1. Conceptos básicos del perfecto
1. Introducción al Perfecto
Perfetto es una pila de código abierto de nivel de producción para mejorar la instrumentación de rendimiento y el análisis de seguimiento. A diferencia de Systrace, proporciona un superconjunto de fuentes de datos que pueden registrar rastros de longitud arbitraria en forma de flujos binarios codificados en protobuf. Perfetto puede entenderse como una versión mejorada de systrace, utilizada en plataformas actualizadas y nuevos gráficos para mostrar más información. Puede ayudar a los desarrolladores a recopilar información en ejecución de subsistemas clave de Android (como SurfaceFlinger/SystemServer/Input/Display y otros módulos clave de Framework, servicios, sistemas de visualización, etc.), ayudando así a los desarrolladores a analizar los cuellos de botella del sistema de manera más intuitiva y mejorar el rendimiento.
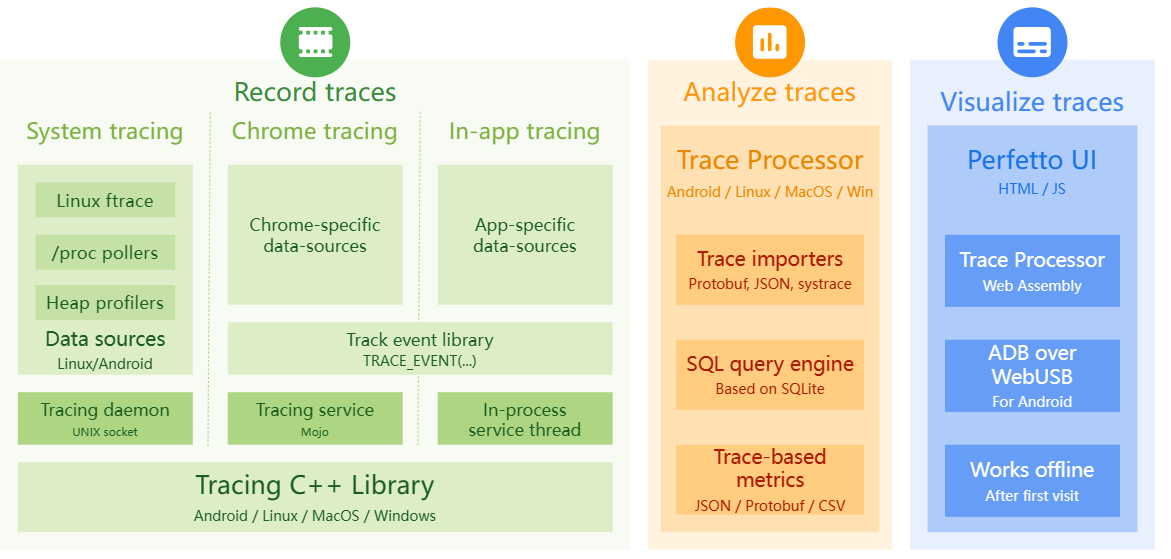
Sus funciones básicas incluyen las siguientes partes:
Para conocer la introducción oficial y el uso de Perfetto, puede consultar aquí: sitio web oficial de perfetto
2.Proceso de uso de Perfectto
Antes de usar Perfetto, primero debes comprender cómo usar Perfetto en cada plataforma. El proceso básico es el siguiente:
- Su teléfono está listo para la interfaz que desea rastrear.
- Haga clic para comenzar a rastrear (si usa la línea de comando, comienza a ejecutar el comando)
- Inicie la operación en su teléfono móvil (no tarde demasiado, el archivo se bloqueará si es demasiado grande y será difícil localizar el problema)
- Una vez transcurrido el tiempo establecido, se generará el archivo xxxtrace.html. Utilice el siguiente sitio web para abrir la interfaz de usuario de Perfetto.
Los archivos Perfetto generalmente capturados son los siguientes:
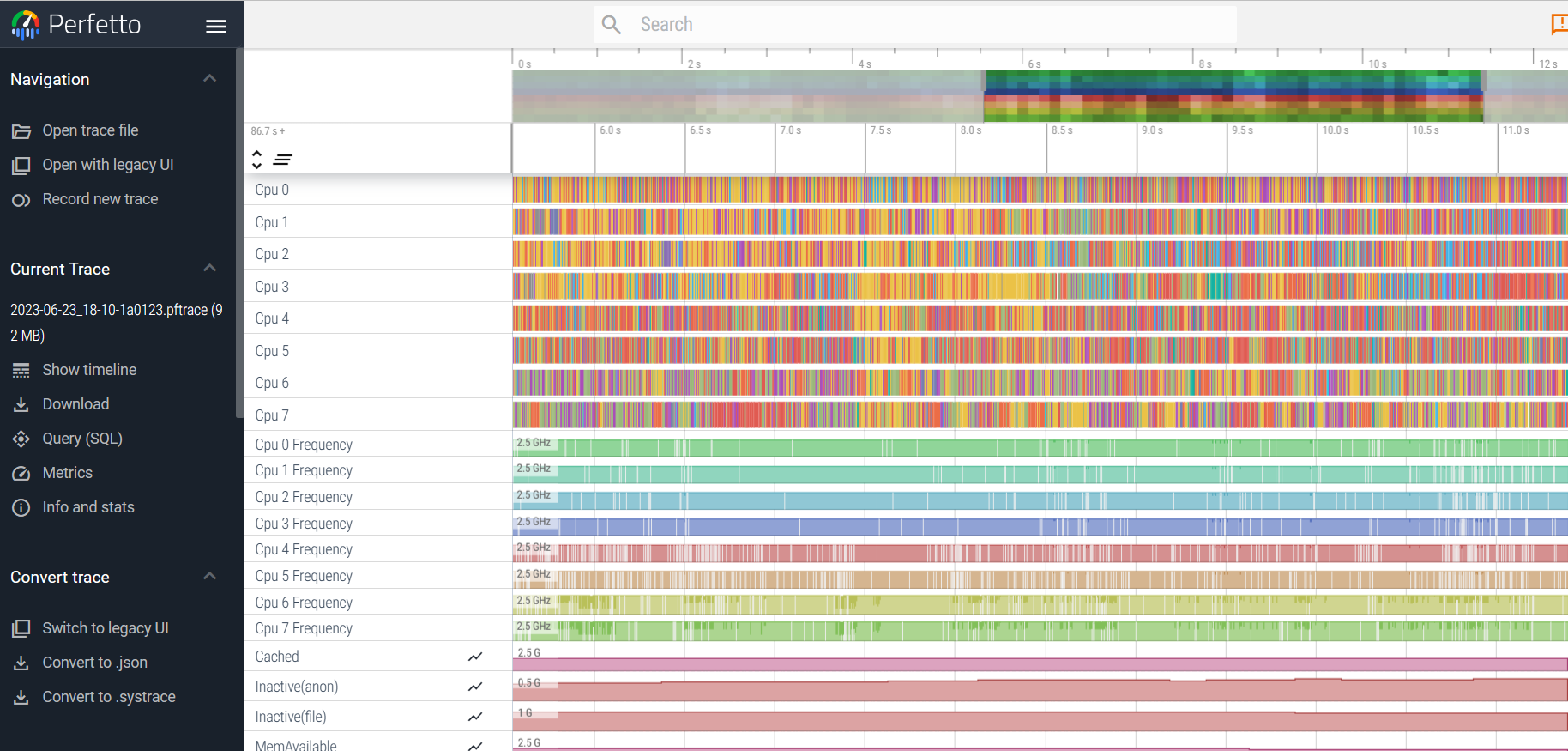
3. Varias formas de capturar Trace
3.1 Método de captura de comandos perfetto-traces
El formulario de línea de comando es más flexible y rápido. Después de configurar la TAG relevante una vez, los resultados se obtendrán rápidamente cuando se use nuevamente en el futuro. También puede escribir los comandos relevantes en un script, lo que será más conveniente para el próximo uso. .
Aunque hay muchos parámetros relacionados con el comando, no es necesario considerar tantos al usar la herramienta. Simplemente marque el elemento correspondiente. Solo agregará parámetros manualmente cuando use la línea de comando.
En términos generales, los más utilizados
- -o: indica la ruta y el nombre del archivo de salida
- -t: tiempo de recuperación (no es necesario especificar la última versión, presione Entrar para finalizar)
- -b: especifica el tamaño del búfer (generalmente, el búfer predeterminado es suficiente. Si desea capturar un Trae largo, se recomienda aumentar el búfer)
- -a: especifique el nombre del paquete de la aplicación (si desea depurar puntos de seguimiento personalizados, recuerde agregar esto)
Está desactivado de forma predeterminada en versiones inferiores a Android R. Primero debes ejecutar el comando para activarlo:
| adb shell setprop persist.traced.enable 1 |
El comando básico para capturar y exportar perfetto-traces es el siguiente. Si necesita otras etiquetas o comandos relacionados, puede agregarlos usted mismo:
Grab perfetton: adb shell perfetto -o /data/misc/perfetto-traces/trace_file.perfetto-trace -t 10s sched freq idle am wm gfx view binder_driver hal dalvik entrada de cámara res memoria exportar archivo de seguimiento: adb pull /data/misc / perfetto-traces/trace_file.perfetto-trace
3.2 Utilice el comando atrace para capturar systrace, el método específico es el siguiente:
Tome el comando atrace adb shell atrace -z -b 40000 am wm view res ss gfx view halbionic pm sched freq disco inactivo carga sincronización binder_driver binder_lock memreclaim dalvik input -t 10 > /data/local/tmp/trace_output.atrace pull export trace file adb pull /data/local/tmp/trace_output.atrace
3.3 Utilice el script systrace para capturar systrace, el método específico es el siguiente:
1. Es necesario configurar el entorno Python.
2. Descomprima systrace.zip.
Ingrese al directorio systrace descomprimido, el archivo systrace.py se puede encontrar en el directorio y ejecute el siguiente comando:
python systrace.py am wm view res ss gfx rs hal bionic pm sched freq disco inactivo binder_driver binder_lock memreclaim dalvik base de datos de entrada -t 10 -o tracelog\systrace.html
Busque el archivo systrace.html generado en el directorio tracelog en el directorio systrace.
3.4 Captura mediante System Tracing en el teléfono móvil
1. Abra "Opciones de desarrollador", haga clic en Configuración->Sistema->Opciones de desarrollador->Seguimiento del sistema->Mostrar mosaico de Configuración rápida y agregue el icono de acceso directo de seguimiento del sistema.
Establezca las categorías (Categorías) y el tamaño del búfer (Tamaño del búfer) que se registrarán en Configuración - Sistema - Opciones de desarrollador - Seguimiento del sistema (diferentes software pueden tener diferentes rutas)
Abra [Grabar seguimiento] para comenzar a grabar
Después de que aparezca la notificación, puede comenzar a reproducir el problema o realizar operaciones específicas.
Una vez completado, haga clic en [Toque para detener el seguimiento] en la barra de notificaciones para detener y guardar.
2. Antes de realizar la prueba, haga clic en el ícono Registrar seguimiento en la barra de estado desplegable para comenzar a capturar perfetto-trace y luego comenzar a probar.
3. Después de completar la prueba, haga clic en "Desplegar el ícono de seguimiento de registros en la barra de estado " o "Desplegar la notificación de recuperación en la barra de estado" para detener la recuperación de systrace.
4. Después de que aparezca la notificación "rastreo guardado", el archivo perfetto-trace capturado se puede obtener en el directorio del teléfono móvil /data/local/traces .
5. Guarde la ruta del sistema correspondiente localmente mediante el comando adb pull /data/local/traces .
4. Verificar el estado del hilo
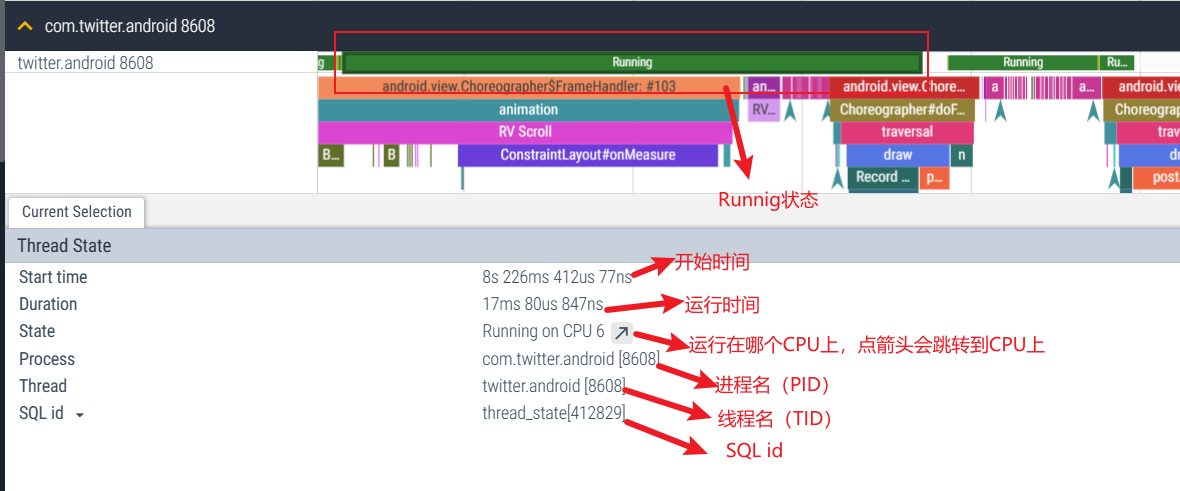
Perfetto usará diferentes colores para identificar diferentes estados de subproceso. Habrá un estado de subproceso correspondiente en cada método para identificar el estado actual del subproceso. Al observar el estado del subproceso, podemos saber cuál es el cuello de botella actual, que es una CPU lenta. ejecución ¿Se debe a llamadas de Binder, operaciones de io o fallas al obtener intervalos de tiempo de la CPU?
El estado del hilo incluye principalmente lo siguiente:
4.1 Verde: corriendo
Sólo los subprocesos en este estado pueden ejecutarse en la CPU. Puede haber varios subprocesos en estado ejecutable al mismo tiempo, y las estructuras task_struct de estos subprocesos se colocan en la cola ejecutable de la CPU correspondiente (un subproceso solo puede aparecer en la cola ejecutable de una CPU como máximo). La tarea del programador es seleccionar un subproceso de la cola ejecutable de cada CPU para ejecutarlo en esa CPU.
Función: a menudo verificamos el estado de ejecución del hilo, verificamos su tiempo de ejecución, lo comparamos con productos de la competencia y analizamos las razones de la velocidad rápida o lenta:
- ¿La frecuencia no es suficiente?
- ¿Se ejecuta en el núcleo pequeño?
- ¿Cambias frecuentemente entre Running y Runnable? ¿Por qué?
- ¿Cambias frecuentemente entre correr y dormir? ¿Por qué?
- ¿Se está ejecutando en un núcleo que no debería ejecutarse? Por ejemplo, los subprocesos sin importancia ocupan un núcleo grande.
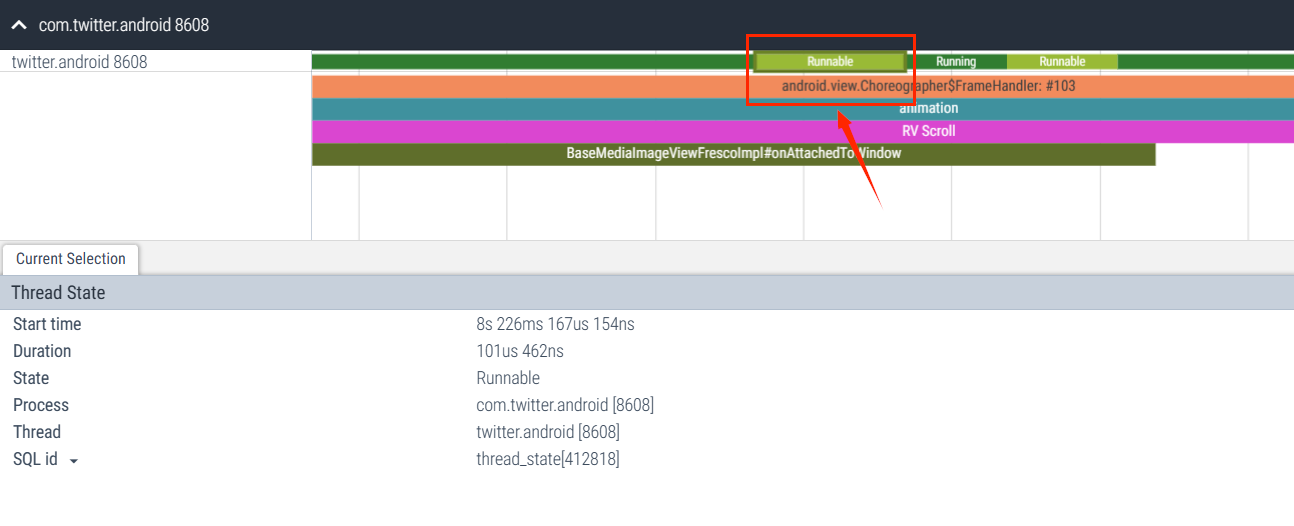
4.2 Azul: Ejecutable
El subproceso se puede ejecutar pero no está programado actualmente y está esperando la programación de la CPU.
Función: cuanto más dura el estado del subproceso en el estado Ejecutable, más ocupada estará la CPU y la tarea no se procesará a tiempo:
- ¿Hay demasiadas tareas ejecutándose en segundo plano?
- ¿No se procesa a tiempo porque la frecuencia es demasiado baja?
- ¿No se procesa a tiempo porque está restringido a un determinado conjunto de CPU, pero la CPU está muy llena?
- ¿Cuál es la tarea de Correr en este momento? ¿Por qué?
4.3 Blanco: Dormir
El hilo no tiene trabajo que hacer. Puede deberse a que el hilo está bloqueado en el bloqueo mutex o puede estar esperando que regrese un hilo. Puede verificar quién lo despertó para ver qué hilo está esperando.
Función: generalmente espera que se produzcan eventos.
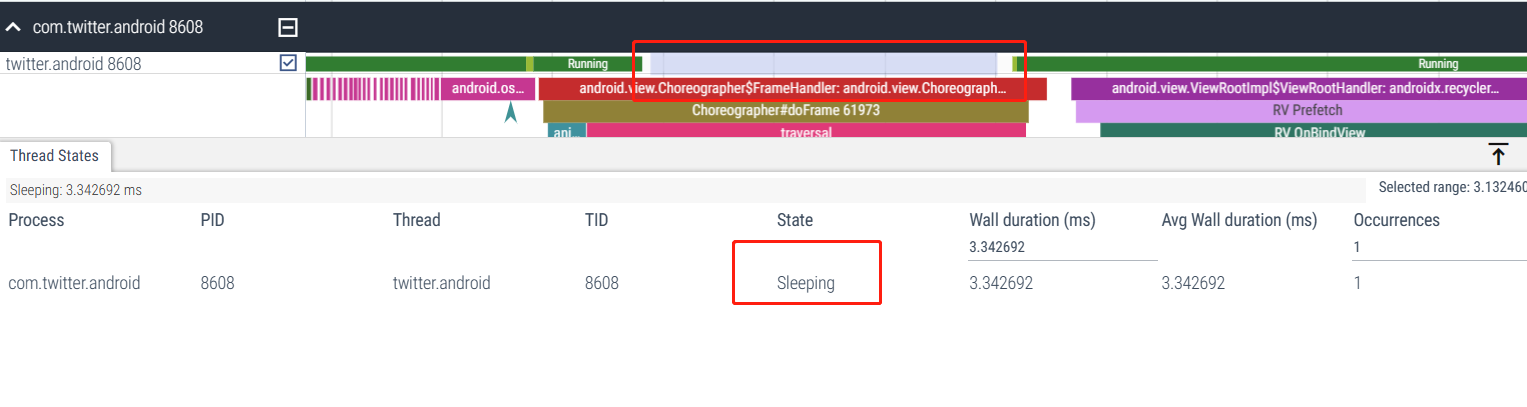
4.4 Naranja: Suspensión ininterrumpida - Bloqueo IO
El hilo está bloqueado en E/S o esperando a que se complete la operación del disco. Generalmente, la línea inferior identificará el sitio de llamada en este momento: wait_on_page_locked_killable
Función: Esto generalmente indica que la operación IO es lenta. Si hay una gran cantidad de estados de suspensión ininterrumpida de color naranja, generalmente se debe a que se ingresa a un estado de memoria baja. PageFault se activa cuando se solicita memoria. Esto a veces aparece en el caché de la página. Lista vinculada del sistema Linux. Algunas páginas aún no están listas (es decir, el contenido del disco no se ha leído por completo), y en este momento cuando el usuario accede a esta página, se bloqueará wait_on_page_locked_killable. Solo cuando el El sistema está ocupado con operaciones de io, cada transacción Cuando todas las operaciones de io deben ponerse en cola, es extremadamente fácil que ocurra y el tiempo de bloqueo suele ser relativamente largo.
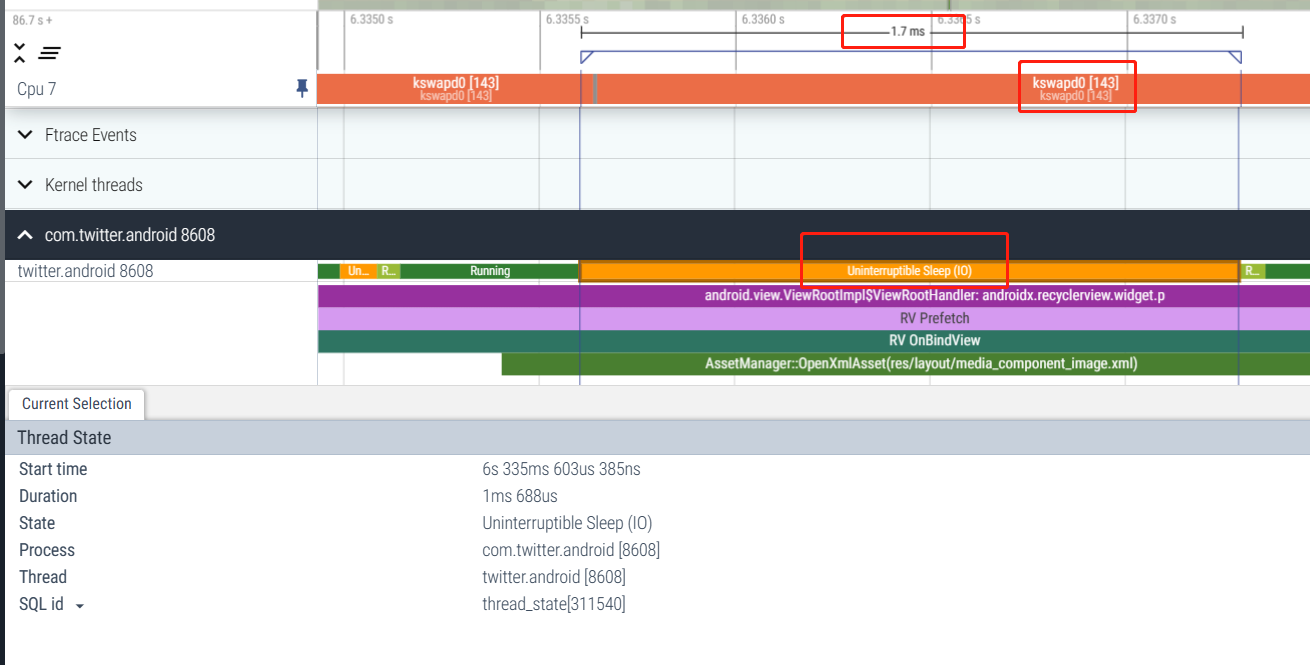
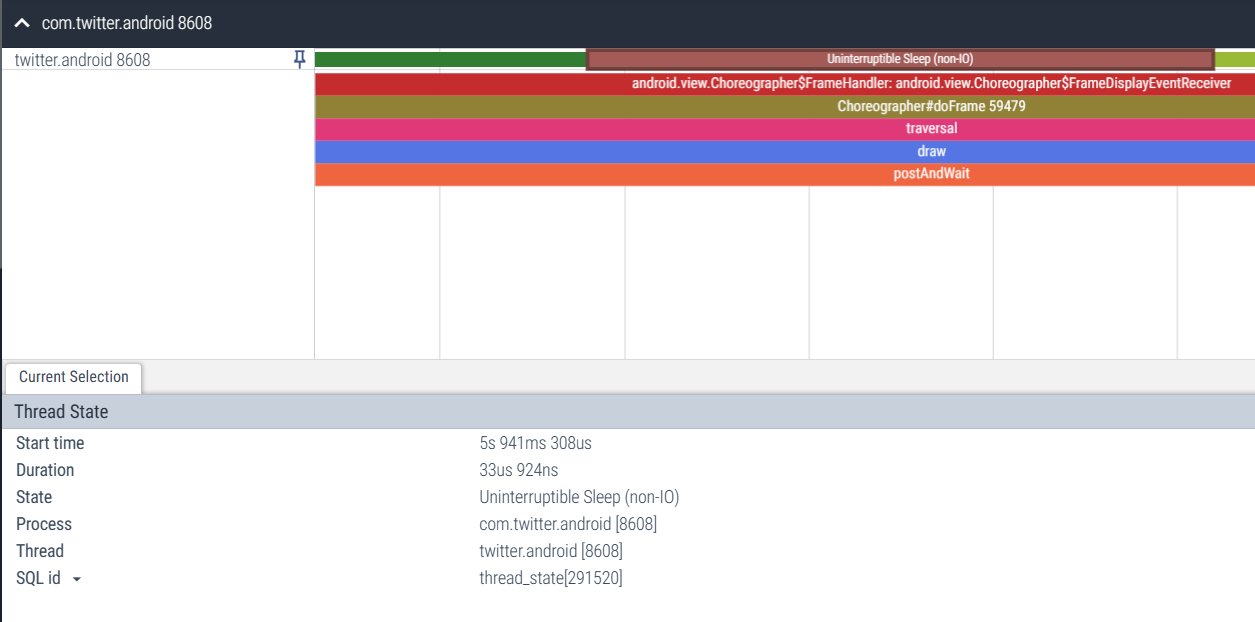
4.5 Marrón: suspensión ininterrumpida (no IO)
El hilo está bloqueado en otra operación del kernel (normalmente gestión de memoria).
Función: Generalmente cae en el estado kernel, en algunos casos es normal y en otros casos es anormal, es necesario analizarlo según la situación específica.
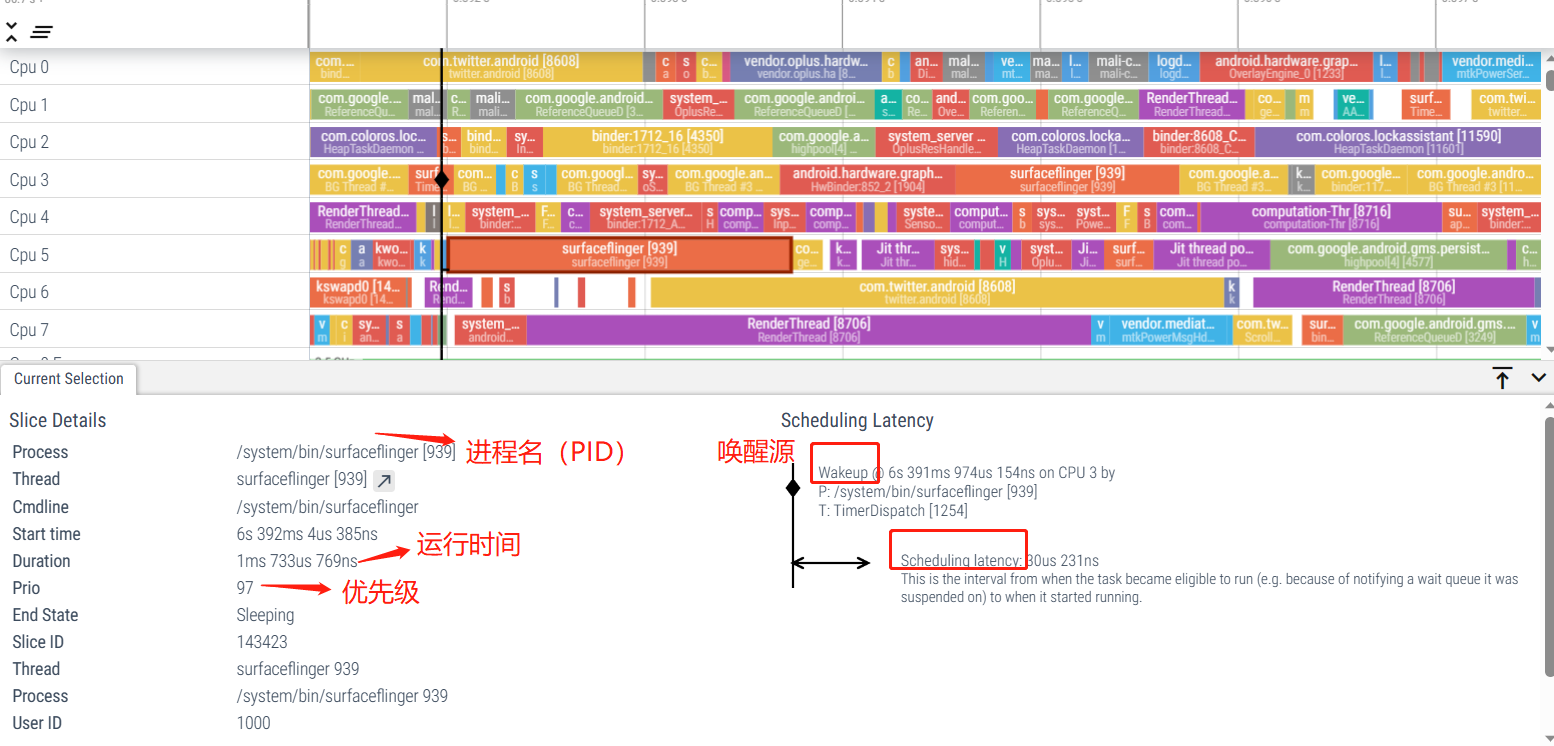
5. Análisis de información de activación de tareas.
Perfetto identificará información muy útil que puede ayudarnos a analizar las esperas de llamadas de subprocesos.
La información sobre el despertar de un hilo suele ser más importante. Si sabemos quién lo despertó, también conoceremos la relación de llamada en espera entre ellos. Si un hilo tiene una situación de suspensión relativamente larga y luego se despierta, entonces podemos Para ver quién despertó en este hilo, puede verificar la información del despertador y ver por qué se despertó tan tarde.
Una situación común es: el hilo principal de la aplicación usa Binder para comunicarse con el AMS de SystemServer, pero esta función de AMS está esperando que se libere el bloqueo (o la función en sí tarda mucho en ejecutarse), entonces el hilo principal de la aplicación necesita Si espera un tiempo relativamente largo, se producirán problemas de rendimiento, como respuestas lentas o retrasos. Esta es una de las razones principales por las que hay una gran cantidad de procesos ejecutándose en segundo plano o el rendimiento general de la máquina disminuirá después Mono corriendo.
