Tabla de contenido
5. Funciones estadísticas personalizadas
La diferencia entre FLOPS y FLOP:
- FLOPS: Atención todo en mayúsculas, es la abreviatura de operaciones de punto flotante por segundo, lo que significa el número de operaciones de punto flotante por segundo, lo que se entiende como la velocidad de cálculo. Es una medida del rendimiento del hardware.
- FLOP: tenga en cuenta que s está en minúsculas, que es la abreviatura de operaciones de punto flotante (s significa plural), lo que significa operandos de punto flotante y se entiende como la cantidad de cálculo. Se puede utilizar para medir la complejidad del algoritmo/modelo.
Antes de presentar el paquete torchstat y el paquete thop, resumamos:
- El paquete torchstat puede contar los parámetros y cálculos de redes neuronales convolucionales y redes neuronales totalmente conectadas.
- El paquete thop puede contar los parámetros y cálculos de redes neuronales convolucionales, redes neuronales totalmente conectadas y redes neuronales recurrentes. Vea a continuación ejemplos de programas.
1, antorcha
pip install torchstat -i https://pypi.tuna.tsinghua.edu.cn/simpleEn funcionamiento real, podemos llamar al paquete torchstat para que nos ayude a contar los parámetros y FLOP del modelo. Si no modifica algunos códigos en este paquete, entonces este paquete solo es adecuado para modelos cuya entrada es imágenes de 3 canales.
import torch
import torch.nn as nn
from torchstat import stat
class Simple(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, padding=1, bias=False)
self.conv2 = nn.Conv2d(16, 32, 3, 1, padding=1, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
model = Simple()
stat(model, (3, 244, 244)) # 统计模型的参数量和FLOPs,(3,244,244)是输入图像的size
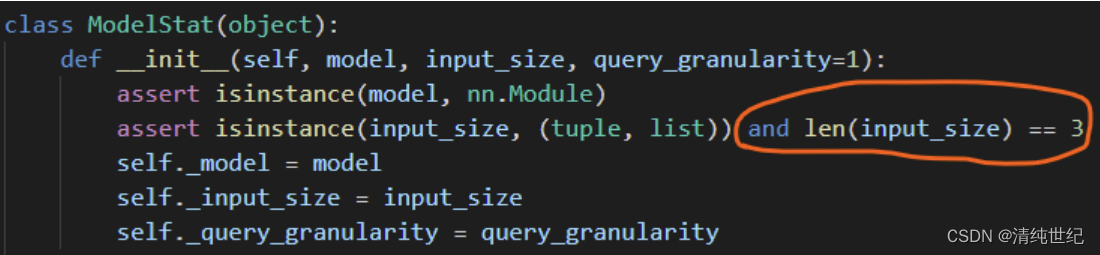
Si el programa de una línea en el paquete torchstat se cambia un poco, entonces este paquete se puede usar para contar los parámetros y cálculos de la red neuronal completamente conectada. Por supuesto, calcular manualmente los parámetros y los cálculos de la red neuronal completamente conectada también es muy rápido =_=. Después de ingresar el código fuente de torchstat, como se muestra en la figura a continuación, comente el círculo rojo y luego use el paquete de torchstat para contar los parámetros y cálculos de la red neuronal completamente conectada.
