Directorio de artículos
prefacio
Anteriormente presentamos los marcos de computación de big data Hadoop y Spark respectivamente. Aunque algunos de ellos tienen buenos sistemas de archivos distribuidos y motores de computación distribuidos, y algunos tienen conjuntos de datos distribuidos y motores de computación distribuidos basados en memoria, no pueden manejarlos. procesado efectivamente Hoy compartiremos una introducción y un análisis de la arquitectura de Flink, un marco de computación distribuida de big data de cuarta generación, y construiremos un entorno operativo básico.
Introducción a Flink
Apache Flink es un marco y un motor de procesamiento distribuido para cálculo con estado en flujos de datos ilimitados y acotados. Flink se ejecuta en todos los entornos de clúster comunes y puede calcular a velocidades de memoria y a cualquier escala.
Los programas Stateful Flink están optimizados para el acceso estatal local. El estado de una tarea siempre se mantiene en la memoria o, si el tamaño del estado excede la memoria disponible, se guarda en una estructura de datos en disco a la que se puede acceder de manera eficiente. Las tareas realizan todos los cálculos accediendo al estado local (normalmente en memoria), lo que da como resultado una latencia de procesamiento muy baja. Flink garantiza la coherencia del estado exactamente una vez en escenarios de falla mediante la persistencia regular y asincrónica del almacenamiento del estado local.
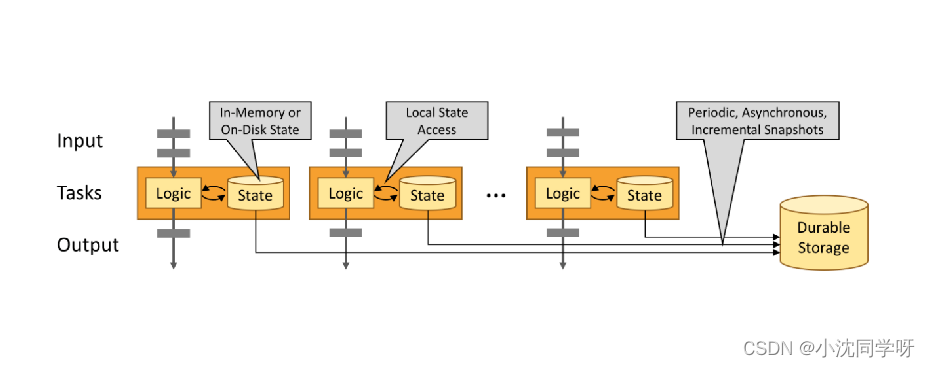
Análisis de conglomerados de Flink
El tiempo de ejecución de Flink consta de dos tipos de procesos: un JobManager y uno o más TaskManagers.
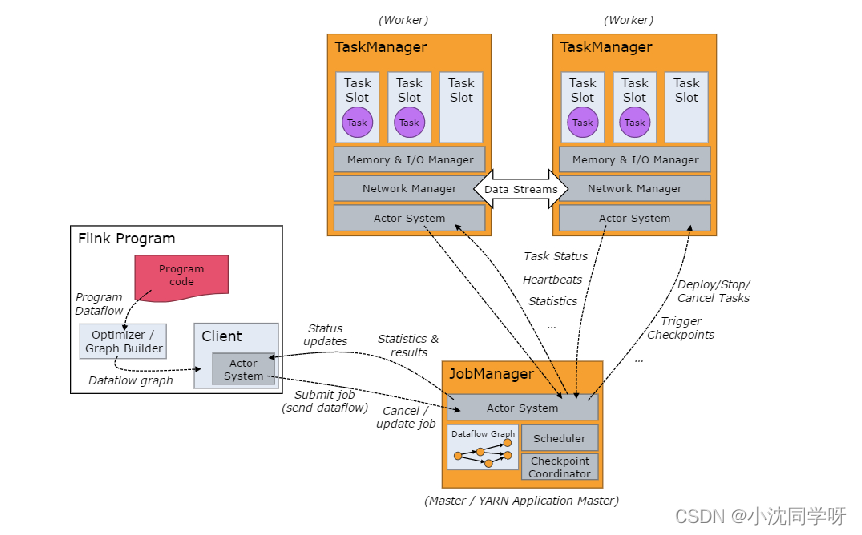
El Cliente no forma parte del tiempo de ejecución ni de la ejecución del programa, pero se utiliza para preparar el flujo de datos y enviarlo al JobManager. Luego, el cliente puede desconectarse (modo independiente) o permanecer conectado para recibir informes de progreso (modo adjunto). El cliente se puede ejecutar como parte de un disparador para ejecutar un programa Java/Scala, o se puede ejecutar en un proceso de línea de comando ./bin/flink run….
JobManager y TaskManager se pueden iniciar de varias maneras: directamente en la máquina como un clúster independiente, iniciado en un contenedor o administrado e iniciado a través de un marco de recursos como YARN o Mesos. Los TaskManagers se conectan a JobManagers, se anuncian como disponibles y se les asignan trabajos.