Otro escenario es: el subproceso principal de la aplicación está esperando los resultados de ejecución de otros subprocesos de la aplicación. En este momento, la información de activación del subproceso se puede utilizar para analizar qué subproceso está bloqueado por el subproceso principal, como se muestra en el siguiente escenario:
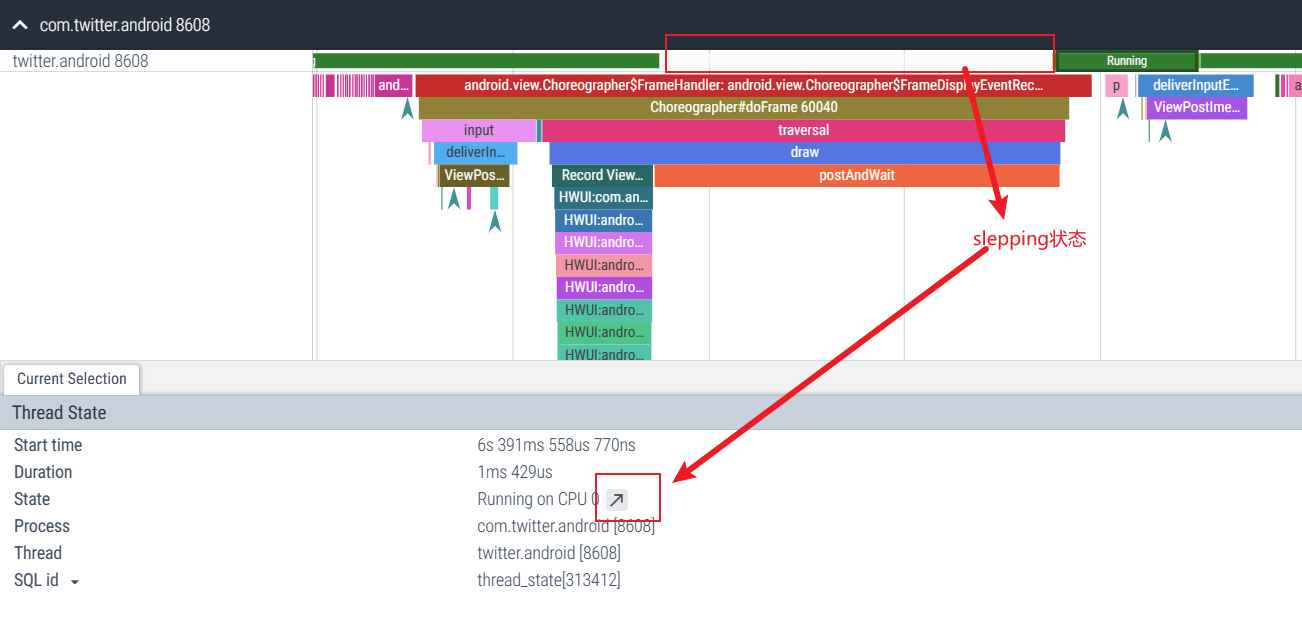
Podemos ver el estado de suspensión durante este período. Podemos hacer clic en el estado Runnig en la parte posterior para ver en qué CPU se está ejecutando. Después de hacer clic, podemos ver qué hilo lo despertó y ver si hay alguna anomalía.
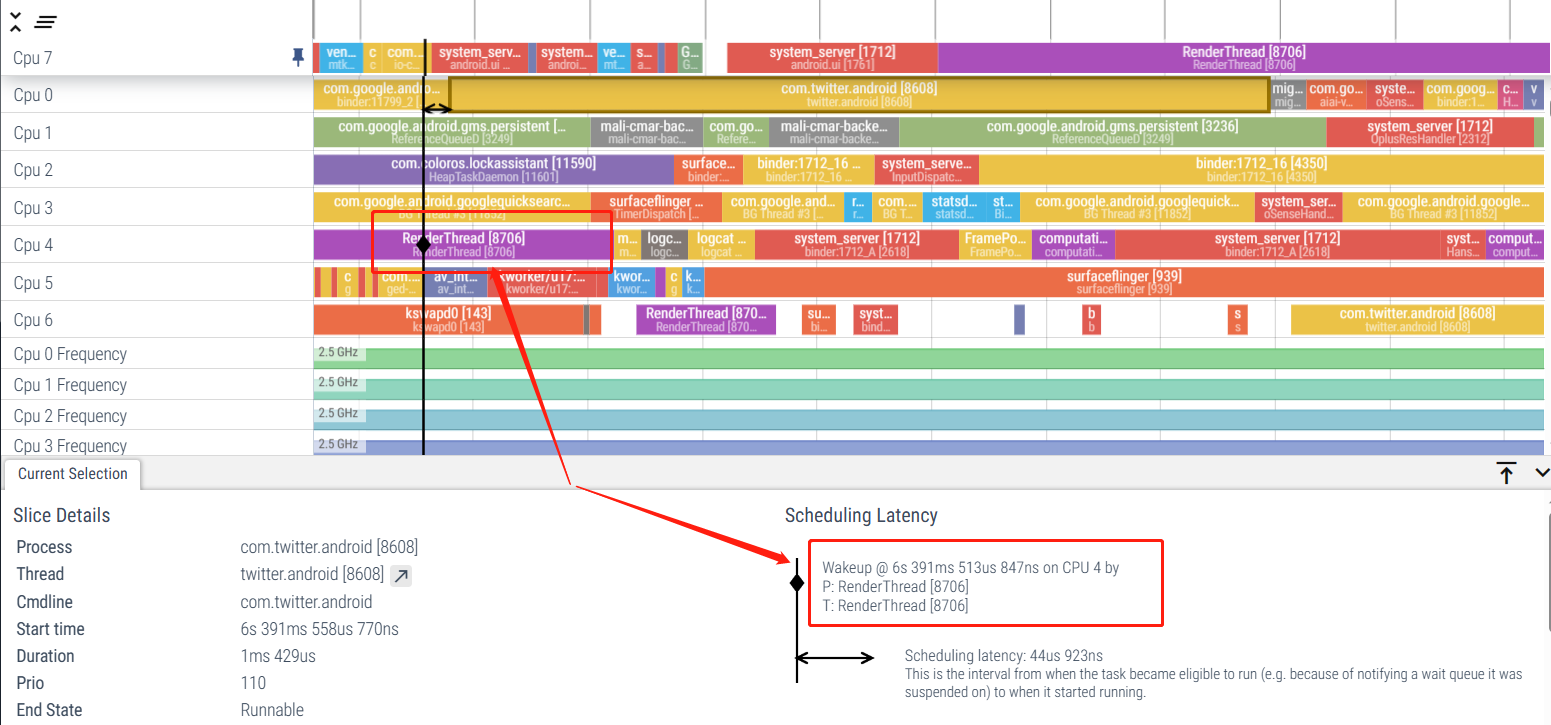
6. Análisis de datos del área de información.
6.1 arquitectura de la CPU
En pocas palabras, las CPU de teléfonos móviles actuales se pueden dividir en las siguientes tres categorías según la cantidad de núcleos y la arquitectura:
- Arquitectura de núcleos pequeños y no grandes (normal, por lo que los núcleos son iguales)
- Arquitectura de núcleos grandes y pequeños (normalmente de 0 a 3 núcleos pequeños, de 4 a 7 núcleos grandes)
- Arquitectura de núcleos grandes, medianos y pequeños (normal 0-3 núcleos pequeños, 4-6 núcleos medianos, 7 núcleos súper grandes)
6.2 Información de la CPU
La información de información de la CPU en Pefetto suele estar en la parte superior y la información que se utiliza a menudo incluye:
- Cambios de frecuencia de la CPU
- Estado de ejecución de la tarea
- Programación de núcleos grandes y pequeños.
- Estado de programación de aumento de CPU
En general, Kernel CPU Info en Systrace generalmente analiza la información de programación de tareas para ver si la frecuencia o la programación están causando problemas de rendimiento en la tarea actual. Los ejemplos son los siguientes:
- Si la ejecución de la tarea de una determinada escena es relativamente lenta, ¿podemos verificar si la tarea está programada para el núcleo pequeño?
- La ejecución de la tarea de una determinada escena es relativamente lenta, ¿es insuficiente la frecuencia actual de la CPU para ejecutar esta tarea?
- Mi tarea es bastante especial, ¿puedo ejecutarla en el núcleo grande?
- Mi escena tiene altos requisitos de CPU. ¿Puedo solicitar limitar la frecuencia mínima de CPU cuando mi escena se está ejecutando?
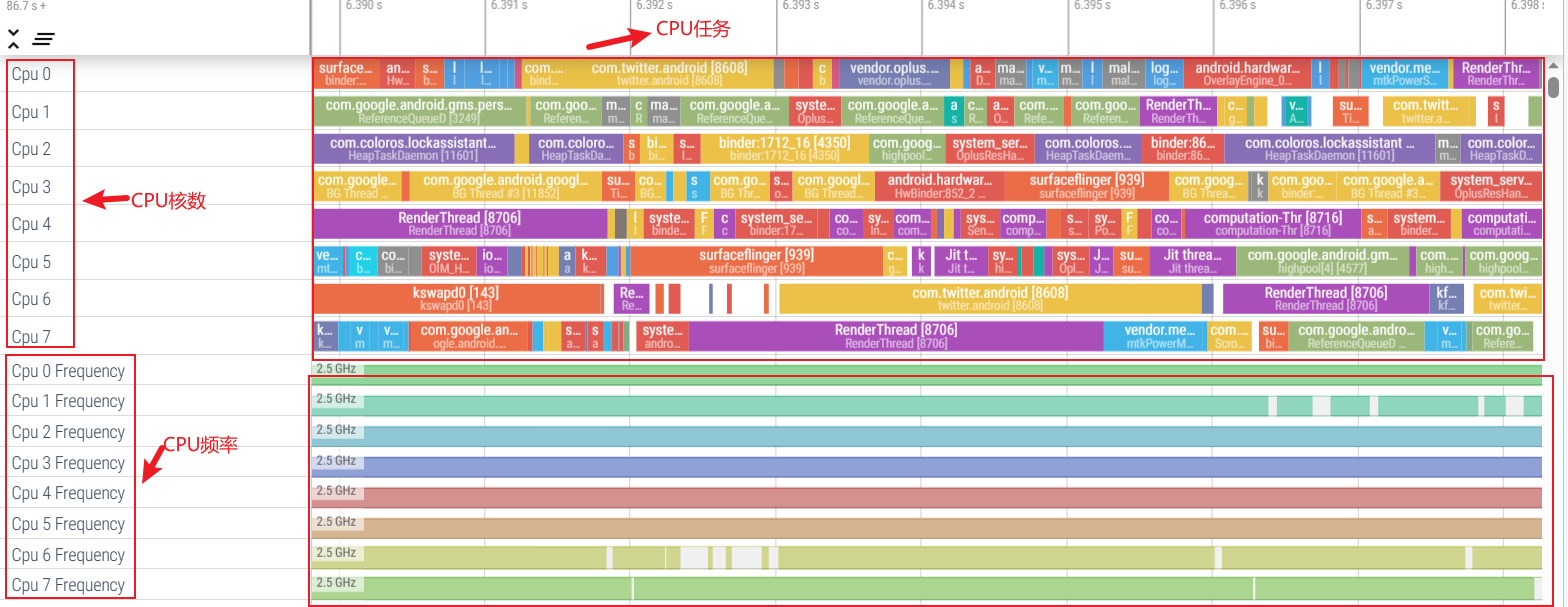
6.3 Análisis de información de selección actual:
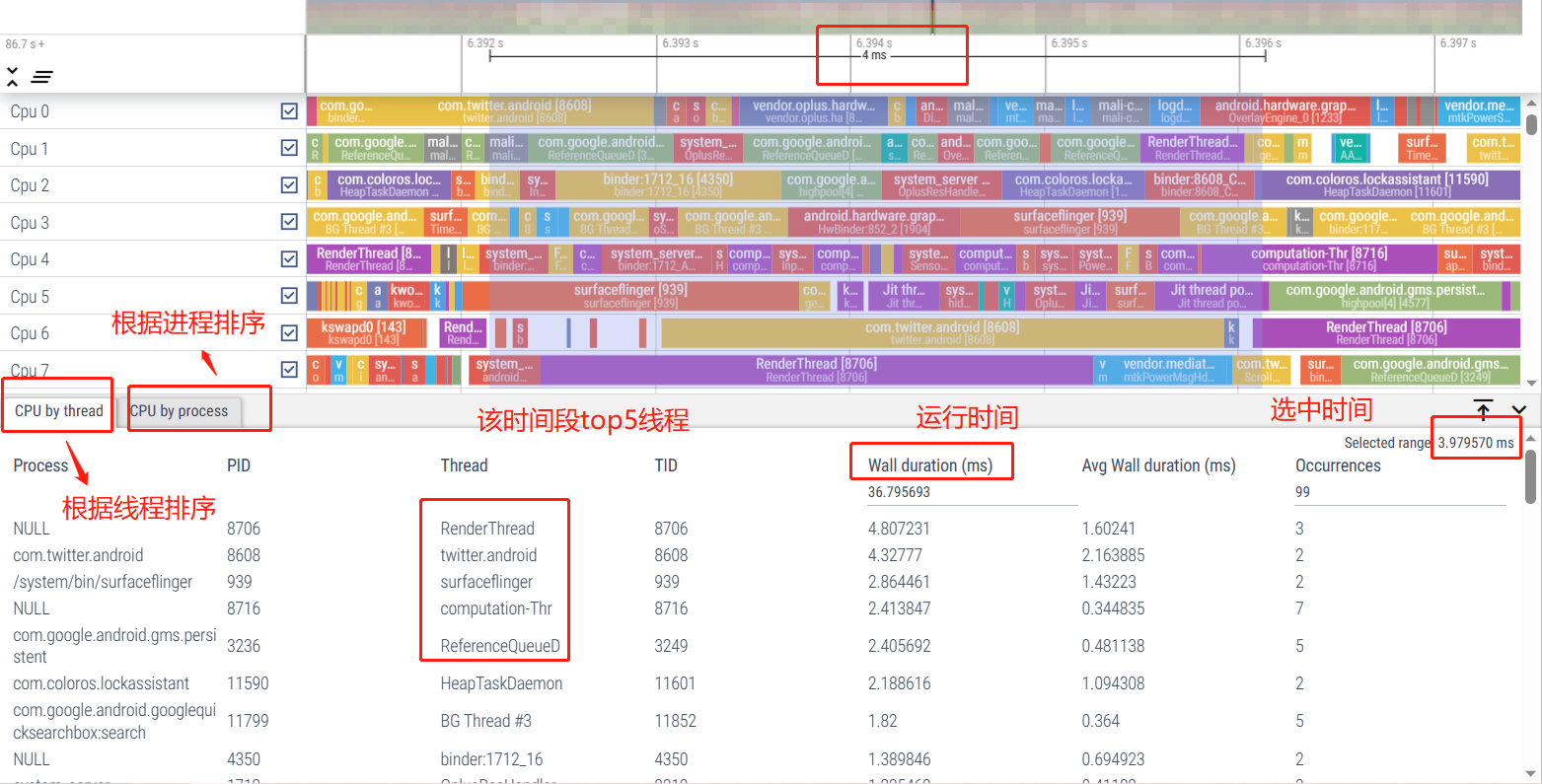
6.4 CPU por análisis de información de subprocesos
7. Uso de teclas de acceso directo
El uso de teclas de método abreviado puede acelerar la visualización de Perfetto. Las siguientes son algunas teclas de método abreviado de uso común.
W : Acercar Perfetto, acercar para ver mejor los detalles locales
S : Alejar en Perfetto, alejar para ver todo
A : Mover hacia la izquierda
D : Mover hacia la derecha
M : Seleccionar el rango del período de tiempo para una fácil visualización hacia arriba y hacia abajo
El cuadro de búsqueda que viene con pefetto requiere más de 4 caracteres. Los datos encontrados serán más detallados y se pueden usar con Ctrl+F. A veces Ctrl+F no puede buscar los datos que vienen con el cuadro de búsqueda.

8. ¿Qué es la frecuencia de actualización?
- 60 fps significa que la imagen se actualiza 60 veces por segundo, lo cual es para software
- Estas 60 actualizaciones deben actualizarse de manera uniforme, lo que no significa que una sea rápida y la otra lenta, de lo contrario no se sentirá fluido visualmente.
- 60 veces por segundo, que es 1/60 ~= 16,67 ms para actualizar una vez
- La frecuencia de actualización de la pantalla mencionada aquí es específica del hardware. Hoy en día, la frecuencia de actualización de la mayoría de las pantallas de los teléfonos móviles se mantiene en 60 HZ. Los dispositivos móviles generalmente usan 60 HZ porque los dispositivos móviles tienen mayores requisitos de consumo de energía y mejoran el teléfono móvil. pantalla.La frecuencia de actualización, para los teléfonos móviles, el consumo de energía lógica aumentará linealmente con el aumento de la frecuencia. Al mismo tiempo, una frecuencia de actualización más alta significa un tiempo de escritura de datos TFT más corto, lo cual es más difícil para el diseño de la pantalla.
2. Hilo principal y hilo de renderizado.
1. Creación del hilo principal.
El proceso de la aplicación de Android se basa en Linux y su gestión también se basa en el mecanismo de gestión de procesos de Linux, por lo que su creación también llama a la función fork.
marcos/base/core/jni/com_android_internal_os_Zygote.cpp
| 1 |
pid_t pid = bifurcación(); |
Podemos considerar el proceso que sale de la bifurcación como el hilo principal aquí, pero este hilo aún no se ha conectado a Android, por lo que no puede procesar el mensaje de la aplicación de Android; dado que el hilo de la aplicación de Android se ejecuta según el mecanismo de mensajes, el hilo principal que sale de la bifurcación debe ser el enlace de mensajes de mensajes de Android que puede manejar varios mensajes de la aplicación de Android.
Aquí se presenta ActivityThread . Para ser precisos, ActivityThread debería llamarse ProcessThread de manera más apropiada. ActivityThread conecta el proceso desde la bifurcación y el mensaje de la aplicación. Su cooperación forma el hilo principal de la aplicación de Android tal como la conocemos. Por lo tanto, ActivityThread no es en realidad un subproceso, pero inicializa MessageQueue, Looper y Handler requeridos por el mecanismo de mensajes, y su controlador es responsable de procesar la mayoría de los mensajes de mensajes, por lo que estamos acostumbrados a pensar que ActivityThread es el hilo principal. pero en realidad es sólo el hilo principal, una unidad de procesamiento lógico.
1.1 Creación de ActivityThread
Después de que el proceso de la aplicación se bifurque, regrese al proceso de la aplicación y busque la función principal de ActivityThread
es/android/internal/os/ZygoteInit.java
| 1 |
static final Runnable childZygoteInit( |
La startClass aquí es ActivityThread. Después de encontrarla y llamarla, la lógica alcanza la función principal de ActivityThread.
android/app/ActivityThread.java
| 1 |
public static void main(String[] args) { //1. Inicializar Looper, MessageQueue Looper.prepareMainLooper(); // 2. Inicializar ActivityThread ActivityThread thread = new ActivityThread(); // 3. Llamar principalmente a AMS.attachApplicationLocked, sincronizar procesar información y realizar algún trabajo de inicialización thread.attach(false, startSeq); // 4. Obtenga el controlador del hilo principal, aquí está H. Básicamente, el mensaje de la aplicación se procesará en este controlador si (sMainThreadHandler == null) { sMainThreadHandler = thread.getHandler(); } // 5. La inicialización está completa, Looper comienza a funcionar Looper.loop(); }
|
Una vez procesada la función principal, el hilo principal está oficialmente en línea y comienza a funcionar. El proceso de Perfetto es el siguiente:

1.2 Funciones de ActivityThread
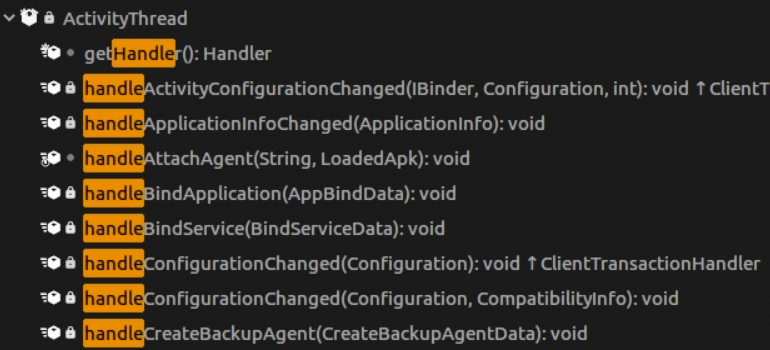
Además, a menudo decimos que los cuatro componentes principales de Android se ejecutan en el hilo principal. De hecho, es fácil de entender aquí: solo mire el mensaje del controlador de ActivityThread.
| 1 |
clase H extiende Handler { //摘抄了部分 |
Como puede ver, la creación de procesos, el inicio de la actividad, la administración de servicios, la administración de receptores y la administración de proveedores se manejarán aquí y luego irán al identificador específicoXXX.
2. Creación y desarrollo de hilos de renderizado.
Ahora que hemos terminado de hablar sobre el hilo principal, hablemos sobre el hilo de renderizado. El hilo de renderizado también es RenderThread. No hay hilo de renderizado en la versión original de Android. Todo el trabajo de renderizado se realiza en el hilo principal, usando la CPU. y llamando a la biblioteca libSkia. RenderThread es un componente recién agregado en Android Lollipop, responsable de participar en el trabajo de renderizado del hilo principal anterior y reducir la carga del hilo principal.
2.1 Dibujo de software
La aceleración de hardware a la que generalmente nos referimos se refiere a la aceleración de GPU, que puede entenderse como el uso de RenderThread para llamar a la GPU para acelerar el renderizado. La aceleración de hardware está activada de forma predeterminada en Android actual, por lo que si no configuramos nada, nuestro proceso tendrá el hilo principal y el hilo de representación (con contenido visible) de forma predeterminada. Si agregamos un
| 1 |
android:hardwareAccelerated="falso" |
Podemos desactivar la aceleración de hardware. Cuando el sistema detecta que su aplicación ha desactivado la aceleración de hardware, no inicializará RenderThread. Solo existe el hilo principal y no hay hilo de renderizado. La CPU llama directamente a libSkia para renderizar.
Dado que el hilo principal tiene que realizar el trabajo de renderizado, el tiempo de ejecución se vuelve más largo y es más propenso a congelarse. Al mismo tiempo, el intervalo de inactividad entre cuadros también se acorta, lo que hace que el tiempo de ejecución de otros mensajes se comprima.
