contenido
1. Operadores comunes de Flink SQL
Flink SQL es un conjunto de lenguaje de desarrollo que se ajusta a la semántica SQL estándar diseñada por la informática en tiempo real de Flink para simplificar el modelo informático y reducir el umbral para que los usuarios utilicen la informática en tiempo real. Desde 2015, Alibaba ha comenzado a investigar motores informáticos de flujo de código abierto y finalmente decidió construir una nueva generación de motores informáticos basados en Flink, optimizar y mejorar las deficiencias de Flink y abrir el código final a principios de 2019, que se conoce como Blink. Una de las contribuciones más significativas de Blink al Flink original es la implementación de Flink SQL.
Flink SQL es una capa de API orientada al usuario. En nuestro campo informático de transmisión tradicional, como Storm y Spark Streaming, se proporcionan algunas API de funciones o flujo de datos. Los usuarios pueden escribir la lógica comercial a través de Java o Scala. Aunque este método es flexible, tiene algunas carencias., por ejemplo, hay ciertos umbrales y la afinación es difícil.Con la continua actualización de versiones, también hay muchas incompatibilidades en la API.
En este contexto, no hay duda de que SQL se ha convertido en nuestra mejor opción.La razón por la que elegimos SQL como la API principal es que tiene varias características muy importantes:
-
SQL es un lenguaje de configuración, los usuarios solo necesitan expresar sus necesidades claramente y no necesitan comprender los métodos específicos;
-
SQL se puede optimizar, con múltiples optimizadores de consultas incorporados, estos optimizadores de consultas pueden traducir el plan de ejecución óptimo para SQL;
-
SQL es fácil de entender, entendido por personas en diferentes industrias y campos, y el costo de aprendizaje es bajo;
-
SQL es muy estable y, en los más de 30 años de historia de la base de datos, el propio SQL ha cambiado menos;
-
Unificación de flujos y lotes, el tiempo de ejecución subyacente de Flink en sí mismo es un motor para la unificación de flujos y lotes, y SQL puede lograr la unificación de flujos y lotes en la capa API.
1. Operadores comunes de Flink SQL
SELECCIONAR :
SELECT se usa para seleccionar datos de un DataSet/DataStream, y se usa para filtrar ciertas columnas.
Ejemplo:
SELECT * FROM Table; // obtener todas las columnas de la tabla
SELECT name,age FROM Table; // Obtener las columnas de nombre y edad de la tabla
Al mismo tiempo, las funciones y los alias se pueden usar en declaraciones SELECT, como WordCount que mencionamos anteriormente:
SELECT word, COUNT(word) FROM table GROUP BY word;
DONDE :
WHERE se usa para filtrar datos de un conjunto de datos/flujo, y se usa junto con SELECT para dividir horizontalmente las relaciones según ciertas condiciones, es decir, para seleccionar registros que cumplan con las condiciones.
Ejemplo:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;
SELECT * FROM Table WHERE age = 20;
WHERE es filtrar a partir de los datos originales, luego en la condición WHERE, Flink SQL también admite la combinación de expresiones =、<、>、<>、>=、<=y AND、OR otras expresiones, y finalmente se seleccionarán los datos que cumplan con las condiciones del filtro. Y WHERE se puede usar en combinación con IN y NOT IN. por ejemplo:
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
DISTINTO :
DISTINCT se usa para deduplicar del conjunto de datos/flujo de acuerdo con el resultado de SELECT.
Ejemplo:
SELECT DISTINCT name FROM Table;
Para las consultas de transmisión, el estado requerido para calcular el resultado de la consulta puede crecer infinitamente y los usuarios deben controlar el rango de estado de la consulta para evitar que el estado sea demasiado grande.
AGRUPAR POR :
GROUP BY es para agrupar datos. Por ejemplo, necesitamos calcular el puntaje total de cada estudiante en el calendario de calificaciones.
Ejemplo:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
UNIÓN y UNIÓN TODOS :
UNION se usa para combinar dos conjuntos de resultados, y los campos de los dos conjuntos de resultados deben ser exactamente iguales, incluido el tipo de campo y el orden de los campos. A diferencia de UNION ALL, UNION deduplica los datos resultantes.