2, parte superior
pip install thop -i https://pypi.tuna.tsinghua.edu.cn/simpleimport torch
import torch.nn as nn
from thop import profile
class Simple(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 10)
def forward(self, x):
x = self.fc1(x)
return x
net = Simple()
input = torch.randn(1, 10) # batchsize=1, 输入向量长度为10
macs, params = profile(net, inputs=(input, ))
print(' FLOPs: ', macs*2) # 一般来讲,FLOPs是macs的两倍
print('params: ', params)3, fv core
pip install fvcore -i https://pypi.tuna.tsinghua.edu.cn/simplees mejor usarlo
import torch
from torchvision.models import resnet50
from fvcore.nn import FlopCountAnalysis, parameter_count_table
# 创建resnet50网络
model = resnet50(num_classes=1000)
# 创建输入网络的tensor
tensor = (torch.rand(1, 3, 224, 224),)
# 分析FLOPs
flops = FlopCountAnalysis(model, tensor)
print("FLOPs: ", flops.total())
# 分析parameters
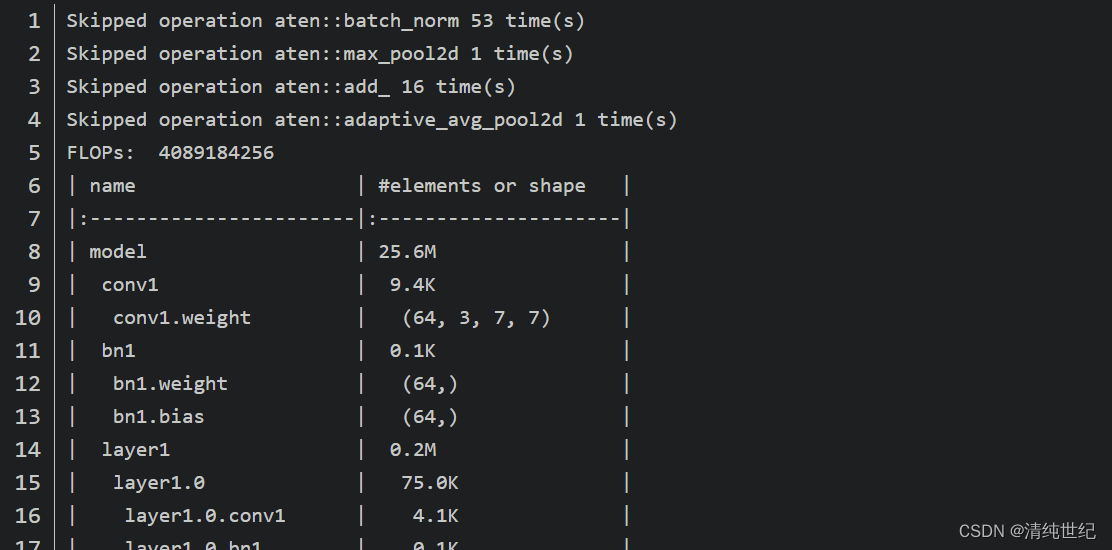
print(parameter_count_table(model))Los resultados de salida del terminal son los siguientes, FLOP es 4089184256 y la cantidad de parámetros del modelo es de aproximadamente 25,6 millones (la cantidad de parámetros aquí es algo diferente de mi propio cálculo, principalmente en el módulo BN, aquí solo dos parámetros de entrenamiento beta y gamma se calculan, no hay estadísticas moving_mean y moving_var dos parámetros), para obtener más detalles, consulte el problema que mencioné en el oficial.
A partir de la información impresa por la terminal, podemos encontrar que la capa BN no está incluida en el cálculo de FLOP, y la capa de agrupación también tiene operaciones de adición ordinarias (descubrí que no existe una regulación uniforme al calcular FLOP, y el cálculo de Los proyectos FLOP en github son básicamente todos diferentes, pero los resultados calculados son similares).
