1. Información general
Spark es un marco de computación paralela de big data de propósito general basado en computación en memoria, con una variedad de componentes integrados, como procesamiento por lotes, procesamiento de flujo, aprendizaje automático y procesamiento de gráficos. Hive es un almacén de datos basado en Hadoop que admite consultas de comandos similares a SQL, lo que mejora la facilidad de uso de Hadoop. Spark generalmente se usa junto con Hive y Hadoop. La partición de datos en Hive se puede usar para administrar y filtrar datos fácilmente y mejorar la eficiencia de las consultas.
DolphinDB es una base de datos de series de tiempo distribuida de alto rendimiento escrita en C ++. Tiene un motor de memoria de columna incorporado con alto rendimiento y baja latencia. Integra un potente lenguaje de programación y admite lenguajes de scripting como Python y SQL. Puede realizar directamente programación compleja y programación en la base de datos. Operación. DolphinDB utiliza la fuente de datos internamente para abstraer los datos de las particiones. En Data Source, se pueden completar tareas informáticas como SQL, aprendizaje automático, procesamiento por lotes y procesamiento de secuencias. Una fuente de datos puede ser una partición de base de datos incorporada o datos externos. Si la fuente de datos es una partición de la base de datos incorporada, la mayoría de los cálculos se pueden realizar localmente, lo que mejora en gran medida la eficiencia del cálculo y la consulta.
Este informe llevará a cabo pruebas de comparación de rendimiento en DolphinDB, Spark accede directamente a HDFS (Spark + Hadoop, en lo sucesivo, Spark) y Spark accede a HDFS a través de componentes de Hive (Spark + Hive + Hadoop, en lo sucesivo Spark + Hive). El contenido de la prueba incluye importación de datos, ocupación de espacio en disco, consulta de datos y consulta simultánea de múltiples usuarios. A través de pruebas comparativas, podemos tener una comprensión más profunda de los principales factores que afectan el rendimiento y los mejores escenarios de aplicación para diferentes herramientas.
2. Configuración del entorno
2.1 Configuración de hardware
Esta prueba utiliza dos servidores (máquina 1, máquina 2) con exactamente la misma configuración, y los parámetros de configuración son los siguientes:
Anfitrión: DELL PowerEdge R730xd
CPU: CPU Intel Xeon (R) E5-2650 v4 (24 núcleos, 48 subprocesos, 2,20 GHz)
Memoria: 512 GB (32 GB × 16, 2666 MHz)
Disco duro: 17T HDD (1.7T × 10, 222 MB / s de lectura; 210 MB / s de escritura)
Red: 10 Gigabit Ethernet
SO: CentOS Linux versión 7.6.1810 (Core)
2.2 Configuración del clúster
La versión de DolphinDB probada es Linux v0.95. El nodo de control del clúster de prueba se implementa en la máquina 1, con tres nodos de datos implementados en cada máquina, para un total de seis nodos de datos. Cada nodo de datos está configurado con 8 trabajadores, 7 ejecutores y memoria 24G.
La versión Spark probada es 2.3.3, equipada con Apache Hadoop 2.9.0. Hadoop y Spark están configurados en un modo totalmente distribuido. La máquina 1 es la maestra y las máquinas 1 y 2 tienen esclavas. La versión de Hive es 1.2.2 y ambas máquinas 1 y 2 tienen Hive. Los metadatos se almacenan en la base de datos MySql en la máquina 1. Spark y Spark + Hive usan el método de cliente en el modo independiente para enviar aplicaciones.
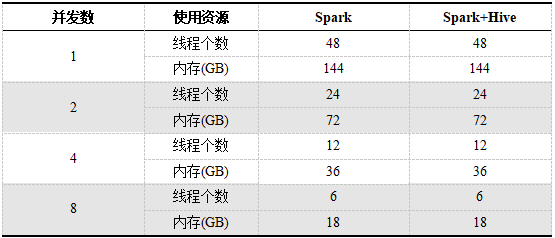
Durante la prueba, DolphinDB, Spark y Spark + Hive están equipados con 6 discos duros, y la suma de CPU y memoria utilizadas en diferentes números de simultaneidad es la misma, con 48 subprocesos y 144G de memoria. Los recursos utilizados por Spark y Spark + Hive son solo para aplicaciones específicas. Cada aplicación tiene 6 ejecutores. En el caso de multiusuario concurrente, los recursos utilizados por un solo usuario de Spark y Spark + Hive disminuirán a medida que aumente el número de usuarios. Los recursos utilizados por cada usuario con diferentes conteos de simultaneidad se muestran en la Tabla 1.
