 1. Características de los datos y puntos débiles de la Internet industrial de las cosas
1. Características de los datos y puntos débiles de la Internet industrial de las cosas
La recopilación de datos de la Internet industrial de las cosas tiene las características de alta frecuencia, múltiples dispositivos y grandes dimensiones. La cantidad de datos es muy grande y existen altos requisitos para el rendimiento del sistema. Al mismo tiempo, el Internet de las cosas industrial a menudo requiere que el sistema pueda procesar datos en tiempo real, para proporcionar una alerta temprana, monitoreo e incluso contracontrol del sistema. Muchos sistemas también necesitan proporcionar terminales gráficos para que los operadores monitoreen el funcionamiento de los equipos en tiempo real, lo que ejerce una mayor presión sobre todo el sistema. Para los datos históricos masivos recopilados, generalmente se requieren modelos y análisis fuera de línea. Por lo tanto, la plataforma de datos del Internet industrial de las cosas tiene requisitos muy exigentes. Debe tener un rendimiento muy alto y baja latencia; debe poder procesar datos en tiempo real en tiempo real, y debe poder procesar cantidades masivas de datos históricos; tanto Para cumplir con los requisitos de consulta puntual simple, pero también para cumplir con los requisitos de análisis complejo de datos por lotes.
Las bases de datos transaccionales tradicionales, como SQL Server, Oracle y MySQL, no pueden cumplir con la escritura de datos de alto rendimiento y el análisis masivo de datos. Incluso si la cantidad de datos es pequeña y puede cumplir con los requisitos de escritura de datos, no puede responder a las solicitudes de computación en tiempo real al mismo tiempo.
El ecosistema de Hadoop proporciona múltiples componentes como motor de mensajería, escritura de datos en tiempo real, cálculo de transmisión de datos, almacenamiento de datos fuera de línea y cálculo de datos fuera de línea. La combinación de estos grandes sistemas de datos puede resolver el problema de la plataforma de datos del Internet industrial de las cosas. Sin embargo, tal esquema es demasiado grande e inflado, y el costo de implementación, operación y mantenimiento es alto.
2. Soluciones industriales de IoT basadas en bases de datos de series temporales
Tome DolphinDB como ejemplo: como base de datos de series de tiempo distribuida de alto rendimiento, la base de datos DolphinDB proporciona una potente plataforma básica para el almacenamiento de datos y el cálculo de la Internet industrial de las cosas.
- La base de datos distribuida de DolphinDB puede admitir fácilmente la expansión horizontal y la expansión vertical, y el rendimiento del sistema y la cantidad de datos admitidos se pueden expandir casi infinitamente.
- El motor de flujo de datos de DolphinDB admite el procesamiento de flujo de datos en tiempo real. El motor de agregación incorporado puede calcular varios indicadores de agregación de acuerdo con el tamaño y la frecuencia de la ventana de tiempo especificada. La agregación puede ser una agregación vertical en el eje del tiempo (de alta frecuencia a baja frecuencia) o una agregación horizontal de múltiples dimensiones.
- La base de datos en memoria de DolphinDB puede admitir escritura, consulta y cálculo de datos rápidos. Por ejemplo, los resultados del motor de agregación se pueden enviar a una tabla de memoria y recibir instrucciones de sondeo de segundo nivel desde la BI de front-end (como Grafana).
- DolphinDB integra bases de datos, computación distribuida y lenguaje de programación, y puede completar rápidamente computación distribuida compleja, como regresión y clasificación, en la biblioteca. Esto acelera enormemente el análisis y el modelado fuera de línea de datos históricos masivos.
- DolphinDB también implementa interfaces con algunas herramientas de BI comerciales o de código abierto. Es conveniente para los usuarios visualizar o monitorear los datos del equipo.
3. Resumen del caso
Hay un total de 1,000 dispositivos sensores en el taller de producción de la empresa, y cada dispositivo recopila datos cada 10 ms. Para simplificar el script de demostración, se supone que los datos recopilados tienen solo tres dimensiones, todas las cuales son temperatura. Las tareas a completar incluyen:
- Almacene los datos sin procesar recopilados en la base de datos. El modelado de datos sin conexión necesita utilizar estos datos históricos.
- El índice de temperatura promedio de cada dispositivo en el último minuto se calcula en tiempo real y la frecuencia de cálculo se realiza cada dos segundos.
- Debido a que el operador del equipo necesita captar el cambio de temperatura en el menor tiempo posible, la interfaz de pantalla frontal consulta los resultados de los cálculos en tiempo real cada segundo y actualiza el gráfico de tendencia del cambio de temperatura.
