Uno, sqoop
sqoop es una herramienta de migración de datos de código abierto que puede importar y exportar datos entre Hive y RDMS. También puede realizar la función de migración de datos entre HDFS y RDMS.
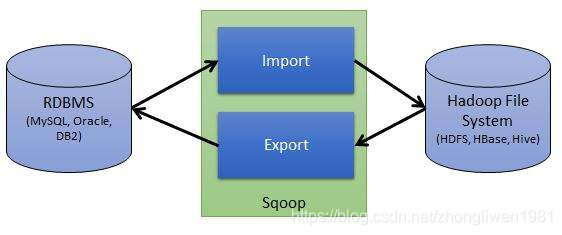
1.1 El mecanismo de trabajo de Sqoop
1.1.1 Mecanismo de importación
La operación de importación de Sqoop es importar datos RDBMS a HDFS.
Al realizar una operación de importación, Sqoop leerá las columnas y los tipos de datos de columna en la tabla a través de JDBC, y luego mapeará los tipos de datos leídos a los tipos de datos Java, y el MapReduce subyacente leerá desde la base de datos a través del objeto InputFormat Data, y el El objeto DataDrivenDBInputFormat se puede dividir en diferentes tareas de mapa de acuerdo con los resultados de la consulta, y finalmente estas tareas se envían al clúster de MapReduce para su ejecución, y los resultados de las tareas de mapa se completarán en las instancias correspondientes.
1.1.2 Mecanismo de exportación
La operación de exportación de Sqoop es exportar datos en HDFS a RDBMS. Antes de exportar, Sqoop elegirá el método de exportación, generalmente JDBC, y luego Sqoop generará una clase Java que puede analizar los datos de texto en HDFS e insertar el valor correspondiente en la tabla. El método de exportación basado en JDBC generará múltiples declaraciones de inserción, y cada declaración de inserción insertará múltiples datos en la tabla. Al mismo tiempo, para garantizar que se puedan ejecutar diferentes E / S en paralelo, al leer datos de HDFS y comunicarse con la base de datos, se inician varios subprocesos para ejecutarse simultáneamente.
1.2 Instalación de Sqoop
Dirección de descarga: http://archive.apache.org/dist/sqoop/, descomprimir después de descargar.
1.2.1 Configuración de Sqoop
cd /export/servers/sqoop-1.4.7/conf
cp sqoop‐env‐template.sh sqoop‐env.sh
vi sqoop-env.sh
Agregue el siguiente contenido al archivo sqoop-env.sh:
export HADOOP_COMMON_HOME/export/servers/hadoop‐3.1.1
export HADOOP_MAPRED_HOME=/export/servers/hadoop‐3.1.1
export HIVE_HOME=/export/servers/apache‐hive‐3.1.1‐bin
1.2.2 Agregar paquete jar dependiente
Sqoop necesita agregar el paquete de controladores de la base de datos y el paquete de dependencia de java-json. Después de preparar los paquetes jar, agréguelos al directorio lib de sqoop.
Una vez completada la adición, ejecute el siguiente comando para verificar si se realizó correctamente:
cd /export/servers/sqoop-1.4.7/
bin/sqoop-version
1.3 Importación de datos
1.3.1 comando sqoop
- Enumere todas las bases de datos en mysql:
bin/sqoop list‐databases ‐‐connect jdbc:mysql://192.168.31.7:3306/ ‐‐username root ‐‐password root
- Compruebe qué tablas están en la base de datos mysql:
bin/sqoop list‐tables ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐username root ‐‐password root
- Ver el documento de ayuda:
bin/sqoop list‐databases ‐‐help
1.3.2 Ejemplo de importación
- Datos de la tabla:
create table emp(
id int primary key auto_increment,
name varchar(255) not null default '',
dep varchar(20) default '',
salary int default 0,
dept char(2) default ''
);
create table emp_add(
id int primary key auto_increment,
hon varchar(20) not null default '',
street varchar(20) default '',
city varchar(20) default ''
);
create table emp_conn(
id int primary key auto_increment,
phone varchar(11) not null default '',
email varchar(50) default ''
);
insert into emp values(1201, 'gopal', 'manager', 50000, 'TP');
insert into emp values(1202, 'manisha', 'proof reader', 50000, 'TP');
insert into emp values(1203, 'khalil', 'php dev', 30000, 'AC');
insert into emp values(1204, 'prasanth', 'php dev', 30000, 'AC');
insert into emp values(1205, 'kranthi', 'admin', 20000, 'TP');
insert into emp_add values(1201, '288A', 'vgiri', 'jublee');
insert into emp_add values(1202, '108I', 'aoc', 'sec-bad');
insert into emp_add values(1203, '144Z', 'pgutta', 'hyd');
insert into emp_add values(1204, '78B', 'old city', 'sec-bad');
insert into emp_add values(1205, '720X', 'hitec', 'sec-bad');
insert into emp_conn values(1201, '2356742', '[email protected]');
insert into emp_conn values(1202, '1661663', '[email protected]');
insert into emp_conn values(1203, '8887776', '[email protected]');
insert into emp_conn values(1204, '9988774', '[email protected]');
