Notas del estudio de certificación ACP de Alibaba Cloud Big Data
- 1. Fundación de Big Data
- 2. Servicio de computación de big data Maxcompute
- 3. Plataforma de desarrollo y gobernanza de big data Dataworks
- 4. Plataforma de análisis de visualización de datos Quick Bi
- 5. Plataforma de aprendizaje automático PAI
1. Fundación de Big Data
2. Servicio de computación de big data Maxcompute
2.1 Conocimientos básicos
2.1.1 Compre Maxcompute y cree un proyecto para agregar subusuarios
1. Primero compre maxcompute en su propia área de servicio:
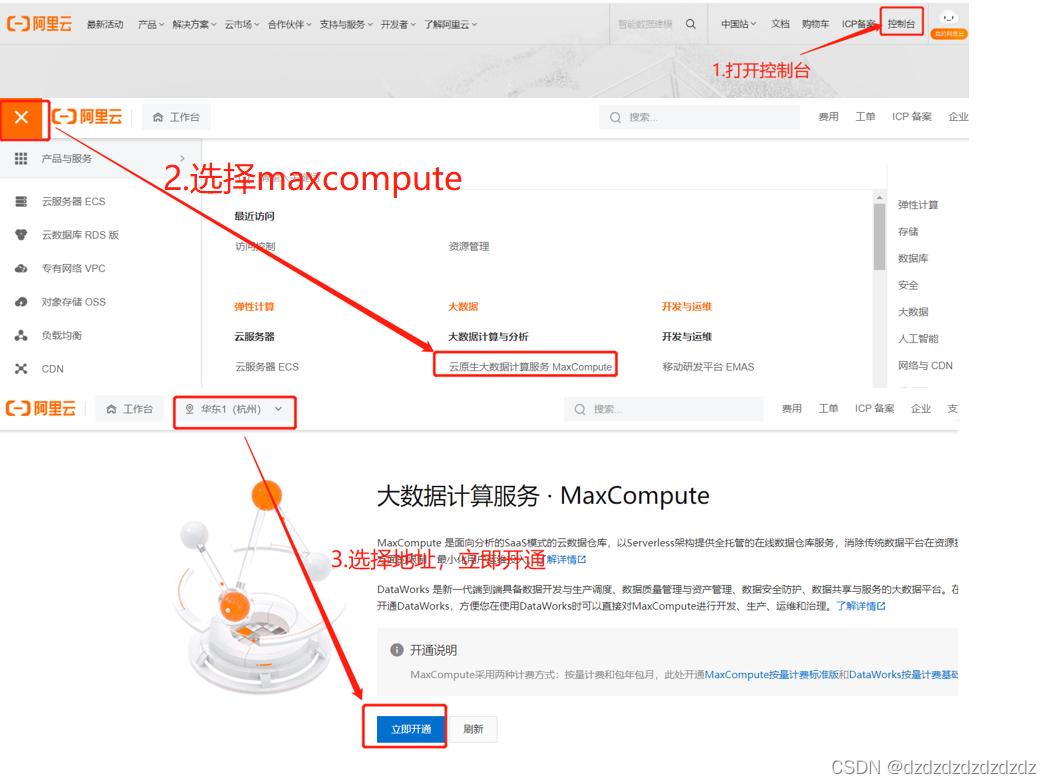
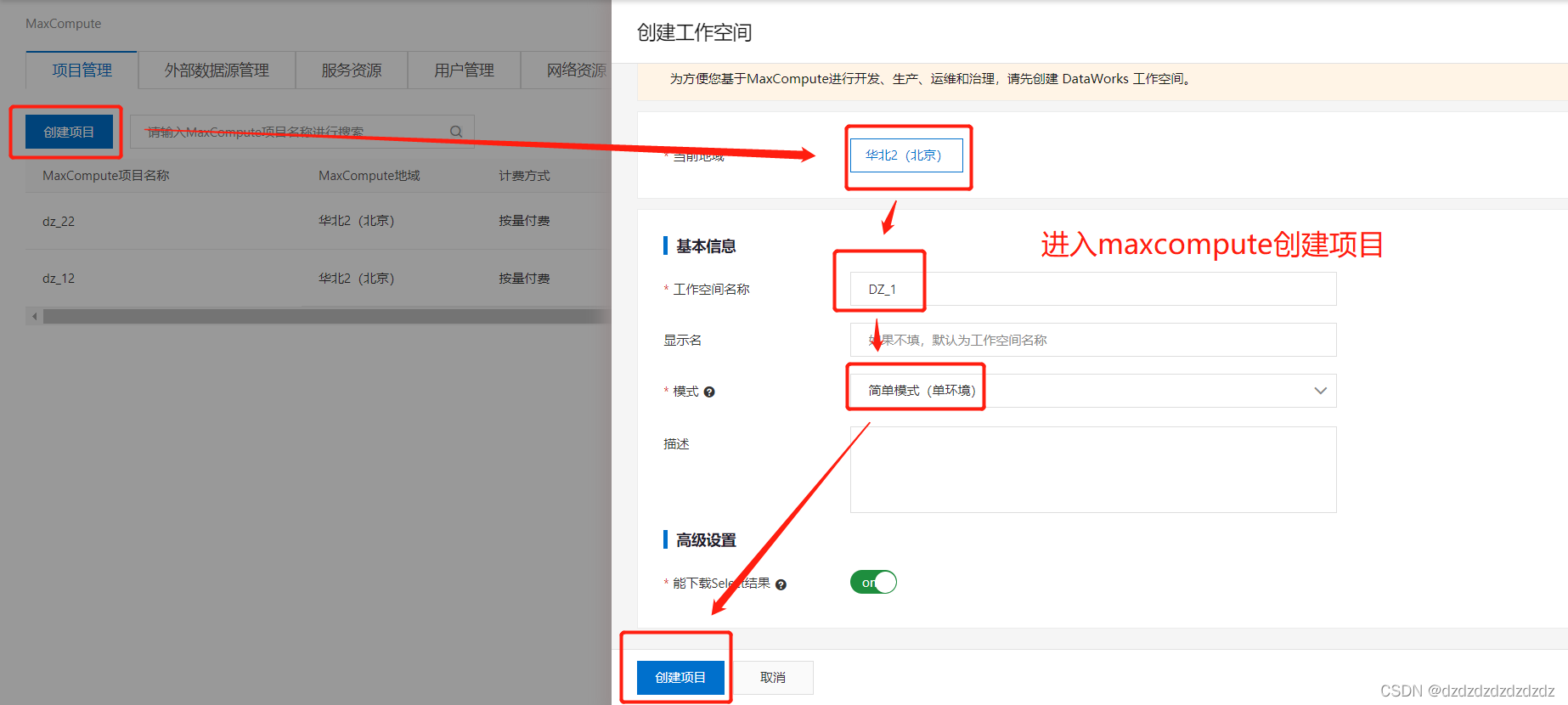
2. Cree un proyecto
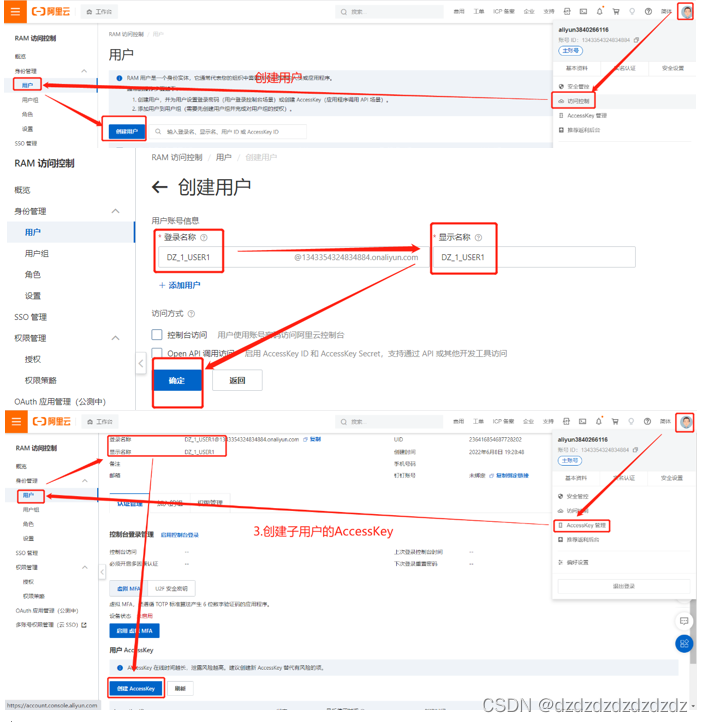
3. Agregue subusuarios y guarde su clave de acceso
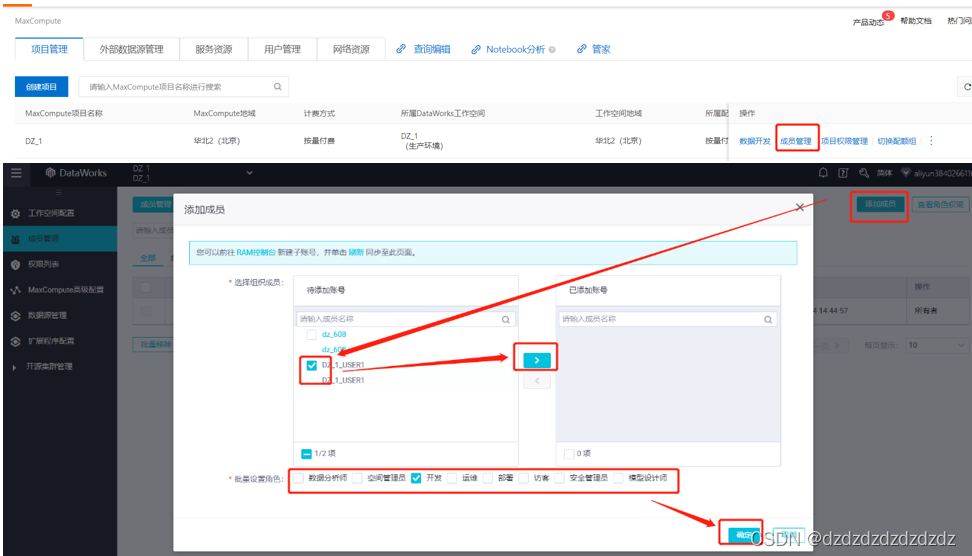
4. Agregue permisos de usuario al proyecto
2.1.2 Crear ODPS
1. Crear ODPS
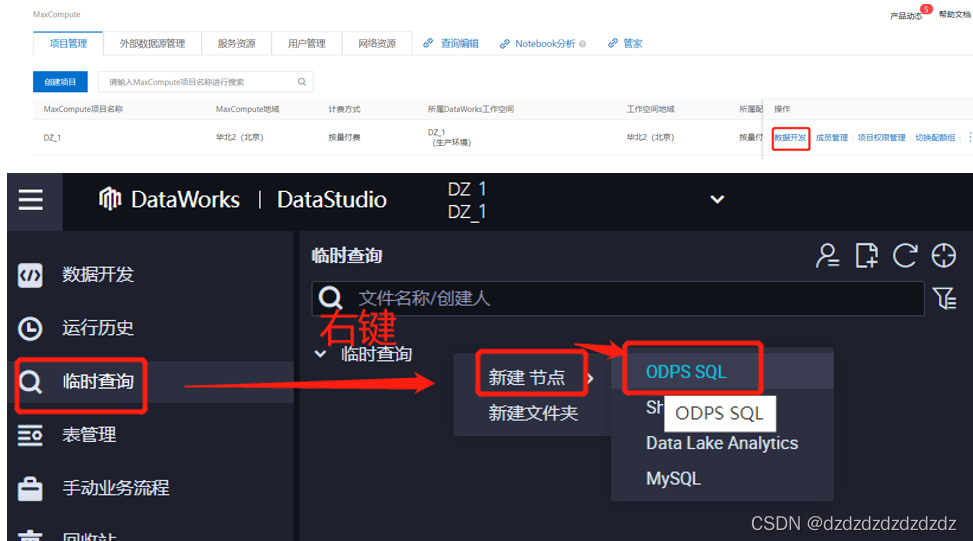
2. Crear una tabla: create table A (id bigint,name string);