2.2 Dibujo acelerado por hardware
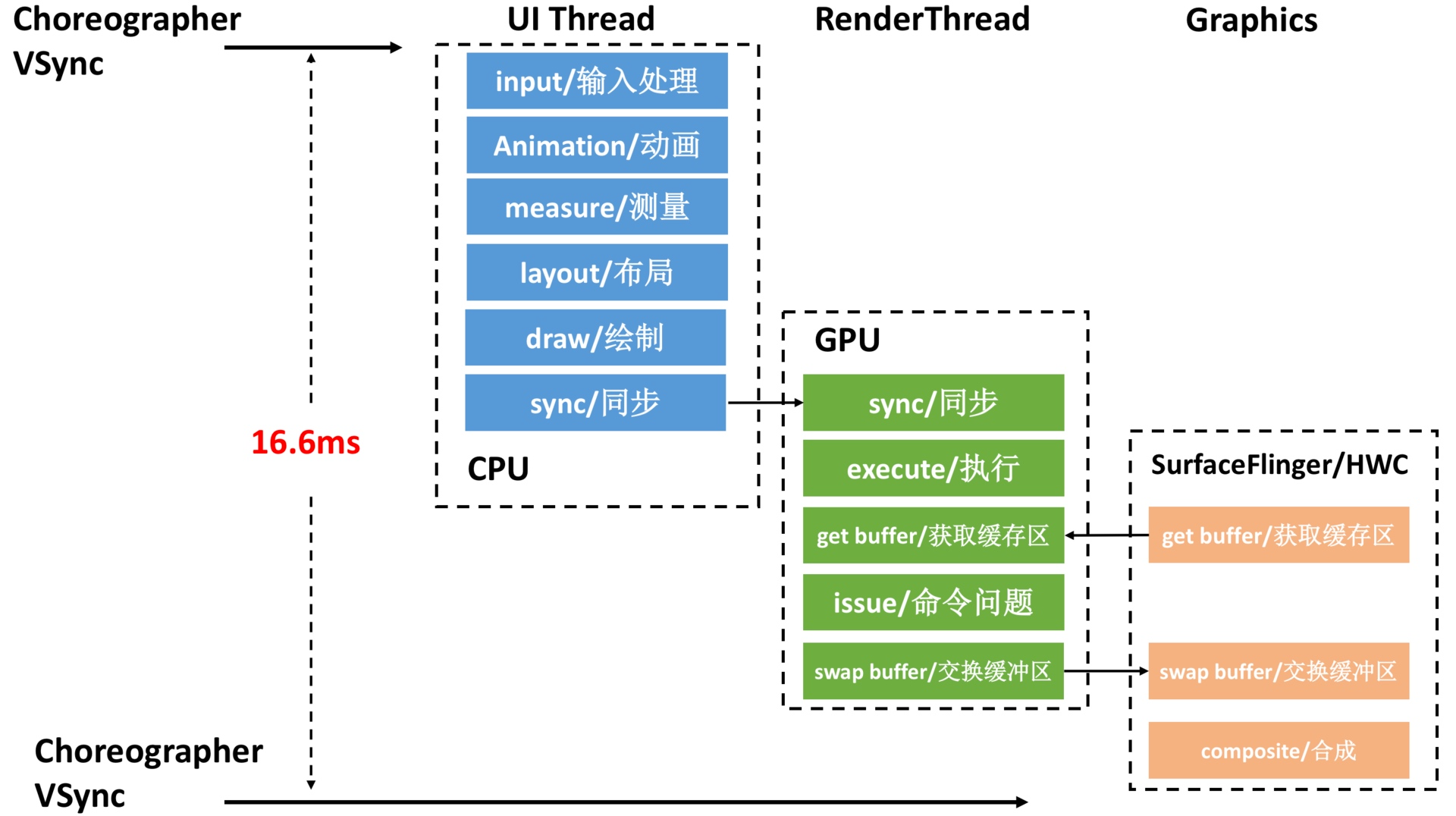
正常情况下,硬件加速是开启的,主线程的 draw 函数并没有真正的执行 drawCall ,而是把要 draw 的内容记录到 DIsplayList 里面,同步到 RenderThread 中,一旦同步完成,主线程就可以被释放出来做其他的事情,RenderThread 则继续进行渲染工作
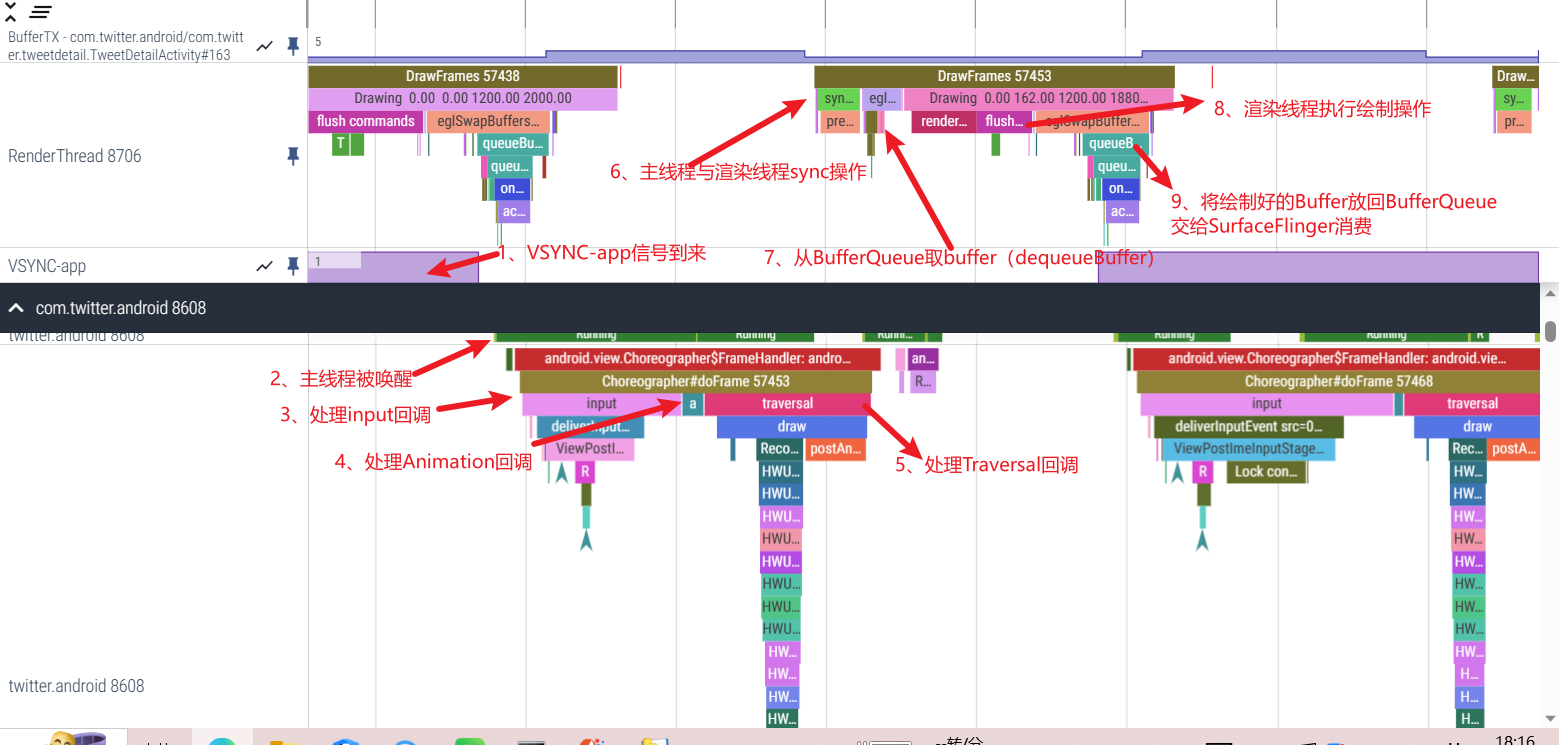
主线程和渲染线程一帧的工作流程(每一帧都会遵循这个流程,不过有的帧需要处理的事情多,有的帧需要处理的事情少) ,重点看 “UI Thread ” 和 RenderThread 这两行
这张图对应的工作流程如下
- 主线程处于 Sleep 状态,等待 Vsync 信号
- Vsync 信号到来,主线程被唤醒,Choreographer 回调 FrameDisplayEventReceiver.onVsync 开始一帧的绘制
- 处理 App 这一帧的 Input 事件(如果有的话)
- 处理 App 这一帧的 Animation 事件(如果有的话)
- 处理 App 这一帧的 Traversal 事件(如果有的话)
- 主线程与渲染线程同步渲染数据,同步结束后,主线程结束一帧的绘制,可以继续处理下一个 Message(如果有的话,IdleHandler 如果不为空,这时候也会触发处理),或者进入 Sleep 状态等待下一个 Vsync
- 渲染线程首先需要从 BufferQueue 里面取一个 Buffer(dequeueBuffer) , 进行数据处理之后,调用 OpenGL 相关的函数,真正地进行渲染操作,然后将这个渲染好的 Buffer 还给 BufferQueue (queueBuffer) , SurfaceFlinger 在 Vsync-SF 到了之后,将所有准备好的 Buffer 取出进行合成(这个流程在下面的SurfaceFlinger会讲解)
2.3 渲染线程初始化
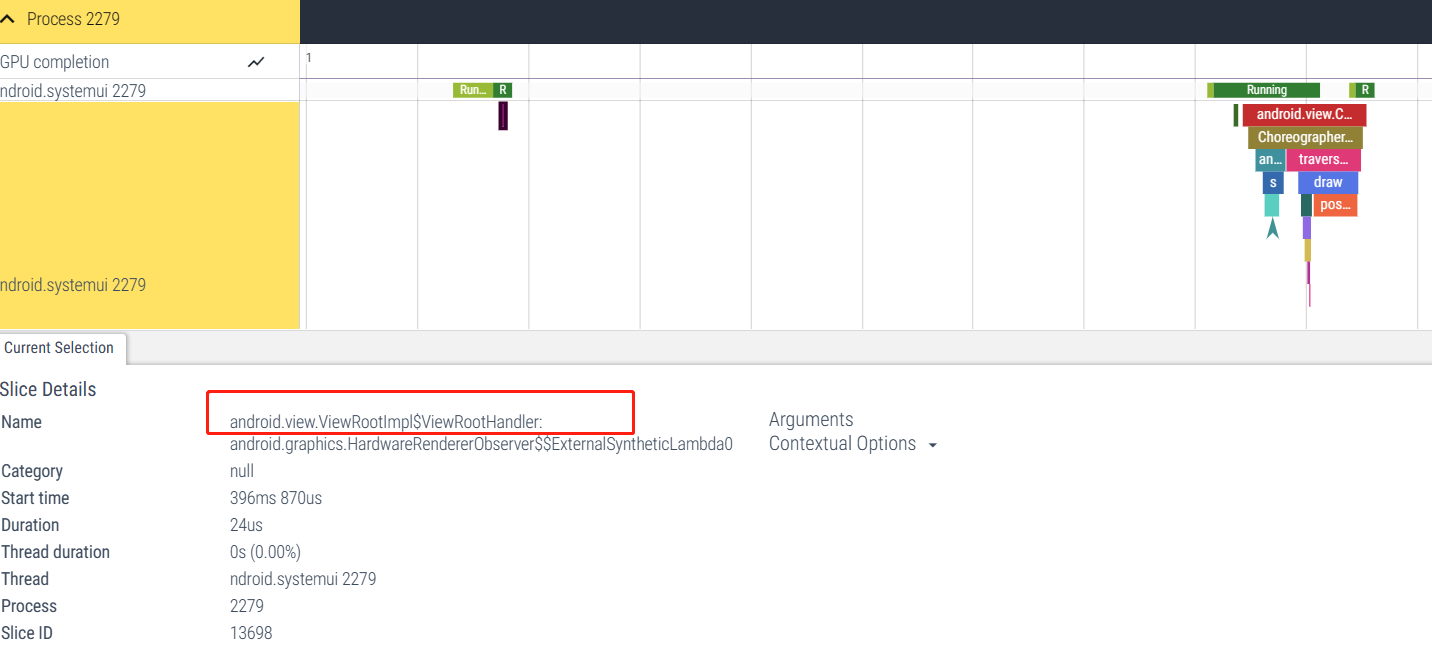
渲染线程初始化在真正需要 draw 内容的时候,一般我们启动一个 Activity ,在第一个 draw 执行的时候,会去检测渲染线程是否初始化,如果没有则去进行初始化
android/view/ViewRootImpl.java
| 1 |
mAttachInfo.mThreadedRenderer.initializeIfNeeded( |
在Perfetto表现如下:
后续直接调用 draw
android/graphics/HardwareRenderer.java
| 1 |
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this); |
上面的 draw 只是更新 DIsplayList ,更新结束后,调用 syncAndDrawFrame ,通知渲染线程开始工作,主线程释放。渲染线程的核心实现在 libhwui 库里面,其代码位于 frameworks/base/libs/hwui
frameworks/base/libs/hwui/renderthread/RenderProxy.cpp
| 1 |
int RenderProxy::syncAndDrawFrame() {
|
其核心流程在 Perfetto 上的表现如下:

2.4 主线程和渲染线程的分工
主线程负责处理进程 Message、处理 Input 事件、处理 Animation 逻辑、处理 Measure、Layout、Draw ,更新 DIsplayList ,但是不涉及 SurfaceFlinger 打交道;渲染线程负责渲染渲染相关的工作,一部分工作也是 CPU 来完成的,一部分操作是调用 OpenGL 函数来完成的
当启动硬件加速后,在 Measure、Layout、Draw 的 Draw 这个环节,Android 使用 DisplayList 进行绘制而非直接使用 CPU 绘制每一帧。DisplayList 是一系列绘制操作的记录,抽象为 RenderNode 类,这样间接的进行绘制操作的优点如下
- DisplayList 可以按需多次绘制而无须同业务逻辑交互
- 特定的绘制操作(如 translation, scale 等)可以作用于整个 DisplayList 而无须重新分发绘制操作
- 当知晓了所有绘制操作后,可以针对其进行优化:例如,所有的文本可以一起进行绘制一次
- 可以将对 DisplayList 的处理转移至另一个线程(也就是 RenderThread)
- 主线程在 sync 结束后可以处理其他的 Message,而不用等待 RenderThread 结束
3、游戏的主线程与渲染线程
游戏大多使用单独的渲染线程 ,直接跟 SurfaceFlinger 进行交互,其主线程的存在感比较低,绝大部分的逻辑都是自己在自己的渲染线程里面实现的。
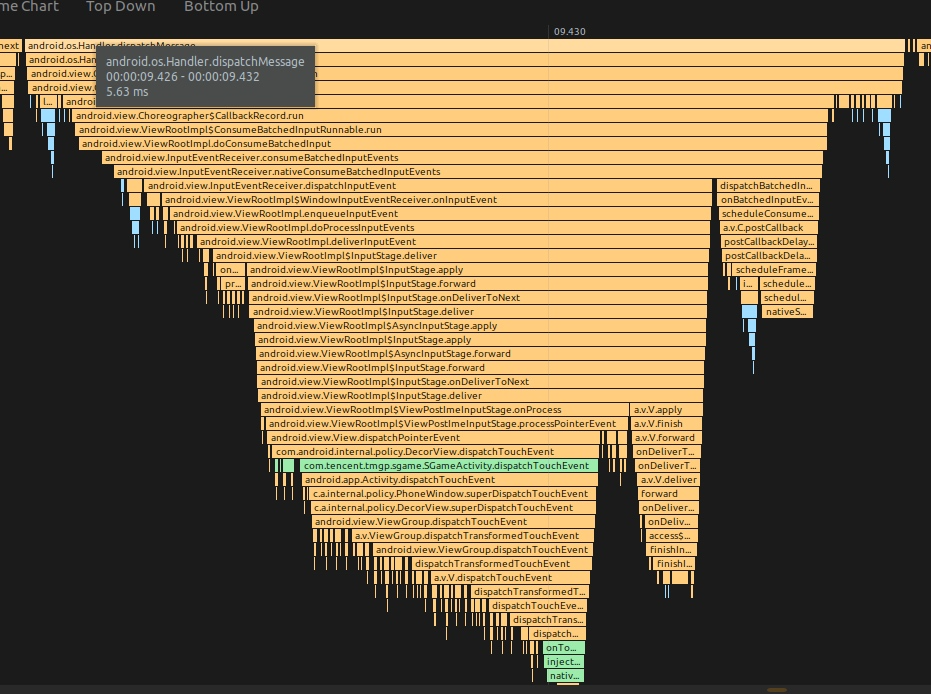
大家可以看一下王者荣耀对应的 Perfetto ,一帧整体流程如下:
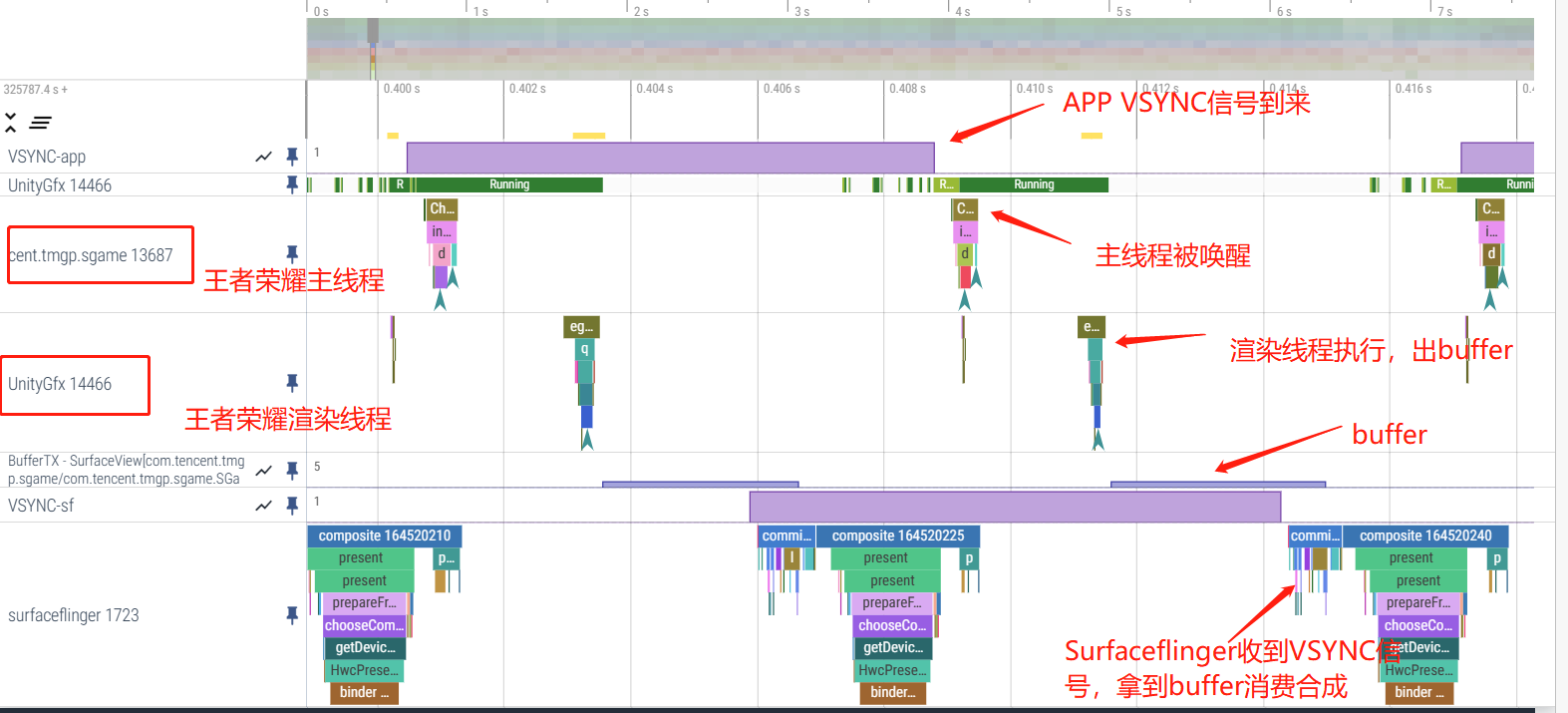
王者荣耀主线程的主要工作,就是把 Input 事件传给 Unity 的渲染线程,渲染线程收到 Input 事件之后,进行逻辑处理,画面更新等。
三、SurfaceFlinger讲解
SurfaceFlinger 的主要功能是接收缓冲区,创建缓冲区,并将缓冲区发送到显示器。WindowManager 为 SurfaceFlinger 提供了缓冲区和窗口元数据,SurfaceFlinger 使用这些缓冲区和窗口元数据来组合具有显示的表面。
详细定义可以看官网: SurfaceFlinger 的定义
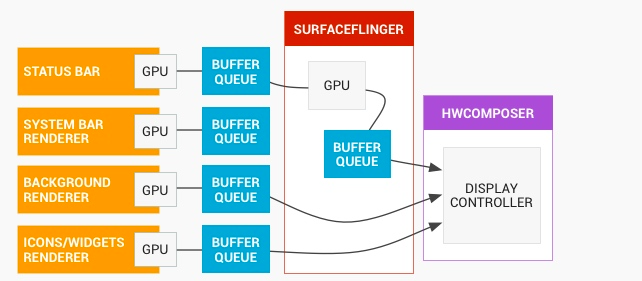
在Perfetto中,我们关注的重点就是上面这幅图对应的部分
- App 部分
- BufferQueue 部分
- SurfaceFlinger 部分
- HWComposer 部分
这四部分,在 Perfetto 中都有可以对应的地方,以时间发生的顺序排序就是 1、2、3、4,下面我们从 Perfetto 的这四部分来看整个渲染的流程
1、App 部分
关于 App 部分,在上面的主线程渲染线程部分已经讲解过了,其主要的流程如下图:
从 SurfaceFlinger 的角度来看,App 部分主要负责生产 SurfaceFlinger 合成所需要的 Surface。
App 与 SurfaceFlinger 的交互主要集中在三点
- Vsync 信号的接收和处理
- RenderThread 的 dequeueBuffer
- RenderThread 的 queueBuffer
1.1 Vsync 信号的接收和处理
App 和 SurfaceFlinger 的第一个交互点就是 Vsync 信号的请求和接收,Vsync-App 信号到达,应用收到这个信号后,开始一帧的渲染准备

2、Triple Buffer
2.1 BufferQueue 部分
如下图,每个有显示界面的进程对应一个 BufferQueue,使用方创建并拥有 BufferQueue 数据结构,并且可存在于与其生产方不同的进程中,BufferQueue 工作流程如下:
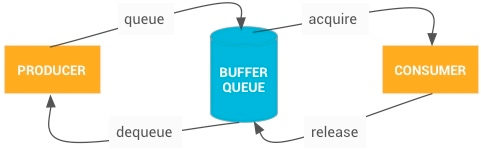
上图主要是 dequeue、queue、acquire、release ,在这个例子里面,App 是生产者,负责填充显示缓冲区(Buffer);SurfaceFlinger 是消费者,将各个进程的显示缓冲区做合成操作
- dequeue(生产者发起) : 当生产者需要缓冲区时,它会通过调用 dequeueBuffer() 从 BufferQueue 请求一个可用的缓冲区,并指定缓冲区的宽度、高度、像素格式和使用标记。
