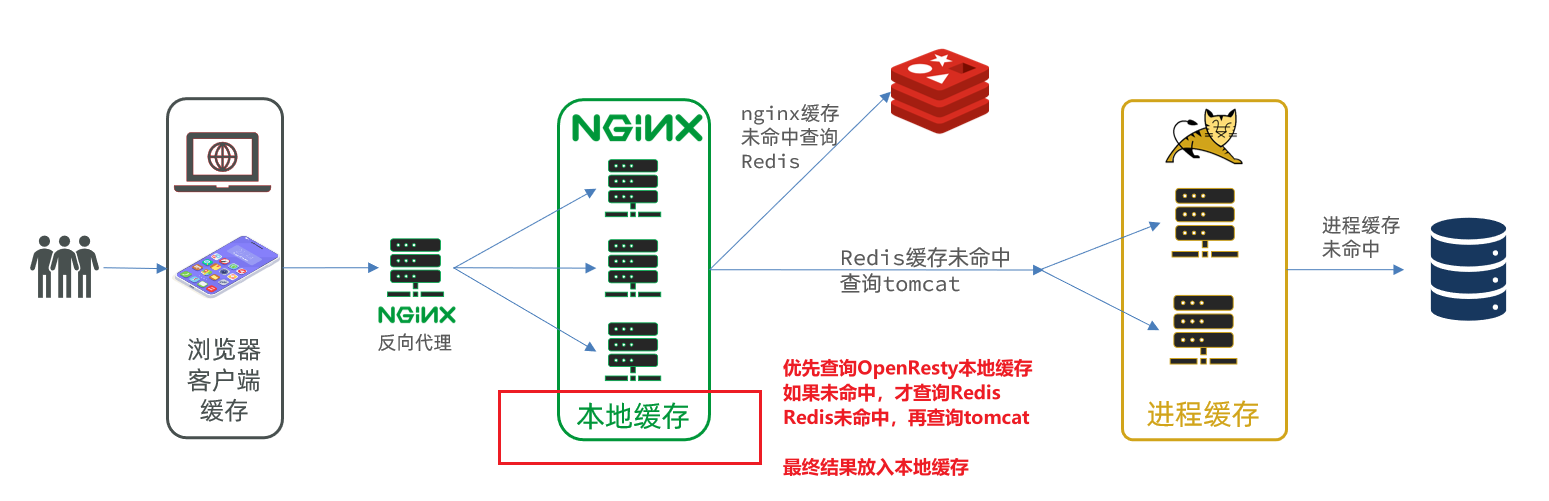
4.7 Caché local de Nginx
Ahora, solo existe el último enlace en todo el caché de varios niveles, que es el caché local de nginx. Como se muestra en la imagen:
4.7.1 API de caché local

OpenResty proporciona a Nginx la función de shard dict , que puede compartir datos entre múltiples trabajadores de nginx y realizar la función de almacenamiento en caché.
1) Abra el diccionario compartido y agregue la configuración en http en nginx.conf en la máquina virtual:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
2) Operar el diccionario compartido:
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')
4.7.2 Realizar consulta de caché local
1) Modifique /usr/local/openresty/lua/item.luael archivo, modifique la función de consulta read_data y agregue lógica de caché local:
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)
-- 查询redis
val = read_redis("127.0.0.1", 6379, key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
2) Modifique el negocio de consultar bienes e inventario en item.lua para implementar la última función read_data:

De hecho, hay más parámetros de tiempo de caché. Después de la expiración, el caché nginx se eliminará automáticamente y el caché se puede actualizar la próxima vez que visite.
Aquí, el período de tiempo de espera para la información básica del producto se establece en 30 minutos y el inventario se establece en 1 minuto.
Debido a que la frecuencia de actualización del inventario es alta, si el tiempo de caché es demasiado largo, puede ser bastante diferente al de la base de datos.
3) Completa el archivo item.lua:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)
-- 查询redis
val = read_redis("127.0.0.1", 6379, key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, 60, "/item/stock/" .. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
reiniciar nginx
nginx -s reload
Supervisar la información de registro
cd /usr/local/openresty/nginx/logs
tail -f error.log
entonces visita
http://localhost:8934/item.html?id=10003
El registro es el siguiente:

Visita de nuevo, sin error
http://localhost:8934/item.html?id=10003

Elimine el caché 10003 en redis

y visite nuevamente
http://localhost:8934/item.html?id=10003
El acceso aún es exitoso, porque nginx tiene un caché local, solo toma 16ms

