1. Estructura del programa Flink
Los bloques de construcción básicos de un programa Flink son flujos y transformaciones (tenga en cuenta que los conjuntos de datos utilizados en la API DataSet de Flink también son flujos internos). Conceptualmente, un flujo es un flujo (posiblemente interminable) de registros de datos, mientras que una transformación es una operación que toma uno o más flujos como uno o más flujos. entrada y producir uno o más flujos de salida.
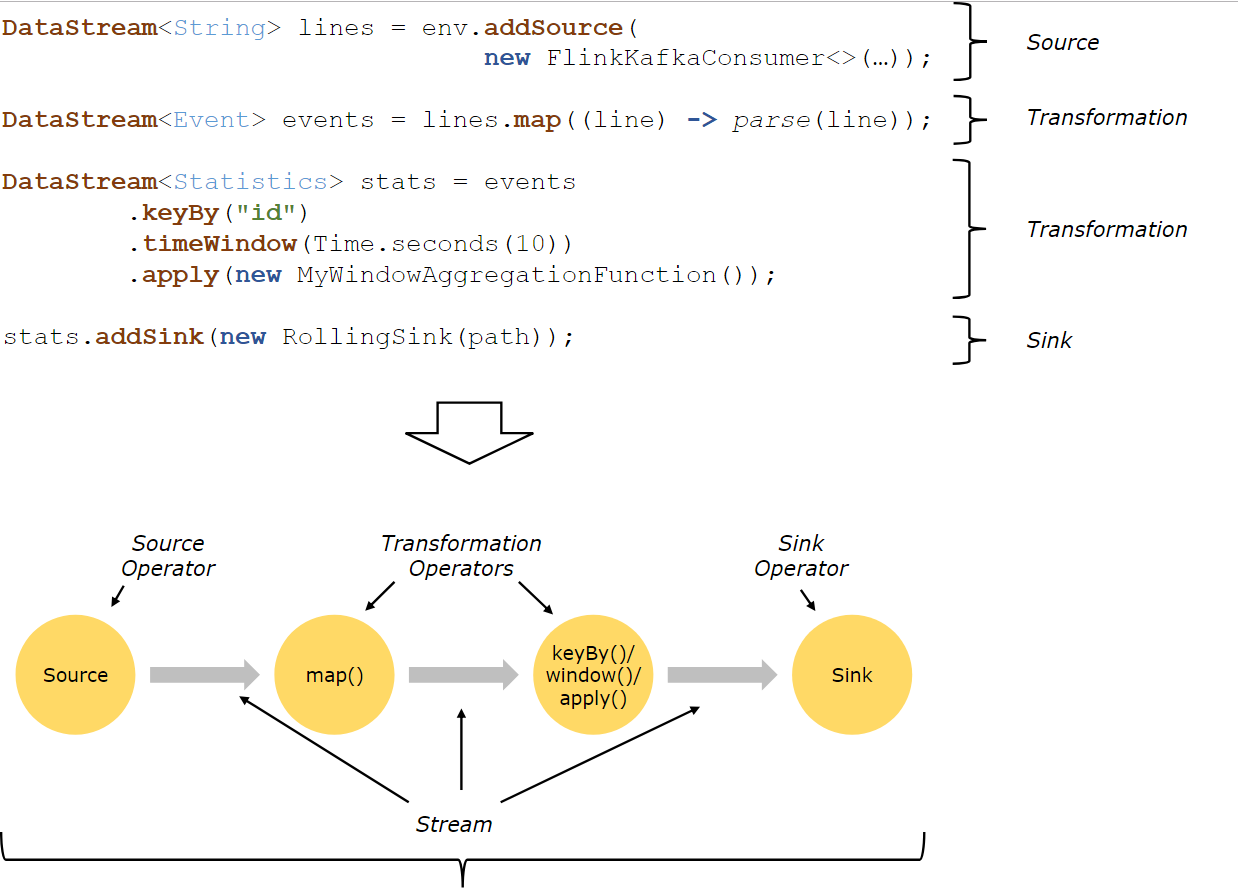
La estructura de la aplicación Flink se muestra en la figura anterior:
Fuente : fuente de datos, Flink tiene cuatro tipos de fuentes en el procesamiento de secuencias y el procesamiento por lotes: fuentes locales basadas en colecciones, fuentes basadas en archivos, fuentes basadas en sockets de red y fuentes personalizadas. Las fuentes personalizadas comunes incluyen Apache kafka, RabbitMQ, etc. Por supuesto, también puede definir su propia fuente.