- queue(生产者发起):生产者填充缓冲区并通过调用 queueBuffer() 将缓冲区返回到队列。
- acquire(消费者发起) :消费者通过 acquireBuffer() 获取该缓冲区并使用该缓冲区的内容
- release(消费者发起) :当消费者操作完成后,它会通过调用 releaseBuffer() 将该缓冲区返回到队列
2.2 Single Buffer
单 Buffer 的情况下,因为只有一个 Buffer 可用,那么这个 Buffer 既要用来做合成显示,又要被应用拿去做渲染
理想情况下,单 Buffer 是可以完成任务的(有 Vsync-Offset 存在的情况下)
- App 收到 Vsync 信号,获取 Buffer 开始渲染
- 间隔 Vsync-Offset 时间后,SurfaceFlinger 收到 Vsync 信号,开始合成
- 屏幕刷新,我们看到合成后的画面
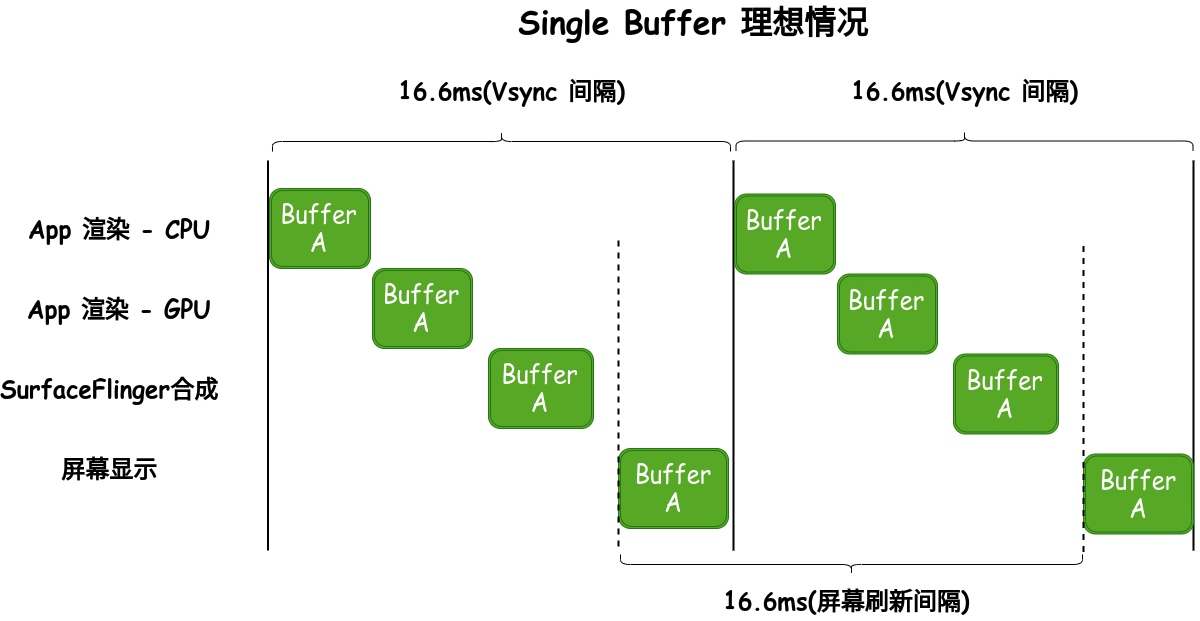
但是很不幸,理想情况我们也就想一想,这期间如果 App 渲染或者 SurfaceFlinger 合成在屏幕显示刷新之前还没有完成,那么屏幕刷新的时候,拿到的 Buffer 就是不完整的,在用户看来,就有种撕裂的感觉
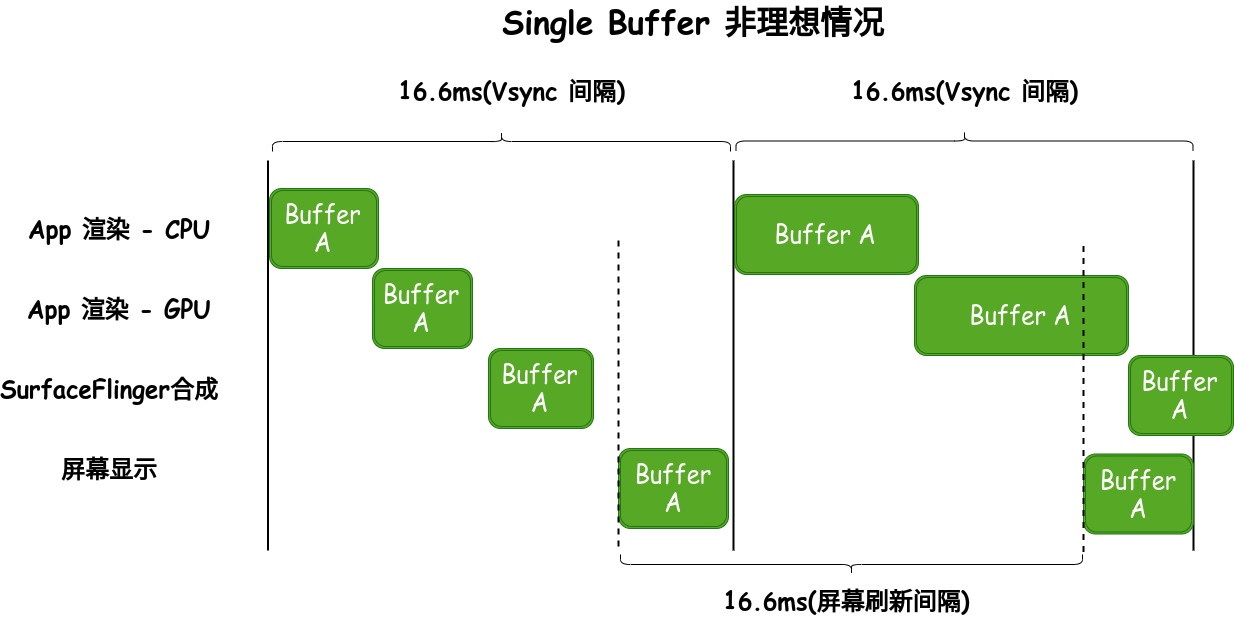
当然 Single Buffer 已经没有在使用,上面只是一个例子
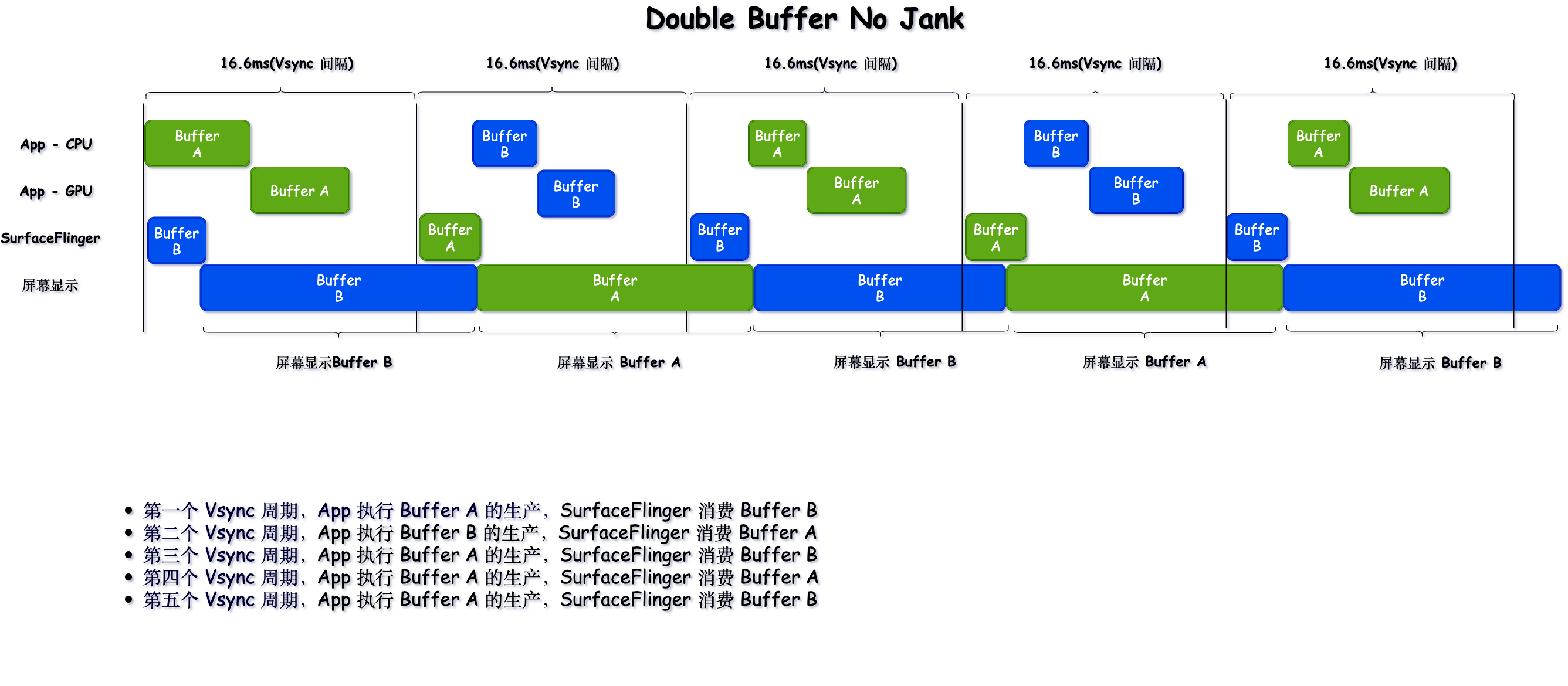
2.3 Double Buffer
Double Buffer 相当于 BufferQueue 中有两个 Buffer 可供轮转,消费者在消费 Buffer的同时,生产者也可以拿到备用的 Buffer 进行生产操作
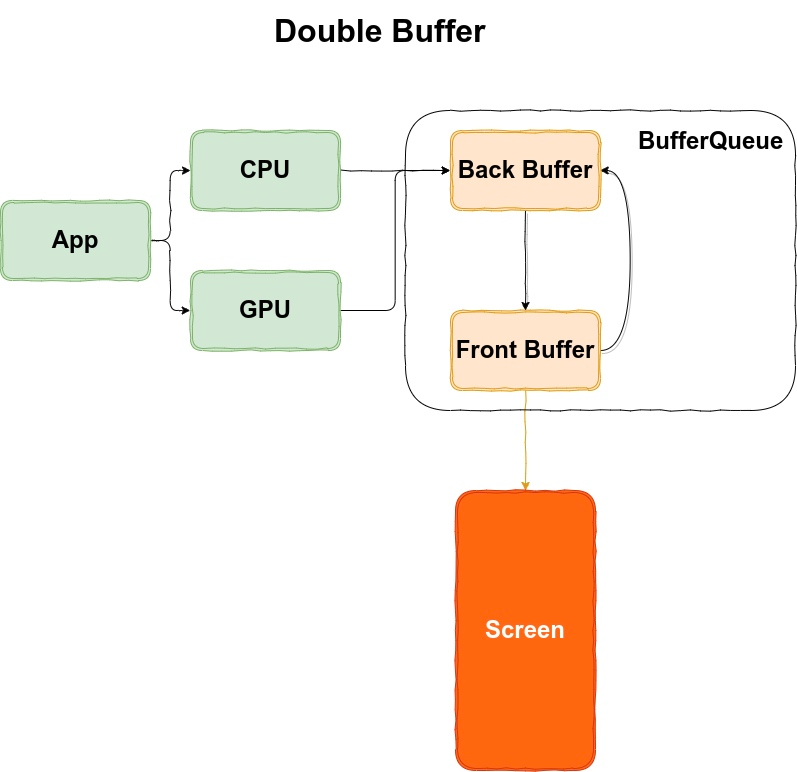
下面我们来看理想情况下,Double Buffer 的工作流程
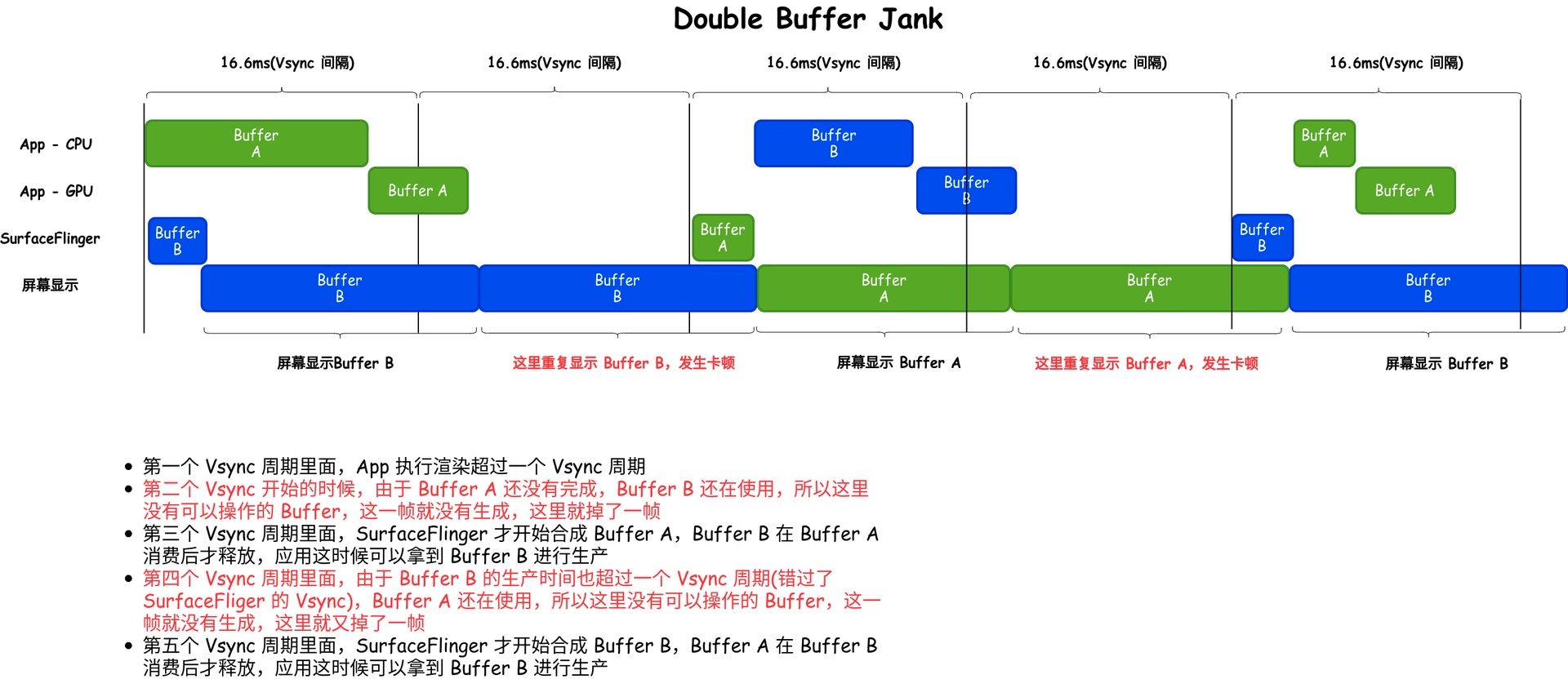
但是 Double Buffer 也会存在性能上的问题,比如下面的情况,App 连续两帧生产都超过 Vsync 周期(准确的说是错过 SurfaceFlinger 的合成时机) ,就会出现掉帧情况
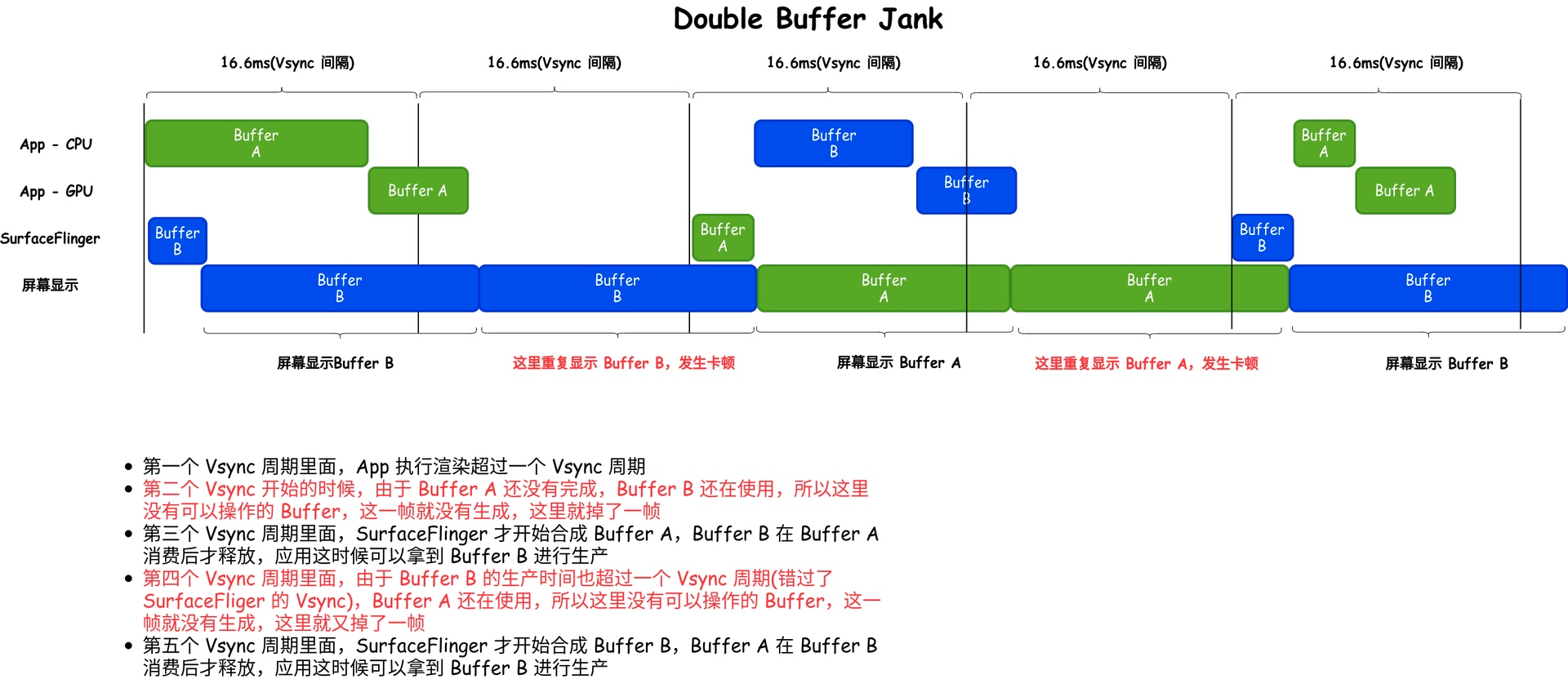
2.4 Triple Buffer
Triple Buffer 中,我们又加入了一个 BackBuffer ,这样的话 BufferQueue 里面就有三个 Buffer 可以轮转了,当 FrontBuffer 在被使用的时候,App 有两个空闲的 Buffer 可以拿去生产,就算生产过程中有 GPU 超时,CPU 任然可以拿到新的 Buffer 进行生产(即 SurfaceFling 消费 FrontBuffer,GPU 使用一个 BackBuffer,CPU使用一个 BackBuffer)
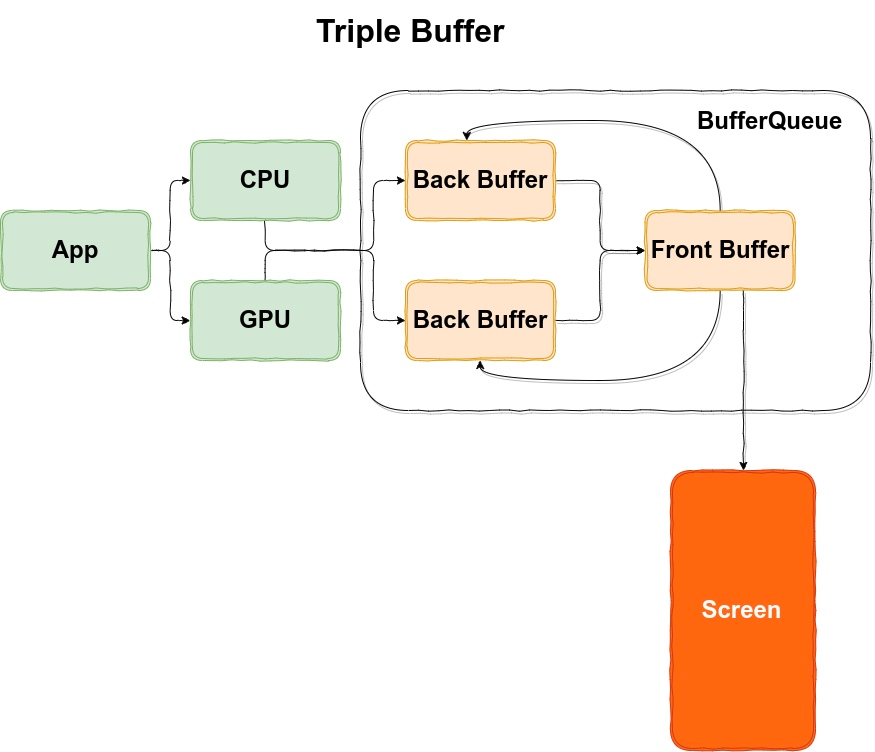
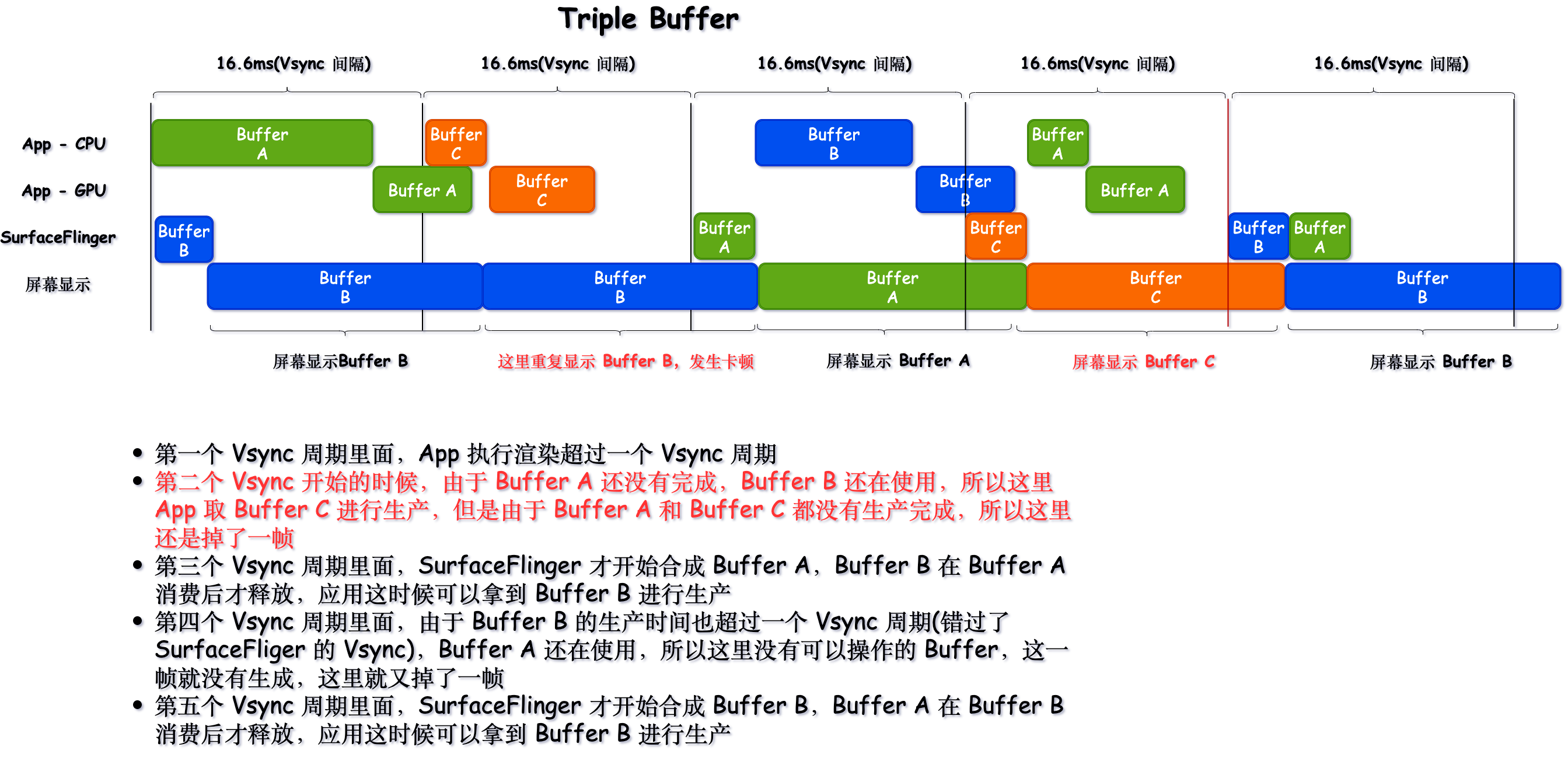
下面就是引入 Triple Buffer 之后,解决了 Double Buffer 中遇到的由于 Buffer 不足引起的掉帧问题
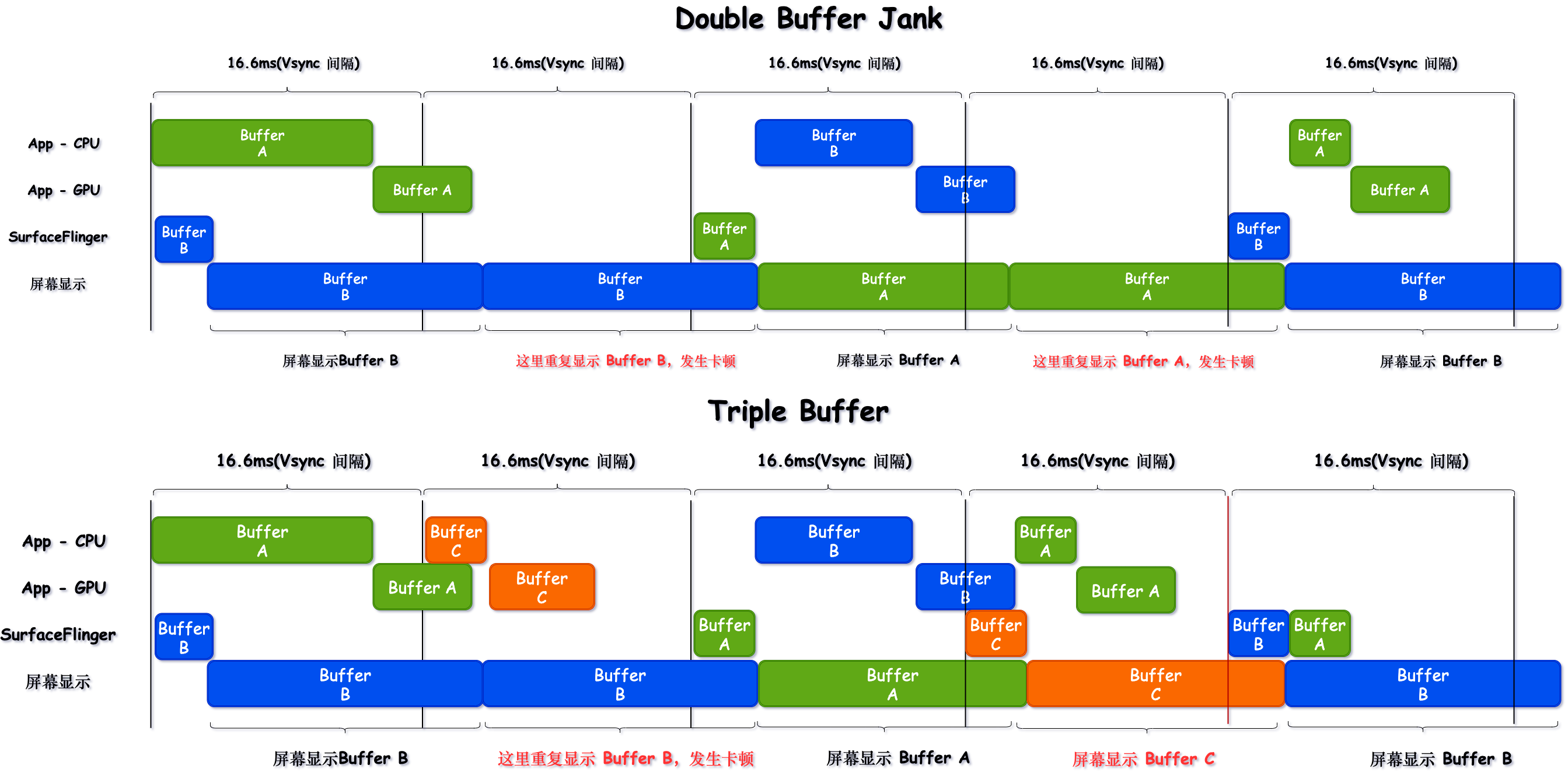
这里把两个图放到一起来看,方便大家做对比(一个是 Double Buffer 掉帧两次,一个是使用 Triple Buffer 只掉了一帧)
3、Triple Buffer 的作用
3.1 缓解掉帧
从上一节 Double Buffer 和 Triple Buffer 的对比图可以看到,在这种情况下(出现连续主线程超时),三个 Buffer 的轮转有助于缓解掉帧出现的次数(从掉帧两次 -> 只掉帧一次)
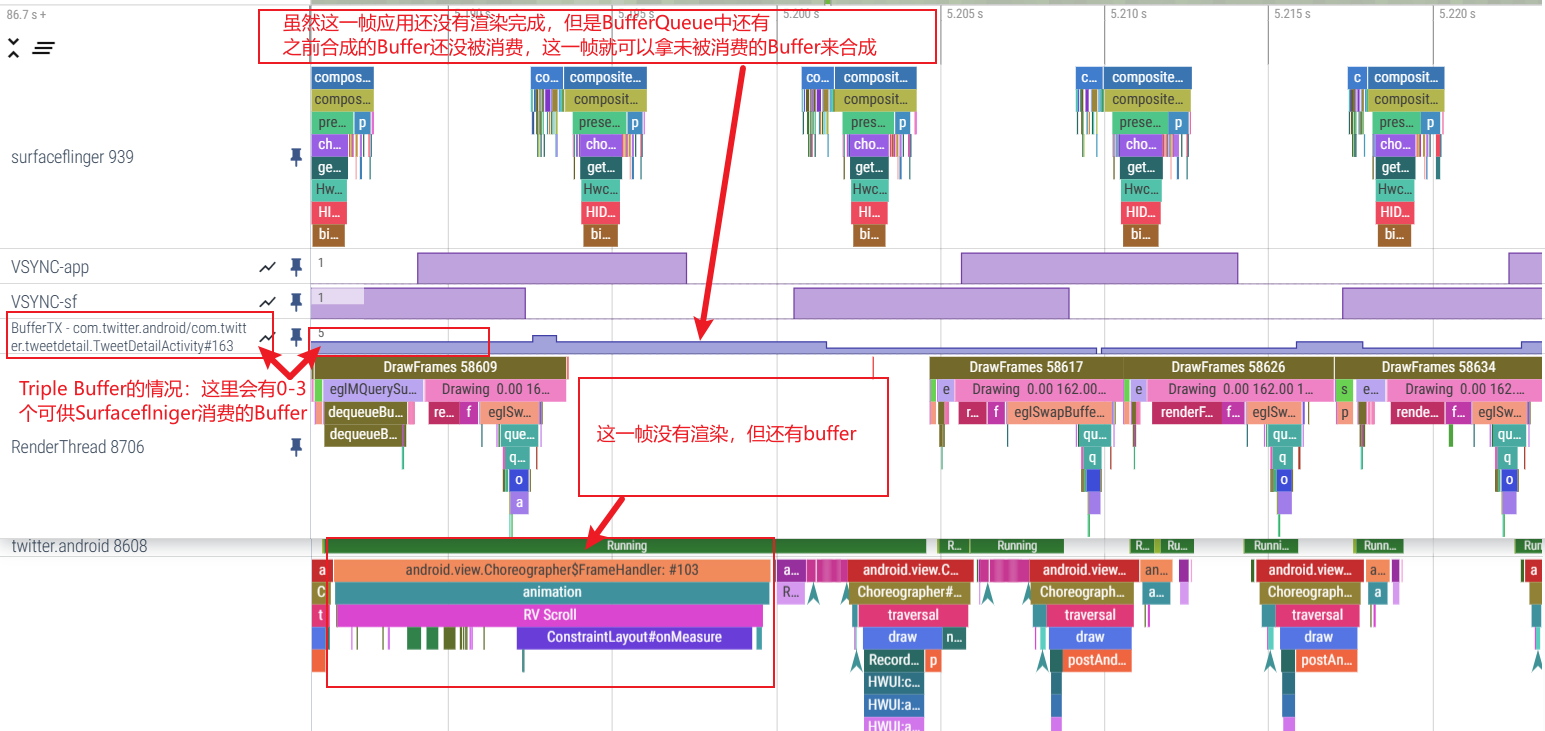
所以从第一节如何定义掉帧这里我们就知道,App 主线程超时不一定会导致掉帧,由于 Triple Buffer 的存在,部分 App 端的掉帧(主要是由于 GPU 导致),到 SurfaceFlinger 这里未必是掉帧,这是看 Perfetto 的时候需要注意的一个点
3.2 减少主线程和渲染线程等待时间
双 Buffer 的轮转, App 主线程有时候必须要等待 SurfaceFlinger(消费者)释放 Buffer 后,才能获取 Buffer 进行生产,这时候就有个问题,现在大部分手机 SurfaceFlinger 和 App 同时收到 Vsync 信号,如果出现App 主线程等待 SurfaceFlinger(消费者)释放 Buffer ,那么势必会让 App 主线程的执行时间延后,比如下面这张图,可以明显看到:Buffer B 并不是在 Vsync 信号来的时候开始被消费(因为还在使用),而是等 Buffer A 被消费后,Buffer B 被释放,App 才能拿到 Buffer B 进行生产,这期间就有一定的延迟,会让主线程可用的时间变短
3.3 降低 GPU 和 SurfaceFlinger 瓶颈
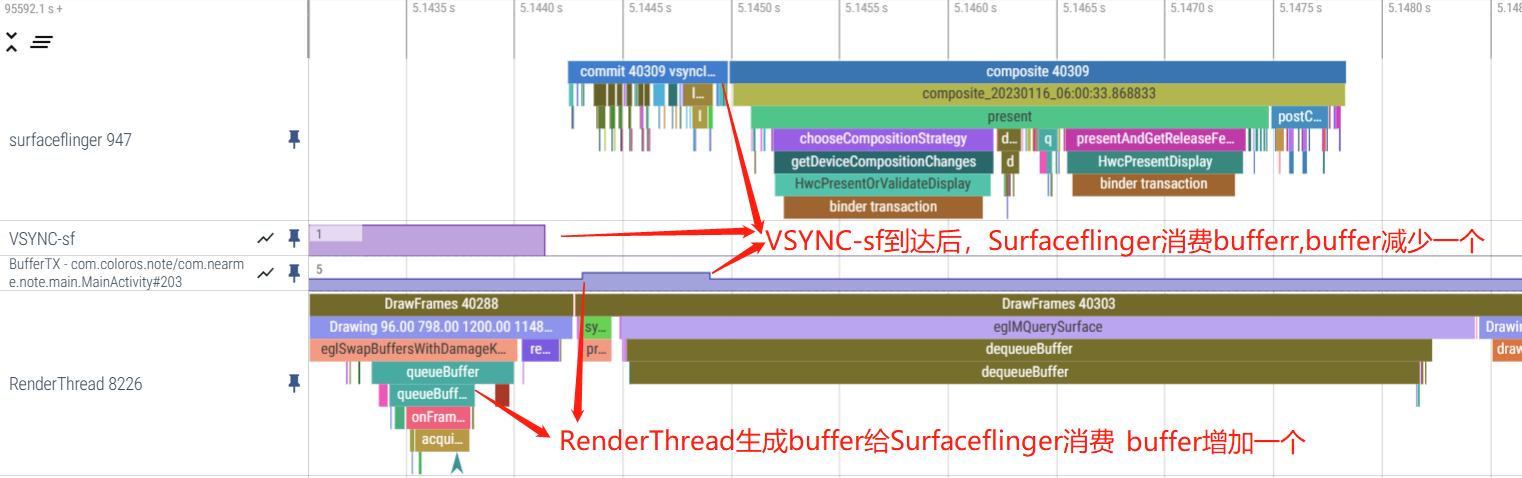
双 Buffer 的时候,App 生产的 Buffer 必须要及时拿去让 GPU 进行渲染,然后 SurfaceFlinger 才能进行合成,一旦 GPU 超时,就很容易出现SurfaceFlinger 无法及时合成而导致掉帧在三个 Buffer 轮转的时候,App 生产的 Buffer 可以及早进入 BufferQueue,让 GPU 去进行渲染(因为不需要等待,就算这里积累了 2 个 Buffer,下下一帧才去合成,这里也会提早进行,而不是在真正使用之前去匆忙让 GPU 去渲染),另外 SurfaceFlinger 本身的负载如果比较大,三个 Buffer 轮转也会有效降低 dequeueBuffer 的等待时间。
SurfaceFlinger 端的 Perfetto 如下所示
4、SurfaceFlinger工作流程
SurfaceFlinger 的主要工作就是合成:
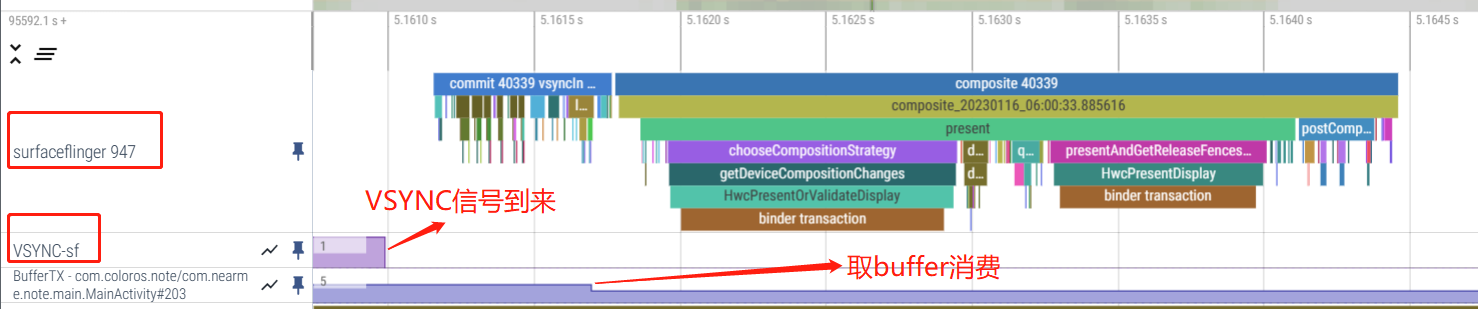
当 VSYNC 信号到达时,SurfaceFlinger 会遍历它的层列表,以寻找新的缓冲区。如果找到新的缓冲区,它会获取该缓冲区;否则,它会继续使用以前获取的缓冲区。SurfaceFlinger 必须始终显示内容,因此它会保留一个缓冲区。如果在某个层上没有提交缓冲区,则该层会被忽略。SurfaceFlinger 在收集可见层的所有缓冲区之后,便会询问 Hardware Composer 应如何进行合成。
其 Perfetto 主线程可用看到其主要是在收到 Vsync 信号后开始工作
SurfaceFlinger相关代码在下面,后续会专门写一篇SurfaceFlinger实现流程:
frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
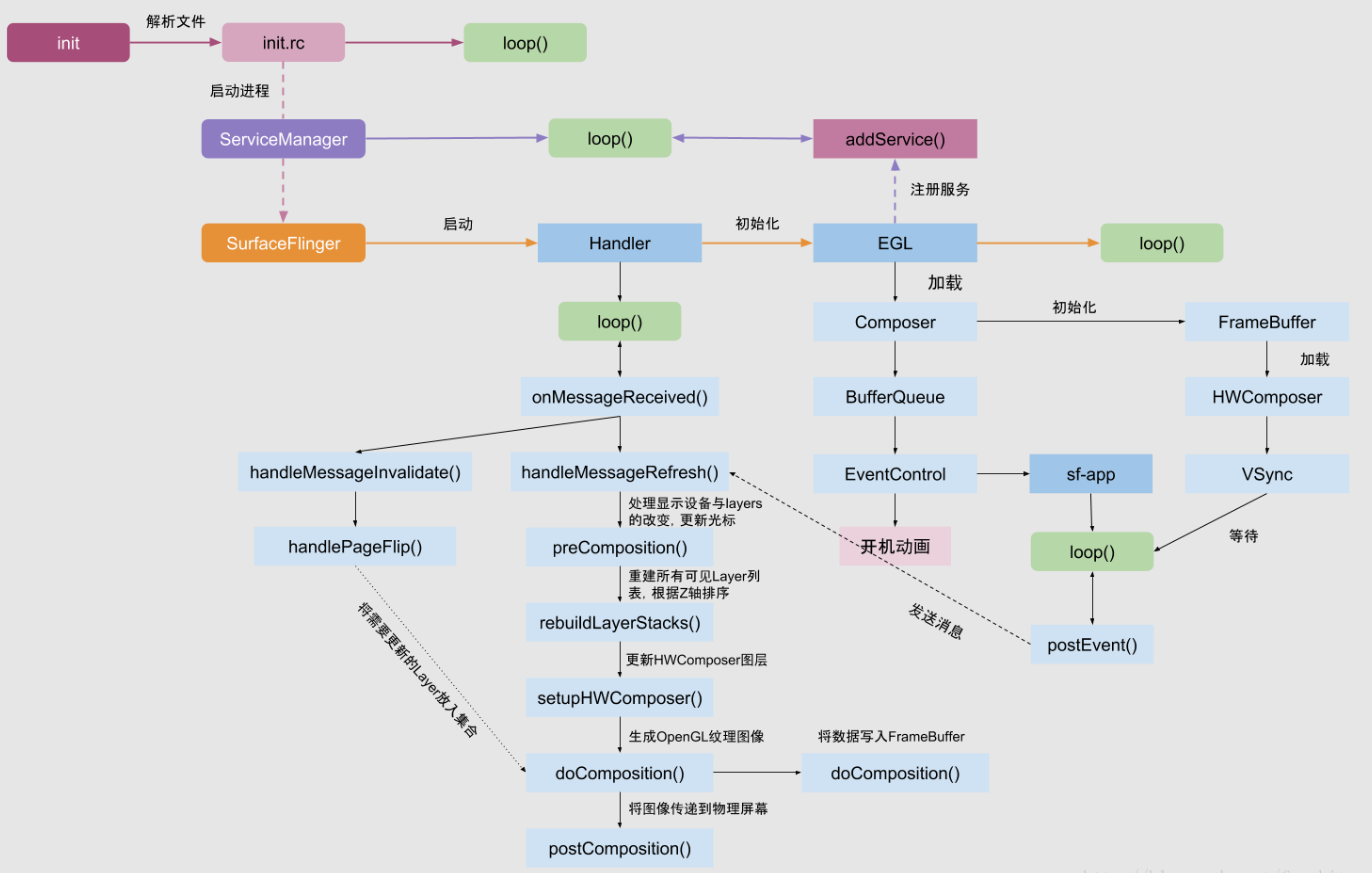
4.1 SurfaceFlinger启动流程图解
4.2 SurfaceFlinger 端判断掉帧
通常我们通过 Perfetto 判断应用是否掉帧的时候,一般是直接看 SurfaceFlinger 部分,主要是下面几个步骤
- SurfaceFlinger 的主线程在每个 Vsync-SF 的时候是否没有合成?
- 如果没有合成操作,那么需要看没有合成的原因:
-
- 因为 SurfaceFlinger 检查发现没有可用的 Buffer 而没有合成操作?
- 因为 SurfaceFlinger 被其他的工作占用(比如截图、HWC 等)?
