API de alto nivel tf.keras-core
Error cuadrático medio: (f (x) -y) 2 / n
Modelo secuencial: secuencial: una
capa de entrada y una de salida : densa
CSV (formato de archivo de valores separados por comas)
- A veces también se denomina valor separado por caracteres, porque el delimitador puede no ser una coma;
- Almacene los datos de la tabla (números y texto) en texto plano;
- El archivo CSV se compone de cualquier número de registros, separados por algún tipo de carácter de nueva línea;
- Cada registro está compuesto por campos, y los separadores entre campos son otros caracteres o cadenas, los más comunes son comas o tabulaciones;
- No deje en blanco al principio, en unidades de comportamiento;
- Puede contener o excluir el nombre de la columna, y el nombre de la columna será la primera línea del archivo.
Ejemplo: predecir salarios basados en años de educación
Cuaderno Jupyter
import tensorflow as tf # 引入tensorflow框架并简写为tf
print('TensorFlow Version:{}'.format(tf.__version__)) # 打印查看tensorflow的版本号
import pandas as pd # 引入pandas并简记为pd
data = pd.read_csv('Income1.csv') #将文件中的数据读取到DataFrame中
data
import matplotlib.pyplot as plt # 引入matplotlib绘图,简记为plt
%matplotlib inline # 直接在python console中生成图像
plt.scatter(data.Education,data.Income) # 根据x,y数据绘制散点图
x=data.Education
y=data.Income
model = tf.keras.Sequential() # 选择模型Sequential:层的线性叠加
model.add(tf.keras.layers.Dense(1,input_shape=(1,))) # 添加层
model.summary()# 模型结构
model.compile(optimizer='adam',loss='mse')# optimizer:优化方法 loss:损失函数
history = model.fit(x,y,epochs=5000) # epochs:所有数据的训练次数
model.predict(x) # 预测
model.predict(pd.Series([20])) # 预测
Perceptrón multicapa

Los perceptrones (refiriéndose a los perceptrones de una sola capa) tienen ciertas limitaciones: no pueden resolver el problema de XOR , es decir, el problema de la linealidad inseparable.
Combine múltiples perceptrones de una sola capa para obtener una estructura de perceptrón de múltiples capas (MLP-Perceptrón de múltiples capas). El perceptrón multicapa contiene una capa de entrada, una o más capas ocultas y una capa de salida . Las neuronas de cada capa están completamente conectadas con la siguiente.
Si la red contiene más de una capa oculta , se denomina red neuronal artificial profunda.
Descripción:
- Por lo general decimos que la capa de la red neuronal se refiere a la capa con cálculos, porque la capa de entrada no está calculada, por lo tanto, generalmente la capa de entrada no está incluida en la capa de la red neuronal.
- Los perceptrones multicapa (redes neuronales profundas) pueden resolver problemas de inseparabilidad lineal.
Función de activación
En la red neuronal, la función de activación se utiliza para definir la salida de cada nodo (neurona), que se puede utilizar como entrada del siguiente nodo (neurona).
Rol: la función de activación proporciona la capacidad de modelado no lineal de la red. Si no se utiliza la función de activación, incluso una red neuronal multicapa no puede resolver el problema de la inseparabilidad lineal.
** Funciones de activación comunes: **
-
Función de paso
-
función sigmoidea

-
función tanh

-
función relu

-
Fuga relu

Ejemplo: pronóstico de ventas basado en canales promocionales
Cuaderno Jupyter
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv("Advertising.csv")
data.head() # 打印前5行数据
plt.scatter(data.TV,data.sales) # 绘制散点图
plt.scatter(data.radio,data.sales)
plt.scatter(data.newspaper,data.sales)
x=data.iloc[:,1:-1] # 除去第一列和最后一列取所有数据
y=data.iloc[:,-1] # 取所有数据的最后一列
model = tf.keras.Sequential([tf.keras.layers.Dense(10,input_shape=(3,),activation='relu'),tf.keras.layers.Dense(1)]) # 线性模型,添加中间隐藏单元数为10个,输入的维度为3维,激活函数为relu,输出维度为1维
model.summary() # 查看网络结构
model.compile(optimizer='adam',loss='mse') # 配置训练模型
model.fit(x,y,epochs=100) # 训练模型
test = data.iloc[:10,1:-1] # 取10行除去第一列和最后一列的数
model.predict(test) # 使用模型对数据进行预测
Regresión logística
La regresión logística da respuestas "sí" y "no".
