El conocimiento científico
La Conferencia Internacional sobre Visión por Computador y Reconocimiento de Patrones (CVPR) es una conferencia académica anual de IEEE. El contenido principal de la conferencia es la tecnología de reconocimiento de patrones y visión por computadora. CVPR es la conferencia de visión por computadora más importante del mundo (una de las tres conferencias principales, las otras dos son ICCV y ECCV). En los últimos años, hay alrededor de 1500 participantes cada año, y el número de artículos incluidos es generalmente alrededor de 300. Esta conferencia tendrá un tema fijo cada año, y cada año, las empresas patrocinarán la conferencia y tendrán la oportunidad de exhibir en el lugar.

# Prefacio
SEP.

Compañeros de clase, finalmente nos volvemos a encontrar. Su editor, Shiwai Layman, ha regresado. Ha pasado casi un mes desde el último artículo sobre 9.26. El editor también los extraña mucho. He estado ocupado escribiendo artículos recientemente y tengo sueño. Ha sido un unos meses, pero es una pena darse por vencido. Si no te rindes, no puedes obtener un buen resultado. El resultado se ha estancado, y finalmente se resuelve, y se ha logrado un resultado comparable a SOTA. Yo Estoy aquí para abrazar a todos en cuanto termine la tesis. Más cerca de casa, seguimos el artículo teórico anterior Teoría del aprendizaje profundo (15): la primera exploración de VGG del misterio de la profundidad.

Combate VGG16 de TensorFlow

Esta estructura de red VGG16, todavía usamos el conjunto de datos de flores anterior, y la parte del código todavía usa la estructura anterior, pero el código de procesamiento de los datos de entrada se ha actualizado ligeramente, y el resto es similar. plataforma de alojamiento de código más tarde Es conveniente que los estudiantes descarguen y prueben.
1. Preparación de datos

Conjunto de datos de flores de cinco categorías: se divide principalmente en conjuntos de entrenamiento y verificación: entrenar y val. Cada conjunto contiene cinco categorías de flores. En términos generales, el número de conjuntos de entrenamiento es mucho mayor que el número de la misma categoría en la verificación. colocar.

