modelo GPT
Modelo GPT: Pre-Entrenamiento Generativo
La estructura general:
Entrenamiento previo no supervisado
Ajuste fino supervisado para tareas posteriores
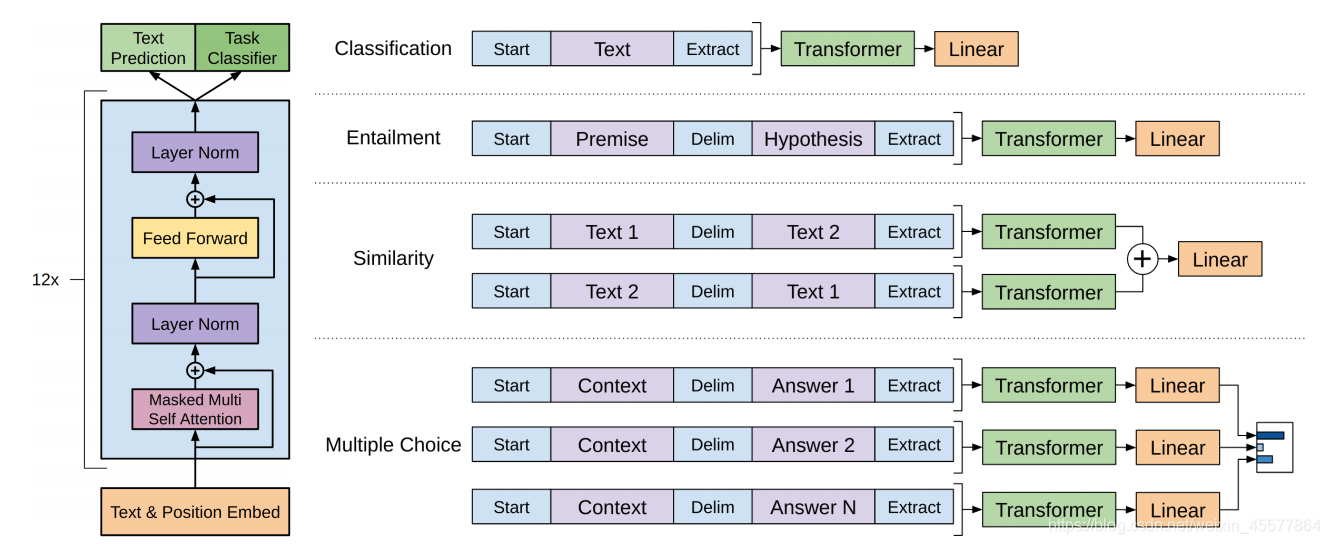
Estructura central: la parte central se compone principalmente de 12 bloques de decodificador de transformador apilados
La siguiente imagen refleja de manera más intuitiva la estructura general del modelo:
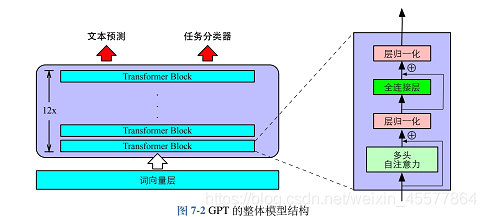
Descripcion del modelo
GPT usa la estructura del decodificador de Transformer y realiza algunos cambios en el decodificador de Transformer. El decodificador original contiene dos estructuras de atención de múltiples cabezales, y GPT solo retiene la atención de máscara de múltiples cabezales, como se muestra en la figura a continuación .
(Muchos datos dicen que es similar a la estructura del decodificador, porque se usa el mecanismo de máscara del decodificador, pero aparte de esto, en realidad se parece más al codificador, por lo que a veces se implementa ajustando el codificador en su lugar. No se )
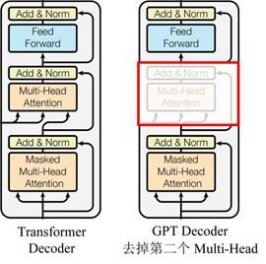
En comparación con la estructura del transformador original.
