1. Introducción a Azkaban
1.1 ¿Qué es Azkaban?
AzkabanEs una herramienta de programación de tareas de flujo de trabajo por lotes de código abierto de Linkedin, que se utiliza para ejecutar un conjunto de trabajos y procesos en un orden específico dentro de un flujo de trabajo. AzkabanSe define un archivo de formato k / v (propiedades) para establecer dependencias entre tareas, y se proporciona una interfaz de usuario web fácil de usar para mantener y rastrear el flujo de trabajo.
1.2 Por qué usar Azkaban
Un sistema completo de análisis de datos generalmente consta de una gran cantidad de unidades de tareas, como scripts de shell, programas Java, programas MapReduce, scripts de colmena, etc. Existe una secuencia de tiempo o una relación de dependencia entre cada unidad de tarea. Para organizar estas unidades de tareas para que se ejecuten de acuerdo con el plan, se necesita un potente sistema de programación de flujo de trabajo para programar la ejecución.
Azkaban es una herramienta de invocación de tareas liviana y de código abierto, su función es similar a la crontab de tareas de sincronización del sistema operativo Linux. Pero en aplicaciones prácticas, usaremos crontab para definir llamadas de tareas simples. En el campo Hadoop, usaremos algunos programadores de tareas más poderosos, como Azkaban, Oozie, etc.
Dos, instalación de Azkaban
2.1 Compilar
En primer lugar, descargue el archivo comprimido desde github, Descarga: https://github.com/azkaban/azkaban. Una vez completada la descarga, se requiere una operación de compilación. Azkaban requiere la instalación de java8 o superior.
# 编译安装,但不运行测试
cd /export/servers/azkaban-3.51.0
bin/gradlew build installDist -x test
2.2 Instalación en modo autónomo
Paso 1: Ingrese al /export/servers/azkaban-3.51.0/azkaban-solo-server/build/distributionsdirectorio, donde se almacenan dos paquetes comprimidos.

Paso 2: descomprima uno de los paquetes comprimidos en el /export/serversdirectorio;
tar -zxvf azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C /export/servers/
Paso 3: Ingrese al /export/servers/azkaban-solo-server-0.1.0-SNAPSHOT/confdirectorio, edite el azkaban.propertiesarchivo y modifique la información de configuración de la zona horaria;
default.timezone.id=Asia/Shanghai
Paso 4: Ingrese al /export/servers/azkaban‐solo‐server‐0.1.0‐SNAPSHOT/plugins/jobtypesdirectorio, edite el commonprivate.propertiesarchivo execute.as.usery memCheck.enabledestablezca la suma en falso;
# 如果为true,代表可以使用非登录用户执行任务
execute.as.user=false
# 关闭内存检测
memCheck.enabled=false
Paso 5: Inicie el servicio;
cd /export/servers/azkaban‐solo‐server‐0.1.0‐SNAPSHOT
bin/start‐solo.sh
Si no está ejecutando en el directorio raíz de azkaban-solo-server bin/start-solo.sh, aparecerá el siguiente error: Después de que el

inicio sea exitoso http://node01:8081, ingrese el nombre de usuario (predeterminado: azkaban) y la contraseña (predeterminada: azkaban) para iniciar sesión después de ingresar el navegador .
2.3 Instalación en modo clúster
Si está en modo autónomo, toda la información de los datos se almacena en la base de datos H2 predeterminada. Si es un modo de clúster, debe instalar la base de datos mysql en el entorno del servidor.
2.3.1 Importar base de datos
Primero ingrese al /export/servers/azkaban-3.51.0/azkaban-db/build/sqldirectorio, que almacena el archivo de script para crear la base de datos create-all-sql-0.1.0-SNAPSHOT.sql.
