Uno, Flume
1.1 Resumen
Flume es un sistema distribuido de recolección, agregación y transmisión de registros masivos, altamente disponible y confiable proporcionado por Cloudera. Flume admite la recopilación de datos de varias fuentes de datos (como archivos, carpetas, paquetes de Socket, Kafka, etc.); al mismo tiempo, Flume proporciona un procesamiento de datos simple y escribe los datos procesados en HDFS, hbase, hive, Kafka y muchos otros sistemas de almacenamiento externo.
1.2 Principio de funcionamiento
Varios conceptos importantes en Flume:
- Agente: Es la función principal de Flume, y el sistema de recolección de Flume está conectado por agentes individuales. Un agente contiene componentes de origen, sumidero y canal;
- Fuente: Componente de recopilación, responsable de obtener los datos recopilados de la fuente de datos;
- Sumidero: componente de sumidero, responsable de transferir datos al siguiente nivel de Agente o de almacenarlos en un dispositivo de almacenamiento (como HDFS);
- Canal: Componente del canal, responsable de transferir datos de la fuente al sumidero;
La relación entre los componentes Fuente, Receptor y Canal se muestra en la siguiente figura:

1.3 Instalación de Flume
Consejo: antes de instalar Flume, primero debe preparar el entorno de Hadoop.
La última versión de Flume es 1.9.0. Enlace de descarga: http://archive.apache.org/dist/flume/1.9.0/.
Una vez completada la descarga, cargue el paquete comprimido en el /export/softwaresdirectorio del servidor y luego descomprímalo /export/servers.
Una vez completada la descompresión, ingrese al cd /export/servers/apache-flume-1.8.0-bin/confdirectorio, edite el archivo flume-env.sh y configure la variable de entorno JAVA_HOME.
cd /export/servers/apache-flume-1.8.0-bin/conf
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
1.4 Aplicación de canal
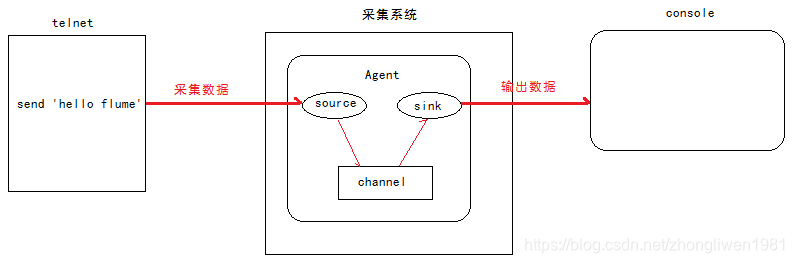
1.4.1 Recopilar datos de equipos terminales
-
Análisis de requisitos:
1) Inicie Flume y vincule la IP y el puerto;
2) Inicie la terminal y use telnet para enviar datos a Flume;
3) Flume envía los datos recopilados a la Consola; -
Pasos de implementación:
Paso 1: Cree un nuevo archivo de configuración /export/servers/apache-flume-1.8.0-bin/conf/netcat-logger.confy establezca el plan de recopilación de datos en el archivo de configuración;
# 定义agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = netcat
# 绑定数据源提供方的地址
a1.sources.r1.bind = 192.168.31.9
# 绑定数据源提供方的端口
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 建立连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
El a1 en la configuración anterior representa el nombre del agente, que se especifica al iniciar Flume.
