Hola a todos, soy Ning Yi.
Han pasado cuatro semanas seguidas sin descanso. Recientemente, tanto mi trabajo principal como el secundario están en la cima de mi apretada agenda. Llego a casa después del trabajo a las 11 p. m. y escribo clases hasta las dos de la mañana.
Desde hace más de un mes, mi mayor deseo cada día es dormir lo suficiente.
Esta etapa finalmente terminó ~ Sigamos actualizando las preguntas de la entrevista SQL ~
Tema cinco:
175. Combinar dos tablas (simple)
Ahora hay dos tablas:
Tabla de personas: contiene PersonId,
Información sobre Apellido y Nombre.
+----------+----------+-----------+| personId | lastName | firstName |+----------+----------+-----------+| 1 | Wang | Allen || 2 | Alice | Bob |+----------+----------+-----------+
Tabla de direcciones: contiene información sobre AddressId, PersonId, ciudad y estado.
+-----------+----------+---------------+------------+| addressId | personId | city | state |+-----------+----------+---------------+------------+| 1 | 2 | New York City | New York || 2 | 3 | Leetcode | California |+-----------+----------+---------------+------------+
Escriba una consulta SQL para informar el apellido, nombre, ciudad y estado de cada persona en la tabla Persona. Si la dirección de personId no está en la tabla de direcciones, se informa nulo.
Resultado de ejemplo:
+-----------+----------+---------------+----------+| firstName | lastName | city | state |+-----------+----------+---------------+----------+| Allen | Wang | Null | Null || Bob | Alice | New York City | New York |+-----------+----------+---------------+----------+
Ideas para resolver problemas:
Esta pregunta es muy simple: la prueba principal es el punto de conocimiento de la conexión JOIN, ya sea para usar la unión izquierda o la unión derecha.
Preste atención a la oración en el título "Si la dirección de personId no está en la tabla de direcciones, el informe está vacío".
Los valores nulos aparecen en la tabla de direcciones, por lo que colocamos la tabla de personas a la izquierda y la tabla de direcciones a la derecha, usando una combinación izquierda.
SELECT firstName,lastName,city,stateFROM Person pLEFT JOIN Address aON p.personId = a.personId;
Si desea realizar la prueba localmente en su propia computadora, puede usar esto para crear rápidamente una declaración de tabla de datos:
-- 创建表PersonCREATE TABLE Person(personId INT,LastName VARCHAR(10),FirstName VARCHAR(10));-- 插入语句INSERT INTO Person VALUES(1,'Wang','Allen'),(2,'Alice','Bob');CREATE TABLE Address(addressId INT,personId INT,City VARCHAR(20),state VARCHAR(20));-- 插入语句INSERT INTO Address VALUES(1,2,'New York City','New York'),(2,3,'Leetcode','California');
Punto de conocimiento: unirse a la conexión
La consulta conjunta de varias tablas de datos requiere el uso de una conexión JOIN. Existen varios tipos de conexión JOIN:
* UNIÓN INTERNA : Conexión interna, también puedes escribir UNIRSE. Solo los datos que coincidan con los criterios de conexión se conservarán en las dos tablas que se unen, lo que equivale a la intersección de las dos tablas. Si se une a la misma tabla antes y después, también se denomina autounión.
* UNIÓN IZQUIERDA : Conexión izquierda, también conocida como conexión exterior izquierda. Se devolverán todos los registros de la tabla del lado izquierdo del operador que coincidan con la cláusula WHERE. Si no hay registros en la tabla del lado derecho del operador que coincidan con las condiciones de unión después de ON, entonces se devolverá el valor del operador seleccionado. La columna de la tabla del lado derecho será NULL.
* UNIÓN DERECHA : Unión derecha, también llamada unión exterior derecha. Se devolverán todos los registros que coincidan con la declaración WHERE en la tabla derecha. Los valores de segmento no coincidentes en la tabla de la izquierda se reemplazan por NULL.
* UNIÓN COMPLETA : Unión completa, devuelve todos los registros en todas las tablas que cumplen con las condiciones de la declaración WHERE. Si no hay ningún valor calificado para el segmento especificado en ninguna tabla, se utiliza NULL en su lugar.