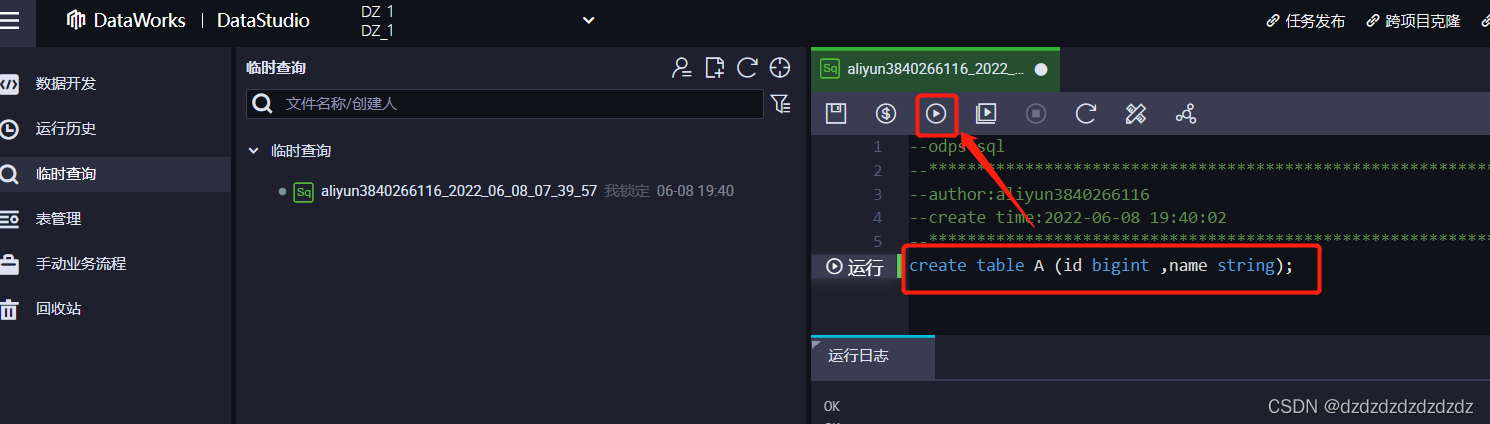
3. Ver esta tabla:desc A;
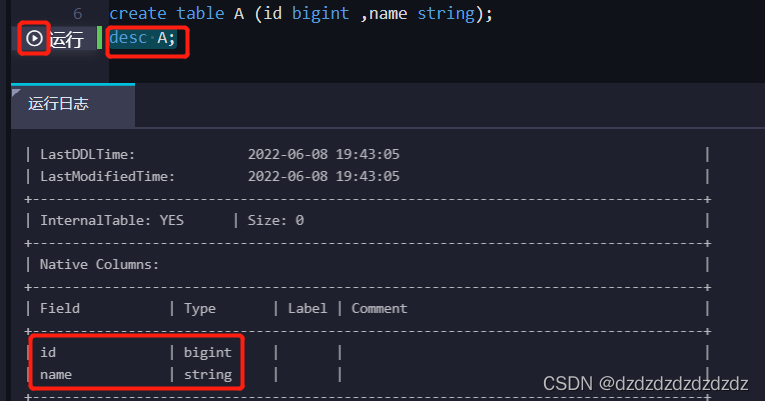
2.1.3 Instalación y comandos básicos del cliente de línea de comandos odpscmd de maxcompute
1. Descargue el paquete de instalación en el sitio web oficial de Ali y descomprímalo
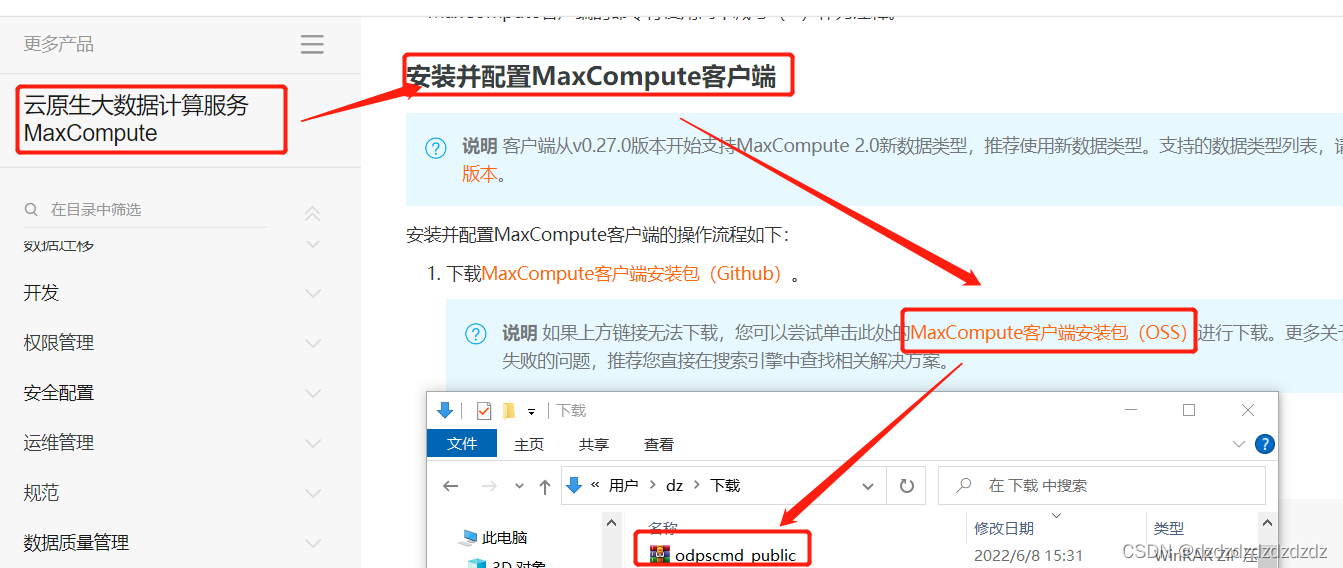
2. Abra el único archivo en el directorio conf después de la presurización y complete la información relevante según el proyecto:
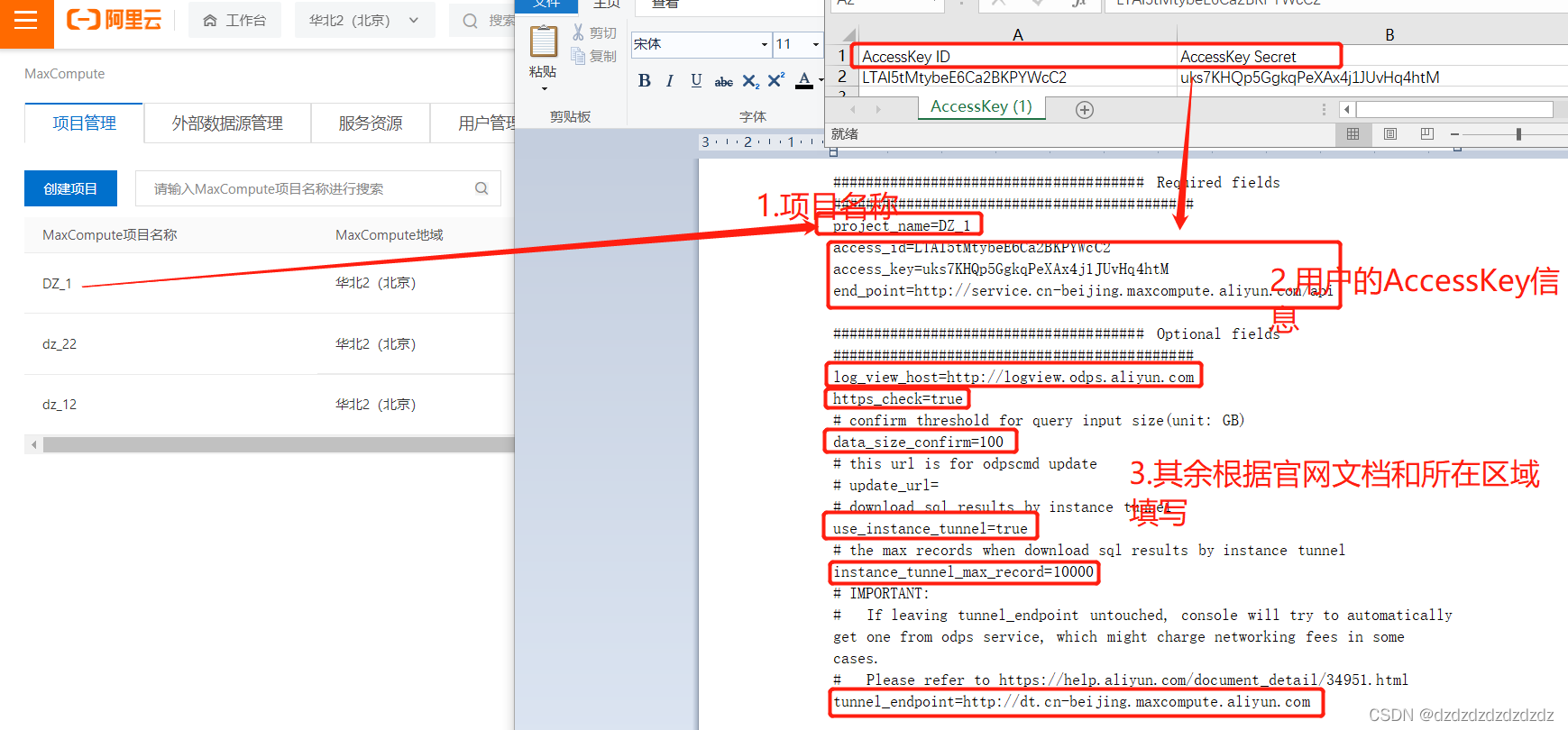