Paso 2: Inicie Flume;
cd /export/servers/apache-flume-1.8.0-bin/bin
flume-ng agent -c ../conf -f ../conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c: especifica el directorio donde se encuentra el archivo de configuración;
-f: especifica la ruta del archivo de configuración;
-n: especifica el nombre del agente;
Paso 3: Inicie la terminal y use telnet para probar;
telnet 192.168.31.9 44444
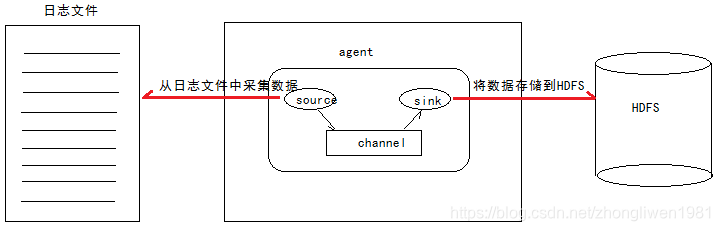
1.3.2 Recopilar datos de archivos
-
Análisis de requisitos: por
ejemplo, hay un archivo de registro que se utiliza para uso comercial y el contenido del archivo de registro seguirá cambiando. Ahora necesitamos recopilar los datos del archivo de registro en tiempo real y luego almacenarlos en HDFS. -
Ideas de implementación:
1) Fuente: monitorizar la actualización del contenido del archivo, el formato del comando esexec ‘tail -F file’;
2) Fregadero: use HDFS;
3) Canal: puede ser de tipo archivo o memoria; -
Pasos de implementación:
Paso 1: Cree un nuevo archivo de configuración /export/servers/apache-flume-1.8.0-bin/conf/tail-file.confy establezca el plan de recopilación de datos en el archivo de configuración;
# 设置agent中各组件的名字
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 描述source组件
a1.sources.source1.type = exec
a1.sources.source1.command = tail -F /export/servers/taillogs/access_log
# 描述Sink组件
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path = hdfs://node01:8020/weblog/flume-collection/%y-%m-%d/%H%M/
a1.sinks.sink1.hdfs.filePrefix = access_log
a1.sinks.sink1.hdfs.maxOpenFiles = 5000
a1.sinks.sink1.hdfs.batchSize= 100
a1.sinks.sink1.hdfs.fileType = DataStream
a1.sinks.sink1.hdfs.writeFormat =Text
a1.sinks.sink1.hdfs.round = true
a1.sinks.sink1.hdfs.roundValue = 10
a1.sinks.sink1.hdfs.roundUnit = minute
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 描述channel组件
a1.channels.channel1.type = memory
a1.channels.channel1.keep-alive = 120
a1.channels.channel1.capacity = 500000
a1.channels.channel1.transactionCapacity = 600
# 建立连接
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
Paso 2: Inicie Flume;
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/bin
flume-ng agent -c ../conf -f ../conf/tail-file.conf -n a1 -Dflume.root.logger=INFO,console
El tercer paso: escriba un script para escribir datos continuamente en el archivo de registro;
# 新建shells文件夹,用于存放脚本文件
mkdir -p /export/servers/shells/
cd /export/servers/shells/
vi tail-file.sh
#!/bin/bash
while true
do
date >> /export/servers/taillogs/access_log;
sleep 0.5;
done
Paso 4: Inicie el script;
mkdir -p /export/servers/taillogs
sh /export/servers/shells/tail-file.sh
1.3.3 Carpeta de colección
-
Análisis de demanda:
por ejemplo, recopile el directorio de registro del servidor de aplicaciones. Siempre que se genere un nuevo archivo de registro, el archivo de registro debe recopilarse en HDFS. -
Ideas de implementación:
1) Fuente: directorio de archivos del monitor, el formato del comando esspooldir’;
2) Fregadero: use HDFS;
3) Canal: puede ser de tipo archivo o memoria; -
Pasos de implementación:
Paso 1: Cree un nuevo archivo de configuración /export/servers/apache-flume-1.8.0-bin/conf/spooldir.confy establezca el plan de recopilación de datos en el archivo de configuración;
# 设置Agent中各个组件的名字
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 描述和配置Source组件
# 注意:监控目录不能够出现同名文件
a1.sources.source1.type = spooldir
a1.sources.source1.spoolDir = /export/servers/dirfile
a1.sources.source1.fileHeader = true
# 描述和配置Sink组件
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path = hdfs://node01:8020/spooldir/files/%y-%m-%d/%H%M/
a1.sinks.sink1.hdfs.filePrefix = events-
a1.sinks.sink1.hdfs.round = true
a1.sinks.sink1.hdfs.roundValue = 10
a1.sinks.sink1.hdfs.roundUnit = minute
a1.sinks.sink1.hdfs.rollInterval = 3
a1.sinks.sink1.hdfs.rollSize = 20
a1.sinks.sink1.hdfs.rollCount = 5
a1.sinks.sink1.hdfs.batchSize = 1
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 生成的文件类型,默认是Sequencefile,DataStream代表普通文本类型
a1.sinks.sink1.hdfs.fileType = DataStream
# 描述和配置通道
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 1000
a1.channels.channel1.transactionCapacity = 100
# 建立连接
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
Paso 2: Inicie Flume;
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/bin
flume-ng agent -c ../conf -f ../conf/spooldir.conf -n a1 -Dflume.root.logger=INFO,console
Una vez que se completa el inicio, puede /export/servers/dirfileagregar archivos continuamente al directorio y luego puede ver los archivos de registro recopilados en la ruta / spooldir de HDFS.
