INICIO: La llamada inteligencia artificial es el uso de métodos estadísticos matemáticos, las leyes en los datos estadísticos, y luego usa estas leyes estadísticas para el procesamiento automatizado de datos, de modo que la computadora muestre algunas características inteligentes, y varios métodos estadísticos matemáticos son algoritmos de grandes datos
1. Introducción
En torno a la clasificación de datos, la minería de datos, el motor de recomendaciones, los principios matemáticos de los algoritmos de big data, los algoritmos de red neuronal, se lanza un "panorama" de algoritmos de big data
2. Clasificación de datos
- La clasificación es cognición
- En la era de Internet, una persona deja más y más información en Internet. Si una computadora usa tecnología de big data para unificar toda esta información para el análisis, en teoría, una persona puede clasificarse por completo, es decir, una persona
- A través de las estadísticas de la regularidad de los datos históricos, se clasifica una gran cantidad de datos y se descubre la relación entre los datos, de modo que cuando ingresan nuevos datos, la computadora puede usar esta relación para clasificar automáticamente. Si este resultado de clasificación se confirmará en el futuro, es utilizar big data para hacer predicciones
3. Texto
3.1 Algoritmo de clasificación KNN
- Para un dato que necesita ser clasificado, compárelo con un conjunto de muestras que han sido clasificadas y etiquetadas, y obtenga las muestras K más cercanas. La categoría a la que más pertenecen las muestras K es la categoría que necesita ser clasificada.
-
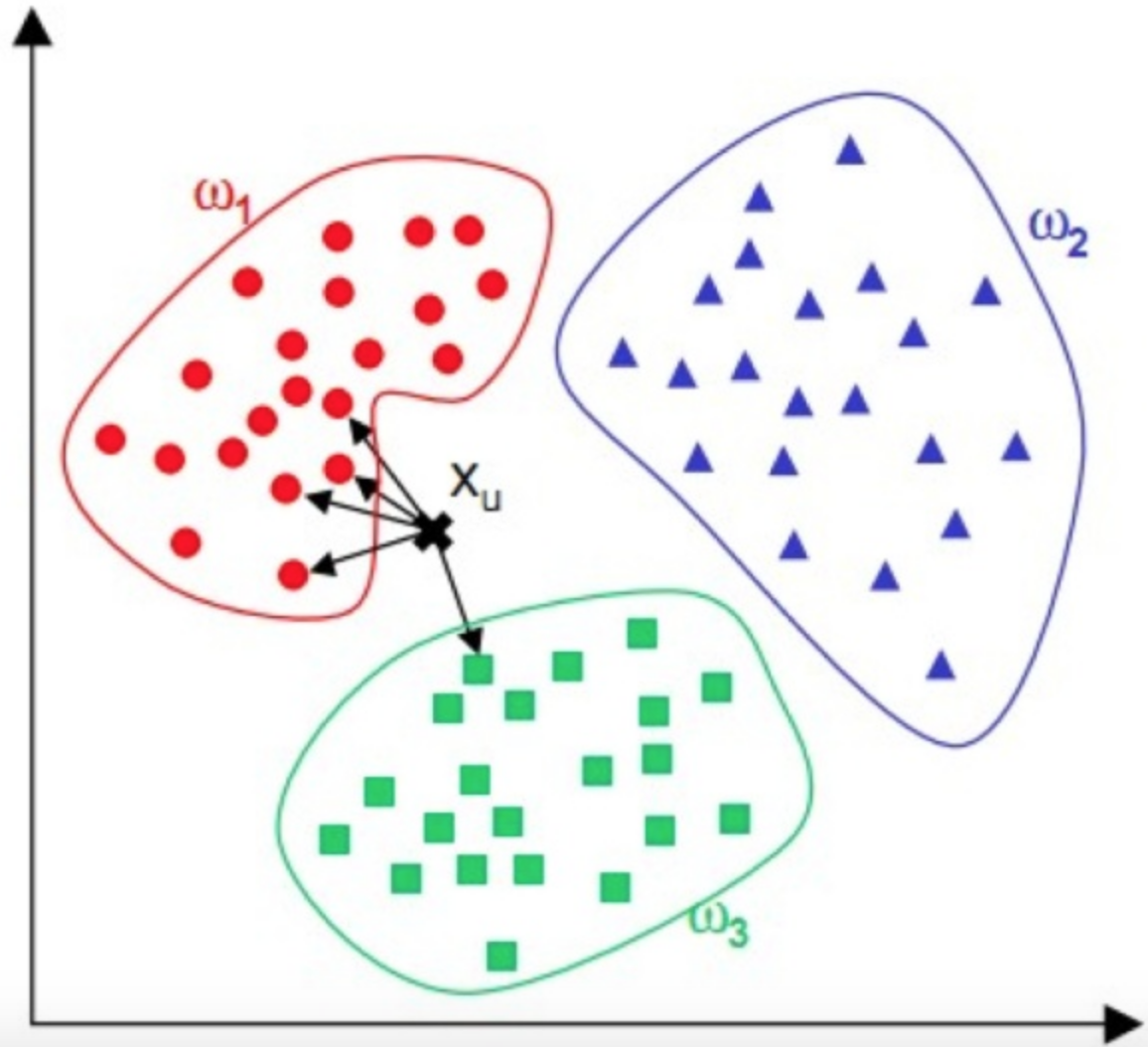
- Calcule los 5 puntos más cercanos (es decir, K es 5), las categorías a las que pertenecen estos 5 puntos como máximo
-
- Se puede utilizar en varios escenarios de clasificación, como clasificación de noticias, clasificación de productos, etc., e incluso reconocimiento de texto simple
- Para la clasificación de noticias, puede etiquetar manualmente algunas noticias por adelantado, marcar la categoría de noticias y calcular el vector de características