Utilice la función sigmoidea como función de pérdida. La sigmoidea es una función de distribución de probabilidad y la salida es un valor de probabilidad.
Ejemplo




Entropía cruzada
Caracterice la distancia entre la salida real (probabilidad) y la salida esperada (probabilidad).
softmax multicategoría
- Softmax requiere que cada muestra pertenezca a una determinada categoría, y todas las muestras posibles están cubiertas
- La suma de los componentes de la muestra es 1
- Cuando solo hay dos categorías, el resultado del cálculo es el mismo que la regresión logarítmica
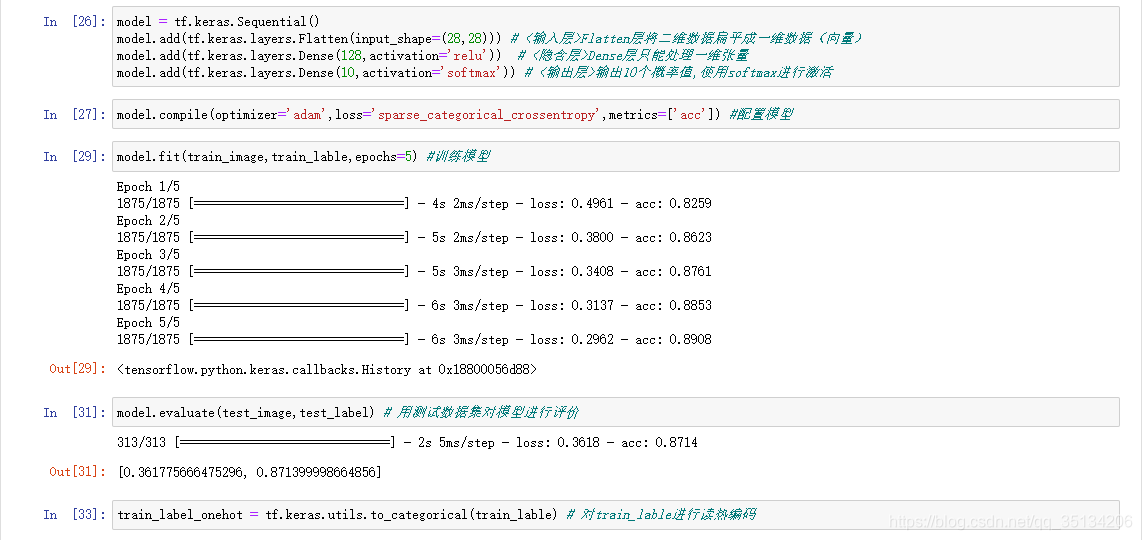
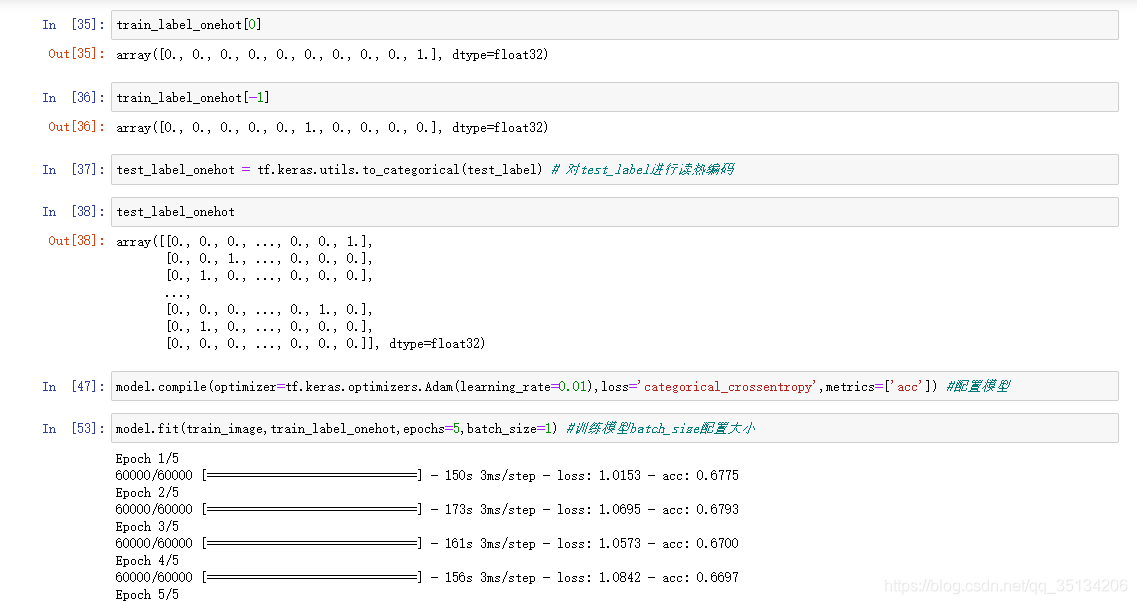
- La función de pérdida de problemas de clasificación múltiple usa categorical_crossentropy <etiqueta para leer la codificación en caliente> y sparse_categorical_crossentropy <etiqueta para usar codificación secuencial> para calcular la entropía cruzada
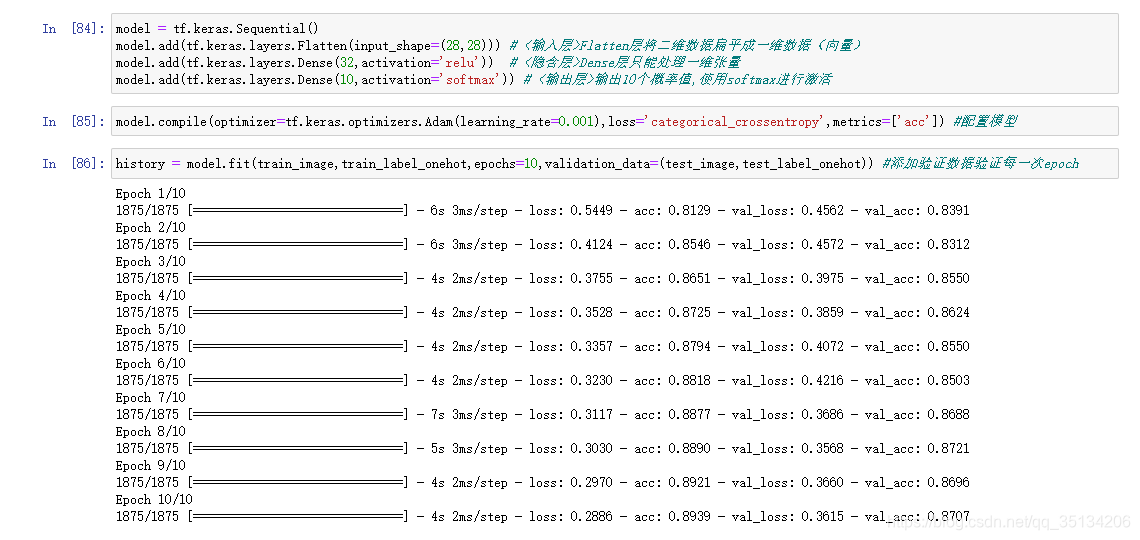
Conjunto de datos Fashion MINIST
El conjunto de datos de imágenes digitales escritas a mano contiene 70.000 imágenes en escala de grises, que cubren 10 categorías.
