DolphinDB proporciona las siguientes 4 funciones para importar datos de texto a la memoria o base de datos:
- loadText: importa un archivo de texto como una tabla de memoria.
- ploadText: Importa archivos de texto en paralelo como tablas de memoria de partición. En comparación con la función loadText, es más rápida.
- loadTextEx: importe archivos de texto a bases de datos, incluidas bases de datos distribuidas, bases de datos de disco local o bases de datos de memoria.
- textChunkDS: divida el archivo de texto en varias fuentes de datos pequeñas y luego use la función mr para un procesamiento de datos flexible.
La importación de datos de texto de DolphinDB no solo es flexible, rica en funciones y muy rápida. En comparación con los sistemas populares en la industria como Clickhouse, MemSQL, Druid, Pandas, DolphinDB, la importación de un solo subproceso es más rápida, hasta un orden de ventaja de magnitud; en el caso de la importación paralela de múltiples subprocesos, la ventaja de la velocidad es más obvia .
Este tutorial presenta problemas comunes, las correspondientes soluciones y precauciones al importar datos de texto.
1. Identificar automáticamente el formato de datos
En la mayoría de los demás sistemas, al importar datos de texto, el usuario debe especificar el formato de los datos. Para comodidad de los usuarios, DolphinDB puede reconocer automáticamente el formato de datos al importar datos.
El formato de datos de identificación automática incluye dos partes: identificación del nombre de campo e identificación del tipo de datos. Si ninguna columna de la primera línea del archivo comienza con un número, el sistema considera que la primera línea es el encabezado del archivo y contiene los nombres de los campos. DolphinDB extraerá una pequeña cantidad de datos como muestras e inferirá automáticamente el tipo de datos de cada columna. Debido a que se basa en datos parciales, la identificación del tipo de datos de algunas columnas puede ser incorrecta. Pero para la mayoría de los archivos de texto, no es necesario que especifique manualmente el nombre de campo y el tipo de datos de cada columna, puede importarlo correctamente a DolphinDB.
Tenga en cuenta: Las versiones anteriores a la 1.20.0 no admiten la importación de los tres tipos de datos INT128, UUID e IPADDR. Si estos tres tipos de datos están incluidos en el archivo csv, asegúrese de que la versión utilizada no sea inferior a 1.20.0.
loadTextLa función se utiliza para importar datos a la tabla de memoria DolphinDB. El siguiente ejemplo llama a la función loadText para importar datos y ver la estructura de la tabla de datos generada. Consulte el apéndice para ver los archivos de datos involucrados en el ejemplo .
dataFilePath="/home/data/candle_201801.csv"
tmpTB=loadText(filename=dataFilePath);Vea las primeras 5 filas de datos en la tabla de datos:
select top 5 * from tmpTB;
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- -------- ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01.02 2018.01.02 93100000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01.02 2018.01.02 93200000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01.02 2018.01.02 93300000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01.02 2018.01.02 93400000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01.02 2018.01.02 93500000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000Llame a la schemafunción para ver la estructura de la tabla (nombre de campo, tipo de datos, etc.):
tmpTB.schema().colDefs;
name typeString typeInt comment
---------- ---------- ------- -------
symbol SYMBOL 17
exchange SYMBOL 17
cycle INT 4
tradingDay DATE 6
date DATE 6
time INT 4
open DOUBLE 16
high DOUBLE 16
low DOUBLE 16
close DOUBLE 16
volume INT 4
turnover DOUBLE 16
unixTime LONG 5
2. Especifique el formato de importación de datos
En las 4 funciones de carga de datos descritas en este tutorial, puede usar el parámetro de esquema para especificar una tabla, que contiene el nombre, tipo, formato y columnas que se importarán para cada campo. La tabla puede contener las siguientes 4 columnas:

Entre ellos, se requieren las dos columnas, nombre y tipo, y deben ser las dos primeras columnas. El formato de dos columnas y col son opcionales y no hay ningún requisito de priorización.
Por ejemplo, podemos usar la siguiente tabla de datos como parámetro de esquema:
2.1 Extraer el esquema del archivo de texto
extractTextSchemaLa función se utiliza para obtener el esquema del archivo de texto, incluida información como nombres de campo y tipos de datos.