Ejemplo:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
UNIRSE :
JOIN se utiliza para combinar datos de dos tablas para formar una tabla de resultados. Los tipos de JOIN admitidos por Flink incluyen:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
La semántica de JOIN aquí es consistente con la semántica de JOIN que usamos en las bases de datos relacionales.
Ejemplo:
JOIN (Asociar los datos de la tabla de pedidos con la tabla de productos)
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
La diferencia entre LEFT JOIN y JOIN es que cuando la tabla derecha no tiene datos que se JOINed con la izquierda, el campo correspondiente a la derecha se llena con NULL para la salida. RIGHT JOIN es equivalente a LEFT JOIN donde las tablas izquierda y derecha interactuar. FULL JOIN es equivalente a la operación UNION ALL después de RIGHT JOIN y LEFT JOIN.
Ejemplo:
SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id
Ventana de grupo :
De acuerdo con la división diferente de los datos de la ventana, Apache Flink actualmente tiene los siguientes tres tipos de ventana delimitada:
Tumble, ventana rodante , los datos de la ventana tienen un tamaño fijo y los datos de la ventana no se superponen;
Salto, ventana deslizante , los datos de la ventana tienen un tamaño fijo, y hay una frecuencia de reconstrucción de ventana fija, y los datos de la ventana se superponen;
La sesión, la ventana de sesión y los datos de la ventana no tienen un tamaño fijo. Las ventanas se dividen según el nivel de actividad de los datos de la ventana y los datos de la ventana no se superponen.
Ventana de caída :
La ventana de desplazamiento de Tumble tiene un tamaño fijo y los datos de la ventana no se superponen. La semántica específica es la siguiente:
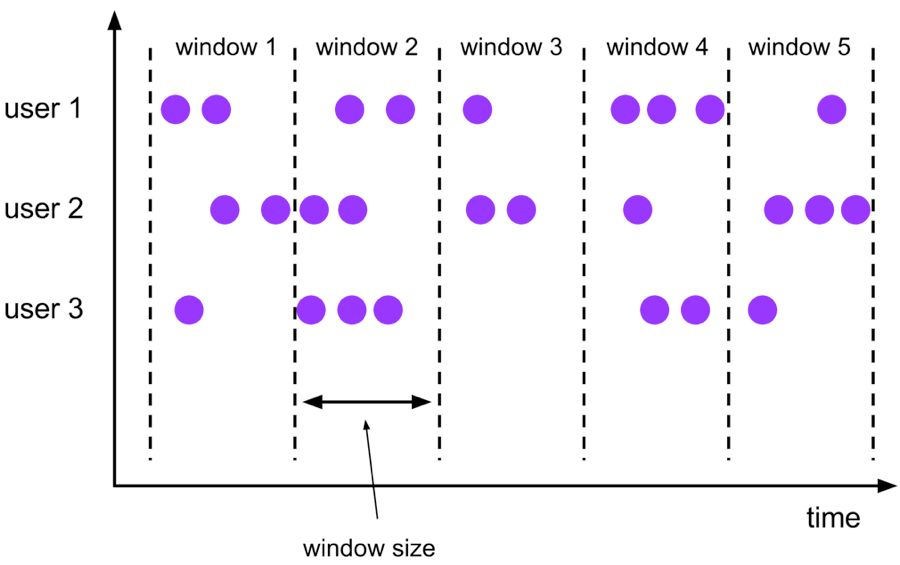
La sintaxis correspondiente a la ventana de desplazamiento de Tumble es la siguiente:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
en:
[gk] determina si agregar por campo;
TUMBLE_START representa la hora de inicio de la ventana;
TUMBLE_END representa la hora de finalización de la ventana;
timeCol es el campo de tiempo en la tabla de flujo;
size indica el tamaño de la ventana, como segundos, minutos, horas, días.
