El modelo GPT4 es hasta ahora el innovador, disponible al público de forma gratuita o a través de su portal comercial (para uso beta público). Inspiró nuevas ideas de proyectos y casos de uso para muchos emprendedores, pero el secreto en torno a los recuentos y modelos de parámetros acabó con todos los entusiastas que apostaban por el primer modelo de 1 billón de parámetros hasta la declaración de 100 billones de parámetros.
Secretos del modelo revelados
El 20 de junio, George Hotz, fundador de la startup autónoma Comma.ai, reveló que GPT-4 no es un modelo único y denso (como GPT-3 y GPT-3.5), sino un modelo híbrido de 8 x 220. composición de mil millones de parámetros
Más tarde ese mismo día, el cofundador de PyTorch de Meta reiteró el incidente.
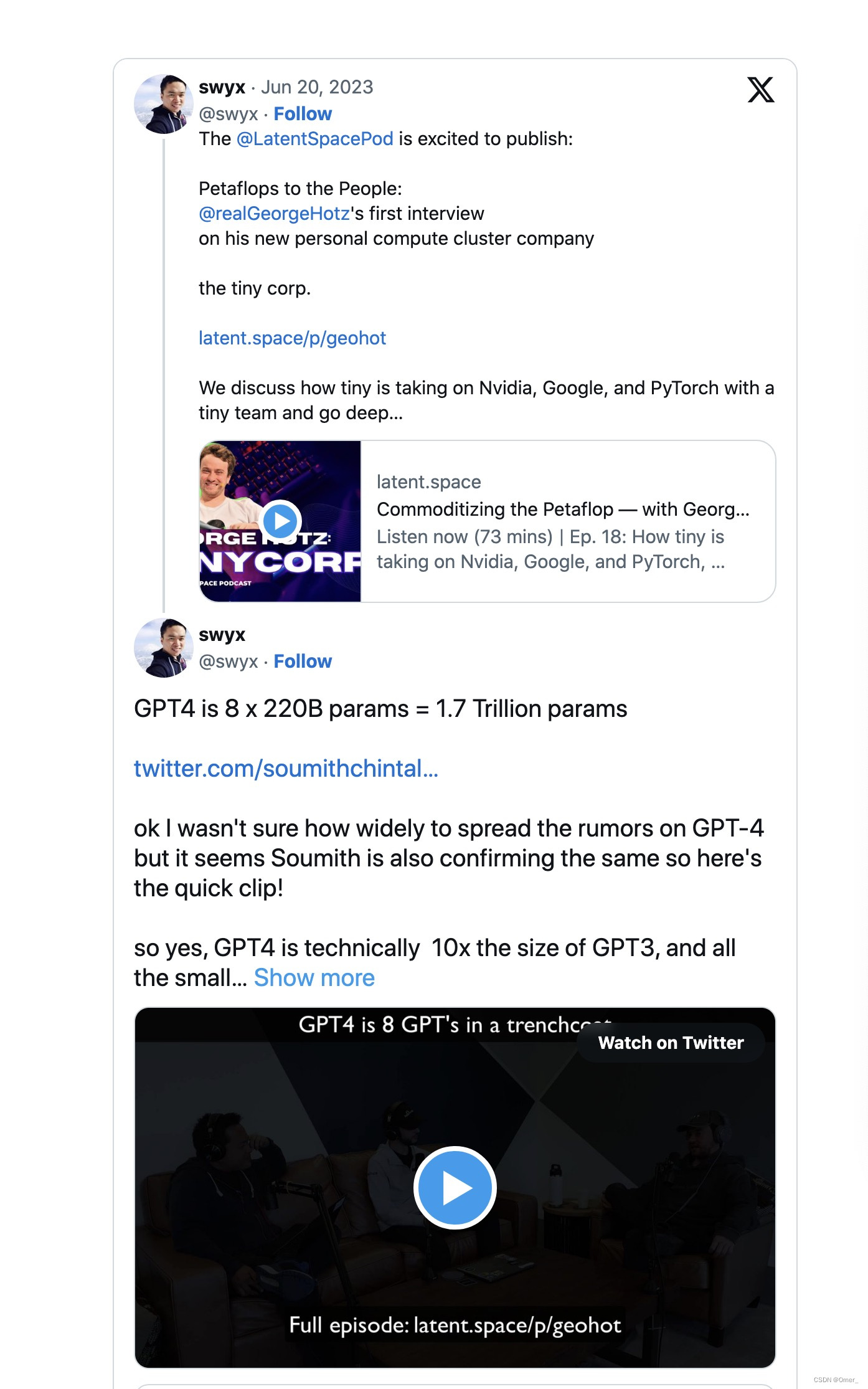
Justo el día anterior, Mikhail Parakhin , jefe de Bing AI de Microsoft , lo insinuó.