Tasa de aprendizaje (hiperparámetro)
Parámetros de configuración manual
Tasa de aprendizaje adecuada , pérdida de función con disminución del tiempo , tasa de aprendizaje inapropiada , pérdida de función puede ocurrir shock
Algoritmo de retropropagación
Una técnica para calcular eficientemente el gradiente en un gráfico de flujo de datos. La derivada de cada capa es el producto de la derivada de la siguiente capa y la salida de la capa anterior .
Capacidad de la red
- Puede considerarse proporcional a los parámetros entrenables en la red.
- Cuantas más unidades neuronales haya en la red y más capas, mayor será la capacidad de adaptación de la red neuronal. Pero cuanto mayor sea la velocidad y la dificultad del entrenamiento, es más probable que se sobreajuste.
- El aumento de la capacidad de la red puede aumentar la cantidad de capas intermedias ocultas y neuronas ocultas
Mejorar la capacidad de adaptación de la red
- Simplemente aumentar la cantidad de neuronas no es obvio para mejorar el rendimiento de la red.
- Agregar capas mejorará en gran medida la capacidad de ajuste de la red
Nota:
La cantidad de neuronas en una sola capa no puede ser demasiado pequeña, ya que demasiado pequeña provocará cuellos de botella de información y hará que el modelo no se ajuste bien.
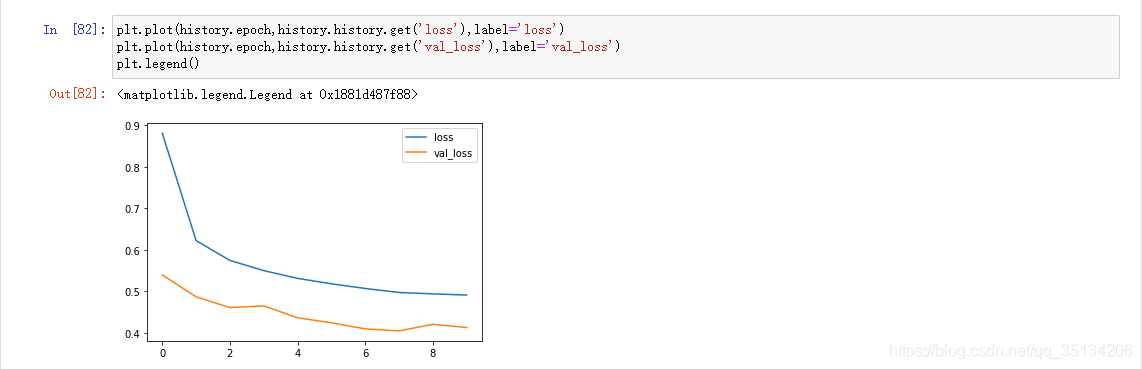
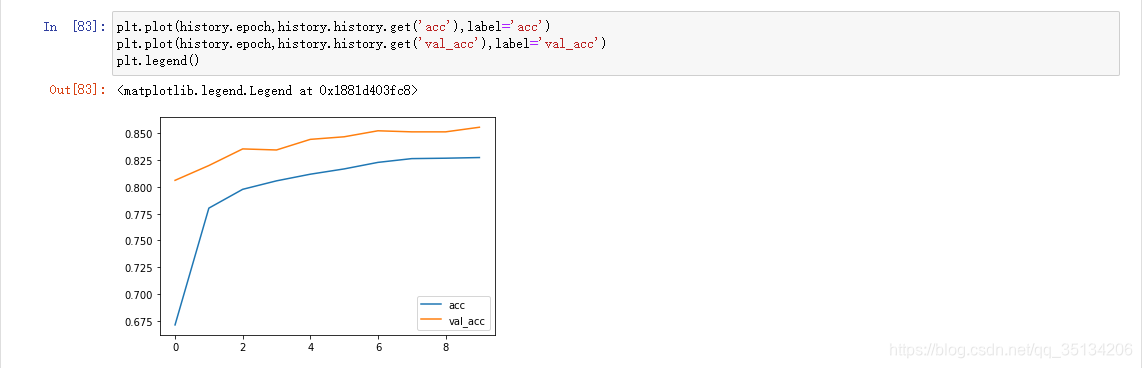
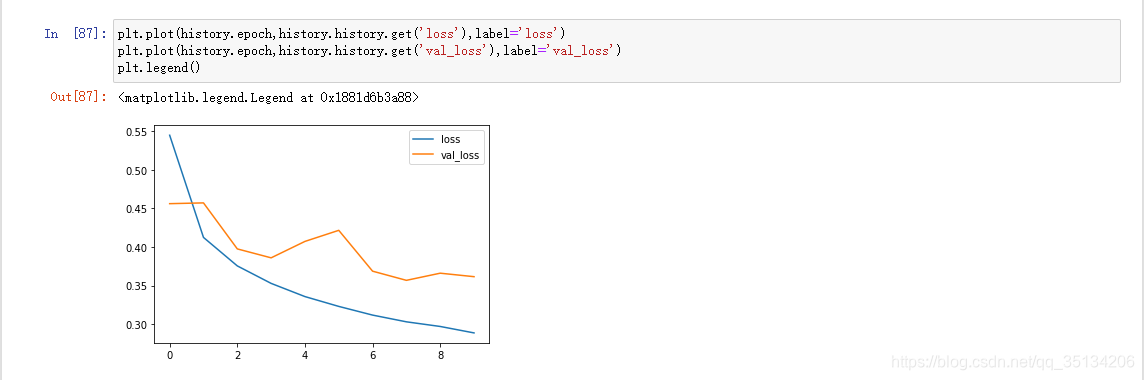
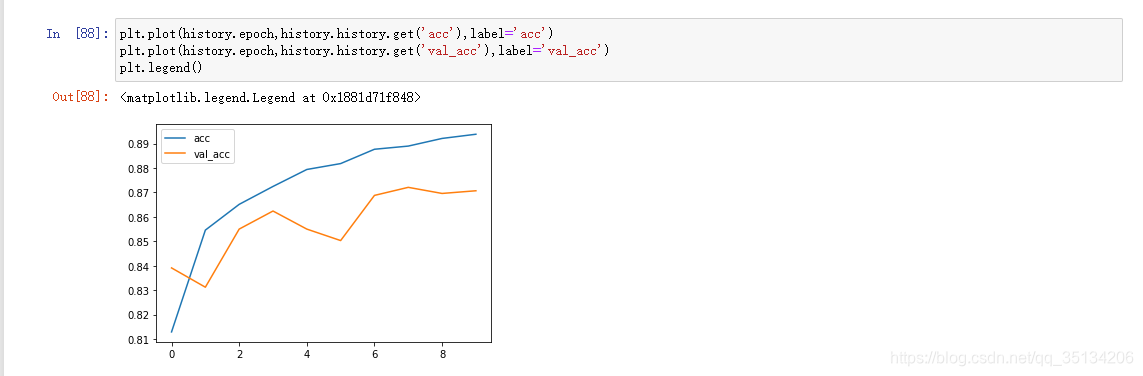
Sobreajuste
El valor de pérdida no disminuye sino que aumenta
. La puntuación es alta en los datos de entrenamiento y la puntuación es baja en los datos de la prueba.