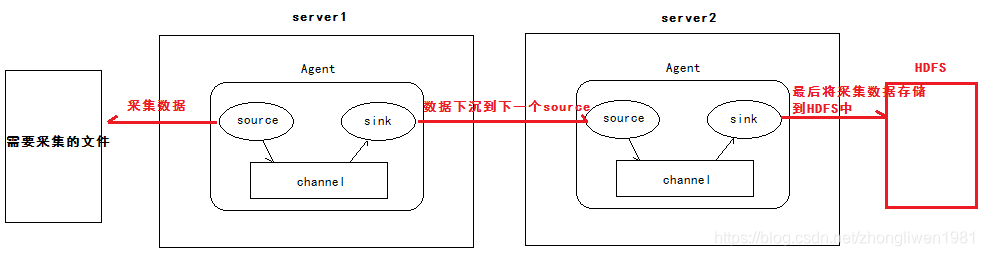
1.3.4 Cascada de agentes
-
Análisis de demanda:
1) El primer agente es responsable de recopilar datos del archivo especificado y luego enviarlo al siguiente agente a través de la red;
2) El segundo agente es responsable de recibir los datos enviados desde el primer agente y guardar los datos. a HDFS; -
Pasos de implementación:
El primer paso: preparar dos hosts para instalar el entorno hadoop y flume, son node01 y node02 respectivamente;
Paso 2: Configure node01 y node02 para usar el protocolo avro para transmitir datos respectivamente;
cd /export/servers/ apache-flume-1.8.0-bin/conf
vi tail-avro-avro-logger.conf
La configuración de node01:
# 设置agent中各个组件的名字
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
a1.sources.source1.type = exec
a1.sources.source1.command = tail -F /export/servers/taillogs/access_log
a1.sources.source1.channels = channel1
# 设置Sink的类型为avro
a1.sinks.sink1.type = avro
# 指定下沉到下一个agent的主机地址
a1.sinks.sink1.hostname = node02
a1.sinks.sink1.port = 4141
a1.sinks.sink1.batch-size = 10
# 配置channel
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 1000
a1.channels.channel1.transactionCapacity = 100
# 建立连接
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
La configuración de node02:
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 设置source的类型为avro
a1.sources.source1.type = avro
# 指定从哪个source获取数据
a1.sources.source1.bind = node01
a1.sources.source1.port = 4141
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path = hdfs://node01:8020/av/%y-%m-%d/%H%M/
a1.sinks.sink1.hdfs.filePrefix = events-
a1.sinks.sink1.hdfs.round = true
a1.sinks.sink1.hdfs.roundValue = 10
a1.sinks.sink1.hdfs.roundUnit = minute
a1.sinks.sink1.hdfs.rollInterval = 3
a1.sinks.sink1.hdfs.rollSize = 20
a1.sinks.sink1.hdfs.rollCount = 5
a1.sinks.sink1.hdfs.batchSize = 1
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.sink1.hdfs.fileType = DataStream
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 1000
a1.channels.channel1.transactionCapacity = 100
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
Paso 3: Inicie el canal de node01 y node2 respectivamente;
cd /export/servers/apache-flume-1.8.0-bin/bin
flume-ng agent -c ../conf -f ../conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
Una vez que se complete el inicio, ejecute la prueba de secuencia de comandos escrita anteriormente.