GPT 4: no es un monolito
¿Qué significan todos los tweets? GPT-4 no es un único modelo grande, sino una unión/conjunto de 8 modelos más pequeños que comparten experiencia. Se rumorea que cada uno de estos modelos tiene 220 mil millones de parámetros.

El enfoque se conoce como un híbrido de paradigmas de modelos expertos (enlace a continuación). Este es un método muy conocido, también conocido como modelo de hidra. Me recuerda a la mitología india y me quedaría con Ravana.
Tómelo con cautela, no es una noticia oficial, pero ha sido afirmado/insinuado por importantes miembros de alto nivel de la comunidad de IA. Microsoft aún no ha confirmado ninguno de estos.
¿Qué es el paradigma mixto de expertos?
Ahora que hemos hablado de la combinación experta, echemos un vistazo más profundo a qué es. La mezcla experta es una técnica de aprendizaje conjunto desarrollada específicamente para redes neuronales. Es ligeramente diferente de la técnica de conjunto general (la forma es generalizada) del modelado tradicional de aprendizaje automático. Por lo tanto, se puede considerar la combinación de especialistas en el Máster en Derecho como un caso especial del enfoque conjunto.
Brevemente, en este método, la tarea se divide en subtareas y se utilizan expertos en cada subtarea para resolver el modelo. Esta es una forma de dividir y conquistar al crear un árbol de decisiones. También se puede considerarlo como un metaaprendizaje además de modelos expertos para cada tarea individual.
Se pueden entrenar modelos mejores y más pequeños para cada subtarea o tipo de problema. El metamodelo aprende qué modelo utilizar para predecir mejor una tarea en particular. El metaaprendiz/modelo actúa como policía de tránsito. Las subtareas pueden superponerse o no, lo que significa que se pueden combinar combinaciones de resultados para llegar al resultado final.
Mixture of Experts (MoE o ME para abreviar) es una técnica de aprendizaje conjunto que implementa la idea de capacitar expertos en subtareas de problemas de modelado predictivo.
En la comunidad de redes neuronales, varios investigadores han trabajado en métodos de factorización. [...] descomponen el espacio de entrada para que cada experto examine una parte diferente del espacio. […] La red cerrada es responsable de combinar a los expertos individuales.
— Página 73, Clasificación de patrones mediante métodos de conjunto , 2010.
El método tiene cuatro elementos, que son:
- Divida las tareas en subtareas.
- Desarrollar un experto para cada subtarea.
- Utilice un modelo de activación para decidir qué experto utilizar.
- Agrupe la predicción y la salida del modelo de activación para hacer predicciones.
El siguiente diagrama, tomado de la página 94 del libro de 2012 " Métodos integrados" , proporciona una descripción útil de los elementos arquitectónicos del método.

Ejemplo de combinación de modelos expertos con membresía experta y red de activación
Tomado de: Ensemble Methods
Subtareas
El primer paso es dividir el problema del modelado predictivo en subtareas. Por lo general, esto implica utilizar el conocimiento del dominio. Por ejemplo, una imagen se puede dividir en elementos individuales como fondo, primer plano, objetos, colores, líneas, etc.
...ME emplea una estrategia de divide y vencerás, donde una tarea compleja se descompone en varias subtareas más simples y más pequeñas, y los alumnos individuales (llamados expertos) reciben capacitación en diferentes subtareas.
— Página 94, Métodos de conjunto , 2012.
Para aquellos problemas en los que la división de tareas en subtareas no es obvia, se pueden utilizar métodos más simples y generales. Por ejemplo, se puede imaginar un método que divida el espacio de características de entrada por grupos de columnas, o separe ejemplos en el espacio de características según medidas de distancia de distribuciones estándar, valores internos y atípicos, etc.
…En ME, un problema clave es cómo encontrar una división natural de tareas y luego derivar la solución general a partir de las subsoluciones.
— Página 94, Métodos de conjunto , 2012.
modelo experto
A continuación, designe un experto para cada subtarea.
Los métodos mixtos de expertos se desarrollaron y exploraron originalmente en el campo de las redes neuronales artificiales, por lo que tradicionalmente los propios expertos son los modelos de redes neuronales utilizados para predecir valores numéricos en el caso de regresión o etiquetas de clase en el caso de clasificación.
Debe quedar claro que podemos "conectar" cualquier modelo para el experto. Por ejemplo, podemos utilizar redes neuronales para representar funciones de puerta y expertos. El resultado se denomina red de densidad mixta.
— Página 344, Aprendizaje automático: una perspectiva probabilística , 2012.
Cada experto recibe el mismo patrón de entrada (filas) y hace una predicción.
modelo de puerta
El modelo se utiliza para explicar las predicciones hechas por cada experto y para ayudar a decidir en qué experto confiar para una determinada información. Esto se denomina modelo cerrado o red cerrada porque tradicionalmente es un modelo de red neuronal.