2. Estructura de la red

'''
Entrada de estructura de red VGG: 224x224x3
1. Bloque de capa de convolución de 64 canales: entrada: 224x224x3, 2 capas de estructura de convolución de 3x3x64, relleno, salida: 64x224x224
2. maxpooling1: entrada: 64x224x224, salida: 64x112x112
3. Bloque de convolución de 128 canales: entrada: 64x112x1122, 2 capas de estructura de convolución de 3x3x128, relleno, salida: 128x112x112
4. maxpooling2: entrada: 128x112x112, salida: 128x56x56
5. Bloque de convolución de 256 canales: entrada: capa de 128x56x563, estructura de convolución de 3x3x256, relleno, salida: 256x56x56.
6. maxpooling3: entrada: 256x56x56, salida: 256x28x28
7. Bloque de convolución de 512 canales: entrada: 256x28x28, 3 capas de estructura de convolución de 3x3x512, relleno, salida: 512x28x28.
8 maxpooling4: entrada: 512x28x28, salida: 512x14x14.
9. Bloque de convolución de 512 canales: entrada: 512x14x14, 3 capas de estructura de convolución de 3x3x512, relleno, salida: 512x14x14.
10. maxpooling4: entrada: 512x14x14, salida: 512x7x7.
11. Capa 1 totalmente conectada: entrada: 512*7*7, salida: 4096
12. Capa 1 completamente conectada: entrada: 4096, salida: 4096
13. Capa 1 completamente conectada: entrada: 4096, salida: 5 (número de categorías)
'''
def inference(images, batch_size, n_classes,drop_rate):
# 一个简单的卷积神经网络,卷积+池化层x2,全连接层x2,最后一个softmax层做分类。
# 卷积层1
# 1. 64通道卷积层块: 输入: 224x224x3, 2层3x3x64的卷积结构, padding, 输出:64x224x224
# 2. maxpooling1:输入: 64x224x224, 输出: 112x112x64
conv1 = Conv_layer(names = 'conv_block1', input = images , w_shape = [3, 3, 3, 64], b_shape = [64], strid = [1, 1])
conv2 = Conv_layer(names = 'conv_block2', input = conv1 , w_shape = [3, 3, 64, 64], b_shape = [64], strid = [1, 1])
pool_1 = Max_pool_lrn(names = 'pooling1', input = conv2 , ksize = [1, 2, 2, 1], is_lrn = True)
# 3. 128通道卷积块:输入: 64x112x1122, 2层3x3x128的卷积结构, padding,输出:128x112x112
# 4. maxpooling2: 输入: 128x112x112, 输出: 128x56x56
conv3 = Conv_layer(names = 'conv_block3', input = pool_1 , w_shape = [3, 3, 64, 128], b_shape = [128], strid = [1, 1])
conv4 = Conv_layer(names = 'conv_block4', input = conv3 , w_shape = [3, 3, 128, 128], b_shape = [128], strid = [1, 1])
pool_2 = Max_pool_lrn(names = 'pooling2', input = conv4 , ksize = [1, 2, 2, 1], is_lrn = False)
# 5. 256通道卷积块:输入: 128x56x56, 3层3x3x256的卷积结构, padding, 输出:256x56x56。
# 6. maxpooling3: 输入: 256x56x56, 输出: 256x28x28
conv5 = Conv_layer(names = 'conv_block5', input = pool_2 , w_shape = [3, 3, 128, 256], b_shape = [256], strid = [1, 1])
conv6 = Conv_layer(names = 'conv_block6', input = conv5 , w_shape = [3, 3, 256, 256], b_shape = [256], strid = [1, 1])
conv7 = Conv_layer(names = 'conv_block7', input = conv6 , w_shape = [3, 3, 256, 256], b_shape = [256], strid = [1, 1])
pool_3 = Max_pool_lrn(names = 'pooling3', input = conv7 , ksize = [1, 2, 2, 1], is_lrn = False)
# 7. 512通道卷积块: 输入: 256x28x28, 3层3x3x512的卷积结构, padding, 输出:512x28x28。
# 8 maxpooling4: 输入:512x28x28, 输出:512x14x14。
conv8 = Conv_layer(names = 'conv_block8', input = pool_3 , w_shape = [3, 3, 256, 512], b_shape = [512], strid = [1, 1])
conv9 = Conv_layer(names = 'conv_block9', input = conv8 , w_shape = [3, 3, 512, 512], b_shape = [512], strid = [1, 1])
conv10 = Conv_layer(names = 'conv_block10', input = conv9 , w_shape = [3, 3, 512, 512], b_shape = [512], strid = [1, 1])
pool_4 = Max_pool_lrn(names = 'pooling4', input = conv10 , ksize = [1, 2, 2, 1], is_lrn = False)
# print(pool_4.shape)
# 9. 512通道卷积块: 输入: 512x14x14, 3层3x3x512的卷积结构, padding, 输出:512x14x14。
# 10. maxpooling4: 输入:512x14x14, 输出:512x7x7。
conv11 = Conv_layer(names = 'conv_block11', input = pool_4 , w_shape = [3, 3, 512, 512], b_shape = [512], strid = [1, 1])
conv12 = Conv_layer(names = 'conv_block12', input = conv11 , w_shape = [3, 3, 512, 512], b_shape = [512], strid = [1, 1])
conv13 = Conv_layer(names = 'conv_block13', input = conv12 , w_shape = [3, 3, 512, 512], b_shape = [512], strid = [1, 1])
pool_5 = Max_pool_lrn(names = 'pooling5', input = conv13 , ksize = [1, 2, 2, 1], is_lrn = False)
# 11. 全连接层1:输入:512*7*7,输出:4096
# 12. 全连接层1:输入:4096,输出:4096
# 13. 全连接层1:输入:4096,输出:5(类别数目)
reshape = tf.reshape(pool_5, shape=[batch_size, -1])
dim = reshape.get_shape()[1].value
local_1 = local_layer(names = 'local1_scope', input = reshape , w_shape = [dim, 4096], b_shape = [4096])
local_2 = local_layer(names = 'local2_scope', input = local_1 , w_shape = [4096, 4096], b_shape = [4096])
with tf.variable_scope('softmax_linear') as scope:
weights = tf.Variable(tf.truncated_normal(shape=[4096, n_classes], stddev=0.005, dtype=tf.float32),
name='softmax_linear', dtype=tf.float32)
biases = tf.Variable(tf.constant(value=0.1, dtype=tf.float32, shape=[n_classes]),
name='biases', dtype=tf.float32)
softmax_linear = tf.add(tf.matmul(local_2, weights), biases, name='softmax_linear')
# print("---------softmax_linear:{}".format(softmax_linear))
return softmax_linear3. Proceso de formación