Por ejemplo, use la función extractTextSchema para obtener la estructura de la tabla del archivo de muestra en este tutorial:
dataFilePath="/home/data/candle_201801.csv"
schemaTB=extractTextSchema(dataFilePath)
schemaTB;
name type
---------- ------
symbol SYMBOL
exchange SYMBOL
cycle INT
tradingDay DATE
date DATE
time INT
open DOUBLE
high DOUBLE
low DOUBLE
close DOUBLE
volume INT
turnover DOUBLE
unixTime LONG
2.2 Especifique el nombre y el tipo del campo
Cuando el nombre del campo o el tipo de datos reconocido automáticamente por el sistema no cumple con las expectativas o los requisitos, puede modificar la tabla de esquema generada por extractTextSchema o crear directamente una tabla de esquema para especificar el nombre de campo y el tipo de datos para cada columna en el archivo de texto.
Por ejemplo, si la columna de volumen de los datos importados se reconoce automáticamente como el tipo INT y el tipo de volumen requerido es LONG, debe modificar la tabla de esquema y especificar el tipo de columna de volumen como LONG.
dataFilePath="/home/data/candle_201801.csv"
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="LONG" where name="volume";Utilice la función loadText para importar un archivo de texto e importe los datos a la base de datos de acuerdo con el tipo de datos de campo especificado por schemaTB.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);El ejemplo anterior presenta la modificación del tipo de datos. Si desea modificar el nombre del campo en la tabla, también puede utilizar el mismo método.
Tenga en cuenta que si el análisis automático de tipos de datos relacionados con la fecha y la hora no cumple con las expectativas, debe resolverlo mediante el método de la sección 2.3 de este tutorial.
2.3 Especificar el formato de los tipos de fecha y hora
Para datos de columna de fecha o columna de hora, si el tipo de datos reconocido automáticamente no cumple con las expectativas, no solo es necesario especificar el tipo de datos en la columna de tipo del esquema, sino también especificar el formato (indicado por una cadena) en la columna de formato , como "MM / dd / aaaa". Consulte el ajuste y formato de fecha y hora para ver cómo mostrar el formato de fecha y hora .
El siguiente es un ejemplo de cómo especificar tipos de datos para columnas de fecha y hora.
Ejecute el siguiente script en DolphinDB para generar el archivo de datos requerido para este ejemplo.
dataFilePath="/home/data/timeData.csv"
t=table(["20190623 14:54:57","20190623 15:54:23","20190623 16:30:25"] as time,`AAPL`MS`IBM as sym,2200 5400 8670 as qty,54.78 59.64 65.23 as price)
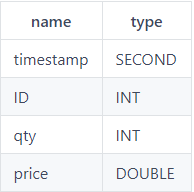
saveText(t,dataFilePath);Antes de cargar los datos, use la función extractTextSchema para obtener el esquema del archivo de datos:
schemaTB=extractTextSchema(dataFilePath)
schemaTB;
name type
----- ------
time SECOND
sym SYMBOL
qty INT
price DOUBLEObviamente, el sistema reconoce que el tipo de datos de la columna de tiempo no cumple con las expectativas. Si carga el archivo directamente, los datos de la columna de tiempo estarán vacíos. Para cargar correctamente los datos de la columna de tiempo del archivo, debe especificar el tipo de datos de la columna de tiempo como DATETIME y especificar el formato de la columna como "aaaaMMdd HH: mm: ss".
update schemaTB set type="DATETIME" where name="time"
schemaTB[`format]=["yyyyMMdd HH:mm:ss",,,];Importe los datos y vea, los datos se muestran correctamente:
tmpTB=loadText(dataFilePath,,schemaTB)
tmpTB;
time sym qty price
------------------- ---- ---- -----
2019.06.23T14:54:57 AAPL 2200 54.78
2019.06.23T15:54:23 MS 5400 59.64
2019.06.23T16:30:25 IBM 8670 65.23
2.4 Importar la columna especificada
Al importar datos, puede especificar importar solo ciertas columnas en el archivo de texto a través del parámetro de esquema.
En el siguiente ejemplo, solo necesita cargar las 7 columnas de símbolo, fecha, apertura, alto, cierre, volumen y rotación en el archivo de texto.