Por ejemplo, si queremos calcular el número de pedidos por persona al día, agregar y agrupar por usuario:
SELECT user,
TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart,
SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;
Ventana de salto :
La ventana deslizante Hop es similar a la ventana móvil. La ventana tiene un tamaño fijo. A diferencia de la ventana móvil, la ventana móvil puede controlar la nueva frecuencia de la ventana móvil a través del parámetro deslizante. Por lo tanto, cuando el valor de la diapositiva es menor que el valor del tamaño de la ventana, varias ventanas deslizantes se superpondrán. La semántica específica es la siguiente:
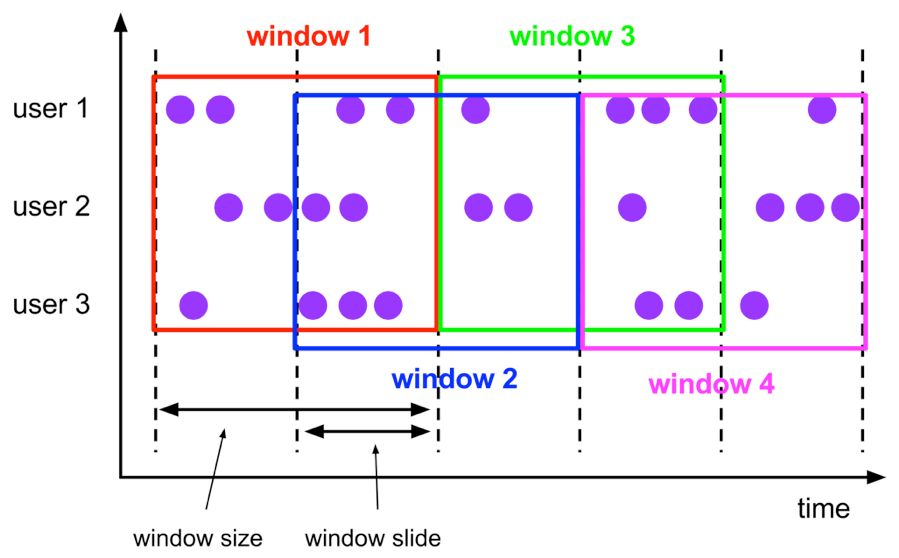
La sintaxis correspondiente de la ventana deslizante Hop es la siguiente:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
El significado de cada campo es similar a la ventana Tumble:
[gk] determina si agregar por campo;
HOP_START indica la hora de inicio de la ventana;
HOP_END indica la hora de finalización de la ventana;
timeCol representa el campo de tiempo en la tabla de flujo;
slide indica el tamaño de cada diapositiva de ventana;
size indica el tamaño de toda la ventana, como segundos, minutos, horas, días.
Como ejemplo, queremos calcular las ventas de cada artículo en las últimas 24 horas cada hora:
SELECT product,
SUM(amount)
FROM Orders
GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product
Ventana de sesión :
Las ventanas de tiempo de sesión no tienen una duración fija, pero sus límites están definidos por el tiempo de inactividad del intervalo, es decir, la ventana de sesión se cierra si no ocurre ningún evento durante el intervalo definido.