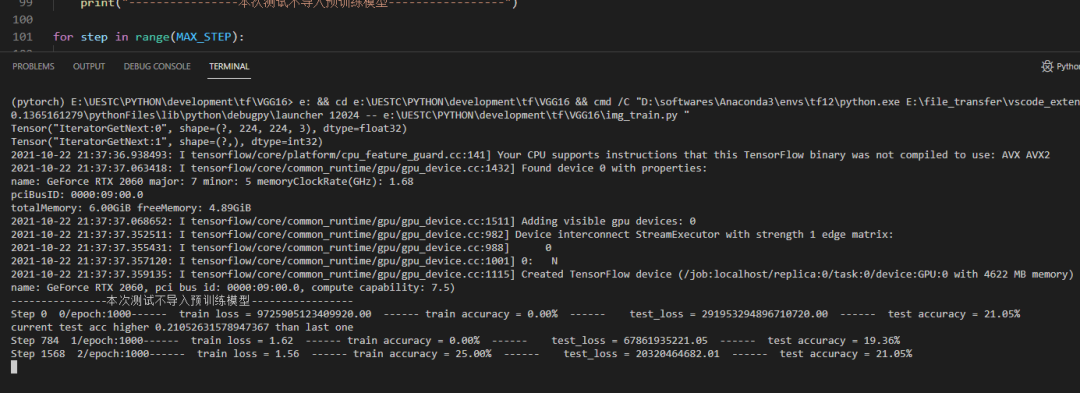
Adquisición del código fuente: https://gitee.com/fengyuxiexie/tensor-flow-vgg16
FIN
epílogo
Este intercambio está aquí Aunque la práctica de código de TensorFlow está completa, preste atención a los siguientes problemas.
1. Dado que solo nos enfocamos en la construcción de la red y no ajustamos los parámetros, es posible que el rendimiento de la red no sea bueno.
2. En el proceso de entrenamiento, es razonable entrenar una ronda de datos y probarla en el conjunto de entrenamiento y el conjunto de prueba.Sin embargo, en nuestro código, el conjunto de prueba se prueba después de entrenar un lote, que necesita mejoras.
3. El código en la sección de datos de entrada se ha mejorado en comparación con antes, preste atención al uso, por ejemplo, la etiqueta para cada categoría está personalizada.
A todos, feliz fin de semana, investigadores, ¡buenas noches!
Editor: Layman Yueyi|Reseña: Layman Xiaoquanquan

Recorrido avanzado de TI
Revisión pasada
1 Capítulo práctico de aprendizaje profundo (13) -- AlexNet de TensorFlow
2 Capítulo práctico de aprendizaje profundo (12) -- LetNet-5 de TensorFlow
3 artículos prácticos de aprendizaje profundo (11) -- TensorFlow Learning Road (8)
Qué hemos hecho en el último año:
[Resumen de fin de año] 2021, adiós a lo viejo y bienvenida a lo nuevo

Haga clic en "Me gusta" y vamos ~