Primero, llame a la función extractTextSchema para obtener la estructura de la tabla del archivo de texto de destino.
dataFilePath="/home/data/candle_201801.csv"
schemaTB=extractTextSchema(dataFilePath);Utilice la función rowNo para generar un número de columna para cada columna, asígnelo a la columna col en la tabla de esquema y luego modifique la tabla de esquema para mantener solo las filas que representan los campos que deben importarse.
update schemaTB set col = rowNo(name)
schemaTB=select * from schemaTB where name in `symbol`date`open`high`close`volume`turnover;precaución:
- El número de columna comienza en 0. En el ejemplo anterior, el número de columna correspondiente a la columna del símbolo en la primera columna es 0.
- Al importar datos, la secuencia de las columnas no se puede cambiar. Si necesita ajustar el orden de las columnas, puede usar la
reorderColumns!función después de cargar el archivo de datos .
Finalmente, use la función loadText y configure los parámetros del esquema para importar las columnas especificadas en el archivo de texto.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);Mirando las primeras 5 filas de la tabla, solo se importan las columnas requeridas:
select top 5 * from tmpTB
symbol date open high close volume turnover
------ ---------- ----- ----- ----- ------- ----------
000001 2018.01.02 13.35 13.39 13.38 2003635 2.678558E7
000001 2018.01.02 13.37 13.38 13.33 867181 1.158757E7
000001 2018.01.02 13.32 13.35 13.35 903894 1.204971E7
000001 2018.01.02 13.35 13.38 13.35 1012000 1.352286E7
000001 2018.01.02 13.35 13.37 13.37 1601939 2.140652E72.5 Omitir las primeras líneas de datos de texto
Al importar datos, si necesita omitir las primeras n líneas del archivo (que puede ser una descripción de archivo), puede especificar el parámetro skipRows como n. Dado que la descripción del archivo de descripción no suele ser muy extensa, el valor máximo de este parámetro es 1024. Las 4 funciones de carga de datos descritas en este tutorial son compatibles con los parámetros skipRows.
En el siguiente ejemplo, importe un archivo de datos a través de la función loadText y vea el número total de filas en la tabla después de importar el archivo y el contenido de las primeras 5 filas.
dataFilePath="/home/data/candle_201801.csv"
tmpTB=loadText(filename=dataFilePath)
select count(*) from tmpTB;
count
-----
5040
select top 5 * from tmpTB;
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- -------- ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01.02 2018.01.02 93100000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01.02 2018.01.02 93200000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01.02 2018.01.02 93300000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01.02 2018.01.02 93400000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01.02 2018.01.02 93500000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000Especifique el valor del parámetro skipRows como 1000, omita las primeras 1000 líneas del archivo de texto para importar el archivo:
tmpTB=loadText(filename=dataFilePath,skipRows=1000)
select count(*) from tmpTB;
count
-----
4041
select top 5 * from tmpTB;
col0 col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12
------ ---- ---- ---------- ---------- --------- ----- ----- ----- ----- ------ ---------- -------------
000001 SZSE 1 2018.01.08 2018.01.08 101000000 13.13 13.14 13.12 13.14 646912 8.48962E6 1515377400000
000001 SZSE 1 2018.01.08 2018.01.08 101100000 13.13 13.14 13.13 13.14 453647 5.958462E6 1515377460000
000001 SZSE 1 2018.01.08 2018.01.08 101200000 13.13 13.14 13.12 13.13 700853 9.200605E6 1515377520000
000001 SZSE 1 2018.01.08 2018.01.08 101300000 13.13 13.14 13.12 13.12 738920 9.697166E6 1515377580000
000001 SZSE 1 2018.01.08 2018.01.08 101400000 13.13 13.14 13.12 13.13 469800 6.168286E6 1515377640000Tenga en cuenta: como se muestra en el ejemplo anterior, al omitir las primeras n filas para la importación, si la primera fila del archivo de datos es un nombre de columna, esa fila se omitirá como la primera fila.