Tabla 1. Recursos utilizados por usuarios individuales en diferentes números simultáneos de Spark y Spark + Hive
3. Diseño de bases de datos y conjuntos de datos
3.1 Conjunto de datos
El conjunto de datos de prueba es el conjunto de datos TAQ proporcionado por la Bolsa de Valores de Nueva York (NYSE). Contiene datos de cotización de nivel 1 de más de 8.000 acciones en un mes desde 2007.08.01 hasta 2007.08.31, incluido el tiempo de negociación, el código de la acción, el precio de compra, Información de cotización como precio de venta, volumen de compra y volumen de venta. Hay un total de 6.500 millones (6.561.693.704) registros de cotizaciones en el conjunto de datos. Un CSV contiene un registro de un día de negociación. Hay 23 días de negociación en el mes. Los 23 archivos CSV sin comprimir suman 277 GB.
Fuente de datos: https: // www. Nyse.com/market-data/hi storical
3.2 Diseño de base de datos
Tabla 2. Tipos de datos TAQ en varios sistemas.

En la base de datos DolphinDB, particionamos de acuerdo con la combinación de columnas de fecha y símbolo. La primera partición usa la fecha DATE para la partición de valor, un total de 23 particiones y la segunda partición usa el código de stock SYMBOL para la partición de rango. El número de particiones es 100, cada partición Aproximadamente 120 millones más o menos.
Los datos almacenados por Spark en HDFS son 23 csv correspondientes a 23 directorios. Spark + Hive usa particiones de dos niveles. La partición de primer nivel usa la columna de fecha FECHA para particiones estáticas y la partición de segundo nivel usa el código de stock SYMBOL para particiones dinámicas.
Consulte el apéndice para ver scripts específicos.
4. Prueba de importación y consulta de datos
4.1 Prueba de importación de datos
Los datos originales se distribuyen uniformemente en los seis discos duros de los dos servidores, de modo que todos los recursos del clúster se pueden utilizar por completo. DolphinDB importa datos en paralelo a través de un método asincrónico de varios nodos. Spark y Spark + Hive inician 6 aplicaciones en paralelo para leer los datos y almacenarlos en HDFS. El tiempo que tarda cada sistema en importar datos se muestra en la Tabla 3. El espacio en disco ocupado por los datos en cada sistema se muestra en la Tabla 4. Consulte el apéndice para ver el script de importación de datos.
Tabla 3. Tiempo de importación de datos de DolphinDB, Spark, Spark + Hive
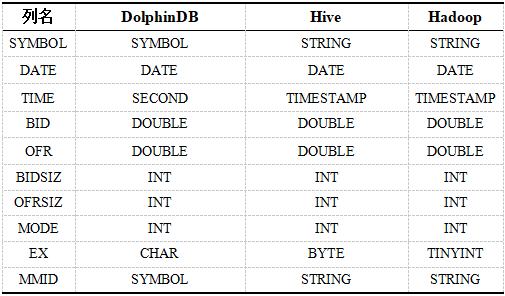
Tabla 4. Espacio en disco ocupado por datos en DolphinDB, Spark, Spark + Hive

El rendimiento de importación de DolphinDB es significativamente mejor que el de Spark y Spark + Hive, que es aproximadamente 4 veces mayor que el de Spark y aproximadamente 6 veces mayor que el de Spark + Hive. DolphinDB está escrito en C ++ y tiene muchas optimizaciones internas, lo que hace un gran uso de E / S de disco.
DolphinDB ocupa más espacio en disco que Spark y Spark + Hive, que es aproximadamente 2 veces mayor que ellos. Esto se debe a que tanto Spark como Spark + Hive usan el formato Parquet en Hadoop, y el formato Parquet se escribe en Hadoop a través de Spark usando compresión rápida de forma predeterminada.