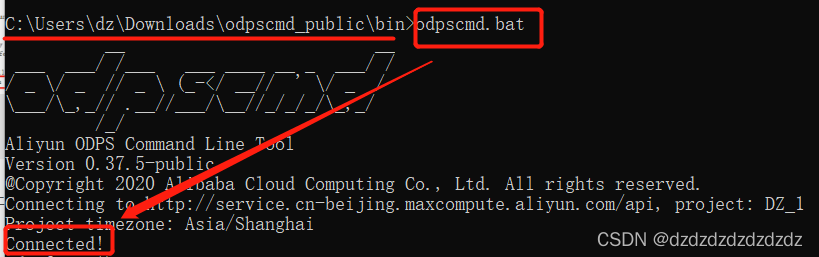
3. Después de configurar el archivo, abra cmd en el directorio bin, ingrese odpscmd.batpara abrir y ejecutar
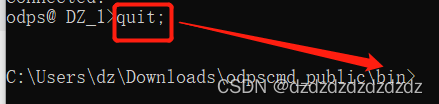
4. Ingrese quit;para salir de odpscmd
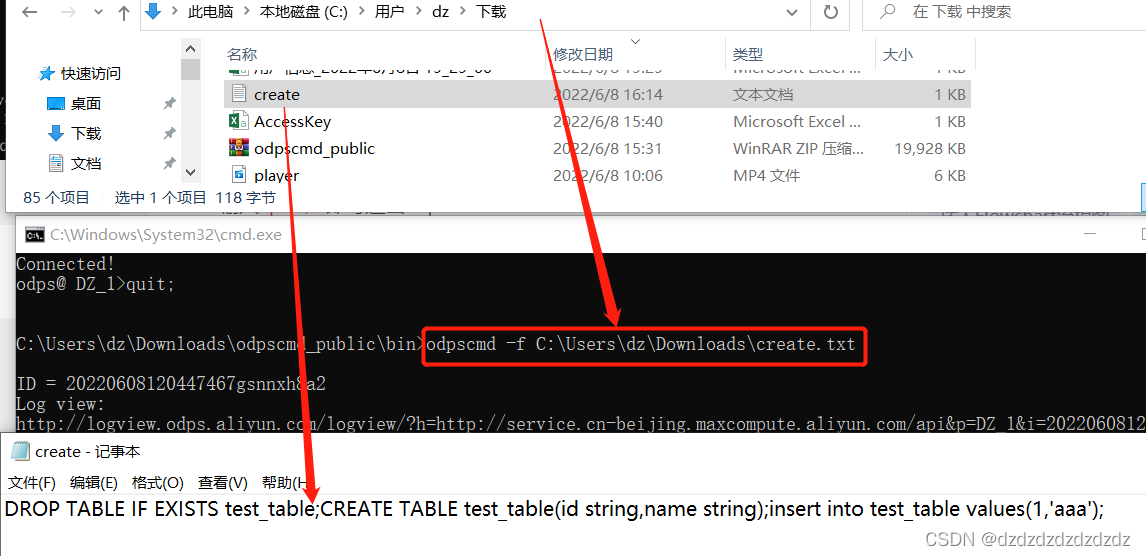
5. El parámetro -f puede ejecutar el comando en el archivo: odpscmd -f create.txt
6. El parámetro -e puede ejecutar la declaración SQL: odpscmd -e "select * from test_table;" 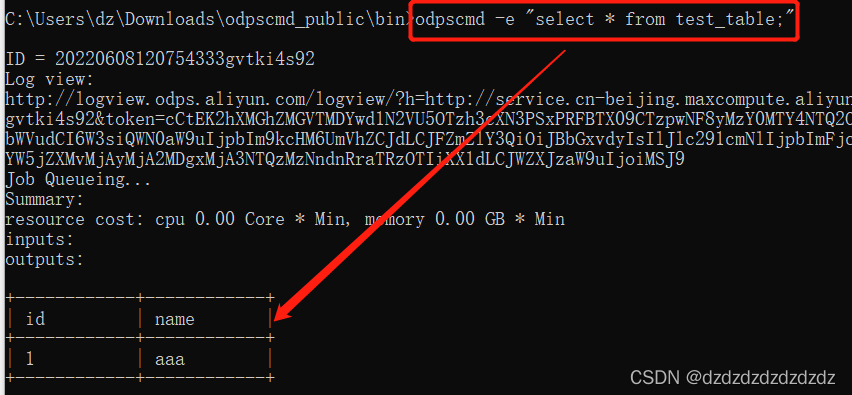
