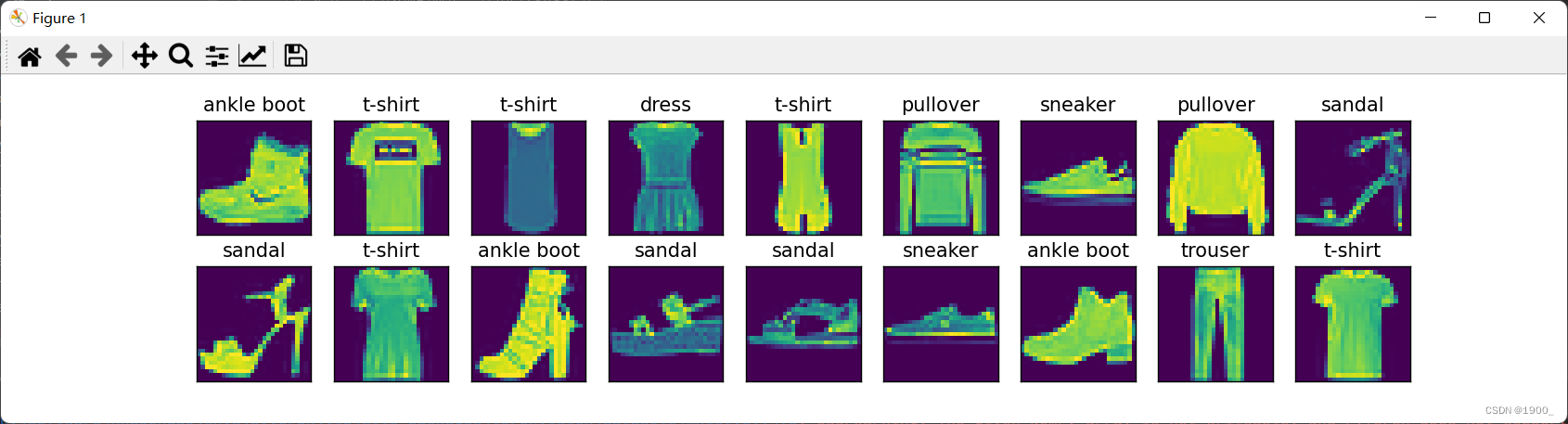
Conjunto de datos de clasificación de imágenes
El conjunto de datos utilizado en el curso es FashionMNIST
un primer vistazo a cómo descargar y utilizar este conjunto de datos:
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
import matplotlib.pyplot as plt
# 定义一个对图像的操作 转化为Tensor类型
trans = transforms.ToTensor()
# root代表数据集存放路径 train代表训练集还是测试集 transform 对图像的处理 download是否下载
# 训练集
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True,transform=trans,download=True)
# 测试集
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False,transform=trans, download=True)
# 输出下长度 看下
print(len(mnist_train))
print(len(mnist_test))
# 写两个函数 展示一下这个数据集
def get_fashion_mnist_labels(labels):
"""返回Fashion-MNIST数据集的文本标签。"""
text_labels = [
't-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt',
'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
plt.show()
return axes
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))
Mostrar los resultados: este es un conjunto de datos sobre ropa
clasificación softmax
softmax
La diferencia obvia entre un problema de regresión y un problema de clasificación es que un problema de regresión predice un valor, como el precio de una vivienda. El problema de clasificación es predecir a qué categoría pertenece.
Hace mucho tiempo, los estadísticos inventaron una forma simple de representar datos categóricos: la codificación one-hot. Una codificación one-hot es un vector que tiene tantos componentes como clases. El componente correspondiente a la categoría se establece en 1 y todos los demás componentes se establecen en 0. En nuestro ejemplo, la etiqueta y será un vector tridimensional donde {1,0,0} corresponde a "gato", {0,1,0} corresponde a "pollo" y {0,0,1} corresponde al "perro".
Esperamos que el modelo pueda generar tres resultados para una imagen (suponiendo que solo haya tres categorías). Cada resultado representa la probabilidad de que la imagen pertenezca a esta categoría.
Luego elegimos la categoría con la probabilidad más alta como nuestro resultado de predicción.