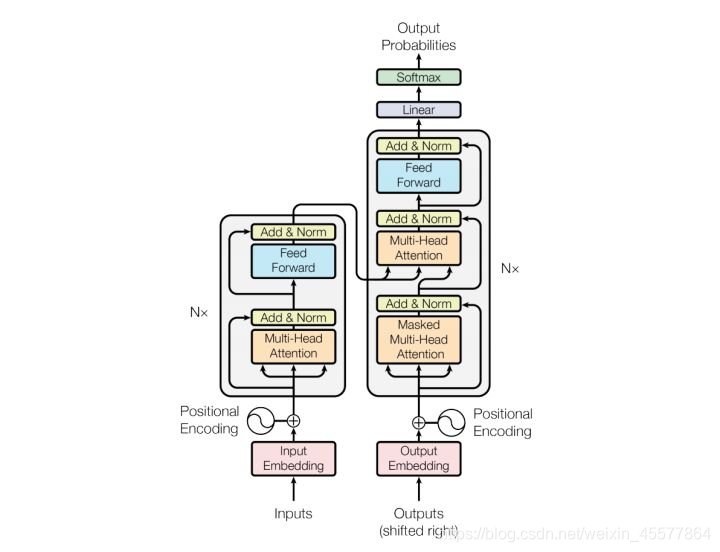
descripción de la etapa
Fase previa al entrenamiento:



La etapa previa al entrenamiento es la predicción de texto, es decir, la predicción de la palabra actual en función de las palabras históricas existentes. Las tres fórmulas 7-2, 7-3 y 7-4 corresponden al diagrama de estructura GPT anterior, y la salida P (x) es la salida. La probabilidad de que se prediga cada palabra, y luego use la fórmula 7-1 para calcular la función de máxima verosimilitud, y construya una función de pérdida basada en esto, es decir, el modelo de lenguaje se puede optimizar.
Etapa de ajuste de tareas aguas abajo

función de pérdida
Una combinación lineal de tareas aguas abajo y pérdidas de tareas aguas arriba

proceso de cálculo:
- ingresar
- incrustación
- Bloque transformador multicapa
- Obtener dos resultados de salida
- calcular la pérdida
- retropropagación
- actualizar parámetros
Un código de ejemplo de GPT específico:
puede ver que en la función directa del modelo GPT, la operación de incrustación se realiza primero, luego la operación se realiza en el bloque del transformador de 12 capas y luego el valor de cálculo final se obtiene a través de dos transformaciones lineales (una para la predicción de texto), una para el clasificador de tareas), el código es consistente con el diagrama de estructura del modelo que se muestra al principio.
Referencia: No se moleste
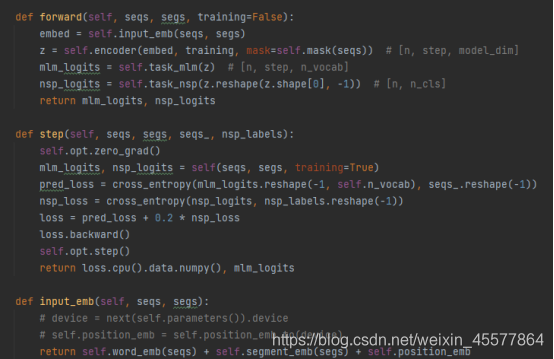
con el código de implementación Python GPT Centrémonos en los pasos de cálculo 2 y 3
Detalles del cálculo:
[Capa de incrustación]:
La capa de incrustación para la operación de búsqueda de tablas
es una capa totalmente conectada con un nodo activo como entrada y nodos de capa intermedia como dimensiones de vector de palabra. Y el parámetro de esta capa totalmente conectada es una "tabla de vectores de palabras".

La multiplicación de matrices del tipo activo es equivalente a una búsqueda en una tabla, por lo que utiliza directamente la búsqueda en una tabla como una operación en lugar de escribirla en una matriz para el cálculo, lo que reduce en gran medida la cantidad de cálculo. Se enfatiza nuevamente que la reducción en la cantidad de cómputo no se debe a la aparición de vectores de palabras, sino a que la operación de una matriz caliente se simplifica a una operación de búsqueda de tabla.