insert into emp_conn values(1205, '1231231', '[email protected]');
Comando de importación:
# 将emp表数据导入到HDFS中
bin/sqoop import ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐password root ‐‐username root ‐‐table emp ‐‐m 1
Después de que la importación sea exitosa, ejecute el comando HDFS para ver el resultado de la importación:
hdfs dfs -cat /user/root/emp/part*
También puede especificar el parámetro -target-dir para especificar el directorio HDFS exportado. tal como:
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --delete-target-dir --table emp --target-dir /sqoop/emp -m 1
De forma predeterminada, sqoop usa una coma "," para separar los datos en cada columna. Si desea especificar el separador, puede especificar el parámetro -fields-terminted-by. tal como:
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --delete-target-dir --table emp --target-dir /sqoop/emp2 -m 1 --fields-terminated-by '\t'
También puede exportar datos a Hive, los pasos de exportación:
- Primero
hive‐exec‐3.1.1.jarcopie el paquete en el directorio lib de sqoop;
cp /export/servers/apache‐hive‐3.1.1‐bin/lib/hive‐exec‐3.1.1.jar /export/servers/sqoop‐1.4.7/lib
- Antes de exportar, debe crear las tablas necesarias en Hive;
create database sqooptohive;
use sqooptohive;
create external table emp_hive(id int,name string,dep string,salary int ,dept string) row format delimited fields terminated by '\001';
- Realizar operaciones de exportación;
bin/sqoop import ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐username root ‐‐password root ‐‐table emp ‐‐fields‐terminated‐by '\001' ‐‐hive‐import ‐‐hive‐table sqooptohive.emp_hive ‐‐hive‐overwrite ‐‐delete‐target‐dir ‐‐m 1
Descripción del parámetro:
‐‐hive‐importEspecifique que el comando va a realizar la operación de importación;:
--hive-tableEl nombre de la tabla de Hive que se exportará ;:
--hive-overwriteEspecifique los datos de origen que se sobrescribirán;:
-mEspecifique cuántas tareas de mapa se ejecutan simultáneamente;
Puede --hive-databaseimportar directamente los datos de mysql y la estructura de la tabla en Hive especificando parámetros;
bin/sqoop import ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐username root ‐‐password root ‐‐table emp_conn ‐‐hive‐import ‐m 1 ‐‐hive‐database sqooptohive
Si solo necesita exportar datos que cumplan las condiciones, puede especificar --whereparámetros.
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp_add --target‐dir /sqoop/emp_add -m 1 --delete‐target‐dir --where "city = 'sec‐bad'"
También puede especificar --queryel comando SQL que se ejecutará especificando parámetros.
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root -m 1 --query 'select * from emp_add where city="sec-bad" and $CONDITIONS' --target-dir /sqoop/emp_add --delete-target-dir
Si repite el comando de importación anterior, encontrará que la operación de importación subsiguiente sobrescribirá los datos importados previamente. Sqoop también admite 增量导入que los datos importados más tarde no sobrescribirán los datos importados previamente. Si está utilizando una importación incremental, es necesario especificar tres --incrementalparámetros: --check-column, --last-value,.
// 导入emp表中id大于1202的记录。
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp --incremental append --check-column id --last-value 1202 -m 1 --target-dir /sqoop/increment
También se puede lograr --whereun control más preciso mediante parámetros.
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp --incremental append --check-column id --where "id > 1202" -m 1 --target-dir /sqoop/increment
Nota: La importación incremental no puede especificar el parámetro -delete-target-dir.
1.4 Exportación de datos
La exportación de datos consiste en exportar datos de HDFS a RDMBS. El contenido de los datos exportados es el siguiente:

Pasos de exportación de datos:
- Paso 1: Cree una tabla en la base de datos mysql Los campos de la tabla deben ser iguales al tipo y número de datos que se exportarán en HDFS;
Nota: antes de realizar la exportación de datos, la tabla de destino ya debe existir.
create table emp_out(id int, name varchar(100), dep varchar(50), sal int, dept varchar(10), create_time timestamp);
- Paso 2: realizar la exportación;
bin/sqoop export --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp_out --export-dir /sqoop/emp --input-fields-terminated-by ","