mkdir -p /export/servers/taillogs
sh /export/servers/shells/tail-file.sh
1.3.5 Alta disponibilidad
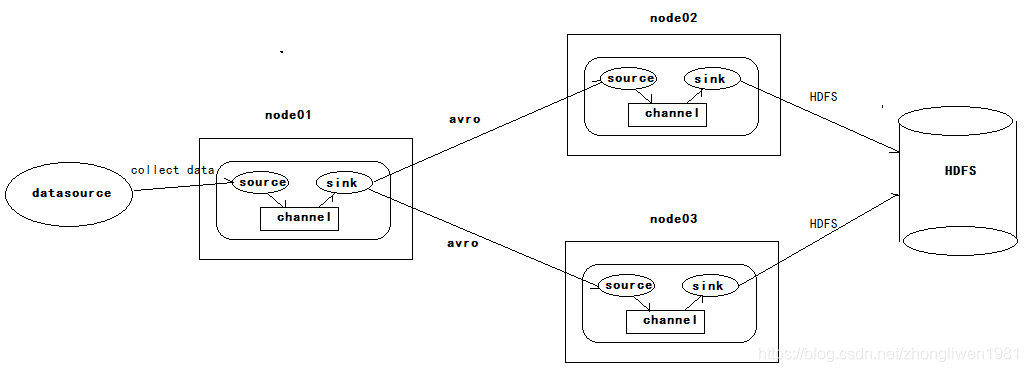
Hay tres hosts en él, node01, node02 y node03. node01 es responsable de recopilar datos desde el exterior y luego transferir los datos recopilados a node02 o node03. El propio Flume NG proporciona un mecanismo de fusible para lograr una alta disponibilidad. Por lo tanto, incluso si node02 o node03 son fusibles, Flume NG puede cambiar o reanudar las operaciones automáticamente.
La versión de Flume en el momento de su lanzamiento se conoce colectivamente como Flume OG. Sin embargo, con la expansión continua de las funciones de Flume, se han expuesto deficiencias como la ingeniería de código de Flume OG inflada, el diseño de componentes del núcleo irrazonable y la configuración del núcleo no estándar. En octubre de 2011, el equipo de desarrollo de Flume refactorizó Flume NG, y la versión refactorizada se conoce colectivamente como Flume NG. Después de la reestructuración, Flume NG se ha convertido en una herramienta de recolección de registros liviana que admite la fusión y el equilibrio de carga.
Para configurar la alta disponibilidad, solo necesita definir dos sumideros en el esquema de recopilación de node01, apuntando a node02 y node03 respectivamente.

configuración del fregadero:
# sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node02
agent1.sinks.k1.port = 52020
# sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = node03
agent1.sinks.k2.port = 52020
# 将sink添加到sink group里面
agent1.sinkgroups.g1.sinks = k1 k2
Para habilitar la fusión, debe establecer el tipo de procesamiento de gourp del fregadero en failover.
agent1.sinkgroups.g1.processor.type = failover
# 设置权重,权重越高,优先级也就越高
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
# 设置failover time的上限,单位是毫秒,如果没有设置,默认为30秒
agent1.sinkgroups.g1.processor.maxpenalty = 10000
- Trabajo de prueba:
Primero, cargamos archivos en Node01, y Node01 es responsable de recopilar datos del directorio de registro especificado. Dado que el peso de sink1 es más pesado que el de sink2, el agente de Node02 se recopila y se carga primero en el sistema de almacenamiento. Luego matamos node02. En este momento, Node03 es responsable de la recopilación y carga de registros. Luego restauramos manualmente el servicio Flume del nodo Node02, y luego cargamos archivos en Node01 nuevamente, y encontramos que Node02 reanuda la recopilación de niveles de prioridad.
