Hola a todos, hoy compartiré con ustedes cómo usar Tensorflow para construir un modelo de red neuronal convolucional ConvNeXt.
Dirección en papel : https://arxiv.org/pdf/2201.03545.pdf
El código completo está en mi Gitee: https://gitee.com/dgvv4/neural-network-model/tree/master/
En los últimos 21 años, Transformer ha cruzado con frecuencia el campo de visión. Primero fue superado por Google ViT en clasificación de imágenes y luego ganado por Microsoft Swin Transformer en detección de objetos y segmentación de imágenes. A medida que más y más académicos se involucran en la investigación de Transformador visual, las tres principales listas de tareas están dominadas por Transformador o un modelo que combina las dos arquitecturas. En este momento, ConvNeXt significa Red neuronal convolucional.

1. Módulo de bloque ConvNeXt
1.1 Estructura básica

(1) ConvNeXt utiliza la idea de convolución agrupada , que es lo mismo que la convolución en profundidad ( Developmentwise Conv ) en MobileNetV1. Hay tantos núcleos de convolución como canales en el mapa de características de entrada. Cada núcleo de convolución procesa un canal correspondiente y cada núcleo de convolución genera un mapa de características. Al apilar todos los mapas de características producidos en la dimensión del canal, hay mapas de características de entrada con la misma cantidad de canales que los mapas de características de salida.
(2) Invierta la estructura residual, primero convolución 1*1 para aumentar la dimensión, y luego convolución 1*1 para reducir la dimensión . Se toma prestada la estructura residual inversa de MobileNetV2. La precisión aumentó de 1 a 2 en los modelos más pequeños y de 1 a 1 en los modelos más grandes .80.5%80.6%81.9%82.6%
Puede consultar mi artículo anterior: https://blog.csdn.net/dgvv4/article/details/123476899
(3) Menos capas de normalización, utilizando Layer Normalization en lugar de Batch Normalization . El autor toma prestada la estructura de Transformer y solo retiene la capa de normalización después de la convolución en profundidad, y la tasa de precisión mejora ligeramente después del reemplazo.
1.2 Visualización de código
En el siguiente código, gama escala los datos del mapa de características de salida de la convolución de reducción de dimensionalidad 1*1. gama es una variable que se puede aprender, y la retropropagación optimiza el valor de gama durante el entrenamiento de la red.
gama es un vector unidimensional con el mismo número de elementos que el número de canales en el mapa de características de salida. Cada elemento del vector procesa un mapa de características correspondiente, y todos los valores de píxeles de un mapa de características se multiplican por un elemento del vector a su vez para lograr el propósito de escalar los datos del mapa de características.
Definir el parámetro entrenable add_weight() es un método bajo la clase Layer. Antes de usarlo , crea una instancia de la clase Layer, layers.Layer()
#(2)ConvNeXt Block
def block(inputs, dropout_rate=0.2, layer_scale_init_value=1e-6):
'''
layer_scale_init_value 缩放比例gama的初始化值
'''
# 获取输入特征图的通道数
dim = inputs.shape[-1]
# 残差边
residual = inputs
# 7*7深度卷积
x = layers.DepthwiseConv2D(kernel_size=(7,7), strides=1, padding='same')(inputs)
# 标准化
x = layers.LayerNormalization()(x)
# 1*1标准卷积上升通道数4倍
x = layers.Conv2D(filters=dim*4, kernel_size=(1,1), strides=1, padding='same')(x)
# GELU激活函数
x = layers.Activation('gelu')(x)
# 1*1标准卷积下降通道数
x = layers.Conv2D(filters=dim, kernel_size=(1,1), strides=1, padding='same')(x)
# 创建可学习的向量gama,该函数用于向某一层添加权重变量,类实例化layers.Layer()
gama = layers.Layer().add_weight(shape=[dim], # 向量个数和输出特征图通道数量一致
initializer=tf.initializers.Constant(layer_scale_init_value), # 权重初始化
dtype=tf.float32, # 指定数据类型
trainable=True) # 可训练参数,可通过反向传播调整权重
# layer scale 对特征图的每一个通道数据进行缩放,缩放比例gama
x = x * gama # [56,56,96]*[96]==>[56,56,96]
# Dropout层随机杀死神经元
x = layers.Dropout(rate=dropout_rate)(x)
# 残差连接输入和输出
x = layers.add([x, residual])
return x2. Red troncal
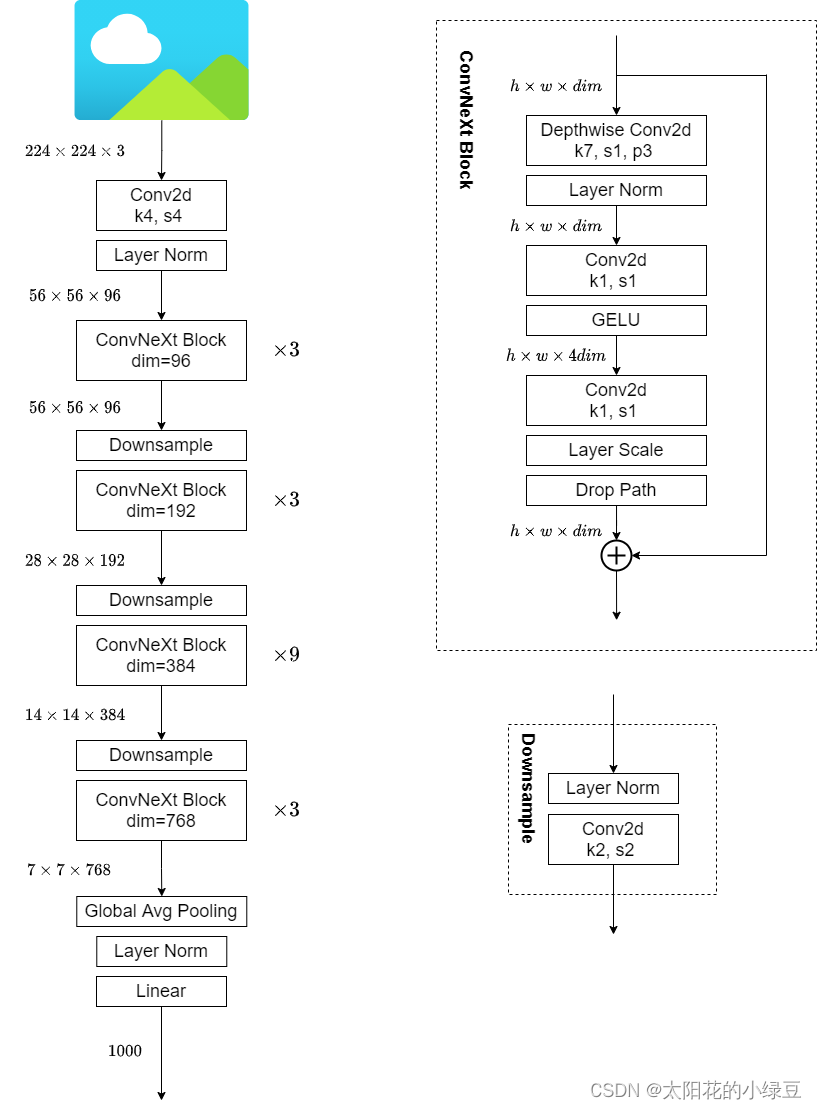
2.1 Diagrama de estructura de red
2.2 Esquema de diseño
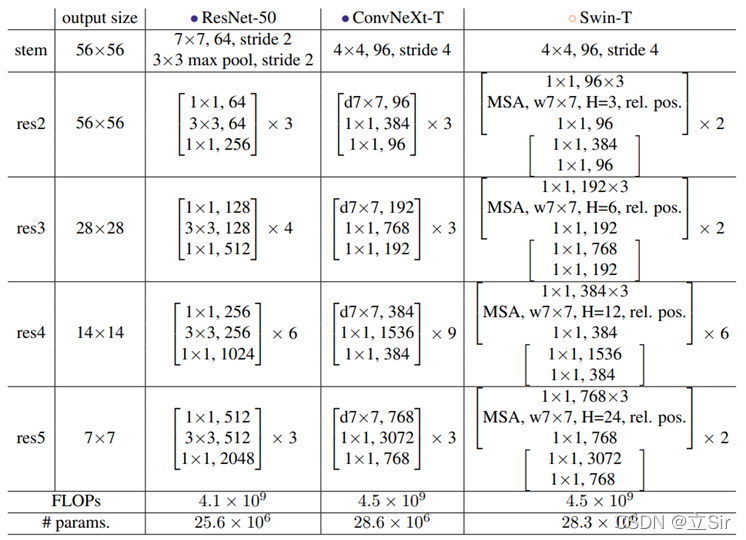
arquitectura de red . Como se muestra arriba, en la red ResNet50 , el número de bloques de apilamiento de res2 a res5 es (3, 4, 6, 3), y la proporción es de aproximadamente 1:1:2:1, pero en Swin Transformer , por ejemplo, la relación de Swin-T es 1:1:3:1, la relación de Swin-L es 1:1:9:1. Obviamente, la proporción de bloques apilados es mayor en el Swin Transformer. Entonces, el autor ajustó los tiempos de apilamiento en ResNet50 de (3, 4, 6, 3) a (3, 3, 9, 3), que tiene FLOP similares a Swin-T .
Diseño de capas de downsampling . La reducción de muestreo de la red ResNet se realiza estableciendo la zancada de la capa convolucional 3x3 en la rama principal en 2, y la zancada de la capa convolucional 1x1 en el lado residual en 2. Pero en Swin Transformer se logra a través de un Patch Merging separado. El autor recurre a Swin-T para usar una única capa de reducción de resolución para la red ConvNext, que consta de una normalización de Lairer más una capa convolucional con kernel_size=2 y strides=2 .
2.3 Visualización del código completo
ConvNeXtSe utilizan todas las estructuras y métodos existentes, no hay innovación de ninguna estructura o método. Y el código también está muy optimizado, se pueden construir más de 100 líneas de código
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Model, layers
#(1)输入图像经过的第一个卷积块
def pre_Conv(inputs, out_channel):
# 4*4卷积+标准化
x = layers.Conv2D(filters=out_channel, # 输出特征图的通道数
kernel_size=(4,4),
strides=4, # 下采样
padding='same')(inputs)
x = layers.LayerNormalization()(x)
return x
#(2)ConvNeXt Block
def block(inputs, dropout_rate=0.2, layer_scale_init_value=1e-6):
'''
layer_scale_init_value 缩放比例gama的初始化值
'''
# 获取输入特征图的通道数
dim = inputs.shape[-1]
# 残差边
residual = inputs
# 7*7深度卷积
x = layers.DepthwiseConv2D(kernel_size=(7,7), strides=1, padding='same')(inputs)
# 标准化
x = layers.LayerNormalization()(x)
# 1*1标准卷积上升通道数4倍
x = layers.Conv2D(filters=dim*4, kernel_size=(1,1), strides=1, padding='same')(x)
# GELU激活函数
x = layers.Activation('gelu')(x)
# 1*1标准卷积下降通道数
x = layers.Conv2D(filters=dim, kernel_size=(1,1), strides=1, padding='same')(x)
# 创建可学习的向量gama,该函数用于向某一层添加权重变量,类实例化layers.Layer()
gama = layers.Layer().add_weight(shape=[dim], # 向量个数和输出特征图通道数量一致
initializer=tf.initializers.Constant(layer_scale_init_value), # 权重初始化
dtype=tf.float32, # 指定数据类型
trainable=True) # 可训练参数,可通过反向传播调整权重
# layer scale 对特征图的每一个通道数据进行缩放,缩放比例gama
x = x * gama # [56,56,96]*[96]==>[56,56,96]
# Dropout层随机杀死神经元
x = layers.Dropout(rate=dropout_rate)(x)
# 残差连接输入和输出
x = layers.add([x, residual])
return x
#(3)下采样层
def downsampling(inputs, out_channel):
# 标准化+2*2卷积下采样
x = layers.LayerNormalization()(inputs)
x = layers.Conv2D(filters=out_channel, # 输出通道数个数
kernel_size=(2,2),
strides=2, # 下采样
padding='same')(x)
return x
#(4)卷积块,一个下采样层+多个block卷积层
def stage(x, num, out_channel, downsampe=True):
'''
num:重复执行多少次block ; out_channel代表下采样层输出通道数
downsampe:判断是否执行下采样层
'''
if downsampe is True:
x = downsampling(x, out_channel)
# 重复执行num次block,每次输出的通道数都相同
for _ in range(num):
x = block(x)
return x
#(5)主干网络
def convnext(input_shape, classes): # 输入图像shape和分类类别数
# 构造输入层
inputs = keras.Input(shape=input_shape)
# [224,224,3]==>[56,56,96]
x = pre_Conv(inputs, out_channel=96)
# [56,56,96]==>[56,56,96]
x = stage(x, num=3, out_channel=96, downsampe=False)
# [56,56,96]==>[28,28,192]
x = stage(x, num=3, out_channel=192, downsampe=True)
# [28,28,192]==>[14,14,384]
x = stage(x, num=9, out_channel=384, downsampe=True)
# [14,14,384]==>[7,7,768]
x = stage(x, num=3, out_channel=768, downsampe=True)
# [7,7,768]==>[None,768]
x = layers.GlobalAveragePooling2D()(x)
x = layers.LayerNormalization()(x)
# [None,768]==>[None,classes]
logits = layers.Dense(classes)(x) # 不经过softmax
# 构建网络
model = Model(inputs, logits)
return model
#(6)接收网络模型
if __name__ == '__main__':
# 构造网络,传入输入图像的shape,和最终输出的分类类别数
model = convnext(input_shape=[224,224,3], classes=1000)
model.summary() # 查看网络结构
Los parámetros de la red son los siguientes
==================================================================================================
Total params: 28,582,504
Trainable params: 28,582,504
Non-trainable params: 0
__________________________________________________________________________________________________3. Diagrama del modelo de red
Gracias al diagrama del modelo del pequeño blogger de frijol mungo de Sunflower