Pasos para importar la base de datos mysql:
- Paso 1: Abra la terminal mysql e inicie sesión en la base de datos mysql;
mysql ‐uroot ‐p
- Paso 2: crea una base de datos;
CREATE DATABASE azkaban;
use azkaban;
- Paso 3: crear un usuario de base de datos y autorizarlo;
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';
GRANT all privileges ON azkaban.* to 'azkaban'@'%' identified by 'azkaban' WITH GRANT OPTION;
flush privileges;
- Paso 4: Importe la base de datos;
source /export/servers/azkaban-3.51.0/azkaban-db/build/sql/create-all-sql-0.1.0-SNAPSHOT.sql;
Todas las tablas construidas en azkaban:
2.3.2 Software de descompresión
Después de ejecutar la operación de compilación anterior, azkaban-3.51.0se generarán dos subdirectorios en el directorio: azkaban-exec-servery azkaban-web-server. El módulo azkaban-exec-server es responsable de realizar tareas específicas; el módulo azkaban-web-server es responsable de proporcionar la visualización de la interfaz web y recibir solicitudes http.
A continuación se muestra cómo descomprimir estos dos módulos:
# 解压azkaban-exec-server
cd /export/servers/azkaban-3.51.0/azkaban-exec-server/build/distributions
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C /export/servers
# 解压azkaban-exec-server
cd /export/servers/azkaban-3.51.0/azkaban-web-server/build/distributions
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C /export/servers
2.3.3 Generar certificado ssl
Para poder utilizar https para acceder al servicio web, necesitamos azkaban-web-server-0.1.0-SNAPSHOTgenerar el certificado SSL en el directorio descomprimido .
cd /export/servers/azkaban-web-server-0.1.0-SNAPSHOT
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
2.3.4 Instalar el servidor web azkaban
Ingrese al /export/servers/azkaban-web-server-0.1.0-SNAPSHOT/confdirectorio y luego modifique el azkaban.propertiesarchivo.
# 修改时区
default.timezone.id=Asia/Shanghai
# 启用ssl
jetty.use.ssl=true
# 配置ssl
jetty.ssl.port=8443
jetty.keystore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.trustpassword=azkaban
# 无需刷新执行程序统计信息即可处理的最长时间(以毫秒为单位)
azkaban.activeexecutor.refresh.milisecinterval=10000
# 从Web服务器初始化中启用队列处理器
azkaban.queueprocessing.enabled=true
# 无需刷新执行程序统计信息即可处理的最大队列流数
azkaban.activeexecutor.refresh.flowinterval=10
# 刷新执行程序统计信息的最大线程数
azkaban.executorinfo.refresh.maxThreads=10
2.3.5 Instalar el servidor ejecutor de azkaban
El primer paso: ingrese al /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/confdirectorio y luego modifique el azkaban.propertiesarchivo.
# 修改时区
default.timezone.id=Asia/Shanghai
# 启用ssl
jetty.use.ssl=true
# 配置ssl
jetty.keystore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.trustpassword=azkaban
azkaban.webserver.url=https://node01:8443
Paso 2: Ingrese al /export/servers/azkaban-3.51.0/az-exec-util/src/main/cdirectorio y execute-as-user.ccopie los archivos al /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypesdirectorio;
cd /export/servers/azkaban-3.51.0/az-exec-util/src/main/c
cp execute-as-user.c /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
El tercer paso: ejecutar la compilación;
cd /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
gcc execute-as-user.c -o execute-as-user
chown root execute-as-user
chmod 6050 execute-as-user
Paso 4: Modifique el commonprivate.propertiesarchivo de configuración;
cd /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
vi commonprivate.properties
# 添加下面两行配置信息
memCheck.enabled=false
azkaban.native.lib=/export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
2.3.6 Iniciar servicio
El primer paso: iniciar azkaban-exec-server;
cd /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT
bin/start-exec.sh
Paso 2: Active azkaban-exec-server;
# 可以在任意目录下执行如下命令做激活操作
curl -G "node01:$(<./executor.port)/executor?action=activate" && echo
Paso 3: Inicie azkaban-web-server;
cd /export/servers/azkaban-web-server-0.1.0-SNAPSHOT
bin/start-web.sh
Una vez que se complete el inicio, ingréselo en el navegador https://node01:8443y luego ingrese el nombre de usuario y la contraseña (lo mismo que azkaban) para iniciar sesión en la plataforma de administración.