- 如果有合成操作,那么需要看对应的 App 的 可用 Buffer 个数是否正常:如果 App 此时可用 Buffer 为 0,那么看 App 端为何没有及时 queueBuffer(这就一般是应用自身的问题了),因为 SurfaceFlinger 合成操作触发可能是其他的进程有可用的 Buffer
下图为APP耗时导致的掉帧:
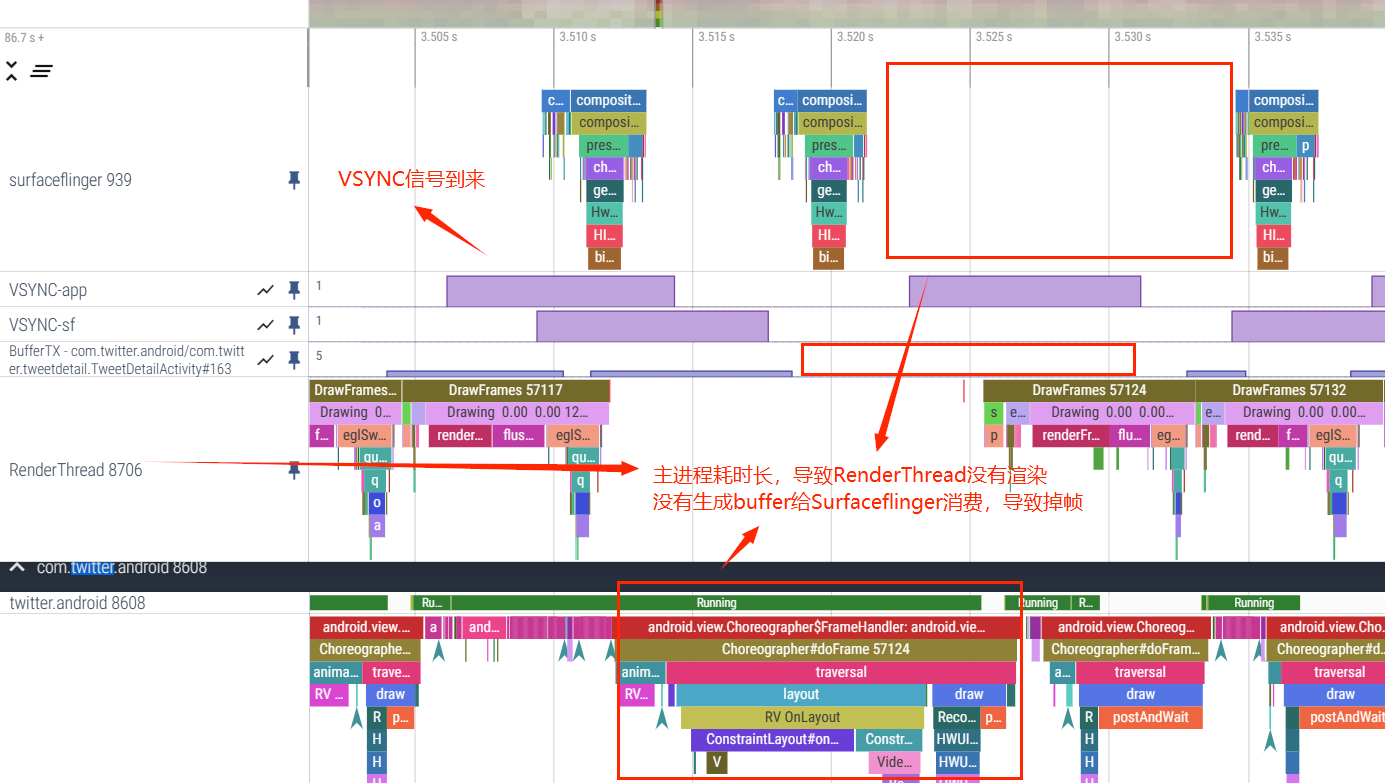
SurfaceFlinger 端可以看到 SurfaceFlinger 主线程和合成情况和应用对应的 BufferQueue 中 Buffer 的情况。如上图,就是一个掉帧的例子。App 没有及时渲染完成,且此时 BufferQueue 中也没有前几帧的 Buffer,所以这一帧 SurfaceFlinger 没有合成对应 App 的 Layer,在用户看来这里就掉了一帧
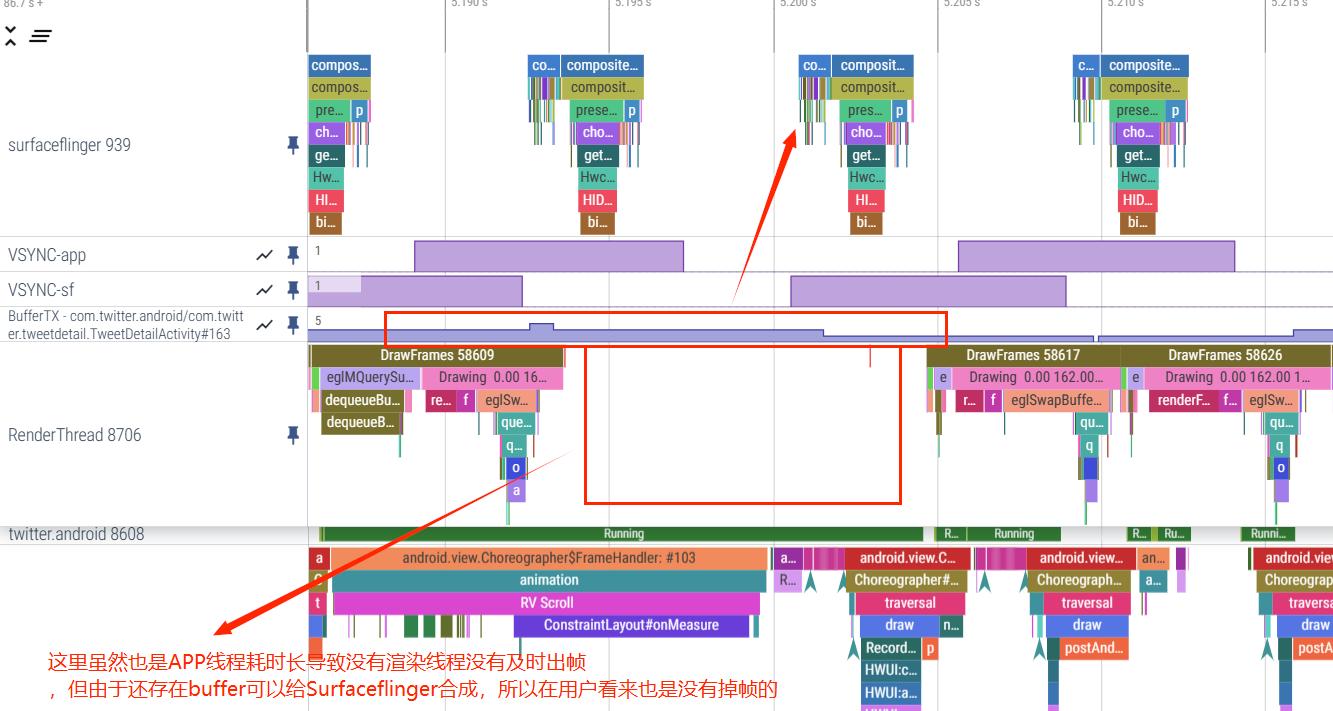
从 App 端无法看出是否掉帧,对应的 SurfaceFlinger 的 Trace 如下, 可以看到由于有 Triple Buffer 的存在, SF 这里有之前 App 的 Buffer,所以尽管 App 超过了一帧的时间, 但是 SF 这里依然有可用来合成的 Buffer, 所以没有掉帧
4.3 逻辑掉帧
上面的掉帧我们是从渲染这边来看的,这种掉帧在 Perfetto 中可以很容易就发现;还存在一种掉帧情况叫逻辑掉帧
逻辑掉帧指的是由于应用自己的代码逻辑问题,导致画面更新的时候,不是以均匀或者物理曲线的方式,而是出现跳跃更新的情况,这种掉帧一般在 Perfetto 上没法看出来,但是用户在使用的时候可以明显感觉到
举一个简单的例子,比如说列表滑动的时候,如果我们滑动松手后列表的每一帧前进步长是一个均匀变化的曲线,最后趋近于 0,这样就是完美的;但是如果出现这一帧相比上一帧走了 20,下一帧相比这一帧走了 10,下下一帧相比下一帧走了 30,这种就是跳跃更新,在 Perfetto 上每一帧都是及时渲染且 SurfaceFlinger 都及时合成的,但是用户用起来就是觉得会卡. 不过我列举的这个例子中,Android 已经针对这种情况做了优化,感兴趣的可以去看一下 android/view/animation/AnimationUtils.java 这个类,重点看下面三个方法的使用
| 1 |
public static void lockAnimationClock(long vsyncMillis) |
Android 系统的动画一般不会有这个问题,但是应用开发者就保不齐会写这种代码,比如做动画的时候根据当前的时间(而不是 Vsync 到来的时间)来计算动画属性变化的情况,这种情况下,一旦出现掉帧,动画的变化就会变得不均匀。
5、HWComposer 部分
- Hardware Composer HAL (HWC) 用于确定通过可用硬件来合成缓冲区的最有效方法。作为 HAL,其实现是特定于设备的,而且通常由显示设备硬件原始设备制造商 (OEM) 完成。
- 当您考虑使用叠加平面时,很容易发现这种方法的好处,它会在显示硬件(而不是 GPU)中合成多个缓冲区。例如,假设有一部普通 Android 手机,其屏幕方向为纵向,状态栏在顶部,导航栏在底部,其他区域显示应用内容。每个层的内容都在单独的缓冲区中。您可以使用以下任一方法处理合成(后一种方法可以显著提高效率):
-
- 将应用内容渲染到暂存缓冲区中,然后在其上渲染状态栏,再在其上渲染导航栏,最后将暂存缓冲区传送到显示硬件。
- 将三个缓冲区全部传送到显示硬件,并指示它从不同的缓冲区读取屏幕不同部分的数据。
- 显示处理器功能差异很大。叠加层的数量(无论层是否可以旋转或混合)以及对定位和叠加的限制很难通过 API 表达。为了适应这些选项,HWC 会执行以下计算(由于硬件供应商可以定制决策代码,因此可以在每台设备上实现最佳性能):
-
- SurfaceFlinger 向 HWC 提供一个完整的层列表,并询问“您希望如何处理这些层?”
- HWC 的响应方式是将每个层标记为叠加层或 GLES 合成。
- SurfaceFlinger 会处理所有 GLES 合成,将输出缓冲区传送到 HWC,并让 HWC 处理其余部分。
- 当屏幕上的内容没有变化时,叠加平面的效率可能会低于 GL 合成。当叠加层内容具有透明像素且叠加层混合在一起时,尤其如此。在此类情况下,HWC 可以选择为部分或全部层请求 GLES 合成,并保留合成的缓冲区。如果 SurfaceFlinger 返回来要求合成同一组缓冲区,HWC 可以继续显示先前合成的暂存缓冲区。这可以延长闲置设备的电池续航时间。
- 运行 Android 4.4 或更高版本的设备通常支持 4 个叠加平面。尝试合成的层数多于叠加层数会导致系统对其中一些层使用 GLES 合成,这意味着应用使用的层数会对能耗和性能产生重大影响。
四、Choreographer讲解
Choreographer 的引入,主要是配合 Vsync ,给上层 App 的渲染提供一个稳定的 Message 处理的时机,也就是 Vsync 到来的时候 ,系统通过对 Vsync 信号周期的调整,来控制每一帧绘制操作的时机. 目前大部分手机都是 60Hz 的刷新率,也就是 16.6ms 刷新一次,系统为了配合屏幕的刷新频率,将 Vsync 的周期也设置为 16.6 ms,每个 16.6 ms , Vsync 信号唤醒 Choreographer 来做 App 的绘制操作 ,这就是引入 Choreographer 的主要作用. 了解 Choreographer 还可以帮助 App 开发者知道程序每一帧运行的基本原理,也可以加深对 Message、Handler、Looper、MessageQueue、Measure、Layout、Draw 的理解
1、主线程运行机制的本质
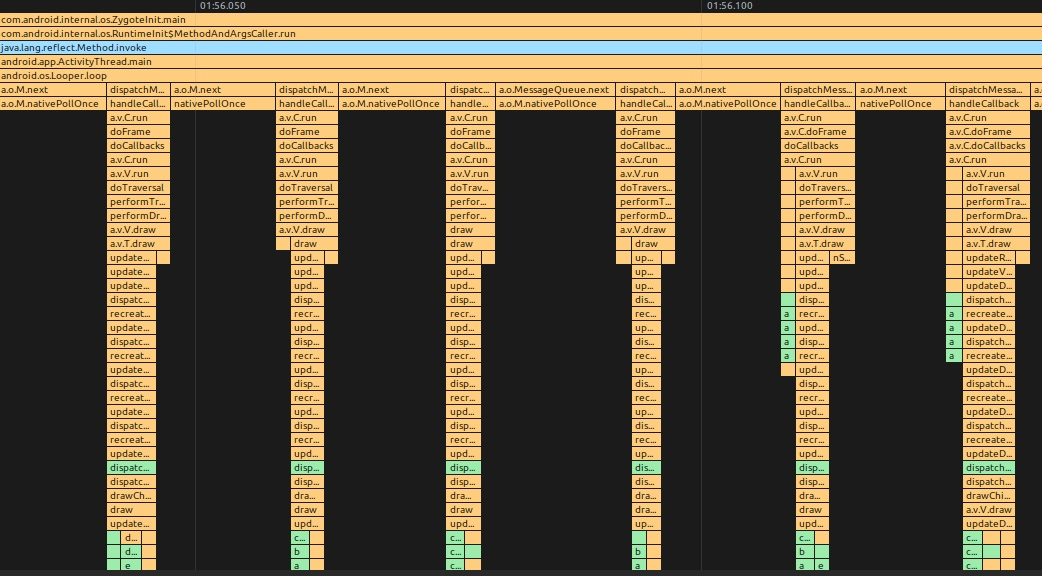
在讲 Choreographer 之前,我们先理一下 Android 主线程运行的本质,其实就是 Message 的处理过程,我们的各种操作,包括每一帧的渲染操作 ,都是通过 Message 的形式发给主线程的 MessageQueue ,MessageQueue 处理完消息继续等下一个消息,MethodTrace 如下图所示
1.1 引入Choreographer前
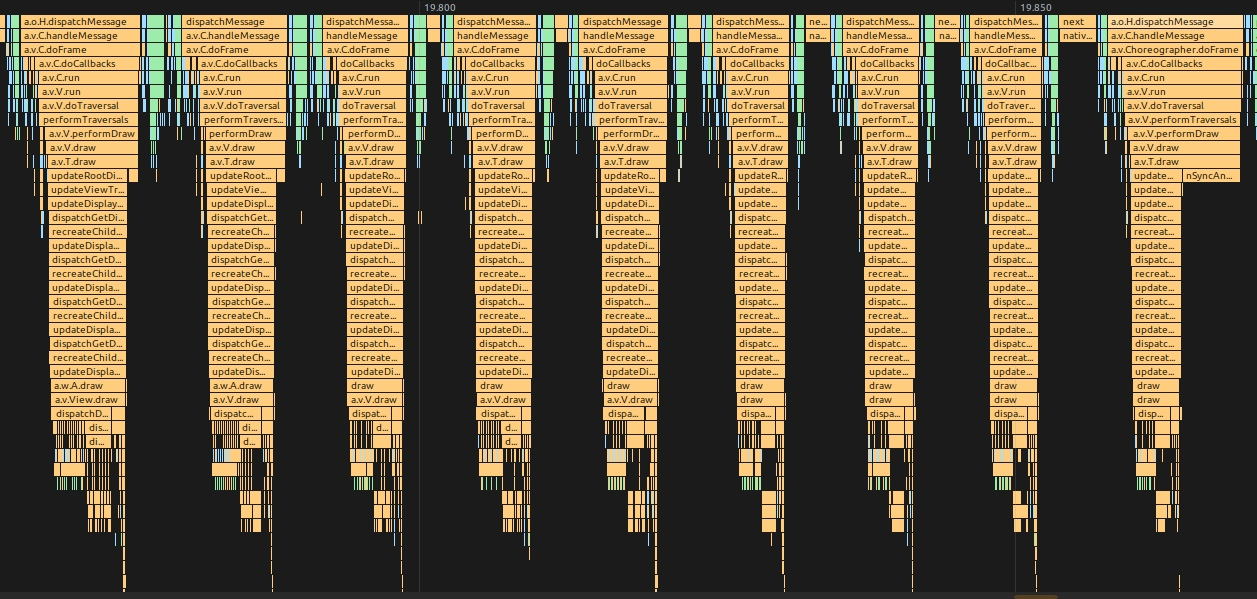
引入 Vsync 之前的 Android 版本,渲染一帧相关的 Message ,中间是没有间隔的,上一帧绘制完,下一帧的 Message 紧接着就开始被处理。这样的问题就是,帧率不稳定,可能高也可能低,不稳定,MethodTrace 如下图所示
对于用户来说,稳定的帧率才是好的体验,比如你玩王者荣耀,相比 fps 在 60 和 40 之间频繁变化,用户感觉更好的是稳定在 50 fps 的情况.
所以 Android 的演进中,引入了 Vsync + TripleBuffer + Choreographer 的机制,其主要目的就是提供一个稳定的帧率输出机制,让软件层和硬件层可以以共同的频率一起工作。
1.2 引入 Choreographer后
Choreographer 的引入,主要是配合 Vsync ,给上层 App 的渲染提供一个稳定的 Message 处理的时机,也就是 Vsync 到来的时候 ,系统通过对 Vsync 信号周期的调整,来控制每一帧绘制操作的时机 ,Vsync 信号到来唤醒 Choreographer 来做 App 的绘制操作 ,如果每个 Vsync 周期应用都能渲染完成,给用户的感觉就是非常流畅,这就是引入 Choreographer 的主要作用.
上面主要是以60HZ为例,当然目前使用 90Hz 刷新率屏幕的手机越来越多,Vsync 周期从 16.6ms 到了 11.1ms,上图中的操作要在更短的时间内完成,对性能的要求也越来越高。
2、Choreographer 作用
Choreographer 扮演 Android 渲染链路中承上启下的角色
- 承上:负责接收和处理 App 的各种更新消息和回调,等到 Vsync 到来的时候统一处理。比如集中处理 Input(主要是 Input 事件的处理) 、Animation(动画相关)、Traversal(包括 measure、layout、draw 等操作) ,判断卡顿掉帧情况,记录 CallBack 耗时等
- 启下:负责请求和接收 Vsync 信号。接收 Vsync 事件回调(通过 FrameDisplayEventReceiver.onVsync );请求 Vsync(FrameDisplayEventReceiver.scheduleVsync)
从上面可以看出来, Choreographer 担任的是一个工具人的角色,他之所以重要,是因为通过 Choreographer + SurfaceFlinger + Vsync + TripleBuffer 这一套从上到下的机制,保证了 Android App 可以以一个稳定的帧率运行(20fps、90fps 或者 60fps),减少帧率波动带来的不适感。
了解 Choreographer 还可以帮助 App 开发者知道程序每一帧运行的基本原理,也可以加深对 Message、Handler、Looper、MessageQueue、Input、Animation、Measure、Layout、Draw 的理解 , 很多 APM 工具也用到了 Choreographer( 利用 FrameCallback + FrameInfo ) + MessageQueue ( 利用 IdleHandler ) + Looper ( 设置自定义 MessageLogging) 这些组合拳,深入了解了这些之后,再去做优化,脑子里的思路会更清晰。
另外虽然画图是一个比较好的解释流程的好路子,但是我个人不是很喜欢画图,因为平时 Perfetto 和 MethodTrace 用的比较多,Perfetto 是按从左到右展示整个系统的运行情况的一个工具(包括 cpu、SurfaceFlinger、SystemServer、App 等关键进程),使用 Perfetto 和 MethodTrace 也可以很方便地展示关键流程。当你对系统代码比较熟悉的时候,看 Perfetto 就可以和手机运行的实际情况对应起来。所以下面的文章除了一些网图之外,其他的我会多以 Perfetto 来展示。
2.1 从 Perfetto 的角度来看 Choreogrepher 的工作流程
下图以滑动推特APP为例子,我们先看一下从左到右滑动桌面的一个完整的预览图(App 进程),可以看到 Perfetto 中从左到右,每一个绿色的帧都表示一帧,表示最终我们可以手机上看到的画面
- 图中每一个紫色的条宽度是一个 Vsync 的时间,这个是120HZ也就是 8.3ms
- 每一帧处理的流程:接收到 Vsync 信号回调-> UI Thread –> RenderThread –> SurfaceFlinger(图中未显示)
- UI Thread 和 RenderThread 就可以完成 App 一帧的渲染,渲染完的 Buffer 抛给 SurfaceFlinger 去合成,然后我们就可以在屏幕上看到这一帧了
- 可以看到推特滑动的每一帧耗时都很短(Ui Thread 耗时 + RenderThread 耗时),但是由于 Vsync 的存在,每一帧都会等到 Vsync 才会去做处理
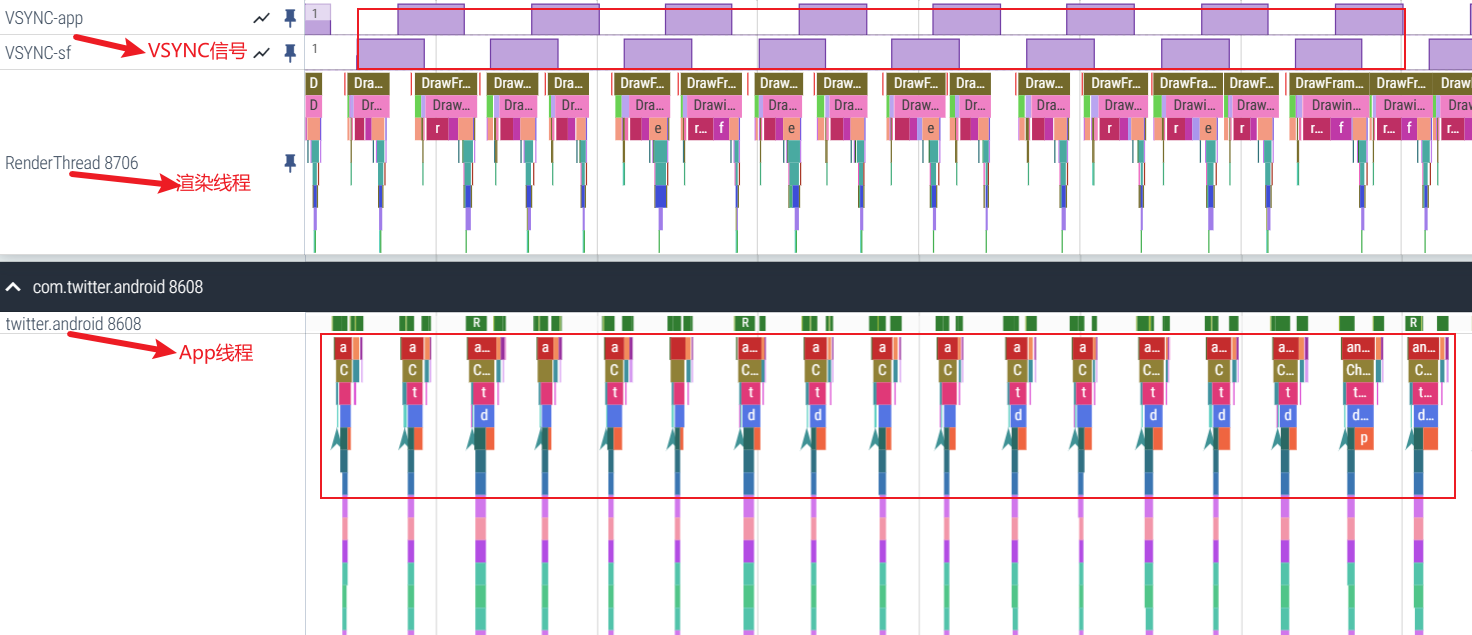
有了上面这个整体的概念,我们将 UI Thread 的每一帧放大来看,看看 Choreogrepher 的位置以及 Choreogrepher 是怎么组织每一帧的
2.2 Choreographer 的工作流程
- Choreographer 初始化
-
- 初始化 FrameHandler ,绑定 Looper
- 初始化 FrameDisplayEventReceiver ,与 SurfaceFlinger 建立通信用于接收和请求 Vsync
- 初始化 CallBackQueues
- SurfaceFlinger 的 appEventThread 唤醒发送 Vsync ,Choreographer 回调 FrameDisplayEventReceiver.onVsync , 进入 Choreographer 的主处理函数 doFrame
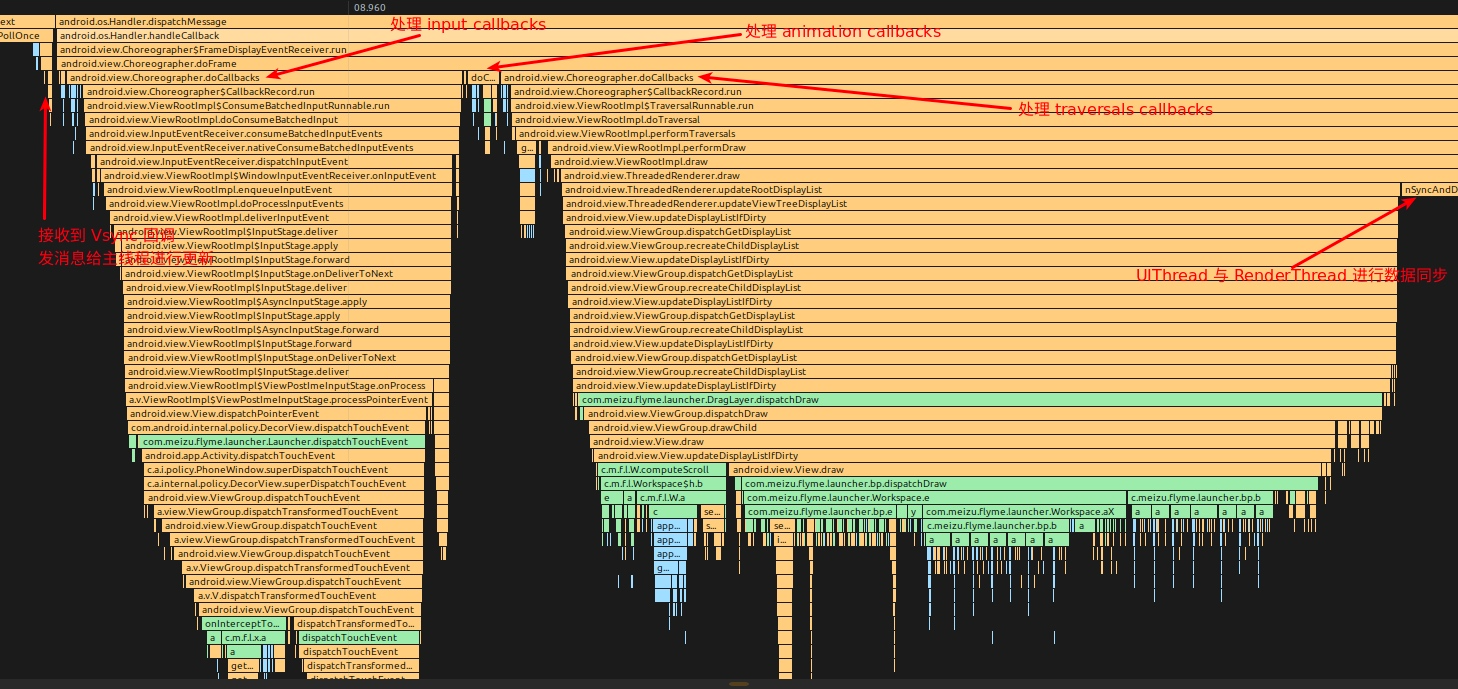
- Choreographer.doFrame 计算掉帧逻辑
- Choreographer.doFrame 处理 Choreographer 的第一个 callback : input
- Choreographer.doFrame 处理 Choreographer 的第二个 callback : animation
- Choreographer.doFrame 处理 Choreographer 的第三个 callback : insets animation
- Choreographer.doFrame 处理 Choreographer 的第四个 callback : traversal
-
- traversal-draw 中 UIThread 与 RenderThread 同步数据
- Choreographer.doFrame 处理 Choreographer 的第五个 callback : commit ?