La red de activación toma como entrada los patrones de entrada proporcionados al modelo experto y genera la contribución que cada experto debe hacer al hacer predicciones sobre la entrada.
…los pesos determinados por la red de activación se asignan dinámicamente dada la entrada, ya que el MoE aprende efectivamente qué parte del espacio de características ha aprendido cada miembro del conjunto
— Página 16, Integración del aprendizaje automático , 2012.
La red de activación es la clave del método, y el modelo aprende de manera eficiente a seleccionar subtareas de tipo para una entrada determinada y luego selecciona expertos confiables para hacer predicciones sólidas.
La combinación de expertos también puede verse como un algoritmo de selección de clasificadores en el que los clasificadores individuales son capacitados para ser expertos en alguna parte del espacio de características.
— Página 16, Integración del aprendizaje automático , 2012.
Cuando se utiliza un modelo de red neuronal, la red de activación se entrena con expertos para que aprenda cuándo confiar en cada experto para hacer predicciones. Este proceso de formación se implementa tradicionalmente mediante la maximización de expectativas (EM). La red de activación puede tener una salida softmax que proporciona puntuaciones de confianza similares a las de probabilidad para cada experto.
En general, el proceso de entrenamiento intenta lograr dos objetivos: para un experto dado, encontrar la función de puerta óptima; para una función de puerta dada, entrenar al experto de acuerdo con la distribución especificada por la función de puerta.
— Página 95, Métodos de conjunto , 2012.
método de agrupación
Finalmente, una combinación de modelos expertos tiene que hacer predicciones, lo que se logra mediante mecanismos de agrupación o agregación. Esto podría ser tan simple como seleccionar al experto con el mayor rendimiento o confianza que brinda la red de control.
Alternativamente, se pueden realizar ponderaciones y predicciones, combinando explícitamente las predicciones realizadas por cada experto con la confianza estimada por la red de activación. Probablemente se le ocurran otras formas de hacer un uso eficiente de las salidas de la red predictiva y de activación.
El sistema de agrupación/combinación puede entonces elegir el clasificador único con el peso más alto, o calcular una suma ponderada de las salidas del clasificador para cada clase y elegir la clase que recibe la suma ponderada más alta.
— Página 16, Integración del aprendizaje automático , 2012.
enrutamiento del interruptor
También deberíamos analizar brevemente los métodos de enrutamiento de conmutadores que difieren del documento del MoE. Menciono esto porque Microsoft parece estar usando enrutamiento de conmutadores en lugar de modelos expertos para ahorrar algo de complejidad computacional, pero estoy feliz de que se demuestre que estoy equivocado. Cuando hay varios modelos de expertos, sus funciones de enrutamiento pueden tener un gradiente no trivial (cuándo usar qué modelo). Este límite de decisión está controlado por la capa de conmutación.
Los beneficios de la capa de conmutación son triples.
- Los cálculos de enrutamiento se reducen si los tokens solo se enrutan a un único modelo experto.
- Dado que un solo token va a un solo modelo, el tamaño del lote (capacidad experta) se puede reducir al menos a la mitad.
- Simplifica la implementación de enrutamiento y reduce la comunicación.
La superposición del mismo token con más de 1 modelo experto se denomina factor de capacidad. A continuación se muestra una descripción conceptual de cómo funciona el enrutamiento con diferentes factores de capacidad expertos.

Una ilustración de la dinámica del enrutamiento de tokens.