4. Implementación de casos
4.1 El diseño del módulo funcional del sistema
Para el caso anterior, primero debemos habilitar la base de datos distribuida de DolphinDB y crear una base de datos distribuida llamada iotDemoDB para guardar los datos recopilados en tiempo real. La base de datos está dividida en dos dimensiones: fecha y dispositivo. La fecha está dividida por valor y el dispositivo está dividido por rango. Para limpiar los datos caducados en el futuro, simplemente puede eliminar la partición de fecha anterior.
Habilite las funciones de suscripción y publicación de datos de transmisión. Suscríbase a flujos de datos de alta frecuencia para realizar cálculos en tiempo real. La función createStreamingAggregator puede crear un motor de agregación de indicadores para el cálculo en tiempo real. En el caso, especificamos que el tamaño de la ventana de cálculo es de 1 minuto, calculamos la temperatura promedio del último minuto cada 2 segundos y luego guardamos el resultado del cálculo en la tabla de datos de baja frecuencia para el sondeo frontal.
Implemente la plataforma Grafana de front-end para mostrar el gráfico de tendencias de los resultados del cálculo, configure el servidor DolphinDB para sondear una vez cada 1 segundo y actualice la interfaz de pantalla.
4.2 Implementación del servidor
En esta demostración, para usar una base de datos distribuida, necesitamos usar un clúster de múltiples nodos de una sola máquina. Puede consultar la guía de implementación de clústeres de múltiples nodos de una sola máquina . Aquí hemos configurado un clúster de 1 controlador + 1 agente + 4 nodos de datos. Los archivos de configuración principales se enumeran a continuación como referencia:
cluster.nodes:
localSite, modo localhost: 8701: agent1, agent localhost: 8081: node1, datanode localhost: 8083: node2, datanode localhost: 8082: node3, datanode localhost: 8084: node4, datanode
Dado que el sistema DolphinDB no habilita la función del módulo Streaming de forma predeterminada, debemos habilitarlo configurándolo explícitamente en cluster.cfg. Debido a que la cantidad de datos utilizados en esta demostración no es grande, para evitar la complejidad de la demostración, así que aquí solo El nodo 1 está habilitado para la suscripción de datos.
cluster.cfg :
maxMemSize = 2 workerNum = 4 persistenceDir = dbcache maxSubConnections = 4 node1.subPort = 8085 maxPubConnections = 4
En el entorno de producción real, se recomienda utilizar un clúster de máquinas multifísicas. Puede consultar la guía de implementación de clústeres de máquinas multifísicas .
4.3 Pasos de implementación
Primero, definimos una tabla de datos de flujo sensorTemp para recibir datos de temperatura recopilados en tiempo real. Usamos la función enableTablePersistence para conservar la tabla sensorTemp. La cantidad máxima de datos retenidos en la memoria es de 1 millón de filas.
compartir streamTable (1000000: 0, `hardwareId`ts`temp1`temp2`temp3, [INT, TIMESTAMP, DOUBLE, DOUBLE, DOUBLE]) como sensorTemp enableTablePersistence (sensorTemp, true, false, 1000000)
Al suscribirse a la tabla de transmisión de datos sensorTmp, los datos recopilados se guardan en una base de datos distribuida en lotes casi en tiempo real. La tabla distribuida utiliza dos dimensiones de partición: fecha y número de dispositivo. En el escenario de big data del Internet de las cosas, los datos obsoletos a menudo se borran, de modo que el modo de partición puede borrar rápidamente los datos caducados simplemente eliminando la partición en la fecha especificada. Los dos últimos parámetros de la función subscribeTable controlan la frecuencia de almacenamiento de datos. Solo cuando los datos de suscripción alcancen 1 millón o el intervalo de tiempo alcance los 10 segundos, los datos se escribirán en la base de datos distribuida en lotes.