[Capa de decodificador similar al transformador en GPT]:
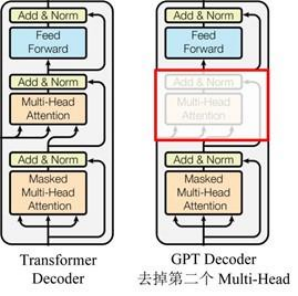
Cada capa del decodificador contiene dos subcapas
- subcapa1: capa de atención de múltiples cabezas para máscara
- subcapa2: ffn (red de avance) red de avance (perceptrón multicapa)
subcapa1: capa de atención de múltiples cabezas de la máscara
输入:q, k, v, máscara
计算注意力:Lineal (multiplicación de matriz)→Atención de producto punto escalado→Concat (resultados de atención múltiple, remodelación)→Lineal(multiplicación de matriz)
残差连接和归一化操作:Operación de abandono → conexión residual → operación de normalización de capa
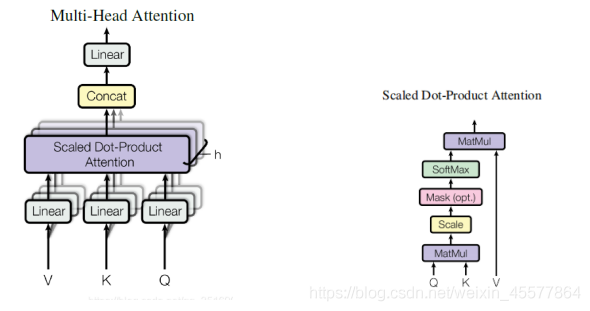
proceso de cálculo:
El siguiente párrafo describe el proceso general de cálculo de la atención:

Instrucciones de explosión:
Mascarilla Multi-cabeza Atención
1. Multiplicación de matrices:
Transformar la entrada q, k, v
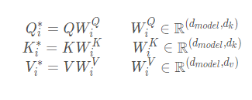
2. Atención de producto de punto escalado
Lo principal es realizar el cálculo de atención y la operación de máscara.Operación de máscara
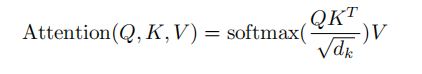
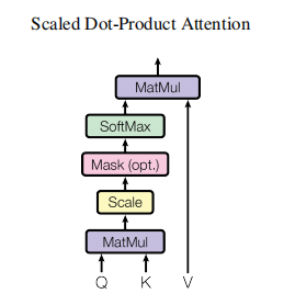
: masked_fill_(máscara, valor)
operación de máscara, rellena con valor el elemento en el tensor correspondiente al valor 1 en la máscara. La forma de la máscara debe coincidir con la forma del tensor a rellenar. (Aquí, se usa el relleno -inf, de modo que el softmax se convierte en 0, lo que equivale a no ver las siguientes palabras)
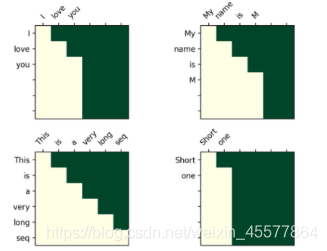
La operación de máscara en el transformador
Matriz de visualización después de la máscara:
la comprensión intuitiva es que cada palabra solo puede ver la palabra anterior (porque el propósito es predecir la palabra futura, si la ve, no necesita predecirla)
3. Operación concat:
La combinación de los resultados de múltiples cabezas de atención en realidad transforma la matriz: operaciones de permutación, remodelación y reducción de la dimensionalidad. (Como se muestra en el recuadro rojo de la siguiente figura)
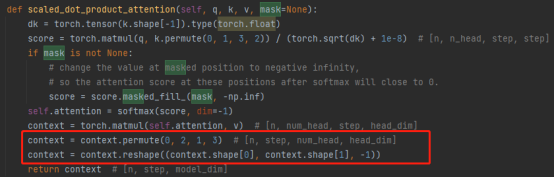
4. Multiplicación de matrices: una capa lineal, que transforma linealmente los resultados de atención
La capa de atención de múltiples cabezales de toda la máscara 代码:
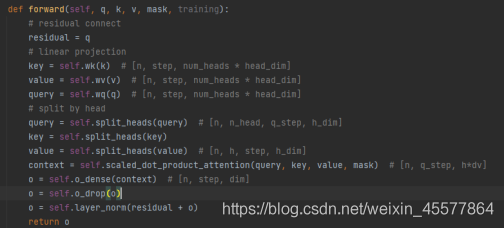
Nota: las siguientes líneas en el código anterior son para 残差连接和归一化操作
explicar el proceso de resultados de atención:
Operaciones de normalización y conexión residual:
5. Capa de abandono
6. Adición de matrices
7. Normalización de capas
La normalización por lotes es la normalización de una sola neurona entre diferentes datos de entrenamiento, y la normalización de capa es la normalización de un solo dato de entrenamiento entre todas las neuronas de una determinada capa.