5. Sincronización de caché
En la mayoría de los casos, lo que consulta el navegador son datos almacenados en caché. Si hay una gran diferencia entre los datos almacenados en caché y los datos de la base de datos, pueden ocurrir consecuencias graves.
Por lo tanto, debemos garantizar la consistencia de los datos de la base de datos y los datos del caché, que es la sincronización entre el caché y la base de datos.
5.1 Estrategia de sincronización de datos
Hay tres formas comunes de sincronizar datos en caché:
Establecer período de validez : establezca un período de validez para el caché, y se eliminará automáticamente después de la expiración. actualizar al consultar de nuevo
- Ventajas: simple y conveniente.
- Desventajas: poca puntualidad, puede ser inconsistente antes de que caduque el caché
- Escenario: negocio con baja frecuencia de actualización y bajos requisitos de puntualidad
Escritura doble síncrona : modifica directamente el caché mientras modifica la base de datos
- Ventajas: gran puntualidad, gran coherencia entre la memoria caché y la base de datos
- Desventajas: intrusión de código, alto acoplamiento;
- Escenario: Caché de datos que requiere alta consistencia y puntualidad
**Notificación asíncrona: **Envíe una notificación de evento cuando se modifique la base de datos y los servicios relacionados modifiquen los datos almacenados en caché después de escuchar la notificación
- Ventajas: bajo acoplamiento, se pueden notificar varios servicios de caché al mismo tiempo
- Desventajas: puntualidad general, puede haber inconsistencias intermedias
- Escenario: requisitos generales de puntualidad, es necesario sincronizar varios servicios