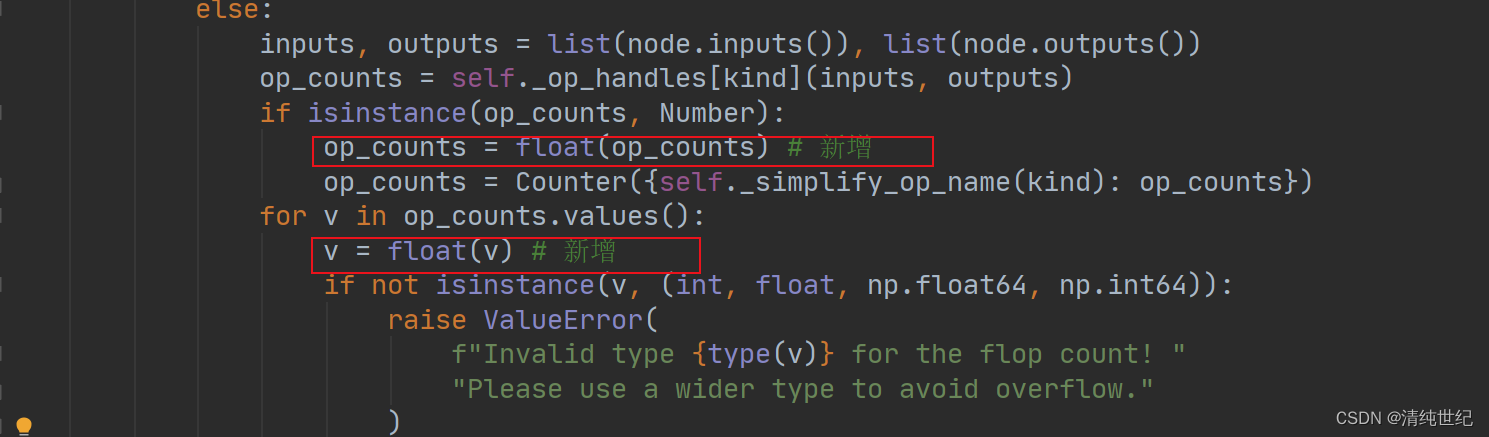
Nota: Al usar el módulo fvcore para calcular los fracasos del modelo, encontré un problema y registré la solución. El primero es un error en la línea 589 de jit_analysis.py. Después de la depuración, se encuentra que el tipo de op_counts.values() es int32, pero los tipos requeridos para el cálculo solo pueden ser int, float, np.float64 y np.int64, por lo que se requiere conversión manual. Modificar de la siguiente manera:
4, contador_flops
pip install ptflops -i https://pypi.tuna.tsinghua.edu.cn/simpleUsarlo también está bien, el resultado es el mismo que fvcore
from ptflops import get_model_complexity_info
macs, params = get_model_complexity_info(model, (112, 9, 9), as_strings=True,
print_per_layer_stat=True, verbose=True)
print('{:<30} {:<8}'.format('Computational complexity: ', macs))
print('{:<30} {:<8}'.format('Number of parameters: ', params))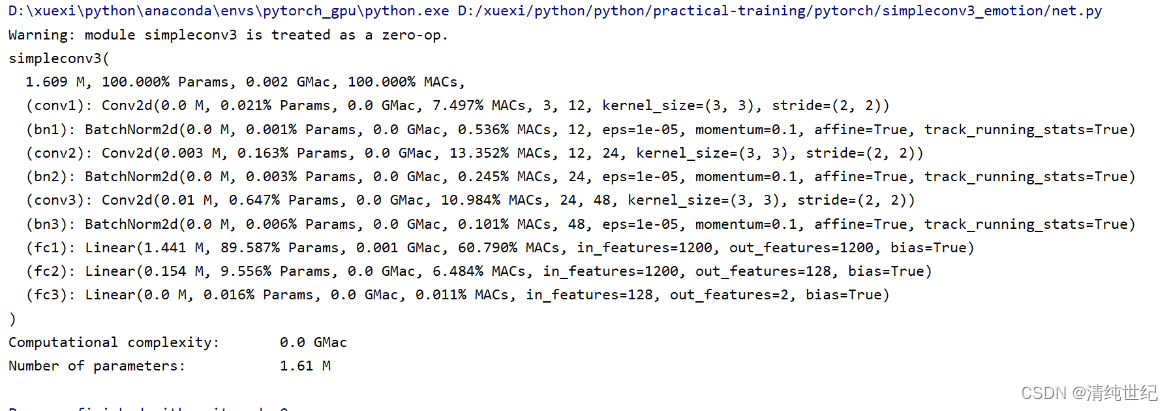
5. Funciones estadísticas personalizadas
import torch
import numpy as np
def calc_flops(model, input):
def conv_hook(self, input, output):
batch_size, input_channels, input_height, input_width = input[0].size()
output_channels, output_height, output_width = output[0].size()
kernel_ops = self.kernel_size[0] * self.kernel_size[1] * (self.in_channels / self.groups) * (
2 if multiply_adds else 1)
bias_ops = 1 if self.bias is not None else 0
params = output_channels * (kernel_ops + bias_ops)
flops = batch_size * params * output_height * output_width
list_conv.append(flops)
def linear_hook(self, input, output):
batch_size = input[0].size(0) if input[0].dim() == 2 else 1
num_steps = input[0].size(0)
weight_ops = self.weight.nelement() * (2 if multiply_adds else 1)
bias_ops = self.bias.nelement() if self.bias is not None else 0
flops = batch_size * (weight_ops + bias_ops)
flops *= num_steps
list_linear.append(flops)
def fsmn_hook(self, input, output):
batch_size = input[0].size(0) if input[0].dim() == 2 else 1
weight_ops = self.filter.nelement() * (2 if multiply_adds else 1)
num_steps = input[0].size(0)
flops = num_steps * weight_ops
flops *= batch_size
list_fsmn.append(flops)
def gru_cell(input_size, hidden_size, bias=True):