- RenderThread 处理绘制命令,将处理好的绘制命令发给 GPU 处理
- 调用 swapBuffer 提交给 SurfaceFlinger 进行合成(此时 Buffer 并没有真正完成,需要等 CPU 完成后 SurfaceFlinger 才能真正使用,新版本的 Perfetto 中有 gpu 的 fence 来标识这个时间)
第一步初始化完成后,后续就会在步骤 2-9 之间循环
同时也附上这一帧所对应的 MethodTrace(这里预览一下即可,下面会有详细的大图)
下面我们就从源码的角度,来看一下具体的实现
3、源码解析
下面从源码的角度来简单看一下,源码只摘抄了部分重要的逻辑,其他的逻辑则被剔除,另外 Native 部分与 SurfaceFlinger 交互的部分也没有列入,不是本文的重点,有兴趣的可以自己去跟一下。
3.1 Choreographer 的初始化
Choreographer 的单例初始化
| 1 |
// Thread local storage for the choreographer. |
Choreographer 的构造函数
| 1 |
private Choreographer(Looper looper, int vsyncSource) {
|
FrameHandler
| 1 |
private final class FrameHandler extends Handler {
|
Choreographer 初始化链
在 Activity 启动过程,执行完 onResume 后,会调用 Activity.makeVisible(),然后再调用到 addView(), 层层调用会进入如下方法
| 1 |
ActivityThread.handleResumeActivity(IBinder, boolean, boolean, String) (android.app) |
3.2 FrameDisplayEventReceiver
Vsync 的注册、申请、接收都是通过 FrameDisplayEventReceiver 这个类,所以可以先简单介绍一下。 FrameDisplayEventReceiver 继承 DisplayEventReceiver , 有三个比较重要的方法
- onVsync – Vsync 信号回调
- run – 执行 doFrame
- scheduleVsync – 请求 Vsync 信号
| 1 |
private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable {
|
3.3 Choreographer 中 Vsync 的注册
从下面的函数调用栈可以看到,Choreographer 的内部类 FrameDisplayEventReceiver.onVsync 负责接收 Vsync 回调,通知 UIThread 进行数据处理。
那么 FrameDisplayEventReceiver 是通过什么方式在 Vsync 信号到来的时候回调 onVsync 呢?答案是 FrameDisplayEventReceiver 的初始化的时候,最终通过监听文件句柄的形式,其对应的初始化流程如下
android/view/Choreographer.java
| 1 |
private Choreographer(Looper looper, int vsyncSource) {
|
android/view/Choreographer.java
| 1 |
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
|
android/view/DisplayEventReceiver.java
| 1 |
public DisplayEventReceiver(Looper looper, int vsyncSource) {
|
简单来说,FrameDisplayEventReceiver 的初始化过程中,通过 BitTube(本质是一个 socket pair),来传递和请求 Vsync 事件,当 SurfaceFlinger 收到 Vsync 事件之后,通过 appEventThread 将这个事件通过 BitTube 传给 DisplayEventDispatcher ,DisplayEventDispatcher 通过 BitTube 的接收端监听到 Vsync 事件之后,回调 Choreographer.FrameDisplayEventReceiver.onVsync ,触发开始一帧的绘制,如下图
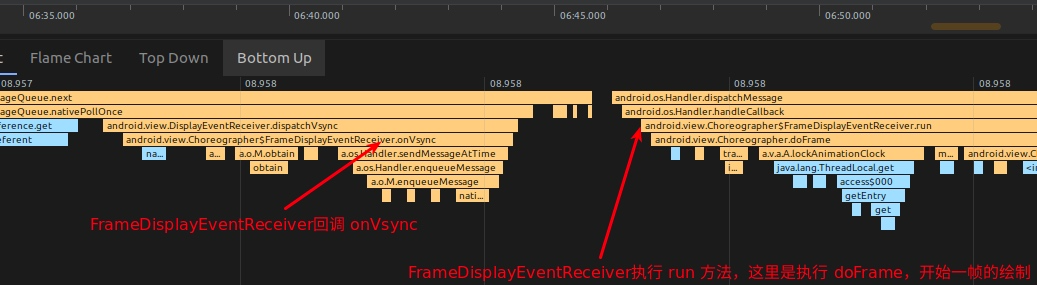
3.4 Choreographer 处理一帧的逻辑
Choreographer 处理绘制的逻辑核心在 Choreographer.doFrame 函数中,从下图可以看到,FrameDisplayEventReceiver.onVsync post 了自己,其 run 方法直接调用了 doFrame 开始一帧的逻辑处理
android/view/Choreographer.java
| 1 |
public void onVsync(long timestampNanos, long physicalDisplayId, int frame) {
|
doFrame 函数主要做下面几件事
- 计算掉帧逻辑
- 记录帧绘制信息
- 执行 CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_INSETS_ANIMATION、CALLBACK_TRAVERSAL、CALLBACK_COMMIT
计算掉帧逻辑
| 1 |
void doFrame(long frameTimeNanos, int frame) {
|
Choreographer.doFrame 的掉帧检测比较简单,从下图可以看到,Vsync 信号到来的时候会标记一个 start_time ,执行 doFrame 的时候标记一个 end_time ,这两个时间差就是 Vsync 处理时延,也就是掉帧
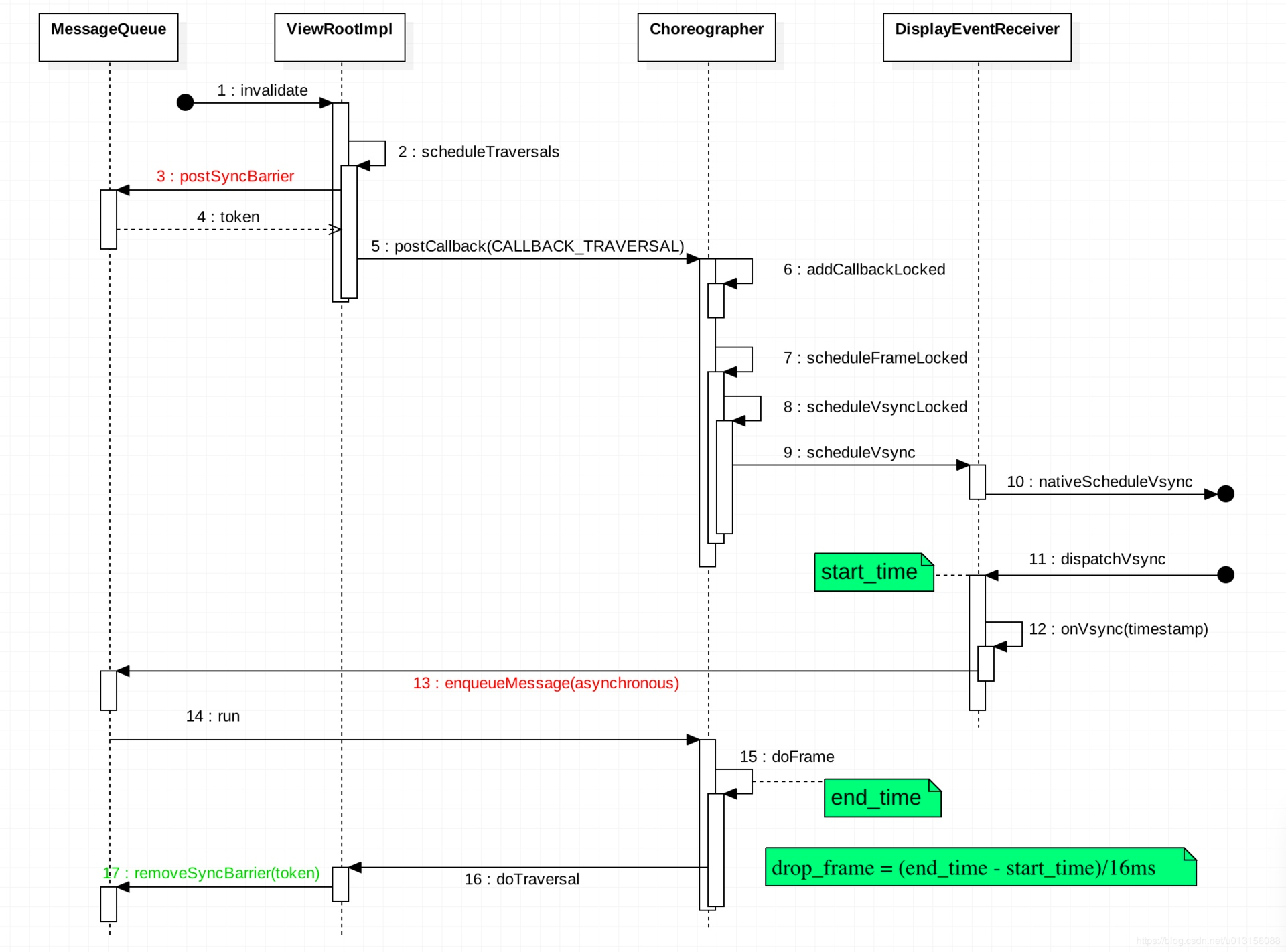
记录帧绘制信息
Choreographer 中 FrameInfo 来负责记录帧的绘制信息,doFrame 执行的时候,会把每一个关键节点的绘制时间记录下来,我们使用 dumpsys gfxinfo 就可以看到。当然 Choreographer 只是记录了一部分,剩余的部分在 hwui 那边来记录。
从 FrameInfo 这些标志就可以看出记录的内容,后面我们看 dumpsys gfxinfo 的时候数据就是按照这个来排列的
| 1 |
// Various flags set to provide extra metadata about the current frame |
doFrame 函数记录从 Vsync time 到 markPerformTraversalsStart 的时间
| 1 |
void doFrame(long frameTimeNanos, int frame) {
|
执行 Callbacks
| 1 |
void doFrame(long frameTimeNanos, int frame) {
|
Input 回调调用栈
input callback 一般是执行 ViewRootImpl.ConsumeBatchedInputRunnable
android/view/ViewRootImpl.java
| 1 |
final class ConsumeBatchedInputRunnable implements Runnable {
|
Input 时间经过处理,最终会传给 DecorView 的 dispatchTouchEvent,这就到了我们熟悉的 Input 事件分发
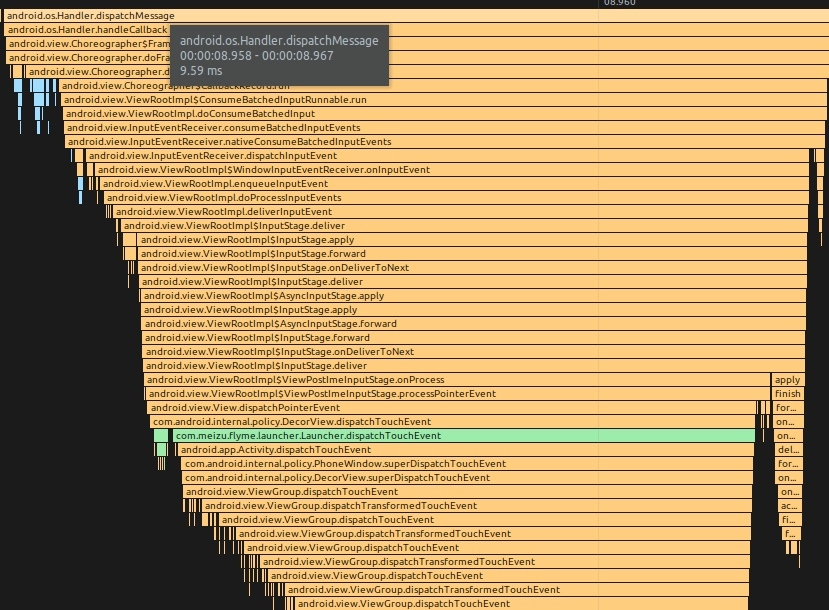
Animation 回调调用栈
一般我们接触的多的是调用 View.postOnAnimation 的时候,会使用到 CALLBACK_ANIMATION
| 1 |
public void postOnAnimation(Runnable action) {
|
那么一般是什么时候回调用到 View.postOnAnimation 呢,我截取了一张图,大家可以自己去看一下,接触最多的应该是 startScroll,Fling 这种操作
其调用栈根据其 post 的内容,下面是桌面滑动松手之后的 fling 动画。
另外我们的 Choreographer 的 FrameCallback 也是用的 CALLBACK_ANIMATION
| 1 |
public void postFrameCallbackDelayed(FrameCallback callback, long delayMillis) {
|
Traversal 调用栈
| 1 |
void scheduleTraversals() {
|
doTraversal 的 TraceView 示例
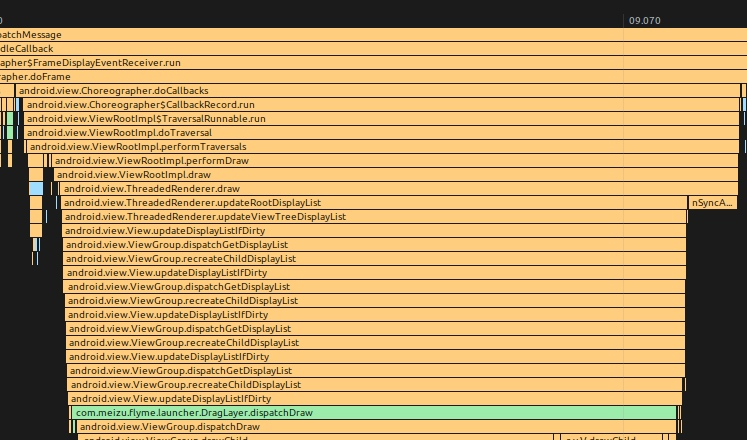
3.5 下一帧的 Vsync 请求
由于动画、滑动、Fling 这些操作的存在,我们需要一个连续的、稳定的帧率输出机制。这就涉及到了 Vsync 的请求逻辑,在连续的操作,比如动画、滑动、Fling 这些情况下,每一帧的 doFrame 的时候,都会根据情况触发下一个 Vsync 的申请,这样我们就可以获得连续的 Vsync 信号。
看下面的 scheduleTraversals 调用栈(scheduleTraversals 中会触发 Vsync 请求)
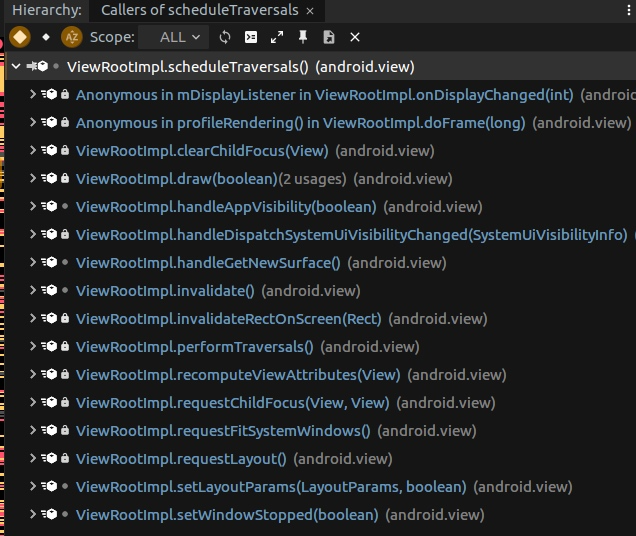
我们比较熟悉的 invalidate 和 requestLayout 都会触发 Vsync 信号请求
我们下面以 Animation 为例,看看 Animation 是如何驱动下一个 Vsync ,来持续更新画面的
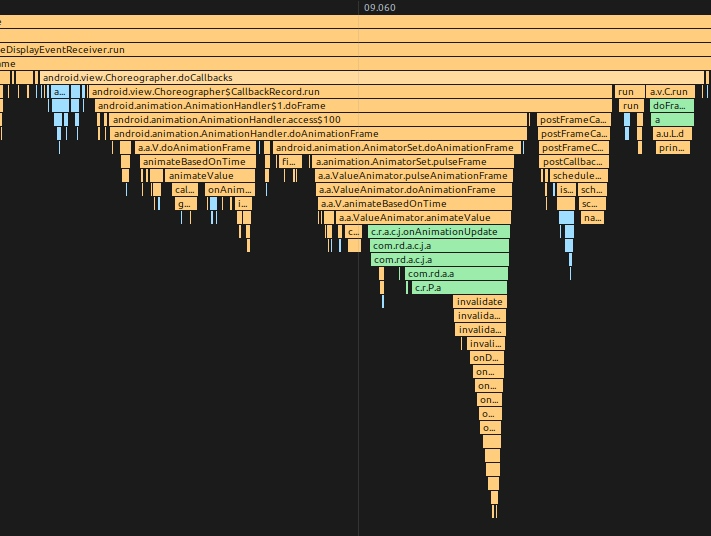
ObjectAnimator 动画驱动逻辑
android/animation/ObjectAnimator.java
| 1 |
public void start() {
|
android/animation/ValueAnimator.java
| 1 |
private void start(boolean playBackwards) {
|
android/animation/AnimationHandler.java
| 1 |
public void addAnimationFrameCallback(final AnimationFrameCallback callback, long delay) {
|
调用 postFrameCallback 会走到 mChoreographer.postFrameCallback ,这里就会触发 Choreographer 的 Vsync 请求逻辑
android/animation/AnimationHandler.java
| 1 |
public void postFrameCallback(Choreographer.FrameCallback callback) {
|
android/view/Choreographer.java
| 1 |
private void postCallbackDelayedInternal(int callbackType, |
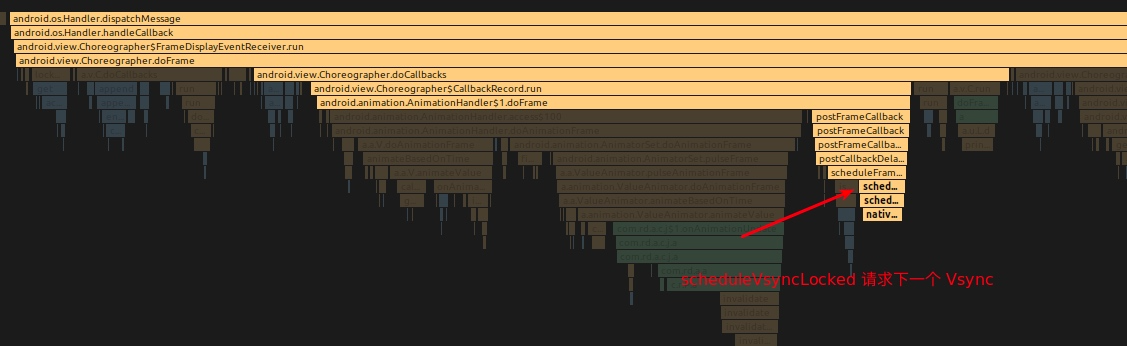
通过上面的 Animation.start 设置,利用了 Choreographer.FrameCallback 接口,每一帧都去请求下一个 Vsync
动画过程中一帧的 TraceView 示例
3.6 源码小结
- Choreographer 是线程单例的,而且必须要和一个 Looper 绑定,因为其内部有一个 Handler 需要和 Looper 绑定,一般是 App 主线程的 Looper 绑定
- DisplayEventReceiver 是一个 abstract class,其 JNI 的代码部分会创建一个IDisplayEventConnection 的 Vsync 监听者对象。这样,来自 AppEventThread 的 VSYNC 中断信号就可以传递给 Choreographer 对象了。当 Vsync 信号到来时,DisplayEventReceiver 的 onVsync 函数将被调用。
- DisplayEventReceiver 还有一个 scheduleVsync 函数。当应用需要绘制UI时,将首先申请一次 Vsync 中断,然后再在中断处理的 onVsync 函数去进行绘制。
- Choreographer 定义了一个 FrameCallback interface,每当 Vsync 到来时,其 doFrame 函数将被调用。这个接口对 Android Animation 的实现起了很大的帮助作用。以前都是自己控制时间,现在终于有了固定的时间中断。
- Choreographer 的主要功能是,当收到 Vsync 信号时,去调用使用者通过 postCallback 设置的回调函数。目前一共定义了五种类型的回调,它们分别是:
-
- CALLBACK_INPUT : 处理输入事件处理有关
- CALLBACK_ANIMATION : 处理 Animation 的处理有关
- CALLBACK_INSETS_ANIMATION : 处理 Insets Animation 的相关回调
- CALLBACK_TRAVERSAL : 处理和 UI 等控件绘制有关
- CALLBACK_COMMIT : 处理 Commit 相关回调,主要是是用于执行组件 Application/Activity/Service 的 onTrimMemory,在 ApplicationThread 的 scheduleTrimMemory 方法中向 Choreographer 插入的;另外这个 Callback 也提供了一个监测一帧耗时的时机
- ListView 的 Item 初始化(obtain\setup) 会在 input 里面也会在 animation 里面,这取决于
- CALLBACK_INPUT 、CALLBACK_ANIMATION 会修改 view 的属性,所以要先与 CALLBACK_TRAVERSAL 执行
4、APM 与 Choreographer
由于 Choreographer 的位置,许多性能监控的手段都是利用 Choreographer 来做的,除了自带的掉帧计算,Choreographer 提供的 FrameCallback 和 FrameInfo 都给 App 暴露了接口,让 App 开发者可以通过这些方法监控自身 App 的性能,其中常用的方法如下:
- 利用 FrameCallback 的 doFrame 回调
- 利用 FrameInfo 进行监控
-
- 使用 :adb shell dumpsys gfxinfo framestats
- 示例 :adb shell dumpsys gfxinfo com.meizu.flyme.launcher framestats
- 利用 SurfaceFlinger 进行监控
-
- 使用 :adb shell dumpsys SurfaceFlinger –latency
- 示例 :adb shell dumpsys SurfaceFlinger –latency com.meizu.flyme.launcher/com.meizu.flyme.launcher.Launcher#0