1.3.6 Equilibrio de carga
Si el Agente1 es un nodo de enrutamiento, es responsable de equilibrar el Evento almacenado temporalmente en el Canal con varios componentes del Sink correspondientes, y cada componente del Sink está conectado a un Agente independiente. Como sigue:
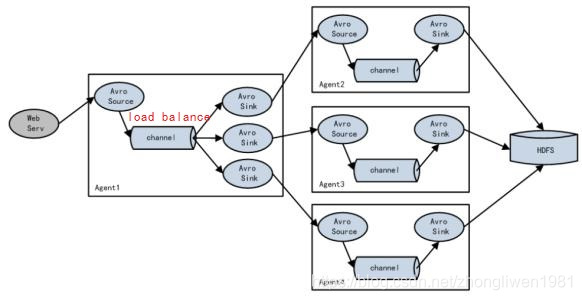
Función de balanceo de carga automático Flume NG. Si desea iniciar el equilibrio de carga, solo necesita establecer el tipo de procesamiento del grupo receptor en load_balance.
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut = 10000
1.3.7 Interceptor
Suponga que hay dos hosts A y B que recopilan datos de archivos de registro en tiempo real. Finalmente, haga un resumen en el host C y luego guárdelo en HDFS.
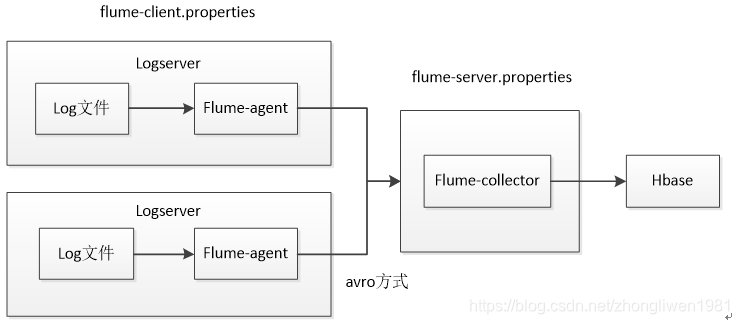
Dos servidores de registro se implementan arriba para recopilar datos de registro. Envían los datos recopilados a Flume-collector para su agregación y luego almacenan los datos agregados en Hbase o HDFS.
Pregunta: Dado que los datos del archivo de registro se recopilan cuando hay dos hosts, ¿cómo sabe Flume-Collector de qué archivo de registro provienen los datos recopilados? ? ? ? ? La respuesta es utilizar interceptores.
1.3.7.1 Qué es un interceptor
El interceptor es un conjunto de componentes entre la Fuente y el Canal. El interceptor puede convertir o eliminar estos eventos antes de escribir la hora recibida por la fuente en el canal. Cada interceptor solo procesa eventos recibidos por la misma fuente.
- Interceptor incorporado:
1) Interceptor de marca de tiempo: con este interceptor, el Agente insertará la marca de tiempo enevent headerél. Si no usa ningún interceptor, Flume solo recibirá mensajes.
