1. ¿Por qué particionar los datos?
La partición de la base de datos puede reducir en gran medida la demora en la respuesta del sistema al tiempo que aumenta el rendimiento de los datos. Específicamente, la partición tiene los siguientes beneficios:
- El particionamiento hace que las tablas grandes sean más fáciles de administrar. Las operaciones de mantenimiento en subconjuntos de datos también son más eficientes, porque estas operaciones son solo para los datos requeridos en lugar de para toda la tabla. Una buena estrategia de partición reducirá la cantidad de datos que se escanearán leyendo solo los datos relevantes necesarios para satisfacer la consulta. Cuando todos los datos se encuentran en la misma partición, las consultas, los cálculos y otras operaciones en la base de datos estarán restringidas al cuello de botella de E / S de acceso al disco.
- El particionamiento permite al sistema hacer un uso completo de todos los recursos. Con un buen esquema de particionamiento y computación paralela, la computación distribuida puede hacer un uso completo de todos los nodos para completar tareas que generalmente se completan en un nodo. Cuando una tarea se puede dividir en varias subtareas dispersas y cada subtarea accede a una partición diferente, se puede mejorar la eficiencia.
- El particionamiento aumenta la disponibilidad del sistema. Porque la copia de la partición generalmente se almacena en diferentes nodos físicos. Entonces, una vez que una partición no está disponible, el sistema aún puede llamar a otras particiones de réplica para garantizar el funcionamiento normal del trabajo.
2. Método de partición
DolphinDB admite múltiples métodos de particionamiento: partición de rango (RANGE), partición hash (HASH), partición de valor (VALUE), partición de lista (LIST), partición compuesta (COMPO).
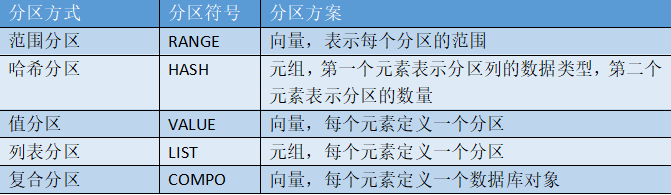
- La partición por rango crea una partición para cada intervalo, que es el método de partición más utilizado y recomendado. Puede poner todos los registros cuyos valores están en un rango en una partición.
- El particionamiento hash utiliza funciones hash para operar en columnas de partición para facilitar el establecimiento de un número específico de particiones.
- La partición de valor crea una partición para cada valor, como la fecha de negociación de acciones y el mes de negociación de acciones.
- La partición de listas se basa en listas enumeradas por el usuario, que es más flexible que la partición de valores.
- La partición compuesta es adecuada para cantidades muy grandes de datos y las consultas a menudo involucran dos o más columnas de partición. Cada selección de partición puede utilizar una partición de intervalo, valor o lista. Por ejemplo, la partición de valor se basa en la fecha de la transacción de acciones y la partición de rango se basa en el código de existencias.
Podemos usar la función de base de datos para crear una base de datos.
语法 :base de datos (directorio, [tipo de partición], [ esquema de partición], [ubicaciones])
parámetro
directorio: el directorio donde se guarda la base de datos. DolphinDB tiene tres tipos de bases de datos, que son base de datos en memoria, base de datos en disco y base de datos en sistema de archivos distribuido. Para crear una base de datos en memoria, el directorio está vacío; para crear una base de datos local, el directorio debe ser un directorio del sistema de archivos local; para crear una base de datos en un sistema de archivos distribuido, el directorio debe comenzar con "dfs: //". Este tutorial toma como ejemplo la creación de una base de datos local de Windows.
partitionType: modo de partición, hay 5 formas: partición de rango (RANGE), partición hash (HASH), partición de valor (VALUE), partición de lista (LIST), partición compuesta (COMPO).
partitionScheme: esquema de partición. Los esquemas de partición correspondientes a varios métodos de partición son los siguientes:
ubicaciones: especifique la ubicación del nodo donde se encuentra cada partición. Si es una base de datos de sistema de archivos distribuido o una base de datos de tipo de partición compuesta (COMPO), no se puede utilizar el parámetro de ubicaciones.
2.1 Partición de rango
La partición de rango está determinada por el vector de partición. El vector de partición representa el intervalo, incluido el valor inicial pero no el valor final.
En el siguiente ejemplo, la base de datos db tiene dos particiones: [0,5) y [5,10). Utilice la función append! Para guardar la tabla t como la tabla de particiones pt en la base de datos de la base de datos, y utilice el ID como columna de partición.
n = 1000000
ID = rand (10, n)
x = rand (1.0, n)
t = tabla (ID, x)
db = database ("dfs: // rangedb", RANGE, 0 5 10)
pt = db.createPartitionedTable (t, `pt,` ID)
pt.append! (t);
pt = loadTable (db, `pt)
seleccione count (x) de pt
2.2 partición hash
La partición hash utiliza una función hash en la columna de la partición para generar particiones. El particionamiento hash es una forma fácil de generar un número específico de particiones. Sin embargo, debe tenerse en cuenta que la partición hash no puede garantizar el mismo tamaño de la partición, especialmente cuando la distribución del valor de la columna de la partición está sesgada. Además, cuando se buscan datos en un área continua en la columna de partición, la eficiencia de la partición hash es menor que la partición de área o la partición de valor.
En el siguiente ejemplo, la base de datos db tiene dos particiones. Use la función append! Para guardar la tabla t como la tabla de particiones pt en la base de datos db, y use el ID como columna de partición.
n = 1000000
ID = rand (10, n)
x = rand (1.0, n)
t = tabla (ID, x)
db = database ("dfs: // hashdb", HASH, [INT, 2])
pt = db .createPartitionedTable (t, `pt,` ID)
pt.append! (t);
pt = loadTable (db, `pt)
seleccione count (x) de pt
2.3 Partición de valor
La partición de valor utiliza un valor para representar una partición. El siguiente ejemplo define 204 particiones. Cada zona representa un mes entre enero de 2000 y diciembre de 2016.
n = 1000000
mes = take (2000.01M..2016.12M, n)
x = rand (1.0, n)
t = tabla (mes, x)
db = database ("dfs: // valuedb", VALUE, 2000.01M .. 2016.12M)
pt = db.createPartitionedTable (t, `pt,` month)
pt.append! (T)
pt = loadTable (db, `pt)
seleccione count (x) from pt
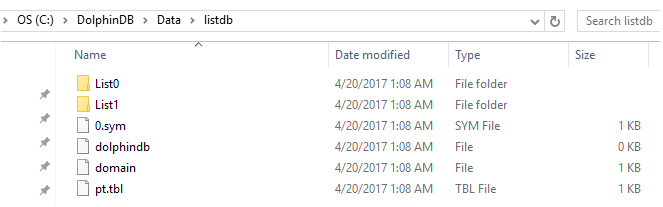
2.4 Partición de lista
En la partición LIST, usamos una lista que contiene múltiples elementos para representar una partición. El siguiente ejemplo tiene dos particiones, la primera partición contiene 3 códigos de stock y la segunda partición contiene 2 códigos de stock.
n = 1000000
ticker = rand (`MSFT`GOOG`FB`ORCL`IBM, n);
x = rand (1.0, n)
t = table (ticker, x)
db = database ("dfs: // listdb", LIST, [`IBM`ORCL`MSFT,` GOOG`FB])
pt = db.createPartitionedTable ( t, `pt,` ticker)
pt.append! (t)
pt = loadTable (db, `pt)
seleccione count (x) from pt
2.5 Partición combinada
La partición combinada (COMPO) puede definir 2 o 3 columnas de partición. Cada columna se puede dividir de forma independiente por rango (RANGO), valor (VALOR) o lista (LISTA). Las múltiples columnas de la partición combinada son lógicamente paralelas y no hay subordinación o relación de prioridad.
n = 1000000
ID = rand (100, n)
fechas = 2017.08.07..2017.08.11
fecha = rand (fechas, n)
x = rand (10.0, n)
t = tabla (ID, fecha, x)
dbDate = base de datos (, VALOR, 2017.08.07..2017.08.11)
dbID = database (, RANGE, 0 50100)
db = database ("dfs: // compoDB", COMPO, [dbDate, dbID])
pt = db.createPartitionedTable ( t, `pt,` date`ID)
pt.append! (t)
pt = loadTable (db, `pt)
seleccione count (x) from pt
El ejemplo anterior crea 5 particiones de valor.
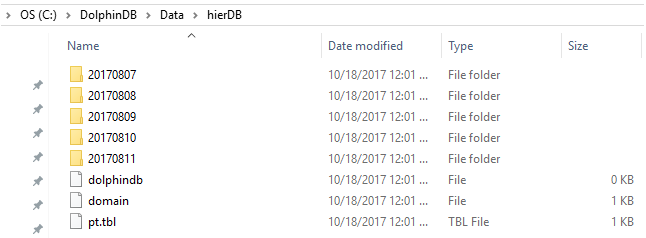
En la partición 20170807, hay 2 particiones de rango.

El tutorial de partición de bases de datos (2) presentará los principios de partición de bases de datos y esquemas especiales de partición.