4.2 Prueba de consulta de datos
Para garantizar la imparcialidad de la prueba, cada declaración de consulta debe probarse varias veces, y la caché de página del sistema, la caché de elementos de directorio y la caché del disco duro se borran respectivamente mediante comandos del sistema Linux antes de cada prueba. DolphinDB también borra su caché incorporado.
Las declaraciones de consulta de la Tabla 5 cubren la mayoría de los escenarios de consulta, incluida la agrupación, clasificación, condiciones, cálculos de agregación, consultas de puntos y consultas de tabla completa para evaluar el rendimiento de DolphinDB, Spark y Spark + Hive con diferentes números de usuarios.
Tabla 5. Declaraciones de consulta de DolphinDB, Spark, Spark + Hive

4.2.1 Prueba de consulta de un solo usuario de DolphinDB y Spark
Los siguientes son los resultados de las consultas de un solo usuario de DolphinDB y Spark. El tiempo en los resultados es el tiempo promedio de 8 consultas.
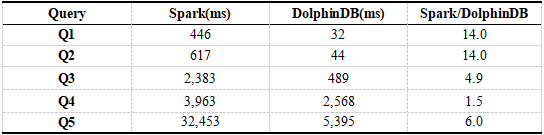
Tabla 6. Resultados de consultas de un solo usuario de DolphinDB, Spark
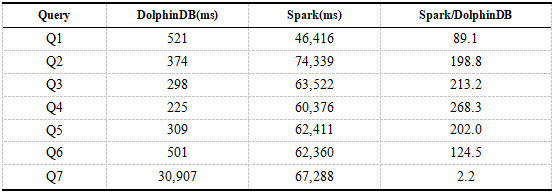
Se puede ver en los resultados que el rendimiento de consultas de DolphinDB es aproximadamente 200 veces mayor que el de Spark + HDFS. Las consultas Q1 a Q6 se basan todas en el campo de partición de DolphinDB como condición de filtro. DolphinDB solo necesita cargar los datos de la partición especificada sin un escaneo completo de la tabla. Spark requiere un escaneo completo de la tabla del Q1 al Q6, lo que consume mucho tiempo. Para la consulta Q7, tanto DolphinDB como Spark requieren un escaneo completo de la tabla, pero DolphinDB solo carga columnas relacionadas, no todas las columnas, mientras que Spark necesita cargar todos los datos. Dado que el tiempo de ejecución de Query está dominado por la carga de datos, la brecha de rendimiento entre DolphinDB y Spark no es tan grande como la declaración de consulta anterior.
4.2.2 Prueba de consulta de un solo usuario de DolphinDB y Spark + Hive
Debido a que los datos de DolphinDB están particionados y el predicado se empuja hacia abajo durante la consulta, la eficiencia es significativamente mayor que Spark. Aquí usamos Spark con componentes de Hive para acceder a HDFS y comparar el rendimiento de consultas de DolphinDB y Spark + Hive. Los siguientes son los resultados de las consultas de un solo usuario de DolphinDB y Spark + Hive. El tiempo en los resultados es el tiempo promedio de 8 consultas.
Tabla 7. Resultados de consultas de un solo usuario de DolphinDB, Spark + Hive
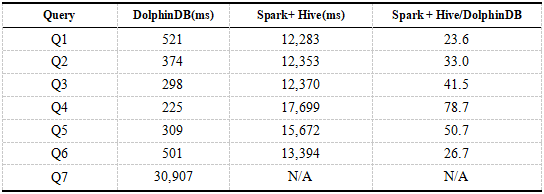
Los resultados muestran que el rendimiento de las consultas de DolphinDB es significativamente mejor que Spark + Hive, que es decenas de veces mayor que el de Spark + Hive. En comparación con los resultados de la Tabla 6, la velocidad de consulta de Spark + Hive es mucho más rápida que Spark y las ventajas de DolphinDB se reducen significativamente. Esto se debe a que Hive particiona los datos, y solo una parte de los datos se carga cuando la condición de la instrucción de consulta contiene el campo de partición, que realiza el filtrado de datos y mejora la eficiencia. Cuando la instrucción de consulta Q7 escanea toda la tabla, se produce un desbordamiento de memoria.