Transformación : varias operaciones de transformación de datos, Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Selectetc. Hay muchas operaciones que pueden transformar los datos en los datos que desee.
Sumidero : Receptor, la ubicación donde Flink convertirá los datos calculados para enviarlos, es posible que deba almacenarlos. Los sumideros comunes de Flink se encuentran aproximadamente en las siguientes categorías: escribir en archivo, imprimir, escribir en socket y sumidero personalizado. Los sumideros personalizados comunes incluyen Apache kafka, RabbitMQ, MySQL, ElasticSearch, Apache Cassandra, Hadoop FileSystem, etc. De manera similar, también puede definir su propio sumidero.
2. Flink flujo de datos paralelo
Cuando se ejecuta un programa Flink, se asignará a un flujo de datos de transmisión.Un flujo de datos de transmisión se compone de un conjunto de flujos y operadores de transformación. Comienza con uno o más operadores de origen al inicio y termina con uno o más operadores de receptor.
Los programas de Flink son inherentemente paralelos y distribuidos.Durante la ejecución, un flujo (stream) contiene una o más particiones de flujo, y cada operador contiene una o más subtareas de operador. Las subtareas operativas son independientes entre sí, se ejecutan en diferentes subprocesos, o incluso en diferentes máquinas o diferentes contenedores. El número de subtareas del operador es el grado de paralelismo de este operador en particular. Diferentes operadores en el mismo programa tienen diferentes niveles de paralelismo.
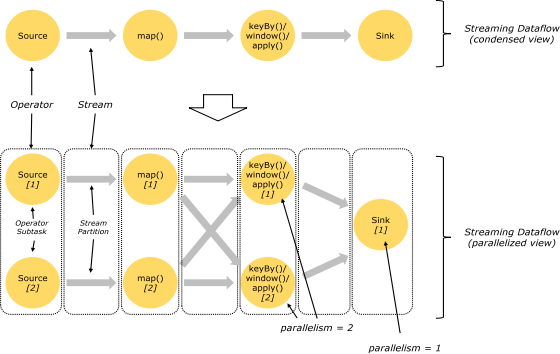
Un flujo se puede dividir en varias particiones de flujo, es decir, partición de flujo. Un Operador también se puede dividir en múltiples Subtareas de Operador. Como se muestra en la figura anterior, Source se divide en Source1 y Source2, que son las subtareas del operador de Source, respectivamente. Cada subtarea del operador se ejecuta de forma independiente en un subproceso diferente. El grado de paralelismo de un Operador es igual al número de Subtareas del Operador. El grado de paralelismo de la Fuente en la figura anterior es 2. El paralelismo de un Stream es igual al paralelismo del Operador que genera.
Hay dos modos cuando los datos se pasan entre dos operadores:
Modo uno a uno : cuando se pasan dos operadores en este modo, se mantendrá el número de particiones de datos y el orden de los datos; como se muestra en Source1 to Map1 en la figura anterior, conserva las características de partición de Source y el orden de sexo de procesamiento de elementos de partición.