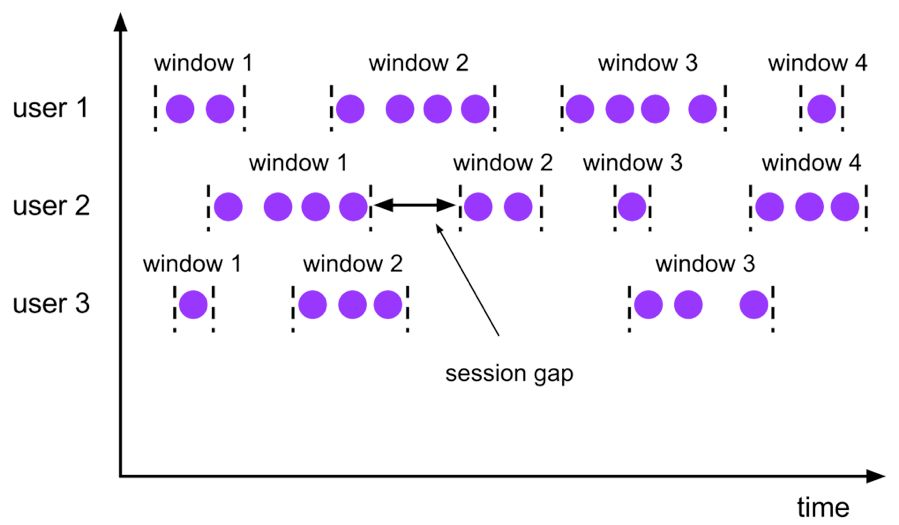
La sintaxis correspondiente de la ventana de sesión de Seeeion es la siguiente:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
[gk] determina si agregar por campo;
SESSION_START representa la hora de inicio de la ventana;
SESSION_END indica la hora de finalización de la ventana;
timeCol representa el campo de tiempo en la tabla de flujo;
gap indica la duración del período inactivo de los datos de la ventana.
Por ejemplo, necesitamos calcular el volumen de pedidos para el tiempo de visita de cada usuario dentro de las 12 horas:
SELECT user,
SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart,
SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd,
SUM(amount)
FROM Orders
GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
Table API y SQL se incluyen en el artefacto Maven flink-table. Las siguientes dependencias deben agregarse a su proyecto para usar Table API y SQL:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
Además, debe agregar dependencias para el lote de Scala de Flink o la API de transmisión. Para consultas masivas, debe agregar:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
2. Caso práctico Flink SQL
1) SQL de datos por lotes
uso:
-
Cree el entorno de tiempo de ejecución de Table
-
Registrar el DataSet como una tabla
-
Use el método sqlQuery del entorno de tiempo de ejecución de Table para ejecutar sentencias SQL
Ejemplo: use Flink SQL para contar la cantidad total, la cantidad máxima, la cantidad mínima y la cantidad total de pedidos de consumo de los usuarios .
| Solicitar ID | nombre de usuario | fecha de orden | cantidad de consumo |
|---|---|---|---|
| 1 | Zhangsan | 2018-10-20 15:30 | 358.5 |
Datos de prueba (ID de pedido, nombre de usuario, fecha de pedido, cantidad de pedido):
Order(1, "zhangsan", "2018-10-20 15:30", 358.5),
Order(2, "zhangsan", "2018-10-20 16:30", 131.5),
Order(3, "lisi", "2018-10-20 16:30", 127.5),
Order(4, "lisi", "2018-10-20 16:30", 328.5),
Order(5, "lisi", "2018-10-20 16:30", 432.5),
Order(6, "zhaoliu", "2018-10-20 22:30", 451.0),
Order(7, "zhaoliu", "2018-10-20 22:30", 362.0),
Order(8, "zhaoliu", "2018-10-20 22:30", 364.0),
Order(9, "zhaoliu", "2018-10-20 22:30", 341.0)
paso:
-
Obtenga un entorno de tiempo de ejecución por lotes
-
Obtener un entorno de tiempo de ejecución de Table
-
Cree un pedido de clase de muestra para asignar datos (nombre del pedido, nombre de usuario, fecha del pedido, monto del pedido)
-
Cree una fuente de conjunto de datos basada en la colección de pedidos local
-
Registre el DataSet como una tabla utilizando el entorno de tiempo de ejecución de Table
-
Use declaraciones SQL para manipular datos (para contar la cantidad total, la cantidad máxima, la cantidad mínima y la cantidad total de pedidos de consumo de los usuarios)
-
Convertir tabla a conjunto de datos usando TableEnv.toDataSet
-
prueba de impresión
código de muestra :
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.table.api.{Table, TableEnvironment}
import org.apache.flink.table.api.scala.BatchTableEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.types.Row
/**
* 使用Flink SQL统计用户消费订单的总金额、最大金额、最小金额、订单总数。
*/
object BatchFlinkSqlDemo {