La implementación asíncrona se puede implementar en base a MQ o Canal:
1) Notificación asíncrona basada en MQ:
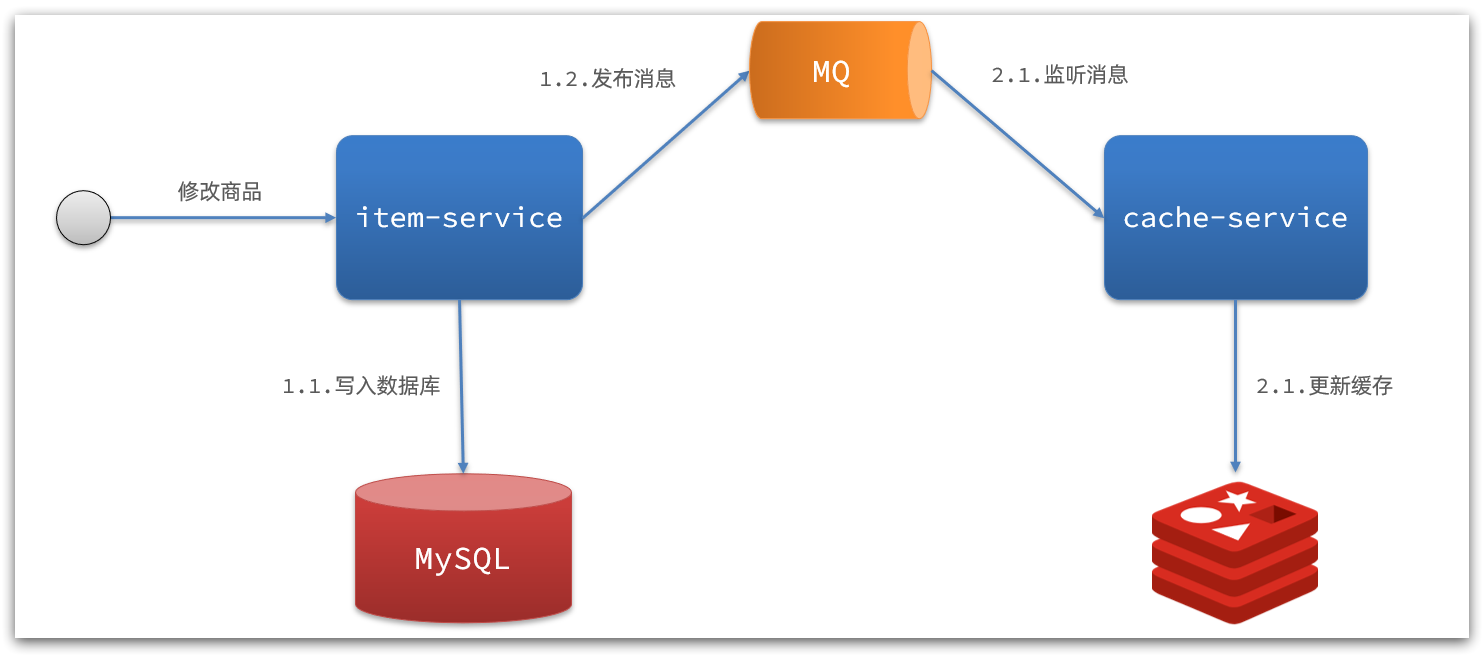
Interpretación:
- Una vez que el servicio básico termina de modificar los datos, solo necesita enviar un mensaje a MQ.
- El servicio de caché escucha el mensaje MQ y luego completa la actualización del caché.
Todavía hay una pequeña cantidad de intrusión de código.
2) Interpretación de notificación basada en Canal
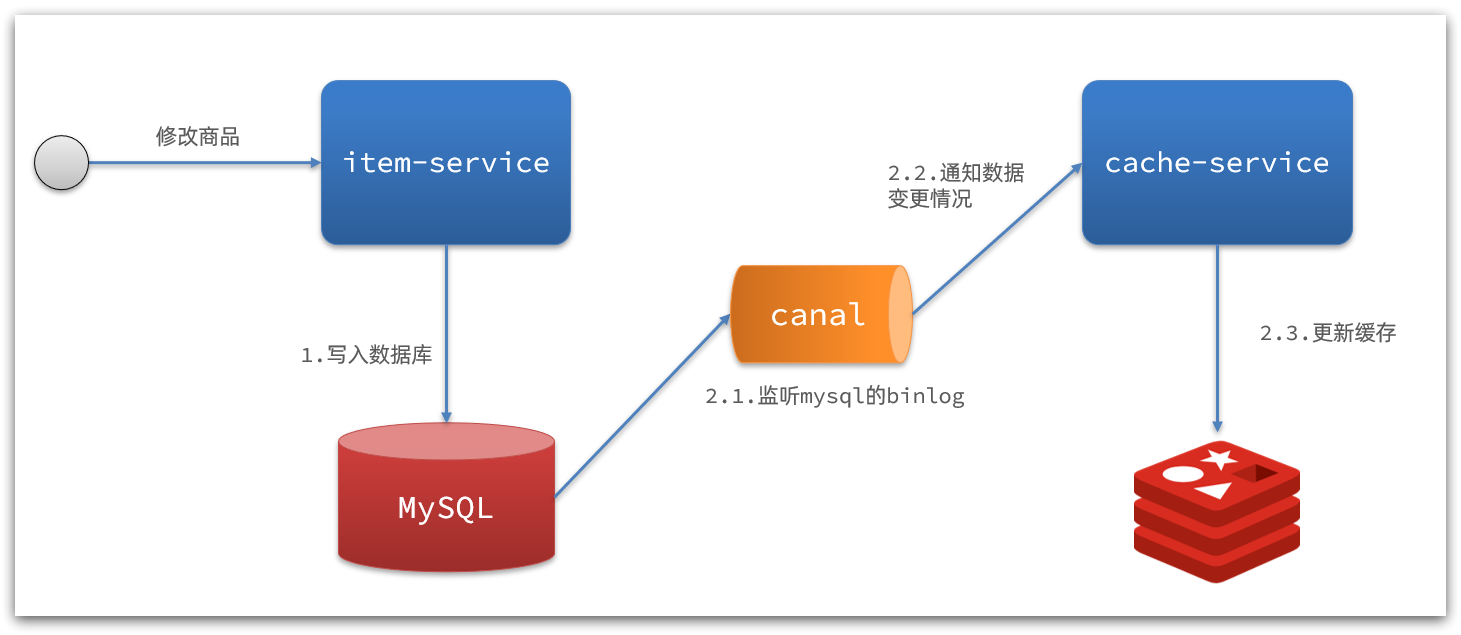
:
- Una vez que el servicio de productos básicos completa la modificación de productos básicos, el negocio finaliza directamente sin ninguna intrusión de código
- Canal monitorea los cambios de MySQL y notifica inmediatamente al servicio de caché cuando se encuentra un cambio
- El servicio de caché recibe la notificación del canal y actualiza el caché.
código cero intrusión
5.2 Instalar Canal
5.2.1 Entendiendo el Canal
Canal [kə'næl] , traducido como canal/tubería/zanja, canal es un proyecto de código abierto de Alibaba, desarrollado en Java. Proporciona suscripción y consumo de datos incrementales en función del análisis de registros incrementales de la base de datos. Dirección de GitHub: https://github.com/alibaba/canal
Canal se implementa en base a la sincronización maestro-esclavo de mysql. El principio de la sincronización maestro-esclavo de MySQL es el siguiente:
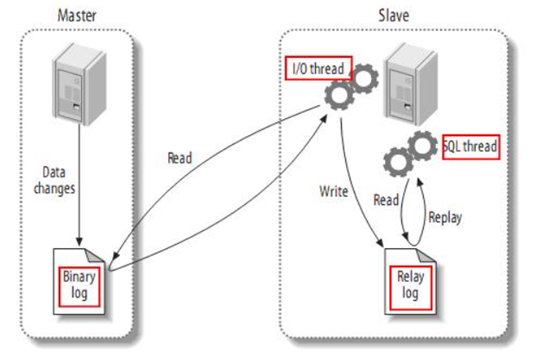
- 1) El maestro MySQL escribe los cambios de datos en el registro binario (registro binario), y los datos registrados se denominan eventos de registro binario