Cada experto procesa un tamaño de lote fijo de tokens modulado por un factor de capacidad. Cada token se enruta al experto con la mayor probabilidad de enrutamiento
, pero cada experto tiene un tamaño de lote fijo
(total de tokens/número de expertos) × factor de capacidad. Si la distribución de tokens es desigual
, algunos expertos se desbordarán (indicado por la línea de puntos roja), lo que hará que
la capa no procese estos tokens. Los factores de capacidad más grandes alivian
este problema de desbordamiento, pero también aumentan los costos computacionales y de comunicación
(indicados por espacios vacíos/blancos llenos). (Fuente https://arxiv.org/pdf/2101.03961.pdf )
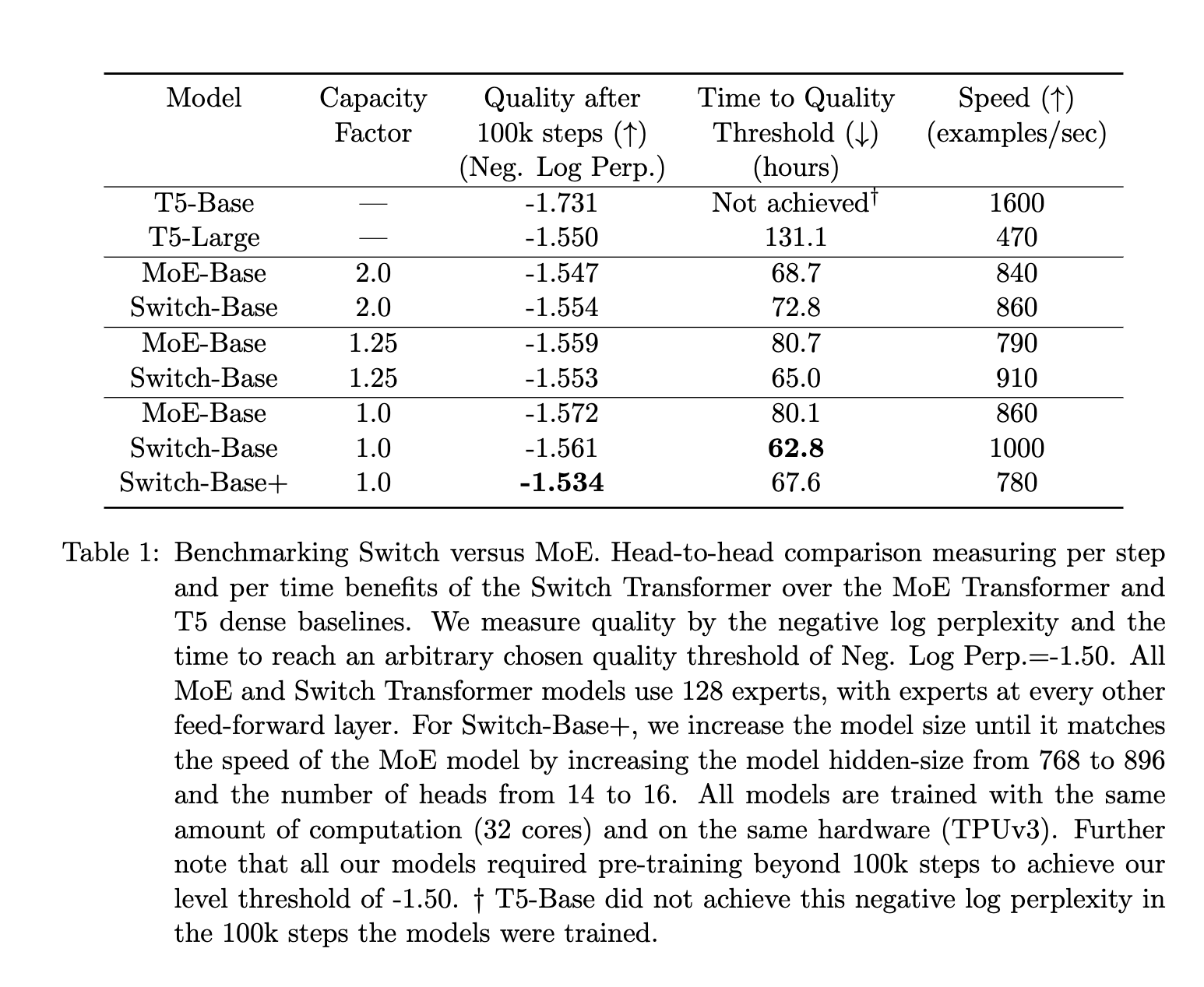
En comparación con el MoE, las conclusiones de los documentos del MoE y Switch muestran que:
- Los transformadores de conmutación superan a los modelos densos bien ajustados y a los transformadores MoE en términos de velocidad y calidad.
- Espacio de cálculo más pequeño para cambiar transformadores que MoE
- Los transformadores de conmutación funcionan mejor con factores de capacitancia más bajos (1–1,25).
en conclusión
Dos advertencias: en primer lugar, todo esto proviene de rumores y, en segundo lugar, mi comprensión de estos conceptos es bastante débil, por lo que insto a los lectores a que lo tomen con cautela.
Pero ¿qué consiguió Microsoft ocultando esta arquitectura? Bueno, crearon revuelo y provocaron suspenso. Esto puede ayudarles a contar mejor sus historias. Se guardan sus innovaciones para sí mismos, evitando que otros las alcancen más rápidamente. Es probable que la idea sea el plan habitual de Microsoft de invertir 10.000 millones de dólares en una empresa y al mismo tiempo frustrar la competencia.
El rendimiento del GPT-4 es excelente, pero no es un diseño innovador o rompedor. Es una implementación ingeniosa de un enfoque desarrollado por ingenieros e investigadores complementado con un despliegue corporativo/capitalista. OpenAI no niega ni está de acuerdo con estas afirmaciones ( https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed ), lo que me hace pensar que es muy probable que esta arquitectura de GPT-4 sea real.