En el ejemplo anterior, después de que el archivo de texto especifica el parámetro skipRows para importar, debido a que se omite la primera fila de nombres de columna, los nombres de columna se convierten en los nombres de columna predeterminados: col0, col1, col2, etc. Si necesita mantener los nombres de las columnas y especificar que se omitan las primeras n filas, primero puede obtener el esquema del archivo de texto a través de la función extractTextSchema y especificar el parámetro de esquema al importar:
schema=extractTextSchema(dataFilePath)
tmpTB=loadText(filename=dataFilePath,schema=schema,skipRows=1000)
select count(*) from tmpTB;
count
-----
4041
select top 5 * from tmpTB;
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- --------- ----- ----- ----- ----- ------ ---------- -------------
000001 SZSE 1 2018.01.08 2018.01.08 101000000 13.13 13.14 13.12 13.14 646912 8.48962E6 1515377400000
000001 SZSE 1 2018.01.08 2018.01.08 101100000 13.13 13.14 13.13 13.14 453647 5.958462E6 1515377460000
000001 SZSE 1 2018.01.08 2018.01.08 101200000 13.13 13.14 13.12 13.13 700853 9.200605E6 1515377520000
000001 SZSE 1 2018.01.08 2018.01.08 101300000 13.13 13.14 13.12 13.12 738920 9.697166E6 1515377580000
000001 SZSE 1 2018.01.08 2018.01.08 101400000 13.13 13.14 13.12 13.13 469800 6.168286E6 1515377640000
3. Importar datos en paralelo
3.1 Un solo archivo se carga en la memoria en varios subprocesos
La función ploadText puede cargar un archivo de texto en la memoria de manera multiproceso. La sintaxis de esta función es la misma que la de la función loadText, la diferencia es que la función ploadText puede cargar rápidamente archivos grandes y generar una tabla de particiones de memoria. Hace un uso completo de las CPU de varios núcleos para cargar archivos en paralelo. El grado de paralelismo depende del número de núcleos de CPU en el servidor y de la configuración localExecutors del nodo.
A continuación, se compara el rendimiento de la función loadText y la función ploadText al importar el mismo archivo.
Primero, genere un archivo de texto de aproximadamente 4GB a través del script:
filePath="/home/data/testFile.csv"
appendRows=100000000
t=table(rand(100,appendRows) as int,take(string('A'..'Z'),appendRows) as symbol,take(2010.01.01..2018.12.30,appendRows) as date,rand(float(100),appendRows) as float,00:00:00.000 + rand(86400000,appendRows) as time)
t.saveText(filePath);Cargue el archivo a través de loadText y ploadText respectivamente. El nodo utilizado en este ejemplo es una CPU con 6 núcleos y 12 hyperthreads.
timer loadText(filePath);
Time elapsed: 12629.492 ms
timer ploadText(filePath);
Time elapsed: 2669.702 msLos resultados muestran que bajo esta configuración, el rendimiento de ploadText es aproximadamente 4.5 veces mayor que el de loadText.
3.2 Importación paralela de varios archivos
En el campo de las aplicaciones de big data, la importación de datos a menudo no es solo la importación de uno o dos archivos, sino la importación por lotes de docenas o incluso cientos de archivos grandes. Para lograr un mejor rendimiento de importación, se recomienda importar archivos de datos por lotes en paralelo.
La función loadTextEx puede importar archivos de texto a una base de datos específica, incluidas bases de datos distribuidas, bases de datos de disco local o bases de datos de memoria. Debido a que la tabla de particiones de DolphinDB admite lectura y escritura simultáneas, puede admitir la importación de datos multiproceso.
Use loadTextEx para importar datos de texto a una base de datos distribuida. La realización concreta es que los datos se importan primero a la memoria y luego se escriben en la base de datos desde la memoria. Estos dos pasos se completan con la misma función para garantizar una alta eficiencia.
El siguiente ejemplo muestra cómo escribir por lotes varios archivos en el disco en la tabla de particiones DolphinDB. Primero, ejecute el siguiente script en DolphinDB para generar 100 archivos, un total de 778 MB, incluidos 10 millones de registros.
n=100000
dataFilePath="/home/data/multi/multiImport_"+string(1..100)+".csv"
for (i in 0..99){
trades=table(sort(take(100*i+1..100,n)) as id,rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,take(2000.01.01..2000.06.30,n) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5)
trades.saveText(dataFilePath[i])
};Cree la base de datos y la tabla:
login(`admin,`123456)
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,1..10000)
tb=db.createPartitionedTable(trades,`tb,`id);Las cutfunciones de DolphinDB pueden agrupar elementos en un vector. A continuación, llame a la función de corte para agrupar las rutas de archivo que se importarán y luego llame a la submitJobfunción para asignar tareas de escritura a cada hilo e importar datos en lotes.