Supongamos que todavía usamos un modelo lineal con 4 características y una categoría prevista de 3. Es solo que ahora tenemos un conjunto de entradas y requerimos múltiples salidas. La fórmula es la siguiente:
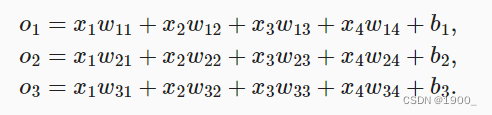
Podemos convertir esta fórmula en una forma vectorial: o = W x + bo = Wx+bo=ancho x+b , W es una matriz de 3x4. Pero tenga en cuenta que el oo
que calculamos de esta manerao no cumple con nuestros requisitos, porque esperamos que los tres valores de salida sean las probabilidades pronosticadas de las tres categorías, por lo que como es una probabilidad, se deben cumplir al menos dos condiciones: 1, mayor que 0, y no puede ser negativo. 2. La suma es igual a 1.
Por lo tanto, la predicción no normalizada no puede considerarse directamente como nuestra salida. Aquí presentaremos nuestra función softmax.
La función softmax transforma las predicciones no normalizadas en números no negativos que suman 1 mientras mantiene el modelo diferenciable.
Primero exponenciamos cada predicción no normalizada, lo que garantiza que la salida no sea negativa. Para garantizar que las probabilidades de salida final sumen 1, dividimos cada resultado de exponenciación por su suma.

La operación softmax no cambia el orden de magnitud entre las predicciones no normalizadas, solo determina la probabilidad asignada a cada clase. Por lo tanto, después de la operación softmax, seguimos seleccionando el valor máximo como nuestro resultado de predicción.
Aunque softmax es una función no lineal, la salida de la regresión softmax todavía está determinada por la transformación afín de las características de entrada. Por lo tanto, la regresión softmax es un modelo lineal.
entropía cruzada
Con softmax, hablemos aquí de entropía cruzada.
Cuando usamos un modelo lineal para hacer una sola salida antes, usamos el error cuadrático medio para medir la diferencia entre el valor predicho y el valor real.
Entonces, ¿todavía usamos el error cuadrático medio aquí para medir la diferencia entre nuestra probabilidad predicha y la probabilidad real? No
(en el problema de clasificación, use sigmoid/softmx para obtener la probabilidad, cuando use la función de pérdida de MSE, cuando use el método de descenso de gradiente para el aprendizaje, habrá una situación en la que la tasa de aprendizaje sea muy lenta cuando el modelo comience a entrenar) Aquí hablaremos del
crossover Entropy ido. (Puede consultar este artículo: https://zhuanlan.zhihu.com/p/35709485)
La entropía cruzada a menudo se usa para medir la diferencia entre dos probabilidades. Suponiendo que las dos probabilidades son p y q, la entropía cruzada es como sigue:
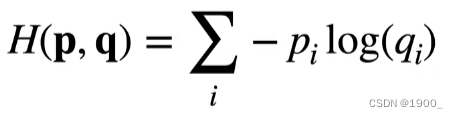
Luego hablamos de este cruce La entropía se usa como una función de pérdida, y es el valor real, y ^ \hat yy^Es nuestro valor predicho, la función de pérdida l ( y , y ^ ) l(y,\hat y)yo ( y ,y^)
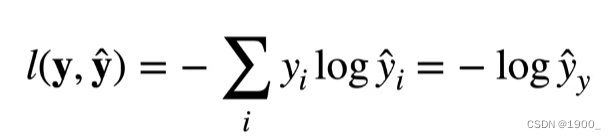

Código
Antes de hablar, hablemos de algunas gramáticas de Python:
1.
import torch
X = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 对列求和 (沿y轴压缩)
print(X.sum(0, keepdim=True))
# 对行求和 (沿x轴压缩)
print(X.sum(1, keepdim=True))
Salida:
tensor([[5., 7., 9.]])
tensor([[ 6.],
[15.]])