Escenarios de aplicación de Flink
1. Aplicaciones controladas
Las aplicaciones controladas por eventos son un tipo de aplicación con estado que extrae datos de uno o más flujos de eventos y activa cálculos, actualizaciones de estado u otras acciones externas basadas en eventos entrantes.
Ejemplos típicos de aplicaciones basadas en eventos#
Antifraude
Detección de anomalías
Alarma basada en reglas
Monitoreo de procesos de negocio
(red social) Aplicación web
2. Aplicación de análisis de datos
Las tareas de análisis de datos necesitan extraer información e indicadores valiosos de los datos sin procesar, para poder obtener los últimos datos Para los resultados del análisis, primero debe agregarlos al conjunto de datos de análisis y volver a ejecutar la consulta o ejecutar la aplicación, y luego escribir los resultados en el sistema de almacenamiento o generar un informe.
Ejemplos típicos de aplicaciones de análisis de datos
#Monitoreo de la calidad de la red de telecomunicaciones
Actualizaciones de productos y análisis de evaluación experimental en aplicaciones móviles
Análisis ad hoc de datos en tiempo real en tecnología de consumo
Análisis de gráficos a gran escala
3. La aplicación de canalización de datos
Extract-Transform-Load (ETL) es una Un método común para convertir y migrar datos entre sistemas de almacenamiento. Los trabajos de ETL generalmente se activan periódicamente para copiar datos de una base de datos transaccional a una base de datos analítica o un almacén de datos.
Construcción de índices de consultas en tiempo real
en comercio electrónico ETL continuo en comercio electrónico
Construyendo el entorno operativo básico de Flink
Instalación de ventana acoplable
Instale Docker y Docker-Compose y otorgue permisos
docker与docker-compose安装
#安装docker社区版
yum install docker-ce
#版本查看
docker version
#docker-compose插件安装
curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
#可执行权限
chmod +x /usr/local/bin/docker-compose
#版本查看
docker-compose version
escritura de archivos docker-compose
vim docker-compose-flink.yaml
version: "3.3"
services:
jobmanager:
image: registry.cn-hangzhou.aliyuncs.com/senfel/flink:1.9.2-scala_2.12
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: registry.cn-hangzhou.aliyuncs.com/senfel/flink:1.9.2-scala_2.12
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
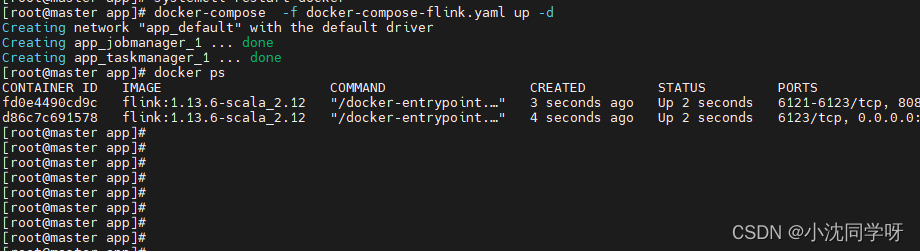
Crear y ejecutar el contenedor.
docker-compose -f docker-compose-flink.yaml up -d
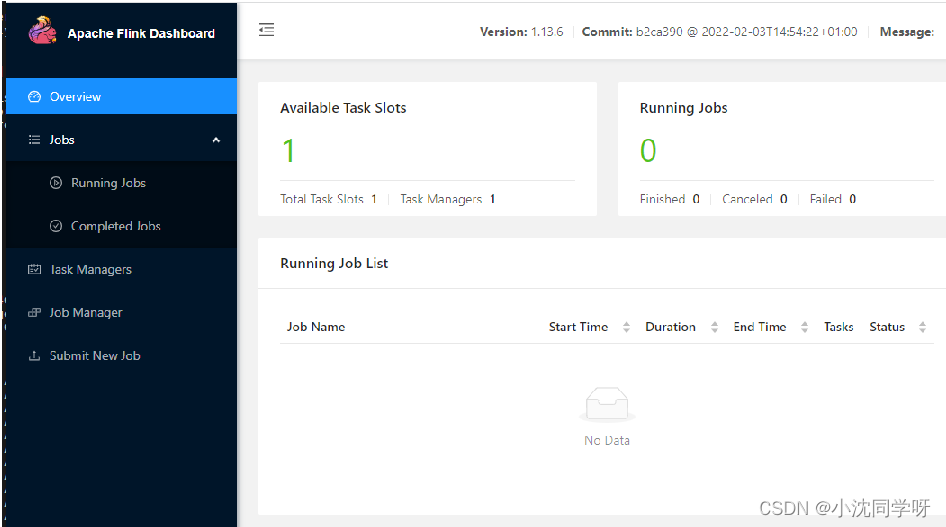
Acceda a la interfaz web de Flink
IP: 8081