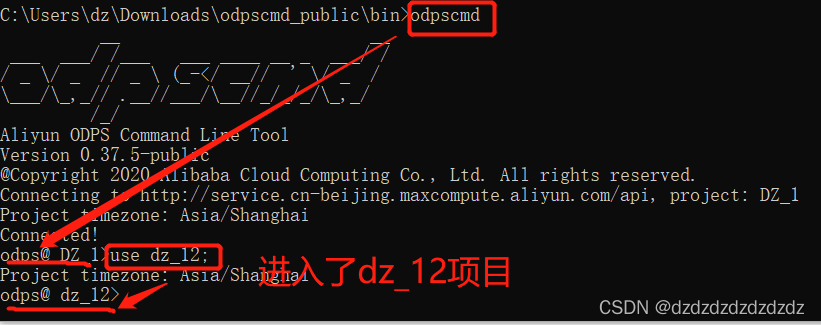
7. Use use 项目名;para saltar a otro proyecto de el usuario, siempre que el usuario tenga varios proyectos.
2.2 Carga y descarga de datos
2.2.1 Túnel de procesamiento por lotes fuera de línea
2.2.1.1 Carga de túnel
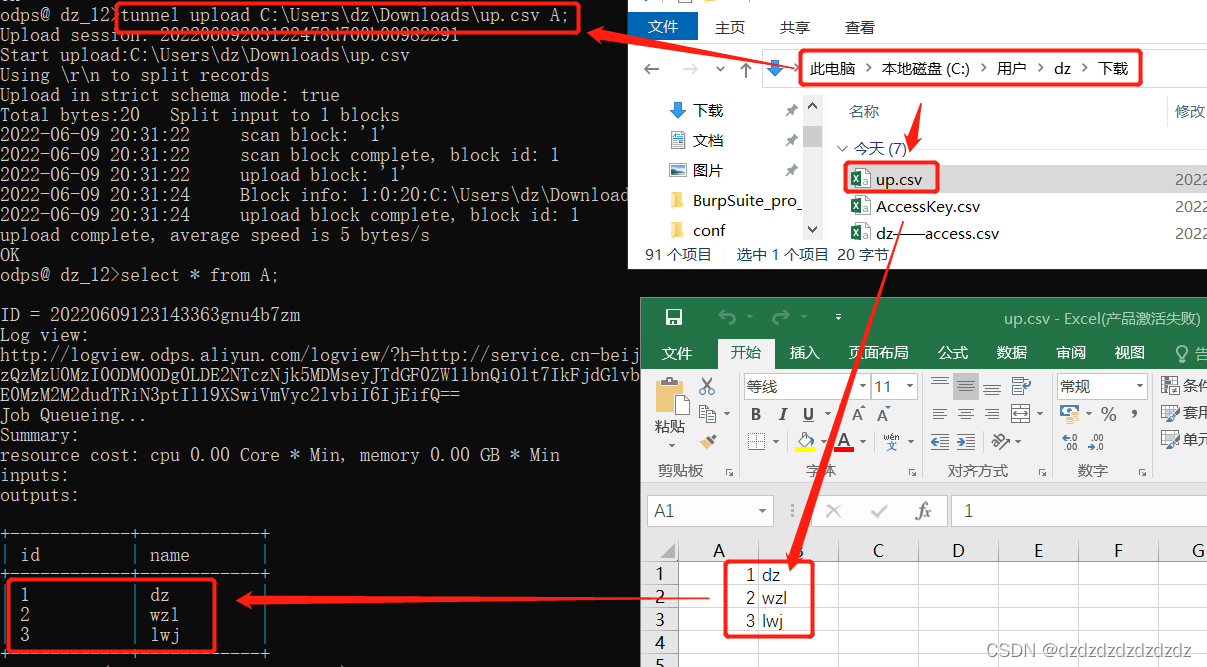
1. Carga adicionaltunnel upload C:\Users\dz\Downloads\up.csv A;
drop table if exists A;#如果表存在删除
create table A(id int,name string);#创造表A,键是id和name
desc A;#查看表A
tunnel help;#查看tunel命令
tunnel upload C:\Users\dz\Downloads\up.csv A;#本地表up.csv内容追加上传到A表;
select * from A;#查看表A
truncate table A;#清理表A里的内容
2. Carga de la tabla de particiones
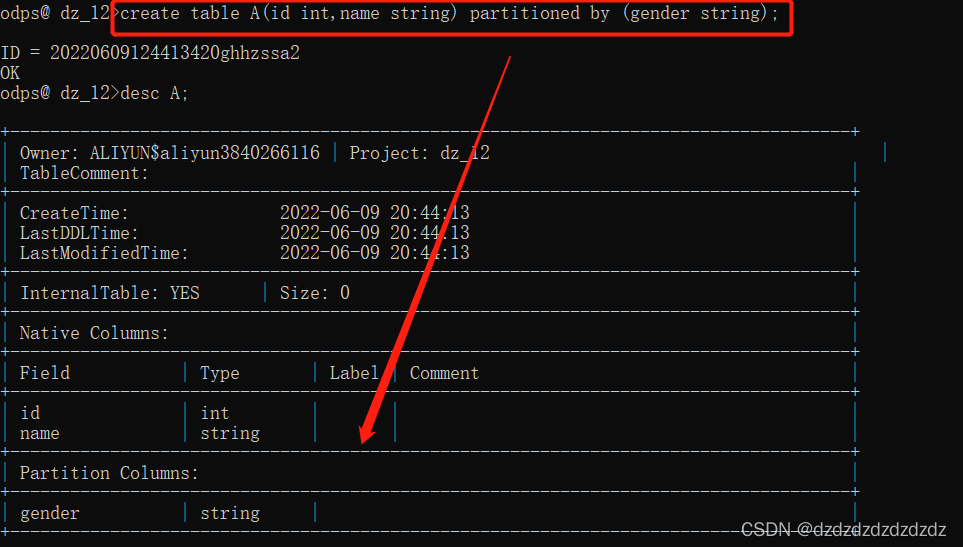
Primero cree una tabla de particiones
create table A(id int,name string) partitioned by (gender string);#按gender创造分区表
Entonces
tunnel upload C:\Users\dz\Downloads\up_p\up_1.csv A/gender='male' -acp=true;#上传本地表到此分区,没有此分区值则创建
select * from A where gender='male';查看分区值是此的分区表
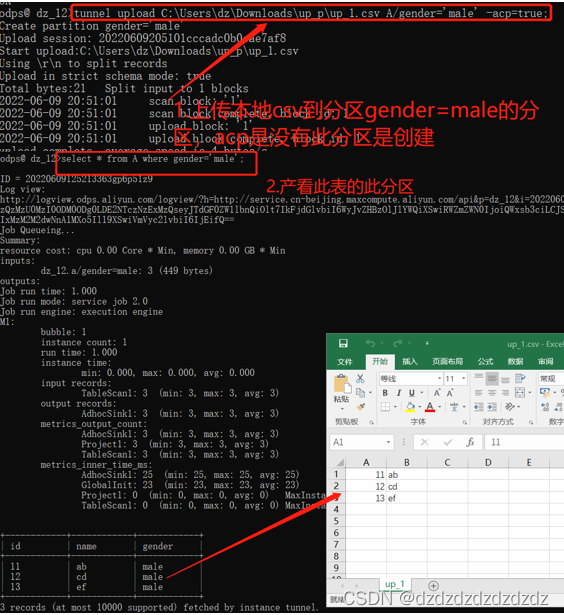
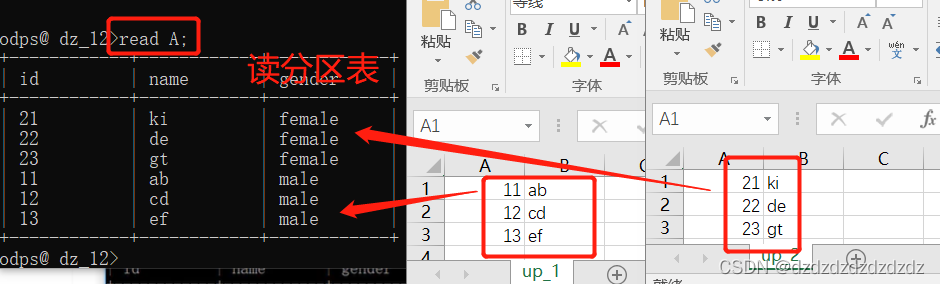
read A;#查看分区表的所有分区
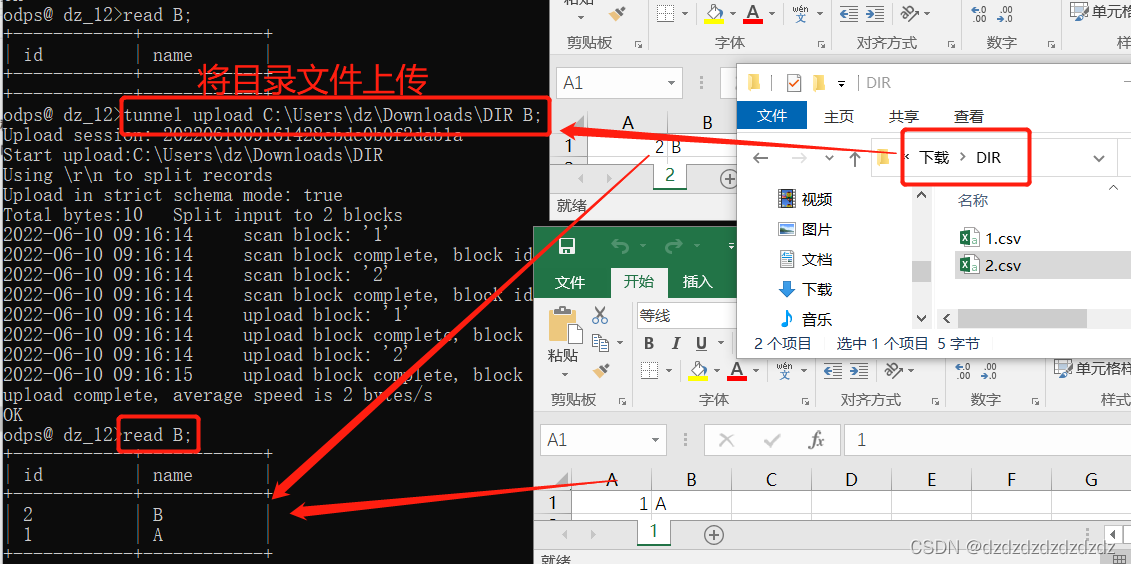
3. Carga del directorio de archivos
tunnel upload C:\Users\dz\Downloads\DIR B;#将C:\Users\dz\Downloads\DIR下的所有文件上传到表B;
Cuando hay tablas con diferentes formatos en la carpeta: -dbr=true significa que solo se ingresa el formato correcto y se descarta la tabla incorrecta;
tunnel upload C:\Users\dz\Downloads\DIR B -dbr=true;#有格式错误的表格,抛弃此表格
4. Escaneo de escaneo de parámetros
Cuando scan=true, primero escanea los datos, el formato es correcto y luego importa los datos;
cuando scan=false, no escanea los datos, sino que los importa directamente;
cuando scan=only, solo escanea los datos locales y no importar después de escanear
5. Separador
Separador de filas - rd (predeterminado \r\n) y separador de columnas - fd (,)
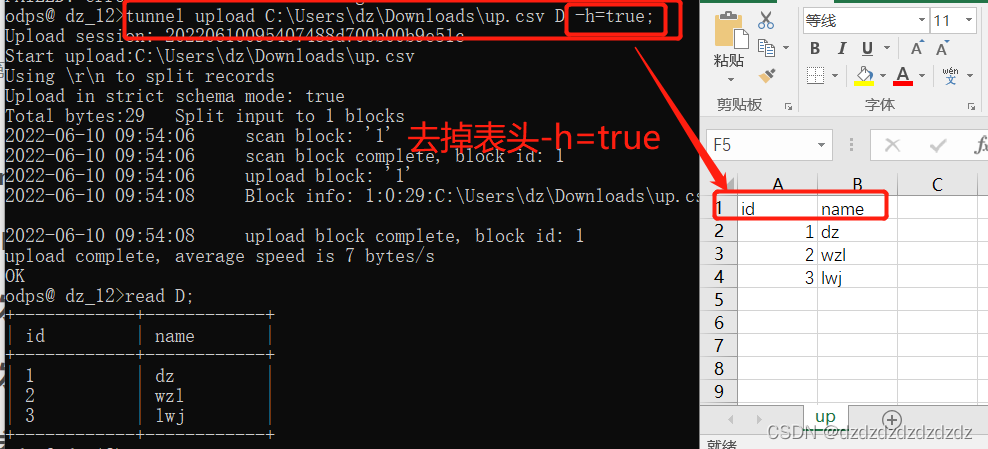
6. El encabezado de la primera línea
Elimina el encabezado de la primera línea del archivo csv: -h=true

2.2.1.2 descarga de túnel
1. Descarga la tabla de particiones
tunnel download A C:\Users\dz\Downloads\download\A_d.csv;#下载分区表的所有分区
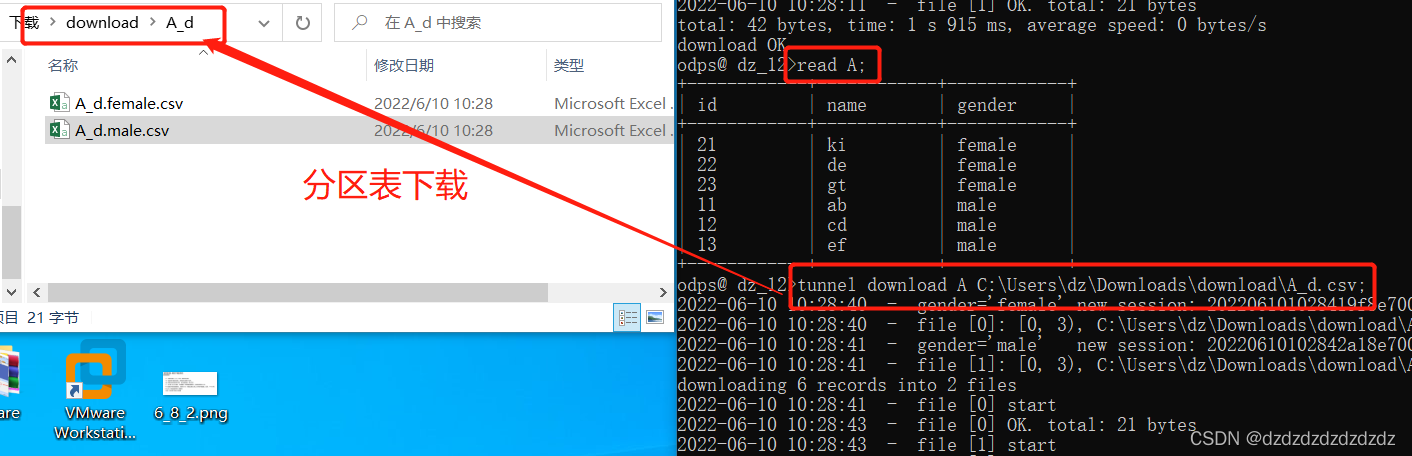
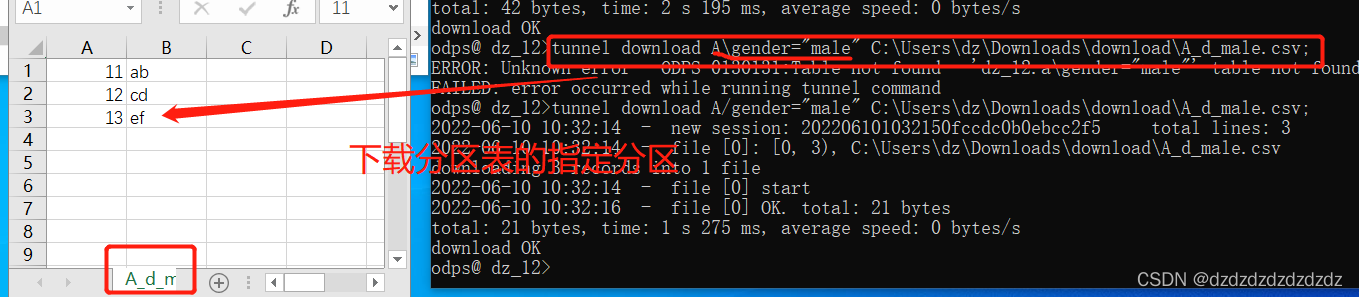
tunnel download A\gender="male" C:\Users\dz\Downloads\download\A_d_male.csv;#下载分区表的指定分区