Tanto DolphinDB como Spark + Hive particionan los datos y pueden lograr un empuje de predicado hacia abajo al cargar datos, logrando el efecto de filtrado de datos, pero la velocidad de consulta de DolphinDB es mejor que Spark + Hive. Esto se debe a que el área Spark + Hive lee los datos en HDFS a través del acceso entre diferentes sistemas. Los datos tienen que pasar por el proceso de serialización, transmisión de red y deserialización, que consume mucho tiempo y afecta el rendimiento. La mayoría de los cálculos de DolphinDB se realizan localmente, lo que reduce la transmisión de datos y, por lo tanto, es más eficiente.
4.2.3 Comparación de la potencia informática entre DolphinDB y Spark
El rendimiento de consulta de DolphinDB anterior se compara con Spark y Spark + Hive. Dado que la partición de datos, el filtrado de datos y la transmisión durante la consulta afectan el rendimiento de Spark, aquí primero cargamos los datos en la memoria y luego realizamos cálculos relacionados, comparamos DolphinDB Y Spark + Hive. Omitimos Spark + Hive porque Hive solo se usa para el filtrado de datos. Es más eficiente leer datos en HDFS. Los datos de prueba aquí ya están en la memoria.
La tabla 8 es una oración para probar la potencia informática. Cada prueba contiene dos declaraciones, la primera declaración es para cargar datos en la memoria y la segunda declaración es para calcular los datos en la memoria. DolphinDB almacenará automáticamente los datos en caché y Spark volverá a crear una tabla temporal TmpTbl a través de su mecanismo de almacenamiento en caché predeterminado.
Tabla 8. Enunciado comparativo de potencia informática entre DolphinDB y Spark
Los siguientes son los resultados de las pruebas de la potencia de cálculo de DolphinDB y Spark. El tiempo en los resultados es el tiempo promedio de 5 pruebas.
Tabla 9. Resultados de las pruebas de potencia informática de DolphinDB y Spark
Dado que los datos ya están en la memoria, en comparación con la Tabla 6, el tiempo utilizado por Spark se ha reducido considerablemente, pero la potencia de cálculo de DolphinDB sigue siendo superior a la de Spark. DolphinDB está escrito en C ++ y administra la memoria por sí mismo, lo que es más eficiente que Spark usando JVM para administrar la memoria. Además, DolphinDB tiene incorporados algoritmos más eficientes para mejorar el rendimiento informático.
La computación distribuida de DolphinDB usa particiones como una unidad para calcular datos en la memoria designada. Spark carga todo el bloque en HDFS. Un bloque de datos contiene datos con diferentes valores de símbolo. Aunque está almacenado en caché, aún debe filtrarse, por lo que la proporción de Q1 a Q2 es mayor. Las variables de transmisión utilizadas en los cálculos de Spark se comprimen y se transmiten a otros ejecutores y se descomprimen para afectar el rendimiento.
4.2.4 Consulta concurrente multiusuario
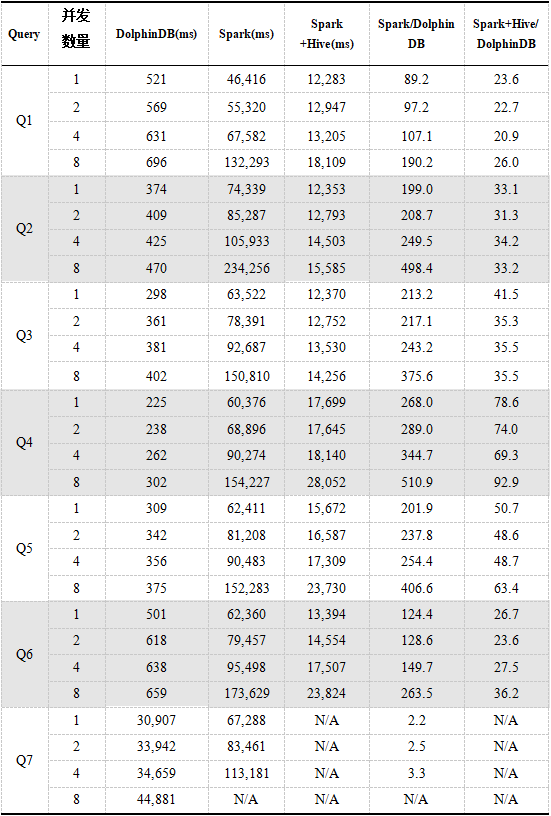
Usamos las declaraciones de consulta de la Tabla 5 para probar DolphinDB, Spark y Spark + Hive para consultas simultáneas de múltiples usuarios. El siguiente es el resultado de la prueba. El tiempo en el resultado es el tiempo promedio de 8 consultas.