def writeData(db,file){
loop(loadTextEx{db,`tb,`id,},file)
}
parallelLevel=10
for(x in dataFilePath.cut(100/parallelLevel)){
submitJob("loadData"+parallelLevel,"loadData",writeData{db,x})
};Tenga en cuenta: la tabla de particiones de DolphinDB no permite que varios subprocesos escriban datos en una partición al mismo tiempo. En el ejemplo anterior, el valor de la columna de partición (columna de identificación) en cada archivo es diferente, por lo que no provocará que varios subprocesos escriban en la misma partición. Al diseñar lecturas y escrituras simultáneas de la tabla de particiones, asegúrese de que no haya varios subprocesos que escriban en la misma partición al mismo tiempo.
A través de la getRecentJobsfunción, se puede obtener el estado de los últimos n trabajos por lotes en el nodo local actual. Usando la instrucción select para calcular el tiempo requerido para importar archivos por lotes en paralelo, tomó alrededor de 1.59 segundos ingresar a una CPU con 6 núcleos y 12 hyperthreads.
select max(endTime) - min(startTime) from getRecentJobs() where jobId like "loadData"+string(parallelLevel)+"%";
max_endTime_sub
---------------
1590Ejecute el siguiente script para importar 100 archivos a la base de datos secuencialmente en un solo hilo y registre el tiempo requerido, que toma alrededor de 8,65 segundos.
timer writeData(db, dataFilePath);
Time elapsed: 8647.645 msLos resultados muestran que en esta configuración, la velocidad de importación de 10 subprocesos en paralelo es aproximadamente 5,5 veces la de la importación de un solo subproceso.
Ver el número de registros en la tabla de datos:
select count(*) from loadTable("dfs://DolphinDBdatabase", `tb);
count
------
10000000
4. Procesamiento previo antes de importar la base de datos
Antes de importar los datos a la base de datos, si necesita preprocesar los datos, como convertir tipos de datos de fecha y hora, completar valores vacíos, etc., puede loadTextExespecificar el parámetro de transformación al llamar a la función. El parámetro tansform acepta una función como parámetro y requiere que la función acepte solo un parámetro. La entrada de la función es una tabla de memoria no particionada y la salida también es una tabla de memoria no particionada. Cabe señalar que solo la función loadTextEx proporciona el parámetro de transformación.
4.1 Especificar el tipo de datos de fecha y hora
4.1.1 Convierta la fecha y hora representadas por el tipo numérico al tipo especificado
Los datos que representan el tiempo en el archivo de datos pueden ser enteros o enteros largos, y durante el análisis de datos, a menudo es necesario forzar que dichos datos se conviertan a un formato de tipo de tiempo y se importen y almacenen en la base de datos. Para este escenario, puede especificar el tipo de datos correspondiente para las columnas de fecha y hora en el archivo de texto a través del parámetro de transformación de la función loadTextEx.
Primero, cree una base de datos y tablas distribuidas.
login(`admin,`123456)
dataFilePath="/home/data/candle_201801.csv"
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="TIME" where name="time"
tb=table(1:0,schemaTB.name,schemaTB.type)
tb=db.createPartitionedTable(tb,`tb1,`date);La función personalizada i2t se utiliza para preprocesar los datos y devolver la tabla de datos procesados.
def i2t(mutable t){
return t.replaceColumn!(`time,time(t.time/10))
}Tenga en cuenta: al procesar datos en el cuerpo de una función personalizada, intente utilizar modificaciones locales (funciones que terminan en!) Para mejorar el rendimiento.
Llame a la función loadTextEx y especifique el parámetro de transformación como la función i2t. El sistema ejecutará la función i2t en los datos del archivo de texto y guardará el resultado en la base de datos.
tmpTB=loadTextEx(dbHandle=db,tableName=`tb1,partitionColumns=`date,filename=dataFilePath,transform=i2t);Vea las primeras 5 filas de datos en la tabla. Se puede ver que la columna de tiempo se almacena en el tipo TIME, no en el tipo INT en el archivo de texto:
select top 5 * from loadTable(dbPath,`tb1);
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- ------------------ ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01.02 2018.01.02 02:35:10.000000000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:20.000000000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:30.000000000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:40.000000000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:50.000000000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000
4.1.2 Conversión entre tipos de datos de fecha u hora
Si la fecha en el archivo de texto está almacenada en el tipo DATE, desea almacenarla en forma de MES al importar la base de datos. En este caso, también puede convertir el tipo de datos de la columna de fecha a través del parámetro de transformación de la Función loadTextEx Los pasos son los mismos que en la sección anterior.