Normalización de entrada, normalización por lotes (BN) y normalización de capas (LN)
代码展示:
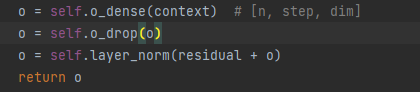
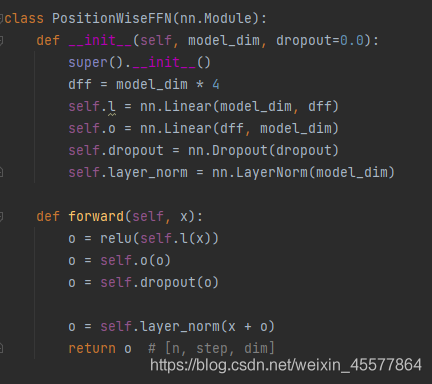
subcapa2: ffn (red de avance) red de avance
1. Capa lineal (multiplicación de matrices)
2. Activación de la función Relu
3. Capa lineal (multiplicación de matrices)
4. Operación de abandono
5. Normalización de capas
[Capa lineal]:
Los resultados de salida del bloque multicapa se colocan en dos capas lineales para la transformación, que es relativamente simple y no se describirá en detalle.
Suplemento: Diagrama de flujo de la capa de atención
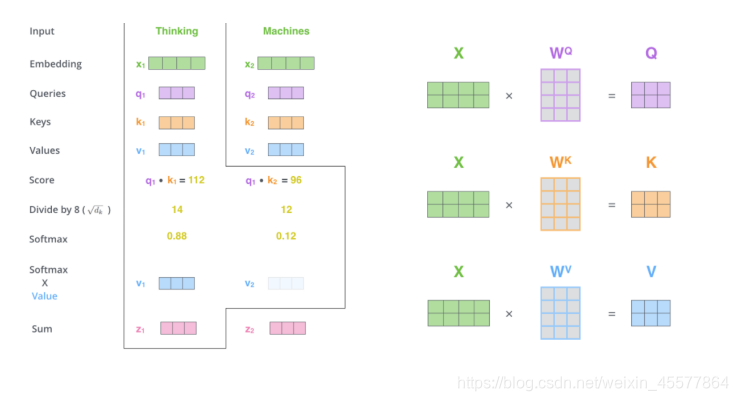
Referencias
1. Documento de referencia: Radford et al., "Mejora de la comprensión del lenguaje mediante el entrenamiento previo generativo"
2. Libro de referencia: "Procesamiento del lenguaje natural basado en el método del modelo de entrenamiento previo" Che Wanxiang, Guo Jiang, Cui Yiming
3. La fuente del código en este artículo: No se moleste con el código de implementación Python GPT
4. Otros enlaces de referencia (partes mencionadas en la publicación del blog):
Análisis del proceso de cálculo de incrustación de Word
Análisis de la dimensión de la matriz del transformador y explicación detallada de la máscara