Tabla 10. Resultados de consultas simultáneas multiusuario DolphinDB, Spark, Spark + Hive
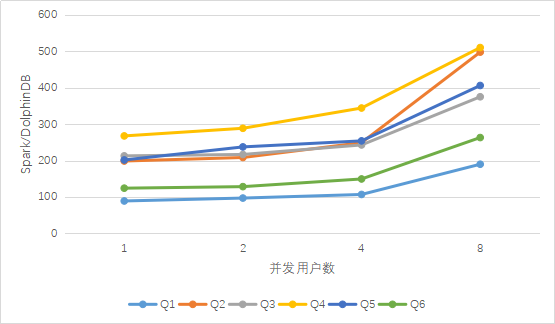
Figura 1. Comparación de los resultados de las consultas multiusuario de DolphinDB y Spark

Figura 2. Comparación de los resultados de las consultas multiusuario de DolphinDB y Spark + Hive
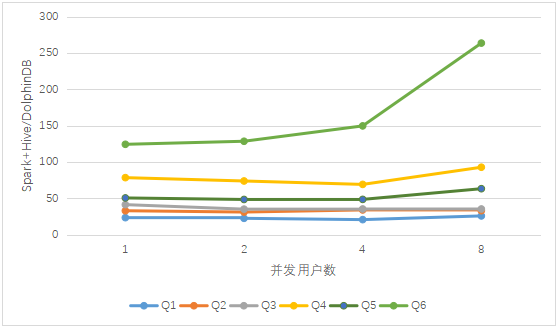
Como puede verse en los resultados anteriores, a medida que aumenta el número de concurrentes, el tiempo de consulta de los tres aumenta gradualmente. Cuando llega a 8 usuarios concurrentes, el rendimiento de Spark cae significativamente en comparación con el caso anterior de un pequeño número de usuarios concurrentes, Spark provocará la muerte del trabajador al ejecutar Q7. Spark + Hive es básicamente estable como DolphinDB cuando varios usuarios acceden a él, pero la excepción de desbordamiento de memoria siempre ocurre cuando se ejecuta la instrucción de consulta Q7.
La configuración de consulta de Spark + Hive es la misma que la de Spark. Debido a que tiene la función de particionar y puede filtrar datos, el volumen de datos de consulta es relativamente pequeño, por lo que la eficiencia es mejor que la de Spark escaneando todos los datos.
El rendimiento de DolphinDB en consultas concurrentes es significativamente mejor que Spark y Spark + Hive. De la figura anterior, se puede ver que en el caso de acceso concurrente de múltiples usuarios, a medida que aumenta el número de usuarios, la ventaja de DolphinDB sobre Spark es un crecimiento casi lineal, en comparación con Spark + Las ventajas de Hive permanecen básicamente sin cambios, lo que refleja la importancia de la partición de datos para lograr el filtrado de datos al realizar consultas.
DolphinDB realiza el intercambio de datos entre múltiples usuarios en el caso de concurrencia entre múltiples usuarios, a diferencia de que los datos de Spark son solo para aplicaciones específicas. Por lo tanto, en el caso de 8 usuarios simultáneos, Spark asigna menos recursos a cada usuario y el rendimiento se reduce significativamente. El intercambio de datos de DolphinDB puede reducir el uso de recursos. Con recursos limitados, se reservan más recursos para que los usuarios los calculen y usen, lo que mejora la eficiencia de la concurrencia de usuarios y aumenta el número de usuarios al mismo tiempo.
5. Resumen
En términos de importación de datos, DolphinDB se puede cargar en paralelo, mientras que Spark y Spark + Hive pueden importar datos mediante la carga simultánea de múltiples aplicaciones. La velocidad de importación de DolphinDB es de 4 a 6 veces la de Spark y Spark + Hive. En términos de espacio en disco, el espacio en disco ocupado por DolphinDB es aproximadamente el doble del espacio en disco ocupado por Spark y Spark + Hive en Hadoop. Spark y Spark + Hive usan compresión rápida.