2,
import torch
# 假设一共有三个类别 猫 狗 鸡
# 提供样本数据y
# 样本y 里面共有两个样本
# 这两个样本的真实类别分别是0 和 2(猫和鸡)
y = torch.tensor([0, 2])
# y_hat是我们对这两个样本的预测 2x3 每行三个元素 代表对该样本属于三个类别的预测概率
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
# 这个语法的意思是访问y_hat里面的元素
# 这个横轴写的是[0,1] 纵轴写的是y y又等于[0,2]
# x和y给的都是一个列表 所以其实就是依次
# 依次访问 y_hat[0,0] y_hat[1,2]
# 因为y是他们真实的类别
# 所以通过这个语法可以拿出每个样本预测的三个概率中真实值的那个概率
print(y_hat[[0, 1], y])
Salida:
tensor ([0.1000, 0.5000])
3. En el video de la clase, el profesor lo implementó en jupyter, yo uso pycharm,
por lo que hay que prestar atención a dos puntos:
1. Agregar dos oraciones a la penúltima línea de la función agregar en la clase en d2l.torch , y puede Se muestra el gráfico de líneas. Jupyter llamará automáticamente a la función de visualización de imágenes cada vez, por lo que no hay código fuente, pero se puede mostrar en jupyter 2, no se puede mostrar, debe agregar una oraciónClass Animatorplt.draw()plt.pause(0.001)d2l.show_images()d2l.plt.show()
Código:
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
import matplotlib.pyplot as plt
from IPython import display
# 定义一个对图像的操作 转化为Tensor类型
trans = transforms.ToTensor()
# root代表数据集存放路径 train代表训练集还是测试集 transform 对图像的处理 download是否下载
# 训练集
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True,transform=trans,download=True)
# 测试集
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False,transform=trans, download=True)
# X 是(batch_size,786)
# 这里我们用的数据集是28x28的 通道数为1 所以 数据集展平之后是 784
# 当然展平之前我们一般要经过卷积操作 但是此处只是为了实现softmax 所以直接展平
# 那么我们的输入就是 784 希望输出一个10类别的预测结果
num_inputs = 784
num_outputs = 10
# 所以整个权重矩阵是 784行 10列的矩阵 每一列代表一组权重
# 因为待会W要转置 转置之后就是 10行 784列 列向量转为行向量 一组权重与一组输入相乘
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
# 偏差就是一个长为10的向量
b = torch.zeros(num_outputs, requires_grad=True)
# 学习率
lr = 0.1
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中。"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root="./data",train=True,
transform=trans,download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data",train=False,
transform=trans,download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=4),
data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=4))
# 声明一个类 这个类中初始化为n个变量
# 有两个操作 一个是累加 一个是清零
# 累加就是 输入一个有n个变量的列表,对应累加到自身去
class Accumulator:
"""在`n`个变量上累加。"""
def __init__(self, n):
self.data = [0.0] * n
# 这里是一个累加的效果
# 比如 传入参数 args=(5,10) 那么5就会累加到data[0]上 10累加到data[1]上
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 定义一个在动画中绘制数据的实用程序类 后面我们封装好了 放在d2l库里面
class Animator:
"""在动画中绘制数据。"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes,]
self.config_axes = lambda: d2l.set_axes(self.axes[
0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