Modo de redistribución : este modo cambiará la cantidad de particiones de datos; cada subtarea del operador enviará datos a diferentes subtareas de destino de acuerdo con la transformación seleccionada, como keyBy() volverá a particionar a través de hashcode, broadcast() y rebalance () método volver a particionar al azar;
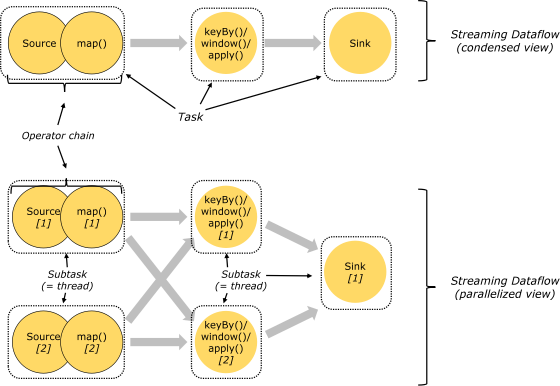
3. Cadena de tareas y operadores
Todas las operaciones de Flink se denominan operadores. El cliente optimizará los operadores al enviar tareas. Los operadores que se pueden fusionar se fusionarán en un solo operador. El operador fusionado se denomina cadena de operadores, que en realidad es una cadena de ejecución, cada cadena de ejecución ejecutarse en un subproceso separado en el Administrador de tareas.
4. Programación y ejecución de tareas
-
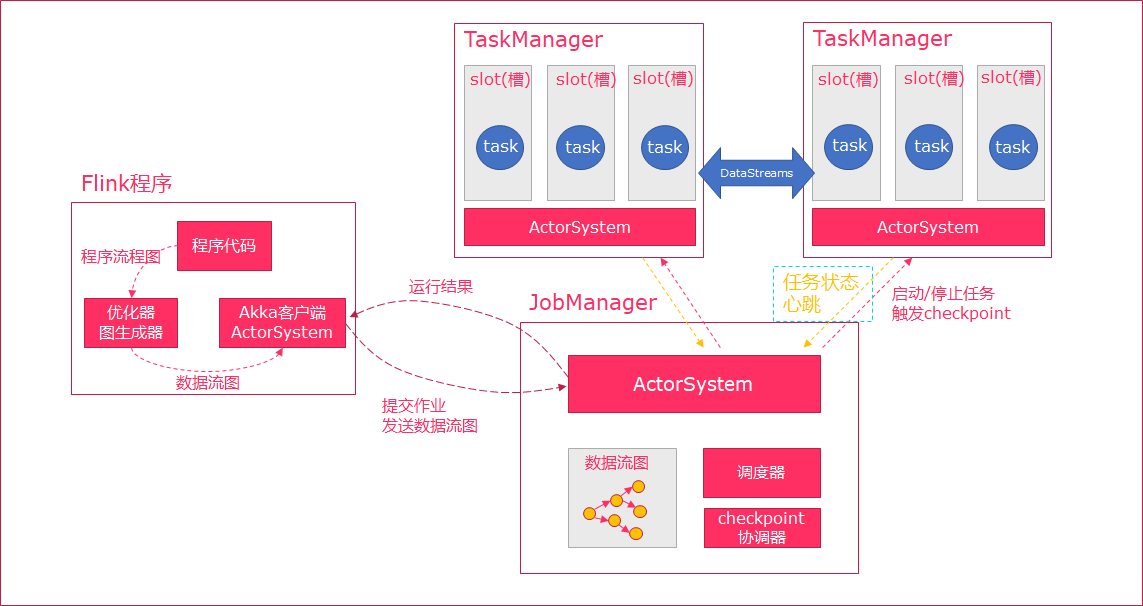
Cuando Flink ejecuta el ejecutor, generará automáticamente el diagrama de flujo de datos DAG de acuerdo con el código del programa;
-
ActorSystem crea Actor para enviar un gráfico de flujo de datos a Actor en JobManager;
-
JobManager continuará recibiendo los mensajes de latido del TaskManager, para que pueda obtener un TaskManager válido;
-
JobManager programa y ejecuta tareas en TaskManager a través del programador (en Flink, la unidad de programación más pequeña es una tarea, que corresponde a un hilo);
-
Durante la ejecución del programa, los datos se pueden transferir entre tareas.