En términos de consulta SQL de datos, DolphinDB tiene ventajas más obvias. Las ventajas provienen principalmente de cuatro aspectos: (1) computación localizada, (2) filtrado de particiones, (3) computación de memoria optimizada, (4) intercambio de datos entre sesiones. En el caso de la consulta de un solo usuario, la velocidad de consulta de DolphinDB es de varias a cientos de veces mayor que la de Spark y decenas de veces mayor que la de Spark + Hive. Spark Reading HDFS es una llamada entre diferentes sistemas, que incluye serialización de datos, red y deserialización, consume mucho tiempo y ocupa muchos recursos. La mayoría de las consultas SQL de DolphinDB son cálculos localizados, lo que reduce en gran medida el tiempo de transmisión y carga de datos. Spark + Hive es relativamente más rápido que Spark. La razón principal es que Spark + Hive solo escanea los datos en las particiones relevantes y logra el filtrado de datos. Después de eliminar los factores de localización y filtrado de particiones (es decir, todos los datos ya están en la memoria), la potencia informática de DolphinDB sigue siendo varias veces mejor que Spark. La computación distribuida basada en particiones de DolphinDB es altamente eficiente y su administración de memoria es mejor que la administración basada en JVM de Spark. La concurrencia multiusuario de Spark disminuirá gradualmente su eficiencia a medida que aumente el número de usuarios. Cuando se consultan grandes cantidades de datos, demasiados usuarios causarán la muerte de los trabajadores. La concurrencia multiusuario de Spark + Hive es relativamente estable, pero demasiados datos causarán errores de desbordamiento de memoria. En el caso de múltiples usuarios, DolphinDB puede compartir datos, reduciendo así los recursos utilizados para cargar datos. La velocidad de consulta es cientos de veces mayor que la de Spark y docenas de veces mayor que la de Spark + Hive. A medida que aumenta el número de usuarios, la ventaja de rendimiento de DolphinDB sobre Spark se vuelve más obvia. En el caso de consultas particionadas, Spark + Hive y DolphinDB mejoran significativamente el rendimiento de las consultas.
Spark es un excelente motor de computación distribuida de uso general con un excelente rendimiento en consultas SQL, procesamiento por lotes, procesamiento de secuencias y aprendizaje automático. Sin embargo, debido a que las consultas SQL generalmente solo necesitan calcular los datos una vez, en comparación con los cientos de iteraciones requeridas para el aprendizaje automático, las ventajas de la computación de memoria no se pueden aprovechar por completo. Por lo tanto, recomendamos usar Spark para el aprendizaje automático computacionalmente intensivo.
Durante la prueba, también descubrimos que DolphinDB es una implementación muy ligera, el clúster es simple y rápido de construir, y la instalación y configuración del clúster Spark + Hive + Hadoop son muy complicadas.
apéndice
Apéndice 1. Vista previa de datos
Apéndice 2. Declaración de creación de tabla de Hive
CREAR TABLA SI NO EXISTE TAQ (time TIMESTAMP, bid DOUBLE, ofr DOUBLE, bidsiz INT, ofrsiz INT, mode INT, ex TINYINT, mmid STRING) PARTICIONADO POR (fecha FECHA, símbolo STRING) ALMACENADO COMO PARQUET;
Apéndice 3.
Script de importación de datos de DolphinDB:
fps1 y fps2 representan los vectores de todas las rutas csv en las máquinas 1 y 2 respectivamente.
fps son los vectores que contienen fps1 y fps2.
allSites1 y allSites2 representan los vectores de los nombres de los nodos de datos en las máquinas 1
y 2. allSite es el vector que contiene allSites1 y allSites2.
DATE_RANGE = 2007.07 .01..2007.09.01
date_schema = database ('', VALUE, DATE_RANGE)
symbol_schema = database ('', RANGE, buckets)
db = database (FP_DB, COMPO, [date_schema, symbol_schema])
taq = db.createPartitionedTable (esquema , `taq,` date`symbol)
for (i in 0..1) {
for (j in 0 .. (size (fps [i]) - 1)) {
rpc (allSites [i] [j]% size (allSite [i])], submitJob, "loadData", "loadData", loadTextEx {database (FP_DB), "taq", `date`symbol, fps [i] [j]})
}
}
Configuración de datos de importación de Spark y Hive:
--master local [8] --executor-memory 24G