- Para una noticia no categorizada, después de calcular su vector de características, el cálculo de distancia se realiza con todas las noticias marcadas.
- Luego, use el algoritmo KNN para la clasificación automática
3.2 Distancia de datos
La clave del algoritmo KNN es comparar la distancia entre los datos que se clasificarán y los datos de la muestra.
- Extraiga los valores propios de los datos, forme un espacio vectorial real n-dimensional (este espacio también se denomina espacio propio) de acuerdo con los valores propios, y luego calcule la distancia espacial entre los vectores.
- La distancia euclidiana es la fórmula de cálculo de datos más utilizada, pero en el aprendizaje automático de datos de texto y datos de evaluación del usuario, el método de cálculo de distancia más utilizado es la similitud del coseno
- Cuanto más cercano sea el valor de la similitud del coseno a 1, cuanto más similar sea y más cercano a 0, mayor será la diferencia. Por
ejemplo, los valores de características de dos artículos son: "Big Data", "Machine Learning" y "Geek Time", las características del artículo A El vector es (3, 3, 3), es decir, el número de ocurrencias de estas tres palabras es 3; el vector de características del artículo B es (6, 6, 6), es decir, el número de ocurrencias de estas tres palabras es 6. Si observa los vectores de características, los dos vectores son muy diferentes. Si utiliza el cálculo de la distancia euclidiana, en realidad son muy grandes, pero los dos artículos son muy similares, pero la longitud es diferente. Su similitud de coseno es 1, lo que significa que son muy similares. . La similitud del coseno es en realidad el cálculo del ángulo entre los vectores, y la fórmula de la distancia euclidiana es calcular la distancia espacial. La similitud de coseno está más relacionada con la similitud de datos: por ejemplo, dos usuarios calificaron dos productos como (3, 3) y (4, 4), luego las preferencias de los dos usuarios para los dos productos son similares. En el caso, la similitud del coseno es más razonable que la distancia euclidiana.