Suprimir el sobreajuste:Aumentar los datos de entrenamiento, reducir la capacidad de la red (la mejor manera)
1. Abandono
2. Regularización
3. Mejora de la imagen
Adecuado
Puntaje bajo en datos de entrenamiento, puntaje bajo en datos de prueba
Validación cruzada

Ejemplo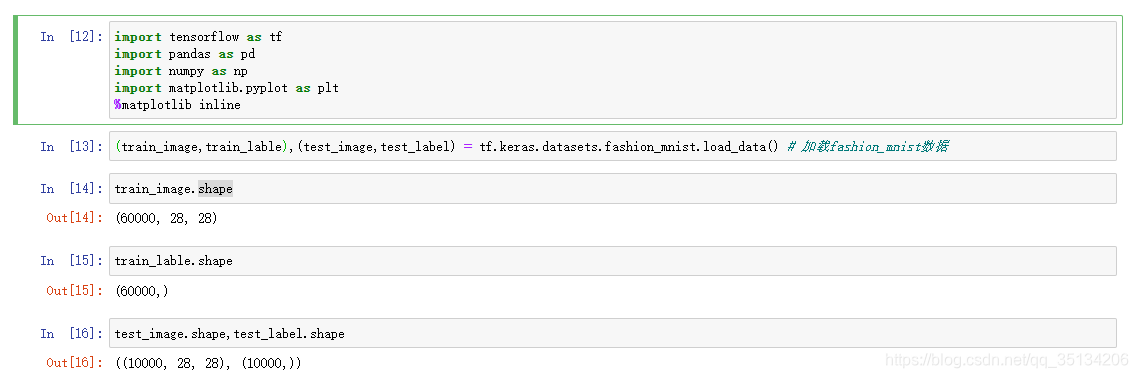
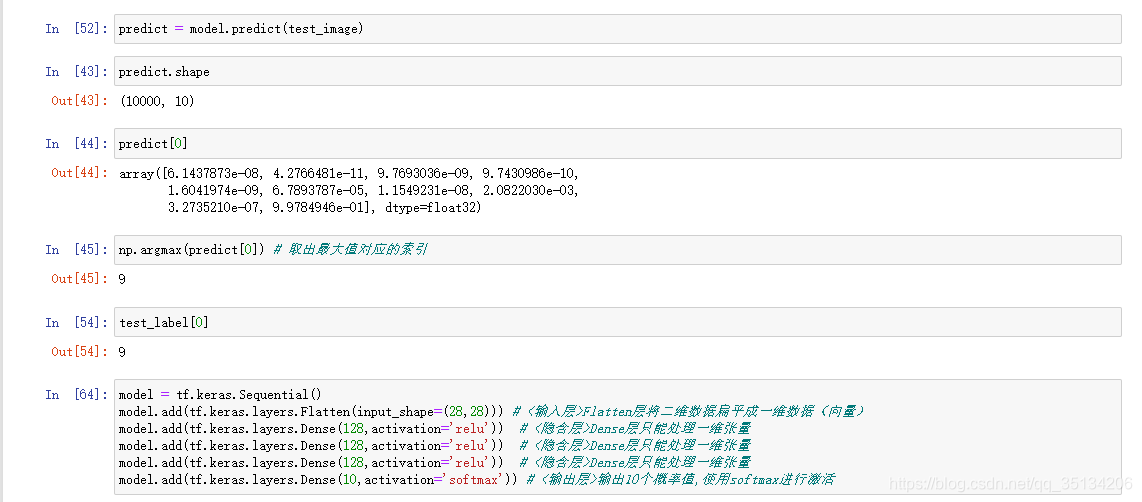
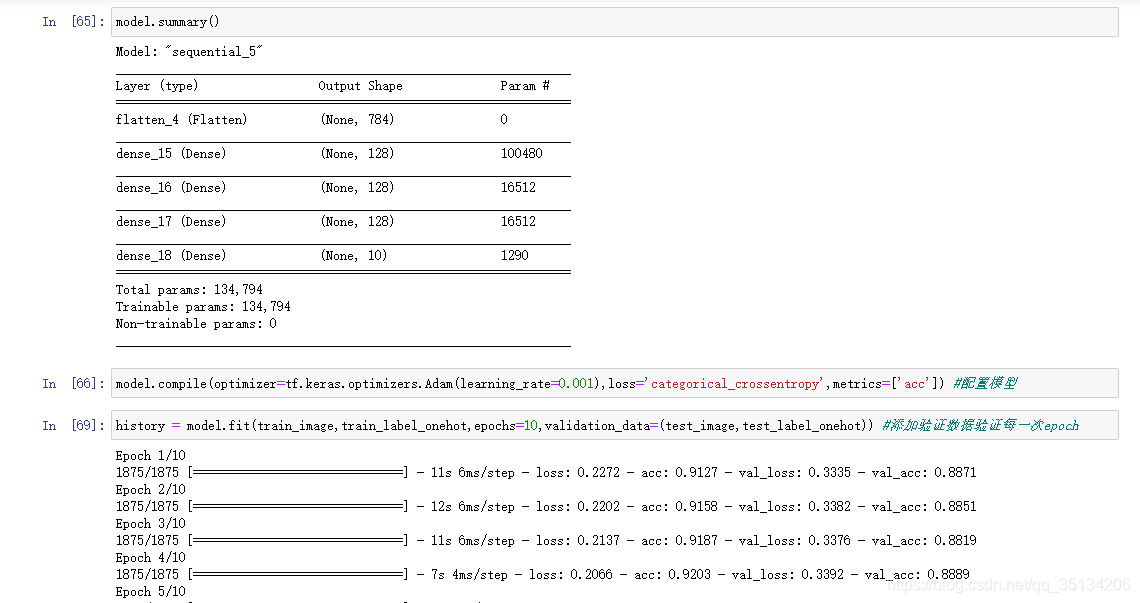
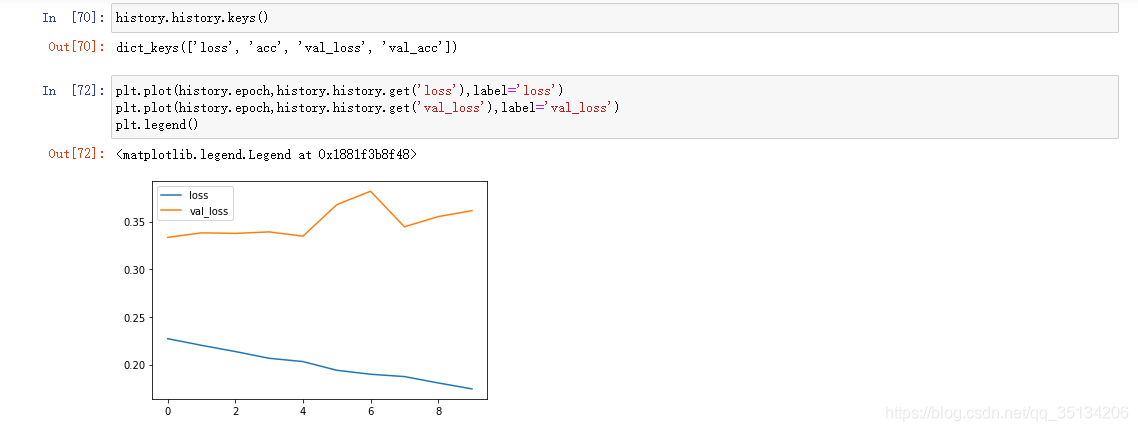
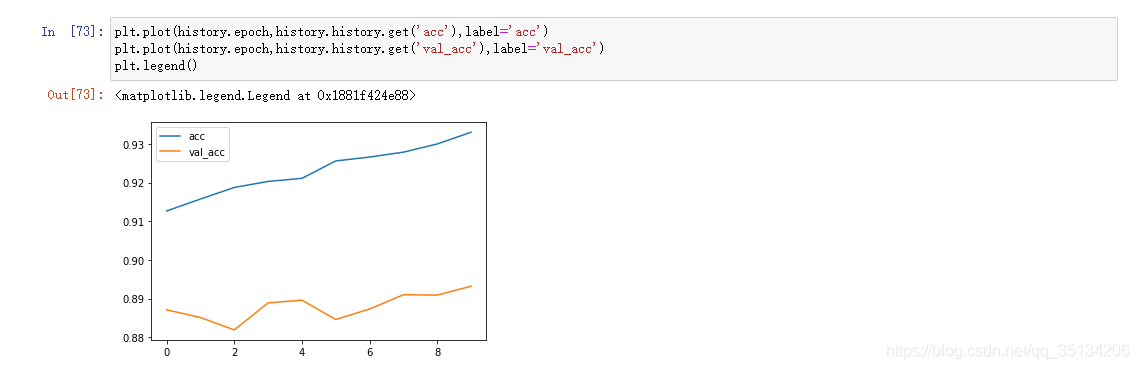