login(`admin,`123456)
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="MONTH" where name="tradingDay"
tb=table(1:0,schemaTB.name,schemaTB.type)
tb=db.createPartitionedTable(tb,`tb1,`date)
def d2m(mutable t){
return t.replaceColumn!(`tradingDay,month(t.tradingDay))
}
tmpTB=loadTextEx(dbHandle=db,tableName=`tb1,partitionColumns=`date,filename=dataFilePath,transform=d2m);Vea las primeras 5 filas de datos en la tabla. Se puede ver que la columna tradingDay se almacena en el tipo MES, no en el tipo FECHA en el archivo de texto:
select top 5 * from loadTable(dbPath,`tb1);
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- -------- ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01M 2018.01.02 93100000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01M 2018.01.02 93200000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01M 2018.01.02 93300000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01M 2018.01.02 93400000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01M 2018.01.02 93500000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000
4.2 Completar valores vacíos
El parámetro de transformación puede llamar a las funciones integradas de DolphinDB. Cuando la función incorporada requiere múltiples parámetros, podemos usar algunas aplicaciones para convertir la función multiparamétrica en una función de un parámetro. Por ejemplo, llame a una nullFill!función para completar valores vacíos en un archivo de texto.
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
tb=db.createPartitionedTable(tb,`tb1,`date)
tmpTB=loadTextEx(dbHandle=db,tableName=`pt,partitionColumns=`date,filename=dataFilePath,transform=nullFill!{,0});
5. Utilice Map-Reduce para importar datos personalizados
DolphinDB admite el uso de Map-Reduce para importar datos personalizados, dividir los datos en filas e importar los datos divididos en DolphinDB a través de Map-Reduce.
Puede usar textChunkDSfunciones para dividir archivos en múltiples fuentes de datos de archivos pequeños y luego mrescribirlos en la base de datos a través de la función. Antes de llamar a la función mr para almacenar los datos en la base de datos, los usuarios también pueden realizar un procesamiento de datos flexible para lograr requisitos de importación más complejos.
5.1 Almacene los datos de acciones y futuros en el archivo en dos tablas de datos diferentes
Ejecute el siguiente script en DolphinDB para generar un archivo de datos con un tamaño de aproximadamente 1 GB, que incluye datos de acciones y datos de futuros.
n=10000000
dataFilePath="/home/data/chunkText.csv"
trades=table(rand(`stock`futures,n) as type, rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,take(2000.01.01..2000.06.30,n) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5,10000.0+rand(4000.0,n) as price6,rand(10,n) as qty1,rand(100,n) as qty2,rand(1000,n) as qty3,rand(10000,n) as qty4,rand(10000,n) as qty5,rand(10000,n) as qty6)
trades.saveText(dataFilePath);Cree bases de datos y tablas distribuidas para almacenar datos de acciones y datos de futuros respectivamente:
login(`admin,`123456)
dbPath1="dfs://stocksDatabase"
dbPath2="dfs://futuresDatabase"
db1=database(dbPath1,VALUE,`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S)
db2=database(dbPath2,VALUE,2000.01.01..2000.06.30)
tb1=db1.createPartitionedTable(trades,`stock,`sym)
tb2=db2.createPartitionedTable(trades,`futures,`date);Defina las siguientes funciones para dividir datos y escribir datos en diferentes bases de datos.
def divideImport(tb, mutable stockTB, mutable futuresTB)
{
tdata1=select * from tb where type="stock"
tdata2=select * from tb where type="futures"
append!(stockTB, tdata1)
append!(futuresTB, tdata2)
}Luego, divida el archivo de texto por la función textChunkDS, con 300 MB como unidad para dividir el archivo en 4 partes.
ds=textChunkDS(dataFilePath,300)
ds;
(DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment)Llame a la función mr, especifique el resultado de la función textChunkDS como fuente de datos e importe el archivo a la base de datos. Dado que la función de mapa (especificada por el parámetro mapFunc) solo acepta una tabla como parámetro, aquí usamos algunas aplicaciones para convertir una función de múltiples parámetros en una función de un parámetro.
mr(ds=ds, mapFunc=divideImport{,tb1,tb2}, parallel=false);
Tenga en cuenta que diferentes fuentes de datos de archivos pequeños pueden contener datos de la misma partición. DolphinDB no permite que varios subprocesos escriban simultáneamente en la misma partición, por lo que el
mr
parámetro de función paralelo establecido en falso, de lo contrario, arrojará una excepción.