//3. 创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)
case class Order(id:Int, userName:String, createTime:String, money:Double)
def main(args: Array[String]): Unit = {
/**
* 实现思路:
* 1. 获取一个批处理运行环境
* 2. 获取一个Table运行环境
* 3. 创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)
* 4. 基于本地 Order 集合创建一个DataSet source
* 5. 使用Table运行环境将DataSet注册为一张表
* 6. 使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
* 7. 使用TableEnv.toDataSet将Table转换为DataSet
* 8. 打印测试
*/
//1. 获取一个批处理运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2. 获取一个Table运行环境
val tabEnv: BatchTableEnvironment = TableEnvironment.getTableEnvironment(env)
//4. 基于本地 Order 集合创建一个DataSet source
val orderDataSet: DataSet[Order] = env.fromElements(
Order(1, "zhangsan", "2018-10-20 15:30", 358.5),
Order(2, "zhangsan", "2018-10-20 16:30", 131.5),
Order(3, "lisi", "2018-10-20 16:30", 127.5),
Order(4, "lisi", "2018-10-20 16:30", 328.5),
Order(5, "lisi", "2018-10-20 16:30", 432.5),
Order(6, "zhaoliu", "2018-10-20 22:30", 451.0),
Order(7, "zhaoliu", "2018-10-20 22:30", 362.0),
Order(8, "zhaoliu", "2018-10-20 22:30", 364.0),
Order(9, "zhaoliu", "2018-10-20 22:30", 341.0)
)
//5. 使用Table运行环境将DataSet注册为一张表
tabEnv.registerDataSet("t_order", orderDataSet)
//6. 使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
//用户消费订单的总金额、最大金额、最小金额、订单总数。
val sql =
"""
| select
| userName,
| sum(money) totalMoney,
| max(money) maxMoney,
| min(money) minMoney,
| count(1) totalCount
| from t_order
| group by userName
|""".stripMargin //在scala中stripMargin默认是“|”作为多行连接符
//7. 使用TableEnv.toDataSet将Table转换为DataSet
val table: Table = tabEnv.sqlQuery(sql)
table.printSchema()
tabEnv.toDataSet[Row](table).print()
}
}
2) Transmisión de datos SQL
SQL también se puede admitir en el procesamiento de secuencias. Pero es necesario tener en cuenta los siguientes puntos:
-
Para usar la transmisión de SQL, debe agregar el tiempo de marca de agua
-
Cuando use el registro registerDataStream, use ' para especificar el campo
-
Al registrarse, se debe especificar un tiempo de fila, de lo contrario, la ventana no se puede usar en SQL
-
Se debe importar el parámetro implícito de import org.apache.flink.table.api.scala._
-
Use trumble (nombre de la columna de tiempo, segundo intervalo de 'tiempo') para definir la ventana en SQL
Ejemplo: use Flink SQL para contar el número total de pedidos, el monto máximo del pedido y el monto mínimo del pedido del usuario en 5 segundos .
paso
-
Obtener el entorno de tiempo de ejecución de procesamiento de secuencias
-
Obtener el entorno de tiempo de ejecución de la tabla
-
Establezca el tiempo de procesamiento en EventTime
-
Cree un pedido de clase de muestra Pedido con cuatro campos (ID de pedido, ID de usuario, monto del pedido, marca de tiempo)
- Crear una fuente de datos personalizada
-
Genere 1000 pedidos usando for loop
-
ID de pedido generado aleatoriamente (UUID)
-
ID de usuario generado aleatoriamente (0-2)
-
Importe del pedido generado aleatoriamente (0-100)
-
La marca de tiempo es la hora actual del sistema
-
Generar una orden cada 1 segundo
-
-
Agregar marca de agua, permitir un retraso de 2 segundos
-
importar importar org.apache.flink.table.api.scala._ parámetro implícito
-