Cliente de trabajo :
-
La principal responsabilidad es enviar la tarea.Después de enviar, el proceso se puede finalizar o se puede devolver el resultado;
-
Job Client no es una parte interna de la ejecución del programa Flink, pero es el punto de partida de la ejecución de tareas;
-
El cliente de trabajo es responsable de aceptar el código de programa del usuario, luego crea el flujo de datos y lo envía al administrador de trabajo para su posterior ejecución. Una vez completada la ejecución, Job Client devuelve el resultado al usuario.
Administrador de trabajos :
-
La responsabilidad principal es programar el trabajo y coordinar tareas para el control;
-
Debe haber al menos un maestro en el clúster.El maestro es responsable de programar tareas, coordinar puntos de control y tolerancia a fallas;
-
Para configuraciones de alta disponibilidad, puede haber varios maestros, pero asegúrese de que uno sea el líder y el otro el de reserva;
-
Job Manager contiene tres componentes importantes, Actor System, Scheduler y CheckPoint;
-
Después de que JobManager recibe la tarea del cliente, primero genera un plan de ejecución optimizado y luego lo programa en TaskManager para su ejecución.
Administrador de tareas :
-
La responsabilidad principal es recibir tareas de JobManager, implementar e iniciar tareas, recibir datos y procesos ascendentes;
-
Los administradores de tareas son nodos trabajadores que ejecutan tareas en uno o más subprocesos en la JVM;
-
TaskManager configura Slots al comienzo de la creación, y cada Slot puede ejecutar una tarea.
5. Ranuras de tareas y uso compartido de ranuras
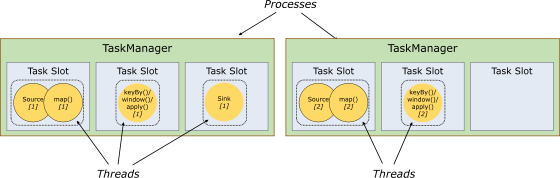
Cada TaskManager es un proceso JVM que puede ejecutar una o más subtareas en diferentes subprocesos. Con el fin de controlar cuántas tareas puede recibir un trabajador. Los trabajadores están controlados por espacios de tareas (un trabajador tiene al menos un espacio de tareas).
1) Ranura de tarea
Cada ranura de tarea representa un subconjunto de recursos de tamaño fijo propiedad del Administrador de tareas.
Flink divide la memoria del proceso en múltiples ranuras.
Hay 2 administradores de tareas en la figura, cada administrador de tareas tiene 3 ranuras y cada ranura ocupa 1/3 de la memoria.
Después de dividir la memoria en diferentes ranuras, se pueden obtener los siguientes beneficios:
-
Se puede controlar la cantidad máxima de tareas que TaskManager puede ejecutar simultáneamente al mismo tiempo, es decir, 3, porque no se puede exceder la cantidad de ranuras.
-
Las ranuras tienen espacio de memoria exclusivo, por lo que se pueden ejecutar varios trabajos diferentes en un Administrador de tareas y los trabajos no se ven afectados.
2) Compartir tragamonedas
De forma predeterminada, Flink permite que las subtareas compartan espacios, incluso si son subtareas de diferentes tareas, siempre que sean del mismo trabajo. El resultado es que una ranura puede contener toda la canalización de trabajos. Permitir compartir slots tiene dos beneficios principales:
-
Simplemente calcule la ranura de la tarea con el paralelismo más alto en el trabajo, siempre que esto se cumpla, también se pueden cumplir otros trabajos.
-
La asignación de recursos es más justa, y si hay un espacio libre, se le pueden asignar más tareas. Si no se comparten ranuras de tareas en la figura, las subtareas como Fuente/Mapa con carga baja ocuparán muchos recursos, mientras que las subtareas de ventana con carga alta carecerán de recursos.
-
Con el uso compartido de ranuras de tareas, el paralelismo base se puede aumentar de 2 a 6. Se mejora la utilización de los recursos ranurados. Al mismo tiempo, también puede garantizar que el esquema de ranuras asignado por TaskManager a las subtareas sea más justo.