2) Interceptor de host: este interceptor insertará la dirección IP del host o el nombre de host enevent headerél;
3) Interceptor estático: este interceptor insertará k / v enevent headerél;
4) Interceptor de filtrado de expresiones regulares: este interceptor puede insertar Se filtran algunos registros innecesarios , y los datos de registro que cumplen con las condiciones regulares se pueden recopilar según sea necesario;
5) Regex Extractor Interceptor:event headeragregue el k / v especificado para cumplir con el contenido regular;
6) UUID Interceptor:events headergenere en cada cadena de UUID A, el UUID generado puede ser leer en el sumidero;
7) Interceptor de Morphline: Este interceptor utiliza Morphline para convertir los datos de cada evento en consecuencia;
8) Interceptor de búsqueda y reemplazo: Este interceptor se basa en expresiones regulares de Java Proporciona funciones simples de búsqueda y reemplazo basadas en cadenas;
1.3.7.2 Uso de interceptores
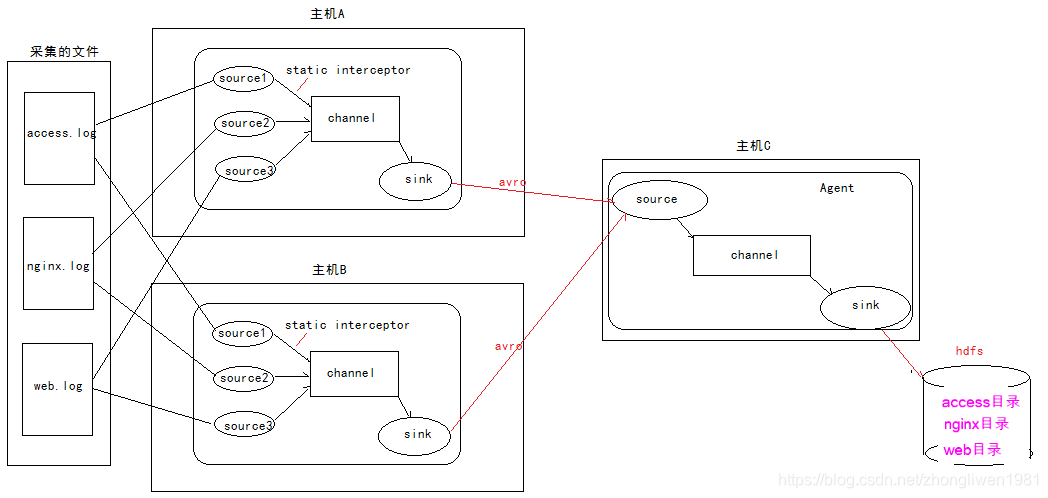
Defina tres fuentes en el host a y el host b para recopilar datos de diferentes archivos de registro. Debido a que el static interceptorinterceptor está definido en el host a y el host b , el interceptor agregará el k / v especificado (como tipo = acceso, tipo = nginx, tipo = web) event header. Luego, coloque los datos recopilados en el host c para obtener un resumen. Después del resumen, c del host event headeradquiere el valor del tipo de archivos de directorio almacenados en hdfs como el tipo, el último almacenamiento de datos agregados (un formato de almacenamiento de datos) en el directorio especificado de hdfs.

1.3.7.3 Configuración del interceptor
- La configuración de node01 y node02:
# 定义3个source
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# 第一个source采集access.log文件数据
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access.log
# 定义静态拦截器,每一个source定义一个拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
# 第二个source采集nginx.log文件数据
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /export/servers/taillogs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
# 第三个source采集web.log文件数据
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /export/servers/taillogs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# 定义Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
# 定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# 与channel建立连接
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
- La configuración de node03:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port =41414
# 添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
# 定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# 定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://node01:8020/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
# 按时间生成,单位为秒
a1.sinks.k1.hdfs.rollInterval = 30
# 按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
# 批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 10000
# 操作hdfs的线程数
a1.sinks.k1.hdfs.threadsPoolSize=10
# 操作hdfs超时时间,单位为毫秒
a1.sinks.k1.hdfs.callTimeout=30000
# 与channel建立连接
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- Script de recopilación de datos:
# !/bin/bash
while true
do
date >> /export/servers/taillogs/access.log;
date >> /export/servers/taillogs/web.log;
date >> /export/servers/taillogs/nginx.log;
sleep 0.5;
done