API funcional
Se puede realizar un modelo de múltiples entradas y múltiples salidas
Ejemplo
from tensorflow import keras
import matplotlib.pyplot as plt
%matplotlib inline
(train_image,train_label),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data() # 加载fashion_mnist数据
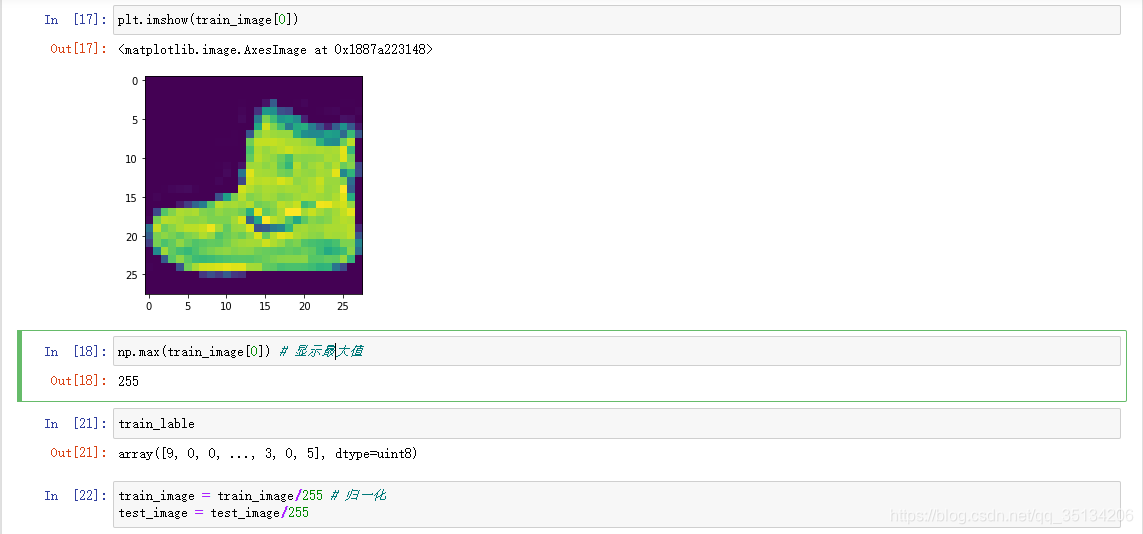
train_image = train_image/255 # 归一化
test_image = test_image/255
#设置输入
input = keras.Input(shape=(28*28))
#调用Flatten,将Flatten看成一个函数
x = keras.layers.Flatten()(input)
x = keras.layers.Dense(32,activation='relu')(x)
x = keras.layers.Dropout(0.5)(x)
x = keras.layers.Dense(64,activation='relu')(x)
output = keras.layers.Dense(10,activation='softmax')(x) # 输出层
model = keras.Model(inputs = input,outputs = output) # 依据指定的输入输出初始化模型
model.summary()
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
histroy = model.fit(train_image,
train_label,
epochs=30,
validation_data=(test_image,test_label))