- 利用 SurfaceFlinger PageFlip 机制进行监控
-
- 使用 : adb service call SurfaceFlinger 1013
- 备注:需要系统权限
- Choreographer 自身的掉帧计算逻辑
- BlockCanary 基于 Looper 的性能监控
4.1 利用 FrameCallback 的 doFrame 回调
FrameCallback 接口
| 1 |
public interface FrameCallback {
|
接口使用
| 1 |
Choreographer.getInstance().postFrameCallback(youOwnFrameCallback ); |
接口处理
| 1 |
public void postFrameCallbackDelayed(FrameCallback callback, long delayMillis) {
|
4.2 利用 FrameInfo 进行监控
adb shell dumpsys gfxinfo framestats
| 1 |
Window: StatusBar |
4.3 利用 SurfaceFlinger 进行监控
命令解释:
- 数据的单位是纳秒,时间是以开机时间为起始点
- 每一次的命令都会得到128行的帧相关的数据
数据:
- 第一行数据,表示刷新的时间间隔refresh_period
- 第1列:这一部分的数据表示应用程序绘制图像的时间点
- 第2列:在SF(软件)将帧提交给H/W(硬件)绘制之前的垂直同步时间,也就是每帧绘制完提交到硬件的时间戳,该列就是垂直同步的时间戳
- 第3列:在SF将帧提交给H/W的时间点,算是H/W接受完SF发来数据的时间点,绘制完成的时间点。
掉帧 jank 计算
每一行都可以通过下面的公式得到一个值,该值是一个标准,我们称为jankflag,如果当前行的jankflag与上一行的jankflag发生改变,那么就叫掉帧
ceil((C - A) / refresh-period)
4.4 利用 SurfaceFlinger PageFlip 机制进行监控
| 1 |
Parcel data = Parcel.obtain(); |
4.5 Choreographer 自身的掉帧计算逻辑
SKIPPED_FRAME_WARNING_LIMIT 默认为30 , 由 debug.choreographer.skipwarning 这个属性控制
| 1 |
if (jitterNanos >= mFrameIntervalNanos) {
|
4.6 BlockCanary
Blockcanary 做性能监控使用的是 Looper 的消息机制,通过对 MessageQueue 中每一个 Message 的前后进行记录,打到监控性能的目的
android/os/Looper.java
| 1 |
public static void loop() {
|
5、MessageQueue 与 Choreographer
所谓的异步消息其实就是这样的,我们可以通过 enqueueBarrier 往消息队列中插入一个 Barrier,那么队列中执行时间在这个 Barrier 以后的同步消息都会被这个 Barrier 拦截住无法执行,直到我们调用 removeBarrier 移除了这个 Barrier,而异步消息则没有影响,消息默认就是同步消息,除非我们调用了 Message 的 setAsynchronous,这个方法是隐藏的。只有在初始化 Handler 时通过参数指定往这个 Handler 发送的消息都是异步的,这样在 Handler 的 enqueueMessage 中就会调用 Message 的 setAsynchronous 设置消息是异步的,从上面 Handler.enqueueMessage 的代码中可以看到。
所谓异步消息,其实只有一个作用,就是在设置 Barrier 时仍可以不受 Barrier 的影响被正常处理,如果没有设置 Barrier,异步消息就与同步消息没有区别,可以通过 removeSyncBarrier 移除 Barrier
5.1 SyncBarrier 在 Choreographer 中使用的一个示例
scheduleTraversals 的时候 postSyncBarrier
| 1 |
void scheduleTraversals() {
|
doTraversal 的时候 removeSyncBarrier
| 1 |
void doTraversal() {
|
Choreographer post Message 的时候,会把这些消息设为 Asynchronous ,这样 Choreographer 中的这些 Message 的优先级就会比较高,
| 1 |
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action); |
五、SystemServer
1、窗口动画
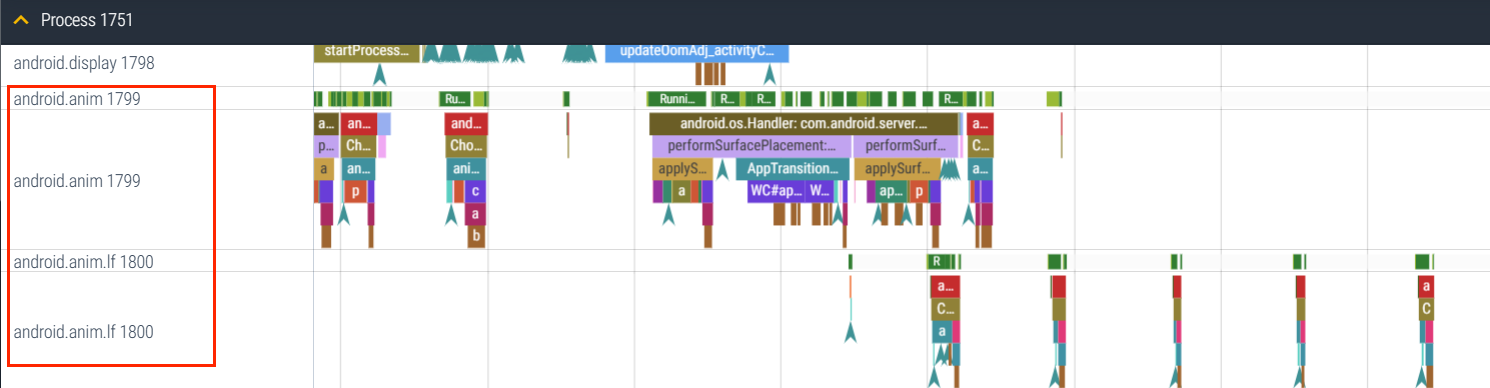
Systrace 中的 SystemServer 一个比较重要的地方就是窗口动画,由于窗口归 SystemServer 来管,那么窗口动画也就是由 SystemServer 来进行统一的处理,其中涉及到两个比较重要的线程,Android.Anim 和 Android.Anim.if 这两个线程。
2、ActivityManagerService
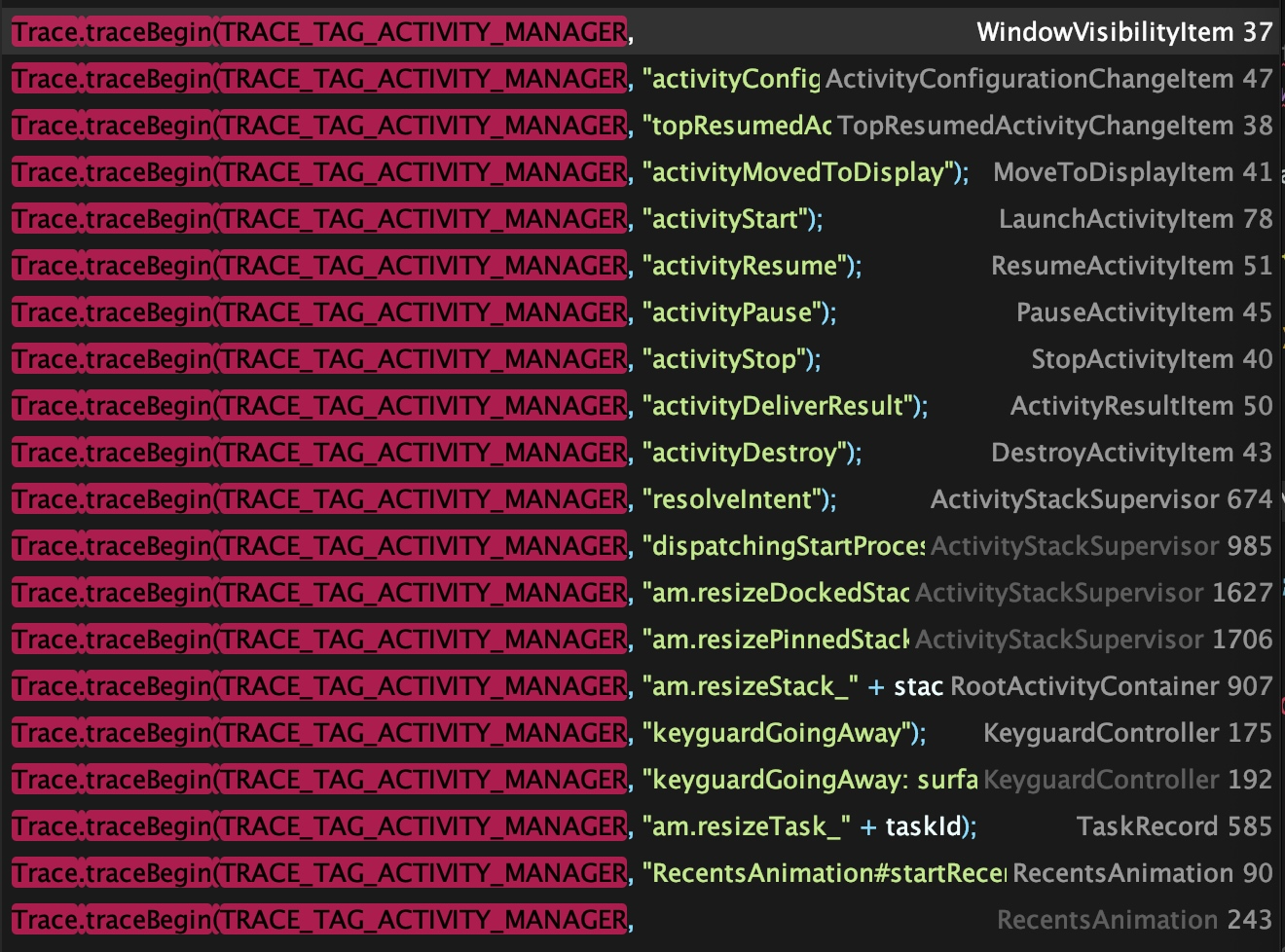
AMS 和 WMS 算是 SystemServer 中最繁忙的两个 Service 了,与 AMS 相关的 Trace 一般会用 TRACE_TAG_ACTIVITY_MANAGER 这个 TAG,在 Systrace 中的名字是 ActivityManager
下面是启动一个新的进程的时候,AMS 的输出
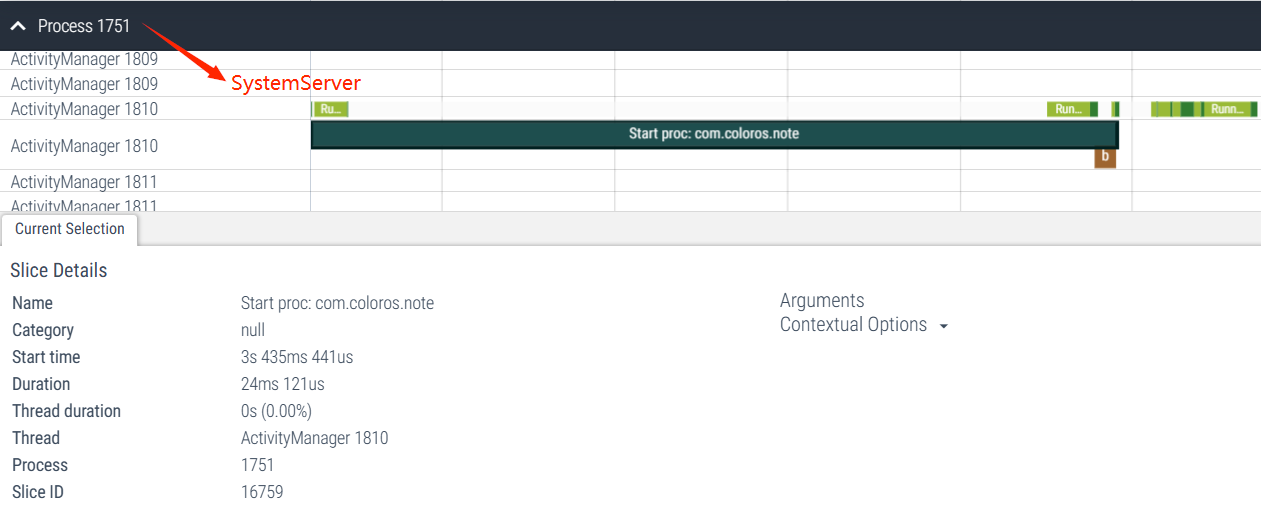
在进程和四大组件的各种场景一般都会有对应的 Trace 点来记录,比如大家熟悉的 ActivityStart、ActivityResume、activityStop 等,这些 Trace 点有一些在应用进程,有一些在 SystemServer 进程,所以大家在看 Activity 相关的代码逻辑的时候,需要不断在这两个进程之间进行切换,这样才能从一个整体的角度来看应用的状态变化和 SystemServer 在其中起到的作用。
3、WindowManagerService
与 WMS 相关的 Trace 一般会用 TRACE_TAG_WINDOW_MANAGER 这个 TAG,在 Systrace 中 WindowManagerService 在 SystemServer 中多在对应的 Binder 中出现,比如下面应用启动的时候,relayoutWindow 的 Trace 输出
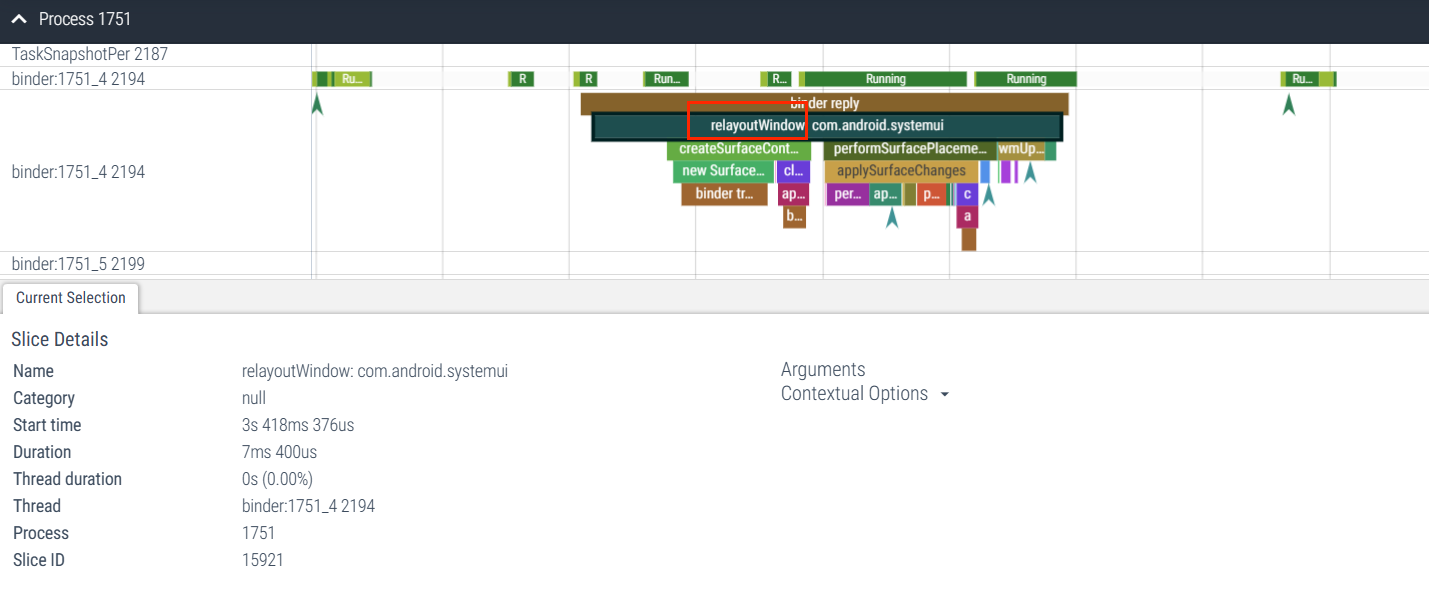
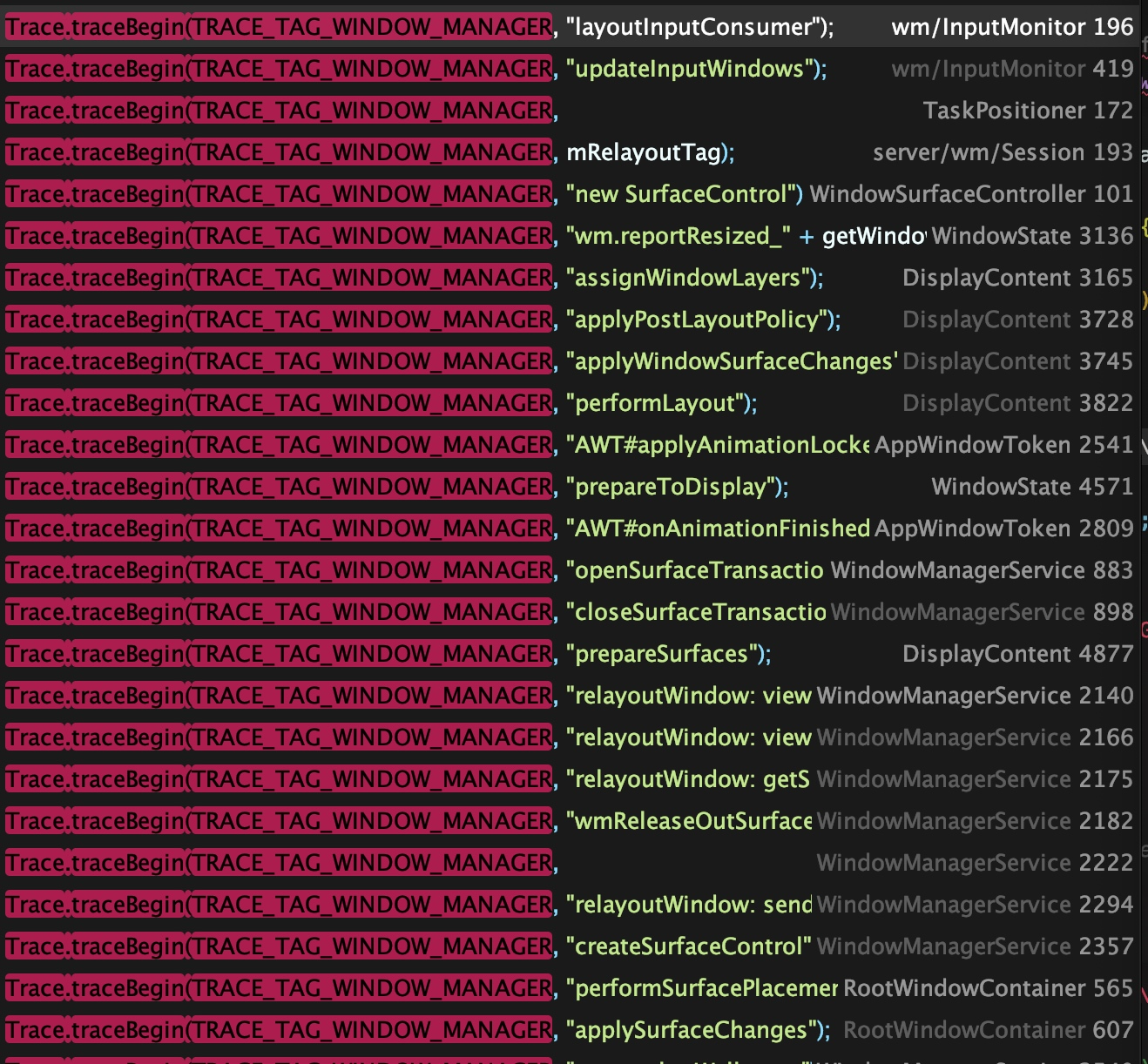
在 Window 的各种场景一般都会有对应的 Trace 点来记录,比如大家熟悉的 relayoutWIndow、performLayout、prepareToDisplay 等
4、Input
4.1 input在Perfetto的实现流程
下面这张图是一个概览图,以滑动推特app为例 (滑动应用包括一个 Input_Down 事件 + 若干个 Input_Move 事件 + 一个 Input_Up 事件,这些事件和事件流都会在 Perfetto 上有所体现,这也是我们分析 Perfetto 的一个重要的切入点),主要牵扯到的模块是 SystemServer 和 App 模块,下图是他们各个区域在Perfetto上表现
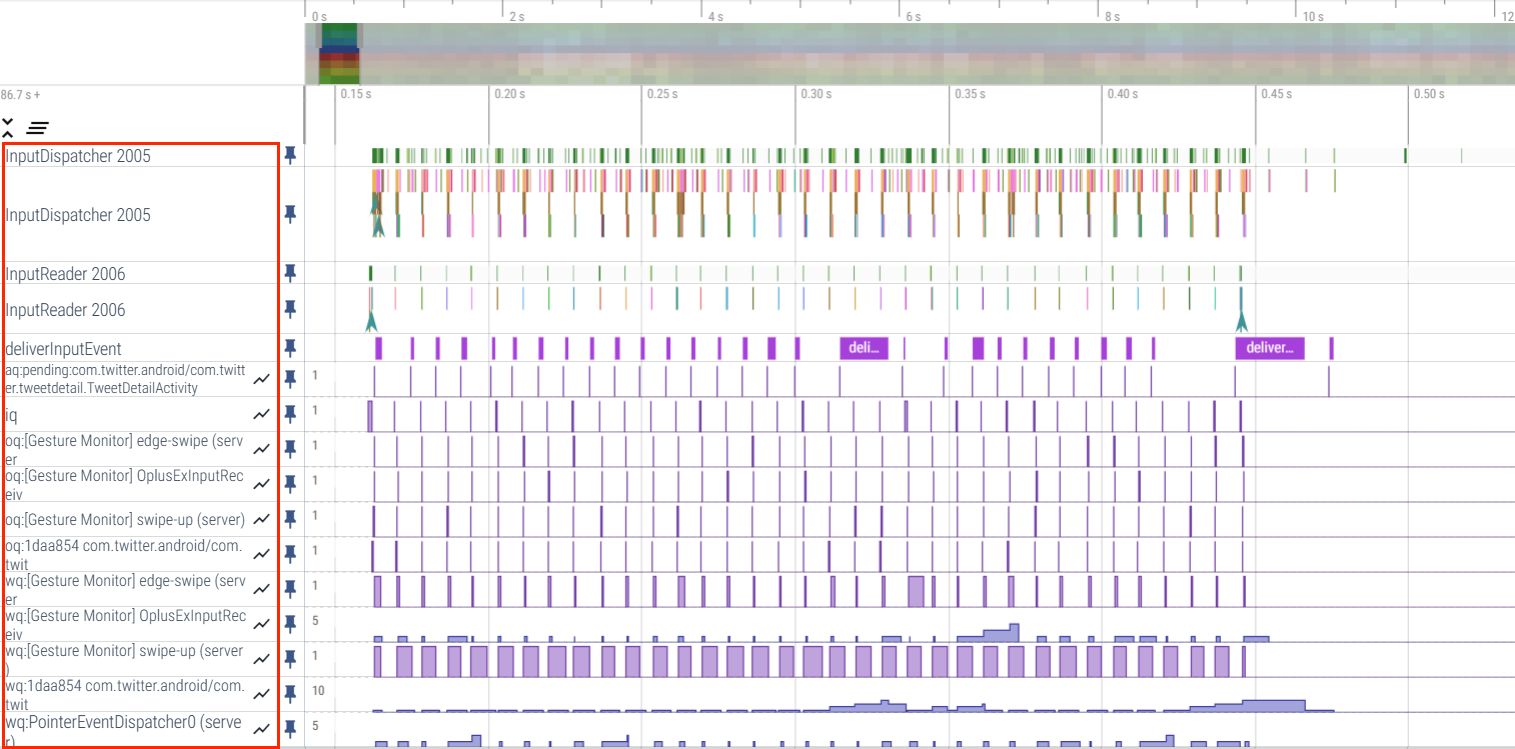
放大后Input在Perfetto上的表现
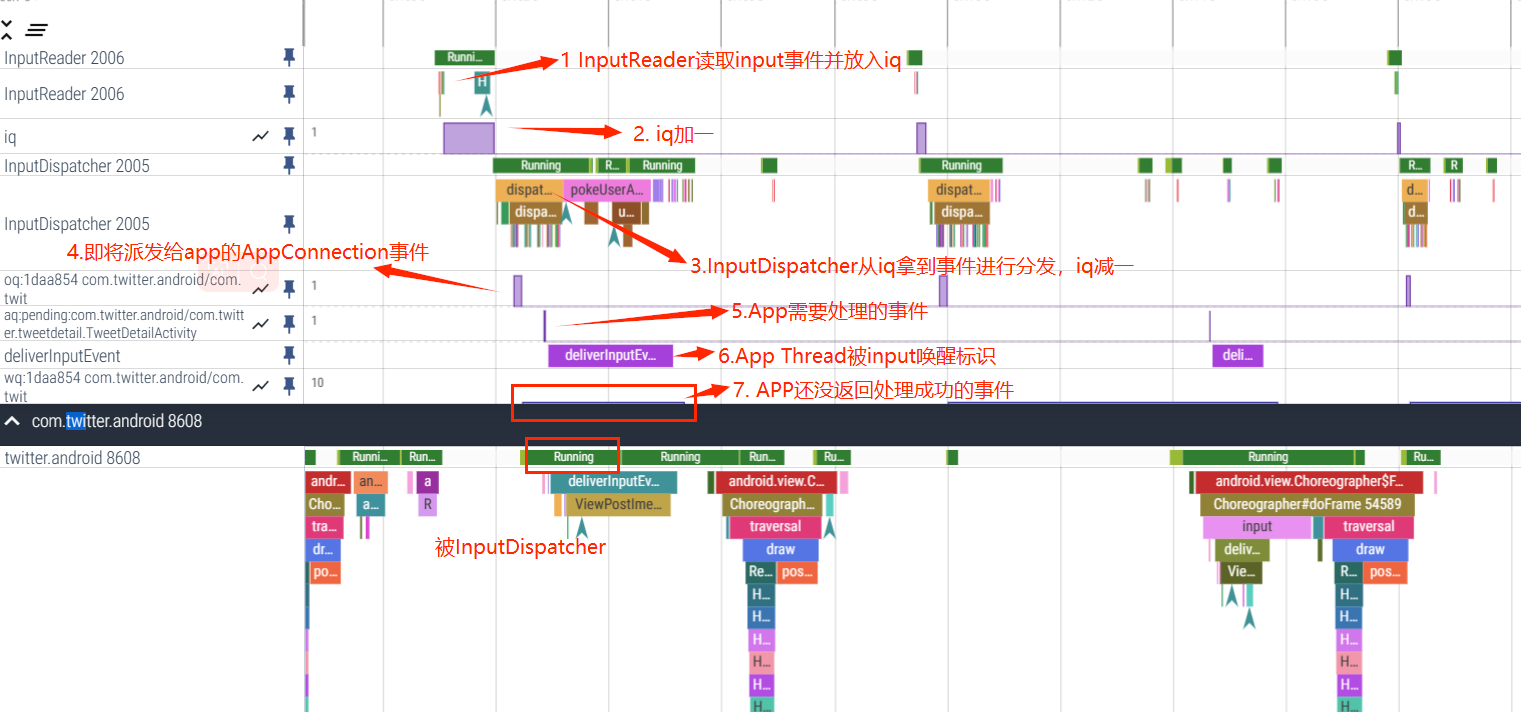
InputReader 和 InputDispatcher 是跑在 SystemServer 里面的两个 Native 线程,负责读取和分发 Input 事件,我们分析 Perfetto 的 Input 事件流,首先是找到这里。下面针对上图中标号进行简单说明
1.触摸屏每隔几毫秒扫描一次,如果有触摸事件,那么把事件上报到对应的驱动
2.InputReader 负责从 EventHub 里面把 Input 事件读取出来,放到 InboundQueue 中然后交给 InputDispatcher 进行事件分发
3.InputDispatcher 从 InboundQueue 中取出 Input 事件进行包装然后派发到各个 App(连接) 的 OutBoundQueue ,同时将事件记录到各个 App(连接) 的 WaitQueue。
4.App 接收到 Input 事件,同时记录到 PendingInputEventQueue ,然后对事件进行分发处理
5.App 处理完成后,回调 InputManagerService 将负责监听的 WaitQueue 中对应的 Input 移除
注:
OutboundQueue 里面放的是即将要被派发给对应 AppConnection 的事件
WaitQueue 里面记录的是已经派发给 AppConnection 但是 App 还在处理没有返回处理成功的事件
deliverInputEvent 标识 App UI Thread 被 Input 事件唤醒
PendingInputEventQueue 里面记录的是 App 需要处理的 Input 事件,这里可以看到已经到了应用进程 。
通过上面的流程,一次 Input 事件就被消耗掉了(当然这只是正常情况,还有很多异常情况、细节处理,这里就不细说了,自己看相关流程的时候可以深挖一下)
① InputReader
InputReader 是一个 Native 线程,跑在 SystemServer 进程里面,其核心功能是从 EventHub 读取事件、进行加工、将加工好的事件发送到 InputDispatcher
InputReader Loop 流程如下
- getEvents:通过 EventHub (监听目录 /dev/input )读取事件放入 mEventBuffer ,而mEventBuffer 是一个大小为256的数组, 再将事件 input_event 转换为 RawEvent
- processEventsLocked: 对事件进行加工, 转换 RawEvent -> NotifyKeyArgs(NotifyArgs)
- QueuedListener->flush:将事件发送到 InputDispatcher 线程, 转换 NotifyKeyArgs -> KeyEntry(EventEntry)
核心代码 loopOnce 处理流程如下:

InputReader 核心 Loop 函数 loopOnce 逻辑如下
| 1 |
void InputReader::loopOnce() {
|
② InputDispatcher
上面的 InputReader 调用 mQueuedListener->flush 之后 ,将 Input 事件加入到InputDispatcher 的 mInboundQueue ,然后唤醒 InputDispatcher
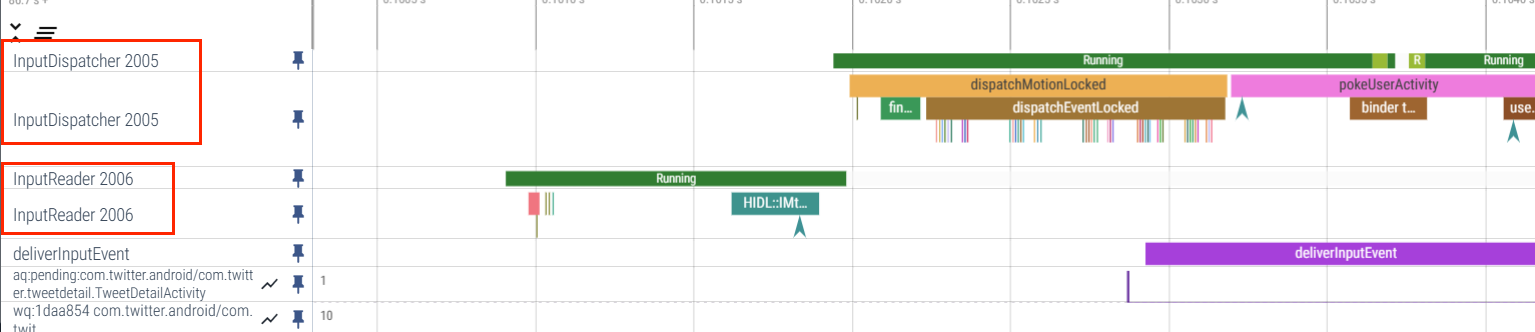
InputDispatcher 的核心逻辑如下:
- dispatchOnceInnerLocked(): 从 InputDispatcher 的 mInboundQueue 队列,取出事件 EventEntry。另外该方法开始执行的时间点 (currentTime) 便是后续事件 dispatchEntry 的分发时间 (deliveryTime)
- dispatchKeyLocked():满足一定条件时会添加命令 doInterceptKeyBeforeDispatchingLockedInterruptible;
- enqueueDispatchEntryLocked():生成事件 DispatchEntry 并加入 connection 的 outbound 队列
- startDispatchCycleLocked():从 outboundQueue 中取出事件 DispatchEntry, 重新放入 connection 的 waitQueue 队列;
- InputChannel.sendMessage 通过 socket 方式将消息发送给远程进程;
- runCommandsLockedInterruptible():通过循环遍历的方式,依次处理 mCommandQueue 队列中的所有命令。而 mCommandQueue 队列中的命令是通过 postCommandLocked() 方式向该队列添加的。
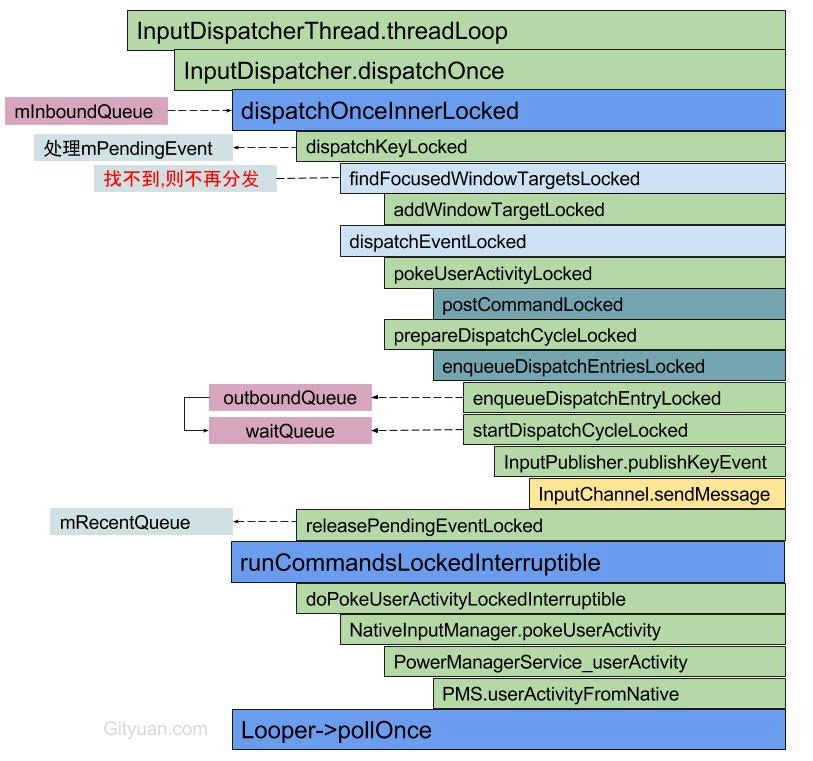
其核心处理逻辑在 dispatchOnceInnerLocked 这里
| 1 |
void InputDispatcher::dispatchOnceInnerLocked(nsecs_t* nextWakeupTime) {
|
③ InboundQueue
InputDispatcher 执行 notifyKey 的时候,会将 Input 事件封装后放到 InboundQueue 中,后续 InputDispatcher 循环处理 Input 事件的时候,就是从 InboundQueue 取出事件然后做处理
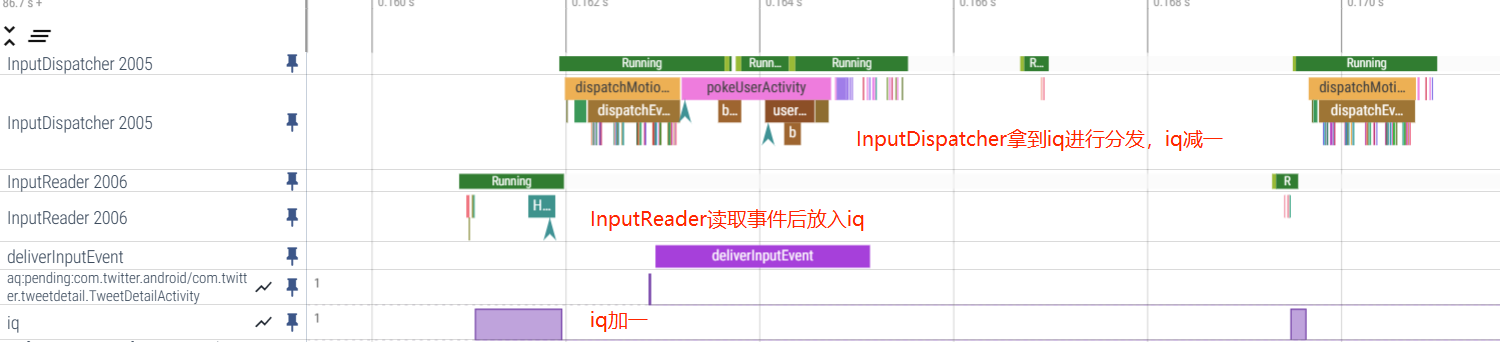
④ OutboundQueue
Outbound 意思是出站,这里的 OutboundQueue 指的是要被 App 拿去处理的事件队列,每一个 App(Connection) 都对应有一个 OutboundQueue ,从 InboundQueue 那一节的图来看,事件会先进入 InboundQueue ,然后被 InputDIspatcher 派发到各个 App 的 OutboundQueue
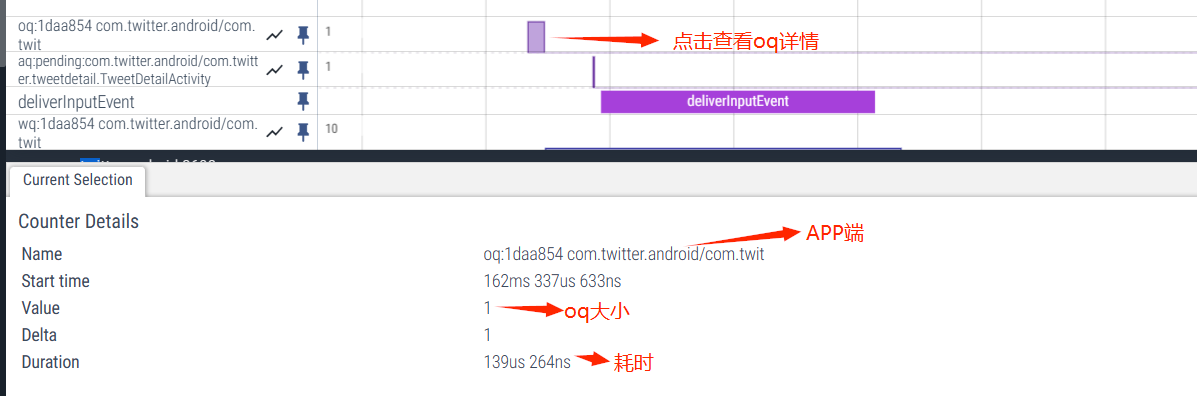
⑤ waitQueue
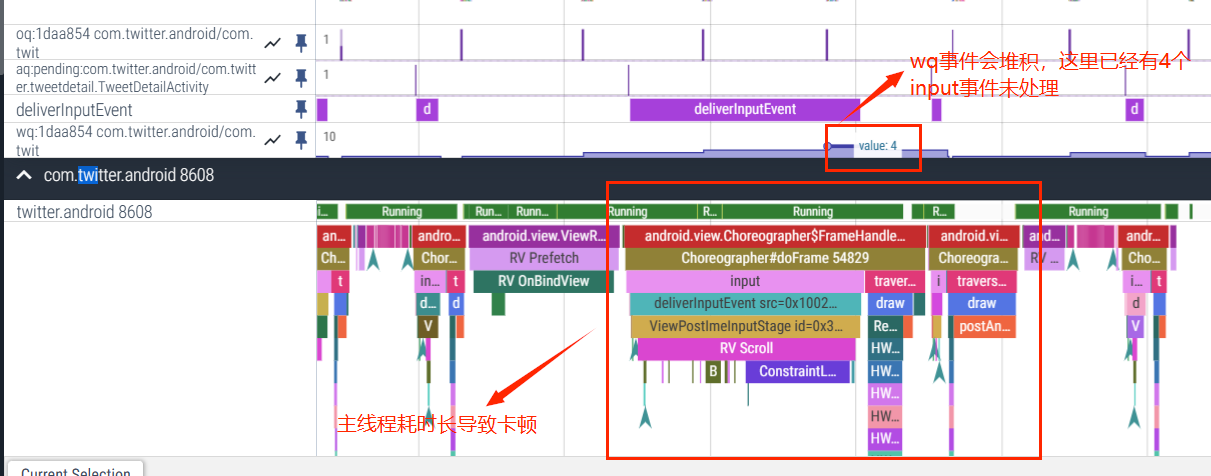
当 InputDispatcher 将 Input 事件分发出去之后,将 DispatchEntry 从 outboundQueue 中取出来放到 WaitQueue 中,当 publish 出去的事件被处理完成(finished),InputManagerService 就会从应用中得到一个回复,此时就会取出 WaitQueue 中的事件,从 Perfetto 中看就是对应 App 的 WaitQueue 减少
如果主线程发生卡顿,那么 Input 事件没有及时被消耗,也会在 WaitQueue 这里体现出来,如下图:
4.2 Input 刷新与 Vsync
Input 的刷新取决于触摸屏的采样,目前比较多的屏幕采样率是 120Hz,对应就是 8.3ms 采样一次,我们来看一下其在 Perfetto 上的展示
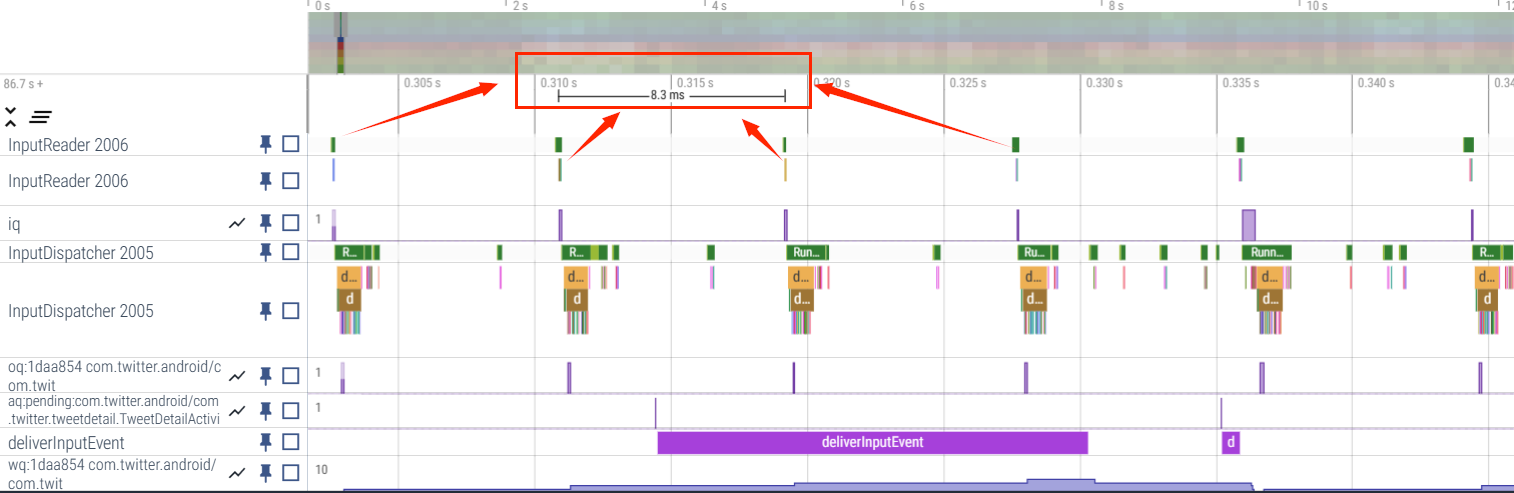
可以看到上图中, InputReader 每隔 8.3ms 就可以读上来一个数据,交给 InputDispatcher 去分发给 App ,那么是不是屏幕采样率越高越好呢?也不一定,比如上面那张图,虽然 InputReader 每隔 8.3ms 就可以读上来一个数据给 InputDispatcher 去分发给 App ,但是从 WaitQueue 的表现来看,应用并没有消耗这个 Input 事件,这是为什么呢?