Cabe señalar aquí que debido a que hemos activado la función ssl, se requiere el protocolo https para acceder a la dirección del fondo.
Tres, combate real
3.1 Trabajo de tipo único
- El primer paso: crear un archivo de texto, el formato de codificación del archivo usa "UTF-8 sin bom";
vi single_command.job
type=command
command=echo 'hello world'
- Paso 2: empaque los archivos en un paquete zip;
zip single_command.zip single_command.job
- Paso 3: Cree un proyecto en el fondo de administración de azkaban y cargue el paquete zip;
- Paso 4: Inicie el trabajo;
3.2 Trabajo de varios tipos
- Paso 1: Cree un nuevo archivo de texto, llamado foo.job, el contenido del archivo es el siguiente:
type=command
command=echo 'foo'
- Paso 2: Cree un segundo archivo de texto y asígnele el nombre bar.job. El contenido del archivo es el siguiente:
type=command
command=echo 'bar'
dependencies=foo
- Paso 3: empaque los dos archivos en formato zip;
- Paso 4: Implemente el paquete zip en azkaban y ejecute el trabajo;
3.3 Funcionamiento de HDFS
- Paso 1: crea un archivo de texto con el siguiente contenido:
type=command
command=/export/servers/hadoop‐3.1.1/bin/hdfs dfs ‐mkdir /azkaban
Paso 2: empaque el archivo en formato zip;
Paso 3: cargue el paquete zip en azkaban y ejecute el trabajo;
3.4 Tarea MapReduce
- Paso 1: Crea un archivo de texto, el contenido del archivo es el siguiente:
type=command
command=/export/servers/hadoop‐3.1.1/bin/hadoop jar /export/servers/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar pi 3 5
- Paso 2: Empaquete el archivo en formato zip y luego cárguelo en azkaban;
- El tercer paso: iniciar el trabajo;
3.5 Ejecutar el script de Hive
- Paso 1: Prepare el archivo de secuencia de comandos de Hive y asígnele un nombre
hive.sql;
create database if not exists azkaban;
use azkaban;
create table if not exists emp(id string,name string) row format
delimited fields terminated by '\t';
- Paso 2: Cree un archivo de trabajo, el contenido del archivo es el siguiente:
type=command
command=/export/servers/apache‐hive‐3.1.1‐bin ‐f 'hive.sql'
- Paso 3: empaque el archivo de trabajo y el archivo de secuencia de comandos de la colmena en un paquete zip;
- Paso 4: Cargue el paquete zip en azkaban e inicie el trabajo;
3.6 Tareas de cronometraje
azkaban proporciona la función de programador para realizar la programación temporal de nuestras tareas laborales.
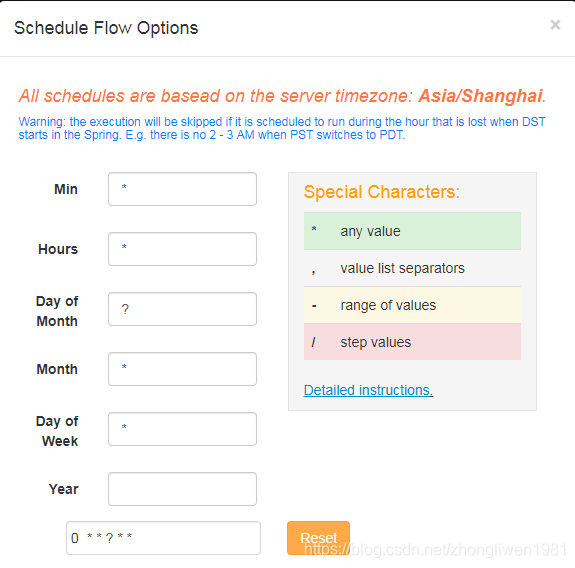
*/1 * ? * *Ejecute la tarea programada cada minuto;
0 1 ? * *ejecute esta tarea a la una en punto de la mañana todas las noches ; ejecute esta tarea
0 */2 ? * *regularmente cada dos horas;
30 21 ? * *ejecute esta tarea regularmente a las 9:30 cada noche;