total_ops = 0
# r = \sigma(W_{ir} x + b_{ir} + W_{hr} h + b_{hr}) \\
# z = \sigma(W_{iz} x + b_{iz} + W_{hz} h + b_{hz}) \\
state_ops = (hidden_size + input_size) * hidden_size + hidden_size
if bias:
state_ops += hidden_size * 2
total_ops += state_ops * 2
# n = \tanh(W_{in} x + b_{in} + r * (W_{hn} h + b_{hn})) \\
total_ops += (hidden_size + input_size) * hidden_size + hidden_size
if bias:
total_ops += hidden_size * 2
# r hadamard : r * (~)
total_ops += hidden_size
# h' = (1 - z) * n + z * h
# hadamard hadamard add
total_ops += hidden_size * 3
return total_ops
def gru_hook(self, input, output):
batch_size = input[0].size(0) if input[0].dim() == 2 else 1
if self.batch_first:
batch_size = input[0].size(0)
num_steps = input[0].size(1)
else:
batch_size = input[0].size(1)
num_steps = input[0].size(0)
total_ops = 0
bias = self.bias
input_size = self.input_size
hidden_size = self.hidden_size
num_layers = self.num_layers
total_ops = 0
total_ops += gru_cell(input_size, hidden_size, bias)
for i in range(num_layers - 1):
total_ops += gru_cell(hidden_size, hidden_size, bias)
total_ops *= batch_size
total_ops *= num_steps
list_lstm.append(total_ops)
def lstm_cell(input_size, hidden_size, bias):
total_ops = 0
state_ops = (input_size + hidden_size) * hidden_size + hidden_size
if bias:
state_ops += hidden_size * 2
total_ops += state_ops * 4
total_ops += hidden_size * 3
total_ops += hidden_size
return total_ops
def lstm_hook(self, input, output):
batch_size = input[0].size(0) if input[0].dim() == 2 else 1
if self.batch_first:
batch_size = input[0].size(0)
num_steps = input[0].size(1)
else:
batch_size = input[0].size(1)
num_steps = input[0].size(0)
total_ops = 0
bias = self.bias
input_size = self.input_size
hidden_size = self.hidden_size
num_layers = self.num_layers
total_ops = 0
total_ops += lstm_cell(input_size, hidden_size, bias)
for i in range(num_layers - 1):
total_ops += lstm_cell(hidden_size, hidden_size, bias)
total_ops *= batch_size
total_ops *= num_steps
list_lstm.append(total_ops)
def bn_hook(self, input, output):
list_bn.append(input[0].nelement())
def relu_hook(self, input, output):
list_relu.append(input[0].nelement())
def pooling_hook(self, input, output):