Tema seis:
178. Clasificación de puntuación (mediana)
Hay una tabla de puntuación: Puntuaciones
+----+-------+| id | score |+----+-------+| 1 | 3.50 || 2 | 3.65 || 3 | 4.00 || 4 | 3.85 || 5 | 4.00 || 6 | 3.65 |+----+-------+
Escriba una consulta SQL para ordenar las puntuaciones de mayor a menor. Si dos puntuaciones son iguales, ambas puntuaciones deben clasificarse de la misma manera. Se requiere que las clasificaciones sean continuas y sin números vacíos en el medio.
El formato del resultado de la consulta es el siguiente.
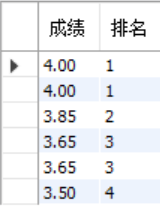
+-------+------+| score | rank |+-------+------+| 4.00 | 1 || 4.00 | 1 || 3.85 | 2 || 3.65 | 3 || 3.65 | 3 || 3.50 | 4 |+-------+------+
Ideas para resolver problemas:
Esta pregunta examina principalmente las "subconsultas correlacionadas": en las subconsultas correlacionadas, las subconsultas se realizan secuencialmente en el nivel de cada registro de la consulta principal y las subconsultas dependen de la consulta principal.
Para esta pregunta, primero ordenamos las puntuaciones en orden inverso, escribimos la columna de clasificación como una subconsulta y calculamos el número de duplicados que son mayores o iguales que la puntuación de la consulta externa actual. Este número es la clasificación.
Paso 1 : Primero ordene las puntuaciones en orden descendente.
SELECT a.Score AS '成绩'FROM Scores aORDER BY a.score DESC
Paso 2 : escriba la columna "clasificación" después de seleccionarla como subconsulta. Calcule el número de duplicados que son mayores o iguales que la puntuación de la consulta externa actual. Este número es la clasificación.
SELECT a.Score AS '成绩',(SELECT COUNT(DISTINCT score)FROM ScoresWHERE score >= a.score) AS '排名'FROM Scores aORDER BY a.score DESC
Si desea realizar la prueba localmente en su propia computadora, puede usar esto para crear rápidamente una declaración de tabla de datos:
-- 创建表CREATE TABLE Scores(Id INT,score DECIMAL(10,2));-- 插入语句INSERT INTO Scores VALUES(1,3.50),(2,3.65),(3,4.00),(4,3.85),(5,4.00),(6,3.65);
Tema 7:
183. Clientes que nunca hacen pedidos (fácil)
Un sitio web contiene dos tablas, la tabla Clientes y la tabla Pedidos. Escriba una consulta SQL para encontrar todos los clientes que nunca piden nada.
Tabla de clientes:
+----+-------+| Id | Name |+----+-------+| 1 | Joe || 2 | Henry || 3 | Sam || 4 | Max |+----+-------+
Tabla de pedidos:
+----+------------+| Id | CustomerId |+----+------------+| 1 | 3 || 2 | 1 |+----+------------+
Por ejemplo, dada la tabla anterior, su consulta debería devolver:
+-----------+| Customers |+-----------+| Henry || Max |+-----------+
Ideas para resolver problemas:
Esta pregunta examina las subconsultas. Si queremos encontrar clientes que no han realizado pedidos antes, primero encontramos los clientes que ya han realizado pedidos en la tabla Pedidos y luego excluimos a estos clientes de la tabla Clientes. Es muy fácil. Sepa quién Nunca ha pedido.
Paso 1 : Primero, busque los clientes que ya realizaron pedidos en la tabla de pedidos Pedidos
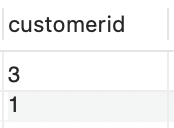
SELECT customeridFROM orders
Paso 2 : utilice NOT IN para consultar a los clientes que no están en esta lista.
SELECT name AS '未订购客户'FROM customersWHERE id NOT IN(SELECT customeridFROM orders);
Si desea realizar la prueba localmente en su propia computadora, puede usar esto para crear rápidamente una declaración de tabla de datos:
-- 创建表CREATE TABLE Customers(Id INT,Name VARCHAR(10));-- 插入语句INSERT INTO Customers VALUES(1,'Joe'),(2,'Henry'),(3,'Sam'),(4,'Max');CREATE TABLE Orders(Id INT,CustomerId INT);-- 插入语句INSERT INTO Orders VALUES(1,3),(2,1);
Tema 8:
184. Empleado mejor pagado del departamento (medio)
Ahora hay dos tablas, la tabla de información del empleado Empleado y la tabla de departamento Departamento.