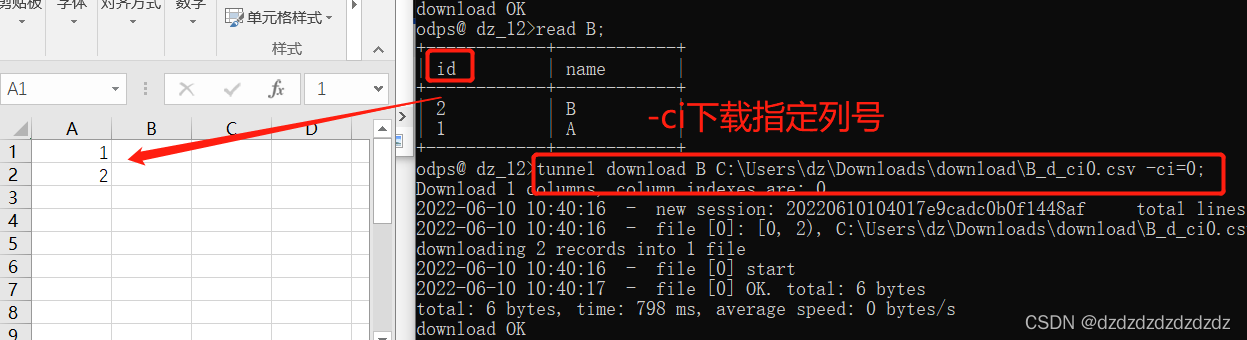
2. Descargue la columna especificada:
-ci=número de columna (el número de serie comienza en 0)
-cn=nombre de columna
tunnel download B C:\Users\dz\Downloads\download\B_d_ci0.csv -ci=0;
tunnel download B C:\Users\dz\Downloads\download\B_d_cnname.csv -cn="name";

3. Descarga de encabezado representativo -h=true
tunnel download B C:\Users\dz\Downloads\download\B_d_h.csv -h=true;

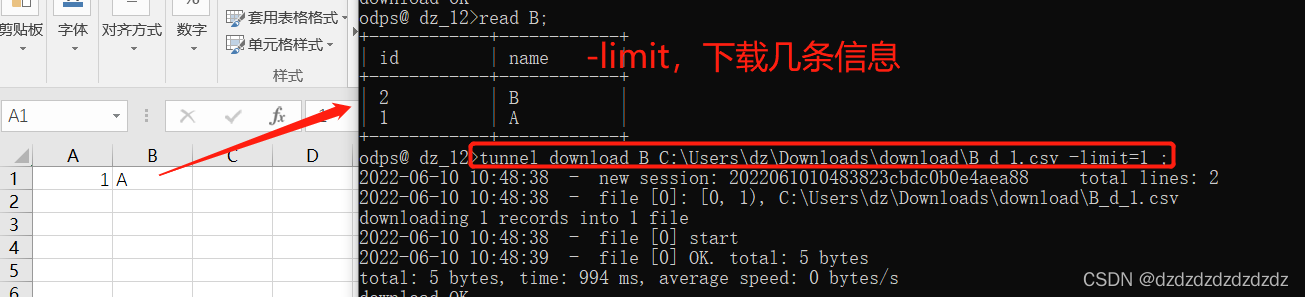
4. Solo se permite descargar algunos datos: -limit=num;
tunnel download B C:\Users\dz\Downloads\download\B_d_1.csv -limit=1 ;

2.2.2 Use javaSDK para desarrollar carga y descarga
1. Primero descargue javasdk del sitio web oficial de Alibaba Cloud e instale eclipse.
2.2.3 canal de procesamiento en tiempo real del centro de datos

1. Crear un proyecto de centro de datos
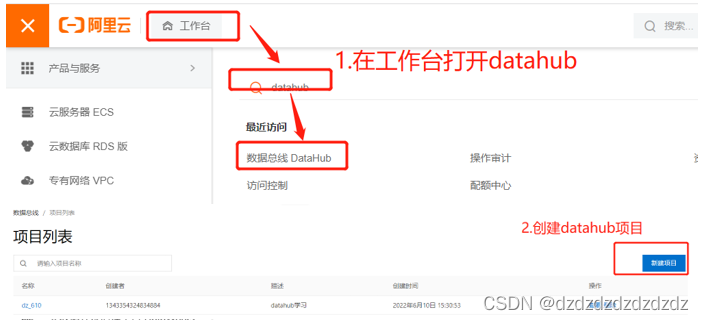
2. Escribir tema en el proyecto
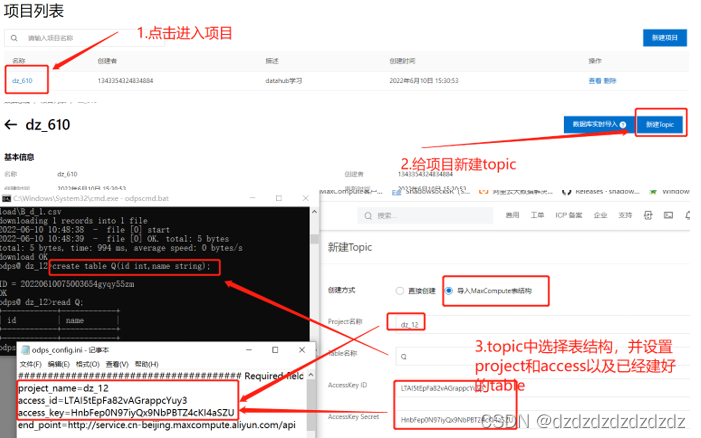
3. Cree una tarea de sincronización de conexión en el tema.

2.3 Conceptos básicos de desarrollo de maxcomputeSQL
2.3.1DDL
create table t_table01(id bigint,name string);#1.建表
desc t_table01;#2.看表
show create table t_table01;#3.查看建表语句
drop table t_table01;#4.删除表
select * from t_table01;#查看表
create table t_table01_p(id bigint,name string) partitioned by(class string);#1.创建分区表
desc t_table01_p;#2.查看分区表
create table AA as select * from A where gender="male";#使用as拿数据,不拿分区
create table AB like A;#使用like拿了表结构包括分区,不拿数据
alter table A set lifecycle 30;#1.设置分区表的生命周期是30天
alter table A disable lifecycle;#2.撤销分区表生命周期
select * from A where gender="male";#1.查看分区表,需要指定分区where
alter table A add if not exists partition(gender="unknown");#2.分区表增加分区gender=“unknown”
insert into A partition(gender="unknown") select 7,"someone";#3.指定分区unknow插入一条(7,someone)的数据
alter table A partition(gender="unknown") rename to partition(gender="trans");#4.将unknown分区名改为trans
alter table A merge partition(gender="male"),partition(gender="trans") overwrite partition(gender="unknow") purge;#5.将male和trans分区合并为unknow分区
alter table A rename to a_new;#6.修改表名A为a_new
alter table a_new add columns(desc string);#7.表加一列
create view v as select * from a_new;#1.创建视图
2.3.2DML
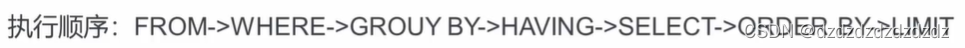
1. Consulta
list tables;#1.列出库内所有的表
select name,gender from aa;#2.查看aa表的name和gender两列
select name,gender from aa group by name,gender;#3.通过分组group by对这两列进行去重
select distinct name,gender from aa;#4.通过distinct对这两列进行去重
select * from aa limit 2;#5.查看aa表前两行
select * from (select * from aa where gender = 'female') a join (select * from aa where id = '21' and name = 'ki')b on a.id = b.id;#6.子查询
2. insertar
insert into aa values(10,'dz','female');#1.aa表插入一行数据
create table aa2 like aa;#2.做一个aa的备份表,拿结构不拿数据
insert into aa2 select * from aa;2.把aa的数据全追加到aa2
insert overwrite table aa2 select * from aa;2.把aa的数据全覆盖到aa2,aa2里原数据删掉了
3. Tabla de particiones
create table t_class_p (id int,name string)partitioned by(gender string);#1.创建分区表,gender分区
from aa insert into t_class_p partition(gender = '1') select id,name where id = 10 insert into t_class_p partition(gender = '2') select id,name where id = 11 insert into t_class_p partition(gender = '3') select id,name where id = 12;#2.多路输出,从aa表给分区表分别插入三个数据
set odps.sql.allow.fullscan =true;#3.设置分区表可以全局扫描
select * from t_class_p;#4.查询分区表所有内容
4. Pagar, fusionar, compensar, unirse
create table a1 as select * from aa where gender="female";#1.从aa表里分出gender为female的建表a1
create table a2 as select * from aa where gender="male";#2.从aa表里分出gender为male的建表a2
select id from a1 union all select id from a2;#3.a1表的id和a2表的id通过unio all求并集
select id from a1 union select id from a2;#4.使用union并集去重
select id from a1 intersect all select id from a2;#5.a1表的id和a2表的id通过intersect求交集
select id from a1 except all select id from a2;#6.使用except all求补集,在a1存在但在a2不存在
2.3.3 Funciones integradas
1. Operaciones matemáticas y procesamiento de caracteres
select 0.5*10*20*sin(60/180*3.1415926);#1.sin三角函数
select ceil(3.1415926),floor(3.1415926),round(3.1415926),trunc(3.1415926),conv('3.1415926',10,2);#2.ceil向上取整,floor向下取整,round四舍五入,trunc截取,conv10进制转换2进制。
select rand();#3.随机值,可以给种子
select abs(-2);#4.abs取绝对值
select power(-2,5);#5.-2的5次方
select sqrt(16);#6.16的均方根
select length("dacadc中文");#7.字符串长度,每个中文1个字符
select length("dacadc中文");#8.字符串长度,每个中文3个字符
select char_matchcount('asdf','asbrgdgf');#9.字符串1里面有几个在字符串2里面出现
select is_encoding("测试","utf-8");#10.测试编码是否utf-8
select instr("sdsdvfg","s");#11第2个字符在第1个字符的哪一个位置第一次出现,以1开头计数
select substr("dasdf",2,3);#从第2个字符开始剪切,剪切长度为3
2. Procesamiento de fechas y funciones de ventana
select getdate();#1.查询系统日期
select datediff(datetime '2022-06-18 20:00:00',datetime '2022-06-15 19:00:00','dd');#2.查看两个时间相差几天
select unix_timestamp(datetime '2022-06-13 20:00:00');#3.时间转换成时间戳
select from_unixtime(1655121600);#4.时间戳转换成时间
3. Agregación y otras funciones
在这里插入代码片
2.4 Base de desarrollo UDF
función definida por el usuario
2.5 Fundamentos del desarrollo de MR
MapReduce es un modelo de programación para operaciones paralelas en conjuntos de datos a gran escala (más de 1 TB). Los conceptos "Mapear" y "Reducir", que son sus ideas principales, se toman prestados de los lenguajes de programación funcionales, así como las características de los lenguajes de programación de vectores. Facilita enormemente a los programadores ejecutar sus programas en sistemas distribuidos sin programación paralela distribuida. La implementación actual del software consiste en especificar una función Map (mapeo) para mapear un conjunto de pares clave-valor en un nuevo conjunto de pares clave-valor, y especificar una función Reducir (reducción) simultánea para garantizar que todos los pares clave-valor asignados son Cada una de las acciones el mismo juego de llaves.
Crear: mapear, reducir, manejar tres archivos java
2.6 Conceptos básicos de desarrollo de gráficos
2.7 Permisos y Seguridad
show grants;#1.查看此用户在此项目下的权限
3. Plataforma de desarrollo y gobernanza de big data Dataworks
3.1 Integración de datos
1. Primero cree una nueva fuente de datos, aquí cree una fuente de datos mysql

3.2 Desarrollo de datos
3.3 Operación y mantenimiento de tareas
3.4 Gestión de datos
4. Plataforma de análisis de visualización de datos Quick Bi
5. Plataforma de aprendizaje automático PAI
1. Abra Alibaba Cloud pai
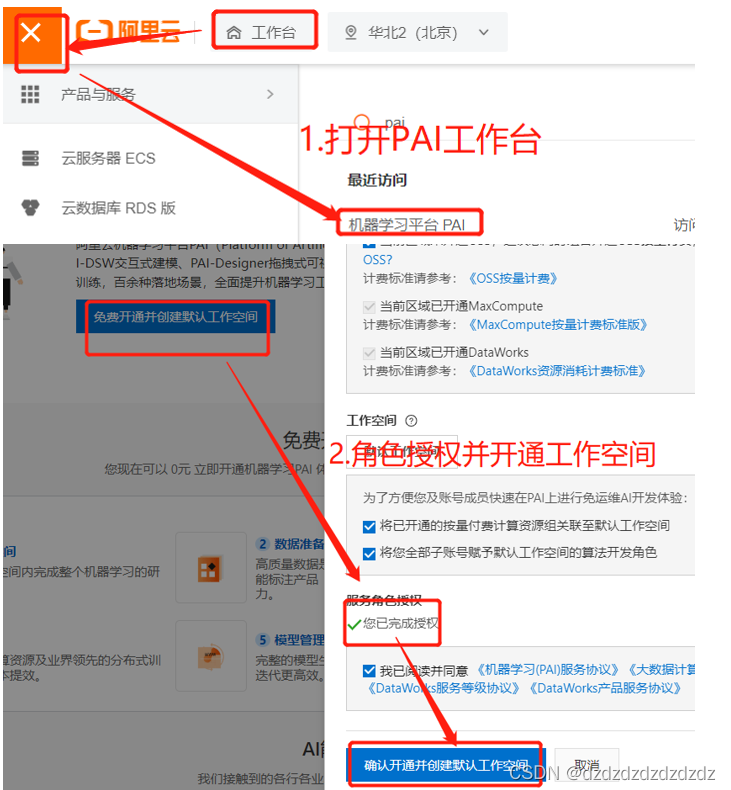
2. Cree un flujo de trabajo e ingrese
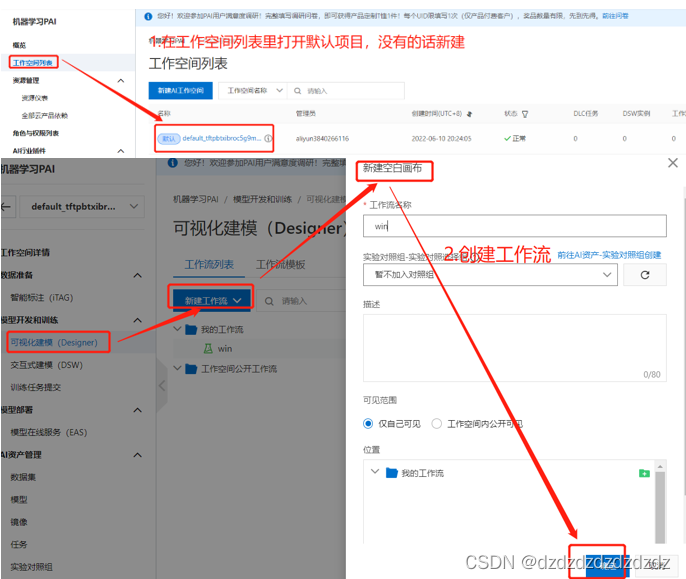
3. Descargue el conjunto de datos , que está clasificado por vino tinto, y luego importe los datos al espacio de trabajo.
La operación puede referirse a: https://blog.csdn.net/wyn_365/article/details/107284561