batch_size, input_channels, input_height, input_width = input[0].size()
output_channels, output_height, output_width = output[0].size()
kernel_ops = self.kernel_size * self.kernel_size
bias_ops = 0
params = output_channels * (kernel_ops + bias_ops)
flops = batch_size * params * output_height * output_width
list_pooling.append(flops)
def foo(net):
childrens = list(net.children())
if not childrens:
print(net)
if isinstance(net, torch.nn.Conv2d) or isinstance(net, torch.nn.ConvTranspose2d):
net.register_forward_hook(conv_hook)
# print('conv_hook_ready')
if isinstance(net, torch.nn.Linear):
net.register_forward_hook(linear_hook)
# print('linear_hook_ready')
if isinstance(net, torch.nn.BatchNorm2d):
net.register_forward_hook(bn_hook)
# print('batch_norm_hook_ready')
if isinstance(net, torch.nn.ReLU) or isinstance(net, torch.nn.PReLU):
net.register_forward_hook(relu_hook)
# print('relu_hook_ready')
if isinstance(net, torch.nn.MaxPool2d) or isinstance(net, torch.nn.AvgPool2d):
net.register_forward_hook(pooling_hook)
# print('pooling_hook_ready')
if isinstance(net, torch.nn.LSTM):
net.register_forward_hook(lstm_hook)
# print('lstm_hook_ready')
if isinstance(net, torch.nn.GRU):
net.register_forward_hook(gru_hook)
# if isinstance(net, FSMNZQ):
# net.register_forward_hook(fsmn_hook)
# print('fsmn_hook_ready')
return
for c in childrens:
foo(c)
multiply_adds = False
list_conv, list_bn, list_relu, list_linear, list_pooling, list_lstm, list_fsmn = [], [], [], [], [], [], []
foo(model)
_ = model(input)
total_flops = (sum(list_conv) + sum(list_linear) + sum(list_bn) + sum(list_relu) + sum(list_pooling) + sum(
list_lstm) + sum(list_fsmn))
fsmn_flops = (sum(list_fsmn) + sum(list_linear))
lstm_flops = sum(list_lstm)
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
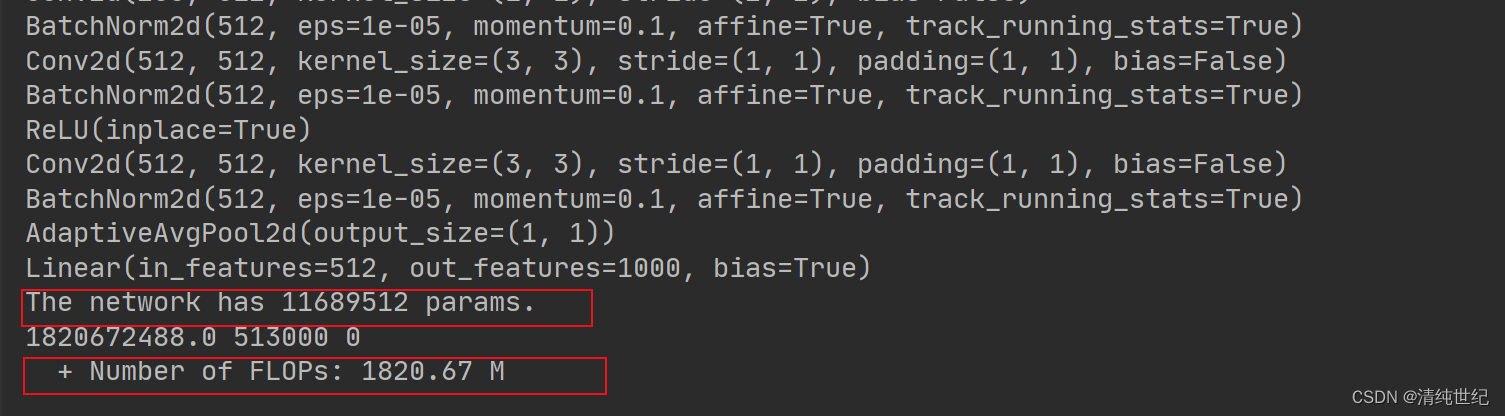
print('The network has {} params.'.format(params))
print(total_flops, fsmn_flops, lstm_flops)
print(' + Number of FLOPs: %.2f M' % (total_flops / 1000 ** 2))
return total_flops
if __name__ == '__main__':
from torchvision.models import resnet18
model = resnet18(num_classes=1000)
imput_size = torch.rand((1,3,224,224))
calc_flops(model, imput_size)