d2l.plt.draw()
d2l.plt.pause(0.001)
display.display(self.fig)
display.clear_output(wait=True)
def softmax(X):
"""softmax。"""
# 对X中所有元素做指数操作
X_exp = torch.exp(X)
# X.sum(1,keepdim=True)代表 按行求和
partition = X_exp.sum(1, keepdim=True)
# 这里使用广播机制 每个元素值都会除以其对应的partition(该行之和)
return X_exp / partition
def net(X):
# XW + b
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
def cross_entropy(y_hat, y):
"""交叉熵损失。"""
# 对所有样本的预测概率 拿出其对应的真实值的预测概率
return -torch.log(y_hat[range(len(y_hat)), y])
def accuracy(y_hat, y):
"""计算预测正确的数量。"""
# 拿出每一行概率最大的那个 当作预测结果
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
# 与真实值相比较 得到比较结果 cmp是bool数组
cmp = y_hat.type(y.dtype) == y
# 求和 看有多少预测正确
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度。"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型转为评估模型(不用计算梯度了)
metric = Accumulator(2)
for X, y in data_iter:
# 传进去两个数值 一个是本批量数据的正确预测个数
# y.numel()是本批量数据的总数
metric.add(accuracy(net(X), y), y.numel())
# 相除得到准确率
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型一个迭代周期。"""
if isinstance(net, torch.nn.Module):# 如果我们的net是nn.Module类型的话
net.train() # 训练模式(计算梯度)
metric = Accumulator(3)
for X, y in train_iter: # 遍历数据
y_hat = net(X) # 计算预测值
l = loss(y_hat, y) # 计算损失
if isinstance(updater, torch.optim.Optimizer):# 如果我们的updater是用了pytorch的话
updater.zero_grad() # 梯度清零
l.backward() # 计算梯度
updater.step() # 更新参数
metric.add( # 记录并累加三个数:损失,正确数量,样本数
float(l) * len(y), accuracy(y_hat, y),
y.size().numel())
else:# 如果我们使用的是自己实现的 交叉熵损失
l.sum().backward() # 累加 并求梯度
updater(X.shape[0]) # 更新参数
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 对损失求平均 准确数/总数=准确率
return metric[0] / metric[2], metric[1] / metric[2]
# 训练函数
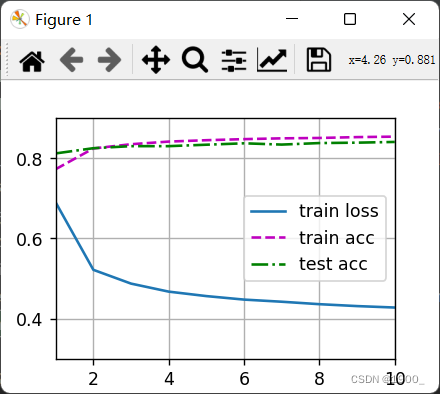
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型。"""
# 展示数据
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
# 每一代训练
for epoch in range(num_epochs):
# 训练一代
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
# 测试并评估
test_acc = evaluate_accuracy(net, test_iter)
# 展示数据
animator.add(epoch + 1, train_metrics + (test_acc,))
# loss 和 准确率
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
# 优化器
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
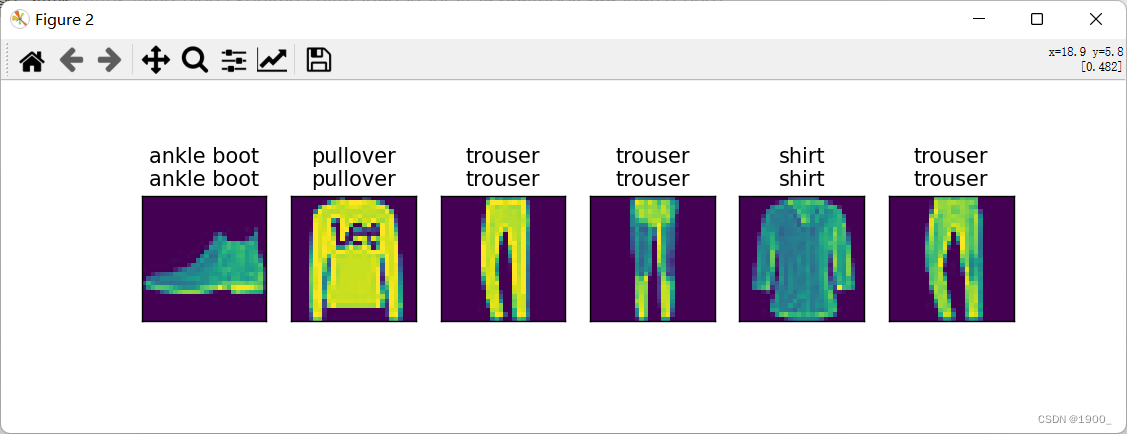
def predict_ch3(net, test_iter, n=6):
"""预测标签(定义见第3章)。"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true + '\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
d2l.plt.show()
if __name__=="__main__":
batch_size = 128
# 返回我们训练集和测试集的迭代器
train_iter, test_iter = load_data_fashion_mnist(batch_size)
num_epochs = 10
# 训练
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
# 预测一下
predict_ch3(net, test_iter)
Resultado de salida: