SinoPac Securities es una gran empresa de corretaje con la cuarta participación de mercado más grande en el negocio económico de Taiwán. Los usuarios externos y los empleados internos acceden al sistema a través de varias plataformas electrónicas para enviar requisitos de servicio, como Web, aplicaciones móviles, aplicaciones de Windows y B2B, B2C API. etc.
En la actualidad, el procesamiento y respuesta de la demanda del servicio de cada plataforma electrónica de SinoPac Securities lo realiza el departamento de información. Se entiende que el número máximo de personas en línea al mismo tiempo en la plataforma puede llegar a 12.000. Entre ellos, la consulta, el procesamiento, el aterrizaje y la reaplicación de datos de mercado son los negocios más onerosos.
El 23 de marzo de 2020, la Bolsa de Valores de Taiwán cambió el mecanismo de conciliación de transacciones del sistema de conciliación centralizado original de 5 segundos a un sistema de conciliación de transacciones de microsegundos (millonésima de segundo), y el volumen general de datos aumentó a 2-4 veces el original. , la cantidad de datos durante el período pico ha aumentado de 4 a 6 veces. Ante el aumento de los datos del mercado, el sistema de procesamiento original de la industria de SinoPac Securities se ha atascado y es necesario buscar nuevas soluciones.
Después de una consideración exhaustiva del rendimiento, la escalabilidad, la madurez, el costo integral de propiedad, etc., SinoPac Securities abandonó kdb +, InfluxDB y Kafka y finalmente eligió DolphinDB como la plataforma básica del sistema de datos de mercado.
1. Puntos débiles empresariales a los que se enfrentan
Para proporcionar a los usuarios los servicios correspondientes, la estructura de servicio de SinoPac Securities debe proporcionar retención de ticks y consulta de cotizaciones de mercado, consulta de series de tiempo en tiempo real (dividida en K, K diaria), instantáneas de diversa información de mercado y una base de datos. de análisis técnico. Sin embargo, la arquitectura del servicio de datos de mercado anterior tiene muchos problemas, como dificultad en la expansión de funciones, bajo rendimiento, altos costos de integración del sistema y dificultad en la resolución de problemas.
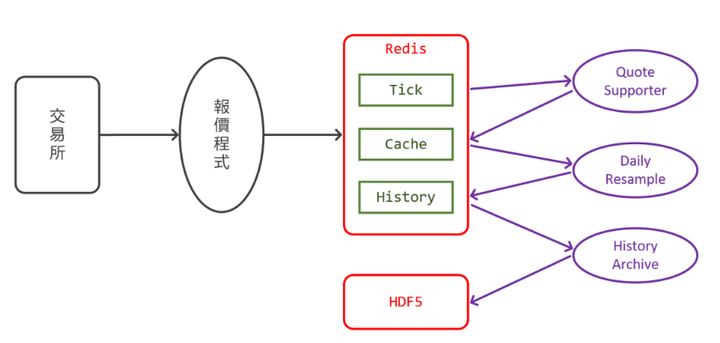
Diagrama de arquitectura de servicio de datos de mercado pasados
- La expansión de funciones no es fácil
Antes, SinoPac Securities usaba el formato de archivo C-ISAM / HDF5 para el aterrizaje y la reaplicación de datos de mercado, pero su soporte para el sistema de desarrollo no era bueno (solo API C / C ++), y también se vería afectado por la versión del servidor. (Solaris 32bit). El tamaño máximo de cada archivo es de 2GB. Cuando se obtienen los datos de mercado, hay un límite en la sección de tiempo de retención. Además, la tabla de la base de datos de formato de archivo encontrará el problema de la flexibilidad insuficiente cuando se expanda. Al mismo tiempo, debido a que es un formato de archivo, cada servidor necesita tener una copia de seguridad de los datos históricos del mercado, lo que aumenta los costos de almacenamiento y aumenta datos Riesgo de incoherencia.
- Bajo rendimiento
SinoPac Securities utiliza pandas para calcular y aplicar datos de mercado. En las consultas de clientes de alta concurrencia, Redis Tick se transpone al componente K mediante un nuevo muestreo. Este proceso dura aproximadamente 1 segundo.
Para la empresa, este desempeño es realmente malo. La compañía intentó distribuir diferentes negocios en diferentes servidores, pero desafortunadamente, aún no pudo brindar servicios eficientes y una buena experiencia para el cliente.
- Costos elevados de integración del sistema
Cada dato de mercado tiene que pasar por varios procesos, como la recopilación, el procesamiento y el aterrizaje. Sin embargo, SinoPac Securities eligió diferentes soluciones en cada etapa al seleccionar la tecnología, como la recopilación de datos de mercado en tiempo real a través de Redis. Utilice pandas para procesar aplicaciones y C-ISAM / HDF5 para servir el almacenamiento de datos de mercado.
En base a esto, si desea integrar y desarrollar cada arquitectura de servicio, debe comprender el uso de cada capa de servicio y luego integrar los servicios que el sistema necesita proporcionar. Por ejemplo, la tarea de reducir la dimensionalidad de los datos de mercado (convertir datos de alta frecuencia a nivel de tick en líneas K de nivel de minutos o de nivel diario) y empalmar futuros de diferentes meses en contratos continuos requiere requisitos de tecnología y costos extremadamente altos para el sistema. integración.
- Descartar anomalías
Los servicios basados en una arquitectura abierta enfrentarán varias excepciones, como excepciones en el lado de los datos, y no se pueden bloquear de manera efectiva y precisa. Para eliminar tales anomalías, tenemos que invertir mucha mano de obra y recursos materiales en el desarrollo secundario del código de la arquitectura de desarrollo, lo que hace que los desarrolladores no puedan concentrarse en el negocio.
2. Elección de la plataforma tecnológica
En vista de los puntos débiles comerciales y las características del equipo anteriores, esperamos encontrar una plataforma tecnológica que tenga en cuenta el procesamiento de datos históricos y datos en tiempo real y, al mismo tiempo, cumpla con los requisitos informáticos de los servicios de cotización del mercado financiero. de la caja, excelente rendimiento, bajos costos de aprendizaje y desarrollo.
En junio de 2019, evaluamos sucesivamente los sistemas kdb +, InfluxDB, Kafka y DolphinDB.
- kdb +
kdb + es una base de datos de series de tiempo ampliamente utilizada por Wall Street para servicios de información de mercado y es conocida por su alta velocidad. Debido a que el principal problema del sistema de cotización de mercado original era un rendimiento insuficiente en el negocio de conciliación de transacciones, muchas personas recomiendan utilizar kdb + para resolver el problema de rendimiento.
Después de una evaluación preliminar, decidimos abandonar kdb + por dos razones principales: una es que la formación técnica de los miembros del equipo es principalmente Python, los lenguajes Q y K que cruzan a kdb + son demasiado difíciles y si los datos del mercado El sistema se basa en kdb +, necesita contratar consultores kdb + costosos adicionales. El segundo es que kdb + es un sistema de tarea única de una sola máquina. Aunque un solo nodo de kdb puede soportar el volumen de datos del mercado actual y el acceso de los usuarios, si se requiere la expansión horizontal posterior de las capacidades de almacenamiento y computación, se requiere mucho desarrollo Se requiere trabajo de integración.
- Kafka
Muchas tareas del sistema de servicios de información de mercado requieren computación de flujo en tiempo real, lo que nos llevó a considerar a Kafka como el centro para construir el sistema.
Después de una prueba simple, encontramos que Kafka es un sistema de mensajería universal y personalizable, pero si se va a aplicar a un campo profesional como el mercado financiero, especialmente para lograr un funcionamiento estable y eficiente, se requiere mucho desarrollo, integración y ajuste. requerido Trabajo técnico optimizado. Para los pequeños equipos de desarrollo que se centran en los negocios más que en la tecnología en sí, Kafka puede no ser la mejor opción.
Además, la ventaja de Kafka radica en un alto rendimiento, no en una baja latencia. Durante el período pico de transacciones del mercado financiero, Kafka puede tener un retraso de varios segundos, lo cual es un gran problema para el sistema de servicios de mercado con requisitos de alta puntualidad.
- InfluxDB
El servicio de información de mercado es un escenario típico de aplicación de datos de series de tiempo, por lo que también probamos la base de datos de series de tiempo de código abierto más popular, InfluxDB.
Descubrimos que InfluxDB organiza los datos de acuerdo con métricas, y el valor de la serie temporal de un conjunto de combinaciones de etiquetas en un determinado indicador formará una secuencia. Estas diferentes secuencias son casi independientes entre sí en términos de almacenamiento lógico y físico. Está diseñado para la recopilación de datos y la consulta de los sensores de IoT. Cuando se enfrentan a muchos problemas en los servicios del mercado, pueden carecer de habilidades expresivas: como el procesamiento. datos, necesitamos correlacionar los precios del mercado de valores; al calcular los indicadores técnicos, nos preocupamos por la relación entre máximo, mínimo y cierre de la misma acción, o la relación entre los rendimientos de diferentes acciones.
Dado que InfluxDB en sí no puede cumplir con los requisitos de cálculos complejos en los servicios de cotización del mercado financiero, ¿se puede utilizar InfluxDB como un motor de almacenamiento puro para transferir cálculos complejos a un tercero (como pandas) para su procesamiento? Comparamos el modo de procesamiento de InfluxDB-pandas con el modo de cálculo en la biblioteca DolphinDB, el último está más de 100 veces por delante del primero en rendimiento.
Esta ventaja proviene de tres aspectos:
- La velocidad de acceso a datos de DolphinDB es más rápida que la de InfluxDB.
- DolphinDB proporciona potencia informática en la biblioteca para ahorrar el costo de la transferencia de datos.
- La velocidad de cálculo de DolphinDB es más rápida que la de los pandas.
- DolphinDB
DolphinDB es un producto descubierto inesperadamente durante la evaluación de kdb +. Luego de las pruebas, se comprueba que su desempeño en todos los aspectos es sobresaliente, lo cual está en línea con los requerimientos de los servicios del mercado financiero.
En comparación con kdb +, DolphinDB es una base de datos de series de tiempo distribuida y no se requiere trabajo adicional para la expansión horizontal. El lenguaje de DolphinDB es como una combinación de SQL y Python, y los recién llegados pueden comenzar rápidamente; en comparación con Kafka, el propio sistema de transmisión de datos de DolphinDB no solo está estrechamente integrado con la base de datos, sino que también se utiliza el motor informático de transmisión box, a través de una configuración simple y Scripting puede completar más del 95% del trabajo de los servicios de información de mercado; en comparación con InfluxDB, el rendimiento es mejor.
Combinado con múltiples dimensiones como recursos de hardware, costos de desarrollo y mantenimiento y ciclos de entrega de productos, encontramos que el costo integral de DolphinDB es el más bajo.
3. La situación actual después de la introducción de DolphinDB
En agosto de 2019, comenzamos a probar DolphinDB. En octubre, decidimos utilizar DolphinDB como plataforma tecnológica. En marzo de 2020, se lanzó oficialmente el nuevo sistema de servicio de información de mercado.
- Utilice la vista de funciones para ampliar rápidamente los servicios
La vista de funciones de DolphinDB es una abstracción de los servicios de datos. Originalmente, el servicio de función necesitaba calcular el procesamiento requerido por el cliente después de obtener los datos, pero ahora se puede transferir a la base de datos para un procesamiento centralizado, y el cliente solo necesita usar la API para llamar a la vista de función. Cuando otros departamentos comerciales presentan una nueva solicitud de servicio de datos de mercado, solo necesitan desarrollar una vista de función en un lenguaje similar a SQL y autorizar su uso, sin exponer toda la estructura de datos y permisos originales.
Este enfoque no solo acelera el desarrollo de los servicios de datos, sino que también simplifica la gobernanza y el control de los datos. La vista de funciones también tiene el efecto de acelerar el desarrollo y simplificar la gestión para la gestión del sistema y la expansión funcional.
Tomando como ejemplo la visualización de información de mercado en el lado web, originalmente era necesario realizar el procesamiento de cálculos en el backend web. Ahora, usando la vista de funciones, la lógica de procesamiento de back-end original se encapsula de manera más concisa y eficiente a través de DolphinDB, y el código de back-end web original desarrollado extensamente se reduce a una línea de funciones, y se puede obtener el mismo resultado. En el pasado, la adquisición de productos entre mercados también requería que la Web reuniera la información de la lista de productos de cada mercado a través de múltiples consultas repetidas. Debido a que DolphinDB mismo ha recopilado la cotización del mercado de cada mercado, se obtiene mediante gramática SQL simple y vector- adquisición basada La eficiencia y el desarrollo se han optimizado en gran medida. Al mismo tiempo, los detalles de los datos se encapsularán en DolphinDB. Otros colegas en el backend de la Web solo necesitan definir la interfaz de datos para resolver el problema del fuerte acoplamiento entre los datos y el sistema en el pasado.
Las vistas funcionales de DolphinDB son conceptualmente similares a los procedimientos almacenados de las bases de datos relacionales. Pero supera muchas limitaciones de los procedimientos almacenados:
- No apto para manejar lógica empresarial compleja;
- Escasa legibilidad del código;
- La computación paralela y la computación distribuida no pueden realizarse.
No hay una diferencia sustancial entre usar DolphinDB para desarrollar una vista de función y usar Python para desarrollar una función de lógica empresarial. Es solo que el lenguaje de scripting de DolphinDB es compatible de forma nativa con la programación funcional, vectorial y distribuida de múltiples paradigmas, el código es más conciso y la operación es más eficiente.
- Cómodo procesamiento de transmisión de datos
En el proceso de importación de DolphinDB, la función principal más interesante es la potencia de procesamiento de su motor de transmisión. Para cada requerimiento comercial, los diferentes motores de transmisión de datos brindarán las capacidades de procesamiento necesarias, de modo que la carga informática previa pueda obtener los datos en tiempo real y procesarlos en tiempo real. El tiempo de retorno del cliente para una consulta se reduce de 1 a 2 segundos a 10 milisegundos.
Los motores de procesamiento de transmisión de datos actualmente en uso incluyen:
- Los datos de K-line se pueden generar instantáneamente a través de Time Series Aggregator.
- Produzca un resumen del mercado y la clasificación de varias condiciones del mercado a través del Agregador de sección transversal.
- Utilice el motor de detección de anomalías para analizar todos los datos del mercado en tiempo real, filtrar las reglas de transacción y dar advertencias.
El script eficiente y conveniente de DolphinDB combina varios complementos y API para crear Dashboard rápidamente. Los datos de monitoreo y advertencia de datos se pueden integrar de manera efectiva con marcos de Dashboard como Grafana y NetData para establecer rápidamente un mecanismo de monitoreo del sistema.
- Consulta y análisis de datos históricos eficientes
El volumen de datos diario actual de las acciones de Taiwán es de aproximadamente 60 millones de datos de mercado, y el tamaño de los datos originales es de aproximadamente 10G. Después de importar DolphinDB, se requieren aproximadamente 2 GB de espacio en el disco duro y la tasa de compresión es de aproximadamente el 20%. Con los mismos recursos del sistema, se pueden retener más y más datos.
DolphinDB es una base de datos de series de tiempo distribuida que puede particionar datos de manera razonable para mejorar el rendimiento del sistema. A diferencia de otras bases de datos de series de tiempo que se particionan automáticamente en la dimensión de tiempo de acuerdo con la cantidad de datos, DolphinDB proporciona una gran cantidad de métodos de partición (incluida la partición de valor, la partición de rango, la partición hash, la partición de lista y la partición combinada) y permite a los usuarios las características comerciales y distribución de datos, elija una estrategia de partición razonable de forma independiente. Independientemente de las consideraciones de optimización del rendimiento, esto también está en consonancia con las necesidades comerciales de los servicios del mercado. El procesamiento de datos históricos por parte del servicio de información de mercado generalmente se basa en días y no se puede dividir en ventanas de tiempo arbitrarias.
Con respecto a los datos de mercado de Taiwán, la parte Tick actualmente usa una partición por día para almacenamiento, y la parte OrderBook, debido al número extremadamente alto, usa una partición dual (Símbolo + Fecha), que puede cumplir con los requisitos actuales del sistema en términos de acceso. . OrderBook solía ser datos cuya estructura no se podía implementar, y ahora se ha guardado a través de DolphinDB, y además, se agregan los elementos de contenido de SinoPac Securities para proporcionar datos de mercado de los clientes.
Además, debido al diseño de DolphinDB, el mismo tipo de mercado puede considerarse como una tabla de datos completa en uso, y los datos con condiciones específicas pueden consultarse a través de simples declaraciones SQL. En el pasado, la forma de acceder a HDF5 / Redis mediante una interfaz de consulta autodefinida a menudo tenía que desarrollar parámetros de consulta adicionales debido a las nuevas condiciones de consulta.
DolphinDB tiene una API rica y abierta, y capacidades de servicio eficientes. Por lo tanto, SinoPac Securities ha creado un conjunto de DolphinDB y adopta el estado de modo único para cumplir con los requisitos del lado del AP de consulta. No es necesario crear varios servidores. rendimiento y funcionalidad requeridos.
- Reducir significativamente los costos de desarrollo
En el pasado, los productos de SinoPac Securities se creaban apilando varias arquitecturas de sistemas abiertos, algunas de las cuales no estaban diseñadas para la industria financiera, por lo que tuvimos que dedicar mucho tiempo y energía para integrarnos. Después de importar DolphinDB, el procesamiento que originalmente se dispersó en varios servicios se ha transferido a DolphinDB para su finalización, incluidos datos de transmisión en tiempo real, datos almacenados en búfer, datos históricos y datos de informes, que se procesan a través de un motor informático unificado, lo que mejora la servicio global Al mismo tiempo de eficiencia, también reduce la dificultad de desarrollo e integración, así como la complejidad de la gestión del hardware.
Con los servicios de DolphinDB, cada plataforma electrónica puede desarrollar funciones relacionadas con el lenguaje de programación incorporado de DolphinDB. Originalmente, se requerían cientos de líneas de código Python, pero ahora se puede completar con más de una docena de líneas de código DolphinDB, lo que mejora la velocidad de desarrollo, ahorra mucho tiempo y la complejidad de la depuración.
Durante el proceso de importación, la fábrica original de DolphinDB también desarrolló nuevas funciones para nuestros escenarios de uso especial, lo que redujo en gran medida el costo técnico y el umbral.
resumen
Al procesar datos de mercado, además de garantizar la exactitud de los datos, el mayor desafío al que nos enfrentamos es la expansión flexible de los requisitos y funciones de desempeño.
Después de la introducción de DolphinDB, la implementación real de nuestro equipo de desarrollo se redujo de 2-3 personas a 1 (no a tiempo completo), y la cantidad de servidores se redujo de 6 a 2 (uno de los cuales es un respaldo recuperación ante desastres remota). Pero obtuvo una velocidad de desarrollo más rápida, una mejor mejora del rendimiento y una mejor experiencia de usuario.