3.3 Valores propios del texto
Calcular la distancia requiere conocer el vector de características de los datos, por lo que extraer el vector de características de los datos es un trabajo importante para los ingenieros de aprendizaje automático
El valor de característica de los datos de texto es extraer palabras clave de texto, algoritmo TF-IDF; use TF como valor de característica
TF es el término frecuencia (Frecuencia de término), lo que significa con qué frecuencia aparece una palabra en un documento. Cuanto más frecuentemente aparece una palabra en un documento, mayor es el valor de TF
IDF es la frecuencia de documento inversa (Frecuencia de documento inversa), que indica la escasez de esta palabra en todos los documentos. Cuantos menos documentos, mayor será el valor de IDF.
El producto de TF e IDF es TF-IDF
Por ejemplo, en un artículo técnico sobre energía atómica, las palabras "fisión nuclear", "radiactividad" y "vida media" aparecerán con frecuencia en este documento, es decir, TF es muy alta, pero la frecuencia de aparición en todos los documentos es relativamente baja, es decir, IDF. Relativamente alto. Por lo tanto, el valor TF-IDF de estas palabras será muy alto. Puede ser que después de extraer las palabras clave de este documento, la frecuencia de palabras de las palabras clave se pueda utilizar para construir el vector de características. Las tres palabras "fisión nuclear", "radiactividad" y "vida media" son valores característicos, y el número de ocurrencias es 12, 9 y 4, respectivamente. Entonces el vector de características de este artículo es (12, 9, 4). Luego use la fórmula de cálculo de distancia espacial antes mencionada para calcular la distancia a otros documentos. Combinado con el algoritmo KNN, se puede lograr la clasificación automática de documentos.
3.4 Clasificación bayesiana
La fórmula de Bayes es un algoritmo de clasificación basado en probabilidad condicional
Si ya conocemos la probabilidad de ocurrencia de A y B, y sabemos la probabilidad de ocurrencia de A en el caso de B, podemos usar la fórmula de Bayes para calcular la probabilidad de ocurrencia de B en el caso de A. De hecho, podemos juzgar la probabilidad de B, es decir, la posibilidad de B de acuerdo con la situación de A, es decir, los datos de entrada, y luego clasificar
La ley estadística de una gran cantidad de datos puede reflejar con precisión la probabilidad de clasificación de las cosas.
Una aplicación típica de la clasificación bayesiana es la clasificación de spam
A través de las estadísticas del correo de muestra, sabemos la probabilidad de que cada palabra aparezca en el correo [Error de procesamiento matemático] P (Ai), también sabemos la probabilidad de correo normal [Error de procesamiento matemático] P (B0) y la probabilidad de spam [Matemáticas Error de procesamiento] P (B1), también puede contar la probabilidad de aparición de cada palabra en el correo no deseado [Error de procesamiento matemático] P (Ai | B1), entonces ahora llega un nuevo correo, podemos según las palabras que aparecen en el correo, Calcule [Error de procesamiento matemático] P (B1 | Ai), es decir, la probabilidad de que el mensaje sea spam en presencia de estas palabras, y luego determine si el mensaje es spam.
Y si establecemos una probabilidad que excede un cierto valor y creemos que sucederá, entonces hemos clasificado y predicho estos datos
En primer lugar, debe marcar el correo original, debe marcar qué correo es normal, qué correo es spam. Este tipo de entrenamiento de aprendizaje automático que requiere la anotación de datos también se llama aprendizaje automático supervisado
3.5 Resumen
Muchas IA son en realidad algoritmos de clasificación en el trabajo
Por ejemplo, el algoritmo AI Go AlphaGo es esencialmente un algoritmo de clasificación. El tablero Go tiene 361 intersecciones. Se puede considerar que hay 361 opciones de clasificación. AlphaGo solo necesita seleccionar una opción de clasificación con el mayor resultado ganador cada vez.