Vea las primeras 5 filas de las tablas en las dos bases de datos. La base de datos de acciones incluye todos los datos de acciones y la base de datos de futuros incluye todos los datos de futuros.
tabla de valores:
select top 5 * from loadTable("dfs://DolphinDBTickDatabase", `stock);
type sym date price1 price2 price3 price4 price5 price6 qty1 qty2 qty3 qty4 qty5 qty6
----- ---- ---------- --------- ---------- ----------- ------------ ------------ ------------ ---- ---- ---- ---- ---- ----
stock AMZN 2000.02.14 11.224234 112.26763 1160.926836 11661.418403 11902.403305 11636.093467 4 53 450 2072 9116 12
stock AMZN 2000.03.29 10.119057 111.132165 1031.171855 10655.048121 12682.656303 11182.317321 6 21 651 2078 7971 6207
stock AMZN 2000.06.16 11.61637 101.943971 1019.122963 10768.996906 11091.395164 11239.242307 0 91 857 3129 3829 811
stock AMZN 2000.02.20 11.69517 114.607763 1005.724332 10548.273754 12548.185724 12750.524002 1 39 270 4216 8607 6578
stock AMZN 2000.02.23 11.534805 106.040664 1085.913295 11461.783565 12496.932604 12995.461331 4 35 488 4042 6500 4826futuros 表 :
select top 5 * from loadTable("dfs://DolphinDBFuturesDatabase", `futures);
type sym date price1 price2 price3 price4 price5 price6 qty1 qty2 qty3 qty4 qty5 ...
------- ---- ---------- --------- ---------- ----------- ------------ ------------ ------------ ---- ---- ---- ---- ---- ---
futures MSFT 2000.01.01 11.894442 106.494131 1000.600933 10927.639217 10648.298313 11680.875797 9 10 241 524 8325 ...
futures S 2000.01.01 10.13728 115.907379 1140.10161 11222.057315 10909.352983 13535.931446 3 69 461 4560 2583 ...
futures GM 2000.01.01 10.339581 112.602729 1097.198543 10938.208083 10761.688725 11121.888288 1 1 714 6701 9203 ...
futures IBM 2000.01.01 10.45422 112.229537 1087.366764 10356.28124 11829.206165 11724.680443 0 47 741 7794 5529 ...
futures TSLA 2000.01.01 11.901426 106.127109 1144.022732 10465.529256 12831.721586 10621.111858 4 43 136 9858 8487 ...
5.2 Cargue rápidamente algunos datos al principio y al final de un archivo grande
Puede utilizar textChunkDS para dividir un archivo grande en varias fuentes de datos pequeñas (fragmentos) y luego cargar la primera y la última fuente de datos. Ejecute el siguiente script en DolphinDB para generar archivos de datos:
n=10000000
dataFilePath="/home/data/chunkText.csv"
trades=table(rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,sort(take(2000.01.01..2000.06.30,n)) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5,10000.0+rand(4000.0,n) as price6,rand(10,n) as qty1,rand(100,n) as qty2,rand(1000,n) as qty3,rand(10000,n) as qty4, rand(10000,n) as qty5, rand(1000,n) as qty6)
trades.saveText(dataFilePath);Luego, divida el archivo de texto por la función textChunkDS y divídalo en unidades de 10 MB.
ds=textChunkDS(dataFilePath, 10);Llame a la función mr para cargar los datos del primero y los dos últimos fragmentos. Debido a que los datos de estos dos fragmentos son muy pequeños, la velocidad de carga es muy rápida.
head_tail_tb = mr(ds=[ds.head(), ds.tail()], mapFunc=x->x, finalFunc=unionAll{,false});Vea el número de registros en la tabla head_tail_tb:
select count(*) from head_tail_tb;
count
------
192262
6. Otros asuntos que requieren atención
6.1 Procesamiento de diferentes datos codificados
Dado que las cadenas de DolphinDB están codificadas en UTF-8, si el archivo cargado no está codificado en UTF-8, debe convertirse después de la importación. DolphinDB proporciona convertEncode, fromUTF8y toUTF8funciones para la conversión de la cadena de codificación después de la importación de datos.