db1 = base de datos ("", VALOR, 2018.08.14..2018.12.20)
db2 = base de datos ("", RANGO, 0..10 * 100)
db = database ("dfs: // iotDemoDB", COMPO, [db1 , db2])
dfsTable = db.createPartitionedTable (sensorTemp, "sensorTemp", `ts`hardwareId)
subscribeTable (," sensorTemp "," save_to_db ", -1, append! {dfsTable}, true, 1000000, 10)
Mientras que los datos de transmisión se almacenan en una base de datos distribuida, el sistema utiliza la función createStreamAggregator para crear un motor de agregación de indicadores para el cálculo en tiempo real. El primer parámetro de la función especifica el tamaño de la ventana como 60 segundos, el segundo parámetro especifica la operación promedio cada 2 segundos, y el tercer parámetro es el metacódigo de la operación. El usuario puede especificar la función de cálculo, cualquier sistema admite O las funciones de agregación definidas por el usuario se pueden admitir aquí. Al especificar el campo de agrupación hardwareId, la función dividirá los datos de flujo en 1000 colas por dispositivo para el cálculo promedio, y cada dispositivo calculará la temperatura promedio correspondiente de acuerdo con su propia ventana. Finalmente, suscríbase a la transmisión de datos a través de subscribeTable, active el cálculo en tiempo real cuando ingresen nuevos datos y guarde el resultado de la operación en una nueva tabla de transmisión de datos sensorTempAvg.
Descripción del parámetro createStreamAggregator: tiempo de ventana, tiempo de intervalo de operación, código de operando de agregación, tabla de entrada de datos original, tabla de salida de resultado de operación, campo de serie de tiempo, campo de grupo, umbral para el número de registros de GC de activación.
compartir streamTable (1000000: 0, `time`hardwareId`tempavg1`tempavg2`tempavg3, [TIMESTAMP, INT, DOUBLE, DOUBLE, DOUBLE]) como sensorTempAvg
metrics = createStreamAggregator (60000,2000, <[avg (temp1), avg (temp2 ), avg (temp3)]>, sensorTemp, sensorTempAvg, `ts,` hardwareId, 2000)
subscribeTable (, "sensorTemp", "metric_engine", -1, append! {metrics}, true)
Cuando DolphinDB Server guarda y analiza flujos de datos de alta frecuencia, el programa front-end de Grafana sondea los resultados de los cálculos en tiempo real cada segundo y actualiza el gráfico de tendencia de la temperatura promedio. DolphinDB proporciona un complemento de origen de datos para Grafana_DolphinDB. Para la instalación de Grafana y la configuración del complemento DolphinDB, consulte el tutorial de configuración de Grafana .
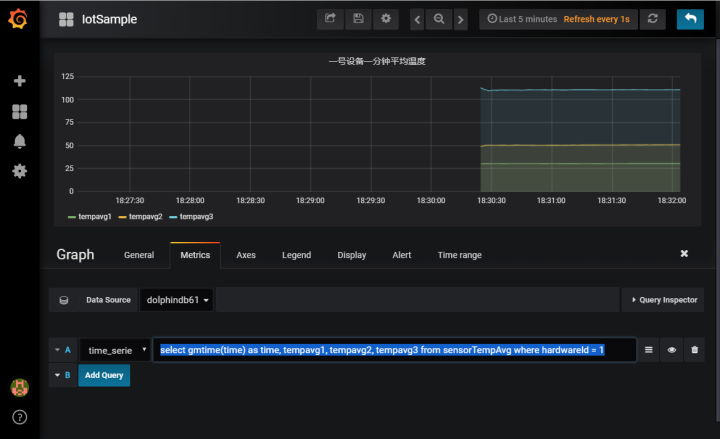
Luego de completar la configuración básica de grafana, agregue un Graph Panel, ingrese en la pestaña Metrics:
seleccione gmtime (tiempo) como tiempo, tempavg1, tempavg2, tempavg3 de sensorTempAvg donde hardwareId = 1
Este script es para seleccionar la tabla de temperatura promedio obtenida por el cálculo en tiempo real del dispositivo No. 1.
Finalmente, inicie el programa de generación de simulación de datos para generar datos de temperatura simulados y escríbalos en la tabla de datos de flujo.
Escala de datos: 1000 dispositivos, 3 dimensiones por punto, frecuencia de 10 ms para generar datos, cálculo de 8 bytes por dimensión (tipo doble), el flujo de datos es de 24 Mbps, con una duración de 100 segundos.
def writeData () {
hardwareNumber = 1000
for (i in 0: 10000) {
data = table (tome (1..hardwareNumber, hardwareNumber) como hardwareId, tome (ahora (), hardwareNumber) como ts, rand (20..41 , hardwareNumber) como temp1, rand (30..71, hardwareNumber) como temp2, rand (70..151, hardwareNumber) como temp3)
sensorTemp.append! (data)
sleep (10)
}
}
submitJob ("simulateData", " simular datos del sensor ", writeData)
Haga clic aquí para descargar el script de demostración completo.