Escriba una consulta SQL para encontrar los tres empleados mejor pagados de cada departamento. Devuelve una tabla de resultados en cualquier orden.
Tabla de empleados:
+----+--------+--------+--------------+| id | name | salary | departmentId |+----+--------+--------+--------------+| 1 | Joe | 85000 | 1 || 2 | Henry | 80000 | 2 || 3 | Sam | 60000 | 2 || 4 | Max | 90000 | 1 || 5 | Janet | 69000 | 1 || 6 | Randy | 85000 | 1 || 7 | Will | 70000 | 1 |+----+---------+---------+------------+
Tabla de departamentos:
+------+---------+| id | name |+------+---------+| 1 | IT || 2 | Sales |+------+---------+
Ejemplo de salida:
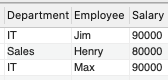
+------------+----------+--------+| Department | Employee | Salary |+------------+----------+--------+| IT | Jim | 90000 || Sales | Henry | 80000 || IT | Max | 90000 |+------------+----------+--------+
Ideas para resolver problemas:
Esta pregunta examina las uniones de tablas y las subconsultas.
Primero agrupamos los departamentos en grupos y averiguamos el salario máximo correspondiente a cada departamento. Luego coloque el resultado de esta consulta después de la declaración Where, combinada con la declaración IN, para consultar la relación entre el nombre del departamento y el salario.
Cabe señalar que un departamento puede tener varios empleados con el salario más alto al mismo tiempo, por lo que no incluya información del nombre del empleado en la subconsulta.
Paso 1 : Primero, agrupe el campo DepartmentId en la tabla de empleados Empleado para obtener el valor salarial máximo de cada departamento.
SELECT DepartmentId, MAX( Salary )FROM EmployeeGROUP BY DepartmentId
Paso dos :
Luego conecte la tabla de empleados Empleado y la tabla de departamento Departamento a través del campo DepartmentId. Una vez completada la conexión, busque los nombres de todos los empleados correspondientes según el ID de departamento (DepartmentId) encontrado en el paso anterior y el salario máximo correspondiente.
SELECTd.name AS 'Department',e.name AS 'Employee',SalaryFROM Employee eJOIN Department dON e.DepartmentId = d.IdWHERE (e.DepartmentId , Salary) IN(SELECT DepartmentId, MAX(Salary)FROM EmployeeGROUP BY DepartmentId);
Si desea realizar la prueba localmente en su propia computadora, puede usar esto para crear rápidamente una declaración de tabla de datos:
-- 创建表CREATE TABLE Employee(id INT,name VARCHAR(10),salary INT,departmentId INT);-- 插入语句INSERT INTO Employee VALUES(1,'Joe',70000,1),(2,'Jim',90000,1),(3,'Henry',80000,2),(4,'Sam',60000,2),(5,'Max',90000,1);CREATE TABLE Department(id INT,name VARCHAR(20));-- 插入语句INSERT INTO Department VALUES(1,'IT'),(2,'Sales’);
Puntos de conocimiento:
(1) Función de agregación:
Las funciones de agregación, como sugiere el nombre, son funciones que agregan registros de datos.
Por ejemplo, hay 100 registros en la base de datos original. Si utiliza una función agregada para consultar el valor máximo entre estos 100 registros, al final solo se generará el registro con el valor máximo.
Las funciones agregadas comúnmente utilizadas incluyen:
MAX( ) valor máximo
MIN( ) valor mínimo
SUMA( ) valor total
PROMEDIO( ) promedio
COUNT( ) número de registros
(2) Subconsulta:
Las declaraciones SQL se pueden anidar y la más común es el anidamiento de declaraciones de consulta. Generalmente llamamos a la declaración anidada externa consulta principal y a la declaración anidada interna subconsulta.
(3) grupo por grupo :
La cláusula GROUP BY se usa para agrupar conjuntos de resultados y generalmente se usa junto con funciones agregadas.