原因在于应用消耗 Input 事件的时机是 Vsync 信号来了之后,刷新率为 60Hz 的屏幕,一般系统也是 60 fps ,也就是说两个 Vsync 的间隔在 16.6ms ,这期间如果有两个或者三个 Input 事件,那么必然有一个或者两个要被抛弃掉,只拿最新的那个。也就是说:
- 在屏幕刷新率和系统 FPS 都是 60 的时候,盲目提高触摸屏的采样率,是没有太大的效果的,反而有可能出现上面图中那样,有的 Vsync 周期中有两个 Input 事件,而有的 Vsync 周期中有三个 Input 事件,这样造成事件不均匀,可能会使 UI 产生抖动
- 在屏幕刷新率和系统 FPS 都是 60 的时候,使用 120Hz 采样率的触摸屏就可以了
- 如果在屏幕刷新率和系统 FPS 都是 90 的时候 ,那么 120Hz 采样率的触摸屏显然不够用了,这时候应该采用 180Hz 采样率的屏幕
4.3 Input 调试信息
Dumpsys Input 主要是 Debug 用,我们也可以来看一下其中的一些关键信息,到时候遇到了问题也可以从这里面找 , 其命令如下:
| 1 |
adb shell dumpsys input |
其中的输出比较多,我们终点截取 Device 信息、InputReader、InputDispatcher 三段来看就可以了
① Device 信息
主要是目前连接上的 Device 信息,下面摘取的是 touch 相关的
| 1 |
3: main_touch |
② Input Reader 状态
InputReader 这里就是当前 Input 事件的一些展示
| 1 |
Device 3: main_touch |
③ InputDispatcher 状态
InputDispatch 这里的重要信息主要包括
- FocusedApplication :当前获取焦点的应用
- FocusedWindow : 当前获取焦点的窗口
- TouchStatesByDisplay
- Windows :所有的 Window
- MonitoringChannels :Window 对应的 Channel
- Connections :所有的连接
- AppSwitch: not pending
- Configuration
| 1 |
Input Dispatcher State: |
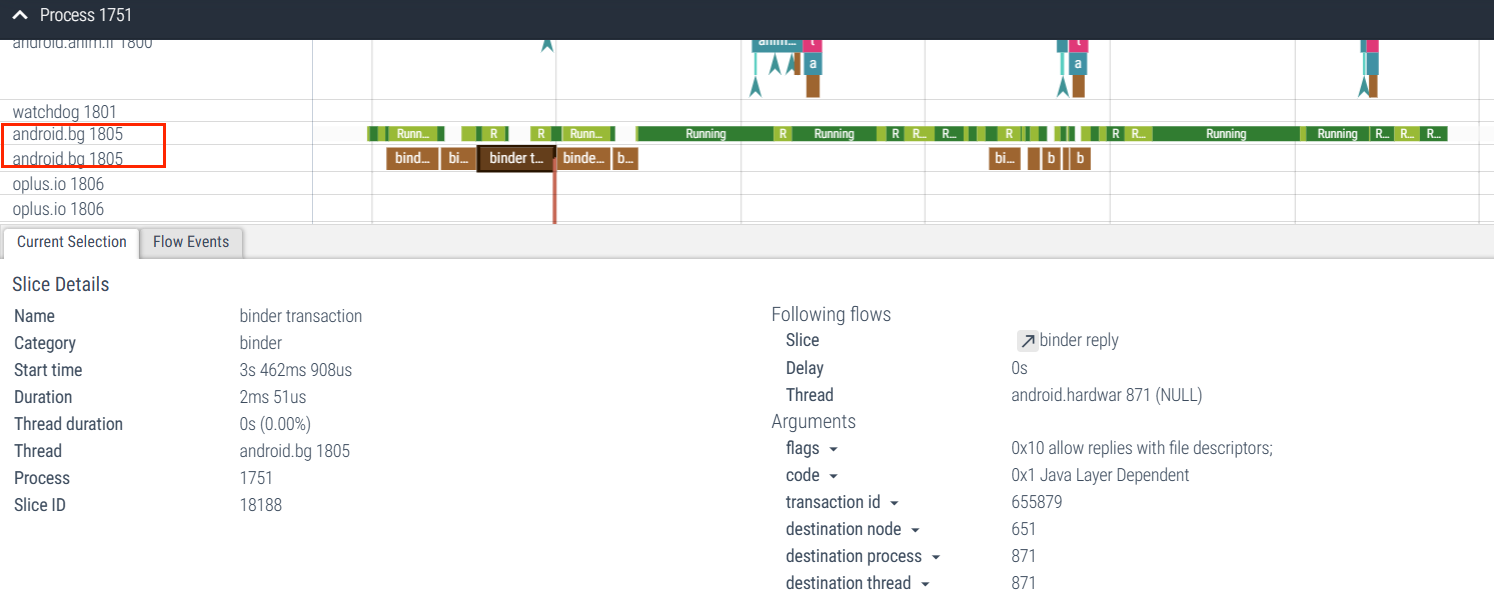
5、Binder
很多卡顿问题和响应速度的问题,是因为跨进程 binder 通信的时候,锁竞争导致 binder 通信事件变长,影响了调用端。最常见的就是应用渲染线程 dequeueBuffer 的时候 SurfaceFlinger 主线程阻塞导致 dequeueBuffer 耗时,从而导致应用渲染出现卡顿; 或者 SystemServer 中的 AMS 或者 WMS 持锁方法等待太多, 导致应用调用的时候等待时间比较长导致主线程卡顿
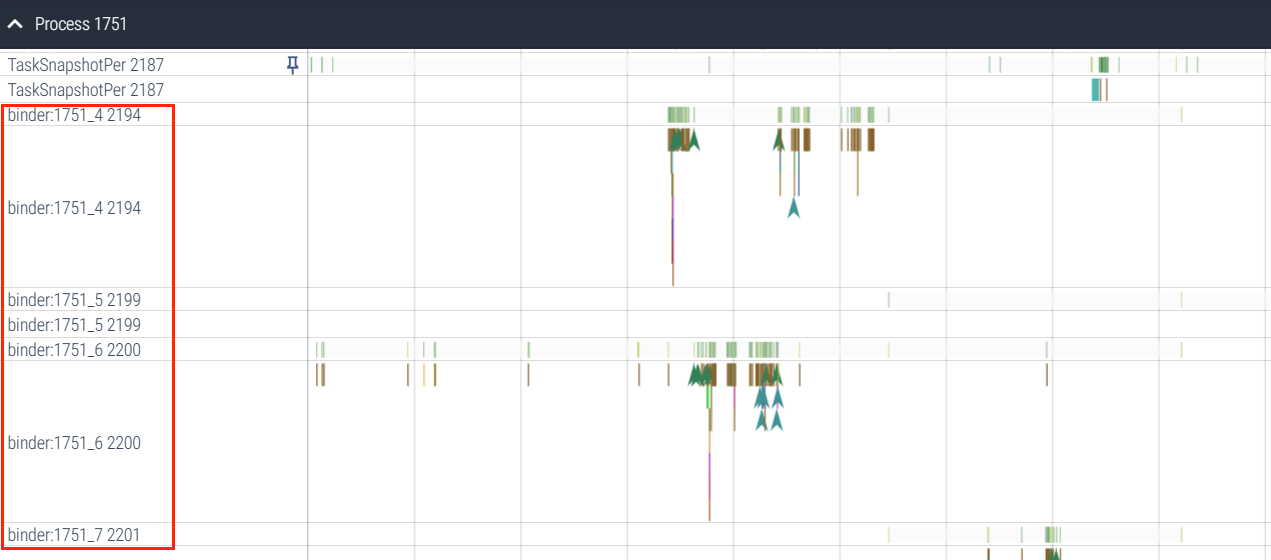
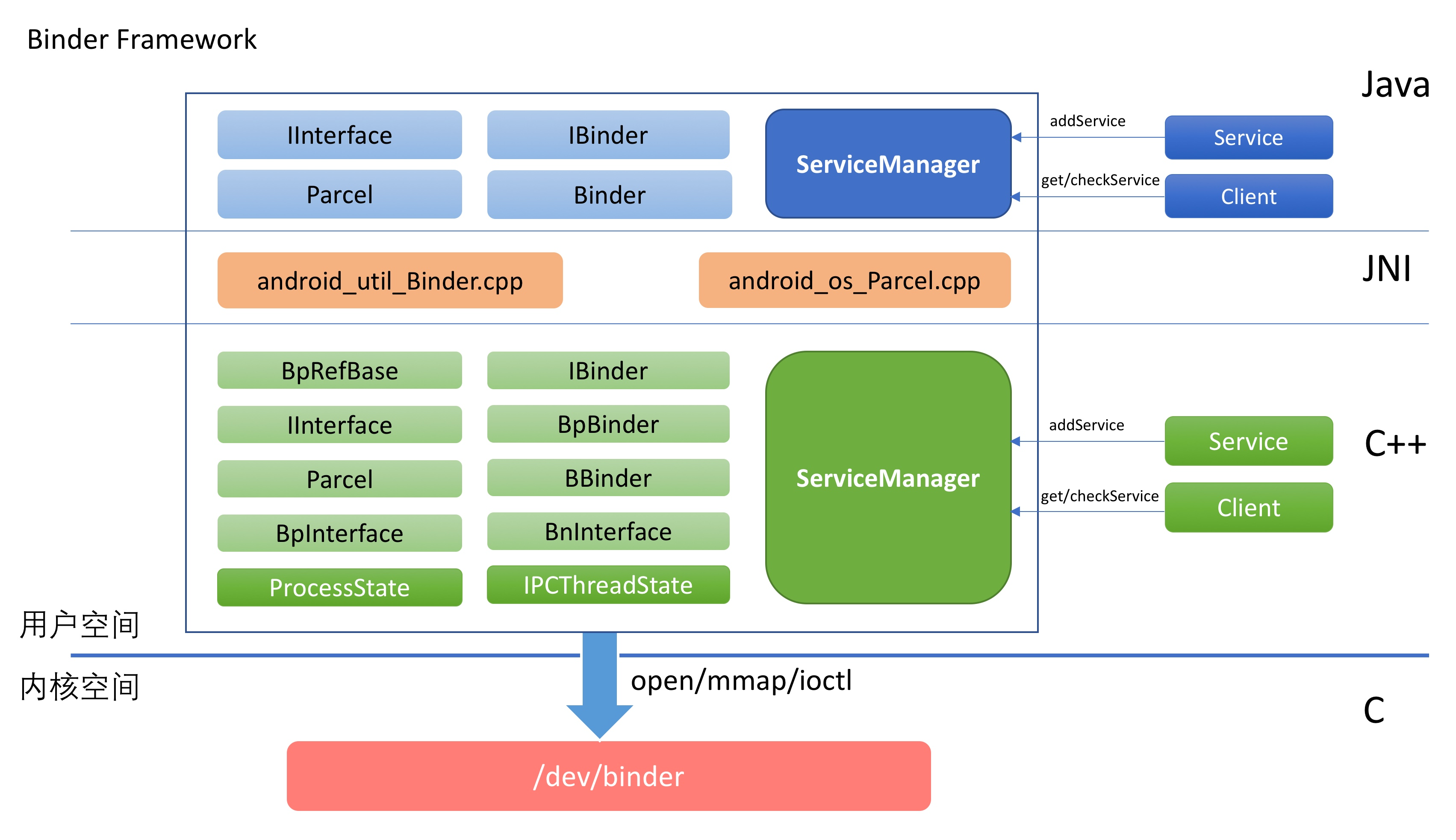
5.1 Binder 架构图
5.2 Binder调用图解
Binder 主要是用来跨进程进行通信,可以看下面这张图,简单显示了在 Perfetto 中 ,Binder 通信是如何显示的
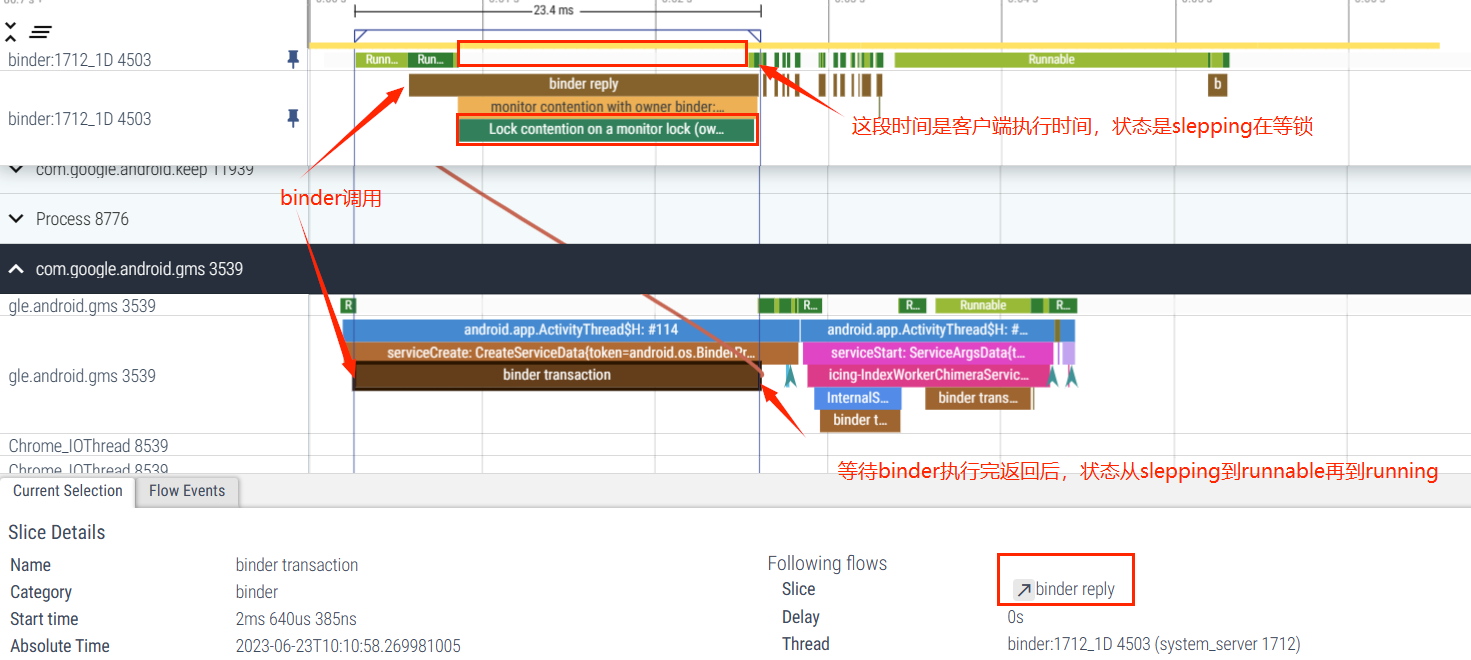
点击 Binder 可以查看其详细信息,其中有的信息在分析问题的时候可以用到,这里不做过多的描述
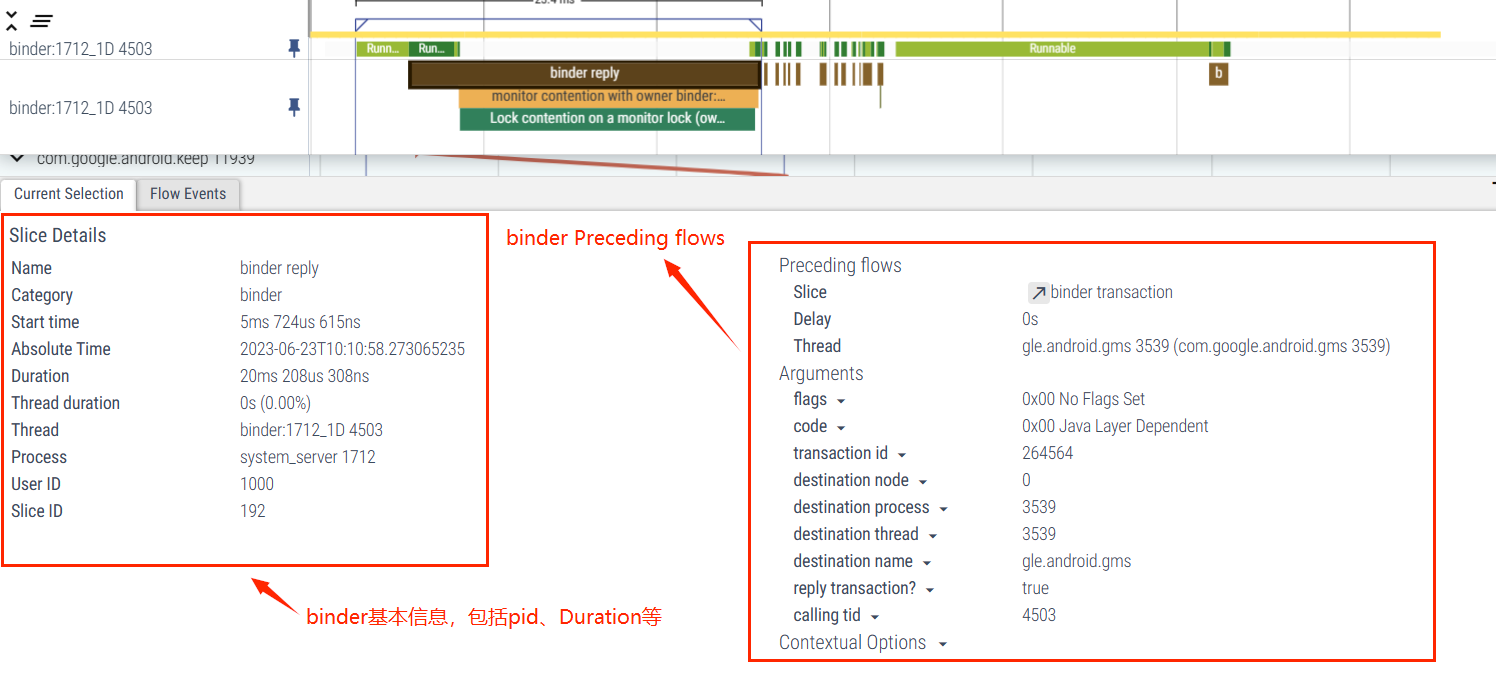
5.3 Binder 持锁图解
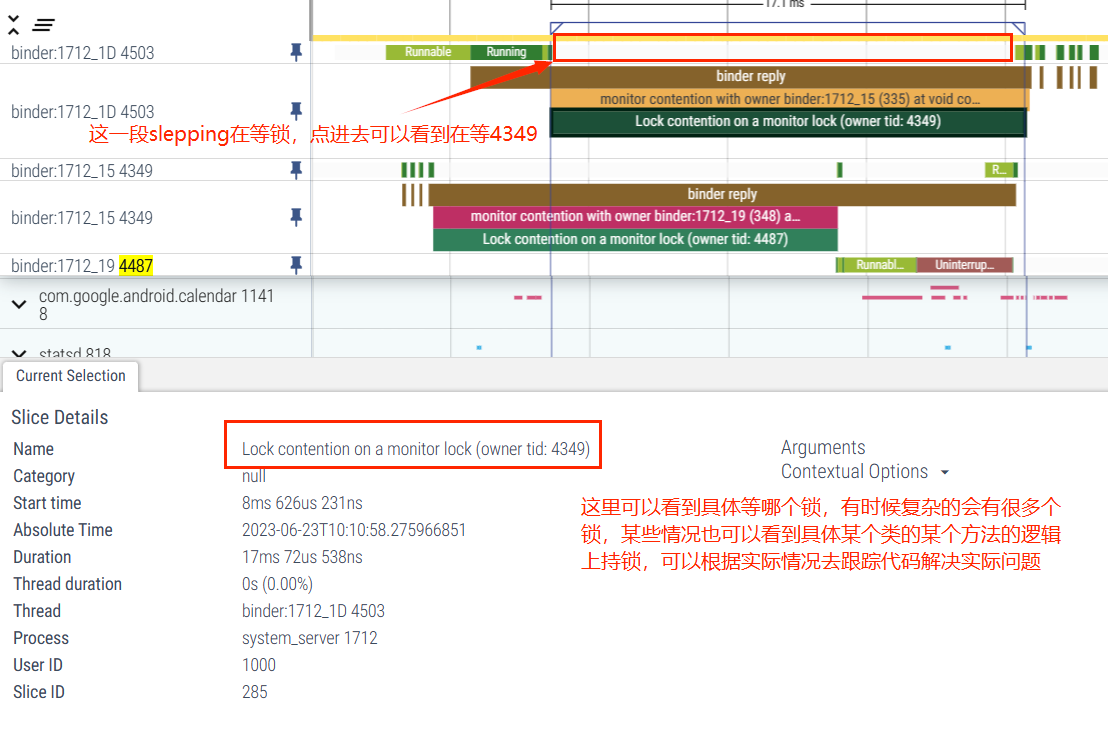
Monitor 指的是当前锁对象的池,在 Java 中,每个对象都有两个池,锁(monitor)池和等待池:
锁池(同步队列 SynchronizedQueue ):假设线程 A 已经拥有了某个对象(注意:不是类 )的锁,而其它的线程想要调用这个对象的某个 synchronized 方法(或者 synchronized 块),由于这些线程在进入对象的 synchronized 方法之前必须先获得该对象的锁的拥有权,但是该对象的锁目前正被线程 A 拥有,所以这些线程就进入了该对象的锁池中。
这里用了争夺(contention)这个词,意思是这里由于在和目前对象的锁正被其他对象(Owner)所持有,所以没法得到该对象的锁的拥有权,所以进入该对象的锁池
Owner : 指的是当前拥有这个对象的锁的对象。这里是 Binder:1605_B,4667 是其线程 ID。
6、HandlerThread
6.1 BackgroundThread
com/android/internal/os/BackgroundThread.java
| 1 |
private BackgroundThread() {
|
Systrace 中的 BackgroundThread
BackgroundThread 在系统中使用比较多,许多对性能没有要求的任务,一般都会放到 BackgroundThread 中去执行
7、ServiceThread
ServiceThread 继承自 HandlerThread ,下面介绍的几个工作线程都是继承自 ServiceThread ,分别实现不同的功能,根据线程功能不同,其线程优先级也不同:UIThread、IoThread、DisplayThread、AnimationThread、FgThread、SurfaceAnimationThread
每个 Thread 都有自己的 Looper 、Thread 和 MessageQueue,互相不会影响。Android 系统根据功能,会使用不同的 Thread 来完成。
7.1 UiThread
com/android/server/UiThread.java
| 1 |
private UiThread() {
|
Systrace 中的 UiThread,一般分析手写笔问题的时候会看
UiThread 被使用的地方如下,具体的功能可以自己去源码里面查看,关键字是 UiThread.get()

7.2 IoThread
com/android/server/IoThread.java
| 1 |
private IoThread() {
|
IoThread 被使用的地方如下,具体的功能可以自己去源码里面查看,关键字是 IoThread.get()

7.3 DisplayThread
com/android/server/DisplayThread.java
| 1 |
private DisplayThread() {
|
Systrace 中的 DisplayThread


7.4 AnimationThread
com/android/server/AnimationThread.java
| 1 |
private AnimationThread() {
|
Systrace 中的 AnimationThread

AnimationThread 在源码中的使用,可以看到 WindowAnimator 的动画执行也是在 AnimationThread 线程中的,Android P 增加了一个 SurfaceAnimationThread 来分担 AnimationThread 的部分工作,来提高 WindowAnimation 的动画性能
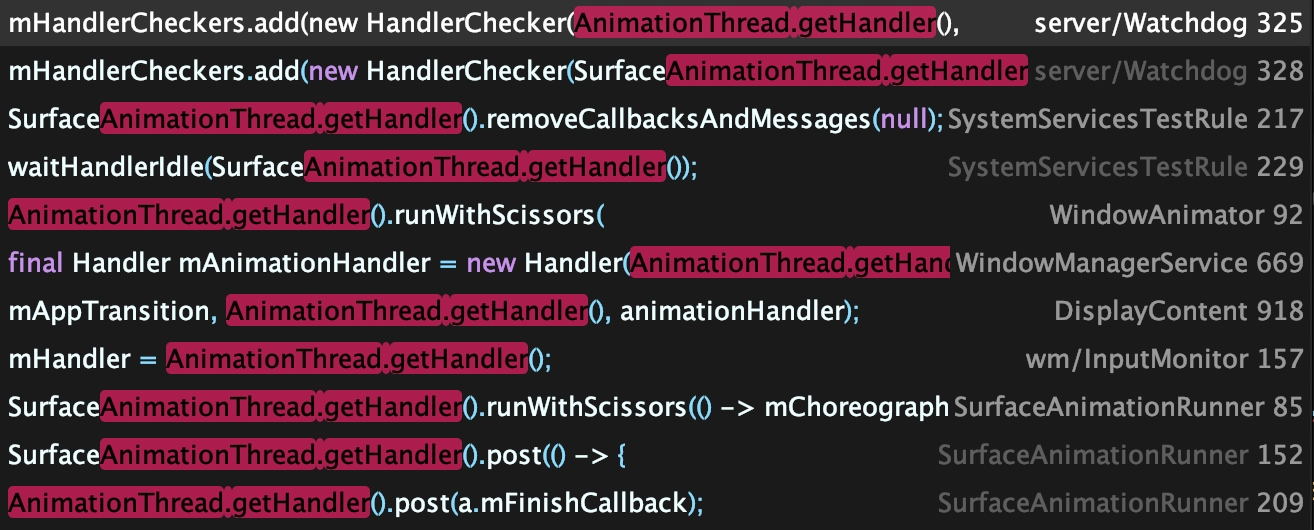
7.5 FgThread
com/android/server/FgThread.java
| 1 |
private FgThread() {
|
Systrace 中的 FgThread
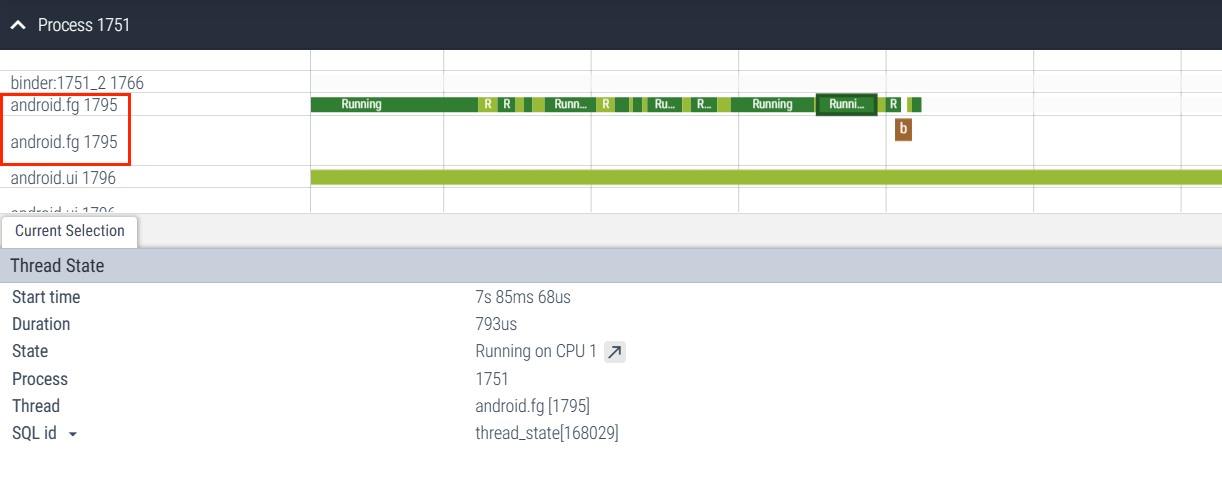
FgThread 在源码中的使用,可以自己搜一下,下面是具体的使用的一个例子
| 1 |
FgThread.getHandler().post(() -> {
|
7.6 SurfaceAnimationThread
| 1 |
com/android/server/wm/SurfaceAnimationThread.java |
Systrace 中的 SurfaceAnimationThread
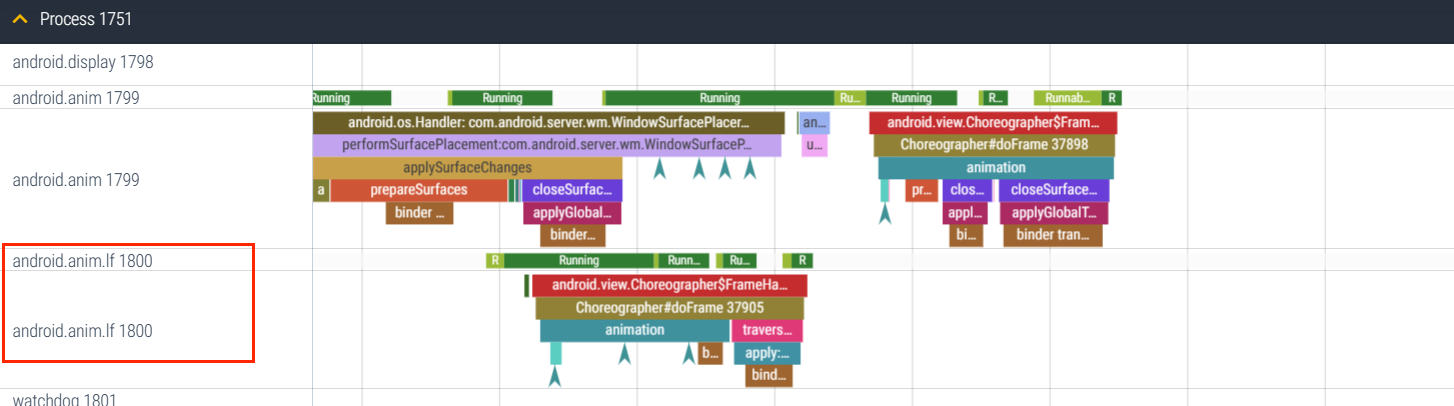
SurfaceAnimationThread 的名字叫 android.anim.lf , 与 android.anim 有区别,
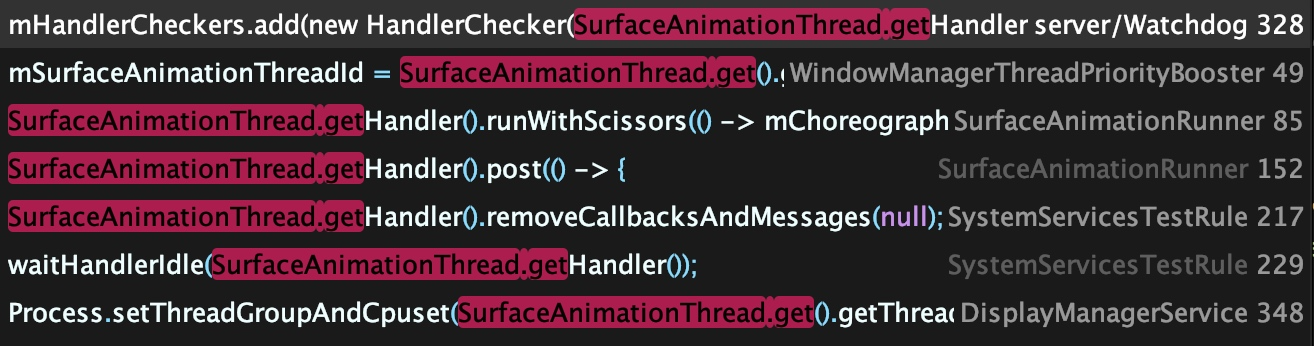
这个 Thread 主要是执行窗口动画,用于分担 android.anim 线程的一部分动画工作,减少由于锁导致的窗口动画卡顿问题
| 1 |
SurfaceAnimationRunner(@Nullable AnimationFrameCallbackProvider callbackProvider, |
六、参考文档:
- VSYNC
- CPU 电源状态
- Curso de Maestría en Desarrollo de Android
- Generación y entrega de SW-VSYNC
- Una herramienta poderosa para vincular núcleos lógicos de CPU: conjunto de tareas
- Rendimiento de Android
- Sistema de entrada: hilo InputReader-blog de Gityuan | Blog de tecnología de Yuan Huihui
- Sistema de entrada - inicio - Blog de Gityuan | Blog de tecnología de Yuan Huihui
- Sistema de entrada: hilo InputDispatcher-blog de Gityuan | Blog de tecnología de Yuan Huihui
- Pareces haber llegado a un páramo donde no hay conocimiento - Zhihu
- Comprensión del mecanismo de carpeta de Android 1/3: Capítulo del controlador
- Comprensión del mecanismo de carpeta de Android 2/3: capa C++
- Comprensión del mecanismo de carpeta de Android 3/3: capa de Java
- Gráficos | Proyecto de código abierto de Android | Proyecto de código abierto de Android
- [Traducción] Entendiendo RenderThread - Nuggets
- actualización del sitio web…
- Un breve análisis del proceso de renderizado de Flutter: Nuggets
- Mecanismo de representación de aleteo: hilo de interfaz de usuario-blog de Gityuan | Blog de tecnología de Yuan Huihui
- Descripción general de procesos y subprocesos | Calidad de la aplicación | Desarrolladores de Android
- El proceso de establecer una conexión entre una aplicación de Android y SurfaceFlinger: un libro breve
- Principio del coreógrafo - Blog de Gityuan | Blog técnico de Yuan Huihui
- https://developer.android.com/reference/android/view/Choreographer
- https://www.jishuwen.com/d/2Vcc
- Evaluación y optimización del rendimiento de Android-evaluación de fluidez-Nuggets
- Aceleración de hardware de Android (2) -RenderThread y OpenGL GPU Rendering-Nuggets
- Descripción general del sistema de gráficos Android - Blog de Gityuan | Blog de tecnología de Yuan Huihui
- http://echuang54.blogspot.com/2015/01/dispsync.html