Por ejemplo, use la función convertEncode para convertir la codificación de la columna de intercambio en la tabla tmpTB:
dataFilePath="/home/data/candle_201801.csv"
tmpTB=loadText(filename=dataFilePath, skipRows=0)
tmpTB.replaceColumn!(`exchange, convertEncode(tmpTB.exchange,"gbk","utf-8"));
6.2 Análisis de tipos numéricos
La primera sección de este tutorial presenta el mecanismo de análisis automático de tipos de datos de DolphinDB al importar datos. Esta sección explica el análisis de datos numéricos (incluidos CHAR, SHORT, INT, LONG, FLOAT y DOUBLE). El sistema puede reconocer las siguientes formas de datos numéricos:
- El valor numérico representado por un número, por ejemplo: 123
- Valor numérico con separador de miles, por ejemplo: 100.000
- Un valor con un punto decimal, es decir, un número de punto flotante, por ejemplo: 1.231
- Valor expresado en notación científica, por ejemplo: 1.23E5
Si el tipo de datos especificado es un tipo numérico, DolphinDB ignorará automáticamente las letras y otros símbolos antes y después del número al importar. Si no aparece ningún número, se analizará como un valor NULO. La siguiente es una descripción específica con ejemplos.
Primero, ejecute el siguiente script para crear un archivo de texto.
dataFilePath="/home/data/testSym.csv"
prices1=["2131","$2,131", "N/A"]
prices2=["213.1","$213.1", "N/A"]
totals=["2.658E7","-2.658e7","2.658e-7"]
tt=table(1..3 as id, prices1 as price1, prices2 as price2, totals as total)
saveText(tt,dataFilePath);En el archivo de texto creado, hay números y caracteres en las columnas precio1 y precio2. Si el parámetro de esquema no se especifica al importar datos, el sistema reconocerá ambas columnas como tipo SÍMBOLO:
tmpTB=loadText(dataFilePath)
tmpTB;
id price1 price2 total
-- ------ ------ --------
1 2131 213.1 2.658E7
2 $2,131 $213.1 -2.658E7
3 N/A N/A 2.658E-7
tmpTB.schema().colDefs;
name typeString typeInt comment
------ ---------- ------- -------
id INT 4
price1 SYMBOL 17
price2 SYMBOL 17
total DOUBLE 16Si especifica la columna precio1 como tipo INT y la columna precio2 como tipo DOBLE, el sistema ignorará las letras y otros símbolos antes y después del número al importar. Si no aparece ningún número, se resolverá como un valor NULO.
schemaTB=table(`id`price1`price2`total as name, `INT`INT`DOUBLE`DOUBLE as type)
tmpTB=loadText(dataFilePath,,schemaTB)
tmpTB;
id price1 price2 total
-- ------ ------ --------
1 2131 213.1 2.658E7
2 2131 213.1 -2.658E7
3 2.658E-7
6.3 Eliminar automáticamente las comillas dobles
En los archivos CSV, las comillas dobles se utilizan a veces para tratar campos que contienen caracteres especiales (como separadores de miles) en los valores. Cuando DolphinDB procesa dichos datos, eliminará automáticamente las comillas dobles fuera del texto. La siguiente es una descripción específica con ejemplos.
En el archivo de datos utilizado en el siguiente ejemplo, num aparece como un valor numérico expresado en miles de secciones.
dataFilePath="/home/data/test.csv"
tt=table(1..3 as id, ["\"500\"","\"3,500\"","\"9,000,000\""] as num)
saveText(tt,dataFilePath);Importe datos y visualice los datos en la tabla. DolphinDB elimina automáticamente las comillas dobles fuera del texto.
tmpTB=loadText(dataFilePath)
tmpTB;
id num
-- -------
1 500
2 3500
3 9000000
apéndice
El archivo de datos utilizado en los ejemplos de este tutorial: candle_201801.csv .