Use el registro registerDataStream y especifique los campos por separado, y también especifique el campo de tiempo de fila
-
Al escribir declaraciones SQL para contar el número total de pedidos de usuarios, la cantidad máxima y la agrupación de cantidad mínima, use tumble (columna de tiempo, intervalo 'tiempo de ventana' segundo) para crear una ventana
-
Ejecute la declaración sql usando tableEnv.sqlQuery
-
Convierta el resultado de la ejecución de SQL en DataStream e imprímalo
-
iniciar controlador de flujo
código de muestra :
import java.util.UUID
import java.util.concurrent.TimeUnit
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.table.api.{Table, TableEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.types.Row
import scala.util.Random
/**
* 需求:
* 使用Flink SQL来统计5秒内 用户的 订单总数、订单的最大金额、订单的最小金额
*
* timestamp是关键字不能作为字段的名字(关键字不能作为字段名字)
*/
object StreamFlinkSqlDemo {
/**
* 1. 获取流处理运行环境
* 2. 获取Table运行环境
* 3. 设置处理时间为 EventTime
* 4. 创建一个订单样例类 Order ,包含四个字段(订单ID、用户ID、订单金额、时间戳)
* 5. 创建一个自定义数据源
* 使用for循环生成1000个订单
* 随机生成订单ID(UUID)
* 随机生成用户ID(0-2)
* 随机生成订单金额(0-100)
* 时间戳为当前系统时间
* 每隔1秒生成一个订单
* 6. 添加水印,允许延迟2秒
* 7. 导入 import org.apache.flink.table.api.scala._ 隐式参数
* 8. 使用 registerDataStream 注册表,并分别指定字段,还要指定rowtime字段
* 9. 编写SQL语句统计用户订单总数、最大金额、最小金额
* 分组时要使用 tumble(时间列, interval '窗口时间' second) 来创建窗口
* 10. 使用 tableEnv.sqlQuery 执行sql语句
* 11. 将SQL的执行结果转换成DataStream再打印出来
* 12. 启动流处理程序
*/
// 3. 创建一个订单样例类`Order`,包含四个字段(订单ID、用户ID、订单金额、时间戳)
case class Order(orderId:String, userId:Int, money:Long, createTime:Long)
def main(args: Array[String]): Unit = {
// 1. 创建流处理运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 设置处理时间为`EventTime`
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//获取table的运行环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
// 4. 创建一个自定义数据源
val orderDataStream = env.addSource(new RichSourceFunction[Order] {
var isRunning = true
override def run(ctx: SourceFunction.SourceContext[Order]): Unit = {
// - 随机生成订单ID(UUID)
// - 随机生成用户ID(0-2)
// - 随机生成订单金额(0-100)
// - 时间戳为当前系统时间
// - 每隔1秒生成一个订单
for (i <- 0 until 1000 if isRunning) {
val order = Order(UUID.randomUUID().toString, Random.nextInt(3), Random.nextInt(101),
System.currentTimeMillis())
TimeUnit.SECONDS.sleep(1)
ctx.collect(order)
}
}
override def cancel(): Unit = { isRunning = false }
})
// 5. 添加水印,允许延迟2秒
val watermarkDataStream = orderDataStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[Order](Time.seconds(2)) {
override def extractTimestamp(element: Order): Long = {
val eventTime = element.createTime
eventTime
}
}
)
// 6. 导入`import org.apache.flink.table.api.scala._`隐式参数
// 7. 使用`registerDataStream`注册表,并分别指定字段,还要指定rowtime字段
import org.apache.flink.table.api.scala._
tableEnv.registerDataStream("t_order", watermarkDataStream, 'orderId, 'userId, 'money,'createTime.rowtime)
// 8. 编写SQL语句统计用户订单总数、最大金额、最小金额
// - 分组时要使用`tumble(时间列, interval '窗口时间' second)`来创建窗口
val sql =
"""
|select
| userId,
| count(1) as totalCount,
| max(money) as maxMoney,
| min(money) as minMoney
| from
| t_order
| group by
| tumble(createTime, interval '5' second),
| userId
""".stripMargin
// 9. 使用`tableEnv.sqlQuery`执行sql语句
val table: Table = tableEnv.sqlQuery(sql)
// 10. 将SQL的执行结果转换成DataStream再打印出来
table.toRetractStream[Row].print()
env.execute("StreamSQLApp")
}
}