- 2) El esclavo MySQL copia los eventos de registro binario del maestro en su registro de retransmisión (registro de retransmisión)
- 3) MySQL esclavo reproduce los eventos en el registro de retransmisión y refleja los cambios de datos en sus propios datos
Y Canal pretende ser un nodo esclavo de MySQL, para monitorear los cambios de registro binario del maestro. Luego notifique al cliente del Canal la información de cambio obtenida y luego complete la sincronización de otras bases de datos.
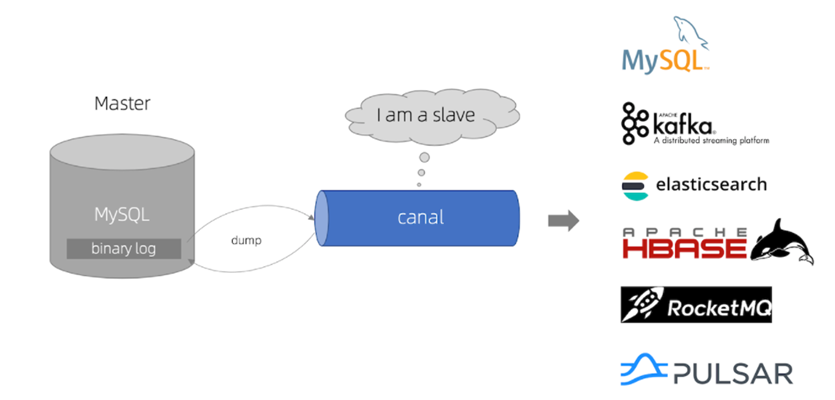
5.2.2 Instalar Canal
Instalar y configurar la documentación previa a la clase de referencia de Canal:
Instalar y configurar Canal
A continuación, abriremos el mecanismo de sincronización maestro-esclavo de mysql y dejaremos que Canal simule la solución.
1. Abra MySQL maestro-esclavo
Canal se basa en la función de sincronización maestro-esclavo de MySQL, por lo que primero se debe habilitar la función maestro-esclavo de MySQL.
Aquí hay un ejemplo de mysql ejecutándose con Docker:
1.1 Abrir binlog
Abra el archivo de registro montado en el contenedor mysql, el mío está en /tmp/mysql_cluster/confel directorio:
modifique el archivo:
vi /tmp/mysql_cluster/conf/my.cnf
Agregar contenido:
log-bin=/var/lib/mysql_cluster/mysql-bin
binlog-do-db=heima
Interpretación de la configuración:
log-bin=/var/lib/mysql_cluster/mysql-bin: establezca la dirección de almacenamiento y el nombre de archivo del archivo de registro binario, llamado mysql-binbinlog-do-db=heima: Especifique qué base de datos para registrar eventos de registro binario, aquí registre la biblioteca heima
Reinicie mysql_cluster después de completar la configuración
docker restart mysql_cluster
efecto final:

[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima
1.2 Establecer permisos de usuario
A continuación, agregue una cuenta que solo se use para la sincronización de datos. Por razones de seguridad, aquí solo se proporciona el permiso de operación para la biblioteca heima.
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;

Simplemente reinicie el contenedor mysql
docker restart mysql
Pruebe si la configuración es exitosa: en la consola mysql o Navicat, ingrese el comando:
show master status;

2. Instalar canal
2.1 Crear una red
Necesitamos crear una red para poner MySQL, Canal y MQ en la misma red Docker:
docker network create heima
Deje que mysql se una a esta red:
docker network connect heima mysql
2.2 Instalar Canal
El paquete de compresión de imágenes del canal se proporciona en los materiales previos a la clase:
puede cargarlo en la máquina virtual y luego importarlo mediante el comando:

docker load -i canal.tar
Luego ejecute el comando para crear el contenedor Canal:
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:v1.1.5
ilustrar:
-p 11111:11111: Este es el puerto de escucha predeterminado del canal.-e canal.instance.master.address=mysql:3306: dirección y puerto de la base de datos, si no conoce la dirección del contenedor mysql, puededocker inspect 容器idcomprobarlo-e canal.instance.dbUsername=canal:nombre de usuario de la base de datos-e canal.instance.dbPassword=canal: contraseña de la base de datos-e canal.instance.filter.regex=: El nombre de la tabla a monitorear
Sintaxis admitida por el oyente de nombre de tabla:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2
Después del inicio, verifique el registro
docker logs -f canal

comando de entrada
docker exec -it canal bash
Verifique el registro de operaciones
tail -f canal-server/logs/canal/canal.log
tail -f canal-server/logs/heima/heima.log

