Preparar
Consulte la cantidad de parámetros y la cantidad de cálculo del modelo: ThanatosShinji/onnx-tool: inferencia de forma del modelo ONNX y conteo de MAC (FLOP) (github.com) Estos cuatro modelos son los cuatro modelos onnx más importantes de Stable Diffusion 1.4:
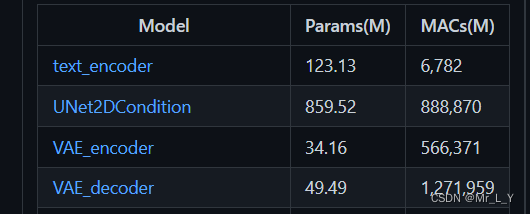
El disco de red de Baidu en github puede descargar el modelo con la forma del tensor intermedio. Por ejemplo:

codificador de texto
Este modelo es muy similar al BERT, Bert Base de 12 capas, el volumen de cálculo es de 6.7GMACs.
Al igual que BertBase, el 98 % del cálculo se concentra en MatMul.
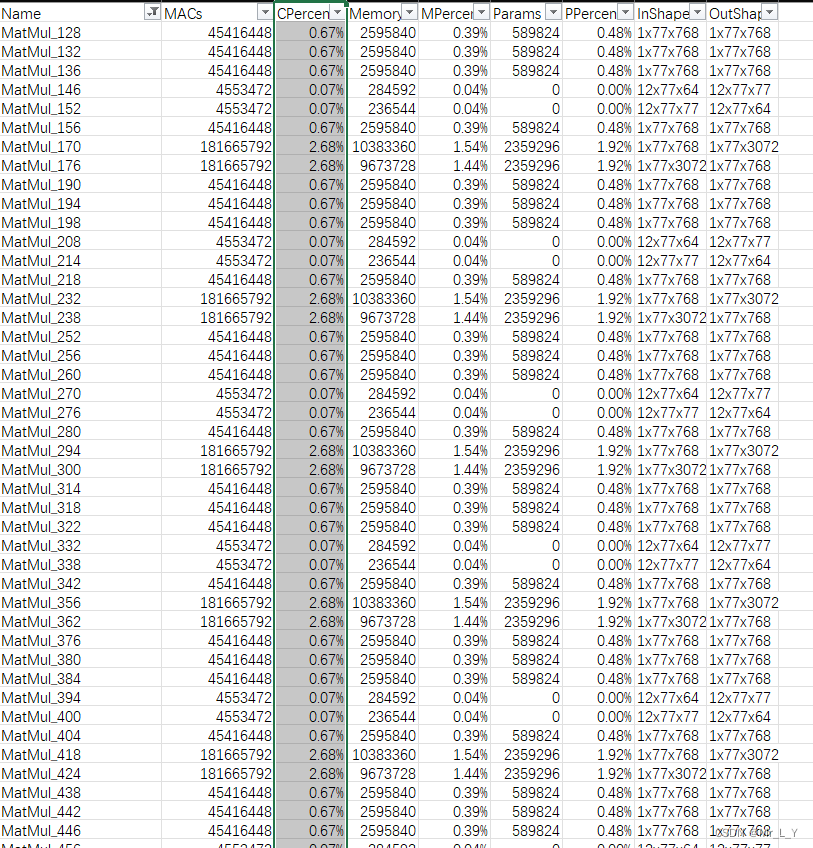
Este token genera un estado oculto de 1x77x768 y debe enviarse a UNetCondition.
UNet2DCondición
Este es UNet+Transformer. Es la parte responsable de la generación de imágenes en toda StableDiffusion. El volumen del parámetro es tan alto como 859M, y el archivo del modelo supera los 3G. Se puede entender que este parámetro del modelo recuerda mucha información de la textura de la imagen. y se puede ajustar dinámicamente de acuerdo con la descripción del texto de entrada. Texturas para varias partes de la imagen.
La resolución de la entrada del modelo es 64x64, según el método de UNet, use conv2d con stride==2 para realizar 2 veces la reducción de resolución a 32x32, 16x16, 8x8:

A diferencia de la convolución continua de UNet, utiliza la siguiente estructura para convertir hw en una estructura matricial y usarla para hacer MHA (atención de múltiples cabezas):
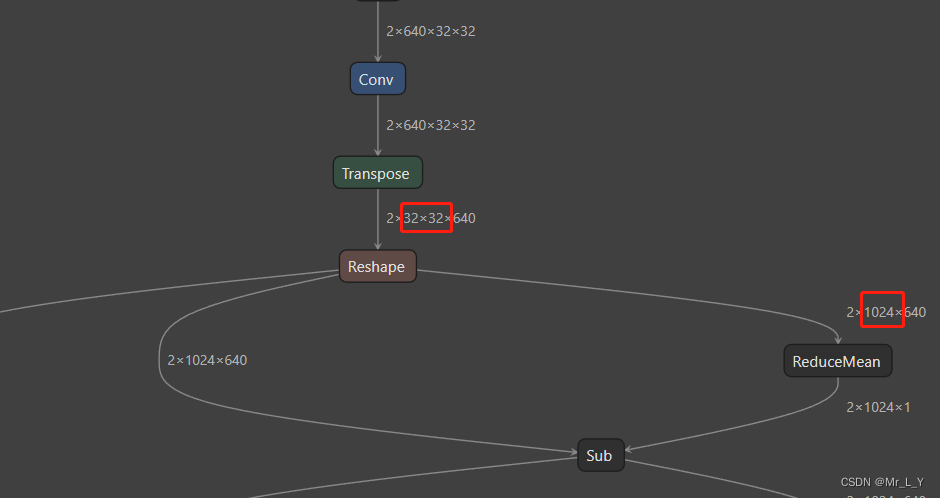
Cambio de forma de entrada de 2x640x32x32 (estructura común de UNet) a 2x1024x640 (estructura común de BERT.
Luego use este tensor tipo BERT como un codificador de transformador:

Aquí cambió MatMul de QKV a Einsum.
Entonces, UNet2DCondition es reemplazar la estructura de CNN después de la reducción de muestreo de UNet con la estructura de Transformador.
En general: la convolución representa el 49% de las operaciones totales, los cálculos matriciales representan el 31% (más Einsum para un total del 45%)
Codificador + Decodificador VAE
Estos dos modelos se usan en pares, por lo que se juntan. Estos dos modelos también son relativamente inteligentes, y ambos tienen la estructura de CV+transformador.
El codificador redujo la muestra del tensor de entrada de 3x512x512 a 512x64x64 a través de CNN e inmediatamente realizó otro MHA:

Después de hacerlo, después de varias capas de convolución, se generan las características comprimidas de 8x64x64.
Después de que el decodificador obtenga las características comprimidas de 4x64x64, primero se convierte en 512x64x64 y luego en una estructura MHA de transformador:

Después de este MHA, el tensor se restaura a 3x512x512 mediante Conv+Resize.
Probablemente algo como esto:
Codificador:
Conversión 3x512x512
....
Conversión 512x64x64
MHA 4096x512
Conversión 8x64x64
Descifrador:
Conversión 4x64x64
Conversión 512x64x64
MHA 4096x512
....
Conversión 3x512x512
Entre ellos, estos dos cálculos son los más grandes porque el procesamiento de la resolución máxima 512x512 está aquí. Codificador: 566G MACs Decodificador: 1271G MACs. Conv representa el 95% y el 97% de los cálculos respectivamente. El MatMul de Transformer básicamente se puede ignorar.
Resumir
Transformer es realmente una buena estructura para proporcionar interpretación de modelos.
No se recomienda considerar aumentar la resolución del modelo a 64x64 para aumentar la resolución de la imagen generada. La resolución tiene un alto impacto en el cálculo general del modelo. Puede considerar generar una resolución más baja, como una salida de 32x32 para 256x256, y luego use otra red de súper resolución para aumentar la resolución de salida.
Para el informe de análisis de la cantidad de cálculo, puede usar la línea de comando para generar un archivo csv usted mismo:
python -m onnx_tool -i .\vae_encoder.onnx -f vae_encoder.csv