5.3 Canal de vigilancia
Canal proporciona clientes en varios idiomas, cuando Canal detecte cambios en el binlog, lo notificará al cliente de Canal.
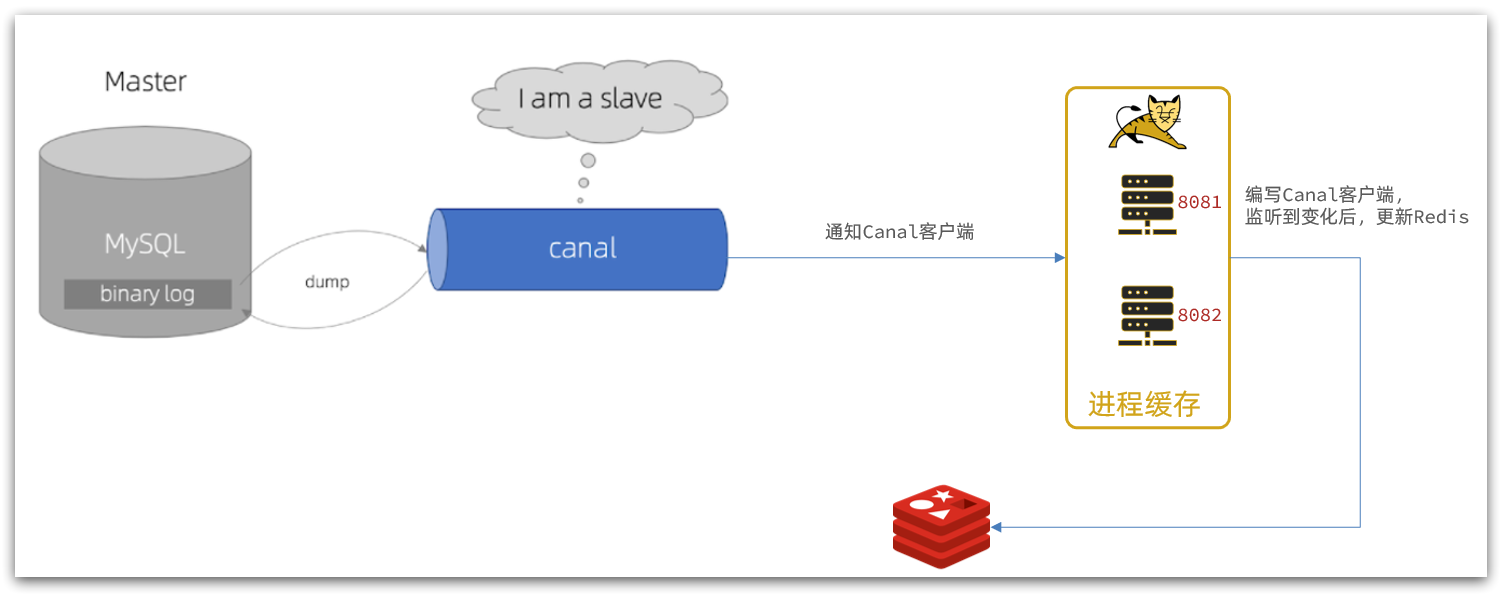
Podemos utilizar el cliente Java proporcionado por Canal para escuchar los mensajes de notificación de Canal. Cuando se recibe un mensaje de cambio, la memoria caché se actualiza.
Pero aquí usaremos el cliente de inicio de canal de código abierto de terceros en GitHub. Dirección: https://github.com/NormanGyllenhaal/canal-client
Perfecta integración con SpringBoot, montaje automático, mucho más sencillo y fácil de usar que el cliente oficial.
5.3.1 Introducción de dependencias:
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
5.3.2 Configuración de escritura:
canal:
destination: heima # canal的集群名字,要与安装canal时设置的名称一致
server: 192.168.150.101:11111 # canal服务地址
5.3.3 Modificar la clase de entidad Item
Complete la asignación entre los campos de la tabla de la base de datos y el elemento a través de @Id, @Column y otras anotaciones:
package com.heima.item.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;
import javax.persistence.Column;
import java.util.Date;
@Data
@TableName("tb_item")
public class Item {
@TableId(type = IdType.AUTO)
@Id
private Long id;//商品id
@Column(name = "name")
private String name;//商品名称
private String title;//商品标题
private Long price;//价格(分)
private String image;//商品图片
private String category;//分类名称
private String brand;//品牌名称
private String spec;//规格
private Integer status;//商品状态 1-正常,2-下架
private Date createTime;//创建时间
private Date updateTime;//更新时间
@TableField(exist = false)
@Transient
private Integer stock;
@TableField(exist = false)
@Transient
private Integer sold;
}
5.3.4 Oyentes de escritura
EntryHandler<T>Escriba un oyente implementando la interfaz para escuchar los mensajes del Canal. Tenga en cuenta dos puntos:
- La clase de implementación
@CanalTable("tb_item")especifica la información de la tabla para monitorear - El tipo genérico de EntryHandler es la clase de entidad correspondiente a la tabla
package com.heima.item.canal;
import com.github.benmanes.caffeine.cache.Cache;
import com.heima.item.config.RedisHandler;
import com.heima.item.pojo.Item;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {
@Autowired
private RedisHandler redisHandler;
@Autowired
private Cache<Long, Item> itemCache;
@Override
public void insert(Item item) {
// 写数据到JVM进程缓存
itemCache.put(item.getId(), item);
// 写数据到redis
redisHandler.saveItem(item);
}
@Override
public void update(Item before, Item after) {
// 写数据到JVM进程缓存
itemCache.put(after.getId(), after);
// 写数据到redis
redisHandler.saveItem(after);
}
@Override
public void delete(Item item) {
// 删除数据到JVM进程缓存
itemCache.invalidate(item.getId());
// 删除数据到redis
redisHandler.deleteItemById(item.getId());
}
}
Las operaciones en Redis aquí están todas encapsuladas en el objeto RedisHandler, que es una clase que escribimos cuando estábamos calentando el caché. El contenido es el siguiente:
package com.heima.item.config;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void afterPropertiesSet() throws Exception {
// 初始化缓存
// 1.查询商品信息
List<Item> itemList = itemService.list();
// 2.放入缓存
for (Item item : itemList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(item);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:id:" + item.getId(), json);
}
// 3.查询商品库存信息
List<ItemStock> stockList = stockService.list();
// 4.放入缓存
for (ItemStock stock : stockList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(stock);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);
}
}
public void saveItem(Item item) {
try {
String json = MAPPER.writeValueAsString(item);
redisTemplate.opsForValue().set("item:id:" + item.getId(), json);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
public void deleteItemById(Long id) {
redisTemplate.delete("item:id:" + id);
}
}
Reinicie la prueba
y vea que siempre hay salida en la consola IDEA:

acceso
http://localhost:8081/item/10001

Mira la estática en IDEA

entrevista directa
http://localhost:8081/
Modificar el primer artículo

Modificar talla y precio

Visitar aquí de nuevo
http://localhost:8081/item/10001

Verifique redis nuevamente y descubra que la modificación síncrona es exitosa

.
